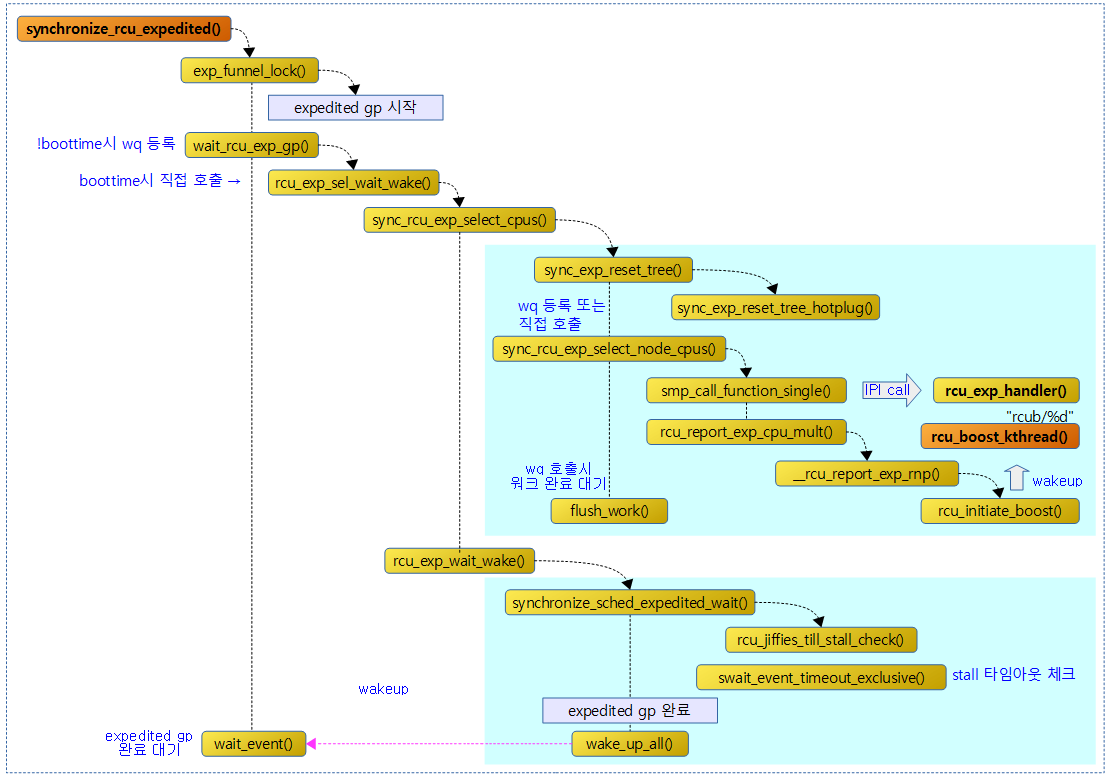
<kernel v5.4>
RCU 콜백 리스트
RCU Segmented 콜백 리스트
커널 v4.12에서 콜백 리스트의 관리 방법이 바뀌어 콜백 리스트를 4 등분하여 관리하는 segmented 콜백 리스트로 이름이 바뀌었다.
다음 4개의 세그먼트들을 알아본다.
include/linux/rcu_segcblist.h
/* Complicated segmented callback lists. 😉 */
/*
* Index values for segments in rcu_segcblist structure.
*
* The segments are as follows:
*
* [head, *tails[RCU_DONE_TAIL]):
* Callbacks whose grace period has elapsed, and thus can be invoked.
* [*tails[RCU_DONE_TAIL], *tails[RCU_WAIT_TAIL]):
* Callbacks waiting for the current GP from the current CPU's viewpoint.
* [*tails[RCU_WAIT_TAIL], *tails[RCU_NEXT_READY_TAIL]):
* Callbacks that arrived before the next GP started, again from
* the current CPU's viewpoint. These can be handled by the next GP.
* [*tails[RCU_NEXT_READY_TAIL], *tails[RCU_NEXT_TAIL]):
* Callbacks that might have arrived after the next GP started.
* There is some uncertainty as to when a given GP starts and
* ends, but a CPU knows the exact times if it is the one starting
* or ending the GP. Other CPUs know that the previous GP ends
* before the next one starts.
*
* Note that RCU_WAIT_TAIL cannot be empty unless RCU_NEXT_READY_TAIL is also
* empty.
*
* The ->gp_seq[] array contains the grace-period number at which the
* corresponding segment of callbacks will be ready to invoke. A given
* element of this array is meaningful only when the corresponding segment
* is non-empty, and it is never valid for RCU_DONE_TAIL (whose callbacks
* are already ready to invoke) or for RCU_NEXT_TAIL (whose callbacks have
* not yet been assigned a grace-period number).
*/
#define RCU_DONE_TAIL 0 /* Also RCU_WAIT head. */
#define RCU_WAIT_TAIL 1 /* Also RCU_NEXT_READY head. */
#define RCU_NEXT_READY_TAIL 2 /* Also RCU_NEXT head. */
#define RCU_NEXT_TAIL 3
#define RCU_CBLIST_NSEGS 4
콜백 리스트는 done 구간, wait 구간, next-ready 구간, next 구간과 같이 총 4개의 구간으로 나누어 관리한다.
먼저 tails[0] 과 *tails[0]의 의미를 구분해야 한다.
- tails[0]
- *tails[0]
- tails[0]의 값으로 이 값은 다음 콜백을 가리킨다.
수의 범위 괄호 표기법
다음과 같이 수의 범위 괄호 표기법을 기억해둔다.
- [1, 5]
- 실수: 1 <= x <= 5
- 정수: 1, 2, 3, 4, 5
- (1, 5)
- 실수: 1 < x < 5
- 정수: 2, 3, 4
- [1, 5)
- 실수: 1 <= x < 5
- 정수: 1, 2, 3, 4
[head, *tails[0])
- head 위치부터 tails[0]의 값이 가리키는 다음 콜백의 전까지
- 예) CB1, CB2, CB3가 범위에 포함된다.
- head tails[0] *tails[0]
- CB1 —–> CB2 —–> CB3 —–> CB4
rcu의 segmented 콜백 리스트는 다음과 같이 4개의 구간으로 나뉘어 관리한다.

4개의 구간 관리를 위해 cb 리스트는 1개의 head와 4개의 포인터 tails[0~3]를 사용한다.
- 1개의 콜백 리스트 = rdp->cblist = rsclp
- 1개의 시작 : rsclp->head
- 4개의 구간에 대한 포인터 배열: rsclp->tails[]
- 1 번째 done 구간:
- [head, *tails[0])
- head에 연결된 콜백 위치부터 tails[RCU_DONE_TAIL] 까지
- g.p가 완료하여 처리 가능한 구간이다. blimit 제한으로 인해 다 처리되지 못한 콜백들이 이 구간에 남아 있을 수 있다.
- 이 구간의 콜백들은 아무때나 처리 가능하다.
- 2 번째 wait 구간
- [*tails[0], *tails[1])
- tails[RCU_DONE_TAIL]에 연결된 다음 콜백 위치부터 tails[RCU_WAIT_TAIL] 까지
- current gp 이전에 추가된 콜백으로 current gp가 끝난 후에 처리될 예정인 콜백들이 대기중인 구간이다.
- 3 번째 next-ready 구간 (=wait 2 구간)
- [*tails[1], *tails[2])
- tails[RCU_WAIT_TAIL]에 연결된 다음 콜백 위치부터 tails[RCU_NEXT_READY_TAIL] 까지
- current gp 진행 중에 추가된 콜백들이 추가된 구간이다. 이 콜백들은 current gp가 완료되어도 곧바로 처리되면 안되고, 다음 gp가 완료된 후에 처리될 예정인 콜백들이 있는 구간이다.
- 이 구간의 콜백들은 current gp 및 next gp 까지 완료된 후에 처리되어야 한다.
- 전통적인(classic) rcu에서는 이 구간이 없이 1개의 wait 구간만으로 처리가 되었지만 preemptible rcu 처리를 위해 1 번의 gp를 더 연장하기 위해 구간을 추가하였다. preemptible rcu 에서 rcu_read_lock()에서 메모리 배리어를 사용하지 않게 하기 위해 gp를 1단계 더 delay하여 처리한다.
- 4 번째 next 구간
- [*tails[2], tails[3])
- tails[RCU_NEXT_READY_TAIL]에 연결된 다음 콜백 위치부터 tails[RCU_NEXT_TAIL] 까지
- 새 콜백이 추가되면 이 구간의 마지막에 추가되고, tails[RCU_NEXT_TAIL]이 추가된 마지막 콜백을 항상 가리키게 해야한다.
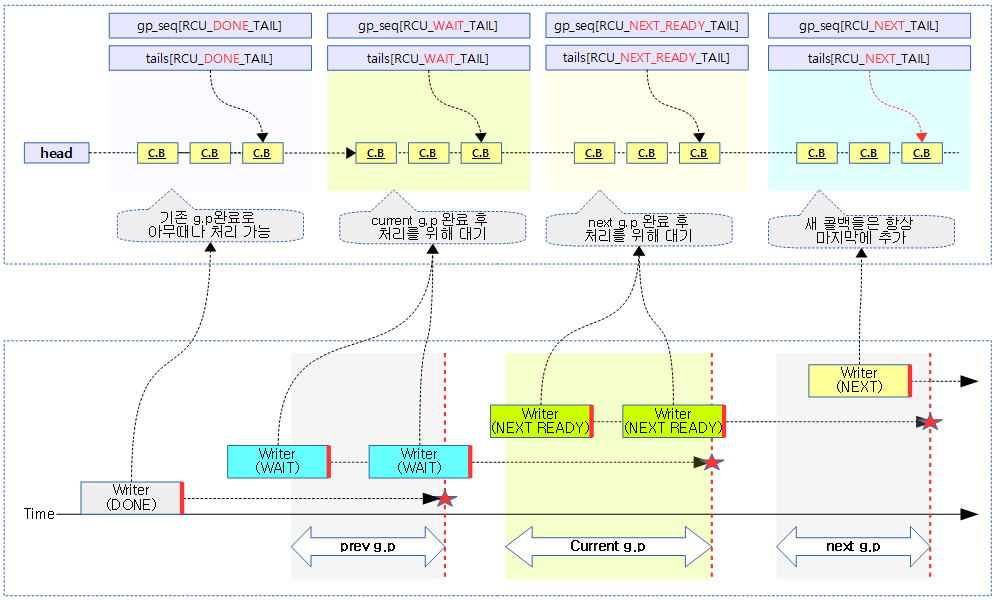
- 일반적인 콜백 진행은 위와 같지만 cpu가 16개를 초과하면 1 단계가 느려질 수도 있고, 반대로 acceleration 조건에 부합하여 1단계씩 전진될 수도 있다.
un-segmented 콜백 리스트 관련
rcu un-segmented 콜백 리스트는 구간을 나뉘지 않고 그냥 하나로 관리된다.
rcu_cblist_init()
kernel/rcu/rcu_segcblist.c
/* Initialize simple callback list. */
void rcu_cblist_init(struct rcu_cblist *rclp)
{
rclp->head = NULL;
rclp->tail = &rclp->head;
rclp->len = 0;
rclp->len_lazy = 0;
}
rcu 콜백 리스트를 초기화한다. (주의: unsegmented 콜백 리스트이다)
rcu_cblist_enqueue()
kernel/rcu/rcu_segcblist.c
/*
* Enqueue an rcu_head structure onto the specified callback list.
* This function assumes that the callback is non-lazy because it
* is intended for use by no-CBs CPUs, which do not distinguish
* between lazy and non-lazy RCU callbacks.
*/
void rcu_cblist_enqueue(struct rcu_cblist *rclp, struct rcu_head *rhp)
{
*rclp->tail = rhp;
rclp->tail = &rhp->next;
WRITE_ONCE(rclp->len, rclp->len + 1);
};
rcu 콜백리스트의 뒷부분에 rcu 콜백을 추가한다.
다음 그림은 rcu 콜백 리스트에 rcu 콜백을 엔큐하는 모습을 보여준다.

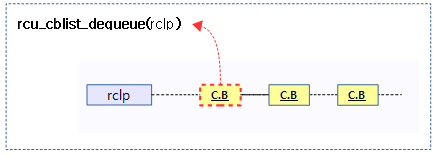
rcu_cblist_dequeue()
kernel/rcu/rcu_segcblist.c
/*
* Dequeue the oldest rcu_head structure from the specified callback
* list. This function assumes that the callback is non-lazy, but
* the caller can later invoke rcu_cblist_dequeued_lazy() if it
* finds otherwise (and if it cares about laziness). This allows
* different users to have different ways of determining laziness.
*/
struct rcu_head *rcu_cblist_dequeue(struct rcu_cblist *rclp)
{
struct rcu_head *rhp;
rhp = rclp->head;
if (!rhp)
return NULL;
rclp->len--;
rclp->head = rhp->next;
if (!rclp->head)
rclp->tail = &rclp->head;
return rhp;
};
rcu 콜백리스트의 앞부분에서 rcu 콜백을 하나 디큐해온다.
다음 그림은 rcu 콜백 리스트로부터 rcu 콜백을 디큐하는 모습을 보여준다.
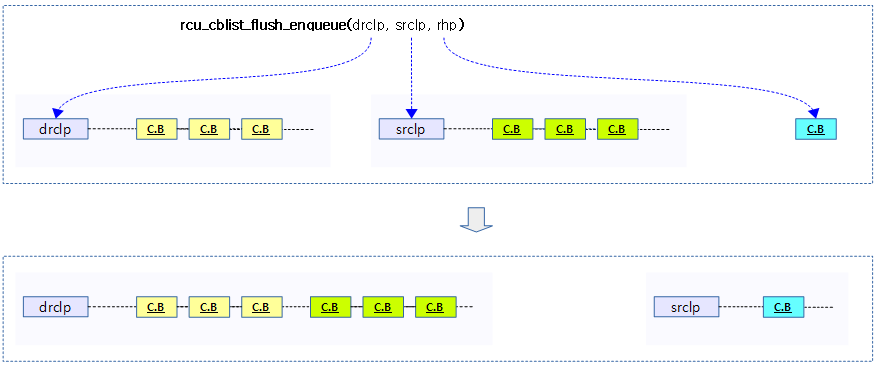
rcu_cblist_flush_enqueue()
kernel/rcu/rcu_segcblist.c
/*
* Flush the second rcu_cblist structure onto the first one, obliterating
* any contents of the first. If rhp is non-NULL, enqueue it as the sole
* element of the second rcu_cblist structure, but ensuring that the second
* rcu_cblist structure, if initially non-empty, always appears non-empty
* throughout the process. If rdp is NULL, the second rcu_cblist structure
* is instead initialized to empty.
*/
void rcu_cblist_flush_enqueue(struct rcu_cblist *drclp,
struct rcu_cblist *srclp,
struct rcu_head *rhp)
{
drclp->head = srclp->head;
if (drclp->head)
drclp->tail = srclp->tail;
else
drclp->tail = &drclp->head;
drclp->len = srclp->len;
drclp->len_lazy = srclp->len_lazy;
if (!rhp) {
rcu_cblist_init(srclp);
} else {
rhp->next = NULL;
srclp->head = rhp;
srclp->tail = &rhp->next;
WRITE_ONCE(srclp->len, 1);
srclp->len_lazy = 0;
}
};
콜백 리스트 @drclp을 모두 콜백 리스트 @srclp로 옮기고, 콜백 리스트 @srclp에 새로운 콜백 헤드 @rhp를 대입한다. (@rhp가 null인 경우에는 콜백 리스트 @srclp를 초기화한다)
다음 그림은 소스측의 rcu 콜백리스트를 목적측에 flush하고, 새로운 콜백을 대입하는 모습을 보여준다.
rcu_cblist_n_cbs()
kernel/rcu/rcu_segcblist.h
/* Return number of callbacks in the specified callback list. */
static inline long rcu_cblist_n_cbs(struct rcu_cblist *rclp)
{
return READ_ONCE(rclp->len);
}
콜백 리스트에 있는 콜백 수를 반환한다.
rcu_cblist_dequeued_lazy()
kernel/rcu/rcu_segcblist.h
/*
* Account for the fact that a previously dequeued callback turned out
* to be marked as lazy.
*/
static inline void rcu_cblist_dequeued_lazy(struct rcu_cblist *rclp)
{
rclp->len_lazy--;
}
콜백 리스트에서 lazy 카운터를 감소시킨다.
segmented 콜백 리스트 관련
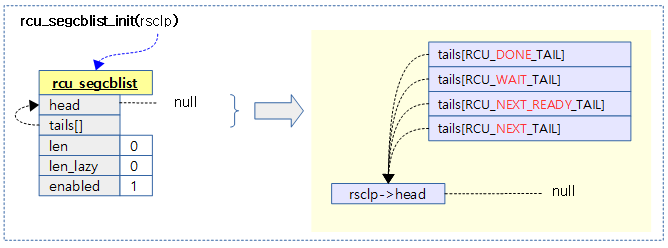
rcu_segcblist_init()
kernel/rcu/rcu_segcblist.c
/*
* Initialize an rcu_segcblist structure.
*/
void rcu_segcblist_init(struct rcu_segcblist *rsclp)
{
int i;
BUILD_BUG_ON(RCU_NEXT_TAIL + 1 != ARRAY_SIZE(rsclp->gp_seq));
BUILD_BUG_ON(ARRAY_SIZE(rsclp->tails) != ARRAY_SIZE(rsclp->gp_seq));
rsclp->head = NULL;
for (i = 0; i < RCU_CBLIST_NSEGS; i++)
rsclp->tails[i] = &rsclp->head;
rcu_segcblist_set_len(rsclp, 0);
rsclp->len_lazy = 0;
rsclp->enabled = 1;
};
rcu segmented 콜백 리스트를 초기화한다.
다음 그림은 segmented 콜백 리스트를 초기화하는 모습을 보여준다.
rcu_segcblist_set_len()
kernel/rcu/rcu_segcblist.c
/* Set the length of an rcu_segcblist structure. */
void rcu_segcblist_set_len(struct rcu_segcblist *rsclp, long v)
{
#ifdef CONFIG_RCU_NOCB_CPU
atomic_long_set(&rsclp->len, v);
#else
WRITE_ONCE(rsclp->len, v);
#endif
}
rcu seg 콜백 리스트에 콜백 수를 기록한다.
rcu_segcblist_add_len()
kernel/rcu/rcu_segcblist.c
/*
* Increase the numeric length of an rcu_segcblist structure by the
* specified amount, which can be negative. This can cause the ->len
* field to disagree with the actual number of callbacks on the structure.
* This increase is fully ordered with respect to the callers accesses
* both before and after.
*/
void rcu_segcblist_add_len(struct rcu_segcblist *rsclp, long v)
{
#ifdef CONFIG_RCU_NOCB_CPU
smp_mb__before_atomic(); /* Up to the caller! */
atomic_long_add(v, &rsclp->len);
smp_mb__after_atomic(); /* Up to the caller! */
#else
smp_mb(); /* Up to the caller! */
WRITE_ONCE(rsclp->len, rsclp->len + v);
smp_mb(); /* Up to the caller! */
#endif
};
rcu seg 콜백 리스트에 콜백 수 @v를 추가한다.
rcu_segcblist_inc_len()
kernel/rcu/rcu_segcblist.c
/*
* Increase the numeric length of an rcu_segcblist structure by one.
* This can cause the ->len field to disagree with the actual number of
* callbacks on the structure. This increase is fully ordered with respect
* to the callers accesses both before and after.
*/
void rcu_segcblist_inc_len(struct rcu_segcblist *rsclp)
{
rcu_segcblist_add_len(rsclp, 1);
};
rcu seg 콜백 리스트에 콜백 수를 1 증가시킨다.
rcu_segcblist_xchg_len()
kernel/rcu/rcu_segcblist.c
/*
* Exchange the numeric length of the specified rcu_segcblist structure
* with the specified value. This can cause the ->len field to disagree
* with the actual number of callbacks on the structure. This exchange is
* fully ordered with respect to the callers accesses both before and after.
*/
long rcu_segcblist_xchg_len(struct rcu_segcblist *rsclp, long v)
{
#ifdef CONFIG_RCU_NOCB_CPU
return atomic_long_xchg(&rsclp->len, v);
#else
long ret = rsclp->len;
smp_mb(); /* Up to the caller! */
WRITE_ONCE(rsclp->len, v);
smp_mb(); /* Up to the caller! */
return ret;
#endif
};
rcu seg 콜백 리스트에 콜백 수를 @v 값으로 치환한다. 그리고 반환 값은 기존 값을 반환한다.
rcu_segcblist_disable()
kernel/rcu/rcu_segcblist.c
/*
* Disable the specified rcu_segcblist structure, so that callbacks can
* no longer be posted to it. This structure must be empty.
*/
void rcu_segcblist_disable(struct rcu_segcblist *rsclp)
{
WARN_ON_ONCE(!rcu_segcblist_empty(rsclp));
WARN_ON_ONCE(rcu_segcblist_n_cbs(rsclp));
WARN_ON_ONCE(rcu_segcblist_n_lazy_cbs(rsclp));
rsclp->enabled = 0;
};
rcu seg 콜백 리스트를 disable 한다.
rcu_segcblist_offload()
kernel/rcu/rcu_segcblist.c
/*
* Mark the specified rcu_segcblist structure as offloaded. This
* structure must be empty.
*/
void rcu_segcblist_offload(struct rcu_segcblist *rsclp)
{
rsclp->offloaded = 1;
};
rcu seg 콜백 리스트를 offloaded 상태로 변경한다.
rcu_segcblist_ready_cbs()
kernel/rcu/rcu_segcblist.c
/*
* Does the specified rcu_segcblist structure contain callbacks that
* are ready to be invoked?
*/
bool rcu_segcblist_ready_cbs(struct rcu_segcblist *rsclp)
{
return rcu_segcblist_is_enabled(rsclp) &&
&rsclp->head != rsclp->tails[RCU_DONE_TAIL];
};
rcu seg 콜백 리스트에 호출 준비된 콜백들이 있는지 여부를 반환한다.
- done 구간에 있는 콜백들이 있는지 여부를 반환한다.
rcu_segcblist_pend_cbs()
kernel/rcu/rcu_segcblist.c
/*
* Does the specified rcu_segcblist structure contain callbacks that
* are still pending, that is, not yet ready to be invoked?
*/
bool rcu_segcblist_pend_cbs(struct rcu_segcblist *rsclp)
{
return rcu_segcblist_is_enabled(rsclp) &&
!rcu_segcblist_restempty(rsclp, RCU_DONE_TAIL);
};
rcu seg 콜백 리스트에 콜백들이 있는지 여부를 반환한다.
rcu_segcblist_first_cb()
kernel/rcu/rcu_segcblist.c
/*
* Return a pointer to the first callback in the specified rcu_segcblist
* structure. This is useful for diagnostics.
*/
struct rcu_head *rcu_segcblist_first_cb(struct rcu_segcblist *rsclp)
{
if (rcu_segcblist_is_enabled(rsclp))
return rsclp->head;
return NULL;
};
rcu seg 콜백 리스트의 첫 콜백을 알아온다.
rcu_segcblist_first_pend_cb()
kernel/rcu/rcu_segcblist.c
/*
* Return a pointer to the first pending callback in the specified
* rcu_segcblist structure. This is useful just after posting a given
* callback -- if that callback is the first pending callback, then
* you cannot rely on someone else having already started up the required
* grace period.
*/
struct rcu_head *rcu_segcblist_first_pend_cb(struct rcu_segcblist *rsclp)
{
if (rcu_segcblist_is_enabled(rsclp))
return *rsclp->tails[RCU_DONE_TAIL];
return NULL;
};
rcu seg 콜백 리스트의 호출 준비된 첫 콜백을 반환한다.
rcu_segcblist_nextgp()
kernel/rcu/rcu_segcblist.c
/*
* Return false if there are no CBs awaiting grace periods, otherwise,
* return true and store the nearest waited-upon grace period into *lp.
*/
bool rcu_segcblist_nextgp(struct rcu_segcblist *rsclp, unsigned long *lp)
{
if (!rcu_segcblist_pend_cbs(rsclp))
return false;
*lp = rsclp->gp_seq[RCU_WAIT_TAIL];
return true;
};
rcu seg 콜백 리스트에서 콜백들이 있는 경우 여부를 반환한다. 만일 콜백들이 있는 경우 출력 인자 @lp에 gp 대기 중인 gp 시퀀스를 기록한다.
rcu_segcblist_enqueue()
kernel/rcu/rcu_segcblist.c
/*
* Enqueue the specified callback onto the specified rcu_segcblist
* structure, updating accounting as needed. Note that the ->len
* field may be accessed locklessly, hence the WRITE_ONCE().
* The ->len field is used by rcu_barrier() and friends to determine
* if it must post a callback on this structure, and it is OK
* for rcu_barrier() to sometimes post callbacks needlessly, but
* absolutely not OK for it to ever miss posting a callback.
*/
void rcu_segcblist_enqueue(struct rcu_segcblist *rsclp,
struct rcu_head *rhp, bool lazy)
{
rcu_segcblist_inc_len(rsclp);
if (lazy)
rsclp->len_lazy++;
smp_mb(); /* Ensure counts are updated before callback is enqueued. */
rhp->next = NULL;
WRITE_ONCE(*rsclp->tails[RCU_NEXT_TAIL], rhp);
WRITE_ONCE(rsclp->tails[RCU_NEXT_TAIL], &rhp->next);
};
rcu seg 콜백 리스트에 rcu 콜백을 엔큐한다.
- 코드 라인 4에서 rcu cb 수를 하나 추가한다.
- 코드 라인 5~6에서 @lazy 요청인 경우 len_lazy 카운터도 증가시킨다.
- 코드 라인 7에서 카운터가 완전히 업데이트 된 후 tails[]에 대한 처리를 수행하게 한다. (읽기 측에서는 tails[]를 먼저 확인한 후 카운터를 보게 한다)
- 코드 라인 9에서 tails[RCU_NEXT_TAIL]이 가리키는 곳의 다음에 cb를 추가한다. 즉 가장 마지막에 cb를 추가한다.
- tails[RCU_NEXT_TAIL]은 항상 마지막에 추가된 cb들을 가리킨다.
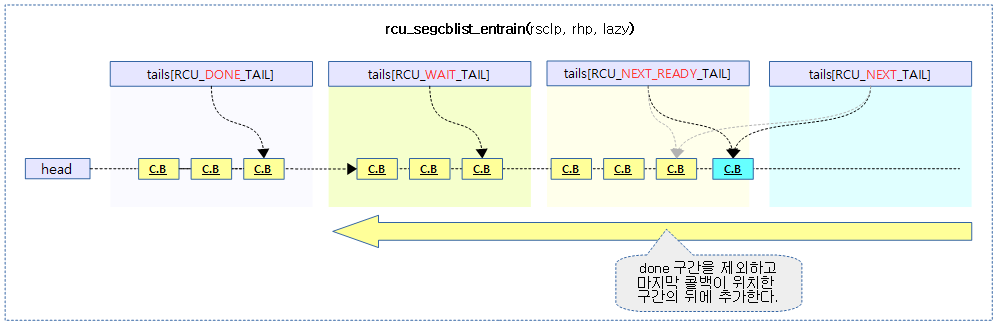
rcu_segcblist_entrain()
kernel/rcu/rcu_segcblist.c
/*
* Entrain the specified callback onto the specified rcu_segcblist at
* the end of the last non-empty segment. If the entire rcu_segcblist
* is empty, make no change, but return false.
*
* This is intended for use by rcu_barrier()-like primitives, -not-
* for normal grace-period use. IMPORTANT: The callback you enqueue
* will wait for all prior callbacks, NOT necessarily for a grace
* period. You have been warned.
*/
bool rcu_segcblist_entrain(struct rcu_segcblist *rsclp,
struct rcu_head *rhp, bool lazy)
{
int i;
if (rcu_segcblist_n_cbs(rsclp) == 0)
return false;
rcu_segcblist_inc_len(rsclp);
if (lazy)
rsclp->len_lazy++;
smp_mb(); /* Ensure counts are updated before callback is entrained. */
rhp->next = NULL;
for (i = RCU_NEXT_TAIL; i > RCU_DONE_TAIL; i--)
if (rsclp->tails[i] != rsclp->tails[i - 1])
break;
WRITE_ONCE(*rsclp->tails[i], rhp);
for (; i <= RCU_NEXT_TAIL; i++)
WRITE_ONCE(rsclp->tails[i], &rhp->next);
return true;
};
rcu seg 콜백 리스트에 rcu 콜백을 추가한다. done 구간을 제외하고, 마지막 콜백이 있는 구간에 콜백을 추가하고 true를 반환한다. 만일 seg 콜백 리스트의 모든 구간이 비어 있는 경우 false를 반환한다.
- 코드 라인 6~7에서 seg 콜백 리스트가 비어 있는 경우 false를 반환한다.
- 코드 라인 8에서 콜백 수를 1 증가 시킨다.
- 코드 라인 9~10에서 @lazy 요청한 경우 lazy 카운터를 1 증가시킨다.
- 코드 라인 11에서 콜백을 추가하기 전에 반드시 먼저 카운터를 갱신해야 하므로 메모리 베리어를 수행한다.
- 코드 라인 12에서 추가되는 콜백의 다음이 없으므로 null을 대입한다.
- 코드 라인 13~15에서 done을 제외하고 가장 마지막 콜백이 위치한 구간을 찾는다. (i=3, 2, 1 순)
- 코드 라인 16에서 찾은 구간에 콜백을 추가하낟.
- 코드 라인 17~18에서 마지막 구간부터 찾은 구간의 tails[] 포인터가 새로 추가한 콜백을 가리키게 한다.
- 코드 라인 19에서 성공에 해당하는 true를 반환한다.
rcu seg 콜백 리스트의 적절한 위치에 콜백이 추가되는 모습을 보여준다.
rcu_segcblist_empty()
kernel/rcu/rcu_segcblist.h
/*
* Is the specified rcu_segcblist structure empty?
*
* But careful! The fact that the ->head field is NULL does not
* necessarily imply that there are no callbacks associated with
* this structure. When callbacks are being invoked, they are
* removed as a group. If callback invocation must be preempted,
* the remaining callbacks will be added back to the list. Either
* way, the counts are updated later.
*
* So it is often the case that rcu_segcblist_n_cbs() should be used
* instead.
*/
static inline bool rcu_segcblist_empty(struct rcu_segcblist *rsclp)
{
return !READ_ONCE(rsclp->head);
}
seg 콜백 리스트가 비어 있는지 여부를 반환한다.
rcu_segcblist_n_cbs()
kernel/rcu/rcu_segcblist.h
/* Return number of callbacks in segmented callback list. */
static inline long rcu_segcblist_n_cbs(struct rcu_segcblist *rsclp)
{
#ifdef CONFIG_RCU_NOCB_CPU
return atomic_long_read(&rsclp->len);
#else
return READ_ONCE(rsclp->len);
#endif
}
seg 콜백 리스트의 콜백 수를 반환한다.
rcu_segcblist_n_lazy_cbs()
kernel/rcu/rcu_segcblist.h
/* Return number of lazy callbacks in segmented callback list. */
static inline long rcu_segcblist_n_lazy_cbs(struct rcu_segcblist *rsclp)
{
return rsclp->len_lazy;
}
seg 콜백 리스트의 lazy 콜백 수를 반환한다.
rcu_segcblist_n_nonlazy_cbs()
kernel/rcu/rcu_segcblist.h
/* Return number of lazy callbacks in segmented callback list. */
static inline long rcu_segcblist_n_nonlazy_cbs(struct rcu_segcblist *rsclp)
{
return rcu_segcblist_n_cbs(rsclp) - rsclp->len_lazy;
}
seg 콜백 리스트의 non-lazy 콜백 수를 반환한다.
rcu_segcblist_is_enabled()
kernel/rcu/rcu_segcblist.h
/*
* Is the specified rcu_segcblist enabled, for example, not corresponding
* to an offline CPU?
*/
static inline bool rcu_segcblist_is_enabled(struct rcu_segcblist *rsclp)
{
return rsclp->enabled;
}
seg 콜백 리스트의 enabled 여부를 반환한다.
rcu_segcblist_is_offloaded()
kernel/rcu/rcu_segcblist.h
/* Is the specified rcu_segcblist offloaded? */
static inline bool rcu_segcblist_is_offloaded(struct rcu_segcblist *rsclp)
{
return rsclp->offloaded;
}
seg 콜백 리스트의 offloaded 여부를 반환한다.
rcu_segcblist_restempty()
kernel/rcu/rcu_segcblist.h
/*
* Are all segments following the specified segment of the specified
* rcu_segcblist structure empty of callbacks? (The specified
* segment might well contain callbacks.)
*/
static inline bool rcu_segcblist_restempty(struct rcu_segcblist *rsclp, int seg)
{
return !READ_ONCE(*READ_ONCE(rsclp->tails[seg]));
}
seg 콜백 리스트의 @seg 구간 뒤 대기중인 콜백이 비어 있는지 여부를 반환한다.
RCU 콜백 이동
rcu_segcblist_merge()
kernel/rcu/rcu_segcblist.c
/*
* Merge the source rcu_segcblist structure into the destination
* rcu_segcblist structure, then initialize the source. Any pending
* callbacks from the source get to start over. It is best to
* advance and accelerate both the destination and the source
* before merging.
*/
void rcu_segcblist_merge(struct rcu_segcblist *dst_rsclp,
struct rcu_segcblist *src_rsclp)
{
struct rcu_cblist donecbs;
struct rcu_cblist pendcbs;
rcu_cblist_init(&donecbs);
rcu_cblist_init(&pendcbs);
rcu_segcblist_extract_count(src_rsclp, &donecbs);
rcu_segcblist_extract_done_cbs(src_rsclp, &donecbs);
rcu_segcblist_extract_pend_cbs(src_rsclp, &pendcbs);
rcu_segcblist_insert_count(dst_rsclp, &donecbs);
rcu_segcblist_insert_done_cbs(dst_rsclp, &donecbs);
rcu_segcblist_insert_pend_cbs(dst_rsclp, &pendcbs);
rcu_segcblist_init(src_rsclp);
}
done 구간 -> rcu 콜백으로 옮기기
rcu_segcblist_extract_done_cbs()
kernel/rcu/rcu_segcblist.c
/*
* Extract only those callbacks ready to be invoked from the specified
* rcu_segcblist structure and place them in the specified rcu_cblist
* structure.
*/
void rcu_segcblist_extract_done_cbs(struct rcu_segcblist *rsclp,
struct rcu_cblist *rclp)
{
int i;
if (!rcu_segcblist_ready_cbs(rsclp))
return; /* Nothing to do. */
*rclp->tail = rsclp->head;
WRITE_ONCE(rsclp->head, *rsclp->tails[RCU_DONE_TAIL]);
WRITE_ONCE(*rsclp->tails[RCU_DONE_TAIL], NULL);
rclp->tail = rsclp->tails[RCU_DONE_TAIL];
for (i = RCU_CBLIST_NSEGS - 1; i >= RCU_DONE_TAIL; i--)
if (rsclp->tails[i] == rsclp->tails[RCU_DONE_TAIL])
WRITE_ONCE(rsclp->tails[i], &rsclp->head);
};
rcu seg 콜백리스트의 done 구간의 콜백들을 extract하여 rcu 콜백리스트로 옮긴다.
다음 그림은 rcu seg 콜백리스트의 done 구간의 콜백들을 extract하여 rcu 콜백리스트로 옮기는 모습을 보여준다.

done 구간 제외 -> rcu 콜백으로 옮기기
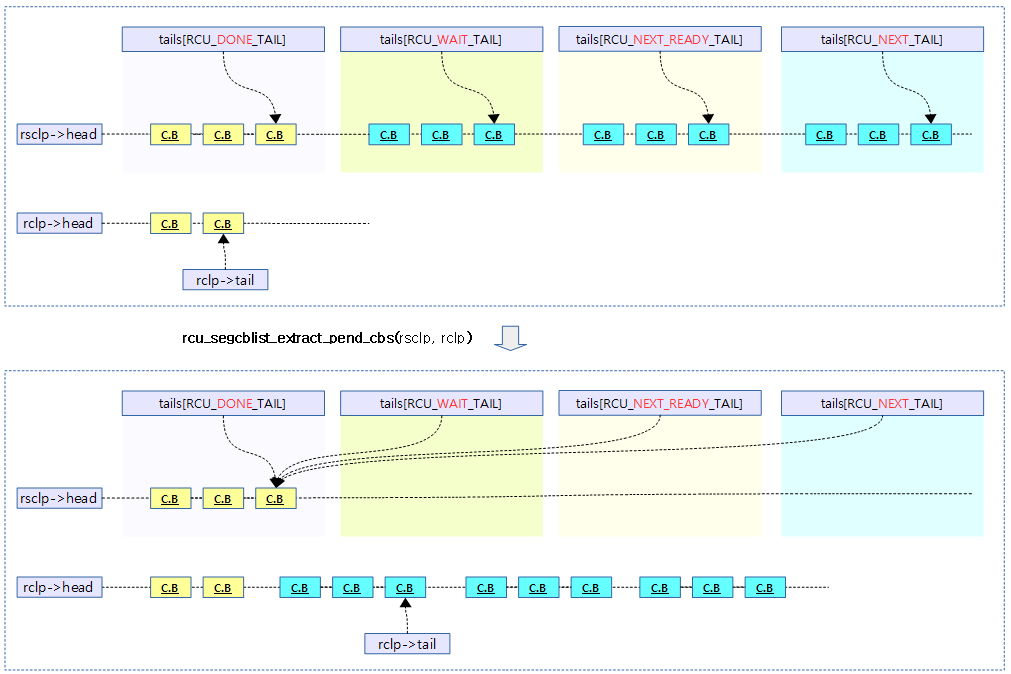
rcu_segcblist_extract_pend_cbs()
kernel/rcu/rcu_segcblist.c
/*
* Extract only those callbacks still pending (not yet ready to be
* invoked) from the specified rcu_segcblist structure and place them in
* the specified rcu_cblist structure. Note that this loses information
* about any callbacks that might have been partway done waiting for
* their grace period. Too bad! They will have to start over.
*/
void rcu_segcblist_extract_pend_cbs(struct rcu_segcblist *rsclp,
struct rcu_cblist *rclp)
{
int i;
if (!rcu_segcblist_pend_cbs(rsclp))
return; /* Nothing to do. */
*rclp->tail = *rsclp->tails[RCU_DONE_TAIL];
rclp->tail = rsclp->tails[RCU_NEXT_TAIL];
WRITE_ONCE(*rsclp->tails[RCU_DONE_TAIL], NULL);
for (i = RCU_DONE_TAIL + 1; i < RCU_CBLIST_NSEGS; i++)
WRITE_ONCE(rsclp->tails[i], rsclp->tails[RCU_DONE_TAIL]);
};
rcu seg 콜백리스트의 done 구간을 제외한 나머지 콜백들을 extract하여 rcu 콜백리스트로 옮긴다.
다음 그림은 rcu seg 콜백리스트의 done 구간을 제외한 나머지 콜백들을 extract하여 rcu 콜백리스트로 옮기는 모습을 보여준다.
rcu_segcblist_extract_count()
kernel/rcu/rcu_segcblist.c
/*
* Extract only the counts from the specified rcu_segcblist structure,
* and place them in the specified rcu_cblist structure. This function
* supports both callback orphaning and invocation, hence the separation
* of counts and callbacks. (Callbacks ready for invocation must be
* orphaned and adopted separately from pending callbacks, but counts
* apply to all callbacks. Locking must be used to make sure that
* both orphaned-callbacks lists are consistent.)
*/
void rcu_segcblist_extract_count(struct rcu_segcblist *rsclp,
struct rcu_cblist *rclp)
{
rclp->len_lazy += rsclp->len_lazy;
rsclp->len_lazy = 0;
rclp->len = rcu_segcblist_xchg_len(rsclp, 0);
};
rcu seg 콜백 리스트에 rcu 콜백 리스트의 lazy 카운터를 extract하여 누적시킨다. (rcu 콜백 리스트의 콜백 수 및 lazy 카운터는 0으로 클리어된다)
rcu 콜백 -> done 구간으로 옮기기
rcu_segcblist_insert_done_cbs()
kernel/rcu/rcu_segcblist.c
/*
* Move callbacks from the specified rcu_cblist to the beginning of the
* done-callbacks segment of the specified rcu_segcblist.
*/
void rcu_segcblist_insert_done_cbs(struct rcu_segcblist *rsclp,
struct rcu_cblist *rclp)
{
int i;
if (!rclp->head)
return; /* No callbacks to move. */
*rclp->tail = rsclp->head;
WRITE_ONCE(rsclp->head, rclp->head);
for (i = RCU_DONE_TAIL; i < RCU_CBLIST_NSEGS; i++)
if (&rsclp->head == rsclp->tails[i])
WRITE_ONCE(rsclp->tails[i], rclp->tail);
else
break;
rclp->head = NULL;
rclp->tail = &rclp->head;
};
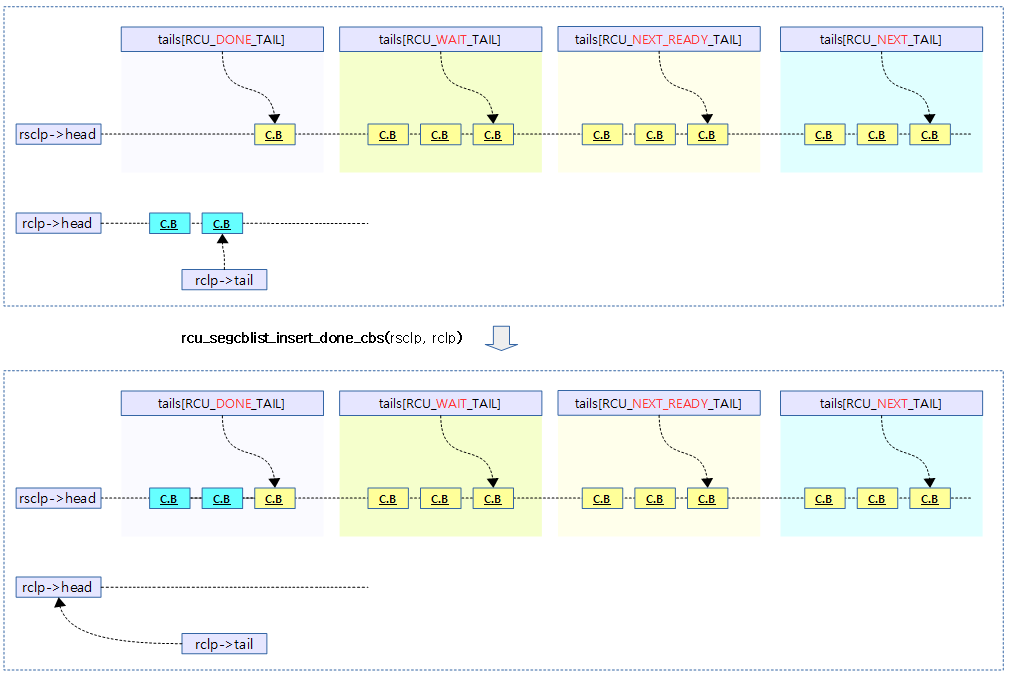
rcu 콜백 리스트의 콜백들을 rcu seg 콜백리스트의 done 구간으로 옮긴다.
다음 그림은 rcu 콜백 리스트의 콜백들을 rcu seg 콜백리스트의 done 구간으로 옮기는 모습을 보여준다.
rcu 콜백 -> next 구간으로 옮기기
rcu_segcblist_insert_pend_cbs()
kernel/rcu/rcu_segcblist.c
/*
* Move callbacks from the specified rcu_cblist to the end of the
* new-callbacks segment of the specified rcu_segcblist.
*/
void rcu_segcblist_insert_pend_cbs(struct rcu_segcblist *rsclp,
struct rcu_cblist *rclp)
{
if (!rclp->head)
return; /* Nothing to do. */
WRITE_ONCE(*rsclp->tails[RCU_NEXT_TAIL], rclp->head);
WRITE_ONCE(rsclp->tails[RCU_NEXT_TAIL], rclp->tail);
rclp->head = NULL;
rclp->tail = &rclp->head;
};
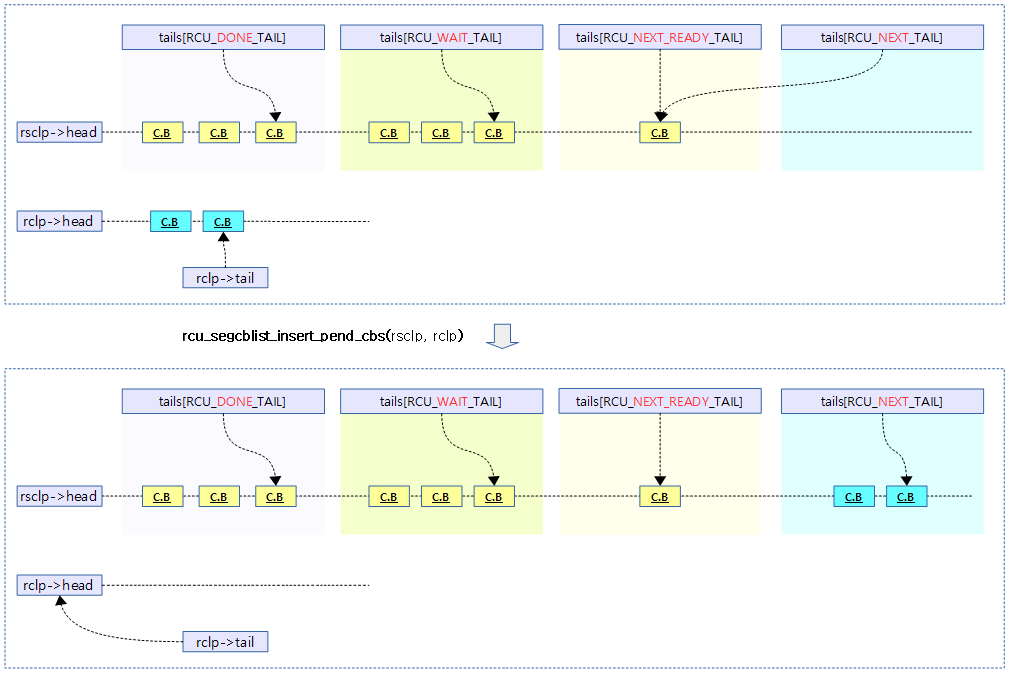
rcu 콜백 리스트의 콜백들을 rcu seg 콜백리스트의 next 구간으로 옮긴다.
다음 그림은 rcu 콜백 리스트의 콜백들을 rcu seg 콜백리스트의 next 구간으로 옮기는 모습을 보여준다.
rcu_segcblist_insert_count()
kernel/rcu/rcu_segcblist.c
/*
* Insert counts from the specified rcu_cblist structure in the
* specified rcu_segcblist structure.
*/
void rcu_segcblist_insert_count(struct rcu_segcblist *rsclp,
struct rcu_cblist *rclp)
{
rsclp->len_lazy += rclp->len_lazy;
rcu_segcblist_add_len(rsclp, rclp->len);
rclp->len_lazy = 0;
rclp->len = 0;
};
rcu 콜백리스트의 len_lazy 카운터와 콜백 수를 extract하여 rcu seg 콜백리스트에 추가한다.
RCU Cascading 처리
rcu_advance_cbs()
kernel/rcu/tree.c
/*
* Move any callbacks whose grace period has completed to the
* RCU_DONE_TAIL sublist, then compact the remaining sublists and
* assign ->gp_seq numbers to any callbacks in the RCU_NEXT_TAIL
* sublist. This function is idempotent, so it does not hurt to
* invoke it repeatedly. As long as it is not invoked -too- often...
* Returns true if the RCU grace-period kthread needs to be awakened.
*
* The caller must hold rnp->lock with interrupts disabled.
*/
static bool rcu_advance_cbs(struct rcu_node *rnp, struct rcu_data *rdp)
{
rcu_lockdep_assert_cblist_protected(rdp);
raw_lockdep_assert_held_rcu_node(rnp);
/* If no pending (not yet ready to invoke) callbacks, nothing to do. */
if (!rcu_segcblist_pend_cbs(&rdp->cblist))
return false;
/*
* Find all callbacks whose ->gp_seq numbers indicate that they
* are ready to invoke, and put them into the RCU_DONE_TAIL sublist.
*/
rcu_segcblist_advance(&rdp->cblist, rnp->gp_seq);
/* Classify any remaining callbacks. */
return rcu_accelerate_cbs(rnp, rdp);
}
콜백들을 앞쪽으로 옮기는 cascade 처리를 수행한다.
- 코드 라인 7~8에서 pending 콜백들이 없는 경우 false를 반환한다.
- 코드 라인 14에서 콜백들을 앞쪽으로 옮기는 cascade 처리를 수행한다.
- 코드 라인 17에서 남은 콜백들에 대해 accelerate 처리가 가능한 콜백들을 묶어 앞으로 옮긴다.
rcu_segcblist_advance()
kernel/rcu/rcu_segcblist.c
/*
* Advance the callbacks in the specified rcu_segcblist structure based
* on the current value passed in for the grace-period counter.
*/
void rcu_segcblist_advance(struct rcu_segcblist *rsclp, unsigned long seq)
{
int i, j;
WARN_ON_ONCE(!rcu_segcblist_is_enabled(rsclp));
if (rcu_segcblist_restempty(rsclp, RCU_DONE_TAIL))
return;
/*
* Find all callbacks whose ->gp_seq numbers indicate that they
* are ready to invoke, and put them into the RCU_DONE_TAIL segment.
*/
for (i = RCU_WAIT_TAIL; i < RCU_NEXT_TAIL; i++) {
if (ULONG_CMP_LT(seq, rsclp->gp_seq[i]))
break;
WRITE_ONCE(rsclp->tails[RCU_DONE_TAIL], rsclp->tails[i]);
}
/* If no callbacks moved, nothing more need be done. */
if (i == RCU_WAIT_TAIL)
return;
/* Clean up tail pointers that might have been misordered above. */
for (j = RCU_WAIT_TAIL; j < i; j++)
WRITE_ONCE(rsclp->tails[j], rsclp->tails[RCU_DONE_TAIL]);
/*
* Callbacks moved, so clean up the misordered ->tails[] pointers
* that now point into the middle of the list of ready-to-invoke
* callbacks. The overall effect is to copy down the later pointers
* into the gap that was created by the now-ready segments.
*/
for (j = RCU_WAIT_TAIL; i < RCU_NEXT_TAIL; i++, j++) {
if (rsclp->tails[j] == rsclp->tails[RCU_NEXT_TAIL])
break; /* No more callbacks. */
WRITE_ONCE(rsclp->tails[j], rsclp->tails[i]);
rsclp->gp_seq[j] = rsclp->gp_seq[i];
}
};
콜백들을 앞쪽으로 옮기는 cascade 처리를 수행한다. gp가 만료된 콜백들을 done 구간으로 옮기고, wait 구간이 빈 경우 next-ready 구간의 콜백들을 wait구간으로 옮긴다. 신규 진입한 콜백들의 경우 동일한 completed 발급번호를 사용하는 구간이 있으면 그 구간(wait or next-ready)과 합치는 acceleration작업도 수행한다. gp kthread를 깨워야 하는 경우 true를 반환한다.
- 코드 라인 6~7에서 done 구간 이후에 대기중인 콜백이 없으면 true를 반환한다.
- 코드 라인 13~17에서 1단계) 완료 처리. wait 구간과 next_ready 구간에 이미 만료된 콜백을 done 구간으로 옮긴다.
- rnp->gp_seq < gp_seq[]인 경우는 gp가 아직 완료되지 않아 처리할 수 없는 콜백들이다.
- 코드 라인 20~21에서 옮겨진 콜백이 없는 경우 함수를 빠져나간다.
- 코드 라인 24~25에서 위에서 wait 구간 또는 next 구간에 콜백들이 있었던 경우 wait tail 또는 next ready tail이 done tail 보다 앞서 있을 수 있다. 따라서 해당 구간을 일단 done tail과 동일하게 조정한다.
- 코드 라인 33~33에서 2단계) cascade 처리. 하위 (next ready, next) 구간에 있었던 콜백들을 한 단계 상위 구간으로 옮긴다.
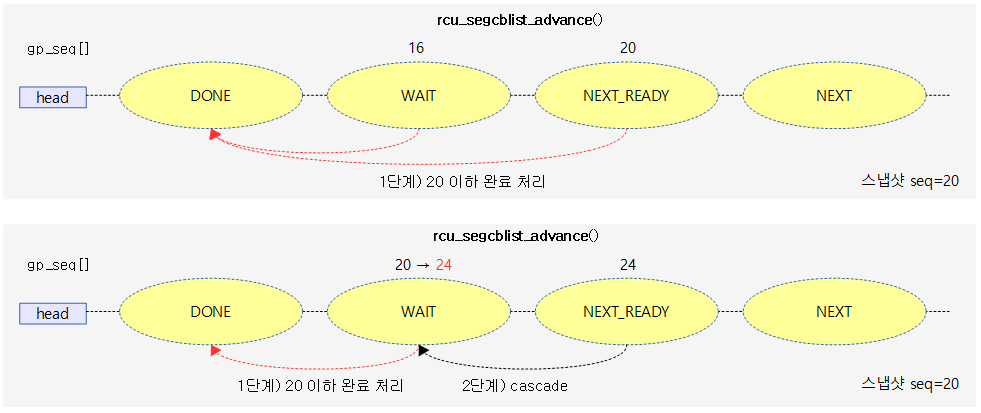
다음 그림은 rcu_segcblist_advance() 함수를 통해 cascade 처리가 가능한 경우를 보여준다.
- wait 및 next-ready 구간의 완료 처리 가능한 콜백들을 done 구간으로 옮긴다. wait 구간만 옮겨진 경우 next-ready 구간의 콜백을 wait 구간으로 옮기는 모습을 볼 수 있다.
신규 콜백들의 accelerate 처리
rcu_accelerate_cbs_unlocked()
kernel/rcu/tree.c
/*
* Similar to rcu_accelerate_cbs(), but does not require that the leaf
* rcu_node structure's ->lock be held. It consults the cached value
* of ->gp_seq_needed in the rcu_data structure, and if that indicates
* that a new grace-period request be made, invokes rcu_accelerate_cbs()
* while holding the leaf rcu_node structure's ->lock.
*/
static void rcu_accelerate_cbs_unlocked(struct rcu_node *rnp,
struct rcu_data *rdp)
{
unsigned long c;
bool needwake;
rcu_lockdep_assert_cblist_protected(rdp);
c = rcu_seq_snap(&rcu_state.gp_seq);
if (!rdp->gpwrap && ULONG_CMP_GE(rdp->gp_seq_needed, c)) {
/* Old request still live, so mark recent callbacks. */
(void)rcu_segcblist_accelerate(&rdp->cblist, c);
return;
}
raw_spin_lock_rcu_node(rnp); /* irqs already disabled. */
needwake = rcu_accelerate_cbs(rnp, rdp);
raw_spin_unlock_rcu_node(rnp); /* irqs remain disabled. */
if (needwake)
rcu_gp_kthread_wake();
}
신규 콜백들을 묶어 가능한 경우 앞으로 accelerate 처리한다. (leaf 노드 락 없이 진입)
- 코드 라인 8에서 rdp->gp_seq_needed 값이 gp 시퀀스의 스냅샷 보다 크거나 같은 경우 신규 콜백들을 묶어 가능한 경우 앞으로 accelerate 처리하고 함수를 빠져나간다.
- 코드 라인 10~12에서 노드 락을 건후 신규 콜백들을 묶어 가능한 경우 앞으로 accelerate 처리한다.
- 코드 라인 13~14에서 결과 값이 true인 경우 gp 커널 스레드를 깨워야 한다.
rcu_accelerate_cbs()
kernel/rcu/tree.c
/*
* If there is room, assign a ->gp_seq number to any callbacks on this
* CPU that have not already been assigned. Also accelerate any callbacks
* that were previously assigned a ->gp_seq number that has since proven
* to be too conservative, which can happen if callbacks get assigned a
* ->gp_seq number while RCU is idle, but with reference to a non-root
* rcu_node structure. This function is idempotent, so it does not hurt
* to call it repeatedly. Returns an flag saying that we should awaken
* the RCU grace-period kthread.
*
* The caller must hold rnp->lock with interrupts disabled.
*/
static bool rcu_accelerate_cbs(struct rcu_node *rnp, struct rcu_data *rdp)
{
unsigned long gp_seq_req;
bool ret = false;
rcu_lockdep_assert_cblist_protected(rdp);
raw_lockdep_assert_held_rcu_node(rnp);
/* If no pending (not yet ready to invoke) callbacks, nothing to do. */
if (!rcu_segcblist_pend_cbs(&rdp->cblist))
return false;
/*
* Callbacks are often registered with incomplete grace-period
* information. Something about the fact that getting exact
* information requires acquiring a global lock... RCU therefore
* makes a conservative estimate of the grace period number at which
* a given callback will become ready to invoke. The following
* code checks this estimate and improves it when possible, thus
* accelerating callback invocation to an earlier grace-period
* number.
*/
gp_seq_req = rcu_seq_snap(&rcu_state.gp_seq);
if (rcu_segcblist_accelerate(&rdp->cblist, gp_seq_req))
ret = rcu_start_this_gp(rnp, rdp, gp_seq_req);
/* Trace depending on how much we were able to accelerate. */
if (rcu_segcblist_restempty(&rdp->cblist, RCU_WAIT_TAIL))
trace_rcu_grace_period(rcu_state.name, rdp->gp_seq, TPS("AccWaitCB"));
else
trace_rcu_grace_period(rcu_state.name, rdp->gp_seq, TPS("AccReadyCB"));
return ret;
}
신규 콜백들을 묶어 가능한 경우 앞으로 accelerate 처리한다. 결과 값이 true인 경우 콜러에서 gp 커널 스레드를 깨워야 한다. (반드시 leaf 노드 락이 획득된 상태에서 진입되어야 한다)
- 코드 라인 10~11에서 pending 콜백들이 없는 경우 함수를 빠져나간다.
- 코드 라인 23~25에서 스냅된 gp 시퀀스 요청 값에 따라 신규 콜백들의 accelerate 처리를 수행한다. 만일 accelerate 처리가 성공한 경우 스냅된 gp 시퀀스 번호로 gp를 시작 요청한다.
rcu_segcblist_accelerate()
kernel/rcu/rcu_segcblist.c
/*
* "Accelerate" callbacks based on more-accurate grace-period information.
* The reason for this is that RCU does not synchronize the beginnings and
* ends of grace periods, and that callbacks are posted locally. This in
* turn means that the callbacks must be labelled conservatively early
* on, as getting exact information would degrade both performance and
* scalability. When more accurate grace-period information becomes
* available, previously posted callbacks can be "accelerated", marking
* them to complete at the end of the earlier grace period.
*
* This function operates on an rcu_segcblist structure, and also the
* grace-period sequence number seq at which new callbacks would become
* ready to invoke. Returns true if there are callbacks that won't be
* ready to invoke until seq, false otherwise.
*/
bool rcu_segcblist_accelerate(struct rcu_segcblist *rsclp, unsigned long seq)
{
int i;
WARN_ON_ONCE(!rcu_segcblist_is_enabled(rsclp));
if (rcu_segcblist_restempty(rsclp, RCU_DONE_TAIL))
return false;
/*
* Find the segment preceding the oldest segment of callbacks
* whose ->gp_seq[] completion is at or after that passed in via
* "seq", skipping any empty segments. This oldest segment, along
* with any later segments, can be merged in with any newly arrived
* callbacks in the RCU_NEXT_TAIL segment, and assigned "seq"
* as their ->gp_seq[] grace-period completion sequence number.
*/
for (i = RCU_NEXT_READY_TAIL; i > RCU_DONE_TAIL; i--)
if (rsclp->tails[i] != rsclp->tails[i - 1] &&
ULONG_CMP_LT(rsclp->gp_seq[i], seq))
break;
/*
* If all the segments contain callbacks that correspond to
* earlier grace-period sequence numbers than "seq", leave.
* Assuming that the rcu_segcblist structure has enough
* segments in its arrays, this can only happen if some of
* the non-done segments contain callbacks that really are
* ready to invoke. This situation will get straightened
* out by the next call to rcu_segcblist_advance().
*
* Also advance to the oldest segment of callbacks whose
* ->gp_seq[] completion is at or after that passed in via "seq",
* skipping any empty segments.
*/
if (++i >= RCU_NEXT_TAIL)
return false;
/*
* Merge all later callbacks, including newly arrived callbacks,
* into the segment located by the for-loop above. Assign "seq"
* as the ->gp_seq[] value in order to correctly handle the case
* where there were no pending callbacks in the rcu_segcblist
* structure other than in the RCU_NEXT_TAIL segment.
*/
for (; i < RCU_NEXT_TAIL; i++) {
WRITE_ONCE(rsclp->tails[i], rsclp->tails[RCU_NEXT_TAIL]);
rsclp->gp_seq[i] = seq;
}
return true;
};
이 함수에서는 next 구간에 새로 진입한 콜백들이 여건이 되면 next-ready 또는 더 나아가 wait 구간으로 옮겨 빠르게 처리할 수 있도록 앞당긴다.(acceleration). rcu gp kthread를 깨워햐 하는 경우 true를 반환한다.
- 코드 라인 6~7에서 done 구간 이후에 대기중인 콜백이 없으면 false를 반환한다.
- 코드 라인 17~20에서 next-ready(2) 구간과 wait(1) 구간에 대해 역순회한다. 만일 assign된 콜백들이 존재하면 루프를 벗어난다.
- 코드 라인 35~36에서 next-ready(2) 구간에 이미 assign된 콜백이 있으면 신규 콜백들을 acceleration 할 수 없으므로 false를 반환하고 함수를 빠져나간다.
- 코드 라인 45~48에서 next(3) 구간의 콜백들을 wait(1) 또는 next-ready(2) 구간에 통합하고, 글로벌 진행 중인 seq 번호로 gp_seq 번호를 갱신한다.
- 코드 라인 49에서 성공 true를 반환한다.
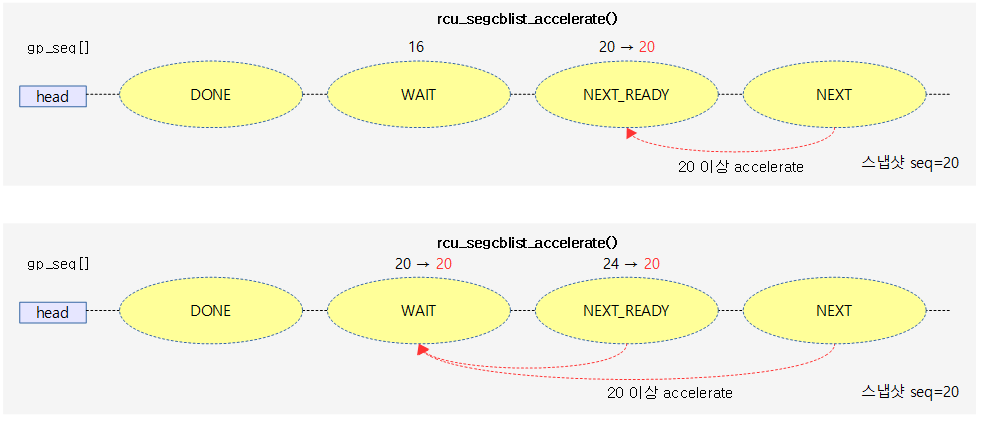
다음 그림은 next 구간에 새로 진입한 콜백을 next-ready 또는 wait 구간으로 acceleration하여 빠르게 처리할 수 있도록 하는 모습을 보여준다.
구조체
rcu_cblist 구조체
include/linux/rcu_segcblist.h”
/* Simple unsegmented callback lists. */
struct rcu_cblist {
struct rcu_head *head;
struct rcu_head **tail;
long len;
long len_lazy;
};
rcu un-segmented 콜백 리스트 구조체이다.
- *head
- rcu 콜백들이 연결된다.
- 비어있는 경우 null이 사용된다.
- **tail
- 마지막 rcu 콜백을 가리킨다.
- 비어있는 경우 head를 가리킨다.
- len
- len_lazy
- lazy 콜백 수
- 참고) non-lazy 콜백 수 = len – len_lazy
rcu_segcblist 구조체
include/linux/rcu_segcblist.h”
struct rcu_segcblist {
struct rcu_head *head;
struct rcu_head **tails[RCU_CBLIST_NSEGS];
unsigned long gp_seq[RCU_CBLIST_NSEGS];
#ifdef CONFIG_RCU_NOCB_CPU
atomic_long_t len;
#else
long len;
#endif
long len_lazy;
u8 enabled;
u8 offloaded;
};
rcu segmented 콜백 리스트 구조체이다.
- *head
- rcu 콜백들이 연결된다.
- 비어있는 경우 null이 사용된다.
- **tails[]
- 4 단계로 구성되며, 각각 구간의 마지막 rcu 콜백을 가리킨다.
- 비어있는 경우 이전 구간의 콜백을 가리키고, 모두 비어 있는 경우 head를 가리킨다.
- gp_seq[]
- len
- len_lazy
- lazy 콜백 수
- 참고) non-lazy 콜백 수 = len – len_lazy
- enabled
- 활성화 여부가 담긴다. (1=enabled, 0=disabled)
- offloaded
- 커널 v5.4-rc1에서 no-cb 처리를 위한 오프로드 여부가 담긴다. (1=offloaded, 0=none)
참고