- 최초 뮤텍스 구현은 Ingo Molnar에 의해 시작되었다.
- 뮤텍스는 커널에서 학계 또는 유사한 이론 서적에서 발견된 ‘상호 배제(mutual exclusiion)’를 참고하는 것 뿐만아니라 공유 메모리에서의 직렬화(serialization)를 수행하는 특정 원시 locking도 참고한다.
- 2006년에 sleeping 가능한 뮤텍스 락이 소개되었고 이는 바이너리 세마포어와 유사한 동작을 한다.
- Sleeping lock은 critical section이 긴 경우(long hold times) 효과적이지만 그 특징으로 인해 인터럽트 핸들러에서 사용할 수 없다.
- 뮤텍스를 빠른 시간 내에 얻을 수 없는 상황에서는 뮤텍스를 얻을 때 까지 현 태스크를 sleep(다른 태스크에 제어권을 넘긴다) 시킨다.
- Generic Mutex Subsystem은 RT(Real Time) 커널에 있는 소스를 메인 스트림에 upstream 하였는데, 이 소스는 x86 계열의 샘플이고 다른 아키텍처로의 포팅이 쉽게될 수 있도록 가이드한다.
- 뮤텍스는 실제 원래 설계 및 목적과 다르게 뮤텍스 오브젝트가 세마포어 오브젝트보다 크기가 커져서 CPU cache와 메모리 footprint에 용량이 더 소모되는 단점이 있다.
- 2013.11월 kernel 디렉토리의 락 관련 화일이 모두 kernel/locking 디렉토리로 이전됨.
- Kernel용 mutex는 recursive lock을 지원하지 않는다.
- 성능을 개선하기 위해 성능순으로 3단계 패스(fastpath, midpath, slowpath)를 구성하였다.
- Fastpath에서는 한 번의 atomic operation 으로 뮤텍스를 가장 빠르게 얻을 수 있되 락을 얻기 전에 unlock 상태의 조건에서만 사용 가능하다.
- Optimistic spinning lock (adaptive spinning for mutex 또는 advanced MCS (queued) lock) 기술은 midpath로 non-sleepable busy wait 를 구현하였는데 SMP 시스템에서 특정 조건을 만족시키면 사용 가능하다.
- 여러 문서들에서 뮤텍스가 sleeping lock이라고 소개되지만 실상은 조금 더 복잡하다. 실제 구현에서는 락 상태별로 몇 개의 조건을 성립하면 fastpath나 midpath를 사용하여 sleep 하지 않고 뮤텍스 락을 얻게될 수 있다. 그러나 그 조건에 부합되지 않은 경우 slowpath가 동작하며 이 때 sleep 한다.
- Wait/Wound Deadlock Proof Mutex(ww-mutex)는 일반 뮤텍스와 달리 deadlock 회피가 가능하다.
사전 지식
- likely(), unlikely() 매크로
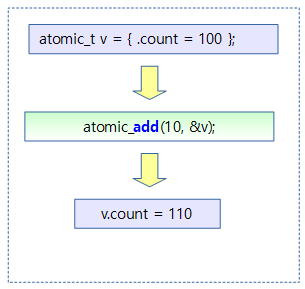
- Atomic operation
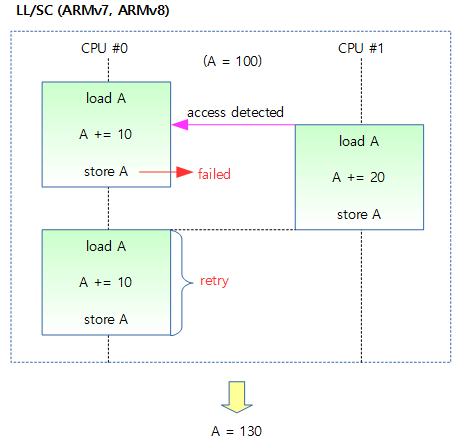
- ldrex, strex
- Spin lock
- spin_lock(), spin_unlock()
- Preemption
- preempt_enable(), preempt_disable()
- RT(Real Time) Kernel
- Interrupt
- local_irq_enable(), local_irq_disable(), local_irq_save(), local_irq_restore()
- Lockdep
- lock_acquire(), lock_release()
- Scheduler
- preemption에 따른 priority 개념, sleep 개념정도만
뮤텍스 옵션
CONFIG_DEBUG_LOCKDEP
- Lock Dependency Engine을 디버깅하는 경우 선택하는 옵션
- 참고: Lockdep, ftrace, TRACE_EVENT, Kernel Debugging
CONFIG_DEBUG_LOCK_ALLOC
- 락뎁(LOCKDEP), 디버그 스핀락(DEBUG_SPINLOCK), 디버그 뮤텍스(DEBUG MUTEXES) 등을 선택하는 경우 락을 디버깅하기 위해 사용되는데 커널에 의해 락 메모리가 올바르게 해제(kfree(), kmem_cache_free(), free_pages(), vfree(), etc…)되지 않는 경우를 감지한다.
- 해당 옵션이 동작하는 경우 mutex_lock() 매크로는 mutex_lock_nested() 함수를 호출하고 fastpath 과정을 건너뛴다.
#define mutex_lock(lock) mutex_lock_nested(lock, 0)
void __sched mutex_lock_nested(struct mutex *lock, unsigned int subclass)
{
might_sleep();
__mutex_lock_common(lock, TASK_UNINTERRUPTIBLE,
subclass, NULL, _RET_IP_, NULL, 0);
}
CONFIG_LOCK_STAT
- 락뎁(LOCKDEP), 디버그 스핀락(DEBUG_SPINLOCK), 디버그 뮤텍스(DEBUG MUTEXES), 디버그 락할당(DEBUG_LOCK_ALLOC) 등을 선택하는 경우 락을 디버깅하기 위해 락 사용 통계를 제공한다.
- 참고: Documentation/locking/lockstat.txt
CONFIG_DEBUG_MUTEXES
- 디버깅 기능을 사용할 수 있으며 이로 인해 약간의 제한을 갖지만 락 개체에 대해 분석할 수 있다.
- 이 옵션을 사용하는 경우 fastpath 루틴은 사용할 수 없으며 항상 slowpath(midpath) 루틴만을 호출한다.
- 이 옵션의 사용 유무에 따른 구현 루틴 구분
- .enable: <linux/mutex-debug.h>, “kernel/locking/mutex-debug.h”, <asm-generic/mutex-null.h>에 있는 헤더파일이 사용됨.
- .disable: “kernel/locking/mutex.h”, <asm/mutex.h> -> <asm-generic/mutex-dec.h>
CONFIG_PROVE_LOCKING
- lock 체인을 분석하고 잘못을 디텍트해 아래와 같이 경고 메시지를 출력한다.
- circular_lock_dependency: “[ INFO: possible circular locking dependency detected ]”
- bad_irq_lock_dependency: “[ INFO: XXXXX-safe -> YYYYY-unsafe lock order detected ]”
- deadlock_bug: “[ INFO: possible recursive locking detected ]”
- usage_bug: “[ INFO: inconsistent lock state ]”
- irq_inversion_bug: “[ INFO: possible irq lock inversion dependency detected ]”
- nested_lock_not_held: “[ BUG: Nested lock was not taken ]”
- unlock_imbalance_bug: “[ BUG: bad unlock balance detected! ]”
- contention_bug: “[ BUG: bad contention detected! ]”
- held_locks_bug: “[ BUG: %s/%d still has locks held! ]”
- 참고: Documentation/locking/lockdep-design.txt
Recursive Lock vs Non-Recursive Lock
- POSIX 뮤텍스는 Recursive Lock을 허락한다. 그 의미는 같은 스레드에서 같은 뮤텍스에 대해 두 번 락을 할 수 있고 dead-lock이 되지 않는다는 뜻이다. 물론 두 번 락을 한 것에 대해 두 번 언락을 해야 한다.
- POSIX 뮤텍스를 사용하는 pthread_mutex는 PTHREAD_MUTEX_RECURSIVE 속성을 사용하여 Recursive lock을 사용할 수 있다.
- 커널에서 사용하는 뮤텍스는 Non-Recursive lock 이다. 같은 스레드에서 두 번 락을 하게되면 두 번째 lock을 획득하는 순간 멈춘다(hold)
Wait/Wound Deadlock Proof Mutex
- Maarten이 개발한 패치로 deadlock을 회피하여 뮤텍스 락을 처리하는 알고리즘으로 ww-mutex라고도 불린다.
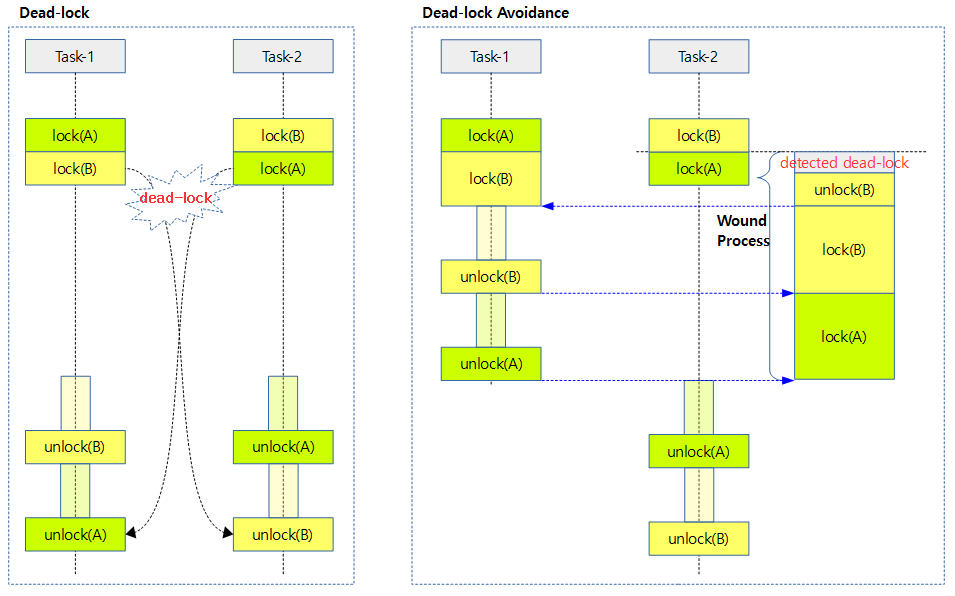
- 커널 코드는 lock ordering과 Lockdep의 체킹 툴로 비정상 상황을 찾아낼 수 있다. 그럼에도 불구하고 deadlock 상황이 발생하는 경우 ww-mutex를 사용하는 경우 다음과 같이 dead-lock 회피 알고리즘이 동작한다.
- 첫 번째 스레드가 락A를 소유하고, 두 번째 스레드가 락B를 소유한 상태에서
- 첫 번째 스레드가 락B의 소유를 시도하고, 두 번째 스레드도 락A를 소유하려고 시도할 때 패치 적용전에는 deadlock 상황에 들어간다.
- 패치가 적용되는 경우 첫 번째 스레드가 락B의 소유를 시도하다 블럭되고
- 두 번째 스레드가 락A를 소유하려고 시도할 때 서로 교차되는 락을 발견하여 “wounded” 된다.
- wounded 의미: 현재 기존에 홀드하고 있는 잠금을 해제하고 처음부터 다시 시작해야 한다라고 말하다(told)
- 두 번째 스레드가 “wound” 처리를 위해 이미 소유하고 있던 락B를 풀었다가 다시 얻으려고 시도하지만
- 두 번째 스레드가 락B를 풀자마자 그 시점에 첫 번째 스레드가 락B를 먼저 획득한다.
- 따라서 두 번째 스레드는 락B를 얻지 못하고 블럭된다.
- 첫 번째 스레드하고 critical section을 지난 후 락B와 락A를 차례대로 반납한다.
- 첫 번째 스레드가 락B를 반납하자마자 두 번째 스레드가 락B를 소유하게 되고
- 다시 첫 번째 스레드가 락A를 반납하자마자 역시 두 번째 스레드가 락A를 소유하게 된다.
- 두 번째 스레드가 critical section을 통과한 후 락A와 락B를 연달아 해제하는 것으로 두 스레드의 모든 락의 사용이 완료된다.
- 이의 구현을 위해 ww_mutex, ww_class, ww_acquire_ctx라는 구조체가 사용된다.
- 사용 시
- mutex_lock() 대신 별도의 ww_mutex_lock()을 사용한다.
- 헤더 화일로 mutex.h 대신 ww-mutex.h를 사용한다.
Fastpath, Midpath, Slowpath Mutex Lock
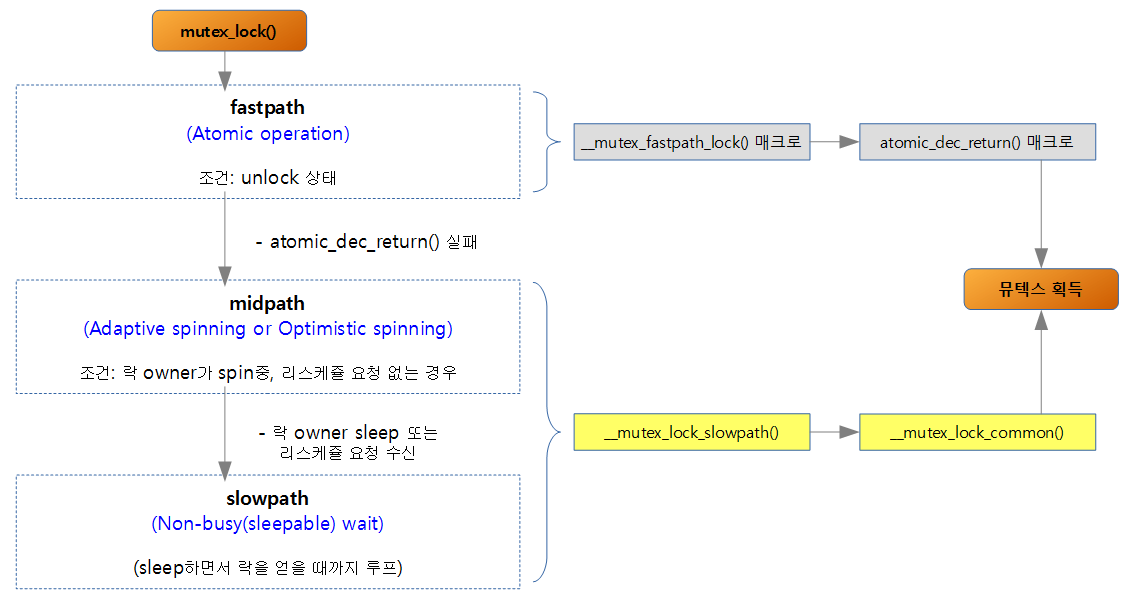
- fastpath (Atomic Operation)
- unlock 상태에서 lock을 획득할 때 fastpath를 사용할 수 있다.
- atomic opeation(몇 개의 인스트럭션이며 아키텍처마다 다름)의 수행만으로 락/언락을 처리하므로 속도가 빠르다.
- count 변수를 atomic하게 감소(또는 교환) 시키는 기법으로 락을 획득하는 방법이다.
- 사전에 count 변수가 1(unlock)인 경우만 fastpath 방법으로 lock을 획득할 수 있다.
- fastpath의 구현은 다음과 같이 두 개로 나뉘어 있다.
- atomic 기반의 감소(decrement)/증가(increment) 명령으로 구현
- atomic 기반의 교환(xchg) 명령으로 구현
- fastpath는 아키텍처에 따라 일반적으로 dec/inc 기반의 사용이 적절한 경우 먼저 선택 사용된다.
- midpath (Optimistic spinning)
- optimistic spinning 또는 adaptive spinning for mutex라 불림
- 이미 락이 걸려 있는 상태에서 아래 조건이 만족하면 빠르게 락을 얻을 가능성이 있어서 midpath를 사용한다.
- 락 owner 태스크가 러닝중
- 리스케쥴 요청이 없는 경우 (현재 태스크보다 더 높은 우선 순위(need_resched)로 동작할 태스크가 없는)
- 뮤텍스 스피너(spinner)는 OSQ(MCS) lock(simple spinlock)을 사용하여 wait_queue에 큐잉(queued up)되고 블러킹되며 기존 spinlock처럼 busy-wait한다. 가장 먼저 큐에 인입된 오직 하나의 스피너만이 뮤텍스를 얻기 위해 경쟁할 수 있다.
- 실제 구현 루틴에서 fastpath 및 slowpath와 다르게 midpath라는 함수명으로 구분되어 있지 않다.
- midpath 루틴은 __mutex_lock_slowpath() 루틴의 전반부에서 호출됨
- CONFIG_MUTEX_SPIN_ON_OWNER 옵션을 사용하여 동작시킨다.
- slowpath와 다르게 sleep/wake-up 사이클 없이 락을 획득한다.
- 다음 문제도 해결 완료
- cache line 충돌(contention) 문제 해결. (Spin on our own cache line)
- ticket spinlock처럼 불공정(fairness) 문제를 해결.
- 참고: Preventing overly-optimistic spinning | LWN.net
- slowpath
- mutex 획득의 3가지 방법 중 가장 느린 방법으로 mutex를 얻을 때까지 루프를 돌며 sleep하고 제어권을 다른 태스크에게 양도한다.
- 디버깅 옵션(CONFIG_DEBUG_MUTEXES)을 사용하는 경우에는 항상 slowpath 방법만을 사용한다.
- wait_lock spinlock을 사용하고, 태스크는 대기큐에 추가되고 unlock path에 의해 깨어날 때 까지 슬립된다.
- 여러 태스크가 경쟁적으로 slowpath에서 mutex를 소유하려고 경쟁하는 경우에는 mutex_lock() 함수 접근 순서대로 처리되지 않는다. 각 태스크가 sleep 되었다가 wake-up 될 때마다 mutex를 얻을 수 있는지 조사하고 얻을 수 있을 때 mutex를 획득한다. 나머지 태스크는 다시 sleep되며 루프를 돈다.
- sleep 기반에서 동작하는 경우에는 각 태스크가 깨어나는 타이밍이 달라서 mutex의 획득 순서에 대하여 공정하게 처리하기 위해 mutex_unlock() 함수 내부에서 대기자들 중 가장 먼저 대기했던 태스크를 먼저 깨울 수 있도록 지시하고 mutex를 release하여 최대한 해당 태스크가 빨리 mutex를 획득할 수 있도록 도와 성능을 높인다.
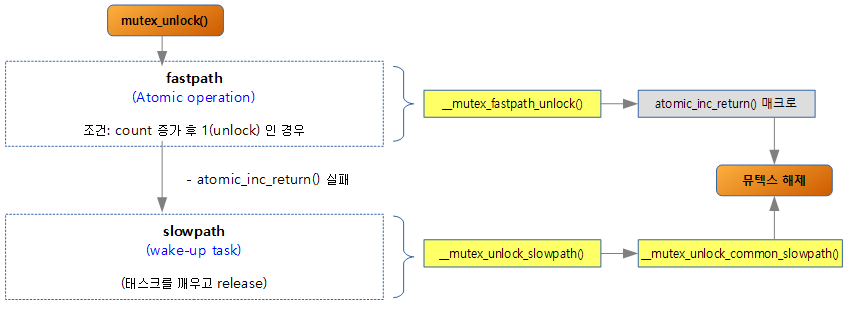
Fastpath, slowpath Mutex Unlock
성능 관련한 접근 방법으로 뮤텍스 해제를 위해 락상태에 따라 2가지의 방법 중 하나를 가장 빠른 fastpath와 slowpath를 선택 사용한다. 처음에 fastpath를 사용하여 뮤텍스가 해제되면 slowpath 루틴을 사용하지 않는다.
Fastpath Mutex Lock 구현 방법
- dec/inc 기반의 fastpath lock (for ARM)
- xchg 기반의 fastpath lock
- fastpath 없이 곧장 slowpath(with midpath) lock
1) dec/inc 기반의 fastpath lock
- ARM 아키텍처에서 사용
- 먼저 atomic_dec_return()으로 이루어진 뮤텍스 fastpath 루틴을 동작시켜 count 값 감소 결과 값이 적은 확률로 값이 0보다 작으면 fail_fn(__mutex_lock_slowpath 함수) 호출.
- atomic_dec_return() 결과값이 0이거나 음수로 예상되는데 이에 따른 의미
- 0: unlock(1) -> lock(0)으로 상태가 바뀜.
- 음수: 기존에 뮤텍스 락이 이미 걸린 상태에서 뮤텍스 락이 또 호출되어 중첩(2번 이상)된 경우
- unlikely() 매크로는 성능향상 즉 optimization을 목적으로 주로 false가 예상되는 경우에 사용된다.
- atomic_dec()이 값을 감소시키기 전의 값을 리턴하는데 반하여 atomic_dec_return()은 값을 감소 시킨 후의 값을 리턴한다.
- atomic_dec_return() 결과값이 0이거나 음수로 예상되는데 이에 따른 의미
static inline void __mutex_fastpath_lock(atomic_t *count, void (*fail_fn)(atomic_t *))
{
if (unlikely(atomic_dec_return(count) < 0))
fail_fn(count);
}
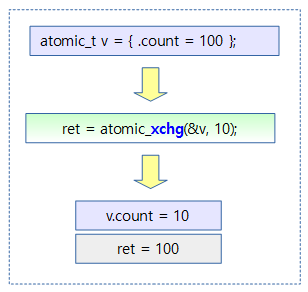
2) xchg 기반의 fastpath lock
- 첫 번째, count 값을 0(lock)으로 교체하기 전 count 값이…
- 적은 확률로 1(unlock)이 아니면 즉, 이미 락이 있으면서 또 락이 호출된 경우 두 번째 조건 수행
- 많은 확률로 1(unlock)인 경우 조건을 빠져나간다.
- fastpath로 싱글 뮤텍스 락 성립
- 두 번째, count 값을 -1(double lock)로 교체하기 전 count 값이…
- 많은 확률로 1(unlock)이 아니면 fail_fn(__mutex_lock_slowpath 함수) 호출 (중첩 락 성립)
- 적은 확률로 1이면 조건을 빠져나간다.
- fastpath로 싱글 뮤텍스 락 성립
- 첫 번째 조건 수행 후 두 번째 조건으로 오기 전에 우선 순위가 높은 태스크가 preempt되어 unlock된 후 다시 이 태스크로 돌아와 계속 수행하게 되는 경우 이렇게 unlock 된 상태로 있을 수 있음.
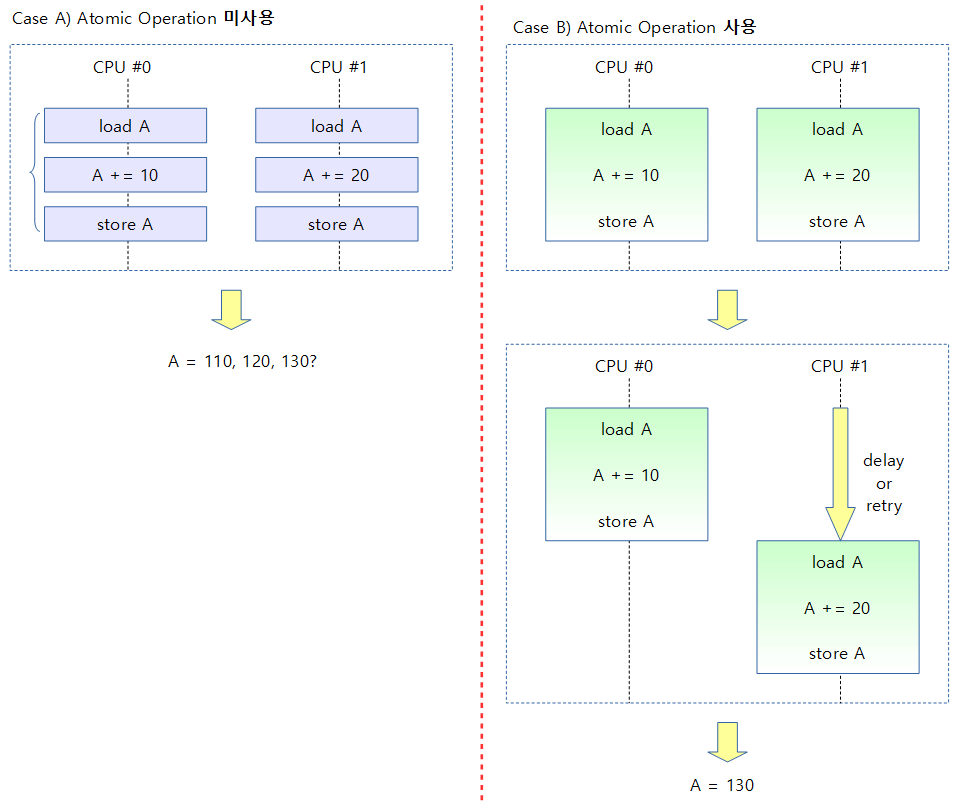
- 개개의 atomic operation은 수행 결과가 분리될 수 없지만 이렇게 개개의 atomic operation을 수행하는 경우에는 preemption 상황을 준비해야 한다.
static inline void __mutex_fastpath_lock(atomic_t *count, void (*fail_fn)(atomic_t *))
{
if (unlikely(atomic_xchg(count, 0) != 1))
/*
* We failed to acquire the lock, so mark it contended
* to ensure that any waiting tasks are woken up by the
* unlock slow path.
*/
if (likely(atomic_xchg(count, -1) != 1))
fail_fn(count);
}
3) slowpath(midpath)로 직행
- 항상 fastpath를 생략하고 fail_fn(__mutex_lock_slowpath 함수) 호출.
#define __mutex_fastpath_lock(count, fail_fn) fail_fn(count)
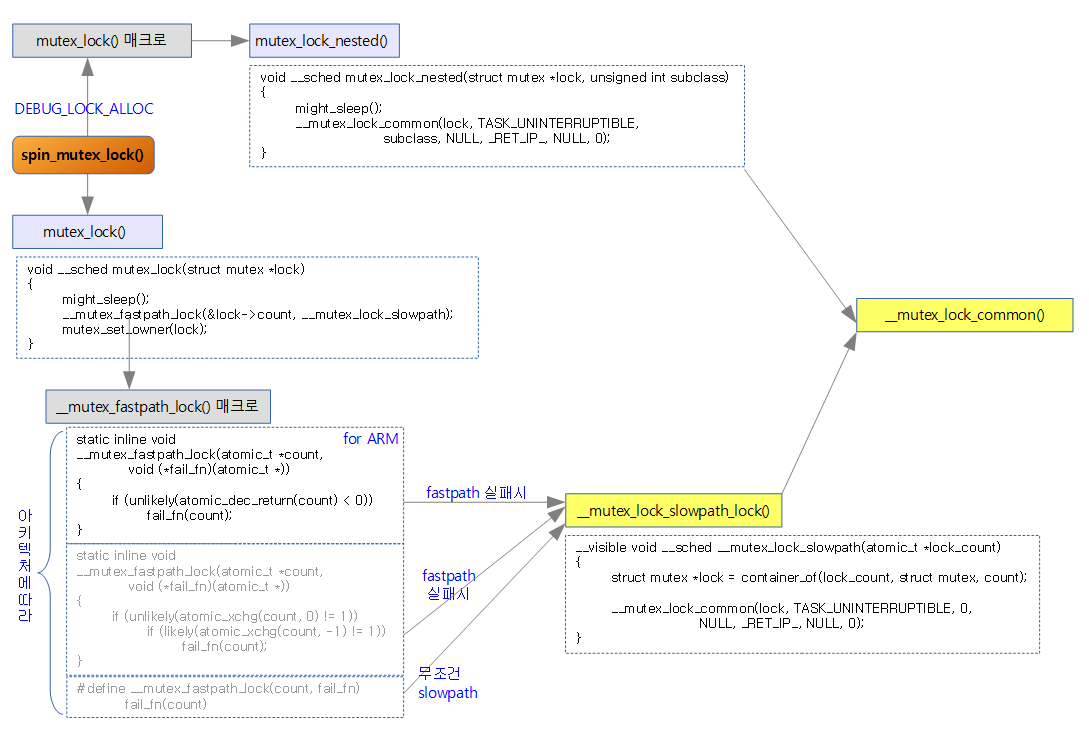
mutex_lock()
- mutex_lock()의 흐름은 아래와 같다. CONFIG_DEBUG_LOCK_ALLOC 기능을 사용하는 경우 mutex_lock_nested() 함수에서 fastpath를 생략하고 곧장 __mutex_lock_common() 함수(midpath와 slowpath 루틴)로 진입한다.
- 옵션이 없는 경우 ARM 아키텍처인경우 atomic_dec_return()을 호출하는 __mutex_fastpath_lock() 매크로를 호출하여 fastpath를 처음부터 호출하여 사용한다.
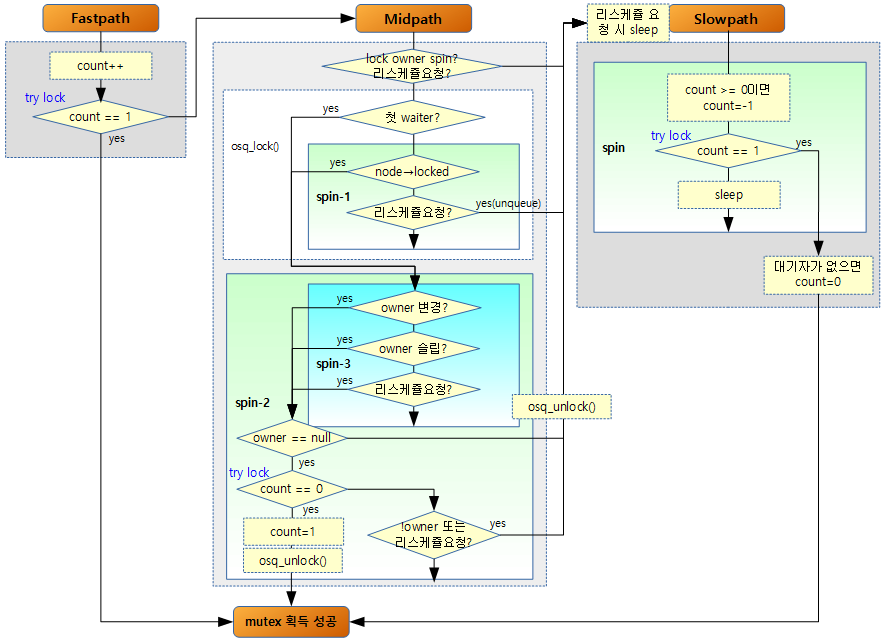
아래 그림은 mutex를 획득하는 조건에 대해서 흐름도로 간략히 표현하였다.
/**
* mutex_lock - acquire the mutex
* @lock: the mutex to be acquired
*
* Lock the mutex exclusively for this task. If the mutex is not
* available right now, it will sleep until it can get it.
*
* The mutex must later on be released by the same task that
* acquired it. Recursive locking is not allowed. The task
* may not exit without first unlocking the mutex. Also, kernel
* memory where the mutex resides must not be freed with
* the mutex still locked. The mutex must first be initialized
* (or statically defined) before it can be locked. memset()-ing
* the mutex to 0 is not allowed.
*
* ( The CONFIG_DEBUG_MUTEXES .config option turns on debugging
* checks that will enforce the restrictions and will also do
* deadlock debugging. )
*
* This function is similar to (but not equivalent to) down().
*/
void __sched mutex_lock(struct mutex *lock)
{
might_sleep();
/*
* The locking fastpath is the 1->0 transition from
* 'unlocked' into 'locked' state.
*/
__mutex_fastpath_lock(&lock->count, __mutex_lock_slowpath);
mutex_set_owner(lock);
}
- 현재 태스크를 위해 베타적으로 뮤텍스를 lock한다. 만일 뮤텍스가 지금 당장 가능하지 않으면 소유할 때 까지 sleep 한다.
- 뮤텍스는 나중에 뮤텍스를 획득한 동일한 태스크에 의해 release 되야 한다.
- Recursive lock은 허용하지 않는다.
- 태스크는 처음 뮤텍스의 unlocking 없이 종료(exit) 할 수 없다.
- 또한 뮤텍스가 lock된 채로 뮤텍스가 자리한 커널 메모리가 해제(free)될 순 없다.
- 처음 뮤텍스를 lock하기 전에 먼저 초기화(또는 정적으로 defined) 되어야 한다.
- memset()으로 뮤텍스를 0으로 초기화 하는 것은 허락되지 않는다.
- CONFIG_DEBUG_MUTEXES: 이 옵션을 동작시키면(turn on) 제약 사항(fastpath를 수행하지 않는)이 있으며 dead-lock 디버깅 등을 수행할 수 있다.
- mutex_lock() 함수는 완전히 동일하진 않지만 down() 함수와 유사하다.
소스 루틴을 살펴보면…
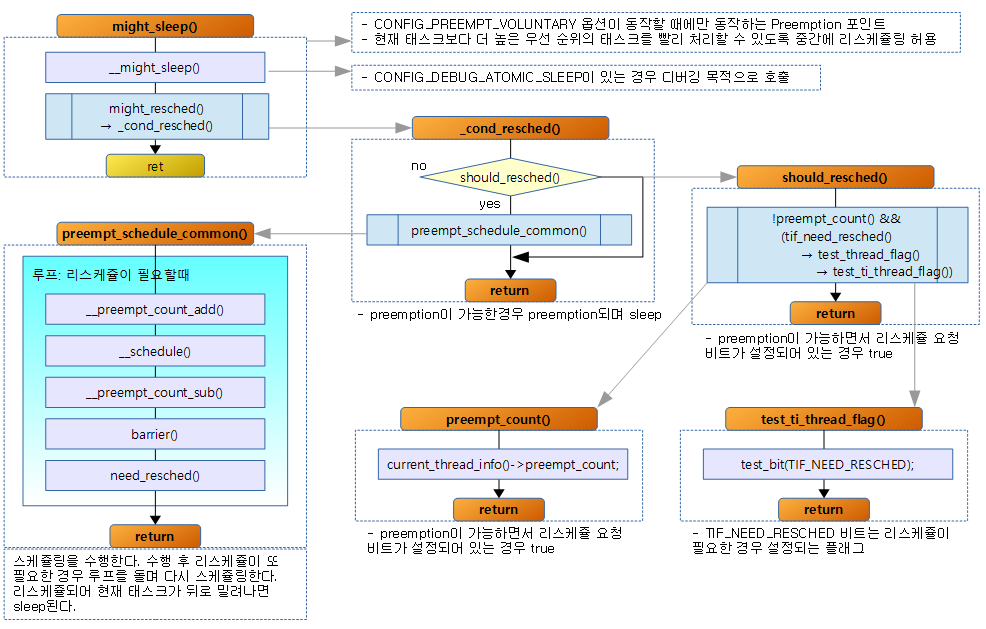
- might_sleep()은 리스케쥴 요청을 받았을 때 sleep하는 preemption points이다. (참고: preemption, might_sleep())
- 이 루틴은 CONFIG_PREEMPT_VOLUNTARY 옵션을 사용하는 경우만 호출된다.
- __mutex_fastpath_lock(&lock->count, __mutex_lock_slowpath);
- fastpath를 호출하고 실패 시 slowpath(midpath)로 구현된 mutex lock 루틴을 호출한다.
- 아키텍처마다 약간 다르지만 ARM 아키텍처에서는 atomic_dec_return()을 사용하는 fastpath 루틴이다.
- 참고: Atomic operation | 문c
- 위에서 자세히 설명하였었지만 fastpath는 락 count 값이 1(unlock) -> 0(lock)으로 상태가 변환될 때만 성공이다.
- 뮤텍스 락에 owner를 설정해둔다.
- CONFIG_MUTEX_SPIN_ON_OWNER 옵션을 사용한 경우에만 owner를 설정한다.
__mutex_lock_slowpath()
__visible void __sched __mutex_lock_slowpath(atomic_t *lock_count)
{
struct mutex *lock = container_of(lock_count, struct mutex, count);
__mutex_lock_common(lock, TASK_UNINTERRUPTIBLE, 0,
NULL, _RET_IP_, NULL, 0);
}
- container_of()는 구조체의 멤버변수를 사용하여 구조체의 처음을 알아내는 함수
- container_of 매크로 | TickTalk
- __mutex_lock_common()에는 뮤텍스 락에 대한 midpath와 slowpath 로직이 담겨있다.
__mutex_lock_common()
static __always_inline int __sched __mutex_lock_common(struct mutex *lock, long state, unsigned int subclass,
struct lockdep_map *nest_lock, unsigned long ip,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
{
struct task_struct *task = current;
struct mutex_waiter waiter;
unsigned long flags;
int ret;
preempt_disable();
mutex_acquire_nest(&lock->dep_map, subclass, 0, nest_lock, ip);
if (mutex_optimistic_spin(lock, ww_ctx, use_ww_ctx)) {
/* got the lock, yay! */
preempt_enable();
return 0;
}
- preempt를 disable하여 리스케쥴링하지 않도록 하므로 슬립되지 않는다.
- mutex_acquire_nest()은 락 추척을 위한 디버깅 기능을 위해 호출한다.
- midpath인 mutex_optimistic_spin()으로 락 획득이 성공하면 preempt를 enable 한 후 성공리에 빠져나간다.
- 인수의 마지막에 use_ww_ctx가 있는데 보통 0이며, ww_mutex를 사용하는 경우엔 1이다.
- mutex_lock()을 사용하지 않고 dead-lock avoidance 기능이 있는 ww_mutex_lock()을 사용한 경우에 해당
spin_lock_mutex(&lock->wait_lock, flags);
/*
* Once more, try to acquire the lock. Only try-lock the mutex if
* it is unlocked to reduce unnecessary xchg() operations.
*/
if (!mutex_is_locked(lock) && (atomic_xchg(&lock->count, 0) == 1))
goto skip_wait;
- spin_lock_mutex(): 인터럽트되지 않도록 하면서 뮤텍스의 wait_lock에 spinlock을 건다.
- spin_lock을 거는 이유는 wait_list 등의 자료 구조를 보호하면서 access를 하고 동시에 두 개 이상의 태스크가 접근할 때 조금이라도 먼저 접근한 태스크에게 mutex를 획득할 수 있는 기회를 주기 위함이다.
- 본격적으로 slowpath를 수행하기 전에 한 번 더 midpath 처럼 락을 얻을 수 있는지 시도한다.
- !mutex_is_locked(): 만일 뮤텍스가 unlock 상태이고(이 루틴까지 오면서 lock 상태가 변해 unlock(release)된 경우에 해당)
- atomic_xchg(): lock(0)을 획득하였을 때 변경 전 count 값이 1(unlock)이면 락을 정상적으로 획득한 것이므로 skip_wait 라벨로 점프한다.
debug_mutex_lock_common(lock, &waiter);
debug_mutex_add_waiter(lock, &waiter, task_thread_info(task));
/* add waiting tasks to the end of the waitqueue (FIFO): */
list_add_tail(&waiter.list, &lock->wait_list);
waiter.task = task;
lock_contended(&lock->dep_map, ip);
- debug_mutex_lock_common(): 로컬 변수인 waiter를 초기화한다.
- debug_mutex_add_waiter(): 현재 태스크의 blocked_on에 위에서 초기화한 waiter를 대입한다.
- waiter(대기자)를 wait_list(FIFO wait queue)의 마지막에 추가한다.
- wait_list(락의 대기 FIFO )의 마지막에 waiter를 추가한다.
- waiter.task 현재 task를 대입
- lock_contended() 함수는 CONFIG_LOCK_STAT이 설정된 상태면 “lock_contension_bug”를 디텍트해 출력할 수 있다.
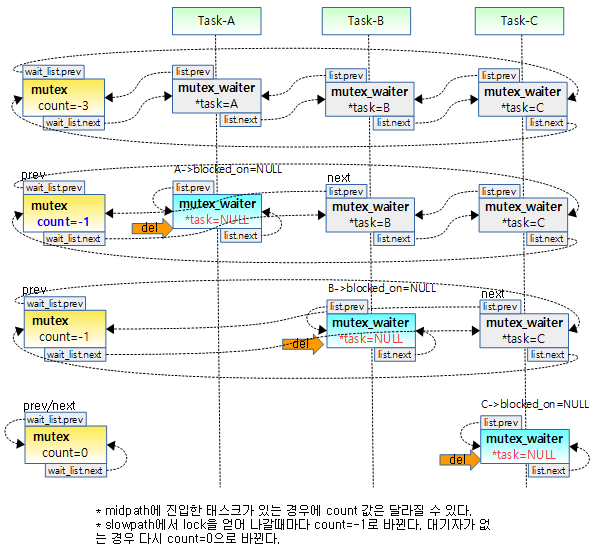
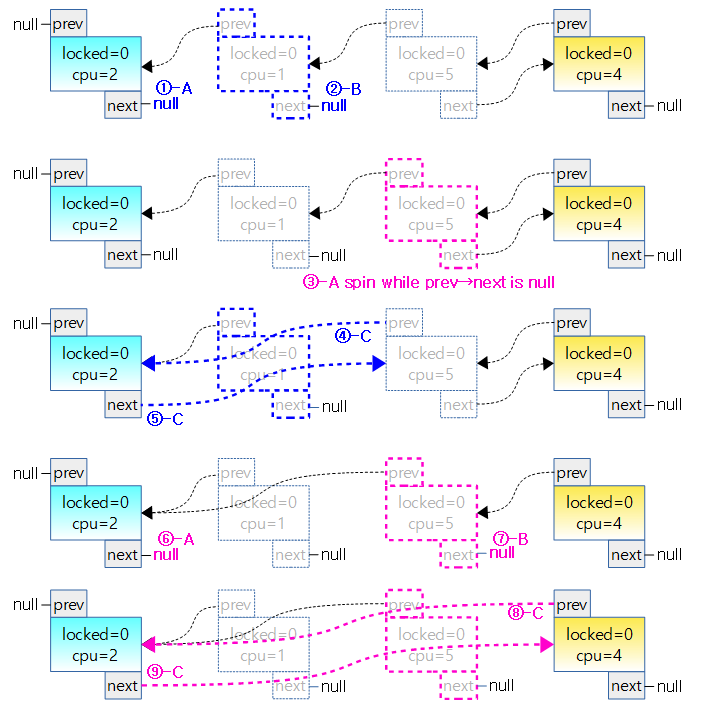
아래 그림은 wait_list에 waiter가 추가되는 과정을 나타냈다.
- 처음엔 wait_list가 비어있고 waiter(대기자)가 하나도 없는 경우는 lock owner만이 mutex를 소유한 상태이므로 count=0이다.
- 두 번째에서 task-A가 wait_list의 뒤에 waiter(대기자)로 추가되었다.
- 세 번째와 네 번째에서 task-B와 task-C가 순차적으로 wait_list의 뒤에waiter(대기자)로 추가되었다.

for (;;) {
/*
* Lets try to take the lock again - this is needed even if
* we get here for the first time (shortly after failing to
* acquire the lock), to make sure that we get a wakeup once
* it's unlocked. Later on, if we sleep, this is the
* operation that gives us the lock. We xchg it to -1, so
* that when we release the lock, we properly wake up the
* other waiters. We only attempt the xchg if the count is
* non-negative in order to avoid unnecessary xchg operations:
*/
if (atomic_read(&lock->count) >= 0 &&
(atomic_xchg(&lock->count, -1) == 1))
break;
/*
* got a signal? (This code gets eliminated in the
* TASK_UNINTERRUPTIBLE case.)
*/
if (unlikely(signal_pending_state(state, task))) {
ret = -EINTR;
goto err;
}
if (use_ww_ctx && ww_ctx->acquired > 0) {
ret = __ww_mutex_lock_check_stamp(lock, ww_ctx);
if (ret)
goto err;
}
__set_task_state(task, state);
/* didn't get the lock, go to sleep: */
spin_unlock_mutex(&lock->wait_lock, flags);
schedule_preempt_disabled();
spin_lock_mutex(&lock->wait_lock, flags);
}
- SMP의 여러 코어가 경쟁적으로 atomic_xchg()를 서로 호출하는 경우 각 코어의 캐시에서 update를 하면서 cache chherent 알고리즘을 통해 많은 부하가 생긴다. 이 때 발생하는 cache bouncing 문제를 해결 하기 위해 atomic_xchg()를 호출하기 전에 atomic_read()를 하도록 루틴이 추가되었다.
- count가 0보다 같거나 크다는 말은 기존에 걸려 있던 락이 풀려 더 이상의 대기자가 없다(락이 하나만 있거나 unlock된 상태)는 뜻이다.
- atomic_xchg()의 리턴값이 1이면(atomic_xchg가 수행되기 전의 count 값) unlock 상태였다는 뜻이다. 이렇게 lock을 획득하면 루프를 빠져나온다.
- 작은 확률로 시그널 상태에 따라 시그널이 펜딩된 상태라면 락 획득 실패되며 에러 처리 루틴으로 점프
- TASK_INTERRUPTIBLE 이거나 TASK_WAKE_KILL 인 상태에서 시그널이 펜딩된경우 true
- TASK_UNINTERRUPTIBLE 케이스인 경우는 코드를 무시하면 됨.
- ww_mutex를 사용하면서 ww_ctx->acquired 값이 0보다 크면
- __ww_mutex_lock_check_stamp()를 호출하여 데드락 상황을 체크하여 true면 에러 처리 루틴으로 점프
- __set_task_state(task, state)
- 태스크 상태를 인수로 받은 상태로 변경한다.
- 인수로 받는 상태는 다음과 같다.
- mutex_lock(), ww_mutex_lock() -> TASK_UNINTERUPTIBLE
- mutex_lock_interruptable(), ww_mutex_interruptable() -> TASK_INTERRUPTIBLE
- mutex_lock_killable() -> TAKS_KILLABLE
- 인수로 받는 상태는 다음과 같다.
- 태스크 상태를 인수로 받은 상태로 변경한다.
- spin lock을 풀고 슬립한다. 슬립이 깨면 다시 spin lock을 얻은 후 루프 처음으로 되돌아가 다시 뮤텍스 획득을 시도한다.
__set_task_state(task, TASK_RUNNING);
mutex_remove_waiter(lock, &waiter, current_thread_info());
/* set it to 0 if there are no waiters left: */
if (likely(list_empty(&lock->wait_list)))
atomic_set(&lock->count, 0);
debug_mutex_free_waiter(&waiter);
- 태스크 상태를 TASK_RUNNING으로 바꾼다.
- slowpath에서 sleep 한 후 깨어나 lock을 얻을 때까지 문제없이 잘 동작하려면 명시적으로 태스크를 TASK_RUNNING 상태로 설정해야 한다.
- mutex_remove_waiter()
- 현재 태스크의 blocked_on을 null로 초기화 한다. (초기화전에 waiter가 지정)
- waiter들끼리 연결이 되어 있는 구조에서 자신의 waiter 노드만 제거하고 초기화 한다.
- waiter->task를 null로 초기화 한다.
- 많은 확률로 락의 wait_list(대기큐)가 비어 있으면(대기자들이 하나도 없으면) atomic하게 count를 0(single lock, 대기자 없는 락 상태)으로 바꾼다.
- debug_mutex_free_waiter()
- waiter 구조체 정보를 깨끗이 지운다.
skip_wait:
/* got the lock - cleanup and rejoice! */
lock_acquired(&lock->dep_map, ip);
mutex_set_owner(lock);
if (use_ww_ctx) {
struct ww_mutex *ww = container_of(lock, struct ww_mutex, base);
ww_mutex_set_context_slowpath(ww, ww_ctx);
}
spin_unlock_mutex(&lock->wait_lock, flags);
preempt_enable();
return 0;
err:
mutex_remove_waiter(lock, &waiter, task_thread_info(task));
spin_unlock_mutex(&lock->wait_lock, flags);
debug_mutex_free_waiter(&waiter);
mutex_release(&lock->dep_map, 1, ip);
preempt_enable();
return ret;
}
- lock_acquired(): lockdep 디버그 코드로 트레이스 목적이며, lock_contention_bug도 디텍트하여 출력한다.
- 락 owner를 현재 태스크로 설정
- ww_mutex를 동작시킨 경우
- container_of()는 구조체의 멤버변수를 사용하여 구조체의 처음을 알아내는 함수
- container_of 매크로 | TickTalk
- ww_mutex_set_context_slowpath()는 deadlock 회피용 slowpath 락으로 분석 생략
- container_of()는 구조체의 멤버변수를 사용하여 구조체의 처음을 알아내는 함수
- spin_unlock_mutex(): spin lock을 release 한다.
- 락 디버그 옵션에서는 리스케쥴 필요한 경우 슬립도 한다.
- 마지막으로 preempt_enable()을 하고 종료
- err: 레이블은 뮤텍스 획득 실패 후 처리되는 루틴으로 분석 생략
아래 그림은 wait_list에 waiter가 삭제되는 과정을 나타냈다.
- 처음엔 wait_list에 waiter(대기자)가 3개가 있는 상태이고 이 때 mutex lock count=-3이다.
- lock count가 음수인 경우 대기자가 있다는 뜻인데 이 숫자를 파악하여 대기자의 수를 알아낼 수는 없다.
- 정확한 대기자의 수는 wait_list에 존재하는 waiter 들의 수이다.
- 두 번째엔 task-A가 wait_list의 선두에서 삭제되고 mutex를 얻게된다.
- 세 번쨰엔 task-B가 wait_list의 선두에서 삭제되고 mutex를 얻게된다.
- 네 번째에 최종 task-C가 wait_list에서 빠져나가면서 mutex를 얻게되고 그 때에 mutex lock count=0이다.
midpath (optimistic spinning)
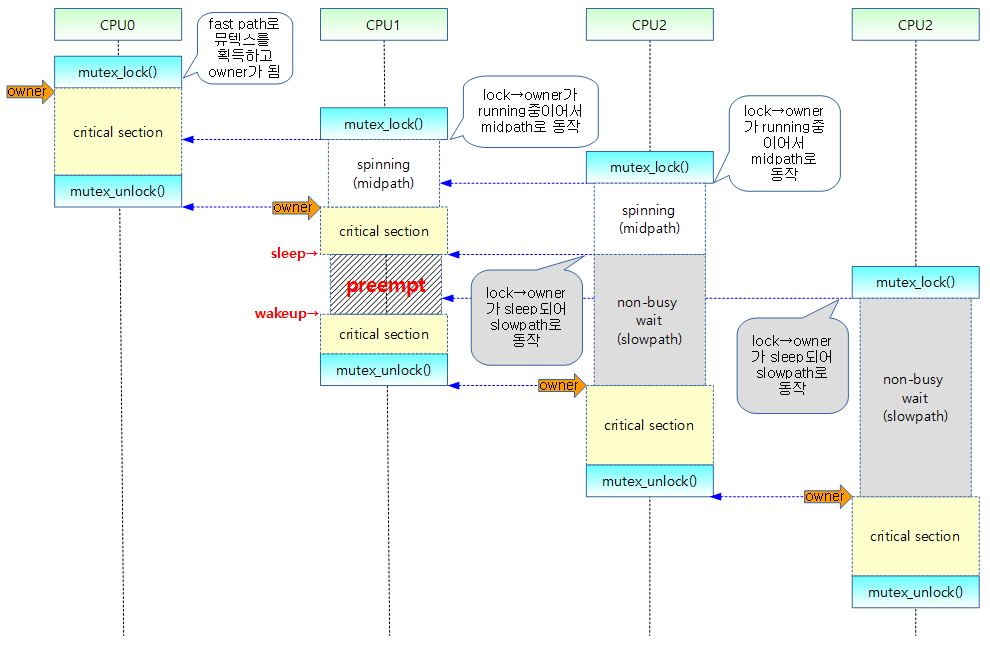
- owner가 다른 CPU에서 러닝(running) 중이면서 현재 태스크가 리스케쥴할 필요가 없을 때 현재 태스크에서 스핀하며 락을 획득하려 시도한다.(busy(non-sleepable ) wait)
- owner가 러닝중이라면 그것은 곧 락을 release 할 것이라는 근거이다.
- 이러한 뮤텍스 구현 방식은 lock field에서 owner를 atomic하게 추적하지 않고 non-atomic하게 추적한다.
- 당연히 fastpath 및 midpath에서는 빠른 속도를 내는 것이 목적이므로 락에 대한 추적을 하지 않는다. (락 추적 목적으로 관련 기록 루틴을 호출하지 않는다)
- Optimistic spinning에서는 모든것을 직렬화(serialize)하는 wait_lock에 기반하기 때문에 DBUG_MUTEXES 옵션 즉 디버깅을 위해 잘 동작하지 않는다.
- 뮤텍스 스피너들은 OSQ(MCS lock)에 큐 up된다. 그래서 오직 하나의 spinner만 뮤텍스에 대해 경쟁한다. 반면에 뮤텍스가 스피닝하지 않을 것 같으면 lock/unlock 오버헤드를 통과하므로 아무 문제 없다.
- 락을 획득하게 되면 true를 리턴하고, 그렇지 않은 경우 false를 리턴하며 slowpath 로 가서 sleep 할 필요가 있다.
- Optimistic spinning은 MCS(Mellor-Crummey and Scott)가 제안한 FIFO queue 구조의 ticket spin lock과 유사한 구조로 구현되었다. (MCS like)
mutex_optimistic_spin()
- 락 owner가 다른 CPU에서 현재 러닝 중
- 락 owner가 다른 CPU에서 돌고 있다는 뜻은 곧 critical section이 끝나고 락이 release 될 가능성이 높다는 뜻
- 현재 태스크의 preemption 요청이 없음
- 리스케쥴 요청이 없다는 뜻으로 결국 락 오너가 락을 release 하자 마자 현재의 태스크에서 곧 락을 얻을 수 있음을 의미
/*
* Optimistic spinning.
*
* We try to spin for acquisition when we find that the lock owner
* is currently running on a (different) CPU and while we don't
* need to reschedule. The rationale is that if the lock owner is
* running, it is likely to release the lock soon.
*
* Since this needs the lock owner, and this mutex implementation
* doesn't track the owner atomically in the lock field, we need to
* track it non-atomically.
*
* We can't do this for DEBUG_MUTEXES because that relies on wait_lock
* to serialize everything.
*
* The mutex spinners are queued up using MCS lock so that only one
* spinner can compete for the mutex. However, if mutex spinning isn't
* going to happen, there is no point in going through the lock/unlock
* overhead.
*
* Returns true when the lock was taken, otherwise false, indicating
* that we need to jump to the slowpath and sleep.
*/
static bool mutex_optimistic_spin(struct mutex *lock,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
{
struct task_struct *task = current;
if (!mutex_can_spin_on_owner(lock))
goto done;
/*
* In order to avoid a stampede of mutex spinners trying to
* acquire the mutex all at once, the spinners need to take a
* MCS (queued) lock first before spinning on the owner field.
*/
if (!osq_lock(&lock->osq))
goto done;
- !mutex_can_spin_on_owner()
- 리스케쥴 요청이 있거나 lock의 owner가 러닝중이 아니면 midpath 불성립
- osq_lock을 획득하지 못하면 midpath 불성립
- 동시에 midpath에 진입하는 cpu들이 서로 lock을 획득하기 위해 쇄도(반복적인 시도로 인해)하는 것을 방지하기 위해서 serialization을 하여 가장 먼저 OSQ(MCS) lock을 획득한 cpu가 성공적으로 리턴된다.
- OSQ(MCS) lock은 FIFO에 의한 큐방식으로 가장 처음에 진입한 spinner만이 뮤텍스에 대해 경쟁을 할 권한을 가지고 있다.
- 따라서 midpath에서도 뮤텍스 획득에 대한 공정성에 접근하였다.
- FIFO 큐에서 대기하고 있는 cpu 들은 대기하면서 만일 리스케쥴 요청이 있는 경우는 실패로 리턴된다.
- 물론 OSQ(MCS) lock을 획득한 cpu가 당장 mutex lock을 얻게되는 것이 아니라 이미 mutex lock을 가진 owner가 mutex unlock될 때 까지 spin된 후에 얻게될 것이다.
while (true) {
struct task_struct *owner;
if (use_ww_ctx && ww_ctx->acquired > 0) {
struct ww_mutex *ww;
ww = container_of(lock, struct ww_mutex, base);
/*
* If ww->ctx is set the contents are undefined, only
* by acquiring wait_lock there is a guarantee that
* they are not invalid when reading.
*
* As such, when deadlock detection needs to be
* performed the optimistic spinning cannot be done.
*/
if (ACCESS_ONCE(ww->ctx))
break;
}
/*
* If there's an owner, wait for it to either
* release the lock or go to sleep.
*/
owner = ACCESS_ONCE(lock->owner);
if (owner && !mutex_spin_on_owner(lock, owner))
break;
/* Try to acquire the mutex if it is unlocked. */
if (mutex_try_to_acquire(lock)) {
lock_acquired(&lock->dep_map, ip);
if (use_ww_ctx) {
struct ww_mutex *ww;
ww = container_of(lock, struct ww_mutex, base);
ww_mutex_set_context_fastpath(ww, ww_ctx);
}
mutex_set_owner(lock);
osq_unlock(&lock->osq);
return true;
}
/*
* When there's no owner, we might have preempted between the
* owner acquiring the lock and setting the owner field. If
* we're an RT task that will live-lock because we won't let
* the owner complete.
*/
if (!owner && (need_resched() || rt_task(task)))
break;
/*
* The cpu_relax() call is a compiler barrier which forces
* everything in this loop to be re-loaded. We don't need
* memory barriers as we'll eventually observe the right
* values at the cost of a few extra spins.
*/
cpu_relax_lowlatency();
}
- usw_ww_mutex: ww_mutex 를 사용하는 경우이면서 deadlock 디텍션이 된경우(ww->ctx가 true) 루프를 벗어나 에러 처리를 한다.
- owner 값을 가져와서(volatile 방식으로 메모리 접근) owner가 존재하면서 owner가 스핀하지 않으면 루프를 벗어난다. (midpath 실패)
- ACCESS_ONCE()
- 2015년 2월 kernel v4.1-rc1에서 모든 ACCESS_ONCE() 매크로 함수는 READ_ONCE() 또는 WRITE_ONCE()로 교체되었다.
- 참고: locking: Remove ACCESS_ONCE() usage
- 참고: [Linux] ACCESS_ONCE()와 volatile | F/OSS
- ACCESS_ONCE()
- 뮤텍스 획득을 시도하여 성공하면 다음과 같이 처리하고 리턴한다.
- lock_acquired(): lockdep 디버그 코드로 트레이스 목적이며, lock_contention_bug도 디텍트하여 출력한다.
- ww_mutex_ctx: ww_mutex를 사용하는 경우 ww_mutex_set_context_fastpath()를 호출한다. (분석 생략)
- 뮤텍스 오너(owner)를 설정
- osq(optimistic spinner queue)에서 언락(MCS queue에서 노드 제거)
- owner가 없으면서 리스케쥴링 요청이 있거나 현재 태스크가 RT task 인 경우 루프를 벗어난다.
- 락은 걸려있는 상태인데 owner가 없다는 뜻은 owner가 lock을 획득하고 owner필드를 설정하려고 하는 사이 즉 아직 owner field의 설정을 다 못한 사이인 경우라면 현재 태스크가 선점했을 수도 있다고 판단하여 루프를 벗어난다.(midpath 실패)
- cpu_relax_lowlatency(): 다시 스핀하기 전에 아키텍처에 따라 메모리 배리어를 동작시킨다.
- cpu_relax()
- 일반적인 ARMv7 SMP 및 UP 시스템은 컴파일러 배리어인 barrier() 함수만 호출한다.
- ARMv7 SMP 코어중 Cortex-A9 r2p0 이전 리비전 및 ARMv6 SMP 아키텍처는 자동 store buffer drain 기능이 없어 dmb_ish 명령을 수행하여야 한다.
- cpu_relax()
osq_unlock(&lock->osq);
done:
/*
* If we fell out of the spin path because of need_resched(),
* reschedule now, before we try-lock the mutex. This avoids getting
* scheduled out right after we obtained the mutex.
*/
if (need_resched()) {
/*
* We _should_ have TASK_RUNNING here, but just in case
* we do not, make it so, otherwise we might get stuck.
*/
__set_current_state(TASK_RUNNING);
schedule_preempt_disabled();
}
return false;
}
- osq(optimistic spinner queue)에서 언락(MCS queue에서 노드 제거)
- 리스케쥴 요청이 있는 경우 태스크 상태를 러닝으로 바꾸고 preemption되어 리스케쥴링이 되지 않도록 막는다.
mutex_can_spin_on_owner()
/*
* Initial check for entering the mutex spinning loop
*/
static inline int mutex_can_spin_on_owner(struct mutex *lock)
{
struct task_struct *owner;
int retval = 1;
if (need_resched())
return 0;
rcu_read_lock();
owner = ACCESS_ONCE(lock->owner);
if (owner)
retval = owner->on_cpu;
rcu_read_unlock();
/*
* if lock->owner is not set, the mutex owner may have just acquired
* it and not set the owner yet or the mutex has been released.
*/
return retval;
}
- 리스케쥴 요청 플래그가 설정되어 있으면 false(0) 리턴
- owner가 설정되어 있지 않으면 true(1) 리턴
- owner가 설정되어 있으면 owner->on_cpu 값을 리턴
- on_cpu: 1=task running, 0=task not running
mutex_spin_on_owner()
/*
* Look out! "owner" is an entirely speculative pointer
* access and not reliable.
*/
static noinline bool mutex_spin_on_owner(struct mutex *lock, struct task_struct *owner)
{
bool ret = true;
rcu_read_lock();
while (lock->owner == owner) {
/*
* Ensure we emit the owner->on_cpu, dereference _after_
* checking lock->owner still matches owner. If that fails,
* owner might point to freed memory. If it still matches,
* the rcu_read_lock() ensures the memory stays valid.
*/
barrier();
if (!owner->on_cpu || need_resched()) {
ret = false;
break;
}
cpu_relax_lowlatency();
}
rcu_read_unlock();
return ret;
}
루프 전체가 rcu_read_lock()에 들어있으므로 현재 태스크가 슬립되지 않도록 하였고 빠르게 처리가 될 것을 가정하고 작성된 코드이다.
- 락 owner 태스크의 critical section 내부에서 슬립하지 않은 채 많은 시간 소모를 하는 경우 문제가 된다. (락 owner 태스크에서 preemption 되면 차라리 실패가되어 이 루프를 벗어날 수 있다)
- lock의 owner와 인수 owner가 같은 경우에만 루프를 돈다. 다른 경우 락 획득 준비가 끝났기 때문에 ture를 리턴한다.
- 락 owner 태스크에서 critical section을 다 통과한 후 락을 release하면 락의 owner에 null이 들어가는 것을 이용하여 락 사용완료를 기다리는 스핀(루프)이다.
- lock->owner를 null하고 비교하지 않는 이유는 lock->owner에 다른 태스크가 들어갈 확률도 있기 때문이다. (다른 태스크에서 lock을 획득한 경우)
- owner의 on_cpu(태스크 가동 여부 플래그)가 false 이거나 리스케쥴 요청이 있는 경우 루프를 벗어나고 false를 리턴한다.
아래 두 개의 함수 코드는 변경되었으므로 상단 부분의 mutex_spin_on_owner() 함수 코드를 참고해야 한다.
static noinline int mutex_spin_on_owner(struct mutex *lock, struct task_struct *owner)
{
rcu_read_lock();
while (owner_running(lock, owner)) {
if (need_resched())
break;
cpu_relax_lowlatency();
}
rcu_read_unlock();
/*
* We break out the loop above on need_resched() and when the
* owner changed, which is a sign for heavy contention. Return
* success only when lock->owner is NULL.
*/
return lock->owner == NULL;
}
static inline bool owner_running(struct mutex *lock, struct task_struct *owner)
{
if (lock->owner != owner)
return false;
/*
* Ensure we emit the owner->on_cpu, dereference _after_ checking
* lock->owner still matches owner, if that fails, owner might
* point to free()d memory, if it still matches, the rcu_read_lock()
* ensures the memory stays valid.
*/
barrier();
return owner->on_cpu;
}
osq_lock()
kernel/locking/osq_lock.c
bool osq_lock(struct optimistic_spin_queue *lock)
{
struct optimistic_spin_node *node = this_cpu_ptr(&osq_node);
struct optimistic_spin_node *prev, *next;
int curr = encode_cpu(smp_processor_id());
int old;
node->locked = 0;
node->next = NULL;
node->cpu = curr;
old = atomic_xchg(&lock->tail, curr);
if (old == OSQ_UNLOCKED_VAL)
return true;
prev = decode_cpu(old);
node->prev = prev;
ACCESS_ONCE(prev->next) = node;
/*
* Normally @prev is untouchable after the above store; because at that
* moment unlock can proceed and wipe the node element from stack.
*
* However, since our nodes are static per-cpu storage, we're
* guaranteed their existence -- this allows us to apply
* cmpxchg in an attempt to undo our queueing.
*/
while (!ACCESS_ONCE(node->locked)) {
/*
* If we need to reschedule bail... so we can block.
*/
if (need_resched())
goto unqueue;
cpu_relax_lowlatency();
}
return true;
- struct optimistic_spin_node *node = this_cpu_ptr(&osq_node);
- per-cpu 데이터인 즉 현재 cpu에 매치되는 osq_node 구조체 포인터를 알아온다.
- int curr = encode_cpu(smp_processor_id());
- OSQ(MCS) lock에서 사용하는 cpu 번호는 1번 부터 시작하므로 0번 부터 시작하는 현재 CPU 번호에 1을 더한다.
- curr = 현재 cpu + 1
- OSQ(MCS) lock에 하나의 엔트리도 없는 경우 가장 빨리 OSQ(MCS) lock을 획득한다.
- old = atomic_xchg(&lock->tail, curr);
- &lock->tail에 curr 값을 대입하고 old에 대입 전 lock->tail 값을 가져온다.
- if (old == OSQ_UNLOCKED_VAL)
- 가져온 cpu 값이 0인경우는 OSQ(MCS) lock이 unlock 상태이므로 가장 빠르게 OSQ(MCS) lock을 획득하게 되어 루틴을 빠져나간다.
- old = atomic_xchg(&lock->tail, curr);
- 노드를 뒤에 추가한다.
- prev = decode_cpu(old);
- per-cpu 데이터를 사용하기 위해 old 값에서 1을 뺀 후 &osq_node 구조체 포인터 값을 알아온다.
- node->prev = prev;
- 현재 노드의 앞에 이전 노드 구조체 정보를 대입하여 연결한다.
- ACCESS_ONCE(prev->next) = node;
- 이전 노드의 뒤에 현재노드를 연결한다.
- prev = decode_cpu(old);
- spin 하며 리스케쥴 요청이 없는 동안 OSQ(MCS) lock을 획득할 때까지 기다린다.
- while (!ACCESS_ONCE(node->locked)) {
- node->locked가 0(lock status)인 경우 spin 한다.
- 0=locked status, 1=unlocked status
- node->locked가 0(lock status)인 경우 spin 한다.
- if (need_resched())
- 현재 태스크에 리스케쥴 요청이 있느지 확인하여 있는 경우 OSQ(MCS) lock 획득을 포기하기 위해 unqueue 루틴으로 이동한다.
- cpu_relax_lowlatency();
- rpi2: ARMv7 SMP인 Cortex-A7은 컴파일러 배리어인 barrier() 함수를 호출한다.
- while (!ACCESS_ONCE(node->locked)) {
unqueue:
/*
* Step - A -- stabilize @prev
*
* Undo our @prev->next assignment; this will make @prev's
* unlock()/unqueue() wait for a next pointer since @lock points to us
* (or later).
*/
for (;;) {
if (prev->next == node &&
cmpxchg(&prev->next, node, NULL) == node)
break;
/*
* We can only fail the cmpxchg() racing against an unlock(),
* in which case we should observe @node->locked becomming
* true.
*/
if (smp_load_acquire(&node->locked))
return true;
cpu_relax_lowlatency();
/*
* Or we race against a concurrent unqueue()'s step-B, in which
* case its step-C will write us a new @node->prev pointer.
*/
prev = ACCESS_ONCE(node->prev);
}
- unqueue 루틴으로 오는 케이스는 lock->owner가 sleep되거나 현재 태스크가 리스케쥴링 요청 받아 midpath를 포기해야 하는 경우 발생한다.
- OSQ(MCS) lock을 포기하기 위해 OSQ에서 spin되고 있는 현재 cpu에 대한 노드의 연결을 제거해야한다.
- lock->owner가 sleep되는 경우 OSQ에서 spin되고 있는 모든 cpu에 대한 노드의 연결을 제거하기 위해 경쟁하는 상황이 벌어지므로 이에 대해 문제 없이 동작하도록 2 단계에 대해 나누어 atomic operation을 사용한다.
- 1단계 prev 노드에서 현재 노드에 대한 연결을 제거될 때까지 루프를 돌며 반복한다. 루프를 반복하는 이유는 여러 cpu가 unqueue를 동시에 진행해야 하는 상황에서 안정적으로 하나씩 처리할 수 있도록 루틴 처리가 되야 한다. 하는 상황에서 내노드에 연결된 이전 노드의 정보를 변경하여 내 연결정보를 없애려고 하는데 이전 노드의 처리가 더 빠르게 처리되는 경우 실시간으로 node->prev 값이 바뀔 수도 있다.
- if (prev->next == node &&
- 먼저 현재 노드가 prev->next인지 확인
- cmpxchg(&prev->next, node, NULL) == node)
- atomic operation에 의해 prev 노드에 현재 노드가 연결되어 있는 경우 현재 노드를 제거한다. 제거가 성공되면 loop를 빠져나간다.
- if (smp_load_acquire(&node->locked))
- node->locked가 1로 설정되어 완전히 종료됨을 알게 되면 루틴을 빠져나간다.
- cpu_relax_lowlatency();
- rpi2: 컴파일러 배리어인 barrier()를 호출한다.
- prev = ACCESS_ONCE(node->prev);
- 다시 한번 내 노드와 연결되어 있는 이전(prev) 노드를 알아온다.
- if (prev->next == node &&
/*
* Step - B -- stabilize @next
*
* Similar to unlock(), wait for @node->next or move @lock from @node
* back to @prev.
*/
next = osq_wait_next(lock, node, prev);
if (!next)
return false;
/*
* Step - C -- unlink
*
* @prev is stable because its still waiting for a new @prev->next
* pointer, @next is stable because our @node->next pointer is NULL and
* it will wait in Step-A.
*/
ACCESS_ONCE(next->prev) = prev;
ACCESS_ONCE(prev->next) = next;
return false;
}
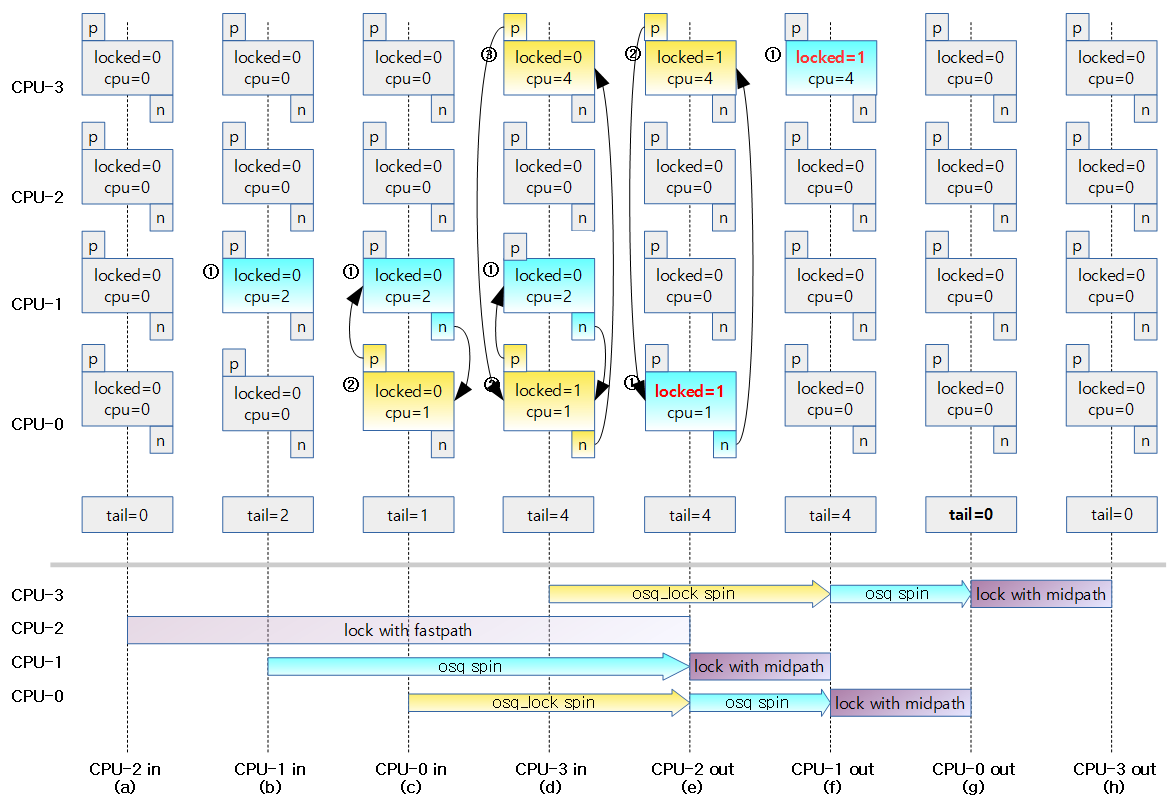
- 아래의 그림은 4개의 task가 각각의 cpu에서 동작한다고 가정하고 1개의 task는 mutex를 소유한 상태이고 3개의 task는 midpath에 진입하여 spin하고 있는 상태이다.
- FIFO 구조의 OSQ(MCS) lock에서 가장 선두에 위치한 task 홀로 mutex 소유자가 release되면 곧바로 mutex를 취득할 수 있도록 spin하고 있다.
- 나머지 2개의 task는 순번대로 연결되어 있다.

- 아래 그림은 3개의 task가 midpath에서 spin하고 있는데 두 번째 task가 리스쥴링 요청을 받아 중간에 unqueue되는 것을 보여준다.
- 단순히 현재 노드를 제거하고 prev 노드와 next 노드를 연결하면 되는데 실제 코드에서는 prev->next와 node->next에 null을 대입하여 먼저 연결을 끊는다.
- midpath에서 대기하는 task 들 중 일부 또는 전부가 동시에 unquque되는 상황이라면 각 cpu에서 동시에 이 구조체에 접근하게 되는데 함부로 연결을 끊고 이어 붙이면 서로 중복 처리되어 정상적인 연결이 되지 않기 때문에 atomic operation을 이용하여 null을 집어넣어 먼저 연결을 끊어 주어야 한다.
- prev->next와 node->next에 null을 집어 넣은 후에는 경쟁(racing) 상황에서 벗어났기 때문에 prev와 next 노드를 연결해준다.
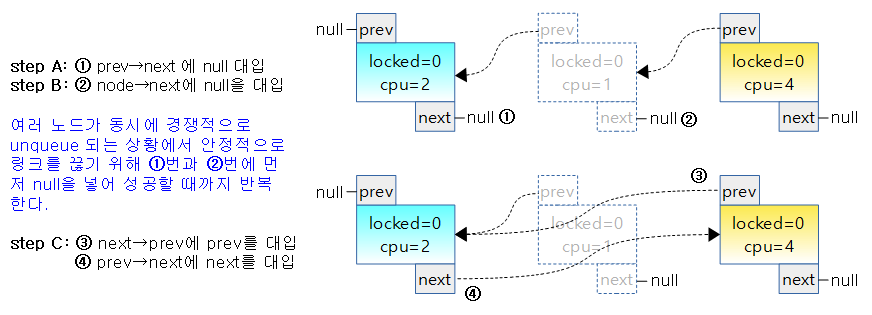
- 아래 그림은 2개의 task가 경쟁적으로 unqueue되어 빠져나가는 상황을 나타내었는데 두 번째 노드와 세 번째 노드가 거의 동시에 step-A까지 동작하였고 그 다음 step-B 동작이 미세하게 두 번째 노드가 먼저 진입한 상태이다.
- 1) 두 번째 노드가 step-A: prev->next에 null을 대입하여 이전 노드로의 연결을 끊는다.
- 2) 세 번째 노드가 step-A: prev->next에 null을 대입하여 이전 노드로의 연결을 끊는다.
- 3) 두 번째 노드가 step-B: node->next가 null인 관계로 null이 아닐 때 까지 spin
- 4) 세 번째 노드가 step-B: node->next가 null이 아니므로 null을 대입하여 다음 노드로의 연결을 끊는다.
- 5, 6) 세 번째 노드가 step-C: 이전 노드와 다음 노드를 서로 연결한다. (자신의 노드는 앞 뒤 노드로 부터의 연결이 unlink 된다.)
- 7) 두 번째 노드가 spin 하고 있다가 step-B: node->next가 null이 아니게 되자마자 null을 대입하여 다음 노드로의 연결을 끊는다.
- 8, 9) 두 번째 노드가 step-C: 이전 노드와 다음 노드를 서로 연결한다. (자신의 노드는 앞 뒤 노드로 부터의 연결이 unlink 된다.)
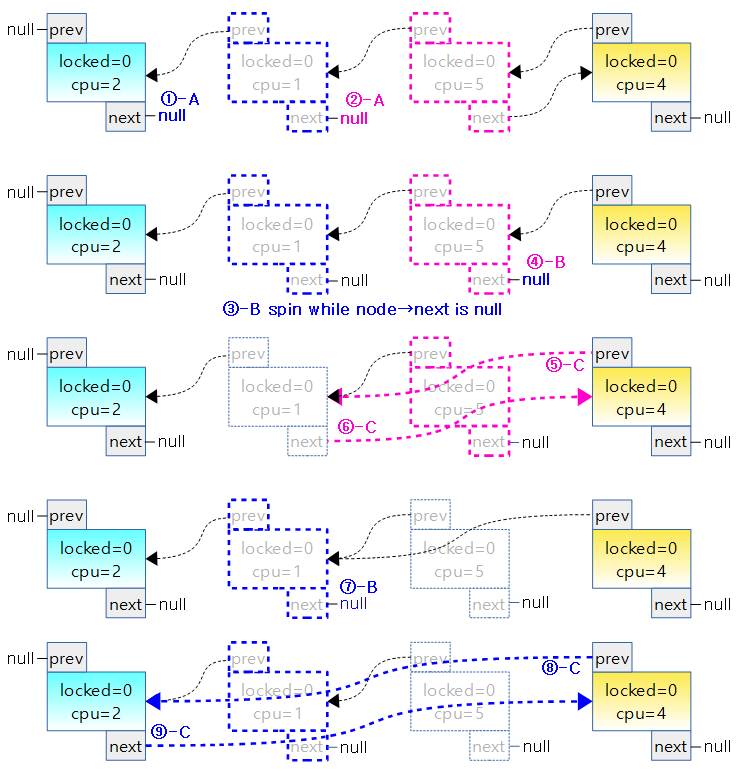
- 아래 그림은 2개의 task가 경쟁적으로 unqueue되어 빠져나가는 상황을 나타내었는데 두 번째 노드가 조금 먼저 진입하여 이미 step-B까지 먼저 진행된 상태에서 세 번째 노드가 step-A에 진입한 경우이다.
- 1) 두 번째 노드가 step-A: prev->next에 null을 대입하여 이전 노드로의 연결을 끊는다.
- 2) 두 번째 노드가 step-B: node->next에 null을 대입하여 다음 노드로의 연결을 끊는다.
- 3) 세 번째 노드가 step-A: prev->next가 null인 관계로 null이 아닐 때 까지 spin 한다.
- 4, 5) 두 번째 노드가 step-C: 이전 노드와 다음 노드를 서로 연결한다. (자신의 노드는 앞 뒤 노드로 부터의 연결이 unlink 된다.)
- 6) 세 번째 노드가 spin 하고 있다가 step-A: prev->next가 null이 아니게 되자마자 null을 대입하여 다음 노드로의 연결을 끊는다.
- 7) 세 번째 노드가 step-B: node->next에 null을 대입하여 다음 노드로의 연결을 끊는다.
- 8, 9) 세 번째 노드가 step-C: 이전 노드와 다음 노드를 서로 연결한다. (자신의 노드는 앞 뒤 노드로 부터의 연결이 unlink 된다.)
osq_unlock()
kernel/locking/osq_lock.c
void osq_unlock(struct optimistic_spin_queue *lock)
{
struct optimistic_spin_node *node, *next;
int curr = encode_cpu(smp_processor_id());
/*
* Fast path for the uncontended case.
*/
if (likely(atomic_cmpxchg(&lock->tail, curr, OSQ_UNLOCKED_VAL) == curr))
return;
/*
* Second most likely case.
*/
node = this_cpu_ptr(&osq_node);
next = xchg(&node->next, NULL);
if (next) {
ACCESS_ONCE(next->locked) = 1;
return;
}
next = osq_wait_next(lock, node, NULL);
if (next)
ACCESS_ONCE(next->locked) = 1;
}
- curr는 현재 cpu(0부터 시작) + 1
- osq_unlock()의 구현도 처리 성능별 3단계로 구현되어 있다.
- fastpath
- OSQ의 마지막 노드가 현재 cpu 노드인 경우
- if (atomic_cmpxchg(&lock->tail, curr, OSQ_UNLOCKED_VAL) == curr))
- &lock->tail이 curr와 같은 경우 OSQ_UNLOCKED_VAL(0)로 대입한다.
- 높은 확률로 atomic_cmpxchg() 함수 결과가 true이면 return 한다.
- atomic_cmpxchg()의 결과가 curr 라는 것은 FIFO 구조의 OSQ(MCS)의 tail이 curr라는 것과 동일하다.
- 참고: Atomic Operation | 문c
- midpath
- OSQ에서 내 뒤에 노드가 존재하는 경우 다음 노드를 osq spin 상태에서 벗어나도록 locked flag를 1로 설정한다.
- node = this_cpu_ptr(&osq_node);
- per-cpu 데이터 구조의 osq_node 구조체 포인터를 알아온다.
- next = xchg(&node->next, NULL);
- xchg()
- #define xchg(ptr,x) ((__typeof__(*(ptr)))__xchg((unsigned long)(x),(ptr),sizeof(*(ptr))))
- &node->next <- NULL을 대입하는데 결과로 대입 이전 값을 리턴한다.
- 참고: Atomic Operation | 문c
- xchg()
- if (next)
- 기존에 다음 노드가 존재하였었다면 next->locked에 1(unlocked)을 대입하고 함수를 빠져나온다.
- 다음 노드가 OSQ(MCS) lock에서 가장 선두 노드이므로 그 노드가 osq spin 상태에서 벗어나도록 지시한다.
- slowpath
- 두 번째 노드가 분명 있지만 연결이 되어 있지 않은 경우 연결될 때까지 기다린 후 다음 노드를 알아와서 그 노드의 locked에 1로 설정하여 osq spin 상태에서 벗어나도록 지시한다.
- next = osq_wait_next(lock, node, NULL)
- 임시적으로 링크가 아직 연결되지 않아 안정되지 않은 상태인 경우 링크가 연결될 때까지 기다려서 다음 노드를 알아온 다음 next->locked에 1(unlocked)을 대입하고 함수를 빠져나온다.
- 역시 다음 노드가 OSQ(MCS) lock에서 가장 선두 노드이므로 그 노드가 osq spin 상태에서 벗어나도록 지시한다.
- fastpath
아래 그림은 midpath로 mutex 요청이 여러 개가 동시에 인입되어 osq_lock() 함수가 호출되어 OSQ(MCS) lock을 얻게되는 과정을 나타내었다.
- 적색 locked=1은 osq_unlock() 호출될 때 OSQ 노드 중 두 번째 노드를 locked=1로 표시하여 두 번째 노드가 osq_lock spin 에서 빠져나올 수 있도록 한다.
osq_wait_next()
kernel/locking/osq_lock.c
/*
* Get a stable @node->next pointer, either for unlock() or unqueue() purposes.
* Can return NULL in case we were the last queued and we updated @lock instead.
*/
static inline struct optimistic_spin_node *
osq_wait_next(struct optimistic_spin_queue *lock,
struct optimistic_spin_node *node,
struct optimistic_spin_node *prev)
{
struct optimistic_spin_node *next = NULL;
int curr = encode_cpu(smp_processor_id());
int old;
/*
* If there is a prev node in queue, then the 'old' value will be
* the prev node's CPU #, else it's set to OSQ_UNLOCKED_VAL since if
* we're currently last in queue, then the queue will then become empty.
*/
old = prev ? prev->cpu : OSQ_UNLOCKED_VAL;
for (;;) {
if (atomic_read(&lock->tail) == curr &&
atomic_cmpxchg(&lock->tail, curr, old) == curr) {
/*
* We were the last queued, we moved @lock back. @prev
* will now observe @lock and will complete its
* unlock()/unqueue().
*/
break;
}
/*
* We must xchg() the @node->next value, because if we were to
* leave it in, a concurrent unlock()/unqueue() from
* @node->next might complete Step-A and think its @prev is
* still valid.
*
* If the concurrent unlock()/unqueue() wins the race, we'll
* wait for either @lock to point to us, through its Step-B, or
* wait for a new @node->next from its Step-C.
*/
if (node->next) {
next = xchg(&node->next, NULL);
if (next)
break;
}
cpu_relax_lowlatency();
}
return next;
}
- 내 노드의 다음에 연결된 노드를 알아오는데 다른 cpu가 unque되면서 연결이 잠시 끊어질 때가 있다 그런 경우는 기다렸다가 연결된 후 즉 안정상태가 된 후 알아와야 한다.
- int curr = encode_cpu(smp_processor_id());
- curr = cpu 번호 + 1
- old = prev ? prev->cpu : OSQ_UNLOCKED_VAL;
- prev 노드가 존재하는 경우 prev노드의 cpu 번호(1부터 시작하는)를 알아오고 없으면 0을 대입한다.
- 0을 대입하는 것은 내 노드가 마지막인데 prev가 없는 경우 empty 큐가 되기 때문이다.
- if (atomic_read(&lock->tail) == curr &&
- lock의 tail이 현재 노드이면서 (내 노드가 마지막 노드이면서)
- atomic_cmpxchg(&lock->tail, curr, old) == curr) {
- atomic operation으로 lock->tail이 curr인 경우 old로 변경시킨다. 변경 시키기 전의 tail 값이 curr인 경우 루프를 빠져나간다.
- 마지막 노드 표식(lock->tail)에 prev->cpu 값을 집어 넣어 이전 노드를 마지막 노드로 만든다.
- if (node->next) {
- 누군가 실시간으로 내 노드의 next 값에 null을 넣어 연결을 끊지 않았으면
- next = xchg(&node->next, NULL);
- 내 노드의 next에 null 값을 집어 넣고 변경되기 전 next 값을 알아와서 next 노드가 존재하는 경우 리턴한다.
- cpu_relax_lowlatency();
- 아직 node->next 값이 설정되지 않았으므로 배리어를 동작시킨 후 다시 루프를 돈다.
mutex_unlock()
kernel/locking/mutex.c
/**
* mutex_unlock - release the mutex
* @lock: the mutex to be released
*
* Unlock a mutex that has been locked by this task previously.
*
* This function must not be used in interrupt context. Unlocking
* of a not locked mutex is not allowed.
*
* This function is similar to (but not equivalent to) up().
*/
void __sched mutex_unlock(struct mutex *lock)
{
/*
* The unlocking fastpath is the 0->1 transition from 'locked'
* into 'unlocked' state:
*/
#ifndef CONFIG_DEBUG_MUTEXES
/*
* When debugging is enabled we must not clear the owner before time,
* the slow path will always be taken, and that clears the owner field
* after verifying that it was indeed current.
*/
mutex_clear_owner(lock);
#endif
__mutex_fastpath_unlock(&lock->count, __mutex_unlock_slowpath);
}
EXPORT_SYMBOL(mutex_unlock);
- fastpath mutex unlock 처리를 위해 __mutex_fastpath_unlock() 함수를 호출한다.
- mutex_lock()과 동일하게 fastpath는 atomic operation으로 구현된다.
- fastpath가 실패하는 경우 __mutex_unlock_slowpath() 함수로 이동한다.
__mutex_fastpath_unlock()
include/asm-generic/mutex-dec.h
/**
* __mutex_fastpath_unlock - try to promote the count from 0 to 1
* @count: pointer of type atomic_t
* @fail_fn: function to call if the original value was not 0
*
* Try to promote the count from 0 to 1. If it wasn't 0, call <fail_fn>.
* In the failure case, this function is allowed to either set the value to
* 1, or to set it to a value lower than 1.
*
* If the implementation sets it to a value of lower than 1, then the
* __mutex_slowpath_needs_to_unlock() macro needs to return 1, it needs
* to return 0 otherwise.
*/
static inline void
__mutex_fastpath_unlock(atomic_t *count, void (*fail_fn)(atomic_t *))
{
if (unlikely(atomic_inc_return(count) <= 0))
fail_fn(count);
}
–
- fastpath는 atomic operation lock count를 증가시켜 적은 확률로 0이하이면(lock 상태) __mutex_unlock_slowpath() 함수를 호출한다.
__mutex_unlock_slowpath()
kernel/locking/mutex.c
/*
* Release the lock, slowpath:
*/
__visible void
__mutex_unlock_slowpath(atomic_t *lock_count)
{
struct mutex *lock = container_of(lock_count, struct mutex, count);
__mutex_unlock_common_slowpath(lock, 1);
}
- __mutex_unlock_common_slowpath() 루틴을 호출한다.
__mutex_unlock_common_slowpath()
kernel/locking/mutex.c
/*
* Release the lock, slowpath:
*/
static inline void
__mutex_unlock_common_slowpath(struct mutex *lock, int nested)
{
unsigned long flags;
/*
* As a performance measurement, release the lock before doing other
* wakeup related duties to follow. This allows other tasks to acquire
* the lock sooner, while still handling cleanups in past unlock calls.
* This can be done as we do not enforce strict equivalence between the
* mutex counter and wait_list.
*
*
* Some architectures leave the lock unlocked in the fastpath failure
* case, others need to leave it locked. In the later case we have to
* unlock it here - as the lock counter is currently 0 or negative.
*/
if (__mutex_slowpath_needs_to_unlock())
atomic_set(&lock->count, 1);
spin_lock_mutex(&lock->wait_lock, flags);
mutex_release(&lock->dep_map, nested, _RET_IP_);
debug_mutex_unlock(lock);
if (!list_empty(&lock->wait_list)) {
/* get the first entry from the wait-list: */
struct mutex_waiter *waiter =
list_entry(lock->wait_list.next,
struct mutex_waiter, list);
debug_mutex_wake_waiter(lock, waiter);
wake_up_process(waiter->task);
}
spin_unlock_mutex(&lock->wait_lock, flags);
}
- __mutex_slowpath_nees_to_unlock()
- 아키텍처마다 다르지만 ARM의 경우 1로 설정된다.
- ARM에서 구현된 midpath를 위한 조건을 동작시키기 위해 1로 설정된다.
- 아키텍처마다 다르지만 ARM의 경우 1로 설정된다.
- atomic_set(&lock->count, 1)
- midpath에서 lock을 획득하기 위해 spin하고 있는 태스크가 있는 경우 mutex를 획득할 수 있는 기회를 slowpath 보다 먼저 주기위해 lock->count를 1(unlock)로 설정한다.
- if (!list_empty(&lock->wait_list)) {
- 대기자가 있는 경우
- struct mutex_waiter *waiter = list_entry(lock->wait_list.next, struct mutex_waiter, list);
- 선두에 있는 대기자를 알아온다.
- wake_up_process(waiter->task);
- 알아온 대기자를 깨어나게 요청한다.
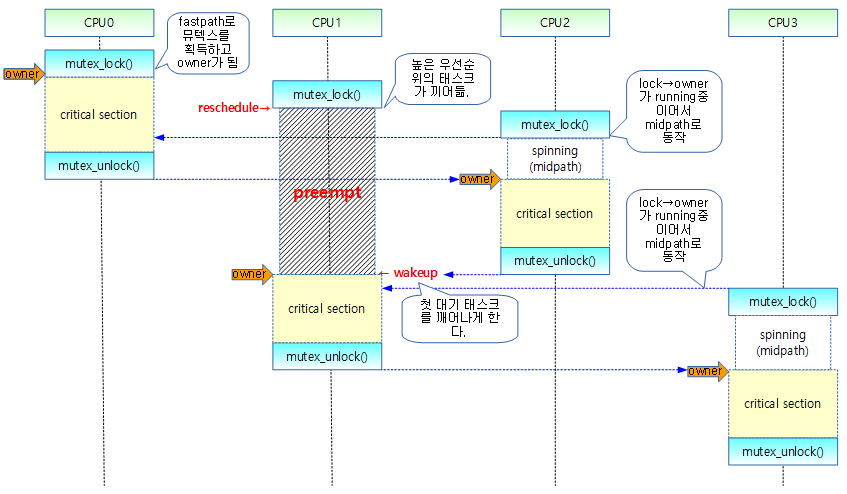
다음 그림을 보고 slowpath에서 잠들어 있는 태스크를 깨우는 동작을 확인한다.
- CPU 1에 있는 mutex는 task가 preemption요청을 받아 slowpath로 동작하여 sleep되어 있다가 CPU2가 unlock될 때 첫 대기자인 CPU1에서 구동되고 있는 태스크를 미리 깨워서 mutex를 얻을 수 있도록 기회를 준다.
기타 함수
spin_lock_mutex()
#define spin_lock_mutex(lock, flags) \
do { \
struct mutex *l = container_of(lock, struct mutex, wait_lock); \
DEBUG_LOCKS_WARN_ON(in_interrupt()); \
local_irq_save(flags); \
arch_spin_lock(&(lock)->rlock.raw_lock);\
DEBUG_LOCKS_WARN_ON(l->magic != l); \
} while (0)
kernel/locking/mutex.h
#define spin_lock_mutex(lock, flags) \
do { spin_lock(lock); (void)(flags); } while (0)
debug_mutex_lock_common()
void debug_mutex_lock_common(struct mutex *lock, struct mutex_waiter *waiter)
{
memset(waiter, MUTEX_DEBUG_INIT, sizeof(*waiter));
waiter->magic = waiter;
INIT_LIST_HEAD(&waiter->list);
}
-
waiter 구조체를 초기화한다.
debug_mutex_add_waiter()
kernel/locking/mutex-debug.c
void debug_mutex_add_waiter(struct mutex *lock, struct mutex_waiter *waiter,
struct thread_info *ti)
{
SMP_DEBUG_LOCKS_WARN_ON(!spin_is_locked(&lock->wait_lock));
/* Mark the current thread as blocked on the lock: */
ti->task->blocked_on = waiter;
}
- 인수로 전달된 현재 context에 연결된 태스크 구조체의 blocked_on에 waiter를 추가한다. (대기 태스크들이 연결된다.)
__ww_mutex_lock_check_stamp()
static inline int __sched __ww_mutex_lock_check_stamp(struct mutex *lock, struct ww_acquire_ctx *ctx)
{
struct ww_mutex *ww = container_of(lock, struct ww_mutex, base);
struct ww_acquire_ctx *hold_ctx = ACCESS_ONCE(ww->ctx);
if (!hold_ctx)
return 0;
if (unlikely(ctx == hold_ctx))
return -EALREADY;
if (ctx->stamp - hold_ctx->stamp <= LONG_MAX &&
(ctx->stamp != hold_ctx->stamp || ctx > hold_ctx)) {
#ifdef CONFIG_DEBUG_MUTEXES
DEBUG_LOCKS_WARN_ON(ctx->contending_lock);
ctx->contending_lock = ww;
#endif
return -EDEADLK;
}
return 0;
}
-
ww_mutex 사용 시에 사용되는 함수로 deadlock 상황을 디텍트하여 _EDEADLK를 리턴한다.
구조체
struct mutex
/*
* Simple, straightforward mutexes with strict semantics:
*
* - only one task can hold the mutex at a time
* - only the owner can unlock the mutex
* - multiple unlocks are not permitted
* - recursive locking is not permitted
* - a mutex object must be initialized via the API
* - a mutex object must not be initialized via memset or copying
* - task may not exit with mutex held
* - memory areas where held locks reside must not be freed
* - held mutexes must not be reinitialized
* - mutexes may not be used in hardware or software interrupt
* contexts such as tasklets and timers
*
* These semantics are fully enforced when DEBUG_MUTEXES is
* enabled. Furthermore, besides enforcing the above rules, the mutex
* debugging code also implements a number of additional features
* that make lock debugging easier and faster:
*
* - uses symbolic names of mutexes, whenever they are printed in debug output
* - point-of-acquire tracking, symbolic lookup of function names
* - list of all locks held in the system, printout of them
* - owner tracking
* - detects self-recursing locks and prints out all relevant info
* - detects multi-task circular deadlocks and prints out all affected
* locks and tasks (and only those tasks)
*/
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock;
struct list_head wait_list;
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_MUTEX_SPIN_ON_OWNER)
struct task_struct *owner;
#endif
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
간단하고도 엄격한 의미의 뮤텍스
- 한 개의 태스크는 한 번에 하나의 뮤텍스를 hold(lock이 걸려 대기하는 상태)할 수 있다.
- owner만이 뮤텍스를 unlock 할 수 있다.
- 다중 unlock은 허가되지 않는다.
- 재귀(recursive) locking은 허가되지 않는다.
- 뮤텍스 오브젝트는 반드시 API를 이용하여 초기화 하여야 한다.
- 뮤텍스 오브젝트는 절대 memset나 memcpy에 의해 초기화되어 사용될 수 없다.
- 태스크는 뮤텍스가 held된 채로 종료할 수 없다.
- held된 락이 위치한 메모리 영역은 절대 free 되면 안된다.
- held된 락은 절대 재 초기화될 수 없다.
- 뮤텍스는 tasklets와 타이머같은 하드웨어 또는 소프트웨어 인터럽트 컨텍스트를 사용할 수 없다.
- CONFIG_DEBUG_MUTEXES 옵션을 사용한 경우
- 디버그 출력 시 뮤텍스의 심볼명 사용
- 락획득지점(point-of-acquire) 추적, 펑션명으로 심볼 검색(lookup)
- 시스템에서 held된 모든 락 목록을 출력
- 소유자 추적
- 재귀(self-recursing) 락의 검출과 관련 정보 출력
- 멀티 태스크 dead-lock의 검출과 영향을 끼친 락과 태스크의 출력
- 구조체 멤버 변수
- counter: 3가지의 뮤텍스 상태를 나타내는데 초기화 후 unlock(1) 상태로 시작한다.
- 1: unlock
- 0: 대기자 없는 lock
- 음수: 대기자 있는 lock
- wait_lock: slowpath 구현에 사용되는 spin lock으로 spin_lock_mutex()의 인수로 사용
- wait_list: 대기자 리스트 (ticket 구현)
- ownner: 락 소유한 태스크의 포인터, CONFIG_MUTEX_SPIN_ON_OWNER 옵션 또는 락 디버깅에서 사용
- osq: optimisitc spin queue(spinner MCS lock), CONFIG_MUTEX_SPIN_ON_OWNER 옵션에서 사용
- magic: 락 디버깅에서 사용
- dep_map: CONFIG_DEBUG_LOCK_ALLOC 옵션에서 사용
- counter: 3가지의 뮤텍스 상태를 나타내는데 초기화 후 unlock(1) 상태로 시작한다.
struct mutex_waiter
include/linux/mutex.h
/*
* This is the control structure for tasks blocked on mutex,
* which resides on the blocked task's kernel stack:
*/
struct mutex_waiter {
struct list_head list;
struct task_struct *task;
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
};
- list
- wait_list의 뒤에서 각 mutex_waiter들이 연결되는데 사용된다.
- task
- 대기하고 있는 태스크
struct optimistic_spin_node
include/linux/osq_lock.h
/*
* An MCS like lock especially tailored for optimistic spinning for sleeping
* lock implementations (mutex, rwsem, etc).
*/
struct optimistic_spin_node {
struct optimistic_spin_node *next, *prev;
int locked; /* 1 if lock acquired */
int cpu; /* encoded CPU # + 1 value */
};
- optimistic_spin_node 구조체는 per-cpu 데이터인 전역 변수 osq_node에서 사용된다.
- next 및 prev에 null이 있는 경우 OSQ(MCS) unlock 상태이고 FIFO 구조로 나중에 추가된 노드들은 꼬리 부분에 추가된다.
- locked
- 보통 0상태에 있고 midpath에서 mutex를 얻기 위해 경쟁을 하는 cpu가 osq_unlock()되어 나갈 때 OSQ에서 후 순위로 대기하고 cpu가 osq_lock()에서 빠져나올 수 있도록 하게 한다.
- cpu
- 1번 부터 사직되는 CPU 번호
struct optimistic_spin_queue
include/linux/osq_lock.h
struct optimistic_spin_queue {
/*
* Stores an encoded value of the CPU # of the tail node in the queue.
* If the queue is empty, then it's set to OSQ_UNLOCKED_VAL.
*/
atomic_t tail;
};
- OSQ(MCS)에서 가장 마지막에 위치한 노드로 1번 부터 시작하는 cpu 번호이다. 0이 들어있는 경우 대기자가 없는 경우이다.
뮤텍스 초기화
- DEFINE_MUTEX() 매크로를 사용하여 정적 선언으로 뮤텍스를 초기화
- mutex_init() 매크로 함수를 호출하여 다이나믹하게 뮤텍스를 초기화
1) DEFINE_MUTEX()
#define DEFINE_MUTEX(mutexname) \
struct mutex mutexname = __MUTEX_INITIALIZER(mutexname)
include/linux/mutex-debug.h
#ifdef CONFIG_DEBUG_MUTEXES
#define __DEBUG_MUTEX_INITIALIZER(lockname) \
, .magic = &lockname
#else
# define __DEBUG_MUTEX_INITIALIZER(lockname)
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define __DEP_MAP_MUTEX_INITIALIZER(lockname) \
, .dep_map = { .name = #lockname }
#else
# define __DEP_MAP_MUTEX_INITIALIZER(lockname)
#endif
#define __MUTEX_INITIALIZER(lockname) \
{ .count = ATOMIC_INIT(1) \
, .wait_lock = __SPIN_LOCK_UNLOCKED(lockname.wait_lock) \
, .wait_list = LIST_HEAD_INIT(lockname.wait_list) \
__DEBUG_MUTEX_INITIALIZER(lockname) \
__DEP_MAP_MUTEX_INITIALIZER(lockname) }
- CONFIG_DEBUG_MUTEXES 옵션이 있는 경우 mutex 구조체의 magic 멤버 변수에 lockname의 주소를 대입한다.
- CONFIG_DEBUG_LOCK_ALLOC 옵션이 있는 경우 mutex 구조체의 dep_map 멤버 구조체 변수중 name에 lockname을 직접 대입한다.
2) mutex_init()
/**
* mutex_init - initialize the mutex
* @mutex: the mutex to be initialized
*
* Initialize the mutex to unlocked state.
*
* It is not allowed to initialize an already locked mutex.
*/
# define mutex_init(mutex) \
do { \
static struct lock_class_key __key; \
__mutex_init((mutex), #mutex, &__key); \
} while (0)
- 이미 lock된 뮤텍스는 초기화를 허락하지 않는다.
kernel/locking/mutex.c
void __mutex_init(struct mutex *lock, const char *name, struct lock_class_key *key)
{
atomic_set(&lock->count, 1);
spin_lock_init(&lock->wait_lock);
INIT_LIST_HEAD(&lock->wait_list);
mutex_clear_owner(lock);
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
osq_lock_init(&lock->osq);
#endif
debug_mutex_init(lock, name, key);
}
- 뮤텍스 내에서 사용하는 spin_lock은 wait_list라는 링크드 리스트 구조체를 관리하기 위해 필요하다.
- wait_list를 초기화한다. (리스트의 prev와 next 포인터들은 null이 아니라 wait_list 구조체 자기 자신을 가리킨다)
- owner는 null로 초기화된다.
- CONFIG_MUTEX_SPIN_ON_OWNER 옵션을 사용하는 경우 optimistic spinning queue 락을 초기화한다.
- debug_mutex_init()함수는 디버그 기능에서 사용하며 설명은 생략
Mutex 인터페이스
- 뮤텍스 획득, 언인터럽터블
- void mutex_lock(struct mutex *lock);
- void mutex_lock_nested(struct mutex *lock, unsigned int subclass);
- int mutex_trylock(struct mutex *lock);
- 뮤텍스 획득, 인터럽터블
- int mutex_lock_interruptible_nested(struct mutex *lock, int subclass);
- int mutex_lock_interruptible(struct mutex *lock);
- 뮤텍스 획득, 인터럽터블, 감소시켜서 0되면
- int atomic_dec_and_mutex_lock(atomic_t *cnt, struct mutex *lock);
- 뮤텍스 언락
- void mutex_unlock(struct mutex *lock);
- 뮤텍스 락 획득 여부 체크
- int mutex_is_locked(struct mutex *lock);
참고
- Generic Mutex System | kernel.org
- MCS locks and qspinlocks | LWN.net
- MCS spinlocks: Cancellable MCS spinlock rework | LWN.net
- Ticket spinlocks | LWN.net
- futex(3) man page, final draft for pre-release review | LWN.net
- futex: introduce an optimistic spinning futex | LWN.net
- A surprise with mutexes and reference counts | LWN.net
- Wait/wound mutexes | LWN.net
- Wait/wound mutex implementation, v3 | LWN.net
- ww-mutex-design.txt | LWN.net
- Generic Mutex Subsystem | LWN.net