<kernel v5.4>
VFP(Vector Floating Point)
- VFP는 반정도(half precision), 단정도(single precision) 및 배정도(double precision) 고정 소수점 연산을 지원하는 보조 연산 장치이다.
- SIMD(Single Instruction Multiple Data)라고도 불린다.
버전별 특징
- VPFv1
- ARM10에서 사용
- VFP 예외를 트래핑해야 한다. (VFP 지원 코드가 필요 하다)
- gcc 컴파일 시: -mfpu=vfp
- VFPv2
- ARM11, ARMv5, ARMv6에서 사용
- ARM10200E가 제공하는 VFP10 수정 버전 1
- ARM926E/946E/966E에 대해 별도로 허가된 옵션으로 사용되는 VFP9-S
- ARM1136JF-S, ARM1176JZF-S 및 ARM11 MPCore에서 제공되는 VFP11
- VFP 예외를 트래핑해야 한다. (VFP 지원 코드가 필요 하다)
- 16개의 64-bit FPU 레지스터
- gcc 컴파일 시: -mfpu=vfp
- ARM11, ARMv5, ARMv6에서 사용
- VFPv3
- ARMv7인 Cortex-A8부터 사용하고 NEON으로 불린다.
- VFPv3-D16
- 오직 16개의 64-bit FPU 레지스터
- VFPv3-F16 variant
- 일반적이지 않지만 단정도 고정 소수점 연산을 지원한다.
- VFPv3-D16
- VFP에서 벡터 기능이 퇴색하고(deprecated) 파이프라인화되어 advanced SIMD로 진보되어 VFPv2의 2배 성능을 확보하였다.
- 실제 배정도 고정 소수점 연산을 지원하는 scalar 명령셋과 지원하지 않는 vector 명령셋으로 구분된다.
- 단 ARMv8에서는 vector 명령셋에서도 배정도 고정 소수점 연산을 지원한다.
- 기존의 벡터 명령도 advanced SIMD와 같이 병렬 처리된다.
- 실제 배정도 고정 소수점 연산을 지원하는 scalar 명령셋과 지원하지 않는 vector 명령셋으로 구분된다.
- VFP 예외를 트래핑할 필요가 없다는 점을 제외하고 VFPv2와 동일하다. (VFP 지원 코드가 필요 없다)
- 32개의 64-bit FPU 레지스터
- 단정도 고정 소수점 연산(optional)
- gcc 컴파일 시: -mfpu=neon
- 참고: NEON | arm
- ARMv7인 Cortex-A8부터 사용하고 NEON으로 불린다.
GCC로 FP 코드 연동
- -mfloat-abi=
- soft
- Floating Point 라이브러리를 호출하도록 생성하고 호출 방법으로 Floating Poing ABI 규격의 calling convention을 사용한다.
- hard
- -mfpu에서 지정한 VFP 하드웨어 코드를 생성하고 호출 방법 역시 각자의 방법을 사용한다.
- softfp
- -mfpu에서 지정한 VFP 하드웨어 코드를 생성하되 호출 방법은 soft 방식을 따른다.
- soft
- -mfpu=
- vfpv2’, ‘vfpv3’, ‘vfpv3-fp16’, ‘vfpv3-d16’, ‘vfpv3-d16-fp16’, ‘vfpv3xd’, ‘vfpv3xd-fp16’, ‘neon-vfpv3’, ‘neon-fp16’, ‘vfpv4’, ‘vfpv4-d16’, ‘fpv4-sp-d16’, ‘neon-vfpv4’, ‘fpv5-d16’, ‘fpv5-sp-d16’, ‘fp-armv8’, ‘neon-fp-armv8’ 및 ‘crypto-neon-fp-armv8’
- neon
- VFP 코드를 생성할 경우에 NEON(‘vfpv3’ alias)용으로 생성한다.
- vfp
- VFP 코드를 생성할 경우에 VFPv2(‘vfpv2’ alias)용으로 생성한다.
- 참고: ABI(Application Binary Interface) | 문c
VFP 지원 코드
하드웨어 VFP 만으로는 처리할 수 없어서 아래와 같은 상황에서 VFP 지원을 받아 소프트웨어적으로 처리한다.
- NaN 관련된 부동 소수점 연산
- 비정규 값과 관련된 부동 소수점 연산
- 부동 소수점 오버플로
- 부동 소수점 언더플로
- 정확하지 않은 결과
- 0으로 나누기 오류
- 잘못된 연산
FPE(Floating Point Emulation)
- VFP가 없는 arm 아키텍처에서 커널이 제공하는 라이브러리를 통해 소프트 에뮬레이션 방법으로 동작한다.
- arm에서는 VFP가 여러 가지 아키텍처에 따라 다르므로 특별히 고성능을 요구하지 않는 경우 호환 목적의 코드를 만들기 위해 FPE를 사용하기도 한다.
Undefined instruction으로부터 진입
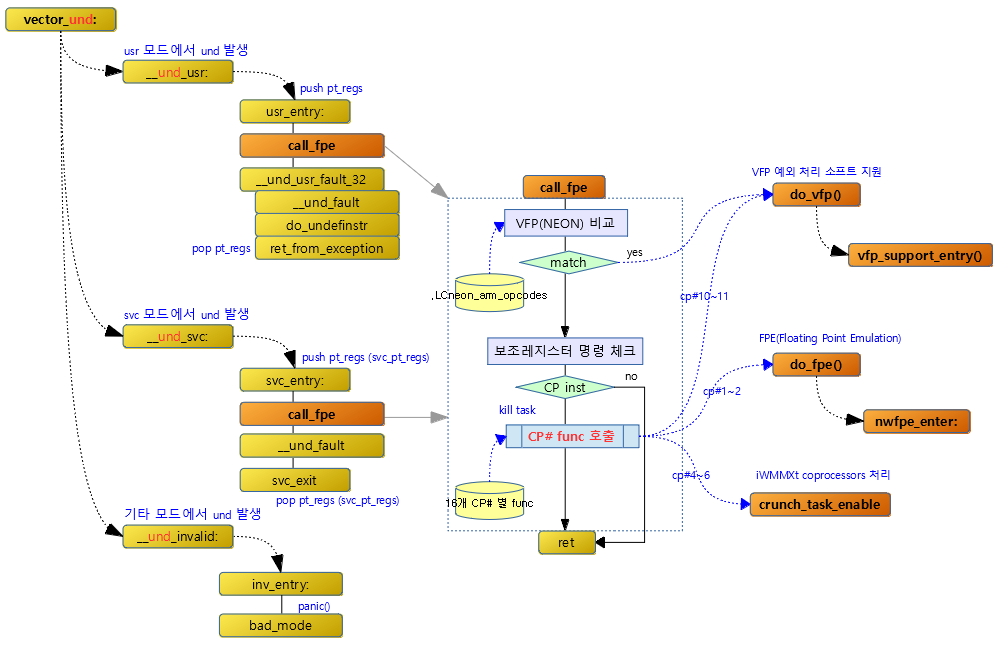
call_fpe
arch/arm/kernel/entry-armv.S
call_fpe:
get_thread_info r10 @ get current thread
#ifdef CONFIG_NEON
adr r6, .LCneon_arm_opcodes
2: ldr r5, [r6], #4 @ mask value
ldr r7, [r6], #4 @ opcode bits matching in mask
cmp r5, #0 @ end mask?
beq 1f
and r8, r0, r5
cmp r8, r7 @ NEON instruction?
bne 2b
mov r7, #1
strb r7, [r10, #TI_USED_CP + 10] @ mark CP#10 as used
strb r7, [r10, #TI_USED_CP + 11] @ mark CP#11 as used
b do_vfp @ let VFP handler handle this
1:
#endif
tst r0, #0x08000000 @ only CDP/CPRT/LDC/STC have bit 27
tstne r0, #0x04000000 @ bit 26 set on both ARM and Thumb-2
reteq lr
and r8, r0, #0x00000f00 @ mask out CP number
THUMB( lsr r8, r8, #8 )
mov r7, #1
add r6, r10, #TI_USED_CP
ARM( strb r7, [r6, r8, lsr #8] ) @ set appropriate used_cp[]
THUMB( strb r7, [r6, r8] ) @ set appropriate used_cp[]
#ifdef CONFIG_IWMMXT
@ Test if we need to give access to iWMMXt coprocessors
ldr r5, [r10, #TI_FLAGS]
rsbs r7, r8, #(1 << 8) @ CP 0 or 1 only
movscs r7, r5, lsr #(TIF_USING_IWMMXT + 1)
bcs iwmmxt_task_enable
#endif
ARM( add pc, pc, r8, lsr #6 )
THUMB( lsl r8, r8, #2 )
THUMB( add pc, r8 )
nop
instruction이 VFPv3(NEON) 또는 소프트 지원이 필요한 VFPv1/v2 아키텍처에서 동작되는 경우 각각 커널의 VFP 소프트 지원 또는 FPE(Floating Point Emulation) 라이브러리를 통해 해당 예외 처리를 수행한다.
- 코드 라인 3~15에서 instruction이 VFP이고 지원되지 않는 아키텍처에서 undefined exception으로 진입한 경우이므로 이에 대응하는 VFP 소프트 지원 라이브러리를 통해 해당 명령을 수행한다.
- 코드 라인 3~8에서 instruction이 VFP 명령어인지 비교하기 위해 LCneon_arm_opcodes 테이블의 값들과 비교하는데 테이블의 끝까지 비교해도 일치하지 않은 경우 이므로 레이블 1로 이동한다. 즉 VFP 명령이 아닐 경우 보조 프로세서 명령 여부를 찾을 계획이다.
- 코드 라인 9~11에서 instruction(r0)을 mask(r5)하여 opcode(r7) 값과 비교하여 같지 않은 경우 다음 테이블 엔트리와 비교하기 위해 레이블 2로 이동하여 루프를 돈다.
- 코드 라인 12~15에서 보조 프로세서 인수 전달용 구조체 curr->used_cp[] 배열의 10번째와 11번째에 1을 저장한 후 do_vfp 레이블로 이동한다.
- 코드 라인 15~33에서 VFP가 없는 아키텍처에서 undefined exception으로 진입한 경우이므로 이에 대응하기 위해 FPE(Floating Point Emulation)를 호출하여 지원한다.
- 코드 라인 15~19에서 보조프로세서관련 명령이 아닌 경우 fault 처리를 위해 lr(__und_usr_fault_32 )주소로 복귀한다.
- 보조 프로세서 관련 명령
- CDP(Coprocessor Data oPerations), CPRT(COprocessor Register Transfer)
- LDC(Load Data from Coprocessor) 및 STC(Store To Coprocessor) 등
- 보조 프로세서 관련 명령
- 코드 라인 20~25에서 CP 번호를 r8 레지스터에 대입하고 이 값을 인덱스로 curr->used_cp[]에 1을 저장한다.
- 코드 라인 26~32에서 보조프로세서가 iWMMXt인지 판단되는 경우 iwmmxt_task_enable 레이블로 이동한다.
- 코드 라인 33에서 보조 프로세서 번호에 해당하는 테이블 위치로 jump 한다.
- CP 번호가 1~2번인 경우 FPE(Floating Point Emulation)를 처리하러 do_fpe 레이블로 이동한다.
- CONFIG_CRUNCH 커널 옵션이 설정되고 CP 번호가 4~6번인 경우 MaverickCrunch를 처리하러 crunch_task_enable 레이블로 이동한다.
- CONFIG_VFP가 설정되고 CP번호가 10~11번인 경우 VFP를 처리하러 do_vfp 레이블로 이동한다.
- 이 외의 경우에는 fault 처리를 위해 lr(__und_usr_fault_32) 주소로 복귀한다.
- 코드 라인 15~19에서 보조프로세서관련 명령이 아닌 경우 fault 처리를 위해 lr(__und_usr_fault_32 )주소로 복귀한다.
CP 별(보조프로세서 인덱스) jump 테이블
ret.w lr @ CP#0
W(b) do_fpe @ CP#1 (FPE)
W(b) do_fpe @ CP#2 (FPE)
ret.w lr @ CP#3
#ifdef CONFIG_CRUNCH
b crunch_task_enable @ CP#4 (MaverickCrunch)
b crunch_task_enable @ CP#5 (MaverickCrunch)
b crunch_task_enable @ CP#6 (MaverickCrunch)
#else
ret.w lr @ CP#4
ret.w lr @ CP#5
ret.w lr @ CP#6
#endif
ret.w lr @ CP#7
ret.w lr @ CP#8
ret.w lr @ CP#9
#ifdef CONFIG_VFP
W(b) do_vfp @ CP#10 (VFP)
W(b) do_vfp @ CP#11 (VFP)
#else
ret.w lr @ CP#10 (VFP)
ret.w lr @ CP#11 (VFP)
#endif
ret.w lr @ CP#12
ret.w lr @ CP#13
ret.w lr @ CP#14 (Debug)
ret.w lr @ CP#15 (Control)
.LCneon_arm_opcodes
arch/arm/kernel/entry-armv.S
#ifdef CONFIG_NEON
.align 6
.LCneon_arm_opcodes:
.word 0xfe000000 @ mask
.word 0xf2000000 @ opcode
.word 0xff100000 @ mask
.word 0xf4000000 @ opcode
.word 0x00000000 @ mask
.word 0x00000000 @ opcode
NEON instruction을 구분하기 위한 mask와 opcode이다.
- 마지막 word 두 개는 종료를 구분하기 위한 값이다.
ARM instruction set format
bit 27~26이 설정된 명령이 보조 프로세서 관련 명령이다.
- STC, STC2, LDC, LDC2, MCRR, MCRR2, MRRC, MRRC2, CDP, CDP2, MCR, MCR2, MRC, MRC2

Advanced SIMD (NEON) instruction set format

ARMv7에서 동작하는 Floating Point 장치이다.
- VLD1~4, VST1~4, VADD, VSUB, VDIV, …)
- 참고: VFP Instruction Set Quick Reference | arm – 다운로드 pdf
VFP 소프트 지원 호출 함수
do_vfp
arch/arm/vfp/entry.S
@ VFP entry point. @ @ r0 = instruction opcode (32-bit ARM or two 16-bit Thumb) @ r2 = PC value to resume execution after successful emulation @ r9 = normal "successful" return address @ r10 = this threads thread_info structure @ lr = unrecognised instruction return address @ IRQs enabled. @
ENTRY(do_vfp)
inc_preempt_count r10, r4
ldr r4, .LCvfp
ldr r11, [r10, #TI_CPU] @ CPU number
add r10, r10, #TI_VFPSTATE @ r10 = workspace
ldr pc, [r4] @ call VFP entry point
ENDPROC(do_vfp)
VFP 소프트 지원용 핸들러 함수를 호출한다.
- VFPv1 및 VFPv2 아키텍처에서는 고정 소수 연산의 예외처리를 소프트웨어의 도움을 받아 처리하게 되어 있다.
- .LCvfp
- vfp/vfpmodule.c – core_initcall(vfp_init)을 통해 초기화된다.
- 초기화 전에는 .LCvfp 값은 vfp_null_entry() 함수 주소를 가리킨다.
- 초기화가 정상적으로 완료되면 .LCvfp 값은 vfp_support_entry() 함수 주소를 가리킨다.
- vfp/vfpmodule.c – core_initcall(vfp_init)을 통해 초기화된다.
vfp_null_entry()
arch/arm/vfp/entry.S
ENTRY(vfp_null_entry)
dec_preempt_count_ti r10, r4
ret lr
ENDPROC(vfp_null_entry)
preemption 카운터를 감소시키고 복귀한다.
FPE 호출 함수
do_fpe
arch/arm/kernel/entry-armv.S
do_fpe:
ldr r4, .LCfp
add r10, r10, #TI_FPSTATE @ r10 = workspace
ldr pc, [r4] @ Call FP module USR entry point
FPE(Floating Point Emulation) 핸들러 함수를 호출한다.
- .LCfp
- nwfpe/fpmodule.c – module_init(fpe_init)을 통해 초기화된다.
- 초기화되면 nwfpe_enter: 레이블 주소를 가리킨다.
- nwfpe/fpmodule.c – module_init(fpe_init)을 통해 초기화된다.
참고
- Exception -1- (ARM32 Vector) | 문c
- Exception -2- (ARM32 Handler 1) | 문c
- Exception -3- (ARM32 Handler 2) | 문c
- Exception -4- (ARM32 VFP & FPE) | 문c – 현재 글
- Exception -5- (Extable) | 문c
- Exception -6- (MM Fault Handler) | 문c
- 우리는패밀리 (ARM, THUMB, Coprocessor, NEON) | 히언
- ArmHardFloatPort VfpComparison | debian.org