<kernel v5.10>
Atomic Operation
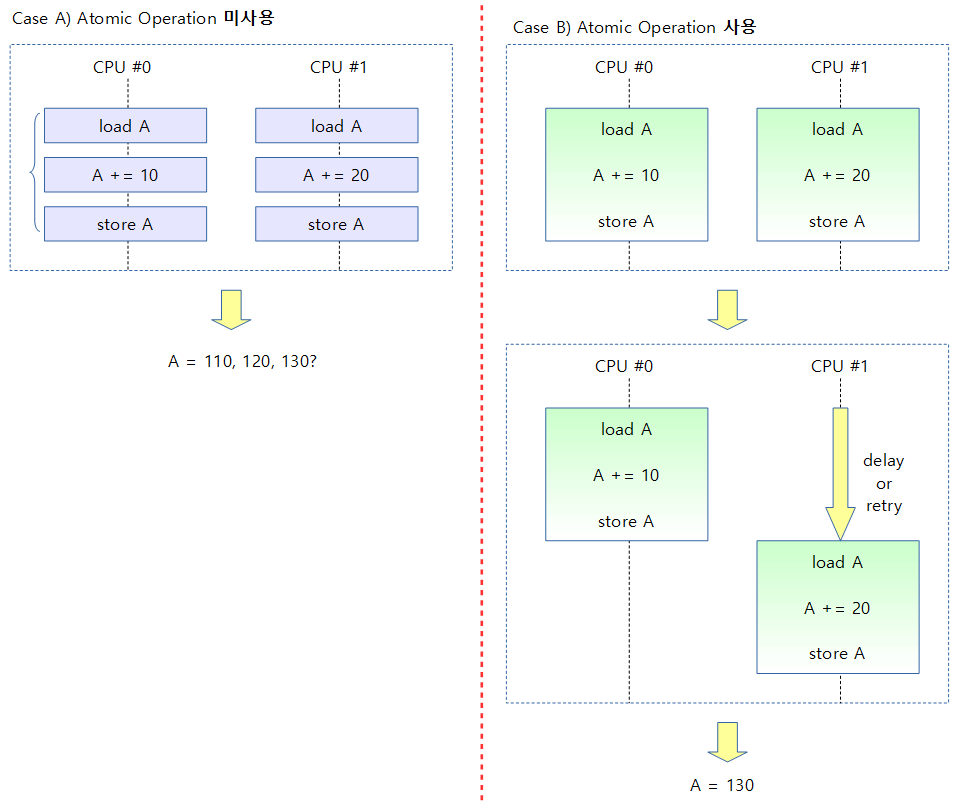
Atomic Operation은 공유 자원에 대해 멀티 프로세서 및 멀티 스레드가 동시에 경쟁적으로 요청 시 조작(Operation)이 한 번에 하나씩 동작하여 그 중간에 끼어 들 수 없도록 한다.
아래 그림은 2개의 멀티 프로세서를 사용하는 시스템에서 Atomic Operation 적용 유무에 따른 결과를 보여준다. (처음 A 값은 100)
- Atomic Operation을 사용하지 않은 경우
- 각 CPU에서 명령들을 순서대로 처리하지 않고 거의 동시에 실행하면 공유된 자원의 결과 값이 예측되지 않는다.
- Atomic Operation을 사용하는 경우
- 아키텍처마다 많은 방법이 있는데 CAS(Compare-and-Swap) 방식 처럼 hardware가 어느 한 쪽을 지연시켜 동기화를 하거나 또는 LL/SC(Load-Linked and Conditional-Store) 방식처럼 hardware의 도움(exclusive monitor로 태그 사용)을 받아 동시 접근을 인지하여 어느 한 쪽을 실패시키 원복시키며, 다시 재시도하는 방법 등으로 atomic 함수들이 올바른 결과를 얻을 수 있게 작성되어 있다.
아키텍처별 Atomic Operation 구현 분류
Atomic Operation은 아키텍처마다 처리하는 명령과 방법이 조금씩 다르므로 정확한 처리 방법은 해당 아키텍처 소스를 참고하길 바라며, 이 글에서는 ARM 및 ARM64를 우선하여 설명한다.
- 시스템 메모리에 있는 공유 변수를 증/감시키기 위해서는 보통 한 개의 명령으로 처리되지 않아 LL/SC 또는 CAS(LSE 포함) 방식을 사용하여 여러 개의 명령이 순차적으로 수행되어야 하는데 이를 보장하는 방법을 Atomic Operation이라고 하며 시스템에서 사용할 수 있는 가장 작은 단위의 동기화 기법이기도 하다.
- critical section을 보호하는 각종 lock을 사용하지 않고 atomic operation을 사용하는 이유는 dead-lock 등이 없고 동기화 기법 중 가장 빠른 성능을 가지고 있다.
아키텍처들이 사용하는 큰 두 가지 유형
아키텍처들의 atomic 구현 방법은 세부적으로 모두 다르지만 크게 다음 두 가지 방법을 사용한다.
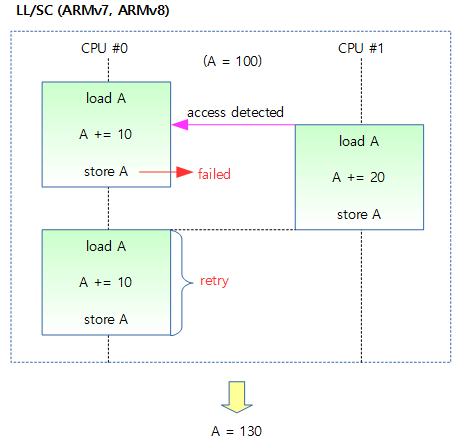
- LL/SC(Load-Linked and Conditional-Store)
- load 표식을 한 후 연산 후 동시에 다른 프로세스나 디바이스가 이 영역에 접근 여부를 hardware가 감지하여 없는 경우에만 store한다. 접근이 감지되면 다시 성공할 때까지 반복하는 방법을 사용한다. 단점으로 ARM의 경우 동시 접근한 atomic operation의 처리 순서는 가장 마지막에 접근한 atomic operation을 먼저 성공시킨다.
- 사용 패턴
- 1) load from memory
- 2) 연산(inc/dec, …)
- 3) store to memory
- 4) 실패 시 반복
- 적용 아키텍처
- ARM
- 68k
- Alpha
- ARM (ARMv6 ~ ARMv8)
- ARMv8의 경우 Load-Exclusive/Store-Exclusive로도 불리운다. (ldxr/stxr)
- MIPS
- POWERPC
- 참고: Exclusive loads and store | 문c
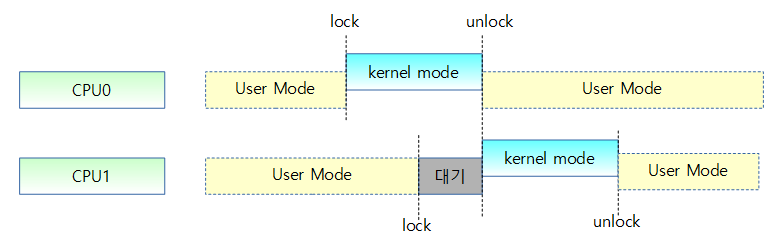
- CAS(Compare-and-Swap)
- hardware lock을 잡고 add 또는 exchange 후 unlock을 하는 방식이다. 언제나 한 번에 성공하므로 반복하지 않는다.
- 사용 패턴
- 1) lock
- 2) 연산(add/exchange)
- 3) unlock
- 적용 아키텍처
- LSE(Large System Extensions)
- ARMv8.1 아키텍처의 경우 LL/SC 방식 이외에도 LSE를 추가적으로 지원한다.
- LSE를 지원하는 커널은 시스템이 LSE feature를 인식하면 커널 부팅 과정에서 모든 atomic 명령을 LSE 방식으로 명령을 교체하여 동작한다.
- LSE atomic은 LL/SC 방식 이외에도 hardware lock을 지원하는 LA/SR(Load-Acquire/Store-Release) atomic과 CAS atomic을 동시에 지원한다.
- 대표 명령: ldar/stlr 명령과 cas 명령
- 이전 글에서 LSE atomic을 CAS atomic으로 분류하였으나, ARM 매뉴얼은 항상 LSE atomic으로 표기하므로 별도로 분류하였다.
ARM 아키텍처에서의 구현
ARM & ARM64 시스템에 구현된 방법은 다음과 같다.
- ARMv5 이하
- 모두 UP(Uni Processor) 시스템용으로만 구현되어 있어 인터럽트를 막는 것으로 구현
- ARMv6, ARMv7
- UP로 커널을 빌드하여 사용 시 인터럽트를 막는 것으로 구현
- SMP로 커널을 빌드하여 사용 시 LL/SC 방식으로 구현
- ARMv8
- UP/SMP 가리지 않고 LL/SC 방식으로 구현
- ARMv8.1~
- UP/SMP 가리지 않고 LSE 방식으로 구현
1) UP 시스템에서의 구현 – 인터럽트 disable 구현 방식
- 해당 atomic operation 수행 중 태스크의 문맥교환이 일어나거나(태스크가 preemption) 인터럽트 루틴에서 해당 메모리에 대해 동시 처리되지 않도록 아예 인터럽트를 막아서 해결한다.
- UP에서는 인터럽트만 막아도 태스크의 문맥교환이 일어나지 않으므로 인터럽트를 enable하기 전까지 atomic opeation을 보장하게 된다.
2) SMP 시스템에서의 구현 – LL/SC 구현 방식
- UP 이외에도 SMP 시스템까지 동시에 처리 될 수 있도록 LL/SC(Load-Link/Store-Conditional)라는 테크닉을 사용하였다.
- CPU에서 atomic operation을 수행하는 도중 인터럽트 또는 preemption 되는 것을 막지 않는다.
- 여러 CPU에서 atomic operation이 동시에 수행되는 것도 막지 않는다.
- 공유 메모리의 접근이 서로 중복되는 경우가 발생하면 해당 atomic operation을 취소하고 중복이 발생되지 않을 때 까지 retry하는 기법으로 atomic operation이 한 번에 하나만 수행되는 것을 보장한다.
- 해당 공유 메모리의 접근이 중복되는 것을 알아채는 것은 하드웨어의 도움을 받아 처리한다.
- ARMv6, ARMv7에서는 ldrex와 strex 명령 쌍으로 처리할 수 있다.
- ARMv8에서는 ldxr과 stxr 명령 쌍으로 처리할 수 있다. 그 외에 성능 극대화를 위해 배리어의 적용을 없앨 수 있게, 4 가지 타입의 오더링 명령셋이 추가되었다.
- ARMv8: Cortex A53, A57, A72
다음 그림은 LL/SC 방식에서 동시에 요청된 atomic operation들이 처리되는 과정을 보여준다.
3) SMP 시스템에서의 구현 – LSE 구현 방식
- ARMv8.1 이상에서는 LL/SC와는 다른 x86 진영에서 사용하는 방식인 CAS와 유사한 LSE(Large System Extension) atomic 명령이 채용되었다.
- ARM 진영에서는 ARMv8.0 아키텍처까지 LL/SC 방식을 사용하였고, CPU가 많아지면서 LL/SC의 retry 부담이 커졌다. 따라서 x86 진영에서 사용하는 hardware lock을 사용한 CAS 명령과 비슷하게 동작하는 새로운 ARMv8.1 LSE(Large System Extension) 기능을 지원하는 것으로 변경되었다.
- 리눅스가 EL2에서 시작하고 성능을 높이기 위해 동작도 EL2에서 수행하려면 ARMv8.1의 VHE(Virtualization Host Extension)와 ARMv8.1의 LSE 기능 둘 다 필요하다. 이 기능이 없으면 EL2에서 부팅하여 stub code만 남기고, EL1으로 전환하여 커널을 운영한다.
- ARMv8.2: Cortex A75, A76
아키텍처별 헤더 파일
Atomic operation은 기본 구현 헤더와 asm-generic 헤더 및 아키텍처에 따라 전용 구현이 준비되어 있다.
- 기본 구현 헤더
- include/linux/atomic.h
- include/linux/atomic-fallback.h
- include/linux/atomic-arch-fallback.h
- include/asm-generic/atomic.h
- include/asm-generic/atomic64.h
- include/asm-generic/atomic-long.h
- 아키텍처와 연결을 도와주기 위한 헤더
- include/asm-generic/atomic-instrumented.h
- 아키텍처별 헤더 (asm-generic 보다 아키텍처 전용 코드 사용을 우선)
- arch/arm/include/asm/atomic.h
- 32bit ARM 시스템 전용 코드로 구성
- asm-generic 보다 아키텍처 전용 코드 사용을 우선한다.
- arch/arm64/include/asm/atomic.h (ARMv8.x 공통)
- LL/SC 방식을 사용하는 64bit ARM 시스템 전용 코드로 구성
- arch/arm64/include/asm/atomic_ll_sc.h (ARMv8)
- LL/SC 방식을 사용하는 ARMv8 아키텍처 전용 코드로 구성
- arch/arm64/include/asm/atomic_lse.h (ARMv8.1~)
- LSE atomic 방식을 사용하는 ARMv8.1~ 아키텍처 전용 코드로 구성
SW atomic operation vs HW atomic operation 지원
1) S/W 접근 방법 (ARMv5 까지 사용)
- 인터럽트를 막음으로 atomic operation을 수행 중 다른 태스크가 preemption 되지 않게 한다.
- ARMv5까지는 UP(Uni Processor) 시스템이므로 현재 CPU의 인터럽트만 막아도 atomic operation이 성립한다.
- 참고로 SDRAM에 존재하는 한 변수를 증감하려 할 때 cpu clock은 캐시 상태(hit/miss)에 따라 수 cycle ~ 수십 cycle이 소요된다.
- 매크로로 만들어진 아래 함수를 설명하면…
- 현재 CPU의 인터럽트 상태를 보관 하고 disable하여 인터럽트 호출을 막는다.
- atomic operation에 필요한 add/sub 또는 xchg 연산등을 수행한다.
- 다시 인터럽트 상태를 원래대로 돌려놓는다.
static inline void atomic_add(int i, atomic_t *v)
{
unsigned long flags;
raw_local_irq_save(flags);
v->counter += i;
raw_local_irq_restore(flags);
}
2) LL/SC – H/W 접근 방법 (ARMv6 ~ ARMv8까지 사용)
atomic_add() – ARM32
아래는 실제 매크로 코드들을 풀어썻다.
arch/arm/include/asm/atomic.h
static inline void atomic_add(int i, atomic_t *v)
{
unsigned long tmp;
int result;
prefetchw(&v->counter);
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %0, %0, %4\n"
" strex %1, %0, [%3]\n"
" teq %1, #0\n"
" bne 1b"
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter)
: "r" (&v->counter), "Ir" (i)
: "cc"); /* clobbers */
}
- ldrex/strex 사용: UP에서의 멀티스레드에서의 preemption 이외에도 SMP 시스템에서는 메모리 access가 여러 개의 CPU에서 동시 처리될 수 있기 때문에 데이터에 대해 Atomic operation(load – operation – store, 읽고 연산하고 기록) 수행 시 다른 CPU가 끼어들면 실패를 감지할 수 있어야 한다. 따라서 ARM 아키텍처에서는 이를 위해 ldr과 str 대신 별도로 ldrex와 strex 명령을 사용하여 처리하게 하였다.
- pld(pldw) 사용:
- ldrex와 strex 사이에 처리되어야 하는 메모리가 캐시 미스되어 ldrex 부터 strex 까지의 처리에 CPU clock의 지연을 일으키므로 이를 막기 위해 사용하려는 메모리를 ldrex로 로드하기 전에 미리 캐시에 사전 로드하는 방법을 사용하기 위해 ARM 아키텍처 전용 명령인 pld(pldw) 명령을 사용하여 지정된 메모리의 데이터가 캐시에 없는 경우 이를 캐시에 미리로드(linefill)하라고 지시한다.
- 처음 사용 시 critical section을 최소화 시키는 것과 유사한 효과를 보이므로 strex에서 실패할 확률을 줄여준다.
- Out of order execution 및 Out of order access memory 기능을 가지고 있는 ARM 아키텍처를 위해 atomic_xxx_return() 및 atomic_cmpxchg_relaxed() 명령의 경우 smp_mb() 베리어를 추가 사용한다.
- 참고: 최근 2015년 8월 커널v4.3-rc1에서는 smp_mb()를 사용하지 않는다.
- “Qo” memory constraints
atomic_add() – ARM64 (ARMv8.0)
아래는 실제 매크로 코드들을 풀어썻다.
arch/arm64/include/asm/atomic_ll_sc.h
static inline void atomic_add(int i, atomic_t *v)
{
unsigned long tmp;
int result;
asm volatile(
" prfm pstl1strm, %2\n"
"1: ldxr %w0, %2\n"
" add %w0, %w0, %w3\n"
" stxr %w1, %w0, %2\n"
" cbnz %w1, 1b\n"
: "=&r" (result), "=&r" (tmp), "+Q" (v->counter)
: __stringify(constraint) "r" (i));
}
3) LSE – H/W 접근 방법 (ARMv8.1 LSE)
아래는 실제 매크로 코드들을 풀어썻다.
arch/arm64/include/asm/atomic_lse.h
static inline void atomic_add(int i, atomic_t *v)
{
asm volatile(
" .arch_extension lse\n"
" stadd %w[i], %w[i], %[v]\n"
: [i] "+r" (i), [v] "+Q" (v->counter)
: "r" (v)
: cl);
}
- ll/sc 방식과는 다르게 prefetch 및 반복문이 없이 하나의 명령문만을 사용한 것을 확인할 수 있다.
- stadd 명령은 atomic add 명령으로 32비트의 w레지스터 또는 64비트의 x레지스터를 다룬다. 또한 메모리 오더링을 사용하지 않는다.
Atomic operation 명령
리눅스 커널이 제공하는 Atomic Operation 명령들을 알아보자. (v=32bit 카운터 값을 가진 atomic_t 구조체 주소)
RMW vs non-RMW
atomic API들은 크게 다음과 같이 분류할 수 있다.
- RMW(Read-Modify-Write)
- 종류
- 산술연산(add, sub, inc, dec)
- 비트조작(xor, andnot, and)
- 교체(xchg, …)
- 기타(add_unless, …)
- 특징
- 결과 값이 없는 RMW 명령들은 weaked(out-of) 오더를 가질 수 있다.
- 결과 값이 있는 RMW 명령들은 strong(in, full) 오더를 가진다.
- non-RWM
- 종류
- 특징
- non-RMW 명령들의 특징은 weaked(out-of) 메모리 오더를 가질 수 있다.
1) 기본 명령
커널 v4.3-rc1부터 atomic_or() 명령이외에 atomic_xor(), atomic_and() 명령들도 추가되었다.
- atomic_add(i, &v)
- atomic_sub(i, &v)
- atomic_and(i, &v)
- v값을 읽은 후 i값을 and 연산한 후 저장한다.
- atomic_andnot(i, &v)
- v값을 읽은 후 i값을 andnot 연산한 후 저장한다.
- atomic_or(i, &v)
- v값을 읽은 후 i값을 or 연산한 후 저장한다.
- atomic_xor(i, &v)
- v값을 읽은 후 i값을 xor 연산한 후 저장한다.
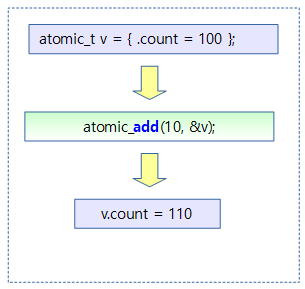
아래 그림은 단순하게 atomic_t 변수 100에 10을 더해 110이 되어 저장하는 과정을 보여준다.
2) Return 추가 명령
- atomic_add_return(i, &v)
- v값을 읽은 후 i만큼 증가시키고 저장한다. 또한 증가시켜 저장한 값을 반환한다.
- atomic_sub_return(i, &v)
- v값을 읽은 후 i만큼 감소시키고 저장한다. 또한 감소시켜 저장한 값을 반환한다.
아래 그림은 atomic_t 변수 100에 10을 더해 110이 되어 저장하는 것과, 연산 후의 값을 결과 값으로 반환하는 것을 보여준다.

3) Fetch 추가 명령
커널 v4.3-rc1부터 _set, _clear 명령대신 andnot 명령을 사용하게 하였고, 커널 v4.8-rc에서 삭제하였다.
- atomic_clear_mask() 및 atomic_set_mask()대신 atomic_andnot() 명령을 사용하게 하였다.
- 참고:
- atomic_fetch_add(i, &v)
- v값을 읽은 후 i만큼 증가시키고 저장한다. 그리고 연산 전의 v 값을 반환한다.
- atomic_fetch_sub(i, &v)
- v값을 읽은 후 i만큼 증가시키고 저장한다. 그리고 연산 전의 v 값을 반환한다.
- atomic_fetch_and(i, &v)
- v값을 읽은 후 i값을 and 연산한 후 저장한다. 그리고 연산 전의 v 값을 반환한다.
- atomic_fetch_andnot(i, &v)
- v값을 읽은 후 i값을 andnot 연산한 후 저장한다. 그리고 연산 전의 v 값을 반환한다.
- atomic_fetch_or(i, &v)
- v값을 읽은 후 i값을 or 연산한 후 저장한다. 그리고 연산 전의 v 값을 반환한다.
- 커널 v4.8-rc1에서 이 명령은 삭제되었다.
- atomic_fetch_xor(i, &v)
- v값을 읽은 후 i값을 xor 연산한 후 저장한다. 그리고 연산 전의 v 값을 반환한다.
아래 그림은 atomic_t 변수 100에 10을 더해 110이 되어 저장하는 것과, 연산 전의 값을 결과 값으로 반환하는 것을 보여준다.

4) Exchange 명령
- atomic_xchg(&v, new)
- v값을 읽은 후 new 값으로 교체한 후 다시 저장한다. 그리고 교체 전의 v 값을 반환한다.
- atomic_cmpxchg(&v, old, new)
- v값을 읽어 old와 같은 경우에만 new 값으로 교체한 후 다시 저장한다. 그리고 교체 전의 v 값을 반환한다.
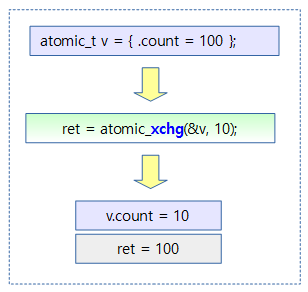
아래 그림은 atomic_t 변수를 10으로 교체하여 저장하는 것과, 교체 전 값을 결과 값으로 반환하는 것을 보여준다.
아래 그림은 atomic_t 변수가 지정된 값(100)과 같은 경우에만 20으로 교체하여 저장하는 것과, 교체 전 값을 결과 값으로 반환하는 것을 보여준다.

- atomic_try_cmpxchg(&v, &val, new)
5) read & set 명령
non-RMW 타입의 atomic 명령들은 다음과 같다.
- atomic_read(&v)
- atomic_set(&v, i)
arch/arm/include/asm/atomic.h – for ARM
/*
* On ARM, ordinary assignment (str instruction) doesn't clear the local
* strex/ldrex monitor on some implementations. The reason we can use it for
* atomic_set() is the clrex or dummy strex done on every exception return.
*/
#define atomic_read(v) READ_ONCE((v)->counter)
#define atomic_set(v,i) WRITE_ONCE(((v)->counter), (i))
READ_ONCE()와 WRITE_ONCE() 매크로 함수는 컴파일러 메모리 배리어 및 아키텍처 메모리 배리어를 사용하여 atomic read/write를 수행한다.
- ARM 및 ARM64 시스템에서는 atomic_read() 구현 시 1개의 atomic instruction으로 처리가능하므로 아키텍처 배리어는 사용하지 않는다.
6) 기타 명령
- atomic_inc(&v)
- atomic_dec(&v)
- atomic_inc_and_test(&v)
- v값을 읽은 후 1 증가시키고 저장한다. 또한 증가시킨 값이 0이면 true(1)를 반환하고, 그 외의 값이면 false(0)를 반환한다.
- atomic_dec_and_test(&v)
- v값을 읽은 후 1 감소시키고 저장한다. 또한 감소시킨 값이 0이면 true(1)를 반환한고, 그 외의 값이면 false(0)를 반환한다.
- atomic_inc_return(&v)
- v값을 읽은 후 1 증가시키고 저장한다. 또한 증가시켜 저장한 값을 반환한다.
- atomic_dec_return(&v)
- v값을 읽은 후 1 감소시키고 저장한다. 또한 감소시켜 저장한 값을 반환한다.
- atomic_add_negative(&v)
- v 값을 읽은 후 i만큼 증가시키고 저장한다. 또한 증가시켜 저장한 값이 음수(-)이면 true(1)를 반환한고, 그 외의 값이면 false(0)을 반환한다.
- atomic_add_unless(&v, i, u)
- v 값을 읽은 후 u 값과 다른 경우에 한해 i 값을 더해 저장한다. 결과 값이 u 값과 다른 경우 true(1)를 반환한다.
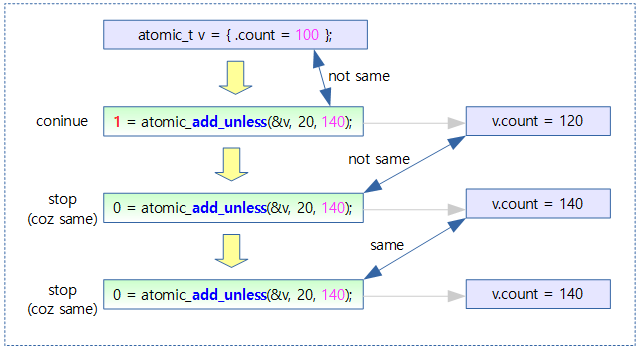
아래 그림은 atomic v값이 비교 값(140)이 아닌 경우에만 20을 더하여 저장하는 것을 보여준다. 결과 값이 비교 값(140)과 다른 경우 1을 반환한다.
- atomic_inc_not_zero(&v)
- v 값을 읽은 후 0이 아니면 1을 증가시키고 저장한다. 결과 값이 0이면 0을 반환하고, 그 외 1을 반환한다.
- atomic_inc_not_zero_hint(&v, hint)
- hint 값에 따라 가 다음과 같은 동작을 한다.
- hint = 0인 경우
- atomic_inc_not_zero()와 같이 동작하고,
- hint가 1인 경우
- 네트워크 스택에서 atomic_inc_not_zero()를 많이 사용하는데, 이 함수는 read/modify/write를 단계를 거친다. 이러한 단계를 거치지 않고 atomic하게 exchange를 할 수 있는 아키텍처를 위해 hint를 제공하는 API를 추가하였다.
- hint가 제공되는 경우 CAS 방식의 atomic operation을 지원하는 아키텍처의 경우 캐시 코히런스 프로토콜(예: x86의 MESI, arm의 MOESI)의 공유 상태 진입 없이 처리가능하다.
- 아키텍처 specific한 함수를 include/linux/atomic.h으로 만들었는데 아직 호응은 별로 없다.
- 현재 /net/atm/pppoatm.c에만 적용되어 있다.
- 참고: atomic: add atomic_inc_not_zero_hint()
- 드디어 아키텍처를 가리는 이 함수가 커널 v4.19-rc1에서 제거되었다.
- atomic_dec_if_positive(&v)
Barrier 포함 atomic 명령
성능 향상을 위해 대부분의 아키텍처들이 메모리에 대한 접근 순서를 요구한 순서대로 하지 않고, 때에 따라서는 변경하여 처리한다. atomic_add_return() 타입같은 경우 명령 자체가 순차 처리를 강제하게 되어 있다. 더 극대화된 성능 처리를 위해 이러한 오더링 타입을 변경하도록 atomic operation들도 이에 대응하는 명령들을 아래와 같이 지원한다.
relaxed, …
커널 v4.3-rc부터Atomic 오퍼레이션 동작 시 메모리 오더링에 대한 옵션을 사용할 수 있도록 3가지 접미사(_acquire, _release, _relaxed)를 가진 명령들을 포함하였다. 현재 대부분의 아키텍처들은 모든 명령들이 full 오더링 개런티로 동작되고있다. 그러나 일부 아키텍처들은 성능 향상을 위해 일부 함수에 대해 오더링 옵션들을 아래 의도대로 정확히 적용시키고 있다.
- 무접미사
- Atomic 오퍼레이션시 full ordering 개런티를 한다. (최저 성능)
- 순차 처리하도록 강제한다.
- ARMv8: dmb ish 추가 수행, stxr 대신 xtlxr 사용
- *_acquire
- acquire 이후의 읽기 및 쓰기 조작 전에 이 atomic operation이 완료되는 것을 보장하게 강제한다.
- 사용 사례:
- queued_read_lock() – atomic_add_return_acquire()
- queued_write_lock() – atomic_cmpxchg_acquire()
- queued_spin_lock() – atomic_cmpxchg_acquire()
- osq_lock() – osq_wait_next() – atomic_cmpxchg_acquire()
- *_release
- release 이전의 모든 읽기 및 쓰기 작업이 완료된 후 이 atomic operation이 시작하는 것을 보장하게 강제한다.
- 사용 사례:
- queued_read_unlock()- atomic_sub_return_release()
- queued_write_unlock()- atomic_cmpxchg_release()
- queued_spin_unlock() – atomic_cmpxchg_release()
- osq_unlock() – atomic_cmpxchg_release()
- *_relaxed
- Atomic 오퍼레이션 시 ordering 개런티를 하지 않아도 될 때 사용한다. (최고 성능)
- 강제하지 않기 때문에 아키텍처가 ordering을 하든 안하든 관여하지 않는다.
- 사용 사례:
- queued_spin_lock_slowpath() – atomic_cmpxchg_relaxed()
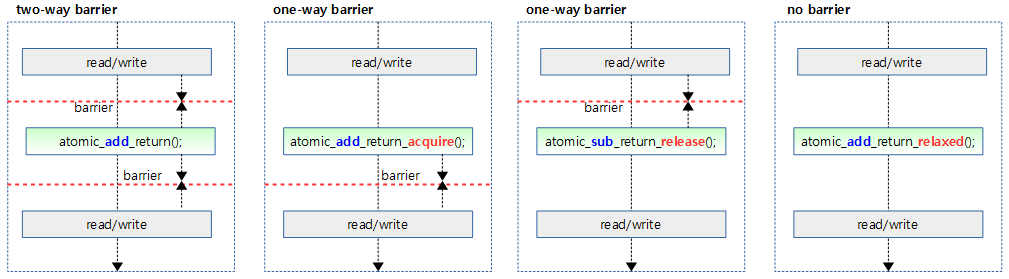
아래 그림은 atomic 함수와 배리어 관련 접미사가 붙었을 때 배리어가 동작하는 과정을 보여준다.
- barrier cost가 높기 때문에 성능을 극대화하려면 *_relaxed를 사용하여 atomic operation 위 아래로 barrier 없이 동작할 수 있는 코드를 사용할 수 있는지 여부를 판단한 후에 적용해야 한다.
before | after atomic
여러 개의 atomic opeartion 전/후로 smp_mb()를 수행하는 API들을 없애고, 두 개의 API로 단축하여 사용한다.
- smp_mb__before_atomic()
- Atomic operation 전에 smp_mb()를 수행한다.
- smp_mb__after_atomic()
- Atomic operation 후에 smp_mb()를 수행한다.
read/set
- atomic_read_acquire(&v)
- 단방향 배리어와 함께 v 주소 값을 읽어온다.
- 이 매크로 함수는 smp_load_acquire() 배리어 함수를 호출한다.
- 거의 대부분의 코드들은 atomic_read_acquire() atomic 함수를 사용하지 않고 smp_load_acquire() 배리어 함수를 직접 사용한다.
- atomic_read_acquire() 사용 사례:
- include/linux/qrwlock.h – rspin_until_writer_unlock()
- atomic_set_release(&v, i)
- 단방향 배리어와 함께 v 주소 값에 i 값을 대입한다.
- smp_store_release() 배리어 함수를 호출한다.
- 거의 대부분의 코드들은 atomic_set_release() atomic 함수를 사용하지 않고 smp_store_release() 배리어 함수를 직접 사용한다.
- atomic_set_release() 사용 사례:
- kernel/jump_label.c – static_key_slow_inc_cpuslocked()
Atomic 함수 분석
산술/비트 연산 관련 – for ARM32 (LL/SC atomic)
atomic_add() 등 6개 함수
아래 ATOMIC_OPS() 및 ATOMIC_OP() 매크로 함수를 통해 다음 함수들을 생성한다.
- atomic_add()
- atomic_add_return_relaxed()
- atomic_fetch_add_relaxed()
- atomic_sub()
- atomic_sub_return_relaxed()
- atomic_fetch_sub_relaxed()
arch/arm/include/asm/atomic.h
#define ATOMIC_OPS(op, c_op, asm_op) \
ATOMIC_OP(op, c_op, asm_op) \
ATOMIC_OP_RETURN(op, c_op, asm_op) \
ATOMIC_FETCH_OP(op, c_op, asm_op)
ATOMIC_OPS(add, +=, add)
ATOMIC_OPS(sub, -=, sub)
atomic_and() 등 12개 함수
아래 ATOMIC_OPS() 및 ATOMIC_OP() 매크로 함수를 통해 다음 함수들을 생성한다.
- atomic_and()
- atomic_and_return_relaxed()
- atomic_fetch_and_relaxed()
- atomic_andnot()
- atomic_andnot_return_relaxed()
- atomic_fetch_andnot_relaxed()
- atomic_or()
- atomic_or_return_relaxed()
- atomic_fetch_or_relaxed()
- atomic_xor()
- atomic_xor_return_relaxed()
- atomic_fetch_xor_relaxed()
arch/arm/include/asm/atomic.h
#undef ATOMIC_OPS
#define ATOMIC_OPS(op, c_op, asm_op) \
ATOMIC_OP(op, c_op, asm_op) \
ATOMIC_FETCH_OP(op, c_op, asm_op)
ATOMIC_OPS(and, &=, and)
ATOMIC_OPS(andnot, &= ~, bic)
ATOMIC_OPS(or, |=, orr)
ATOMIC_OPS(xor, ^=, eor)
ATOMIC_OP()
arch/arm/include/asm/atomic.h
/*
* ARMv6 UP and SMP safe atomic ops. We use load exclusive and
* store exclusive to ensure that these are atomic. We may loop
* to ensure that the update happens.
*/
#define ATOMIC_OP(op, c_op, asm_op) \
static inline void atomic_##op(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
prefetchw(&v->counter); \
__asm__ __volatile__("@ atomic_" #op "\n" \
"1: ldrex %0, [%3]\n" \
" " #asm_op " %0, %0, %4\n" \
" strex %1, %0, [%3]\n" \
" teq %1, #0\n" \
" bne 1b" \
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) \
: "r" (&v->counter), "Ir" (i) \
: "cc"); \
}
v 주소의 32비트 값을 읽은 후 i 값을 연산(add, sub, and, andnot, or 및 xor)시켜 저장한다. 이를 atomic 하게 처리한다.
- atomic operation이 실패하여 재반복 하는 case
- 현재 프로세스가 v 주소에 접근하는 중에 다른 프로세스가 v 라인값이 저장된 캐시 라인에 접근하는 경우 실패
ATOMIC_OP_RETURN()
arch/arm/include/asm/atomic.h
#define ATOMIC_OP_RETURN(op, c_op, asm_op) \
static inline int atomic_##op##_return_relaxed(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
prefetchw(&v->counter); \
\
__asm__ __volatile__("@ atomic_" #op "_return\n" \
"1: ldrex %0, [%3]\n" \
" " #asm_op " %0, %0, %4\n" \
" strex %1, %0, [%3]\n" \
" teq %1, #0\n" \
" bne 1b" \
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) \
: "r" (&v->counter), "Ir" (i) \
: "cc"); \
\
smp_mb(); \
\
return result; \
}
v 주소의 32비트값을 읽은 후 i 값을 연산(add, sub, and, andnot, or 및 xor)시킨 후 저장한다. 이를 atomic 하게 처리하는 것은 동일하지만 결과 값으로 연산시켜 저장한 값을 그대로 반환한다.
ATOMIC_FETCH_OP()
arch/arm/include/asm/atomic.h
#define ATOMIC_FETCH_OP(op, c_op, asm_op) \
static inline int atomic_fetch_##op##_relaxed(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result, val; \
\
prefetchw(&v->counter); \
\
__asm__ __volatile__("@ atomic_fetch_" #op "\n" \
"1: ldrex %0, [%4]\n" \
" " #asm_op " %1, %0, %5\n" \
" strex %2, %1, [%4]\n" \
" teq %2, #0\n" \
" bne 1b" \
: "=&r" (result), "=&r" (val), "=&r" (tmp), "+Qo" (v->counter) \
: "r" (&v->counter), "Ir" (i) \
: "cc"); \
\
return result; \
}
v 주소의 32비트값을 읽은 후 i 값을 연산(add, sub, and, andnot, or 및 xor)시키고 저장한다. 이를 atomic 하게 처리하는 것은 동일하지만 결과 값으로 연산전에 fetch한 v값을 반환한다.
산술/비트 연산 관련 – ARM64 (LL/SC & LSE atomic 공통)
atomic_add() 등 9개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- atomic_add()
- atomic_add_return()
- atomic_add_return_acquire()
- atomic_add_return_release()
- atomic_add_return_relaxed()
- atomic_fetch_add()
- atomic_fetch_add_acquire()
- atomic_fetch_add_release()
- atomic_fetch_add_relaxed()
include/asm-generic/atomic-instrumented.h
static __always_inline void
atomic_add(int i, atomic_t *v)
{
instrument_atomic_read_write(v, sizeof(*v));
arch_atomic_add(i, v);
}
#define atomic_add atomic_add
#if !defined(arch_atomic_add_return_relaxed) || defined(arch_atomic_add_return)
static __always_inline int
atomic_add_return(int i, atomic_t *v)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_add_return(i, v);
}
#define atomic_add_return atomic_add_return
#endif
#if defined(arch_atomic_add_return_acquire)
static __always_inline int
atomic_add_return_acquire(int i, atomic_t *v)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_add_return_acquire(i, v);
}
#define atomic_add_return_acquire atomic_add_return_acquire
#endif
#if defined(arch_atomic_add_return_release)
static __always_inline int
atomic_add_return_release(int i, atomic_t *v)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_add_return_release(i, v);
}
#define atomic_add_return_release atomic_add_return_release
#endif
#if defined(arch_atomic_add_return_relaxed)
static __always_inline int
atomic_add_return_relaxed(int i, atomic_t *v)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_add_return_relaxed(i, v);
}
#define atomic_add_return_relaxed atomic_add_return_relaxed
#endif
atomic_sub() 등 9개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다. (코드 생략)
- atomic_sub()
- atomic_sub_return()
- atomic_sub_return_acquire()
- atomic_sub_return_release()
- atomic_sub_return_relaxed()
- atomic_fetch_sub()
- atomic_fetch_sub_acquire()
- atomic_fetch_sub_release()
- atomic_fetch_sub_relaxed()
atomic_inc() 등 9개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다. (코드 생략)
- atomic_inc()
- atomic_inc_return()
- atomic_inc_return_acquire()
- atomic_inc_return_release()
- atomic_inc_return_relaxed()
- atomic_fetch_inc()
- atomic_fetch_inc_acquire()
- atomic_fetch_inc_release()
- atomic_fetch_inc_relaxed()
atomic_dec() 등 9개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다. (코드 생략)
- atomic_dec()
- atomic_dec_return()
- atomic_dec_return_acquire()
- atomic_dec_return_release()
- atomic_dec_return_relaxed()
- atomic_fetch_dec()
- atomic_fetch_dec_acquire()
- atomic_fetch_dec_release()
- atomic_fetch_dec_relaxed()
atomic_and() 등 5개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다. (코드 생략)
- atomic_and()
- atomic_fetch_and()
- atomic_fetch_and_acquire()
- atomic_fetch_and_release()
- atomic_fetch_and_relaxed()
atomic_andnot() 등 5개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다. (코드 생략)
- atomic_andnot()
- atomic_fetch_andnot()
- atomic_fetch_andnot_acquire()
- atomic_fetch_andnot_release()
- atomic_fetch_andnot_relaxed()
atomic_or() 등 5개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다. (코드 생략)
- atomic_or()
- atomic_fetch_or()
- atomic_fetch_or_acquire()
- atomic_fetch_or_release()
- atomic_fetch_or_relaxed()
atomic_xor() 등 5개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다. (코드 생략)
- atomic_xor()
- atomic_fetch_xor()
- atomic_fetch_xor_acquire()
- atomic_fetch_xor_release()
- atomic_fetch_xor_relaxed()
arch_atomic_add() 등 6개 함수
아래 ATOMIC_OP() 매크로 함수를 통해 다음 함수들을 생성한다.
- arch_atomic_andnot()
- arch_atomic_or()
- arch_atomic_xor()
- arch_atomic_add()
- arch_atomic_and()
- arch_atomic_sub()
arch/arm64/include/asm/atomic.h – for ARM64
#define ATOMIC_OP(op) \
static inline void arch_##op(int i, atomic_t *v) \
{ \
__lse_ll_sc_body(op, i, v); \
}
ATOMIC_OP(atomic_andnot)
ATOMIC_OP(atomic_or)
ATOMIC_OP(atomic_xor)
ATOMIC_OP(atomic_add)
ATOMIC_OP(atomic_and)
ATOMIC_OP(atomic_sub)
arch_atomic_fetch_add() 등 32개 함수
아래 ATOMIC_FETCH_OPS() 및 ATOMIC_FETCH_OP() 매크로 함수를 통해 다음 함수들이 생성된된다.
- arch_atomic_fetch_andnot()
- arch_atomic_fetch_andnot_relaxed()
- arch_atomic_fetch_andnot_acquire()
- arch_atomic_fetch_andnot_release()
- arch_atomic_fetch_or()
- arch_atomic_fetch_or_relaxed()
- arch_atomic_fetch_or_acquire()
- arch_atomic_fetch_or_release()
- arch_atomic_fetch_xor()
- arch_atomic_fetch_xor_relaxed()
- arch_atomic_fetch_xor_acquire()
- arch_atomic_fetch_xor_release()
- arch_atomic_fetch_add()
- arch_atomic_fetch_add_relaxed()
- arch_atomic_fetch_add_acquire()
- arch_atomic_fetch_add_release()
- arch_atomic_fetch_and()
- arch_atomic_fetch_and_relaxed()
- arch_atomic_fetch_and_acquire()
- arch_atomic_fetch_and_release()
- arch_atomic_fetch_sub()
- arch_atomic_fetch_sub_relaxed()
- arch_atomic_fetch_sub_acquire()
- arch_atomic_fetch_sub_release()
- arch_atomic_add_return()
- arch_atomic_add_return_relaxed()
- arch_atomic_add_return_acquire()
- arch_atomic_add_return_release()
- arch_atomic_sub_return()
- arch_atomic_sub_return_relaxed()
- arch_atomic_sub_return_acquire()
- arch_atomic_sub_return_release()
arch/arm64/include/asm/atomic.h – for ARM64
#define ATOMIC_FETCH_OP(name, op) \
static inline int arch_##op##name(int i, atomic_t *v) \
{ \
return __lse_ll_sc_body(op##name, i, v); \
}
#define ATOMIC_FETCH_OPS(op) \
ATOMIC_FETCH_OP(_relaxed, op) \
ATOMIC_FETCH_OP(_acquire, op) \
ATOMIC_FETCH_OP(_release, op) \
ATOMIC_FETCH_OP( , op)
ATOMIC_FETCH_OPS(atomic_fetch_andnot)
ATOMIC_FETCH_OPS(atomic_fetch_or)
ATOMIC_FETCH_OPS(atomic_fetch_xor)
ATOMIC_FETCH_OPS(atomic_fetch_add)
ATOMIC_FETCH_OPS(atomic_fetch_and)
ATOMIC_FETCH_OPS(atomic_fetch_sub)
ATOMIC_FETCH_OPS(atomic_add_return)
ATOMIC_FETCH_OPS(atomic_sub_return)
CONFIG_ARM64_LSE_ATOMICS
CONFIG_ARM64_LSE_ATOMICS 컴파일러 옵션은 gas 툴이 lse 명령을 지원하는지 여부에 따라 결정된다. 만일 지원하지 않는 경우 LL/SC atomic 명령을 사용한다. gas 툴이 lse 명령을 지원하는 경우 런타임에 ARMv8.1 이상의 아키텍처에 구현된 LSE 기능 지원 여부에 따라 Static branch를 사용하여 자동으로 분기하는 방식으로 LL/SC atomic 명령과 LSE atomic 명령을 선택하여 사용할 수 있도록 한다.
__lse_ll_sc_body() – LL/SC 전용
#define __lse_ll_sc_body(op, ...) __ll_sc_##op(__VA_ARGS__)
LL/SC atomic 명령을 사용하도록 __ll_sc_ 접두사를 사용하는 함수를 사용하도록 한다.
__lse_ll_sc_body() – LL/SC & LSE
#define __lse_ll_sc_body(op, ...) \
({ \
system_uses_lse_atomics() ? \
__lse_##op(__VA_ARGS__) : \
__ll_sc_##op(__VA_ARGS__); \
})
시스템의 LSE atomic 지원 여부에 따라 분기한다.
- LSE를 지원하는 경우
- LSE atomic 명령을 사용하도록 __lse_ 접두사를 사용하는 함수를 호출하도록 한다.
- LSE를 지원하지 않는 경우
- LL/SC atomic 명령을 사용하도록 __ll_sc_ 접두사를 사용하는 함수를 호출하도록 한다.
for ARM64 (LL/SC atomic)
64bit ARMv8 아케턱처에서도 32비트에서 atomic assembly 명령인 ldrex/strex 명령이 사용하는 LL/SC(Load excLusive/Store excLusive) 방식과 동일한 방식을 사용한다. ARMv8에서는 ldxr과 stxr 명령을 사용한다.
- ARMv8 아키텍처에서는 return 및 fetch를 포함하는 atomic operation들은 모두 4가지 타입의 배리어 관련 명령들도 제공한다.
__ll_sc_atomic_add() 등 18개 함수
아래 ATOMIC_FETCH_OPS(), ATOMIC_OP(), ATOMIC_OP_RETURN() 및 ATOMIC_FETCH_OP() 매크로 함수를 통해 다음 함수들이 생성된다.
- __ll_sc_atomic_add()
- __ll_sc_atomic_add_return()
- __ll_sc_atomic_add_return_relaxed()
- __ll_sc_atomic_add_return_acquire()
- __ll_sc_atomic_add_return_release()
- __ll_sc_atomic_fetch_add()
- __ll_sc_atomic_fetch_add_relaxed()
- __ll_sc_atomic_fetch_add_acquire()
- __ll_sc_atomic_fetch_add_release()
- __ll_sc_atomic_sub()
- __ll_sc_atomic_sub_return()
- __ll_sc_atomic_sub_return_relaxed()
- __ll_sc_atomic_sub_return_acquire()
- __ll_sc_atomic_sub_return_release()
- __ll_sc_atomic_fetch_sub()
- __ll_sc_atomic_fetch_sub_relaxed()
- __ll_sc_atomic_fetch_sub_acquire()
- __ll_sc_atomic_fetch_sub_release()
arch/arm64/include/asm/atomic_ll_sc.h
#define ATOMIC_OPS(...) \
ATOMIC_OP(__VA_ARGS__) \
ATOMIC_OP_RETURN( , dmb ish, , l, "memory", __VA_ARGS__)\
ATOMIC_OP_RETURN(_relaxed, , , , , __VA_ARGS__)\
ATOMIC_OP_RETURN(_acquire, , a, , "memory", __VA_ARGS__)\
ATOMIC_OP_RETURN(_release, , , l, "memory", __VA_ARGS__)\
ATOMIC_FETCH_OP ( , dmb ish, , l, "memory", __VA_ARGS__)\
ATOMIC_FETCH_OP (_relaxed, , , , , __VA_ARGS__)\
ATOMIC_FETCH_OP (_acquire, , a, , "memory", __VA_ARGS__)\
ATOMIC_FETCH_OP (_release, , , l, "memory", __VA_ARGS__)
ATOMIC_OPS(add, add)
ATOMIC_OPS(sub, sub)
__ll_sc_atomic_and() 등 20개 함수
아래 ATOMIC_FETCH_OPS(), ATOMIC_OP() 및 ATOMIC_FETCH_OP() 매크로 함수를 통해 다음 함수들이 생성된다.
- __ll_sc_atomic_and()
- __ll_sc_atomic_fetch_and()
- __ll_sc_atomic_fetch_and_relaxed()
- __ll_sc_atomic_fetch_and_acquire()
- __ll_sc_atomic_fetch_and_release()
- __ll_sc_atomic_andnot()
- __ll_sc_atomic_fetch_andnot()
- __ll_sc_atomic_fetch_andnot_relaxed()
- __ll_sc_atomic_fetch_andnot_acquire()
- __ll_sc_atomic_fetch_andnot_release()
- __ll_sc_atomic_or()
- __ll_sc_atomic_fetch_or()
- __ll_sc_atomic_fetch_or_relaxed()
- __ll_sc_atomic_fetch_or_acquire()
- __ll_sc_atomic_fetch_or_release()
- __ll_sc_atomic_xor()
- __ll_sc_atomic_fetch_xor()
- __ll_sc_atomic_fetch_xor_relaxed()
- __ll_sc_atomic_fetch_xor_acquire()
- __ll_sc_atomic_fetch_xor_release()
arch/arm64/include/asm/atomic_ll_sc.h
#undef ATOMIC_OPS
#define ATOMIC_OPS(...) \
ATOMIC_OP(__VA_ARGS__) \
ATOMIC_FETCH_OP ( , dmb ish, , l, "memory", __VA_ARGS__)\
ATOMIC_FETCH_OP (_relaxed, , , , , __VA_ARGS__)\
ATOMIC_FETCH_OP (_acquire, , a, , "memory", __VA_ARGS__)\
ATOMIC_FETCH_OP (_release, , , l, "memory", __VA_ARGS__)
ATOMIC_OPS(and, and)
ATOMIC_OPS(andnot, bic)
ATOMIC_OPS(or, orr)
ATOMIC_OPS(xor, eor)
ATOMIC_OP()
arch/arm64/include/asm/atomic_ll_sc.h
/*
* AArch64 UP and SMP safe atomic ops. We use load exclusive and
* store exclusive to ensure that these are atomic. We may loop
* to ensure that the update happens.
*/
#define ATOMIC_OP(op, asm_op, constraint) \
static inline void \
__ll_sc_atomic_##op(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
asm volatile("// atomic_" #op "\n" \
__LL_SC_FALLBACK( \
" prfm pstl1strm, %2\n" \
"1: ldxr %w0, %2\n" \
" " #asm_op " %w0, %w0, %w3\n" \
" stxr %w1, %w0, %2\n" \
" cbnz %w1, 1b\n") \
: "=&r" (result), "=&r" (tmp), "+Q" (v->counter) \
: __stringify(constraint) "r" (i)); \
}
ldxr 및 stxr 명령을 사용하여 성공리에 변경이 된 경우에만 함수를 빠져나간다.
- prefetch destination word를 위해 prfm 명령을 사용한다.
- ldxr/stxr 명령은 load/store exclusive register 명령이다.
- 뒤에 w레지스터가 오는 경우 32bit general 레지스터를 처리
- 뒤에 x레지스터가 오는 경우 64bit general 레지스터를 처리
ATOMIC_OP_RETURN()
arch/arm64/include/asm/atomic_ll_sc.h
#define ATOMIC_OP_RETURN(name, mb, acq, rel, cl, op, asm_op, constraint)\
static inline int \
__ll_sc_atomic_##op##_return##name(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
asm volatile("// atomic_" #op "_return" #name "\n" \
__LL_SC_FALLBACK( \
" prfm pstl1strm, %2\n" \
"1: ld" #acq "xr %w0, %2\n" \
" " #asm_op " %w0, %w0, %w3\n" \
" st" #rel "xr %w1, %w0, %2\n" \
" cbnz %w1, 1b\n" \
" " #mb ) \
: "=&r" (result), "=&r" (tmp), "+Q" (v->counter) \
: __stringify(constraint) "r" (i) \
: cl); \
\
return result; \
}
ldxr 및 stxr 명령을 사용하여 성공리에 변경이 된 경우에만 함수를 빠져나간다. 결과 값으로 변경 후의 값을 반환한다.
- _acquire 접미사를 사용하는 경우 배리어 적용을 위해 “memory” 클로버를 사용하고, ldxr 대신 ldaxr 명령을 사용한다.
- ldaxr은 load-acquire exclusive register 명령이다.
- _release 접미사를 사용하는 경우 배리어 적용을 위해 “memory” 클로버를 사용하고, stxr 대신 stlxr 명령을 사용한다.
- stlxr은 store-release exclusive register 명령이다.
- 접미사가 없는 경우 위의 두 배리어를 적용한다.
- _relaxed 접미사를 사용하는 경우 “memory” 클로버도 사용하지 않고, 어떠한 배리어도 적용하지 않는다.
ATOMIC_FETCH_OP()
arch/arm64/include/asm/atomic_ll_sc.h
#define ATOMIC_FETCH_OP(name, mb, acq, rel, cl, op, asm_op, constraint) \
static inline int \
__ll_sc_atomic_fetch_##op##name(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int val, result; \
\
asm volatile("// atomic_fetch_" #op #name "\n" \
__LL_SC_FALLBACK( \
" prfm pstl1strm, %3\n" \
"1: ld" #acq "xr %w0, %3\n" \
" " #asm_op " %w1, %w0, %w4\n" \
" st" #rel "xr %w2, %w1, %3\n" \
" cbnz %w2, 1b\n" \
" " #mb ) \
: "=&r" (result), "=&r" (val), "=&r" (tmp), "+Q" (v->counter) \
: __stringify(constraint) "r" (i) \
: cl); \
\
return result; \
}
- ldxr 및 stxr 명령을 사용하여 성공리에 변경이 된 경우에만 함수를 빠져나간다. 결과 값으로 변경 전 값을 반환한다.
- 위의 return 함수들과 동일한 방식으로 4가지 타입의 배리어 명령을 지원한다.
for ARM64 (LSE atomic)
__lse_atomic_add()등 4개 함수
아래 ATOMIC_OP() 매크로 함수를 통해 다음 함수들이 생성된다. (ordering을 하지 않는 명령들이다)
- __lse_atomic_andnot()
- __lse_atomic_or()
- __lse_atomic_xor()
- __lse_atomic_add()
arch/arm64/include/asm/atomic_lse.h
#define ATOMIC_OP(op, asm_op) \
static inline void __lse_atomic_##op(int i, atomic_t *v) \
{ \
asm volatile( \
__LSE_PREAMBLE \
" " #asm_op " %w[i], %[v]\n" \
: [i] "+r" (i), [v] "+Q" (v->counter) \
: "r" (v)); \
}
ATOMIC_OP(andnot, stclr)
ATOMIC_OP(or, stset)
ATOMIC_OP(xor, steor)
ATOMIC_OP(add, stadd)
__lse_atomic_fetch_add()등 16개 함수
아래 ATOMIC_FETCH_OPS() 및 ATOMIC_FETCH_OP() 매크로 함수를 통해 다음 함수들이 생성된다. (ordering 선택이 필요한 명령들이다)
- __lse_atomic_andnot()
- __lse_atomic_andnot_relaxed()
- __lse_atomic_andnot_acquire()
- __lse_atomic_andnot_release()
- __lse_atomic_or()
- __lse_atomic_or_relaxed()
- __lse_atomic_or_acquire()
- __lse_atomic_or_release()
- __lse_atomic_xor()
- __lse_atomic_xor_relaxed()
- __lse_atomic_xor_acquire()
- __lse_atomic_xor_release()
- __lse_atomic_add()
- __lse_atomic_add_relaxed()
- __lse_atomic_add_acquire()
- __lse_atomic_add_release()
arch/arm64/include/asm/atomic_lse.h
#define ATOMIC_FETCH_OP(name, mb, op, asm_op, cl...) \
static inline int __lse_atomic_fetch_##op##name(int i, atomic_t *v) \
{ \
asm volatile( \
__LSE_PREAMBLE \
" " #asm_op #mb " %w[i], %w[i], %[v]" \
: [i] "+r" (i), [v] "+Q" (v->counter) \
: "r" (v) \
: cl); \
\
return i; \
}
#define ATOMIC_FETCH_OPS(op, asm_op) \
ATOMIC_FETCH_OP(_relaxed, , op, asm_op) \
ATOMIC_FETCH_OP(_acquire, a, op, asm_op, "memory") \
ATOMIC_FETCH_OP(_release, l, op, asm_op, "memory") \
ATOMIC_FETCH_OP( , al, op, asm_op, "memory")
ATOMIC_FETCH_OPS(andnot, ldclr)
ATOMIC_FETCH_OPS(or, ldset)
ATOMIC_FETCH_OPS(xor, ldeor)
ATOMIC_FETCH_OPS(add, ldadd)
사용하는 lse atomic은 4가지 메모리 오더링 명령을 지원한다.
- andnot
- ldclr, ldclra, ldclrl, ldclral
- or
- ldset, ldseta, ldsetl, ldsetal
- xor
- ldeor, ldeora, ldeorl, ldeoral
- add
- ldadd, ldadda, ldaddl, ldaddal
__lse_atomic_add_return()등 4개 함수
아래 ATOMIC_OP_ADD_RETURN() 매크로 함수를 통해 다음 함수들이 생성된다. (ordering 선택이 필요한 명령들이다)
- __lse_atomic_add_return()
- __lse_atomic_add_return_relaxed()
- __lse_atomic_add_return_acquire()
- __lse_atomic_add_return_release()
arch/arm64/include/asm/atomic_lse.h
#define ATOMIC_OP_ADD_RETURN(name, mb, cl...) \
static inline int __lse_atomic_add_return##name(int i, atomic_t *v) \
{ \
u32 tmp; \
\
asm volatile( \
__LSE_PREAMBLE \
" ldadd" #mb " %w[i], %w[tmp], %[v]\n" \
" add %w[i], %w[i], %w[tmp]" \
: [i] "+r" (i), [v] "+Q" (v->counter), [tmp] "=&r" (tmp) \
: "r" (v) \
: cl); \
\
return i; \
}
ATOMIC_OP_ADD_RETURN(_relaxed, )
ATOMIC_OP_ADD_RETURN(_acquire, a, "memory")
ATOMIC_OP_ADD_RETURN(_release, l, "memory")
ATOMIC_OP_ADD_RETURN( , al, "memory")
사용하는 lse atomic은 4가지 메모리 오더링 명령을 지원한다.
- add
- ldadd, ldadda, ldaddl, ldaddal
__lse_atomic_and()
arch/arm64/include/asm/atomic_lse.h
static inline void __lse_atomic_and(int i, atomic_t *v)
{
asm volatile(
__LSE_PREAMBLE
" mvn %w[i], %w[i]\n"
" stclr %w[i], %[v]"
: [i] "+&r" (i), [v] "+Q" (v->counter)
: "r" (v));
}
and 연산 atomic 함수는 매크로를 사용하지 않고 별도로 작성되어 있다.
__lse_atomic_fetch_and()등 4개 함수
아래 ATOMIC_FETCH_OP_AND() 매크로 함수를 통해 다음 함수들이 생성된다. (ordering 선택이 필요한 명령들이다)
- __lse_atomic_fetch_add()
- __lse_atomic_fetch_add_relaxed()
- __lse_atomic_fetch_add_acquire()
- __lse_atomic_fetch_add_release()
arch/arm64/include/asm/atomic_lse.h
#define ATOMIC_FETCH_OP_AND(name, mb, cl...) \
static inline int __lse_atomic_fetch_and##name(int i, atomic_t *v) \
{ \
asm volatile( \
__LSE_PREAMBLE \
" mvn %w[i], %w[i]\n" \
" ldclr" #mb " %w[i], %w[i], %[v]" \
: [i] "+&r" (i), [v] "+Q" (v->counter) \
: "r" (v) \
: cl); \
\
return i; \
}
ATOMIC_FETCH_OP_AND(_relaxed, )
ATOMIC_FETCH_OP_AND(_acquire, a, "memory")
ATOMIC_FETCH_OP_AND(_release, l, "memory")
ATOMIC_FETCH_OP_AND( , al, "memory")
__lse_atomic_sub()
arch/arm64/include/asm/atomic_lse.h
static inline void __lse_atomic_sub(int i, atomic_t *v)
{
asm volatile(
__LSE_PREAMBLE
" neg %w[i], %w[i]\n"
" stadd %w[i], %[v]"
: [i] "+&r" (i), [v] "+Q" (v->counter)
: "r" (v));
}
sub 연산 atomic 함수는 매크로를 사용하지 않고 별도로 작성되어 있다.
__lse_atomic_sub_return()등 4개 함수
아래 ATOMIC_OP_SUB_RETURN() 매크로 함수를 통해 다음 함수들이 생성된다. (ordering 선택이 필요한 명령들이다)
- __lse_atomic_sub_return()
- __lse_atomic_sub_return_relaxed()
- __lse_atomic_sub_return_acquire()
- __lse_atomic_sub_return_release()
arch/arm64/include/asm/atomic_lse.h
#define ATOMIC_OP_SUB_RETURN(name, mb, cl...) \
static inline int __lse_atomic_sub_return##name(int i, atomic_t *v) \
{ \
u32 tmp; \
\
asm volatile( \
__LSE_PREAMBLE \
" neg %w[i], %w[i]\n" \
" ldadd" #mb " %w[i], %w[tmp], %[v]\n" \
" add %w[i], %w[i], %w[tmp]" \
: [i] "+&r" (i), [v] "+Q" (v->counter), [tmp] "=&r" (tmp) \
: "r" (v) \
: cl); \
\
return i; \
}
ATOMIC_OP_SUB_RETURN(_relaxed, )
ATOMIC_OP_SUB_RETURN(_acquire, a, "memory")
ATOMIC_OP_SUB_RETURN(_release, l, "memory")
ATOMIC_OP_SUB_RETURN( , al, "memory")
사용하는 lse atomic은 add 명령을 사용하여 sub를 구현하였고, 4가지 메모리 오더링 명령을 지원한다.
- ldadd
- ldadd, ldadda, ldaddl, ldaddal
__lse_atomic_fetch_sub()등 4개 함수
아래 ATOMIC_FETCH_OP_SUB() 매크로 함수를 통해 다음 함수들이 생성된다. (ordering 선택이 필요한 명령들이다)
- __lse_atomic_fetch_sub()
- __lse_atomic_fetch_sub_relaxed()
- __lse_atomic_fetch_sub_acquire()
- __lse_atomic_fetch_sub_release()
arch/arm64/include/asm/atomic_lse.h
#define ATOMIC_FETCH_OP_SUB(name, mb, cl...) \
static inline int __lse_atomic_fetch_sub##name(int i, atomic_t *v) \
{ \
asm volatile( \
__LSE_PREAMBLE \
" neg %w[i], %w[i]\n" \
" ldadd" #mb " %w[i], %w[i], %[v]" \
: [i] "+&r" (i), [v] "+Q" (v->counter) \
: "r" (v) \
: cl); \
\
return i; \
}
ATOMIC_FETCH_OP_SUB(_relaxed, )
ATOMIC_FETCH_OP_SUB(_acquire, a, "memory")
ATOMIC_FETCH_OP_SUB(_release, l, "memory")
ATOMIC_FETCH_OP_SUB( , al, "memory")
Exchange atomic – for ARM32 (LL/SC atomic)
atomic_xchg()
arch/arm/include/asm/atomic.h
#define atomic_xchg(v, new) (xchg(&((v)->counter), new))
- v값을 읽은 후 new 값으로 교체한 후 다시 저장한다. 그리고 교체 전의 v 값을 반환한다.
xchg()
arch/arm/include/asm/cmpxchg.h
#define xchg(ptr, x) ({ \
((__typeof__(*(ptr))) \
__xchg((unsigned long)(x), (ptr), sizeof(*(ptr)))); \
})
__xchg()
arch/arm/include/asm/cmpxchg.h
static inline
unsigned long __xchg(unsigned long x, volatile void *ptr, int size)
{
unsigned long ret, flags;
switch (size) {
case 1:
#ifdef __xchg_u8
return __xchg_u8(x, ptr);
#else
local_irq_save(flags);
ret = *(volatile u8 *)ptr;
*(volatile u8 *)ptr = x;
local_irq_restore(flags);
return ret;
#endif /* __xchg_u8 */
case 2:
#ifdef __xchg_u16
return __xchg_u16(x, ptr);
#else
local_irq_save(flags);
ret = *(volatile u16 *)ptr;
*(volatile u16 *)ptr = x;
local_irq_restore(flags);
return ret;
#endif /* __xchg_u16 */
case 4:
#ifdef __xchg_u32
return __xchg_u32(x, ptr);
#else
local_irq_save(flags);
ret = *(volatile u32 *)ptr;
*(volatile u32 *)ptr = x;
local_irq_restore(flags);
return ret;
#endif /* __xchg_u32 */
#ifdef CONFIG_64BIT
case 8:
#ifdef __xchg_u64
return __xchg_u64(x, ptr);
#else
local_irq_save(flags);
ret = *(volatile u64 *)ptr;
*(volatile u64 *)ptr = x;
local_irq_restore(flags);
return ret;
#endif /* __xchg_u64 */
#endif /* CONFIG_64BIT */
default:
__xchg_called_with_bad_pointer();
return x;
}
}
atomic_cmpxchg_relaxed()
mutex(optimistic spin lock), futex, qrwlock 등에서 사용하는 함수이다.
아래 소스도 ARMv6 이상 SMP 시스템용 코드이다.
- 주요 어셈블리 코드는 다음과 같다.
- ldrex oldval <- [&ptr->counter]
- mov res, #0
- teq oldval, old
- strexeq res, new, [&ptr->counter]
- ptr->counter 값이 old와 같은 경우에만 new 값을 기록한다.
- smp_mb()
- 동기화를 위해 결과 값이 store buffer를 통해 메모리에 기록되는데 완전히 기록이 완료될 때까지 기다리고 oldval 값을 리턴한다.
arch/arm/include/asm/atomic.h
static inline int atomic_cmpxchg_relaxed(atomic_t *ptr, int old, int new)
{
int oldval;
unsigned long res;
prefetchw(&ptr->counter);
do {
__asm__ __volatile__("@ atomic_cmpxchg\n"
"ldrex %1, [%3]\n"
"mov %0, #0\n"
"teq %1, %4\n"
"strexeq %0, %5, [%3]\n"
: "=&r" (res), "=&r" (oldval), "+Qo" (ptr->counter)
: "r" (&ptr->counter), "Ir" (old), "r" (new)
: "cc");
} while (res);
return oldval;
}
ptr값을 읽어 old와 같은 경우에만 new 값으로 교체한 후 다시 저장한다. 그리고 교체 전의 ptr 값을 반환한다.
- *ptr <- new (if *ptr == old)
Exchange atomic – for ARM64 (LL/SC & LSE atomic 공통)
atomic_xchg() 함수 추적 경로
ARM64 시스템에서 atomic_xchg() 함수를 추적해보면 다음과 같다.
atomic_xchg()
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- atomic_xchg()
- atomic_xchg_acquire()
- atomic_xchg_release()
- atomic_xchg_relaxed()
include/asm-generic/atomic-instrumented.h
#if !defined(arch_atomic_xchg_relaxed) || defined(arch_atomic_xchg)
static __always_inline int
atomic_xchg(atomic_t *v, int i)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_xchg(v, i);
}
#define atomic_xchg atomic_xchg
#endif
#if defined(arch_atomic_xchg_acquire)
static __always_inline int
atomic_xchg_acquire(atomic_t *v, int i)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_xchg_acquire(v, i);
}
#define atomic_xchg_acquire atomic_xchg_acquire
#endif
#if defined(arch_atomic_xchg_release)
static __always_inline int
atomic_xchg_release(atomic_t *v, int i)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_xchg_release(v, i);
}
#define atomic_xchg_release atomic_xchg_release
#endif
#if defined(arch_atomic_xchg_relaxed)
static __always_inline int
atomic_xchg_relaxed(atomic_t *v, int i)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_xchg_relaxed(v, i);
}
#define atomic_xchg_relaxed atomic_xchg_relaxed
#endif
@ptr 주소에 @v 값으로 atomic 하게 치환한다.
arch_atomic_xchg()
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- arch_atomic_xchg()
- arch_atomic_xchg_acquire()
- arch_atomic_xchg_release()
- arch_atomic_xchg_relaxed()
arch/arm64/include/asm/atomic.h
#define arch_atomic_xchg_relaxed(v, new) \
arch_xchg_relaxed(&((v)->counter), (new))
#define arch_atomic_xchg_acquire(v, new) \
arch_xchg_acquire(&((v)->counter), (new))
#define arch_atomic_xchg_release(v, new) \
arch_xchg_release(&((v)->counter), (new))
#define arch_atomic_xchg(v, new) \
arch_xchg(&((v)->counter), (new))
arch_xchg() 등 4개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- arch_xchg()
- arch_xchg_acquire()
- arch_xchg_release()
- arch_xchg_relaxed()
arch/arm64/include/asm/cmpxchg.h
#define arch_xchg_relaxed(...) __xchg_wrapper( , __VA_ARGS__)
#define arch_xchg_acquire(...) __xchg_wrapper(_acq, __VA_ARGS__)
#define arch_xchg_release(...) __xchg_wrapper(_rel, __VA_ARGS__)
#define arch_xchg(...) __xchg_wrapper( _mb, __VA_ARGS__)
__xchg_wrapper()
arch/arm64/include/asm/cmpxchg.h
#define __xchg_wrapper(sfx, ptr, x) \
({ \
__typeof__(*(ptr)) __ret; \
__ret = (__typeof__(*(ptr))) \
__xchg##sfx((unsigned long)(x), (ptr), sizeof(*(ptr))); \
__ret; \
})
__xchg() 등 4개 함수
아래 __XCHG_GEN() 매크로 함수를 통해 메모리 ordering에 따라 다음 함수들이 준비되었다.
- __xchg()
- __xchg_acq()
- __xchg_rel()
- __xchg_mb()
arch/arm64/include/asm/cmpxchg.h
#define __XCHG_GEN(sfx) \
static __always_inline unsigned long __xchg##sfx(unsigned long x, \
volatile void *ptr, \
int size) \
{ \
switch (size) { \
case 1: \
return __xchg_case##sfx##_8(x, ptr); \
case 2: \
return __xchg_case##sfx##_16(x, ptr); \
case 4: \
return __xchg_case##sfx##_32(x, ptr); \
case 8: \
return __xchg_case##sfx##_64(x, ptr); \
default: \
BUILD_BUG(); \
} \
\
unreachable(); \
}
__XCHG_GEN()
__XCHG_GEN(_acq)
__XCHG_GEN(_rel)
__XCHG_GEN(_mb)
__xchg_case_8() 등 16개 함수
아래 __XCHG_CASE() 매크로 함수를 통해 메모리 ordering 및 데이터 사이즈에 따라 다음 함수들이 준비되었다.
- __xchg_case_8()
- __xchg_case_acq_8()
- __xchg_case_rel_8()
- __xchg_case_mb_8()
- __xchg_case_16()
- __xchg_case_acq_16()
- __xchg_case_rel_16()
- __xchg_case_mb_16()
- __xchg_case_32()
- __xchg_case_acq_32()
- __xchg_case_rel_32()
- __xchg_case_mb_32()
- __xchg_case_64()
- __xchg_case_acq_64()
- __xchg_case_rel_64()
- __xchg_case_mb_64()
arch/arm64/include/asm/cmpxchg.h
/*
* We need separate acquire parameters for ll/sc and lse, since the full
* barrier case is generated as release+dmb for the former and
* acquire+release for the latter.
*/
#define __XCHG_CASE(w, sfx, name, sz, mb, nop_lse, acq, acq_lse, rel, cl) \
static inline u##sz __xchg_case_##name##sz(u##sz x, volatile void *ptr) \
{ \
u##sz ret; \
unsigned long tmp; \
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
" prfm pstl1strm, %2\n" \
"1: ld" #acq "xr" #sfx "\t%" #w "0, %2\n" \
" st" #rel "xr" #sfx "\t%w1, %" #w "3, %2\n" \
" cbnz %w1, 1b\n" \
" " #mb, \
/* LSE atomics */ \
" swp" #acq_lse #rel #sfx "\t%" #w "3, %" #w "0, %2\n" \
__nops(3) \
" " #nop_lse) \
: "=&r" (ret), "=&r" (tmp), "+Q" (*(u##sz *)ptr) \
: "r" (x) \
: cl); \
\
return ret; \
}
__XCHG_CASE(w, b, , 8, , , , , , )
__XCHG_CASE(w, h, , 16, , , , , , )
__XCHG_CASE(w, , , 32, , , , , , )
__XCHG_CASE( , , , 64, , , , , , )
__XCHG_CASE(w, b, acq_, 8, , , a, a, , "memory")
__XCHG_CASE(w, h, acq_, 16, , , a, a, , "memory")
__XCHG_CASE(w, , acq_, 32, , , a, a, , "memory")
__XCHG_CASE( , , acq_, 64, , , a, a, , "memory")
__XCHG_CASE(w, b, rel_, 8, , , , , l, "memory")
__XCHG_CASE(w, h, rel_, 16, , , , , l, "memory")
__XCHG_CASE(w, , rel_, 32, , , , , l, "memory")
__XCHG_CASE( , , rel_, 64, , , , , l, "memory")
__XCHG_CASE(w, b, mb_, 8, dmb ish, nop, , a, l, "memory")
__XCHG_CASE(w, h, mb_, 16, dmb ish, nop, , a, l, "memory")
__XCHG_CASE(w, , mb_, 32, dmb ish, nop, , a, l, "memory")
__XCHG_CASE( , , mb_, 64, dmb ish, nop, , a, l, "memory")
atomic xchg 명령을 수행하는데 LSE 기능이 있는 시스템의 경우 lse 방식, 그렇지 않은 경우 ll_sc 방식으로 치환한다.
- ll/sc의 경우 양방향 베리어에 cost가 높은 dmb ish를 사용한다.
atomic_cmpxchg() 함수 추적 경로
ARM64 시스템에서 atomic_cmpxchg() 함수를 추적해보면 다음과 같다.
- atomic_cmpxchg()
- arch_atomic_cmpxchg()
- arch_cmpxchg()
- __cmpxchg_wrapper()
- __cmpxchg()
- __cmpxchg_case_32()
- __ll_sc__cmpxchg_case_32() 또는 __lse__cmpxchg_case_32()
atomic_cmpxchg() 등 4개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- atomic_cmpxchg()
- atomic_cmpxchg_acquire()
- atomic_cmpxchg_release()
- atomic_cmpxchg_relaxed()
include/asm-generic/atomic-instrumented.h
#if !defined(arch_atomic_cmpxchg_relaxed) || defined(arch_atomic_cmpxchg)
static __always_inline int
atomic_cmpxchg(atomic_t *v, int old, int new)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_cmpxchg(v, old, new);
}
#define atomic_cmpxchg atomic_cmpxchg
#endif
#if defined(arch_atomic_cmpxchg_acquire)
static __always_inline int
atomic_cmpxchg_acquire(atomic_t *v, int old, int new)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_cmpxchg_acquire(v, old, new);
}
#define atomic_cmpxchg_acquire atomic_cmpxchg_acquire
#endif
#if defined(arch_atomic_cmpxchg_release)
static __always_inline int
atomic_cmpxchg_release(atomic_t *v, int old, int new)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_cmpxchg_release(v, old, new);
}
#define atomic_cmpxchg_release atomic_cmpxchg_release
#endif
#if defined(arch_atomic_cmpxchg_relaxed)
static __always_inline int
atomic_cmpxchg_relaxed(atomic_t *v, int old, int new)
{
instrument_atomic_read_write(v, sizeof(*v));
return arch_atomic_cmpxchg_relaxed(v, old, new);
}
#define atomic_cmpxchg_relaxed atomic_cmpxchg_relaxed
#endif
@ptr 주소에 @old 값이 있는 경우 @v 값으로 atomic 하게 치환한다.
arch_atomic_cmpxchg() 등 4개 매크로 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- arch_atomic_cmpxchg()
- arch_atomic_cmpxchg_acquire()
- arch_atomic_cmpxchg_release()
- arch_atomic_cmpxchg_relaxed()
arch/arm64/include/asm/atomic.h
#define arch_atomic_cmpxchg_relaxed(v, old, new) \
arch_cmpxchg_relaxed(&((v)->counter), (old), (new))
#define arch_atomic_cmpxchg_acquire(v, old, new) \
arch_cmpxchg_acquire(&((v)->counter), (old), (new))
#define arch_atomic_cmpxchg_release(v, old, new) \
arch_cmpxchg_release(&((v)->counter), (old), (new))
#define arch_atomic_cmpxchg(v, old, new) \
arch_cmpxchg(&((v)->counter), (old), (new))
arch_cmpxchg() 등 4개 매크로 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- arch_cmpxchg()
- arch_cmpxchg_acquire()
- arch_cmpxchg_release()
- arch_cmpxchg_relaxed()
arch/arm64/include/asm/cmpxchg.h
/* cmpxchg */
#define arch_cmpxchg_relaxed(...) __cmpxchg_wrapper( , __VA_ARGS__)
#define arch_cmpxchg_acquire(...) __cmpxchg_wrapper(_acq, __VA_ARGS__)
#define arch_cmpxchg_release(...) __cmpxchg_wrapper(_rel, __VA_ARGS__)
#define arch_cmpxchg(...) __cmpxchg_wrapper( _mb, __VA_ARGS__)
__cmpxchg_wrapper()
arch/arm64/include/asm/cmpxchg.h
#define __cmpxchg_wrapper(sfx, ptr, o, n) \
({ \
__typeof__(*(ptr)) __ret; \
__ret = (__typeof__(*(ptr))) \
__cmpxchg##sfx((ptr), (unsigned long)(o), \
(unsigned long)(n), sizeof(*(ptr))); \
__ret; \
})
__cmpxchg() 등 4개 함수
아래 __CMPXCHG_GEN() 매크로 함수를 통해 메모리 ordering에 따라 다음 함수들이 준비되었다.
- __cmpxchg()
- __cmpxchg_acq()
- __cmpxchg_rel()
- __cmpxchg_mb()
arch/arm64/include/asm/cmpxchg.h
#define __CMPXCHG_GEN(sfx) \
static __always_inline unsigned long __cmpxchg##sfx(volatile void *ptr, \
unsigned long old, \
unsigned long new, \
int size) \
{ \
switch (size) { \
case 1: \
return __cmpxchg_case##sfx##_8(ptr, old, new); \
case 2: \
return __cmpxchg_case##sfx##_16(ptr, old, new); \
case 4: \
return __cmpxchg_case##sfx##_32(ptr, old, new); \
case 8: \
return __cmpxchg_case##sfx##_64(ptr, old, new); \
default: \
BUILD_BUG(); \
} \
\
unreachable(); \
}
__CMPXCHG_GEN()
__CMPXCHG_GEN(_acq)
__CMPXCHG_GEN(_rel)
__CMPXCHG_GEN(_mb)
__cmpxchg_case_8() 등 16개 함수
아래 __CMPXCHG_CASE() 매크로 함수를 통해 메모리 ordering 및 데이터 사이즈에 따라 다음 함수들이 준비되었다.
- __cmpxchg_case_8()
- __cmpxchg_case_acq_8()
- __cmpxchg_case_rel_8()
- __cmpxchg_case_mb_8()
- __cmpxchg_case_16()
- __cmpxchg_case_acq_16()
- __cmpxchg_case_rel_16()
- __cmpxchg_case_mb_16()
- __cmpxchg_case_32()
- __cmpxchg_case_acq_32()
- __cmpxchg_case_rel_32()
- __cmpxchg_case_mb_32()
- __cmpxchg_case_64()
- __cmpxchg_case_acq_64()
- __cmpxchg_case_rel_64()
- __cmpxchg_case_mb_64()
arch/arm64/include/asm/cmpxchg.h
#define __CMPXCHG_CASE(name, sz) \
static inline u##sz __cmpxchg_case_##name##sz(volatile void *ptr, \
u##sz old, \
u##sz new) \
{ \
return __lse_ll_sc_body(_cmpxchg_case_##name##sz, \
ptr, old, new); \
}
__CMPXCHG_CASE( , 8)
__CMPXCHG_CASE( , 16)
__CMPXCHG_CASE( , 32)
__CMPXCHG_CASE( , 64)
__CMPXCHG_CASE(acq_, 8)
__CMPXCHG_CASE(acq_, 16)
__CMPXCHG_CASE(acq_, 32)
__CMPXCHG_CASE(acq_, 64)
__CMPXCHG_CASE(rel_, 8)
__CMPXCHG_CASE(rel_, 16)
__CMPXCHG_CASE(rel_, 32)
__CMPXCHG_CASE(rel_, 64)
__CMPXCHG_CASE(mb_, 8)
__CMPXCHG_CASE(mb_, 16)
__CMPXCHG_CASE(mb_, 32)
__CMPXCHG_CASE(mb_, 64)
__ll_sc__cmpxchg_case_8() 등 16개 함수 – for LL/SC atomic
아래 __CMPXCHG_CASE() 매크로 함수를 통해 메모리 ordering 및 데이터 사이즈에 따라 다음 함수들이 준비되었다.
- __ll_sc__cmpxchg_case_8()
- __ll_sc__cmpxchg_case_acq_8()
- __ll_sc__cmpxchg_case_rel_8()
- __ll_sc__cmpxchg_case_mb_8()
- __ll_sc__cmpxchg_case_16()
- __ll_sc__cmpxchg_case_acq_16()
- __ll_sc__cmpxchg_case_rel_16()
- __ll_sc__cmpxchg_case_mb_16()
- __ll_sc__cmpxchg_case_32()
- __ll_sc__cmpxchg_case_acq_32()
- __ll_sc__cmpxchg_case_rel_32()
- __ll_sc__cmpxchg_case_mb_32()
- __ll_sc__cmpxchg_case_64()
- __ll_sc__cmpxchg_case_acq_64()
- __ll_sc__cmpxchg_case_rel_64()
- __ll_sc__cmpxchg_case_mb_64()
arch/arm64/include/asm/atomic_ll_sc.h
#define __CMPXCHG_CASE(w, sfx, name, sz, mb, acq, rel, cl, constraint) \
static inline u##sz \
__ll_sc__cmpxchg_case_##name##sz(volatile void *ptr, \
unsigned long old, \
u##sz new) \
{ \
unsigned long tmp; \
u##sz oldval; \
\
/* \
* Sub-word sizes require explicit casting so that the compare \
* part of the cmpxchg doesn't end up interpreting non-zero \
* upper bits of the register containing "old". \
*/ \
if (sz < 32) \
old = (u##sz)old; \
\
asm volatile( \
__LL_SC_FALLBACK( \
" prfm pstl1strm, %[v]\n" \
"1: ld" #acq "xr" #sfx "\t%" #w "[oldval], %[v]\n" \
" eor %" #w "[tmp], %" #w "[oldval], %" #w "[old]\n" \
" cbnz %" #w "[tmp], 2f\n" \
" st" #rel "xr" #sfx "\t%w[tmp], %" #w "[new], %[v]\n" \
" cbnz %w[tmp], 1b\n" \
" " #mb "\n" \
"2:") \
: [tmp] "=&r" (tmp), [oldval] "=&r" (oldval), \
[v] "+Q" (*(u##sz *)ptr) \
: [old] __stringify(constraint) "r" (old), [new] "r" (new) \
: cl); \
\
return oldval; \
}
/*
* Earlier versions of GCC (no later than 8.1.0) appear to incorrectly
* handle the 'K' constraint for the value 4294967295 - thus we use no
* constraint for 32 bit operations.
*/
__CMPXCHG_CASE(w, b, , 8, , , , , K)
__CMPXCHG_CASE(w, h, , 16, , , , , K)
__CMPXCHG_CASE(w, , , 32, , , , , K)
__CMPXCHG_CASE( , , , 64, , , , , L)
__CMPXCHG_CASE(w, b, acq_, 8, , a, , "memory", K)
__CMPXCHG_CASE(w, h, acq_, 16, , a, , "memory", K)
__CMPXCHG_CASE(w, , acq_, 32, , a, , "memory", K)
__CMPXCHG_CASE( , , acq_, 64, , a, , "memory", L)
__CMPXCHG_CASE(w, b, rel_, 8, , , l, "memory", K)
__CMPXCHG_CASE(w, h, rel_, 16, , , l, "memory", K)
__CMPXCHG_CASE(w, , rel_, 32, , , l, "memory", K)
__CMPXCHG_CASE( , , rel_, 64, , , l, "memory", L)
__CMPXCHG_CASE(w, b, mb_, 8, dmb ish, , l, "memory", K)
__CMPXCHG_CASE(w, h, mb_, 16, dmb ish, , l, "memory", K)
__CMPXCHG_CASE(w, , mb_, 32, dmb ish, , l, "memory", K)
__CMPXCHG_CASE( , , mb_, 64, dmb ish, , l, "memory", L)
@ptr 주소에 담긴 값을 읽어온 값이 입출력 인자 @old와 동일한 경우에만 입력 인자 @new 값을 기록한다. 또한 기록 여부와 상관 없이 입출력 인자 @old에 기록 전의 값을 알아온다.
- 코드 라인 15~16에서 8비트 또는 16비트 사이즈 타입인 경우 해당 타입에 맞게 old 값을 변환한다.
- 코드 라인 20에서 입력 인자 @ptr 주소에 담긴 값을 캐시에 미리 로드해둔다.
- exclusive 모니터에 의해 해당 캐시라인이 atomic 경쟁이 감지되면 실패하여 다시 시도하는데 이 retry latency를 짧게 하기 위해 캐시에 미리 로드한다.
- 코드 라인 21에서 입력 인자 @ptr 주소에 담긴 값을 임시 변수 oldval에 로드해온다.
- 코드 라인 22~23에서 읽어온 oldval 값에 입출력 인자 @old 값과 비교하여 다른 경우 입력 인자 @new 값을 기록하지 않기 위해 레이블 2로 이동한다.
- 코드 라인 24~25에서 입력 인자 @new 값을 @ptr 주소에 기록하는데, 만일 @ptr 주소가 담긴 캐시라인에 외부에서 atomic 접근이 감지되면 실패로 인식하여 재시도 하기 위해 레이블 1로 이동한다.
- 코드 라인 26에서 양방향 베리어가 필요한 atomic 명령인 경우 dmb ish를 수행한다.
__lse__cmpxchg_case_8() 등 16개 함수 – for LSE atomic
아래 __CMPXCHG_CASE() 매크로 함수를 통해 메모리 ordering 및 데이터 사이즈에 따라 다음 함수들이 준비되었다.
- __lse__cmpxchg_case_8()
- __lse__cmpxchg_case_acq_8()
- __lse__cmpxchg_case_rel_8()
- __lse__cmpxchg_case_mb_8()
- __lse__cmpxchg_case_16()
- __lse__cmpxchg_case_acq_16()
- __lse__cmpxchg_case_rel_16()
- __lse__cmpxchg_case_mb_16()
- __lse__cmpxchg_case_32()
- __lse__cmpxchg_case_acq_32()
- __lse__cmpxchg_case_rel_32()
- __lse__cmpxchg_case_mb_32()
- __lse__cmpxchg_case_64()
- __lse__cmpxchg_case_acq_64()
- __lse__cmpxchg_case_rel_64()
- __lse__cmpxchg_case_mb_64()
arch/arm64/include/asm/atomic_lse.h
#define __CMPXCHG_CASE(w, sfx, name, sz, mb, cl...) \
static __always_inline u##sz \
__lse__cmpxchg_case_##name##sz(volatile void *ptr, \
u##sz old, \
u##sz new) \
{ \
register unsigned long x0 asm ("x0") = (unsigned long)ptr; \
register u##sz x1 asm ("x1") = old; \
register u##sz x2 asm ("x2") = new; \
unsigned long tmp; \
\
asm volatile( \
__LSE_PREAMBLE \
" mov %" #w "[tmp], %" #w "[old]\n" \
" cas" #mb #sfx "\t%" #w "[tmp], %" #w "[new], %[v]\n" \
" mov %" #w "[ret], %" #w "[tmp]" \
: [ret] "+r" (x0), [v] "+Q" (*(unsigned long *)ptr), \
[tmp] "=&r" (tmp) \
: [old] "r" (x1), [new] "r" (x2) \
: cl); \
\
return x0; \
}
__CMPXCHG_CASE(w, b, , 8, )
__CMPXCHG_CASE(w, h, , 16, )
__CMPXCHG_CASE(w, , , 32, )
__CMPXCHG_CASE(x, , , 64, )
__CMPXCHG_CASE(w, b, acq_, 8, a, "memory")
__CMPXCHG_CASE(w, h, acq_, 16, a, "memory")
__CMPXCHG_CASE(w, , acq_, 32, a, "memory")
__CMPXCHG_CASE(x, , acq_, 64, a, "memory")
__CMPXCHG_CASE(w, b, rel_, 8, l, "memory")
__CMPXCHG_CASE(w, h, rel_, 16, l, "memory")
__CMPXCHG_CASE(w, , rel_, 32, l, "memory")
__CMPXCHG_CASE(x, , rel_, 64, l, "memory")
__CMPXCHG_CASE(w, b, mb_, 8, al, "memory")
__CMPXCHG_CASE(w, h, mb_, 16, al, "memory")
__CMPXCHG_CASE(w, , mb_, 32, al, "memory")
__CMPXCHG_CASE(x, , mb_, 64, al, "memory")
@ptr 주소에 담긴 값을 읽어온 값이 입출력 인자 @old와 동일한 경우에만 입력 인자 @new 값을 기록한다. 또한 기록 여부와 상관 없이 입출력 인자 @old에 기록 전의 값을 알아온다.
- 코드 라인 14에서 임시 변수 레지스터 tmp에 @old 값을 대입해둔다.
- 코드 라인 15~16에서 cas 명령을 사용하여 @ptr 주소에 담긴 값이 tmp와 같은 경우 @new 값을 기록한다. 기록 여부와 상관 없이 tmp에 @ptr 주소에 담겼었던 값을 알아온 후 결과 값으로 반환한다.
기타 Read/Write(Set) 관련 – ARM64
atomic_read() 및 atomic_set() 등 4개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- atomic_read()
- atomic_set()
static __always_inline int
atomic_read(const atomic_t *v)
{
instrument_atomic_read(v, sizeof(*v));
return arch_atomic_read(v);
}
#define atomic_read atomic_read
#if defined(arch_atomic_read_acquire)
static __always_inline int
atomic_read_acquire(const atomic_t *v)
{
instrument_atomic_read(v, sizeof(*v));
return arch_atomic_read_acquire(v);
}
#define atomic_read_acquire atomic_read_acquire
#endif
static __always_inline void
atomic_set(atomic_t *v, int i)
{
instrument_atomic_write(v, sizeof(*v));
arch_atomic_set(v, i);
}
#define atomic_set atomic_set
#if defined(arch_atomic_set_release)
static __always_inline void
atomic_set_release(atomic_t *v, int i)
{
instrument_atomic_write(v, sizeof(*v));
arch_atomic_set_release(v, i);
}
#define atomic_set_release atomic_set_release
#endif
arch_atomic_read() 등 4개 함수
다음 함수들이 메모리 ordering 옵션에 따라 준비되어 있다.
- arch_atomic_read()
- arch_atomic_read_acquire()
- arch_atomic_set()
- arch_atomic_set_release()
arch/arm64/include/asm/atomic.h
#define arch_atomic_read(v) __READ_ONCE((v)->counter)
#define arch_atomic_set(v, i) __WRITE_ONCE(((v)->counter), (i))
- arch_atomic_read()
- atomic_t 주소 @v가 가리키는 값을 한 번에(atomically) 읽어온다.
- arch_atomic_set()
- atomic_t 주소 @v에 @i 값을 한 번에(atomically) 기록한다.
아래 두 개 함수는 arm64 아키텍처에 정의되지 않아 fallback 함수를 사용한다.
include/linux/atomic-arch-fallback.h
#ifndef arch_atomic_read_acquire
static __always_inline int
arch_atomic_read_acquire(const atomic_t *v)
{
return smp_load_acquire(&(v)->counter);
}
#define arch_atomic_read_acquire arch_atomic_read_acquire
#endif
#ifndef arch_atomic_set_release
static __always_inline void
arch_atomic_set_release(atomic_t *v, int i)
{
smp_store_release(&(v)->counter, i);
}
#define arch_atomic_set_release arch_atomic_set_release
#endif
smp_load_acquire() 및 smp_store_release() 단방향 베리어 함수를 호출하여 사용한다.
- smp_load_acquire() 및 smp_store_release() 함수는 다음 글을 참고
조건부 Read Atomic
atomic_cond_read_acquire()
include/linux/atomic.h
#define atomic_cond_read_acquire(v, c) smp_cond_load_acquire(&(v)->counter, (c))
주소 v의 데이터를 읽은 후 조건 c가 true인 경우 읽은 데이터를 반환한다. 데이터를 읽을 때 단방향 acquire 베리어를 사용한다. 만일 조건을 만족하지 못하는 경우 반복하며 시도한다.
- ARM64의 경우 절전을 위해 spin wait 시 wfe(wait for event)와 sev를 사용한다.
- smp_cond_load_acquire() 함수는 다음 글을 참고
atomic_cond_read_relaxed()
include/linux/atomic.h
#define atomic_cond_read_relaxed(v, c) smp_cond_load_relaxed(&(v)->counter, (c))
주소 v의 데이터를 읽은 후 조건 c가 true인 경우 읽은 데이터를 반환한다. 만일 조건을 만족하지 못하는 경우 반복하며 시도한다.
- ARM64의 경우 절전을 위해 spin wait 시 wfe(wait for event)와 sev를 사용한다.
위의 64비트 액세스 API는 다음과 같다.
- atomic64_cond_read_acquire()
- atomic64_cond_read_relaxed()
atomic 구조체 타입
atomic_t
include/linux/types.h
typedef struct {
int counter;
} atomic_t;
- 32bit counter 변수 하나로만 구성되어 있다.
atomic64_t
include/linux/types.h
#ifdef CONFIG_64BIT
typedef struct {
long counter;
} atomic64_t;
#endif
- 64bit counter 변수 하나로만 구성되어 있다.