<kernel v5.4>
Timer -6- (Clock Source & Timer Driver)
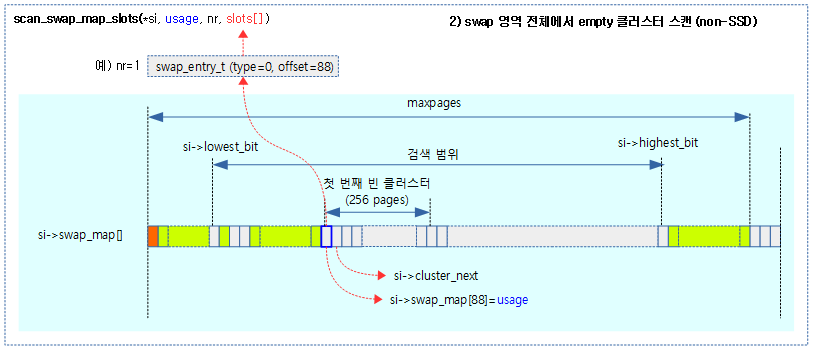
리눅스는 clock sources subsystem에 등록된 클럭 소스들 중 가장 정확도가 높고 안정적인 클럭 소스를 찾아 제공한다. 이 클럭 소스를 읽어 리눅스 시간 관리를 수행하는 timekeeping subsystem에 제공된다.
- 주요 연관 관계
- clk(common clock foundation) -> clock sources subsystem -> timekeeping subsystem
또한 타이머를 사용하기 위해 커널은 timer 및 hrtimer API를 제공하고, 이의 타이머 hw 제어를 위해 최대한 아키텍처 독립적인 코드를 사용하여 clock events subsystem에 제공된다.
- 주요 연관 관계
- 타이머 프로그램: hrtimer API -> clock events susbsystem -> tick device -> timer hw
- 타이머 만료: clk(common clock foundation) ->timer hw -> interrupt controller hw -> irq subsystem -> hrtimer API로 등록한 콜백 함수
clock events subsystem은 다음 두 가지 운용 모드를 사용하여 커널에 타이머 이벤트를 전달할 수 있다.
- periodic
- 규칙적으로 타이머 인터럽트를 발생시킨다.
- oneshot
- 단발 타이머 인터럽트가 발생할 수 있도록 만료시간을 프로그램할 수 있다.
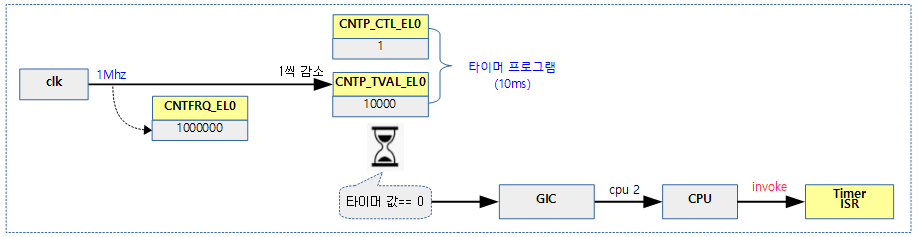
다음 그림과 같이 1Mhz(1초에 100만번) 클럭 주파수를 사용하는 타이머 hw의 다운카운터에 10000 값을 설정하면, 10000 값이 0이 되기까지 10ms가 소요되며 그 후 타이머 인터럽트에가 발생되고, 이에 해당하는 타이머 ISR이 동작하는 것을 알 수 있다.

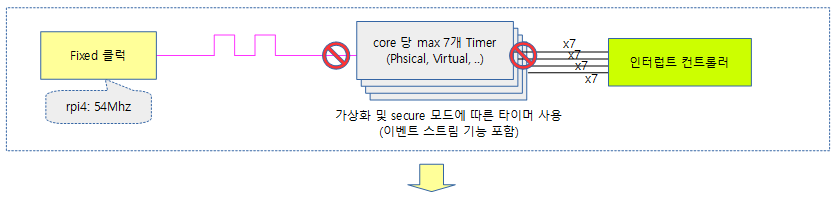
다음 그림은 각각의 cpu에 포함된 타이머에 기준 클럭을 공급하는 모습을 보여준다.
- cpu마다 사용되는 타이머 인터럽트를 통해 타이머가 깨어나고 다음 타이머를 프로그램하는 과정이다.

타이머 클럭 주파수
타이머에 공급되는 클럭 주파수는 높으면 높을 수록 타이머의 해상도는 높아진다. 커널에 구현된 hrtimer는 1나노초 단위부터 제어 가능하다. 따라서 정밀도를 높이기 위해 이상적인 클럭 주파수는 1Ghz 이상을 사용하면 좋다. 그러나 외부 클럭 주파수가 높으면 높을 수록 전력 소모가 크므로 적절한 선으로 제한하여 사용한다. 현재 수 Mhz ~ 100Mhz의 클럭을 사용하며, 언젠가 필요에 의해 1Ghz 클럭도 사용되리라 판단된다. 저전력 시스템을 위해 500~20Khz를 사용하는 경우도 있다.
타이머 하드웨어 종류
타이머 하드웨어는 매우 다양하다. 이들을 크게 두 그룹으로 나눈다.
- 아키텍처 내장 타이머 (architected timer)
- arm per-core 아키텍처 내장 타이머 (rpi2, rpi3, rpi4)
- arm 메모리 맵드 아키텍처 내장 타이머
- 아키텍처 비내장 타이머 (SoC에 포함)
- arm 글로벌 타이머
- bcm2835 타이머 (rpi)
- …
arm 아키텍처 내장형 generic 타이머 hw 타입
arm 아키텍처에 따라 generic timer extension이 적용되어 아키텍처에 내장된 generic 타이머들이다. 이 타이머는 SoC 제조 업체에서 설계에 따라 다음 2 가지 타입으로 나뉘어 사용된다. 스마트 폰등의 절전(deep sleep)을 위해 아키텍처 내장형 타이머는 주 타이머로 사용하고, 절전을 위해 메모리 매핑형 타이머를 브로드 캐스트 타이머로 나누어 동시에 동작시키기도 한다.
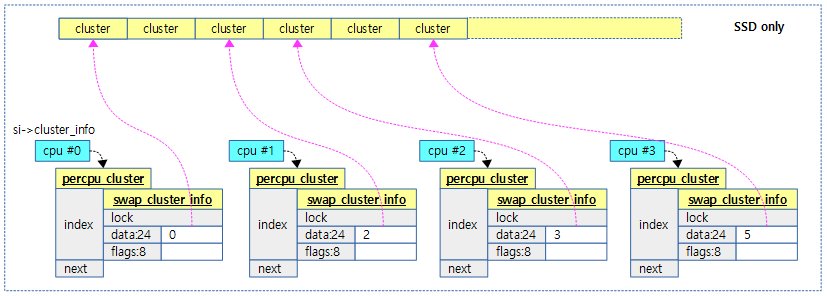
- 코어별 아키텍처 내장 타이머(per-core architected timer)
- per-cpu 보조프로세서 cp15를 통해 타이머 레지스터를 사용한다.
- GIC의 PPIs를 사용하여 인터럽트를 전달한다.
- armv7 및 armv8 아키텍처에서 사용된다.
- 메모리 매핑형 아키텍처 내장 타이머(memory mapped architected timer)
- 타이머 레지스터들을 주소 공간에 매핑하여 사용한다.
- 장점으로 user 영역에서도 타이머에 접근할 수 있다.
- 타이머당 8개까지의 프레임(타이머)을 사용할 수 있다.
- GIC의 SPIs를 사용하여 인터럽트를 전달한다.
- 특정 1개의 cpu만 인터럽트를 받을 수 있으므로 수신을 원하는 cpu로 인터럽트를 미리 라우팅해두어야 한다.
- 틱 브로드 캐스트용 타이머로 사용한다.
- 타이머 레지스터들을 주소 공간에 매핑하여 사용한다.
코어별 아키텍처 내장 타이머 디바이스
rpi3용 “arm,armv7-timer” 타이머
arch/arm/boot/dts/bcm2837.dtsi
timer {
compatible = "arm,armv7-timer";
interrupt-parent = <&local_intc>;
interrupts = <0 IRQ_TYPE_LEVEL_HIGH>, // PHYS_SECURE_PPI
<1 IRQ_TYPE_LEVEL_HIGH>, // PHYS_NONSECURE_PPI
<3 IRQ_TYPE_LEVEL_HIGH>, // VIRT_PPI
<2 IRQ_TYPE_LEVEL_HIGH>; // HYP_PPI
always-on;
};
rpi4용 “arm,armv8-timer” 타이머
https://github.com/raspberrypi/linux/blob/rpi-4.19.y/arch/arm/boot/dts/bcm2838.dtsi
- 아래 GIC_PPI 14은 rpi4가 사용하는 non-secure timer로 SGI에서 사용하는 irq 수 16을 더해 PPI ID30(hwirq=30)이다.
timer {
compatible = "arm,armv7-timer";
interrupts = <GIC_PPI 13 (GIC_CPU_MASK_SIMPLE(4) |
IRQ_TYPE_LEVEL_LOW)>,
<GIC_PPI 14 (GIC_CPU_MASK_SIMPLE(4) |
IRQ_TYPE_LEVEL_LOW)>,
<GIC_PPI 11 (GIC_CPU_MASK_SIMPLE(4) |
IRQ_TYPE_LEVEL_LOW)>,
<GIC_PPI 10 (GIC_CPU_MASK_SIMPLE(4) |
IRQ_TYPE_LEVEL_LOW)>;
arm,cpu-registers-not-fw-configured;
always-on;
};
arm,armv7-timer” 또는 “arm,armv8-timer” 타이머에 대한 속성의 용도는 다음과 같다.
- compatible
- 타이머 디바이스 드라이버명 “arm,armv7-timer” 또는 “arm,armv8-timer”
- interrupt-parent
- 타이머 만료 시각에 local_intc 인터럽트 컨트롤러에 인터럽트가 발생된다.
- interrupts
- cpu core마다 최대 4개의 타이머가 사용될 수 있으며 각각에 대해 인터럽트가 발생된다. 각 타이머 인터럽트에 연결된 PPI 번호를 지정한다.
- 4개 타이머 용도는 각각 다르다.
- 시큐어 펌웨어용
- non 시큐어용으로 커널이 사용
- Guest 커널용
- 하이퍼바이저용
- always-on
- 타이머에 c3 절전 기능이 없다. 즉 별도의 파워 블럭으로 관리되지 않고 항상 켜져있는 타이머이다.
- suspend시에도 절대 타이머 전원이 다운되지 않는 시스템에서 이 속성을 사용한다.
다음은 옵션 파라미터이다.
- clock-frequency
- 타이머를 이용하기 위해 펌웨어가 CNTFREQ 레지스터에 클럭 주파수를 먼저 설정한다. 따라서 커널은 부팅 시 CNTFREQ 레지스터를 설정할 필요 없이 해당 레지스터의 값을 읽어오는 것으로 클럭 주파수를 알아올 수 있다. 만일 펌웨어가 CNTFREQ 레지스터에 클럭 주파수를 설정하지 않는 시스템을 사용하는 경우 이 속성 항목을 읽어 타이머를 초기화하여야 한다.가능하면 이 속성은 사용하지 않는 것을 권장한다.
- arm,cpu-registers-not-fw-configured
- 펌웨어(주로 시큐어 펌웨어)가 어떠한 타이머 레지스터도 사용하지 않는 시스템이다. 이러한 경우 현재 커널이 시큐어용 타이머를 사용하도록 한다.
- arm,no-tick-in-suspend
- 시스템 suspend(깊은 절전) 시 타이머가 stop 되는 기능이 있는 경우 사용된다.
메모리 매핑형 아키텍처 내장 타이머 디바이스
타이머 레지스터를 별도의 주소 공간에 매핑하므로 추가로 reg 속성을 사용하고, 최대 8개까지 frame을 사용한다.
arch/arm/boot/dts/qcom-apq8084.dtsi
soc: soc {
#address-cells = <1>;
#size-cells = <1>;
ranges;
compatible = "simple-bus";
timer@f9020000 {
#address-cells = <1>;
#size-cells = <1>;
ranges;
compatible = "arm,armv7-timer-mem";
reg = <0xf9020000 0x1000>;
clock-frequency = <19200000>;
frame@f9021000 {
frame-number = <0>;
interrupts = <0 8 0x4>,
<0 7 0x4>;
reg = <0xf9021000 0x1000>,
<0xf9022000 0x1000>;
};
(...생략...)
ARM per-core 아키텍처 내장 Generic Timer
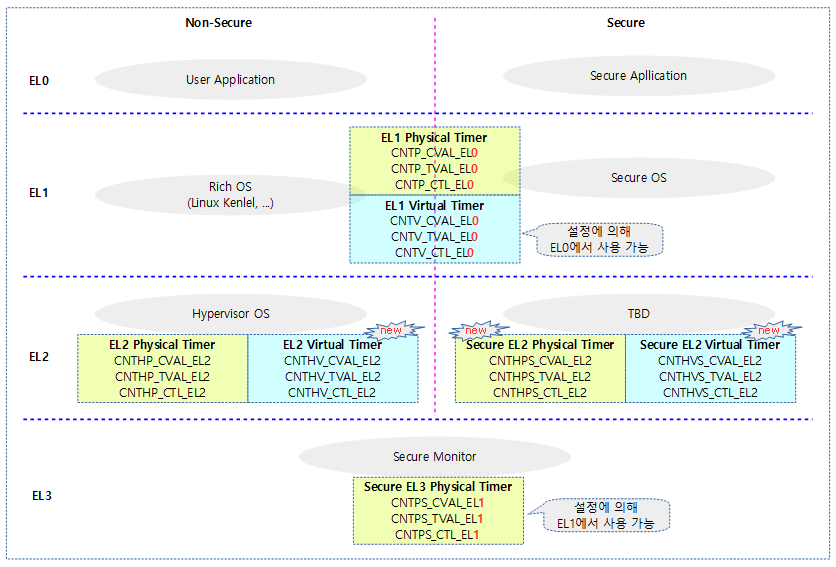
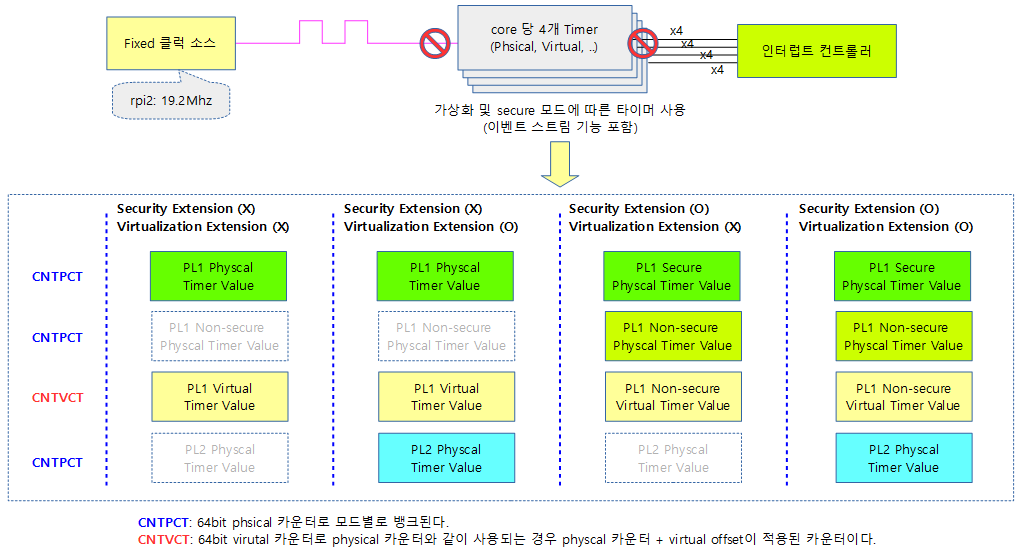
다음 그림은 ARM SMP 각 core에 내장된 generic 타이머가 각 모드별로 사용하는 타이머 종류를 보여준다.
각 core 마다 최대 7개(4+3)개의 타이머가 인터럽트와 연결되어 있다.
- EL1 physical timer
- non 시큐어용으로 커널이 사용
- 예) rpi4에서 부팅되는 메인 커널이 사용
- non 시큐어용으로 커널이 사용
- EL1 virtual timer
- Guest 커널용
- 예) kvm용 guest 타이머
- Guest 커널용
- Non-secure EL2 physical timer
- 하이퍼바이저용
- 예) xen 하이퍼바이저
- 하이퍼바이저용
- Non-secure EL2 virtual timer
- ARMv8.1-VHE 구현시 사용 가능
- Secure EL2 virtual timer
- ARMv8.4-SecEL2 구현시 사용 가능
- Secure EL2 physical timer
- ARMv8.4-SecEL2 구현시 사용 가능
- EL3 physical timer
- 시큐어 펌웨어용
- 시큐어 펌웨어를 사용하지 않는 경우 커널이 사용할 수도 있다.
다음 그림은 arm64 시스템에서 core별로 최대 7개의 타이머를 사용할 수 있음을 보여준다.
arm32 시스템에서는 core마다 최대 4개의 타이머를 사용할 수 있다.
- Physical 타이머는 뱅크되어 3개의 모드에서 각각 사용된다.
- PL1 Secure 모드
- PL1 Non-Secure 모드
- PL2 하이퍼 모드
- Virtual 타이머는 guest OS에 사용되며 하이퍼 바이저가 설정하는 voffset을 더해 사용된다.
다음은 rpi4 시스템에서 사용 중인 타이머를 보여준다. 4개 각 cpu에 내장된 타이머이며 PPI ID30(hwirq=30)에 non-secure physical timer가 동작하고 있다.
- PPI#27은 KVM을 사용하여 두 개의 cpu에 배정하여 동작시키고 있다.
$ cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
1: 0 0 0 0 GICv2 25 Level vgic
3: 18098867 2706362 12943752 3421084 GICv2 30 Level arch_timer
4: 4109642 550709 0 0 GICv2 27 Level kvm guest timer
8: 282 0 0 0 GICv2 114 Level DMA IRQ
16: 1645412 0 0 0 GICv2 65 Level fe00b880.mailbox
19: 6648 0 0 0 GICv2 153 Level uart-pl011
21: 0 0 0 0 GICv2 169 Level brcmstb_thermal
22: 3790111 0 0 0 GICv2 158 Level mmc1, mmc0
24: 0 0 0 0 GICv2 48 Level arm-pmu
25: 0 0 0 0 GICv2 49 Level arm-pmu
26: 0 0 0 0 GICv2 50 Level arm-pmu
27: 0 0 0 0 GICv2 51 Level arm-pmu
28: 0 0 0 0 GICv2 106 Level v3d
30: 27727409 0 0 0 GICv2 189 Level eth0
31: 3055759 0 0 0 GICv2 190 Level eth0
37: 32 0 0 0 GICv2 66 Level VCHIQ doorbell
39: 1921424 0 0 0 Brcm_MSI 524288 Edge xhci_hcd
IPI0: 1796626 2697423 5510661 2638902 Rescheduling interrupts
IPI1: 8372 356892 286341 302455 Function call interrupts
IPI2: 0 0 0 0 CPU stop interrupts
IPI3: 0 0 0 0 CPU stop (for crash dump) interrupts
IPI4: 0 0 0 0 Timer broadcast interrupts
IPI5: 5243413 274725 4761277 692912 IRQ work interrupts
IPI6: 0 0 0 0 CPU wake-up interrupts
클럭 소스와 클럭 이벤트용 레지스터
클럭 소스에 사용되는 카운터 레지스터
- 7개의 CNTxxCT_ELx 레지스터는 64비트 up-counter 레지스터로 클럭 주파수에 맞춰 계속 증가한다. 이 사이클 값을 읽어 리눅스 커널의 timekeeping 및 sched_clock 등에 제공하여 리눅스 시각과 태스크 소요 시간등을 갱신한다.
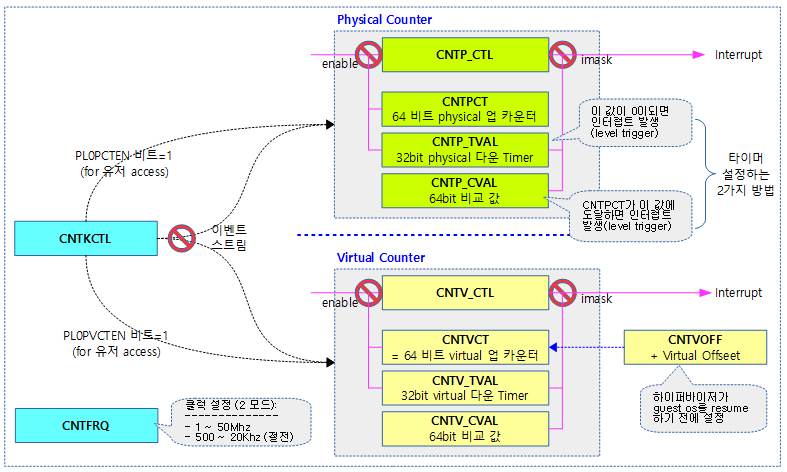
클럭 이벤트 프로그래밍에 사용되는 2 가지 타이머 레지스터
- 첫 번째 방법
- Timer value(7개의 CNTxxTVAL_ELx )레지스터는 32비트 down-counter로 클럭 주파수에 맞춰 감소하다 0이되면 타이머 인터럽트가 발생한다.
- 인터럽트 조건 = timer value == 0
- arm32, arm64 리눅스 커널은 이 레지스터를 사용하여 타이머를 동작시킨다.
- 두 번째 방법
- Compare value(7개의 CNTxxCVAL_ELx) 64비트 레지스터 값을 Counter(CNTxxCT_ELx) 레지스터 값이 같거나 초과하는 순간 타이머 인터럽트가 발생한다.
- 인터럽트 조건 = counter – offset – compare value
- Virtual 타이머의 경우 offset을 추가해야 한다.
- Compare value(7개의 CNTxxCVAL_ELx) 64비트 레지스터 값을 Counter(CNTxxCT_ELx) 레지스터 값이 같거나 초과하는 순간 타이머 인터럽트가 발생한다.
다음 그림은 arm32에서 generic 타이머들의 구성을 보여준다.
- 하이퍼 바이저용 Physical 카운터 관련 레지스터들(CNTHP_CTL, CNTHPCT, CNTHP_TVAL, CNTHP_CVAL) 생략
- 이벤트 스트림 기능은 ARM 전용으로 atomic하게 busy wait 하는 delay 류의 API를 위해 ARM에서 절전을 위해 사용하는 wfe를 사용하는 중에 지속적으로 깨워 loop를 벗어나는 조건을 체크하기 위해 사용된다.
타이머 하드웨어
1) ARM 코어별 아키텍처 내장형 generic 타이머
대부분의 arm 및 arm64 시스템에서 사용하는 방법이다.
특징
- 아키텍처 코어마다 2~4개의 타이머를 제공한다. (32bit down 카운터 및 64bit up 카운터를 제공)
- no Security Extension & no Virutalization Extension
- Physical 타이머 (커널용)
- Virtual 타이머 (Guest OS용)
- Security Extension only
- Non-secure physical 타이머 (커널용)
- Secure physical 타이머 (Secure 펌웨어용)
- Virtual 타이머 (Guest OS용)
- Security Extension & Virtualization Extension
- Non-secure PL1 타이머 (커널용)
- Secure PL1 physical 타이머 (Secure 펌웨어용)
- Non-secure PL2 physical 타이머 (하이퍼바이저용)
- Virtual 타이머 (Guest OS용)
- no Security Extension & no Virutalization Extension
- Generic 타이머는 ARM 아키텍처가 Generic Timer Extension을 지원하는 경우에 사용할 수 있다.
- ARMv7 및 ARMv8에 채용되었다.
- 연속(continuous) 및 one shot event 지원
- GIC의 PPI를 통해 만료 타임 시 인터럽트 시그널을 보낼 수 있다.
- 고해상도 타이머(hrtimer)로 동작한다.
- 타이머 레지스터에 접근하기 위해 코프로세서를 통해 사용할 수 있다.(CP14 & cp15)
다음 그림은 core별로 타이머가 내장되었고, GIC(Global Interrupt Controller)의 PPI를 통해 연결된 것을 확인할 수 있다.
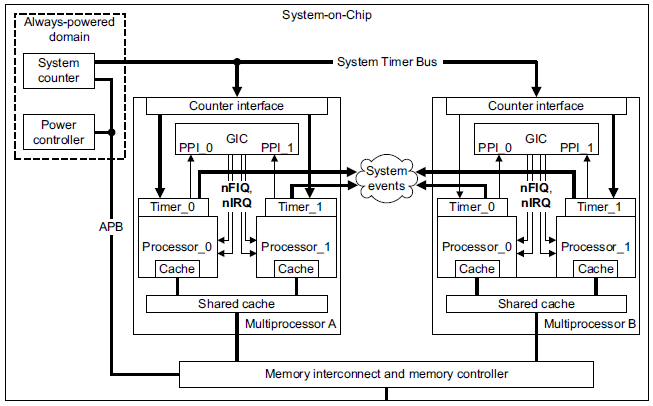
Generic 타이머 레지스터
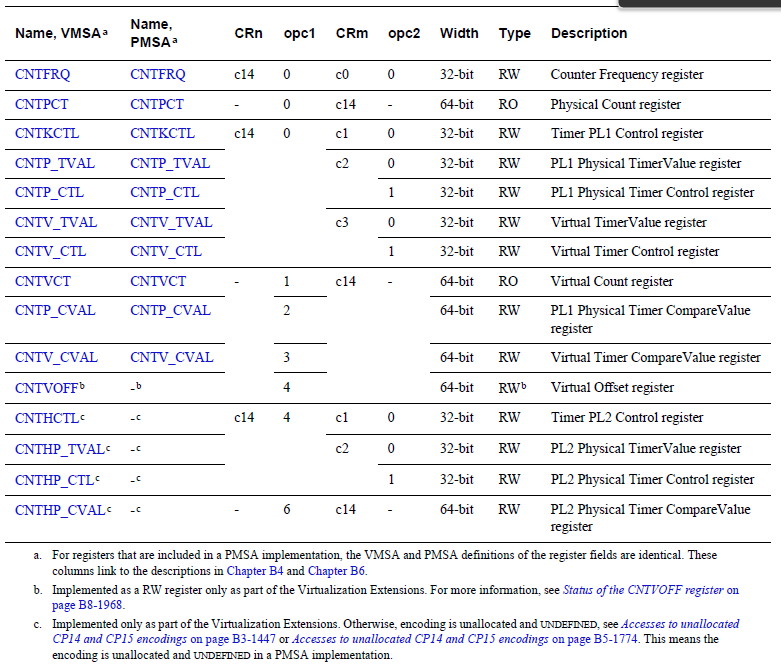
ARM64용 generic 타이머 레지스터
다음은 ARM64 generic 타이머 레지스터들 중 리눅스 커널과 관련된 레지스터들만 표현하였다.
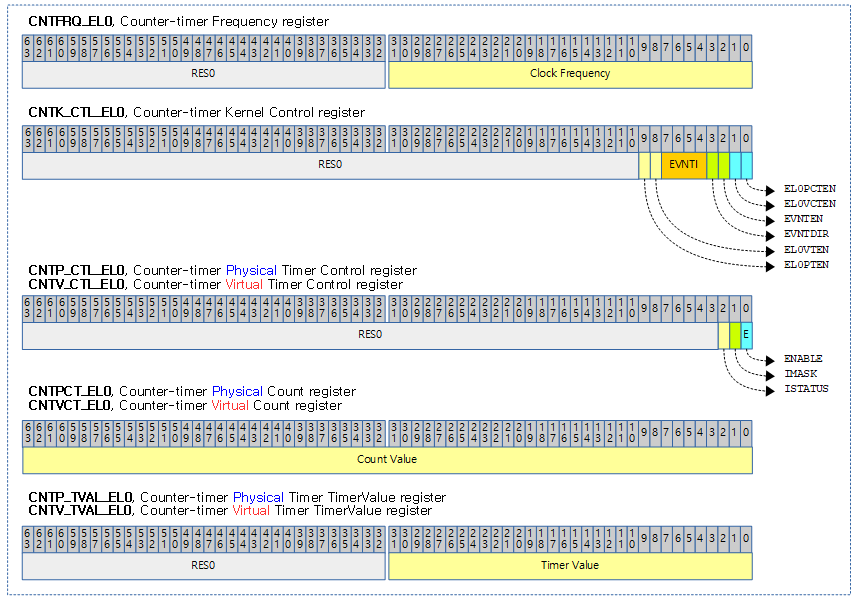
- CNTFRQ_EL0, Counter-timer Frequency register
- bit[31..0]에 클럭 주파수가 설정된다.
- 이 레지스터 값에 접근하려면 다음과 같이 코프로세서 명령을 사용한다.
- MSR or MRC p15, 0, <Register>, c14, c0, 0
- 예) 19.2Mhz의 클럭이 공급되는 경우 19200000 값이 설정된다.
- CNTKCTL_EL1, Counter-timer Kernel Control register
- EL0PTEN
- EL0에서 physical 카운터 관련 레지스터들의 접근 설정. 0=disable, 1=enable
- EL0VTEN
- EL0에서 virtual 카운터 관련 레지스터들의 접근 설정. 0=disable, 1=eable
- EVNTI
- virtual 카운터로 트리거되는 이벤트 스트림 값
- EVNTDIR
- EVNTI 값으로 트리거될 때 방향. 0=0→1로 전환, 1→0 전환
- EVNTEN
- virtual 카운터로부터 event 스트림 생성. 0=disable, 1=enable
- EL0VCTEN
- PL0에서 virtual 카운터 및 frequency 레지스터의 접근 설정. 0=disable, 1=enable
- EL0PCTEN
- PL0에서 physical 카운터 및 frequency 레지스터의 접근 설정. 0=disable, 1=enable
- EL0PTEN
- CNTP_CTL_EL0, Counter-timer Physical Timer Control register
- CNTV_CTL_EL0, Counter-timer Virtual Timer Control register
- ISTATUS
- 타이머 조건 만족 여부. 1=meet condition, 0=not meet condition
- IMASK
- 타이머 조건을 만족시키는 경우 인터럽트 발생 여부를 제어한다. 0=assert(타이머 설정 시 사용), 1=none
- ENABLE
- 타이머 사용 여부. 1=enable, 0=disable(shutdown)
- ISTATUS
- CNTPCT_EL0, Counter-timer Physical Count register
- CNTVCT_EL0, Counter-timer Virtual Count register
- bit[61..0]에 카운터 값이 있다.
- CNTP_TVAL_EL0, Counter-timer Physical Timer TimerValue register
- CNTV_TVAL_EL0, Counter-timer Virtual Timer TimerValue register
- bit[31..0]에 타이머 값이 설정된다.
- CNTHCTL_EL2, Counter-timer Hypervisor Control register
- CNTHP_CTL_EL2, Counter-timer Hypervisor Physical Timer Control register
- CNTHP_CVAL_EL2, Counter-timer Physical Timer CompareValue register (EL2)
- CNTHP_TVAL_EL2, Counter-timer Physical Timer TimerValue register (EL2)
- CNTHPS_CTL_EL2, Counter-timer Secure Physical Timer Control register (EL2)
- CNTHPS_CVAL_EL2, Counter-timer Secure Physical Timer CompareValue register (EL2)
- CNTHPS_TVAL_EL2, Counter-timer Secure Physical Timer TimerValue register (EL2)
- CNTHV_CTL_EL2, Counter-timer Virtual Timer Control register (EL2)
- CNTHV_CVAL_EL2, Counter-timer Virtual Timer CompareValue register (EL2)
- CNTHV_TVAL_EL2, Counter-timer Virtual Timer TimerValue Register (EL2)
- CNTHVS_CTL_EL2, Counter-timer Secure Virtual Timer Control register (EL2)
- CNTHVS_CVAL_EL2, Counter-timer Secure Virtual Timer CompareValue register (EL2)
- CNTHVS_TVAL_EL2, Counter-timer Secure Virtual Timer TimerValue register (EL2)
- CNTP_CVAL_EL0, Counter-timer Physical Timer CompareValue register
- CNTPS_CTL_EL1, Counter-timer Physical Secure Timer Control register
- CNTPS_CVAL_EL1, Counter-timer Physical Secure Timer CompareValue register
- CNTPS_TVAL_EL1, Counter-timer Physical Secure Timer TimerValue register
- CNTV_CVAL_EL0, Counter-timer Virtual Timer CompareValue register
- CNTVOFF_EL2, Counter-timer Virtual Offset register
다음 그림은 10ms 타이머를 설정하고 만료 시 타이머 인터럽트가 발생하는 과정을 타이머 레지스터로 보여준다.
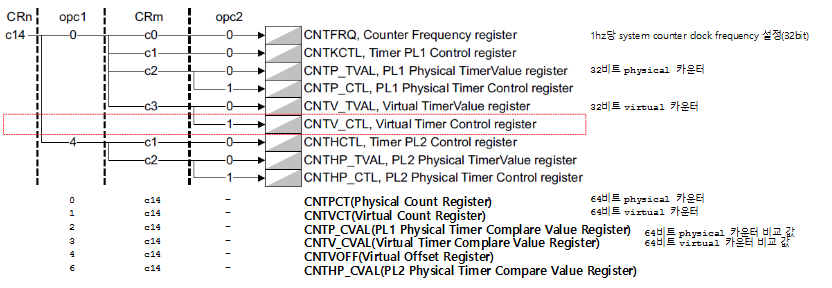
ARM32용 generic 타이머 레지스터
다음은 ARMv7의 타이머 관련 레지스터들을 보여준다.
2) BCM2708(rpi) 타이머
32비트 raspberry pi에서 사용된 글로벌 타이머이다. 이외에 몇몇 시스템에서 한정하여 사용된다.
특징
- 1개의 글로벌 타이머 제공
- 연속(continuous) 모드만 지원
- extra 클럭 분주기 레지스터
- extra stop 디버그 모드 컨트롤 비트
- 32bit 프리 러닝 카운터
- ARM 시스템 타이머를 일부 개량하였다.
- rpi: 1Mhz 클럭을 사용
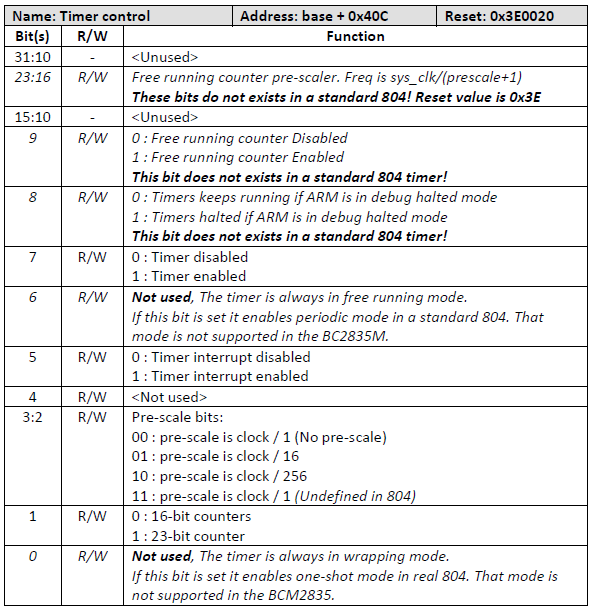
시스템 타이머 레지스터
- Timer Load
- Timer Value (RO)
- Timer Control (RW)
- 아래 그림 참고
- Timer IRQ Clear/Ack (WO)
- 1을 기록 시 인터럽트 pending bit를 클리어한다.
- 리셋 값: 0x003e_0020
- Timer RAW IRQ (RO)
- 인터럽트 pending bit 상태를 알아온다.
- 0=clear, 1=set
- 인터럽트 pending bit 상태를 알아온다.
- Timer Masked IRQ (RO)
- 인터럽트 마스크 상태를 알아온다.
- 0=인터럽트 disable(mask), 1=인터럽트 enabled(unmask)
- 인터럽트 마스크 상태를 알아온다.
- Timer Reload (RW)
- Load 레지스터의 사본과 동일하다 다만 다른 점은 값을 설정해도 리로드가 즉시 발생하지 않는다.
- Timer Pre-divider (RW)
- APB 클럭을 설정된 lsb 10비트 값 + 1로 분주한다.
- timer_clock = apb_clock / (pre_divider + 1)
- 리셋 시 0x7d가 설정된다.
- APB 클럭을 설정된 lsb 10비트 값 + 1로 분주한다.
- Timer Free Running Counter
Timer Control Register
ARM의 SP804는 8비트만 사용하는데 Boradcomm이 이를 확장하여 24bit를 운용한다.
- 8bit pre-scaler를 사용하여 시스템 클럭 / (prescaler 값 + 1)이 사용된다.
- 리셋 값: 0x003e_0020
- pre-scaler: 62 (0x3e)
- timer interrupt enable (bit5)
Device Tree 기반 타이머 초기화
다음 그림은 arm 및 arm64 아키텍처에 내장된 generic 타이머를 사용하는 드라이버의 초기화 함수를 호출하는 예를 보여준다.
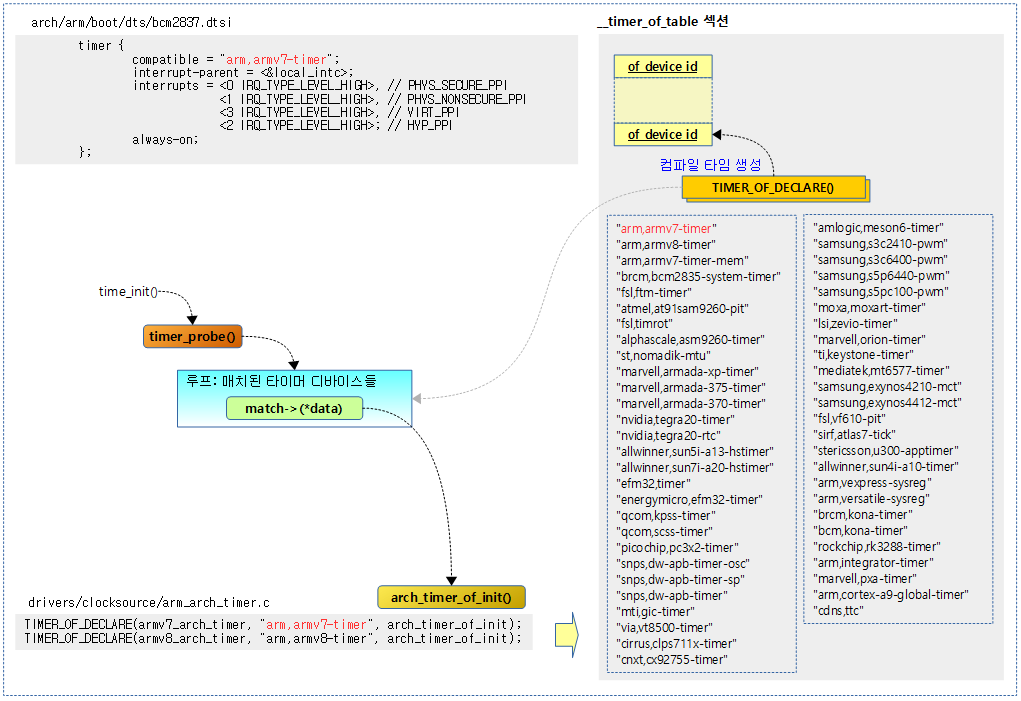
timer_probe()
drivers/clocksource/timer-probe.c
void __init timer_probe(void)
{
struct device_node *np;
const struct of_device_id *match;
of_init_fn_1_ret init_func_ret;
unsigned timers = 0;
int ret;
for_each_matching_node_and_match(np, __timer_of_table, &match) {
if (!of_device_is_available(np))
continue;
init_func_ret = match->data;
ret = init_func_ret(np);
if (ret) {
if (ret != -EPROBE_DEFER)
pr_err("Failed to initialize '%pOF': %d\n", np,
ret);
continue;
}
timers++;
}
timers += acpi_probe_device_table(timer);
if (!timers)
pr_crit("%s: no matching timers found\n", __func__);
}
커널에 등록된 디바이스 드라이버들 중 디바이스 트리 또는 ACPI 정보가 요청한 타이머를 찾아 초기화(probe) 함수를 호출한다.
- _timer_of_table 섹션에 등록된 디바이스 드라이버들의 이름과 Device Tree 또는 ACPI 테이블로 부터 읽은 노드의 디바이스명이 매치되는 드라이버들의 초기화 함수들을 호출한다.
per core 아키텍처 내장 타이머 초기화 (armv7, armv8)
다음 그림은 arm 및 arm64 아키텍처 내장형 generic 타이머 초기화 함수의 함수 호출 관계를 보여준다.

arch_timer_of_init()
drivers/clocksource/arm_arch_timer.c
static int __init arch_timer_of_init(struct device_node *np)
{
int i, ret;
u32 rate;
if (arch_timers_present & ARCH_TIMER_TYPE_CP15) {
pr_warn("multiple nodes in dt, skipping\n");
return 0;
}
arch_timers_present |= ARCH_TIMER_TYPE_CP15;
for (i = ARCH_TIMER_PHYS_SECURE_PPI; i < ARCH_TIMER_MAX_TIMER_PPI; i++)
arch_timer_ppi[i] = irq_of_parse_and_map(np, i);
arch_timer_populate_kvm_info();
rate = arch_timer_get_cntfrq();
arch_timer_of_configure_rate(rate, np);
arch_timer_c3stop = !of_property_read_bool(np, "always-on");
/* Check for globally applicable workarounds */
arch_timer_check_ool_workaround(ate_match_dt, np);
/*
* If we cannot rely on firmware initializing the timer registers then
* we should use the physical timers instead.
*/
if (IS_ENABLED(CONFIG_ARM) &&
of_property_read_bool(np, "arm,cpu-registers-not-fw-configured"))
arch_timer_uses_ppi = ARCH_TIMER_PHYS_SECURE_PPI;
else
arch_timer_uses_ppi = arch_timer_select_ppi();
if (!arch_timer_ppi[arch_timer_uses_ppi]) {
pr_err("No interrupt available, giving up\n");
return -EINVAL;
}
/* On some systems, the counter stops ticking when in suspend. */
arch_counter_suspend_stop = of_property_read_bool(np,
"arm,no-tick-in-suspend");
ret = arch_timer_register();
if (ret)
return ret;
if (arch_timer_needs_of_probing())
return 0;
return arch_timer_common_init();
}
TIMER_OF_DECLARE(armv7_arch_timer, "arm,armv7-timer", arch_timer_of_init);
TIMER_OF_DECLARE(armv8_arch_timer, "arm,armv8-timer", arch_timer_of_init);
armv7 & armv8 아키텍처에 내장된 Generic 타이머를 사용하는 디바이스 트리용 디바이스 드라이버의 초기화 함수이다.
- 코드 라인 6~11에서 디바이스 트리에서 cp15를 사용하는 방식의 per-core 아키텍처 내장형 타이머가 이 드라이버를 사용하여 초기화 함수로 진입하는 경우 한 번만 초기화하고 그 이후 호출되는 경우 skip 한다.
- 참고로 cp15를 사용하는 arm per-core 아키텍처 내장형 타이머와 arm 메모리 맵드 아키텍처 내장 타이머 두 개 다 같이 운영될 수 있다.
- 코드 라인 12~13에서 아키텍처의 각 코어가 지원하는 최대 4개 타이머 수만큼 순회하며 타이머 노드의 “intrrupts” 속성 값을 읽어 각 타이머가 연결된 PPI에 해당하는 인터럽트를 요청하고 그 결과인 virq를 저장한다.
- 코드 라인 15에서 커널의 타이머 virq와 Guest 커널용 타이머 virq를 각각 kvm 타이머 정보에 저장한다.
- 코드 라인 17~18에서 다음 두 가지 방법으로 클럭 주파수 값을 알아와서 arch_timer_rate에 저장한다.
- 디바이스 트리를 사용하는 경우
- “clock-frequency” 속성 값에서 클럭 주파수 값을 알아온다. 만일 속성이 지정되지 않은 경우 CNTFRQ(Counter Frequency Register) 레지스터에서 읽은 값을 클럭 주파수 값으로 사용한다.
- ACPI를 사용하는 경우
- CNTFRQ 레지스터에서 읽은 값을 클럭 주파수 값으로 사용한다.
- 디바이스 트리를 사용하는 경우
- 코드 라인 20에서 절전(c3stop) 기능 여부를 알아온다.
- 타이머 노드의 “always-on” 속성이 없는 경우 절전 기능이 사용되도록 arch_timer_c3stop을 true로 설정한다.
- deep-sleep 상태의 코어에 대해 타이머 장치나 인터럽트 장치도 절전을 위해 파워가 off될 수 있는데 이러한 절전(c3stop) 기능이 사용되면 안되는 시스템에서는 “always-on”을 설정한다.
- 코드 라인 23에서 Cortex-A72 타이머 errta 루틴을 동작시킨다.
- unstable한 코어를 찾으면 유저 스페이스 인터페이스(vdso-direct 포함)에서 직접 타이머 레지스터의 액세스를 사용하지 않게 한다.
- 코드 라인 29~38에서 시스템이 지원하는 최대 4개의 타이머들 중 현재 커널이 사용할 적절한 타이머를 선택한다.
- 타이머 노드의 “arm,cpu-registers-not-fw-configured” 속성이 있는 경우 시큐어 펌웨어를 사용하지 않는 경우이다. 이러한 경우 시큐어용 타이머를 커널에서 사용하도록 선택한다. 이 옵션을 사용하는 장점으로 남는 두 타이머(non-secure phys 타이머 및 virt 타이머)들을 guest os를 위해 더 남겨둘 수 있다.
- 코드 라인 41~42에서 “arm,no-tick-in-suspend” 속성이 존재하는 경우 타이머가 suspend 기능이 있다고 판단하도록 arch_counter_suspend_stop을 true로 설정한다.
- 코드 라인 44~46에서 현재 커널이 사용하도록 지정된 Generic 타이머를 per-cpu 인터럽트에 등록하고 boot cpu용은 즉시 enable하고 클럭 이벤트 디바이스에 등록한다
- 이 함수에서 선택한 타이머에 해당하는 타이머 인터럽트 핸들러가 지정된다.
- 참고: Timer -5- (Clock Events Subsystem) | 문c
- 코드 라인 48~51에서 cp15를 사용하는 arm per-core 아키텍처 내장형 타이머와 arm 메모리 맵드 아키텍처 내장 타이머 두 개 다 같이 운영해야 하는 경우 둘 다 probe 된 경우에만 마지막에 arch_timer_common_init() 함수가 호출되도록 한다. 이 루틴에서는 가장 높은 rate의 Generic 타이머를 클럭 소스 및 스케줄러 클럭으로 등록한다.
다음 그림은 디바이스 트리의 타이머 노드 정보를 읽어오는 모습을 보여준다. (예: rpi3 & rpi4)
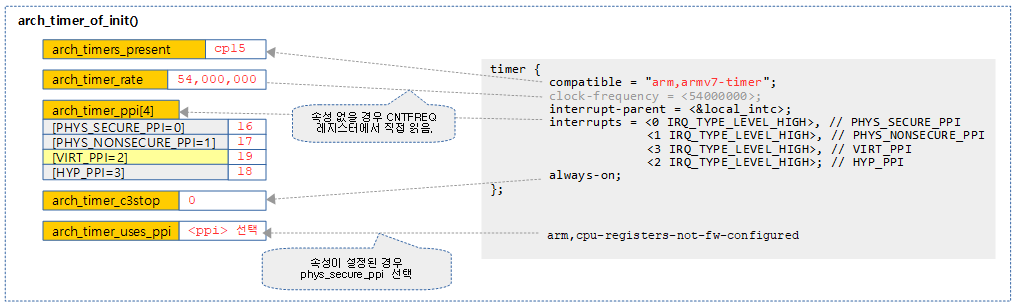
arch_timer_populate_kvm_info()
drivers/clocksource/arm_arch_timer.c
static void __init arch_timer_populate_kvm_info(void)
{
arch_timer_kvm_info.virtual_irq = arch_timer_ppi[ARCH_TIMER_VIRT_PPI];
if (is_kernel_in_hyp_mode())
arch_timer_kvm_info.physical_irq = arch_timer_ppi[ARCH_TIMER_PHYS_NONSECURE_PPI];
}
kvm을 위해 사용할 타이머 정보를 저장한다.
- 코드 라인 3에서 guest os용 타이머 irq를 kvm용 가상 타이머 정보에 저장한다.
- 코드 라인 4~5에서 커널이 하이퍼모드에서 동작한 경우 non-secure 물리 타이머용 irq를 kvm용 물리 타이머 정보에 저장한다.
타이머 Rate 읽기
arch_timer_get_cntfrq() – ARM64
arch/arm64/include/asm/arch_timer.h
static inline u32 arch_timer_get_cntfrq(void)
{
return read_sysreg(cntfrq_el0);
}
CNTFRQ_EL0(Counter Frequency Register)로부터 rate 값을 읽어 반환한다.
read_sysreg() – ARM64
arch/arm64/include/asm/sysreg.h
/* * Unlike read_cpuid, calls to read_sysreg are never expected to be * optimized away or replaced with synthetic values. */
#define read_sysreg(r) ({ \
u64 __val; \
asm volatile("mrs %0, " __stringify(r) : "=r" (__val)); \
__val; \
})
@r 레지스터 값을 읽어온다. (u64 값 반환)
arch_timer_get_cntfrq() – ARM32
arch/arm/include/asm/arch_timer.h
static inline u32 arch_timer_get_cntfrq(void)
{
u32 val;
asm volatile("mrc p15, 0, %0, c14, c0, 0" : "=r" (val));
return val;
}
CNTFRQ(Counter Frequency Register)로부터 rate 값을 읽어 반환한다.
- CNTFRQ(Counter Frequency Register)
- 시스템 카운터의 주파수가 담겨있다. 32bit 값을 사용한다.
- rpi2: 19,200,000 (19.2Mhz)
arch_timer_of_configure_rate()
drivers/clocksource/arm_arch_timer.c
/* * For historical reasons, when probing with DT we use whichever (non-zero) * rate was probed first, and don't verify that others match. If the first node * probed has a clock-frequency property, this overrides the HW register. */
static void arch_timer_of_configure_rate(u32 rate, struct device_node *np)
{
/* Who has more than one independent system counter? */
if (arch_timer_rate)
return;
if (of_property_read_u32(np, "clock-frequency", &arch_timer_rate))
arch_timer_rate = rate;
/* Check the timer frequency. */
if (arch_timer_rate == 0)
pr_warn("frequency not available\n");
}
디바이스 트리의 @np 타이머 노드에서 “clock-frequency” 속성을 읽어 아키텍처 내장형 타이머의 rate 값을 저장한다.
- 코드 라인 4~5에서 아키텍처 내장형 타이머의 rate 값이 이미 설정된 경우 함수를 빠져나간다.
- 코드 라인 7~8에서 디바이스 트리의 @np 타이머 노드에서 “clock-frequency” 속성을 읽어 아키텍처 내장형 타이머의 rate 값을 저장한다.
- 코드 라인 11~12에서 rate 값이 여전히 0이면 경고 메시지를 출력한다.
적절한 타이머 PPI 선택
arch_timer_select_ppi()
drivers/clocksource/arm_arch_timer.c
/** * arch_timer_select_ppi() - Select suitable PPI for the current system. * * If HYP mode is available, we know that the physical timer * has been configured to be accessible from PL1. Use it, so * that a guest can use the virtual timer instead. * * On ARMv8.1 with VH extensions, the kernel runs in HYP. VHE * accesses to CNTP_*_EL1 registers are silently redirected to * their CNTHP_*_EL2 counterparts, and use a different PPI * number. * * If no interrupt provided for virtual timer, we'll have to * stick to the physical timer. It'd better be accessible... * For arm64 we never use the secure interrupt. * * Return: a suitable PPI type for the current system. */
static enum arch_timer_ppi_nr __init arch_timer_select_ppi(void)
{
if (is_kernel_in_hyp_mode())
return ARCH_TIMER_HYP_PPI;
if (!is_hyp_mode_available() && arch_timer_ppi[ARCH_TIMER_VIRT_PPI])
return ARCH_TIMER_VIRT_PPI;
if (IS_ENABLED(CONFIG_ARM64))
return ARCH_TIMER_PHYS_NONSECURE_PPI;
return ARCH_TIMER_PHYS_SECURE_PPI;
}
현재 커널 시스템이 사용할 적절한 타이머 PPI를 선택한다.
- 코드 라인 3~4에서 커널이 하이퍼 모드에서 동작하는 경우 하이퍼 바이저용 타이머 PPI를 선택한다.
- 참고: arm64: Allow the arch timer to use the HYP timer (2014, v4.6-rc1)
- 코드 라인 6~7에서 시스템이 제공하지 않거나 다른 상위에서 하이퍼 바이저가 동작 중이라, 하이퍼 모드를 사용할 수 없는 경우 이 커널은 guest os용 타이머 PPI를 선택한다.
- 코드 라인 9~12에서 arm64 커널인 경우 non-secure 커널 타이머 PPI를 선택하고, arm32 커널인 경우 secure 커널 타이머를 선택한다.
- 참고: clocksource: arm_arch_timer: rework PPI selection (2017, v4.12-rc1)
arch_timer_needs_of_probing()
drivers/clocksource/arm_arch_timer.c
static bool __init arch_timer_needs_of_probing(void)
{
struct device_node *dn;
bool needs_probing = false;
unsigned int mask = ARCH_TIMER_TYPE_CP15 | ARCH_TIMER_TYPE_MEM;
/* We have two timers, and both device-tree nodes are probed. */
if ((arch_timers_present & mask) == mask)
return false;
/*
* Only one type of timer is probed,
* check if we have another type of timer node in device-tree.
*/
if (arch_timers_present & ARCH_TIMER_TYPE_CP15)
dn = of_find_matching_node(NULL, arch_timer_mem_of_match);
else
dn = of_find_matching_node(NULL, arch_timer_of_match);
if (dn && of_device_is_available(dn))
needs_probing = true;
of_node_put(dn);
return needs_probing;
}
cp15 및 mmio 두 타입의 아키텍처 내장형 타이머가 둘 다 이미 probe 되었는지 여부를 반환한다.
- 코드 라인 5~9에서 cp15 및 mmio 타입 둘 다 probing 완료되었으면 더 이상 probing이 필요 없으므로 false를 반환한다.
- 코드 라인 15~16에서 cp15 타이머가 이미 probing된 경우 mmio 타입 타이머가 매치되는지 확인한다.
- 코드 라인 17~18에서 mmio 타이머가 이미 probing된 경우 cp15 타입 타이머가 매치되는지 확인한다.
- 코드 라인 20~25에서 디바이스가 사용 가능한 상태라면 probing을 하기 위해 true를 반환한다. 그렇지 않은 경우 false를 반환한다.
arch_timer_common_init()
drivers/clocksource/arm_arch_timer.c
static int __init arch_timer_common_init(void)
{
arch_timer_banner(arch_timers_present);
arch_counter_register(arch_timers_present);
return arch_timer_arch_init();
}
generic 타이머를 클럭 소스로 등록하고 스케줄러 클럭과 딜레이 타이머로 등록한다.
- 코드 3에서 generic 타이머 정보를 출력한다. cp15 타이머인지 mmio 타이머인지 여부를 가려낼 수 있다.
- arm64-rpi4: “arch_timer: cp15 timer(s) running at 54.00MHz (phys).”를 출력한다.
- arm32 rpi2: “Architected cp15 timer(s) running at 19.20MHz (virt).”를 출력한다.
- arm32 rpi3: “Architected cp15 timer(s) running at 19.20MHz (phys).”를 출력한다.
- 코드 4에서 generic 타이머를 클럭 소스, timercounter 및 스케쥴 클럭으로 등록한다.
- 코드 5에서 아키텍처별 타이머 초기화 루틴을 수행한다.
- arm32에서 generic 타이머를 딜레이 루프 타이머로 등록한다.
- arm64에서 별도의 초기화 코드가 없다.
타이머 제어
타이머 프로그램
4가지 타입 타이머를 프로그램하는 함수이다.
- arch_timer_set_next_event_virt()
- 이 함수만 소스를 아래에 보여준다. 나머지는 유사 동등.
- ARCH_TIMER_VIRT_ACCESS 레지스터를 사용한다.
- arch_timer_set_next_event_phys()
- ARCH_TIMER_PHYS_ACCESS 레지스터를 사용한다.
- arch_timer_set_next_event_virt_mem()
- ARCH_TIMER_MEM_VIRT_ACCESS 레지스터를 사용한다.
- arch_timer_set_next_event_phys_mem()
- ARCH_TIMER_MEM_PHYS_ACCESS 레지스터를 사용한다.
arch_timer_set_next_event_virt()
drivers/clocksource/arm_arch_timer.c
static int arch_timer_set_next_event_virt(unsigned long evt,
struct clock_event_device *clk)
{
set_next_event(ARCH_TIMER_VIRT_ACCESS, evt, clk);
return 0;
}
virt 타이머를 프로그램한다.
set_next_event()
drivers/clocksource/arm_arch_timer.c
static __always_inline void set_next_event(const int access, unsigned long evt,
struct clock_event_device *clk)
{
unsigned long ctrl;
ctrl = arch_timer_reg_read(access, ARCH_TIMER_REG_CTRL, clk);
ctrl |= ARCH_TIMER_CTRL_ENABLE;
ctrl &= ~ARCH_TIMER_CTRL_IT_MASK;
arch_timer_reg_write(access, ARCH_TIMER_REG_TVAL, evt, clk);
arch_timer_reg_write(access, ARCH_TIMER_REG_CTRL, ctrl, clk);
}
@access 타입 타이머 액세스 컨트롤 레지스터를 읽어 타이머를 프로그램한다. 이 때 타이머 레지스터도 @evt 값을 기록한다.
타이머 shutdown
4가지 타입 타이머를 shutdown 하는 함수이다.
- arch_timer_shutdown_virt()
- 이 함수만 소스를 아래에 보여준다. 나머지는 유사 동등.
- ARCH_TIMER_VIRT_ACCESS 레지스터를 사용한다.
- arch_timer_shutdown_phys()
- ARCH_TIMER_PHYS_ACCESS 레지스터를 사용한다.
- arch_timer_shutdown_virt_mem()
- ARCH_TIMER_MEM_VIRT_ACCESS 레지스터를 사용한다.
- arch_timer_shutdown_phys_mem()
- ARCH_TIMER_MEM_PHYS_ACCESS 레지스터를 사용한다.
arch_timer_shutdown_virt()
drivers/clocksource/arm_arch_timer.c
static int arch_timer_shutdown_virt(struct clock_event_device *clk)
{
return timer_shutdown(ARCH_TIMER_VIRT_ACCESS, clk);
}
virt 타이머 기능을 정지시킨다.
timer_shutdown()
drivers/clocksource/arm_arch_timer.c
static __always_inline int timer_shutdown(const int access,
struct clock_event_device *clk)
{
unsigned long ctrl;
ctrl = arch_timer_reg_read(access, ARCH_TIMER_REG_CTRL, clk);
ctrl &= ~ARCH_TIMER_CTRL_ENABLE;
arch_timer_reg_write(access, ARCH_TIMER_REG_CTRL, ctrl, clk);
return 0;
}
@access 타입 타이머 컨트롤 레지스터를 읽어 bit0만 클리어 한 후 다시 기록하여 타이머 기능을 정지시킨다.
클럭 소스, Timecounter 및 스케줄 클럭으로 등록
arch_counter_register()
drivers/clocksource/arm_arch_timer.c
static void __init arch_counter_register(unsigned type)
{
u64 start_count;
/* Register the CP15 based counter if we have one */
if (type & ARCH_TIMER_TYPE_CP15) {
u64 (*rd)(void);
if ((IS_ENABLED(CONFIG_ARM64) && !is_hyp_mode_available()) ||
arch_timer_uses_ppi == ARCH_TIMER_VIRT_PPI) {
if (arch_timer_counter_has_wa())
rd = arch_counter_get_cntvct_stable;
else
rd = arch_counter_get_cntvct;
} else {
if (arch_timer_counter_has_wa())
rd = arch_counter_get_cntpct_stable;
else
rd = arch_counter_get_cntpct;
}
arch_timer_read_counter = rd;
clocksource_counter.archdata.vdso_direct = vdso_default;
} else {
arch_timer_read_counter = arch_counter_get_cntvct_mem;
}
if (!arch_counter_suspend_stop)
clocksource_counter.flags |= CLOCK_SOURCE_SUSPEND_NONSTOP;
start_count = arch_timer_read_counter();
clocksource_register_hz(&clocksource_counter, arch_timer_rate);
cyclecounter.mult = clocksource_counter.mult;
cyclecounter.shift = clocksource_counter.shift;
timecounter_init(&arch_timer_kvm_info.timecounter,
&cyclecounter, start_count);
/* 56 bits minimum, so we assume worst case rollover */
sched_clock_register(arch_timer_read_counter, 56, arch_timer_rate);
}
generic 타이머를 클럭 소스로 등록하고 스케줄러 클럭으로도 등록한다. 단 cp15 및 mmio generic 두 타이머가 사용가능하면 cp15를 우선 사용한다.
- 코드 라인 6~23에서 가능하면 cp15 기반의 타이머를 우선 사용하도록 전역 arch_timer_read_counter 함수에 virtual 또는 physical 타이머용 함수를 대입한다.
- 커널에 CONFIG_ARM_ARCH_TIMER_OOL_WORKAROUND 적용된 경우 stable용 함수를 사용한다.
- 코드 라인 24~26에서 메모리 mapped(mmio) 방식의 타이머를 사용하는 경우 전역 arch_timer_read_counter 함수에 메모리 mapped 방식의 virtual 타이머를 읽어내는 함수를 대입한다.
- 코드 라인 28~29에서 “arm,no-tick-in-suspend” 속성이 없는 일반적인 시스템인 경우 CLOCK_SOURCE_SUSPEND_NONSTOP 플래그를 추가한다.
- 코드 라인 30에서 타이머 값을 읽어 시작 카운터 값으로 사용한다.
- 코드 라인 31에서 “arch_sys_counter”라는 이름의 56비트 클럭소스카운터를 클럭 소스로 등록한다.
- 코드 라인 32~35에서 56비트 타임카운터/사이클 카운터를 초기화한다.
- rpi2: 아키텍처 Generic 타이머를 사용하여 타임카운터를 초기화한다.
- mult=0x3415_5555, shift=24로 설정하여 19.2Mhz 클럭 카운터로 1 cycle 당 52ns가 소요되는 것을 알 수 있다.
- cyclecounter_cyc2ns() 함수를 호출하여 변동된 cycle 카운터 값으로 소요 시간 ns를 산출한다.
- rpi2: 아키텍처 Generic 타이머를 사용하여 타임카운터를 초기화한다.
- 코드 라인 38에서 56비트 카운터를 사용하여 스케줄러 클럭으로 등록한다.
다음 그림은 arch_counter_register() 함수의 처리 과정을 보여준다.

사이클 카운터 값 읽기
arch_counter_read_cc()
drivers/clocksource/arm_arch_timer.c
static cycle_t arch_counter_read_cc(const struct cyclecounter *cc)
{
return arch_timer_read_counter();
}
커널에서 사용하는 사이클 카운터 레지스터 값을 읽어온다.
/* * Default to cp15 based access because arm64 uses this function for * sched_clock() before DT is probed and the cp15 method is guaranteed * to exist on arm64. arm doesn't use this before DT is probed so even * if we don't have the cp15 accessors we won't have a problem. */ u64 (*arch_timer_read_counter)(void) = arch_counter_get_cntvct;
사이클 카운터 레지스터 값을 읽어오는 함수가 대입되며, 초기 값은 virtual 카운터를 읽어오는 함수가 지정된다.
arch_counter_get_cntvct()
arch/arm/include/asm/arch_timer.h
static inline u64 arch_counter_get_cntvct(void)
{
u64 cval;
isb();
asm volatile("mrrc p15, 1, %Q0, %R0, c14" : "=r" (cval));
return cval;
}
CNTVCT(64bit Virtual Counter Register)을 읽어 반환한다.
Delay 타이머로 등록(for arm32)
arch_timer_arch_init()
arch/arm/kernel/arch_timer.c
int __init arch_timer_arch_init(void)
{
u32 arch_timer_rate = arch_timer_get_rate();
if (arch_timer_rate == 0)
return -ENXIO;
arch_timer_delay_timer_register();
return 0;
}
아키텍처 generic 타이머를 딜레이 루프 타이머로 등록한다.
arch_timer_delay_timer_register()
arch/arm/kernel/arch_timer.c
static void __init arch_timer_delay_timer_register(void)
{
/* Use the architected timer for the delay loop. */
arch_delay_timer.read_current_timer = arch_timer_read_counter_long;
arch_delay_timer.freq = arch_timer_get_rate();
register_current_timer_delay(&arch_delay_timer);
}
아키텍처 generic 타이머를 딜레이 루프 타이머로 등록하고 초기화한다.
타이머(clock events) 등록
arch_timer_register()
drivers/clocksource/arm_arch_timer.c
static int __init arch_timer_register(void)
{
int err;
int ppi;
arch_timer_evt = alloc_percpu(struct clock_event_device);
if (!arch_timer_evt) {
err = -ENOMEM;
goto out;
}
ppi = arch_timer_ppi[arch_timer_uses_ppi];
switch (arch_timer_uses_ppi) {
case ARCH_TIMER_VIRT_PPI:
err = request_percpu_irq(ppi, arch_timer_handler_virt,
"arch_timer", arch_timer_evt);
break;
case ARCH_TIMER_PHYS_SECURE_PPI:
case ARCH_TIMER_PHYS_NONSECURE_PPI:
err = request_percpu_irq(ppi, arch_timer_handler_phys,
"arch_timer", arch_timer_evt);
if (!err && arch_timer_has_nonsecure_ppi()) {
ppi = arch_timer_ppi[ARCH_TIMER_PHYS_NONSECURE_PPI];
err = request_percpu_irq(ppi, arch_timer_handler_phys,
"arch_timer", arch_timer_evt);
if (err)
free_percpu_irq(arch_timer_ppi[ARCH_TIMER_PHYS_SECURE_PPI],
arch_timer_evt);
}
break;
case ARCH_TIMER_HYP_PPI:
err = request_percpu_irq(ppi, arch_timer_handler_phys,
"arch_timer", arch_timer_evt);
break;
default:
BUG();
}
if (err) {
pr_err("can't register interrupt %d (%d)\n", ppi, err);
goto out_free;
}
err = arch_timer_cpu_pm_init();
if (err)
goto out_unreg_notify;
/* Register and immediately configure the timer on the boot CPU */
err = cpuhp_setup_state(CPUHP_AP_ARM_ARCH_TIMER_STARTING,
"clockevents/arm/arch_timer:starting",
arch_timer_starting_cpu, arch_timer_dying_cpu);
if (err)
goto out_unreg_cpupm;
return 0;
out_unreg_cpupm:
arch_timer_cpu_pm_deinit();
out_unreg_notify:
free_percpu_irq(arch_timer_ppi[arch_timer_uses_ppi], arch_timer_evt);
if (arch_timer_has_nonsecure_ppi())
free_percpu_irq(arch_timer_ppi[ARCH_TIMER_PHYS_NONSECURE_PPI],
arch_timer_evt);
out_free:
free_percpu(arch_timer_evt);
out:
return err;
}
ARMv7 & ARMv8 아키텍처에 내장된 Generic 타이머를 클럭 이벤트 디바이스로 per-cpu 인터럽트에 등록하고 boot cpu용은 즉시 enable한다.
- 코드 라인 6~10에서 clock_event_device 구조체를 할당받아 온다. 메모리 할당이 실패하는 경우 -ENOMEM 에러를 반환한다.
- 코드 라인 12에서 아키텍처 내장 generic 타이머에 사용될 인터럽트 ppi를 알아온다.
- 코드 라인 13~42에서 ppi에 해당하는 인터럽트를 요청하고, 핸들러를 설정한다.
- 코드 라인 44~46에서 CONFIG_CPU_PM 커널 옵션을 사용하는 경우 cpu 절전 상태 변화에 따라 호출되도록 cpu pm notify chain에 arch_timer_cpu_pm_notify() 함수를 등록한다.
- 코드 라인 49~54에서 cpu 상태 변화에 따라 호출되도록 cpu notify chain에 arch_timer_cpu_notify() 함수를 등록하고, boot cpu에 대한 cp15용 generic 타이머 설정 및 per-cpu 인터럽트를 enable 한 후 정상 값 0을 반환한다.
- secondary cpu가 on될 때마다 타이머가 초기화되고 off될 때마다 migration된다.
다음 그림은 클럭 이벤트 디바이스를 통해 per-cpu 인터럽트 핸들러가 등록되는 것을 보여준다.
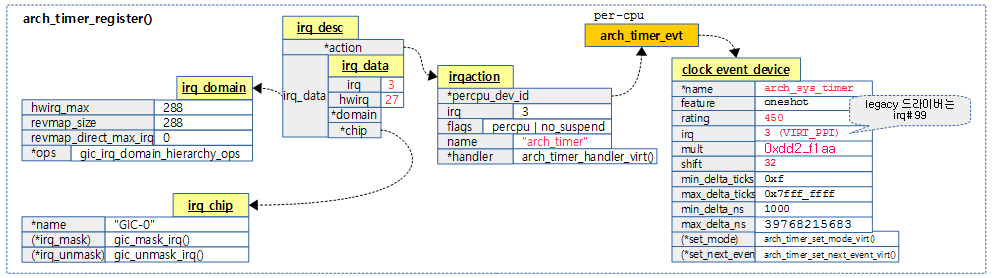
arch_timer_starting_cpu()
drivers/clocksource/arm_arch_timer.c
static int arch_timer_starting_cpu(unsigned int cpu)
{
struct clock_event_device *clk = this_cpu_ptr(arch_timer_evt);
u32 flags;
__arch_timer_setup(ARCH_TIMER_TYPE_CP15, clk);
flags = check_ppi_trigger(arch_timer_ppi[arch_timer_uses_ppi]);
enable_percpu_irq(arch_timer_ppi[arch_timer_uses_ppi], flags);
if (arch_timer_has_nonsecure_ppi()) {
flags = check_ppi_trigger(arch_timer_ppi[ARCH_TIMER_PHYS_NONSECURE_PPI]);
enable_percpu_irq(arch_timer_ppi[ARCH_TIMER_PHYS_NONSECURE_PPI],
flags);
}
arch_counter_set_user_access();
if (evtstrm_enable)
arch_timer_configure_evtstream();
return 0;
}
요청한 cpu의 per-core 아키텍처 내장형 generic 타이머를 가동한다.
- 코드 라인 6에서 per-cpu 클럭 이벤트 디바이스에 대한 cp15용 generic 타이머 설정을 한다. (초기 shutdown)
- 코드 라인 8~9에서 사용하는 타이머의 per-cpu 인터럽트를 enable한다.
- 코드 라인 11~15에서 nonsecure ppi인 경우 nonsecure용 물리 타이머의 per-cpu 인터럽트를 enable한다.
- 코드 라인 17에서 타이머의 user access를 허용한다
- CNTKCTL(Timer PL1 Control Register).PL0VCTEN 비트를 설정하여 Virtual 타이머의 PL0 access를 허용하게 한다.
- 코드 라인 18~19에서 시스템에 따라 이벤트 스트림(10khz)도 구성한다.
- arm/arm64에서 wfe 기반 user 락을 구현 시 누락되는 이벤트를 보상하기 위해 100us의 타임 아웃을 부과하였다.
- 참고: drivers: clocksource: add support for ARM architected timer event stream
__arch_timer_setup()
drivers/clocksource/arm_arch_timer.c
static void __arch_timer_setup(unsigned type,
struct clock_event_device *clk)
{
clk->features = CLOCK_EVT_FEAT_ONESHOT;
if (type == ARCH_TIMER_TYPE_CP15) {
typeof(clk->set_next_event) sne;
arch_timer_check_ool_workaround(ate_match_local_cap_id, NULL);
if (arch_timer_c3stop)
clk->features |= CLOCK_EVT_FEAT_C3STOP;
clk->name = "arch_sys_timer";
clk->rating = 450;
clk->cpumask = cpumask_of(smp_processor_id());
clk->irq = arch_timer_ppi[arch_timer_uses_ppi];
switch (arch_timer_uses_ppi) {
case ARCH_TIMER_VIRT_PPI:
clk->set_state_shutdown = arch_timer_shutdown_virt;
clk->set_state_oneshot_stopped = arch_timer_shutdown_virt;
sne = erratum_handler(set_next_event_virt);
break;
case ARCH_TIMER_PHYS_SECURE_PPI:
case ARCH_TIMER_PHYS_NONSECURE_PPI:
case ARCH_TIMER_HYP_PPI:
clk->set_state_shutdown = arch_timer_shutdown_phys;
clk->set_state_oneshot_stopped = arch_timer_shutdown_phys;
sne = erratum_handler(set_next_event_phys);
break;
default:
BUG();
}
clk->set_next_event = sne;
} else {
clk->features |= CLOCK_EVT_FEAT_DYNIRQ;
clk->name = "arch_mem_timer";
clk->rating = 400;
clk->cpumask = cpu_possible_mask;
if (arch_timer_mem_use_virtual) {
clk->set_state_shutdown = arch_timer_shutdown_virt_mem;
clk->set_state_oneshot_stopped = arch_timer_shutdown_virt_mem;
clk->set_next_event =
arch_timer_set_next_event_virt_mem;
} else {
clk->set_state_shutdown = arch_timer_shutdown_phys_mem;
clk->set_state_oneshot_stopped = arch_timer_shutdown_phys_mem;
clk->set_next_event =
arch_timer_set_next_event_phys_mem;
}
}
clk->set_state_shutdown(clk);
clockevents_config_and_register(clk, arch_timer_rate, 0xf, 0x7fffffff);
}
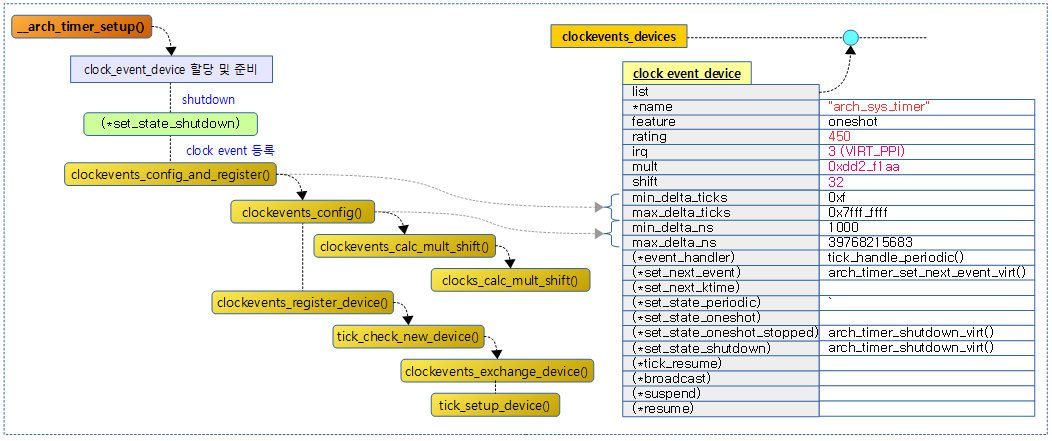
아키텍처에 내장된 generic 타이머를 클럭 이벤트 디바이스로 설정하여 per-cpu 인터럽트와 핸들러를 설정하고 타이머는 shutdown 한다.
- 코드 라인 4에서 generic 타이머에 oneshot 기능을 부여한다.
- 코드 라인 6~12에서 보조프로세서 cp15로 제어되는 타이머인 경우이면서 c3stop 기능이 있는 경우 features에 C3STOP 플래그를 추가한다.
- rpi2: “Always-on” 속성을 사용하여 c3stop을 사용하지 않는다.
- 코드 라인 13~34에서 “arch_sys_timer”라는 이름으로 현재 cpu에 대해서만 cpumask를 설정하고 rating을 450으로 설정한다. 그리고 ppi 타입에 해당하는 타이머 인터럽트 및 핸들러를 설정한다.
- 코드 라인 35~51에서 메모리 mapped 타이머를 지원하는 경우 feauters에 DYNIRQ 플래그를 추가하고 “arch_mem_timer”라는 이름으로 전체 cpu에 대해서 cpumask를 설정하고 rating을 400으로 설정한다.그리고 virtual 또는 physical 두 타입 중 하나의 타이머 인터럽트 및 핸들러를 설정한다.
- 코드 라인 53에서 현재 cpu의 타이머 출력을 정지시킨다.
- 코드 라인 55에서 클럭 이벤트 디바이스 설정 및 등록을 진행한다.
다음 그림은 __arch_timer_setup() 함수의 처리 과정을 보여준다.
이벤트 스트림 (for ARM)
ARM 아키텍처에서 delay() API의 내부 polling을 최소화하고, 저전력으로 구동하기 위해 wfe 명령을 사용한 구현에서 일정 스트림 간격으로 cpu를 깨우기 위해 사용된다.
이벤트 스트림 설정 및 가동
arch_timer_configure_evtstream()
drivers/clocksource/arm_arch_timer.c
static void arch_timer_configure_evtstream(void)
{
int evt_stream_div, pos;
/* Find the closest power of two to the divisor */
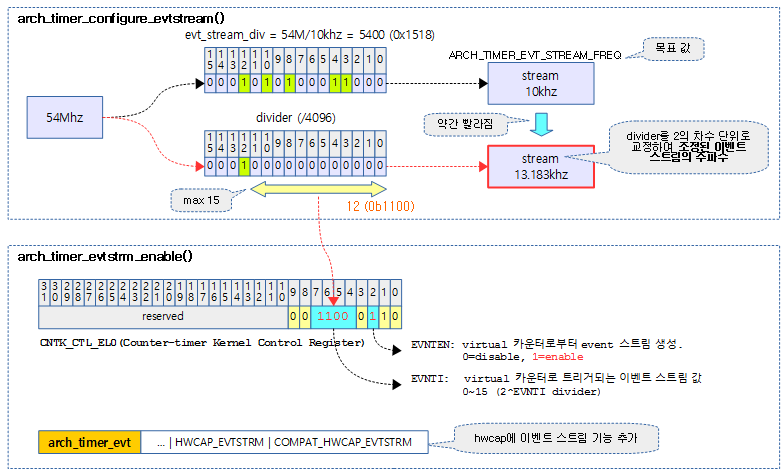
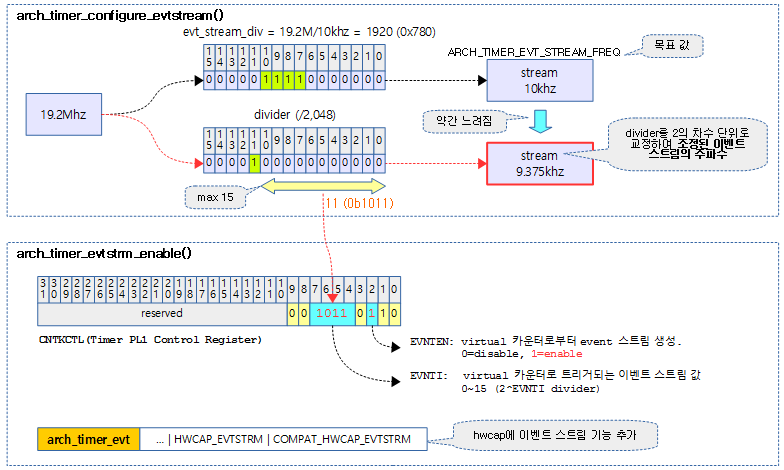
evt_stream_div = arch_timer_rate / ARCH_TIMER_EVT_STREAM_FREQ;
pos = fls(evt_stream_div);
if (pos > 1 && !(evt_stream_div & (1 << (pos - 2))))
pos--;
/* enable event stream */
arch_timer_evtstrm_enable(min(pos, 15));
}
아키텍처 generic 타이머 중 virtual 타이머에 이벤트 스트림을 위해 약 10Khz에 해당하는 트리거를 설정하고 동작시킨다.
- 코드 라인 6에서 divider 값으로 사용할 값을 구한다.
- 19.2Mhz / 10Khz = 1920
- 코드 라인 7~9에서 divider 값을 2의 차수 단위로 정렬한 값에 해당하는 비트 수 pos를 구한다.
- pos = 11 (2 ^ 11 = 2048 분주)
- 코드 라인 11에서 virtual 타이머에 이벤트 스트림의 분주율에 사용할 pos 값으로 설정하고 이벤트 스트림 기능을 enable한다.
다음 그림은 54Mhz의 클럭 소스를 4096 분주하여 목표치 10Khz에 가장 근접한 13.183Khz 주기의 이벤트 스트림용 트리거를 enable하는 것을 보여준다.
다음 그림은 19.2Mhz의 클럭 소스를 2048 분주하여 목표치 10Khz에 가장 근접한 9.375Khz 주기의 이벤트 스트림용 트리거를 enable하는 것을 보여준다.
arch_timer_evtstrm_enable()
drivers/clocksource/arm_arch_timer.c
static void arch_timer_evtstrm_enable(int divider)
{
u32 cntkctl = arch_timer_get_cntkctl();
cntkctl &= ~ARCH_TIMER_EVT_TRIGGER_MASK;
/* Set the divider and enable virtual event stream */
cntkctl |= (divider << ARCH_TIMER_EVT_TRIGGER_SHIFT)
| ARCH_TIMER_VIRT_EVT_EN;
arch_timer_set_cntkctl(cntkctl);
arch_timer_set_evtstrm_feature();
cpumask_set_cpu(smp_processor_id(), &evtstrm_available);
}
Generic 타이머의 이벤트 스트림 기능을 enable하기 위해 CNTKCTL 레지스터에 divider(0~15) 값과 enable 비트를 설정한다.
- 코드 라인 3에서 CNTKCTL 레지스터 값을 읽어온다.
- 코드 라인 5에서 CNTKCTL.EVNTI(bit7:4)에 해당하는 비트를 클리어한다.
- 코드 라인 7~9에서 divider 값과 enable 비트를 추가하고 CNTKCTL 레지스터에 저장한다.
- 코드 라인 10에서 전역 elf_hwcap에 이벤트 스트림에 대한 플래그들을 추가한다.
- 코드 라인 11에서 evestrm_available 비트마스크에 현재 cpu를 설정한다.
arch_timer_get_cntkctl() – ARM64
arch/arm64/include/asm/arch_timer.h
static inline u32 arch_timer_get_cntkctl(void)
{
return read_sysreg(cntkctl_el1);
}
CNTKCTL(Timer Control for EL0) 레지스터 값을 읽어온다.
arch_timer_get_cntkctl() – ARM32
arch/arm/include/asm/arch_timer.h
static inline u32 arch_timer_get_cntkctl(void)
{
u32 cntkctl;
asm volatile("mrc p15, 0, %0, c14, c1, 0" : "=r" (cntkctl));
return cntkctl;
}
CNTKCTL(Timer PL1 Control) 레지스터 값을 읽어온다.
참고
- Timer -1- (Lowres Timer) | 문c
- Timer -2- (HRTimer) | 문c
- Timer -3- (Clock Sources Subsystem) | 문c
- Timer -4- (Clock Sources Watchdog) | 문c
- Timer -5- (Clock Events Subsystem) | 문c
- Timer -6- (Clock Source & Timer Driver) | 문c – 현재 글
- Timer -7- (Sched Clock & Delay Timers) | 문c
- Timer -8- (Timecounter) | 문c
- Timer -9- (Tick Device) | 문c
- Timer -10- (Timekeeping) | 문c
- Timer -11- (Posix Clock & Timers) | 문c
- time_init() | 문c
- sched_clock_postinit() | 문c
- tick_init() | 문c
- timekeeping_init() | 문c
- calibrate_delay() | 문c