<kernel v5.0>
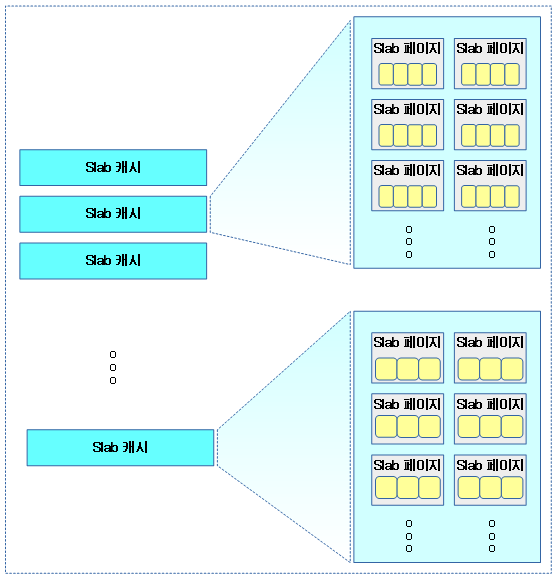
슬랩 캐시 생성
빠른 성능으로 규격화된 object를 지속적으로 공급하기 위해 커널 메모리용 슬랩 캐시를 생성 시켜 준비한다.
Hardened usercopy whitelisting
보안을 목적으로 커널 데이터를 유저측과 교환할 때 슬랩 캐시도 그 영역을 제한하는 방법을 추가하였다. 따라서 슬랩 캐시를 생성할 때 슬랩 캐시에서 object의 useroffset 위치 부터 usersize 만큼만 허용할 수 있도록 지정하는 kmem_cache_create_usercopy() 함수가 추가되었다. 커널 전용 슬랩 캐시를 만드는 경우에는 유저로 데이터 복사를 허용하지 않는다. 그러나 kmalloc의 경우는 전체 object size를 허용하도록 생성하는 것이 특징이다.
alias 슬랩 캐시
만일 기존에 생성한 슬랩 캐시와 object 사이즈가 같고 플래그 설정이 유사한 슬랩 캐시를 생성하는 경우 기존에 생성한 슬랩 캐시를 공유하여 사용하는데, 이렇게 만들어진 슬랩 캐시는 alias 슬랩 캐시라고 한다.
다음 그림은 슬랩 캐시를 만들기 위한 함수 호출 관계를 보여준다.
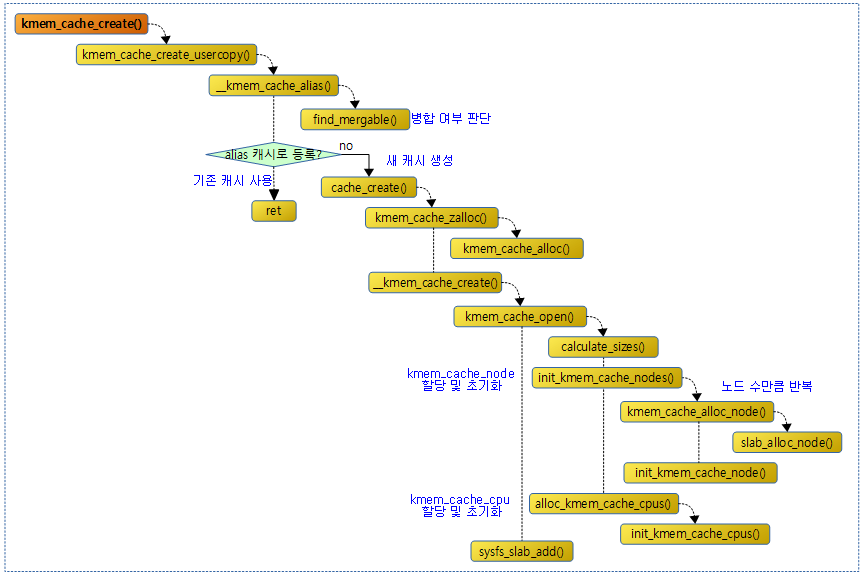
kmem_cache_create()
mm/slab_common.c
/** * kmem_cache_create - Create a cache. * @name: A string which is used in /proc/slabinfo to identify this cache. * @size: The size of objects to be created in this cache. * @align: The required alignment for the objects. * @flags: SLAB flags * @ctor: A constructor for the objects. * * Cannot be called within a interrupt, but can be interrupted. * The @ctor is run when new pages are allocated by the cache. * * The flags are * * %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5) * to catch references to uninitialised memory. * * %SLAB_RED_ZONE - Insert `Red` zones around the allocated memory to check * for buffer overruns. * * %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware * cacheline. This can be beneficial if you're counting cycles as closely * as davem. * * Return: a pointer to the cache on success, NULL on failure. */
struct kmem_cache *
kmem_cache_create(const char *name, unsigned int size, unsigned int align,
slab_flags_t flags, void (*ctor)(void *))
{
return kmem_cache_create_usercopy(name, size, align, flags, 0, 0,
ctor);
}
EXPORT_SYMBOL(kmem_cache_create);
요청한 @size 및 @align 단위로 @name 명칭의 슬랩 캐시를 생성한다. 유사한 사이즈와 호환 가능한 플래그를 사용한 슬랩 캐시가 있는 경우 별도로 생성하지 않고, alias 캐시로 등록한다. 실패하는 경우 null을 반환한다.
kmem_cache_create_usercopy()
mm/slab_common.c
/** * kmem_cache_create_usercopy - Create a cache with a region suitable * for copying to userspace * @name: A string which is used in /proc/slabinfo to identify this cache. * @size: The size of objects to be created in this cache. * @align: The required alignment for the objects. * @flags: SLAB flags * @useroffset: Usercopy region offset * @usersize: Usercopy region size * @ctor: A constructor for the objects. * * Cannot be called within a interrupt, but can be interrupted. * The @ctor is run when new pages are allocated by the cache. * * The flags are * * %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5) * to catch references to uninitialised memory. * * %SLAB_RED_ZONE - Insert `Red` zones around the allocated memory to check * for buffer overruns. * * %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware * cacheline. This can be beneficial if you're counting cycles as closely * as davem. * * Return: a pointer to the cache on success, NULL on failure. */
struct kmem_cache *
kmem_cache_create_usercopy(const char *name,
unsigned int size, unsigned int align,
slab_flags_t flags,
unsigned int useroffset, unsigned int usersize,
void (*ctor)(void *))
{
struct kmem_cache *s = NULL;
const char *cache_name;
int err;
get_online_cpus();
get_online_mems();
memcg_get_cache_ids();
mutex_lock(&slab_mutex);
err = kmem_cache_sanity_check(name, size);
if (err) {
goto out_unlock;
}
/* Refuse requests with allocator specific flags */
if (flags & ~SLAB_FLAGS_PERMITTED) {
err = -EINVAL;
goto out_unlock;
}
/*
* Some allocators will constraint the set of valid flags to a subset
* of all flags. We expect them to define CACHE_CREATE_MASK in this
* case, and we'll just provide them with a sanitized version of the
* passed flags.
*/
flags &= CACHE_CREATE_MASK;
/* Fail closed on bad usersize of useroffset values. */
if (WARN_ON(!usersize && useroffset) ||
WARN_ON(size < usersize || size - usersize < useroffset))
usersize = useroffset = 0;
if (!usersize)
s = __kmem_cache_alias(name, size, align, flags, ctor);
if (s)
goto out_unlock;
cache_name = kstrdup_const(name, GFP_KERNEL);
if (!cache_name) {
err = -ENOMEM;
goto out_unlock;
}
s = create_cache(cache_name, size,
calculate_alignment(flags, align, size),
flags, useroffset, usersize, ctor, NULL, NULL);
if (IS_ERR(s)) {
err = PTR_ERR(s);
kfree_const(cache_name);
}
out_unlock:
mutex_unlock(&slab_mutex);
memcg_put_cache_ids();
put_online_mems();
put_online_cpus();
if (err) {
if (flags & SLAB_PANIC)
panic("kmem_cache_create: Failed to create slab '%s'. Error %d\n",
name, err);
else {
pr_warn("kmem_cache_create(%s) failed with error %d\n",
name, err);
dump_stack();
}
return NULL;
}
return s;
}
EXPORT_SYMBOL(kmem_cache_create_usercopy);
요청한 @size 및 @align 단위로 @name 명칭의 슬랩 캐시를 생성한다. 유사한 사이즈와 호환 가능한 플래그를 사용한 슬랩 캐시가 있는 경우 별도로 생성하지 않고, alias 캐시로 등록한다. 실패하는 경우 null을 반환한다.
- 코드 라인 12에서 CONFIG_HOTPLUG_CPU 커널 옵션을 사용하는 경우에만 cpu_hotplug.refcount를 증가시켜 cpu를 분리하는 경우 동기화(지연)시킬 목적으로 설정한다.
- 코드라인13에서 CONFIG_MEMORY_HOTPLUG 커널 옵션을 사용하는 경우에만 mem_hotplug.refcount를 증가시켜 memory를 분리하는 경우 동기화(지연)시킬 목적으로 설정한다.
- 코드 라인 14에서 MEMCG_KMEM 커널 옵션을 사용하여 슬랩 캐시 사용량을 제어하고자 할 목적으로 read 세마포어 락을 사용한다.
- 코드 라인 18~21에서 CONFIG_DEBUG_VM 커널 옵션을 사용하는 경우에만 name과 size에 대한 간단한 체킹을 수행한다. 이 커널 옵션을 사용하지 않는 경우에는 항상 false를 반환한다.
- 코드 라인 24~27에서 허가된 플래그가 아닌 경우 -EINVAL 에러를 반환한다.
- 코드 라인 35에서 kmem_cache를 생성할 때 유효한 플래그만 통과시킨다.
- 코드 라인 38~40에서 유저에서 접근 가능해야 하는 영역의 useroffset 및 usersize가 size 범위를 벗어나는 경우 0으로 만든다.
- 코드 라인 42~45에서 기존 슬랩 캐시 중 병합가능한 슬랩 캐시를 찾은 경우 캐시 생성을 포기하고 alias 캐시로 등록한다.
- 코드 라인 47~51에서 name을 clone한 후 cache_name으로 반환한다. 단 name이 .rodata 섹션에 있는 경우 name을 그대로 반환한다.
- 코드 라인 53~57에서 새 캐시를 생성한다.
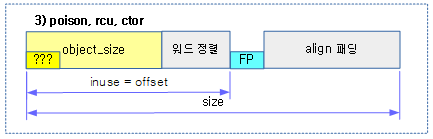
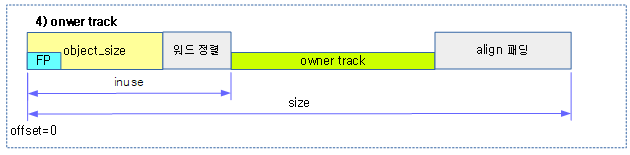
다음 그림은 각종 플래그들에 대한 매크로 상수이다. (각 플래그 다음에 위치한 한 글자의 알파벳 문자는 slabinfo 유틸리티를 사용하여 플래그 속성값이 출력될 때 사용되는 알파벳 문자이다.)
- 커널 디렉토리에서 tools/vm/slabinfo.c를 컴파일하여 사용한다.
- 참고: Slub Memory Allocator (slubinfo) | 문c

kmem_cache_sanity_check()
mm/slab_common.c
static int kmem_cache_sanity_check(const char *name, unsigned int size)
{
if (!name || in_interrupt() || size < sizeof(void *) ||
size > KMALLOC_MAX_SIZE) {
pr_err("kmem_cache_create(%s) integrity check failed\n", name);
return -EINVAL;
}
WARN_ON(strchr(name, ' ')); /* It confuses parsers */
return 0;
}
CONFIG_DEBUG_VM 커널 옵션을 사용하는 경우 슬랩 캐시를 생성하기 위한 간단한 체크를 수행한다. 성공 시 0을 반환한다.
- 인터럽트 수행 중에 호출되는 경우 -EINVAL 에러를 반환한다.
- 32비트 시스템에서 4 바이트, 64비트 시스템에서 8 바이트보다 작은 사이즈를 지정하는 경우 -EINVAL 에러를 반환한다.
Alias 캐시 생성
__kmem_cache_alias()
mm/slub.c
struct kmem_cache *
__kmem_cache_alias(const char *name, unsigned int size, unsigned int align,
slab_flags_t flags, void (*ctor)(void *))
{
struct kmem_cache *s, *c;
s = find_mergeable(size, align, flags, name, ctor);
if (s) {
s->refcount++;
/*
* Adjust the object sizes so that we clear
* the complete object on kzalloc.
*/
s->object_size = max(s->object_size, size);
s->inuse = max(s->inuse, ALIGN(size, sizeof(void *)));
for_each_memcg_cache(c, s) {
c->object_size = s->object_size;
c->inuse = max(c->inuse, ALIGN(size, sizeof(void *)));
}
if (sysfs_slab_alias(s, name)) {
s->refcount--;
s = NULL;
}
}
return s;
}
유사한 사이즈와 호환 가능한 플래그를 사용한 슬랩 캐시가 있는 경우 별도로 생성하지 않고, alias 캐시로 등록한다. alias 캐시로 등록하지 않고 별도로 캐시를 만들어야 하는 경우에는 null을 반환한다.
- 코드 라인 7에서 병합 가능한 캐시를 알아온다. 병합할 수 없으면 null을 반환한다.
- 실제 생성되는 캐시는 /sys/kernel/slabs에서 슬랩명으로 디렉토리가 생성되지만, alias 캐시는 병합된 캐시 디렉토리를 가리키는 링크를 생성한다.
- 코드 라인 8~16에서 요청한 캐시는 alias 캐시로 등록되고 실제 병합될 캐시를 사용하므로 레퍼런스 카운터를 증가시키고, 병합될 캐시의 object_size보다 요청 캐시의 @size가 더 큰 경우 갱신한다. 또한 병합될 캐시의 inuse보다 요청한 @size가 큰 경우도 갱신한다.
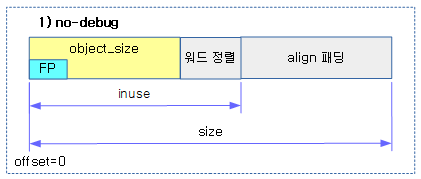
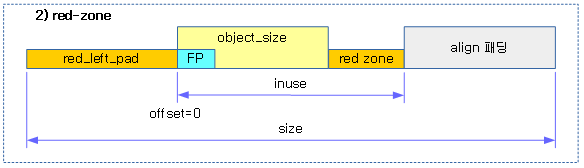
- c->object_size <- 요청한 @size가 담긴다.
- 메타 데이터를 제외한 실제 object 데이터가 저장될 공간의 사이즈
- c->size
- 메타 데이터를 포함한 사이즈
- c->inuse
- 메타 데이터(REDZONE은 포함되지 않음)까지의 offset 값(메타 데이터가 없는 경우 워드 단위로 정렬한 size와 동일)
- c->object_size <- 요청한 @size가 담긴다.
- 코드 라인 18~21에서 병합될 캐시의 모든 memcg 캐시들을 순회하며 memcg용 object size를 병합될 캐시의 object size와 동일하게 갱신한다. 또한 memcg용 캐시의 inuse보다 @size가 더 큰 경우 갱신한다.
- 코드 라인 23~26에서 CONFIG_SYSFS 커널 옵션을 사용하는 경우 생성된 캐시에 대한 sysfs 링크를 만든다. 단 커널이 부트업 프로세스 중인 경우 링크 생성을 slab_sysfs 드라이버 가동후로 미룬다. 링크가 만들어지지 않는 경우 에러(0이 아닌)를 반환한다.
- 에러를 반환한 경우 병합될 캐시로의 사용을 포기하기 위해 refcount를 감소 시키고 null을 반환한다.
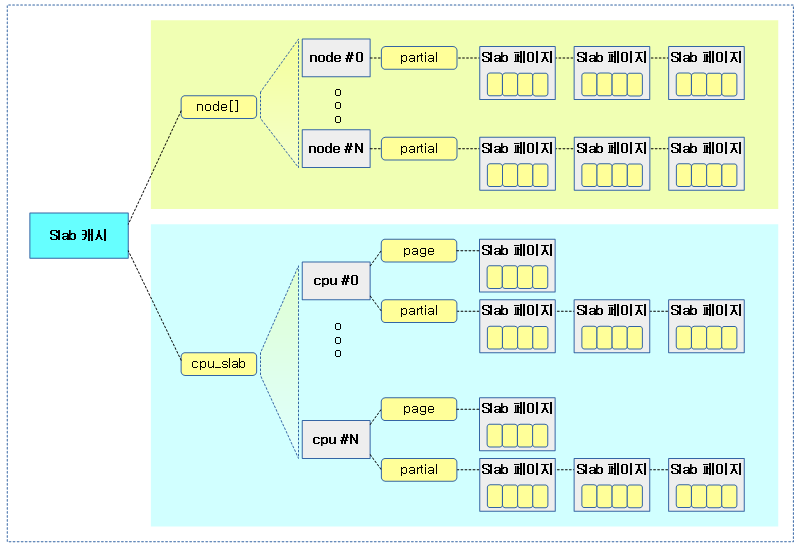
다음 그림은 생성 요청한 캐시에 대해 병합될 캐시를 찾은 경우 새로운 캐시를 등록하지 않고 그냥 alias 캐시 리스트에 등록하는 경우를 보여준다.
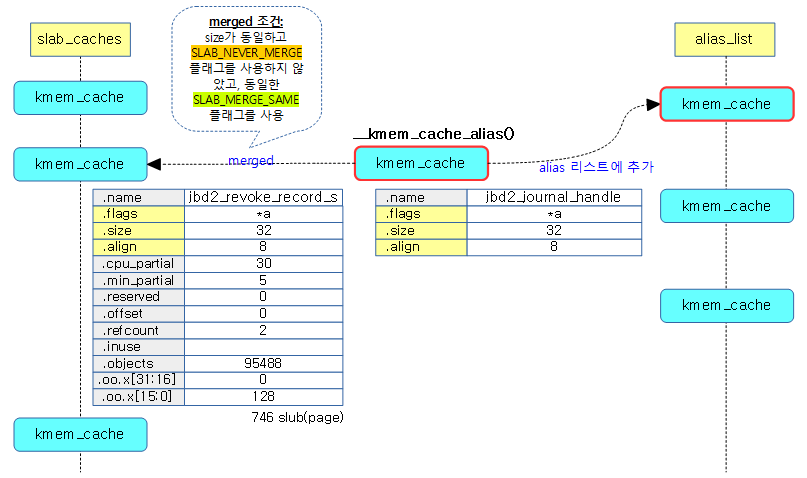
병합 캐시 검색
find_mergeable()
mm/slab_common.c
struct kmem_cache *find_mergeable(unsigned int size, unsigned int align,
slab_flags_t flags, const char *name, void (*ctor)(void *))
{
struct kmem_cache *s;
if (slab_nomerge)
return NULL;
if (ctor)
return NULL;
size = ALIGN(size, sizeof(void *));
align = calculate_alignment(flags, align, size);
size = ALIGN(size, align);
flags = kmem_cache_flags(size, flags, name, NULL);
if (flags & SLAB_NEVER_MERGE)
return NULL;
list_for_each_entry_reverse(s, &slab_root_caches, root_caches_node) {
if (slab_unmergeable(s))
continue;
if (size > s->size)
continue;
if ((flags & SLAB_MERGE_SAME) != (s->flags & SLAB_MERGE_SAME))
continue;
/*
* Check if alignment is compatible.
* Courtesy of Adrian Drzewiecki
*/
if ((s->size & ~(align - 1)) != s->size)
continue;
if (s->size - size >= sizeof(void *))
continue;
if (IS_ENABLED(CONFIG_SLAB) && align &&
(align > s->align || s->align % align))
continue;
return s;
}
return NULL;
}
병합 가능한 캐시를 검색하여 아래의 엄격한 조건을 만족하는 캐시를 찾아 반환하고 찾지 못한 경우 null을 반환한다.
- “slub_nomerge” 커널 파라메터를 사용한 경우는 병합하지 않는다
- 요청 캐시의 플래그에서 SLAB_NEVER_MERGE 플래그들 중 하나라도 사용하면 안된다. (대부분 디버그용 플래그)
- 요청 캐시가 별도의 object 생성자를 사용하면 안된다.
- 전체 캐시들에 대해 루프를 돌며 다음 조건을 비교한다.
- 캐시의 플래그에서 SLAB_NEVER_MERGE 플래그들 중 하나라도 사용하면 안된다.
- 루트 캐시가 아니면 안된다.
- 캐시에 별도의 object 생성자가 사용되면 안된다.
- 유저사이즈가 지정된 경우는 안된다.
- 레퍼런스 카운터가 0보다 작으면 안된다. (초기화 중)
- 기존 캐시 사이즈와 유사해야한다 (기존 캐시 사이즈와 같거나 워드 범위 이내로 작아야한다. )
- 요청 플래그에 사용한 SLAB_MERGE_SAME 플래그들이 캐시에서 사용된 플래그와 동일하지 않으면 안된다.
- 캐시의 size가 재조정된 요청 align 단위로 정렬되지 않으면 안된다.
mm/slab_common.c
/*
* Set of flags that will prevent slab merging
*/
#define SLAB_NEVER_MERGE (SLAB_RED_ZONE | SLAB_POISON | SLAB_STORE_USER | \
SLAB_TRACE | SLAB_DESTROY_BY_RCU | SLAB_NOLEAKTRACE | \
SLAB_FAILSLAB | SLAB_KASAN)
디버그 옵션들을 사용한 캐시에 대해 병합을 할 수 없다.
#define SLAB_MERGE_SAME (SLAB_RECLAIM_ACCOUNT | SLAB_CACHE_DMA | \
SLAB_ACCOUNT)
캐시 병합을 하기 위해서는 대상 캐시의 플래그와 요청 캐시의 플래그에 대해 위의 3개 플래그가 서로 동일하여야 한다.
kmem_cache_flags()
/* * kmem_cache_flags - apply debugging options to the cache * @object_size: the size of an object without meta data * @flags: flags to set * @name: name of the cache * @ctor: constructor function * * Debug option(s) are applied to @flags. In addition to the debug * option(s), if a slab name (or multiple) is specified i.e. * slub_debug=<Debug-Options>,<slab name1>,<slab name2> ... * then only the select slabs will receive the debug option(s). */
slab_flags_t kmem_cache_flags(unsigned int object_size,
slab_flags_t flags, const char *name,
void (*ctor)(void *))
{
char *iter;
size_t len;
/* If slub_debug = 0, it folds into the if conditional. */
if (!slub_debug_slabs)
return flags | slub_debug;
len = strlen(name);
iter = slub_debug_slabs;
while (*iter) {
char *end, *glob;
size_t cmplen;
end = strchr(iter, ',');
if (!end)
end = iter + strlen(iter);
glob = strnchr(iter, end - iter, '*');
if (glob)
cmplen = glob - iter;
else
cmplen = max_t(size_t, len, (end - iter));
if (!strncmp(name, iter, cmplen)) {
flags |= slub_debug;
break;
}
if (!*end)
break;
iter = end + 1;
}
return flags;
}
CONFIG_SLUB_DEBUG 커널 옵션을 사용하는 경우 전역 변수 slub_debug에 저장된 플래그들을 추가한다.
- “slub_debug=” 커널 파라메터를 통해서 각종 디버그 옵션을 선택하면 slub_debug 값(SLAB_DEBUG_FREE, SLAB_RED_ZONE, SLAB_POISON, SLAB_STORE_USER, SLAB_TRACE, SLAB_FAILSLAB)이 결정되고 “,” 뒤의 문자열이 slub_debug_slabs에 저장된다.
병합 불가능 조건
slab_unmergeable()
mm/slab_common.c
/* * Find a mergeable slab cache */
int slab_unmergeable(struct kmem_cache *s)
{
if (slab_nomerge || (s->flags & SLAB_NEVER_MERGE))
return 1;
if (!is_root_cache(s))
return 1;
if (s->ctor)
return 1;
if (s->usersize)
return 1;
/*
* We may have set a slab to be unmergeable during bootstrap.
*/
if (s->refcount < 0)
return 1;
return 0;
}
캐시를 병합할 수 없는 경우 true를 반환한다. 다음은 병합이 불가능한 조건이다.
- “slub_nomerge” 커널 파라메터를 사용하는 경우 또는 캐시의 플래그에 SLAB_NEVER_MERGE 관련 플래그를 사용한 경우 병합 불가능
- 루트 캐시가 아닌 경우
- 별도의 object 생성자가 주어진 경우
- usersize가 지정된 경우
- refcount가 0보다 작은 경우
- 캐시가 부트업 프로세스 중에 만들어져 아직 동작하지 않는 상태
alias 캐시용 sysfs 링크 생성
sysfs_slab_alias()
mm/slub.c
static int sysfs_slab_alias(struct kmem_cache *s, const char *name)
{
struct saved_alias *al;
if (slab_state == FULL) {
/*
* If we have a leftover link then remove it.
*/
sysfs_remove_link(&slab_kset->kobj, name);
return sysfs_create_link(&slab_kset->kobj, &s->kobj, name);
}
al = kmalloc(sizeof(struct saved_alias), GFP_KERNEL);
if (!al)
return -ENOMEM;
al->s = s;
al->name = name;
al->next = alias_list;
alias_list = al;
return 0;
}
CONFIG_SYSFS 커널 옵션을 사용하는 경우 생성된 캐시에 대한 sysfs 링크를 만든다. 단 커널이 부트업 프로세스 중인 경우 링크 생성을 slab_sysfs 드라이버 가동 후로 미룬다. 링크가 만들어지지 않는 경우 에러(0이 아닌)를 반환한다.
- 코드 라인 5~11에서slub 메모리 할당자가 완전히 동작을 시작한 경우 기존 링크를 삭제하고, 다시 name으로 링크를 만들고 반환한다.
- 코드 라인 13~21에서 saved_alias 구조체 메모리 영역을 할당하고 초기화한다. 초기화된alias 캐시정보를 전역 alias_list에 추가한다.
- 이렇게 추가된 alias_list는 나중에 커널이 각 드라이버를 호출할 때 __initcall() 함수에 등록된 slab_sysfs_init() 루틴이 호출될 때 slab_state를 full 상태로 바꾸고 alias_list에 있는 모든 alias 캐시에 대해 sysfs_slab_alias() 루틴이 다시 호출되면서 sysfs를 사용하여 링크를 만들게 된다.
정규 슬랩 캐시 생성
create_cache()
mm/slab_common.c
static struct kmem_cache *create_cache(const char *name,
unsigned int object_size, unsigned int align,
slab_flags_t flags, unsigned int useroffset,
unsigned int usersize, void (*ctor)(void *),
struct mem_cgroup *memcg, struct kmem_cache *root_cache)
{
struct kmem_cache *s;
int err;
if (WARN_ON(useroffset + usersize > object_size))
useroffset = usersize = 0;
err = -ENOMEM;
s = kmem_cache_zalloc(kmem_cache, GFP_KERNEL);
if (!s)
goto out;
s->name = name;
s->size = s->object_size = object_size;
s->align = align;
s->ctor = ctor;
s->useroffset = useroffset;
s->usersize = usersize;
err = init_memcg_params(s, memcg, root_cache);
if (err)
goto out_free_cache;
err = __kmem_cache_create(s, flags);
if (err)
goto out_free_cache;
s->refcount = 1;
list_add(&s->list, &slab_caches);
memcg_link_cache(s);
out:
if (err)
return ERR_PTR(err);
return s;
out_free_cache:
destroy_memcg_params(s);
kmem_cache_free(kmem_cache, s);
goto out;
}
정규 슬랩 캐시를 생성한다.
- 코드 라인 10~11에서 유저영역에 복사할 영역이 object 범위를 벗어나는경우 useroffset와 usersize를0으로만든다
- 코드 라인 12~22에서새로운 캐시를 만들어 관리하기 위해 kmem_cache에서 slub object를 할당 받고 초기화한다.
- 코드 라인 23~25에서 CONFIG_MEMCG_KMEM 커널 옵션을 사용하는 경우 memcg에서 커널 메모리에 대한 관리를 위해 각 파라메터들을 초기화한다.
- 코드 라인 27~29에서 요청한 캐시를 생성한다.
- 코드 라인 30~31에서 캐시 레퍼런스 카운터를 1로 만들고 캐시를 전역 slab_caches에 추가한다.
- 실제 캐시 또는 alias 캐시를 생성할 때 마다 실제 캐시의 레퍼런스가 증가되고, 반대로 캐시 또는 alias 캐시를 소멸(삭제)시킬 때 마다 실제 캐시의 레퍼런스 카운터 값을 감소시킨다. 0 값이 되는 경우 실제 캐시를 소멸(삭제)시킬 수 있다.
- 코드라인 32에서 memcg에 슬랩 캐시 링크를 추가한다.
- 코드라인 33~36에서 out: 레이블이다 결과를 반환한다.
다음은 anon_vma 슬랩 캐시가 sysfs에 반영되어동작중인예를 보여준다. (위치: /sys/kernel/slab/<캐시명>)
$ cd /sys/kernel/slab/anon_vma KVM /sys/kernel/slab/anon_vma$ ls aliases destroy_by_rcu objects_partial red_zone slabs_cpu_partial align free_calls objs_per_slab remote_node_defrag_ratio store_user alloc_calls hwcache_align order sanity_checks total_objects cpu_partial min_partial partial shrink trace cpu_slabs object_size poison slab_size usersize ctor objects reclaim_account slabs validate
memcg_link_cache()
mm/slab_common.c
void memcg_link_cache(struct kmem_cache *s)
{
if (is_root_cache(s)) {
list_add(&s->root_caches_node, &slab_root_caches);
} else {
list_add(&s->memcg_params.children_node,
&s->memcg_params.root_cache->memcg_params.children);
list_add(&s->memcg_params.kmem_caches_node,
&s->memcg_params.memcg->kmem_caches);
}
}
캐시가 루트 캐시인 경우 전역 slab_root_caches 리스트에 추가하고 루트 캐시가 아닌 경우 memcg에추가한다
__kmem_cache_create()
mm/slub.c
int __kmem_cache_create(struct kmem_cache *s, unsigned long flags)
{
int err;
err = kmem_cache_open(s, flags);
if (err)
return err;
/* Mutex is not taken during early boot */
if (slab_state <= UP)
return 0;
memcg_propagate_slab_attrs(s);
err = sysfs_slab_add(s);
if (err)
kmem_cache_close(s);
return err;
}
캐시를 생성하고, 커널이 부트업 중이 아닌 경우 memcg용 속성들을 읽어서 설정한 후 sysfs에 생성한 캐시에 대한 링크들을 생성한다.
- 코드 라인 5~7에서 캐시를 생성한다.
- 코드 라인 10~11에서 완전히 full slab 시스템이 가동되기 전, 즉 early bootup이 진행 중에는 함수를 빠져나간다.
- 코드 라인 13에서 CONFIG_MEMCG_KMEM 커널 옵션을 사용한 경우 생성한 캐시의 루트 캐시에 대한 모든 속성을 읽어서 다시 한 번 재 설정한다.
- 코드 라인 14~16에서 생성된 캐시에 대한 내용을 파일 시스템을 통해 속성들을 보거나 설정할 수 있도록 링크들을 생성한다.
캐시 할당자 상태
mm/slab.h
/* * State of the slab allocator. * * This is used to describe the states of the allocator during bootup. * Allocators use this to gradually bootstrap themselves. Most allocators * have the problem that the structures used for managing slab caches are * allocated from slab caches themselves. */
enum slab_state {
DOWN, /* No slab functionality yet */
PARTIAL, /* SLUB: kmem_cache_node available */
PARTIAL_NODE, /* SLAB: kmalloc size for node struct available */
UP, /* Slab caches usable but not all extras yet */
FULL /* Everything is working */
};
slab(slub) 메모리 할당자의 운영 상태로 slub 메모리 시스템에 대해서는 다음과 같다. (PARTIAL_NODE는 slub에서 사용하지않는다.)
- DOWN
- 아직 커널이 부트업 프로세스를 진행중이며 slub 메모리 시스템이 만들어지지 않은 상태
- PARTIAL
- 슬랩 캐시를 생성하지 못하지만 이미 생성된 슬랩 캐시로부터 슬랩 object의 할당은 가능한 상태
- kmem_cache_node 슬랩 캐시가 존재하는 상태
- 캐시를 생성하기 위해 캐시 내부에 필요한 kmem_cache_node가 필요한데 이를 만들기 위해 부트업 처리 중 가장 먼저 만든 캐시이다.
- UP
- kmem_cache 시스템은 동작하나 다른 엑스트라 시스템이 아직 활성화 되지 않은 상태
- FULL
- slub 메모리 할당자에 대한 부트업 프로세스가 완료되어 slub에 대한 모든 것이 동작하는 상태
kmem_cache_open()
mm/slub.c
static int kmem_cache_open(struct kmem_cache *s, slab_flags_t flags)
{
s->flags = kmem_cache_flags(s->size, flags, s->name, s->ctor);
#ifdef CONFIG_SLAB_FREELIST_HARDENED
s->random = get_random_long();
#endif
if (!calculate_sizes(s, -1))
goto error;
if (disable_higher_order_debug) {
/*
* Disable debugging flags that store metadata if the min slab
* order increased.
*/
if (get_order(s->size) > get_order(s->object_size)) {
s->flags &= ~DEBUG_METADATA_FLAGS;
s->offset = 0;
if (!calculate_sizes(s, -1))
goto error;
}
}
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
if (system_has_cmpxchg_double() && (s->flags & SLAB_NO_CMPXCHG) == 0)
/* Enable fast mode */
s->flags |= __CMPXCHG_DOUBLE;
#endif
/*
* The larger the object size is, the more pages we want on the partial
* list to avoid pounding the page allocator excessively.
*/
set_min_partial(s, ilog2(s->size) / 2);
set_cpu_partial(s);
#ifdef CONFIG_NUMA
s->remote_node_defrag_ratio = 1000;
#endif
/* Initialize the pre-computed randomized freelist if slab is up */
if (slab_state >= UP) {
if (init_cache_random_seq(s))
goto error;
}
if (!init_kmem_cache_nodes(s))
goto error;
if (alloc_kmem_cache_cpus(s))
return 0;
free_kmem_cache_nodes(s);
error:
if (flags & SLAB_PANIC)
panic("Cannot create slab %s size=%u realsize=%u order=%u offset=%u flags=%lx\n",
s->name, s->size, s->size,
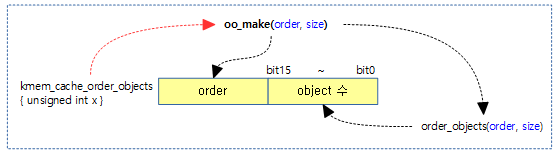
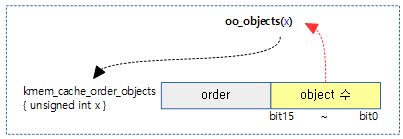
oo_order(s->oo), s->offset, (unsigned long)flags);
return -EINVAL;
}
캐시를 생성한다.
- 코드 라인 3에서”slab_debug=” 커널 파라메터에 의해 몇 개의 디버그 요청이 있는 경우 object를 만들 때 반영하기 위해 해당 기능의 slub 디버그 플래그를 추가한다.
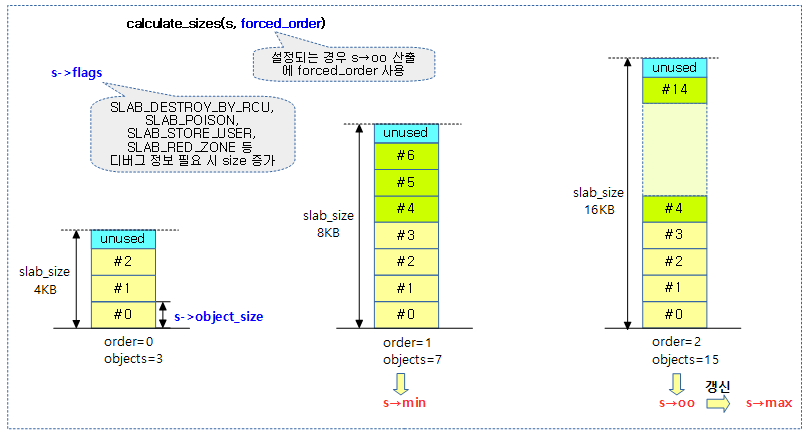
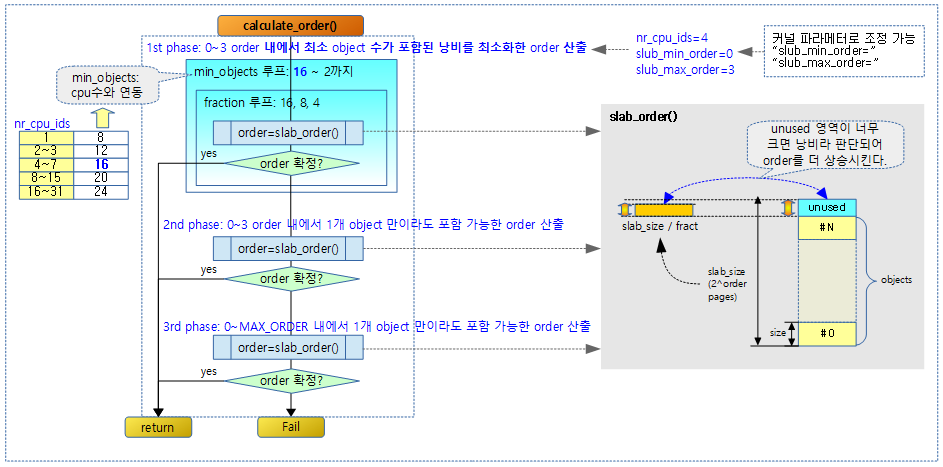
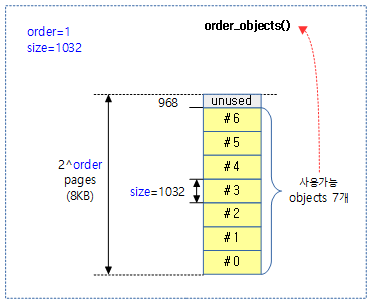
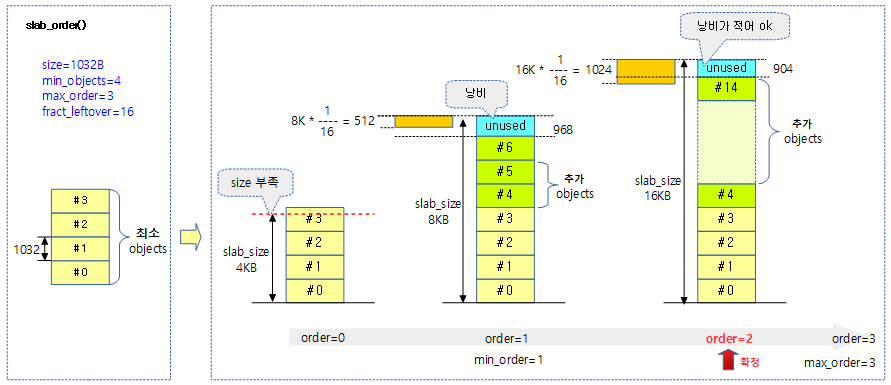
- 코드 라인 8~9에서 객체 size에 따른 order 및 객체 수 등이 산출되지 않는 경우 에러 처리로 이동 한다.
- 참고: Slub Memory Allocator (order 계산) | 문c
- 코드 라인 10~21에서 “slub_debug=O” 커널 파라메터가 사용된 경우 디버깅 기능으로 인해 order 값이 상승되는 경우 해당캐시의 디버깅 기능을 disable하게 한다. s->size를 할당하기 위해 계산된 order 값이 s->object_size를 할당하기 위해 계산된 order 값보다 큰 경우 즉, 디버그등 목적으로 메타데이터가 추가되어 페이지 할당이 더 필요한 경우이다. 이러한 경우 메타 데이타가 추가되는 플래그들을 클리어하고, offset을 0으로 대입하여 메타 데이터로 인해 order가 커지게 되면 메타 데이터를 추가하지 못하게 막는다.
- 코드 라인 25~27에서 시스템이 더블 워드 데이터 형에 대해 cmpxchg 기능을 지원하면서 slab 디버그 플래그를 사용하지 않는 경우 플래그에 __CMPXCHG_DOUBLE가 추가된다.
- x86 아키텍처나 64bit arm 아키텍처 등에서 지원하고 32bit arm에서는 지원하지 않는다.
- 코드 라인 34에서 object의 size를 표현하는데 필요한 비트 수의 절반을 min_partial에 저장한다. 단 5~10 범위 사이로 조정한다.
- 예)
- size가 4K -> 필요한 비트 수=12 -> min_partial = 6
- size가 1M -> 필요한 비트 수=20 -> min_partial = 10
- 예)
- 코드 라인 36에서 size에 적합한 cpu_partial 갯수를 산출한다.
- 코드 라인 39에서 NUMA 시스템인 경우 remote_node_defrag_ratio에 1000을 대입한다.
- 로컬 노드의 partial 리스트가 부족할 때 리모트 노드의 partial 리스트를 이용할 수 있도록 하는데 이의 허용률을 1000으로 설정한다.
- 허용 수치는 0~100까지 입력하는 경우 그 값을 10배 곱하고, 100이상 수치 입력하는 경우 그대로 허용한다.
- 1000으로 설정하는 경우 약 98%의 성공률로 설정된다.
- 하드웨어 딜레이 타이머를 1024로 나눈 나머지가 이 수치 이하인 경우에만 허용(성공)한다.
- 1024 이상으로 설정하는 경우 100% 허용(성공)
- 로컬 노드의 partial 리스트가 부족할 때 리모트 노드의 partial 리스트를 이용할 수 있도록 하는데 이의 허용률을 1000으로 설정한다.
- 코드 라인 43~46에서 슬랩이 정상 동작하는 경우 FP 값을 엔코딩하여 숨길 랜덤 시퀀스를 초기화한다.
- 코드 라인 48~49에서per 노드의 초기화가 실패하는 경우 error로 이동한다.
- 코드 라인 51~52에서 per cpu에 대한 할당이 성공하면 함수를 종료한다.
- 코드 라인 54에서 슬랩 캐시의 할당이 실패한 경우이다. per 노드를 해제하고 에러를 리턴한다.
- 코드 라인 55~59에서 error: 레이블이다. SLAB_PANIC 플래그가설정된경우panic 로그를출력하고 panic 동작에들어간다.
- 코드 라인 60에서 -EINVAL 에러를반환한다.
set_min_partial()
mm/slub.c
static void set_min_partial(struct kmem_cache *s, unsigned long min)
{
if (min < MIN_PARTIAL)
min = MIN_PARTIAL;
else if (min > MAX_PARTIAL)
min = MAX_PARTIAL;
s->min_partial = min;
}
지정한 캐시의 min_partial 값을 설정한다. 단 min 값은 MIN_PARTIAL(5) ~ MAX_PARTIAL(10)을 벗어나는 경우 조정된다.
set_cpu_partial()
mm/slub.c
static void set_cpu_partial(struct kmem_cache *s)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
/*
* cpu_partial determined the maximum number of objects kept in the
* per cpu partial lists of a processor.
*
* Per cpu partial lists mainly contain slabs that just have one
* object freed. If they are used for allocation then they can be
* filled up again with minimal effort. The slab will never hit the
* per node partial lists and therefore no locking will be required.
*
* This setting also determines
*
* A) The number of objects from per cpu partial slabs dumped to the
* per node list when we reach the limit.
* B) The number of objects in cpu partial slabs to extract from the
* per node list when we run out of per cpu objects. We only fetch
* 50% to keep some capacity around for frees.
*/
if (!kmem_cache_has_cpu_partial(s))
s->cpu_partial = 0;
else if (s->size >= PAGE_SIZE)
s->cpu_partial = 2;
else if (s->size >= 1024)
s->cpu_partial = 6;
else if (s->size >= 256)
s->cpu_partial = 13;
else
s->cpu_partial = 30;
#endif
}
size에따라 per-cpu의 partial 리스트에서 유지 가능한 최대 슬랩 object 수(s->cpu_partial)를 정한다.
- 1 페이지 이상 -> 2개
- 1024 이상 -> 6개
- 256 이상 -> 13개
- 256 미만 -> 30개
kmem_cache_has_cpu_partial()
mm/slub.c
static inline bool kmem_cache_has_cpu_partial(struct kmem_cache *s)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
return !kmem_cache_debug(s);
#else
return false;
#endif
}
CONFIG_SLUB_CPU_PARTIAL 커널 옵션이 사용되는 경우 지정된 캐시에서 디버그 플래그가 설정되어 사용되지 않는 경우에 cpu partial 리스트의 사용이 지원된다. 그렇지 않은 경우 false를 반환한다.
- true=지정된 캐시의 cpu partial 리스트 사용을 지원한다.
- false=지정된 캐시의 cpu partial 리스트 사용을 지원하지 않는다.
kmem_cache_debug()
mm/slub.c
static inline int kmem_cache_debug(struct kmem_cache *s)
{
#ifdef CONFIG_SLUB_DEBUG
return unlikely(s->flags & SLAB_DEBUG_FLAGS);
#else
return 0;
#endif
}
CONFIG_SLUB_DEBUG 커널 옵션이 사용되는 경우 지정된 캐시에서 SLAB_DEBUG_FLAGS 들 중 하나라도 설정되었는지 여부를 반환하고 그렇지 않은 경우 0을 반환한다.
- 1=지정된 캐시의 디버그 플래그 설정됨
- 0=지정된 캐시의 디버그 플래그가 설정되지 않음
kmem_cache_node 초기화
init_kmem_cache_nodes()
mm/slub.c
static int init_kmem_cache_nodes(struct kmem_cache *s)
{
int node;
for_each_node_state(node, N_NORMAL_MEMORY) {
struct kmem_cache_node *n;
if (slab_state == DOWN) {
early_kmem_cache_node_alloc(node);
continue;
}
n = kmem_cache_alloc_node(kmem_cache_node,
GFP_KERNEL, node);
if (!n) {
free_kmem_cache_nodes(s);
return 0;
}
init_kmem_cache_node(n);
s->node[node] = n;
}
return 1;
}
메모리를 가진 모든 노드에 대해 슬랩 시스템 상태에 따라 다음 2가지 중 하나를 수행한다.
- 아직 슬랩 시스템이 하나도 가동되지 않은 상태인 경우에는 슬랩 object를 할당 받지 못한다. 따라서 kmem_cache_node 구조체의 할당을 위해 슬랩 object가 아닌 버디 시스템을 통해 페이지를 할당 받고 이 페이지를 kmem_cache_node 크기 단위로 나누어 수동으로 슬랩 object를 구성한다. 그런 후 첫 object 항목을 할당 받아 kmem_cache_node 구조체 정보를 구성한다.
- 슬랩 시스템이 조금이라도 가동하면 가장 처음 준비한 슬랩 캐시가 kmem_cache_node 슬랩 캐시이다. 이를 통해 object를 할당 받고 초기화 루틴을 수행한다.
kmem_cache_node early 초기화
early_kmem_cache_node_alloc()
mm/slub.c
/* * No kmalloc_node yet so do it by hand. We know that this is the first * slab on the node for this slabcache. There are no concurrent accesses * possible. * * Note that this function only works on the kmem_cache_node * when allocating for the kmem_cache_node. This is used for bootstrapping * memory on a fresh node that has no slab structures yet. */
static void early_kmem_cache_node_alloc(int node)
{
struct page *page;
struct kmem_cache_node *n;
BUG_ON(kmem_cache_node->size < sizeof(struct kmem_cache_node));
page = new_slab(kmem_cache_node, GFP_NOWAIT, node);
BUG_ON(!page);
if (page_to_nid(page) != node) {
pr_err("SLUB: Unable to allocate memory from node %d\n", node);
pr_err("SLUB: Allocating a useless per node structure in order to be able to continuu
e\n");
}
n = page->freelist;
BUG_ON(!n);
#ifdef CONFIG_SLUB_DEBUG
init_object(kmem_cache_node, n, SLUB_RED_ACTIVE);
init_tracking(kmem_cache_node, n);
#endif
n = kasan_kmalloc(kmem_cache_node, n, sizeof(struct kmem_cache_node),
GFP_KERNEL);
page->freelist = get_freepointer(kmem_cache_node, n);
page->inuse = 1;
page->frozen = 0;
kmem_cache_node->node[node] = n;
init_kmem_cache_node(n);
inc_slabs_node(kmem_cache_node, node, page->objects);
/*
* No locks need to be taken here as it has just been
* initialized and there is no concurrent access.
*/
__add_partial(n, page, DEACTIVATE_TO_HEAD);
}
아직 슬랩 시스템이 하나도 가동되지 않은 상태인 경우에는 슬랩 object를 할당받는 kmem_cache_alloc() 함수 등을 사용할 수 없다. 그래서 버디시스템으로 부터 슬랩 용도의 페이지를 할당 받아올 수 있는 new_slab() 함수를 대신 사용하였다. 이 과정은 동시 처리를 보장하지 않으며 오직 슬랩 캐시를 만들기 위해 처음 kmem_cache_node를 구성하기 위해서만 사용될 수 있다. (커널 메모리 캐시 시스템을 운영하기 위해 가장 처음에 만들 캐시는 kmem_cache_node 라는 이름이며 이 캐시를 통해 kmem_cache_node object를 공급해 주어야 한다.)
- 코드 라인 8에서 kmem_cache_node 구조체에 사용할 슬랩 페이지를 할당 받아온다
- slub 시스템이 아직 동작하지 않아 slub object로 할당을 받지 못하므로 버디 시스템으로 부터 페이지를 할당 받아 슬랩 페이지로 구성한다.
- 코드 라인 11~15에서 할당 받은 슬랩 페이지가 리모트 노드인경우 경고를 출력한다.
- “SLUB: Unable to allocate memory from node %d\n”
- “SLUB: Allocating a useless per node structure in order to be able to continue\n”
- 코드 라인 17~29에서 할당받은 kmem_cache_node용 슬랩 페이지를 초기화하고 per 노드에 할당받은 첫 object를 연결한다.
- 코드 라인 30~31에서 kmem_cache_node를 초기화한다. 슬랩 캐시 카운터를 증가시킨다.
- 코드 라인 37에서 노드의 partial 리스트에 추가한다.
init_kmem_cache_node()
mm/slub.c
static void
init_kmem_cache_node(struct kmem_cache_node *n)
{
n->nr_partial = 0;
spin_lock_init(&n->list_lock);
INIT_LIST_HEAD(&n->partial);
#ifdef CONFIG_SLUB_DEBUG
atomic_long_set(&n->nr_slabs, 0);
atomic_long_set(&n->total_objects, 0);
INIT_LIST_HEAD(&n->full);
#endif
}
per 노드에 대한 초기화를 수행한다.
- per 노드의 partial 리스트에 등록된 slub 페이지는 0으로 초기화
- per 노드의 partial 리스트를 초기화
inc_slabs_node()
static inline void inc_slabs_node(struct kmem_cache *s, int node, int objects)
{
struct kmem_cache_node *n = get_node(s, node);
/*
* May be called early in order to allocate a slab for the
* kmem_cache_node structure. Solve the chicken-egg
* dilemma by deferring the increment of the count during
* bootstrap (see early_kmem_cache_node_alloc).
*/
if (likely(n)) {
atomic_long_inc(&n->nr_slabs);
atomic_long_add(objects, &n->total_objects);
}
}
CONFIG_SLUB_DEBUG 커널 옵션이 사용될 때에 동작하며 지정 노드에 대한 slab 수를 증가시킨다.
__add_partial()
/* * Management of partially allocated slabs. */
static inline void
__add_partial(struct kmem_cache_node *n, struct page *page, int tail)
{
n->nr_partial++;
if (tail == DEACTIVATE_TO_TAIL)
list_add_tail(&page->lru, &n->partial);
else
list_add(&page->lru, &n->partial);
}
slub 페이지를 지정된 per 노드의 partial 리스트의 선두 또는 후미에 tail 옵션에 따라 방향을 결정하여 추가한다. 또한 해당 노드의 partial 수를 증가시킨다.
참고
- Slab Memory Allocator -1- (구조) | 문c
- Slab Memory Allocator -2- (캐시 초기화) | 문c
- Slub Memory Allocator -3- (캐시 생성) | 문c – 현재 글
- Slub Memory Allocator -4- (Order 계산) | 문c
- Slub Memory Allocator -5- (Slub 할당) | 문c
- Slub Memory Allocator -6- (Object 할당) | 문c
- Slub Memory Allocator -7- (Object 해제) | 문c
- Slub Memory Allocator -8- (Drain/Flash 캐시) | 문c
- Slub Memory Allocator -9- (캐시 Shrink) | 문c
- Slub Memory Allocator -10- (Slub 해제) | 문c
- Slub Memory Allocator -11- (캐시 삭제) | 문c
- Slub Memory Allocator -12- (Slub 디버깅) | 문c
- Slub Memory Allocator -13- (slabinfo) | 문c