<kernel v5.0>
swap 엔트리 할당/해제
swapon으로 지정된 swap 파일이나 swap 블록 디바이스가 swap 영역으로 지정되면 swap_map[] 이라는 1바이트 배열을 사용하여 swap 엔트리들의 할당을 관리한다.
- swap_map[offset]에 사용되는 offset 인덱스는 swap 영역의 offset 페이지를 의미한다.
- swap_map[0]은 swap 영역의 0번 페이지를 의미한다.
- swap_map[]에 사용되는 값
- 0
- free 상태에서 사용되는 값
- 1~SWAP_MAP_MAX(0x3e)
- in-use 상태에서 사용되는 값으로 swap 엔트리의 참조 카운터가 저장된다.
- 초과시 SWAP_MAP_CONTINUED(0x80) 플래그가 추가되고 이의 관리를 위해 별도의 swap_map[] 페이지가 생성된다.
- SWAP_MAP_BAD (0x3f)
- bad 페이지로 사용되는 값
- SWAP_HAS_CACHE (0x40)
- cache 페이지 (추가 플래그)
- SWAP_MAP_SHMEM (0xbf)
- 0
- swap 엔트리들은 중간에 per-cpu swap 슬롯 캐시에 충전되어 사용된다.
swap 엔트리들 할당
get_swap_pages()
mm/swapfile.c
int get_swap_pages(int n_goal, swp_entry_t swp_entries[], int entry_size)
{
unsigned long size = swap_entry_size(entry_size);
struct swap_info_struct *si, *next;
long avail_pgs;
int n_ret = 0;
int node;
/* Only single cluster request supported */
WARN_ON_ONCE(n_goal > 1 && size == SWAPFILE_CLUSTER);
avail_pgs = atomic_long_read(&nr_swap_pages) / size;
if (avail_pgs <= 0)
goto noswap;
if (n_goal > SWAP_BATCH)
n_goal = SWAP_BATCH;
if (n_goal > avail_pgs)
n_goal = avail_pgs;
atomic_long_sub(n_goal * size, &nr_swap_pages);
spin_lock(&swap_avail_lock);
start_over:
node = numa_node_id();
plist_for_each_entry_safe(si, next, &swap_avail_heads[node], avail_lists[node]) {
/* requeue si to after same-priority siblings */
plist_requeue(&si->avail_lists[node], &swap_avail_heads[node]);
spin_unlock(&swap_avail_lock);
spin_lock(&si->lock);
if (!si->highest_bit || !(si->flags & SWP_WRITEOK)) {
spin_lock(&swap_avail_lock);
if (plist_node_empty(&si->avail_lists[node])) {
spin_unlock(&si->lock);
goto nextsi;
}
WARN(!si->highest_bit,
"swap_info %d in list but !highest_bit\n",
si->type);
WARN(!(si->flags & SWP_WRITEOK),
"swap_info %d in list but !SWP_WRITEOK\n",
si->type);
__del_from_avail_list(si);
spin_unlock(&si->lock);
goto nextsi;
}
if (size == SWAPFILE_CLUSTER) {
if (!(si->flags & SWP_FS))
n_ret = swap_alloc_cluster(si, swp_entries);
} else
n_ret = scan_swap_map_slots(si, SWAP_HAS_CACHE,
n_goal, swp_entries);
spin_unlock(&si->lock);
if (n_ret || size == SWAPFILE_CLUSTER)
goto check_out;
pr_debug("scan_swap_map of si %d failed to find offset\n",
si->type);
spin_lock(&swap_avail_lock);
nextsi:
/*
* if we got here, it's likely that si was almost full before,
* and since scan_swap_map() can drop the si->lock, multiple
* callers probably all tried to get a page from the same si
* and it filled up before we could get one; or, the si filled
* up between us dropping swap_avail_lock and taking si->lock.
* Since we dropped the swap_avail_lock, the swap_avail_head
* list may have been modified; so if next is still in the
* swap_avail_head list then try it, otherwise start over
* if we have not gotten any slots.
*/
if (plist_node_empty(&next->avail_lists[node]))
goto start_over;
}
spin_unlock(&swap_avail_lock);
check_out:
if (n_ret < n_goal)
atomic_long_add((long)(n_goal - n_ret) * size,
&nr_swap_pages);
noswap:
return n_ret;
}
swap 엔트리들을 준비하고 그 수를 반환한다. (THP swap 엔트리도 1건으로 반환한다)
- 코드 라인 3에서 THP swap을 지원하는 커널인 경우 @entry_size를 size에 대입한다. 지원하지 않는 경우 size는 항상 1이다.
- THP swap을 지원하는 경우 엔트리 크기로 HPAGE_PMD_NR을 사용한다.
- 예) 4K 페이지를 사용하는 경우 pmd 사이즈가 2M이고 HPAGE_PMD_NR=512이다.
- THP swap을 지원하는 경우 엔트리 크기로 HPAGE_PMD_NR을 사용한다.
- 코드 라인 10에서 클러스터 방식에서는 @n_goal에서 1개만 요청가능하다.
- 코드 라인 12~14에서 남은 swap 페이지를 size로 나눈 수를 avail_pgs에 대입하고 그 수가 0 이하이면 noswap 레이블로 이동한다.
- 코드 라인 16~20에서 @n_goal이 SWAP_BATCH(64) 또는 avail_pgs를 초과하지 않도록 제한한다.
- 코드 라인 22에서 남은 swap 페이지에서 @n_goal * size 만큼 뺀다.
- 코드 라인 26~28에서 start_over: 레이블이다. 전역 swap_avail_heads[node] priority 리스트에 등록된 각 swap 영역을 순회한다.
- swap 영역: swap_info_struct 노드
- 코드 라인 30에서 si->avail_lists[node] 노드들을 전역 swap_avail_heads[node] priority 리스트의 끝에 다시 추가한다.
- 코드 라인 33~48에서 si->highest_bit가 설정되지 않았거나 write 불가능한 swap 영역인 경우 경고 메시지를 출력하고 si->avail_lists[node] 노드들을 swap_avail_heads[node[ priority 리스트에서 제거하고 nextsi: 레이블로 이동한다.
- 코드 라인 49~51에서 THP swap 요청 시 파일 시스템을 사용하지 않은 swap 영역인 경우 THP 클러스터용 swap 엔트리들을 준비하고 swp_entries에 대입한다.
- 코드 라인 52~54에서 THP swap 요청이 아닌 경우 @n_goal 만큼 swap 엔트리들을 준비하고 swp_entries에 대입한다.
- 코드 라인 56~57에서 swap 엔트리가 준비되었거나, THP 클러스터 요청인 경우 check_out: 레이블로 이동한다.
- 코드 라인 58~59에서 swap 엔트리가 준비되지 못한 경우 “scan_swap_map of si %d failed to find offset\n” 디버그 메시지를 출력한다.
- 코드 라인 62~76에서 nextsi: 레이블이다. 다음 swap 영역을 계속 진행한다.
- 코드 라인 80~83에서 check_out: 레이블이다. 처리가 다 완료되었다. 목표(@n_goal) 이하의 swap 엔트리가 준비된 경우 남은 swap 페이지 수를 그 차이만큼 추가하여 갱신한다.
- 코드 라인 84~85에서 noswap: 레이블이다. 준비된 swap 엔트리 수를 반환한다.
swap_map을 스캔하여 1 개의 swap 엔트리 할당
scan_swap_map()
mm/swapfile.c
static unsigned long scan_swap_map(struct swap_info_struct *si,
unsigned char usage)
{
swp_entry_t entry;
int n_ret;
n_ret = scan_swap_map_slots(si, usage, 1, &entry);
if (n_ret)
return swp_offset(entry);
else
return 0;
}
swap 영역에서 1개의 free swap 엔트리를 스캔한 후 offset 값을 반환한다. 실패 시 0을 반환한다.
swap_map을 스캔하여 swap 엔트리들 할당
scan_swap_map_slots()
mm/swapfile.c -1/3-
static int scan_swap_map_slots(struct swap_info_struct *si,
unsigned char usage, int nr,
swp_entry_t slots[])
{
struct swap_cluster_info *ci;
unsigned long offset;
unsigned long scan_base;
unsigned long last_in_cluster = 0;
int latency_ration = LATENCY_LIMIT;
int n_ret = 0;
if (nr > SWAP_BATCH)
nr = SWAP_BATCH;
/*
* We try to cluster swap pages by allocating them sequentially
* in swap. Once we've allocated SWAPFILE_CLUSTER pages this
* way, however, we resort to first-free allocation, starting
* a new cluster. This prevents us from scattering swap pages
* all over the entire swap partition, so that we reduce
* overall disk seek times between swap pages. -- sct
* But we do now try to find an empty cluster. -Andrea
* And we let swap pages go all over an SSD partition. Hugh
*/
si->flags += SWP_SCANNING;
scan_base = offset = si->cluster_next;
/* SSD algorithm */
if (si->cluster_info) {
if (scan_swap_map_try_ssd_cluster(si, &offset, &scan_base))
goto checks;
else
goto scan;
}
if (unlikely(!si->cluster_nr--)) {
if (si->pages - si->inuse_pages < SWAPFILE_CLUSTER) {
si->cluster_nr = SWAPFILE_CLUSTER - 1;
goto checks;
}
spin_unlock(&si->lock);
/*
* If seek is expensive, start searching for new cluster from
* start of partition, to minimize the span of allocated swap.
* If seek is cheap, that is the SWP_SOLIDSTATE si->cluster_info
* case, just handled by scan_swap_map_try_ssd_cluster() above.
*/
scan_base = offset = si->lowest_bit;
last_in_cluster = offset + SWAPFILE_CLUSTER - 1;
/* Locate the first empty (unaligned) cluster */
for (; last_in_cluster <= si->highest_bit; offset++) {
if (si->swap_map[offset])
last_in_cluster = offset + SWAPFILE_CLUSTER;
else if (offset == last_in_cluster) {
spin_lock(&si->lock);
offset -= SWAPFILE_CLUSTER - 1;
si->cluster_next = offset;
si->cluster_nr = SWAPFILE_CLUSTER - 1;
goto checks;
}
if (unlikely(--latency_ration < 0)) {
cond_resched();
latency_ration = LATENCY_LIMIT;
}
}
offset = scan_base;
spin_lock(&si->lock);
si->cluster_nr = SWAPFILE_CLUSTER - 1;
}
swap 영역에서 @nr 수 만큼 free swap 엔트리를 스캔하여 @slots[] 배열에 저장해온다. 이 때 스캔해온 free swap 엔트리 수를 반환한다.
- 코드 라인 12~13에서 한 번에 스캔할 최대 수를 SWAP_BATCH(64)개로 제한한다.
- 코드 라인 26에서 swap 영역에 스캐닝이 완료될 때 까지 스캐닝 중이라고 SWP_SCANNING 플래그를 추가한다.
- 코드 라인 27에서 스캔 시작점은 si->cluster_next 페이지부터이다.
- 코드 라인 30~35에서 SSD 클러스터 방식을 사용하는 경우이다.
2) 빈 클러스터(256개 free swap 페이지) 스캔 (non-SSD)
- 코드 라인 37에서 non-SSD 클러스터 방식을 사용하는 경우이다. 클러스터 번호를 1 감소시키는데 이미 0인 경우의 처리이다.
- 코드 라인 38~41에서 swap 영역의 남은 free swap 페이지가 SWAPFILE_CLUSTER(256)보다 적은 경우 클러스터 번호를 255로 변경하고 checks 레이블로 이동한다.
- 코드 라인 43~55에서 swap 영역에서 락을 잡은채로 첫 번째 empty 클러스터를 찾는다. 즉 lowest_bit ~ highest_bit까지 256개의 연속된 free 페이지가 발견되면 checks: 레이블로 이동한다.
- non-ssd 방식이므로 256개의 free swap 페이지의 시작이 클러스터 단위로 정렬되어 있지 않아도 된다.
- 코드 라인 56~57에서 offset에 해당하는 swap 페이지가 이미 swap되어 사용 중인 경우 다음 클러스터의 페이지를 진행하기 위해 진행중인 offset 페이지 += 256으로 증가시킨다.
- 코드 라인 58~64에서 순회 중인 클러스터의 마지막 페이지에 도달한 경우 offset을 다시 해당 클러스터의 가장 첫 페이지로 되돌리고, cluster_next에 순회중인 offset을 지정하고, 클러스터 번호를 255로 변경하고 checks 레이블로 이동한다.
- 코드 라인 65~68에서 순회중에 LATENCY_LIMIT(256) 페이지 마다 preemption point를 수행한다.
- 코드 라인 71~73에서 첫 빈 클러스터를 찾지 못한 경우이다. offset을 시작점으로 다시 되돌리고, 클러스터 번호를 255로 변경한다.
mm/swapfile.c -2/3-
checks:
if (si->cluster_info) {
while (scan_swap_map_ssd_cluster_conflict(si, offset)) {
/* take a break if we already got some slots */
if (n_ret)
goto done;
if (!scan_swap_map_try_ssd_cluster(si, &offset,
&scan_base))
goto scan;
}
}
if (!(si->flags & SWP_WRITEOK))
goto no_page;
if (!si->highest_bit)
goto no_page;
if (offset > si->highest_bit)
scan_base = offset = si->lowest_bit;
ci = lock_cluster(si, offset);
/* reuse swap entry of cache-only swap if not busy. */
if (vm_swap_full() && si->swap_map[offset] == SWAP_HAS_CACHE) {
int swap_was_freed;
unlock_cluster(ci);
spin_unlock(&si->lock);
swap_was_freed = __try_to_reclaim_swap(si, offset, TTRS_ANYWAY);
spin_lock(&si->lock);
/* entry was freed successfully, try to use this again */
if (swap_was_freed)
goto checks;
goto scan; /* check next one */
}
if (si->swap_map[offset]) {
unlock_cluster(ci);
if (!n_ret)
goto scan;
else
goto done;
}
si->swap_map[offset] = usage;
inc_cluster_info_page(si, si->cluster_info, offset);
unlock_cluster(ci);
swap_range_alloc(si, offset, 1);
si->cluster_next = offset + 1;
slots[n_ret++] = swp_entry(si->type, offset);
/* got enough slots or reach max slots? */
if ((n_ret == nr) || (offset >= si->highest_bit))
goto done;
/* search for next available slot */
/* time to take a break? */
if (unlikely(--latency_ration < 0)) {
if (n_ret)
goto done;
spin_unlock(&si->lock);
cond_resched();
spin_lock(&si->lock);
latency_ration = LATENCY_LIMIT;
}
/* try to get more slots in cluster */
if (si->cluster_info) {
if (scan_swap_map_try_ssd_cluster(si, &offset, &scan_base))
goto checks;
else
goto done;
}
/* non-ssd case */
++offset;
/* non-ssd case, still more slots in cluster? */
if (si->cluster_nr && !si->swap_map[offset]) {
--si->cluster_nr;
goto checks;
}
done:
si->flags -= SWP_SCANNING;
return n_ret;
case 1) 현재 페이지(si->cluster_next) 할당 체크 (non-SSD)
- 코드 라인 1에서 checks: 레이블이다.
- 코드 라인 2~11에서 SSD 클러스터 방식을 사용하는 경우이다.
- 코드 라인 12~13에서 swap 영역에 SWP_WRITEOK 플래그가 없으면 no_page 레이블로 이동한다.
- 코드 라인 14~15에서 swap 영역에 가장 큰 페이지 번호인 highest_bit가 설정되지 않은 경우에도 no_page 레이블로 이동한다.
- 코드 라인 16~17에서 offset 페이지가 가장 큰 페이지 번호를 초과한 경우에는 다시 scan_base와 offset을 가장 낮은 페이지 번호인 lowest_bit로 변경한다.
- 코드 라인 19에서 offset에 해당하는 클러스터를 lock 하고 가져온다.
- 코드 라인 21~31에서 전체 swap 페이지가 사용 가능한 free swap 영역의 절반을 초과한 경우이면서 offset에 SWAP_HAS_CACHE 값으로 설정된 경우 해당 swap 캐시를 제거한다. 제거가 성공한 경우 checks 레이블로 이동하고, 그렇지 않은 경우 다음을 위해 scan 레이블로 이동한다.
- 코드 라인 33~39에서 offset 페이지에 대한 swap_map[]이 이미 사용 중인 경우이다. n_ret 값이 있으면 done 레이블로 이동하고, 없으면 다음을 위해 scan 레이블로 이동한다.
- 코드 라인 40~42에서 offset 페이지에 대한 swap_map[]이 빈 경우이다. free swap 상태이므로 할당을 위해 참조 카운터 @usage 값을 대입하고, 클러스터를 사용 중으로 표기한다. 그런 후 클러스터 lock을 푼다.
- 코드 라인 44에서 swap 영역(lowest_bit, highest_bit)을 1 페이지만큼 추가 갱신한다. 만일 swap 영역내의 모든 페이지가 할당 완료된 경우 swap_avail_heads에서 swap 영역을 제거한다.
- 코드 라인 45~46에서 다음 클러스터를 위해 현재 offset 페이지 + 1을 한다. 출력 인자 @slots[]에 offset에 해당하는 swap 엔트리를 저장한다.
- 코드 라인 49~50에서 요청한 수만큼 슬롯을 채웠거나 영역의 끝까지 진행을 한 경우 done 레이블로 이동한다.
- 코드 라인 55~62에서 인터럽트 레이튼시를 줄이는 방법이다. swap 영역에 대해 오랫동안 락을 잡고 있지 않기 위해 LATENCY_LIMIT(256) 페이지 마다 잠시 lock을 풀었다가 다시 획득한다.
- 코드 라인 65~70에서 SSD 클러스터 방식을 사용하는 경우이다.
- 코드 라인 72~78에서 SSD 클러스터 방식이 아닌 경우의 동작이다. 다음 페이지를 위해 offset을 증가시키고 슬롯이 더 필요한 경우 클러스터 번호를 감소시키고 checks 레이블로 이동한다.
- 코드 라인 80~82에서 done: 레이블이다. 스캐닝일 수행하는 동안 설정한 SWP_SCANNING 플래그를 swap 영역에서 제거하고 슬롯에 준비한 swap 엔트리 수를 반환한다.
mm/swapfile.c -3/3-
scan:
spin_unlock(&si->lock);
while (++offset <= si->highest_bit) {
if (!si->swap_map[offset]) {
spin_lock(&si->lock);
goto checks;
}
if (vm_swap_full() && si->swap_map[offset] == SWAP_HAS_CACHE) {
spin_lock(&si->lock);
goto checks;
}
if (unlikely(--latency_ration < 0)) {
cond_resched();
latency_ration = LATENCY_LIMIT;
}
}
offset = si->lowest_bit;
while (offset < scan_base) {
if (!si->swap_map[offset]) {
spin_lock(&si->lock);
goto checks;
}
if (vm_swap_full() && si->swap_map[offset] == SWAP_HAS_CACHE) {
spin_lock(&si->lock);
goto checks;
}
if (unlikely(--latency_ration < 0)) {
cond_resched();
latency_ration = LATENCY_LIMIT;
}
offset++;
}
spin_lock(&si->lock);
no_page:
si->flags -= SWP_SCANNING;
return n_ret;
}
3) 현재 페이지 ~ 영역 끝까지 스캔 (non-SSD)
- 코드 라인 1~16에서 scan: 레이블이다. swap 영역의 free 할당 가능한 마지막 페이지까지 순회하며 offset을 증가하며 다음 두 경우에 한하여 checks 레이블로 이동한다. 또한 순회중에 LATENCY_LIMIT(256) 페이지 마다 preemption point를 수행한다.
- swap_map[offset]이 free 상태로 할당 가능한 상태이다.
- swap 영역이 50% 이상 가득 차고 offset에 해당하는 swap 영역은 free 상태고 swap 캐시만 존재하는 경우이다.
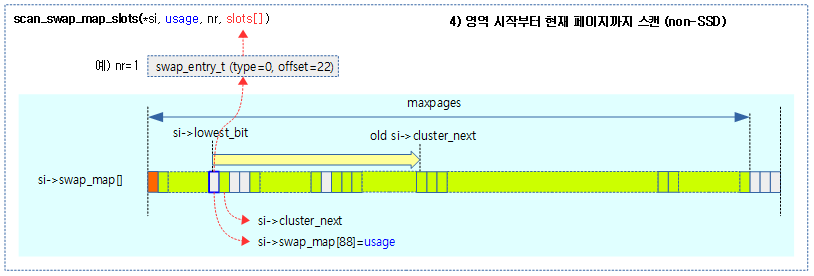
4) 시작 페이지 ~ 현재 페이지까지 스캔 (non-SSD)
- 코드 라인 17~32에서 offset을 swap 영역의 free 할당 가능한 첫 페이지부터 scan_base까지 순회하며 다음 두 경우에 한하여 checks 레이블로 이동한다. 또한 순회중에 LATENCY_LIMIT(256) 페이지 마다 preemption point를 수행한다.
- swap_map[offset]이 free 상태로 할당 가능한 상태이다.
- swap 영역이 50% 이상 가득 차고 offset에 해당하는 swap 영역은 free 상태고 swap 캐시만 존재하는 경우이다.
- 코드 라인 35~37에서 no_page: 레이블이다. 스캐닝일 수행하는 동안 설정한 SWP_SCANNING 플래그를 swap 영역에서 제거하고 슬롯에 준비한 swap 엔트리 수를 반환한다.
다음 4개의 그림은 1개의 free swap 엔트리를 찾는 순서이다.
첫 번째, si->cluster_next가 현재 위치의 페이지로 할당 가능한 상태인지 체크한다.
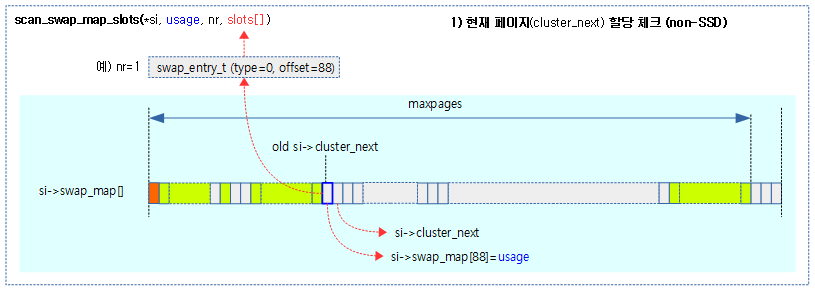
두 번째, 현재 위치의 페이지로 할당 불가능한 경우 다음으로 swap 영역 전체에서 256개의 빈 swap 페이지가 있는지 확인한다.
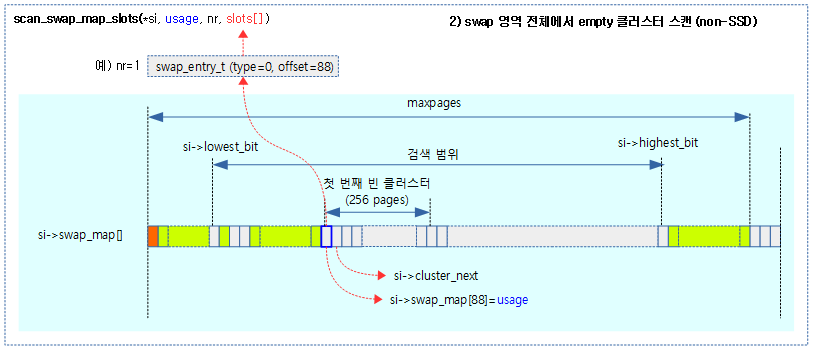
세 번째, 빈 클러스터가 없는 경우 현재 위치에서 swap 영역 끝까지 스캔한다.
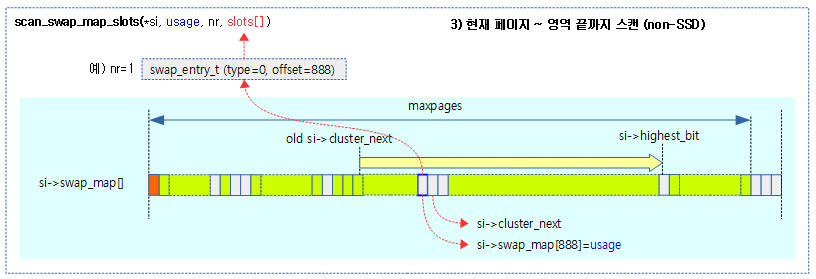
네 번째, 마지막으로 swap 영역 처음부터 현재 위치까지 스캔한다.
swap 엔트리들을 swap 영역으로 반환
swapcache_free_entries()
mm/swapfile.c
void swapcache_free_entries(swp_entry_t *entries, int n)
{
struct swap_info_struct *p, *prev;
int i;
if (n <= 0)
return;
prev = NULL;
p = NULL;
/*
* Sort swap entries by swap device, so each lock is only taken once.
* nr_swapfiles isn't absolutely correct, but the overhead of sort() is
* so low that it isn't necessary to optimize further.
*/
if (nr_swapfiles > 1)
sort(entries, n, sizeof(entries[0]), swp_entry_cmp, NULL);
for (i = 0; i < n; ++i) {
p = swap_info_get_cont(entries[i], prev);
if (p)
swap_entry_free(p, entries[i]);
prev = p;
}
if (p)
spin_unlock(&p->lock);
}
@n개의 swap 엔트리 @entries를 free 상태로 변경한다.
- 코드 라인 6~7에서 @n이 0개 이하이면 함수를 빠져나간다.
- 코드 라인 17~18에서 요청한 swap 엔트리들의 swap 영역이 섞여 있으면 이를 접근하기 위해 lock을 잡아야 하는데 이의 빈번함을 피하기 위해 먼저 swap 엔트리의 소팅을 수행 한다.
- 코드 라인 19~24에서 @n개를 순회하며 swap 엔트리를 free 한다. 만일 swap 영역이 바뀌는 경우 unlock하고 다시 새로운 swap 영역을 lock 한다.
swap_info_get_cont()
mm/swapfile.c
static struct swap_info_struct *swap_info_get_cont(swp_entry_t entry,
struct swap_info_struct *q)
{
struct swap_info_struct *p;
p = _swap_info_get(entry);
if (p != q) {
if (q != NULL)
spin_unlock(&q->lock);
if (p != NULL)
spin_lock(&p->lock);
}
return p;
}
swap 영역이 바뀌면 기존 swap 영역 @q를 unlock하고 새로운 swap 영역 p의 lock을 획득한다.
swap 엔트리 할당 해제
swap_entry_free()
mm/swapfile.c
static void swap_entry_free(struct swap_info_struct *p, swp_entry_t entry)
{
struct swap_cluster_info *ci;
unsigned long offset = swp_offset(entry);
unsigned char count;
ci = lock_cluster(p, offset);
count = p->swap_map[offset];
VM_BUG_ON(count != SWAP_HAS_CACHE);
p->swap_map[offset] = 0;
dec_cluster_info_page(p, p->cluster_info, offset);
unlock_cluster(ci);
mem_cgroup_uncharge_swap(entry, 1);
swap_range_free(p, offset, 1);
}
swap 엔트리를 할당 해제한다.
- 코드 라인 7에서 offset 페이지가 소속된 클러스터의 락을 획득한다.
- 코드 라인 7~10에서 offset 페이지에 대한 swap_map[]의 값을 count로 알아온 후 0으로 클리어하여 free 상태로 변경 한다.
- 코드 라인 11에서 offset 페이지가 소속된 클러스터의 사용 카운터를 1 감소시킨다.
- 코드 라인 12에서 클러스터 락을 푼다.
- 코드 라인 14에서 memcg를 통해 swap 엔트리의 회수를 보고한다.
- 코드 라인 15에서 swap 엔트리의 할당 해제로 인해 할당 가능한 범위를 조정한다.
swap 영역 할당/해제 후 사용 가능 영역 조정
swap_range_alloc()
mm/swapfile.c
static void swap_range_alloc(struct swap_info_struct *si, unsigned long offset,
unsigned int nr_entries)
{
unsigned int end = offset + nr_entries - 1;
if (offset == si->lowest_bit)
si->lowest_bit += nr_entries;
if (end == si->highest_bit)
si->highest_bit -= nr_entries;
si->inuse_pages += nr_entries;
if (si->inuse_pages == si->pages) {
si->lowest_bit = si->max;
si->highest_bit = 0;
del_from_avail_list(si);
}
}
swap 영역의 @offset 부터 @nr_entries 만큼 할당을 통한 할당 가능 범위를 갱신한다.
- 코드 라인 6~9에서 offset ~ nr_entries -1 범위를 할당할 때 최소 페이지 또는 최대 페이지를 필요 시 갱신한다.
- 코드 라인 10에서 si->inuse_pages를 할당 한 페이지 수 만큼 추가한다.
- 코드 라인 11~15에서 swap 영역을 다 사용한 경우 이 swap 영역을 swap_avail_heads 리스트에서 제거한다.
swap_range_free()
mm/swapfile.c
static void swap_range_free(struct swap_info_struct *si, unsigned long offset,
unsigned int nr_entries)
{
unsigned long end = offset + nr_entries - 1;
void (*swap_slot_free_notify)(struct block_device *, unsigned long);
if (offset < si->lowest_bit)
si->lowest_bit = offset;
if (end > si->highest_bit) {
bool was_full = !si->highest_bit;
si->highest_bit = end;
if (was_full && (si->flags & SWP_WRITEOK))
add_to_avail_list(si);
}
atomic_long_add(nr_entries, &nr_swap_pages);
si->inuse_pages -= nr_entries;
if (si->flags & SWP_BLKDEV)
swap_slot_free_notify =
si->bdev->bd_disk->fops->swap_slot_free_notify;
else
swap_slot_free_notify = NULL;
while (offset <= end) {
frontswap_invalidate_page(si->type, offset);
if (swap_slot_free_notify)
swap_slot_free_notify(si->bdev, offset);
offset++;
}
}
swap 영역의 @offset 부터 @nr_entries 만큼 할당 해제를 통한 할당 가능 범위를 갱신한다.
- 코드 라인 4~12에서 offset ~ nr_entries -1 범위를 할당 해제할 때 최소 페이지 또는 최대 페이지를 필요 시 갱신한다.
- 코드 라인 13~14에서 새로 사용 가능한 영역이 생긴 경우이므로 이 swap 영역을 &swap_avail_heads 리스트에 추가한다.
- 코드 라인 17에서 si->inuse_pages를 할당 해제한 페이지 수 만큼 감소시킨다.
- 코드 라인 18~28에서 offset ~ nr_entries -1 범위에 대해 frontswap에서 페이지를 invalidate 한다. 그리고 블럭 디바이스를 사용한 swap 영역인 경우 (*swap_slot_free_notify) 후크 함수를 호출하여 swap 영역이 free 되었음을 통지한다.
swap_avail_heads[] 리스트
swap_avail_heads[] 리스트는 노드별로 운영되며, 사용 가능한 swap 영역이 등록되어 있다.
swapfile_init()
mm/swapfile.c”
static int __init swapfile_init(void)
{
int nid;
swap_avail_heads = kmalloc_array(nr_node_ids, sizeof(struct plist_head),
GFP_KERNEL);
if (!swap_avail_heads) {
pr_emerg("Not enough memory for swap heads, swap is disabled\n");
return -ENOMEM;
}
for_each_node(nid)
plist_head_init(&swap_avail_heads[nid]);
return 0;
}
subsys_initcall(swapfile_init);
swap_avail_heads[] 리스트를 노드 수 만큼 할당한 후 초기화한다.
- 이 리스트에는 swapon시 사용될 swap 영역이 등록된다.
add_to_avail_list()
mm/swapfile.c
static void add_to_avail_list(struct swap_info_struct *p)
{
int nid;
spin_lock(&swap_avail_lock);
for_each_node(nid) {
WARN_ON(!plist_node_empty(&p->avail_lists[nid]));
plist_add(&p->avail_lists[nid], &swap_avail_heads[nid]);
}
spin_unlock(&swap_avail_lock);
}
요청한 swap 영역을 swap_avail_heads[]을 모든 노드에 추가한다.
del_from_avail_list()
mm/swapfile.c
static void del_from_avail_list(struct swap_info_struct *p)
{
spin_lock(&swap_avail_lock);
__del_from_avail_list(p);
spin_unlock(&swap_avail_lock);
}
요청한 swap 영역을 swap_avail_heads[] 리스트에서 제거한다.
__del_from_avail_list()
mm/swapfile.c
static void __del_from_avail_list(struct swap_info_struct *p)
{
int nid;
for_each_node(nid)
plist_del(&p->avail_lists[nid], &swap_avail_heads[nid]);
}
요청한 swap 영역을 모든 노드의 swap_avail_heads[] 리스트에서 제거한다.
클러스터를 사용한 swap 페이지 할당
SSD 및 persistent 메모리를 사용한 블럭 디바이스를 swap 영역으로 사용할 때 가능한 방법이다. 메모리 부족 시 여러 cpu에서 동시에 swap을 시도하게 되는데 각 cpu들이 클러스터별로 동작을 하게 설계되어 있다. 그 외에도 각 cpu가 각자의 cpu에 해당하는 swap_cluster_info 구조체에 접근할 때 false cache line share 현상으로 성능이 저하되는 것을 최대한 줄이기 위해 free 클러스터 리스트에 각 클러스터들을 그냥 순번대로 등록하지 않고 최소한 캐시 라인 크기 이상으로 떨어뜨리면 이러한 문제를 해결할 수 있다.
구조체
swap_cluster_info 구조체
include/linux/swap.h
/* * We use this to track usage of a cluster. A cluster is a block of swap disk * space with SWAPFILE_CLUSTER pages long and naturally aligns in disk. All * free clusters are organized into a list. We fetch an entry from the list to * get a free cluster. * * The data field stores next cluster if the cluster is free or cluster usage * counter otherwise. The flags field determines if a cluster is free. This is * protected by swap_info_struct.lock. */
struct swap_cluster_info {
spinlock_t lock; /*
* Protect swap_cluster_info fields
* and swap_info_struct->swap_map
* elements correspond to the swap
* cluster
*/
unsigned int data:24;
unsigned int flags:8;
};
하나의 클러스터 상태 및 다음 free 클러스터 번호를 가리키기 위해 사용되는 자료 구조이다.
- lock
- 클러스터 락
- data:24
- free 클러스터 상태
- 다음 free 클러스터 번호
- free 클러스터 상태
- flags:8
- CLUSTER_FLAG_FREE (1)
- free 클러스터
- CLUSTER_FLAG_NEXT_NULL (2)
- 마지막 free 클러스터
- CLUSTER_FLAG_HUGE (4)
- thp용 클러스터
- CLUSTER_FLAG_FREE (1)
percpu_cluster 구조체
include/linux/swap.h
/* * We assign a cluster to each CPU, so each CPU can allocate swap entry from * its own cluster and swapout sequentially. The purpose is to optimize swapout * throughput. */
struct percpu_cluster {
struct swap_cluster_info index; /* Current cluster index */
unsigned int next; /* Likely next allocation offset */
};
per-cpu에 사용되는 클러스터 자료 구조이다.
- index
- 현재 클러스터를 담고 있다.
- next
- 높은 확률로 다음 할당 페이지 offset을 담고 있다.
swap_cluster_list 구조체
include/linux/swap.h
struct swap_cluster_list {
struct swap_cluster_info head;
struct swap_cluster_info tail;
};
다음 swap 클러스터 리스트에 사용된다.
- si->free_clusters 리스트
- si->discard_clusters 리스트
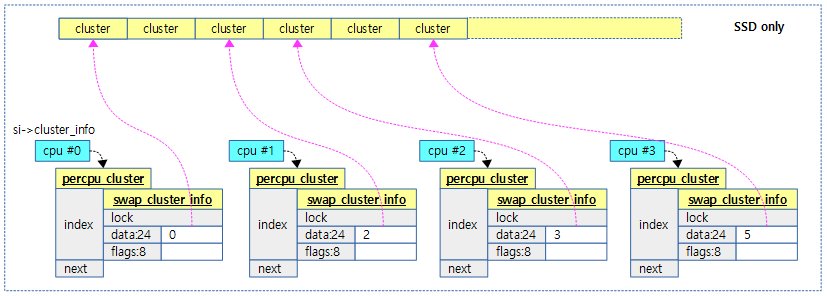
다음 그림은 각 cpu가 클러스터를 하나씩 지정하여 사용하는 모습을 보여준다.
- 지정되지 않는 경우 해당 cpu의 si->cluster 값에 null을 사용한다.
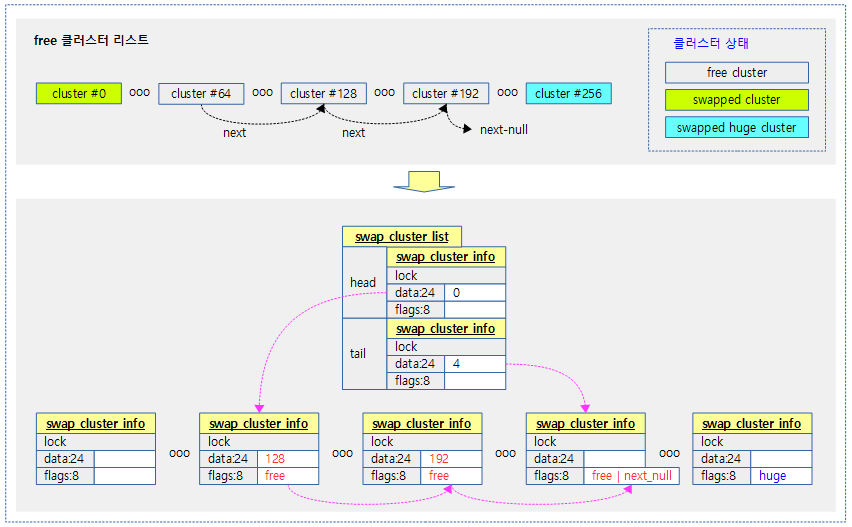
다음 그림은 free swap 클러스터들을 연결한 상태의 free swap 클러스터 리스트를 보여준다.
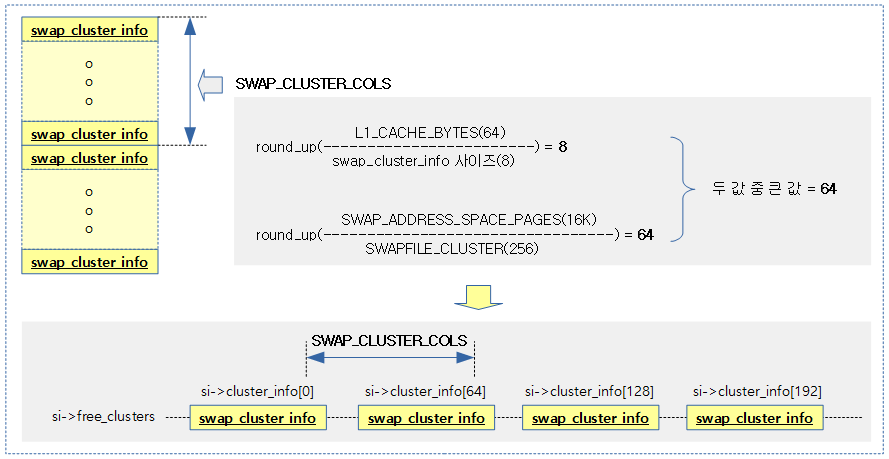
SWAP_CLUSTER_COLS
mm/swapfile.c
#define SWAP_CLUSTER_COLS \
max_t(unsigned int, SWAP_CLUSTER_INFO_COLS, SWAP_CLUSTER_SPACE_COLS)
free 클러스터 리스트를 처음 구성할 때 false cache line share 현상을 감소시키기 위해 swap_info_cluster 구조체를 건너뛰어야 할 간격을 산출한다.
mm/swapfile.c
#define SWAP_CLUSTER_INFO_COLS \
DIV_ROUND_UP(L1_CACHE_BYTES, sizeof(struct swap_cluster_info))
#define SWAP_CLUSTER_SPACE_COLS \
DIV_ROUND_UP(SWAP_ADDRESS_SPACE_PAGES, SWAPFILE_CLUSTER)
다음과 같이 swap_cluster_info 구조체들이 free_clusters 리스트에 구성될 때 SWAP_CLUSTER_COLS 번호 간격으로 등록되는 모습을 보여준다.
- 모든 클러스터를 다음과 같은 순서대로 등록한다.
- 0, 64, 128, 192, ….
- 1, 65, 129, 193, ….
- 2, 66, 130, 194, ….
- …
클러스터 하나 통째 할당 (SSD 아니더라도 사용 가능)
swap_alloc_cluster()
mm/swapfile.c
static int swap_alloc_cluster(struct swap_info_struct *si, swp_entry_t *slot)
{
unsigned long idx;
struct swap_cluster_info *ci;
unsigned long offset, i;
unsigned char *map;
/*
* Should not even be attempting cluster allocations when huge
* page swap is disabled. Warn and fail the allocation.
*/
if (!IS_ENABLED(CONFIG_THP_SWAP)) {
VM_WARN_ON_ONCE(1);
return 0;
}
if (cluster_list_empty(&si->free_clusters))
return 0;
idx = cluster_list_first(&si->free_clusters);
offset = idx * SWAPFILE_CLUSTER;
ci = lock_cluster(si, offset);
alloc_cluster(si, idx);
cluster_set_count_flag(ci, SWAPFILE_CLUSTER, CLUSTER_FLAG_HUGE);
map = si->swap_map + offset;
for (i = 0; i < SWAPFILE_CLUSTER; i++)
map[i] = SWAP_HAS_CACHE;
unlock_cluster(ci);
swap_range_alloc(si, offset, SWAPFILE_CLUSTER);
*slot = swp_entry(si->type, offset);
return 1;
}
thp swap을 위해 사용될 free swap 클러스터(256 페이지)를 통째로 할당할 swap 엔트리를 출력 인자 @slot에 저장한다. 성공하는 경우 1을 반환한다.
- 코드 라인 12~15에서 thp swap을 지원하지 않는 커널의 경우 실패로 0을 반환한다.
- 코드 라인 17~18에서 free 클러스터 리스트에 남은 free 클러스터가 없는 경우 실패로 0을 반환한다.
- 코드 라인 20~24에서 free 클러스터 리스트의 첫 클러스터 번호(idx)에 해당하는 클러스터를 huge 할당 상태로 변경한다.
- 코드 라인 26~28에서 해당 클러스터에 포함된 페이지들에 대한 할당 상태를 SWAP_HAS_CACHE로 변경한다.
- 코드 라인 30에서 해당 클러스터를 할당 상태로 바꿈에 따라 lowest_bit 및 highest_bit 범위의 변경 시 갱신한다.
- 코드 라인 31~33에서 출력 인자 @slot에 swap 엔트리를 저장하고, 성공 1을 반환한다.
scan_swap_map_ssd_cluster_conflict()
mm/swapfile.c
/* * It's possible scan_swap_map() uses a free cluster in the middle of free * cluster list. Avoiding such abuse to avoid list corruption. */
static bool
scan_swap_map_ssd_cluster_conflict(struct swap_info_struct *si,
unsigned long offset)
{
struct percpu_cluster *percpu_cluster;
bool conflict;
offset /= SWAPFILE_CLUSTER;
conflict = !cluster_list_empty(&si->free_clusters) &&
offset != cluster_list_first(&si->free_clusters) &&
cluster_is_free(&si->cluster_info[offset]);
if (!conflict)
return false;
percpu_cluster = this_cpu_ptr(si->percpu_cluster);
cluster_set_null(&percpu_cluster->index);
return true;
}
요청한 @offset 페이지가 free 클러스터의 첫 free 클러스터인지 확인한다. 만일 그렇지 않은 경우 conflict 상황이므로 true를 반환한다.
- 코드 라인 8~11에서 scan_swap_map()은 사용 가능한 클러스터 리스트 중간에 있는 free 클러스터를 사용할 수 있다. 이러한 목록 손상을 피하기는 방법이다. 만일 요청한 @offset 페이지가 free 클러스터의 처음이 아닌 경우 conflict 상황이다.
- 코드 라인 13~14에서 conflict 상황이 아니면 정상적으로 false를 반환한다.
- 코드 라인 16~18에서 conflict 상황인 경우 현재 cpu의 percpu_cluster를 null로 설정하고 true를 반환한다.
SSD 클러스터 단위 swap 맵 할당
scan_swap_map_try_ssd_cluster()
mm/swapfile.c
/* * Try to get a swap entry from current cpu's swap entry pool (a cluster). This * might involve allocating a new cluster for current CPU too. */
static bool scan_swap_map_try_ssd_cluster(struct swap_info_struct *si,
unsigned long *offset, unsigned long *scan_base)
{
struct percpu_cluster *cluster;
struct swap_cluster_info *ci;
bool found_free;
unsigned long tmp, max;
new_cluster:
cluster = this_cpu_ptr(si->percpu_cluster);
if (cluster_is_null(&cluster->index)) {
if (!cluster_list_empty(&si->free_clusters)) {
cluster->index = si->free_clusters.head;
cluster->next = cluster_next(&cluster->index) *
SWAPFILE_CLUSTER;
} else if (!cluster_list_empty(&si->discard_clusters)) {
/*
* we don't have free cluster but have some clusters in
* discarding, do discard now and reclaim them
*/
swap_do_scheduled_discard(si);
*scan_base = *offset = si->cluster_next;
goto new_cluster;
} else
return false;
}
found_free = false;
/*
* Other CPUs can use our cluster if they can't find a free cluster,
* check if there is still free entry in the cluster
*/
tmp = cluster->next;
max = min_t(unsigned long, si->max,
(cluster_next(&cluster->index) + 1) * SWAPFILE_CLUSTER);
if (tmp >= max) {
cluster_set_null(&cluster->index);
goto new_cluster;
}
ci = lock_cluster(si, tmp);
while (tmp < max) {
if (!si->swap_map[tmp]) {
found_free = true;
break;
}
tmp++;
}
unlock_cluster(ci);
if (!found_free) {
cluster_set_null(&cluster->index);
goto new_cluster;
}
cluster->next = tmp + 1;
*offset = tmp;
*scan_base = tmp;
return found_free;
}
현재 cpu에 지정된 클러스터에서 free swap 엔트리를 찾아 출력 인자 @offset과 @scan_base에 저장한다. 실패하는 경우 false를 반환한다.
- 코드 라인 9에서 새 클러스터를 다시 찾아야 할 때 이동될 new_cluster: 레이블이다.
- 코드 라인 10~26에서 현재 cpu에 지정된 클러스터가 없는 경우 다음 중 하나를 수행한다.
- free 클러스터 리스트에서 준비한다.
- free 클러스터 리스트에 등록된 free 클러스터가 없으면 discard 클러스터 리스트에 있는 클러스터들을 블럭 디바이스에 discard 요청하고 free 클러스터에 옮긴다. 그런 후 다시 new_cluster: 레이블로 이동하여 다시 시도한다.
- free 클러스터 리스트 및 discard 클러스터 리스트에 등록된 클러스터가 없는 경우 사용할 수 있는 클러스터가 없어 false를 반환한다.
- 코드 라인 34~40에서 클러스터 내 찾을 next 페이지를 tmp에 대입하고, 다음 클러스터의 마지막 페이지를 벗어난 경우 현재 cpu가 이 클러스터에 null을 대입하여 사용을 포기하게 한다. 그리고 다시 새로운 클러스터를 찾으러 new_cluster 레이블로 이동한다. 클러스터의 락을 획득한 상태가 아니므로 경쟁 상황에서 이미 다른 cpu가 이 클러스터를 사용했을 수 있으므로 이 클러스터를 포기한다.
- 코드 라인 41~53에서 tmp 페이지가 소속한 클러스터 락을 획득하 상태에서 tmp ~ max 페이지까지 순회하며 swap_map[]에 free swap 페이지가 있는지 찾아 발견되면 found_free에 true를 대입하고 루프를 탈출한다. 만일 이 클러스터에 free swap 페이지가 하나도 발견되지 않으면 이 클러스터를 포기하고, 다시 새로운 클러스터를 찾으러 new_cluster: 레이블로 이동한다.
- 코드 라인 54~57에서 찾은 페이지를 @offset과 @scan_base에 저장하고 성공 결과인 true를 반환한다.
클러스터 사용 증가
inc_cluster_info_page()
mm/swapfile.c
/* * The cluster corresponding to page_nr will be used. The cluster will be * removed from free cluster list and its usage counter will be increased. */
static void inc_cluster_info_page(struct swap_info_struct *p,
struct swap_cluster_info *cluster_info, unsigned long page_nr)
{
unsigned long idx = page_nr / SWAPFILE_CLUSTER;
if (!cluster_info)
return;
if (cluster_is_free(&cluster_info[idx]))
alloc_cluster(p, idx);
VM_BUG_ON(cluster_count(&cluster_info[idx]) >= SWAPFILE_CLUSTER);
cluster_set_count(&cluster_info[idx],
cluster_count(&cluster_info[idx]) + 1);
}
@page_nr에 해당하는 클러스터의 사용 카운터를 증가시킨다. 처음 사용되는 경우 free 클러스터를 할당 상태로 변경한다.
- 코드 라인 6~7에서 SSD 클러스터 방식을 사용하지 않는 경우 아무것도 하지 않고 함수를 빠져나간다.
- 코드 라인 8~9에서 @idx 클러스터가 free 상태이면 free 클러스터에서 제거하고 할당 상태로 변경한다.
- 코드 라인 11에서 @idx 클러스터의 사용 카운터가 256 이상이 되면 버그다.
- 코드 라인 12~13에서 @idx 클러스터의 사용 카운터를 1 증가 시킨다.
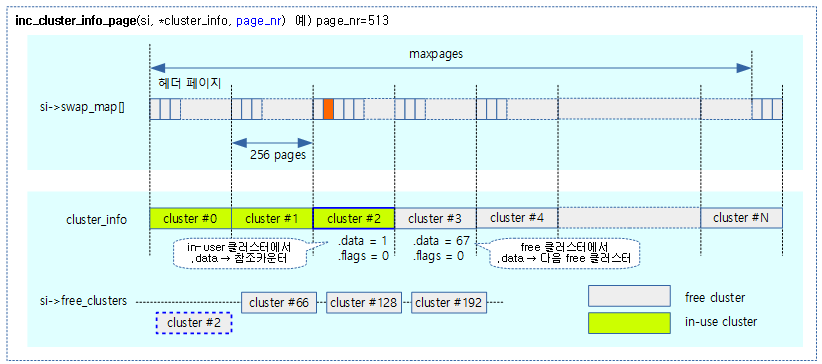
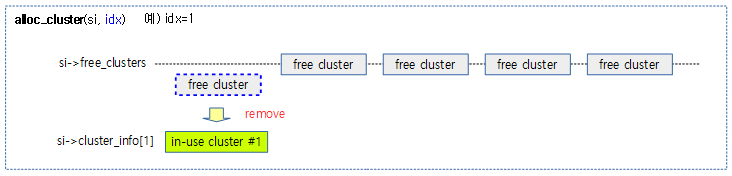
alloc_cluster()
mm/swapfile.c
static void alloc_cluster(struct swap_info_struct *si, unsigned long idx)
{
struct swap_cluster_info *ci = si->cluster_info;
VM_BUG_ON(cluster_list_first(&si->free_clusters) != idx);
cluster_list_del_first(&si->free_clusters, ci);
cluster_set_count_flag(ci + idx, 0, 0);
}
@idx 클러스터를 free 클러스터에서 제거하고, 사용 카운터를 0으로 설정한다.
클러스터 사용 감소
dec_cluster_info_page()
mm/swapfile.c
/* * The cluster corresponding to page_nr decreases one usage. If the usage * counter becomes 0, which means no page in the cluster is in using, we can * optionally discard the cluster and add it to free cluster list. */
static void dec_cluster_info_page(struct swap_info_struct *p,
struct swap_cluster_info *cluster_info, unsigned long page_nr)
{
unsigned long idx = page_nr / SWAPFILE_CLUSTER;
if (!cluster_info)
return;
VM_BUG_ON(cluster_count(&cluster_info[idx]) == 0);
cluster_set_count(&cluster_info[idx],
cluster_count(&cluster_info[idx]) - 1);
if (cluster_count(&cluster_info[idx]) == 0)
free_cluster(p, idx);
}
@page_nr에 해당하는 클러스터의 사용 카운터를 감소시킨다. 사용 카운터가 0이 되면 free 상태로 변경하고 free 클러스터 리스트에 추가한다.
- 코드 라인 6~7에서 SSD 클러스터 방식을 사용하지 않는 경우 아무것도 하지 않고 함수를 빠져나간다.
- 코드 라인 9에서 @idx 클러스터의 사용 카운터가 0인 경우 버그다.
- 코드 라인 10~11에서 @idx 클러스터의 사용 카운터를 1 감소 시킨다.
- 코드 라인 13~14에서 @idx 클러스터의 사용 카운터가 0이되면 free 상태로 변경하고 free 클러스터 리스트의 마지막에 추가한다.
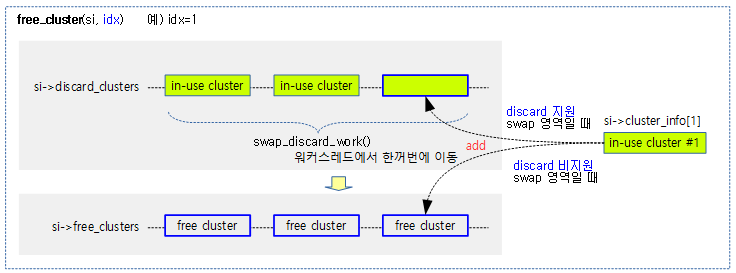
free_cluster()
mm/swapfile.c
static void free_cluster(struct swap_info_struct *si, unsigned long idx)
{
struct swap_cluster_info *ci = si->cluster_info + idx;
VM_BUG_ON(cluster_count(ci) != 0);
/*
* If the swap is discardable, prepare discard the cluster
* instead of free it immediately. The cluster will be freed
* after discard.
*/
if ((si->flags & (SWP_WRITEOK | SWP_PAGE_DISCARD)) ==
(SWP_WRITEOK | SWP_PAGE_DISCARD)) {
swap_cluster_schedule_discard(si, idx);
return;
}
__free_cluster(si, idx);
}
@idx 클러스터를 free 상태로 변경하고 free 클러스터 리스트에 추가한다.
- 코드 라인 11~15에서 discard가 허용된 기록 가능한 swap 영역인 경우 @idx 클러스트에 대해 워커 스레드를 통해 discard 후 free 상태로 변경하고 free 클러스터 리스트의 마지막에 추가한다.
- 코드 라인 17에서 그 외의 경우 @idx 클러스터를 곧바로 free 상태로 변경하고 free 클러스터 리스트의 마지막에 추가한다.
discard 정책
SSD 장치가 discard 옵션을 사용하여 마운트되었거나 트림(trim) 작업을 지원하는 경우 swapon을 사용하여 swap 영역을 지정할 때 discard 옵션을 추가하여 swap discard 기능을 사용할 수 있다. 이러한 경우 일부 SSD 장치의 성능을 향상시킬 수도 있다. swapon의 discard 옵션은 다음 두 가지를 지정하거나, 지정하지 않으면 두 가지 정책을 다 사용한다.
- –discard=once
- 전체 swap 영역에 대해 한 번만 discard 작업을 수행한다.
- –discard=pages
- 사용 가능한 swap 페이지를 재사용하기 전에 비동기적으로 discard 한다.
__free_cluster()
mm/swapfile.c
static void __free_cluster(struct swap_info_struct *si, unsigned long idx)
{
struct swap_cluster_info *ci = si->cluster_info;
cluster_set_flag(ci + idx, CLUSTER_FLAG_FREE);
cluster_list_add_tail(&si->free_clusters, ci, idx);
}
@idx 클러스터를 free 상태로 변경하고 free 클러스터 리스트에 추가한다.
스케줄드 discard 클러스터
swap_cluster_schedule_discard()
mm/swapfile.c
/* Add a cluster to discard list and schedule it to do discard */
static void swap_cluster_schedule_discard(struct swap_info_struct *si,
unsigned int idx)
{
/*
* If scan_swap_map() can't find a free cluster, it will check
* si->swap_map directly. To make sure the discarding cluster isn't
* taken by scan_swap_map(), mark the swap entries bad (occupied). It
* will be cleared after discard
*/
memset(si->swap_map + idx * SWAPFILE_CLUSTER,
SWAP_MAP_BAD, SWAPFILE_CLUSTER);
cluster_list_add_tail(&si->discard_clusters, si->cluster_info, idx);
schedule_work(&si->discard_work);
}
스케줄 워크를 동작시켜 @idx 클러스터를 discard 요청 후 free 클러스터에 추가하게 한다.
- 코드 라인 11~12에서 @idx 클러스터의 모든 페이지에 해당하는 swap_map[]을 bad 페이지로 마크한다.
- 코드 라인 14에서 이 클러스터를 discard 클러스터에 등록한다.
- 코드 라인 16에서 스케줄 워크를 동작시켜 swap_discard_work() 함수를 호출한다. 이 함수에서는 블럭 디바이스에 discard를 요청 후 free 상태로 변경하고 free 클러스터 리스트에 추가하는 작업을 수행한다.
swap_discard_work()
mm/swapfile.c
static void swap_discard_work(struct work_struct *work)
{
struct swap_info_struct *si;
si = container_of(work, struct swap_info_struct, discard_work);
spin_lock(&si->lock);
swap_do_scheduled_discard(si);
spin_unlock(&si->lock);
}
discard 클러스터 리스트의 클러스터들을 discard 요청 후 free 클러스터로 옮긴다.
swap_do_scheduled_discard()
mm/swapfile.c
/* * Doing discard actually. After a cluster discard is finished, the cluster * will be added to free cluster list. caller should hold si->lock. */
static void swap_do_scheduled_discard(struct swap_info_struct *si)
{
struct swap_cluster_info *info, *ci;
unsigned int idx;
info = si->cluster_info;
while (!cluster_list_empty(&si->discard_clusters)) {
idx = cluster_list_del_first(&si->discard_clusters, info);
spin_unlock(&si->lock);
discard_swap_cluster(si, idx * SWAPFILE_CLUSTER,
SWAPFILE_CLUSTER);
spin_lock(&si->lock);
ci = lock_cluster(si, idx * SWAPFILE_CLUSTER);
__free_cluster(si, idx);
memset(si->swap_map + idx * SWAPFILE_CLUSTER,
0, SWAPFILE_CLUSTER);
unlock_cluster(ci);
}
}
discard 클러스터 리스트의 클러스터들을 discard 요청 후 free 클러스터로 옮긴다.
- 코드 라인 8~9에서 discard 클러스터 리스트의 모든 클러스터를 순회하며 discard 클러스터 리스트에서 제거한다.
- 코드 라인 12~13에서 블록 디바이스에 각 클러스터에 포함된 페이지들을 모두 discard 요청한다.
- 코드 라인 15~20에서 cluster 락을 획득한 채로 순회 중인 클러스터를 free 상태로 변경하고 free 클러스터 리스트의 마지막에 추가한다.
discard_swap_cluster()
mm/swapfile.c
/* * swap allocation tell device that a cluster of swap can now be discarded, * to allow the swap device to optimize its wear-levelling. */
static void discard_swap_cluster(struct swap_info_struct *si,
pgoff_t start_page, pgoff_t nr_pages)
{
struct swap_extent *se = si->curr_swap_extent;
int found_extent = 0;
while (nr_pages) {
if (se->start_page <= start_page &&
start_page < se->start_page + se->nr_pages) {
pgoff_t offset = start_page - se->start_page;
sector_t start_block = se->start_block + offset;
sector_t nr_blocks = se->nr_pages - offset;
if (nr_blocks > nr_pages)
nr_blocks = nr_pages;
start_page += nr_blocks;
nr_pages -= nr_blocks;
if (!found_extent++)
si->curr_swap_extent = se;
start_block <<= PAGE_SHIFT - 9;
nr_blocks <<= PAGE_SHIFT - 9;
if (blkdev_issue_discard(si->bdev, start_block,
nr_blocks, GFP_NOIO, 0))
break;
}
se = list_next_entry(se, list);
}
}
discard를 지원하는 SSD 스타일의 swap 장치에 @start_page 부터 @nr_pages만큼 discard 요청한다.
Per-cpu Swap 슬롯 캐시
swap 영역의 swap_map[]을 통해 swap 엔트리를 할당한다. 이 때마다 swap 영역의 락이 필요하다. 이의 성능 향상을 위해 swap 엔트리 할당을 위해 앞단에 per-cpu swap 슬롯 캐시를 사용하여 swap 영역의 잠금 없이 빠르게 할당/해제할 수 있게 하였다.
- 참고: mm/swap: add cache for swap slots allocation (v4.11-rc1)
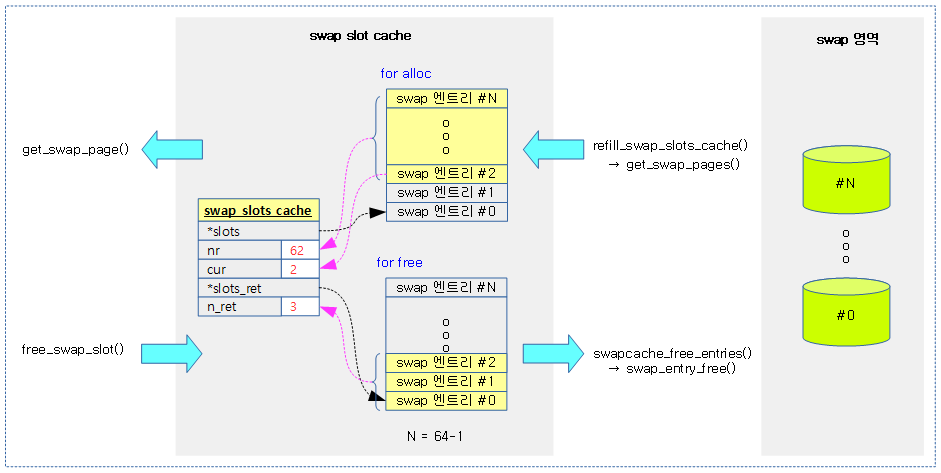
swap_slots_cache 구조체
include/linux/swap_slots.h
struct swap_slots_cache {
bool lock_initialized;
struct mutex alloc_lock; /* protects slots, nr, cur */
swp_entry_t *slots;
int nr;
int cur;
spinlock_t free_lock; /* protects slots_ret, n_ret */
swp_entry_t *slots_ret;
int n_ret;
};
swap 슬롯 캐시 하나에는 할당용과 회수용 swap 엔트리 배열을 가진다.
- lock_initialized
- 락 초기화 여부를 표시한다.
- alloc_lock
- swap 엔트리 할당용 swap 슬롯 캐시 락
- *slots
- swap 엔트리 할당용 swap 엔트리 배열
- nr
- swap 엔트리 할당용 swap 엔트리 수
- cur
- swap 엔트리 할당용 현재 swap 엔트리 번호
- free_lock
- swap 엔트리 회수용 swap 슬롯 캐시 락
- *slots_ret
- swap 엔트리 회수용 swap 엔트리 배열
- n_ret
- swap 엔트리 회수용 swap 엔트리 수
다음 그림은 swap 슬롯 캐시의 두 swap 엔트리 배열의 용도를 보여준다.
swap 슬롯 캐시에서 swap 엔트리 할당
get_swap_page()
mm/swap_slots.c
swp_entry_t get_swap_page(struct page *page)
{
swp_entry_t entry, *pentry;
struct swap_slots_cache *cache;
entry.val = 0;
if (PageTransHuge(page)) {
if (IS_ENABLED(CONFIG_THP_SWAP))
get_swap_pages(1, &entry, HPAGE_PMD_NR);
goto out;
}
/*
* Preemption is allowed here, because we may sleep
* in refill_swap_slots_cache(). But it is safe, because
* accesses to the per-CPU data structure are protected by the
* mutex cache->alloc_lock.
*
* The alloc path here does not touch cache->slots_ret
* so cache->free_lock is not taken.
*/
cache = raw_cpu_ptr(&swp_slots);
if (likely(check_cache_active() && cache->slots)) {
mutex_lock(&cache->alloc_lock);
if (cache->slots) {
repeat:
if (cache->nr) {
pentry = &cache->slots[cache->cur++];
entry = *pentry;
pentry->val = 0;
cache->nr--;
} else {
if (refill_swap_slots_cache(cache))
goto repeat;
}
}
mutex_unlock(&cache->alloc_lock);
if (entry.val)
goto out;
}
get_swap_pages(1, &entry, 1);
out:
if (mem_cgroup_try_charge_swap(page, entry)) {
put_swap_page(page, entry);
entry.val = 0;
}
return entry;
}
swap 슬롯 캐시를 통해 요청 페이지에 사용할 swap 엔트리를 얻어온다. 실패 시 null을 반환한다.
- 코드 라인 8~12에서 thp의 경우 thp swap이 지원될 때에만 HPAGE_PMD_NR 단위로 swap 엔트리를 확보한다.
- 현재 x86_64 아키텍처가 thp swap이 지원되고 있다.
- 코드 라인 23~42에서 thp가 아닌 경우이다. swap 슬롯 캐시가 활성화된 경우 swap 슬롯 캐시를 통해 swap 엔트리를 얻어온다. swap 슬롯 캐시가 부족하면 리필한다.
- 코드 라인 44에서 swap 슬롯 캐시가 활성화되지 않은 경우에는 직접 swap 엔트리를 얻어온다.
- 코드 라인 45~49에서 out: 레이블이다. memcg를 통해 메모리 + swap 용량이 메모리 한계를 초과하는 경우 swap 엔트리를 drop 한다.
- memory.memsw.limit_in_bytes
- 코드 라인 50에서 swap 엔트리를 반환한다.
swap 슬롯 캐시 충전
refill_swap_slots_cache()
mm/swap_slots.c
/* called with swap slot cache's alloc lock held */
static int refill_swap_slots_cache(struct swap_slots_cache *cache)
{
if (!use_swap_slot_cache || cache->nr)
return 0;
cache->cur = 0;
if (swap_slot_cache_active)
cache->nr = get_swap_pages(SWAP_SLOTS_CACHE_SIZE,
cache->slots, 1);
return cache->nr;
}
슬롯 캐시에 swap 영역에서 검색해온 swap 엔트리들을 충전(refill)하고 그 수를 반환한다.
- 코드 라인 4~5에서 swap 슬롯 캐시를 사용하지 않거나 캐시에 swap 엔트리들이 이미 있는 경우 0을 반환한다.
- 코드 라인 7~10에서 슬롯 캐시가 활성화된 경우 swap_map을 검색하여 swap 엔트리들을 SWAP_SLOTS_CACHE_SIZE(64) 만큼 가져온다.
- 코드 라인 12에서 가져온 swap 엔트리 수를 반환한다.
swap 슬롯 캐시로 swap 엔트리 회수
free_swap_slot()
mm/swap_slots.c
int free_swap_slot(swp_entry_t entry)
{
struct swap_slots_cache *cache;
cache = raw_cpu_ptr(&swp_slots);
if (likely(use_swap_slot_cache && cache->slots_ret)) {
spin_lock_irq(&cache->free_lock);
/* Swap slots cache may be deactivated before acquiring lock */
if (!use_swap_slot_cache || !cache->slots_ret) {
spin_unlock_irq(&cache->free_lock);
goto direct_free;
}
if (cache->n_ret >= SWAP_SLOTS_CACHE_SIZE) {
/*
* Return slots to global pool.
* The current swap_map value is SWAP_HAS_CACHE.
* Set it to 0 to indicate it is available for
* allocation in global pool
*/
swapcache_free_entries(cache->slots_ret, cache->n_ret);
cache->n_ret = 0;
}
cache->slots_ret[cache->n_ret++] = entry;
spin_unlock_irq(&cache->free_lock);
} else {
direct_free:
swapcache_free_entries(&entry, 1);
}
return 0;
}
swap 슬롯 캐시를 통해 swap 엔트리 하나를 회수한다. (put_swap_page() 함수에서 호출된다)
- 코드 라인 5에서 현재 cpu에 대한 swap 슬롯 캐시를 알아온다.
- 코드 라인 6~12에서 swap 슬롯 캐시를 사용할 수 있는 경우이다. swap 슬롯 캐시의 lock을 획득한 채로 다시 한 번 swap 슬롯 캐시를 사용 가능한지 체크한다. 사용 불가능한 경우 락을 풀고 direct_free 레이블로 이동하여 slot 캐시로 반환하지 않고 직접 swap 영역에 반환한다.
- 코드 라인 13~22에서 슬롯 캐시가 관리하는 최대 수를 초과하는 경우 기존 swap 슬롯 캐시에 존재하는 swap 엔트리들을 한꺼번에 각 글로벌 swap 영역으로 회수한다.
- 코드 라인 23~24에서 swap 슬롯 캐시로 swap 엔트리 하나를 회수한다.
- 코드 라인 25~28에서 direct_free: 레이블이다. swap 슬롯 캐시가 아닌 글로벌 swap 영역으로 직접 swap 엔트리 하나를 회수한다.
참고
- Swap -1- (Basic, 초기화) | 문c
- Swap -2- (Swapin & Swapout) | 문c
- Swap -3- (swap 영역 할당/해제) | 문c – 현재글
- Swap -4- (Swap 엔트리) | 문c