<kernel v5.0>
Zoned Allocator -8- (Direct Compact-Isolation)
Isolation을 사용하는 용도는 다음과 같다.
- Compaction
- 부족한 high order 페이지를 확보하기 위해 migratable 페이지들을 존의 상위 부분으로 migration 한다.
- Direct-compaction, manual-compaction, kcompactd
- Off-line Memory
- offline할 메모리 영역에 위치한 모든 사용 중인 movable 페이지들을 다른 영역으로 migration 한다.
- CMA
- CMA 영역에서 요청한 범위내의 연속된 물리 공간 확보를 위해 CMA 영역에 임시 입주(?) 중인 movable 페이지들을 migration 한다.
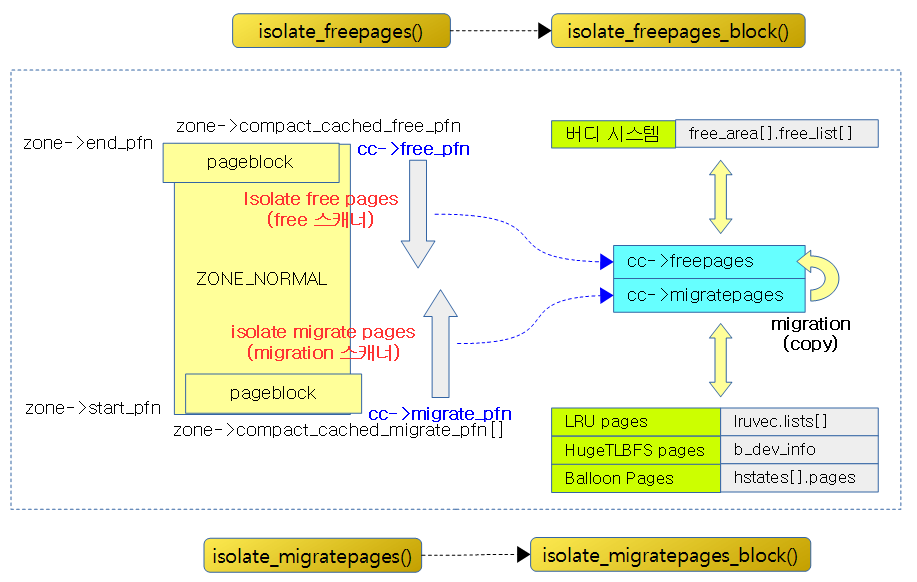
다음 그림은 isolation을 위한 주요 함수 호출 과정을 양쪽으로 나눠 보여준다. 좌측은 옮길 페이지를 isolation 하는 과정이고 우측은 free 페이지를 isolation 또는 확보하는 과정이다.

Compaction을 위한 두 개의 스캐너
다음 그림은 Compaction을 수행 시 두 개의 migration 스캐너와 free 스캐너가 각각의 목적에 사용될 페이지들을 isolation 할 때 동작하는 방향을 보여준다.
- migration 스캐너는 migratable 페이지들을 확보하기 위해 페이지 블럭들을 대상으로 윗 방향으로 스캔을 한다.
- isolate_migratepages_block()은 선택된 하나의 페이지 블럭에서 migratable 페이지를 분리(isolate)하여 cc->migratepages 리스트에 추가한다.
- free 스캐너는 free 페이지들을 확보하기 위해 페이지 블럭들을 대상으로 아래 방향으로 스캔을 한다.
- isolate_freepages_block()은 선택된 하나의 페이지 블럭에서 요청 타입의 free 페이지를 분리(isolate)하여 cc->freepages 리스트에 추가한다.
Migrate 스캐너
Isolate migratepages
isolate_migratepages()
mm/compaction.c
/* * Isolate all pages that can be migrated from the first suitable block, * starting at the block pointed to by the migrate scanner pfn within * compact_control. */
static isolate_migrate_t isolate_migratepages(struct zone *zone,
struct compact_control *cc)
{
unsigned long block_start_pfn;
unsigned long block_end_pfn;
unsigned long low_pfn;
struct page *page;
const isolate_mode_t isolate_mode =
(sysctl_compact_unevictable_allowed ? ISOLATE_UNEVICTABLE : 0) |
(cc->mode != MIGRATE_SYNC ? ISOLATE_ASYNC_MIGRATE : 0);
/*
* Start at where we last stopped, or beginning of the zone as
* initialized by compact_zone()
*/
low_pfn = cc->migrate_pfn;
block_start_pfn = pageblock_start_pfn(low_pfn);
if (block_start_pfn < zone->zone_start_pfn)
block_start_pfn = zone->zone_start_pfn;
/* Only scan within a pageblock boundary */
block_end_pfn = pageblock_end_pfn(low_pfn);
/*
* Iterate over whole pageblocks until we find the first suitable.
* Do not cross the free scanner.
*/
for (; block_end_pfn <= cc->free_pfn;
low_pfn = block_end_pfn,
block_start_pfn = block_end_pfn,
block_end_pfn += pageblock_nr_pages) {
/*
* This can potentially iterate a massively long zone with
* many pageblocks unsuitable, so periodically check if we
* need to schedule, or even abort async compaction.
*/
if (!(low_pfn % (SWAP_CLUSTER_MAX * pageblock_nr_pages))
&& compact_should_abort(cc))
break;
page = pageblock_pfn_to_page(block_start_pfn, block_end_pfn,
zone);
if (!page)
continue;
/* If isolation recently failed, do not retry */
if (!isolation_suitable(cc, page))
continue;
/*
* For async compaction, also only scan in MOVABLE blocks.
* Async compaction is optimistic to see if the minimum amount
* of work satisfies the allocation.
*/
if (!suitable_migration_source(cc, page))
continue;
/* Perform the isolation */
low_pfn = isolate_migratepages_block(cc, low_pfn,
block_end_pfn, isolate_mode);
if (!low_pfn || cc->contended)
return ISOLATE_ABORT;
/*
* Either we isolated something and proceed with migration. Or
* we failed and compact_zone should decide if we should
* continue or not.
*/
break;
}
/* Record where migration scanner will be restarted. */
cc->migrate_pfn = low_pfn;
return cc->nr_migratepages ? ISOLATE_SUCCESS : ISOLATE_NONE;
}
요청한 zone에서 migratable 페이지들을 isolation한다.
- 코드 라인 8~10에서 isolate 모드를 결정한다.
- ISOLATE_UNMAPPED(0x2)
- 매핑되지 않은 페이지들만 isolation을 지원하고, 매핑(file 캐시, swap 캐시 등)된 파일들은 처리하지 않는다.
- ISOLATE_ASYNC_MIGRATE(0x4)
- isolation 및 migration을 간략히 수행한다. migrate 타입이 블럭의 50% 이상인 페이지 블럭에 대해서만 수행하고, 1개의 order isolation이 가능하면 더 이상 진행하지 않고 중단한다. 이 외에 preempt 요청에 대해서도 중단한다.
- ISOLATE_UNEVICTABLE(0x8)
- unevictable 페이지라도 isolation을 수행하게 한다.
- ISOLATE_UNMAPPED(0x2)
- 코드 라인 16~22에서 migrate 스캐너가 윗 방향으로 스캔할 위치를 가리키는 pfn으로 스캔할 블럭의 시작과 끝 pfn을 구한다.
- 예) migrate_pfn=0x250, pageblock_order=9
- block_start_pfn=0x200, block_end_pfn=0x400
- 예) migrate_pfn=0x250, pageblock_order=9
- 코드 라인 28~31에서 아래 쪽으로 스캔하는 free 스캐너 위치까지 migrate 스캐너를 블럭 단위로 순회한다.
- 코드 라인 38~40에서 처리할 범위가 크므로 주기적으로 중단 요소가 있는지 체크한다.
- 체크 주기
- SWAP_CLUSTER_MAX(32) 페이지 블럭 단위
- 중단요소
- async migration 처리 중이면서 더 높은 우선 순위 태스크로부터 preemption 요청이 있는 경우
- 체크 주기
- 코드 라인 42~45에서 요청 존 범위내 페이지 블럭의 첫 페이지를 가져온다. 페이지가 요청 존을 벗어나면 null을 반환하며 skip 한다.
- 코드 라인 48~49에서 해당 zone의 블럭에서 isolation을 하지 않으려는 경우 skip 한다.
- direct-compact를 async 모드로 동작시킬 때 최근에 해당 페이지블럭에서 isolation이 실패한 경우 설정되는 skip 비트가 설정되었으면 해당 블럭을 skip하도록 false를 반환한다.
- 코드 라인 56~57에서 비동기 direct-compact 모드로 동작할 때 해당 블럭 migrate 타입이 요청한 migrate 타입과 동일하지 않으면 skip 한다. 단 동기(migrate_sync*) 방식이거나 매뉴얼 및 kcompactd 요청인 경우 항상 true를 반환하여 해당 블럭을 무조건 isolation 시도하게 한다.
- 코드 라인 60~61에서 해당 블럭의 페이지들에서 migratable 페이지들만 isolation 한다.
- 코드 라인 63~64에서 isolation이 실패하거나 도중에 중단해야 하는 경우 ISOLATE_ABORT 결과로 빠져나간다.
- 코드 라인 71에서 정상적으로 isolation이 완료된 경우 루프를 벗어난다.
- 코드 라인 75~77에서 처리 중인 migrate 스캐너의 현재 위치를 기억 시키고, isolation 결과를 반환한다.
다음 그림은 isolate_migratepages() 함수를 통해 migrate 스캐너가 적합 조건의 페이지 블럭들을 대상으로 movable lru 페이지들을 isolation 하는 과정을 보여준다.
- 적합한 movable lru 페이지 isolation (X) -> migratable 페이지
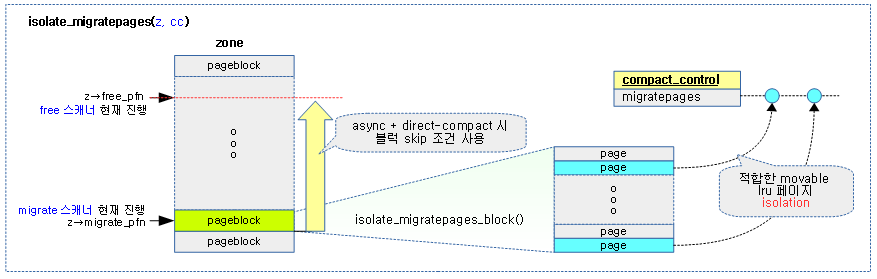
Isolate migratepages 블럭
다음 함수는 다음 두 용도에서 호출되어 사용된다.
- Compaction
- isolate_migratepages() 함수에서 다음 isolate 모드 관련 두 플래그가 추가되어 호출될 수 있다.
- sync compaction 모드가 아닌 경우 ISOLATE_ASYNC_MIGRATE가 추가된다.
- sysctl_compact_unevictable_allowed(디폴트=1)이 설정된 경우 ISOLATE_UNEVICTABLE 모드가 추가된다.
- isolate_migratepages() 함수에서 다음 isolate 모드 관련 두 플래그가 추가되어 호출될 수 있다.
- CMA
- isolate_migratepages_range() 함수에서 ISOLATE_UNEVICTABLE 모드로 호출된다.
isolate_migratepages_block()
mm/compaction.c -1/4-
/** * isolate_migratepages_block() - isolate all migrate-able pages within * a single pageblock * @cc: Compaction control structure. * @low_pfn: The first PFN to isolate * @end_pfn: The one-past-the-last PFN to isolate, within same pageblock * @isolate_mode: Isolation mode to be used. * * Isolate all pages that can be migrated from the range specified by * [low_pfn, end_pfn). The range is expected to be within same pageblock. * Returns zero if there is a fatal signal pending, otherwise PFN of the * first page that was not scanned (which may be both less, equal to or more * than end_pfn). * * The pages are isolated on cc->migratepages list (not required to be empty), * and cc->nr_migratepages is updated accordingly. The cc->migrate_pfn field * is neither read nor updated. */
isolate_migratepages_block(struct compact_control *cc, unsigned long low_pfn,
unsigned long end_pfn, isolate_mode_t isolate_mode)
{
struct zone *zone = cc->zone;
unsigned long nr_scanned = 0, nr_isolated = 0;
struct lruvec *lruvec;
unsigned long flags = 0;
bool locked = false;
struct page *page = NULL, *valid_page = NULL;
unsigned long start_pfn = low_pfn;
bool skip_on_failure = false;
unsigned long next_skip_pfn = 0;
/*
* Ensure that there are not too many pages isolated from the LRU
* list by either parallel reclaimers or compaction. If there are,
* delay for some time until fewer pages are isolated
*/
while (unlikely(too_many_isolated(zone))) {
/* async migration should just abort */
if (cc->mode == MIGRATE_ASYNC)
return 0;
congestion_wait(BLK_RW_ASYNC, HZ/10);
if (fatal_signal_pending(current))
return 0;
}
if (compact_should_abort(cc))
return 0;
if (cc->direct_compaction && (cc->mode == MIGRATE_ASYNC)) {
skip_on_failure = true;
next_skip_pfn = block_end_pfn(low_pfn, cc->order);
}
/* Time to isolate some pages for migration */
for (; low_pfn < end_pfn; low_pfn++) {
if (skip_on_failure && low_pfn >= next_skip_pfn) {
/*
* We have isolated all migration candidates in the
* previous order-aligned block, and did not skip it due
* to failure. We should migrate the pages now and
* hopefully succeed compaction.
*/
if (nr_isolated)
break;
/*
* We failed to isolate in the previous order-aligned
* block. Set the new boundary to the end of the
* current block. Note we can't simply increase
* next_skip_pfn by 1 << order, as low_pfn might have
* been incremented by a higher number due to skipping
* a compound or a high-order buddy page in the
* previous loop iteration.
*/
next_skip_pfn = block_end_pfn(low_pfn, cc->order);
}
요청한 migratetype의 한 페이지 블럭 범위에서 migratable 페이지들을 isolation 한다.
- 코드 라인 5에서 스캔 페이지 수와 isolated 페이지 수를 0으로 초기화한다.
- 코드 라인 19~28에서 작은 확률로 isolated 페이지가 과다한 경우에만 루프를 돌며 100ms 씩 처리를 지연시킨다. 단 다음 상황에서는 처리를 중단하고 0을 반환한다.
- 비동기 migration 중에는 과다한 처리를 포기한다.
- SIGKILL 시그널의 처리가 지연된 경우 함수 처리를 중단한다.
- 코드 라인 30~31에서 비동기 처리 중에 더 높은 우선 순위의 태스크로부터 preemption 요청이 있는 경우 함수 처리를 중단한다.
- 코드 라인 33~36에서 direct-compaction 방식으로 async migration 처리 중이면 skip_on_failure를 true로 설정한다.
- skip_on_failure
- 요청한 order를 빠르게 할당할 목적으로 가볍게 처리하기 위해 1 페이지 블럭이 아니라 order 단위로 페이지를 검색하여 isolation이 하나라도 있으면 종료시킨다.
- skip_on_failure
- 코드 라인 39~61에서 처리할 범위의 페이지들을 하나씩 순회하되 skip_on_failure가 설정되었고, order 단위별 처리가 완료된 경우 다음 order의 끝 pfn을 지정한다. 만일 블럭내에 하나라도 isolation된 페이지가 있으면 루프를 벗어난다.
mm/compaction.c -2/4-
. /*
* Periodically drop the lock (if held) regardless of its
* contention, to give chance to IRQs. Abort async compaction
* if contended.
*/
if (!(low_pfn % SWAP_CLUSTER_MAX)
&& compact_unlock_should_abort(zone_lru_lock(zone), flags,
&locked, cc))
break;
if (!pfn_valid_within(low_pfn))
goto isolate_fail;
nr_scanned++;
page = pfn_to_page(low_pfn);
if (!valid_page)
valid_page = page;
/*
* Skip if free. We read page order here without zone lock
* which is generally unsafe, but the race window is small and
* the worst thing that can happen is that we skip some
* potential isolation targets.
*/
if (PageBuddy(page)) {
unsigned long freepage_order = page_order_unsafe(page);
/*
* Without lock, we cannot be sure that what we got is
* a valid page order. Consider only values in the
* valid order range to prevent low_pfn overflow.
*/
if (freepage_order > 0 && freepage_order < MAX_ORDER)
low_pfn += (1UL << freepage_order) - 1;
continue;
}
/*
* Regardless of being on LRU, compound pages such as THP and
* hugetlbfs are not to be compacted. We can potentially save
* a lot of iterations if we skip them at once. The check is
* racy, but we can consider only valid values and the only
* danger is skipping too much.
*/
if (PageCompound(page)) {
const unsigned int order = compound_order(page);
if (likely(order < MAX_ORDER))
low_pfn += (1UL << order) - 1;
goto isolate_fail;
}
/*
* Check may be lockless but that's ok as we recheck later.
* It's possible to migrate LRU and non-lru movable pages.
* Skip any other type of page
*/
if (!PageLRU(page)) {
/*
* __PageMovable can return false positive so we need
* to verify it under page_lock.
*/
if (unlikely(__PageMovable(page)) &&
!PageIsolated(page)) {
if (locked) {
spin_unlock_irqrestore(zone_lru_lock(zone),
flags);
locked = false;
}
if (!isolate_movable_page(page, isolate_mode))
goto isolate_success;
}
goto isolate_fail;
}
- 코드 라인 6~9에서 처리할 범위가 크므로 이 루틴에서 주기적으로 unlock 하여 irq latency를 높이기 위해 노력한다. 또한 중단 요소가 있는 경우 처리를 중단하고 루프를 빠져나간다.
- 체크 주기
- SWAP_CLUSTER_MAX(32) 페이지 블럭단위
- 중단요소
- SIGKILL 신호가 처리 지연된 경우
- 비동기 migration 중에 높은 우선 순위 태스크의 preemption 요청이 있는 경우
- 체크 주기
- 코드 라인 11~18에서 첫 유효 페이지를 갱신하고, 스캔 카운터를 증가한다. 만일 유효한 페이지가 아닌 경우 isolate_fail 레이블로 이동한다.
- 코드 라인 26~37에서 migrate 스캐너는 사용 중인 movable 페이지만 migrate한다. 따라서 버디시스템에서 관리하는 free 페이지인 경우 skip한다.
- 코드 라인 46~52에서 compound(slab, hugetlbfs, thp) 페이지도 compaction 효과가 없으므로 isolate_fail 레이블로 이동한다.
- 코드 라인 59~77에서 유저 할당한 lru 페이지가 아닌 경우 isolate_fail 레이블로 이동한다. 다만 작은 확률로 이미 isolation이 진행되지 되지 않은 non-lru movable 페이지이면 isolation하고, 성공한 경우 isolate_success 레이블로 이동한다.
- gpu, zsram(z3fold, zsmalloc) 및 balloon 드라이버에서 non-lru-movable 페이지의 migration을 지원한다.
mm/compaction.c -3/4-
/*
* Migration will fail if an anonymous page is pinned in memory,
* so avoid taking lru_lock and isolating it unnecessarily in an
* admittedly racy check.
*/
if (!page_mapping(page) &&
page_count(page) > page_mapcount(page))
goto isolate_fail;
/*
* Only allow to migrate anonymous pages in GFP_NOFS context
* because those do not depend on fs locks.
*/
if (!(cc->gfp_mask & __GFP_FS) && page_mapping(page))
goto isolate_fail;
/* If we already hold the lock, we can skip some rechecking */
if (!locked) {
locked = compact_trylock_irqsave(zone_lru_lock(zone),
&flags, cc);
if (!locked)
break;
/* Recheck PageLRU and PageCompound under lock */
if (!PageLRU(page))
goto isolate_fail;
/*
* Page become compound since the non-locked check,
* and it's on LRU. It can only be a THP so the order
* is safe to read and it's 0 for tail pages.
*/
if (unlikely(PageCompound(page))) {
low_pfn += (1UL << compound_order(page)) - 1;
goto isolate_fail;
}
}
lruvec = mem_cgroup_page_lruvec(page, zone->zone_pgdat);
/* Try isolate the page */
if (__isolate_lru_page(page, isolate_mode) != 0)
goto isolate_fail;
VM_BUG_ON_PAGE(PageCompound(page), page);
/* Successfully isolated */
del_page_from_lru_list(page, lruvec, page_lru(page));
inc_node_page_state(page,
NR_ISOLATED_ANON + page_is_file_cache(page));
isolate_success:
list_add(&page->lru, &cc->migratepages);
cc->nr_migratepages++;
nr_isolated++;
/*
* Record where we could have freed pages by migration and not
* yet flushed them to buddy allocator.
* - this is the lowest page that was isolated and likely be
* then freed by migration.
*/
if (!cc->last_migrated_pfn)
cc->last_migrated_pfn = low_pfn;
/* Avoid isolating too much */
if (cc->nr_migratepages == COMPACT_CLUSTER_MAX) {
++low_pfn;
break;
}
continue;
- 코드 라인 6~8에서 anonymous 페이지가 다른 커널 context에서 사용 중에 있는 경우 isolate_fail로 이동한다.
- 코드 라인 14~15에서 파일 시스템에 매핑되었지만 GFP_NOFS를 사용하여 fs를 사용할 수 없으면 isolate_fail 레이블로 이동한다.
- 코드 라인 18~37에서 일정 주기로 lock을 위에서 풀었다. 이러한 경우 다시 획득한 후 다시 페이지 조건들을 확인해야 한다. lru 페이지가 아니거나 compound 페이지인 경우 isolate_fail 레이블로 이동한다.
- 코드 라인 39에서 lru 리스트로 노드의 lru 또는 memcg의 노드 lru를 선택한다.
- 코드 라인 42~50에서 lru 리스트에서 페이지를 분리한 후 NR_ISOLATED_ANON 또는 NR_ISOLATE_FILE 카운터를 증가시킨다.
- 코드 라인 52~55에서 isolation이 성공되었다고 간주되어 이동되어올 수 있는 isolate_success: 레이블이다. migratepages 리스트에 분리한 페이지를 추가하고 관련 stat들을 증가시킨다.
- 코드 라인 63~64에서 마지막 migrate된 페이지가 한 번도 지정되지 않은 경우 갱신한다.
- 코드 라인 67~70에서 migrate 페이지가 적정량(32)이 된 경우 처리를 중단한다.
- 코드 라인 72에서 계속 다음 페이지를 처리하도록 루프를 돈다.
mm/compaction.c -4/4-
isolate_fail:
if (!skip_on_failure)
continue;
/*
* We have isolated some pages, but then failed. Release them
* instead of migrating, as we cannot form the cc->order buddy
* page anyway.
*/
if (nr_isolated) {
if (locked) {
spin_unlock_irqrestore(zone_lru_lock(zone), flags);
locked = false;
}
putback_movable_pages(&cc->migratepages);
cc->nr_migratepages = 0;
cc->last_migrated_pfn = 0;
nr_isolated = 0;
}
if (low_pfn < next_skip_pfn) {
low_pfn = next_skip_pfn - 1;
/*
* The check near the loop beginning would have updated
* next_skip_pfn too, but this is a bit simpler.
*/
next_skip_pfn += 1UL << cc->order;
}
}
/*
* The PageBuddy() check could have potentially brought us outside
* the range to be scanned.
*/
if (unlikely(low_pfn > end_pfn))
low_pfn = end_pfn;
if (locked)
spin_unlock_irqrestore(zone_lru_lock(zone), flags);
/*
* Update the pageblock-skip information and cached scanner pfn,
* if the whole pageblock was scanned without isolating any page.
*/
if (low_pfn == end_pfn)
update_pageblock_skip(cc, valid_page, nr_isolated, true);
trace_mm_compaction_isolate_migratepages(start_pfn, low_pfn,
nr_scanned, nr_isolated);
cc->total_migrate_scanned += nr_scanned;
if (nr_isolated)
count_compact_events(COMPACTISOLATED, nr_isolated);
return low_pfn;
}
- 코드 라인 1~3에서 isolate_faile: 레이블이다. isolation이 실패한 경우 skip_on_failure가 false인 경우 다음 페이지를 계속 처리한다.
- 코드 라인 10~19에서 isolate된 페이지들을 다시 되돌려 무효화 시킨다.
- skip_on_failure가 true인 경우 order 단위별 페이지들을 isolation 시 실패하면 다음 order 단위 페이지에서 시도한다.
- 코드 라인 21~28에서 low_pfn을 다음 order 단위 페이지로 변경한다.
- 코드 라인 35~36에서 low_pfn이 처리 범위의 끝을 넘어가지 않게 제한한다.
- 코드 라인 38~39에서 lock이 걸려 있는 경우 unlock 한다.
- 코드 라인 45~46에서 페이지 블럭의 끝까지 처리하였고 처리된 isolated 페이지가 없는 경우 valid_page에 해당하는 페이지 블럭의 migrate skip 비트를 1로 설정하여 다음 스캔에서 skip하도록 한다. 그리고 migrate 스캐너(async, sync 모두)의 시작 pfn을 해당 페이지로 설정한다.
- 코드 라인 51~53에서 스캔 카운터와 isolation 카운터를 갱신한다.
다음 그림은 isolate_migratepages_block() 함수를 통해 migratable 페이지를 isolation하는 모습을 보여준다.

too_many_isolated()
mm/compaction.c
/* Similar to reclaim, but different enough that they don't share logic */
static bool too_many_isolated(struct zone *zone)
{
unsigned long active, inactive, isolated;
inactive = zone_page_state(zone, NR_INACTIVE_FILE) +
zone_page_state(zone, NR_INACTIVE_ANON);
active = zone_page_state(zone, NR_ACTIVE_FILE) +
zone_page_state(zone, NR_ACTIVE_ANON);
isolated = zone_page_state(zone, NR_ISOLATED_FILE) +
zone_page_state(zone, NR_ISOLATED_ANON);
return isolated > (inactive + active) / 2;
}
isolated 페이지 수가 너무 많은 경우 true를 반환한다.
- file(active+inactive) 페이지의 절반을 초과하는 경우 true
compact_should_abort()
mm/compaction.c
/* * Aside from avoiding lock contention, compaction also periodically checks * need_resched() and either schedules in sync compaction or aborts async * compaction. This is similar to what compact_unlock_should_abort() does, but * is used where no lock is concerned. * * Returns false when no scheduling was needed, or sync compaction scheduled. * Returns true when async compaction should abort. */
static inline bool compact_should_abort(struct compact_control *cc)
{
/* async compaction aborts if contended */
if (need_resched()) {
if (cc->mode == MIGRATE_ASYNC) {
cc->contended = true;
return true;
}
cond_resched();
}
return false;
}
비동기 migration 처리 중이면서 우선 순위 높은 태스크의 리스케쥴 요청이 있는 경우 true가 반환된다.
compact_unlock_should_abort()
mm/compaction.c
/* * Compaction requires the taking of some coarse locks that are potentially * very heavily contended. The lock should be periodically unlocked to avoid * having disabled IRQs for a long time, even when there is nobody waiting on * the lock. It might also be that allowing the IRQs will result in * need_resched() becoming true. If scheduling is needed, async compaction * aborts. Sync compaction schedules. * Either compaction type will also abort if a fatal signal is pending. * In either case if the lock was locked, it is dropped and not regained. * * Returns true if compaction should abort due to fatal signal pending, or * async compaction due to need_resched() * Returns false when compaction can continue (sync compaction might have * scheduled) */
static bool compact_unlock_should_abort(spinlock_t *lock,
unsigned long flags, bool *locked, struct compact_control *cc)
{
if (*locked) {
spin_unlock_irqrestore(lock, flags);
*locked = false;
}
if (fatal_signal_pending(current)) {
cc->contended = true;
return true;
}
if (need_resched()) {
if (cc->mode == MIGRATE_ASYNC) {
cc->contended = true;
return true;
}
cond_resched();
}
return false;
}
lock된 경우 unlock하고 중단 요소가 있는 경우 cc->contended에 true를 설정하고 true를 반환한다.
- 중단 요소
- SIGKILL 신호가 처리 지연된 경우
- 비동기 migration 중에 높은 우선 순위의 태스크의 리스케쥴 요청이 있는 경우
compact_trylock_irqsave()
mm/compaction.c
/* * Compaction requires the taking of some coarse locks that are potentially * very heavily contended. For async compaction, back out if the lock cannot * be taken immediately. For sync compaction, spin on the lock if needed. * * Returns true if the lock is held * Returns false if the lock is not held and compaction should abort */
static bool compact_trylock_irqsave(spinlock_t *lock, unsigned long *flags,
struct compact_control *cc)
{
if (cc->mode == MIGRATE_ASYNC) {
if (!spin_trylock_irqsave(lock, *flags)) {
cc->contended = true;
return false;
}
} else {
spin_lock_irqsave(lock, *flags);
}
return true;
}
비동기 migration 처리 중 compaction에 사용된 spin lock이 다른 cpu와 경쟁하여 한 번에 획득 시도가 실패한 경우 cc->contended에 true(compaction 락 혼잡)을 대입하고 false로 반환한다.
- 동기 migration인 경우 무조건 lock 획득을 한다.
mem_cgroup_page_lruvec()
mm/memcontrol.c
/** * mem_cgroup_page_lruvec - return lruvec for isolating/putting an LRU page * @page: the page * @zone: zone of the page * * This function is only safe when following the LRU page isolation * and putback protocol: the LRU lock must be held, and the page must * either be PageLRU() or the caller must have isolated/allocated it. */
struct lruvec *mem_cgroup_page_lruvec(struct page *page, struct pglist_data *pgdat)
{
struct mem_cgroup_per_node *mz;
struct mem_cgroup *memcg;
struct lruvec *lruvec;
if (mem_cgroup_disabled()) {
lruvec = &pgdat->lruvec;
goto out;
}
memcg = page->mem_cgroup;
/*
* Swapcache readahead pages are added to the LRU - and
* possibly migrated - before they are charged.
*/
if (!memcg)
memcg = root_mem_cgroup;
mz = mem_cgroup_page_nodeinfo(memcg, page);
lruvec = &mz->lruvec;
out:
/*
* Since a node can be onlined after the mem_cgroup was created,
* we have to be prepared to initialize lruvec->zone here;
* and if offlined then reonlined, we need to reinitialize it.
*/
if (unlikely(lruvec->pgdat != pgdat))
lruvec->pgdat = pgdat;
return lruvec;
}
memcg가 활성화 되어 있는 경우 해당 페이지에 기록된 memcg의 해당 노드 lruvec을 반환하고, memcg가 비활성화 되어 있는 경우 해당 노드의 lruvec를 반환한다.
Isolate LRU 페이지
__isolate_lru_page()
mm/vmscan.c
/* * Attempt to remove the specified page from its LRU. Only take this page * if it is of the appropriate PageActive status. Pages which are being * freed elsewhere are also ignored. * * page: page to consider * mode: one of the LRU isolation modes defined above * * returns 0 on success, -ve errno on failure. */
int __isolate_lru_page(struct page *page, isolate_mode_t mode)
{
int ret = -EINVAL;
/* Only take pages on the LRU. */
if (!PageLRU(page))
return ret;
/* Compaction should not handle unevictable pages but CMA can do so */
if (PageUnevictable(page) && !(mode & ISOLATE_UNEVICTABLE))
return ret;
ret = -EBUSY;
/*
* To minimise LRU disruption, the caller can indicate that it only
* wants to isolate pages it will be able to operate on without
* blocking - clean pages for the most part.
*
* ISOLATE_ASYNC_MIGRATE is used to indicate that it only wants to pages
* that it is possible to migrate without blocking
*/
if (mode & ISOLATE_ASYNC_MIGRATE) {
/* All the caller can do on PageWriteback is block */
if (PageWriteback(page))
return ret;
if (PageDirty(page)) {
struct address_space *mapping;
bool migrate_dirty;
/*
* Only pages without mappings or that have a
* ->migratepage callback are possible to migrate
* without blocking. However, we can be racing with
* truncation so it's necessary to lock the page
* to stabilise the mapping as truncation holds
* the page lock until after the page is removed
* from the page cache.
*/
if (!trylock_page(page))
return ret;
mapping = page_mapping(page);
migrate_dirty = !mapping || mapping->a_ops->migratepage;
unlock_page(page);
if (!migrate_dirty)
return ret;
}
}
if ((mode & ISOLATE_UNMAPPED) && page_mapped(page))
return ret;
if (likely(get_page_unless_zero(page))) {
/*
* Be careful not to clear PageLRU until after we're
* sure the page is not being freed elsewhere -- the
* page release code relies on it.
*/
ClearPageLRU(page);
ret = 0;
}
return ret;
}
페이지에서 LRU의 제거를 시도한다. 성공시 0을 반환하고, 실패하는 경우 -EINVAL 또는 -EBUSY를 반환한다.
- 코드 라인 6~7에서 LRU 페이지가 아닌 경우 처리를 중단한다.
- 코드 라인 10~11에서 unevictable 페이지이면서 isolation 모드가 ISOLATE_UNEVICTABLE을 지원하지 않는 경우 처리를 중단한다.
- 코드 라인 23~26에서 ISOLATE_ASYNC_MIGRATE 모드로 동작하는 경우 WriteBack 중인 페이지는 -EBUSY로 처리를 중단한다.
- 코드 라인 28~49에서 Dirty 설정된 페이지에 대해 migratepage 핸들러 함수가 등록되어 있지 않은 매핑 페이지인 경우 처리를 중단한다.
- 코드 라인 52~53에서 ISOLATE_UNMAPPED 모드로 동작할 때 매핑 페이지들은 처리를 중단한다.
- 코드 라인 55~65에서 많은 확률로 사용 중인 페이지인 경우 lru 플래그를 클리어하고 정상적으로 함수를 빠져나간다.
Isolate movable 페이지
아래 함수를 이용하는 대상들은 다음과 같은 용도에서 사용된다.
- Compaction
- Direct-compaction에서 non-lru movable 페이지들의 migration
- Off-line Memory
- 메모리를 off-line 시키기 위해 non-lru movable 페이지들의 migration
isolate_movable_page()
mm/migrate.c
int isolate_movable_page(struct page *page, isolate_mode_t mode)
{
struct address_space *mapping;
/*
* Avoid burning cycles with pages that are yet under __free_pages(),
* or just got freed under us.
*
* In case we 'win' a race for a movable page being freed under us and
* raise its refcount preventing __free_pages() from doing its job
* the put_page() at the end of this block will take care of
* release this page, thus avoiding a nasty leakage.
*/
if (unlikely(!get_page_unless_zero(page)))
goto out;
/*
* Check PageMovable before holding a PG_lock because page's owner
* assumes anybody doesn't touch PG_lock of newly allocated page
* so unconditionally grapping the lock ruins page's owner side.
*/
if (unlikely(!__PageMovable(page)))
goto out_putpage;
/*
* As movable pages are not isolated from LRU lists, concurrent
* compaction threads can race against page migration functions
* as well as race against the releasing a page.
*
* In order to avoid having an already isolated movable page
* being (wrongly) re-isolated while it is under migration,
* or to avoid attempting to isolate pages being released,
* lets be sure we have the page lock
* before proceeding with the movable page isolation steps.
*/
if (unlikely(!trylock_page(page)))
goto out_putpage;
if (!PageMovable(page) || PageIsolated(page))
goto out_no_isolated;
mapping = page_mapping(page);
VM_BUG_ON_PAGE(!mapping, page);
if (!mapping->a_ops->isolate_page(page, mode))
goto out_no_isolated;
/* Driver shouldn't use PG_isolated bit of page->flags */
WARN_ON_ONCE(PageIsolated(page));
__SetPageIsolated(page);
unlock_page(page);
return 0;
out_no_isolated:
unlock_page(page);
out_putpage:
put_page(page);
out:
return -EBUSY;
}
non-lru movable 페이지를 isolation한다.
- 코드 라인 14~15에서 지금 막 free 페이지가 된 상황이면 -EBUSY 에러로 함수를 빠져나간다.
- 코드 라인 22~23에서 non-lru movable 페이지가 아닌 경우 -EBUSY 에러로 함수를 빠져나간다.
- 코드 라인 35~36에서 페이지 lock을 획득하고 다시 한 번 non-lru movable 페이지 여부 및 이미 isolate된 페이지인지 확인한다. 확인하여 non-lru movable 페이지가 아니거나 이미 isolate된 페이지라면 -EBUSY 에러로 함수를 빠져나간다.
- 코드 라인 38~42에서 non-lru movable 페이지가 아니거나 isolate 페이지인 경우 out_no_isolated 레이블로 이동한다.
- non-lru movable이 적용된 드라이버(예: z3fold, zsmalloc 등)의 (*isolate_page) 후크에 등록된 함수를 호출하여 false 반환된 경우 -EBUSY 에러로 함수를 빠져나간다.
- 코드 라인 46~49에서 isolate 플래그를 설정하고, 성공(0) 결과로 함수를 빠져나간다.
Isolatin 적합 여부 관련
isolation 적합 여부
블럭에 대한 isolation 여부
sync-full을 제외한 모드의 direct-compaction은 빠른 compaction을 위해 스캐닝 중인 페이지 블럭에서 skip 비트를 만나면 해당 페이지 블럭의 isolation을 skip 한다.
- 최근 해당 페이지 블럭에서 isolation이 실패한 경우 해당 블럭에 skip 마크를 한다.
다음 그림은 페이지 블럭들에 대한 usemap의 skip 비트의 사용 용도를 보여준다.
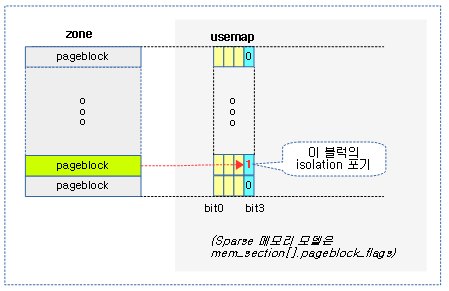
isolation 강제(force)
다음과 같은 수행 조건에서는 skip 비트의 설정 여부와 관계 없이 내부에서 ignore_skip_hint를 설정하여 모든 블럭의 isolation을 시도하도록 강제한다.
- 가장 높은 우선 순위의 sync-full을 제외한 compact 모드를 사용하는 direct-compact 사용 시
- manual-compact 사용 시
- kcompactd 사용 시
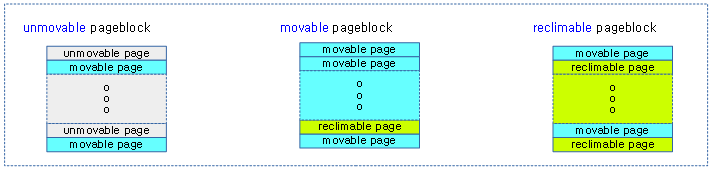
페이지블럭의 mobility 특성
다음 그림과 같이 페이지블럭의 타입은 해당 블럭 내에서 절반(50%) 이상의 페이지(migratetype) 타입을 가진 대표 mobility 특성을 가진다.
- 빠르게 동작해야 하는 async 모드 direct-compaction을 사용 시 movable 페이지 블럭만을 대상으로 compaction을 수행한다.
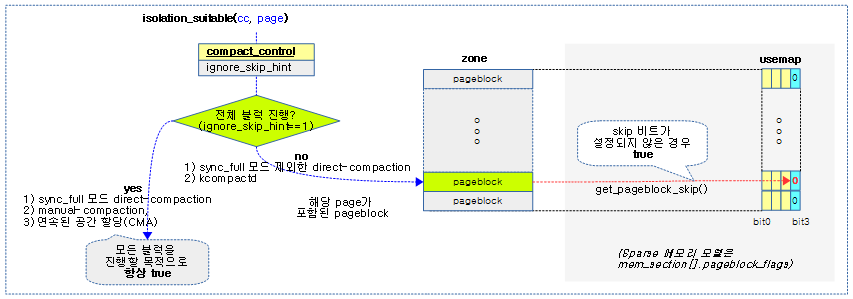
isolation_suitable()
mm/compaction.c
/* Returns true if the pageblock should be scanned for pages to isolate. */
static inline bool isolation_suitable(struct compact_control *cc,
struct page *page)
{
if (cc->ignore_skip_hint)
return true;
return !get_pageblock_skip(page);
}
해당 블럭에서 isolation을 시도해도 되는지 여부를 체크한다.
- 코드 라인 5~6에서 ignore_skip_hint가 설정된 경우 페이지 블럭의 skip 여부와 관계없이 isolation을 진행할 수 있게 true를 반환한다.
- 코드 라인 8에서 최근에 해당 페이지 블럭에서 isolation이 실패한 적이 있는 경우 skip하도록 false를 반환한다.
- usemap에 각 페이지 블럭의 skip 비트를 저장하고 있다.
다음 그림은 해당 블럭의 isolation 여부를 반환하는 isolation_suitable() 함수의 처리 과정을 보여준다.
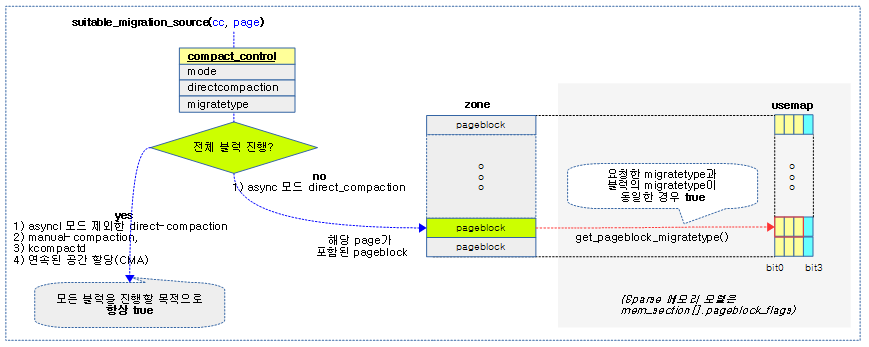
migration 소스로의 적합 여부
suitable_migration_source()
mm/compaction.c
static bool suitable_migration_source(struct compact_control *cc,
struct page *page)
{
int block_mt;
if ((cc->mode != MIGRATE_ASYNC) || !cc->direct_compaction)
return true;
block_mt = get_pageblock_migratetype(page);
if (cc->migratetype == MIGRATE_MOVABLE)
return is_migrate_movable(block_mt);
else
return block_mt == cc->migratetype;
}
하나의 페이지 블럭에 포함된 페이지가 migration 타겟에 적합하지 여부를 반환한다. 비동기 모드로 direct-compaction 진행 시 가볍고 빠르게 진행하기 위해 해당 블럭 migrate 타입이 요청한 migrate 타입과 동일할 경우에만 true를 반환한다. 그 외 방식의 경우에는 항상 true를 반환한다.
- 코드 라인 6~7에서 다음 2 가지의 경우에 한하여 해당 블럭을 무조건 isolation 한 후 migration 가능한 페이지들을 처리하도록 true를 반환한다.
- migrate_async가 아닌 요청
- direct_compaction 타입이 아닌 매뉴얼 compaction이나 kcompactd 요청
- 코드 라인 9~12에서 movable 할당 요청 시에는 movable 및 cma 블럭 타입 여부를 반환한다.
- unmovable, reclimable, highatomic, iolate 타입은 migration 대상이 될 수 없다.
- 코드 라인 13~14에서 movable 할당 요청이 아닌 경우 요청한 타입에 해당하는 블럭 타입의 동일 여부를 반환한다.
다음 그림은 해당 블럭이 migration 소스로 적절한지 여부를 반환하는 suitable_migration_source() 함수의 처리 과정을 보여준다.
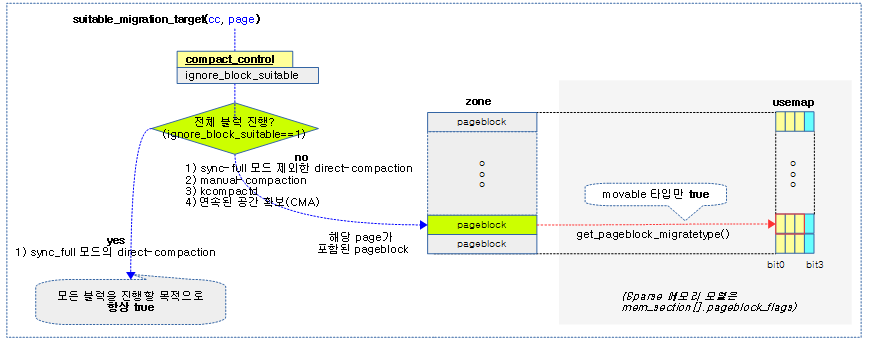
migration 타겟으로의 적합 여부
suitable_migration_target()
mm/compaction.c
/* Returns true if the page is within a block suitable for migration to */
static bool suitable_migration_target(struct compact_control *cc,
struct page *page)
{
/* If the page is a large free page, then disallow migration */
if (PageBuddy(page)) {
/*
* We are checking page_order without zone->lock taken. But
* the only small danger is that we skip a potentially suitable
* pageblock, so it's not worth to check order for valid range.
*/
if (page_order_unsafe(page) >= pageblock_order)
return false;
}
if (cc->ignore_block_suitable)
return true;
/* If the block is MIGRATE_MOVABLE or MIGRATE_CMA, allow migration */
if (is_migrate_movable(get_pageblock_migratetype(page)))
return true;
/* Otherwise skip the block */
return false;
}
하나의 페이지 블럭에 포함된 페이지가 migration 타겟에 적합하지 여부를 반환한다. 단 sync-full 모드로 direct-compaction 진행 시 항상 true를 반환한다.
- 코드 라인 6~14에서 페이지 블럭보다 큰 버디 시스템의 free 페이지는 false를 반환한다.
- 코드 라인 16~17에서 페이지 블럭 타입의 유형과 상관 없이 무조건 대상으로 지정하기 위해 true를 반환한다.
- ignore_block_suitable은 sync-full 모드의 direct-compaction이 동작할 때만 설정된다.
- 코드 라인 20~24에서 페이지 블럭이 movable 타입인 경우에만 true를 반환하고 그 외에는 false를 반환한다.
다음 그림은 해당 블럭이 migration 타겟으로 적절한지 여부를 반환하는 suitable_migration_target() 함수의 처리 과정을 보여준다.
페이지 블럭 skip 지정
update_pageblock_skip()
mm/compaction.c
/* * If no pages were isolated then mark this pageblock to be skipped in the * future. The information is later cleared by __reset_isolation_suitable(). */
static void update_pageblock_skip(struct compact_control *cc,
struct page *page, unsigned long nr_isolated,
bool migrate_scanner)
{
struct zone *zone = cc->zone;
unsigned long pfn;
if (cc->no_set_skip_hint)
return;
if (!page)
return;
if (nr_isolated)
return;
set_pageblock_skip(page);
pfn = page_to_pfn(page);
/* Update where async and sync compaction should restart */
if (migrate_scanner) {
if (pfn > zone->compact_cached_migrate_pfn[0])
zone->compact_cached_migrate_pfn[0] = pfn;
if (cc->mode != MIGRATE_ASYNC &&
pfn > zone->compact_cached_migrate_pfn[1])
zone->compact_cached_migrate_pfn[1] = pfn;
} else {
if (pfn < zone->compact_cached_free_pfn)
zone->compact_cached_free_pfn = pfn;
}
}
처리된 isolated 페이지가 없는 경우 해당 페이지 블럭에 migrate skip 비트를 설정하고 migrate 또는 free 스캐너의 시작 pfn을 해당 페이지로 설정한다.
- 코드 라인 8~15에서 다음의 3 가지 경우 해당 페이지 블럭의 skip 비트를 설정하지 않도록 중단한다.
- no_set_skip_hint가 설정된 경우
- cma 영역의 확보를 위해 isolation이 진행될 때 설정된다.
- 페이지가 없는 경우
- isolated된 페이지가 없는 경우
- no_set_skip_hint가 설정된 경우
- 코드 라인 17에서 해당 페이지 블럭의 skip 비트를 설정한다.
- 코드 라인 22~27에서 migrate 스캐너 루틴에서 요청이 온 경우 migrate 스캔 시작 pfn을 갱신한다.
- 코드 라인 28~31에서 free 스캐너 루틴에서 요청이 온 경우 free 스캔 시작 pfn을 갱신한다.
다음 그림은 해당 블럭의 isolation을 금지하도록 skip 비트를 설정하는 update_pageblock_skip() 함수의 처리 과정을 보여준다.

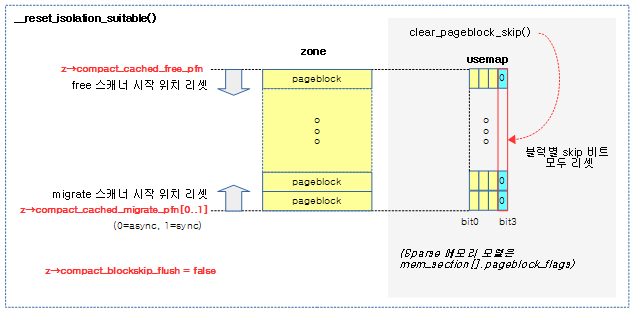
리셋 존 skip 비트
__reset_isolation_suitable()
mm/compaction.c
/* * This function is called to clear all cached information on pageblocks that * should be skipped for page isolation when the migrate and free page scanner * meet. */
static void __reset_isolation_suitable(struct zone *zone)
{
unsigned long start_pfn = zone->zone_start_pfn;
unsigned long end_pfn = zone_end_pfn(zone);
unsigned long pfn;
zone->compact_blockskip_flush = false;
/* Walk the zone and mark every pageblock as suitable for isolation */
for (pfn = start_pfn; pfn < end_pfn; pfn += pageblock_nr_pages) {
struct page *page;
cond_resched();
page = pfn_to_online_page(pfn);
if (!page)
continue;
if (zone != page_zone(page))
continue;
if (pageblock_skip_persistent(page))
continue;
clear_pageblock_skip(page);
}
reset_cached_positions(zone);
}
해당 zone의 isolate 및 free 스캔 시작 주소를 리셋하고 페이지블럭의 skip bit를 모두 클리어한다. 단 페이지 블럭 order 이상의 order를 사용하는 compound 페이지에 대한 skip 비트는 제외한다.
- migration 대상 영역은 zone의 시작 pfn과 끝 pfn이다.
- isolate 스캐너가 시작할 pfn으로 compact_cached_migrate_pfn[0..1]에 zone의 시작 pfn을 대입한다.
- free 스캐너가 시작할 pfn으로 compact_cached_free_pfn에 zone의 끝 pfn을 대입한다.
- pageblock->flags
- Sparse 메모리 모델이 아닌 경우 zone->pageblock_flags가 지정한 usemap
- Sparse 메모리 모델인 경우 mem_section[].pageblock_flags가 지정한 usemap
다음 그림은 해당 존의 모든 블럭의 isolation을 허용하도록 skip 비트를 클리어하고, 스캐너들의 시작 위치를 리셋하는 __reset_isolation_suitable() 함수의 처리 과정을 보여준다.
Isolation Freepages
다음 함수는 direct-compact, manual-compact 및 kcompactd 기능을 사용하는 곳에서 high order 페이지 부족 시 compaction을 위해 사용된다.
isolate_freepages()
mm/compaction.c
/* * Based on information in the current compact_control, find blocks * suitable for isolating free pages from and then isolate them. */
static void isolate_freepages(struct compact_control *cc)
{
struct zone *zone = cc->zone;
struct page *page;
unsigned long block_start_pfn; /* start of current pageblock */
unsigned long isolate_start_pfn; /* exact pfn we start at */
unsigned long block_end_pfn; /* end of current pageblock */
unsigned long low_pfn; /* lowest pfn scanner is able to scan */
struct list_head *freelist = &cc->freepages;
/*
* Initialise the free scanner. The starting point is where we last
* successfully isolated from, zone-cached value, or the end of the
* zone when isolating for the first time. For looping we also need
* this pfn aligned down to the pageblock boundary, because we do
* block_start_pfn -= pageblock_nr_pages in the for loop.
* For ending point, take care when isolating in last pageblock of a
* a zone which ends in the middle of a pageblock.
* The low boundary is the end of the pageblock the migration scanner
* is using.
*/
isolate_start_pfn = cc->free_pfn;
block_start_pfn = pageblock_start_pfn(cc->free_pfn);
block_end_pfn = min(block_start_pfn + pageblock_nr_pages,
zone_end_pfn(zone));
low_pfn = pageblock_end_pfn(cc->migrate_pfn);
/*
* Isolate free pages until enough are available to migrate the
* pages on cc->migratepages. We stop searching if the migrate
* and free page scanners meet or enough free pages are isolated.
*/
for (; block_start_pfn >= low_pfn;
block_end_pfn = block_start_pfn,
block_start_pfn -= pageblock_nr_pages,
isolate_start_pfn = block_start_pfn) {
/*
* This can iterate a massively long zone without finding any
* suitable migration targets, so periodically check if we need
* to schedule, or even abort async compaction.
*/
if (!(block_start_pfn % (SWAP_CLUSTER_MAX * pageblock_nr_pages))
&& compact_should_abort(cc))
break;
page = pageblock_pfn_to_page(block_start_pfn, block_end_pfn,
zone);
if (!page)
continue;
/* Check the block is suitable for migration */
if (!suitable_migration_target(cc, page))
continue;
/* If isolation recently failed, do not retry */
if (!isolation_suitable(cc, page))
continue;
/* Found a block suitable for isolating free pages from. */
isolate_freepages_block(cc, &isolate_start_pfn, block_end_pfn,
freelist, false);
/*
* If we isolated enough freepages, or aborted due to lock
* contention, terminate.
*/
if ((cc->nr_freepages >= cc->nr_migratepages)
|| cc->contended) {
if (isolate_start_pfn >= block_end_pfn) {
/*
* Restart at previous pageblock if more
* freepages can be isolated next time.
*/
isolate_start_pfn =
block_start_pfn - pageblock_nr_pages;
}
break;
} else if (isolate_start_pfn < block_end_pfn) {
/*
* If isolation failed early, do not continue
* needlessly.
*/
break;
}
}
/* __isolate_free_page() does not map the pages */
map_pages(freelist);
/*
* Record where the free scanner will restart next time. Either we
* broke from the loop and set isolate_start_pfn based on the last
* call to isolate_freepages_block(), or we met the migration scanner
* and the loop terminated due to isolate_start_pfn < low_pfn
*/
cc->free_pfn = isolate_start_pfn;
}
- 코드 라인 22~25에서 free 스캐너의 시작 pfn을 위해 중단되었었던 cc->free_pfn 부터 시작하게 한다. 그리고 블럭의 시작과 끝 pfn을 지정한다.
- free 스캐너는 존의 아래 방향으로 블럭을 이동하며 스캔한다. 페이지 블록 내에서 free 페이지들을 isolation 할 때에는 상위 방향으로 진행한다.
- 코드 라인26에서 migrate 스캐너가 작업하는 블럭을 침범하지 않게 하기 위해 low_pfn에 migrate 스캐너가 활동하는 페이지 블럭의 끝 pfn을 대입한다.
- 코드 라인 33~36에서 free 스캐너는 migrate 스캐너가 위치한 아래 방향으로 페이지 블럭 단위로 감소하며 순회한다.
- 코드 라인 42~44에서 zone을 free 스캐너로 한꺼번에 isolation하는 경우 영역이 너무 커서 중간에 주기적으로 한 번씩 compaction 중단 요소가 있는지 확인한다.
- 체크 주기
- SWAP_CLUSTER_MAX(32) 페이지 블럭 단위로 체크한다.
- 중단 요소
- 비동기 compaction 처리 중이면서 더 높은 우선 순위 태스크의 preemption 요청이 있는 경우
- 체크 주기
- 코드 라인 46~49에서 페이지 블럭의 첫 페이지를 가져온다. pfn 범위가 요청한 zone에 없는 경우 skip 한다.
- zone의 마지막 페이지블럭이 partial인 경우도 skip 한다
- 코드 라인 52~53에서 페이지 블럭이 migration의 타겟으로 적합하지 않는 경우 skip 한다.
- 코드 라인 56~57에서 페이지 블럭이 isolation에 적합하지 않는 경우 skip 한다.
- 최근에 해당 페이지블럭에서 isolation이 취소된적이 있는 경우 skip하도록 false를 반환한다.
- 코드 라인 60~61에서 페이지 블럭을 isolation 하여 cc->freepages 리스트에 이동시킨다.
- 코드 라인 67~77에서migrate스캐너가 확보한 migratable 페이지들 보다 free 스캐너가 확보한 free 페이지가 더 많거나 lock contention 상황이면 루프를 중단시킨다.
- 코드 라인 78~84에서 한 블럭도 스캔하지 못한 상황이면 루프를 중단시킨다.
- 코드라인 88에서 isolation된 free 페이지들이 담긴 리스트를 대상으로 각 페이지를 LRU 리스트에서 제거하고, 0 order로 분해한다.
- 코드 라인 96에서 다음 스캐닝을 위해 free 스캐너의 위치를 기억해둔다.
Isolate freepages 블럭
다음 함수는 다음 두 용도에서 사용되기 위해 호출된다.
- Compaction
- isolate_freepages() 함수
- direct-compact, manual-compact 및 kcompactd 에서 high order 페이지를 확보하기 위한 compaction을 위해 사용된다.
- isolate_freepages() 함수
- CMA
- isolate_freepages_range() 함수에서 호출된다.
- CMA 영역의 요청한 범위를 비우기 위해 사용된다.
- isolate_freepages_range() 함수에서 호출된다.
isolate_freepages_block()
mm/compaction.c -1/2-
/* * Isolate free pages onto a private freelist. If @strict is true, will abort * returning 0 on any invalid PFNs or non-free pages inside of the pageblock * (even though it may still end up isolating some pages). */
static unsigned long isolate_freepages_block(struct compact_control *cc,
unsigned long *start_pfn,
unsigned long end_pfn,
struct list_head *freelist,
bool strict)
{
int nr_scanned = 0, total_isolated = 0;
struct page *cursor, *valid_page = NULL;
unsigned long flags = 0;
bool locked = false;
unsigned long blockpfn = *start_pfn;
unsigned int order;
cursor = pfn_to_page(blockpfn);
/* Isolate free pages. */
for (; blockpfn < end_pfn; blockpfn++, cursor++) {
int isolated;
struct page *page = cursor;
/*
* Periodically drop the lock (if held) regardless of its
* contention, to give chance to IRQs. Abort if fatal signal
* pending or async compaction detects need_resched()
*/
if (!(blockpfn % SWAP_CLUSTER_MAX)
&& compact_unlock_should_abort(&cc->zone->lock, flags,
&locked, cc))
break;
nr_scanned++;
if (!pfn_valid_within(blockpfn))
goto isolate_fail;
if (!valid_page)
valid_page = page;
/*
* For compound pages such as THP and hugetlbfs, we can save
* potentially a lot of iterations if we skip them at once.
* The check is racy, but we can consider only valid values
* and the only danger is skipping too much.
*/
if (PageCompound(page)) {
const unsigned int order = compound_order(page);
if (likely(order < MAX_ORDER)) {
blockpfn += (1UL << order) - 1;
cursor += (1UL << order) - 1;
}
goto isolate_fail;
}
if (!PageBuddy(page))
goto isolate_fail;
/*
* If we already hold the lock, we can skip some rechecking.
* Note that if we hold the lock now, checked_pageblock was
* already set in some previous iteration (or strict is true),
* so it is correct to skip the suitable migration target
* recheck as well.
*/
if (!locked) {
/*
* The zone lock must be held to isolate freepages.
* Unfortunately this is a very coarse lock and can be
* heavily contended if there are parallel allocations
* or parallel compactions. For async compaction do not
* spin on the lock and we acquire the lock as late as
* possible.
*/
locked = compact_trylock_irqsave(&cc->zone->lock,
&flags, cc);
if (!locked)
break;
/* Recheck this is a buddy page under lock */
if (!PageBuddy(page))
goto isolate_fail;
}
- 코드 라인 14~19에서 블럭 내에서 시작 pfn부터 끝 pfn까지 페이지를 순회한다.
- 코드 라인 26~29에서 한 block을 스캔하는 동안 처리할 범위가 크므로 주기적으로 lock된 경우 unlock을 하고 중단 요소가 있는 경우 cc->contended에 ture를 설정하고 루프를 빠져나간다.
- 체크 주기
- SWAP_CLUSTER_MAX(32) 페이지 블럭단위
- 중단요소
- SIGKILL 신호가 처리 지연된 경우
- 비동기 migration 중에 더 높은 우선 순위 태스크의 preemption 요청이 있는 경우
- 체크 주기
- 코드 라인 31에서 스캔 카운터를 증가시킨다.
- 코드 라인 32~36에서 유효 페이지가 아닌 경우 isolate_fail 레이블로 이동한다. 첫 유효 페이지인 경우 해당 페이지를 기억시킨다.
- 코드 라인 44~52에서 compound 페이지인 경우 isolate_fail 레이블로 이동한다.
- 코드 라인 54~55에서 버디 시스템이 관리하는 free 페이지가 아닌 경우 isolate_fail 레이블로 이동한다.
- 코드 라인 64~81에서 만일 lock이 걸려있지 않은 경우 lock을 획득하고, 다시 한번 버디 시스템이 관리하는 free 페이지 여부를 체크하여 아닌 경우 isolate_fail 레이블로 이동한다.
mm/compaction.c -2/2-
/* Found a free page, will break it into order-0 pages */
order = page_order(page);
isolated = __isolate_free_page(page, order);
if (!isolated)
break;
set_page_private(page, order);
total_isolated += isolated;
cc->nr_freepages += isolated;
list_add_tail(&page->lru, freelist);
if (!strict && cc->nr_migratepages <= cc->nr_freepages) {
blockpfn += isolated;
break;
}
/* Advance to the end of split page */
blockpfn += isolated - 1;
cursor += isolated - 1;
continue;
isolate_fail:
if (strict)
break;
else
continue;
}
if (locked)
spin_unlock_irqrestore(&cc->zone->lock, flags);
/*
* There is a tiny chance that we have read bogus compound_order(),
* so be careful to not go outside of the pageblock.
*/
if (unlikely(blockpfn > end_pfn))
blockpfn = end_pfn;
trace_mm_compaction_isolate_freepages(*start_pfn, blockpfn,
nr_scanned, total_isolated);
/* Record how far we have got within the block */
*start_pfn = blockpfn;
/*
* If strict isolation is requested by CMA then check that all the
* pages requested were isolated. If there were any failures, 0 is
* returned and CMA will fail.
*/
if (strict && blockpfn < end_pfn)
total_isolated = 0;
/* Update the pageblock-skip if the whole pageblock was scanned */
if (blockpfn == end_pfn)
update_pageblock_skip(cc, valid_page, total_isolated, false);
cc->total_free_scanned += nr_scanned;
if (total_isolated)
count_compact_events(COMPACTISOLATED, total_isolated);
return total_isolated;
}
- 코드 라인 2~6에서 버디 시스템의 free 리스트에서 free 페이지를 분리하고 order를 기록한다.
- 코드 라인 8~9에서 isolate 카운터 및 확보한 free 페이지 카운터를 증가시킨다.
- 코드 라인 10에서 분리한 페이지를 free 스캐너 리스트에 추가한다.
- 코드 라인 12~15에서 @strict가 true인 경우 CMA 영역의 연속된 페이지를 확보하려고 요청되는데 이 때 하나라도 실패하면 처리를 중단시킨다. 만일 @strict가 0이고 free 스캐너가 확보한 페이지가 migration 스캐너가 확보한 페이지보다 많으면 이러한 경우에도 처리를 중단시킨다.
- 코드 라인 17~19에서 다음 페이지를 위해 루프를 계속하게 한다.
- 코드 라인 21~25에서 isolate_fail: 레이블이다. @strict가 1인 경우 실패하면 곧바로 루프를 빠져나가고, 그렇지 않은 경우 루프를 계속하게 한다.
- 코드 라인 29~30에서 획득한 lock을 풀어준다.
- 코드 라인 36~37에서 진행 중인 pfn이 끝 pfn을 초과하지 않게 제한한다.
- 코드 라인 43에서 입출력 인자로 받은 @start_pfn 값을 현재 pfn 값으로 갱신한다.
- 코드 라인 50~51에서 @strict가 true인 경우 CMA 영역의 연속된 페이지를 확보하려고 요청되는데 이러한 경우 total_isolated 값을 0으로 변경하여 실패 값을 0으로 반환하기 위함이다.
- 코드 라인 54~55에서 끝까지 진행하였지만 실패하였기 때문에 이 페이지 블럭을 skip 마크를 기록하게 한다.
- 코드 라인 57에서 스캔된 페이지 수와 isolation한 페이지 수를 추가하고 isolation된 페이지 수를 반환한다.
Isolate Free 페이지
__isolate_free_page()
mm/page_alloc.c
int __isolate_free_page(struct page *page, unsigned int order)
{
unsigned long watermark;
struct zone *zone;
int mt;
BUG_ON(!PageBuddy(page));
zone = page_zone(page);
mt = get_pageblock_migratetype(page);
if (!is_migrate_isolate(mt)) {
/*
* Obey watermarks as if the page was being allocated. We can
* emulate a high-order watermark check with a raised order-0
* watermark, because we already know our high-order page
* exists.
*/
watermark = min_wmark_pages(zone) + (1UL << order);
if (!zone_watermark_ok(zone, 0, watermark, 0, ALLOC_CMA))
return 0;
__mod_zone_freepage_state(zone, -(1UL << order), mt);
}
/* Remove page from free list */
list_del(&page->lru);
zone->free_area[order].nr_free--;
rmv_page_order(page);
/*
* Set the pageblock if the isolated page is at least half of a
* pageblock
*/
if (order >= pageblock_order - 1) {
struct page *endpage = page + (1 << order) - 1;
for (; page < endpage; page += pageblock_nr_pages) {
int mt = get_pageblock_migratetype(page);
if (!is_migrate_isolate(mt) && !is_migrate_cma(mt)
&& !is_migrate_highatomic(mt))
set_pageblock_migratetype(page,
MIGRATE_MOVABLE);
}
}
return 1UL << order;
}
order page가 free page인 경우 order-0 free page로 분해하여 반환한다. 정상인 경우 2^order에 해당하는 페이지 수가 반환된다.
- 코드 라인 9~10에서 페이지에 해당하는 zone과 migrate 타입을 알아온다.
- 코드 라인 12~24에서 isolation이 불가능한 migrate 타입인 경우 order 0을 요청하여 low 워터마크 + order 페이지 수 값으로도 워터마크 경계를 통과(ok)하지 못한 경우 실패로 0을 반환한다. 통과할 수 있는 경우 free 페이지 수를 order page 수 만큼 감소시킨다.
- 코드 라인 27~29에서 버디 시스템의 해당 리스트에서 페이지를 분리하고 페이지에서 buddy 정보를 제거하기 위해 buddy 플래그 제거 및 order 정보가 기록되어 있는 private 값을 0으로 클리어한다.
- 코드 라인 35~44에서 order 페이지를 free할 때 페이지 블럭의 50% 이상인 경우 페이지 블럭의 기존 타입이 unmovable 및 reclaimable인 경우 페이지 블럭의 타입을 movable로 변경할 수 있다. 단 isolate, cma, highatomic 타입은 변경할 수 없다.
- order 페이지내에 페이지 블럭이 여러 개 있을 수 있으므로 order 페이지의 끝까지 페이지 블럭 단위로 순회하며 해당 페이지 블럭이 isolate, cma 및 highatomic 3 가지 타입 모두 아닌 경우 movable 타입으로 변경한다.
split_page()
mm/page_alloc.c
/* * split_page takes a non-compound higher-order page, and splits it into * n (1<<order) sub-pages: page[0..n] * Each sub-page must be freed individually. * * Note: this is probably too low level an operation for use in drivers. * Please consult with lkml before using this in your driver. */
void split_page(struct page *page, unsigned int order)
{
int i;
VM_BUG_ON_PAGE(PageCompound(page), page);
VM_BUG_ON_PAGE(!page_count(page), page);
for (i = 1; i < (1 << order); i++)
set_page_refcounted(page + i);
split_page_owner(page, order);
}
EXPORT_SYMBOL_GPL(split_page);
분리(split)된 페이지 모두에 참조 카운터를 1로 설정한다. 그리고 기존 페이지의 owner를 모두 옮긴다.
Get new page 후크 함수
compaction_alloc()
mm/compaction.c
/* * This is a migrate-callback that "allocates" freepages by taking pages * from the isolated freelists in the block we are migrating to. */
static struct page *compaction_alloc(struct page *migratepage,
unsigned long data,
int **result)
{
struct compact_control *cc = (struct compact_control *)data;
struct page *freepage;
/*
* Isolate free pages if necessary, and if we are not aborting due to
* contention.
*/
if (list_empty(&cc->freepages)) {
if (!cc->contended)
isolate_freepages(cc);
if (list_empty(&cc->freepages))
return NULL;
}
freepage = list_entry(cc->freepages.next, struct page, lru);
list_del(&freepage->lru);
cc->nr_freepages--;
return freepage;
}
free 스캐너로부터 isolation된 cc->freepages 리스트에서 선두의 free 페이지를 반환한다. 만일 반환할 free 페이지가 없으면 free 스캐너를 가동한다. 실패한 경우 null을 반환한다.
Put new page 후크 함수
compaction_free()
mm/compaction.c
/* * This is a migrate-callback that "frees" freepages back to the isolated * freelist. All pages on the freelist are from the same zone, so there is no * special handling needed for NUMA. */
static void compaction_free(struct page *page, unsigned long data)
{
struct compact_control *cc = (struct compact_control *)data;
list_add(&page->lru, &cc->freepages);
cc->nr_freepages++;
}
페이지를 다시 cc->freepages 리스트에 추가한다.
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c – 현재 글
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd) | 문c
오타로 보이는 부분 신고합니다.
__isolate_free_page() 코드 설명 에서 “코드 라인 27~29에서 버디 시스템의 해당 리스트에서” 등 몇부분이
설명과 코드 라인이 맞지 않습니다.
감사합니다
오타 찾아주셔서 감사합니다.
블로그 코드는 4.0 버전으로 되어 있었고, 설명은 5.4 버전으로 하였었네요.
(주석 등으로 인해 라인 번호가 변경)
해당 코드를 5.4 코드로 바꾸고, 35~44번 라인의 설명도 약간 보강하였습니다.
커널 분석 계속하시면서 이상한 점들 찾아주시면 고맙겠습니다.
감사합니다.
네 ^^ 그리고 커널 버전이 v4.x, v5.0, v5.4 이렇게 있나 보네요.
__reset_isolation_suitable() 함수도 변경이 되어서(v5.1 기준) 업데이트가 안되었나 했는데
페이지 상단에 kernel v5.0으로 명시되어 있네요.
네. 맞습니다. 블로그 초기에 4.0으로 글을 썼고,
작년부터 계속 5.x 버전으로 소스를 바꾸고 있습니다.
대부분의 메모리 부분은 5.0 소스코드를 사용했었고, 그 후 스케줄러등은 LTS 버전인 5.4로 올렸습니다.
그런데 가끔 변경하지 못한 소스를 저도 발견하곤 합니다. ^^;
__reset_isolation_suitable() 함수도 수정하였습니다.
감사합니다.