<kernel v5.0>
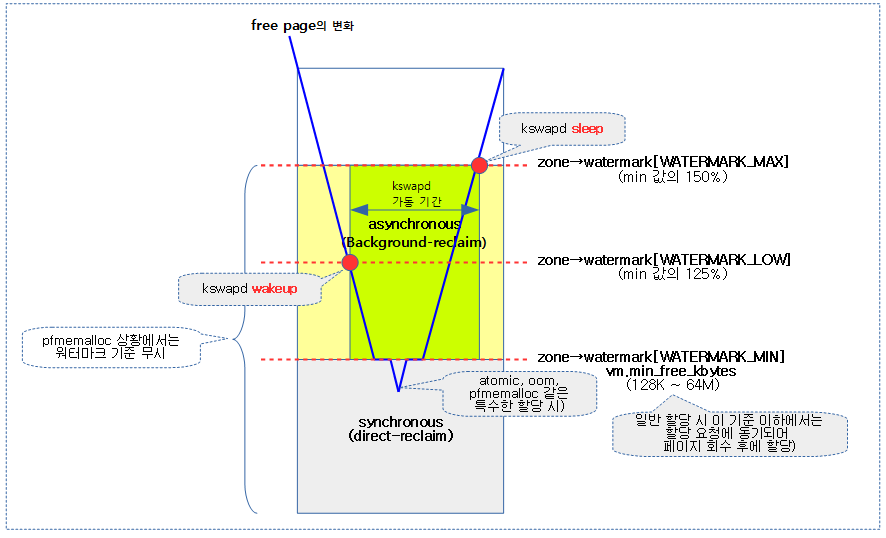
Zone 워터마크
zone에서 페이지 할당을 시도할 때 남은 free 페이지가 zone 별 워터마크 기준과 비교하여 메모리 할당 여부를 판단한다. 이러한 워터마크는 다음과 같이 3 가지 워터 마크 기준 값을 지정하여 사용하며 각각의 의미는 다음과 같다.
- WATERMARK_MIN
- 메모리 부족의 최저 기준 점과 동일하다.
- vm.min_free_kbytes 값에 해당하는 페이지 수를 가진다.
- 산출된 free 페이지가 이 값 미만이 되는 경우 페이지 회수가 불가능하다. 이러한 경우 동기되어 직접(direct) 페이지 회수 작업을 허용하는 경우 페이지 회수 후 할당이 계속 진행된다.
- 특수한 상황(atomic, oom, pfmemalloc을 제외한)에서는 이 기준 이하의 상황에서도 페이지 할당이 가능해진다.
- WATERMARK_LOW
- 디폴트로 min 값의 125% 값을 가진 페이지 수이다. kswapd가 자동으로 wakeup되는 시점이다.
- 사용자가 watermark_scale_factor를 변경하여 이 기준을 더 높일 수 있다.
- 디폴트로 min 값의 125% 값을 가진 페이지 수이다. kswapd가 자동으로 wakeup되는 시점이다.
- WATERMARK_MAX
- 디폴트로 min 값의 150% 값을 가진 페이지 수이고 kswapd가 자동으로 sleep되는 시점이다.
- 사용자가 watermark_scale_factor를 변경하여 이 기준을 더 높일 수 있다.
다음 그림은 zone 워터마크 설정에 따른 할당과 페이지 회수에 따른 관계를 보여준다.
다음과 같이 nr_free_pages 및 min, low, high 워터마크 값을 확인할 수 있다.
$ cat /proc/zoneinfo
Node 0, zone DMA32
per-node stats
(...생략...)
pages free 633680
min 5632 <-----
low 7040 <-----
high 8448 <-----
spanned 786432
present 786432
managed 765771
protection: (0, 0, 0)
nr_free_pages 633680 <-----
(...생략...)
managed_pages
버디 시스템이 zone 별로 관리하는 페이지 수로 dma 및 normal 존에서의 초기 값은 다음과 같다.
- managed_pages = present_pages – 버디 시스템이 동작하기 직전 reserve한 페이지들 수
- managed_pages = spanned_pages – absent_pages – (memmap_pages + dma_reserve + …)
- present_pages = spanned_pages – absent_pages
다음과 같이 존별 managed_pages 값을 확인할 수 있다.
$ cat /proc/zoneinfo
Node 0, zone DMA32
per-node stats
(...생략...)
pages free 633680
min 5632
low 7040
high 8448
spanned 786432
present 786432
managed 765771 <-----
protection: (0, 0, 0)
nr_free_pages 633680
(...생략...)
빠른 워터마크 비교
zone_watermark_fast()
mm/page_alloc.c
static inline bool zone_watermark_fast(struct zone *z, unsigned int order,
unsigned long mark, int classzone_idx, unsigned int alloc_flags)
{
long free_pages = zone_page_state(z, NR_FREE_PAGES);
long cma_pages = 0;
#ifdef CONFIG_CMA
/* If allocation can't use CMA areas don't use free CMA pages */
if (!(alloc_flags & ALLOC_CMA))
cma_pages = zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
/*
* Fast check for order-0 only. If this fails then the reserves
* need to be calculated. There is a corner case where the check
* passes but only the high-order atomic reserve are free. If
* the caller is !atomic then it'll uselessly search the free
* list. That corner case is then slower but it is harmless.
*/
if (!order && (free_pages - cma_pages) > mark + z->lowmem_reserve[classzone_idx])
return true;
return __zone_watermark_ok(z, order, mark, classzone_idx, alloc_flags,
free_pages);
}
요청한 @z 존에서 @mark 기준보다 높은 free 페이지에서 @order 페이지를 확보할 수 있는지 여부를 빠르게 판단하여 반환한다. order 0 할당 요청 전용으로 판단 로직이 추가되었다. (true=워터마크 기준 이상으로 ok, false=워터마크 기준 이하로 not-ok)
- 코드 라인 4에서 해당 존의 free 페이지를 알아온다.
- 코드 라인 9~10에서 movable 페이지 요청이 아닌 경우 cma 영역의 페이지들을 사용할 수 없다. 일단 cma 영역을 사용하는 페이지 수를 알아온다.
- 코드 라인 19~20에서 order 0 할당 요청인 경우 빠른 판단을 할 수 있다. cma 페이지를 제외한 free 페이지가 lowmem 리저브 영역을 더한 워터 마크 기준을 초과하는 경우 true를 반환한다.
- 코드 라인 22~23에서 order 1 이상의 할당 요청에서 워터 마크 기준을 초과하는지 여부를 반환한다.
다음 그림은 order 0 페이지 할당 요청 시 워터마크 기준에 의해 빠른 할당 가능 여부를 판단하는 모습을 보여준다.
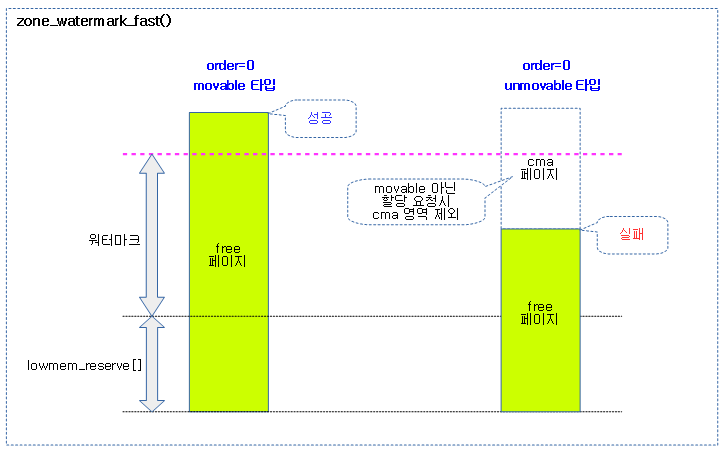
기본 워터마크 비교
zone_watermark_ok()
mm/page_alloc.c
bool zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int classzone_idx, int alloc_flags)
{
return __zone_watermark_ok(z, order, mark, classzone_idx, alloc_flags,
zone_page_state(z, NR_FREE_PAGES));
}
해당 zone에서 order 페이지를 처리하기 위해 free 페이지가 워터마크 값의 기준 보다 충분한지 확인한다.
__zone_watermark_ok()
mm/page_alloc.c
/* * Return true if free base pages are above 'mark'. For high-order checks it * will return true of the order-0 watermark is reached and there is at least * one free page of a suitable size. Checking now avoids taking the zone lock * to check in the allocation paths if no pages are free. */
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int classzone_idx, unsigned int alloc_flags,
long free_pages)
{
long min = mark;
int o;
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
/* free_pages may go negative - that's OK */
free_pages -= (1 << order) - 1;
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
/*
* If the caller does not have rights to ALLOC_HARDER then subtract
* the high-atomic reserves. This will over-estimate the size of the
* atomic reserve but it avoids a search.
*/
if (likely(!alloc_harder)) {
free_pages -= z->nr_reserved_highatomic;
} else {
/*
* OOM victims can try even harder than normal ALLOC_HARDER
* users on the grounds that it's definitely going to be in
* the exit path shortly and free memory. Any allocation it
* makes during the free path will be small and short-lived.
*/
if (alloc_flags & ALLOC_OOM)
min -= min / 2;
else
min -= min / 4;
}
#ifdef CONFIG_CMA
/* If allocation can't use CMA areas don't use free CMA pages */
if (!(alloc_flags & ALLOC_CMA))
free_pages -= zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
/*
* Check watermarks for an order-0 allocation request. If these
* are not met, then a high-order request also cannot go ahead
* even if a suitable page happened to be free.
*/
if (free_pages <= min + z->lowmem_reserve[classzone_idx])
return false;
/* If this is an order-0 request then the watermark is fine */
if (!order)
return true;
/* For a high-order request, check at least one suitable page is free */
for (o = order; o < MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!list_empty(&area->free_list[mt]))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!list_empty(&area->free_list[MIGRATE_CMA])) {
return true;
}
#endif
if (alloc_harder &&
!list_empty(&area->free_list[MIGRATE_HIGHATOMIC]))
return true;
}
return false;
}
해당 zone에서 order 페이지를 처리하기 위해 free 페이지가 워터마크 값의 기준 보다 충분한지 확인한다.
- 코드 라인 5에서 워터마크 값을 min 값에 일단 대입한다.
- 코드 라인 7에서 최대한 워터마크 기준을 낮춰서라도 할당을 해야 하는지 판단여부를 alloc_harder에 대입한다.
- gfp_atomic 요청 및 oom 상황에서의 할당은 시스템이 최대한 할당을 성공시켜야 한다.
- 코드 라인 10에서 free 페이지를 할당 요청한 페이지 수-1 만큼 감소시킨다.
- 코드 라인 12~13에서 atomic 요청 상황인 경우 ALLOC_HIGH 할당 플래그가 설정되는데 최대한 할당할 수 있게 하기 위해 워터마크 기준을 절반으로 줄인다.
- 코드 라인 20~21에서 alloc_harder 상황이 아니면 reserved_highatomic 페이지들은 사용을 하지 않게 하기 위해 빼둔다.
- 코드 라인 22~33에서 alloc_harder 상황인 경우 워터마크를 더 낮추는데 atomic 요청인 경우 25%, oom 상황인 경우 50%를 더 낮춘다.
- 코드 라인 38~39에서 movable 페이지 할당 요청이 아닌 경우에는 cma 영역을 사용할 수 없다. 따라서 free 페이지 수에서 cma 영역의 페이지들을 먼저 제외시킨다.
- 코드 라인 47~48에서 free 페이지가 lowmem 리저브 영역을 포함한 워터마크 기준 이하로 메모리가 부족한 상황이면 false를 반환한다.
- 코드 라인 51~52에서 order 0 할당 요청인 경우 true를 반환한다.
- 코드 라인 55~76에서 order 1 이상의 요청에 대해서 실제 free 리스트를 검색하여 할당가능한지 여부를 체크하여 반환한다. [요청 order, MAX_ORDER) 범위의 free_area를 순회하며 다음 3 가지 기준에 포함된 경우 할당 가능하므로 true를 반환한다.
- unmovable, movable, reclaimable 타입의 리스트에 free 페이지가 있는 경우
- cma 영역을 사용해도 되는 movable 페이지 요청인 경우 cma 타입의 리스트에 free 페이지가 있는 경우
- alloc_harder 상황인 경우 highatomic 타입의 리스트에 free 페이지가 있는 경우
다음 그림은 zone 워터마크 설정에 따른 free 페이지 할당 가능 여부를 체크하는 모습을 보여준다.
- 좌측 그림과 같이 남은 free 페이지 수에 여유가 있는지 확인 후
- 우측 그림에서와 같이 free_area[]를 검색하여 최종적으로 할당 가능한지 여부를 확인한다.
- lowmem_reserve[]에 사용된 존 인덱스는 처음 요청한 preferred 존 인덱스이다.
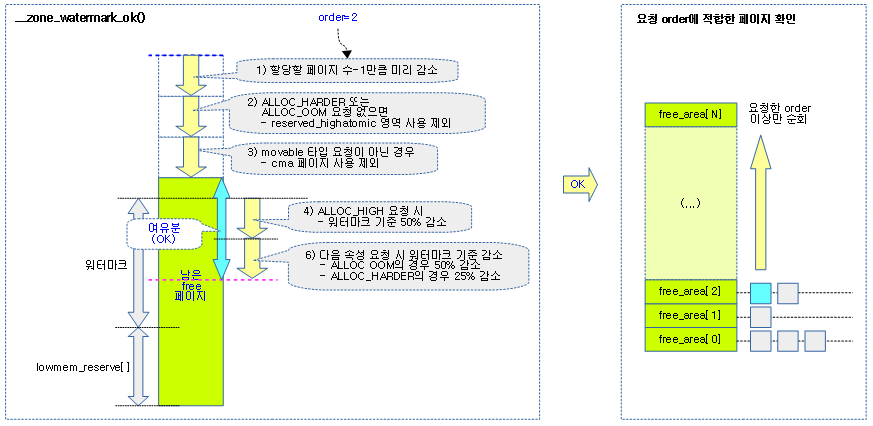
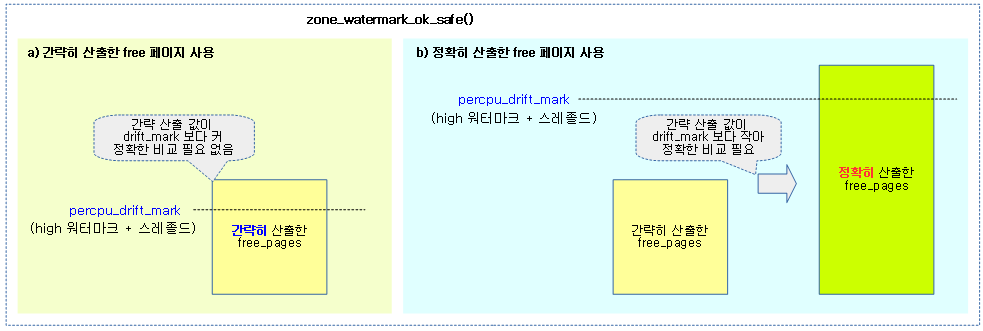
정확한 워터마크 비교
zone_watermark_ok_safe()
page_alloc.c
bool zone_watermark_ok_safe(struct zone *z, unsigned int order,
unsigned long mark, int classzone_idx)
{
long free_pages = zone_page_state(z, NR_FREE_PAGES);
if (z->percpu_drift_mark && free_pages < z->percpu_drift_mark)
free_pages = zone_page_state_snapshot(z, NR_FREE_PAGES);
return __zone_watermark_ok(z, order, mark, classzone_idx, 0,
free_pages);
}
해당 zone에서 order 페이지를 처리하기 위해 정확히 산출한 free 페이지가 워터마크 값의 기준 보다 충분한지 확인한다.
- 코드 라인 4에서 먼저 대략적인 free 페이지 수를 알아온다.
- 코드 라인 6~7에서 알아온 free 페이지 수가 percpu_drift_mark 이하인 경우 free 페이지를 정확히 산출한다.
- percpu_drift_mark 값은 refresh_zone_stat_thresholds() 함수에서 설정된다.
- 코드 라인 9~10에서 free 페이지 수를 워터마크와 비교하여 할당 가능 여부를 반환한다.
존 카운터(stat)
존 카운터(stat)들은 성능을 위해 존 카운터 및 per-cpu 카운터 2개를 각각 별도로 운영하고 있다. 존의 대략적인 값만을 요구할 때에는 성능을 위해 존 카운터 값을 그대로 반환하고, 정확한 산출이 필요한 경우에만 존 카운터와 per-cpu 카운터를 더해 반환한다.
percpu_drift_mark
커널 메모리 관리 시 남은 free 페이지 수를 읽어 워터마크와 비교하는 것으로 메모리 부족을 판단하는 루틴들이 많이 사용된다. 그런데 정확한 free 페이지 값을 읽어내려면 존 카운터와 per-cpu 카운터를 모두 읽어 더해야하는데, 이렇게 매번 계산을 하는 경우 성능을 떨어뜨리므로, 존 카운터 값만 읽어 high 워터마크보다 일정 기준 더 큰 크기로 설정된 percpu_drift_mark 값과 비교하여 이 값 이하일 때에만 보다 정확한 연산을 하도록 유도하는 방법을 사용하여 성능을 유지시킨다.
stat_threshold
카운터의 증감이 발생하면 성능을 위해 per-cpu 카운터를 먼저 증감시킨다. 존 카운터의 정확도를 위해 per-cpu 카운터의 값이 일정 기준의 stat_threshold를 초과할 경우에만 이 값을 존 카운터로 옮겨 더하는 방식을 사용한다.
다음 그림은 해당 cpu의 zone 카운터에 변동이 있을 때 stat_threshold를 초과하면 존 카운터에 옮겨지는 과정을 보여준다.
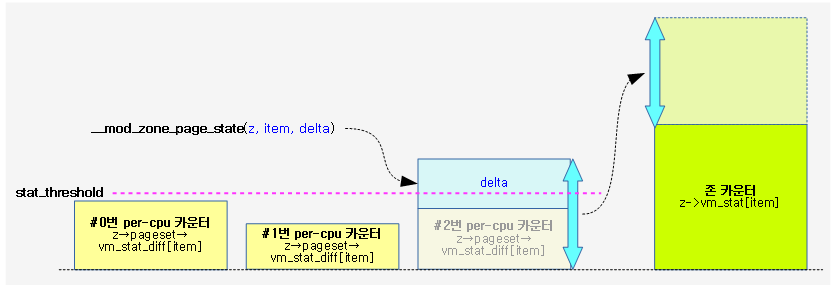
다음과 같이 stat_threshold 값을 확인할 수 있다.
$ cat /proc/zoneinfo
Node 0, zone DMA32
per-node stats
(...생략...)
pagesets
cpu: 0
count: 143
high: 378
batch: 63
vm stats threshold: 24 <-----
cpu: 1
count: 285
high: 378
batch: 63
vm stats threshold: 24 <-----
(...생략...)
zone_page_state()
include/linux/vmstat.h
static inline unsigned long zone_page_state(struct zone *zone,
enum zone_stat_item item)
{
long x = atomic_long_read(&zone->vm_stat[item]);
#ifdef CONFIG_SMP
if (x < 0)
x = 0;
#endif
return x;
}
존의 @item에 해당하는 대략적인 vm stat 값을 반환한다.
- 존의 vm stat 값만을 반환한다.
zone_page_state_snapshot()
include/linux/vmstat.h
/* * More accurate version that also considers the currently pending * deltas. For that we need to loop over all cpus to find the current * deltas. There is no synchronization so the result cannot be * exactly accurate either. */
static inline unsigned long zone_page_state_snapshot(struct zone *zone,
enum zone_stat_item item)
{
long x = atomic_long_read(&zone->vm_stat[item]);
#ifdef CONFIG_SMP
int cpu;
for_each_online_cpu(cpu)
x += per_cpu_ptr(zone->pageset, cpu)->vm_stat_diff[item];
if (x < 0)
x = 0;
#endif
return x;
}
존의 @item에 해당하는 vm stat 값을 정확히 산출한다.
- 정확한 값을 반환하기 위해 다음 수식을 사용한다.
- 존의 vm stat 값 + 모든 per-cpu vm stat 값
다음 그림은 zone_page_state_snapshop() 함수와 zone_page_state() 함수의 차이를 보여준다.

zone_watermark_ok() 함수와 zone_watermark_ok_safe() 함수의 다른 점
- zone_watermark_ok() 함수
- 워터마크와 비교할 free 페이지 수를 대략적으로 산출된 free 페이지 값을 사용한다.
- zone_watermark_ok_safe() 함수
- 워터마크와 비교할 free 페이지 수에 정확히 산출된 free 페이지 값을 사용한다.
아래는 zone stat 스레졸드를 이용한 zone_watermark_ok_safe() 함수의 사용예를 보여준다.
워터마크 및 관련 설정 초기화
워터마크 및 관련 설정들의 초기화는 다음과 같이 진행된다.
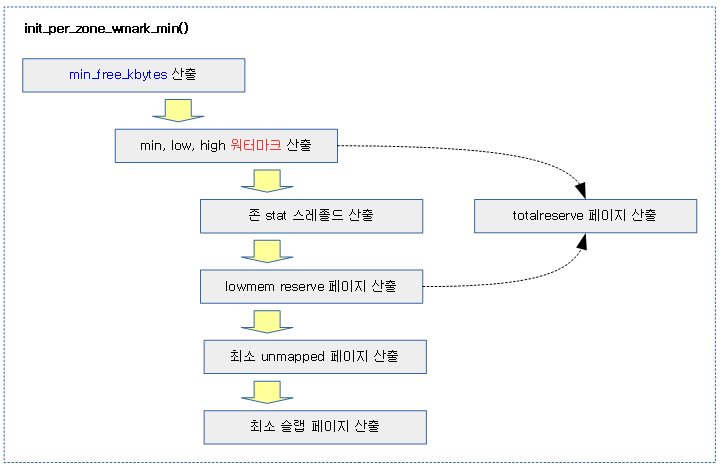
워터마크 min 값 설정
init_per_zone_wmark_min()
mm/page_alloc.c
/* * Initialise min_free_kbytes. * * For small machines we want it small (128k min). For large machines * we want it large (64MB max). But it is not linear, because network * bandwidth does not increase linearly with machine size. We use * * min_free_kbytes = 4 * sqrt(lowmem_kbytes), for better accuracy: * min_free_kbytes = sqrt(lowmem_kbytes * 16) * * which yields * * 16MB: 512k * 32MB: 724k * 64MB: 1024k * 128MB: 1448k * 256MB: 2048k * 512MB: 2896k * 1024MB: 4096k * 2048MB: 5792k * 4096MB: 8192k * 8192MB: 11584k * 16384MB: 16384k */
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
if (new_min_free_kbytes > user_min_free_kbytes) {
min_free_kbytes = new_min_free_kbytes;
if (min_free_kbytes < 128)
min_free_kbytes = 128;
if (min_free_kbytes > 65536)
min_free_kbytes = 65536;
} else {
pr_warn("min_free_kbytes is not updated to %d because user defined value %d is prefee
rred\n",
new_min_free_kbytes, user_min_free_kbytes);
}
setup_per_zone_wmarks();
refresh_zone_stat_thresholds();
setup_per_zone_lowmem_reserve();
#ifdef CONFIG_NUMA
setup_min_unmapped_ratio();
setup_min_slab_ratio();
#endif
return 0;
}
core_initcall(init_per_zone_wmark_min)
lowmem의 가용 페이지 크기를 사용하여 워터마크 기준으로 사용하는 min_free_kbytes 값을 산출한다. 그 외에 각 zone의 워터마크, lowmem_reserve, totalreserve, min umpapped, min slap 페이지 등을 산출한다.
- 코드 라인 6~18에서 lowmem의 가용 페이지 수를 사용하여 워터마크 기준 값으로 사용되는 min_free_kbytes 값을 산출한다.
- lowmem 가용 페이지 산출식
- managed_pages – high 워터마크 페이지
- min_free_kbytes 산출식
- sqrt((lowmem의 가용 페이지 수 >> 10) * 16)
- 예) sqrt(512M * 0x10) -> 2M
- 산출된 값은 128 ~ 65536 범위 이내로 제한 (128K ~ 64M 범위)
- sqrt((lowmem의 가용 페이지 수 >> 10) * 16)
- 커널이 초기화될 때 이외에도 hotplug 메모리를 사용하여 메모리가 hot add/del 될 때마다 이 초기화 루틴이 수행된다.
- 커널이 처음 초기화될 때에는 각 zone의 워터마크 초기값은 모두 0이다.
- lowmem 가용 페이지 산출식
- 코드 라인 19에서 각 존의 워터 마크 값 및 totalreserve_pages 값을 산출한다.
- 코드 라인 20에서 각 존의 stat 스레졸드와 percpu_drift_mark 를 산출한다.
- 코드 라인 21에서 zone->lowmem_reserve 및 totalreserve 페이지를 산출한다.
- 코드 라인 24에서 최소 ummapped 페이지를 산출한다.
- 코드 라인 25에서 최소 slab 페이지를 산출한다.
다음 그림은 전역 min_free_kbytes 값이 산출되는 과정을 보여준다.
- lowmem(dma, normal)의 가용 페이지(managed – high 워터마크)를 16으로 곱하고 제곱근하여 산출한다.
- 최초 부트업 시 high 워터마크 값은 0 이다.
- ARM64의 경우 dma32 존을 사용하고, highmem 존은 사용하지 않는다.
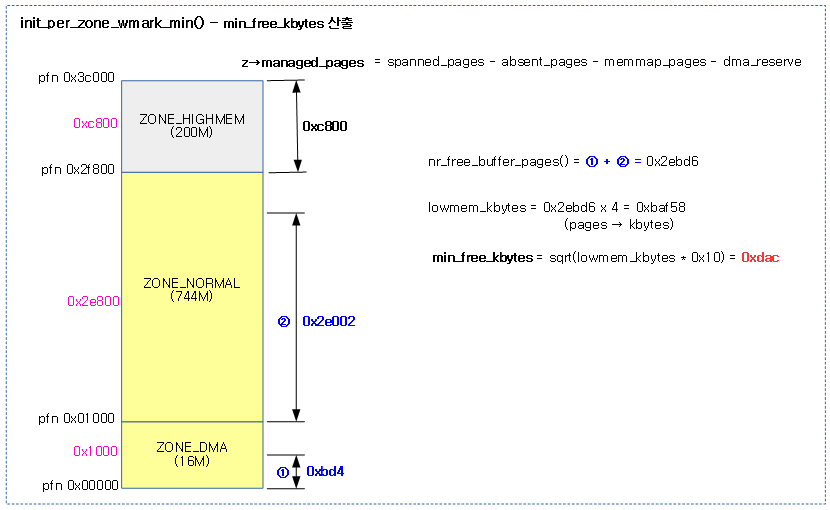
lowmem 가용 페이지 수 산출
nr_free_buffer_pages()
mm/page_alloc.c
/** * nr_free_buffer_pages - count number of pages beyond high watermark * * nr_free_buffer_pages() counts the number of pages which are beyond the high * watermark within ZONE_DMA and ZONE_NORMAL. */
unsigned long nr_free_buffer_pages(void)
{
return nr_free_zone_pages(gfp_zone(GFP_USER));
}
EXPORT_SYMBOL_GPL(nr_free_buffer_pages);
현재 노드의 zonelist에서 normal 존 이하의 존들을 대상으로 가용 페이지 수를 산출하여 반환한다.
- 참고로 처음 커널 설정을 위해 호출될 때에는 high 워터마크가 0이다.
- 가용 페이지 수
- managed_pages – high 워터마크 페이지
nr_free_zone_pages()
mm/page_alloc.c
/** * nr_free_zone_pages - count number of pages beyond high watermark * @offset: The zone index of the highest zone * * nr_free_zone_pages() counts the number of counts pages which are beyond the * high watermark within all zones at or below a given zone index. For each * zone, the number of pages is calculated as: * * nr_free_zone_pages = managed_pages - high_pages */
static unsigned long nr_free_zone_pages(int offset)
{
struct zoneref *z;
struct zone *zone;
/* Just pick one node, since fallback list is circular */
unsigned long sum = 0;
struct zonelist *zonelist = node_zonelist(numa_node_id(), GFP_KERNEL);
for_each_zone_zonelist(zone, z, zonelist, offset) {
unsigned long size = zone_managed_pages(zone);
unsigned long high = high_wmark_pages(zone);
if (size > high)
sum += size - high;
}
return sum;
}
현재 노드의 zonelist에서 offset 이하의 zone들을 대상으로 가용한 페이지를 모두 더한 수를 반환한다.
- 가용 페이지 수
- managed_pages – high 워터마크 페이지
워터 마크 비율 설정
워터마크 간의 간격은 디폴트로 워터마크 min 값의 25%를 사용하는데 kswapd 효율을 높이기 위해 사용자가 워터 마크 비율을 변경할 수 있다.
watermark_scale_factor
/proc/sys/vm/watermark_scale_factor를 통해 설정할 수 있으며 초깃값은 10이다. 초깃값이 10일 때 메모리의 0.1% 값이라는 의미이고, 최댓값으로 1000이 주어질 때 메모리의 10% 값이 된다. 이러한 경우 min과 low 및 low와 high와의 최대 간격은 메모리(managed_pages)의 10%까지 가능해진다.
- 커널 v4.6-rc1에서 대규모 메모리를 갖춘 시스템에서 kswapd 효율을 높이기 위해 워터마크 low와 high 값의 임계점을 기존보다 더 높일 수 있도록 추가되었다.
min, low, high 워터마크 산출
메모리의 양으로 결정된 min_free_kbytes 값을 사용하여 존 별 min, low, high 워터마크를 산출한다.
setup_per_zone_wmarks()
mm/page_alloc.c
/**
* setup_per_zone_wmarks - called when min_free_kbytes changes
* or when memory is hot-{added|removed}
*
* Ensures that the watermark[min,low,high] values for each zone are set
* correctly with respect to min_free_kbytes.
*/
void setup_per_zone_wmarks(void)
{
mutex_lock(&zonelists_mutex);
__setup_per_zone_wmarks();
mutex_unlock(&zonelists_mutex);
}
zone별 min, low, high 워터마크를 산출한다.
__setup_per_zone_wmarks()
mm/page_alloc.c
static void __setup_per_zone_wmarks(void)
{
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
for_each_zone(zone) {
if (!is_highmem(zone))
lowmem_pages += zone_managed_pages(zone);
}
for_each_zone(zone) {
u64 tmp;
spin_lock_irqsave(&zone->lock, flags);
tmp = (u64)pages_min * zone_managed_pages(zone);
do_div(tmp, lowmem_pages);
if (is_highmem(zone)) {
/*
* __GFP_HIGH and PF_MEMALLOC allocations usually don't
* need highmem pages, so cap pages_min to a small
* value here.
*
* The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN)
* deltas control asynch page reclaim, and so should
* not be capped for highmem.
*/
unsigned long min_pages;
min_pages = zone_managed_pages(zone) / 1024;
min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL);
zone->_watermark[WMARK_MIN] = min_pages;
} else {
/*
* If it's a lowmem zone, reserve a number of pages
* proportionate to the zone's size.
*/
zone->_watermark[WMARK_MIN] = tmp;
}
/*
* Set the kswapd watermarks distance according to the
* scale factor in proportion to available memory, but
* ensure a minimum size on small systems.
*/
tmp = max_t(u64, tmp >> 2,
mult_frac(zone_managed_pages(zone),
watermark_scale_factor, 10000));
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;
zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2;
zone->watermark_boost = 0;
spin_unlock_irqrestore(&zone->lock, flags);
}
/* update totalreserve_pages */
calculate_totalreserve_pages();
}
존별 low, min, high 워터마크를 산출하고 totalreserve 페이지를 갱신한다.
- 코드 라인 3에서 전역 min_free_kbytes 값을 페이지 수 단위로 바꾸어 pages_min에 대입한다.
- 코드 라인 9~12에서 lowmem 영역의 managed_pages를 합산하여 lowmem_pages를 구한다.
- 코드 라인 14~19에서 각 존을 돌며 tmp에 pages_min(min_free_kbytes를 페이지로 환산)을 현재 존의 비율만큼의 페이지 수로 설정한다.
- 코드 라인 20~41에서 highmem 존인 경우에는 실제 managed_pages를 1024로 나눈 값을 32~128까지의 범위로 제한한 값을 min 워터마크에 저장하고, highmem 존이 아닌 경우에는 min 워터마크에 위에서 산출한 tmp 값을 설정한다.
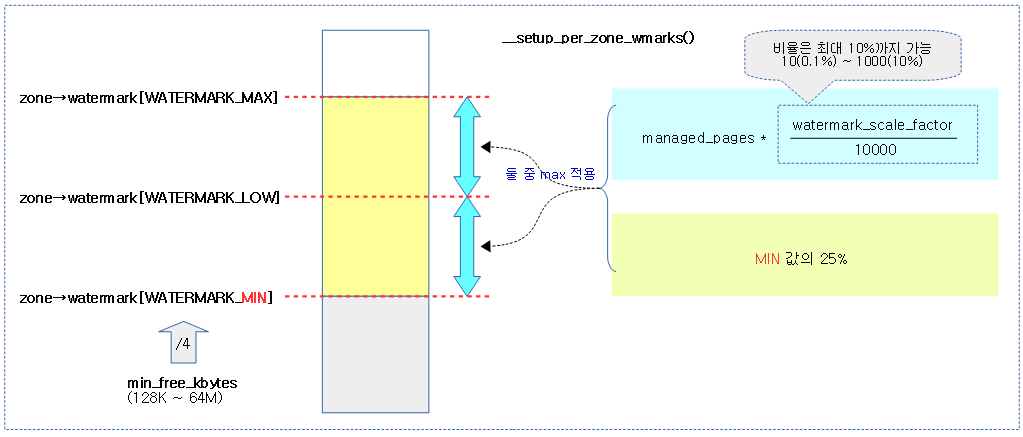
- 코드 라인 48~53에서 각 워터마크 간의 간격은 다음 두 산출 값 중 큰 값으로 결정한다.
- 최초 산출된 min 값의 25%
- managed_pages * 워터마크 비율(0.1 ~ 10%)
- 코드 라인 54에서 워터마크 부스트 값을 0으로 초기화한다.
- 코드 라인 60에서 high 워터마크 값이 갱신되었으므로 totalreserve 페이지 수를 산출하여갱신한다.
- high 워터마크와 lowmem reserve 페이지가 재산출될 때 마다 totalreserve 값도 갱신된다.
다음 그림은 min_free_kbytes 값과 lowmem 영역의 가용 페이지(managed_pages – high 워터마크)를 각 zone의 비율로 min, low, high 워터마크를 산출하는 모습을 보여준다.
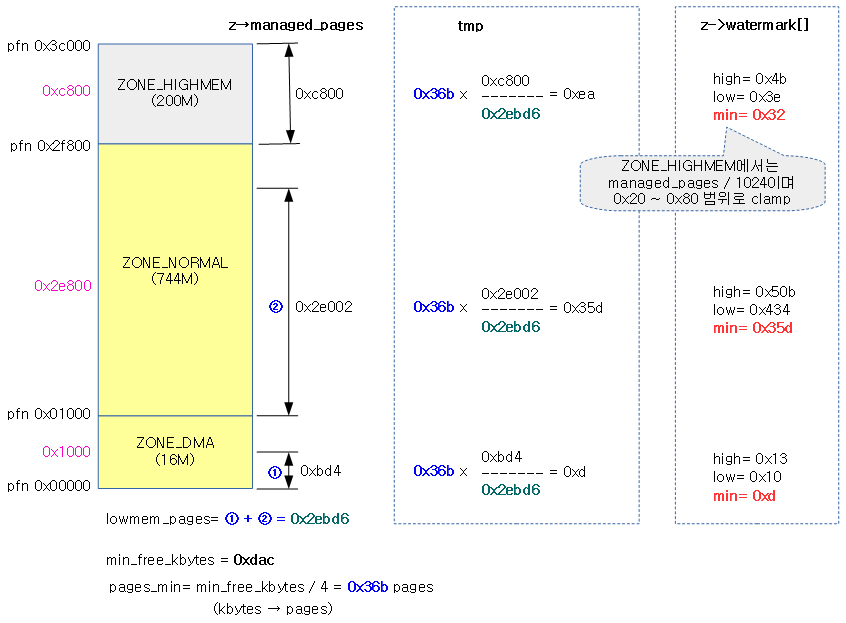
다음 그림은 워터마크 간격 값으로 우측의 두 산출된 값 중 가장 큰 값이 적용되는 모습을 보여준다.
존 stat 스레졸드 산출
high 워터마크를 사용하여 존 및 노드에 대한 stat 스레졸드들을 산출한다. 산출되는 항목들은 다음과 같다.
- 노드 stat 스레졸드
- 존 stat 스레졸드
- percpu_drift_mark
refresh_zone_stat_thresholds()
mm/vmstat.c
/* * Refresh the thresholds for each zone. */
void refresh_zone_stat_thresholds(void)
{
struct pglist_data *pgdat;
struct zone *zone;
int cpu;
int threshold;
/* Zero current pgdat thresholds */
for_each_online_pgdat(pgdat) {
for_each_online_cpu(cpu) {
per_cpu_ptr(pgdat->per_cpu_nodestats, cpu)->stat_threshold = 0;
}
}
for_each_populated_zone(zone) {
struct pglist_data *pgdat = zone->zone_pgdat;
unsigned long max_drift, tolerate_drift;
threshold = calculate_normal_threshold(zone);
for_each_online_cpu(cpu) {
int pgdat_threshold;
per_cpu_ptr(zone->pageset, cpu)->stat_threshold
= threshold;
/* Base nodestat threshold on the largest populated zone. */
pgdat_threshold = per_cpu_ptr(pgdat->per_cpu_nodestats, cpu)->stat_thresholdd
;
per_cpu_ptr(pgdat->per_cpu_nodestats, cpu)->stat_threshold
= max(threshold, pgdat_threshold);
}
/*
* Only set percpu_drift_mark if there is a danger that
* NR_FREE_PAGES reports the low watermark is ok when in fact
* the min watermark could be breached by an allocation
*/
tolerate_drift = low_wmark_pages(zone) - min_wmark_pages(zone);
max_drift = num_online_cpus() * threshold;
if (max_drift > tolerate_drift)
zone->percpu_drift_mark = high_wmark_pages(zone) +
max_drift;
}
}
모든 노드 및 존에 대해 노드 stat 스레졸드, 존 stat 스레졸드 및 percpu_drift_mark 를 산출한다.
- 코드 라인 9~13에서 전체 노드를 순회하며 노드 stat 스레졸드를 0으로 초기화한다.
- 코드 라인 15~25에서 populate존을 순회하며 존 stat 스레졸드 값을 산출한다.
- 코드 라인 28~31에서 노드 stat 스레졸드를 가장 큰 존 stat 스레졸드 값으로 갱신한다.
- 코드 라인 38~42에서 존 멤버인 percpu_drift_mark를 산출한다.
- max_drift = online cpu 수 * 산출한 스레졸드 값
- max_drift 값이 워터마크들 간의 간격보다 큰 경우 high 워터마크 + max_drift 값을 사용한다.
a) 메모리 비압박 시 사용할 스레졸드 산출
노멀 스레졸드 값은 다음과 같은 케이스들에서 호출되어 산출되어 설정된다.
- 부트 업 및 메모리의 hotplug 및 hotremove로 인해 메모리가 변경되면서 호출되는 refresh_zone_stat_thresholds() 함수
- kswapd_try_to_sleep() 함수에서 kswapd가 sleep하기 직전
calculate_normal_threshold()
mm/vmstat.c
int calculate_normal_threshold(struct zone *zone)
{
int threshold;
int mem; /* memory in 128 MB units */
/*
* The threshold scales with the number of processors and the amount
* of memory per zone. More memory means that we can defer updates for
* longer, more processors could lead to more contention.
* fls() is used to have a cheap way of logarithmic scaling.
*
* Some sample thresholds:
*
* Threshold Processors (fls) Zonesize fls(mem+1)
* ------------------------------------------------------------------
* 8 1 1 0.9-1 GB 4
* 16 2 2 0.9-1 GB 4
* 20 2 2 1-2 GB 5
* 24 2 2 2-4 GB 6
* 28 2 2 4-8 GB 7
* 32 2 2 8-16 GB 8
* 4 2 2 <128M 1
* 30 4 3 2-4 GB 5
* 48 4 3 8-16 GB 8
* 32 8 4 1-2 GB 4
* 32 8 4 0.9-1GB 4
* 10 16 5 <128M 1
* 40 16 5 900M 4
* 70 64 7 2-4 GB 5
* 84 64 7 4-8 GB 6
* 108 512 9 4-8 GB 6
* 125 1024 10 8-16 GB 8
* 125 1024 10 16-32 GB 9
*/
mem = zone_managed_pages(zone) >> (27 - PAGE_SHIFT);
threshold = 2 * fls(num_online_cpus()) * (1 + fls(mem));
/*
* Maximum threshold is 125
*/
threshold = min(125, threshold);
return threshold;
}
요청 zone의 managed_pages 크기에 비례하여 메모리 압박 상황이 아닐 때 사용할 스레졸드 값을 구하는데 최대 125로 제한한다.
- 산출식
- threshold = 2 * (log2(온라인 cpu 수) + 1) * (1 + log2(z->managed_pages / 128M) + 1)
- = 2 * fls(온라인 cpu 수) + fls(z->managed_pages / 128M)
- threshold 값은 최대 125로 제한
- 예) 6 cpu이고, zone이 managed_pages=3.5G
- threshold=2 x 3 x 5=30
- 예) 64 cpu이고, zone이 managed_pages=3.5G
- threshold=2 x 7 x 5=70
- threshold = 2 * (log2(온라인 cpu 수) + 1) * (1 + log2(z->managed_pages / 128M) + 1)
b) 메모리 압박 시 사용할 스레졸드 산출
pressure 스레졸드 값은 메모리가 부족하여 동작되는 kswapd가 깨어난 직후에 사용되는 스레졸드 값으로 관련 함수는 다음과 같다.
- kswapd_try_to_sleep() 함수
calculate_pressure_threshold()
mm/vmstat.c
int calculate_pressure_threshold(struct zone *zone)
{
int threshold;
int watermark_distance;
/*
* As vmstats are not up to date, there is drift between the estimated
* and real values. For high thresholds and a high number of CPUs, it
* is possible for the min watermark to be breached while the estimated
* value looks fine. The pressure threshold is a reduced value such
* that even the maximum amount of drift will not accidentally breach
* the min watermark
*/
watermark_distance = low_wmark_pages(zone) - min_wmark_pages(zone);
threshold = max(1, (int)(watermark_distance / num_online_cpus()));
/*
* Maximum threshold is 125
*/
threshold = min(125, threshold);
return threshold;
}
요청 zone의 managed_pages 크기에 비례하여 메모리 압박 상황에서 사용할 스레졸드 값을 구하는데 최대 125로 제한한다.
- cpu가 많은 시스템에서 스레졸드가 크면 각 cpu에서 유지되고 있는 per-cpu 카운터들이 존 카운터에 반영되지 못한 값들이 매우 많을 가능성이 있다. 따라서 메모리 부족 상황에서는 스레졸드 값을 줄일 수 있도록 다음과 같은 산출식을 사용한다.
- 산출식
- threshold = 워터마크 간 간격 / 온라인 cpu 수
- threshold 값은 최대 125로 제한
- 예) 6 cpu이고, min=1975, low=2468, high=2962,
- threshold=493 / 6 = 82
- 예) 64 cpu이고, min=1975, low=2468, high=2962
- threshold=493 / 64 = 7
lowmem reserve 페이지 산출
메모리 할당 요청 시 원하는 존을 지정하는 방법은 다음과 같은 gfp 마스크를 사용한다. 다음 플래그를 사용하지 않는 경우 디폴트로 NORMAL 존을 선택한다.
- __GFP_DMA
- __GFP_DMA32
- __GFP_HIGHMEM
- __GFP_MOVABLE
커널 개발자들은 메모리 할당 시 다음과 같은 gfp 마스크를 사용하여 존을 선택한다.
- GFP_DMA
- __GFP_DMA gfp 플래그를 사용하고, DMA 존을 선택한다.
- GFP_DMA32
- __GFP_DMA32 gfp 플래그를 사용하고, DMA32 존을 선택한다.
- GFP_KERNEL
- 존 지정과 관련한 gfp 플래그를 사용하지 않으면 NORMAL 존을 선택한다.
- GFP_HIGHUSER
- __GFP_HIGHMEM gfp 플래그를 사용하고, HIGHMEM 존을 선택한다.
- GFP_HIGHUSER_MOVABLE
- __GFP_HIGHMEM 및 __GFP_HIGHUSER gfp 플래그를 사용하고, MOVABLE 존을 선택한다.
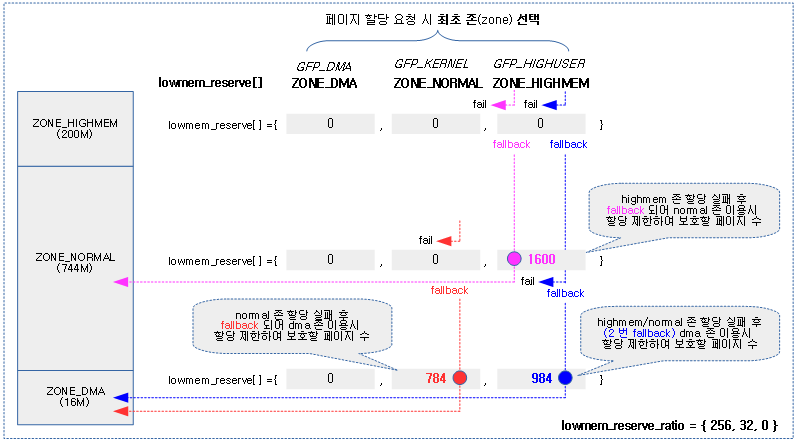
요청한 존에서 할당을 하지 못하면 zonelist를 통해 다음 존으로 fallback 되는데 그 순서는 다음과 같다.
- MOVABLE -> HIGHMEM -> NORMAL -> DMA32 -> DMA
lowmem_reserve
여러 존들 사이에서 lowmem 영역에 해당하는 normal 및 dma/dma32 존에서 사용되는 메모리 영역은 커널에 미리 매핑이 되어 있어 빠른 커널 메모리 할당이 가능한 존이다. 따라서 유저 application에서 사용하는 highmem 및 movable 존에 대한 할당 요청 시 lowmem 영역을 할당하는 것을 선호하지 않는다. 부득이하게 상위 존의 메모리가 부족하여 fallback 되어 lowmem 영역의 존에서 할당해야 할 경우 해당 존의 할당을 제한할 페이지 수가 지정된다. 이 값들은 최초 요청(request) 존과 최종 할당(target) 존에 대한 매트릭스로 지정된다.
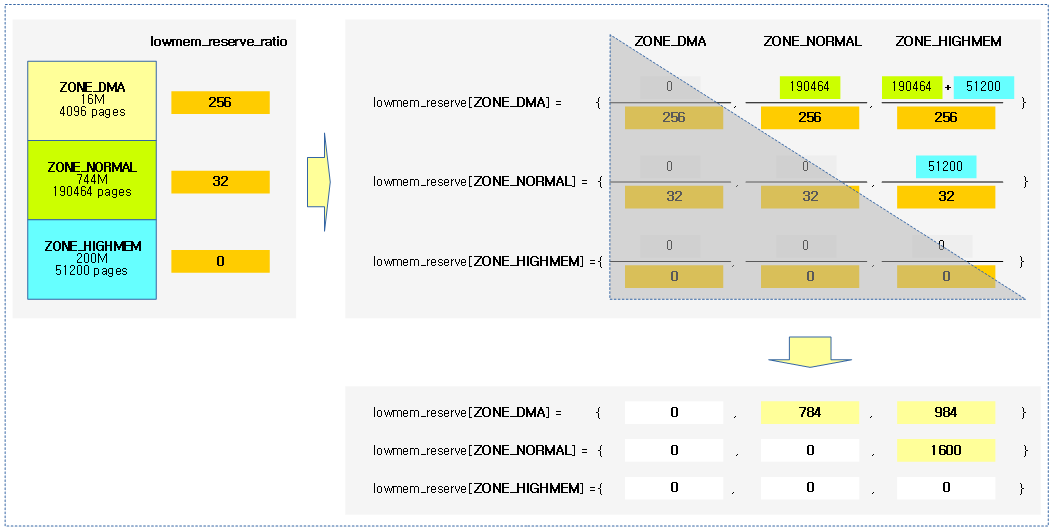
다음 그림의 예와 같이 각 존의 lowmem_reserve 값을 참고해본다.
- 1G 메모리를 가진 ARM32 시스템에 3 개의 존이 각각 dma(16M), normal(784M), highmem(200M)으로 운용되고 있다고 가정한다.
- 괄호{} 안의 값들은 시스템에서 운영되는 존 순서이고 그 값들은 할당 허용 페이지 수가 지정된다.
- 아래 붉은 선을 따라가보면 highmem 요청을 받았으나 fallback 되어 normal 존으로 향했을 때 워터마크 기준보다 1600 페이지를 더 높여 할당을 제한하는 방법으로 lowmem 영역을 보호한다.
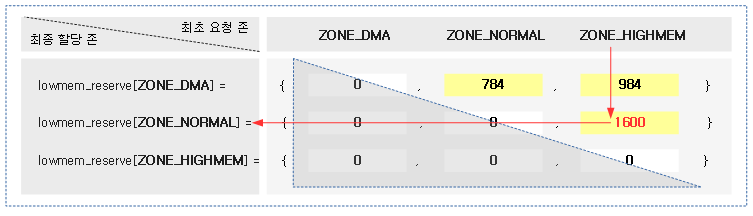
다음 그림과 같이 페이지 할당 시 최초 요구한 존에서 할당 실패할 때 fallback 되어 lowmem 영역으로 향할 때 워터마크 기준보다 더 추가된 페이지 할당 제한을 보여준다.
lowmem_reserve_ratio
각 존의 managed_pages를 사용하여 존별 lowmem_reserve 값을 산출하기 위한 비율이다.
다음과 같이 lowmem_reserve_ratio 값을 확인할 수 있다.
- 시스템에서 운영되는 낮은 zone 부터 높은 zone 순서대로 비율이 설정된다.
- 아래 예제 값은 dma, normal, highmem 존 순서이다.
$ cat /proc/sys/vm/lowmem_reserve_ratio 256 32 0
다음 그림과 같이 할당 요청 존에 대해 fallback 되었을 때 허용되는 페이지 수의 산출은 다음과 같다.
- 분자의 값으로 요청 존에서 할당 실패한 존까지의 managed_pages 수를 더함을 알 수 있다.
- 분모의 값으로 fallback되어 최종 할당 존의 lowmem_reserve_ratio가 지정됨을 알 수 있다.
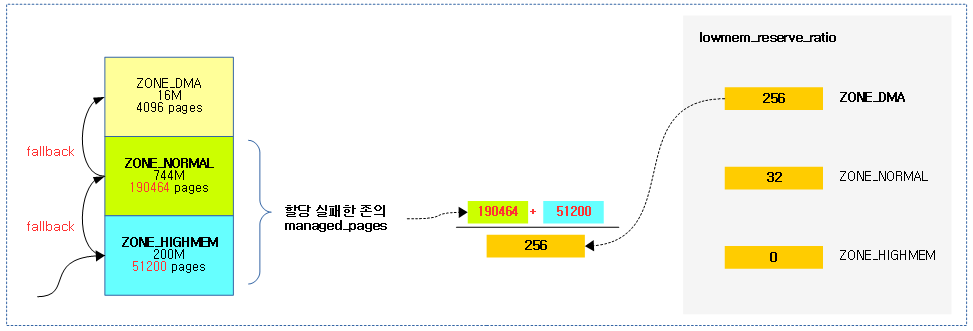
다음 그림과 같이 각 존의 managed_pages 크기와 lowmem_reserve_ratio를 이용해 각 존들의 lowmem_reserve 값이 산출되는 모습을 보여준다.
다음은 NUMA 및 4개의 존(dma, dma32, normal, movable)으로 구성된 x86 시스템에서 노드-존별 lowmem_reserve 값을 확인해본다.
- 아래 protection 항목을 보면된다. 처음 이 기능이 개발될 때 사용한 변수명이 protection 이었고, 나중에 lowmem_reserve로 바뀌었다.
$ cat /proc/zoneinfo
Node 0, zone DMA
pages free 3915
min 5
low 6
high 7
scanned 0
spanned 4095
present 3992
managed 3971
nr_free_pages 3915
...
protection: (0, 1675, 31880, 31880)
...
Node 0, zone DMA32
pages free 59594
min 588
low 735
high 882
scanned 0
spanned 1044480
present 491295
managed 429342
nr_free_pages 59594
...
protection: (0, 0, 30204, 30204)
...
Node 0, zone Normal
pages free 902456
min 10607
low 13258
high 15910
scanned 0
spanned 7864320
present 7864320
managed 7732469
nr_free_pages 902456
...
protection: (0, 0, 0, 0)
...
Node 1, zone Normal
pages free 1133093
min 11326
low 14157
high 16989
scanned 0
spanned 8388608
present 8388608
managed 8256697
nr_free_pages 1133093
...
protection: (0, 0, 0, 0)
...
다음과 같이 한 개의 존만 운영되는 시스템에서의 lowmem_reserve 값은 0이 되는 것을 확인 할 수 있다.
- dma32, normal 존을 운영하는 ARM64 시스템의 경우 dma32 존만으로 모든 메모리를 사용하는 경우 하나의 존으로만 운영한다. 즉 fallback이 없다.
$ cat /proc/zoneinfo
Node 0, zone DMA32
per-node stats
(...생략...)
pages free 633680
min 5632
low 7040
high 8448
spanned 786432
present 786432
managed 765771
protection: (0, 0, 0) <-----
nr_free_pages 633680
(...생략...)
Node 0, zone Normal
pages free 0
min 0
low 0
high 0
spanned 0
present 0
managed 0
protection: (0, 0, 0) <-----
(...생략...)
setup_per_zone_lowmem_reserve()
mm/page_alloc.c
/* * setup_per_zone_lowmem_reserve - called whenever * sysctl_lower_zone_reserve_ratio changes. Ensures that each zone * has a correct pages reserved value, so an adequate number of * pages are left in the zone after a successful __alloc_pages(). */
static void setup_per_zone_lowmem_reserve(void)
{
struct pglist_data *pgdat;
enum zone_type j, idx;
for_each_online_pgdat(pgdat) {
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long managed_pages = zone_managed_pages(zone);
zone->lowmem_reserve[j] = 0;
idx = j;
while (idx) {
struct zone *lower_zone;
idx--;
lower_zone = pgdat->node_zones + idx;
if (sysctl_lowmem_reserve_ratio[idx] < 1) {
sysctl_lowmem_reserve_ratio[idx] = 0;
lower_zone->lowmem_reserve[j] = 0;
} else {
lower_zone->lowmem_reserve[j] =
managed_pages / sysctl_lowmem_reserve_ratio[idx];
}
managed_pages += zone_managed_pages(lower_zone);
}
}
}
/* update totalreserve_pages */
calculate_totalreserve_pages();
}
존의 managed_pages 값과 lowmem_reserve_ratio 비율을 사용하여 존별 lowmem_reserve[] 페이지 값들을 산출한다.
- 코드 라인 6~11에서 전체 온라인 노드 수 만큼 순회하고, 해당 노드내 가용 존 수만큼 내부에서 순회하며 lowmem_reserve[] 값을 0으로 초기화한다.
- 코드 라인 13~30애서 가장 처음 존을 제외하고 루프 카운터로 지정된 존부터 밑으로 루프를 돌며 첫 번째 존(idx=0)을 제외한 managed_pages를 더해 lowmem_reserve에 lowmem_reserve_ratio 비율만큼 지정한다.
- 코드 라인 33에서 lowmem_reserve 값이 변화되었으므로 totalreserve 페이지 수도 갱신한다.
다음 그림은 zone별 lowmem_reserve[]를 산출하는 과정을 보여준다.

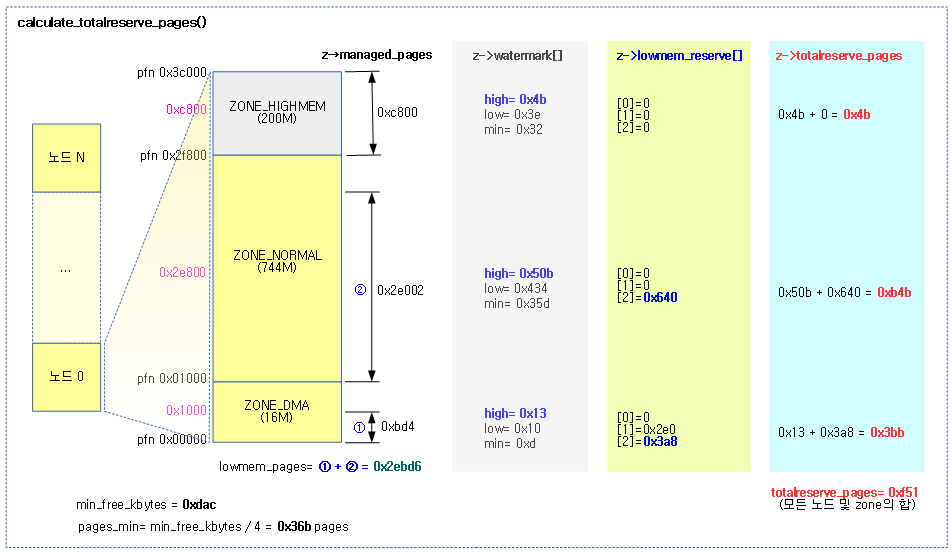
totalreserve 페이지 산출
calculate_totalreserve_pages()
mm/page_alloc.c
/* * calculate_totalreserve_pages - called when sysctl_lower_zone_reserve_ratio * or min_free_kbytes changes. */
static void calculate_totalreserve_pages(void)
{
struct pglist_data *pgdat;
unsigned long reserve_pages = 0;
enum zone_type i, j;
for_each_online_pgdat(pgdat) {
pgdat->totalreserve_pages = 0;
for (i = 0; i < MAX_NR_ZONES; i++) {
struct zone *zone = pgdat->node_zones + i;
long max = 0;
unsigned long managed_pages = zone_managed_pages(zone);
/* Find valid and maximum lowmem_reserve in the zone */
for (j = i; j < MAX_NR_ZONES; j++) {
if (zone->lowmem_reserve[j] > max)
max = zone->lowmem_reserve[j];
}
/* we treat the high watermark as reserved pages. */
max += high_wmark_pages(zone);
if (max > managed_pages)
max = managed_pages;
pgdat->totalreserve_pages += max;
reserve_pages += max;
}
}
totalreserve_pages = reserve_pages;
}
노드별 totalreserve_pages 값과 전역 totalreserve_pages 값을 산출한다.
- 코드 라인 7~9에서 모든 노드를 순회하며 totalreserve_pages를 산출하기 위해 먼저 0으로 초기화한다.
- 코드 라인 11~14에서 모든 존을 순회하며 해당 존의 managed 페이지를 알아온다.
- 코드 라인 17~28에서 순회 중인 존부터 마지막 존에 설정된 lowmem_reserve 값의 최대치를 알아온 후 high 워터마크를 더해 totalreserve_pages에 추가한다. 추가할 값이 순회중인 존의 managed_pages를 초과하지 않게 제한한다.
- 코드 라인 30~33에서 각 노드와 존에서 추가한 값들을 전역 totalreserve_pages에 대입한다.
다음 그림은 totalreserve_pages 값을 산출하기 위해 아래 값들을 각 노드와 존을 모두 더하여 산출하는 과정을 보여준다.
- 각 존 이상의 lowmem_reserve 최대치
- 각 존의 high 워터마크
inactive_ratio 산출
다음 과정들은 커널 v4.7-rc1에서 부트업 시 inactive_ratio를 산출하는 것을 제거하였다. inactive 리스트의 비율은 이제 inactive_list_is_low() 함수내에서 전체 메모리에 맞춰 자동으로 비교되므로 사용하지 않게 되었다.
setup_per_zone_inactive_ratio()
mm/page_alloc.c
static void __meminit setup_per_zone_inactive_ratio(void)
{
struct zone *zone;
for_each_zone(zone)
calculate_zone_inactive_ratio(zone);
}
모든 zone의 inactive anon 비율을 산출한다.
- zone->managed_pages가 256k pages (1GB) 미만인 경우 zone->inactive_ratio가 1이되어 active anon과 inactive anon의 비율을 1:1로 설정한다. 만일 managed_pages가 256k pages (1GB)를 초과한 경우 inactive_ratio 값은 3 이상이 되면서 inactive anon의 비율이 1/3 이하로 줄어든다.
다음 그림은 각 zone의 managed_pages 크기에 따라 inactive_ratio 값이 산출되는 과정을 보여준다.
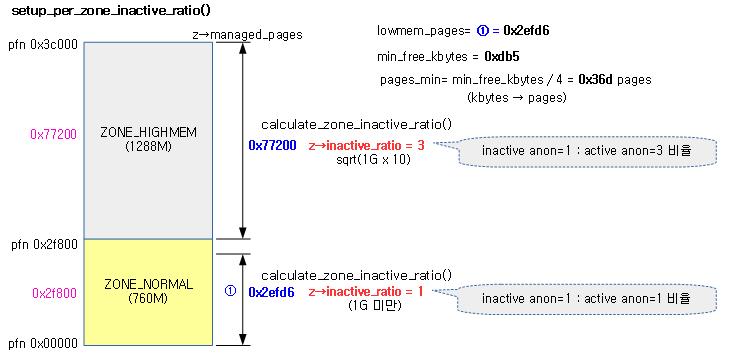
calculate_zone_inactive_ratio()
mm/page_alloc.c
/*
* The inactive anon list should be small enough that the VM never has to
* do too much work, but large enough that each inactive page has a chance
* to be referenced again before it is swapped out.
*
* The inactive_anon ratio is the target ratio of ACTIVE_ANON to
* INACTIVE_ANON pages on this zone's LRU, maintained by the
* pageout code. A zone->inactive_ratio of 3 means 3:1 or 25% of
* the anonymous pages are kept on the inactive list.
*
* total target max
* memory ratio inactive anon
* -------------------------------------
* 10MB 1 5MB
* 100MB 1 50MB
* 1GB 3 250MB
* 10GB 10 0.9GB
* 100GB 31 3GB
* 1TB 101 10GB
* 10TB 320 32GB
*/
static void __meminit calculate_zone_inactive_ratio(struct zone *zone)
{
unsigned int gb, ratio;
/* Zone size in gigabytes */
gb = zone->managed_pages >> (30 - PAGE_SHIFT);
if (gb)
ratio = int_sqrt(10 * gb);
else
ratio = 1;
zone->inactive_ratio = ratio;
}
지정된 zone의 inactive anon 비율을 산출한다.
- managed 페이지가 1G 미만인 경우 ratio는 1이된다.
- inactive anon=1 : active anon=1
- managed 페이지가 1G 이상인 경우 * 10한 후 제곱근(루트)을 하여 ratio를 설정한다. (inactive = 1 / ratio)
- 예) managed pages=1G
- inactive_ratio=3
- inactive anon=1 : active anon=3
- inactive anon=250M : active anon=750M
- inactive anon=1 : active anon=3
- inactive_ratio=3
- 예) managed pages=1G
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c – 현재 글
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd) | 문c
문영일 선배님, 김동현입니다.
블로그에서 많은 것 공부하고 배우고 있습니다. 항상 감사드립니다.
그런데, WATERMARK_MIN 항목의 3번째 줄에서 오타가 보였습니다. ‘문c 블로그’에 Contribution을 하고자 합니다.
‘페지지 회수가 -> 페이지 회수가’
동현님, 년말 잘 보내셨어요?
1990년대에 첫 직장에서 일하면서 ‘2000년이 올까?’ 라는 의심도 하곤 했습니다.
그런데 2000년은 커녕, 오지 않을 것만 같았던 2020년 이라는 숫자도 매일 보게 되었네요.
두 자리 숫자가 바뀐 큰 새해가 밝았으니, 동현님도 새해 복 더 많이 받으시길 바랍니다.
커널 책 출간으로 바쁘실텐데, 올 해 생활도 더 윤택해지시길 바랍니다.
종종 뵙길 바랍니다. ^^
응원해주셔서 감사합니다.
늦었지만 ‘문 선배님’도 새해 복 많이 받으시고 올해 다른 기회로 또 뵀으면 좋겠습니다.
‘문c 블로그’ 처럼 저도 올해 열심히 커널을 공부하겠습니다.
__zone_watermark_ok () 함수 에서 질문이 있습니다.
“코드 라인 10에서 free 페이지를 할당 요청한 페이지 수-1 만큼 감소시킨다.”
요청한 order로 페이지수를 계산하고 1을 뺀 후 free_pages에 넣는데,
여기서 -1을 하는 이유는 무엇인가요?
안녕하세요?
저도 예전에 한 번 왜 -1을 할 까 생각을 한적이 있었습니다만
개발자의 정확한 의미는 모르고 지나간 적이 있었습니다. 다만 아래 코드와 같이 코드를 작성해도 되는데
free_pages -= (1 < < order); ... if ((free_pages + 1) <= min + z->lowmem_reserve[classzone_idx])
커널 코드는 다음과 같이 미리 1을 덜 빼두고 비교 판단 코드를 작성하기 위함이라 판단됩니다.
free_pages -= (1 < < order) - 1; ... if (free_pages <= min + z->lowmem_reserve[classzone_idx])
감사합니다.
생각해 보니 아래와 같이 등호(=)를 빼는 방법도 가능해 보입니다.
free_pages -= (1 < < order); … if ((free_pages) lowmem_reserve[classzone_idx])
말씀하신 위치의 비교 조건에만 관련된 구현의 차이 일뿐,
알고리즘상의 큰 차이는 없어 보입니다.
감사합니다.
if (free_pages lowmem_reserve[classzone_idx])
입니다
네. 부등호(=)를 빼도 될 듯 합니다. ^^
안녕하세요,
좋은 정보 감사합니다.
본문에 나오는 lowmem은 zone_highmem을 제외한 영역인가요? 그렇다면 lowmem을 기준으로 watermark를 산정하는 이유는 무엇인가요?
안녕하세요?
커널에서 사용되는 lowmem은 다음 두 가지 의미로 사용됩니다.
1) 메모리 존을 뜻할 때에는 highmem 존의 반대 의미로 사용되고, lowmem에는 normal, dma32, dma 존이 포함됩니다. (64bit의 경우 highmem이 존재하지 않습니다)
2) 메모리 부족 경계를 의미로 사용되는 lowmem도 있습니다. 따라서 이 기준에 워터마크를 사용합니다.
감사합니다.
아 두가지가 다른 의미를 가지는 군요.
좋은 정보 감사합니다.!