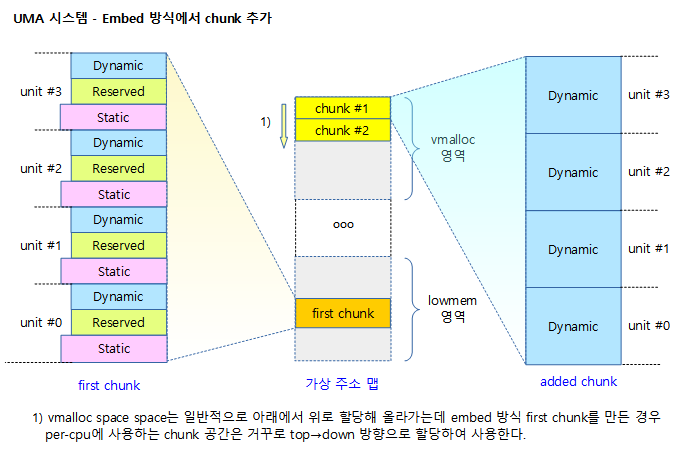
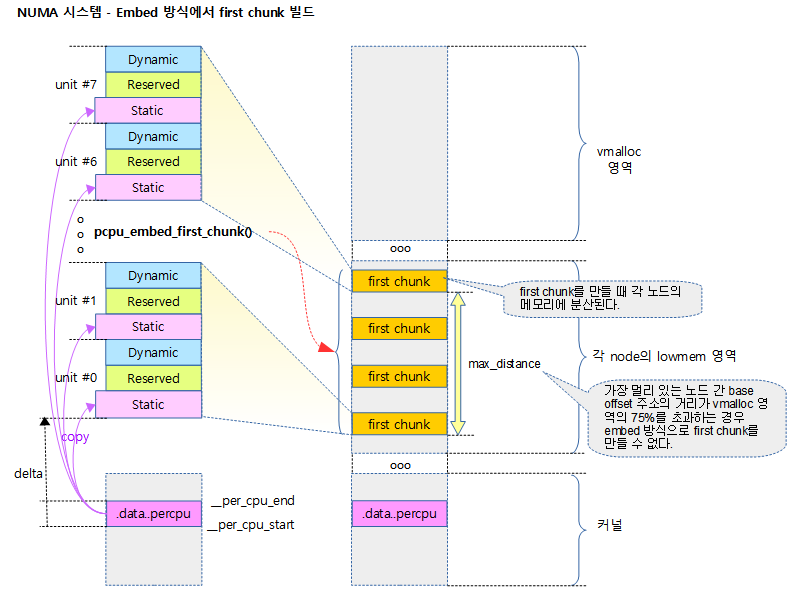
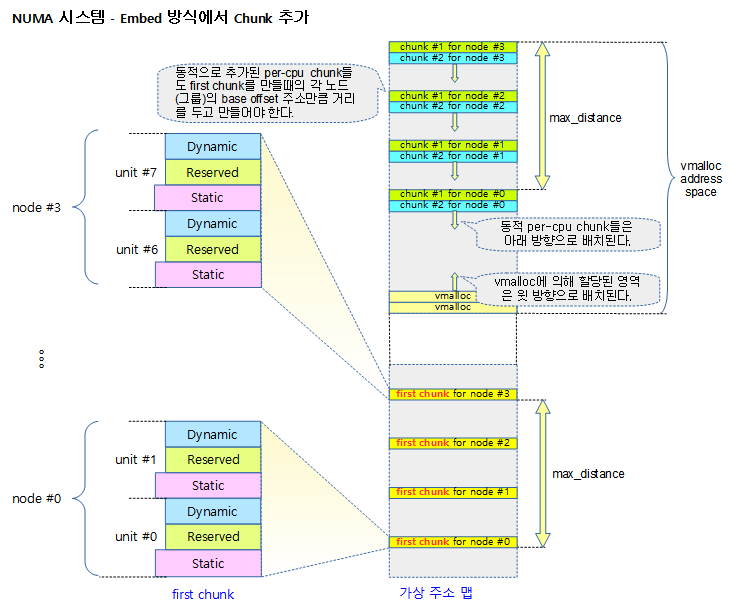
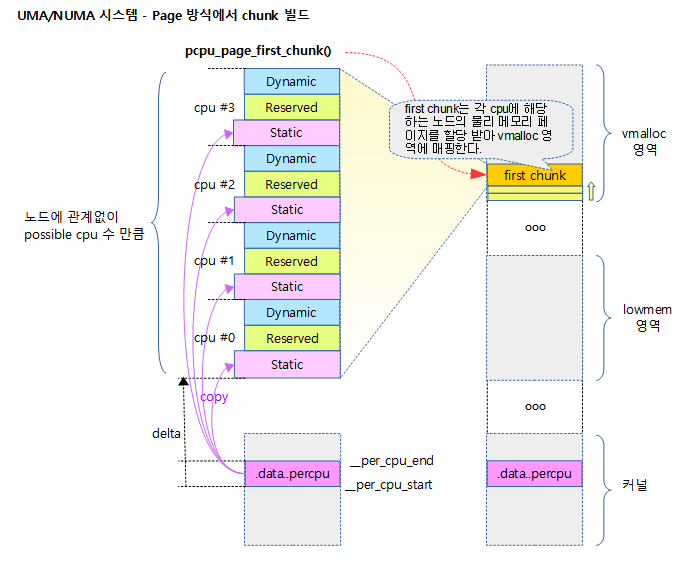
<kernel v5.10>
Bit 관련 매크로
BITS_PER_LONG
include/asm-generic/bitsperlong.h”
#ifdef CONFIG_64BIT
#define BITS_PER_LONG 64
#else
#define BITS_PER_LONG 32
#endif /* CONFIG_64BIT */
long 타입에서 사용될 수 있는 비트 수
BITS_PER_LONG_LONG
include/asm-generic/bitsperlong.h”
#ifndef BITS_PER_LONG_LONG
#define BITS_PER_LONG_LONG 64
#endif
long long 타입에서 사용될 수 있는 비트 수
BIT_ULL()
include/linux/bits.h
#define BIT_ULL(nr) (ULL(1) << (nr))
nr 비트에 해당하는 unsigned long long 값을 반환한다.
- nr=0~63 비트까지 지정할 수 있다.
- 예)
- nr=0 -> 1
- nr=1 -> 2
- ..
- nr=63 -> 0x8000_0000_0000_0000
BIT_MASK()
include/linux/bits.h
#define BIT_MASK(nr) (UL(1) << ((nr) % BITS_PER_LONG))
unsigned long 값(또는 배열)에서 nr 비트에 해당하는 비트를 추출할 목적의 비트 마스크를 만든다.
- nr=0~
- 예)
- nr=0 -> 1
- nr=1 -> 2
- ..
- nr=63 -> 0x8000_0000 (32 bit 기준), 0x8000_0000_0000_0000 (64 bit 기준)
- nr=64 -> 1
BIT_WORD()
include/linux/bits.h
#define BIT_WORD(nr) ((nr) / BITS_PER_LONG)
@nr 비트가 속한 unsigned long 비트맵 배열의 인덱스 번호 (0부터 시작)
- nr=0~
- 예)
- nr=0 -> 0
- nr=31 -> 0
- nr=32 -> 1 (32bit 기준), 0 (64bit 기준)
- nr=63 -> 1 (32bit 기준), 0 (64bit 기준)
- nr=64 -> 2 (32bit 기준), 1 (64bit 기준)
- nr=95 -> 2 (32bit 기준), 1 (64bit 기준)
- nr=96 -> 3 (32bit 기준), 1 (64bit 기준)
- nr=127 -> 3 (32bit 기준), 1 (64bit 기준)
- nr=128 -> 4 (32bit 기준), 2 (64bit 기준)
- nr=159 -> 4 (32bit 기준), 2 (64bit 기준)
- nr=160 -> 5 (32bit 기준), 2 (64bit 기준)
- nr=191 -> 5 (32bit 기준), 2 (64bit 기준)
BIT_ULL_MASK()
include/linux/bits.h
#define BIT_ULL_MASK(nr) (ULL(1) << ((nr) % BITS_PER_LONG_LONG))
unsigned long long 값(또는 배열)에서 nr 비트에 해당하는 비트를 추출할 목적의 비트 마스크를 만든다.
- nr=0~
- 예)
- nr=0 -> 1
- nr=1 -> 2
- ..
- nr=63 -> 0x8000_0000_0000_0000 (32 bit 및 64 bit 동일)
- nr=64 -> 1
BIT_ULL_WORD()
include/linux/bits.h
#define BIT_ULL_WORD(nr) ((nr) / BITS_PER_LONG_LONG)
@nr 비트가 속한 unsigned long long 비트맵 배열에 대한 인덱스 번호 (0부터 시작)
- nr=0~
- 예)
- nr=0 -> 0
- nr=63 -> 0
- nr=64 -> 1
- nr=127 -> 1
- nr=128 -> 2
- nr=191 -> 2
BITS_PER_BYTE
include/linux/bits.h
#define BITS_PER_BYTE 8
byte 타입에서 사용될 수 있는 비트 수
Bit Operations
API들
Search
- fls()
- __fls()
- ffs()
- __ffs()
- ffz()
- fls_long()
Iteration
- for_each_set_bit(bit, addr, size)
- size 비트 한도의 addr 값에서 셋(1) 비트 수 만큼 루프를 돈다.
- 예) addr=0x3f0, size=8
- for_each_set_bit_from(bit, addr, size)
- for_each_set_bit()와 유사하지만 시작 비트를 지정한 곳에서 출발한다.
- 예) addr=0x3f0, size=8, bit=5
- for_each_clear_bit(bit, addr, size)
- size 비트 한도의 addr 값에서 클리어(0) 비트 수 만큼 루프를 돈다.
- 예) addr=0xfff0, size=8
- for_each_clear_bit_from(bit, addr, size)
- for_each_set_bit()와 유사하지만 시작 비트를 지정한 곳에서 출발한다.
- 예) addr=0x3f0, size=8, bit=1
rotate
- rol64()
- ror64()
- rol32()
- ror32()
- rol16()
- ror16()
- rol8()
- ror8()
atomic
- set_bit()
- test_bit()
- clear_bit()
- change_bit()
- test_and_set_bit()
- test_and_clear_bit()
- test_and_change_bit()
- find_first_zero_bit()
- find_next_zero_bit()
- find_last_zero_bit()
- find_first_bit()
- find_next_bit()
- find_last_bit()
lock
- test_and_set_bit_lock()
- clear_bit_unlock()
- clear_bit_unlock_is_negative_byte()
le(little endian)
- find_next_zero_bit_le()
- find_next_bit_le()
- find_first_zero_bit_le()
- test_bit_le()
- set_bit_le()
- clear_bit_le()
- test_and_set_bit_le()
- test_and_clear_bit_le()
- __test_and_clear_bit_le()
etc
- get_bitmask_order()
- hweight_long()
- sign_extend32()
- sign_extend64()
- get_count_order()
- get_count_order_long()
- __ffs64()
- assign_bit()
- set_mask_bits()
- bit_clear_unless()
bitops 아키텍처별 헤더 파일
Bit operation은 기본 구현 헤더, Generic 라이브러리, asm-generic 헤더 및 아키텍처별 헤더에 구현되어 있다.
- 기본 구현 헤더
- include/linux/bitops.h
- include/asm-generic/bitops.h
- include/asm-generic/bitops/*.h
- Generic 라이브러리
- lib/find_bit.c
- lib/hweight.c
- …
- 아키텍처별 헤더
- arch/arm/include/asm/bitops.h
- arch/arm64/include/asm/bitops.h
비트 검색 operations
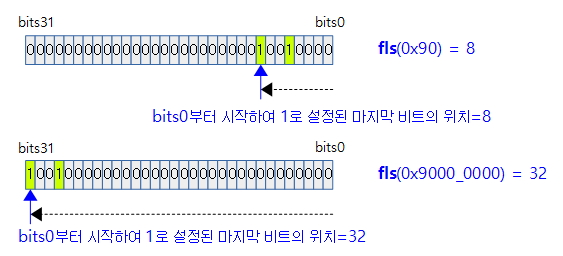
fls()
include/asm-generic/bitops/builtin-fls.h
/**
* fls - find last (most-significant) bit set
* @x: the word to search
*
* This is defined the same way as ffs.
* Note fls(0) = 0, fls(1) = 1, fls(0x80000000) = 32.
*/
static __always_inline int fls(unsigned int x)
{
return x ? sizeof(x) * 8 - __builtin_clz(x) : 0;
}
unsigned int 타입 @x 값에서 셋 되어 있는 마지막(가장 좌측) 비트의 위치(1~32)를 리턴한다. 설정된 비트가 없으면 0을 리턴한다.
- 예)
- 0 -> 0
- 0x0000_0001 -> 1
- 0x0000_0011 -> 2
- 0x8000_0000 -> 32
- 0x8800_0000 -> 32
__fls()
include/asm-generic/bitops/builtin-_ffs.h
/**
* __fls - find last (most-significant) set bit in a long word
* @word: the word to search
*
* Undefined if no set bit exists, so code should check against 0 first.
*/
static __always_inline unsigned long __fls(unsigned long word)
{
return (sizeof(word) * 8) - 1 - __builtin_clzl(word);
}
unsigned long 타입 @word에서 가장 마지막(가장 좌측) bit가 1인 bit 번호를 리턴한다. (based 0)
- 예)
- 0 -> 오류 (0 값이 입력으로 전달되면 안된다)
- 0x0000_0001 -> 0
- 0x0000_0011 -> 1
- 0x8000_0000 -> 31
- 0x8800_0000 -> 31
- 0x8800_0000_0000_0000 -> 63 (64bits only)
ffs()
include/asm-generic/bitops/builtin-ffs.h
/**
* ffs - find first bit set
* @x: the word to search
*
* This is defined the same way as
* the libc and compiler builtin ffs routines, therefore
* differs in spirit from the above ffz (man ffs).
*/
static __always_inline int ffs(int x)
{
return __builtin_ffs(x);
}
int 타입 @x에서 셋 되어 있는 첫(가장 우측) 비트의 위치(1~32)를 리턴한다. x 값이 0 즉, 설정된 비트가 없으면 0을 리턴한다.
- 예)
- 0 -> 0
- 1 -> 1
- 0x0000_0011 -> 1
- 0x8000_0000 -> 32
- 0x8800_0000 -> 31
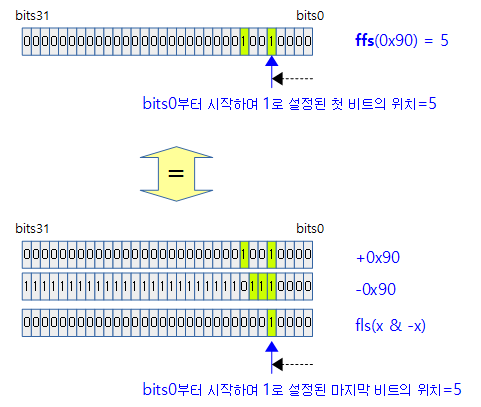
__ffs()
include/asm-generic/bitops/builtin-_ffs.h
/**
* __ffs - find first bit in word.
* @word: The word to search
*
* Undefined if no bit exists, so code should check against 0 first.
*/
static __always_inline unsigned long __ffs(unsigned long word)
{
return __builtin_ctzl(word);
}
unsigned long 타입 @word에서 셋 되어 있는 첫(가장 우측) 비트의 위치(0~31)를 리턴한다. x 값이 0 즉, 설정된 비트가 없으면 -1을 리턴한다.
- 예)
- 0 -> -1
- 0x0000_0001 -> 0
- 0x0000_0011 -> 1
- 0x8000_0000 -> 31
- 0x8800_0000 -> 30
- 0x8800_0000_0000_0000 -> 62 (64bits only)
ffz()
include/asm-generic/bitops/ffz.h
/*
* ffz - find first zero in word.
* @word: The word to search
*
* Undefined if no zero exists, so code should check against ~0UL first.
*/
#define ffz(x) __ffs(~(x))
clear(0) 되어 있는 첫 비트의 위치(0~31)를 리턴한다. x 값이 0xffff_ffff 즉, zero bit가 없으면 -1을 리턴한다.
- 예)
- 0 -> 0
- 0x0000_0001 -> 1
- 0x0000_000f -> 4
- 0x7fff_ffff -> 31
- 0xffff_ffff -> -1
fls_long()
include/linux/bitops.h
static inline unsigned fls_long(unsigned long l)
{
if (sizeof(l) == 4)
return fls(l);
return fls64(l);
}
long형 타입 인수 @l에 대해 lsb 부터 msb 로의 비트 검색을 하여 마지막 set bit를 알아오고 못 찾은 경우 0을 리턴한다. (based=1)
- 예)
- 0 -> 0
- 1 -> 1
- 0x8000_0000 -> 32
- 0x8000_0000_0000_0000 -> 64 (64bits only)
Atomic 비트 조작 operations
다음 API들을 알아본다.
- set_bit()
- clear_bit()
- change_bit()
- test_and_set_bit()
- test_and_clear_bit()
- test_and_change_bit()
Atomic 비트 조작 – Generic (ARM64 포함)
ARM64 아키텍처는 atomic api를 사용하여 처리한다.
set_bit() – Generic (ARM64 포함)
include/asm-generic/bitops/atomic.h
static inline void set_bit(unsigned int nr, volatile unsigned long *p)
{
p += BIT_WORD(nr);
atomic_long_or(BIT_MASK(nr), (atomic_long_t *)p);
}
unsigned long 타입 값(or 배열) @p에서 지정된 비트를 atomic 하게 1로 설정한다.
- 예)
- nr = 0 -> bit0 설정
- nr = 1 -> bit1 설정
- nr = 2 -> bit2 설정
- …
clear_bit() – Generic (ARM64 포함)
include/asm-generic/bitops/atomic.h
static inline void clear_bit(unsigned int nr, volatile unsigned long *p)
{
p += BIT_WORD(nr);
atomic_long_andnot(BIT_MASK(nr), (atomic_long_t *)p);
}
unsigned long 타입 값(or 배열) @p에서 지정된 비트를 atomic 하게 0으로 클리어한다.
- 예)
- nr = 0 -> bit0 클리어
- nr = 1 -> bit1 클리어
- nr = 2 -> bit2 클리어
- …
change_bit() – Generic (ARM64 포함)
include/asm-generic/bitops/atomic.h
static inline void change_bit(unsigned int nr, volatile unsigned long *p)
{
p += BIT_WORD(nr);
atomic_long_xor(BIT_MASK(nr), (atomic_long_t *)p);
}
unsigned long 타입 값(or 배열) @p에서 지정된 비트를 atomic 하게 뒤바꾼다(flip)
- 예)
- nr = 0 -> bit0 flip
- nr = 1 -> bit1 flip
- nr = 2 -> bit2 flip
- …
test_and_set_bit() – Generic (ARM64 포함)
include/asm-generic/bitops/atomic.h
static inline int test_and_set_bit(unsigned int nr, volatile unsigned long *p)
{
long old;
unsigned long mask = BIT_MASK(nr);
p += BIT_WORD(nr);
if (READ_ONCE(*p) & mask)
return 1;
old = atomic_long_fetch_or(mask, (atomic_long_t *)p);
return !!(old & mask);
}
unsigned long 타입 값(or 배열) @p에서 지정된 비트의 설정 여부를 0과 1로 알아오고, 결과와 상관 없이 해당 비트를 atomic 하게 1로 설정한다.
- 예)
- nr = 0 -> bit0 설정, 기존 읽은 old 값 반환
- nr = 1 -> bit1 설정, 기존 읽은 old 값 반환
- nr = 2 -> bit2 설정, 기존 읽은 old 값 반환
- …
test_and_clear_bit() – Generic (ARM64 포함)
include/asm-generic/bitops/atomic.h
static inline int test_and_clear_bit(unsigned int nr, volatile unsigned long *p)
{
long old;
unsigned long mask = BIT_MASK(nr);
p += BIT_WORD(nr);
if (!(READ_ONCE(*p) & mask))
return 0;
old = atomic_long_fetch_andnot(mask, (atomic_long_t *)p);
return !!(old & mask);
}
unsigned long 타입 값(or 배열) @p에서 지정된 비트의 설정 여부를 0과 1로 알아오고, 결과와 상관 없이 해당 비트를 atomic 하게 0으로 클리어한다.
- 예)
- nr = 0 -> bit0 클리어, 기존 읽은 old 값 반환
- nr = 1 -> bit1 클리어, 기존 읽은 old 값 반환
- nr = 2 -> bit2 클리어, 기존 읽은 old 값 반환
- …
test_and_change_bit() – Generic (ARM64 포함)
include/asm-generic/bitops/atomic.h
static inline int test_and_change_bit(unsigned int nr, volatile unsigned long *p)
{
long old;
unsigned long mask = BIT_MASK(nr);
p += BIT_WORD(nr);
old = atomic_long_fetch_xor(mask, (atomic_long_t *)p);
return !!(old & mask);
}
unsigned long 타입 값(or 배열) @p에서 지정된 비트의 설정 여부를 0과 1로 알아오고, 결과와 상관 없이 해당 비트를 atomic 하게 뒤바꾼다(flip)
- 예)
- nr = 0 -> bit0 flip, 기존 읽은 old 값 반환
- nr = 1 -> bit1 flip, 기존 읽은 old 값 반환
- nr = 2 -> bit2 flip, 기존 읽은 old 값 반환
- …
Atomic 비트 조작 – ARM32
set_bit()
arch/arm/include/asm/bitops.h
#define set_bit(nr,p) ATOMIC_BITOP(set_bit,nr,p)
unsigned long 타입 값(or 배열) @p에서 지정된 비트를 atomic 하게 1로 설정한다.
clear_bit()
arch/arm/include/asm/bitops.h
#define clear_bit(nr,p) ATOMIC_BITOP(clear_bit,nr,p)
unsigned long 타입 값(or 배열) @p에서 지정된 비트를 atomic 하게 0으로 클리어한다.
change_bit()
arch/arm/include/asm/bitops.h
#define change_bit(nr,p) ATOMIC_BITOP(change_bit,nr,p)
test_and_set_bit()
arch/arm/include/asm/bitops.h
#define test_and_set_bit(nr,p) ATOMIC_BITOP(test_and_set_bit,nr,p)
unsigned long 타입 값(or 배열) @p에서 지정된 비트의 설정 여부를 0과 1로 알아오고, 결과와 상관 없이 해당 비트를 atomic 하게 1로 설정한다.
test_and_clear_bit()
arch/arm/include/asm/bitops.h
#define test_and_clear_bit(nr,p) ATOMIC_BITOP(test_and_clear_bit,nr,p)
unsigned long 타입 값(or 배열) @p에서 지정된 비트의 설정 여부를 0과 1로 알아오고, 결과와 상관 없이 해당 비트를 atomic 하게 0으로 클리어한다.
test_and_change_bit()
arch/arm/include/asm/bitops.h
#define test_and_change_bit(nr,p) ATOMIC_BITOP(test_and_change_bit,nr,p)
unsigned long 타입 값(or 배열) @p에서 지정된 비트의 설정 여부를 0과 1로 알아오고, 결과와 상관 없이 해당 비트를 atomic 하게 뒤바꾼다(flip)
ATOMIC_BITOP()
#ifndef CONFIG_SMP
/*
* The __* form of bitops are non-atomic and may be reordered.
*/
#define ATOMIC_BITOP(name,nr,p) \
(__builtin_constant_p(nr) ? ____atomic_##name(nr, p) : _##name(nr,p))
#else
#define ATOMIC_BITOP(name,nr,p) _##name(nr,p)
#endif
SMP 시스템에서 nr 값의 상수 여부에 따라 다음 두 함수를 호출한다.
- 예) set_bit()
- 상수인 경우 __atomic_set_bit() 함수 호출
- 변수인 경우 _set_bit() 함수 호출
____atomic_set_bit()
arch/arm/include/asm/bitops.h
static inline void ____atomic_set_bit(unsigned int bit, volatile unsigned long *p)
{
unsigned long flags;
unsigned long mask = BIT_MASK(bit);
p += BIT_WORD(bit);
raw_local_irq_save(flags);
*p |= mask;
raw_local_irq_restore(flags);
}
____atomic_clear_bit()
arch/arm/include/asm/bitops.h
static inline void ____atomic_clear_bit(unsigned int bit, volatile unsigned long *p)
{
unsigned long flags;
unsigned long mask = BIT_MASK(bit);
p += BIT_WORD(bit);
raw_local_irq_save(flags);
*p &= ~mask;
raw_local_irq_restore(flags);
}
____atomic_change_bit()
arch/arm/include/asm/bitops.h
static inline void ____atomic_change_bit(unsigned int bit, volatile unsigned long *p)
{
unsigned long flags;
unsigned long mask = BIT_MASK(bit);
p += BIT_WORD(bit);
raw_local_irq_save(flags);
*p ^= mask;
raw_local_irq_restore(flags);
}
____atomic_test_and_set_bit()
arch/arm/include/asm/bitops.h
static inline int
____atomic_test_and_set_bit(unsigned int bit, volatile unsigned long *p)
{
unsigned long flags;
unsigned int res;
unsigned long mask = BIT_MASK(bit);
p += BIT_WORD(bit);
raw_local_irq_save(flags);
res = *p;
*p = res | mask;
raw_local_irq_restore(flags);
return (res & mask) != 0;
}
____atomic_test_and_clear_bit()
arch/arm/include/asm/bitops.h
static inline int
____atomic_test_and_clear_bit(unsigned int bit, volatile unsigned long *p)
{
unsigned long flags;
unsigned int res;
unsigned long mask = BIT_MASK(bit);
p += BIT_WORD(bit);
raw_local_irq_save(flags);
res = *p;
*p = res & ~mask;
raw_local_irq_restore(flags);
return (res & mask) != 0;
}
____atomic_test_and_change_bit()
arch/arm/include/asm/bitops.h
static inline int
____atomic_test_and_change_bit(unsigned int bit, volatile unsigned long *p)
{
unsigned long flags;
unsigned int res;
unsigned long mask = BIT_MASK(bit);
p += BIT_WORD(bit);
raw_local_irq_save(flags);
res = *p;
*p = res ^ mask;
raw_local_irq_restore(flags);
return (res & mask) != 0;
}
_set_bit()
arch/arm/lib/setbit.S
bitop _set_bit, orr
bitop 매크로를 사용하여 _set_bit에 대한 함수를 정의한다.
_clear_bit()
arch/arm/lib/clearbit.S
bitop _clear_bit, bic
bitop 매크로를 사용하여 _clear_bit에 대한 함수를 정의한다.
_chage_bit()
arch/arm/lib/changebit.S
bitop _change_bit, eor
bitop 매크로를 사용하여 _chage_bit에 대한 함수를 정의한다.
_test_and_set_bit()
arch/arm/lib/testsetbit.S
testop _test_and_set_bit, orreq, streq
bitop 매크로를 사용하여 _test_and_set_bit에 대한 함수를 정의한다.
_test_and_clear_bit()
arch/arm/lib/testclearbit.S
testop _test_and_clear_bit, bicne, strne
bitop 매크로를 사용하여 _test_and_clear_bit에 대한 함수를 정의한다.
_test_and_change_bit()
arch/arm/lib/testchangebit.S
testop _test_and_change_bit, eor, str
bitop 매크로를 사용하여 _test_and_change_bit에 대한 함수를 정의한다.
bitop 매크로
arch/arm/lib/bitops.h
#if __LINUX_ARM_ARCH__ >= 6
.macro bitop, name, instr
ENTRY( \name )
UNWIND( .fnstart )
ands ip, r1, #3
strneb r1, [ip] @ assert word-aligned
mov r2, #1
and r3, r0, #31 @ Get bit offset
mov r0, r0, lsr #5
add r1, r1, r0, lsl #2 @ Get word offset
#if __LINUX_ARM_ARCH__ >= 7 && defined(CONFIG_SMP)
.arch_extension mp
ALT_SMP(W(pldw) [r1])
ALT_UP(W(nop))
#endif
mov r3, r2, lsl r3
1: ldrex r2, [r1]
\instr r2, r2, r3
strex r0, r2, [r1]
cmp r0, #0
bne 1b
bx lr
UNWIND( .fnend )
ENDPROC(\name )
.endm
Atomic 비트 검색 operations
다음 함수들을 알아본다.
- find_next_bit()
- find_next_zero_bit()
- find_next_and_bit()
- find_first_bit()
- find_first_zero_bit()
- find_last_bit()
비트 검색 – Generic (ARM64 포함)
find_next_bit()
include/asm-generic/bitops/find.h
/**
* find_next_bit - find the next set bit in a memory region
* @addr: The address to base the search on
* @offset: The bitnumber to start searching at
* @size: The bitmap size in bits
*
* Returns the bit number for the next set bit
* If no bits are set, returns @size.
*/
lib/find_bit.c
/*
* Find the next set bit in a memory region.
*/
unsigned long find_next_bit(const unsigned long *addr, unsigned long size,
unsigned long offset)
{
return _find_next_bit(addr, NULL, size, offset, 0UL, 0);
}
EXPORT_SYMBOL(find_next_bit);
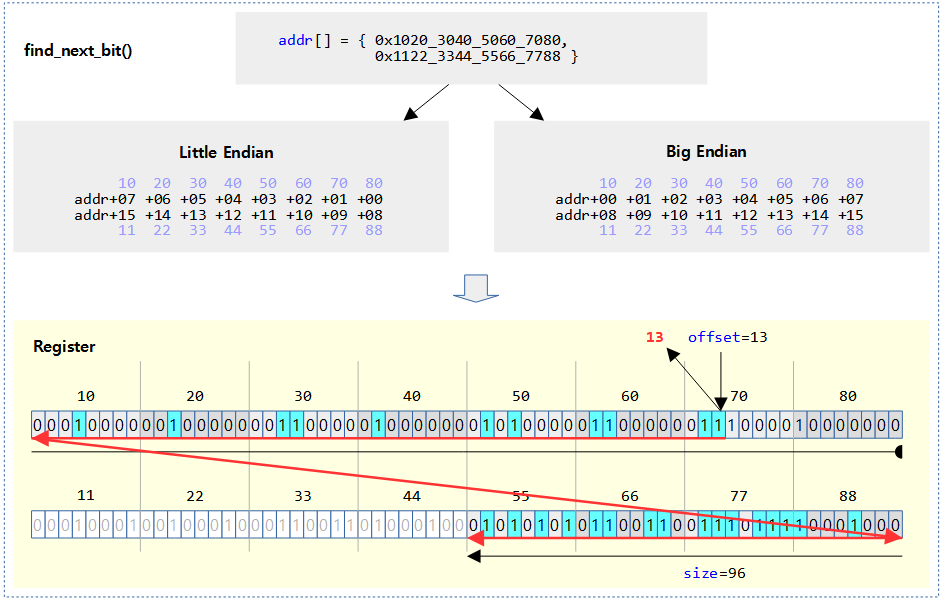
@addr 비트맵의 @size 제한 범위내에서 @offset 비트를 포함하여 비트가 1로 설정된 비트 위치를 찾아 알아온다. 발견하지 못한 경우는 size 값을 반환한다. (based 0)
- 예)
- addr=0xffff_8003, size=16, offset=-1 -> 16
- addr=0xffff_8003, size=16, offset=0 -> 0
- addr=0xffff_8003, size=16, offset=1 -> 1
- addr=0xffff_8003, size=16, offset=2 -> 15
- …
- addr=0xffff_8003, size=16, offset=14 -> 15
- addr=0xffff_8003, size=16, offset=15 -> 15
- addr=0xffff_8003, size=16, offset=16 -> 16
다음 그림은 find_next_bit()에서 검색하는 비트들을 하늘색으로 표시하였다.
find_next_zero_bit()
include/asm-generic/bitops/find.h
/**
* find_next_zero_bit - find the next cleared bit in a memory region
* @addr: The address to base the search on
* @offset: The bitnumber to start searching at
* @size: The bitmap size in bits
*
* Returns the bit number of the next zero bit
* If no bits are zero, returns @size.
*/
lib/find_bit.c
unsigned long find_next_zero_bit(const unsigned long *addr, unsigned long size,
unsigned long offset)
{
return _find_next_bit(addr, NULL, size, offset, ~0UL, 0);
}
EXPORT_SYMBOL(find_next_zero_bit);
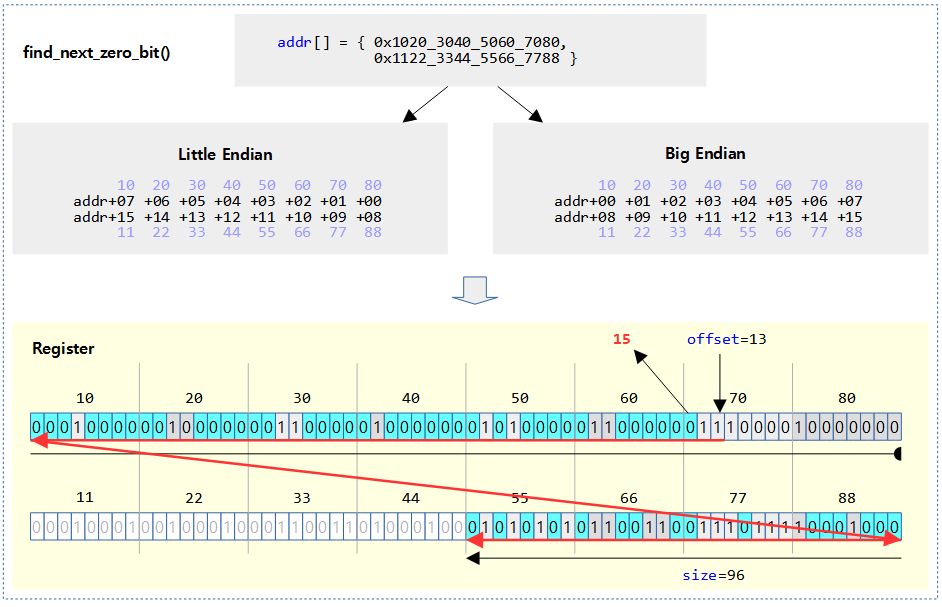
@addr 비트맵의 @size 제한 범위내에서 @offset 비트를 포함하여 비트가 0으로 클리어된 비트 위치를 찾아 알아온다. 발견하지 못한 경우는 size 값을 반환한다. (based 0)
- 예)
- addr=0xffff_800a, size=16, offset=-1 -> 16
- addr=0xffff_800a, size=16, offset=0 -> 0
- addr=0xffff_800a, size=16, offset=1 -> 2
- addr=0xffff_800a, size=16, offset=2 -> 2
- addr=0xffff_800a, size=16, offset=3 -> 4
- …
- addr=0xffff_800a, size=16, offset=14 -> 14
- addr=0xffff_800a, size=16, offset=15 -> 16
- addr=0xffff_800a, size=16, offset=16 -> 16
다음 그림은 find_next_zero_bit()에서 검색하는 비트들을 하늘색으로 표시하였다.
find_next_and_bit()
include/asm-generic/bitops/find.h
/**
* find_next_and_bit - find the next set bit in both memory regions
* @addr1: The first address to base the search on
* @addr2: The second address to base the search on
* @offset: The bitnumber to start searching at
* @size: The bitmap size in bits
*
* Returns the bit number for the next set bit
* If no bits are set, returns @size.
*/
lib/find_bit.c
unsigned long find_next_and_bit(const unsigned long *addr1,
const unsigned long *addr2, unsigned long size,
unsigned long offset)
{
return _find_next_bit(addr1, addr2, size, offset, 0UL, 0);
}
EXPORT_SYMBOL(find_next_and_bit);
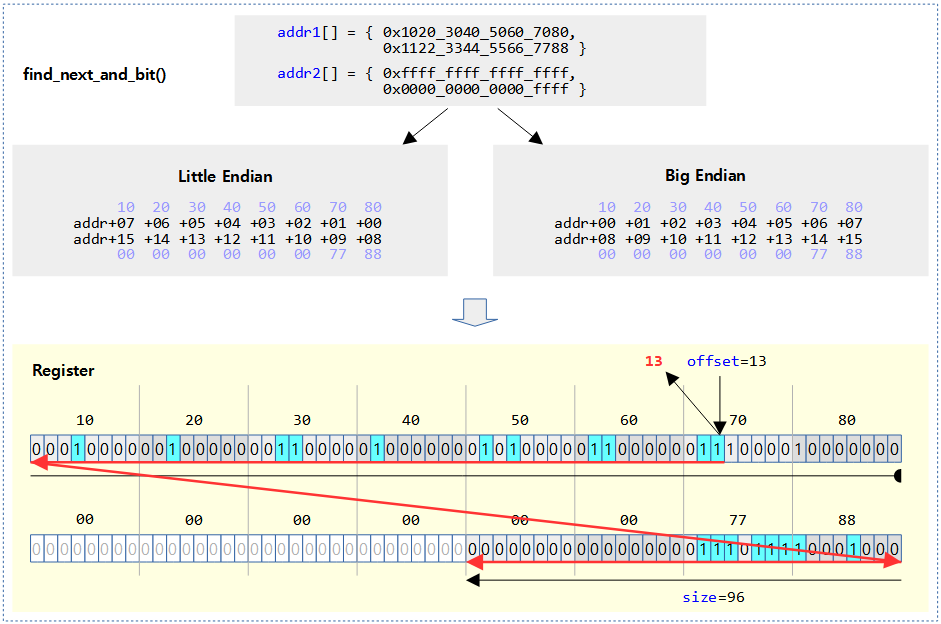
@addr과 @addr2 두 비트맵에서 @size 제한 범위내에서 @offset 비트를 포함하여 비트가 둘 다 1로 설정된 비트 위치를 찾아 알아온다. 발견하지 못한 경우는 size 값을 반환한다. (based 0)
- 예)
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=-1 -> 16
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=0 -> 1
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=1 -> 1
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=2 -> 3
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=3 -> 3
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=4 -> 15
- …
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=14 -> 15
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=15 -> 15
- addr1=0xffff_800a, addr2=0xffff_800f, size=16, offset=16 -> 16
다음 그림은 find_next_and_bit()에서 검색하는 비트들을 하늘색으로 표시하였다.
_find_next_bit()
lib/find_bit.c
/*
* This is a common helper function for find_next_bit, find_next_zero_bit, and
* find_next_and_bit. The differences are:
* - The "invert" argument, which is XORed with each fetched word before
* searching it for one bits.
* - The optional "addr2", which is anded with "addr1" if present.
*/
static unsigned long _find_next_bit(const unsigned long *addr1,
const unsigned long *addr2, unsigned long nbits,
unsigned long start, unsigned long invert, unsigned long le)
{
unsigned long tmp, mask;
if (unlikely(start >= nbits))
return nbits;
tmp = addr1[start / BITS_PER_LONG];
if (addr2)
tmp &= addr2[start / BITS_PER_LONG];
tmp ^= invert;
/* Handle 1st word. */
mask = BITMAP_FIRST_WORD_MASK(start);
if (le)
mask = swab(mask);
tmp &= mask;
start = round_down(start, BITS_PER_LONG);
while (!tmp) {
start += BITS_PER_LONG;
if (start >= nbits)
return nbits;
tmp = addr1[start / BITS_PER_LONG];
if (addr2)
tmp &= addr2[start / BITS_PER_LONG];
tmp ^= invert;
}
if (le)
tmp = swab(tmp);
return min(start + __ffs(tmp), nbits);
}
이 함수는 find_next_bit(), find_next_zero_bit() 및 find_next_and_bit() 함수에서 사용되는 헬퍼 함수이다.
- 코드 라인 7~8에서 시작 위치 @start가 @nbits 이상인 경우 에러 의미를 갖는 @nbits를 반환한다.
- 코드 라인 10~13에서 비트맵 @addr1에서 @start에 해당하는 unsigned long 만큼을 알아온다. 만일 비트맵 @addr2가 지정된 경우 동일하게 @start 에 해당하는 unsigned long 만큼을 알아온 후 먼저 알아온 값과 and 연산을 수행한다. 마지막으로 @invert 값과 exclusive or 연산을 수행하여 tmp에 대입한다.
- 코드 라인 20~24에서 tmp 값에서 @start 비트 미만의 모든 비트를 모두 0으로 클리어하여 처리하지 않도록 한다.
- 예) tmp=3, @start=1
- tmp=2 (bit1 미만의 bit0만 클리어하였다.)
- 만일 리틀 엔디안 @le가 설정된 경우라면 tmp 값을 swap 한다.
- 예) tmp=0x1122_3344_5566_7788, le=1
- tmp=0x8877_6655_4433_2211
- 코드 라인 26에서 @start 값을 BITS_PER_LONG 단위로 절삭한다.
- 코드 라인 28~37에서 만일 tmp 값이 0인 경우 다음 unsigned long 값을 알아온다. 물론 start가 @nbits 이상인 경우 에러 의미를 갖는 @nbits를 반환한다.
- 코드 라인 39~40에서 만일 리틀 엔디안 @le가 설정된 경우라면 tmp 값을 원래 값을 갖기 위해 swap 한다.
- 코드 라인 42에서 tmp에서 1로 설정된 가장 첫(가장 우측) 비트의 위치를 반환한다.
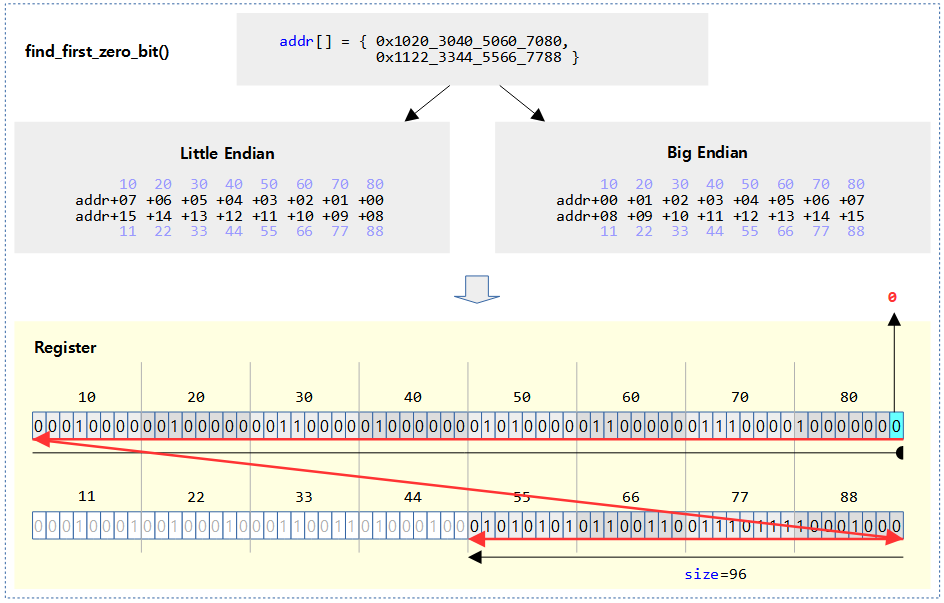
find_first_zero_bit() – Generic (ARM64 포함)
lib/find_bit.c
/*
* Find the first cleared bit in a memory region.
*/
unsigned long find_first_zero_bit(const unsigned long *addr, unsigned long size)
{
unsigned long idx;
for (idx = 0; idx * BITS_PER_LONG < size; idx++) {
if (addr[idx] != ~0UL)
return min(idx * BITS_PER_LONG + ffz(addr[idx]), size);
}
return size;
}
EXPORT_SYMBOL(find_first_zero_bit);
@addr 비트맵의 @size 제한 범위내에서 비트가 0으로 클리어된 가장 처음 비트 위치를 찾아 알아온다. 발견하지 못한 경우는 size 값을 반환한다. (based 0)
- 예) addr=0xffff_800a, size=16 -> 0
다음 그림은 find_first_zero_bit()에서 검색한 첫 번째 비트를 하늘색으로 표시하였다.
find_first_bit() – Generic (ARM64 포함)
lib/find_bit.c
/*
* Find the first set bit in a memory region.
*/
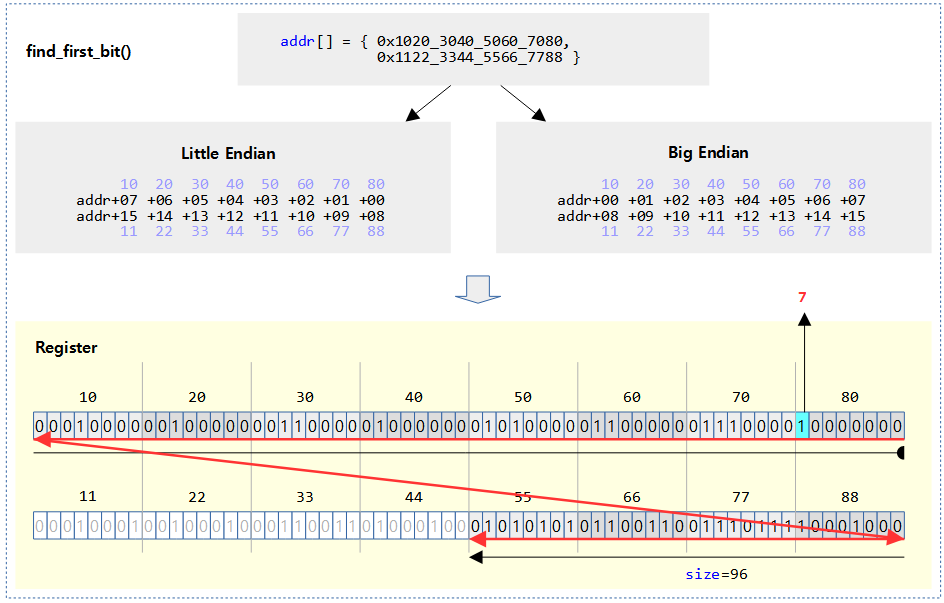
unsigned long find_first_bit(const unsigned long *addr, unsigned long size)
{
unsigned long idx;
for (idx = 0; idx * BITS_PER_LONG < size; idx++) {
if (addr[idx])
return min(idx * BITS_PER_LONG + __ffs(addr[idx]), size);
}
return size;
}
EXPORT_SYMBOL(find_first_bit);
@addr 비트맵의 @size 제한 범위내에서 비트가 1로 설정된 가장 처음(가장 우측) 비트 위치를 찾아 알아온다. 발견하지 못한 경우는 size 값을 반환한다. (based 0)
- 예) addr=0xffff_800a, size=16 -> 1
다음 그림은 find_first_bit()에서 검색한 첫 번째 비트를 하늘색으로 표시하였다.
find_last_bit() – Generic (ARM, ARM64 포함)
lib/find_bit.c
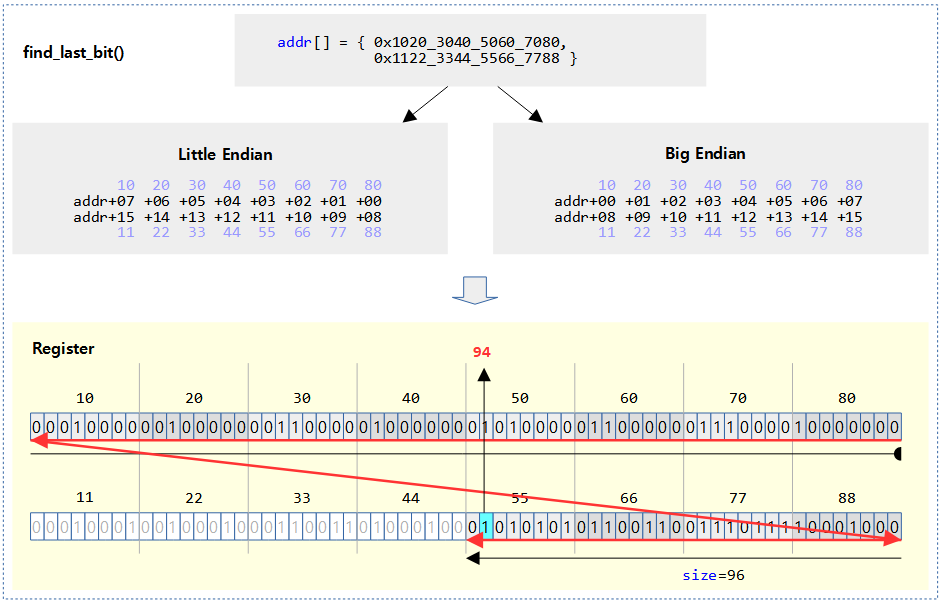
unsigned long find_last_bit(const unsigned long *addr, unsigned long size)
{
if (size) {
unsigned long val = BITMAP_LAST_WORD_MASK(size);
unsigned long idx = (size-1) / BITS_PER_LONG;
do {
val &= addr[idx];
if (val)
return idx * BITS_PER_LONG + __fls(val);
val = ~0ul;
} while (idx--);
}
return size;
}
EXPORT_SYMBOL(find_last_bit);
@addr 비트맵의 @size 제한 범위내에서 비트가 1로 설정된 가장 마지막(가장 좌측) 비트 위치를 찾아 알아온다. 발견하지 못한 경우는 size 값을 반환한다.
- 예) addr=0xffff_800a, size=16 -> 15
다음 그림은 find_last_bit()에서 검색한 첫 번째 비트를 하늘색으로 표시하였다.
비트 검색 – ARM32
find_first_zero_bit()
arch/arm/include/asm/bitops.h
#ifndef __ARMEB__
#define find_first_zero_bit(p,sz) _find_first_zero_bit_le(p,sz)
#else
#define find_first_zero_bit(p,sz) _find_first_zero_bit_be(p,sz)
#endif
비트맵의 size 제한 범위내에서 첫 번째 zero 비트 위치를 반환한다. 발견하지 못한 경우는 size 값을 반환한다. (based 0)
- fls()가 find_first_zero_bit()와 세 가지 다른 점
- 처리되는 데이터 타입이 다르다.
- fls()는 unsigned int 타입에서 동작한다.
- find_last_zero_bit()는 비트 제한이 없는 비트맵에서 동작한다.
- 검색 비트 종류(set(1) bit / clear(0))
- fls()는 set(1) bit를 검색한다.
- find_first_zero_bit는 clear(0) bit를 검색한다.
- 리턴되는 포지션 값
- fls()는 bit0을 검색하면 1로 리턴한다. 검색되지 않으면 0을 리턴한다.
- find_last_zero_bit는 bit0을 검색하면 0으로 리턴한다. 검색되지 않으면 max_bits 값을 리턴한다.
- 이 매크로는 엔디안에 따라 구현 루틴이 다르다.
bits0, bit1, bit32들이 모두 1인 64개의 비트마스크를 예로알아본다.
- 논리적 비트마스크 (first zero bit=2)
- 0x0000_0001_0000_0003 = 0b00000000_00000000_00000000_00000001_00000000_00000000_00000000_00000011
- 리틀 엔디안으로 저장 시:
- {0x03, 0x00, 00, 00, 01, 00, 00, 00}
- 32비트 레지스터에 2번에 나누어 읽어들이면
- 빅 엔디안으로 저장 시:
- {0x00, 00, 00, 01, 00, 00, 00, 03}
- 32비트 레지스터에 2번에 나누어 읽어들이면
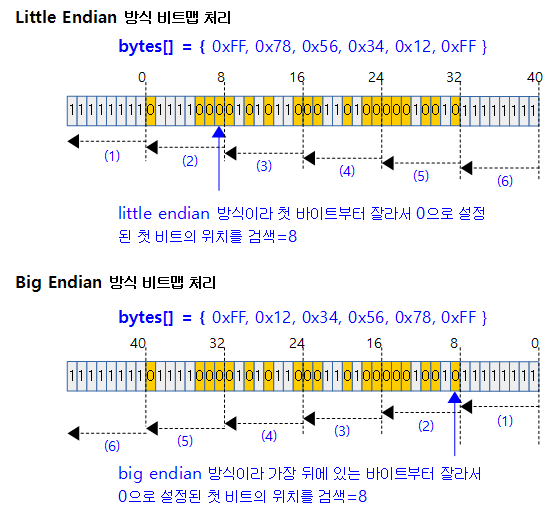
한 번 더 알아보면,
- 논리적 비트마스크 (first zero bit=8)
- 0xff12_3456_78ff = 0b11111111_00010010_00110100_01010110_01111000_11111111
- 리틀 엔디안으로 저장 시:
- { 0xff, 0x78, 0x56, 0x34, 0x12, 0xff }
- 32비트 레지스터에 2번에 나누어 읽어들이면
- 빅 엔디안으로 저장 시:
- {0xff, 0x12, 0x34, 0x56, 0x78, 0xff }
- 32비트 레지스터에 2번에 나누어 읽어들이면
_find_first_zero_bit_le()
arch/arm/lib/findbit.S
/*
* Purpose : Find a 'zero' bit
* Prototype: int find_first_zero_bit(void *addr, unsigned int maxbit);
*/
ENTRY(_find_first_zero_bit_le)
teq r1, #0
beq 3f
mov r2, #0
1:
ARM( ldrb r3, [r0, r2, lsr #3] )
THUMB( lsr r3, r2, #3 )
THUMB( ldrb r3, [r0, r3] )
eors r3, r3, #0xff @ invert bits
bne .L_found @ any now set - found zero bit
add r2, r2, #8 @ next bit pointer
2: cmp r2, r1 @ any more?
blo 1b
3: mov r0, r1 @ no free bits
ret lr
ENDPROC(_find_first_zero_bit_le)
- 레지스터 용도
- r0(addr): 비트맵이 위치한 주소
- r1(maxbit): maxbit로 처리할 최대 비트 수
- r0(결과): clear(0) bit를 찾은 비트 번호를 리턴
- 0~n: 첫 번째 비트가 clear bit.
- maxbit: 비트맵 범위내에서 찾지 못함(not found).
- r2(currbit): 현재 검색하고 있는 비트
- r3(8bit 비트맵): 읽어들인 1바이트(8비트) 비트맵
- 비트맵에서 1 바이트(8비트) 단위로 읽어와서 clear(0) 비트가 있는지 검사하여 있으면 .L_found 레이블로 이동한다.
- teq r1, #0
- 처리할 비트가 없으며(maxbit가 0이면) r0←0(error)를 리턴
- mov r2, #0
- currbit를 0으로 대입(처음 시작 비트)
- 1: ldrb r3, [r0, r2, lsr #3]
- r3에 비트맵 주소 + currbit / 8을 하여 1바이트를 읽어온다.
- eors r3, r3, #0xff
- 읽어들인 데이터를 반전(invert) 시킨다.
- bne .L_found
- 즉, 읽어들인 8비트 비트맵에 clear(bit)가 존재하면 .L_found로 이동
- add r3, r3, #8
- cmp r2, r1
- 아직 끝나지 않았으면(curbit < maxbit) 1b로 이동
- #3: mov r0, r1
- r0 ← r1(maxbit) 값을 리턴(not found)
/*
* One or more bits in the LSB of r3 are assumed to be set.
*/
.L_found:
rsb r0, r3, #0
and r3, r3, r0
clz r3, r3
rsb r3, r3, #31
add r0, r2, r3
cmp r1, r0 @ Clamp to maxbit
movlo r0, r1
ret lr
- rsb r0, r3, #0
- and r3, r3, r0
- r3 &= r0
- 위의 rsb, and 명령은 r3 &= -r3와 동일한 연산이고 이렇게 하면 set(bit)가 lsb 쪽에 하나만 남게된다.
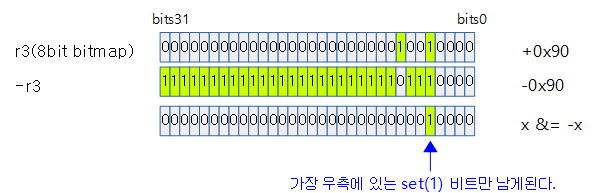
- clz r3, r3
- 시작 비트만 남겨놨으니 그 앞쪽에 있는 0 bit를 카운트한다.
- counter leading zero로 bit31부터 시작해서 set(1) bit가 발견되기 전까지의 clear(0) bit 수를 카운트 한다.
- clz(0x90) -> 24
- clz(0x7777_7777) -> 1
- rsb r3, r3, #31
- add r0, r2, r3
- r0 ← r2(curbit) + r3(바이트 내에서 찾은 위치)
- movlo r0, r1
- 범위를 벗어난 위치에서 비트가 발견되면r0 ← maxbit(not found)를 리턴
- r1(maxbit> < r0(찾은 위치)
find_first_bit() – ARM
arch/arm/include/asm/bitops.h
#define find_first_bit(p,sz) _find_first_bit_le(p,sz)
비트맵의 size 범위내에서 set(1) 비트가 처음 발견되는 비트 번호를 알아온다. 발견하지 못한 경우 size를 반환한다. (based 0)
- 구현은 엔디안에 따라 두 개로 나뉘어 있다.
- 예) *addr[]=0x8800_0000_0000_0000, size=64
- 예) *addr[]=0x0000_0088, size=32
/*
* Purpose : Find a 'one' bit
* Prototype: int find_first_bit(const unsigned long *addr, unsigned int maxbit);
*/
ENTRY(_find_first_bit_le)
teq r1, #0
beq 3f
mov r2, #0
1:
ARM( ldrb r3, [r0, r2, lsr #3] )
THUMB( lsr r3, r2, #3 )
THUMB( ldrb r3, [r0, r3] )
movs r3, r3
bne .L_found @ any now set - found zero bit
add r2, r2, #8 @ next bit pointer
2: cmp r2, r1 @ any more?
blo 1b
3: mov r0, r1 @ no free bits
ret lr
ENDPROC(_find_first_bit_le)
- 레지스터 용도
- r0(addr): 비트맵이 위치한 주소
- r1(maxbit): maxbit로 처리할 최대 비트 수
- r0(결과): clear(0) bit를 찾은 비트 번호를 리턴
- 0~n: set bit가 발견된 비트 위치.
- maxbit: 비트맵 범위내에서 찾지 못함(not found).
- r2(currbit): 현재 검색하고 있는 비트(0, 8, 16, 24, …)
- r3(8bit 비트맵): 읽어들인 1바이트(8비트) 비트맵
비트맵에서 1 바이트(8비트) 단위로 읽어와서 clear(0) 비트가 있는지 검사하여 있으면 .L_found 레이블로 이동한다.
- teq r1, #0
- 처리할 비트가 없으며(maxbit가 0이면) r0←0(error)를 리턴
- mov r2, #0
- currbit를 0으로 대입(처음 시작 비트)
- 1: ldrb r3, [r0, r2, lsr #3]
- r3에 비트맵 주소 + currbit / 8을 하여 1바이트를 읽어온다.
- bne .L_found
- 즉, 읽어들인 8비트 비트맵에 set bit가 존재하면 .L_found로 이동
- add r3, r3, #8
- cmp r2, r1
- 아직 끝나지 않았으면(curbit < maxbit) 1b로 이동
- 3: mov r0, r1
- r0 ← r1(maxbit) 값을 리턴(not found)
- .L_found는 _find_first_zero_bit_le()에서 사용한 루틴과 동일하다.
- 예) byte *addr[] = {0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x88}, size=64
- 예) byte *addr[] = {0x11, 0x00, 0x00, 0x00}, size=32
hweight operations
hweight_long()
include/linux/bitops.h
static inline unsigned long hweight_long(unsigned long w)
{
return sizeof(w) == 4 ? hweight32(w) : hweight64(w);
}
long 타입 w에 대해 1로 설정되어 있는 bit 수를 리턴한다.
hweight**()
include/asm-generic/bitops/const_hweight.h
/*
* Generic interface.
*/
#define hweight8(w) (__builtin_constant_p(w) ? __const_hweight8(w) : __arch_hweight8(w))
#define hweight16(w) (__builtin_constant_p(w) ? __const_hweight16(w) : __arch_hweight16(w))
#define hweight32(w) (__builtin_constant_p(w) ? __const_hweight32(w) : __arch_hweight32(w))
#define hweight64(w) (__builtin_constant_p(w) ? __const_hweight64(w) : __arch_hweight64(w))
1로 설정되어 있는 bit 수를 리턴한다.
__const_hweight**()
include/asm-generic/bitops/const_hweight.h
/*
* Compile time versions of __arch_hweightN()
*/
#define __const_hweight8(w) \
((unsigned int) \
((!!((w) & (1ULL << 0))) + \
(!!((w) & (1ULL << 1))) + \
(!!((w) & (1ULL << 2))) + \
(!!((w) & (1ULL << 3))) + \
(!!((w) & (1ULL << 4))) + \
(!!((w) & (1ULL << 5))) + \
(!!((w) & (1ULL << 6))) + \
(!!((w) & (1ULL << 7)))))
#define __const_hweight16(w) (__const_hweight8(w) + __const_hweight8((w) >> 8 ))
#define __const_hweight32(w) (__const_hweight16(w) + __const_hweight16((w) >> 16))
#define __const_hweight64(w) (__const_hweight32(w) + __const_hweight32((w) >> 32))
1로 설정되어 있는 bit 수를 리턴한다.
__arch_hweight**()
include/asm-generic/bitops/arch_hweight.h
static inline unsigned int __arch_hweight32(unsigned int w)
{
return __sw_hweight32(w);
}
static inline unsigned int __arch_hweight16(unsigned int w)
{
return __sw_hweight16(w);
}
static inline unsigned int __arch_hweight8(unsigned int w)
{
return __sw_hweight8(w);
}
static inline unsigned long __arch_hweight64(__u64 w)
{
return __sw_hweight64(w);
}
__sw_hweight32()
lib/hweight.c
/**
* hweightN - returns the hamming weight of a N-bit word
* @x: the word to weigh
*
* The Hamming Weight of a number is the total number of bits set in it.
*/
unsigned int __sw_hweight32(unsigned int w)
{
#ifdef CONFIG_ARCH_HAS_FAST_MULTIPLIER
w -= (w >> 1) & 0x55555555;
w = (w & 0x33333333) + ((w >> 2) & 0x33333333);
w = (w + (w >> 4)) & 0x0f0f0f0f;
return (w * 0x01010101) >> 24;
#else
unsigned int res = w - ((w >> 1) & 0x55555555);
res = (res & 0x33333333) + ((res >> 2) & 0x33333333);
res = (res + (res >> 4)) & 0x0F0F0F0F;
res = res + (res >> 8);
return (res + (res >> 16)) & 0x000000FF;
#endif
}
EXPORT_SYMBOL(__sw_hweight32);
__sw_hweight16()
lib/hweight.c
unsigned int __sw_hweight16(unsigned int w)
{
unsigned int res = w - ((w >> 1) & 0x5555);
res = (res & 0x3333) + ((res >> 2) & 0x3333);
res = (res + (res >> 4)) & 0x0F0F;
return (res + (res >> 8)) & 0x00FF;
}
EXPORT_SYMBOL(__sw_hweight16);
__sw_hweight8()
lib/hweight.c
unsigned int __sw_hweight8(unsigned int w)
{
unsigned int res = w - ((w >> 1) & 0x55);
res = (res & 0x33) + ((res >> 2) & 0x33);
return (res + (res >> 4)) & 0x0F;
}
EXPORT_SYMBOL(__sw_hweight8);
__sw_hweight64()
lib/hweight.c
unsigned long __sw_hweight64(__u64 w)
{
#if BITS_PER_LONG == 32
return __sw_hweight32((unsigned int)(w >> 32)) +
__sw_hweight32((unsigned int)w);
#elif BITS_PER_LONG == 64
#ifdef CONFIG_ARCH_HAS_FAST_MULTIPLIER
w -= (w >> 1) & 0x5555555555555555ul;
w = (w & 0x3333333333333333ul) + ((w >> 2) & 0x3333333333333333ul);
w = (w + (w >> 4)) & 0x0f0f0f0f0f0f0f0ful;
return (w * 0x0101010101010101ul) >> 56;
#else
__u64 res = w - ((w >> 1) & 0x5555555555555555ul);
res = (res & 0x3333333333333333ul) + ((res >> 2) & 0x3333333333333333ul);
res = (res + (res >> 4)) & 0x0F0F0F0F0F0F0F0Ful;
res = res + (res >> 8);
res = res + (res >> 16);
return (res + (res >> 32)) & 0x00000000000000FFul;
#endif
#endif
}
EXPORT_SYMBOL(__sw_hweight64);
참고