<kernel v5.0>
Memory Reclaiming
메모리가 부족하면 주기적으로 페이지를 해지하는 프로세스가 돌며 페이지를 회수하여 재사용 하는데 여러 가지 메모리 교체 정책이 있다. 그 중 리눅스는 LRU 알고리즘을 사용한다.
커널의 페이지 관리의 핵심을 담당하는 buddy 시스템은 여러 개의 order와 각각의 order 별로 6개의 migratetype 별로 free 페이지를 관리하고 있다. 그런데 이들을 할당하여 사용할 때 메모리가 부족하면 특정 할당 페이지들을 대상으로 이를 회수하여 사용할 수 있는데, 이러한 페이지를 다음에서 알아본다.
- file 페이지들(aka page cache)
- 사용자가 읽어 메모리에 있는 파일 페이지들은 사본이고, 원본은 이미 backing storage system(디스크등)에 저장되어 있으므로 메모리에 있는 페이지들을 해제(free)시켜 즉각 회수가 가능하다. 그 이후 필요하면 다시 그 부분만 로드하여 사용한다.
- 메모리에 로드한 페이지에 수정이 가해진 경우(dirty 상태)에는 디스크에 기록한 후 회수한다.
- LRU 리스트를 통해 관리한다.
- anon 페이지들
- 사용자가 malloc()으로 요청한 메모리 또는 스택 메모리등은 원본이 메모리이므로, swap backing storage system(디스크등)에 임시로 저장한 후 메모리에서 해제(free)시켜 회수할 수 있다.
- LRU 리스트를 통해 관리한다.
- reclaimable 슬랩 캐시들
- 커널에서 할당한 메모리들은 이동이 불가능하여 compaction 및 회수가 불가능하게 설게되어 있지만, GFP_RECLAIMABLE 옵션을 사용하여 만든 슬랩 캐시들은 커널 메모리로 사용할지라도 회수가 가능하도록 설계되어 있다.
- LRU 리스트를 통해 관리하지 않는다.
LRU (Least Recently Used)
회수 관리에 사용되는 페이지들은 LRU 리스트를 통해 관리하고 있다. 이들을 알아본다.
- 최소 빈도로 사용되는 페이지를 회수하는 방식이다.
- 최소 빈도 처리는 실제 구현 시 리스트 내의 head에 회수 관리할 페이지를 추가하고, 회수할 페이지는 리스트의 tail 에서 처리한다.
- file 페이지 및 anon 페이지들이 대상이다.
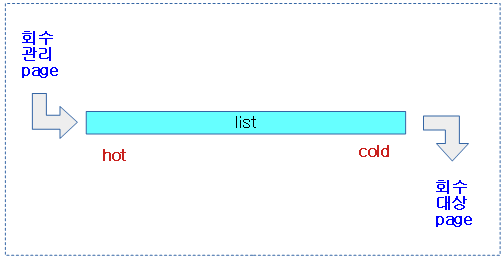
- 회수는 사용자 할당 메모리인 anon 페이지와 페이지 캐시를 대상으로 한다.
- 단 페이지 캐시 중 unevictable로 분류된 ramfs, shm, mlock 페이지들은 제외한다.
- LRU에서 관리하는 페이지들은 compaction을 통해 migrate가 가능한 movable 페이지들이다.
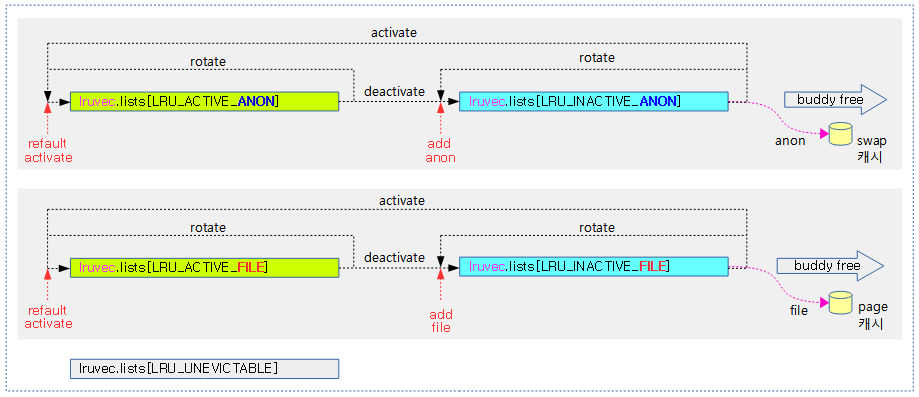
- 커널 v2.6.28-rc1 부터는 기존에 zone별로 2개의 LRU(active_list 와 inactive_list) 리스트만을 관리하였었는데 이를 다시 anon과 file로 나누었고, 회수 대상에서 제외할 페이지들만을 모아놓은 unevictable 리스트까지 총 5개로 확대하여 사용한다.
- 기존
- zone->active_list
- zone->inactive_list
- 신규: 5개로 확장된 LRU 리스트
- zone->lruvec.lists[LRU_INACTIVE_ANON]
- zone->lruvec.lists[LRU_ACTIVE_ANON]
- zone->lruvec.lists[LRU_INACTIVE_FILE]
- zone->lruvec.lists[LRU_ACTIVE_FILE]
- zone->lruvec.lists[LRU_UNEVICTABLE]
- 참고:
- 커널 v4.8-rc1 부터 zone이 아닌 노드별로 관리한다.
memcg/node lruvecs
다음 그림과 같이 cgroup을 사용한 memory 컨트롤러를 memcg라고 하고, 각각의 memcg는 노드별 lruvec을 관리한다.
- lruvec 구조체에 위의 5개 lru list를 포함하여 관리한다.
- lruvec은 각각의 memcg(Cgroup의 memory controller) 및 노드별로 관리된다.
- 즉 하나의 유저 페이지는 수 많은 lruvec 중의 하나에서 관리한다.

LRU 리스트 타입
lru 리스트는 양방향 리스트로 선두는 hot, 페이지 후미는 cold 페이지 성격을 갖는다.
- ANON
- anonymous 유저 메모리를 VM에 매핑하여 사용한 페이지이다.
- 메모리 부족 시 swap 영역에 옮기고 다 옮긴 페이지는 회수한다.
- 현재 리눅스 커널은 성능상의 이유로 swap 크기가 default 0으로 설정되어 있다.
- 최근 torvalds는 ssd 타입의 디스크를 사용하여 다시 swap을 사용하는 것에 관심을 갖고 있다.
- FILE
- 파일을 VM에 매핑하여 사용되는 페이지로 정규 파일에서 읽어 들인 페이지이다.
- 메모리 부족 시 clean 페이지들은 그냥 회수하고, dirty된 페이지들은 file(backing store)에 기록 후에 회수한다.
- ACTIVE
- 처음 할당된 페이지들은 inactive 리스트의 선두(hot)에 추가된다.
- 주기적으로 active와 inactive의 ratio를 비교하여 계속 참조(reference)되지 않는 페이지는 inactive 리스트로 옮기고 참조된 페이지는 다시 active list의 선두로 옮긴다(rotate).
- INACTIVE
- 회수 매커니즘이 동작할 때 inactive 리스트의 후미(cold)에서 회수를 시도한다.
- ANON: swap 영역에 옮긴다.
- FILE: clean 페이지는 곧바로 회수가능하다. dirty 페이지인 경우 writeback으로 바꾸고 async하게 원래의 화일에 기록하게 해놓고 페이지를 inactive list의 선두로 옮긴다(rotate)
- rotate 시켜 즉각 처리를 유보시키고, 나중에 다시 차례가 되어 writeback이 완료된 경우 회수한다.
- UNEVICTABLE
- 메모리 회수 메커니즘에서 사용할 수 없도록 한 페이지로 다음의 경우 사용된다.
- ramfs
- SHM_LOCK(공유 메모리 락)’d shared memory regions
- VM_LOCKED VMAs
- 다음 3가지 case에서는 isolation을 통한 migration을 허용한다.
- 메모리 파편화 관리
- 워크로드 관리
- 메모리 hotplug
- per-cpu를 사용하는 LRU pagevec 매커니즘을 사용하지 않는다.
LRU 리스트 간 이동
- anon 페이지
- fault가 발생하여 새롭게 할당된 페이지는 inactive list의 head에 진입한다.
- 커널 v5.9-rc1에 Workingset Detection 기능이 추가되면서 처음 fault된 anon 페이지들도 file 페이지처럼 inactive 리스트의 선두(head)에 추가된다.
- inactive list의 tail에서 스캔한 페이지에 대해 해당 메모리가 applicaton 또는 커널에 의해 2번 이상 access된 흔적이 있으면 active list의 head로 이동시킨다.
- 이를 page의 activate 또는 promotion이라고 한다.
- incactive list의 tail에서 스캔한 페이지를 swap한 후 buddy로 되돌린다.
- active list의 tail에서 active/inactive 비율에 맞춰 밀려난 페이지는 inactive list의 head로 이동시킨다.
- 이를 page의 deactivate 또는 demotion이라고 한다.
- file 페이지
- fault가 발생하여 새롭게 할당된 페이지는 inactive list의 head에 진입한다.
- deactivate/demotion 또는 activate/promotion 과정은 다음 사항을 제외하곤 anon 페이지와 동일하다.
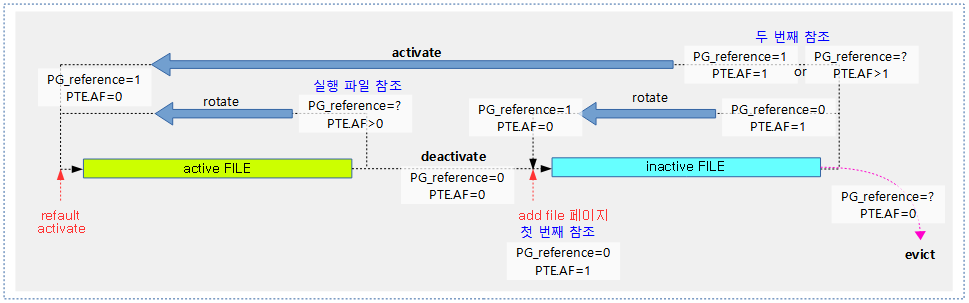
- 실행 파일의 경우는 1번만 access한 경우에도 promotion한다.
- incactive list의 tail에서 스캔한 페이지는 reclaim 전에 dirty 된 페이지는 원본이 있던 backing-storage에 기록한다. writeback이 완료된 페이지는 buddy로 되돌린다.
다음 그림은 페이지 회수 시 사용되는 lru 리스트들을 보여준다.
LRU 관련 페이지 플래그들
LRU 관리를 위해 다음과 같은 페이지 플래그가 사용된다.
- PG_lru
- LRU 리스트에서 관리되는 동안에 사용된다. 페이지가 LRU 캐시인 pagevec 리스트에 있을 경우엔 PG_lru가 클리어상태이다.
- PG_active
- active 리스트에서 관리되는 동안에 설정되며, inactive 리스트로 이동하면 클리어된다.
- PG_swapbacked
- anon 페이지가 처음 생성되면 swap backing storage의 설정 유무와 상관없이, swap 가능한 페이지 상태라는 의미로 이 플래그가 설정된다.
- madvise() API의 MADV_FREE 옵션을 사용하면 해당 페이지를 사용 해제 시 lazy free 상태로 변경시킬 수 있는데 이 때 이 플래그를 클리어하여 일시적으로 clean anon 페이지 상태를 만든다.
- PG_referenced
- 페이지가 최근에 2번 이상 참조되었는지를 확인한 후 활성화하여 active list로 옮길 목적으로 사용되며, PTE(페이지 테이블 엔트리)의 AF(Access Flag)와 같이 사용된다.
- 아래 주제(페이지 참조(reference))에서 자세한 설명을 계속한다.
- PG_writeback
- anon 및 file 페이지를 backing storage에 기록하는동안에만 설정된다.
- PG_dirty
- file 페이지가 open() 후 read() 하여 메모리에 로딩된 이 후 write()에 의해 해당 페이지의 메모리가 변경되면 이 플래그가 설정된다.
- PG_reclaim
- 회수 대상이 된 페이지에 이 플래그가 설정되고, 회수된 free 페이지가 버디 시스템으로 되돌리기 전에 이 플래그는 클리어된다.
- PG_workingset
- active 리스트에서 관리하던 페이지가 inactive로 이동될 때 설정되며, 빈번한 fault에 의해 반복되는 디스크 IO를 통해 성능 저하되지 않도록 페이지의 refault 유무를 가리기 위해 사용된다. 페이지가 backing storage에 저장되면 이 플래그의 상태도 한동안 기억되어야 하는데, 해당 페이지가 backing storage에 읽고 쓸때 사용되는 캐시(page cache 또는 swap cache)가 사용되지 않는 시점의 shadow 엔트리에 저장되어 관리되고 있다.
- 예) file이 로드된 경우 page cache에 담기는데 이러한 정보의 관리는 xarray 자료구조를 사용하여 보관한다. 메모리가 부족하여 page cache를 비우게 되면 xarray에서도 page cache에 대한 정보를 지우는데, 대신 그 이후엔 shadow 정보를 기록하는 용도로 사용한다. 이 shadow 정보는 eviction 페이지에 대한 관련(workingset 여부등) 정보가 포함된다.
조금은 오래된 글이지만 페이지 플래그에 대해 잘 설명해 놓은 주옥같은 글이 있으므로 다음 문서를 참고하고, 이 문서에서 언급하지 않은 페이지 플래그의 변화들을 위주로 보강 설명을 한다.
페이지 플래그 상태 변화
다음과 같은 페이지들이 회수될 때의 플래그 변화를 알아본다.
- anon 페이지
- fault가 발생하여 새롭게 할당된 anon 페이지는 PG_swapbacked 플래그가 설정되고, inactive 리스트에서 시작한다.
- 참고: anon 페이지에 PG_swapbacked가 없는 페이지는 clean anon 페이지라하며, lazy free 상태의 페이지를 의미한다.
- inactive 리스트에서 다시 inactive 리스트로 이동시키거나, active 리스트로 promotion하는 경우가 있는데, 이들 중 promotion 하는 경우 PG_active 플래그가 설정된다.
- incactive list의 tail에서 스캔한 페이지를 swap할 때 PG_writeback 및 PG_reclaim 플래그가 설정된다.
- swap은 add_to_swap() 함수를 통해 시작되는데 swap이 완료되면 PG_writeback 을 클리어하고, 그 후 buddy 시스템으로 되돌리기 위해 PG_reclaim 플래그도 클리어된다.
- active 리스트에서 inactive 리스트로 demotion하는 경우 PG_workingset 플래그가 설정되고, PG_active 플래그가 클리어된다.
- refault된 activate 페이지의 경우 PG_active 플래그를 설정한 후, eviction 당시의 PG_workingset 플래그를 유지하고, activate 리스트에서 시작한다.
- file 페이지
- fault가 발생하여 새롭게 할당된 file 페이지는 inactive list에서부터 시작한다.
- inactive 리스트에서 다시 inactive 리스트로 이동시키거나, active 리스트로 promotion하는 경우가 있는데, 이들 중 promotion 하는 경우 PG_active 플래그가 설정된다.
- 스캔을 통해 회수 대상으로 선정되면 PG_reclaim 플래그가 설정된다.
- 회수는 pageout() 함수를 통새 시작되는데 사용자에 의해 메모리에서 변경된 페이지는 이미 PG_dirty가 설정되어 있어 회수를 하기 전에 먼저 원본이 있던 backing storage에 기록해야 하며, 이 기간동안 PG_writeback이 설정된다.
- writeback이 완료되면 PG_writeback과 PG_dirty 플래그가 클리어된 후 clean file 페이지 상태가 되는데, 그 후 buddy 시스템으로 되돌리기 위해 PG_reclaim 플래그도 클리어된다.
- active 리스트에서 inactive 리스트로 demotion하는 경우 PG_workingset 플래그가 설정되고, PG_active 플래그가 클리어된다.
- refault된 activate 페이지의 경우 PG_active 플래그를 설정한 후, eviction 당시의 PG_workingset 플래그를 유지하고, activate 리스트에서 시작한다.
페이지 참조(reference)
페이지가 applicaton 및 커널에 의해 2번 이상 참조되었는지 여부를 체크하는 것으로 활성 페이지라 판단하여 active 리스트의 선두(head)로 옮긴다.
- active 리스트에 있었던 페이지라면 rotate하여 리스트의 선두(head)로 이동시킨다.
- inactive 리스트에 있었던 페이지라면 promote하여 active 리스트의 선두(head)로 이동시킨다.
1. PTE(Page Table Entry)의 AF(Access Flag)
페이지가 처음 참조되었는지 여부를 체크하기 위해서 커널은 HW 아키텍처의 fault 이벤트를 받아 처리한다. fault 이벤트는 다양한 원인에 의해 발생하지만 페이지 참조와 관련한 항목은 다음과 같이 3가지 항목 정도로 요약할 수 있다.
- PTE fault
- application이 해당 페이지에 접근(access)할 때 매핑하지 않은 가상 주소 공간에 읽기(read)를 시도하는 경우 발생한다.
- do_anonymous_page, do_fault, do_swap_page, do_numa_page
- Permission fault
- application이 읽기 전용으로 매핑된 가상 주소 공간에 기록(write)을 시도하는 경우 발생한다.
- Access Flag fault
- PTE의 AF 비트가 설정되지 않은 페이지에 접근을 시도하는 경우 발생한다.
- 페이지가 액세스 되었으므로 커널은 SW 방식으로 직접 PTE의 AF 비트를 설정한다. 예: ARMv8.0 이하
- pte_mkyoung – ptep_set_access_flags
- 최근 아키텍처는 HW가 직접 PTE 엔트리의 AF 비트를 설정한다. 예: ARMv8.1 이상
2. PG_reference
처음 참조되어 fault가 발생하여 새롭게 로드 또는 생성된 페이지는 처음 액세스되었으므로 커널(또는 HW가 지원하는 경우 자동으로)은 PTE의 AF 비트를 설정한다.
- 이 페이지가 file 페이지인지 anon 페이지인지 여부에 따라 file 페이지는 inactive 리스트, anon 페이지는 active 리스트의 각각 선두(head)에서 시작한다.
- 시작한 리스트에서 해당 페이지가 시간이 흘러 점점 리스트의 끝(tail) 부분으로 슬라이딩하고, 끝 부분에서 reclaim을 위한 스캔 대상이 되어, 이 페이지의 참조여부를 조사(page_check_reference)할 때 매핑된 PTE의 AF 비트의 설정 여부를 알아오고, PG_reference 플래그도 조사한다. 이 때 다음 참조 조사를 위해 PTE의 AF 비트는 클리어해둔다.
다음은 inactive 리스트 후미(tail)에서 스캔한 페이지의 처리 과정을 설명한다.
- 다음의 경우에서는 활성화를 위해 PG_reference 플래그를 설정하고, 곧장 active 리스트의 선두(head)로 옮기는데 이를 promote 또는 activate라고 한다.
- PG_reference 플래그의 설정 유무와 관계없이 2개 이상의 참조를 확인한 경우
- PG_reference 플래그의 설정 유무와 관계없이 1개의 실행 파일이 참조된 경우
- PG_reference 플래그가 설정되었고, 1개의 참조를 확인한 경우
- PG_reference 플래그가 설정되지 않았고, 1개의 참조를 확인한 경우 PG_reference 플래그를 설정하고, 원래 있었던(active or inactive) 리스트에서 일단 유지(keep)하기 리스트의 선두(head)로 rotate 한다.
- 하나의 참조도 발견되지 않은 경우 역시 PG_reference 플래그 설정 여부와 관계없이 이 페이지의 evict를 위해 PG_reclaim을 설정한다. 그 이후의 file 페이지의 dirty 페이지에 대한 writeback 처리 및 anon 페이지의 swap 등은 PG_reference 플래그 설정과 관계 없으므로 생략한다.
다음은 active 리스트 후미(tail)에서 스캔한 페이지의 처리 과정을 설명한다.
- PG_reference 플래그의 유무와 관계없이 1개 이상의 실행 파일이 참조된 경우 active 리스트에서 일단 유지(keep)하기 리스트의 선두(head)로 rotate 한다.
- 위의 참조 조건이 아닌 경우 비활성 페이지라 판단하여 PG_reference 플래그를 클리어하고, inactive 리스트의 선두(head)로 이동시키는데 이를 demote 또는 deactivate라고 한다.
다음 그림은 file 페이지의 참조 관련한 플래그의 변화를 보여준다.
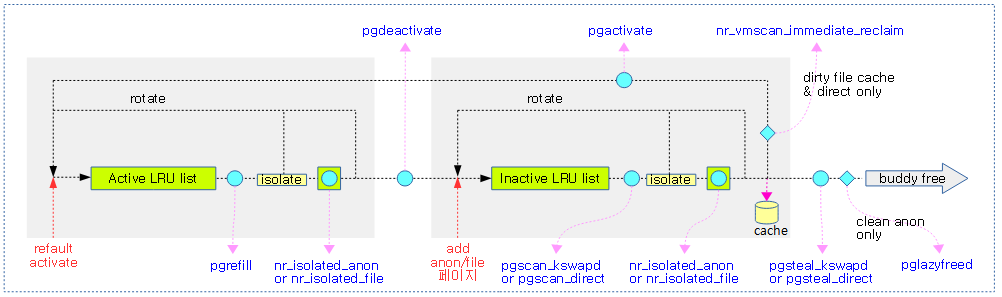
다음 그림은 lru를 통한 페이지 회수가 진행될 때 관련된 vm 카운터 값을 보여준다.
Anon 페이지
Anon 페이지가 생성되는 경로는 다음과 같다.
- 유저 application에서 힙 또는 스택 메모리의 증가로 커널에 anonymous로 할당 요청한 페이지이다.
- open된 공유 파일의 수정이 발생할 때 fault 핸들러로부터 COW(Copy On Write) 기능을 사용하여 복사된 페이지이다.
- KSM(Kernel Same Memory) 기능에 의해 공유된 페이지도 anon 페이지이다.
anon 페이지는 swap 영역을 사용할 수 있는지 여부를 PG_swapbacked 플래그로 나타낸다.
- normal anon 페이지
- swap 영역을 가진 anon 페이지로 PG_swapbacked 플래그가 설정된 anon 페이지이다.
- clean anon 페이지
- swap 영역이 없는 anon 페이지로 PG_swapbacked 플래그가 설정되지 않은 anon 페이지이다.
- MADV_FREE 페이지로 lazy-free 상태의 페이지이다.
pagevecs
pageveces는 lru 캐시이다. 페이지 회수 매커니즘에서는 lru 리스트에서 일정 부분의 페이지를 isolation 시 배치 처리하여 사용한다. 그러나 배치 처리를 할 수 없는 곳에서는 요청 시에 하나씩 lock을 획득하여 처리하면 lock contention에 의해 성능이 저하 되므로 별도의 lru 캐시를 구현하여 사용하고 있다. per-cpu로 구현된 5개의 pagevecs가 있으며 각각은 14개의 페이지를 관리할 수 있다.
- lru_add_pvec
- lru_rotate_pvecs
- lru_deactivate_file_pvecs
- lru_lazyfree_pvecs
- activate_page_pvecs
다음 그림은 lru 캐시인 pagevecs를 사용하는 함수의 호출관계를 보여준다.
- 함수가 호출될 때마다 lru 캐시인 pagevecs에 추가하지만 처리 한도인 14개를 초과 시에는 LRU에 직접 추가한다.
- lru 캐시인 pagevecs에 있는 페이지를 lru 리스트로 회수하려면 lru_add_drain_cpu() 함수를 호출하여 사용한다.

Workingset Detection
페이지의 반복되는 회수로 인해 반복되는 refault로 인해 디스크 IO cost가 증가하는 것을 막기 위해 Workingset Detection 관련한 알고리즘이 적용되었다.
- PG_workingset 플래그와 swap cache 및 page cache의 shadow 엔트리에 정보를 기록하며, lruvec마다 anon/file cost를 산출하여 운영한다.
- 참고:
다음 그림은 캐시를 관리하는 XAraay의 shadow 엔트리를 이용하여 페이지가 evict될 때 페이지에 가지고 있던 정보 중 일부 PG_workingset 및 age 정도등을 기록하고, 나중에 refault되어 다시 로드될 때 이미 workingset 정보였다는 것을 갱신할 수 있도록 하였다.
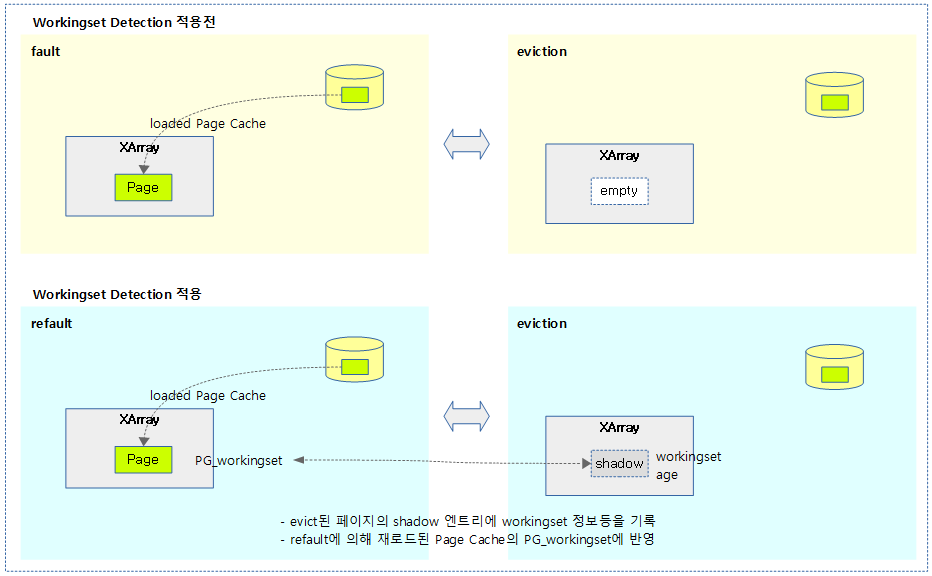
다음 그림은 Xarray의 shadow 엔트리에 저장되는 값을 보여준다.
- eviction시 lruvec→nonresident_age 값을 기록하는데 시스템 메모리가 크거나 또는 32비트 시스템일 경우 저장할 여분 비트가 부족할 수 있으므로 bucket_order만큼 우측 shift하여 저장하고, refault시 꺼내서 사용할 때에는 bucket_order 만큼 좌측 shift하여 사용 한다.
- 값을 shift하여 사용하는 만큼 하위 비트들이 클리어된 상태로 trim되어 거친 값을 가지게되고, 비교할 때 러프하게 비교할 수 밖에 없다.

다음 그림은 Xarray의 shadow 엔트리에 저장되는 값을 eviction시 만들거나(pack) 또는 refault 시 꺼내는(unpack) 과정을 보여준다.

Workingset Detection for file 페이지
Refualt 페이지의 activate 여부를 판단
refault 페이지를 activate해야 할지 여부를 알아내기 위한 요소들은 다음과 같다.
- NR_inactive
- 해당 lru 타입 중 inactive lru 리스트에서 관리하는 페이지 수
- NR_active
- 해당 lru 타입 중 active lru 리스트에서 관리하는 페이지 수
- lruvec->nonresident_age
- 페이지가 activation 및 eviction한 페이지 수로 누적 증가한다. timestamp와 유사하다.
- activation 값은 두 가지가 경로가 있다.
- inactive 리스트에서 promote한 페이지인 경우
- refault 페이지가 곧장 active 리스트로 곧바로 향한 경우
- PG_workingset
- 페이지의 workingset 여부를 알려주는 플래그
Refualt File 페이지의 activate 여부를 판단
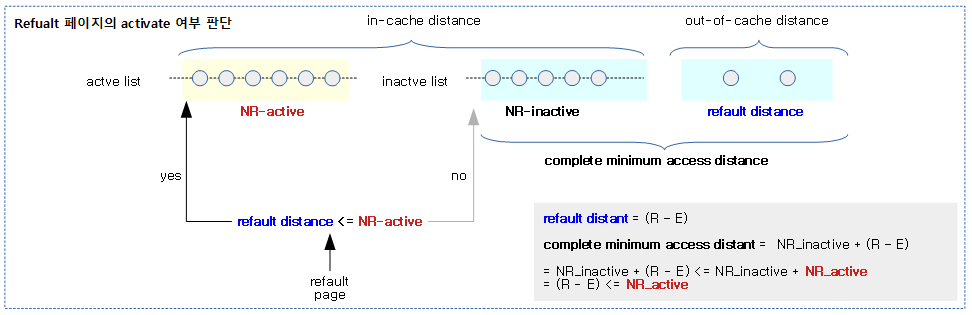
위의 요소를 사용하여 다음과 같은 수식(처음 Workingset Detection 기능이 소개될 때 file 캐시만 지원)을 사용한다.
- R
- refault 순간의 lru->nonresident_age 값
- E
- eviction 순간의 lru->nonresident_age 값
- refault distant
- = (R – E)
- eviction된 이후 refault되었을 때의 간격
- complete minimum access distant
- activate 여부 판단
- = refault distant + NR_inactive <= NR_active + NR_inactive
- = refault distant <= NR_active
다음 그림은 refault file 페이지가 active list로 추가되는 과정을 보여준다.
- 페이지가 짧은 시간(refault distance <= NR_active)에 refault되어 진입하게 되면 activate 한다.
Workingset Detection for anon/file 페이지
anon 페이지도 refault 시 refault distance와 workingset_size(NR_active_file 대신 새롭게 anon을 포함)를 산출한 후 비교하여 activate 여부를 결정할 수 있다.
- anon 페이지 수식:
- = refault distant + NR_inactive_anon <= NR_active_anon + NR_inactive_anon + NR_inactive_file + NR_inactive_file
- = refault distant <= NR_active_anon + NR_inactive_file + NR_inactive_file
- = refault distant <= workingset_size
- workingset_size = NR_active_anon + NR_inactive_file + NR_inactive_file
- file 페이지 수식:
- = refault distant + NR_inactive_file <= NR_active_anon + NR_inactive_anon + NR_inactive_file + NR_inactive_file
- = refault distant <= NR_active_anon + NR_inactive_anon + NR_active_file
- = refault distant <= workingset_size
- workingset_size = NR_active_anon + NR_inactive_anon + NR_active_file
- 단 swap 공간이 없는 경우 anon과 관련된 수는 포함되지 않는다.
- 참고:
다음 그림은 file/anon 페이지에 대한 새로운 Workingset Detection을 지원하는 경우의 refault 페이지를 activate 하는 과정을 보여준다.
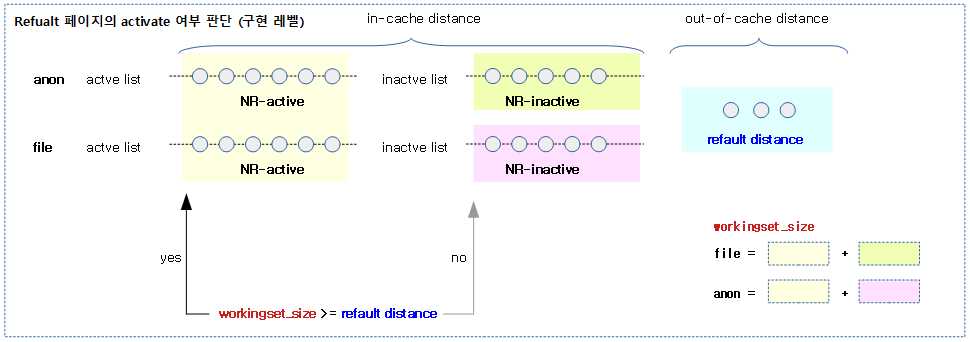
다음 그림은 refault 페이지의 refault distance 값이 작을 때와(short time) 클 때(long time)에 따라 activate 유무를 판단하는 과정을 보여준다.

per-cpu LRU 캐시(pagevec)의 Drain
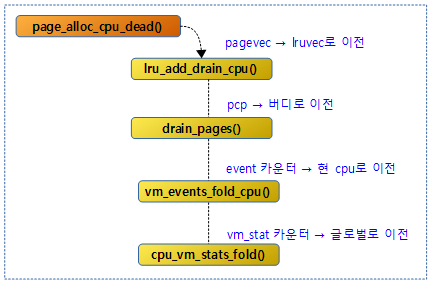
다음 그림은 lru_add_drain_cpu() 함수의 호출 관계이다.
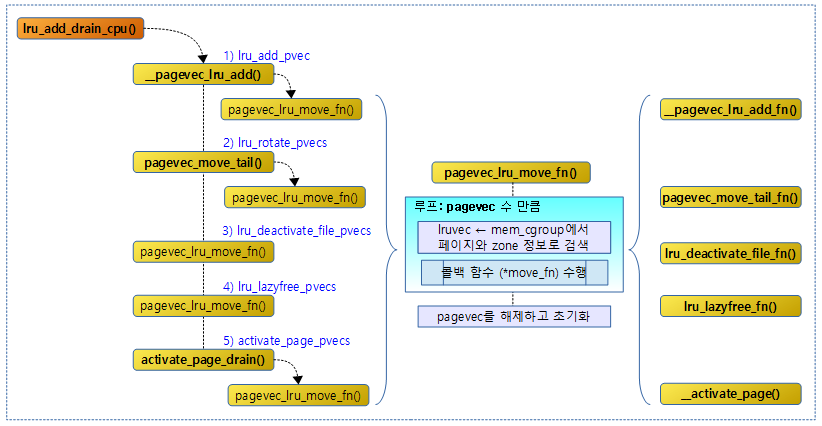
lru_add_drain_cpu()
mm/swap.c
/*
* Drain pages out of the cpu's pagevecs.
* Either "cpu" is the current CPU, and preemption has already been
* disabled; or "cpu" is being hot-unplugged, and is already dead.
*/
void lru_add_drain_cpu(int cpu)
{
struct pagevec *pvec = &per_cpu(lru_add_pvec, cpu);
if (pagevec_count(pvec))
__pagevec_lru_add(pvec);
pvec = &per_cpu(lru_rotate_pvecs, cpu);
if (pagevec_count(pvec)) {
unsigned long flags;
/* No harm done if a racing interrupt already did this */
local_irq_save(flags);
pagevec_move_tail(pvec);
local_irq_restore(flags);
}
pvec = &per_cpu(lru_deactivate_file_pvecs, cpu);
if (pagevec_count(pvec))
pagevec_lru_move_fn(pvec, lru_deactivate_file_fn, NULL);
pvec = &per_cpu(lru_lazyfree_pvecs, cpu);
if (pagevec_count(pvec))
pagevec_lru_move_fn(pvec, lru_lazyfree_fn, NULL);
activate_page_drain(cpu);
}
지정된 @cpu가 사용하던 페이지 할당자의 회수 매커니즘 lruvec에 사용하던 5개의 per-cpu 캐시들인 pagevec들을 회수하여 해당 zone(또는 memcg의 zone)에 있는 lruvec로 이전한다
- 코드 라인 3~6에서 지정된 @cpu 캐시 lru_add_pvec에 등록된 페이지를 해당 페이지 zone의 lruvec로 이전하고 비운다.
- 코드 라인 8~16에서 지정된 @cpu 캐시 lru_rotate_pvecs에 등록된 페이지를 해당 페이지 zone의 lruvec에 마지막 위치로 이전하고 비운다.
- 코드 라인 18~20에서 지정된 @cpu 캐시 lru_deactivate_file_pvecs에 등록된 페이지를 해당 페이지 zone의 lruvec로 이전하고 비운다.
- 코드 라인 22~24에서 지정된 @cpu 캐시 lru_lazyfree_pvecs에 등록된 페이지를 해당 페이지 zone의 lruvec로 이전하고 비운다.
- 코드 라인 26에서 지정된 @cpu 캐시 activate_page_pvecs에 등록된 페이지를 해당 페이지의 zone의 lruvec로 이전하고 비운다.
__pagevec_lru_add()
mm/swap.c
/*
* Add the passed pages to the LRU, then drop the caller's refcount
* on them. Reinitialises the caller's pagevec.
*/
void __pagevec_lru_add(struct pagevec *pvec)
{
pagevec_lru_move_fn(pvec, __pagevec_lru_add_fn, NULL);
}
EXPORT_SYMBOL(__pagevec_lru_add);
cpu 캐시 pagevec에 등록된 페이지를 해당 페이지의 zone(또는 memory cgroup의 zone)->lruvec로 이전하고 pagevec를 비우고 초기화한다.
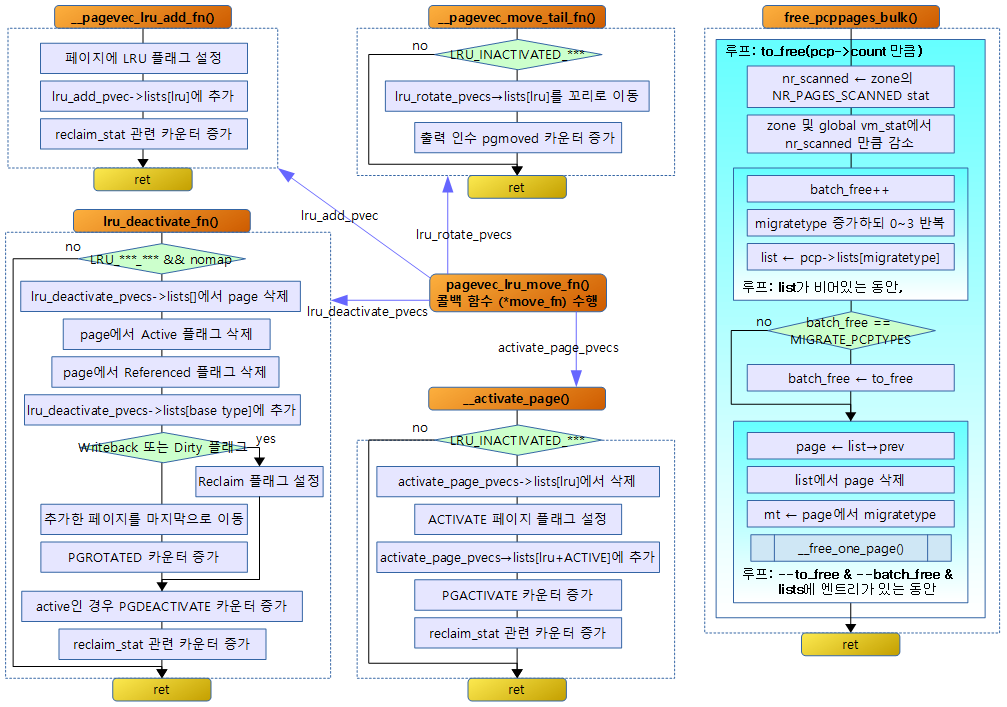
pagevec_move_tail()
mm/swap.c
/*
* pagevec_move_tail() must be called with IRQ disabled.
* Otherwise this may cause nasty races.
*/
static void pagevec_move_tail(struct pagevec *pvec)
{
int pgmoved = 0;
pagevec_lru_move_fn(pvec, pagevec_move_tail_fn, &pgmoved);
__count_vm_events(PGROTATED, pgmoved);
}
pagevec에 등록된 페이지들을 해당 페이지의 memory control group의 lru의 타입별 리스트의 후미에 추가하고 pagevec를 비우고 초기화한다. 추가한 페이지들의 수를 vm_events 관련 pgmoved 항목에 더한다.
activate_page_drain()
mm/swap.c
static void activate_page_drain(int cpu)
{
struct pagevec *pvec = &per_cpu(activate_page_pvecs, cpu);
if (pagevec_count(pvec))
pagevec_lru_move_fn(pvec, __activate_page, NULL);
}
activate_page_pvecs 라는 cpu 캐시 리스트에 등록된 페이지들을 해당 페이지의 memory control group의 lru의 타입별 리스트에서 삭제했다가 lru의 타입 + active를 하여 다시 선두(hot)에 추가하고 active 플래그를 설정하며 vm_events 관련 PGACTIVATE 항목을 증가시키고 reclaim 관련 통계도 증가시킨다. 그런 후 pagevec를 비우고 초기화한다.
5개의 pagevec 이주 함수
1) 공통 이주 함수
pagevec_lru_move_fn()
mm/swap.c
static void pagevec_lru_move_fn(struct pagevec *pvec,
void (*move_fn)(struct page *page, struct lruvec *lruvec, void *arg),
void *arg)
{
int i;
struct pglist_data *pgdat = NULL;
struct lruvec *lruvec;
unsigned long flags = 0;
for (i = 0; i < pagevec_count(pvec); i++) {
struct page *page = pvec->pages[i];
struct pglist_data *pagepgdat = page_pgdat(page);
if (pagepgdat != pgdat) {
if (pgdat)
spin_unlock_irqrestore(&pgdat->lru_lock, flags);
pgdat = pagepgdat;
spin_lock_irqsave(&pgdat->lru_lock, flags);
}
lruvec = mem_cgroup_page_lruvec(page, pgdat);
(*move_fn)(page, lruvec, arg);
}
if (pgdat)
spin_unlock_irqrestore(&pgdat->lru_lock, flags);
release_pages(pvec->pages, pvec->nr);
pagevec_reinit(pvec);
}
pagevec에 등록된 페이지를 해당 페이지의 memory control group의 lruvec로 이전하고 pagevec를 비우고 초기화한다.
- 코드 라인 10~19에서 pagevec 리스트에 등록된 수 만큼 순회하며 노드가 변경될 때마다 spin 락을 풀었다가 다시 획득한다. 장시간 락을 획득하지 못하도록 억제한다.
- 코드 라인 21~22에서 해당 페이지가 소속된 memcg의 lruvec 리스트로 페이지를 이동시킨다. 만일 memcg가 없는 경우 해당 노드의 lruvec 리스트를 사용한다.
- move_fn 인수에 지정된 함수를 호출한다.
- 예) __pagevec_lru_add_fn()
- pagevec의 페이지를 lruvec에 추가한다.
- 코드 라인 25에서 pagevec의 페이지들을 해지한다.
- 코드 라인 26에서 pagevec을 다시 초기화한다.
2) 5개의 이주 함수
__pagevec_lru_add_fn()
mm/swap.c
static void __pagevec_lru_add_fn(struct page *page, struct lruvec *lruvec,
void *arg)
{
enum lru_list lru;
int was_unevictable = TestClearPageUnevictable(page);
VM_BUG_ON_PAGE(PageLRU(page), page);
SetPageLRU(page);
/*
* Page becomes evictable in two ways:
* 1) Within LRU lock [munlock_vma_pages() and __munlock_pagevec()].
* 2) Before acquiring LRU lock to put the page to correct LRU and then
* a) do PageLRU check with lock [check_move_unevictable_pages]
* b) do PageLRU check before lock [clear_page_mlock]
*
* (1) & (2a) are ok as LRU lock will serialize them. For (2b), we need
* following strict ordering:
*
* #0: __pagevec_lru_add_fn #1: clear_page_mlock
*
* SetPageLRU() TestClearPageMlocked()
* smp_mb() // explicit ordering // above provides strict
* // ordering
* PageMlocked() PageLRU()
*
*
* if '#1' does not observe setting of PG_lru by '#0' and fails
* isolation, the explicit barrier will make sure that page_evictable
* check will put the page in correct LRU. Without smp_mb(), SetPageLRU
* can be reordered after PageMlocked check and can make '#1' to fail
* the isolation of the page whose Mlocked bit is cleared (#0 is also
* looking at the same page) and the evictable page will be stranded
* in an unevictable LRU.
*/
smp_mb();
if (page_evictable(page)) {
lru = page_lru(page);
update_page_reclaim_stat(lruvec, page_is_file_cache(page),
PageActive(page));
if (was_unevictable)
count_vm_event(UNEVICTABLE_PGRESCUED);
} else {
lru = LRU_UNEVICTABLE;
ClearPageActive(page);
SetPageUnevictable(page);
if (!was_unevictable)
count_vm_event(UNEVICTABLE_PGCULLED);
}
add_page_to_lru_list(page, lruvec, lru);
trace_mm_lru_insertion(page, lru);
}
지정된 @lruvec의 적절한 타입(inactive_anon, active_anon, inactive_file, active_file, unevictable)의 리스트에 page를 추가한다. 페이지에는 lru 리스트에 소속되었다는 표식을 위해 LRU 플래그 비트가 설정된다.
- 코드 라인 5에서 페이지가 unevictable 리스트에 있었던 페이지인지 확인하고 해당 플래그를 클리어한다.
- 코드 라인 9에서 페이지가 lru 리스트에 소속되었다는 표식을 한다.
- 코드 라인 36에서 메모리 접근 순서를 명확히 해야 하는 케이스에 대한 설명은 위의 주석을 참고한다.
- 코드 라인 38~43에서 페이지가 회수 가능한 상태인 경우 lru 리스트를 선택하고 reclaim 관련 scanned[]와 rocated[] 항목을 증가시킨다. 기존에 unevictable 상태였던 경우 UNEVICTABLE_PGRESCUED 카운터를 증가시킨다.
- 코드 라인 44~50에서 페이지가 회수 가능한 상태가 아닌 경우 unevectable lru 리스트를 선택하고, active 플래그를 클리어하고, unevictable 플래그를 설정한다. 기존에 evictable 상태였었으면 UNEVICTABLE_PGCULLED 카운터를 증가시킨다.
- 코드 라인 52에서 lruvec에 페이지를 추가한다.
pagevec_move_tail_fn()
mm/swap.c
static void pagevec_move_tail_fn(struct page *page, struct lruvec *lruvec,
void *arg)
{
int *pgmoved = arg;
if (PageLRU(page) && !PageUnevictable(page)) {
del_page_from_lru_list(page, lruvec, page_lru(page));
ClearPageActive(page);
add_page_to_lru_list_tail(page, lruvec, page_lru(page));
(*pgmoved)++;
}
}
페이지가 unevictable이 아닌 lru 타입이면 리스트의 후미(cold)에 페이지를 추가한다. 그리고 active 플래그를 제거한다.
- 코드 라인 6에서 페이지가 LRU 플래그 설정되어 있고 unevitable 플래그 상태가 아니면 페이지를 기존 lru 리스트에서 제거한다.
- 코드 라인 7~8에서 페이지의 active 플래그를 제거한 후 lru의 타입별 리스트의 후미에 페이지를 추가한다.
- 코드 라인 9에서 마지막 인자로 전달 받은 카운터를 증가시킨다.
lru_deactivate_file_fn()
mm/swap.c
/*
* If the page can not be invalidated, it is moved to the
* inactive list to speed up its reclaim. It is moved to the
* head of the list, rather than the tail, to give the flusher
* threads some time to write it out, as this is much more
* effective than the single-page writeout from reclaim.
*
* If the page isn't page_mapped and dirty/writeback, the page
* could reclaim asap using PG_reclaim.
*
* 1. active, mapped page -> none
* 2. active, dirty/writeback page -> inactive, head, PG_reclaim
* 3. inactive, mapped page -> none
* 4. inactive, dirty/writeback page -> inactive, head, PG_reclaim
* 5. inactive, clean -> inactive, tail
* 6. Others -> none
*
* In 4, why it moves inactive's head, the VM expects the page would
* be write it out by flusher threads as this is much more effective
* than the single-page writeout from reclaim.
*/
static void lru_deactivate_file_fn(struct page *page, struct lruvec *lruvec,
void *arg)
{
int lru, file;
bool active;
if (!PageLRU(page))
return;
if (PageUnevictable(page))
return;
/* Some processes are using the page */
if (page_mapped(page))
return;
active = PageActive(page);
file = page_is_file_cache(page);
lru = page_lru_base_type(page);
del_page_from_lru_list(page, lruvec, lru + active);
ClearPageActive(page);
ClearPageReferenced(page);
add_page_to_lru_list(page, lruvec, lru);
if (PageWriteback(page) || PageDirty(page)) {
/*
* PG_reclaim could be raced with end_page_writeback
* It can make readahead confusing. But race window
* is _really_ small and it's non-critical problem.
*/
SetPageReclaim(page);
} else {
/*
* The page's writeback ends up during pagevec
* We moves tha page into tail of inactive.
*/
list_move_tail(&page->lru, &lruvec->lists[lru]);
__count_vm_event(PGROTATED);
}
if (active)
__count_vm_event(PGDEACTIVATE);
update_page_reclaim_stat(lruvec, file, 0);
}
페이지가 LRU 타입이면서 unevictable이 아니고 mapped file이 아닌 경우 lru의 타입별 리스트에서 페이지를 삭제한 후 lru의 기본 타입의 선두에 페이지를 추가한다. 페이지 플래그는 active 및 referenced 플래그를 삭제한다. 페이지에 기록 속성이 있는 경우 reclaim 플래그를 설정하고 그렇지 않은 경우 리스트의 후미로 이동시킨다.
- 코드 라인 7~8에서 페이지에 LRU 플래그가 설정되어 있지 않은 경우 더 이상 진행하지 않고 빠져나간다.
- 코드 라인 10~11에서 페이지에 Unevitable 플래그가 설정되어 있는 경우 더 이상 진행하지 않고 빠져나간다.
- 코드 라인 14~15에서 페이지가 이미 매핑되어 프로세스에서 사용 중인 경우 더 이상 진행하지 않고 빠져나간다.
- 코드 라인 17에서 페이지가 active 플래그 상태를 가지고 있는지 여부를 알아온다.
- 코드 라인 18에서 페이지가 file로 부터 캐시되어 있는지 여부를 알아온다.
- 코드 라인 19에서 페이지로부터 lru 베이스 타입을 알아온다.
- LRU_INACTIVE_FILE 또는 LRU_INACTIVE_ANON 타입을 반환한다.
- 코드 라인 21에서 lru + active 배열의 lru 리스트에서 페이지를 찾아 삭제한다.
- 코드 라인 22~24에서 페이지에서 Active 플래그 및 Referencewd 플래그를 삭제한 후 lru 베이스 타입 배열의 lru 리스트에 페이지를 추가한다.
- 코드 라인 26~32에서 페이지에 Writeback 또는 Dirty가 설정된 경우Reclaim 플래그를 설정해 놓는다.
- 코드 라인 33~40에서 그렇지 않은 경우 lru 타입 배열의 lru 리스트의 후미에 페이지를 추가한다. 그런 후 PGROTATED 카운터를 증가시킨다.
-
- 후미에 추가하는 경우 cold 페이지로 최빈도로 사용됨을 나타낸다.
- 코드 라인 42~43에서 active인 경우 PGDEACTIVATE 항목의 vm_event 를 증가시킨다.
- 코드 라인 44에서 reclaim 관련 scanned[]와 rocated[] 항목을 증가시킨다
lru_lazyfree_fn()
mm/swap.c
static void lru_lazyfree_fn(struct page *page, struct lruvec *lruvec,
void *arg)
{
if (PageLRU(page) && PageAnon(page) && PageSwapBacked(page) &&
!PageSwapCache(page) && !PageUnevictable(page)) {
bool active = PageActive(page);
del_page_from_lru_list(page, lruvec,
LRU_INACTIVE_ANON + active);
ClearPageActive(page);
ClearPageReferenced(page);
/*
* lazyfree pages are clean anonymous pages. They have
* SwapBacked flag cleared to distinguish normal anonymous
* pages
*/
ClearPageSwapBacked(page);
add_page_to_lru_list(page, lruvec, LRU_INACTIVE_FILE);
__count_vm_events(PGLAZYFREE, hpage_nr_pages(page));
count_memcg_page_event(page, PGLAZYFREE);
update_page_reclaim_stat(lruvec, 1, 0);
}
}
swap 영역을 가진 normal anon 페이지를 swap 영역을 가지지 않는 clean anon 페이지로 바꾸고 inactive file lru 리스트의 선두(hot)에 추가한다.
- 코드 라인 4~9에서 swap 영역을 가진 normal anon 페이지이면서 swap 캐시된 상태가 아니면 lruvec 리스트에서 제거한다.
- 코드 라인 10~18에서 페이지에서 Active, Referenced, SwapBacked 플래그를 클리어한 후 lru 리스트에 추가한다.
- 코드 라인 20에서 PGLAZYFREE vm 카운터를 페이지 수 만큼 증가시킨다.
- 코드 라인 21에서 memcg에서 PGLAZYFREE 카운터를 증가시킨다.
- 코드 라인 22에서 reclaim 관련 scanned[]와 rocated[] 항목을 증가시킨다
__activate_page()
mm/swap.c
static void __activate_page(struct page *page, struct lruvec *lruvec,
void *arg)
{
if (PageLRU(page) && !PageActive(page) && !PageUnevictable(page)) {
int file = page_is_file_cache(page);
int lru = page_lru_base_type(page);
del_page_from_lru_list(page, lruvec, lru);
SetPageActive(page);
lru += LRU_ACTIVE;
add_page_to_lru_list(page, lruvec, lru);
trace_mm_lru_activate(page);
__count_vm_event(PGACTIVATE);
update_page_reclaim_stat(lruvec, file, 1);
}
}
페이지를 lruvec->lists[basic type]에서 삭제한 후 active 플래그를 설정하고 lruvec->lists[lru+active]의 선두(hot)에 추가한다.
- 코드 라인 4~8에서 페이지에 LRU 설정되어 있고, inactive 이면서 unevictable 플래그 설정이 없는 경우 해당 lru 타입의 lru 리스트에서 제거한다.
- 코드 라인 9~11에서 페이지를 active 설정하고, 해당 타입(file or anon)의 active lru 리스트의 선두에 페이지를 추가한다.
- 코드 라인 14에서 vm_event의 PGACTIVATE 항목의 카운터를 증가시킨다.
- 코드 라인 15에서 reclaim 관련 scanned[]와 rocated[] 항목을 증가시킨다
기타
page_evictable()
mm/vmscan.c
/*
* page_evictable - test whether a page is evictable
* @page: the page to test
*
* Test whether page is evictable--i.e., should be placed on active/inactive
* lists vs unevictable list.
*
* Reasons page might not be evictable:
* (1) page's mapping marked unevictable
* (2) page is part of an mlocked VMA
*
*/
int page_evictable(struct page *page)
{
int ret;
/* Prevent address_space of inode and swap cache from being freed */
rcu_read_lock();
ret = !mapping_unevictable(page_mapping(page)) && !PageMlocked(page);
rcu_read_unlock();
return ret;
}
페이지가 evictable 상태인지 여부를 반환한다.
- 이미 매핑된 페이지 또는 mlock 상태가 아닌 페이지이면 evicatable 상태이다.
page_is_file_cache()
include/linux/mm_inline.h
/**
* page_is_file_cache - should the page be on a file LRU or anon LRU?
* @page: the page to test
*
* Returns 1 if @page is page cache page backed by a regular filesystem,
* or 0 if @page is anonymous, tmpfs or otherwise ram or swap backed.
* Used by functions that manipulate the LRU lists, to sort a page
* onto the right LRU list.
*
* We would like to get this info without a page flag, but the state
* needs to survive until the page is last deleted from the LRU, which
* could be as far down as __page_cache_release.
*/
static inline int page_is_file_cache(struct page *page)
{
return !PageSwapBacked(page);
}
페이지가 file lru에 있는지 anon lru에 있는지 여부를 반환한다.
- 1: file lru에 속한다.
- 파일 캐시 페이지 또는 swap 영역을 가지지 않는 clean anon 페이지
- 0: anon lru에 속한다.
- swap 영역을 가진 normal anon 페이지 또는 tmpfs
page_lru()
include/linux/mm_inline.h
/**
* page_lru - which LRU list should a page be on?
* @page: the page to test
*
* Returns the LRU list a page should be on, as an index
* into the array of LRU lists.
*/
static __always_inline enum lru_list page_lru(struct page *page)
{
enum lru_list lru;
if (PageUnevictable(page))
lru = LRU_UNEVICTABLE;
else {
lru = page_lru_base_type(page);
if (PageActive(page))
lru += LRU_ACTIVE;
}
return lru;
}
페이지에 대한 lru(5가지 상태) 값을 알아온다.
- 코드 라인 5~6에서 페이지가 unevictable 플래그를 가졌으면 LRU_UNEVICTABLE(4)을 리턴한다.
- 코드 라인 7~8에서 페이지가 화일을 캐시한 타입인 경우 LRU_INACTIVE_FILE(2)을 그렇지 않은 경우 LRU_INACTIVE_ANON(0)을 알아온다.
- 코드 라인 9~10에서 페이지가 active 상태인 경우 clear하고 lru에 LRU_ACTIVE(1)를 추가한다.
- LRU_INACTIVE_FILE(2) -> LRU_ACTIVE_FILE(3)
- LRU_INACTIVE_ANON(0) -> LRU_ACTIVE_ANON(1)
add_page_to_lru_list()
include/linux/mm_inline.h
static __always_inline void add_page_to_lru_list(struct page *page,
struct lruvec *lruvec, enum lru_list lru)
{
update_lru_size(lruvec, lru, page_zonenum(page), hpage_nr_pages(page));
list_add(&page->lru, &lruvec->lists[lru]);
}
페이지를 lru 리스트에 추가한다.
- 코드 라인 4에서 lru 관련 통계를 갱신한다.
- 페이지가 huge 페이지인 경우 작은 페이지 수를 알아온다. 아닌 경우는 1이다.
- huge 페이지가 2MB인 경우 -> 512개
- 코드 라인 5에서 lru의 타입별 리스트에 페이지를 선두에 추가한다. 선두에 추가한다는 의미는 사용빈도가 높은 hot page를 의미한다.
update_lru_size()
include/linux/mm_inline.h
static __always_inline void update_lru_size(struct lruvec *lruvec,
enum lru_list lru, enum zone_type zid,
int nr_pages)
{
__update_lru_size(lruvec, lru, zid, nr_pages);
#ifdef CONFIG_MEMCG
mem_cgroup_update_lru_size(lruvec, lru, zid, nr_pages);
#endif
}
- 코드 라인 5에서 노드 및 존의 페이지의 lru 타입에 해당하는 vm 카운터에 페이지 수를 추가한다.
- 코드 라인 7에서 메모리 cgroup의 lru_size[lru]에 페이지 수를 추가한다.
__update_lru_size()
include/linux/mm_inline.h
static __always_inline void __update_lru_size(struct lruvec *lruvec,
enum lru_list lru, enum zone_type zid,
int nr_pages)
{
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
__mod_node_page_state(pgdat, NR_LRU_BASE + lru, nr_pages);
__mod_zone_page_state(&pgdat->node_zones[zid],
NR_ZONE_LRU_BASE + lru, nr_pages);
}
노드 및 존의 페이지의 lru 타입에 해당하는 vm 카운터에 페이지 수를 추가한다.
- 코드 라인 7에서 노드의 페이지의 lru 타입에 해당하는 vm 카운터에 페이지 수를 추가한다.
- 코드 라인 8~9에서 존의 페이지의 lru 타입에 해당하는 vm 카운터에 페이지 수를 추가한다.
mem_cgroup_update_lru_size()
mm/memcontrol.c
/**
* mem_cgroup_update_lru_size - account for adding or removing an lru page
* @lruvec: mem_cgroup per zone lru vector
* @lru: index of lru list the page is sitting on
* @zid: zone id of the accounted pages
* @nr_pages: positive when adding or negative when removing
*
* This function must be called under lru_lock, just before a page is added
* to or just after a page is removed from an lru list (that ordering being
* so as to allow it to check that lru_size 0 is consistent with list_empty).
*/
void mem_cgroup_update_lru_size(struct lruvec *lruvec, enum lru_list lru,
int zid, int nr_pages)
{
struct mem_cgroup_per_node *mz;
unsigned long *lru_size;
long size;
if (mem_cgroup_disabled())
return;
mz = container_of(lruvec, struct mem_cgroup_per_node, lruvec);
lru_size = &mz->lru_zone_size[zid][lru];
if (nr_pages < 0)
*lru_size += nr_pages;
size = *lru_size;
if (WARN_ONCE(size < 0,
"%s(%p, %d, %d): lru_size %ld\n",
__func__, lruvec, lru, nr_pages, size)) {
VM_BUG_ON(1);
*lru_size = 0;
}
if (nr_pages > 0)
*lru_size += nr_pages;
}
메모리 cgroup의 노드별 lru_size[lru]에 페이지 수를 추가한다.
update_page_reclaim_stat()
mm/swap.c
static void update_page_reclaim_stat(struct lruvec *lruvec,
int file, int rotated)
{
struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;
reclaim_stat->recent_scanned[file]++;
if (rotated)
reclaim_stat->recent_rotated[file]++;
}
reclaim 관련 scanned[]와 rocated[] 항목을 증가시킨다. 두 항목은 각각 2개의 배열을 사용하는데 각각의 배열은 다음과 같다.
- [0]: anon LRU stat
- [1]: file LRU stat
LRU 리스트로 복귀
putback_movable_pages()
mm/migrate.c
/*
* Put previously isolated pages back onto the appropriate lists
* from where they were once taken off for compaction/migration.
*
* This function shall be used whenever the isolated pageset has been
* built from lru, balloon, hugetlbfs page. See isolate_migratepages_range()
* and isolate_huge_page().
*/
void putback_movable_pages(struct list_head *l)
{
struct page *page;
struct page *page2;
list_for_each_entry_safe(page, page2, l, lru) {
if (unlikely(PageHuge(page))) {
putback_active_hugepage(page);
continue;
}
list_del(&page->lru);
dec_zone_page_state(page, NR_ISOLATED_ANON +
page_is_file_cache(page));
if (unlikely(isolated_balloon_page(page)))
balloon_page_putback(page);
else
putback_lru_page(page);
}
}
기존에 isolation된 페이지들을 다시 원래의 위치로 되돌린다.
- list_for_each_entry_safe(page, page2, l, lru) {
- if (unlikely(PageHuge(page))) { putback_active_hugepage(page); continue; }
- 적은 확률로 huge 페이지인 경우 hstate[].hugepage_activelist의 후미로 이동시키고 skip 한다.
- huge page는 hstate[]에서 관리한다.
- dec_zone_page_state(page, NR_ISOLATED_ANON + page_is_file_cache(page));
- 페이지의 타입에 따라 NR_ISOLATE_ANON 또는 NR_ISOLATED_FILE stat을 감소시킨다.
- if (unlikely(isolated_balloon_page(page))) balloon_page_putback(page);
- 적은 확률로 balloon 페이지인 경우 balloon_dev_info의 pages 리스트에 되돌린다.
- balloon page는 balloon 디바이스에서 관리한다.
- else putback_lru_page(page);
- 페이지를 lurvec.lists[]에 되돌린다.
putback_lru_page()
mm/vmscan.c
/**
* putback_lru_page - put previously isolated page onto appropriate LRU list
* @page: page to be put back to appropriate lru list
*
* Add previously isolated @page to appropriate LRU list.
* Page may still be unevictable for other reasons.
*
* lru_lock must not be held, interrupts must be enabled.
*/
void putback_lru_page(struct page *page)
{
bool is_unevictable;
int was_unevictable = PageUnevictable(page);
VM_BUG_ON_PAGE(PageLRU(page), page);
redo:
ClearPageUnevictable(page);
if (page_evictable(page)) {
/*
* For evictable pages, we can use the cache.
* In event of a race, worst case is we end up with an
* unevictable page on [in]active list.
* We know how to handle that.
*/
is_unevictable = false;
lru_cache_add(page);
} else {
/*
* Put unevictable pages directly on zone's unevictable
* list.
*/
is_unevictable = true;
add_page_to_unevictable_list(page);
/*
* When racing with an mlock or AS_UNEVICTABLE clearing
* (page is unlocked) make sure that if the other thread
* does not observe our setting of PG_lru and fails
* isolation/check_move_unevictable_pages,
* we see PG_mlocked/AS_UNEVICTABLE cleared below and move
* the page back to the evictable list.
*
* The other side is TestClearPageMlocked() or shmem_lock().
*/
smp_mb();
}
/*
* page's status can change while we move it among lru. If an evictable
* page is on unevictable list, it never be freed. To avoid that,
* check after we added it to the list, again.
*/
if (is_unevictable && page_evictable(page)) {
if (!isolate_lru_page(page)) {
put_page(page);
goto redo;
}
/* This means someone else dropped this page from LRU
* So, it will be freed or putback to LRU again. There is
* nothing to do here.
*/
}
if (was_unevictable && !is_unevictable)
count_vm_event(UNEVICTABLE_PGRESCUED);
else if (!was_unevictable && is_unevictable)
count_vm_event(UNEVICTABLE_PGCULLED);
put_page(page); /* drop ref from isolate */
}
isolation되었던 페이지를 다시 lruvec에 되돌린다.
- int was_unevictable = PageUnevictable(page);
- 페이지가 unevictable 상태인지 여부를 알아온다.
- ClearPageUnevictable(page);
- 페이지의 PG_unevictable 플래그를 클리어한다.
- if (page_evictable(page)) { is_unevictable = false; lru_cache_add(page);
- 페이지 매핑 상태를 보아 evictable 상태인 경우 is_unevictable에 false를 담고 페이지를 lru_add_pvec 캐시에 등록한다.
- } else { is_unevictable = true; add_page_to_unevictable_list(page); smp_mb(); }
- lruvec.list[LRU_UNEVICTABLE]에 페이지를 추가한다.
- if (is_unevictable && page_evictable(page)) { if (!isolate_lru_page(page)) { put_page(page); goto redo; } }
- lruvec.list[LRU_UNEVICTABLE]에 추가한 페이지가 evictable 상태로 바뀐 경우 이 페이지는 절대 free 되지 않는다. 이를 피하기 위해 다시 한 번 이 페이지를 isolation 하여 체크하게 반복한다.
- if (was_unevictable && !is_unevictable) count_vm_event(UNEVICTABLE_PGRESCUED);
- unevictable 이었으면서 지금은 unevictable이 아닌 경우 UNEVICTABLE_PGRESCUED stat을 증가시킨다.
- else if (!was_unevictable && is_unevictable) count_vm_event(UNEVICTABLE_PGCULLED);
- unevictable 이 아니었으면서 지금은 unevictable인 경우 UNEVICTABLE_PG CULLED stat을 증가시킨다.
- put_page(page);
- 페이지에서 LRU 비트 플래그를 클리어하고 lru 리스트에서 제거하며 버디 시스템에 페이지를 hot 방향으로 free한다.
Huge Page & Huge TLB
- Huge TLB를 지원하는 아키텍처에서만 사용할 수 있다.
- x86, ia64, arm with LPAE, sparc64, s390 등에서 사용할 수 있다.
- 참고: hugetlbpage.txt | kernel.org
- Huge TLB를 사용하는 경우 큰 페이지를 하나의 TLB 엔트리로 로드하여 사용하므로 매핑에 대한 overhead가 줄어들어 빠른 access 성능을 유지할 수 있게된다.
- Huge TLB를 사용하는 경우 TLB H/W의 성능 향상을 위해 페이지 블럭을 MAX_ORDER-1 페이지 단위가 아닌 HugeTLB 단위에 맞게 운용할 수 있다.
- 전역 hstate[]는 배열로 구성되어 size가 다른 여러 개의 TLB 엔트리를 구성하여 사용할 수 있다.
- 커널 파라메터를 사용하여 지정된 크기의 공간을 reserve 하여 사용한다.
- 예) “default_hugepagesz=1G hugepagesz=1G”
- 런타임 시 설정 변경
- “/proc/sys/vm/nr_hugepages” 이며 NUMA 시스템에서는 “/sys/devices/system/node/node_id/hugepages/hugepages”을 설정하여 사용한다.
- shared 메모리를 open 하여 만들 때 SHM_HUGETLB 옵션을 사용하여 huge tlb를 사용하게 할 수 있다.
- 예) shmid = shmget(2, LENGTH, SHM_HUGETLB | IPC_CREAT | SHM_R | SHM_W)) < 0)
HugeTLBFS
- 파일 시스템과 같이 동작하므로 마운트하여 사용한다.
- 예) mount -t hugetlbfs -o uid=<value>,gid=<value>,mode=<value>,size=<value>,nr_inodes=<value> none /mnt/huge
- 마운트된 디렉토리(/mnt/huge)내에서 만들어진 파일들은 huge tlb를 사용하여 매핑된다.
putback_active_hugepage()
mm/hugetlb.c
void putback_active_hugepage(struct page *page)
{
VM_BUG_ON_PAGE(!PageHead(page), page);
spin_lock(&hugetlb_lock);
list_move_tail(&page->lru, &(page_hstate(page))->hugepage_activelist);
spin_unlock(&hugetlb_lock);
put_page(page);
}
isolation되었던 페이지를 전역 hstate[]의 hugepage_activelist의 후미에 다시 되돌린다.
- isolation때 증가시킨 참조 카운터를 감소 시킨다.
Balloon 페이지 관리
- 리눅스는 KVM 및 XEN과 같은 가상 머신을 위한 Balloon 디바이스 드라이버를 제공한다.
- 메모리 파편화를 막기위해 Balloon 메모리 compaction을 지원한다.
balloon_page_putback()
mm/balloon_compaction.c
/* putback_lru_page() counterpart for a ballooned page */
void balloon_page_putback(struct page *page)
{
/*
* 'lock_page()' stabilizes the page and prevents races against
* concurrent isolation threads attempting to re-isolate it.
*/
lock_page(page);
if (__is_movable_balloon_page(page)) {
__putback_balloon_page(page);
/* drop the extra ref count taken for page isolation */
put_page(page);
} else {
WARN_ON(1);
dump_page(page, "not movable balloon page");
}
unlock_page(page);
}
isolation되었던 페이지가 ballon 페이지인 경우 페이지에 기록된 ballon 디바이스의 pages 리스트에 다시 되돌린다.
- isolation때 증가시킨 참조 카운터를 감소 시킨다.
__is_movable_balloon_page()
include/linux/balloon_compaction.h
/*
* __is_movable_balloon_page - helper to perform @page PageBalloon tests
*/
static inline bool __is_movable_balloon_page(struct page *page)
{
return PageBalloon(page);
}
Ballon 페이지 여부를 반환한다.
__putback_balloon_page()
mm/balloon_compaction.c
static inline void __putback_balloon_page(struct page *page)
{
struct balloon_dev_info *b_dev_info = balloon_page_device(page);
unsigned long flags;
spin_lock_irqsave(&b_dev_info->pages_lock, flags);
SetPagePrivate(page);
list_add(&page->lru, &b_dev_info->pages);
b_dev_info->isolated_pages--;
spin_unlock_irqrestore(&b_dev_info->pages_lock, flags);
}
페이지에 PG_private 플래그를 설정하고 페이지에 기록된 ballon 페이지 디바이스의 pages 리스트에 되돌린다.
balloon_page_device()
include/linux/balloon_compaction.h
/*
* balloon_page_device - get the b_dev_info descriptor for the balloon device
* that enqueues the given page.
*/
static inline struct balloon_dev_info *balloon_page_device(struct page *page)
{
return (struct balloon_dev_info *)page_private(page);
}
ballon 페이지 디바이스를 알아온다.
구조체
pagevec 구조체
struct pagevec {
unsigned long nr;
boool percpu_pvec_drained;
struct page *pages[PAGEVEC_SIZE];
};
- nr
- percpu_pvec_drained
- *pages[]
- pagevec에서 관리되는 페이지들이다. (최대 15개)
lruvec 구조체
include/linux/mmzone.h
struct lruvec {
struct list_head lists[NR_LRU_LISTS];
struct zone_reclaim_stat reclaim_stat;
/* Evictions & activations on the inactive file list */
atomic_long_t inactive_age;
/* Refaults at the time of last reclaim cycle */
unsigned long refaults;
#ifdef CONFIG_MEMCG
struct pglist_data *pgdat;
#endif
};
- lists[]
- reclaim_stat
- inactive_age
- refaults
- *pgdat
- 노드를 가리킨다.
- memory control cgroup을 사용할 때 lruvec은 노드별로 관리된다.
zone_reclaim_stat 구조체
include/linux/mmzone.h
struct zone_reclaim_stat {
/*
* The pageout code in vmscan.c keeps track of how many of the
* mem/swap backed and file backed pages are referenced.
* The higher the rotated/scanned ratio, the more valuable
* that cache is.
*
* The anon LRU stats live in [0], file LRU stats in [1]
*/
unsigned long recent_rotated[2];
unsigned long recent_scanned[2];
};
lru_list
include/linux/mmzone.h
/*
* We do arithmetic on the LRU lists in various places in the code,
* so it is important to keep the active lists LRU_ACTIVE higher in
* the array than the corresponding inactive lists, and to keep
* the *_FILE lists LRU_FILE higher than the corresponding _ANON lists.
*
* This has to be kept in sync with the statistics in zone_stat_item
* above and the descriptions in vmstat_text in mm/vmstat.c
*/
#define LRU_BASE 0
#define LRU_ACTIVE 1
#define LRU_FILE 2
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
전역 pagevec 캐시
mm/swap.c
static DEFINE_PER_CPU(struct pagevec, lru_add_pvec);
static DEFINE_PER_CPU(struct pagevec, lru_rotate_pvecs);
static DEFINE_PER_CPU(struct pagevec, lru_deactivate_file_pvecs);
static DEFINE_PER_CPU(struct pagevec, lru_lazyfree_pvecs);
#ifdef CONFIG_SMP
static DEFINE_PER_CPU(struct pagevec, activate_page_pvecs);
#endif
참고