<kernel v5.0>
Swap
유저 프로세스에서 사용한 스택 및 anonymous 메모리 할당(malloc 등) 요청 시 커널은 anon 페이지를 할당하여 관리한다. 메모리 부족 시 swap 영역에 저장할 수 있다.
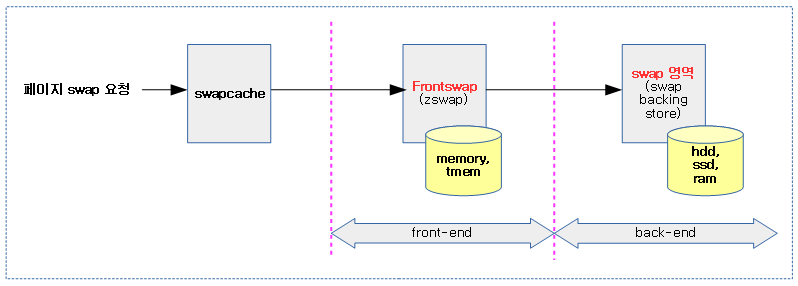
swap 매커니즘은 다음과 같이 3단계 구성을 통해 swap 된다.
- Swap 캐시(swapcache)
- Frontswap
- Swap 영역(Swap Backing Store)
다음 그림은 3단계 swap 컴포넌트들을 보여준다.
clean anon 페이지
swap 가능한 anon 페이지와 다르게 swap 영역을 가지지 않아 swap 할 수 없는 특별한 anon 페이지가 clean anon 페이지이다. 이러한 clean anon 페이지는 swap 할 필요없다.
- PG_swapbacked 가 없는 anon 페이지가 clean anon 페이지 상태이다.
- lazy free 페이지로 매핑을 바로 해제 하지 않기 위해 사용되는데, 이들은 madvise API를 통해 사용된다.
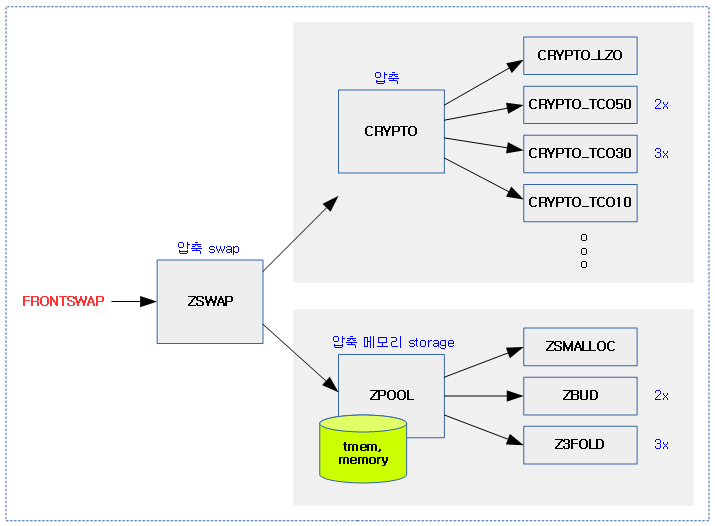
FRONTSWAP
Back-End에 존재하는 swap 영역과 달리 Front-End에 만든 swap 시스템이다.
- 여기에 사용되는 swap 장치는 swap할 페이지에 대해 동기 저장할 수 있는 고속이어야 한다.
- back-end swap 장치는 보통 비동기 저장한다.
- tmem(Transcendent Memory)을 사용하며 현재 Xen에서 제공된다.
- DRAM 메모리 또는 persistent 메모리
- 참고: Frontswap (2012) | Kernel.org
Transcendent Memory
부족한 RAM 개선을 위한 새로운 메모리 관리 기술중 하나이다. 리눅스 커널에서 동기적으로 접근할 수 있을정도로 빠른 메모리로 직접 주소 지정되지 않고, 간접 주소 지정 방식으로 호출되며, 영역은 가변 사이즈로 구성되는 영구적 또는 일시적 메모리를 의미하는 메모리 클래스이다. 이 메모리에 저장된 데이터는 경고없이 사라질 수 있다.
- 참고:
- Transcendent memory (2009) | LWN.net
- Transcendent memory in a nutshell (2011) | LWN.net
- Transcendent Memory and Friends (2011) | Oracle – 다운로드 pdf
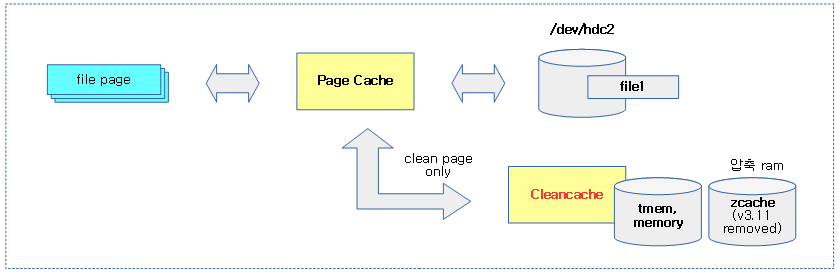
Cleancache
page 캐시 중 clean page 캐시만을 저장할 수 있는 캐시이다. swap 캐시도 swap 영역에 저장된 경우 이 또한 clean page 캐시이므로 이 cleancache를 사용할 수 있다.
- 현재 리눅스 커널은 xen에서 제공하는 tmem을 사용한다.
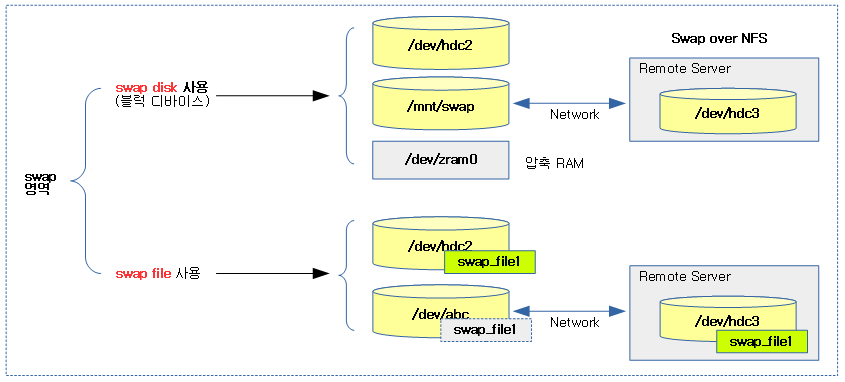
swap 영역(Swap Backing Store)
swap 영역은 다음과 같이 swap 파일 및 swap 디스크(블럭 디바이스)에 지정하여 사용할 수 있다.
- swap 파일
- swap 디스크
다음과 같은 방법으로도 swap 장치를 구성할 수 있다.
- Swap over NFS, sunrpc 등 네트워크를 통해 마운트된 파일 시스템에 위치한 swap 파일
- 기타 로컬 RAM의 일부를 사용하여 압축하여 저장하는 zram을 사용하여 IO 요청을 줄인다.
- 디폴트로 cpu를 사용하여 압축하고, 서버 등에서는 HW를 사용한 압축도 가능하다.
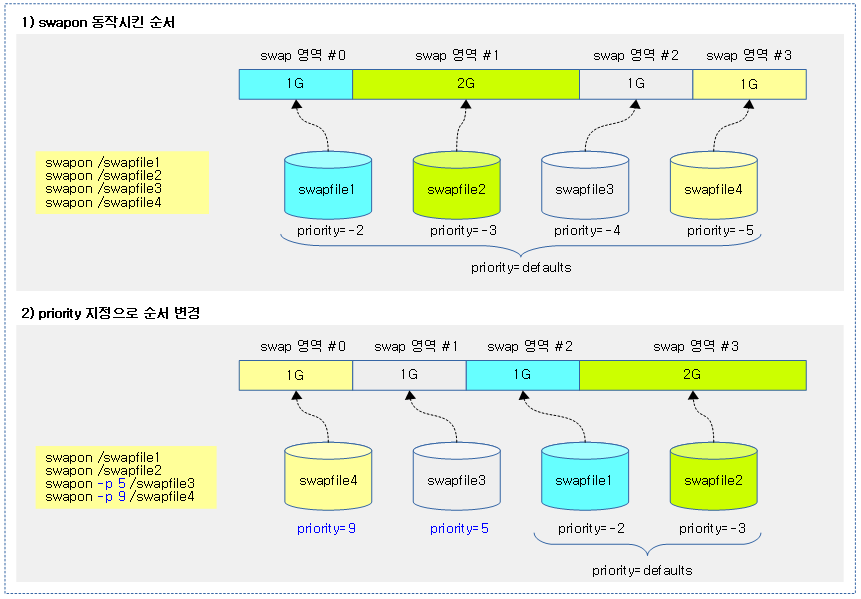
다음 그림과 같이 swap 영역을 지정하는 다양한 방법이 있다.
Swap Priority
다음 그림과 같이 swap 영역은 여러 개를 지정할 수 있다. priority를 부여할 때 높은 번호 priority가 높은 우선 순위로 먼저 사용되고, priority를 부여하지 않은 경우 디폴트로 swapon을 통해 활성화한 순서대로 사용된다.
- default priority 값은 -2부터 순서대로 낮아진다.
- swap 영역 1개의 크기는 아키텍처마다 조금씩 다르다.
- ARM32
- 실제 가상 주소 공간(최대 3G)이내에서 사용 가능하나 보통 2G까지 사용한다.
- ARM64
- 실제 가상 주소 공간(커널 설정마다 다름)이내에서 사용 가능하다.
- ARM32
swap 캐시
anon 페이지가 swap 영역으로 나가고(swap-out) 들어올(swap-in) 때 일시적으로 swap 영역의 내용이 RAM에 존재하는 경우이다. 예를 들어 유저 프로세스가 사용하던 anon 페이지가 메모리 부족으로 인해 swap 영역에 저장이 되었다고 가정한다. 이 때 유저 프로세스가 swap된 페이지에 접근을 시도할 때 fault 가 발생하고, fault 핸들러가 swap 된 페이지임을 확인하면 swap-in을 시도한다. 그런 후 swap 캐시가 발견되면 swap 영역에서 로드를 하지 않고 곧바로 swap 캐시를 찾아 anon 페이지로 변경하여 사용한다.
- swap 캐시 상태는 PG_swapcache 플래그로 표현된다.
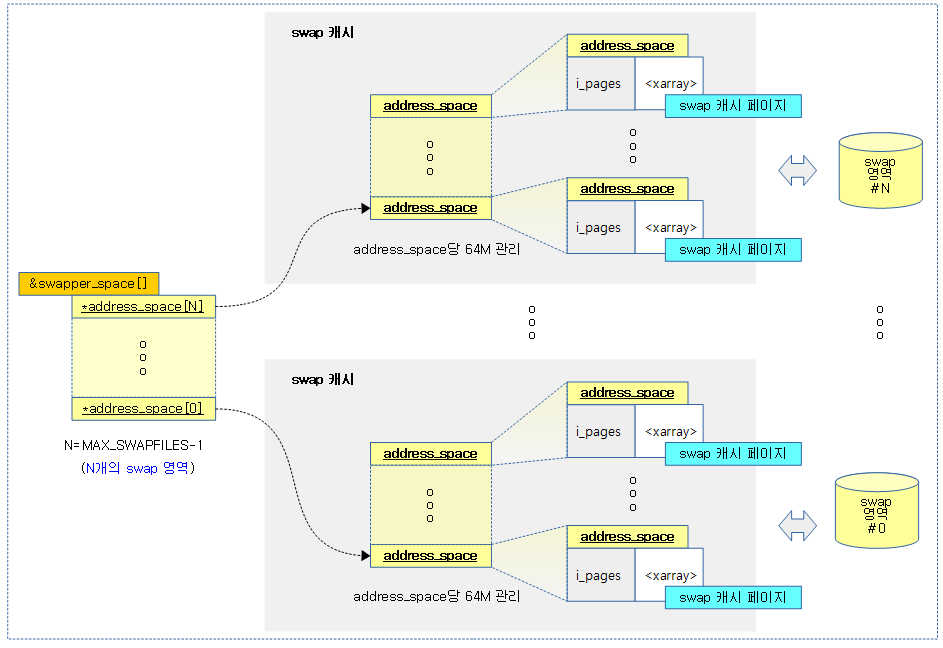
swap 캐시별로 사용하는 address_space는 xarray(기존 radix tree)로 관리되며 이에 접근하기 위해 사용되는 rock 경합에 대한 개선을 위해 각각의 address_space의 크기를 64M로 제한하였다.
- 참고: mm/swap: split swap cache into 64MB trunks (4.11-rc1)
XArray 자료 구조 사용
swap 캐시는 기존 커널에서 radix tree를 사용하여 관리하였지만, 커널 v4.20-rc1부터 XArray 자료 구조로 관리하고 있다.
- address_space->i_pages가 radix tree를 가리켰었는데 지금은 xarray를 가리킨다.
다음 그림은 여러 개의 swap 영역을 사용할 때 64M 단위로 관리되는 swap 캐시의 운용되는 모습을 보여준다.
Swap 슬롯 캐시
swap 영역의 swap_map[]을 통해 swap 엔트리를 할당하는데, 이 때마다 swap 영역의 락이 필요하다. swap 영역을 빈번하게 접근할 때 이의 성능이 저하되는 것을 개선하기 위해 swap 엔트리 할당을 위해 앞단에 per-cpu swap 슬롯 캐시를 사용하여 swap 영역의 잠금 없이 빠르게 할당/해제할 수 있게 하였다.
- 참고: mm/swap: add cache for swap slots allocation (v4.11-rc1)
다음 그림은 anon 페이지를 swap 영역에 저장할 때 swap 엔트리의 빠른 할당 및 회수에 사용되는 각각 64개로 구성된 swap 슬롯 캐시를 보여준다.

Swap 엔트리
swap 엔트리는 swap 페이지를 검색할 수 있는 최소한의 정보를 담고 있다.
- VMA 영역내의 anonymous 페이지가 swap이 되면 swap 엔트리 정보를 구성하여 해당 pte 엔트리에 기록해둔다.
- ARM에서 swap 엔트리의 구성은 다음과 같다.
- offset
- swap 페이지 offset
- type
- swap 영역 구분
- 하위 두 비트=0b00
- ARM 및 ARM64 아키텍처에서 언매핑 상태로, 이 페이지에 접근하는 경우 fault 에러가 발생한다.
- offset
- 참고: Swap 엔트리 | 문c
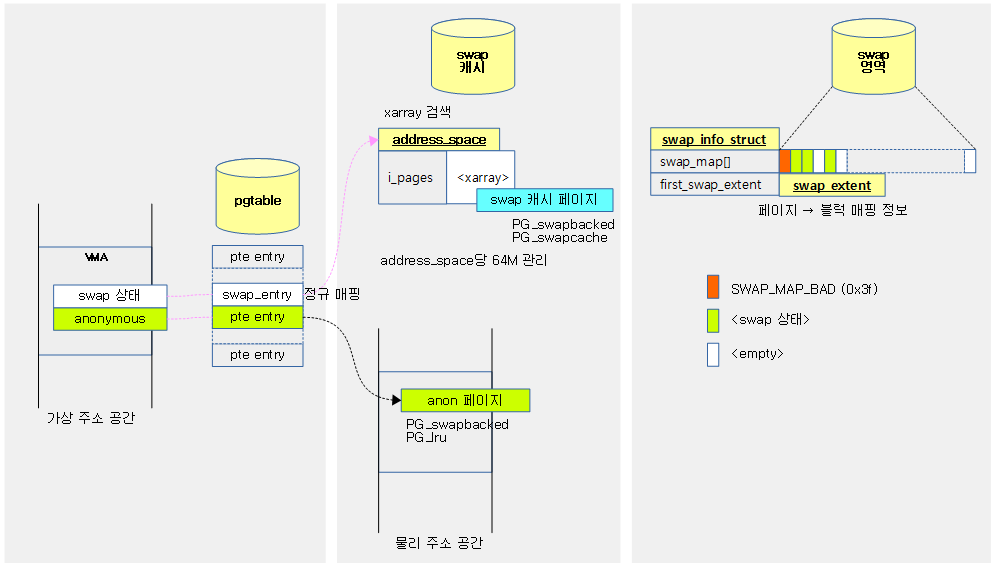
다음 그림은 유저 프로세스의 가상 주소 공간에 swap 상태의 페이지와 사용 중인 상태의 anonymous 페이지들의 관리 상태를 swap 공정 관점으로 보여준다.
- 1개의 swap 영역(type=0)의 첫 번째 헤더 페이지를 제외한 그 다음 페이지(offset=1)를 swap 엔트리로 할당한 경우
- ARM64용 swap 엔트리 값 0x100이 페이지 테이블에 매핑되고, swap 캐시의 xarray에는 엔트리 값을 키로 페이지가 저장된다.
Swap 영역 관리
swap 영역은 swap_info_struct의 멤버인 swap_map이 바이트 단위로 관리되어 사용된다. 이 때 각 바이트 값은 1 페이지의 swap 여부에 대응된다. 이 값에는 페이지의 참조 카운터가 기록된다. 이 swap_map은 다음과 같이 두 가지 관리 방식이 사용된다.
- Legacy swap 맵 관리
- Legacy HDD 및 swap 파일에서 사용되는 일반적인 방식이다. swap 페이지의 할당/해제 관리에 사용되는 swap_map을 SMP 시스템에서 사용하기 위해서 swap을 시도하는 cpu가 swap 영역(swap_info_struct)에 대한 spin-lock을 잡고 swap_map의 선두부터 빈 자리를 검색하여 사용하는 방식이다. 이 방식은 swap할 페이지마다 spin-lock을 획득하고 사용하므로 lock contention이 매우 큰 단점이 있다.
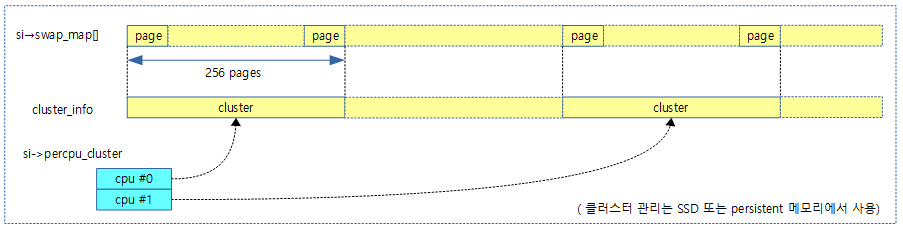
- per-cpu 클러스터 단위 swap 맵 관리
- SSD 및 persistent 메모리가 나타나면서 swap 성능을 높이려는 시도가 시도되었고 이 때 cpu 별로 클러스터 단위로 처리하는 방법이 소개되었다. 이러한 방법은 cpu 마다 일정 클러스터 단위의 페이지를 관리하게 하여 lock contention에 대한 부담을 줄여 성능을 높이는 방법이 2013년 커널 v3.12에 소개되었다.
- 참고
- Making swapping scalable (2016) | LWN.net
- Reconsidering swapping (2016) | LWN.net
- swap: change block allocation algorithm for SSD (v3.12-rc1)
- swap: make cluster allocation per-cpu (v3.12-rc1)
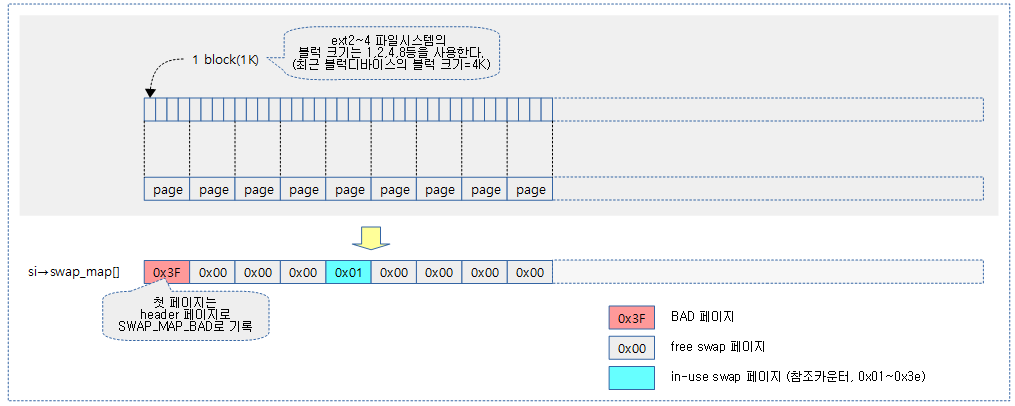
다음 그림과 같이 swap 페이지의 swap 여부는 swap_map[] 배열에 각 swap 페이지가 1바이트 정보로 기록되어 관리된다.
다음 그림은 per-cpu 클러스터 단위로 swap_map을 관리하는 모습을 보여준다.
swap 유틸리티
mkswap
swap 영역을 파일 또는 파티션에 할당하여 생성한다.
$ mkswap -h Usage: mkswap [options] device [size] Set up a Linux swap area. Options: -c, --check check bad blocks before creating the swap area -f, --force allow swap size area be larger than device -p, --pagesize SIZE specify page size in bytes -L, --label LABEL specify label -v, --swapversion NUM specify swap-space version number -U, --uuid UUID specify the uuid to use -V, --version output version information and exit -h, --help display this help and exit
예) 10M(10240K) 사이즈의 /abc 파일명을 생성한 후 swap 파일로 지정한다.
- $ fallocate –length 10485760 /abc
- 또는 dd if=/dev/zero of=/abc bs=1M count=10
- $ mkswap /abc
예) hdc3 파티션을 swap 영역으로 생성한다.
- $ mkswap /dev/hdc3
swapon
swap 영역을 파일 또는 파티션에 지정하여 enable 한다.
$ swapon -h
Usage:
swapon [options] [<spec>]
Enable devices and files for paging and swapping.
Options:
-a, --all enable all swaps from /etc/fstab
-d, --discard[=<policy>] enable swap discards, if supported by device
-e, --ifexists silently skip devices that do not exist
-f, --fixpgsz reinitialize the swap space if necessary
-o, --options <list> comma-separated list of swap options
-p, --priority <prio> specify the priority of the swap device
-s, --summary display summary about used swap devices (DEPRECATED)
--show[=<columns>] display summary in definable table
--noheadings don't print table heading (with --show)
--raw use the raw output format (with --show)
--bytes display swap size in bytes in --show output
-v, --verbose verbose mode
-h, --help display this help and exit
-V, --version output version information and exit
The <spec> parameter:
-L <label> synonym for LABEL=<label>
-U <uuid> synonym for UUID=<uuid>
LABEL=<label> specifies device by swap area label
UUID=<uuid> specifies device by swap area UUID
PARTLABEL=<label> specifies device by partition label
PARTUUID=<uuid> specifies device by partition UUID
<device> name of device to be used
<file> name of file to be used
Available discard policy types (for --discard):
once : only single-time area discards are issued
pages : freed pages are discarded before they are reused
If no policy is selected, both discard types are enabled (default).
Available columns (for --show):
NAME device file or partition path
TYPE type of the device
SIZE size of the swap area
USED bytes in use
PRIO swap priority
UUID swap uuid
LABEL swap label
For more details see swapon(8).
예) /abc 파일명의 swap 파일에서 swap을 활성화한다.
- $ swapon /abc
예) hdc3 파티션의 swap을 활성화한다.
- $ swapon /dev/hdc3
swapoff
swap 영역으로 지정된 파일 또는 파티션의 swap 기능을 disable 한다.
$ swapoff -h Usage: swapoff [options] [<spec>] Disable devices and files for paging and swapping. Options: -a, --all disable all swaps from /proc/swaps -v, --verbose verbose mode -h, --help display this help and exit -V, --version output version information and exit The <spec> parameter: -L <label> LABEL of device to be used -U <uuid> UUID of device to be used LABEL=<label> LABEL of device to be used UUID=<uuid> UUID of device to be used <device> name of device to be used <file> name of file to be used For more details see swapoff(8).
예) /abc 파일명의 swap 파일에서 swap을 비활성화한다.
- $ swapoff /abc
예) hdc3 파티션의 swap을 비활성화한다.
- $ swapoff /dev/hdc3
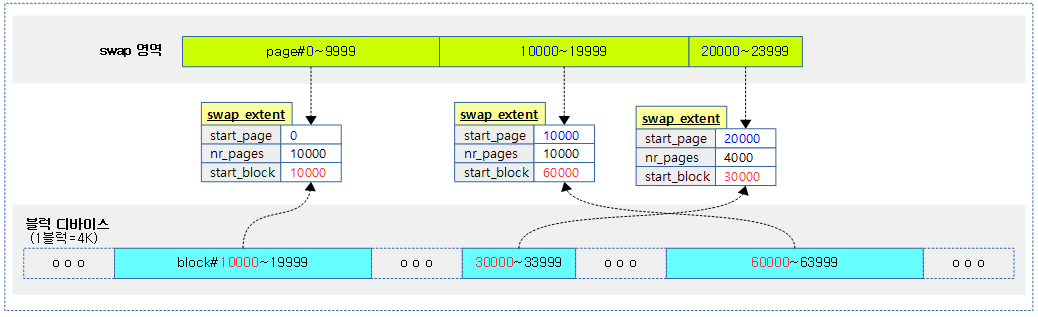
Swap Extent
swap 영역의 페이지 범위를 swap 장치의 블럭에 매핑할 때 사용하는 자료 구조이다. swap 영역이 블럭 디바이스에 직접 사용된 경우에는 swap 영역의 각 페이지가 블럭 디바이스의 각 블럭에 연속적으로 1:1로 동일하게 사용되므로 하나의 매핑만 필요하다. 그러나 swap 영역으로 swap 파일을 이용하는 경우에는 swap 파일의 각 페이지와 블럭 디바이스의 실제 사용된 블럭이 동일하게 연속하지 않으므로 여러 개의 매핑이 필요하다. 그렇다고 하나의 페이지와 하나의 블럭을 각각 매핑하면 이러한 매핑으로 너무 많이 소모된다. 따라서 범위로 묶어서 매핑을 하는데 이 때 사용하는 구조체가 swap_extent이다.
- 하나의 swap_extent에는 시작 페이지 번호와 페이지 수 그리고 매핑할 시작 블럭 번호가 포함된다.
- 리스트로 관리하던 swap extent를 커널 v5.3-rc1에서 rbtree로 변경하였다.
- 참고: mm, swap: use rbtree for swap_extent (2019)
다음 그림은 swap 파일이 위치한 블럭 디바이스에 3개의 연속된 블럭들로 나뉘어 배치된 경우에 필요한 3개의 swap_extent를 보여준다.
Swapon
swap 영역을 파일 또는 블럭 디바이스에 지정하여 활성화한다.
sys_swapon()
mm/swapfile.c -1/3-
SYSCALL_DEFINE2(swapon, const char __user *, specialfile, int, swap_flags)
{
struct swap_info_struct *p;
struct filename *name;
struct file *swap_file = NULL;
struct address_space *mapping;
int prio;
int error;
union swap_header *swap_header;
int nr_extents;
sector_t span;
unsigned long maxpages;
unsigned char *swap_map = NULL;
struct swap_cluster_info *cluster_info = NULL;
unsigned long *frontswap_map = NULL;
struct page *page = NULL;
struct inode *inode = NULL;
bool inced_nr_rotate_swap = false;
if (swap_flags & ~SWAP_FLAGS_VALID)
return -EINVAL;
if (!capable(CAP_SYS_ADMIN))
return -EPERM;
if (!swap_avail_heads)
return -ENOMEM;
p = alloc_swap_info();
if (IS_ERR(p))
return PTR_ERR(p);
INIT_WORK(&p->discard_work, swap_discard_work);
name = getname(specialfile);
if (IS_ERR(name)) {
error = PTR_ERR(name);
name = NULL;
goto bad_swap;
}
swap_file = file_open_name(name, O_RDWR|O_LARGEFILE, 0);
if (IS_ERR(swap_file)) {
error = PTR_ERR(swap_file);
swap_file = NULL;
goto bad_swap;
}
p->swap_file = swap_file;
mapping = swap_file->f_mapping;
inode = mapping->host;
/* If S_ISREG(inode->i_mode) will do inode_lock(inode); */
error = claim_swapfile(p, inode);
if (unlikely(error))
goto bad_swap;
/*
* Read the swap header.
*/
if (!mapping->a_ops->readpage) {
error = -EINVAL;
goto bad_swap;
}
page = read_mapping_page(mapping, 0, swap_file);
if (IS_ERR(page)) {
error = PTR_ERR(page);
goto bad_swap;
}
swap_header = kmap(page);
maxpages = read_swap_header(p, swap_header, inode);
if (unlikely(!maxpages)) {
error = -EINVAL;
goto bad_swap;
}
/* OK, set up the swap map and apply the bad block list */
swap_map = vzalloc(maxpages);
if (!swap_map) {
error = -ENOMEM;
goto bad_swap;
}
swap용 블럭 디바이스 또는 파일을 @type 번호의 swap 영역에 활성화한다. 성공 시 0을 반환한다.
- 코드 라인 20~21에서 잘못된 swap 플래그가 지정된 경우 -EINVAL 에러를 반환한다. 허용되는 플래그들은 다음과 같다.
- SWAP_FLAG_PREFER (0x8000)
- SWAP_FLAG_PRIO_MASK (0x7fff)
- SWAP_FLAG_DISCARD (0x10000)
- SWAP_FLAG_DISCARD_ONCE (0x20000)
- SWAP_FLAG_DISCARD_PAGES (0x40000
- 코드 라인 23~24에서 CAP_SYS_ADMIN 권한이 없는 경우 -EPERM 에러를 반환한다.
- 코드 라인 26~27에서 swap_avail_heads 리스트가 초기화되지 않은 경우 -ENOMEM 에러를 반환한다.
- 코드 라인 29~31에서 swap 영역을 구성하기 위해 swap_info_struct를 할당하고 초기화한다.
- 코드 라인 33에서 워커 스레드에서 swap_discard_work 함수를 호출할 수 있도록 워크를 초기화한다.
- SSD를 사용하는 디스크에서 discard 기능을 사용할 수 있다.
- 코드 라인 35~48에서 swapon할 디바이스 또는 파일을 오픈한 후 swap 정보에 지정한다.
- 코드 라인 49~55에서 swap파일의 address_space와 inode 정보로 다음과 같이 수행한다.
- 블럭 디바이스인 경우 swap 정보의 멤버 bdev에 inode를 포함한 블럭 디바이스를 지정한다. 그리고 멤버 flag에 SWP_BLKDEV 플래그를 추가한다.
- 파일인 경우 swap 정보의 멤버 bdev에 inode->i_sb->s_bdev를 지정한다. 그리고 이 파일이 이미 swapfile로 사용중이면 -EBUSY 에러를 반환한다.
- 코드 라인 60~63에서 swap 파일 시스템의 (*readpage) 후크가 지정되지 않은 경우 -INVAL 에러를 반환한다.
- 코드 라인 64~68에서 swap 파일의 헤더를 읽기 위해 인덱스 0에 대한 대한 페이지 캐시를 읽어온다.
- 코드 라인 69에서 읽어온 페이지를 swap_header로 사용하기 위해 kmap을 사용하여 잠시 매핑해둔다.
- arm64에서는 highmem을 사용하지 않기 때문에 이미 매핑되어 있다.
- 코드 라인 71~75에서 swap 헤더를 파싱하여 swap 정보에 그 시작과 끝 위치를 기록하고, 실제 swap 영역에 해당하는 페이지 수를 알아온다.
- 코드 라인 78~82에서 실제 swap 영역에 해당하는 페이지 수에 해당하는 바이트를 할당하여 swap_map에 할당한다.
mm/swapfile.c -2/3-
. if (bdi_cap_stable_pages_required(inode_to_bdi(inode)))
p->flags |= SWP_STABLE_WRITES;
if (bdi_cap_synchronous_io(inode_to_bdi(inode)))
p->flags |= SWP_SYNCHRONOUS_IO;
if (p->bdev && blk_queue_nonrot(bdev_get_queue(p->bdev))) {
int cpu;
unsigned long ci, nr_cluster;
p->flags |= SWP_SOLIDSTATE;
/*
* select a random position to start with to help wear leveling
* SSD
*/
p->cluster_next = 1 + (prandom_u32() % p->highest_bit);
nr_cluster = DIV_ROUND_UP(maxpages, SWAPFILE_CLUSTER);
cluster_info = kvcalloc(nr_cluster, sizeof(*cluster_info),
GFP_KERNEL);
if (!cluster_info) {
error = -ENOMEM;
goto bad_swap;
}
for (ci = 0; ci < nr_cluster; ci++)
spin_lock_init(&((cluster_info + ci)->lock));
p->percpu_cluster = alloc_percpu(struct percpu_cluster);
if (!p->percpu_cluster) {
error = -ENOMEM;
goto bad_swap;
}
for_each_possible_cpu(cpu) {
struct percpu_cluster *cluster;
cluster = per_cpu_ptr(p->percpu_cluster, cpu);
cluster_set_null(&cluster->index);
}
} else {
atomic_inc(&nr_rotate_swap);
inced_nr_rotate_swap = true;
}
error = swap_cgroup_swapon(p->type, maxpages);
if (error)
goto bad_swap;
nr_extents = setup_swap_map_and_extents(p, swap_header, swap_map,
cluster_info, maxpages, &span);
if (unlikely(nr_extents < 0)) {
error = nr_extents;
goto bad_swap;
}
/* frontswap enabled? set up bit-per-page map for frontswap */
if (IS_ENABLED(CONFIG_FRONTSWAP))
frontswap_map = kvcalloc(BITS_TO_LONGS(maxpages),
sizeof(long),
GFP_KERNEL);
if (p->bdev &&(swap_flags & SWAP_FLAG_DISCARD) && swap_discardable(p)) {
/*
* When discard is enabled for swap with no particular
* policy flagged, we set all swap discard flags here in
* order to sustain backward compatibility with older
* swapon(8) releases.
*/
p->flags |= (SWP_DISCARDABLE | SWP_AREA_DISCARD |
SWP_PAGE_DISCARD);
/*
* By flagging sys_swapon, a sysadmin can tell us to
* either do single-time area discards only, or to just
* perform discards for released swap page-clusters.
* Now it's time to adjust the p->flags accordingly.
*/
if (swap_flags & SWAP_FLAG_DISCARD_ONCE)
p->flags &= ~SWP_PAGE_DISCARD;
else if (swap_flags & SWAP_FLAG_DISCARD_PAGES)
p->flags &= ~SWP_AREA_DISCARD;
/* issue a swapon-time discard if it's still required */
if (p->flags & SWP_AREA_DISCARD) {
int err = discard_swap(p);
if (unlikely(err))
pr_err("swapon: discard_swap(%p): %d\n",
p, err);
}
}
- 코드 라인 1~2에서 swap 기록을 안정적으로 할 수 있는 장치인 경우 SWP_STABLE_WRITES 플래그를 추가한다.
- 코드 라인 4~5에서 swap 기록이 빠른 장치(zram, pmem 등)인 경우 비동기로 처리할 필요 없다. 이 때 SWP_SYNCHRONOUS_IO 플래그를 추가한다.
- 코드 라인 7~11에서 SSD 처럼 non-rotational 블럭 장치인 경우 SWP_SOLIDSTATE 플래그를 추가한다.
- 코드 라인 16에서 다음 사용할 클러스터 위치를 swap 영역내에서 랜덤하게 선택한다.
- 코드 라인 17에서 swap 가용 페이지 수를 사용하여 클러스터의 수를 결정한다.
- 1개의 클러스터는 SWAPFILE_CLUSTER(256) 수 만큼 페이지를 관리한다.
- 현재 x86_64 아키텍처만 THP_SWAP을 지원하고 이 때 256 페이지 대신 HPAGE_PMD_NR 수 만큼 페이지를 관리한다.
- 코드 라인 19~27에서 결정된 클러스터 수만큼 cluster_info를 할당하고 초기화한다.
- 코드 라인 29~38에서 swap 정보의 멤버 percpu_cluster에 per-cpu percpu_cluster 구조체를 할당하여 지정하고 초기화한다.
- 코드 라인 39~42에서 SSD가 아닌 장치인 경우 nr_rotate_swap을 증가시키고 inced_nr_rotate_swap을 true로 지정한다.
- nr_rotate_swap 값이 0이 아니면 vma 기반 readahead를 사용하지 않는다.
- 코드 라인 44~46에서 cgroup용 swapon을 위해 swap_cgroup 배열들을 할당하고 준비한다.
- 코드 라인 48~53에서 swap 맵과 swap_extent를 할당하고 준비한다.
- 코드 라인 55~58에서 frontswap을 지원하는 커널인 경우 frontswap용 맵을 할당한다.
- 맵의 각 비트는 1 페이지에 대응한다.
- 코드 라인 60~88에서 SWAP_FLAG_DISCARD 요청을 처리한다.
mm/swapfile.c -3/3-
error = init_swap_address_space(p->type, maxpages);
if (error)
goto bad_swap;
mutex_lock(&swapon_mutex);
prio = -1;
if (swap_flags & SWAP_FLAG_PREFER)
prio =
(swap_flags & SWAP_FLAG_PRIO_MASK) >> SWAP_FLAG_PRIO_SHIFT;
enable_swap_info(p, prio, swap_map, cluster_info, frontswap_map);
pr_info("Adding %uk swap on %s. Priority:%d extents:%d across:%lluk %s%s%s%s%s\n",
p->pages<<(PAGE_SHIFT-10), name->name, p->prio,
nr_extents, (unsigned long long)span<<(PAGE_SHIFT-10),
(p->flags & SWP_SOLIDSTATE) ? "SS" : "",
(p->flags & SWP_DISCARDABLE) ? "D" : "",
(p->flags & SWP_AREA_DISCARD) ? "s" : "",
(p->flags & SWP_PAGE_DISCARD) ? "c" : "",
(frontswap_map) ? "FS" : "");
mutex_unlock(&swapon_mutex);
atomic_inc(&proc_poll_event);
wake_up_interruptible(&proc_poll_wait);
if (S_ISREG(inode->i_mode))
inode->i_flags |= S_SWAPFILE;
error = 0;
goto out;
bad_swap:
free_percpu(p->percpu_cluster);
p->percpu_cluster = NULL;
if (inode && S_ISBLK(inode->i_mode) && p->bdev) {
set_blocksize(p->bdev, p->old_block_size);
blkdev_put(p->bdev, FMODE_READ | FMODE_WRITE | FMODE_EXCL);
}
destroy_swap_extents(p);
swap_cgroup_swapoff(p->type);
spin_lock(&swap_lock);
p->swap_file = NULL;
p->flags = 0;
spin_unlock(&swap_lock);
vfree(swap_map);
kvfree(cluster_info);
kvfree(frontswap_map);
if (inced_nr_rotate_swap)
atomic_dec(&nr_rotate_swap);
if (swap_file) {
if (inode && S_ISREG(inode->i_mode)) {
inode_unlock(inode);
inode = NULL;
}
filp_close(swap_file, NULL);
}
out:
if (page && !IS_ERR(page)) {
kunmap(page);
put_page(page);
}
if (name)
putname(name);
if (inode && S_ISREG(inode->i_mode))
inode_unlock(inode);
if (!error)
enable_swap_slots_cache();
return error;
}
- 코드 라인 1~3에서 @type에 대한 swap 영역을 초기화한다.
- swapper_spaces[type]에 swap 영역 크기를 SWAP_ADDRESS_SPACE_PAGES(2^14=16K pages=64M) 단위 수로 나누어 address_space 배열을 할당하여 준비한다.
- 코드라인 6~9에서 SWAP_FLAG_PREFER 플래그가 요청된 경우 플래그에 priority 값이 추가되어 있다. 이 경우 priority 값만 분리하여 prio에 대입한다. 그 외의 경우 -1이다.
- 코드 라인 10~19에서 swap 영역을 활성화하고, 메시지를 춮력한다.
- “Adding <페이지수> swap on <파일/블럭 디바이스명>. Priority:<prio> extents:<extent 매핑수> across:<span 크기> [SS][D][s][c][FS]”
- SS: SSD
- D: discardable
- s: swap 영역 discard
- c: swap 페이지 discard
- FS: FrontSwap 맵
- “Adding <페이지수> swap on <파일/블럭 디바이스명>. Priority:<prio> extents:<extent 매핑수> across:<span 크기> [SS][D][s][c][FS]”
- 코드 라인 25~26에서 swap 파일을 사용하는 swap 영역인 경우 inode에 S_SWAPFILE 플래그를 추가한다.
- 코드 라인 27~28에서 에러 없이 성공적으로 처리하려 out 레이블로 이동한다.
- 코드 라인 29~53에서 bad_swap: 레이블이다. swap 영역을 활성화하지 못하는 경우 할당했었던 메모리를 회수한다.
- 코드 라인 54~65에서 out: 레이블이다. swap 영역의 초기화가 성공한 경우 swap 슬롯 캐시를 활성화한다.
swap_info_struct 할당후 초기화
alloc_swap_info()
mm/swapfile.c
static struct swap_info_struct *alloc_swap_info(void)
{
struct swap_info_struct *p;
unsigned int type;
int i;
int size = sizeof(*p) + nr_node_ids * sizeof(struct plist_node);
p = kvzalloc(size, GFP_KERNEL);
if (!p)
return ERR_PTR(-ENOMEM);
spin_lock(&swap_lock);
for (type = 0; type < nr_swapfiles; type++) {
if (!(swap_info[type]->flags & SWP_USED))
break;
}
if (type >= MAX_SWAPFILES) {
spin_unlock(&swap_lock);
kvfree(p);
return ERR_PTR(-EPERM);
}
if (type >= nr_swapfiles) {
p->type = type;
swap_info[type] = p;
/*
* Write swap_info[type] before nr_swapfiles, in case a
* racing procfs swap_start() or swap_next() is reading them.
* (We never shrink nr_swapfiles, we never free this entry.)
*/
smp_wmb();
nr_swapfiles++;
} else {
kvfree(p);
p = swap_info[type];
/*
* Do not memset this entry: a racing procfs swap_next()
* would be relying on p->type to remain valid.
*/
}
INIT_LIST_HEAD(&p->first_swap_extent.list);
plist_node_init(&p->list, 0);
for_each_node(i)
plist_node_init(&p->avail_lists[i], 0);
p->flags = SWP_USED;
spin_unlock(&swap_lock);
spin_lock_init(&p->lock);
spin_lock_init(&p->cont_lock);
return p;
}
swap 영역 정보를 할당한다. (할당한 swap_info_struct 포인터를 반환한다.)
- 코드 라인 6~10에서 swap_info_struct 구조체와 연결하여 노드 수 만큼의 plist_node 구조체 배열을 할당한다.
- 코드 라인 13~16에서 swap 파일 수만큼 swap_info[] 배열에 빈 자리가 있는지 찾아본다.
- 코드 라인 17~21에서 생성한 swap 파일 수가 이미 MAX_SWAPFILES 수 이상인 경우 할당을 취소하고 -EPERM 에러를 반환한다.
- 코드 라인 22~31에서 swap_info[] 배열에 빈 자리가 없으면 마지막에 할당한 메모리를 지정하고, swap 파일 수를 증가시킨다.
- 코드 라인 32~39에서 swap_info[] 배열에 빈 자리가 있으면 이미 할당한 메모리는 취소하고, 기존 할당한 메모리를 사용한다.
- 코드 라인 40~47에서 할당한 swap_info_struct 배열의 관련 멤버들을 초기화하고, SWP_USED 플래그를 설정한다.
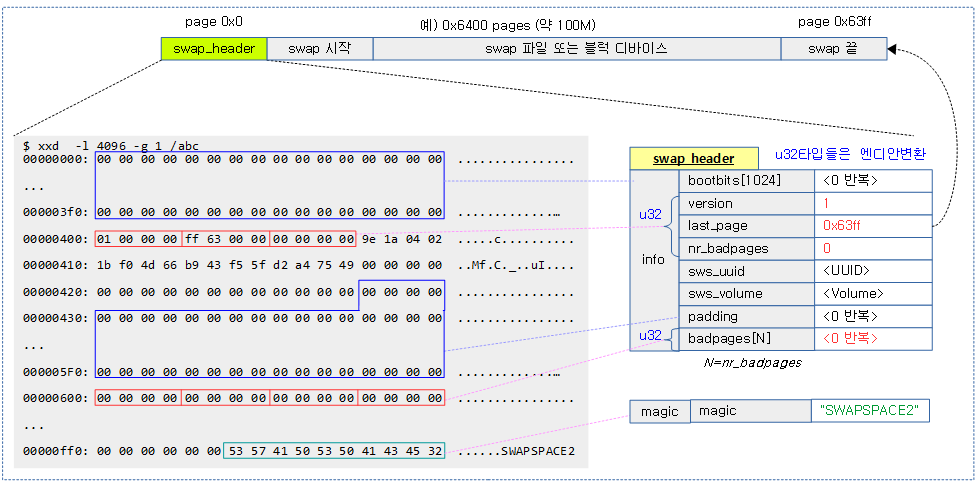
Swap 헤더
swap_header 구조체
include/linux/swap.h
/* * Magic header for a swap area. The first part of the union is * what the swap magic looks like for the old (limited to 128MB) * swap area format, the second part of the union adds - in the * old reserved area - some extra information. Note that the first * kilobyte is reserved for boot loader or disk label stuff... * * Having the magic at the end of the PAGE_SIZE makes detecting swap * areas somewhat tricky on machines that support multiple page sizes. * For 2.5 we'll probably want to move the magic to just beyond the * bootbits... */
union swap_header {
struct {
char reserved[PAGE_SIZE - 10];
char magic[10]; /* SWAP-SPACE or SWAPSPACE2 */
} magic;
struct {
char bootbits[1024]; /* Space for disklabel etc. */
__u32 version;
__u32 last_page;
__u32 nr_badpages;
unsigned char sws_uuid[16];
unsigned char sws_volume[16];
__u32 padding[117];
__u32 badpages[1];
} info;
};
다음 그림은 swap 파일의 헤더 구성을 보여준다.
read_swap_header()
mm/swapfile.c
static unsigned long read_swap_header(struct swap_info_struct *p,
union swap_header *swap_header,
struct inode *inode)
{
int i;
unsigned long maxpages;
unsigned long swapfilepages;
unsigned long last_page;
if (memcmp("SWAPSPACE2", swap_header->magic.magic, 10)) {
pr_err("Unable to find swap-space signature\n");
return 0;
}
/* swap partition endianess hack... */
if (swab32(swap_header->info.version) == 1) {
swab32s(&swap_header->info.version);
swab32s(&swap_header->info.last_page);
swab32s(&swap_header->info.nr_badpages);
if (swap_header->info.nr_badpages > MAX_SWAP_BADPAGES)
return 0;
for (i = 0; i < swap_header->info.nr_badpages; i++)
swab32s(&swap_header->info.badpages[i]);
}
/* Check the swap header's sub-version */
if (swap_header->info.version != 1) {
pr_warn("Unable to handle swap header version %d\n",
swap_header->info.version);
return 0;
}
p->lowest_bit = 1;
p->cluster_next = 1;
p->cluster_nr = 0;
maxpages = max_swapfile_size();
last_page = swap_header->info.last_page;
if (!last_page) {
pr_warn("Empty swap-file\n");
return 0;
}
if (last_page > maxpages) {
pr_warn("Truncating oversized swap area, only using %luk out of %luk\n",
maxpages << (PAGE_SHIFT - 10),
last_page << (PAGE_SHIFT - 10));
}
if (maxpages > last_page) {
maxpages = last_page + 1;
/* p->max is an unsigned int: don't overflow it */
if ((unsigned int)maxpages == 0)
maxpages = UINT_MAX;
}
p->highest_bit = maxpages - 1;
if (!maxpages)
return 0;
swapfilepages = i_size_read(inode) >> PAGE_SHIFT;
if (swapfilepages && maxpages > swapfilepages) {
pr_warn("Swap area shorter than signature indicates\n");
return 0;
}
if (swap_header->info.nr_badpages && S_ISREG(inode->i_mode))
return 0;
if (swap_header->info.nr_badpages > MAX_SWAP_BADPAGES)
return 0;
return maxpages;
}
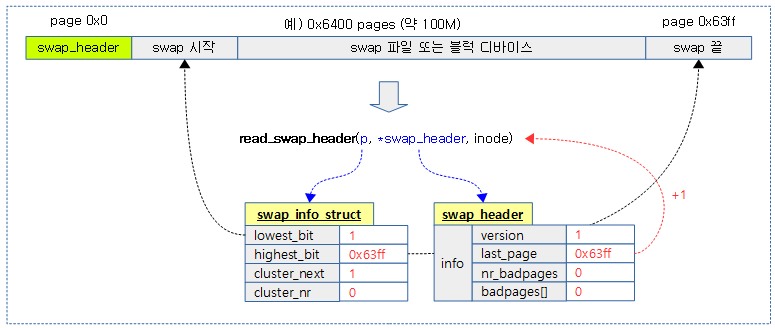
swap 헤더를 파싱하여 swap 정보에 그 시작과 끝 위치를 알아온다.
- 코드 라인 10~13에서 페이지의 마지막 10바이트에 “SWAPSPACE2” 라는 매직 문자열을 확인하고, 없는 경우 에러 메시지를 출력하고 0을 반환한다.
- “Unable to find swap-space signature\n”
- 코드 라인 16~30에서 버전이 1로 확인되는 경우 모든 unsigned int 값들을 바이트 swap 하여 읽는다. 만일 버전이 1이 아닌 경우 다음과 같은 경고 메시지를 출력하고 0을 반환한다.
- “Unable to handle swap header version %d\n”
- 코드 라인 32~34에서 클러스터 수를 0으로하고, 다음 클러스터 번호는 1로 지정하여 초기화한다. 그리고 swap 시작(lowestbit) 페이지로 첫 페이지인 1을 지정한다.
- 코드 라인 36에서 아키텍처가 지원하는 swap offset 페이지 한계를 알아와서 maxpages에 대입한다.
- 코드 라인 37~41에서 swap 헤더에 기록된 last_page 수가 0인 경우 “Empty swap-file” 메시지를 출력하고 0을 반환한다.
- 코드 라인 42~46에서 last_page가 maxpages를 초과하는 경우 경고 메시지를 출력한다.
- 코드 라인 47~52에서 maxpages가 last_page보다 큰 경우 maxpages는 last_page+1을 대입한다.
- 코드 라인 53에서 swap 끝(highestbit) 페이지로 maxpages-1을 지정한다.
- 코드 라인 57~61에서 swap 파일 또는 블럭 디바이스의 페이지 수를 알아와서 maxpages보다 작은 경우 다음과 같은 경고 메시지를 출력하고 0을 반환한다.
- “Swap area shorter than signature indicates\n”
- 코드 라인 62~63에서 swap 파일의 경우 배드 페이지가 존재하는 경우 0을 반환한다.
- 코드 라인 64~65에서 배드 페이지 수가 MAX_SWAP_BADPAGES를 초과하는 경우 0을 반환한다.
- 코드 라인 67에서 maxpages를 반환한다.
다음 그림은 swap 파일 또는 블럭 디바이스에서 swap 헤더를 읽고 swap 정보에 시작(lowest_bit)과 끝(highest_bit) 위치를 처음 지정하는 모습을 보여준다.
Cgroup용 swap
swap_cgroup_swapon()
mm/swap_cgroup.c
int swap_cgroup_swapon(int type, unsigned long max_pages)
{
void *array;
unsigned long array_size;
unsigned long length;
struct swap_cgroup_ctrl *ctrl;
if (!do_swap_account)
return 0;
length = DIV_ROUND_UP(max_pages, SC_PER_PAGE);
array_size = length * sizeof(void *);
array = vzalloc(array_size);
if (!array)
goto nomem;
ctrl = &swap_cgroup_ctrl[type];
mutex_lock(&swap_cgroup_mutex);
ctrl->length = length;
ctrl->map = array;
spin_lock_init(&ctrl->lock);
if (swap_cgroup_prepare(type)) {
/* memory shortage */
ctrl->map = NULL;
ctrl->length = 0;
mutex_unlock(&swap_cgroup_mutex);
vfree(array);
goto nomem;
}
mutex_unlock(&swap_cgroup_mutex);
return 0;
nomem:
pr_info("couldn't allocate enough memory for swap_cgroup\n");
pr_info("swap_cgroup can be disabled by swapaccount=0 boot option\n");
return -ENOMEM;
}
swap cgroup을 할당하고 준비한다. 성공 시 0을 반환한다.
- 코드 라인 8~9에서 memcg swap을 지원하는 커널이 아니면 함수를 빠져나간다.
- CONFIG_MEMCG_SWAP & CONFIG_MEMCG_SWAP_ENABLED 커널 옵션을 사용해야 한다.
- 코드 라인 11~16에서 swap 영역에 필요한 페이지 수만큼 필요한 swap_cgroup 구조체를 수를 산출하고 그 수 만큼 페이지 포인터 배열을 할당한다.
- 코드 라인 18~22에서 전역 swap_cgroup_ctrl[] 배열에서 @type에 해당하는 swap_cgroup_ctrl에 할당한 페이지 포인터 배열을 연결하고, length에 산출한 swap_cgroup 구조체 수를 담는다.
- 코드 라인 23~30에서 swap_cgroup_ctrl에 할당하여 준비한 페이지 포인터 배열에 swap_cgroup 구조체 배열용으로 사용할 페이지들을 할당하고 연결한다.
- 코드 라인 33에서 정상 할당이 완료되면 0을 반환한다.
- 코드 라인 34~37에서 nomem: 레이블이다. swap cgroup을 할당하기에 메모리가 부족하다고 메시지 출력을 한다. 그리고 메모리 부족 시 커널 옵션으로 “swapaccount=0″을 사용하면 swap cgroup을 disable 할 수 있다고 메시지 출력을 한다.
다음 그림은 swap cgroup을 할당하고 준비하는 과정을 보여준다.
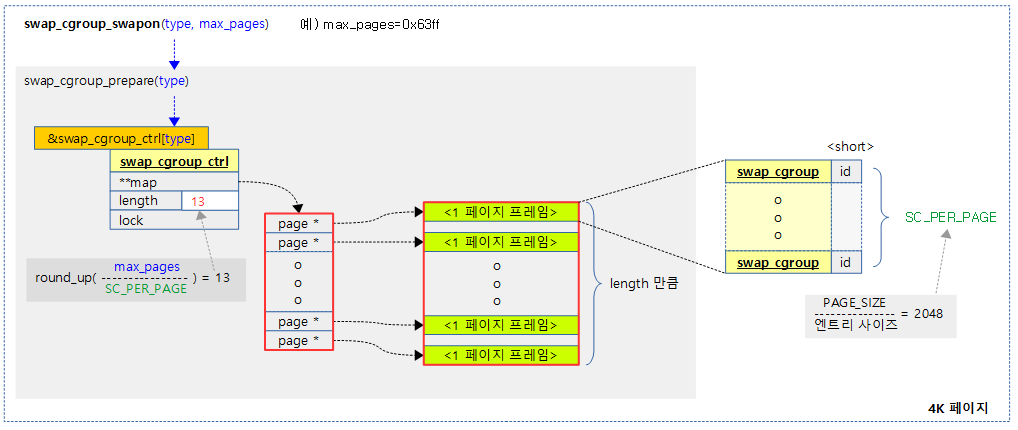
swap_cgroup_prepare()
mm/swap_cgroup.c
/* * allocate buffer for swap_cgroup. */
static int swap_cgroup_prepare(int type)
{
struct page *page;
struct swap_cgroup_ctrl *ctrl;
unsigned long idx, max;
ctrl = &swap_cgroup_ctrl[type];
for (idx = 0; idx < ctrl->length; idx++) {
page = alloc_page(GFP_KERNEL | __GFP_ZERO);
if (!page)
goto not_enough_page;
ctrl->map[idx] = page;
if (!(idx % SWAP_CLUSTER_MAX))
cond_resched();
}
return 0;
not_enough_page:
max = idx;
for (idx = 0; idx < max; idx++)
__free_page(ctrl->map[idx]);
return -ENOMEM;
}
swap_cgroup_ctrl에 할당하여 준비한 각 페이지 포인터 배열에 swap_cgroup 구조체 배열용으로 사용할 페이지들을 할당하고 연결한다.
- 코드 라인 7에서 @type에 해당하는 swap_cgroup_ctrl을 지정한다.
- 코드 라인 9~17에서 ctrl->length 만큼 순회하며 swap_cgroup 구조체 배열용 페이지를 할당하여 ctrl->map[idx]에 연결한다.
- 코드 라인 18에서 성공시 0을 반환한다.
- 코드 라인 19~24에서 not_enough_page: 레이블이다. 메모리 부족 시 할당한 페이지들을 할당 해제하고 -ENOMEM 에러를 반환한다.
swap 맵 초기화
setup_swap_map_and_extents()
mm/swapfile.c
static int setup_swap_map_and_extents(struct swap_info_struct *p,
union swap_header *swap_header,
unsigned char *swap_map,
struct swap_cluster_info *cluster_info,
unsigned long maxpages,
sector_t *span)
{
unsigned int j, k;
unsigned int nr_good_pages;
int nr_extents;
unsigned long nr_clusters = DIV_ROUND_UP(maxpages, SWAPFILE_CLUSTER);
unsigned long col = p->cluster_next / SWAPFILE_CLUSTER % SWAP_CLUSTER_COLS;
unsigned long i, idx;
nr_good_pages = maxpages - 1; /* omit header page */
cluster_list_init(&p->free_clusters);
cluster_list_init(&p->discard_clusters);
for (i = 0; i < swap_header->info.nr_badpages; i++) {
unsigned int page_nr = swap_header->info.badpages[i];
if (page_nr == 0 || page_nr > swap_header->info.last_page)
return -EINVAL;
if (page_nr < maxpages) {
swap_map[page_nr] = SWAP_MAP_BAD;
nr_good_pages--;
/*
* Haven't marked the cluster free yet, no list
* operation involved
*/
inc_cluster_info_page(p, cluster_info, page_nr);
}
}
/* Haven't marked the cluster free yet, no list operation involved */
for (i = maxpages; i < round_up(maxpages, SWAPFILE_CLUSTER); i++)
inc_cluster_info_page(p, cluster_info, i);
if (nr_good_pages) {
swap_map[0] = SWAP_MAP_BAD;
/*
* Not mark the cluster free yet, no list
* operation involved
*/
inc_cluster_info_page(p, cluster_info, 0);
p->max = maxpages;
p->pages = nr_good_pages;
nr_extents = setup_swap_extents(p, span);
if (nr_extents < 0)
return nr_extents;
nr_good_pages = p->pages;
}
if (!nr_good_pages) {
pr_warn("Empty swap-file\n");
return -EINVAL;
}
if (!cluster_info)
return nr_extents;
/*
* Reduce false cache line sharing between cluster_info and
* sharing same address space.
*/
for (k = 0; k < SWAP_CLUSTER_COLS; k++) {
j = (k + col) % SWAP_CLUSTER_COLS;
for (i = 0; i < DIV_ROUND_UP(nr_clusters, SWAP_CLUSTER_COLS); i++) {
idx = i * SWAP_CLUSTER_COLS + j;
if (idx >= nr_clusters)
continue;
if (cluster_count(&cluster_info[idx]))
continue;
cluster_set_flag(&cluster_info[idx], CLUSTER_FLAG_FREE);
cluster_list_add_tail(&p->free_clusters, cluster_info,
idx);
}
}
return nr_extents;
}
swap 맵과 swap_extent를 할당하고 준비하며 할당한 swap_extent 수를 반환한다.
- 코드 라인 11에서 swap 최대 페이지 수로 필요한 클러스터 수를 산출한다.
- 코드 라인 12에서 다음에 진행할 클러스터 번호를 알아온다.
- swap 파일은 최대 64M 단위로 최대 클러스터 번호는
- 코드 라인 15에서 good 페이지 수를 산출할 때 배드 페이지들을 빼기 전에 먼저 헤더 페이지로 1 페이지를 사용하므로 swap 최대 페이지 수에서 1을 뺀다.
- 코드 라인 17~18에서 free_clusters와 discard_clusters 리스트들을 클리어한다.
- 코드 라인 20~33에서 헤더 페이지에 기록된 배드 페이지 수만큼 순회하며 배드 페이지 번호를 알아와서 그에 해당하는 swap_map[]에 SWAP_MAP_BAD 마킹을 하고, good 페이지 수를 감소시킨다. 마킹한 배드 페이지가 있는 클러스터도 사용중으로 설정한다.
- 코드 라인 36~37에서 swap 영역을 클러스터 단위로 관리하는데 끝 부분이 정렬되지 않고 남는 영역의 페이지들도 모두 사용중인 클러스터로 설정한다.
- 코드 라인 39~52에서 good 페이지가 존재하는 경우 swap 영역의 첫 페이지는 SWAP_MAP_BAD로 설정하고, 첫 클러스터를 사용중으로 설정한다. 그리고 swap extent를 구성한다.
- 코드 라인 53~56에서 good 페이지가 하나도 없으면 빈 swap 파일이라고 경고 메시지를 출력하고 -EINVAL 에러를 반환한다.
- 코드 라인 58~59에서 @cluster_info가 지정되지 않은 경우 swap extent 수를 반환한다.
- 코드 라인 65~77에서 false cache line sharing을 줄이기 위해 cluster_info와 address_space를 각 cpu들이 따로 접근하도록 떨어뜨렸다. 사용 가능한 free 클러스터들을 fre_clusters 리스트에 추가하고, cluster_info 정보의 플래그에 CLUSTER_FLAG_FREE를 추가한다.
- 코드 라인 78에서 swap extent 수를 반환한다.
다음 그림은 swap 영역의 헤더 페이지를 분석한 정보로 swap_map을 구성하는 모습을 보여준다.
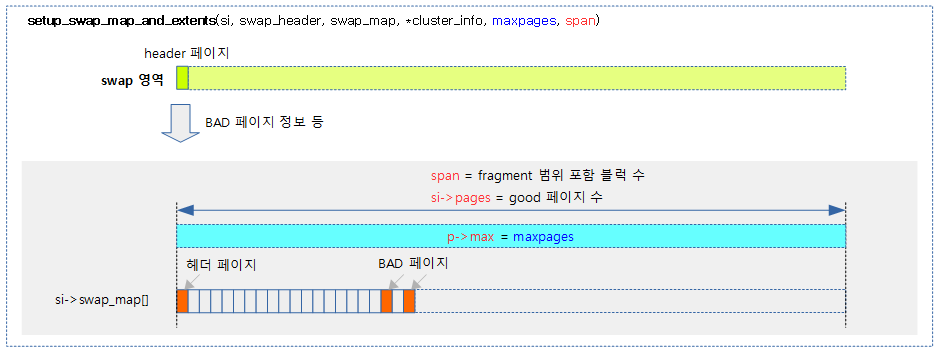
다음 그림은 SSD를 사용 시 클러스터 구성을 위해 free 클러스터 리스트를 준비하는 과정을 보여준다.
- 헤더 페이지, BAD 페이지가 속한 클러스터는 사용 중으로 만들어 free 클러스터 리스트에서 제거한다.
- free 클러스터를 추가할 때 클러스터를 순서대로 넣지 않고 64개씩 분리하여 추가하는 것을 보여준다.

Swap Extents
swap 영역을 블럭 디바이스에 범위를 매핑할 때 사용한다. swap 영역의 종류에 따라 다음 3가지 방법으로 swap extent를 준비한다.
- 블럭 디바이스를 사용하는 경우 swap 영역과 블럭 디바이스는 한 번에 전부 1개의 swap extent를 사용하여 매핑한다.
- 마운트된 파일 시스템에서 (*swap_activate)가 지원되는 swap 파일이 위치한 swap 영역도 한 번에 전부를 매핑하므로 1개의 swap extent만 필요하다.
- nfs, xfs, btrfs, sunrpc, …
- generic swap 파일
- swap 영역으로 swap 파일을 사용하는 경우이다. 이 때에는 블럭 디바이스의 빈 공간이 여러 군데에 fragment된 경우 이므로 여러 개의 swap_extent가 필요하게 된다.
setup_swap_extents()
mm/swapfile.c
/* * A `swap extent' is a simple thing which maps a contiguous range of pages * onto a contiguous range of disk blocks. An ordered list of swap extents * is built at swapon time and is then used at swap_writepage/swap_readpage * time for locating where on disk a page belongs. * * If the swapfile is an S_ISBLK block device, a single extent is installed. * This is done so that the main operating code can treat S_ISBLK and S_ISREG * swap files identically. * * Whether the swapdev is an S_ISREG file or an S_ISBLK blockdev, the swap * extent list operates in PAGE_SIZE disk blocks. Both S_ISREG and S_ISBLK * swapfiles are handled *identically* after swapon time. * * For S_ISREG swapfiles, setup_swap_extents() will walk all the file's blocks * and will parse them into an ordered extent list, in PAGE_SIZE chunks. If * some stray blocks are found which do not fall within the PAGE_SIZE alignment * requirements, they are simply tossed out - we will never use those blocks * for swapping. * * For S_ISREG swapfiles we set S_SWAPFILE across the life of the swapon. This * prevents root from shooting her foot off by ftruncating an in-use swapfile, * which will scribble on the fs. * * The amount of disk space which a single swap extent represents varies. * Typically it is in the 1-4 megabyte range. So we can have hundreds of * extents in the list. To avoid much list walking, we cache the previous * search location in `curr_swap_extent', and start new searches from there. * This is extremely effective. The average number of iterations in * map_swap_page() has been measured at about 0.3 per page. - akpm. */
static int setup_swap_extents(struct swap_info_struct *sis, sector_t *span)
{
struct file *swap_file = sis->swap_file;
struct address_space *mapping = swap_file->f_mapping;
struct inode *inode = mapping->host;
int ret;
if (S_ISBLK(inode->i_mode)) {
ret = add_swap_extent(sis, 0, sis->max, 0);
*span = sis->pages;
return ret;
}
if (mapping->a_ops->swap_activate) {
ret = mapping->a_ops->swap_activate(sis, swap_file, span);
if (ret >= 0)
sis->flags |= SWP_ACTIVATED;
if (!ret) {
sis->flags |= SWP_FS;
ret = add_swap_extent(sis, 0, sis->max, 0);
*span = sis->pages;
}
return ret;
}
return generic_swapfile_activate(sis, swap_file, span);
}
swap extents를 준비한다. 출력 인자 @span에 페이지 수를 지정한다. 결과가 0인 경우 새로 활성화된 경우이다.
- 코드 라인 8~12에서 swap 영역이 블럭 디바이스인 경우 swap 영역 전체(0 ~ sis->max 페이지)를 지정한 블럭 디바이스에 한 번에 매핑할 수 있다. 그렇게 하기 위해 0번 블럭부터 전체를 매핑하도록 1개의 swap_extent를 추가한다.
- 코드 라인 14~24에서 매핑된 오퍼레이션의 (*swap_activate) 후크가 지원되는 경우 호출한 후 이미 활성화된 경우 SWP_ACTIVATED 플래그를 추가한다. 또한 새로 활성화된 경우 SWP_FS 플래그를 설정하고, swap 영역 전체(0 ~ sis->max 페이지)를 한 번에 매핑하도록 1개의 swap_extent를 구성하여 추가한다.
- 코드 라인 26에서 swap 영역이 generic한 swap 파일인 경우 1개 이상의 매핑을 위해 swap_extent 들을 추가하고 활성화한다.
generic_swapfile_activate()
mm/page_io.c
int generic_swapfile_activate(struct swap_info_struct *sis,
struct file *swap_file,
sector_t *span)
{
struct address_space *mapping = swap_file->f_mapping;
struct inode *inode = mapping->host;
unsigned blocks_per_page;
unsigned long page_no;
unsigned blkbits;
sector_t probe_block;
sector_t last_block;
sector_t lowest_block = -1;
sector_t highest_block = 0;
int nr_extents = 0;
int ret;
blkbits = inode->i_blkbits;
blocks_per_page = PAGE_SIZE >> blkbits;
/*
* Map all the blocks into the extent list. This code doesn't try
* to be very smart.
*/
probe_block = 0;
page_no = 0;
last_block = i_size_read(inode) >> blkbits;
while ((probe_block + blocks_per_page) <= last_block &&
page_no < sis->max) {
unsigned block_in_page;
sector_t first_block;
cond_resched();
first_block = bmap(inode, probe_block);
if (first_block == 0)
goto bad_bmap;
/*
* It must be PAGE_SIZE aligned on-disk
*/
if (first_block & (blocks_per_page - 1)) {
probe_block++;
goto reprobe;
}
for (block_in_page = 1; block_in_page < blocks_per_page;
block_in_page++) {
sector_t block;
block = bmap(inode, probe_block + block_in_page);
if (block == 0)
goto bad_bmap;
if (block != first_block + block_in_page) {
/* Discontiguity */
probe_block++;
goto reprobe;
}
}
first_block >>= (PAGE_SHIFT - blkbits);
if (page_no) { /* exclude the header page */
if (first_block < lowest_block)
lowest_block = first_block;
if (first_block > highest_block)
highest_block = first_block;
}
/*
* We found a PAGE_SIZE-length, PAGE_SIZE-aligned run of blocks
*/
ret = add_swap_extent(sis, page_no, 1, first_block);
if (ret < 0)
goto out;
nr_extents += ret;
page_no++;
probe_block += blocks_per_page;
reprobe:
continue;
}
ret = nr_extents;
*span = 1 + highest_block - lowest_block;
if (page_no == 0)
page_no = 1; /* force Empty message */
sis->max = page_no;
sis->pages = page_no - 1;
sis->highest_bit = page_no - 1;
out:
return ret;
bad_bmap:
pr_err("swapon: swapfile has holes\n");
ret = -EINVAL;
goto out;
}
swap 영역이 generic한 swap 파일에서 이를 활성화한다. 성공 시 추가한 extent 수를 반환한다.
- 코드 라인 17~18에서 한 개의 페이지에 들어갈 수 있는 블럭 비트 수를 구해 blocks_per_page에 대입한다.
- 블럭 크기는 512byte 이다. 그러나 여기서 말하는 블럭은 IO 단위로 처리 가능한 가상 블럭을 의미한다. swap 파일이 ext2, ext3, ext4 파일시스템에서 운영되는 경우 가상 블럭 사이즈는 1K, 2K, 4K, 8K를 지원하고, 디폴트로 4K를 사용한다.
- 예) PAGE_SIZE(4096) >> inode->iblkbits(12) = 1 블럭
- 블럭 크기는 512byte 이다. 그러나 여기서 말하는 블럭은 IO 단위로 처리 가능한 가상 블럭을 의미한다. swap 파일이 ext2, ext3, ext4 파일시스템에서 운영되는 경우 가상 블럭 사이즈는 1K, 2K, 4K, 8K를 지원하고, 디폴트로 4K를 사용한다.
- 코드 라인 24~26에서 파일의 시작 페이지(page_no)를 0부터 끝 페이지(sis->max) 까지 순회를 위해 준비한다. 이 때 probe_block도 0부터 시작하고, last_block에는 파일의 끝 블럭 번호를 대입한다.
- 코드 라인 27~28에서 probe_block 부터 blocks_per_page 단위로 증가하며 last_block까지 순회한다.
- swap 파일이 ext2, ext3, ext4 파일시스템에서 운영되는 경우 블럭 사이즈로 디폴트 설정을 사용하면 1페이지가 1블럭과 동일하다. 따라서 blocks_per_page의 경우 1이다.
- 코드 라인 34~36에서 swap 파일의 probe_block 페이지에 대한 디스크 블럭 번호를 알아와서 first_block에 대입한다.
- 코드 라인 41~44에서 알아온 디스크 블럭 번호(first_block)가 blocks_per_page 단위로 정렬되지 않은 경우 정렬될 때까지 swap 파일에 대한 블럭 번호(probe_block)를 증가시키고 reprobe 레이블로 이동한다.
- 코드 라인 46~58에서 페이지 내에 2개 이상의 블럭이 있는 경우 블럭내 두 번째 페이지부터 블럭내 끝 페이지까지 순회한다. probe_block + 순회중인 페이지 순번을 더한 번호로 이에 해당하는 블럭 디바이스의 블럭 번호와 동일하게 연동되는지 확인한다. 만일 일치하지 않으면 reprobe 레이블로 이동한다.
- 코드 라인 60~66에서 헤더 페이지를 제외하고 알아온 블럭 디바이스의 번호(first_block)로 가장 작은 lowest_block과 가장 큰 highest_block을 갱신한다.
- 코드 라인 71~74에서 swap 파일의 page_no에 해당하는 1개 페이지를 알아온 블럭 디바이스 번호(first_block)에 매핑한다. 매핑 시 실제 swap extent가 추가되면 1이 반환된다. 추가되지 않고 기존 swap extent에 merge되면 0이 반환된다. 이렇게 반환된 수를 nr_extents에 합산한다.
- 코드 라인 75~76에서 다음 페이지를 처리하러 계속 진행한다. probe_block은 페이지 단위로 정렬되어야 하므로 blocks_per_page 만큼 증가시킨다.
- 코드 라인 77~79에서 reprobe: 레이블이다. while 루프를 계속 진행한다.
- 코드 라인 80에서 반환할 값으로 추가한 extent 수를 대입한다.
- 코드 라인 81에서 출력 인자 @span에는 가장 작은 블록부터 가장 큰 블록까지의 수를 대입한다.
- 코드 라인 82~83에서 page_no가 한 번도 증가되지 않은 경우 빈 페이지인 경우이다. page_no에 1을 대입한다.
- 코드 라인 84~86에서 max, pages, highest_bit등을 갱신한다.
- 코드 라인 87~88에서 out: 레이블이다. 추가한 extent 수를 반환한다.
- 코드 라인 89~92에서 bad_bmap: 레이블이다. 다음 에러 메시지를 출력하고 -EINVAL 에러를 반환한다.
- “swapon: swapfile has holes\n”
swap_extent 구조체
include/linux/swap.h
/* * A swap extent maps a range of a swapfile's PAGE_SIZE pages onto a range of * disk blocks. A list of swap extents maps the entire swapfile. (Where the * term `swapfile' refers to either a blockdevice or an IS_REG file. Apart * from setup, they're handled identically. * * We always assume that blocks are of size PAGE_SIZE. */
struct swap_extent {
struct list_head list;
pgoff_t start_page;
pgoff_t nr_pages;
sector_t start_block;
};
swap 영역을 블럭 디바이스에 범위를 매핑할 때 사용한다.
- list
- 다음과 같이 두 가지 사용 방법으로 나뉜다.
- swap_info_struct에 내장된 swap_extent의 list인 경우 리스트 헤드로 사용된다.
- 헤드에 추가되는 swap_extent의 list는 추가할 때 사용하는 노드로 사용된다.
- 다음과 같이 두 가지 사용 방법으로 나뉜다.
- start_page
- swap 영역에서 매핑할 시작 페이지이다.
- nr_pages
- swap 영역에서 위의 start_page부터 연속 매핑할 페이지 수이다.
- start_block
- swap 영역의 start_page 부터 nr_pages 만큼 블럭 디바이스의 start_block 부터 매핑된다.
add_swap_extent()
mm/swapfile.c
/* * Add a block range (and the corresponding page range) into this swapdev's * extent list. The extent list is kept sorted in page order. * * This function rather assumes that it is called in ascending page order. */
int
add_swap_extent(struct swap_info_struct *sis, unsigned long start_page,
unsigned long nr_pages, sector_t start_block)
{
struct swap_extent *se;
struct swap_extent *new_se;
struct list_head *lh;
if (start_page == 0) {
se = &sis->first_swap_extent;
sis->curr_swap_extent = se;
se->start_page = 0;
se->nr_pages = nr_pages;
se->start_block = start_block;
return 1;
} else {
lh = sis->first_swap_extent.list.prev; /* Highest extent */
se = list_entry(lh, struct swap_extent, list);
BUG_ON(se->start_page + se->nr_pages != start_page);
if (se->start_block + se->nr_pages == start_block) {
/* Merge it */
se->nr_pages += nr_pages;
return 0;
}
}
/*
* No merge. Insert a new extent, preserving ordering.
*/
new_se = kmalloc(sizeof(*se), GFP_KERNEL);
if (new_se == NULL)
return -ENOMEM;
new_se->start_page = start_page;
new_se->nr_pages = nr_pages;
new_se->start_block = start_block;
list_add_tail(&new_se->list, &sis->first_swap_extent.list);
return 1;
}
EXPORT_SYMBOL_GPL(add_swap_extent);
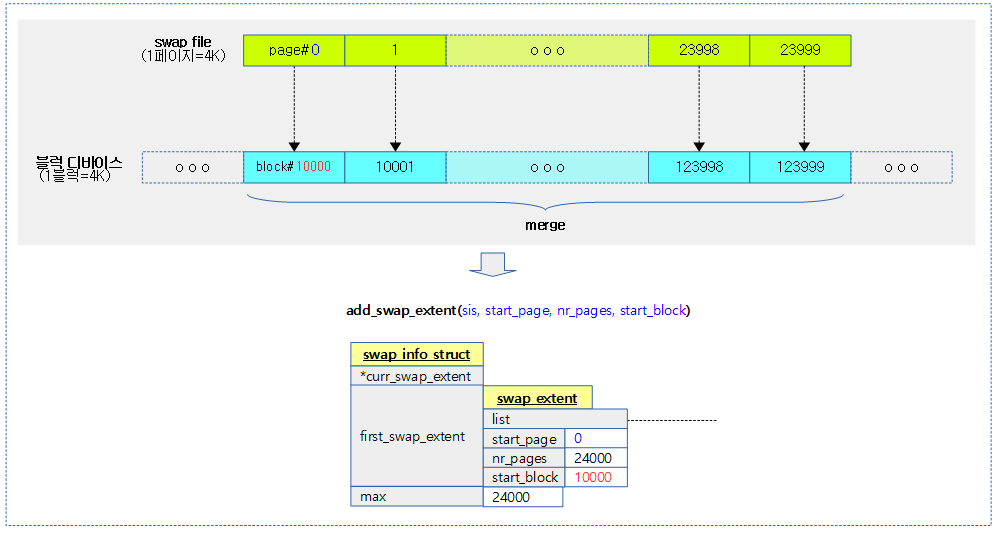
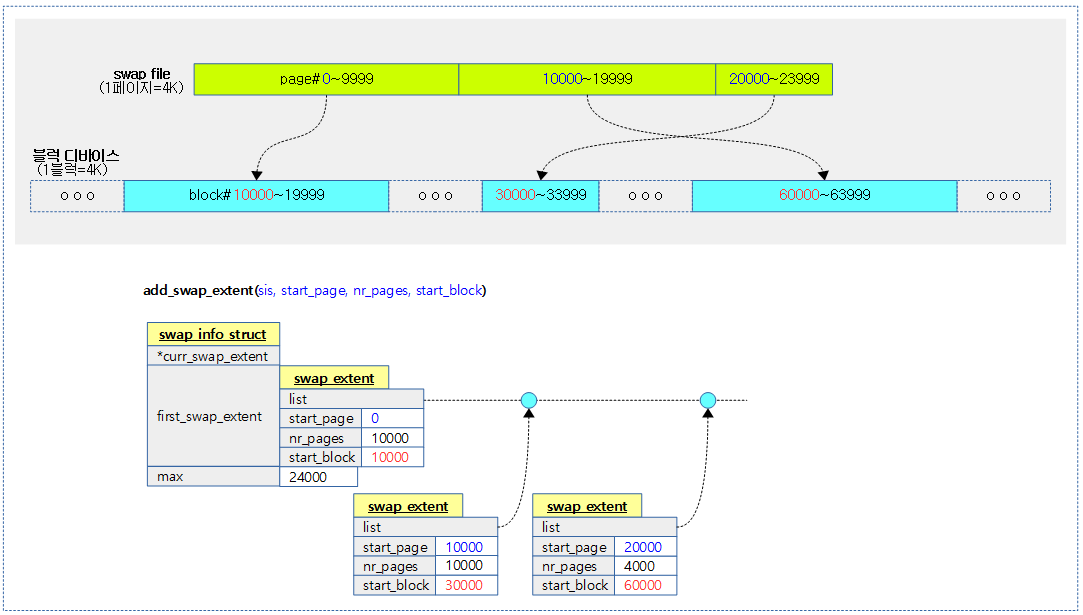
swap 영역의 @start_page부터 @nr_pages를 블럭 디바이스의 @start_block에 매핑한다. 만일 새 swap extent가 할당된 경우 1을 반환한다.
- 코드 라인 9~15에서 swap 영역을 처음 매핑하러 시도할 때 0번 페이지부터 시작하는데 이 때 @nr_pages 만큼 @start_block에 매핑한다. 매핑할 때 사용되는 swap_extent는 swap_info_struct 구조체 내부에 기본으로 사용되는 first_swap_extent를 사용한다. 내장된 swap extent를 사용했어도 추가되었다는 의미로 1을 반환한다.
- 블럭 디바이스를 swap 영역으로 사용 시 swap_extent는 하나만 사용되므로, 한 번의 매핑을 위해 이 조건 한 번만 호출된다.
- 코드 라인 16~25에서 연속된 블럭을 사용할 수 있는 경우 기존 매핑을 merge하여 사용되는 케이스이다. merge 되었으므로 swap extent가 추가되지 않아 0을 반환한다.
- 코드 라인 30~38에서 방금 전에 매핑한 블럭 디바이스 번호가 연속되지 않는 경우 새로운 swap extent를 할당하고 새로운 매핑 정보를 기록한다. 그리고 sis->first_swap_extent.list에 추가한 후 1을 반환한다.
다음 그림은 swap 파일이 마운트된 블럭 디바이스에 흩어지지(fragment) 않고 연속되어 사용되는 경우 swap extent를 1개만 사용하는 모습을 보여준다.
다음 그림은 swap 파일이 마운트된 블럭 디바이스에 3번 흩어져서(fragment) 사용되는 경우 swap extent를 3개 사용한 모습을 보여준다.
destroy_swap_extents()
mm/swapfile.c
/* * Free all of a swapdev's extent information */
static void destroy_swap_extents(struct swap_info_struct *sis)
{
while (!list_empty(&sis->first_swap_extent.list)) {
struct swap_extent *se;
se = list_first_entry(&sis->first_swap_extent.list,
struct swap_extent, list);
list_del(&se->list);
kfree(se);
}
if (sis->flags & SWP_ACTIVATED) {
struct file *swap_file = sis->swap_file;
struct address_space *mapping = swap_file->f_mapping;
sis->flags &= ~SWP_ACTIVATED;
if (mapping->a_ops->swap_deactivate)
mapping->a_ops->swap_deactivate(swap_file);
}
}
모든 swap extent들을 리스트에서 제거하고 할당 해제한다.
swap 엔트리용 address_space 관리
swap용 address_space 생성과 소멸
address_space 구조체는 swapon/swapoff 명령에 의해 생성과 소멸된다.
- swapon -> sys_swapon() -> init_swap_address_space()
- swapoff -> sys_swapoff() -> exit_swap_address_space()
init_swap_address_space()
mm/swap_state.c
int init_swap_address_space(unsigned int type, unsigned long nr_pages)
{
struct address_space *spaces, *space;
unsigned int i, nr;
nr = DIV_ROUND_UP(nr_pages, SWAP_ADDRESS_SPACE_PAGES);
spaces = kvcalloc(nr, sizeof(struct address_space), GFP_KERNEL);
if (!spaces)
return -ENOMEM;
for (i = 0; i < nr; i++) {
space = spaces + i;
xa_init_flags(&space->i_pages, XA_FLAGS_LOCK_IRQ);
atomic_set(&space->i_mmap_writable, 0);
space->a_ops = &swap_aops;
/* swap cache doesn't use writeback related tags */
mapping_set_no_writeback_tags(space);
}
nr_swapper_spaces[type] = nr;
rcu_assign_pointer(swapper_spaces[type], spaces);
return 0;
}
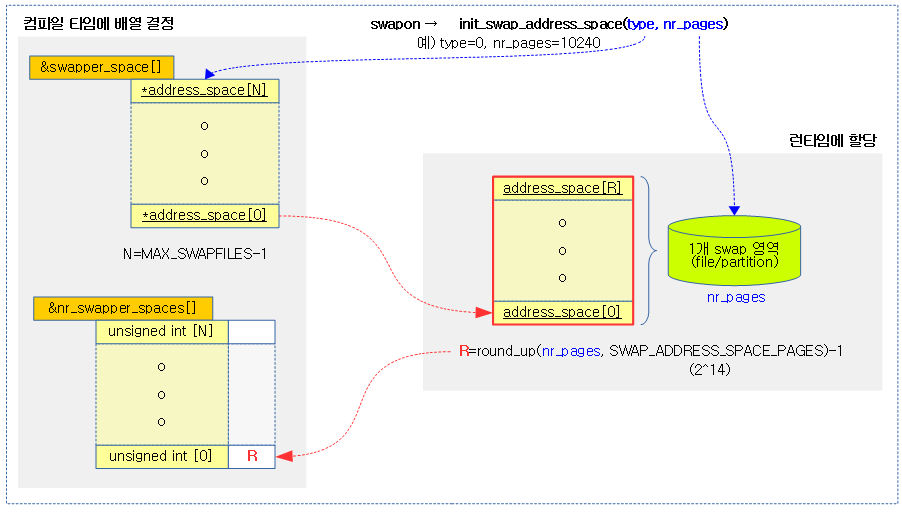
swap용 address_space 구조체를 할당하여 준비한다.
- swapon에 의해 호출되어 nr_pages를 SWAP_ADDRESS_SPACE_PAGES(2^14) 단위로 절상한 수만큼 address_space 구조체를 할당하여 초기화한 후 swapper_space[@type]에 지정한다.
- swap 영역에 사용되는 swap 캐시를 하나의 radix tree로 관리하였었는데, rock 사용 빈도를 줄여 성능을 올리기 위해 swap 캐시를 관리하는 address_space마다 최대 64M만을 관리하도록 나누어 배치하였다. 따라서 swapper_space[] 배열을 사용하는 것이 아니라 swapper_space[][] 이중 배열로 사용하는 것으로 변경되었다.
다음 그림은 swapon 시 swap용 address_space 구조체 배열이 생성되는 과정을 보여준다.
exit_swap_address_space()
mm/swap_state.c
void exit_swap_address_space(unsigned int type)
{
struct address_space *spaces;
spaces = swapper_spaces[type];
nr_swapper_spaces[type] = 0;
rcu_assign_pointer(swapper_spaces[type], NULL);
synchronize_rcu();
kvfree(spaces);
}
swapoff에 의해 호출되어 swapper_space[@type]에 저장된 address_space 배열을 할당 해제한다.
swap 엔트리로 address_space 찾기
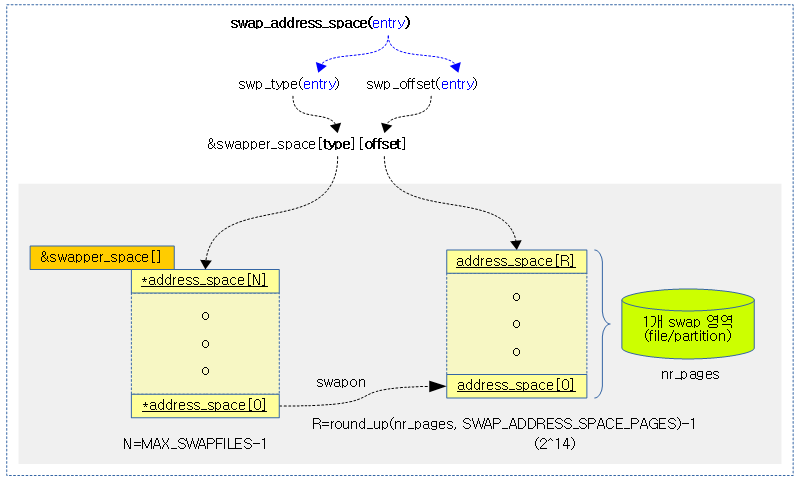
swap_address_space()
include/linux/swap.h
#define swap_address_space(entry) \
(&swapper_spaces[swp_type(entry)][swp_offset(entry) \
>> SWAP_ADDRESS_SPACE_SHIFT])
swap 엔트리에 해당하는 address_space 포인터를 반환한다.
- swap 엔트리의 type과 offset으로 지정된 address_space 포인터를 반환한다.
/* linux/mm/swap_state.c */ /* One swap address space for each 64M swap space */
#define SWAP_ADDRESS_SPACE_SHIFT 14 #define SWAP_ADDRESS_SPACE_PAGES (1 << SWAP_ADDRESS_SPACE_SHIFT)
1 개의 address_space가 관리하는 swap 크기는 64M이다.
다음 그림은 swap_address_space() 함수에서 swap 엔트리로 address_space를 알아오는 과정을 보여준다.
swapper_spaces[]
mm/swap_state.c
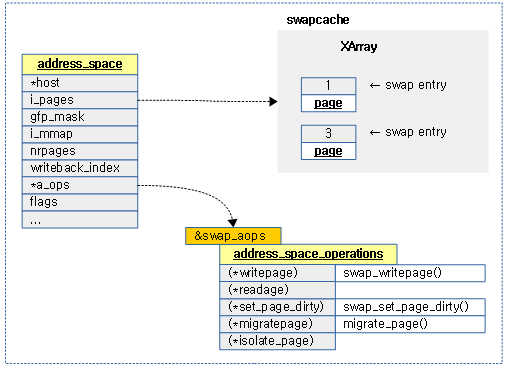
struct address_space *swapper_spaces[MAX_SWAPFILES] __read_mostly;
MAX_SWAPFILES(커널 옵션에 따라 27~32, ARM64 디폴트=29) 수 만큼의 파일과 연결되며 각각은 address_space 배열이 지정된다.
- 이 배열은 static하게 1차원 배열로 생성되지만, 실제 운영은 다음과 같이 2차원 배열로 사용한다.
- address_space[type][offset]
다음 그림은 swap 캐시의 address_space가 관리하는 xarray와 swap opearations를 보여준다.
구조체
swap_info_struct 구조체
/* * The in-memory structure used to track swap areas. */
struct swap_info_struct {
unsigned long flags; /* SWP_USED etc: see above */
signed short prio; /* swap priority of this type */
struct plist_node list; /* entry in swap_active_head */
signed char type; /* strange name for an index */
unsigned int max; /* extent of the swap_map */
unsigned char *swap_map; /* vmalloc'ed array of usage counts */
struct swap_cluster_info *cluster_info; /* cluster info. Only for SSD */
struct swap_cluster_list free_clusters; /* free clusters list */
unsigned int lowest_bit; /* index of first free in swap_map */
unsigned int highest_bit; /* index of last free in swap_map */
unsigned int pages; /* total of usable pages of swap */
unsigned int inuse_pages; /* number of those currently in use */
unsigned int cluster_next; /* likely index for next allocation */
unsigned int cluster_nr; /* countdown to next cluster search */
struct percpu_cluster __percpu *percpu_cluster; /* per cpu's swap location */
struct swap_extent *curr_swap_extent;
struct swap_extent first_swap_extent;
struct block_device *bdev; /* swap device or bdev of swap file */
struct file *swap_file; /* seldom referenced */
unsigned int old_block_size; /* seldom referenced */
#ifdef CONFIG_FRONTSWAP
unsigned long *frontswap_map; /* frontswap in-use, one bit per page */
atomic_t frontswap_pages; /* frontswap pages in-use counter */
#endif
spinlock_t lock; /*
* protect map scan related fields like
* swap_map, lowest_bit, highest_bit,
* inuse_pages, cluster_next,
* cluster_nr, lowest_alloc,
* highest_alloc, free/discard cluster
* list. other fields are only changed
* at swapon/swapoff, so are protected
* by swap_lock. changing flags need
* hold this lock and swap_lock. If
* both locks need hold, hold swap_lock
* first.
*/
spinlock_t cont_lock; /*
* protect swap count continuation page
* list.
*/
struct work_struct discard_work; /* discard worker */
struct swap_cluster_list discard_clusters; /* discard clusters list */
struct plist_node avail_lists[0]; /*
* entries in swap_avail_heads, one
* entry per node.
* Must be last as the number of the
* array is nr_node_ids, which is not
* a fixed value so have to allocate
* dynamically.
* And it has to be an array so that
* plist_for_each_* can work.
*/
};
swap 영역마다 하나씩 사용된다.
- flags
- swap 영역에 사용되는 플래그 값들이다. (아래 참조)
- prio
- 영역의 사용에 대한 순서를 정하기 위한 우선 순위 값이다.
- default 값은 -2부터 생성되는 순서대로 감소된다.
- 사용자가 지정하는 경우 양수를 사용할 수 있다.
- list
- swap_active_head 리스트에 사용되는 노드이다.
- type
- swap 영역에 대한 인덱스 번호이다. (0~)
- max
- swap 영역의 전체 페이지 수 (bad 페이지 포함)
- *swam_map
- swap 영역에 대한 swap 맵으로 1페이지당 1바이트의 값을 사용된다.
- 예) 0=free 상태, 1~0x3e: 사용 상태(usage counter), 0x3f: bad 상태
- *cluster_info
- swap 영역에서 사용하는 모든 클러스터들을 가리킨다.
- free_clusters
- 사용 가능한 free 클러스터들을 담는 리스트이다.
- lowest_bit
- swap 영역에서 가장 낮은 free 페이지의 offset 값이다.
- highest_bit
- swap 영역에서 가장 높은 free 페이지의 offset 값이다.
- pages
- swap 영역의 전체 사용가능한 페이지 수 (bad 페이지 제외)
- inuse_pages
- swap 영역에서 할당되어 사용중인 페이지 수
- cluster_next
- 높은 확률로 다음 할당 시 사용할 페이지 offset를 가리킨다.
- cluster_nr
- 다음 클러스터를 검색하기 위한 countdown 값
- *percpu_cluster
- cpu별 현재 지정된 클러스터를 가리킨다.
- 해당 cpu에 지정된 클러스터가 없는 경우 그 cpu의 값은 null을 가진다.
- *curr_swap_extent
- 현재 사용중인 swap extent를 가리킨다.
- first_swap_extent
- swap 영역에 내장된 첫 swap extent이다.
- *bdev
- swap 영역에 지정된 블럭 디바이스 또는 swap 파일의 블럭 디바이스
- *swap_file
- swap 파일을 가리킨다.
- old_block_size
- swap 블럭 디바이스의 사이즈
- *frontswap_map
- frontswap의 in-use 상태를 비트로 표기하고, 1 비트는 1 페이지에 해당한다.
- frontswap_pages
- fronswap의 in-use 카운터
- lock
- swap 영역에 대한 lock이다.
- cont_lock
- swap_map[]의 usage 카운터가 0x3e를 초과하는 경우에 swap 영역의 맵 관리는 swap count continuation 모드로 관리되는데 이 때 사용되는 swap count continuation 페이지 리스트에 접근할 때 사용하는 lock 이다.
- discard_work
- discard를 지원하는 SSD에서 사용할 워크이다.
- discard_clusters
- discard할 클러스터들이 담긴 리스트이다.
- discard 처리 후 free 클러스터 리스트로 옮긴다.
- avail_lists[0]
- 노드별로 관리되는 swap_avail_heads[] 리스트의 노드로 사용된다.
플래그에 사용되는 값들이다.
enum {
SWP_USED = (1 << 0), /* is slot in swap_info[] used? */
SWP_WRITEOK = (1 << 1), /* ok to write to this swap? */
SWP_DISCARDABLE = (1 << 2), /* blkdev support discard */
SWP_DISCARDING = (1 << 3), /* now discarding a free cluster */
SWP_SOLIDSTATE = (1 << 4), /* blkdev seeks are cheap */
SWP_CONTINUED = (1 << 5), /* swap_map has count continuation */
SWP_BLKDEV = (1 << 6), /* its a block device */
SWP_ACTIVATED = (1 << 7), /* set after swap_activate success */
SWP_FS = (1 << 8), /* swap file goes through fs */
SWP_AREA_DISCARD = (1 << 9), /* single-time swap area discards */
SWP_PAGE_DISCARD = (1 << 10), /* freed swap page-cluster discards */
SWP_STABLE_WRITES = (1 << 11), /* no overwrite PG_writeback pages */
SWP_SYNCHRONOUS_IO = (1 << 12), /* synchronous IO is efficient */
/* add others here before... */
SWP_SCANNING = (1 << 13), /* refcount in scan_swap_map */
};
- SWP_USED
- swapon되어 사용 중인 swap 영역이다.
- SWP_WRITEOK
- swap 영역에 write 가능한 상태이다.
- SWP_DISCARDABLE
- swap 영역이 discard를 지원한다. (SSD)
- SWP_DISCARDING
- swap 영역에 discard 작업을 수행 중이다.
- SWP_SOLIDSTATE
- swap 영역이 SSD이다.
- SWP_CONTINUED
- swap 영역에서 usage 카운터가 0x3e를 초과하여 사용 중이다.
- SWP_BLKDEV
- swap 영역이 블럭 디바이스이다.
- SWP_ACTIVATED
- swap 영역이 swap_activate 후크를 성공한 경우에 설정된다.
- SWP_FS
- 파일 시스템을 통한 swap 파일이다.
- SWP_AREA_DISCARD
- 한 번만 discard를 지원한다.
- SWP_PAGE_DISCARD
- 클러스터 단위로 자유롭게 discard를 사용할 수 있다.
- SWP_STABLE_WRITES
- 체크섬등을 사용한 무결성 저장 장치에 부여한다.
- SCSI Data Integrity Block Device
- SWP_SYNCHRONOUS_IO
- 동기 저장이 가능한 swap 영역이다. (RAM 등)
- SWP_SCANNING
- swap 영역을 검색중일 때 설정된다.
참고
- Swap -1- (Basic, 초기화) | 문c – 현재글
- Swap -2- (Swapin & Swapout) | 문c
- Swap -3- (swap 영역 할당/해제) | 문c
- Swap -4- (Swap 엔트리) | 문c
- Memory Resource Controller (2009) | Kame – 다운로드 pdf
- [Linux] 블록 장치 I/O 동작 방식 (1) | F/OSS
- [Linux] 블록 장치 I/O 동작 방식 (2) | F/OSS
- [Linux] 블록 장치 I/O 동작 방식 (3) | F/OSS
- SWAP 관리 | DrakeOh
- Frontswap (2012) | Kernel.org
- Cleancache (2011) | Kernel.org
- Automatically bind swap device to numa node | Kernel.org
- zsmalloc | Kernel.org
- zswap | Kernel.org
- Transcendent memory (2009) | LWN.net
- Transcendent memory in a nutshell (2011) | LWN.net
- Transcendent Memory and Friends (2011) | Oracle – 다운로드 pdf
- 우분투에서 RAM이 부족합니까? ZRAM 사용 | Eddy lab
# Cleancache 항목
아래 그림이
cleancache-1.png -> 안 보여서
cleancache-1a-1.png -> 이 이미지로 이름이 바뀐건가요?
# Swap Extent 항목
swap_extent 구조체 이미지에서
그림에서 우측 start_block 이 교차하는데
30000 ~ 60000 ~
위로 올라가는 화살표인가요?
안녕하세요?
cleancache-1.png, cleancache-1a-1.png 이미지는 둘 다 동일한 이미지이며 둘 다 제거한 후 cleancache-1a.png 이미지명으로 새롭게 변경하였습니다.
swap extent 항목에서 swap_extent 구조체내의 start_block(30000, 60000)이 뒤 바뀌어 표기되어 정정하였습니다.
교정하여 주셔서 감사합니다. ^^
네 항상 감사드립니다.
swap 내용에서 다른 서브시스템들과 연계 동작하는 개념이 많이 나와서 보고 또 보고하게 되네요!
네. swap 시스템도 만만치가 않지만 잘 준비하시기 바랍니다.
감사합니다. ^^