<kernel v5.10>
배리어
컴파일러나 아키텍처는 성능 향상을 위해 처리 순서에 개연성(dependency)이 없는 경우 순서를 변경하여 처리하는 최적화 동작을 한다. 그러나 개연성이 있지만 컴파일러나 아키텍처가 보기에 개연성이 없어 보이는 것으로 잘못 판단하는 경우도 있으므로 이러한 경우 미리 특정 상황에서 순서를 바꾸지 못하도록 강제해야 하는 경우가 있다. 이럴 때 명령 순서 또는 메모리 접근 동작들 사이에 순서를 바꾸지 못하게 배리어를 사용한다.
실행 오더링 (Execution Ordering)
Out-Of-Order Execution
명령들이 실행될 때 성능 향상을 위해 다음과 같이 컴파일러 또는 H/W 아키텍처 내부에서의 최적화를 통해 명령 실행 순서를 바꾸는 경우들이 있다.
- 컴파일러가 반복 실행되는 구간을 최소화 하도록 최적화
- 예) 1씩 100번 반복하여 증가하는 루틴 -> 한 번에 100을 증가
- 1 개의 프로세스(HW 스레드)가 명령들을 순차 처리하지 않고 일부 병렬로 처리할 때
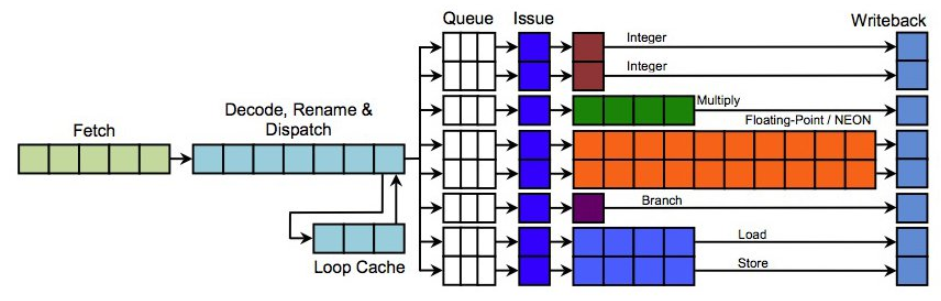
다음은 1개의 프로세스(HW 스레드)에서 Fetch된 명령들이 동시에 처리를 시작할 수 있다.
- 5개의 처리 유형(Integer, Multiply, Floating-Point/NENO, Branch, Load/Store)이 다른 명령이 인입되는 경우 각각에서 동시에 처리를 진행할 수 있다. 완료 시점은 명령마다 다르다. 파이프 라인 스텝(사이클)이 적은 항목이 더 빨리 처리된다. 결국 floating-point 연산 명령 후에 integer 연산이 따라오는 경우 integer 연산이 먼저 처리되어 완료되는 경우가 발생한다. 이렇게 처리 순서가 바뀔 수 있다.
- 같은 처리 유형이라도 Issue 처리기가 2개 이상일 때 동시 처리할 수 있다.
메모리 오더링 (Memory Ordering)
Out-Of-Order Memory
공유 메모리 공간을 CPU들과 디바이스들이 접근하는데 성능 향상을 위해 다음과 같이 컴파일러 또는 H/W 아키텍처 내부에서의 최적화를 통해 접근 순서를 바꾸는 경우들이 있다.
- 컴파일러가 반복기록하는 구간을 최소화 하도록 최적화
- 예) A 주소에 1을 100번 반복하여 기록 -> A 주소에 1을 한 번 기록
- 아키텍처가 출력 버퍼를 사용하여 메모리 접근 순서를 바꿔 최적화
- 예) 캐시 라인에 속한 주소들의 액세스를 가능하면 모아서 처리
예 1) 같은 캐시 라인의 주소를 같이 처리
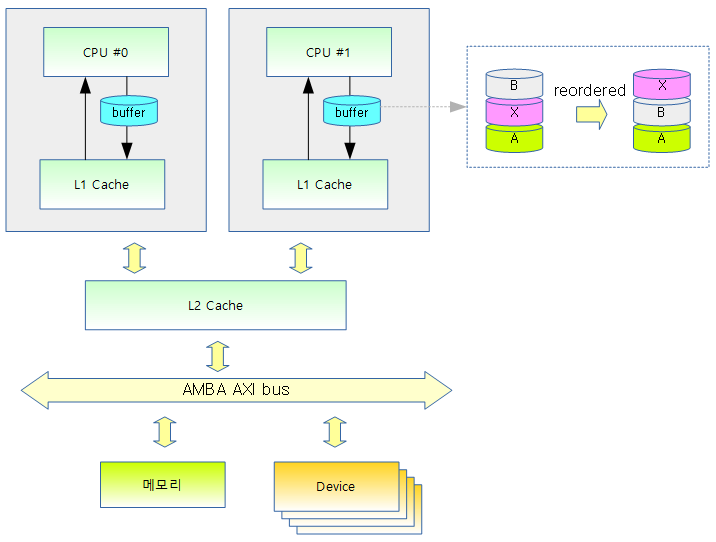
다음 그림과 같이 메모리 액세스 순서가 바뀔 수도 있다.
- A 주소와 B 주소가 같은 캐시라인에 있어서 가능하면 묶어 처리 (아래 그림)
- A, X, B 순서대로 저장하려 했는데 A, B, X 순서로 변경됨
- A, X, B 주소간의 연산이 없어 아키텍처는 관계(dependency)를 모르므로 순서가 바뀔 수 있다.
예 2) 디바이스 주소 레지스터와 데이터 레지스터를 사용 시 Store와 Load 순서 바뀌면서 생기는 문제
- 디바이스 주소 레지스터 A에 주소를 보내고(write),
- 디바이스 데이터 레지스터 B에서 데이터를 받으려(read)하는데
- 아키텍처는 디바이스 레지스터 A와 B의 관계를 모른다. 이러한 경우 A와 B의 순서가 바뀔 수도 있다.
배리어 종류
- Compiler Barrier
- Architecture Barrier
- Implicit barriers and Etc…
Compiler Barrier
컴파일러 최적화 장벽으로 최적화 시 실행 코드가 생략, 축약 또는 실행 순서가 변경되지 못하도록 막아야하는 경우에 사용된다.
- C 함수
- barrier()
- barrier() 이전 메모리 액세스와 이후 메모리 액세스가 컴파일러의 최적화에 의해 순서가 바뀌는 일이 없도록 제한한다.
- barrier()
- 컴파일러 지시어
- __volatile__
- 컴파일러의 optimization을 제한하기 위해 __volatile__을 사용
- 변수 앞에 사용될 때
- 변수 사용에 대한 optimization을 제한한다.
- 컴파일러가 속도 향상을 위해 변수를 레지스터에 배치하는 것을 막는다.
- 변수 사용에 대한 optimization을 제한한다.
- 함수 앞에 사용될 때
- 함수안의 모든 optiomization을 제한한다.
- __volatile__
- 참고: Volatile | 문c
barrier()와 다르게 특정 액세스에 대해서만 동작하는 컴파일러 베리어 API를 알아본다.
- READ_ONCE() 또는 WRITE_ONCE()
- 내부에서 volatile을 사용한다. DEC alpha 아키텍처의 경우 아키텍처 베리어까지 포함한다.
- 싱글 스레드 코드에서는 문제 없지만, 동시성이 있는 코드에서 문제가될 수 있는 최적화들을 방지하게 한다.
- 참고: READ_ONCE() 및 WRITE_ONCE()와 lockless 리스트 | 문c
컴파일러 베리어가 필요한 상황
다음과 같은 여러 가지 상황들에서 컴파일러 베리어를 사용하여 원하지 않는 최적화를 피해야 한다.

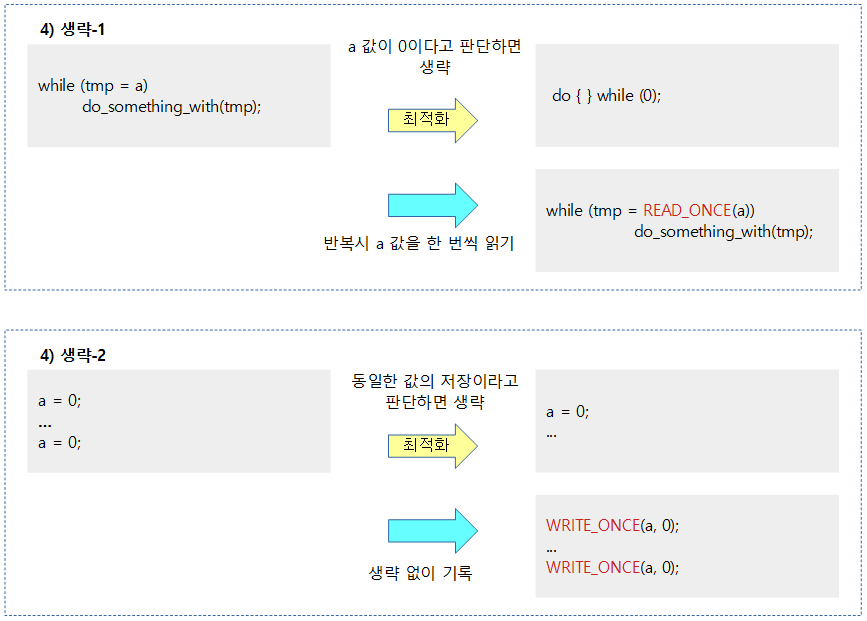

컨트롤 의존성 배리어
컴파일러는 컨트롤 의존성 배리어를 이해하지 못한다.
- LOAD/STORE와 일반 조건(if, for, while, ..)문과의 의존성을 보장하지 않고 예측 처리할 수 있다.
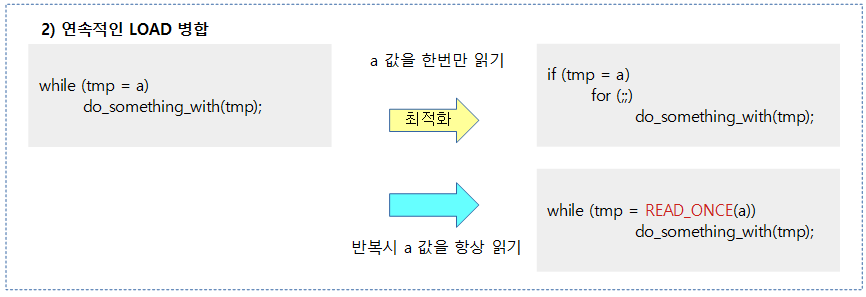
LOAD-LOAD
- LOAD 오퍼레이션간에는 컴파일러에서 컨트롤(if) 의존성이 지원되지 않아 최적화에 의해 예측 수행할 수 있어, 두 LOAD 간의 순서를 보장하지 못한다.
예) 컴파일러의 최적화에 의해 a와 b의 읽는 순서를 보장할 수 없다.
- 최적화에 의해 b 값을 읽은 후, a 값을 읽어 q 값에 대입하고, q가 0이어 조건을 만족하지 않는 경우 q 값을 p에 대입하지 않고 처리될 수도 있다.
q = READ_ONCE(a);
if (q) {
p = READ_ONCE(b);
}
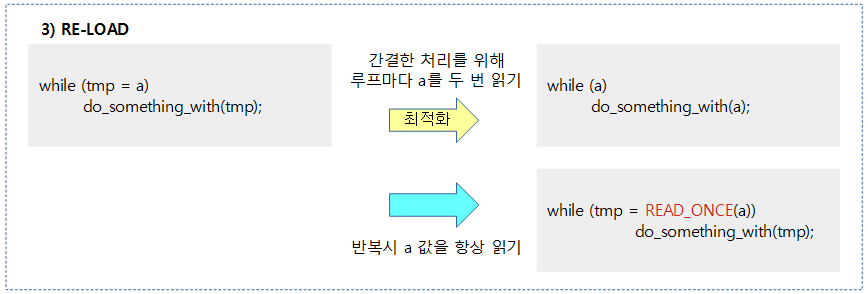
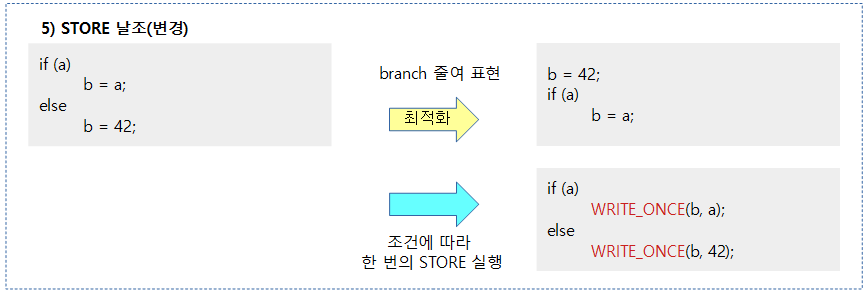
STORE
- STORE 오퍼레이션은 컴파일러가 예측하여 수행하지 않으므로 다른 LOAD 및 STORE 들과의 순서를 보장한다. 그래도 조건 의존성 배리어로 동작하지는 않는다.
예) 컴파일러의 최적화에 의해 b의 기록에 대해 순서를 보장한다.
q = READ_ONCE(a);
if (q) {
WRITE_ONCE(b, 1);
}
그런데 위의 예에서 READ_ONCE() 및 WRITE_ONCE() 없이 사용하면서 컴파일러가 a 값이 0이 아닌 상수라고 판단한 경우 다음과 같이 컴파일러가 최적화를 수행할 수 도 있다.
q = a;
b = 1;
예) 다음 코드를 통해 제대로 순서를 지킬 수 있지 않을까 기대해본다.
q = READ_ONCE(a);
if (q) {
barrier();
WRITE_ONCE(b, 1);
do_something();
} else {
barrier();
WRITE_ONCE(b, 1);
do_something_else();
}
문제 발생) 불행히도 위의 코드는 컴파일러에 의해서 다음과 같이 바꿔버린다.
q = READ_ONCE(a);
barrier();
WRITE_ONCE(b, 1);
if (q) {
do_something();
} else {
do_something_else();
}
해결) 위의 문제를 해결하기 위해 다음과 같이 변경이 필요하다.
q = READ_ONCE(a);
if (q) {
smp_store_release(&b, 1);
do_something();
} else {
smp_store_release(&b, 1);
do_something_else();
}
Architecture Memory Barrier
아키텍처 메모리 베리어 또는 CPU 메모리 베리어라고 불리운다. 가장 기본 아키텍처 barrier인 mb(), rmb(), wmb()를 사용하면 full 배리어로 처리 성능이 가장 느려 성능이 저하된다. 따라서 성능을 더 높이고자 여러가지 barrier를 추가하였는데 그들간의 성능 관계는 다음 그림과 같다.
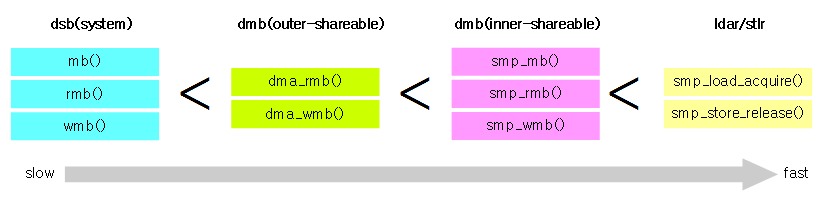
Mandatory barrier
아키텍처가 공유 메모리에 접근 시 생략, 축약 또는 접근 순서를 변경하지 못하도록 막는다. 다음과 같이 기본 4가지 타입의 API를 제공한다.
- mb()
- general 메모리 배리어 타입
- 명령을 기준으로 이전 Load/Store 연산과 이후 Load/Store 연산의 순서(Ordering)를 보장한다.
- 아키텍처에 따른 구현
- dsb, sync, mfence, …
- ARM의 경우 dsb()명령이 사용되어 write 버퍼 flush이외에도 몇 가지 추가 동기화를 수행한다.
- ARM64의 경우 dsb(sy) 명령이 사용되어 write 버퍼 flush이외에도 몇 가지 추가 동기화를 수행한다.
- rmb()
- read 메모리 배리어 타입
- 이 명령을 기준으로 이전 Load 연산과 이후 Load 연산의 순서(Ordering)를 보장한다.
- wmb()
- write 메모리 배리어 타입
- 이 명령을 기준으로 이전 Store 연산과 이후 Store 연산의 순서(Ordering)를 보장한다.
- read_barrier_depends()
- 데이터 의존성(data dependency) 배리어 타입
- Load 연산으로 읽은 값을 결과로 전달해서 다음 Load 연산에 사용해야 하는 경우 atomic Load 연산간의 순서를 보장한다.
- rmb()보다 조금 더 빠른 성능이다.
- ARM, ARM64 및 대부분의 아키텍처 내부에 간단한 데이터 의존성을 체크하므로 별도의 코드가 필요 없으나, 오직 DEC alpha 아키텍처에는 이러한 코드가 구현되어 있다.
추가로 다음 2가지의 묵시적인 one-way 배리어 타입이 있다. (자세한 설명은 좀 뒤에..)
- ACQUIRE operations
- one-way 배리어로 ACQUIRE 조작 이후의 메모리 조작 오더를 보장한다.
- LOCK operations와 smp_load_acquire() 및 smp_cond_acquire() 에서 사용된다.
- smp_load_acquire()
- 이 명령을 기준으로 이후 Read/Write 연산의 순서(Ordering)를 보장한다.
- RELEASE operations
- one-way 배리어로 RELEASE 조작 이전의 메모리 조작 오더를 보장한다.
- UNLOCK operations와 smp_store_release() 에서 사용된다.
- smp_store_release()
- 이 명령을 기준으로 이전 Read/Write 연산의 순서(Ordering)를 보장한다.
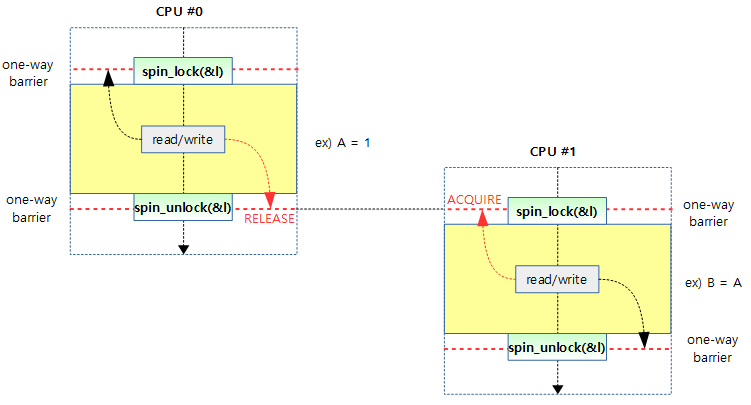
다음 그림은 ACQUIRE 및 RELEASE operation이 spinlock에 구현된 사례를 보여준다.
- A 값이 RELEASE 뒤로 순서가 바뀌지 않게 막으므로 안전하게 B에 A 값이 저장됨을 알 수 있다.
device 지원 barrier
디바이스를 위해 rmb(), wmb()보다 더 가볍고 smp 지원 barrier보다는 좀 더 무거운 outer share 영역까지 공유 가능한 명령을 커널 v3.19-rc1에 추가하였다.
- dma_rmb()
- rmb()와 동일하나 cpu 뿐만 아니라 outer 영역의 디바이스도 접근하는 공유 메모리이다.
- dma_wmb()
- wmb()와 동일하나 cpu 뿐만 아니라 디바이스도 접근하는 공유 메모리이다.
smp 지원 barrier
SMP 시스템의 inner share 영역에서 캐시 일관성을 같이 사용하는 코어 및 디바이스들간 메모리 정합성을 보장하기 위해 다음 함수들을 사용한다.
- smp_mb()
- 이 명령을 기준으로 이전 Read/Write 연산과 이후 Read/Write 연산의 순서(Ordering)를 보장한다.
- smp_rmb()
- 이 명령을 기준으로 이전 Read 연산과 이후 Read 연산의 순서(Ordering)를 보장한다.
- smp_wmb()
- 이 명령을 기준으로 이전 Write 연산과 이후 Write 연산의 순서(Ordering)를 보장한다.
Implicit barriers and Etc…
커널내의 Locking 구조, pthread 동기화 연산들도 implicit 배리어로 동작한다. 하지만 이 자원들을 외부로 공유시에는 명시적인 배리어가 필요할 수 있다.
ACQUIRE/RELEASE 구현
메모리 배리어 요구 시 대부분의 아키텍처는 Read/Write에 관여하는 버퍼가 모두 다 처리되어 비워질(flush) 때까지 기다리는 것으로 처리한다. 그러나 이러한 처리에 상당한 사이클을 사용하므로 성능을 떨어뜨리는 이유가 된다. 보다 빠른 처리를 위해 TSO(Total Store Order)가 지원되는 x86 및 sparc 아키텍처와 Load-Acquire/Store-Release 명령(ldar/stlr)이 지원되는 ARM64 아키텍처를 위해 커널 v3.14-rc1에서 특별한 구현이 소개되었다.
- 참고: arch: Introduce smp_load_acquire(), smp_store_release()
- 지원되지 않는 아키텍처들은 smp_mb()로 구현된다.
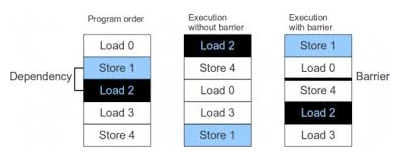
TSO(Total Store Order) 지원 아키텍처
non-TSO 아키텍처에서는 load/store 연산들이 순차적으로 진행되어 순서가 바뀌는 일이 없다. 그러나 성능 향상을 위해 TSO를 지원하는 아키텍처의 경우 Store만 순서대로 처리하고, Load는 weakly(out-of) order로 처리 할 수 있다.
- store 요청 시 아직 처리되지 않아 write buffer에서 대기하는 store할 값을 뒤 따르는 load가 이를 읽을 수 있어 이러한 경우 load가 먼저 처리될 수 있다.
- 이러한 TSO 지원 아키텍처에서는 순서가 바뀌어도 문제가 없으므로 store 및 release operation 구현 시 컴파일러 배리어만 포함하면된다.
다음 그림은 non-TSO 와 TSO 지원 아키텍처를 비교한 그림이다.
- TSO 아키텍처에서 write buffer에 있는 A값을 메모리에 기록하지 않아도 먼저 load를 할 수 있다.

Acquire/Store-Release 명령(ldar/stlr) 지원 아키텍처
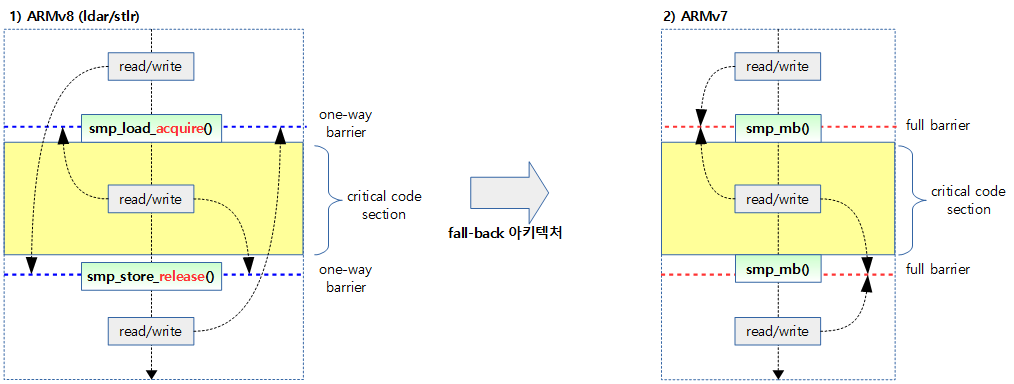
다음 그림은 ARMv8 아키텍처에서의 양방향 barrier와 단방향 barrier의 차이를 보여준다.
- lock()과 unlock()을 구현 시 2개의 양방향 barrier를 사용하는 것 보다 단방향 barrier 페어(pair)를 사용하여 성능을 높일 수 있다.
- ARMv7은 이러한 명령을 지원하지 않아 기존 smp_mb() 명령을 사용하여 구현한다.
- ARMv8에서 이러한 단방향(one-way) barrior 명령 2개를 하나의 페어(pair)로 구성한다.
- 단방향 배리어인 ldar로 smp_load_acquire()
- 단방향 배리어인 stlr로 smp_store_release()
- 참고: Atomic Operation | 문c
Barriers of ARMv7 & ARMv8
- DMB, DSB, ISB의 세 명령
- ARMv6까지는 CP15 레지스터를 이용하여 명령을 수행하지만 ARMv7부터는 전용 명령을 사용한다.
DMB(Data Memory Barrier)
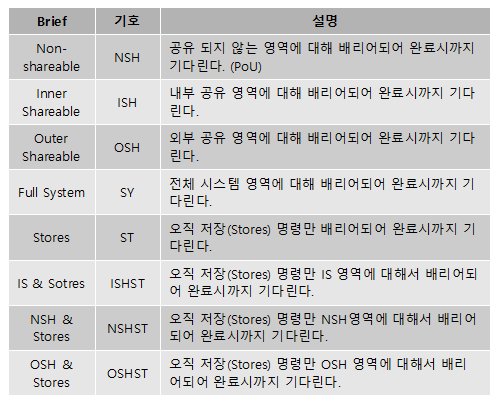
- 데이터 메모리 배리어로 DMB 명령 전과 명령 후의 메모리 접근을 분리하게 만드는데 다음 두 가지 인수를 결합하여 사용할 수 있다.
- shareablity domain
- ish: inner-shareable
- osh: outer-shareable
- sy: system-shareable
- access types
- ld: load
- st: store
- shareablity domain
- 모든 지연된 load/store가 모두 완료(flush)될 때까지 대기한다.
- 예) R,W,R,W,R,W → 효율을 위해 R,R,R,W,W,W 순으로 바꿀 수 있는데 이를 방지하기 위함.
DSB(Data Synchronization Barrier, called DWB)
- 아래의 항목들(DMB 명령이 하는일 포함)이 완료될 때까지 추가 명령이 실행되는 것을 멈추고 기다리므로 DMB보다 훨씬 느리다. 인수의 사용은 DMB와 동일하다.
- Instruction 캐시 및 Data 캐시 조작
- Branch predictor 캐시 flush
- 지연된 load/store 명령의 처리 <- DMB 명령이 하는 일
- TLB 캐시 조작 완료
ISB(Instruction Synchronization Barrier)
- ISB 명령이 동작하는 순간 파이프라인으로 인해 다음 명령이 뒤 따라 들어오게 되는데 이를 모두 버리게한다.(파이프라인 Flush) Out of order execution 기능으로 인해 뒤 따라 Fetch된 명령이 먼저 동작이 될 가능성이 있는데 이럴 경우 문제가 벌어질 가능성이 있다. 특별히 두 명령의 우선 순위를 확실히 구분해야 하는 루틴에서는 두 명령 사이에 ISB를 실행시켜 두 명령어의 실행 순서를 명확히 보장한다.
- ARMv7에서는 ISB를 지원하지만 다른 아키텍처에서 ISB를 지원하지 않는 경우가 있다. 이럴때 파이프 라인을 비우는 것과 비슷한 효과를 내려면 nop 또는 mov a0, a0등의 명령 사용을 사용하여 명령어 수행이 바뀌는 순간에도 문제가 없도록 할 수 있다. 또한 메모리 참조의 순서를 dependency하게 유도하여 일정 루틴을 in-order로 수행될 수 밖에 없도록 만들기도 한다.
- 사용 Case
- 실시간 코드 변경
- 만일 코드부분이 바뀐 후 캐시된 명령이 재실행되면 문제가 발생되므로 이 때에도 ISB를 사용하여야 한다. (JIT가 명령을 바꾸면서 동작)
- MMU on/off
- MMU 전환 시점에도 ISB 명령을 사용함.
- Out of Order Execution: CPU가 Out of Order Execution(ARMv6 아키텍처 부터 지원하지만 대부분 ARMv7부터 제품이 있음)을 지원하는 병렬 Pipeline을 사용하는 경우 캐시 사용이 바뀌는 시점에 이전 명령이 다음 이어지는 명령과 연관성이 없는 경우 다음 명령이 먼저 실행되면서 MMU 상태가 바뀌기 전후로 주소 참조에 문제가 될 수 있음을 막기 위함이다.
- 실시간 코드 변경
Consumption of Speculative Data Barrier (CSDB)
- The CSDB instruction is a memory barrier instruction that controls speculative execution and data value prediction.
Speculative Store Bypass Barrier (SSBB)
- The SSBB is a memory barrier that prevents speculative loads from bypassing earlier stores to the same virtual
address under certain conditions.
Physical Speculative Store Bypass Barrier (PSSBB)
- The PSSBB is a memory barrier that prevents speculative loads from bypassing earlier stores to the same physical
address under certain conditions.
Trace Synchronization Barrier (TSB CSYNC)
- The TSB CSYNC is a memory barrier instruction that preserves the relative order of memory accesses to System
registers due to trace operations and other memory accesses to the same registers.
Barrier Options
배리어 사용처
- SIMPLE ORDERING AND BARRIER CASES
- Simple Weakly Consistent Ordering Example
- Weakly-Ordered Message Passing problem
- Address Dependency with object construction
- Causal consistency issues with Multiple observers
- Multiple observers of writes to multiple locations
- Posting a Store before polling for acknowledgement
- WFE and WFI and Barriers
- LOAD EXCLUSIVE/STORE EXCLUSIVE AND BARRIERS
- Acquiring a Lock
- Releasing a Lock
- Use of Wait For Event (WFE) and Send Event (SEV) with
- SENDING INTERRUPTS AND BARRIERS
- Using a Mailbox to send an interrupt
- CACHE & TLB MAINTENANCE OPERATIONS AND BARRIERS
- Data Cache maintenance operations
- Instruction Cache Maintenance operations
- TLB Maintenance operations and Barriers
코드 분석
UP 시스템
arch/arm/include/asm/barrier.h
#define mb() barrier() #define rmb() barrier() #define wmb() barrier() #define dma_rmb() barrier() #define dma_wmb() barrier()
CPU가 하나만 사용된 시스템에서는 메모리 접근 순서가 바뀌더라도 특별히 영향을 주지 않으므로 컴파일러 배리어만 사용한다.
- UP 시스템이더라도 Write 버퍼가 적용된 시스템의 경우 디바이스와의 연동에서 영향을 받기 떄문에 아래 SMP 코드를 수행한다.
ARMv7 SMP
include/asm-generic/barrier.h
#define smp_mb() __smp_mb() #define smp_rmb() __smp_rmb() #define smp_wmb() __smp_wmb()
arch/arm/include/asm/barrier.h
#define isb(option) __asm__ __volatile__ ("isb " #option : : : "memory")
#define dsb(option) __asm__ __volatile__ ("dsb " #option : : : "memory")
#define dmb(option) __asm__ __volatile__ ("dmb " #option : : : "memory")
#define __arm_heavy_mb(x...) dsb(x)
#define mb() __arm_heavy_mb()
#define rmb() dsb()
#define wmb() __arm_heavy_mb(st)
#define dma_rmb() dmb(osh)
#define dma_wmb() dmb(oshst)
#define __smp_mb() dmb(ish)
#define __smp_rmb() __smp_mb()
#define __smp_wmb() dmb(ishst)
- 외부 캐시와 연동된 특정 시스템의 경우 dsb() 호출 이외에도 outer sync 관련 custom 함수를 호출한다.
- ARMv6의 경우 내장된 isb, dsb, dmb 명령과 동일한 역할을 수행하는 coprocess 레지스터(mcr p15)를 사용한다.
ARMv8
include/asm-generic/barrier.h
#define smp_mb() __smp_mb() #define smp_rmb() __smp_rmb() #define smp_wmb() __smp_wmb()
arch/arm64/include/asm/barrier.h
#define mb() dsb(sy) #define rmb() dsb(ld) #define wmb() dsb(st) #define dma_rmb() dmb(oshld) #define dma_wmb() dmb(oshst) #define __smp_mb() dmb(ish) #define __smp_rmb() dmb(ishld) #define __smp_wmb() dmb(ishst)
arch/arm64/include/asm/barrier.h
#define sev() asm volatile("sev" : : : "memory")
#define wfe() asm volatile("wfe" : : : "memory")
#define wfi() asm volatile("wfi" : : : "memory")
#define isb() asm volatile("isb" : : : "memory")
#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
다음 그림과 같이 ARM 아키텍처별 명령어를 비교하였다.

단방향 베리어 API
smp_load_acquire()
include/asm-generic/barrier.h
#ifndef smp_load_acquire #define smp_load_acquire(p) __smp_load_acquire(p) #endif
단방향 베리어와 함께 주소 p에 해당하는 값을 해당 스칼라 데이터 타입 사이즈(1, 2, 4, 8)에 맞게 읽어온다.
__smp_load_acquire() – ARM64
arch/arm64/include/asm/barrier.h
#define __smp_load_acquire(p) \
({ \
union { __unqual_scalar_typeof(*p) __val; char __c[1]; } __u; \
typeof(p) __p = (p); \
compiletime_assert_atomic_type(*p); \
kasan_check_read(__p, sizeof(*p)); \
switch (sizeof(*p)) { \
case 1: \
asm volatile ("ldarb %w0, %1" \
: "=r" (*(__u8 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 2: \
asm volatile ("ldarh %w0, %1" \
: "=r" (*(__u16 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 4: \
asm volatile ("ldar %w0, %1" \
: "=r" (*(__u32 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 8: \
asm volatile ("ldar %0, %1" \
: "=r" (*(__u64 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
} \
(typeof(*p))__u.__val; \
})
단방향 베리어 명령인 ldsr을 사용하여 주소 p에 해당하는 값을 해당 스칼라 데이터 타입 사이즈(1, 2, 4, 8)에 맞게 읽어온다.
smp_store_release()
include/asm-generic/barrier.h
#ifndef smp_store_release #define smp_store_release(p, v) __smp_store_release(p, v) #endif
단방향 베리어 명령과 함께 주소 p에 값 v를 해당 스칼라 데이터 타입 사이즈(1, 2, 4, 8)에 맞게 기록한다.
__smp_store_release() – ARM64
arch/arm64/include/asm/barrier.h
#define __smp_store_release(p, v) \
do { \
typeof(p) __p = (p); \
union { __unqual_scalar_typeof(*p) __val; char __c[1]; } __u = \
{ .__val = (__force __unqual_scalar_typeof(*p)) (v) }; \
compiletime_assert_atomic_type(*p); \
kasan_check_write(__p, sizeof(*p)); \
switch (sizeof(*p)) { \
case 1: \
asm volatile ("stlrb %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u8 *)__u.__c) \
: "memory"); \
break; \
case 2: \
asm volatile ("stlrh %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u16 *)__u.__c) \
: "memory"); \
break; \
case 4: \
asm volatile ("stlr %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u32 *)__u.__c) \
: "memory"); \
break; \
case 8: \
asm volatile ("stlr %1, %0" \
: "=Q" (*__p) \
: "r" (*(__u64 *)__u.__c) \
: "memory"); \
break; \
} \
} while (0)
단방향 베리어 명령인 stlr을 사용하여 주소 p에 값 v를 해당 스칼라 데이터 타입 사이즈(1, 2, 4, 8)에 맞게 기록한다.
조건부 load
smp_cond_load_acquire() – ARM64
arch/arm64/include/asm/barrier.h
#define smp_cond_load_acquire(ptr, cond_expr) \
({ \
typeof(ptr) __PTR = (ptr); \
__unqual_scalar_typeof(*ptr) VAL; \
for (;;) { \
VAL = smp_load_acquire(__PTR); \
if (cond_expr) \
break; \
__cmpwait_relaxed(__PTR, VAL); \
} \
(typeof(*ptr))VAL; \
})
주소 ptr의 데이터를 읽은 후 조건 cond_expr이 true인 경우 읽은 데이터를 반환한다. 데이터를 읽을 때 단방향 acquire 베리어를 사용한다. 만일 조건을 만족하지 못하는 경우 반복하며 시도한다.
- ARM64의 경우 절전을 위해 spin wait 시 wfe(wait for event)와 sev를 사용한다.
smp_cond_load_relaxed() – ARM64
arch/arm64/include/asm/barrier.h
#define smp_cond_load_relaxed(ptr, cond_expr) \
({ \
typeof(ptr) __PTR = (ptr); \
__unqual_scalar_typeof(*ptr) VAL; \
for (;;) { \
VAL = READ_ONCE(*__PTR); \
if (cond_expr) \
break; \
__cmpwait_relaxed(__PTR, VAL); \
} \
(typeof(*ptr))VAL; \
})
주소 ptr의 데이터를 읽은 후 조건 cond_expr이 true인 경우 읽은 데이터를 반환한다. 만일 조건을 만족하지 못하는 경우 반복하며 시도한다.
- ARM64의 경우 절전을 위해 spin wait 시 wfe(wait for event)와 sev를 사용한다.
- READ_ONCE(), WRITE_ONCE() 및 __unqual_scalar_typeof() 함수는 다음을 참고한다.
__cmpwait_relaxed()
arch/arm64/include/asm/cmpxchg.h
#define __cmpwait_relaxed(ptr, val) \
__cmpwait((ptr), (unsigned long)(val), sizeof(*(ptr)))
__cmp_wait()
아래 __CMPWAIT_GEN() 매크로 함수를 통해 __cmp_wait() 인라인 함수가 만들어진다.
arch/arm64/include/asm/cmpxchg.h
#define __CMPWAIT_GEN(sfx) \
static __always_inline void __cmpwait##sfx(volatile void *ptr, \
unsigned long val, \
int size) \
{ \
switch (size) { \
case 1: \
return __cmpwait_case##sfx##_8(ptr, (u8)val); \
case 2: \
return __cmpwait_case##sfx##_16(ptr, (u16)val); \
case 4: \
return __cmpwait_case##sfx##_32(ptr, val); \
case 8: \
return __cmpwait_case##sfx##_64(ptr, val); \
default: \
BUILD_BUG(); \
} \
\
unreachable(); \
}
__CMPWAIT_GEN()
주소 @ptr의 데이터를 @size 만큼 읽은 후 입력 인자 @val 값과 변동이 없는 경우 대기한다. (절전을 위해 wfe 명령을 사용하여 대기)
__cmpwait_case__<size>()
아래 __CMPWAIT_CASE() 매크로 함수를 통해 비트 사이즈 8, 16, 32, 64에 해당하는 __cmpwait_case__<size>() 인라인 함수가 만들어진다.
arch/arm64/include/asm/cmpxchg.h
#define __CMPWAIT_CASE(w, sfx, sz) \
static inline void __cmpwait_case_##sz(volatile void *ptr, \
unsigned long val) \
{ \
unsigned long tmp; \
\
asm volatile( \
" sevl\n" \
" wfe\n" \
" ldxr" #sfx "\t%" #w "[tmp], %[v]\n" \
" eor %" #w "[tmp], %" #w "[tmp], %" #w "[val]\n" \
" cbnz %" #w "[tmp], 1f\n" \
" wfe\n" \
"1:" \
: [tmp] "=&r" (tmp), [v] "+Q" (*(unsigned long *)ptr) \
: [val] "r" (val)); \
}
__CMPWAIT_CASE(w, b, 8);
__CMPWAIT_CASE(w, h, 16);
__CMPWAIT_CASE(w, , 32);
__CMPWAIT_CASE( , , 64);
주소 @ptr의 데이터를 읽어온 값이 입력 인자 @val 값과 같아 변동이 없는 경우 대기한다.
- 코드 라인 8~9에서 sevl과 wfe 명령을 사용하여 강제로 이벤트 레지스터를 클리어한다.
- ARMv8 아키텍처부터 wfe 명령에 조건부 실행 기능이 없어, 아래에 cbnz 명령을 추가하여 조건부 branch를 하고 있다. 이러한 조건부가 이벤트 발생기에 의해 잘못된 실행을 얻을 수 있어 추가하였다. 아래에 자세한 설명을 추가하였다.
- 코드 라인 10에서 @ptr 주소에서 읽은 값을 tmp 레지스터에 대입한다.
- 코드 라인 11~12에서 읽은 tmp 값이 @val 값과 다른 경우 1: 레이블로 forward 이동한다.
- 코드 라인 13에서 읽은 tmp 값이 @val 값과 동일하여 변화가 없으면 절전을 위해 wfe를 사용하여 대기한다.
- 다른 cpu에서 이 @ptr 주소가 포함된 캐시라인을 수정하는 경우 자동으로 sev와 같이 이벤트가 발생한다. 이 때문에 wfe 명령에서 깨어날 수 있다. 결국 @ptr 주소의 값이 변경되지 않는 경우 절전을 위해 wfe에서 슬립하여 있고, 변경이 발생할 때 깨어날 수 있도록 사용한다.
sevl & wfe 명령
sevl과 wfe 명령을 연속으로 사용하는 이유는 다음과 같다.
- 주기적으로 반복되어 발생하는 이벤트 스트림으로 인해 이미 이벤트 레지스터가 설정되어 있을 수 있다. 그러한 경우 코드 라인 13의 wfe 명령이 이벤트가 올 때까지 대기해야 하는데 이미 이벤트가 온걸로 인식하여 이 함수가 시작하자 깨어날 수도 있다. 이러한 일을 막기 위해 sevl을 사용하여 강제로 이벤트 레지스터를 설정하고, 이어지는 wfe 명령에서 곧바로 빠져나오게 추가하였다. 이는 이벤트 레지스터를 클리어하는 효과를 얻는다.
- sev와 sevl 명령의 차이
- sev 명령
- 모든 core에게 이벤트를 보낸다. (wfe 명령을 통해 대기하고 있는 core들이 깨어난다)
- sevl 명령
- 현재 core에게만 이벤트를 보낸다. (현재 core에서 수행할 다음 wfe 명령 하나만을 통과시키게 하는 효과가 있다)
- sev 명령
참고
- Volatile | 문c
- Atomic Operation | 문c
- READ_ONCE() 및 WRITE_ONCE()와 lockless 리스트 | 문c
- Memory barriers for TSO architectures | LWN.net
- ARM Barrier Litmus Tests and Cookbook – 다운로드
- Memory Barriers: a Hardware View for Software Hackers – 다운로드
- In what situations might I need to insert memory barrier instructions? | ARM
- DMB & ILP | iamroot 11차-A팀
- Documentation/memory-barriers.txt | Kernel.org
- Documentation/memory-barriers.txt의 한글 번역 | 박성재
- Memory Barriers in the Linux Kernel (2016) | SUSE – 다운로드 pdf
- Acquire and Release Semantics (2012) | Preshing on Programming
- Memory barriers in C (2017) | MariaDB – 다운로드 pdf