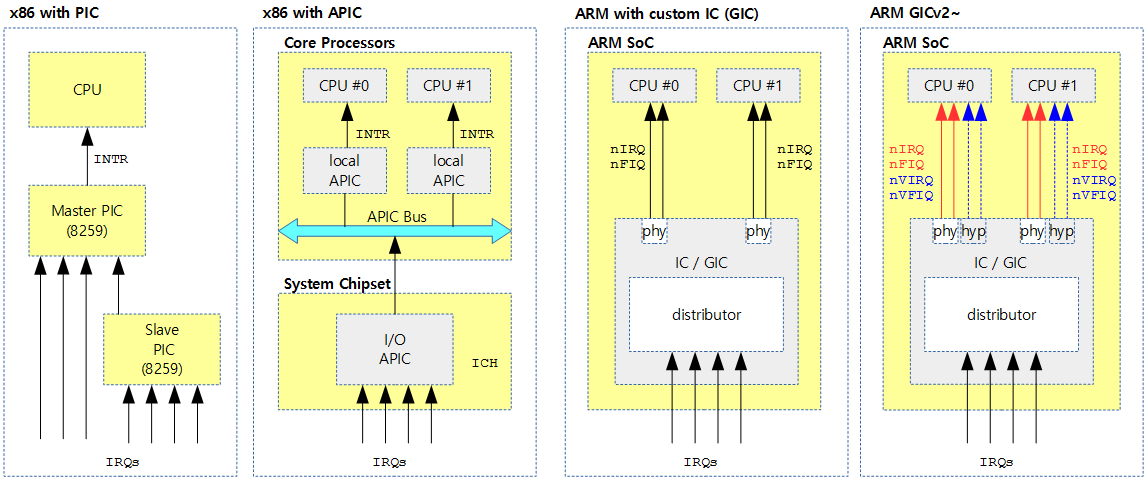
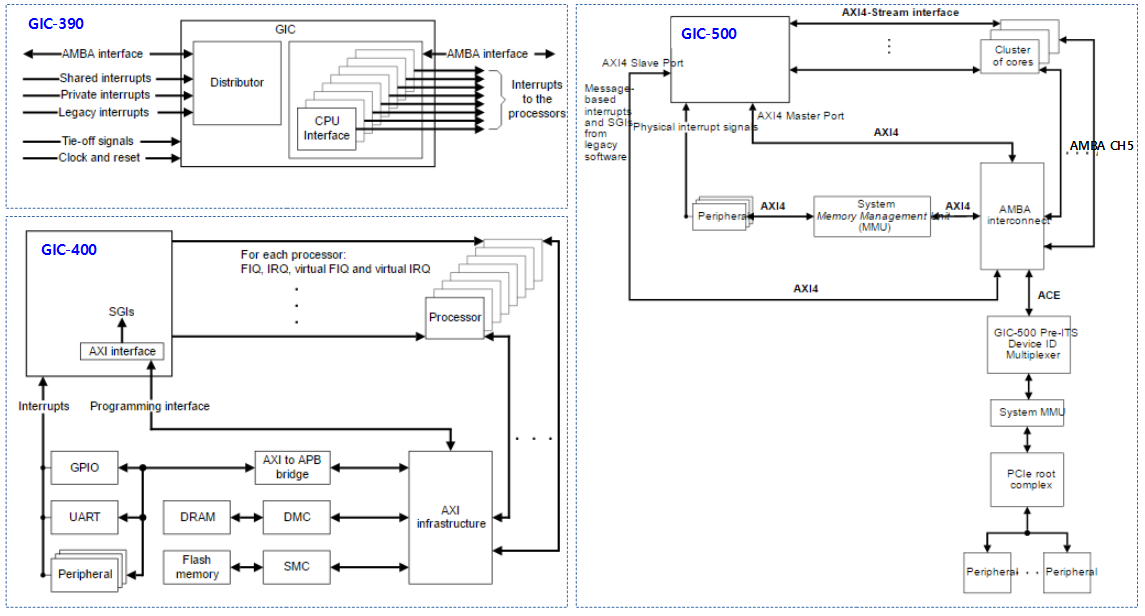
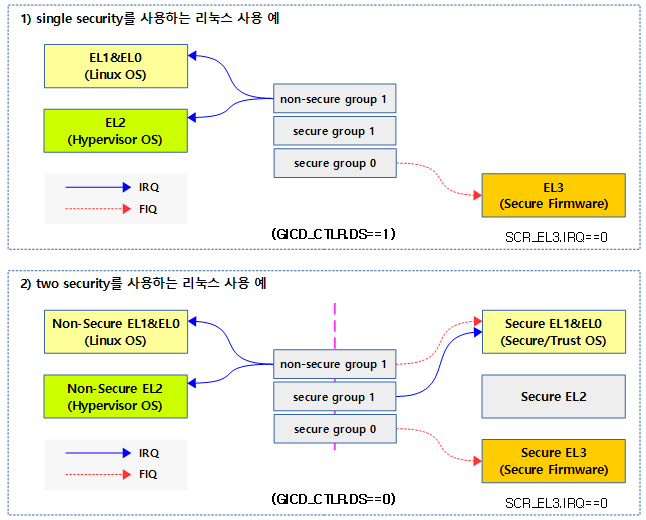
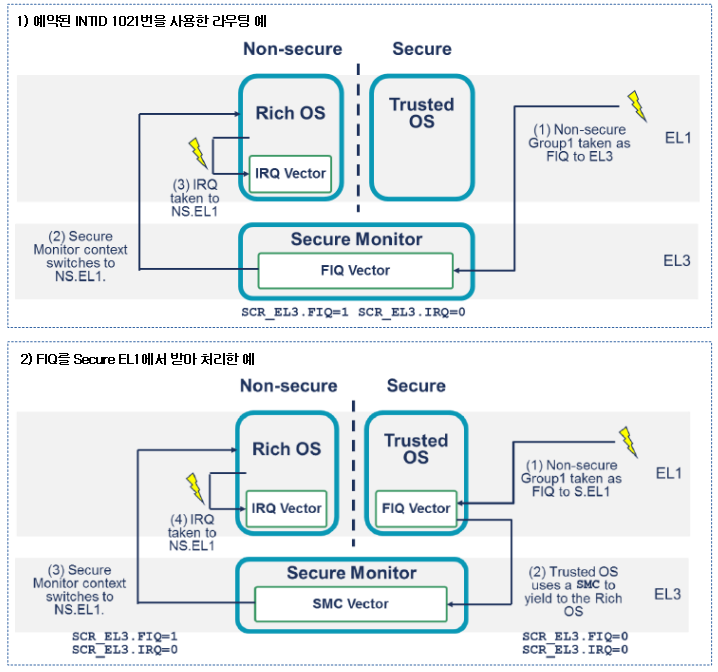
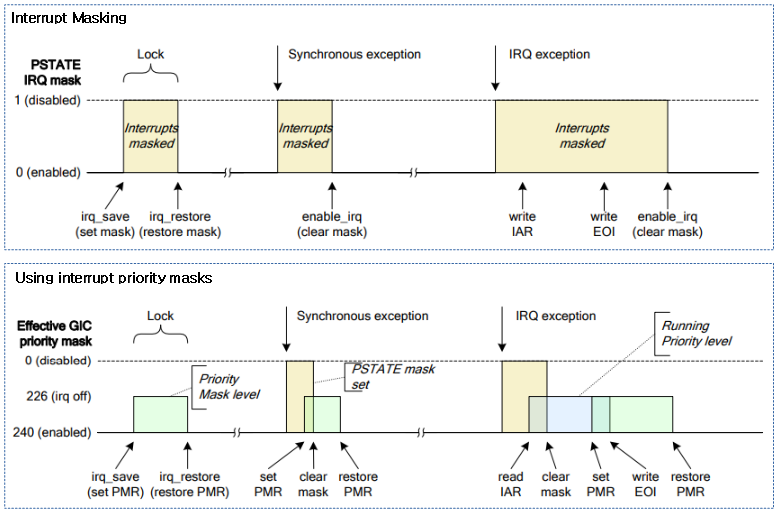
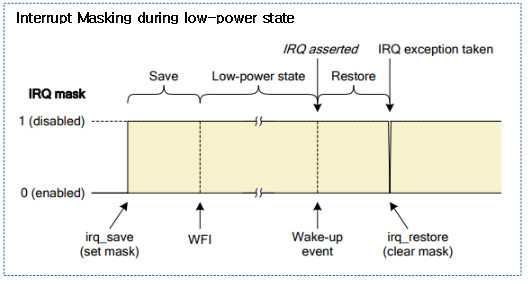
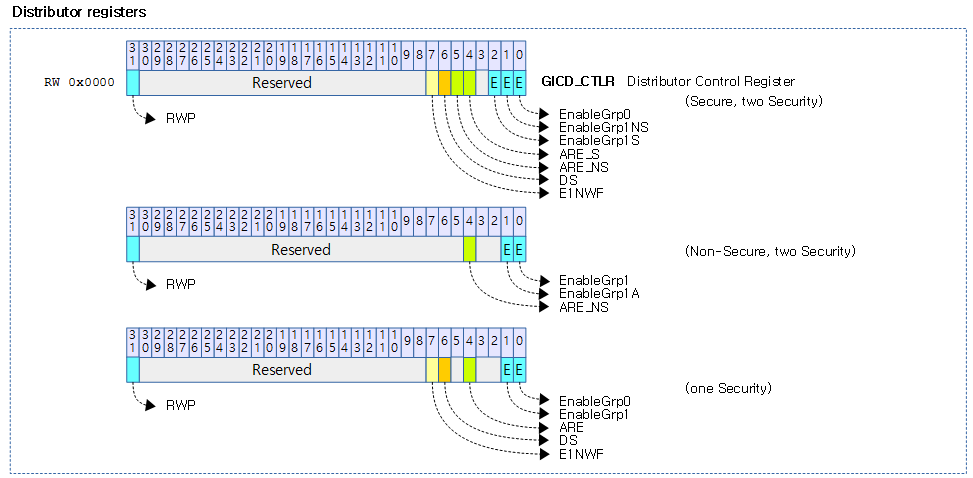
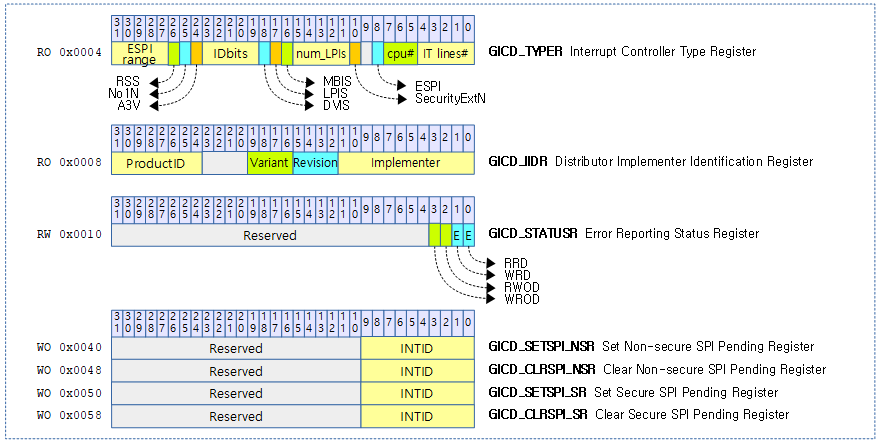
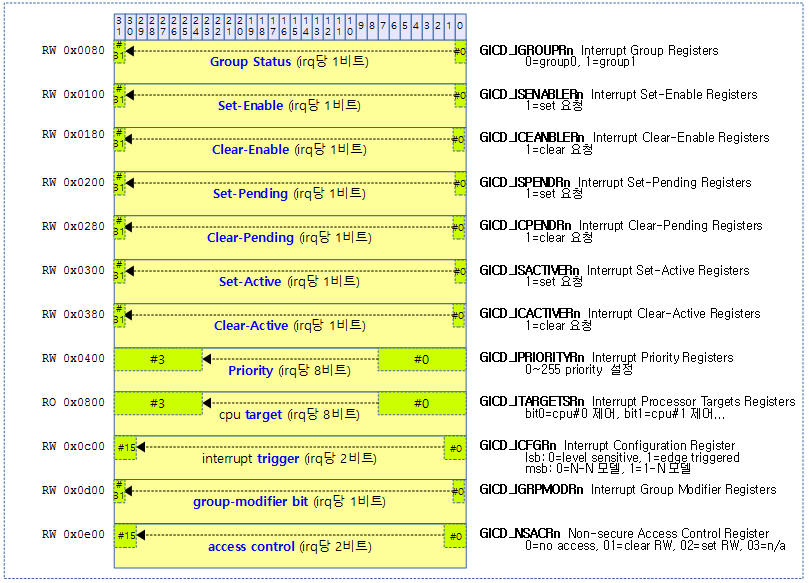
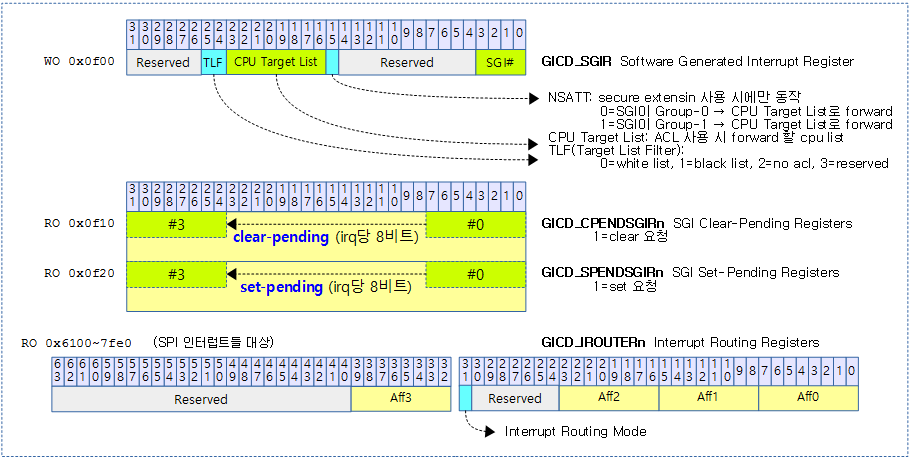
<kernel v5.4>
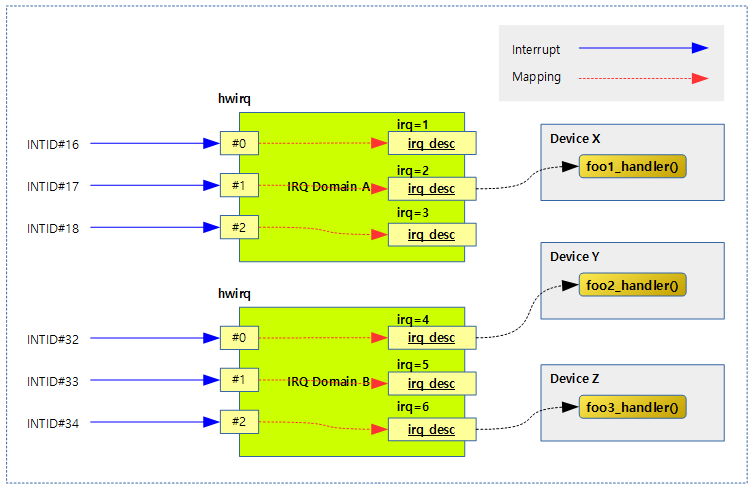
IRQ Domain
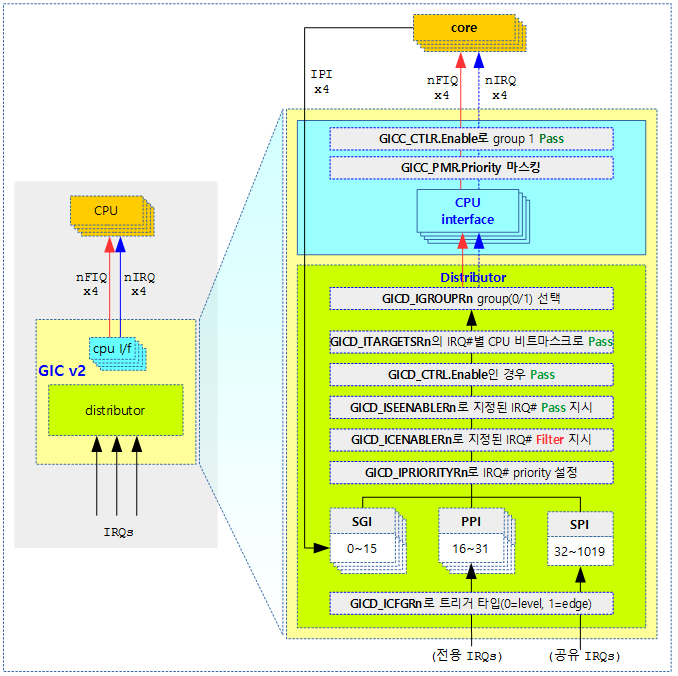
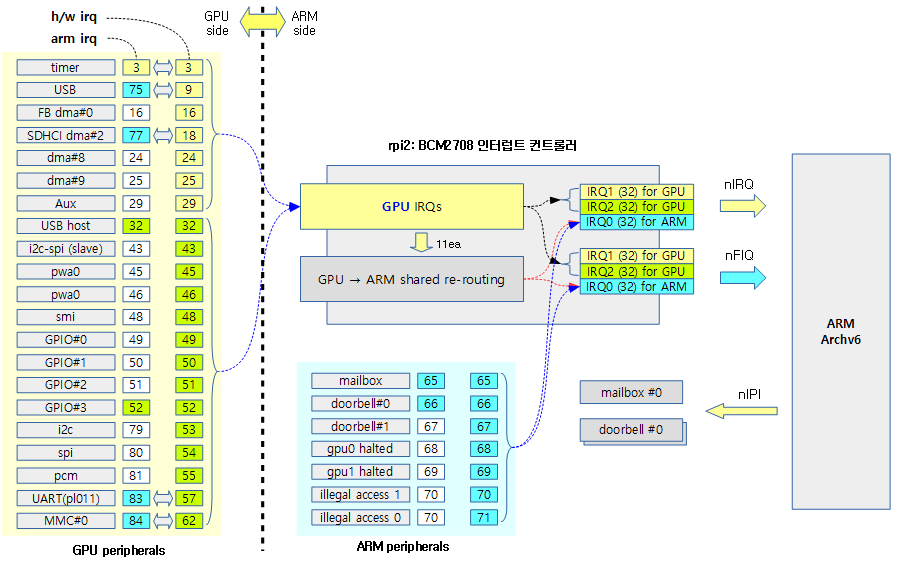
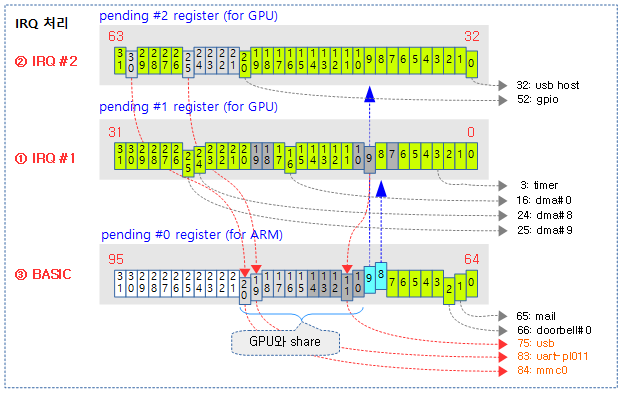
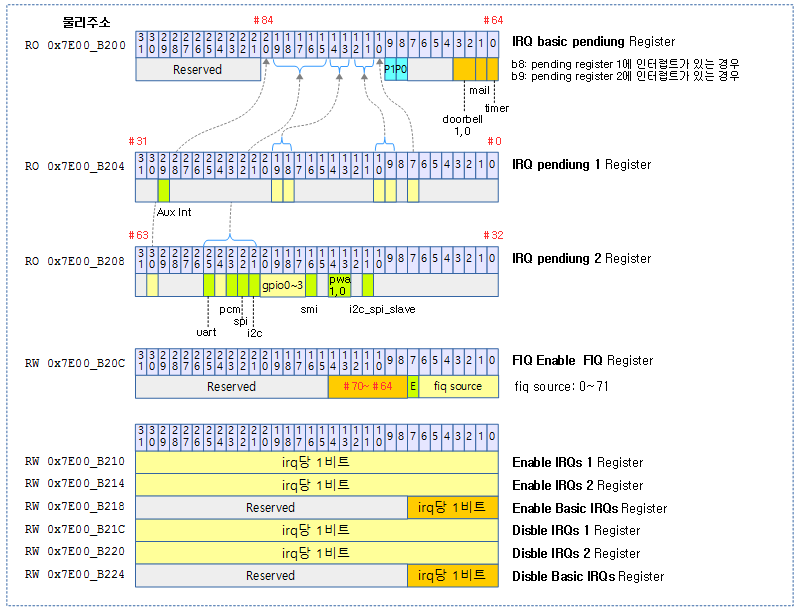
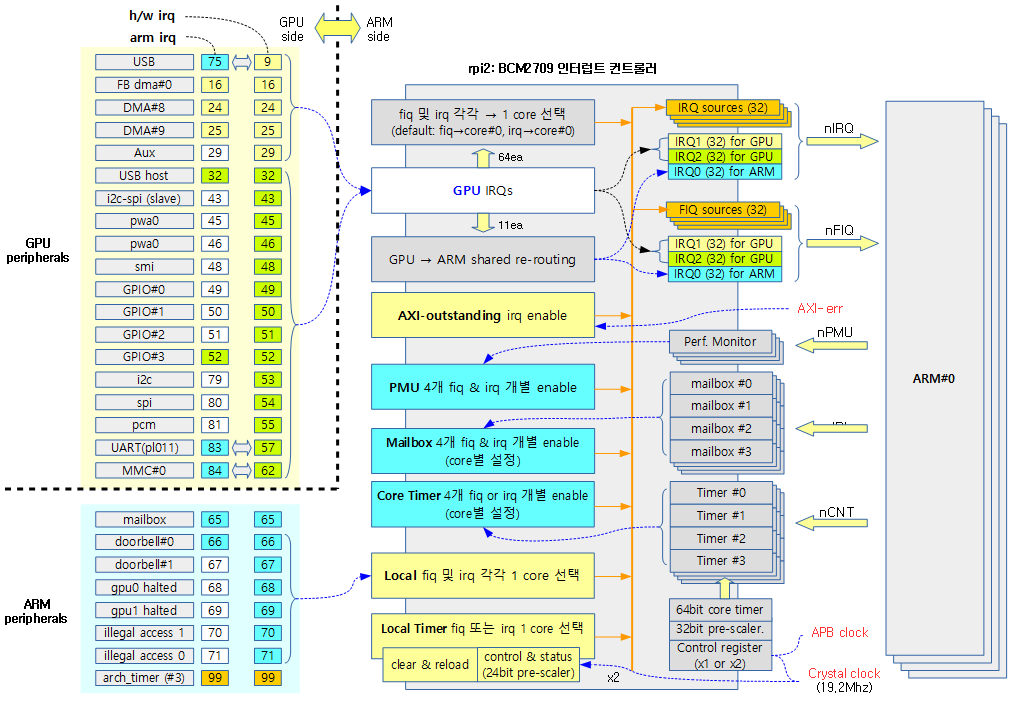
각 제조사의 인터럽트 컨트롤러에는 신호 제어 또는 기능이 다른 인터럽트들을 몇 개의 그룹으로 나누어 관리하기도 한다. 리눅스 커널은 전체 인터럽트를 하나의 그룹 또는 기능별로 나뉜 그룹과 동일하게 IRQ 도메인으로 나누어 관리할 수 있다. 즉 인터럽트들을 IRQ 도메인으로 나누어 관리할 수 있다.
IRQ 도메인은 다음과 같은 특징이 있다.
- hwirq는 도메인내에서 중복되지 않는다.
- 리버스 매핑을 사용하여 구현하였다.
정방향 매핑(리눅스 irq -> hwirq)이 아닌 리버스 매핑(hwirq -> 리눅스 irq)을 사용하는 이유는 인터럽트 발생 시 리눅스 irq를 찾는 동작을 더 빨리 지원하기 위함이다.
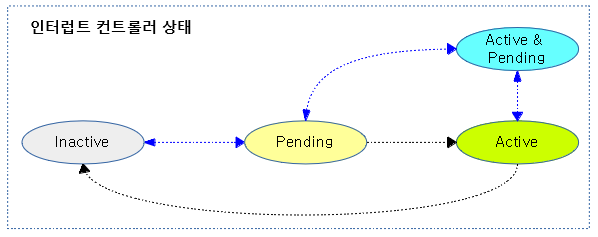
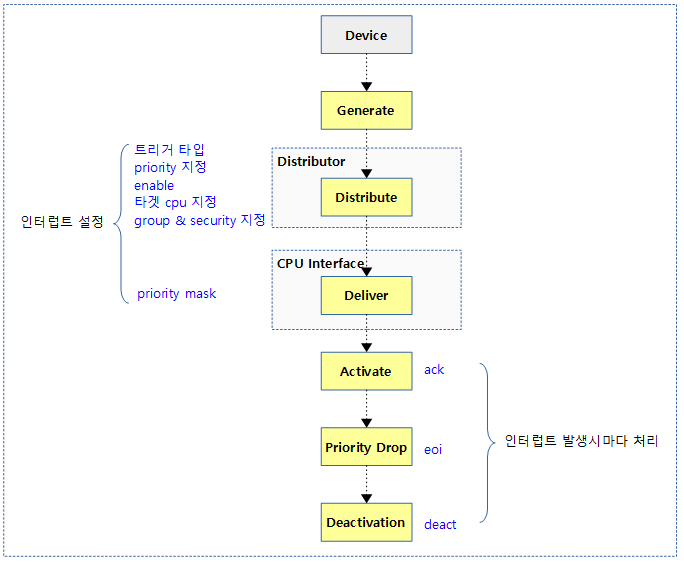
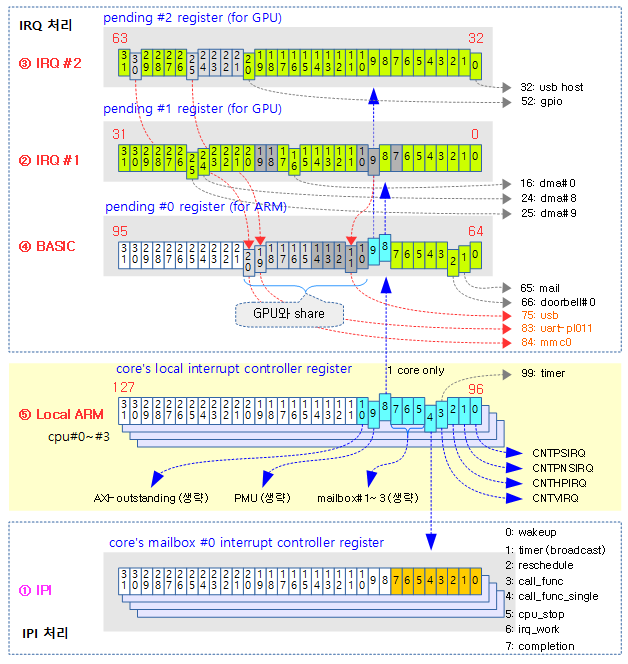
다음 그림은 인터럽트 발생 시 hwirq를 통해 irq 디스크립터를 찾아 연결된 핸들러 함수가 호출되는 과정을 보여준다.
도메인 생성 타입
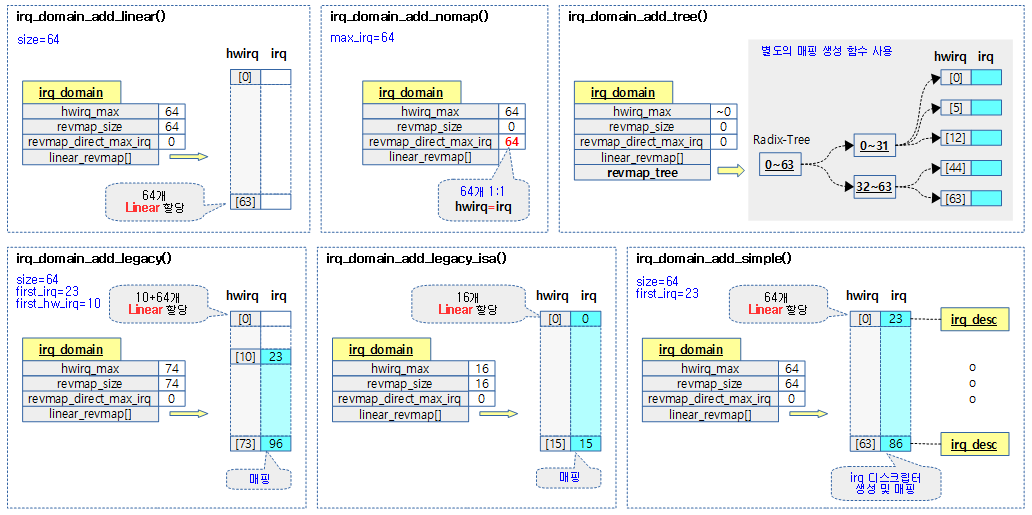
여러 가지 성격의 도메인을 빠르게 구현하기 위해 다음과 같은 방법들을 고려하여 몇 가지의 도메인 생성 방법을 준비하였다.
- 리버스 맵 할당 방법
- Linear
- 연속 할당 매핑 공간
- 장점: hwirq가 수 백번 이하의 번호를 사용하는 경우에 한하여 부트업 타임에 한꺼번에 리니어 매핑 배열을 만들어도 메모리 부담이 크지 않으므로 구현이 간단하다
- Tree
- Radix Tree를 사용한 Dynamic 할당 공간
- 장점: hwirq 번호가 매우 큰 경우 dynamic 하게 필요한 hwirq에 대해서만 할당 구성하여 메모리를 낭비하지 않게 할 때 사용한다.
- No-Map
- 매핑을 위한 공간이 필요 없음 (동일 번호로 자동 매핑)
- Linear
- 매핑 조건
- 매핑 공간 할당 시 같이 매핑하여 사용한다.
- 매핑 공간 할당 후 추후 매핑하여 사용한다.
매핑 구현 방법
다음과 같은 여러 가지 구현 모델에 대해 “irq_domain_add_”로 시작하는 함수를 제공한다.
- Linear
- 요청 size 만큼의 리니어 매핑 공간만 만들고 매핑 연결은 하지 않는다.
- 추후에 매핑 API 등을 사용하여 irq 디스크립터들을 생성하고 hwirq에 매핑하여 사용한다.
- 구현
- irq_domain_add_linear() 함수
- Tree
- 사이즈 제한 없이 Radix Tree를 초기화 시켜 사용한다. 매핑 공간 및 매핑 연결은 하지 않는다.
- 추후에 매핑 API 등을 사용하여 irq 디스크립터들을 생성하고 hwirq에 매핑하여 사용한다.
- 구현
- irq_domain_add_tree() 함수
- Nomap
- irq와 hwirq가 항상 동일하여 매핑을 전혀 필요하지 않는 시스템에서 사용하다.
- 리니어 매핑 테이블을 만들지도 않고, Radix Tree도 사용하지 않는다.
- irq domain을 추가하기 전에 irq 디스크립터들이 미리 구성되어 있어야 한다.
- 구현
- irq_domain_add_nomap() 함수
- irq와 hwirq가 항상 동일하여 매핑을 전혀 필요하지 않는 시스템에서 사용하다.
- Legacy
- 요청 size + first_irq만큼의 리니어 매핑 공간을 만들고, first_hw_irq 매핑 번호부터 first_irq 번부터 자동으로 고정 매핑하여 사용한다.
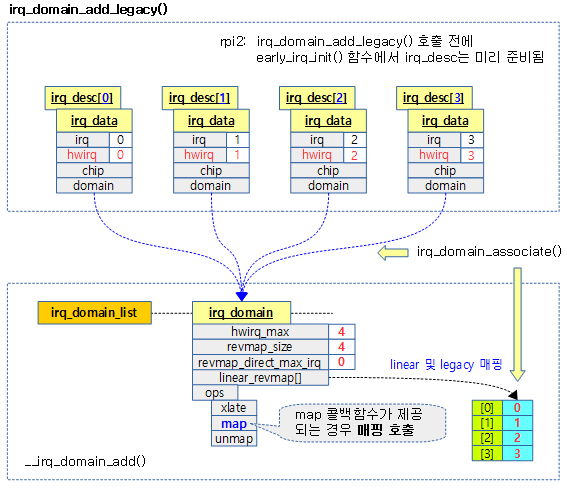
- legacy 방식으로 irq domain을 추가하기 전에 irq 디스크립터들이 미리 할당되어 있어야 한다.
- 구현
- irq_domain_add_legacy() 함수
- Legacy ISA
- Legacy와 동일하나 자동으로 size=16, first_irq=0, first_hw_irq=0과 같이 동작한다. (irq 수가 16개로 제한)
- 구현
- irq_domain_add_legacy_isa() 함수
- Simple
- 요청 size 만큼의 리니어 매핑 공간을 만들고, hwirq=0번부터, 그리고 irq=first_irq 번부터 irq 디스크립터들을 생성해 연결하고 순서대로 고정 매핑하여 사용한다.
- 구현
- irq_domain_add_simple() 함수
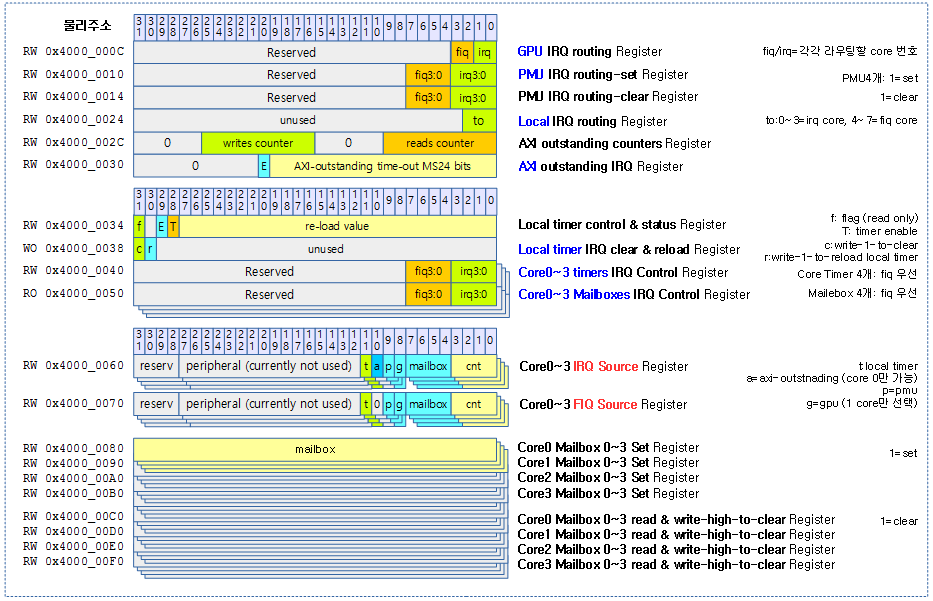
다음 그림은 여러 유형의 도메인 생성 방법을 보여준다.
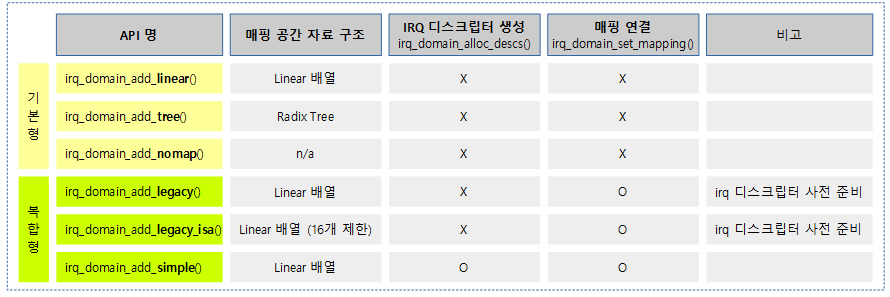
다음 그림은 도메인 매핑 구현 모델에 따라 매핑에 대한 자료 구조, irq 디스크립터 생성 및 매핑 여부를 보여준다.
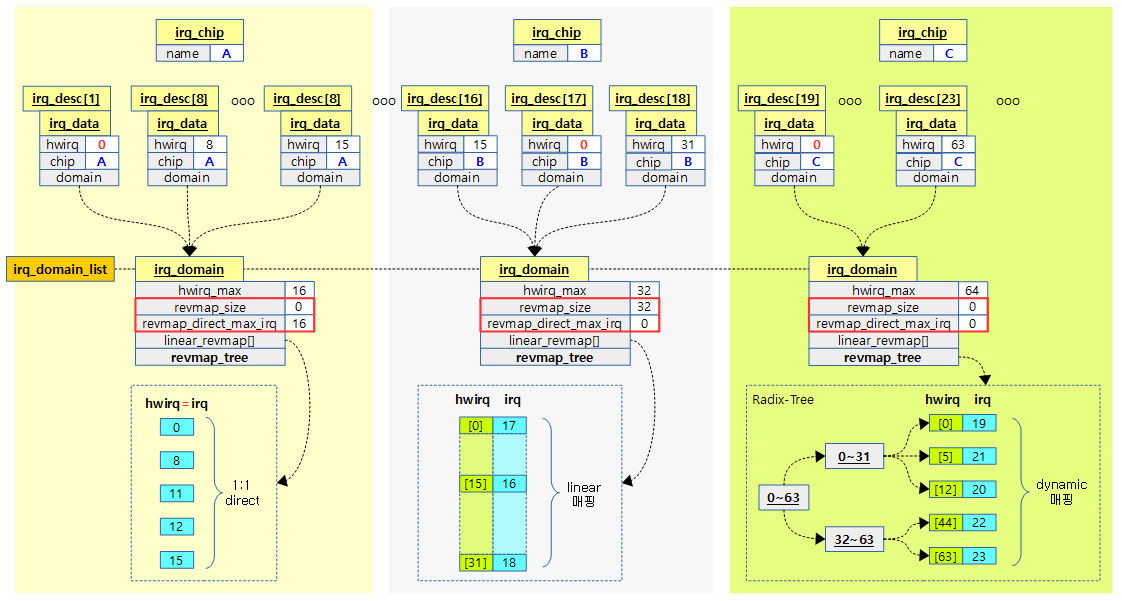
다음 그림은 3개의 인터럽트 컨트롤러에 대응해 nomap, linear, tree 등 3가지 방법을 섞어서 irq_domain을 구성한 예를 보여준다.
IRQ Domain hierarchy
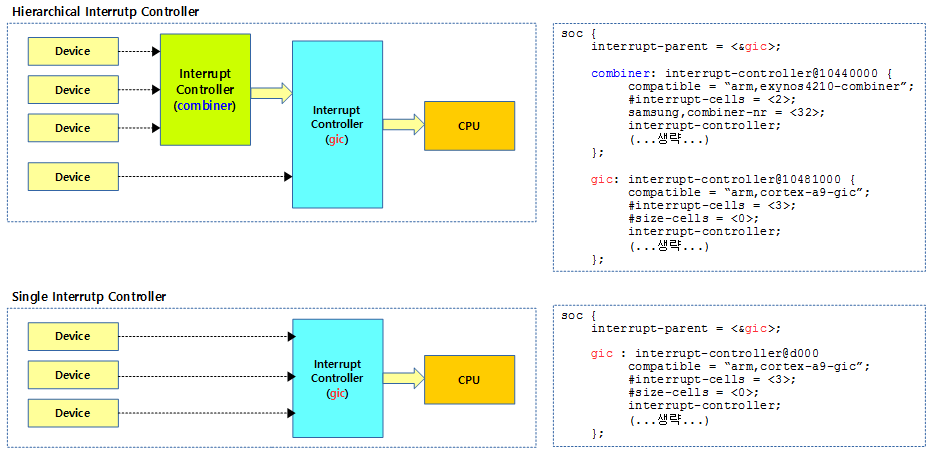
2 개 이상의 인터럽트 컨틀롤러가 PM(파워 블럭 관리) 통제를 받는 경우 상위 인터럽트 컨트롤러에 파워가 공급되지 않는 경우 하위 인터럽트 컨트롤러도 인지하여 대응하는 구조가 필요하다. 이러한 경우를 위해 irq domain 하이라키 구조가 도입되었고 구현 시 기존 irq domain 에 parent 필드를 추가하여 사용할 수 있도록 수정하였다.
- CONFIG_IRQ_DOMAIN_HIERARCHY 커널 옵션을 사용하여 구성한다.
- 참고: irqdomain: Introduce new interfaces to support hierarchy irqdomains
다음 그림은 인터럽트 컨트롤러가 2개 이상 중첩되는 경우와 한 개의 컨트롤러만 사용하는 경우를 비교하였다.
- gic가 parent 인터럽트 컨트롤러이며 먼저 초기화된다.
IRQ Domain 생성(추가) 및 삭제
도메인 추가 -1- (linear)
irq_domain_add_linear()
kernel/irq/irqdomain.c
/** * irq_domain_add_linear() - Allocate and register a linear revmap irq_domain. * @of_node: pointer to interrupt controller's device tree node. * @size: Number of interrupts in the domain. * @ops: map/unmap domain callbacks * @host_data: Controller private data pointer */
static inline struct irq_domain *irq_domain_add_linear(struct device_node *of_node,
unsigned int size,
const struct irq_domain_ops *ops,
void *host_data)
{
return __irq_domain_add(of_node_to_fwnode(of_node), size, size, 0, ops, host_data);
}
size 만큼의 선형 리버스 매핑 블럭을 사용할 계획으로 도메인을 할당한다. 이 함수에서는 매핑을 하지 않으므로, 매핑은 추후 irq_create_mapping() 함수를 사용하여 다이나믹하게 매핑할 수 있다.
- 연속된 리버스 매핑 공간에서 자유로운 인터럽트 매핑 방식이 필요한 인터럽트 컨트롤러 드라이버에 사용된다.
- 예) 약 30개 드라이버에서 사용한다.
- arm,gic
- arm,nvic
- bcm,bcm2835
- bcm,bcm2836
- exynos-combiner
- samsung,s3c24xx
- armada-370-xp
- …
- 예) 약 30개 드라이버에서 사용한다.
도메인 추가 -2- (nomap)
irq_domain_add_nomap()
kernel/irq/irqdomain.c
static inline struct irq_domain *irq_domain_add_nomap(struct device_node *of_node,
unsigned int max_irq,
const struct irq_domain_ops *ops,
void *host_data)
{
return __irq_domain_add(of_node_to_fwnode(of_node), 0, max_irq, max_irq, ops, host_data);
}
리니어 매핑 공간 또는 Radix Tree를 사용한 매핑 공간을 사용하지 않고, max_irq 수 만큼 irq 도메인을 생성한다. 매핑을 하지 않으므로 생성한 개수만큼 hwirq 번호는 irq 번호와 동일하게 사용한다.
- 대부분의 아키텍처에서 사용하지 않는 방식이다. 현재 4 개의 powerpc 아키텍처용 드라이버에서 사용한다.
도메인 추가 -3- (legacy)
irq_domain_add_legacy()
kernel/irq/irqdomain.c
/** * irq_domain_add_legacy() - Allocate and register a legacy revmap irq_domain. * @of_node: pointer to interrupt controller's device tree node. * @size: total number of irqs in legacy mapping * @first_irq: first number of irq block assigned to the domain * @first_hwirq: first hwirq number to use for the translation. Should normally * be '0', but a positive integer can be used if the effective * hwirqs numbering does not begin at zero. * @ops: map/unmap domain callbacks * @host_data: Controller private data pointer * * Note: the map() callback will be called before this function returns * for all legacy interrupts except 0 (which is always the invalid irq for * a legacy controller). */
struct irq_domain *irq_domain_add_legacy(struct device_node *of_node,
unsigned int size,
unsigned int first_irq,
irq_hw_number_t first_hwirq,
const struct irq_domain_ops *ops,
void *host_data)
{
struct irq_domain *domain;
domain = __irq_domain_add(of_node_to_fwnode(of_node), first_hwirq + size,
first_hwirq + size, 0, ops, host_data);
if (domain)
irq_domain_associate_many(domain, first_irq, first_hwirq, size);
return domain;
}
EXPORT_SYMBOL_GPL(irq_domain_add_legacy);
요청 size + first_irq만큼의 리니어 매핑 공간을 만들고, first_hw_irq 매핑 번호부터 first_irq 번호를 자동으로 고정 매핑하여 사용한다. 미리 매핑 후 변경이 필요 없는 구성에서 사용한다.
- 미리 구성해 놓은 연속된 리버스 매핑 공간을 사용한 인터럽트 매핑 방식이 필요한 인터럽트 컨트롤러 드라이버에 사용된다.
- 예) 약 10 여개 드라이버에서 사용한다.
- arm,gic
- mmp
- samsung,s3c24xx
- hip04
- …
- 예) 약 10 여개 드라이버에서 사용한다.
도메인 추가 -4- (legacy, isa)
irq_domain_add_legacy_isa()
kernel/irq/irqdomain.c
static inline struct irq_domain *irq_domain_add_legacy_isa(
struct device_node *of_node,
const struct irq_domain_ops *ops,
void *host_data)
{
return irq_domain_add_legacy(of_node, NUM_ISA_INTERRUPTS, 0, 0, ops,
host_data);
}
고정된 16(legacy ISA 하드웨어가 사용하는 최대 인터럽트 수)개 인터럽트 수 만큼의 이미 만들어놓은 선형 리버스 매핑 블럭을 사용할 계획으로 도메인을 할당받아 구성한다. 매핑 후 변경이 필요 없는 구성에서 사용한다.
- 대부분의 아키텍처에서 사용하지 않는 방식이다. 현재 2 개의 powerpc 아키텍처용 드라이버에서 사용한다.
도메인 추가 -5- (tree)
irq_domain_add_tree()
kernel/irq/irqdomain.c
static inline struct irq_domain *irq_domain_add_tree(struct device_node *of_node,
const struct irq_domain_ops *ops,
void *host_data)
{
return __irq_domain_add(of_node_to_fwnode(of_node), 0, ~0, 0, ops, host_data);
}
Radix tree로 관리되는 리버스 매핑 블럭을 사용할 계획으로 도메인을 할당받아 구성한다. 구성된 후 자유롭게 매핑/해제를 할 수 있다.
- 하드웨어 인터럽트 번호가 매우 큰 시스템에서 메모리 낭비 없이 자유로운 인터럽트 매핑 방식이 필요한 인터럽트 컨트롤러 드라이버에 사용된다.
- 예) arm에서는 최근 버전의 gic 컨트롤러 드라이버 3개가 사용하고, 다른 몇 개의 아키텍처에서도 사용한다.
- arm,gic-v2m
- arm,gic-v3
- arm,gic-v3-its
- …
- 예) arm에서는 최근 버전의 gic 컨트롤러 드라이버 3개가 사용하고, 다른 몇 개의 아키텍처에서도 사용한다.
도메인 추가 -6- (simple)
irq_domain_add_simple()
kernel/irq/irqdomain.c
/** * irq_domain_add_simple() - Register an irq_domain and optionally map a range of irqs * @of_node: pointer to interrupt controller's device tree node. * @size: total number of irqs in mapping * @first_irq: first number of irq block assigned to the domain, * pass zero to assign irqs on-the-fly. If first_irq is non-zero, then * pre-map all of the irqs in the domain to virqs starting at first_irq. * @ops: domain callbacks * @host_data: Controller private data pointer * * Allocates an irq_domain, and optionally if first_irq is positive then also * allocate irq_descs and map all of the hwirqs to virqs starting at first_irq. * * This is intended to implement the expected behaviour for most * interrupt controllers. If device tree is used, then first_irq will be 0 and * irqs get mapped dynamically on the fly. However, if the controller requires * static virq assignments (non-DT boot) then it will set that up correctly. */
struct irq_domain *irq_domain_add_simple(struct device_node *of_node,
unsigned int size,
unsigned int first_irq,
const struct irq_domain_ops *ops,
void *host_data)
{
struct irq_domain *domain;
domain = __irq_domain_add(of_node_to_fwnode(of_node), size, size, 0, ops, host_data);
if (!domain)
return NULL;
if (first_irq > 0) {
if (IS_ENABLED(CONFIG_SPARSE_IRQ)) {
/* attempt to allocated irq_descs */
int rc = irq_alloc_descs(first_irq, first_irq, size,
of_node_to_nid(of_node));
if (rc < 0)
pr_info("Cannot allocate irq_descs @ IRQ%d, assuming pre-allocated\n",
first_irq);
}
irq_domain_associate_many(domain, first_irq, 0, size);
}
return domain;
}
EXPORT_SYMBOL_GPL(irq_domain_add_simple);
요청 size 만큼의 리니어 매핑 공간을 만들고 hwirq=0번부터, irq=first_irq 번호부터 순서대로 자동으로 고정 매핑하여 사용한다.
- 간단하게 irq 도메인을 만들고 매핑하기 위한 시스템 드라이버에서 사용하며 약 10여개 드라이버에서 사용한다.
-
- arm,vic
- versatile-fpga
- sa11x0
- …
-
hierarchy 구성을 위한 도메인 추가
irq_domain_add_hierarchy()
include/linux/irqdomain.h
static inline struct irq_domain *irq_domain_add_hierarchy(struct irq_domain *parent,
unsigned int flags,
unsigned int size,
struct device_node *node,
const struct irq_domain_ops *ops,
void *host_data)
{
return irq_domain_create_hierarchy(parent, flags, size,
of_node_to_fwnode(node),
ops, host_data);
}
하이라키 irq 도메인을 추가한다.
irq_domain_create_hierarchy()
kernel/irq/irqdomain.c
/** * irq_domain_create_hierarchy - Add a irqdomain into the hierarchy * @parent: Parent irq domain to associate with the new domain * @flags: Irq domain flags associated to the domain * @size: Size of the domain. See below * @node: Optional device-tree node of the interrupt controller * @ops: Pointer to the interrupt domain callbacks * @host_data: Controller private data pointer * * If @size is 0 a tree domain is created, otherwise a linear domain. * * If successful the parent is associated to the new domain and the * domain flags are set. * Returns pointer to IRQ domain, or NULL on failure. */
struct irq_domain *irq_domain_create_hierarchy(struct irq_domain *parent,
unsigned int flags,
unsigned int size,
struct device_node *node,
const struct irq_domain_ops *ops,
void *host_data)
{
struct irq_domain *domain;
if (size)
domain = irq_domain_create_linear(node, size, ops, host_data);
else
domain = irq_domain_create_tree(node, ops, host_data);
if (domain) {
domain->parent = parent;
domain->flags |= flags;
}
return domain;
}
EXPORT_SYMBOL_GPL(irq_domain_create_hierarchy);
주어진 인수 size에 따라 선형 또는 Radix tree로 관리되는 리버스 매핑 블럭을 사용할 계획으로 하이라키 도메인을 생성 시 사용한다. 구성된 후 자유롭게 매핑/해제를 할 수 있다.
- domain 간 부모관계를 설정하고자 할 때 사용하며, 현재 몇 개의 arm 및 다른 아키텍처 드라이버에서 사용한다.
-
- tegra
- imx-gpcv2
- mtk-sysirq
- vf610-mscm-ir
- crossbar
- …
-
irq 도메인 추가 공통 함수
__irq_domain_add()
kernel/irq/irqdomain.c -1/2-
/** * __irq_domain_add() - Allocate a new irq_domain data structure * @of_node: optional device-tree node of the interrupt controller * @size: Size of linear map; 0 for radix mapping only * @hwirq_max: Maximum number of interrupts supported by controller * @direct_max: Maximum value of direct maps; Use ~0 for no limit; 0 for no * direct mapping * @ops: domain callbacks * @host_data: Controller private data pointer * * Allocates and initialize and irq_domain structure. * Returns pointer to IRQ domain, or NULL on failure. */
struct irq_domain *__irq_domain_add(struct fwnode_handle *fwnode, int size,
irq_hw_number_t hwirq_max, int direct_max,
const struct irq_domain_ops *ops,
void *host_data)
{
struct device_node *of_node = to_of_node(fwnode);
struct irqchip_fwid *fwid;
struct irq_domain *domain;
static atomic_t unknown_domains;
domain = kzalloc_node(sizeof(*domain) + (sizeof(unsigned int) * size),
GFP_KERNEL, of_node_to_nid(of_node));
if (!domain)
return NULL;
if (fwnode && is_fwnode_irqchip(fwnode)) {
fwid = container_of(fwnode, struct irqchip_fwid, fwnode);
switch (fwid->type) {
case IRQCHIP_FWNODE_NAMED:
case IRQCHIP_FWNODE_NAMED_ID:
domain->fwnode = fwnode;
domain->name = kstrdup(fwid->name, GFP_KERNEL);
if (!domain->name) {
kfree(domain);
return NULL;
}
domain->flags |= IRQ_DOMAIN_NAME_ALLOCATED;
break;
default:
domain->fwnode = fwnode;
domain->name = fwid->name;
break;
}
#ifdef CONFIG_ACPI
} else if (is_acpi_device_node(fwnode)) {
struct acpi_buffer buf = {
.length = ACPI_ALLOCATE_BUFFER,
};
acpi_handle handle;
handle = acpi_device_handle(to_acpi_device_node(fwnode));
if (acpi_get_name(handle, ACPI_FULL_PATHNAME, &buf) == AE_OK) {
domain->name = buf.pointer;
domain->flags |= IRQ_DOMAIN_NAME_ALLOCATED;
}
domain->fwnode = fwnode;
#endif
} else if (of_node) {
char *name;
/*
* DT paths contain '/', which debugfs is legitimately
* unhappy about. Replace them with ':', which does
* the trick and is not as offensive as '\'...
*/
name = kasprintf(GFP_KERNEL, "%pOF", of_node);
if (!name) {
kfree(domain);
return NULL;
}
strreplace(name, '/', ':');
domain->name = name;
domain->fwnode = fwnode;
domain->flags |= IRQ_DOMAIN_NAME_ALLOCATED;
}
하나의 irq 도메인을 추가하고 전달된 인수에 대해 다음과 같이 준비한다.
- 인자 @size가 주어지는 경우 size 만큼의 리니어 리버스 맵을 준비한다.
- 인자 @hwirq_max는 현재 도메인에서 최대 처리할 하드웨어 인터럽트 수이다.
- 인자 @direct_max가 주어지는 경우 해당 범위는 리버스 맵을 사용하지 않는다.
- 인자 @ops는 리버스 매핑과 변환 함수에 대한 콜백 후크를 제공한다.
- 인자 @host_data는 private 데이터 포인터를 전달할 수 있다.
- 코드 라인 12~15에서 irq 도메인 구조체를 할당한다. 구조체의 마지막에 위치한 linear_revmap[]을 위해 @size 만큼의 정수 배열이 추가된다.
- 코드 라인 17~70에서 irq 도메인에 fwnode와 이름 정보를 저장한다. 이름 정보가 저장된 경우 IRQ_DOMAIN_NAME_ALLOCATED 플래그를 설정한다.
- 디바이스 트리 노드가 주어진 경우 노드명으로 이름을 지정하되 ‘:’ 문자열은 ‘/’로 변경된다.
kernel/irq/irqdomain.c -2/2-
if (!domain->name) {
if (fwnode)
pr_err("Invalid fwnode type for irqdomain\n");
domain->name = kasprintf(GFP_KERNEL, "unknown-%d",
atomic_inc_return(&unknown_domains));
if (!domain->name) {
kfree(domain);
return NULL;
}
domain->flags |= IRQ_DOMAIN_NAME_ALLOCATED;
}
of_node_get(of_node);
/* Fill structure */
INIT_RADIX_TREE(&domain->revmap_tree, GFP_KERNEL);
mutex_init(&domain->revmap_tree_mutex);
domain->ops = ops;
domain->host_data = host_data;
domain->hwirq_max = hwirq_max;
domain->revmap_size = size;
domain->revmap_direct_max_irq = direct_max;
irq_domain_check_hierarchy(domain);
mutex_lock(&irq_domain_mutex);
debugfs_add_domain_dir(domain);
list_add(&domain->link, &irq_domain_list);
mutex_unlock(&irq_domain_mutex);
pr_debug("Added domain %s\n", domain->name);
return domain;
}
EXPORT_SYMBOL_GPL(__irq_domain_add);
- 코드 라인 1~11에서 도메인 명이 없는 경우 “unknown-<순번>” 명칭으로 사용한다.
- 코드 라인 16~17에서 tree 형태로 domain을 사용할 수 있도록 radix tree를 초기화한다.
- 코드 라인 18~22에서 전달받은 인수를 domain에 설정한다.
- 코드 라인 23에서 hierarchy 구성인 경우 IRQ_DOMAIN_FLAG_HIERARCHY 플래그를 추가한다.
- 코드 라인 26에서 debugfs에 도메인 디버깅을 위해 디렉토리를 생성한다.
- 코드 라인 27에서 전역 irq_domain_list에 생성한 도메인을 추가한다.
- 코드 라인 30에서 만들어진 도메인 정보를 디버그 출력한다.
- 코드 라인 31에서 성공적으로 생성한 도메인을 반환한다.
irq_domain_check_hierarchy()
kernel/irq/irqdomain.c
static void irq_domain_check_hierarchy(struct irq_domain *domain)
{
/* Hierarchy irq_domains must implement callback alloc() */
if (domain->ops->alloc)
domain->flags |= IRQ_DOMAIN_FLAG_HIERARCHY;
}
도메인이hierarchy 구성인 경우 IRQ_DOMAIN_FLAG_HIERARCHY 플래그를 추가한다.
IRQ Domain 제거
irq_domain_remove()
kernel/irq/irqdomain.c
/** * irq_domain_remove() - Remove an irq domain. * @domain: domain to remove * * This routine is used to remove an irq domain. The caller must ensure * that all mappings within the domain have been disposed of prior to * use, depending on the revmap type. */
void irq_domain_remove(struct irq_domain *domain)
{
mutex_lock(&irq_domain_mutex);
/*
* radix_tree_delete() takes care of destroying the root
* node when all entries are removed. Shout if there are
* any mappings left.
*/
WARN_ON(domain->revmap_tree.height);
list_del(&domain->link);
/*
* If the going away domain is the default one, reset it.
*/
if (unlikely(irq_default_domain == domain))
irq_set_default_host(NULL);
mutex_unlock(&irq_domain_mutex);
pr_debug("Removed domain %s\n", domain->name);
of_node_put(domain->of_node);
kfree(domain);
}
EXPORT_SYMBOL_GPL(irq_domain_remove);
전역 irq_domain_list에서 요청한 irq domain을 제거하고 할당 해제한다.
- 코드 라인 12에서 전역 irq_domain_list에서 요청한 irq domain을 제거한다.
- 코드 라인 17~18에서 낮은 확률로 요청 domain이 irq_default_domain인 경우 irq_default_domain을 null로 설정한다.
- arm이 아닌 하드 코딩된 몇 개의 아키텍처 드라이버에서 irq domain을 구현하지 않고 인터럽트 번호를 사용할 목적으로 irq_create_mapping() 함수에서 domain 대신 NULL을 인자로 사용한다.
- 코드 라인 24~25에서 디바이스 노드의 참조를 해제하고 domain을 할당 해제한다.
IRQ 매핑 및 해제
다음은 도메인내 매핑 연결 및 해제 API들이다.
- irq_domain_associate()
- irq 디스크립터와 <–> hwirq를 매핑한다.
- irq_domain_associate_many()
- 위의 API 기능을 복수로 수행한다.
- irq_domain_disassociate()
- irq 디스크립터와 <–> hwirq를 매핑 해제한다.
매핑 연결 -1- (single)
irq_domain_associate()
kernel/irq/irqdomain.c
int irq_domain_associate(struct irq_domain *domain, unsigned int virq,
irq_hw_number_t hwirq)
{
struct irq_data *irq_data = irq_get_irq_data(virq);
int ret;
if (WARN(hwirq >= domain->hwirq_max,
"error: hwirq 0x%x is too large for %s\n", (int)hwirq, domain->name))
return -EINVAL;
if (WARN(!irq_data, "error: virq%i is not allocated", virq))
return -EINVAL;
if (WARN(irq_data->domain, "error: virq%i is already associated", virq))
return -EINVAL;
mutex_lock(&irq_domain_mutex);
irq_data->hwirq = hwirq;
irq_data->domain = domain;
if (domain->ops->map) {
ret = domain->ops->map(domain, virq, hwirq);
if (ret != 0) {
/*
* If map() returns -EPERM, this interrupt is protected
* by the firmware or some other service and shall not
* be mapped. Don't bother telling the user about it.
*/
if (ret != -EPERM) {
pr_info("%s didn't like hwirq-0x%lx to VIRQ%i mapping (rc=%d)\n",
domain->name, hwirq, virq, ret);
}
irq_data->domain = NULL;
irq_data->hwirq = 0;
mutex_unlock(&irq_domain_mutex);
return ret;
}
/* If not already assigned, give the domain the chip's name */
if (!domain->name && irq_data->chip)
domain->name = irq_data->chip->name;
}
domain->mapcount++;
irq_domain_set_mapping(domain, hwirq, irq_data);
mutex_unlock(&irq_domain_mutex);
irq_clear_status_flags(virq, IRQ_NOREQUEST);
return 0;
}
EXPORT_SYMBOL_GPL(irq_domain_associate);
irq 디스크립터와 hwirq를 매핑한다. 도메인의 ops->map 후크에 등록한 콜백 함수가 있는 경우 해당 컨트롤러를 통해 매핑을 설정한다.
- 코드 라인 4에서 irq 디스크립터의 irq_data를 알아온다.
- 코드 라인 7~13에서 다음과 같이 에러가 있는 경우 경고 메시지를 출력하고 -EINVAL 에러를 반환한다.
- hwirq 번호가 도메인의 hwirq_max 이상인 경우
- irq 디스크립터가 할당되어 있지 않은 경우
- 이미 domain에 연결되어 있는 경우
- 코드 라인 16~17에서 irq_data의 hwirq와 domain 정보를 설정한다.
- 코드 라인 18~34에서 irq domain의 map 후크에 핸들러 함수가 연결된 경우 호출하여 컨트롤러로 하여금 매핑을 수행하게 한다. 만일 매핑이 실패한 경우 허가되지 않은 irq인 경우 단순 메시지만 출력하고 irq_data의 domain과 hwirq에 null과 0을 설정후 함수를 빠져나간다.
- 코드 라인 37~38에서 domain에 이름이 설정되지 않은 경우 컨트롤러 이름을 대입한다.
- 코드 라인 42에서요청한 도메인에서 @hwirq와 irq 디스크립터를 매핑한다.
- 코드 라인 45에서 irq 라인 상태에에서 norequest 플래그를 클리어한다.
- IRQ_NOREQUEST
- 현재 irq 라인에 요청된 인터럽트가 없다.
- IRQ_NOREQUEST
irq_domain_set_mapping()
kernel/irq/irqdomain.c
static void irq_domain_set_mapping(struct irq_domain *domain,
irq_hw_number_t hwirq,
struct irq_data *irq_data)
{
if (hwirq < domain->revmap_size) {
domain->linear_revmap[hwirq] = irq_data->irq;
} else {
mutex_lock(&domain->revmap_tree_mutex);
radix_tree_insert(&domain->revmap_tree, hwirq, irq_data);
mutex_unlock(&domain->revmap_tree_mutex);
}
}
요청한 도메인에서 @hwirq와 irq 디스크립터를 매핑한다.
- 코드 라인 5~6에서 linear 방식에서 사용되는 irq인 경우 리니어용 리버스 맵 테이블에서 hwirq에 대응하는 곳에 irq 디스크립터와 매핑한다.
- 코드 라인 7~11에서 tree 방식에서 사용되는 irq인 경우 radix tree용 리버스 맵에 hwirq를 추가하고 irq 디스크립터와 매핑한다.
매핑 연결 -2- (many)
irq_domain_associate_many()
kernel/irq/irqdomain.c
void irq_domain_associate_many(struct irq_domain *domain, unsigned int irq_base,
irq_hw_number_t hwirq_base, int count)
{
int i;
pr_debug("%s(%s, irqbase=%i, hwbase=%i, count=%i)\n", __func__,
of_node_full_name(domain->of_node), irq_base, (int)hwirq_base, count);
for (i = 0; i < count; i++) {
irq_domain_associate(domain, irq_base + i, hwirq_base + i);
}
}
EXPORT_SYMBOL_GPL(irq_domain_associate_many);
@irq_base로 시작하는 irq 디스크립터들을 @count 수 만큼 @hwirq_base 번호부터 매핑한다. 해당 도메인의 ops->map 후크에 등록한 콜백 함수가 있는 경우 해당 컨트롤러를 통해 각각의 매핑을 설정한다.
매핑 해제
irq_domain_disassociate()
kernel/irq/irqdomain.c
void irq_domain_disassociate(struct irq_domain *domain, unsigned int irq)
{
struct irq_data *irq_data = irq_get_irq_data(irq);
irq_hw_number_t hwirq;
if (WARN(!irq_data || irq_data->domain != domain,
"virq%i doesn't exist; cannot disassociate\n", irq))
return;
hwirq = irq_data->hwirq;
irq_set_status_flags(irq, IRQ_NOREQUEST);
/* remove chip and handler */
irq_set_chip_and_handler(irq, NULL, NULL);
/* Make sure it's completed */
synchronize_irq(irq);
/* Tell the PIC about it */
if (domain->ops->unmap)
domain->ops->unmap(domain, irq);
smp_mb();
irq_data->domain = NULL;
irq_data->hwirq = 0;
/* Clear reverse map for this hwirq */
if (hwirq < domain->revmap_size) {
domain->linear_revmap[hwirq] = 0;
} else {
mutex_lock(&revmap_trees_mutex);
radix_tree_delete(&domain->revmap_tree, hwirq);
mutex_unlock(&revmap_trees_mutex);
}
}
요청 irq에 대해 매핑된 hwirq와의 매핑을 해제한다. 도메인의 ops->unmap 후크에 등록한 콜백 함수가 있는 경우 해당 컨트롤러를 통해 매핑 해제를 설정한다.
arch/arm/mach-bcm2709/armctrl.c
static struct irq_domain_ops armctrl_ops = {
.xlate = armctrl_xlate
};
bcm2708 및 bcm2709는 리눅스 irq와 hw irq의 변환은 인터럽트 컨트롤러에 고정되어 있어 sw로 매핑 구성을 변경할 수 없다. 따라서 매핑 및 언매핑용 함수는 제공되지 않고 argument -> hwirq 변환 함수만 제공한다.
- argument
- “interrupts = < x, … > 값
IRQ 매핑 생성 및 삭제
다음은 도메인내 dynamic하게 매핑을 생성(연결 포함) 및 삭제할 수 있는 API들이다. 이들은 dynamic 매핑 방법을 사용하는 linear, tree 및 hierarchy 방식의 irq domain에서 사용한다.
- irq_create_mapping()
- irq 디스크립터를 할당하고 지정한 hwirq에 매핑한다.
- irq_create_of_mapping()
- irq 디스크립터를 할당하고 디바이스 트리 노드를 통해 알아온 phandle argument 값을 파싱하여 변환한 hwirq에 매핑한다.
- irq_create_fwspec_mapping()
- irq 디스크립터를 할당하고 인자로 전달받은 fwspec 구조체를 통해 변환한 hwirq에 매핑한다.
- irq_create_identity_mapping()
- hwirq와 irq가 동일한 irq 디스크립터를 할당하고 hwirq에 매핑한다.
- irq_create_strict_mapping()
- 복수개의 irq 디스크립터들을 할당하고 지정한 irq 및 hwirq 번호들에 순서대로 매핑한다.
- irq_create_direct_mapping()
- irq 디스크립터를 하나 할당받은 후 hwirq 번호와 동일하게 1:1 직접 매핑 방법으로 매핑한다. (hwirq = irq)
- irq_dispose_mapping()
- 매핑을 해제하고 irq 디스크립터를 삭제한다.
다음 그림은 irq 도메인내에서 irq <–> hwirq 매핑과 irq 디스크립터와의 연동을 수행하는 몇 가지 API들을 보여준다.

매핑 생성 -1- (Dynamic)
irq_create_mapping()
kernel/irq/irqdomain.c
/** * irq_create_mapping() - Map a hardware interrupt into linux irq space * @domain: domain owning this hardware interrupt or NULL for default domain * @hwirq: hardware irq number in that domain space * * Only one mapping per hardware interrupt is permitted. Returns a linux * irq number. * If the sense/trigger is to be specified, set_irq_type() should be called * on the number returned from that call. */
unsigned int irq_create_mapping(struct irq_domain *domain,
irq_hw_number_t hwirq)
{
int virq;
pr_debug("irq_create_mapping(0x%p, 0x%lx)\n", domain, hwirq);
/* Look for default domain if nececssary */
if (domain == NULL)
domain = irq_default_domain;
if (domain == NULL) {
WARN(1, "%s(, %lx) called with NULL domain\n", __func__, hwirq);
return 0;
}
pr_debug("-> using domain @%p\n", domain);
of_node = irq_domain_get_of_node(domain);
/* Check if mapping already exists */
virq = irq_find_mapping(domain, hwirq);
if (virq) {
pr_debug("-> existing mapping on virq %d\n", virq);
return virq;
}
/* Allocate a virtual interrupt number */
virq = irq_domain_alloc_descs(-1, 1, hwirq, of_node_to_nid(domain->of_node), NULL);
if (virq <= 0) {
pr_debug("-> virq allocation failed\n");
return 0;
}
if (irq_domain_associate(domain, virq, hwirq)) {
irq_free_desc(virq);
return 0;
}
pr_debug("irq %lu on domain %s mapped to virtual irq %u\n",
hwirq, of_node_full_name(domain->of_node), virq);
return virq;
}
EXPORT_SYMBOL_GPL(irq_create_mapping);
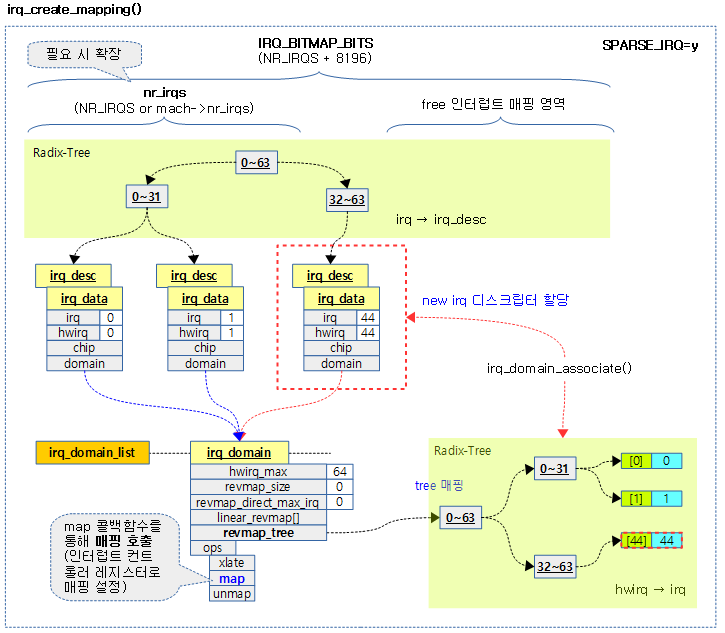
요청한 hwirq로 리눅스 irq를 배정 받아 매핑하고 그 번호를 반환한다. hwirq를 음수로 지정하는 경우 리눅스 irq를 배정한다.
- 코드 라인 9~10에서 domain이 null로 지정된 경우 default domain을 선택한다.
- 코드 라인 11~14에서 domain이 여전히 null인 경우 경고 메시지 출력과 함께 0을 반환한다.
- 코드 라인 17에서 도메인에 대한 디바이스 노드 정보를 알아온다.
- 코드 라인 19~23에서 domain에서 hwirq 에 매핑된 값이 있는지 알아온다. 만일 이미 매핑이 존재하는 경우 디버그 메시지 출력과 함께 0을 반환한다.
- 코드 라인 26~30에서 irq 디스크립터를 할당한다.
- 코드 라인 32~35에서 할당한 irq 디스크립터를 hwirq에 매핑한다.
- 코드 라인 37~40에서 성공한 매핑에 대해 디버그 메시지를 출력하고, virq 값을 반환한다.
다음 그림은 irq 디스크립터를 할당하여 hwirq에 매핑을 생성하는 모습을 보여준다.
매핑 생성 -2- (Device Tree)
irq_create_of_mapping()
kernel/irq/irqdomain.c
unsigned int irq_create_of_mapping(struct of_phandle_args *irq_data)
{
struct irq_fwspec fwspec;
of_phandle_args_to_fwspec(irq_data->np, irq_data->args,
irq_data->args_count, &fwspec);
return irq_create_fwspec_mapping(&fwspec);
}
EXPORT_SYMBOL_GPL(irq_create_of_mapping);
irq 디스크립터를 할당하고 디바이스 트리 노드를 통해 알아온 phandle argument 값을 파싱하여 변환한 hwirq에 매핑한다.
예) irq2의 uart 디바이스
uart0: uart@7e201000 {
compatible = "arm,pl011", "arm,primecell";
reg = <0x7e201000 0x1000>;
interrupts = <2 25>;
...
};
- uart의 인터럽트의 인자는 2개로 <2 25> -> bank #2, bit 25 인터럽트
- hwirq로 변환 -> 57
- 할당한 irq 디스크립터의 irq=83이라고 가정하면 이 irq(83)과 hwirq(57)을 매핑한다.
매핑 생성 -3- (fwspec)
irq_create_fwspec_mapping()
kernel/irq/irqdomain.c -1/2-
unsigned int irq_create_fwspec_mapping(struct irq_fwspec *fwspec)
{
struct irq_domain *domain;
struct irq_data *irq_data;
irq_hw_number_t hwirq;
unsigned int type = IRQ_TYPE_NONE;
int virq;
if (fwspec->fwnode) {
domain = irq_find_matching_fwspec(fwspec, DOMAIN_BUS_WIRED);
if (!domain)
domain = irq_find_matching_fwspec(fwspec, DOMAIN_BUS_ANY);
} else {
domain = irq_default_domain;
}
if (!domain) {
pr_warn("no irq domain found for %s !\n",
of_node_full_name(to_of_node(fwspec->fwnode)));
return 0;
}
if (irq_domain_translate(domain, fwspec, &hwirq, &type))
return 0;
/*
* WARN if the irqchip returns a type with bits
* outside the sense mask set and clear these bits.
*/
if (WARN_ON(type & ~IRQ_TYPE_SENSE_MASK))
type &= IRQ_TYPE_SENSE_MASK;
/*
* If we've already configured this interrupt,
* don't do it again, or hell will break loose.
*/
virq = irq_find_mapping(domain, hwirq);
if (virq) {
/*
* If the trigger type is not specified or matches the
* current trigger type then we are done so return the
* interrupt number.
*/
if (type == IRQ_TYPE_NONE || type == irq_get_trigger_type(virq))
return virq;
/*
* If the trigger type has not been set yet, then set
* it now and return the interrupt number.
*/
if (irq_get_trigger_type(virq) == IRQ_TYPE_NONE) {
irq_data = irq_get_irq_data(virq);
if (!irq_data)
return 0;
irqd_set_trigger_type(irq_data, type);
return virq;
}
pr_warn("type mismatch, failed to map hwirq-%lu for %s!\n",
hwirq, of_node_full_name(to_of_node(fwspec->fwnode)));
return 0;
}
Device Tree 스크립트에서 인터럽트 컨르롤러와 연결되는 디바이스에 대해 매핑을 수행한다.
- 코드 라인 9~15에서 @fwspce을 통해 fwnode가 존재하면 해당 도메인을 알아오고, 찾지 못한 경우 default domain을 사용한다.
- 코드 라인 17~21에서 domain이 없는 경우 경고 메시지를 출력하고 함수를 빠져나간다.
- 코드 라인 23~24에서 도메인에 등록한 변환 함수인 (*xlate) 후크 함수를 호출하여 hwirq 값과 타입을 구해온다.
- 예) Device Tree의 경우 인터럽트를 사용하는 각 장치의 “interrupts = { a1, a2 }”에서 인수 2 개로 hwirq 값을 알아온다.
- 코드 라인 30~31에서 IRQ_TYPE_SENSE_MASK에 해당하는 타입만 허용한다.
- 코드 라인 37에서 도메인 변환을 통해 찾아온 hwirq에 해당하는 매핑을 통해 virq를 알아온다.
- 코드 라인 38~63에서 virq가 이미 매핑된 경우 함수를 빠져나간다. 단 함수 타입 체크를 수행하여 다른 경우 경고 메시지를 출력한다.
kernel/irq/irqdomain.c -2/2-
if (irq_domain_is_hierarchy(domain)) {
virq = irq_domain_alloc_irqs(domain, 1, NUMA_NO_NODE, fwspec);
if (virq <= 0)
return 0;
} else {
/* Create mapping */
virq = irq_create_mapping(domain, hwirq);
if (!virq)
return virq;
}
irq_data = irq_get_irq_data(virq);
if (!irq_data) {
if (irq_domain_is_hierarchy(domain))
irq_domain_free_irqs(virq, 1);
else
irq_dispose_mapping(virq);
return 0;
}
/* Store trigger type */
irqd_set_trigger_type(irq_data, type);
return virq;
}
EXPORT_SYMBOL_GPL(irq_create_fwspec_mapping);
- 코드 라인 1~10에서 hierarch를 지원하는 irq domain인 경우 irq 디스크립터만 할당해오고, 그럲지 않은 경우 irq 디스크립터를 할당해서 hwirq에 매핑한다.
- 코드 라인 12~19에서 irq 디스크립터가 할당되지 않은 경우 매핑을 취소하고 함수를 빠져나간다.
- 코드 라인 22에서 트리거 타입을 지정한다.
- 코드 라인 24에서 성공적으로 할당받은 virq를 반환한다.
매핑 생성 -4- (Identity)
irq_create_identity_mapping()
kernel/irq/irqdomain.c
static inline int irq_create_identity_mapping(struct irq_domain *host,
irq_hw_number_t hwirq)
{
return irq_create_strict_mappings(host, hwirq, hwirq, 1);
}
@hwirq 번호와 동일한 irq를 사용하는 irq 디스크립터를 할당받은 후 @hwirq 번호에 매핑 한다.
매핑 생성 -5- (Strict)
irq_create_strict_mappings()
kernel/irq/irqdomain.c
/** * irq_create_strict_mappings() - Map a range of hw irqs to fixed linux irqs * @domain: domain owning the interrupt range * @irq_base: beginning of linux IRQ range * @hwirq_base: beginning of hardware IRQ range * @count: Number of interrupts to map * * This routine is used for allocating and mapping a range of hardware * irqs to linux irqs where the linux irq numbers are at pre-defined * locations. For use by controllers that already have static mappings * to insert in to the domain. * * Non-linear users can use irq_create_identity_mapping() for IRQ-at-a-time * domain insertion. * * 0 is returned upon success, while any failure to establish a static * mapping is treated as an error. */
int irq_create_strict_mappings(struct irq_domain *domain, unsigned int irq_base,
irq_hw_number_t hwirq_base, int count)
{
struct device_node *of_node;
int ret;
of_node = irq_domain_get_of_node(domain);
ret = irq_alloc_descs(irq_base, irq_base, count,
of_node_to_nid(of_node));
if (unlikely(ret < 0))
return ret;
irq_domain_associate_many(domain, irq_base, hwirq_base, count);
return 0;
}
EXPORT_SYMBOL_GPL(irq_create_strict_mappings);
@irq_base 번호부터 @count 수 만큼 irq 디스크립터를 할당받은 후 @hwirq_base 부터 @count 수 만큼 매핑 한다.
- 코드 라인 7~11에서 irq_base 번호부터 count 만큼의 irq 디스크립터를 할당 받아온다.
- 코드 라인 13에서 irq_base 번호에 해당하는 irq 디스크립터들을 hwirq_base 번호부터 @count 수 만큼 매핑한다.
- 코드 라인 14에서 성공 값 0을 반환한다.
매핑 생성 -6- (Direct)
irq_create_direct_mapping()
kernel/irq/irqdomain.c
/** * irq_create_direct_mapping() - Allocate an irq for direct mapping * @domain: domain to allocate the irq for or NULL for default domain * * This routine is used for irq controllers which can choose the hardware * interrupt numbers they generate. In such a case it's simplest to use * the linux irq as the hardware interrupt number. It still uses the linear * or radix tree to store the mapping, but the irq controller can optimize * the revmap path by using the hwirq directly. */
unsigned int irq_create_direct_mapping(struct irq_domain *domain)
{
struct device_node *of_node;
unsigned int virq;
if (domain == NULL)
domain = irq_default_domain;
of_node = irq_domain_get_of_node(domain);
virq = irq_alloc_desc_from(1, of_node_to_nid(of_node));
if (!virq) {
pr_debug("create_direct virq allocation failed\n");
return 0;
}
if (virq >= domain->revmap_direct_max_irq) {
pr_err("ERROR: no free irqs available below %i maximum\n",
domain->revmap_direct_max_irq);
irq_free_desc(virq);
return 0;
}
pr_debug("create_direct obtained virq %d\n", virq);
if (irq_domain_associate(domain, virq, virq)) {
irq_free_desc(virq);
return 0;
}
return virq;
}
EXPORT_SYMBOL_GPL(irq_create_direct_mapping);
irq 디스크립터를 하나 할당받은 후 hwirq 번호와 동일하게 1:1 직접 매핑 방법으로 매핑한다.
- 코드 라인 6~7에서 domain이 주어지지 않은 경우 default domain을 선택한다.
- 코드 라인 9~14에서 1개의 irq 디스크립터를 할당 받아온다.
- 코드 라인 15~20에서 할당 받은 irq가 no 매핑 방법으로 사용할 수 있는 범위를 초과하는 경우 에러 메시지를 출력하고 할당받은 irq 디스크립터를 다시 할당 해제한 후 0을 반환한다.
- 코드 라인 21에서 매핑한 디버그 정보를 로그로 출력한다.
- 코드 라인 23~26에서 할당받은 irq 번호로 hwirq 번호를 매핑한다.
- 코드 라인 28에서 성공한 경우 할당받은 virq 번호를 반환한다.
리버스 매핑 검색 (hwirq -> irq)
irq_find_mapping()
kernel/irq/irqdomain.c
/** * irq_find_mapping() - Find a linux irq from an hw irq number. * @domain: domain owning this hardware interrupt * @hwirq: hardware irq number in that domain space */
unsigned int irq_find_mapping(struct irq_domain *domain,
irq_hw_number_t hwirq)
{
struct irq_data *data;
/* Look for default domain if nececssary */
if (domain == NULL)
domain = irq_default_domain;
if (domain == NULL)
return 0;
if (hwirq < domain->revmap_direct_max_irq) {
data = irq_domain_get_irq_data(domain, hwirq);
if (data && data->hwirq == hwirq)
return hwirq;
}
/* Check if the hwirq is in the linear revmap. */
if (hwirq < domain->revmap_size)
return domain->linear_revmap[hwirq];
rcu_read_lock();
data = radix_tree_lookup(&domain->revmap_tree, hwirq);
rcu_read_unlock();
return data ? data->irq : 0;
}
EXPORT_SYMBOL_GPL(irq_find_mapping);
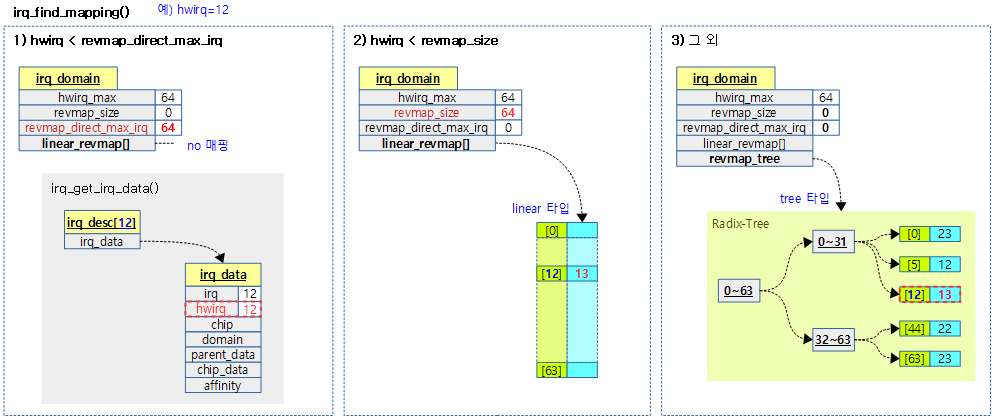
irq domain 내에서 hwirq에 매핑된 irq 번호를 검색한다. 매핑되지 않은 경우 0을 반환한다.
- 코드 라인 7~8에서 domain이 지정되지 않은 경우 default domain을 사용한다.
- 코드 라인 9~10에서 여전히 domain이 null인 경우 0을 반환한다.
- 코드 라인 12~16에서 no 매핑 구간에서 irq(=hwirq) 값을 알아온다.
- hwirq가 리버스 매핑이 필요 없는 구간인 경우 hwirq 값으로 irq_data를 구해온다. 만일 data->hwirq 값과 동일한 경우에 그 대로 hwirq 값을 반환한다.
- 코드 라인 19~20에서 리니어 매핑 구간에서 hwirq에 해당하는 irq 값을 알아온다.
- hwirq가 리버스 매핑 범위 이내인 경우 리니어 리버스 매핑된 값을 반환한다.
- 코드 라인 23~25에서 tree 매핑 구간에서 hwirq로 검색하여 irq 값을 알아온다.
- radix tree에서 hwirq로 검색하여 irq_data를 알아온 다음 data->irq를 반환한다.
다음 그림은 irq_find_mapping() 함수가 hwirq에 매핑된 irq 번호를 찾는 과정 3 가지를 보여준다.
도메인용 irq 디스크립터 할당과 해제
도메인용 irq 디스크립터 할당
irq_domain_alloc_descs()
kernel/irq/irqdomain.c
int irq_domain_alloc_descs(int virq, unsigned int cnt, irq_hw_number_t hwirq,
int node, const struct irq_affinity_desc *affinity)
{
unsigned int hint;
if (virq >= 0) {
virq = __irq_alloc_descs(virq, virq, cnt, node, THIS_MODULE,
affinity);
} else {
hint = hwirq % nr_irqs;
if (hint == 0)
hint++;
virq = __irq_alloc_descs(-1, hint, cnt, node, THIS_MODULE,
affinity);
if (virq <= 0 && hint > 1) {
virq = __irq_alloc_descs(-1, 1, cnt, node, THIS_MODULE,
affinity);
}
}
return virq;
}
irq 디스크립터를 @cnt 수만큼 @node에 할당한다. @affinity로 특정 cpu들을 대상으로 지정할 수 있다. @virq를 지정할 수도 있고, 지정하지 않은 경우(-1) 다음과 같은 기준으로 생성한다.
- hwirq 번호를 irq 번호로 할당 시도한다. 단 hwirq 번호가 0인 경우 hwirq + 1을 irq 번호로 사용한다.
- 할당이 실패한 경우 hwirq 번호가 2 이상이면 irq 번호를 1부터 다시 한 번 시도한다.
- 코드 라인 6~8에서 @virq 번호를 지정한 경우 그 번호부터 @cnt 수 만큼 irq 디스크립터를 @node에 할당하고 @affinity를 지정한다. 그리고 현재 모듈을 irq 디스크립터의 owner로 설정한다.
- 코드 라인 9~14에서 @virq 번호를 지정하지 않은 경우 hwirq 번호(0인 경우 1)부터 @cnt 수 만큼 irq 디스크립터를 @node에 할당하고 @affinity를 지정한다. 그리고 현재 모듈을 irq 디스크립터의 owner로 설정한다.
- 코드 라인 15~18에서 만일 할당이 실패한 경우 hwirq 번호가 2 이상이면 irq 번호를 1부터 다시 한 번 시도한다.
- 코드 라인 21에서 할당한 irq 디스크립터에 대한 virq 번호를 반환한다.
IRQ 도메인 검색
디바이스 노드에 해당하는 도메인 검색
irq_find_host()
include/linux/irqdomain.h
static inline struct irq_domain *irq_find_host(struct device_node *node)
{
struct irq_domain *d;
d = irq_find_matching_host(node, DOMAIN_BUS_WIRED);
if (!d)
d = irq_find_matching_host(node, DOMAIN_BUS_ANY);
return d;
}
디바이스 트리의 @node 정보를 사용하여 일치하는 irq domain을 찾아온다.
- DOMAIN_BUS_WIRED 토큰을 먼저 사용하고, 찾을 수 없는 경우 DOMAIN_BUS_ANY를 사용하여 버스 제한 없이 검색한다.
irq_find_matching_host()
include/linux/irqdomain.h
static inline struct irq_domain *irq_find_matching_host(struct device_node *node,
enum irq_domain_bus_token bus_token)
{
return irq_find_matching_fwnode(of_node_to_fwnode(node), bus_token);
}
디바이스 트리의 @node와 @bus_token 정보를 사용하여 일치하는 irq domain을 찾아온다.
irq_find_matching_fwnode()
include/linux/irqdomain.h
static inline
struct irq_domain *irq_find_matching_fwnode(struct fwnode_handle *fwnode,
enum irq_domain_bus_token bus_token)
{
struct irq_fwspec fwspec = {
.fwnode = fwnode,
};
return irq_find_matching_fwspec(&fwspec, bus_token);
}
인자 @fwnode와 @bus_token 정보를 사용하여 일치하는 irq domain을 찾아온다.
irq_find_matching_fwspec()
kernel/irq/irqdomain.c
/** * irq_find_matching_fwspec() - Locates a domain for a given fwspec * @fwspec: FW specifier for an interrupt * @bus_token: domain-specific data */
struct irq_domain *irq_find_matching_fwspec(struct irq_fwspec *fwspec,
enum irq_domain_bus_token bus_token)
{
struct irq_domain *h, *found = NULL;
struct fwnode_handle *fwnode = fwspec->fwnode;
int rc;
/* We might want to match the legacy controller last since
* it might potentially be set to match all interrupts in
* the absence of a device node. This isn't a problem so far
* yet though...
*
* bus_token == DOMAIN_BUS_ANY matches any domain, any other
* values must generate an exact match for the domain to be
* selected.
*/
mutex_lock(&irq_domain_mutex);
list_for_each_entry(h, &irq_domain_list, link) {
if (h->ops->select && fwspec->param_count)
rc = h->ops->select(h, fwspec, bus_token);
else if (h->ops->match)
rc = h->ops->match(h, to_of_node(fwnode), bus_token);
else
rc = ((fwnode != NULL) && (h->fwnode == fwnode) &&
((bus_token == DOMAIN_BUS_ANY) ||
(h->bus_token == bus_token)));
if (rc) {
found = h;
break;
}
}
mutex_unlock(&irq_domain_mutex);
return found;
}
EXPORT_SYMBOL_GPL(irq_find_matching_fwspec);
인자 @fwspce 정보와 @bus_token 정보를 사용하여 일치하는 irq domain을 찾아온다.
- irq_domain_list에 등록한 모든 엔트리에 대해 루프를 돌며 다음 3가지 중 하나로 도메인을 찾는다.
- 첫 번째, (*select) 후크에 등록된 함수
- 두 번째, (*match) 후크에 등록된 함수
- 세 번째, fwnode가 동일하고, @bus_token이 일치하는 경우
기타 함수
주요 APIs
다음은 본문에서 설명한 API들이다.
- irq_domain_add_linear()
- irq_domain_add_tree()
- irq_domain_add_legacy()
- irq_domain_add_legacy_isa()
- irq_domain_add_simple()
- __irq_domain_add()
- irq_domain_remove()
- irq_domain_create_hierarchy()
- irq_find_mapping()
- irq_find_matching_fwspec()
- irq_domain_associate()
- irq_domain_associate_many()
- irq_domain_disassociate()
- irq_create_mapping()
- irq_create_of_mapping()
- irq_create_fwspec_mapping()
- irq_create_direct_mapping()
- irq_create_identity_mapping()
- irq_create_strict_mappings()
- irq_dispose_mapping()
- irq_domain_free_fwnode()
- irq_domain_set_hwirq_and_chip()
- irq_domain_alloc_descs()
- irq_find_matching_fwspec()
- __irq_domain_alloc_fwnode()
기타 APIs
- irq_set_default_host()
- irq_get_default_host()
- irq_domain_insert_irq()
- irq_domain_remove_irq()
- irq_domain_insert_irq_data()
- irq_domain_free_irq_data()
- irq_domain_alloc_irq_data()
- irq_linear_revmap()
- irq_domain_get_irq_data()
- irq_domain_set_hwirq_and_chip()
- irq_domain_set_info()
- irq_domain_reset_irq_data()
- irq_domain_free_irqs_common()
- irq_domain_free_irqs_top()
- irq_domain_is_auto_recursive()
- irq_domain_free_irqs_recursive()
- irq_domain_alloc_irqs_recursive()
- __irq_domain_alloc_irqs()
- irq_domain_free_irqs()
- irq_domain_alloc_irqs_parent()
- irq_domain_free_irqs_parent()
- irq_domain_activate_irq()
- irq_domain_deactivate_irq()
- irq_domain_check_hierarchy()
- irq_domain_get_irq_data()
- irq_domain_check_msi_remap()
- irq_domain_update_bus_token()
- irq_domain_push_irq()
- irq_domain_pop_irq()
- irq_domain_hierarchical_is_msi_remap()
- irq_domain_xlate_onecell()
- irq_domain_xlate_twocell()
- irq_domain_xlate_onetwocell()
- irq_domain_translate_twocell()
인터럽트 목록 확인
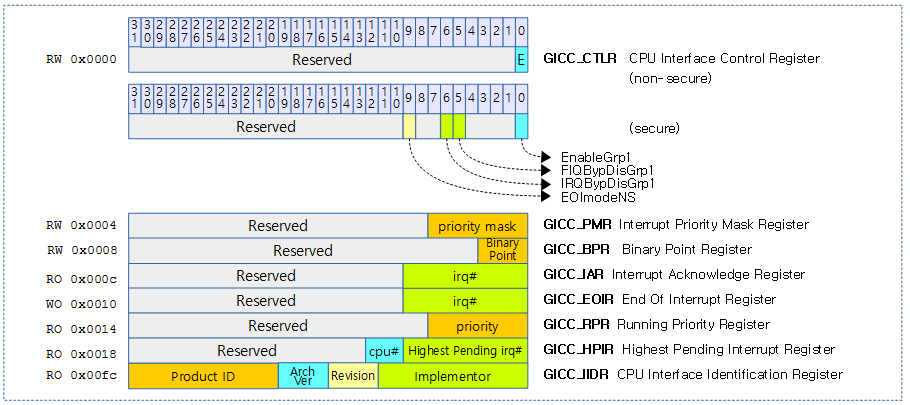
다음은 rock960 보드에서 QEMU/KVM을 사용하여 Guest OS를 동작시켜 확인한 인터럽트 목록들이다.
$ cat /proc/interrupts
CPU0 CPU1
12: 2653 2704 GICv3 27 Level arch_timer
47: 1495 0 GICv3 78 Edge virtio0
48: 32 0 GICv3 79 Edge virtio1
50: 0 0 GICv3 34 Level rtc-pl031
51: 181 0 GICv3 33 Level uart-pl011
52: 0 0 GICv3-23 0 Level arm-pmu
53: 0 0 GICv3-23 1 Level arm-pmu
54: 0 0 9030000.pl061 3 Edge GPIO Key Poweroff
IPI0: 987 1260 Rescheduling interrupts
IPI1: 5 611 Function call interrupts
IPI2: 0 0 CPU stop interrupts
IPI3: 0 0 CPU stop (for crash dump) interrupts
IPI4: 0 0 Timer broadcast interrupts
IPI5: 0 0 IRQ work interrupts
IPI6: 0 0 CPU wake-up interrupts
Err: 0
irq 별 sysfs 속성 확인
arch_timer를 담당하는 인터럽트 번호를 찾고, “cd /sys/kernel/irq/<irq>”를 타이핑하여 해당 인터럽트 디렉토리로 진입하여 다음 속성들을 확인한다.
$ cd /sys/kernel/irq/12 $ ls actions chip_name hwirq name per_cpu_count type wakeup $ cat actions arch_timer $ cat chip_name GICv3 $ cat hwirq 27 $ cat per_cpu_count 2390,2251 $ cat type level $ cat wakeup disabled
FS 디버깅이 가능한 커널에서 irq domain 구성 참고
$ cd /sys/kernel/debug/irq
$ ls
domains irqs
$ ls domains/
default gic400@40041000 gpio@7e200000 unknown-1
$ ls irqs/
1 11 13 15 17 19 20 22 24 26 28 3 31 33 35 37 39 5 7 9
10 12 14 16 18 2 21 23 25 27 29 30 32 34 36 38 4 6 8
$ cat /irqs/3
handler: handle_percpu_devid_irq
device: (null)
status: 0x00031708
_IRQ_NOPROBE
_IRQ_NOTHREAD
_IRQ_NOAUTOEN
_IRQ_PER_CPU_DEVID
istate: 0x00000000
ddepth: 1
wdepth: 0
dstate: 0x02032a08
IRQ_TYPE_LEVEL_LOW
IRQD_LEVEL
IRQD_ACTIVATED
IRQD_IRQ_DISABLED
IRQD_IRQ_MASKED
IRQD_PER_CPU
node: 0
affinity: 0-3
effectiv:
domain: gic400@40041000
hwirq: 0x1e
chip: GICv2
flags: 0x15
IRQCHIP_SET_TYPE_MASKED
IRQCHIP_MASK_ON_SUSPEND
IRQCHIP_SKIP_SET_WAKE
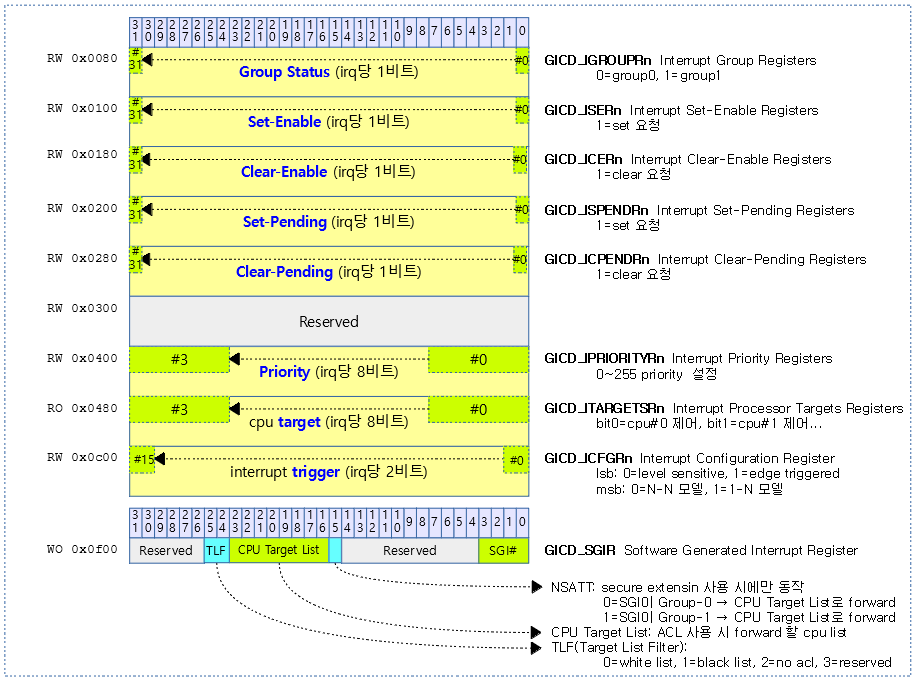
/sys/kernel/debug# cat irq_domain_mapping
name mapped linear-max direct-max devtree-node
IR-IO-APIC 24 24 0
DMAR-MSI 2 0 0
IR-PCI-MSI 6 0 0
(null) 65563 65536 0
IR-PCI-MSI 1 0 0
(null) 65536 65536 0
(null) 0 0 0
(null) 0 0 0
*(null) 31 0 0
irq hwirq chip name chip data active type domain
1 0x00001 IR-IO-APIC 0xffff8802158a6f80 * LINEAR IR-IO-APIC
3 0x00003 IR-IO-APIC 0xffff880214972180 LINEAR IR-IO-APIC
4 0x00004 IR-IO-APIC 0xffff880214972280 LINEAR IR-IO-APIC
5 0x00005 IR-IO-APIC 0xffff880214972380 LINEAR IR-IO-APIC
6 0x00006 IR-IO-APIC 0xffff880214972480 LINEAR IR-IO-APIC
7 0x00007 IR-IO-APIC 0xffff880214972580 LINEAR IR-IO-APIC
8 0x00008 IR-IO-APIC 0xffff880214972680 * LINEAR IR-IO-APIC
9 0x00009 IR-IO-APIC 0xffff880214972780 * LINEAR IR-IO-APIC
10 0x0000a IR-IO-APIC 0xffff880214972880 LINEAR IR-IO-APIC
11 0x0000b IR-IO-APIC 0xffff880214972980 LINEAR IR-IO-APIC
12 0x0000c IR-IO-APIC 0xffff880214972a80 * LINEAR IR-IO-APIC
13 0x0000d IR-IO-APIC 0xffff880214972b80 LINEAR IR-IO-APIC
14 0x0000e IR-IO-APIC 0xffff880214972c80 LINEAR IR-IO-APIC
15 0x0000f IR-IO-APIC 0xffff880214972d80 LINEAR IR-IO-APIC
16 0x00010 IR-IO-APIC 0xffff8800d3e4d940 * LINEAR IR-IO-APIC
17 0x00011 IR-IO-APIC 0xffff8800d3e4da40 LINEAR IR-IO-APIC
18 0x00012 IR-IO-APIC 0xffff8800d3e4db40 LINEAR IR-IO-APIC
19 0x00013 IR-IO-APIC 0xffff8802147d3bc0 LINEAR IR-IO-APIC
20 0x00014 IR-IO-APIC 0xffff8800350411c0 LINEAR IR-IO-APIC
22 0x00016 IR-IO-APIC 0xffff88020f9e8e40 LINEAR IR-IO-APIC
23 0x00017 IR-IO-APIC 0xffff880035670000 * LINEAR IR-IO-APIC
24 0x00000 DMAR-MSI (null) * RADIX DMAR-MSI
25 0x00001 DMAR-MSI (null) * RADIX DMAR-MSI
26 0x50000 IR-PCI-MSI (null) * RADIX IR-PCI-MSI
27 0x7d000 IR-PCI-MSI (null) * RADIX IR-PCI-MSI
28 0x58000 IR-PCI-MSI (null) * RADIX IR-PCI-MSI
29 0x08000 IR-PCI-MSI (null) * RADIX IR-PCI-MSI
30 0x6c000 IR-PCI-MSI (null) * RADIX IR-PCI-MSI
31 0x64000 IR-PCI-MSI (null) * RADIX IR-PCI-MSI
32 0x180000 IR-PCI-MSI (null) * RADIX IR-PCI-MSI
구조체
irq_domain 구조체
include/linux/irqdomain.h
/** * struct irq_domain - Hardware interrupt number translation object * @link: Element in global irq_domain list. * @name: Name of interrupt domain * @ops: pointer to irq_domain methods * @host_data: private data pointer for use by owner. Not touched by irq_domain * core code. * @flags: host per irq_domain flags * @mapcount: The number of mapped interrupts * * Optional elements * @fwnode: Pointer to firmware node associated with the irq_domain. Pretty easy * to swap it for the of_node via the irq_domain_get_of_node accessor * @gc: Pointer to a list of generic chips. There is a helper function for * setting up one or more generic chips for interrupt controllers * drivers using the generic chip library which uses this pointer. * @parent: Pointer to parent irq_domain to support hierarchy irq_domains * @debugfs_file: dentry for the domain debugfs file * * Revmap data, used internally by irq_domain * @revmap_direct_max_irq: The largest hwirq that can be set for controllers that * support direct mapping * @revmap_size: Size of the linear map table @linear_revmap[] * @revmap_tree: Radix map tree for hwirqs that don't fit in the linear map * @linear_revmap: Linear table of hwirq->virq reverse mappings */
struct irq_domain {
struct list_head link;
const char *name;
const struct irq_domain_ops *ops;
void *host_data;
unsigned int flags;
unsigned int mapcount;
/* Optional data */
struct fwnode_handle *fwnode;
enum irq_domain_bus_token bus_token;
struct irq_domain_chip_generic *gc;
#ifdef CONFIG_IRQ_DOMAIN_HIERARCHY
struct irq_domain *parent;
#endif
#ifdef CONFIG_GENERIC_IRQ_DEBUGFS
struct dentry *debugfs_file;
#endif
/* reverse map data. The linear map gets appended to the irq_domain */
irq_hw_number_t hwirq_max;
unsigned int revmap_direct_max_irq;
unsigned int revmap_size;
struct radix_tree_root revmap_tree;
struct mutex revmap_tree_mutex;
unsigned int linear_revmap[];
};
리눅스 인터럽트와 하드웨어 인터럽트 번호를 매핑 및 변환하기 위한 테이블 관리와 함수를 제공한다.
- link
- 전역 irq_domain_list에 연결될 때 사용하다.
- *name
- irq domain 명
- *ops
- irq domain operations 구조체를 가리킨다.
- *host_data
- private data 포인터 주소 (irq domain core 코드에서 사용하지 않는다)
- flags
- irq domain의 플래그
- IRQ_DOMAIN_FLAG_HIERARCHY
- tree 구조 irq domain
- IRQ_DOMAIN_FLAG_AUTO_RECURSIVE
- tree 구조에서 recursive 할당/할당해제를 사용하는 경우
- IRQ_DOMAIN_FLAG_NONCORE
- generic 코어 코드를 사용하지 않고 직접 irq domain에 대해 specific한 처리를 한 경우 사용
- IRQ_DOMAIN_FLAG_HIERARCHY
- irq domain의 플래그
- fwnode
- 연결된 펌에어 노드 핸들 (디바이스 트리, ACPI, …)
- bus_token
- 도메인이 사용되는 목적
- DOMAIN_BUS_ANY (0)
- DOMAIN_BUS_WIRED (1)
- DOMAIN_BUS_GENERIC_MSI (2)
- DOMAIN_BUS_PCI_MSI (3)
- DOMAIN_BUS_PLATFORM_MSI (4)
- DOMAIN_BUS_NEXUS (5)
- DOMAIN_BUS_IPI (6)
- DOMAIN_BUS_FSL_MC_MSI (7)
- DOMAIN_BUS_TI_SCI_INTA_MSI (8)
- 도메인이 사용되는 목적
- *gc
- 연결된 generic chip 리스트 (인터럽트 컨트롤러 리스트)
- *parent
- 상위 irq domain
- irq domain 하이라키를 지원하는 경우 사용
- hwirq_max
- 지원가능한 최대 hwirq 번호
- revmap_direct_max_irq
- 직접 매핑을 지원하는 컨트롤러들에서 설정되는 최대 hw irq 번호
- revmap_size
- 리니어 맵 테이블 사이즈
- revmap_tree
- hwirq를 위한 radix tree 맵
- linear_revmap[]
- hwirq -> virq에 리버스 매핑에 대한 리니어 테이블
irq_domain_ops 구조체
include/linux/irqdomain.h
/** * struct irq_domain_ops - Methods for irq_domain objects * @match: Match an interrupt controller device node to a host, returns * 1 on a match * @map: Create or update a mapping between a virtual irq number and a hw * irq number. This is called only once for a given mapping. * @unmap: Dispose of such a mapping * @xlate: Given a device tree node and interrupt specifier, decode * the hardware irq number and linux irq type value. * * Functions below are provided by the driver and called whenever a new mapping * is created or an old mapping is disposed. The driver can then proceed to * whatever internal data structures management is required. It also needs * to setup the irq_desc when returning from map(). */
struct irq_domain_ops {
int (*match)(struct irq_domain *d, struct device_node *node,
enum irq_domain_bus_token bus_token);
int (*select)(struct irq_domain *d, struct irq_fwspec *fwspec,
enum irq_domain_bus_token bus_token);
int (*map)(struct irq_domain *d, unsigned int virq, irq_hw_number_t hw);
void (*unmap)(struct irq_domain *d, unsigned int virq);
int (*xlate)(struct irq_domain *d, struct device_node *node,
const u32 *intspec, unsigned int intsize,
unsigned long *out_hwirq, unsigned int *out_type);
#ifdef CONFIG_IRQ_DOMAIN_HIERARCHY
/* extended V2 interfaces to support hierarchy irq_domains */
int (*alloc)(struct irq_domain *d, unsigned int virq,
unsigned int nr_irqs, void *arg);
void (*free)(struct irq_domain *d, unsigned int virq,
unsigned int nr_irqs);
int (*activate)(struct irq_domain *d, struct irq_data *irqd, bool reserve);
void (*deactivate)(struct irq_domain *d, struct irq_data *irq_data);
int (*translate)(struct irq_domain *d, struct irq_fwspec *fwspec,
unsigned long *out_hwirq, unsigned int *out_type);
#endif
#ifdef CONFIG_GENERIC_IRQ_DEBUGFS
void (*debug_show)(struct seq_file *m, struct irq_domain *d,
struct irq_data *irqd, int ind);
#endif
};
- (*match)
- 호스와 인터럽트 컨트롤러 디바이스 노드와 매치 여부를 수행하는 함수 포인터. 매치되면 1을 반환한다
- (*select)
- 도메인 선택을 위한 함수 포인터
- (*map)
- 가상 irq와 하드웨어 irq 번호끼리의 매핑을 만들거나 업데이트 하는 함수 포인터.
- (*unmap)
- 매핑을 해제하는 함수 포인터.
- (*xlate)
- 하드웨어 irq와 리눅스 irq와의 변환을 수행하는 함수 포인터.
- (*alloc)
- irq domain의 tree 구조 지원시 irq 할당 함수 포인터
- (*free)
- irq domain의 tree 구조 지원시 irq 할당 해제 함수 포인터
- (*activate)
- irq domain의 tree 구조 지원시 irq activate 함수 포인터
- (*deactivate)
- irq domain의 tree 구조 지원시 irq deactivate 함수 포인터
- (*translate)
- CONFIG_IRQ_DOMAIN_HIERARCHY 구성된 도메인에서 (*xlate)를 대체하여 사용하는 함수 포인터
참고
- Interrupts -1- (Interrupt Controller) | 문c
- Interrupts -2- (irq chip) | 문c
- Interrupts -3- (irq domain) | 문c – 현재 글
- Interrupts -4- (Top-Half & Bottom-Half) | 문c
- Interrupts -5- (Softirq) | 문c
- Interrupts -6- (IPI Cross-call) | 문c
- Interrupts -7- (Workqueue 1) | 문c
- Interrupts -8- (Workqueue 2) | 문c
- Interrupts -9- (GIC v3 Driver) | 문c
- Interrupts -10- (irq partition) | 문c
- Interrupts -11- (RPI2 IC Driver) | 문c
- Interrupts -12- (irq desc) | 문c