<kernel v5.4>
RCU(Read Copy Update) -6- (Expedited GP)
Brute-force RCU-sched grace period(Expedited Grace Period)
고속 네트워크(10G, 100G) 장치를 사용하는 경우 gp 완료를 늦게 감지하면 메모리의 clean-up이 지연되어 OOM(Out Of Memory)가 발생하여 다운될 수도 있다. 이러한 경우를 위해 expedited gp 대기 방식을 사용하면 기본 normal gp 대기 방식보다 더 빠르게 gp의 완료를 수행할 수 있다. 강제로 idle cpu를 제외한 online cpu들에 대해 IPI call을 호출하여 강제로 interrupt context를 발생시키고 메모리 배리어를 호출한다. 이렇게 하는 것으로 호출된 각 cpu의 context 스위칭을 빠르게 유발하여 qs를 보고하게 한다. 이 방법은 모든 cpu들에 대해 ipi call을 호출하므로 대단위 cpu 시스템에서는 많은 cost가 소요되는 단점이 있다.
- 참고: Expedited-Grace-Periods | Kernel.org
sysfs 설정
rcu expedited GP와 관련한 다음 두 설정이 있다.
- /sys/kernel/rcu_expedited
- 1로 설정되면 일반 RCU grace period 방법을 사용하는 대신 Brute-force RCU grace period 방법을 사용한다.
- /sys/kernel/rcu_normal
- 1로 설정되면 Brute-force RCU grace period 방법을 사용하고 있는 중이더라도 일반 RCU grace period 방법을 사용하도록 한다.
boot-up 시 expdited gp 동작
메모리가 적은 시스템의 경우 rcu 스케줄러가 준비되기 전에 쌓이는 콜백들로 인해 지연 처리되느라 OOM이 발생될 수 있다. 이를 회피하기 위해 커널 부트업 타임에 잠시 expedited gp 모드로 동작하고 다시 일반 gp 모드로 복귀하는데 다음 카운터를 사용한다. 물론 위의 커널 파라미터를 통해 enable하여 운영할 수도 있다.
- rcu_expedited_nesting
- 초기 값으로 1이 지정된다. (부트업 cpu를 위해)
- 커널 boot-up이 끝날 때 감소 된다.
- secondary-cpu
- hotplug online시 rcu_expedite_gp() 함수가 호출되며 증가된다.
- hotplug offline시 rcu_unexpedite_gp() 함수가 호출되어 감소된다.
boot-up 종료에 따른 expedited gp 모드 종료
rcu_end_inkernel_boot()
kernel/rcu/update.c
/* * Inform RCU of the end of the in-kernel boot sequence. */
void rcu_end_inkernel_boot(void)
{
rcu_unexpedite_gp();
if (rcu_normal_after_boot)
WRITE_ONCE(rcu_normal, 1);
}
expedited gp를 종료하기 위해 카운터를 감소시킨다. 만일 모듈 파라미터 “rcu_end_inkernel_boot”를 설정한 경우 0번 cpu의 부트업이 완료된 이후에는 항상 normal gp 모드로 동작한다.
rcu_expedite_gp()
kernel/rcu/update.c
/** * rcu_expedite_gp - Expedite future RCU grace periods * * After a call to this function, future calls to synchronize_rcu() and * friends act as the corresponding synchronize_rcu_expedited() function * had instead been called. */
void rcu_expedite_gp(void)
{
atomic_inc(&rcu_expedited_nesting);
}
EXPORT_SYMBOL_GPL(rcu_expedite_gp);
expedited gp를 종료하기 위해 카운터를 증가시킨다. (secondary cpu가 부트업될 때 사용된다)
rcu_unexpedite_gp()
kernel/rcu/update.c
/** * rcu_unexpedite_gp - Cancel prior rcu_expedite_gp() invocation * * Undo a prior call to rcu_expedite_gp(). If all prior calls to * rcu_expedite_gp() are undone by a subsequent call to rcu_unexpedite_gp(), * and if the rcu_expedited sysfs/boot parameter is not set, then all * subsequent calls to synchronize_rcu() and friends will return to * their normal non-expedited behavior. */
void rcu_unexpedite_gp(void)
{
atomic_dec(&rcu_expedited_nesting);
}
EXPORT_SYMBOL_GPL(rcu_unexpedite_gp);
expedited gp를 종료하기 위해 카운터를 감소시킨다.
rcu_gp_is_expedited()
kernel/rcu/update.c
/* * Should normal grace-period primitives be expedited? Intended for * use within RCU. Note that this function takes the rcu_expedited * sysfs/boot variable and rcu_scheduler_active into account as well * as the rcu_expedite_gp() nesting. So looping on rcu_unexpedite_gp() * until rcu_gp_is_expedited() returns false is a -really- bad idea. */
bool rcu_gp_is_expedited(void)
{
return rcu_expedited || atomic_read(&rcu_expedited_nesting);
}
EXPORT_SYMBOL_GPL(rcu_gp_is_expedited);
RCU GP 대기 시 급행 방법 사용 여부를 반환한다.
- /sys/kernel/rcu_expedited 값이 설정된 경우 일반 RCU grace period 방법을 사용하는 대신 Brute-force RCU grace period 방법을 사용한다.
- 커널 부트업 시 expedited gp 모드로 동작시킨다.
rcu_gp_is_normal()
kernel/rcu/update.c
/* * Should expedited grace-period primitives always fall back to their * non-expedited counterparts? Intended for use within RCU. Note * that if the user specifies both rcu_expedited and rcu_normal, then * rcu_normal wins. (Except during the time period during boot from * when the first task is spawned until the rcu_set_runtime_mode() * core_initcall() is invoked, at which point everything is expedited.) */
bool rcu_gp_is_normal(void)
{
return READ_ONCE(rcu_normal) &&
rcu_scheduler_active != RCU_SCHEDULER_INIT;
}
EXPORT_SYMBOL_GPL(rcu_gp_is_normal);
RCU GP 대기 시 normal 방법 사용 여부를 반환한다.
- /sys/kernel/rcu_normal 값이 설정된 경우 gp 대기를 위해 일반 RCU grace period 방법을 사용한다. (expedited gp 방식을 사용중이더라도)
급행 GP 시퀀스 번호
rcu_exp_gp_seq_start()
kernel/rcu/tree_exp.h
/* * Record the start of an expedited grace period. */
static void rcu_exp_gp_seq_start(void)
{
rcu_seq_start(&rcu_state.expedited_sequence);
}
급행 gp 시작을 위해 급행 gp 시퀀스를 1 증가시킨다.
rcu_exp_gp_seq_endval()
kernel/rcu/tree_exp.h
/* * Return then value that expedited-grace-period counter will have * at the end of the current grace period. */
static __maybe_unused unsigned long rcu_exp_gp_seq_endval(void)
{
return rcu_seq_endval(&rcu_state.expedited_sequence);
}
급행 gp 종료를 위해 급행 gp 시퀀스의 카운터 부분을 1 증가시키고, 상태 값은 0(gp idle)인 값을 반환한다.
rcu_exp_gp_seq_end()
kernel/rcu/tree_exp.h
/* * Record the end of an expedited grace period. */
static void rcu_exp_gp_seq_end(void)
{
rcu_seq_end(&rcu_state.expedited_sequence);
smp_mb(); /* Ensure that consecutive grace periods serialize. */
}
급행 gp 종료를 위해 급행 gp 시퀀스의 카운터 부분을 1 증가시키고, 상태 값은 0(gp idle)으로 변경한다.
rcu_exp_gp_seq_snap()
kernel/rcu/tree_exp.h
/* * Take a snapshot of the expedited-grace-period counter. */
static unsigned long rcu_exp_gp_seq_snap(void)
{
unsigned long s;
smp_mb(); /* Caller's modifications seen first by other CPUs. */
s = rcu_seq_snap(&rcu_state.expedited_sequence);
trace_rcu_exp_grace_period(rcu_state.name, s, TPS("snap"));
return s;
}
급행 gp 시퀀스의 다음 단계 뒤의 급행 gp 시퀀스를 반환한다. (gp가 진행 중인 경우 안전하게 두 단계 뒤의 급행 gp 시퀀스를 반환하고, gp가 idle 상태인 경우 다음 단계 뒤의 급행 gp 시퀀스 번호를 반환한다.)
- 예) sp=8 (idle)
- 12 (idle, 1단계 뒤)
- 예) sp=9 (start)
- 16 (idle, 2단계 뒤)
rcu_exp_gp_seq_done()
kernel/rcu/tree_exp.h
/* * Given a counter snapshot from rcu_exp_gp_seq_snap(), return true * if a full expedited grace period has elapsed since that snapshot * was taken. */
static bool rcu_exp_gp_seq_done(unsigned long s)
{
return rcu_seq_done(&rcu_state.expedited_sequence, s);
}
스냅샷 @s를 통해 급행 gp가 완료되었는지 여부를 반환한다.
- 급행 gp 시퀀스 >= 스냅샷 @s
동기화용 급행 rcu gp 대기
다음 그림은 급행 gp 완료를 대기하는 함수의 호출 과정을 보여준다.
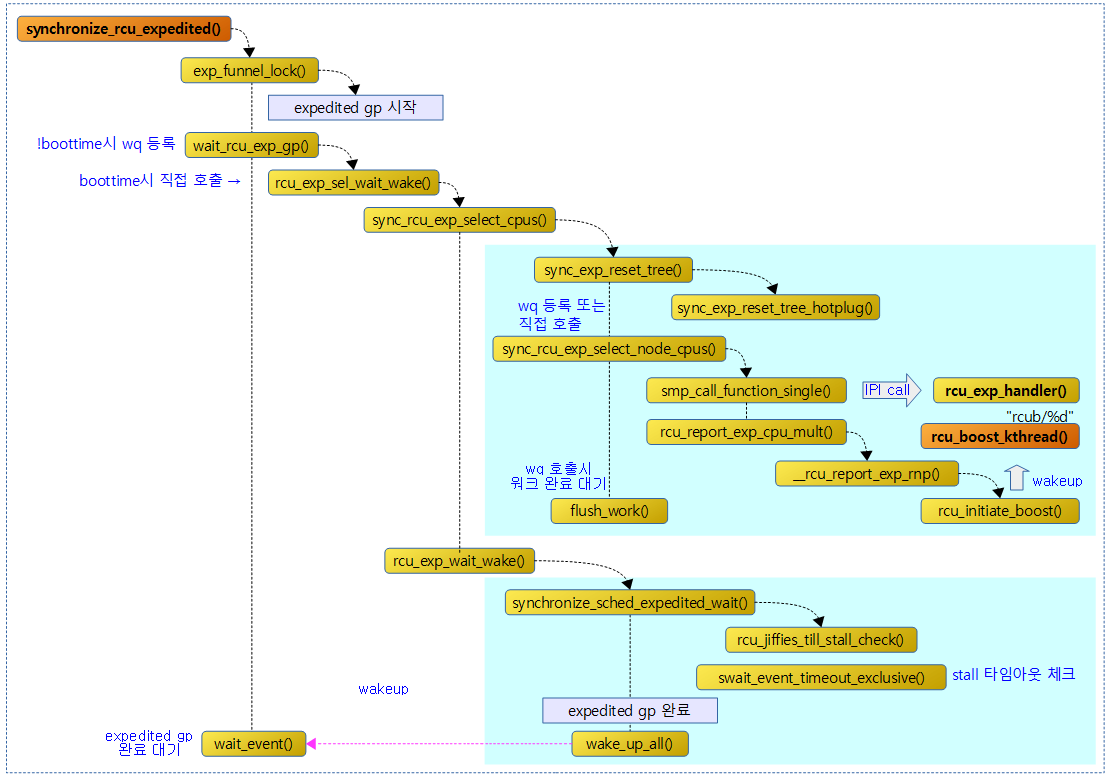
synchronize_rcu_expedited()
kernel/rcu/tree_exp.h
/** * synchronize_rcu_expedited - Brute-force RCU grace period * * Wait for an RCU grace period, but expedite it. The basic idea is to * IPI all non-idle non-nohz online CPUs. The IPI handler checks whether * the CPU is in an RCU critical section, and if so, it sets a flag that * causes the outermost rcu_read_unlock() to report the quiescent state * for RCU-preempt or asks the scheduler for help for RCU-sched. On the * other hand, if the CPU is not in an RCU read-side critical section, * the IPI handler reports the quiescent state immediately. * * Although this is a great improvement over previous expedited * implementations, it is still unfriendly to real-time workloads, so is * thus not recommended for any sort of common-case code. In fact, if * you are using synchronize_rcu_expedited() in a loop, please restructure * your code to batch your updates, and then Use a single synchronize_rcu() * instead. * * This has the same semantics as (but is more brutal than) synchronize_rcu(). */
void synchronize_rcu_expedited(void)
{
bool boottime = (rcu_scheduler_active == RCU_SCHEDULER_INIT);
struct rcu_exp_work rew;
struct rcu_node *rnp;
unsigned long s;
RCU_LOCKDEP_WARN(lock_is_held(&rcu_bh_lock_map) ||
lock_is_held(&rcu_lock_map) ||
lock_is_held(&rcu_sched_lock_map),
"Illegal synchronize_rcu_expedited() in RCU read-side critical section");
/* Is the state is such that the call is a grace period? */
if (rcu_blocking_is_gp())
return;
/* If expedited grace periods are prohibited, fall back to normal. */
if (rcu_gp_is_normal()) {
wait_rcu_gp(call_rcu);
return;
}
/* Take a snapshot of the sequence number. */
s = rcu_exp_gp_seq_snap();
if (exp_funnel_lock(s))
return; /* Someone else did our work for us. */
/* Ensure that load happens before action based on it. */
if (unlikely(boottime)) {
/* Direct call during scheduler init and early_initcalls(). */
rcu_exp_sel_wait_wake(s);
} else {
/* Marshall arguments & schedule the expedited grace period. */
rew.rew_s = s;
INIT_WORK_ONSTACK(&rew.rew_work, wait_rcu_exp_gp);
queue_work(rcu_gp_wq, &rew.rew_work);
}
/* Wait for expedited grace period to complete. */
rnp = rcu_get_root();
wait_event(rnp->exp_wq[rcu_seq_ctr(s) & 0x3],
sync_exp_work_done(s));
smp_mb(); /* Workqueue actions happen before return. */
/* Let the next expedited grace period start. */
mutex_unlock(&rcu_state.exp_mutex);
if (likely(!boottime))
destroy_work_on_stack(&rew.rew_work);
}
EXPORT_SYMBOL_GPL(synchronize_rcu_expedited);
Brute-force RCU grace period 방법을 사용하여 gp가 완료될 때까지 기다린다. 이 방법을 사용할 수 없는 상황인 경우 일반 gp를 대기하는 방식을 사용한다.
- 코드 라인 14~15에서 아직 rcu의 gp 사용이 블러킹상태인 경우엔 gp 대기 없이 곧바로 함수를 빠져나간다.
- 코드 라인 18~21에서 sysfs를 통해 rcu normal 방식을 사용하도록 강제한 경우 normal 방식의 gp 대기를 사용하는 wait_rcu_gp() 함수를 호출한 후 함수를 빠져나간다.
- “/sys/kernel/rcu_normal”에 1이 기록된 경우이다. 디폴트 값은 0이다.
- 코드 라인 24에서 expedited 용 gp 시퀀스의 스냅샷을 얻어온다.
- gp idle에서는 다음 gp 번호를 얻어오고, gp 진행 중일때에는 다다음 gp 번호를 얻어온다.
- 코드 라인 25~26에서 expedited gp를 위한 funnel-lock을 획득해온다. 만일 다른 cpu에서 먼저 처리중이라면 함수를 빠져나간다.
- 코드 라인 29~37에서 낮은 확률로 early 부트중인 경우에는 현재 cpu가 직접 호출하여 급행 gp 대기 처리를 수행하고, 그렇지 않은 경우 워크 큐를 사용하여 처리하도록 wait_rcu_exp_gp() 워크 함수를 엔큐한다.
- 코드 라인 40~42에서 루트 노드의 expedited gp의 완료까지 대기한다. (TASK_UNINTERRUPTIBLE 상태로 슬립한다.)
- 코드 라인 48~50에서 사용한 워크를 삭제한다.
exp_funnel_lock()
kernel/rcu/tree_exp.h
/* * Funnel-lock acquisition for expedited grace periods. Returns true * if some other task completed an expedited grace period that this task * can piggy-back on, and with no mutex held. Otherwise, returns false * with the mutex held, indicating that the caller must actually do the * expedited grace period. */
static bool exp_funnel_lock(unsigned long s)
{
struct rcu_data *rdp = per_cpu_ptr(&rcu_data, raw_smp_processor_id());
struct rcu_node *rnp = rdp->mynode;
struct rcu_node *rnp_root = rcu_get_root();
/* Low-contention fastpath. */
if (ULONG_CMP_LT(READ_ONCE(rnp->exp_seq_rq), s) &&
(rnp == rnp_root ||
ULONG_CMP_LT(READ_ONCE(rnp_root->exp_seq_rq), s)) &&
mutex_trylock(&rcu_state.exp_mutex))
goto fastpath;
/*
* Each pass through the following loop works its way up
* the rcu_node tree, returning if others have done the work or
* otherwise falls through to acquire ->exp_mutex. The mapping
* from CPU to rcu_node structure can be inexact, as it is just
* promoting locality and is not strictly needed for correctness.
*/
for (; rnp != NULL; rnp = rnp->parent) {
if (sync_exp_work_done(s))
return true;
/* Work not done, either wait here or go up. */
spin_lock(&rnp->exp_lock);
if (ULONG_CMP_GE(rnp->exp_seq_rq, s)) {
/* Someone else doing GP, so wait for them. */
spin_unlock(&rnp->exp_lock);
trace_rcu_exp_funnel_lock(rcu_state.name, rnp->level,
rnp->grplo, rnp->grphi,
TPS("wait"));
wait_event(rnp->exp_wq[rcu_seq_ctr(s) & 0x3],
sync_exp_work_done(s));
return true;
}
rnp->exp_seq_rq = s; /* Followers can wait on us. */
spin_unlock(&rnp->exp_lock);
trace_rcu_exp_funnel_lock(rcu_state.name, rnp->level,
rnp->grplo, rnp->grphi, TPS("nxtlvl"));
}
mutex_lock(&rcu_state.exp_mutex);
fastpath:
if (sync_exp_work_done(s)) {
mutex_unlock(&rcu_state.exp_mutex);
return true;
}
rcu_exp_gp_seq_start();
trace_rcu_exp_grace_period(rcu_state.name, s, TPS("start"));
return false;
}
급행 gp 완료 대기를 위해 funnel 락을 획득하고 급행 gp 시퀀스를 시작한다. 만일 이미 급행 gp가 완료된 상태라면 true를 반환한다.
- 코드 라인 8~12에서 다음 조건의 경우 빠른 처리를 위해 fastpath 레이블로 이동한다.
- 루트 노드의 급행 gp 시퀀스 번호 < 스냅샷 @s 이고, 글로벌 락(rcu_state.exp_mutex)의 획득을 시도하여 얻을 수 있는 경우
- 코드 라인 21~23에서 해당 노드부터 최상위 루트 노드까시 순회하며 이미 급행 gp 시퀀스가 완료됨을 확인하면 true를 반환한다.
- 스냅샷을 받은 후 시간이 흘러 급행 gp가 이미 완료될 수도 있다.
- rcu_state->expedited_sequence >= 스냅샷 @s
- 스냅샷을 받은 후 시간이 흘러 급행 gp가 이미 완료될 수도 있다.
- 코드 라인 26~39에서 노드 락을 획득한 채로 노드의 급행 gp 시퀀스 번호를 스냅샷 @s로 갱신한다. 만일 노드의 급행 시퀀스 번호 >= 스냅샷 @s 인 경우에는 누군가 gp 중에 있는 것이므로 급행 gp가 완료될때까지 대기한 후 true를 반환한다.
- 코드 라인 44~48에서 fastpath: 레이블이다. 급행 gp가 이미 완료된 경우 뮤텍스 락을 해제한 후 true를 반환한다.
- 코드 라인 49에서 급행 gp 시퀀스 번호를 1 증가시켜 새로운 gp 시작 상태로 변경한다.
- 코드 라인 51에서 false를 반환한다.
sync_exp_work_done()
kernel/rcu/tree_exp.h
/* Common code for work-done checking. */
static bool sync_exp_work_done(unsigned long s)
{
if (rcu_exp_gp_seq_done(s)) {
trace_rcu_exp_grace_period(rcu_state.name, s, TPS("done"));
smp_mb(); /* Ensure test happens before caller kfree(). */
return true;
}
return false;
}
급행 gp 시퀀스의 스냅샷 @s 값을 기준으로 기존 급행 gp가 완료되었는지 여부를 반환한다.
- rcu_state->expedited_sequence >= 스냅샷 @s
워크큐 핸들러
wait_rcu_exp_gp()
kernel/rcu/tree_exp.h
/* * Work-queue handler to drive an expedited grace period forward. */
static void wait_rcu_exp_gp(struct work_struct *wp)
{
struct rcu_exp_work *rewp;
rewp = container_of(wp, struct rcu_exp_work, rew_work);
rcu_exp_sel_wait_wake(rewp->rew_s);
}
급행 gp를 처리하는 워크큐 핸들러이다. 급행 qs 처리 완료시까지 대기한 후 블럭된 gp 태스크를 wakeup 한다.
rcu_exp_sel_wait_wake()
kernel/rcu/tree_exp.h
/* * Common code to drive an expedited grace period forward, used by * workqueues and mid-boot-time tasks. */
static void rcu_exp_sel_wait_wake(unsigned long s)
{
/* Initialize the rcu_node tree in preparation for the wait. */
sync_rcu_exp_select_cpus();
/* Wait and clean up, including waking everyone. */
rcu_exp_wait_wake(s);
}
급행 qs 처리 완료시까지 대기한 후 블럭된 gp 태스크를 wakeup 한다.
- 코드 라인 4에서 급행 처리할 cpu들을 선택한 후 완료를 기다린다
- 코드 라인 7에서 급행 gp 시퀀스를 완료하고 급행 gp 대기 중인 태스크들을 wakeup 한다.
sync_rcu_exp_select_cpus()
kernel/rcu/tree_exp.h
/* * Select the nodes that the upcoming expedited grace period needs * to wait for. */
static void sync_rcu_exp_select_cpus(void)
{
int cpu;
struct rcu_node *rnp;
trace_rcu_exp_grace_period(rcu_state.name, rcu_exp_gp_seq_endval(), TPS("reset"));
sync_exp_reset_tree();
trace_rcu_exp_grace_period(rcu_state.name, rcu_exp_gp_seq_endval(), TPS("select"));
/* Schedule work for each leaf rcu_node structure. */
rcu_for_each_leaf_node(rnp) {
rnp->exp_need_flush = false;
if (!READ_ONCE(rnp->expmask))
continue; /* Avoid early boot non-existent wq. */
if (!READ_ONCE(rcu_par_gp_wq) ||
rcu_scheduler_active != RCU_SCHEDULER_RUNNING ||
rcu_is_last_leaf_node(rnp)) {
/* No workqueues yet or last leaf, do direct call. */
sync_rcu_exp_select_node_cpus(&rnp->rew.rew_work);
continue;
}
INIT_WORK(&rnp->rew.rew_work, sync_rcu_exp_select_node_cpus);
cpu = find_next_bit(&rnp->ffmask, BITS_PER_LONG, -1);
/* If all offline, queue the work on an unbound CPU. */
if (unlikely(cpu > rnp->grphi - rnp->grplo))
cpu = WORK_CPU_UNBOUND;
else
cpu += rnp->grplo;
queue_work_on(cpu, rcu_par_gp_wq, &rnp->rew.rew_work);
rnp->exp_need_flush = true;
}
/* Wait for workqueue jobs (if any) to complete. */
rcu_for_each_leaf_node(rnp)
if (rnp->exp_need_flush)
flush_work(&rnp->rew.rew_work);
}
급행 처리할 cpu들을 선택한 후 완료를 기다린다.
- 코드 라인 7에서 모든 rcu 노드들의 expmask를 리셋한다.
- 코드 라인 11~14에서 leaf 노드들을 순회하며 처리가 필요 없는 노드(expmask가 0)는 skip 한다.
- 노드의 exp_need_flush 변수는 워크큐 작업을 사용하는 경우에만 노드의 워크큐 작업이 완료되었는지 확인하는 용도로 사용한다.
- 코드 라인 15~21에서 다음 조건들 중 하나라도 해당하는 경우 현재 cpu가 sync_rcu_exp_select_node_cpus() 함수를 직접 호출하여 처리하도록 한다. 그런 후 다음 처리를 위해 skip 한다.
- 워크큐 rcu_par_gp_wq 가 아직 준비되지 않은 경우
- rcu 스케줄러가 아직 동작하지 않는 경우
- 가장 마지막 leaf 노드인 경우
- 코드 라인 22~30에서 rcu용 워크큐(rcu_par_gp_wq)를 통해 cpu bound(해당 cpu)에서 또는 cpu unbound 하에 sync_rcu_exp_select_node_cpus() 함수가 실행되도록 워크를 실행한다. 그 후 exp_need_flush를 설정하고, 작업 완료 후 이 값이 클리어된다.
- 코드 라인 34~36에서 모든 노드에 대해 워크큐에서 실행한 작업이 완료되지 않은 경우(exp_need_flush == true) 완료 시까지 대기한다.
모든 노드들의 expmask 재설정
sync_exp_reset_tree()
kernel/rcu/tree_exp.h
/* * Reset the ->expmask values in the rcu_node tree in preparation for * a new expedited grace period. */
static void __maybe_unused sync_exp_reset_tree(void)
{
unsigned long flags;
struct rcu_node *rnp;
sync_exp_reset_tree_hotplug();
rcu_for_each_node_breadth_first(rnp) {
raw_spin_lock_irqsave_rcu_node(rnp, flags);
WARN_ON_ONCE(rnp->expmask);
rnp->expmask = rnp->expmaskinit;
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
}
}
새 급행 gp를 위한 준비로 모든 노드들을 재설정한다.
- 코드 라인 6에서 최근 online된 cpu를 반영하여 각 노드의 expmaskinit 값을 재설정한다.
- 코드 라인 7~12에서 루트부터 모든 노드를 순회하며 expmask를 expmaskinit 값으로 재설정한다.
sync_exp_reset_tree_hotplug()
kernel/rcu/tree_exp.h
/* * Reset the ->expmaskinit values in the rcu_node tree to reflect any * recent CPU-online activity. Note that these masks are not cleared * when CPUs go offline, so they reflect the union of all CPUs that have * ever been online. This means that this function normally takes its * no-work-to-do fastpath. */
static void sync_exp_reset_tree_hotplug(void)
{
bool done;
unsigned long flags;
unsigned long mask;
unsigned long oldmask;
int ncpus = smp_load_acquire(&rcu_state.ncpus); /* Order vs. locking. */
struct rcu_node *rnp;
struct rcu_node *rnp_up;
/* If no new CPUs onlined since last time, nothing to do. */
if (likely(ncpus == rcu_state.ncpus_snap))
return;
rcu_state.ncpus_snap = ncpus;
/*
* Each pass through the following loop propagates newly onlined
* CPUs for the current rcu_node structure up the rcu_node tree.
*/
rcu_for_each_leaf_node(rnp) {
raw_spin_lock_irqsave_rcu_node(rnp, flags);
if (rnp->expmaskinit == rnp->expmaskinitnext) {
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
continue; /* No new CPUs, nothing to do. */
}
/* Update this node's mask, track old value for propagation. */
oldmask = rnp->expmaskinit;
rnp->expmaskinit = rnp->expmaskinitnext;
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
/* If was already nonzero, nothing to propagate. */
if (oldmask)
continue;
/* Propagate the new CPU up the tree. */
mask = rnp->grpmask;
rnp_up = rnp->parent;
done = false;
while (rnp_up) {
raw_spin_lock_irqsave_rcu_node(rnp_up, flags);
if (rnp_up->expmaskinit)
done = true;
rnp_up->expmaskinit |= mask;
raw_spin_unlock_irqrestore_rcu_node(rnp_up, flags);
if (done)
break;
mask = rnp_up->grpmask;
rnp_up = rnp_up->parent;
}
}
}
최근 online된 cpu를 반영하여 각 노드의 expmaskinit 값을 재설정한다.
- 코드 라인 12~14에서 cpu 수가 변경된 경우 rcu_state.ncpus_snaap에 이를 반영한다. 온라인 이후로 새 cpu 추가가 없는 경우 함수를 빠져나간다.
- 코드 라인 20~25에서 leaf 노드들을 순회하며 노드에 새 cpu 변화가 없으면 skip 한다.
- 코드 라인 28~29에서 기존 expmaskinit 비트들을 oldmask에 담아둔 후, 새 노드에 반영된 expmaskinitnext 비트들을 expmaskinit에 대입한다.
- 코드 라인 33~34에서 oldmask가 존재하는 경우 상위로 전파할 필요 없으므로 skip 한다.
- 코드 라인 37~50에서 상위 노드의 expmaskinit에 하위 grpmask를 추가하여 전파하되, 상위 노드의 expmaskinit에 값이 있었던 경우 더 이상 부모 노드로 이동하지 않고 루프를 탈출한다.
다음 그림은 최근 추가 online된 cpu를 반영하여 각 leaf 노드의 expmaskinit 값이 재설정되는 과정을 보여준다.
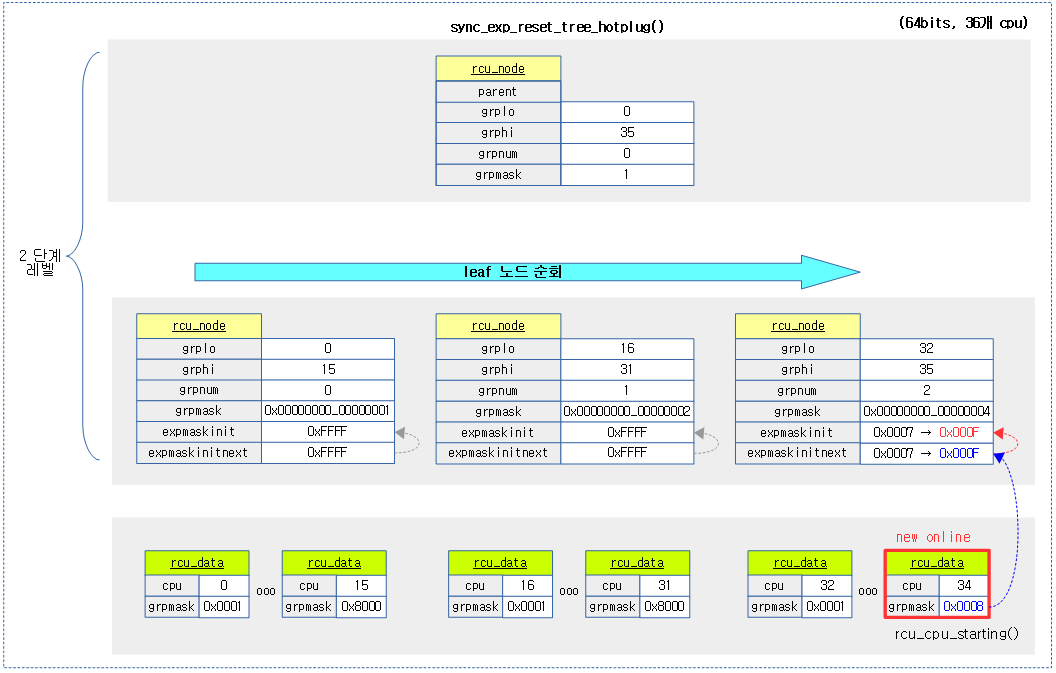
sync_rcu_exp_select_node_cpus()
kernel/rcu/tree_exp.h
/* * Select the CPUs within the specified rcu_node that the upcoming * expedited grace period needs to wait for. */
static void sync_rcu_exp_select_node_cpus(struct work_struct *wp)
{
int cpu;
unsigned long flags;
unsigned long mask_ofl_test;
unsigned long mask_ofl_ipi;
int ret;
struct rcu_exp_work *rewp =
container_of(wp, struct rcu_exp_work, rew_work);
struct rcu_node *rnp = container_of(rewp, struct rcu_node, rew);
raw_spin_lock_irqsave_rcu_node(rnp, flags);
/* Each pass checks a CPU for identity, offline, and idle. */
mask_ofl_test = 0;
for_each_leaf_node_cpu_mask(rnp, cpu, rnp->expmask) {
struct rcu_data *rdp = per_cpu_ptr(&rcu_data, cpu);
unsigned long mask = rdp->grpmask;
int snap;
if (raw_smp_processor_id() == cpu ||
!(rnp->qsmaskinitnext & mask)) {
mask_ofl_test |= mask;
} else {
snap = rcu_dynticks_snap(rdp);
if (rcu_dynticks_in_eqs(snap))
mask_ofl_test |= mask;
else
rdp->exp_dynticks_snap = snap;
}
}
mask_ofl_ipi = rnp->expmask & ~mask_ofl_test;
/*
* Need to wait for any blocked tasks as well. Note that
* additional blocking tasks will also block the expedited GP
* until such time as the ->expmask bits are cleared.
*/
if (rcu_preempt_has_tasks(rnp))
WRITE_ONCE(rnp->exp_tasks, rnp->blkd_tasks.next);
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
/* IPI the remaining CPUs for expedited quiescent state. */
for_each_leaf_node_cpu_mask(rnp, cpu, mask_ofl_ipi) {
struct rcu_data *rdp = per_cpu_ptr(&rcu_data, cpu);
unsigned long mask = rdp->grpmask;
retry_ipi:
if (rcu_dynticks_in_eqs_since(rdp, rdp->exp_dynticks_snap)) {
mask_ofl_test |= mask;
continue;
}
if (get_cpu() == cpu) {
put_cpu();
continue;
}
ret = smp_call_function_single(cpu, rcu_exp_handler, NULL, 0);
put_cpu();
/* The CPU will report the QS in response to the IPI. */
if (!ret)
continue;
/* Failed, raced with CPU hotplug operation. */
raw_spin_lock_irqsave_rcu_node(rnp, flags);
if ((rnp->qsmaskinitnext & mask) &&
(rnp->expmask & mask)) {
/* Online, so delay for a bit and try again. */
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
trace_rcu_exp_grace_period(rcu_state.name, rcu_exp_gp_seq_endval(), TPS("selectofl"));
schedule_timeout_idle(1);
goto retry_ipi;
}
/* CPU really is offline, so we must report its QS. */
if (rnp->expmask & mask)
mask_ofl_test |= mask;
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
}
/* Report quiescent states for those that went offline. */
if (mask_ofl_test)
rcu_report_exp_cpu_mult(rnp, mask_ofl_test, false);
}
선택 cpu들에 IPI 호출을 통해 급행 qs를 처리하도록 강제하고 완료시까지 기다린다.
- 코드 라인 8~10에서 인자로 전달 받은 워크를 통해 rcu_exp_work와 rcu_node를 알아온다.
- 코드 라인 15~32에서 ipi 호출 대상은 rnp->expmask 중 mask_ofl_test 비트들을 산출시킨 후 제외한다. rnp leaf 노드의 cpu를 순회하며 다음에 해당하는 cpu들을 대상에서 제외시키기 위해 mask_ofl_test에 추가(or) 한다.참고로 mask는 cpu 번호에 해당하는 cpu 마스크를 그대로 사용하는 것이 아니라 BIT(cpu – grplo)로 취급된다.
- 현재 cpu
- 해당 cpu가 qsmaskinitnext에 없는 경우
- 새 dynaticks snap 값이 확장(extended) qs 상태인 경우
- 코드 라인 39~40에서 preempt 커널의 rcu critical 섹션에서 preempt되어 발생되는 블럭드 태스크가 존재하는 경우 exp_tasks 리스트가 해당 블럭드 태스크를 제외시키고 다음 태스크를 가리키게 한다.
- 코드 라인 44에서 leaf 노드에 소속된 cpu 중 mask_ofl_ipi에 포함된 cpu들만을 순회한다.
- 코드 라인 48~52에서 retry_ipi: 레이블이다. 이미 dynticks로 확장(extended) qs 시간을 보낸 경우 확장 qs의 완료 처리를 위해 해당 cpu를 mask_ofl_test에 추가(or)한다.
- 코드 라인 53~56에서 현재 cpu는 ipi 대상에서 skip 한다.
- 코드 라인 57~61에서 IPI를 통해 rcu_exp_handler() 함수가 호출되도록 한다. 성공시 ipi 대상에서 현재 cpu를 제외시키고, skip 한다.
- 코드 라인 65~72에서 IPI 호출이 실패한 경우이다. 해당 cpu가 qsmaskinitnext 및 expmask에 여전히 존재하면 1틱 지연후 재시도한다.
- 코드 라인 74~75에서 만일 해당 cpu가 expmask에 없는 경우(offline) ipi 대상에서 제외시킨다.
- 코드 라인 79~80에서 mask_ofl_test에 ipi 대상을 추가하여 노드에 급행 qs를 보고한다.
rcu_exp_wait_wake()
kernel/rcu/tree_exp.h
/* * Wait for the current expedited grace period to complete, and then * wake up everyone who piggybacked on the just-completed expedited * grace period. Also update all the ->exp_seq_rq counters as needed * in order to avoid counter-wrap problems. */
static void rcu_exp_wait_wake(unsigned long s)
{
struct rcu_node *rnp;
synchronize_sched_expedited_wait();
rcu_exp_gp_seq_end();
trace_rcu_exp_grace_period(rcu_state.name, s, TPS("end"));
/*
* Switch over to wakeup mode, allowing the next GP, but -only- the
* next GP, to proceed.
*/
mutex_lock(&rcu_state.exp_wake_mutex);
rcu_for_each_node_breadth_first(rnp) {
if (ULONG_CMP_LT(READ_ONCE(rnp->exp_seq_rq), s)) {
spin_lock(&rnp->exp_lock);
/* Recheck, avoid hang in case someone just arrived. */
if (ULONG_CMP_LT(rnp->exp_seq_rq, s))
rnp->exp_seq_rq = s;
spin_unlock(&rnp->exp_lock);
}
smp_mb(); /* All above changes before wakeup. */
wake_up_all(&rnp->exp_wq[rcu_seq_ctr(rcu_state.expedited_sequence) & 0x3]);
}
trace_rcu_exp_grace_period(rcu_state.name, s, TPS("endwake"));
mutex_unlock(&rcu_state.exp_wake_mutex);
}
모든 급행 gp 완료까지 기다리며 루트 노드에서 급행 gp 완료를 기다리던 태스크들을 깨운다.
- 코드 라인 5에서 stall 시간이내에 모든 cpu들의 급행 qs가 완료되기를 기다린다. 만일 시간내 완료되지 않는 경우 분석을 위해 rcu stall에 대한 커널 메시지를 덤프한다.
- 코드 라인 6에서 급행 gp 시퀀스 번호를 완료 처리한다.
- 코드 라인 15~25에서 루트 노드부터 모든 노드들에 대해 순회하며 급행 gp 완료 대기 중인 경우 이를 깨운다. 만일 급행 gp 시퀀스 번호가 @s 값 보다 작은 경우 갱신한다.
- synchronize_rcu_expedited() 함수 내부에서 wait_event()를 사용하여 급행 gp 완료를 기다리며 잠들어 있는 태스크들을 깨운다.
- 대기 큐는 급행 gp 시퀀스의 하위 2비트로 해시되어 4개로 운영한다.
급행 QS 처리 및 RCU Stall 출력
synchronize_sched_expedited_wait()
kernel/rcu/tree_exp.h
tatic void synchronize_sched_expedited_wait(void)
{
int cpu;
unsigned long jiffies_stall;
unsigned long jiffies_start;
unsigned long mask;
int ndetected;
struct rcu_node *rnp;
struct rcu_node *rnp_root = rcu_get_root();
int ret;
trace_rcu_exp_grace_period(rcu_state.name, rcu_exp_gp_seq_endval(), TPS("startwait"));
jiffies_stall = rcu_jiffies_till_stall_check();
jiffies_start = jiffies;
for (;;) {
ret = swait_event_timeout_exclusive(
rcu_state.expedited_wq,
sync_rcu_preempt_exp_done_unlocked(rnp_root),
jiffies_stall);
if (ret > 0 || sync_rcu_preempt_exp_done_unlocked(rnp_root))
return;
WARN_ON(ret < 0); /* workqueues should not be signaled. */
if (rcu_cpu_stall_suppress)
continue;
panic_on_rcu_stall();
pr_err("INFO: %s detected expedited stalls on CPUs/tasks: {",
rcu_state.name);
ndetected = 0;
rcu_for_each_leaf_node(rnp) {
ndetected += rcu_print_task_exp_stall(rnp);
for_each_leaf_node_possible_cpu(rnp, cpu) {
struct rcu_data *rdp;
mask = leaf_node_cpu_bit(rnp, cpu);
if (!(rnp->expmask & mask))
continue;
ndetected++;
rdp = per_cpu_ptr(&rcu_data, cpu);
pr_cont(" %d-%c%c%c", cpu,
"O."[!!cpu_online(cpu)],
"o."[!!(rdp->grpmask & rnp->expmaskinit)],
"N."[!!(rdp->grpmask & rnp->expmaskinitnext)]);
}
}
pr_cont(" } %lu jiffies s: %lu root: %#lx/%c\n",
jiffies - jiffies_start, rcu_state.expedited_sequence,
rnp_root->expmask, ".T"[!!rnp_root->exp_tasks]);
if (ndetected) {
pr_err("blocking rcu_node structures:");
rcu_for_each_node_breadth_first(rnp) {
if (rnp == rnp_root)
continue; /* printed unconditionally */
if (sync_rcu_preempt_exp_done_unlocked(rnp))
continue;
pr_cont(" l=%u:%d-%d:%#lx/%c",
rnp->level, rnp->grplo, rnp->grphi,
rnp->expmask,
".T"[!!rnp->exp_tasks]);
}
pr_cont("\n");
}
rcu_for_each_leaf_node(rnp) {
for_each_leaf_node_possible_cpu(rnp, cpu) {
mask = leaf_node_cpu_bit(rnp, cpu);
if (!(rnp->expmask & mask))
continue;
dump_cpu_task(cpu);
}
}
jiffies_stall = 3 * rcu_jiffies_till_stall_check() + 3;
}
}
stall 시간이내에 모든 cpu들의 급행 qs가 완료되기를 기다린다. 만일 시간내 완료되지 않는 경우 분석을 위해 rcu stall에 대한 커널 메시지를 덤프하고, 시간을 3배씩 늘려가며 재시도한다. (디폴트 21+5초)
- 코드 라인 13에서 rcu stall에 해당하는 시간(jiffies_stall)을 알아온다. (디폴트 21+5초)
- 코드 라인 16~22에서 최대 rcu stall에 해당하는 시간까지 기다린다. 시간내에 급행 gp가 완료된 경우 함수를 빠져나간다.
- 코드 라인 24~25에서 모듈 변수 “/sys/module/rcupdate/parameters/rcu_cpu_stall_suppress”가 1인 경우 경고 메시지를 출력하지 않기 위해 계속 루프를 돈다. (디폴트=0)
- 코드 라인 26에서 “/proc/sys/kernel/panic_on_rcu_stall”이 1로 설정된 경우 “RCU Stall\n” 메시지와 함께 panic 처리한다. (디폴트=0)
- 코드 라인 27~28에서 panic이 동작하지 않는 경우엔 “INFO: rcu_preempt detected expedited stalls on CPUs/tasks: {“와 같은 에러 메시지를 출력한다.
- 코드 라인 29~31에서 leaf 노드를 순회하며 preempt 커널에서 preempt되어 블럭된 태스크들의 pid를 출력하고 그 수를 알아와서 ndetected에 더한다.
- 코드 라인 32~44에서 순회 중인 노드에 소속된 possible cpu들을 순회하며 qs 보고되지 않은 cpu 정보를 출력한다.
- ” <cpu>-<online 여부를 O 또는 .><expmaskinit 소속 여부를 o 또는 .><expmaskinitnext 소속 여부를 N 또는 .>”
- 예) “4-O..” -> 4번 cpu online되었고, expmaskinit 및 expmaskinitnext에 포함되지 않은 cpu이다.
- ” <cpu>-<online 여부를 O 또는 .><expmaskinit 소속 여부를 o 또는 .><expmaskinitnext 소속 여부를 N 또는 .>”
- 코드 라인 46~48에서 계속하여 stall 시각을 jiffies 기준으로 출력하고, 급행 gp 시퀀스 번호 및 root 노드의 expmask와 exp_tasks 여부를 “T 또는 “.” 문자로 출력한다.
- 예) “} 6002 jiffies s: 173 root: 0x0201/T”
- 코드 라인 49~62에서 ndetected가 있는 경우 최상위 노드를 제외한 모든 노드를 순회하며 qs 보고되지 않은 노드의 정보를 다음과 같이 출력한다.
- ” l=<레벨>:<grplo>-<grphi>:0x2ff/<T or .>”
- 예) “blocking rcu_node structures: l=1:0-15:0x1/. l=1:144-159:0x8002/.”
- ” l=<레벨>:<grplo>-<grphi>:0x2ff/<T or .>”
- 코드 라인 63~70에서 leaf 노드를 순회하고, 순회 중인 노드의 possible cpu들을 대상으로 qs 보고되지 않은 cpu 별로 태스크 백 트레이스 정보를 덤프한다.
- 코드 라인 71에서 jiffies_stall 값을 3배 곱하고 3초를 더해 다시 시도한다.
rcu_jiffies_till_stall_check()
kernel/rcu/tree_stall.h
/* Limit-check stall timeouts specified at boottime and runtime. */
int rcu_jiffies_till_stall_check(void)
{
int till_stall_check = READ_ONCE(rcu_cpu_stall_timeout);
/*
* Limit check must be consistent with the Kconfig limits
* for CONFIG_RCU_CPU_STALL_TIMEOUT.
*/
if (till_stall_check < 3) {
WRITE_ONCE(rcu_cpu_stall_timeout, 3);
till_stall_check = 3;
} else if (till_stall_check > 300) {
WRITE_ONCE(rcu_cpu_stall_timeout, 300);
till_stall_check = 300;
}
return till_stall_check * HZ + RCU_STALL_DELAY_DELTA;
}
EXPORT_SYMBOL_GPL(rcu_jiffies_till_stall_check);
rcu stall 체크에 필요한 시간을 알아온다. (3~300 + 5초에 해당하는 jiffies 틱수, 디폴트=21+5초)
- 코드 라인 3에서 모듈 변수 “/sys/module/rcupdate/parameters/rcu_cpu_stall_timeout” 값을 알아온다. (디폴트 21초)
- 코드 라인 9~11에서 읽어온 값이 3초 미만인 경우 3초로 제한한다.
- 코드 라인 12~15에서 읽어온 값이 300초를 초과하는 경우 300초로 제한한다.
- 코드 라인 16에서 결정된 값 + 5초를 반환한다
rcu_print_task_exp_stall()
kernel/rcu/tree_exp.h
/* * Scan the current list of tasks blocked within RCU read-side critical * sections, printing out the tid of each that is blocking the current * expedited grace period. */
static int rcu_print_task_exp_stall(struct rcu_node *rnp)
{
struct task_struct *t;
int ndetected = 0;
if (!rnp->exp_tasks)
return 0;
t = list_entry(rnp->exp_tasks->prev,
struct task_struct, rcu_node_entry);
list_for_each_entry_continue(t, &rnp->blkd_tasks, rcu_node_entry) {
pr_cont(" P%d", t->pid);
ndetected++;
}
return ndetected;
}
preempt 커널에서 preempt되어 블럭된 태스크들의 pid를 출력하고 그 수를 반환한다.
RCU Expedited IPI 핸들러
rcu_exp_handler()
kernel/rcu/tree_exp.h
/* * Remote handler for smp_call_function_single(). If there is an * RCU read-side critical section in effect, request that the * next rcu_read_unlock() record the quiescent state up the * ->expmask fields in the rcu_node tree. Otherwise, immediately * report the quiescent state. */
static void rcu_exp_handler(void *unused)
{
unsigned long flags;
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
struct rcu_node *rnp = rdp->mynode;
struct task_struct *t = current;
/*
* First, the common case of not being in an RCU read-side
* critical section. If also enabled or idle, immediately
* report the quiescent state, otherwise defer.
*/
if (!t->rcu_read_lock_nesting) {
if (!(preempt_count() & (PREEMPT_MASK | SOFTIRQ_MASK)) ||
rcu_dynticks_curr_cpu_in_eqs()) {
rcu_report_exp_rdp(rdp);
} else {
rdp->exp_deferred_qs = true;
set_tsk_need_resched(t);
set_preempt_need_resched();
}
return;
}
/*
* Second, the less-common case of being in an RCU read-side
* critical section. In this case we can count on a future
* rcu_read_unlock(). However, this rcu_read_unlock() might
* execute on some other CPU, but in that case there will be
* a future context switch. Either way, if the expedited
* grace period is still waiting on this CPU, set ->deferred_qs
* so that the eventual quiescent state will be reported.
* Note that there is a large group of race conditions that
* can have caused this quiescent state to already have been
* reported, so we really do need to check ->expmask.
*/
if (t->rcu_read_lock_nesting > 0) {
raw_spin_lock_irqsave_rcu_node(rnp, flags);
if (rnp->expmask & rdp->grpmask) {
rdp->exp_deferred_qs = true;
t->rcu_read_unlock_special.b.exp_hint = true;
}
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
return;
}
/*
* The final and least likely case is where the interrupted
* code was just about to or just finished exiting the RCU-preempt
* read-side critical section, and no, we can't tell which.
* So either way, set ->deferred_qs to flag later code that
* a quiescent state is required.
*
* If the CPU is fully enabled (or if some buggy RCU-preempt
* read-side critical section is being used from idle), just
* invoke rcu_preempt_deferred_qs() to immediately report the
* quiescent state. We cannot use rcu_read_unlock_special()
* because we are in an interrupt handler, which will cause that
* function to take an early exit without doing anything.
*
* Otherwise, force a context switch after the CPU enables everything.
*/
rdp->exp_deferred_qs = true;
if (!(preempt_count() & (PREEMPT_MASK | SOFTIRQ_MASK)) ||
WARN_ON_ONCE(rcu_dynticks_curr_cpu_in_eqs())) {
rcu_preempt_deferred_qs(t);
} else {
set_tsk_need_resched(t);
set_preempt_need_resched();
}
}
리모트 IPI 호출에 의해 이 함수가 실행되어 급행 qs를 빠르게 보고하게 한다. 이 함수에서는 기존 동작 중이던 태스크가 rcu read-side critical section이 진행 중 여부에 따라 다르게 동작한다. 진행 중인 경우엔 exp_deferred_qs로 설정하고, 그렇지 않은 경우 급행 qs의 완료를 보고한다.
- 코드 라인 13~23에서 첫 번째, 현재 태스크가 rcu read-side critical section 내부 코드를 수행 중이지 않는 일반적인 경우이다. softirq 및 preemption 마스킹되지 않았거나, nohz인 경우 여부에 따라 다음과 같이 동작한 후 함수를 빠져나간다.
- 조건 적합: 즉각 확장(extended) qs를 보고한다.
- 조건 부합: 급행 유예 qs 설정(rdp->exp_deferred_qs = true)을 한 후 리스케줄 요청한다.
- 코드 라인 37~45에서 두 번째, 현재 태스크가 rcu read-side critical section 내부 코드를 수행 중인 경우이다. 이 때엔 qs를 결정할 것이 없어 함수를 그냥 빠져나간다. 단 노드에서 급행 qs를 대기중인 cpu가 현재 cpu 단 하나인 경우엔 급행 유예 qs 설정을 한다. (rdp->exp_deferred_qs = true) 그리고 신속히 급행 유예 qs를 처리하기 위해 unlock special의 exp_hint 비트를 설정하다.
- 참고: rcu: Speed up expedited GPs when interrupting RCU reader (2018, v5.0-rc1)
- 코드 라인 63~70에서 마지막, 급행 유예 qs 설정(rdp->exp_deferred_qs = true)을 한 후 softirq 및 preemption 마스킹되지 않았거나, nohz인 경우 여부에 따라 다음과 같이 동작한다.
- 조건 적학: deferred qs 상태인 경우 deferred qs를 해제하고, blocked 상태인 경우 blocked 해제 후 qs를 보고한다.
- 조건 부합: 리스케줄 요청만 한다.
Expedited QS 보고 – to cpu
rcu_report_exp_rdp()
kernel/rcu/tree_exp.h
/* * Report expedited quiescent state for specified rcu_data (CPU). */
static void rcu_report_exp_rdp(struct rcu_data *rdp)
{
WRITE_ONCE(rdp->exp_deferred_qs, false);
rcu_report_exp_cpu_mult(rdp->mynode, rdp->grpmask, true);
}
@rdp에 해당하는 cpu의 급행 qs를 해당 노드에 보고한다.
rcu_report_exp_cpu_mult()
kernel/rcu/tree_exp.h
/* * Report expedited quiescent state for multiple CPUs, all covered by the * specified leaf rcu_node structure. */
static void rcu_report_exp_cpu_mult(struct rcu_node *rnp,
unsigned long mask, bool wake)
{
unsigned long flags;
raw_spin_lock_irqsave_rcu_node(rnp, flags);
if (!(rnp->expmask & mask)) {
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
return;
}
rnp->expmask &= ~mask;
__rcu_report_exp_rnp(rnp, wake, flags); /* Releases rnp->lock. */
}
@mask에 포함된 cpu들에 급행 qs 상태를 보고한다.
- 코드 라인 6~11에서 노드의 expmask에 cpu들 비트가 포함된 @mask를 제거한다. 만일 하나도 포함되지 않은 경우 함수를 빠져나간다.
- 코드 라인 12에서 해당 노드에 급행 qs 상태를 보고한다.
Expedited qs 보고 – to 노드
rcu_report_exp_rnp()
kernel/rcu/tree_exp.h
/* * Report expedited quiescent state for specified node. This is a * lock-acquisition wrapper function for __rcu_report_exp_rnp(). */
static void __maybe_unused rcu_report_exp_rnp(struct rcu_node *rnp, bool wake)
{
unsigned long flags;
raw_spin_lock_irqsave_rcu_node(rnp, flags);
__rcu_report_exp_rnp(rnp, wake, flags);
}
해당 노드에 급행 qs 상태를 보고한다.
__rcu_report_exp_rnp()
kernel/rcu/tree_exp.h
/* * Report the exit from RCU read-side critical section for the last task * that queued itself during or before the current expedited preemptible-RCU * grace period. This event is reported either to the rcu_node structure on * which the task was queued or to one of that rcu_node structure's ancestors, * recursively up the tree. (Calm down, calm down, we do the recursion * iteratively!) * * Caller must hold the specified rcu_node structure's ->lock. */
static void __rcu_report_exp_rnp(struct rcu_node *rnp,
bool wake, unsigned long flags)
__releases(rnp->lock)
{
unsigned long mask;
for (;;) {
if (!sync_rcu_preempt_exp_done(rnp)) {
if (!rnp->expmask)
rcu_initiate_boost(rnp, flags);
else
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
break;
}
if (rnp->parent == NULL) {
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
if (wake) {
smp_mb(); /* EGP done before wake_up(). */
swake_up_one(&rcu_state.expedited_wq);
}
break;
}
mask = rnp->grpmask;
raw_spin_unlock_rcu_node(rnp); /* irqs remain disabled */
rnp = rnp->parent;
raw_spin_lock_rcu_node(rnp); /* irqs already disabled */
WARN_ON_ONCE(!(rnp->expmask & mask));
rnp->expmask &= ~mask;
}
}
해당 노드에 급행 qs 상태를 보고한다.
- 코드 라인 7~14에서 요청한 노드에서 최상위 노드까지 순회하며 해당 노드의 급행 qs가 모두 완료되지 않았고, 급행 gp 모드에서 블럭된 태스크가 있는 경우 priority boost 스레드를 깨워 동작시킨 후 함수를 빠져나간다.
- 코드 라인 15~22에서 부모 노드가 없는 경우 함수를 빠져나간다.
- 코드 라인 23~28에서 상위 노드의 expmask에서 현재 노드의 grpmask를 제거한다.
sync_rcu_preempt_exp_done()
kernel/rcu/tree_exp.h
/* * Return non-zero if there is no RCU expedited grace period in progress * for the specified rcu_node structure, in other words, if all CPUs and * tasks covered by the specified rcu_node structure have done their bit * for the current expedited grace period. Works only for preemptible * RCU -- other RCU implementation use other means. * * Caller must hold the specificed rcu_node structure's ->lock */
static bool sync_rcu_preempt_exp_done(struct rcu_node *rnp)
{
raw_lockdep_assert_held_rcu_node(rnp);
return rnp->exp_tasks == NULL &&
READ_ONCE(rnp->expmask) == 0;
}
노드의 급행 qs가 모두 완료된 경우 여부를 반환한다.
- 급행 gp를 사용하며 블럭된 태스크가 없으면서
- 해당 노드의 expmask가 모두 클리어되어 child(rcu_node 또는 rcu_data)의 급행 qs가 모두 완료된 상태
참고
- RCU(Read Copy Update) -1- (Basic) | 문c
- RCU(Read Copy Update) -2- (Callback process) | 문c
- RCU(Read Copy Update) -3- (RCU threads) | 문c
- RCU(Read Copy Update) -4- (NOCB process) | 문c
- RCU(Read Copy Update) -5- (Callback list) | 문c
- RCU(Read Copy Update) -6- (Expedited GP) | 문c – 현재글
- RCU(Read Copy Update) -7- (Preemptible RCU) | 문c
- rcu_init() | 문c
- wait_for_completion() | 문c