<kernel v5.0>
Slub Object 할당(Fastpath, Slowpath)
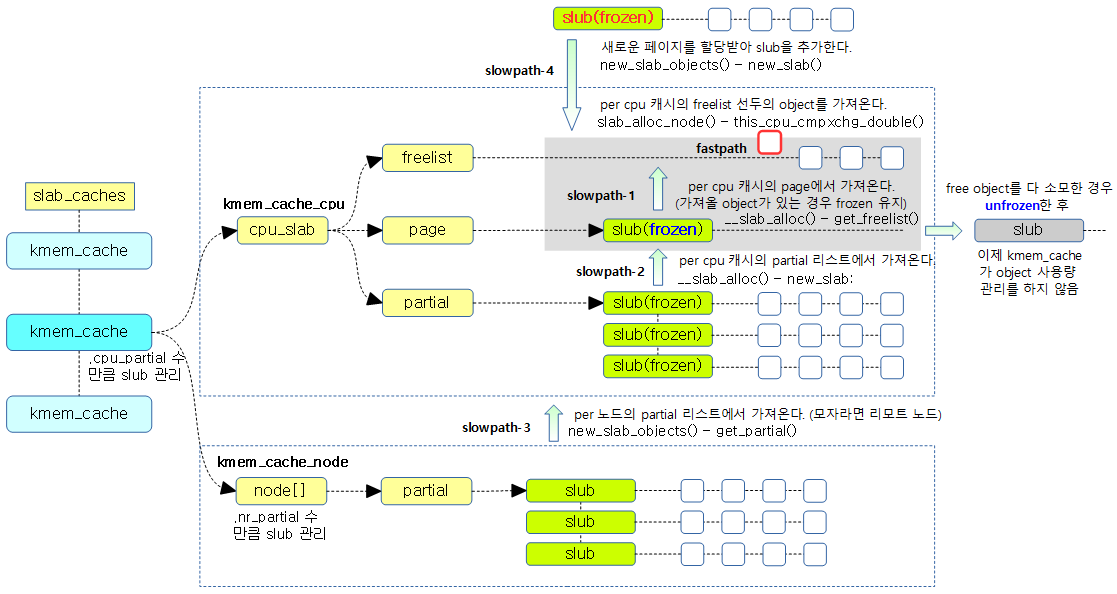
Slub object 할당은 가장 빠른 할당인 Fastpath 단계 부터 가장 느린 최대 4 단계의 slowpath 할당으로 구성되어 있다.
Fastpath
Fastpath 동작으로 per cpu 슬랩 캐시의 freelist에 있는 첫 object를 atomic하게 꺼내온다. 만일 할당할 슬랩 object가 없는 경우 Slowpath 동작으로 넘어간다.
- fastpath 단계:
- c->freelist 에서 즉시 free object 할당
- 참고로 약어는 다음을 의미한다.
- s: 슬랩 캐시를 가리키는 kmem_cache 구조체
- c: per-cpu의 s->cpu_slab (kmem_cache_cpu 구조체)
- n: per-node의 s->node[] (kmem_cache_node 구조체)
Slowpath
c->freelist가 비어 있어 꺼내올 object가 없는 경우 slowpath 동작을 아래와 같이 진행시켜 refill한 후, 다시 Fastpath 동작을 재시도한다.
- slowpath 1단계:
- c->page->freelist —(이동)—> c->freelist
- per cpu 캐시의 page->freelist에 있는 object들을 per cpu 캐시의 freelist로 이주 시킨다. free object가 있는 경우 page를 frozen 시킨다. 만일 free object가 없는 경우 다음 2 단계를 진행한다.
- slowpath 2단계:
- c->partial —(이동)—> c->page
- per cpu 캐시의 partial 리스트에 있는 처음 슬랩 페이지를 per cpu 캐시의 page로 이주시킨다. 만일 per cpu 캐시의 partial 리스트가 비어 있는 경우 다음 3 단계를 진행한다.
- slowpath 3단계:
- n->partial —(첫 슬랩 페이지 이동)—> c->page
- n->partial —(두 번째 슬랩 페이지 부터 몇 개 이동)—> c->partial
- 첫 번째, per 노드의 partial 리스트에 있는 처음 슬랩 페이지를 per cpu 캐시의 page에 이주시킨다.
- 두 번째, per 노드의 partial 리스트에 있는 그 다음 슬랩 페이지부터 per cpu 캐시의 partial 리스트에 추가한다.
- 단 이주 시키고 있는 슬랩 페이지의 free object의 갯수가 s->cpu_partial의 절반을 초과하는 경우에 그 슬랩 페이지까지만 이주시키고 더 이상 반복하지 않는다.
- 만일 per 노드의 partial 리스트가 빈 경우에는 다른 리모트 노드의 partial 리스트에서 재시도한다. 만일 다른 리모트 per 노드들 마저도 사용할 수 없는(일정 퍼센트 이상의 원격 노드 메모리 사용을 제한) 상태이면 다음 4 단계를 진행한다.
- slowpath 4단계:
- 페이지 할당자(버디 시스템) —(할당)—> c->page & c->freelist
- 페이지 할당자(버디 시스템)으로 부터 페이지를 할당받아 슬랩 페이지로 초기화한 후 직접 c->page에 연결하고, c->freelist에 첫 free object를 연결한다.
다음 그림은 슬랩 object를 할당 받는 우선 순위를 보여준다.
Frozened Slub Page
slub 할당자는 lock 없이 slub object의 빠른 할당을 위해 slub 페이지를 per-cpu에서 관리한다.
- cmpxchg double atomic operation을 사용하여 리스트의 추가 삭제를 한다.
page->frozen을 1로 하는 경우 slub 페이지의 freelist를 잠궈 현재 태스크가 직접 관리하도록 한다.
두 개의 Freelist 관리
실질적으로 freelist의 관리가 둘로 나뉘어 다음과 같이 동작한다.
- c->freelist
- 현재 cpu가 freelist를 관리하므로 slub object의 할당과 할당 해제(free)가 가능하다.
- page->freelist
- 다른 cpu들은 이 곳에만 해제(free)가 가능하다.
다음 그림은 slub page가 11개의 object로 동작되고 fozen되어 freelist가 두 개로 나뉘어 관리되는 모습을 보여준다.
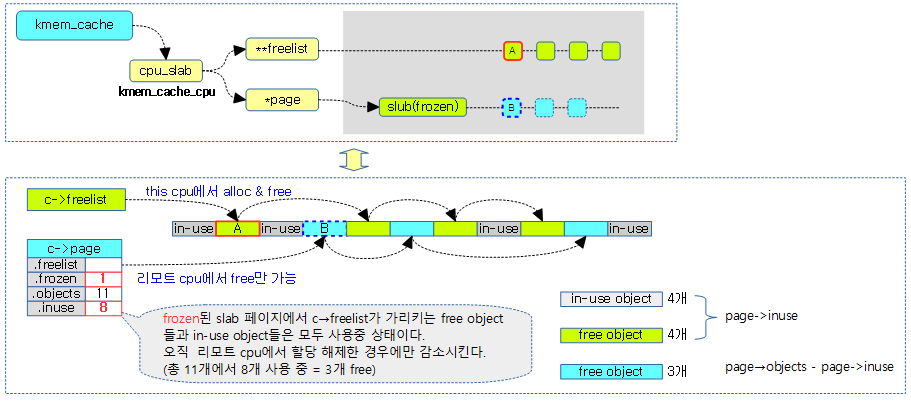
slub 페이지의 inuse 카운터
slub 페이지의 inuse 카운터는 사용 중인 object 수를 의미하며, 단 c->freelist의 free objects 들도 사용 중인 object 수로 포함시킨다. inuse 카운터의 변화는 다음과 같다.
- 초기 값
- 슬랩 페이지를 처음 할당 받은 후 모든 free object들이 c->freelist에 연결하므로 page->inuse 값에 page->objects 수를 대입하여 모두 사용 중으로 표기한다.
- 할당 시
- object를 할당 시에는 page->inuse 카운터에 변화가 없다.
- 해제 시
- 해당(this) cpu에서 해제할 때엔 page->inuse 카운터에 변화가 없다.
- 리모트 cpu에서 해제할 때엔 page->inuse 카운터가 감소된다.
- 이동 시
- c->page->freelist 에서 c->freelist로 이동 시 page->inuse 값은 page->objects 값으로 반영되어 모든 object가 사용중 상태로 바뀐다.
unfrozen 상태
n->partial에서 관리되는 슬랩 페이지들의 free object들은 사용 중인 object 수에 포함되지 않는다.
다음 3개의 그림은 리모트 cpu에서 할당 해제할 때에만 page->inuse 카운터가 감소되는 것을 알 수 있다.
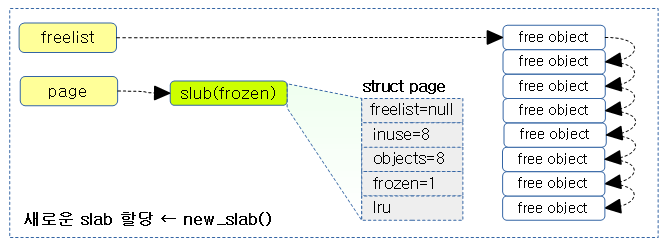
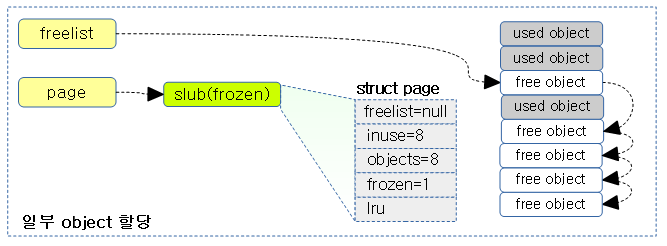

슬랩 캐시 object 할당
다음 그림은 slub object의 할당 요청의 수행 순서를 함수별로 간략히 보여준다. 단계별로 slub onject의 할당을 시도하는데 마지막 단계까지 할당할 object가 없는 경우 버디 시스템으로 부터 페이지를 할당 받아 slub을 구성하고 그 내부에 있는 object들을 초기화한다.
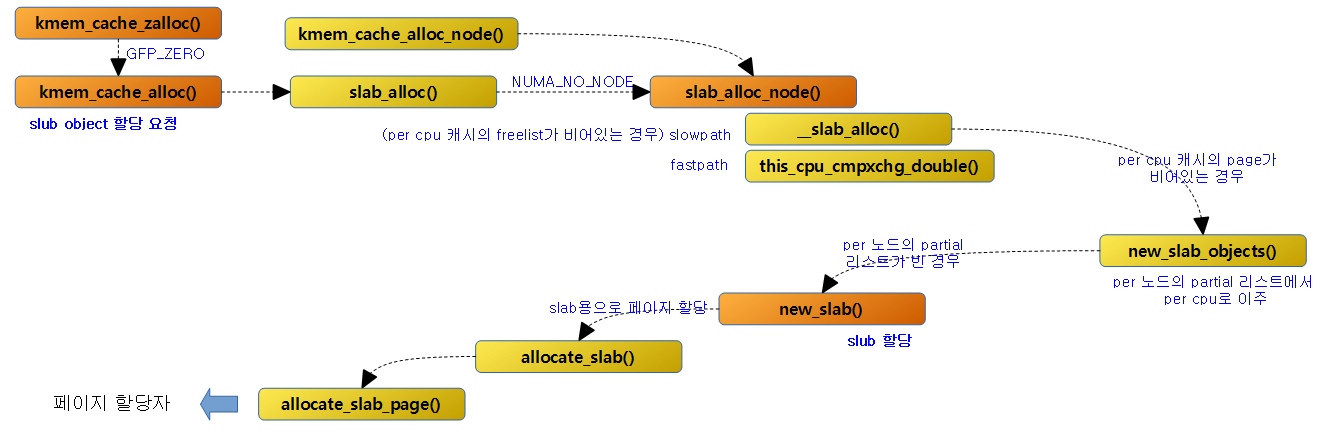
kmem_cache_zalloc()
include/linux/slab.h
/* * Shortcuts */
static inline void *kmem_cache_zalloc(struct kmem_cache *k, gfp_t flags)
{
return kmem_cache_alloc(k, flags | __GFP_ZERO);
}
지정된 캐시에서 0(zero)으로 초기화된 slub object 하나를 할당받아 온다.
kmem_cache_alloc()
mm/slub.c
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags)
{
void *ret = slab_alloc(s, gfpflags, _RET_IP_);
trace_kmem_cache_alloc(_RET_IP_, ret, s->object_size,
s->size, gfpflags);
return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc);
지정된 캐시에서 slub object 하나를 할당받아 온다.
- trace 문자열: “call_site=%lx ptr=%p bytes_req=%zu bytes_alloc=%zu gfp_flags=%s”
kmem_cache_alloc_node()
mm/slub.c
void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node)
{
void *ret = slab_alloc_node(s, gfpflags, node, _RET_IP_);
trace_kmem_cache_alloc_node(_RET_IP_, ret,
s->object_size, s->size, gfpflags, node);
return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc_node);
GFP 플래그를 참고하여 slub object를 지정된 노드에서 할당받아 온다.
slab_alloc()
mm/slub.c
static __always_inline void *slab_alloc(struct kmem_cache *s,
gfp_t gfpflags, unsigned long addr)
{
return slab_alloc_node(s, gfpflags, NUMA_NO_NODE, addr);
}
지정된 캐시에서 전체 노드를 대상으로 slub object 하나를 할당받아 온다.
슬랩 object 할당 – Fastpath
slab_alloc_node() – slub
mm/slub.c
/* * Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc) * have the fastpath folded into their functions. So no function call * overhead for requests that can be satisfied on the fastpath. * * The fastpath works by first checking if the lockless freelist can be used. * If not then __slab_alloc is called for slow processing. * * Otherwise we can simply pick the next object from the lockless free list. */
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void **object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
s = slab_pre_alloc_hook(s, gfpflags);
if (!s)
return NULL;
redo:
/*
* Must read kmem_cache cpu data via this cpu ptr. Preemption is
* enabled. We may switch back and forth between cpus while
* reading from one cpu area. That does not matter as long
* as we end up on the original cpu again when doing the cmpxchg.
*
* We should guarantee that tid and kmem_cache are retrieved on
* the same cpu. It could be different if CONFIG_PREEMPT so we need
* to check if it is matched or not.
*/
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
/*
* Irqless object alloc/free algorithm used here depends on sequence
* of fetching cpu_slab's data. tid should be fetched before anything
* on c to guarantee that object and page associated with previous tid
* won't be used with current tid. If we fetch tid first, object and
* page could be one associated with next tid and our alloc/free
* request will be failed. In this case, we will retry. So, no problem.
*/
barrier();
/*
* The transaction ids are globally unique per cpu and per operation on
* a per cpu queue. Thus they can be guarantee that the cmpxchg_double
* occurs on the right processor and that there was no operation on the
* linked list in between.
*/
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node))) {
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
} else {
void *next_object = get_freepointer_safe(s, object);
/*
* The cmpxchg will only match if there was no additional
* operation and if we are on the right processor.
*
* The cmpxchg does the following atomically (without lock
* semantics!)
* 1. Relocate first pointer to the current per cpu area.
* 2. Verify that tid and freelist have not been changed
* 3. If they were not changed replace tid and freelist
*
* Since this is without lock semantics the protection is only
* against code executing on this cpu *not* from access by
* other cpus.
*/
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH);
}
if (unlikely(gfpflags & __GFP_ZERO) && object)
memset(object, 0, s->object_size);
slab_post_alloc_hook(s, gfpflags, 1, &object);
return object;
}
지정된 캐시의 지정된 노드에서 slub object 하나를 할당받아 온다.
- 코드 라인 9~11에서 슬랩 object 할당을 위해 사전 준비 사항들을 수행하고, 문제가 있는 경우 할당을 포기한다. 이 때 memcg 캐시가 적용중인 경우 memcg 캐시를 얻어온다.
- fault injection으로 인해 슬랩 메모리 할당에 문제가 있는 경우 할당을 포기한다.
- 코드 라인 12에서 redo: 레이블이다. fastpath 용도로 per cpu 캐시로 부터 해당 cpu에 대한 트랜잭션 id가 바뀌어 실패한 경우 다시 반복할 위치다.
- 코드 라인 23~27에서 tid 및 per-cpu 캐시를 atomic하게 읽어온다. 현재 이 시점에서 preemption이 언제라도 가능하기 때문에 수행 중 태스크 전환되었다 다시 돌아왔을 수 있다. 따라서 이 루틴에서는 tid와 캐시가 같은 cpu에서 획득된 것을 보장하게 하기 위해 뒤에서 atomic을 통해 확인 과정을 수행한다.
- 코드 라인 37에서 인터럽트 마스크 없이 slab의 할당/해제 알고리즘이 동작하려면 cpu_slab 데이터를 읽는 순서에 의존하게 된다. object와 page보다 먼저 tid를 읽기 위해 컴파일러로 하여금 optimization을 하지 않도록 컴파일러 배리어를 사용하여 명확히 동작 순서를 구분하게 하였다.
- 코드 라인 46~47에서 per cpu 캐시의 freelist에서 object를 받아오고 page도 받아온다.
- 코드 라인 48~50에서 낮은 확률로 할당할 슬랩 object가 없거나 현재 per cpu 캐시에서 알아온 슬랩 page의 노드가 지정된 노드와 다른 경우 slowpath 동작을 통해 object를 할당받는다. 이 때 ALLOC_SLOWPATH stat을 증가시킨다.
- 코드 라인 51~52에서 성공리에 object를 가져온 경우 FP(Free Pointer) 값, 즉 다음 object의 주소를 알아온다.
- 코드 라인 68~75에서 슬랩 object 할당의 fastpath 동작을 시도한다. atomic하게 freelist가 다음 슬랩 object를 가리키게 하고 tid도 다음 tid로 교체한다. 만일 낮은 확률로 cpu가 바뀌었거나 트랜잭션 id가 바뀐 이유로 실패한 경우 다시 redo 레이블로 되돌아가서 슬랩 object 할당이 성공될 때 까지 재시도한다.
- 태스크가 preemption되었다가 다른 노드의 cpu에서 스케쥴되어 재개한 경우 cpu가 변경되었거나 다른 리모트 cpu에 의해 트랜잭션 id가 변경될 수 있다. 이러한 경우 freelist에서 얻은 object의 사용을 포기하고 다시 시도한다.
- 참고: Per-cpu (atomic operations) | 문c
- 코드 라인 76~77에서 fastpath 동작으로 슬랩 object의 할당이 성공한 경우이다. 다음 free object에 대한 캐시라인을 미리 fetch 하고, ALLOC_FASTPATH stat을 증가시킨다.
- 코드 라인 80~81에서 작은 확률로 GFP_ZERO 플래그를 사용한 경우 할당된 object 크기 만큼 object를 0으로 클리어한다.
- 코드 라인 83에서 할당 완료된 상태에 대해 디버그(kmemcheck, kmemleak, kasan) 루틴등에 알리고 memcg에도 알린다.
- 코드 라인 85에서 할당한 슬랩 object를 반환한다.
Lock-less per-cpu 리스트 조작
일반적으로 리스트 조작을 위해서 lock을 사용하는데, lock을 사용하지 않고 빠른 성능의 리스트 조작을 위해서는 rcu나 per-cpu로 구현하곤 한다. 슬랩 objec의 할당 및 해제는 커널 코드에서 빈번하게 사용되므로 역시 빠른 성능이 필요해 lock-less 구현을 지원하는 솔루션 중 per-cpu를 사용한 방법이 선택되었다. per-cpu를 사용하여 구현하는 경우 일반적으로 preemption 및 인터럽트의 개입을 차단하기 위해 인터럽트를 disable하여 처리를 한다. 그러나 슬랩 object의 할당 및 할당 해제는 더 빠른 성능을 위해 preemption 및 인터럽트를 허용한 상태로 구현하였다. 이러한 기법을 사용하면 슬랩 object의 할당 및 할당 해제 처리 중에 preemption되는 상황에 대해서까지 완벽한 처리를 위해 리스트 조작에 문제가 없도록 이를 확인하여야 한다. 그래서 비교 후 교환(cmpxchg)을 할 수 있는 atomic을 사용하여 안전하게 리스트 조작을 처리하는데, 오브젝트의 포인터만 비교해서는 ABA problem 같은 특별한 상황이 발생하면 이를 안전하게 처리할 수 없는 상태가 발생할 수 있다. 이 때문에 트랜잭션 id를 추가로 적용하였고, 두 개의 값을 한꺼번에 비교하고 처리하기 위해 cpmxchg_double과 같은 기능이 필요하게 되었고, 최신 x86_64및 arm64비트 아키텍처들이 이를 지원하고 있다.
this_cpu_cmpxchg()
- this_cpu_cmpxchg(v, old, new)
- 한 개의 v 값을 old 값과 비교하여 동일한 경우에 한 해 new 값으로 변경한다.
this_cpu_cmpxcgh_double()
- this_cpu_cmpxcgh_double(v1, v2, old1, old2, new1, new2)
- 두 개의 v1 및 v2 값을 old1 및 old2 값과 비교하여 둘 다 동일한 경우에 한 해 new1 및 new2 값으로 변경한다.
트랜잭션 id
- 트랜잭션 id는 각 cpu에서 서로 중복되지 않도록 시작 값을 다르게 하고, 증가치를 서로 교차되지 않도록 큰 값을 사용한다.
- preemption이 enable된 상태에서 per-cpu를 사용하는 경우에는 cpu가 변경되어 현재 access하는 per-cpu 값이 바뀔 수도 있으므로 cpu 변경 여부를 체크하기 위해 트랜잭션 id를 같이 사용하는 것이 안전하다.
- 트랜잭션 id를 사용하지 않고 object 주소만 가지고 변경을 시도하는 경우에는 ABA problem이 발생할 수 있다.
- 참고:
- Multiprocessing and Multicore (2013) | Timothy Roscoe – 다운로드 pdf
- Avoid the ABA problem when using lock-free algorithms | Carnegie Mellon University
- 참고:
다음 그림은 슬랩 object 할당 요청을 받았을 때 per cpu 캐시의 freelist에서 첫 object를 빠르게 할당해주는 것을 보여준다.
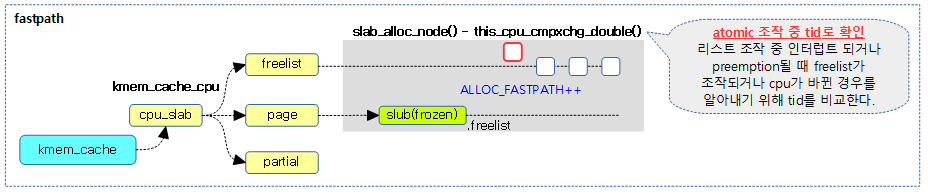
slab_pre_alloc_hook()
mm/slub.c
static inline struct kmem_cache *slab_pre_alloc_hook(struct kmem_cache *s,
gfp_t flags)
{
flags &= gfp_allowed_mask;
fs_reclaim_acquire(flags);
fs_reclaim_release(flags);
might_sleep_if(gfpflags_allow_blocking(flags));
if (should_failslab(s, flags))
return NULL;
if (memcg_kmem_enabled() &&
((flags & __GFP_ACCOUNT) || (s->flags & SLAB_ACCOUNT)))
return memcg_kmem_get_cache(s);
return s;
}
슬랩 object 할당을 위해 사전 준비 사항들을 수행하고, 문제가 있는 경우 할당을 포기한다. 또한 memcg 캐시가 적용중인 경우 memcg 캐시를 반환한다.
- 코드 라인 4에서 early 부트 시 허용된 GFP 플래그들만을 사용하게 한다.
- 코드 라인 9에서 direct-reclaim 중인 경우 preemption point를 동작시킨다.
- 현재 태스크보다 높은 우선 순위 요청을 처리하도록 현재 태스크를 sleep하고 다른 태스크로 cpu를 이양한다.
- 코드 라인 11~12에서 CONFIG_FAILSLAB 커널 옵션을 사용하는 경우 fault-injection 기능으로 강제로 할당 실패를 발생시킨 경우 할당을 포기하도록 null을 반환한다.
- 코드 라인 14~16에서 memcg가 적용된 태스크의 경우 per memcg 캐시를 찾아 반환한다.
memcg_kmem_get_cache()
mm/memcontrol.c
/** * memcg_kmem_get_cache: select the correct per-memcg cache for allocation * @cachep: the original global kmem cache * * Return the kmem_cache we're supposed to use for a slab allocation. * We try to use the current memcg's version of the cache. * * If the cache does not exist yet, if we are the first user of it, we * create it asynchronously in a workqueue and let the current allocation * go through with the original cache. * * This function takes a reference to the cache it returns to assure it * won't get destroyed while we are working with it. Once the caller is * done with it, memcg_kmem_put_cache() must be called to release the * reference. */
struct kmem_cache *memcg_kmem_get_cache(struct kmem_cache *cachep)
{
struct mem_cgroup *memcg;
struct kmem_cache *memcg_cachep;
int kmemcg_id;
VM_BUG_ON(!is_root_cache(cachep));
if (memcg_kmem_bypass())
return cachep;
memcg = get_mem_cgroup_from_current();
kmemcg_id = READ_ONCE(memcg->kmemcg_id);
if (kmemcg_id < 0)
goto out;
memcg_cachep = cache_from_memcg_idx(cachep, kmemcg_id);
if (likely(memcg_cachep))
return memcg_cachep;
/*
* If we are in a safe context (can wait, and not in interrupt
* context), we could be be predictable and return right away.
* This would guarantee that the allocation being performed
* already belongs in the new cache.
*
* However, there are some clashes that can arrive from locking.
* For instance, because we acquire the slab_mutex while doing
* memcg_create_kmem_cache, this means no further allocation
* could happen with the slab_mutex held. So it's better to
* defer everything.
*/
memcg_schedule_kmem_cache_create(memcg, cachep);
out:
css_put(&memcg->css);
return cachep;
}
현재 user 태스크에 memcg 설정이 되어 있는 경우 per memcg 캐시를 선택한다.
- 인터럽트 처리 중이거나 current->mm이 null이거나 커널 스레드로 동작하는 경우에는 cachep를 바꾸지 않는다.
slab_post_alloc_hook()
mm/slab.h
static inline void slab_post_alloc_hook(struct kmem_cache *s, gfp_t flags,
size_t size, void **p)
{
size_t i;
flags &= gfp_allowed_mask;
for (i = 0; i < size; i++) {
p[i] = kasan_slab_alloc(s, p[i], flags);
/* As p[i] might get tagged, call kmemleak hook after KASAN. */
kmemleak_alloc_recursive(p[i], s->object_size, 1,
s->flags, flags);
}
if (memcg_kmem_enabled())
memcg_kmem_put_cache(s);
}
슬랩 object 할당에서 사후 수행을 위한 루틴을 수행한다. KASAN, kmemleak 등 디버깅 루틴을 수행한다.
node_match()
mm/slub.c
/* * Check if the objects in a per cpu structure fit numa * locality expectations. */
static inline int node_match(struct page *page, int node)
{
#ifdef CONFIG_NUMA
if (!page || (node != NUMA_NO_NODE && page_to_nid(page) != node))
return 0;
#endif
return 1;
}
UMA 시스템에서는 항상 true를 반환하고, NUMA 시스템에서는 인수로 지정된 page(slub)의 노드가 인수로 지정된 node와 다른 경우 false를 반환한다.
- NUMA 시스템의 preempt 커널을 사용하여 slub 할당 루틴을 진행 시에 preemption되어 요청한 노드에서 할당받으려 시도할 때 현재 per cpu 캐시의 page(slub)로부터 object를 받게 되는데 그 page(slub)에 소속된 노드와 비교하여 다른 경우 false를 반환하여 현재의 cpu 캐시를 그대로 사용하면 안 된다는 것을 판단할 수 있도록 해야 한다.
FP(Free Pointer) 관련
prefetch_freepointer()
mm/slub.c
static void prefetch_freepointer(const struct kmem_cache *s, void *object)
{
prefetch(object + s->offset);
}
요청한 슬랩 object의 FP(Freelist Pointer) 값을 미리 캐시 라인에 로드한다.
get_freepointer_safe()
mm/slub.c
static inline void *get_freepointer_safe(struct kmem_cache *s, void *object)
{
unsigned long freepointer_addr;
void *p;
if (!debug_pagealloc_enabled())
return get_freepointer(s, object);
freepointer_addr = (unsigned long)object + s->offset;
probe_kernel_read(&p, (void **)freepointer_addr, sizeof(p));
return freelist_ptr(s, p, freepointer_addr);
}
요청한 슬랩 object의 FP(Freelist Pointer) 값을 읽은 후 포인터 주소로 변환하여 읽어온다.
get_freepointer()
mm/slub.c
static inline void *get_freepointer(struct kmem_cache *s, void *object)
{
return freelist_dereference(s, object + s->offset);
}
지정된 object의 FP(Freelist Pointer) 값을 읽어 주소로 반환한다.
freelist_dereference()
mm/slub.c
/* Returns the freelist pointer recorded at location ptr_addr. */
static inline void *freelist_dereference(const struct kmem_cache *s,
void *ptr_addr)
{
return freelist_ptr(s, (void *)*(unsigned long *)(ptr_addr),
(unsigned long)ptr_addr);
}
FP(Freelist Pointer) 값인 @ptr_addr 값을 포인터 주소로 변환하여 반환한다.
freelist_ptr()
mm/slub.c
/* * Returns freelist pointer (ptr). With hardening, this is obfuscated * with an XOR of the address where the pointer is held and a per-cache * random number. */
static inline void *freelist_ptr(const struct kmem_cache *s, void *ptr,
unsigned long ptr_addr)
{
#ifdef CONFIG_SLAB_FREELIST_HARDENED
/*
* When CONFIG_KASAN_SW_TAGS is enabled, ptr_addr might be tagged.
* Normally, this doesn't cause any issues, as both set_freepointer()
* and get_freepointer() are called with a pointer with the same tag.
* However, there are some issues with CONFIG_SLUB_DEBUG code. For
* example, when __free_slub() iterates over objects in a cache, it
* passes untagged pointers to check_object(). check_object() in turns
* calls get_freepointer() with an untagged pointer, which causes the
* freepointer to be restored incorrectly.
*/
return (void *)((unsigned long)ptr ^ s->random ^
(unsigned long)kasan_reset_tag((void *)ptr_addr));
#else
return ptr;
#endif
}
FP(Freelist Pointer) 값인 @ptr_addr 값을 포인터 주소로 변환하여 반환한다.
- CONFIG_SLAB_FREELIST_HARDENED 커널 옵션을 사용하는 경우 FP 값을 알아볼 수 없도록 랜덤 값등과 함께 엔코딩된다.
슬랩 Object 할당 – Slowpath
__slab_alloc()
mm/slub.c
/* * Another one that disabled interrupt and compensates for possible * cpu changes by refetching the per cpu area pointer. */
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *p;
unsigned long flags;
local_irq_save(flags);
#ifdef CONFIG_PREEMPT
/*
* We may have been preempted and rescheduled on a different
* cpu before disabling interrupts. Need to reload cpu area
* pointer.
*/
c = this_cpu_ptr(s->cpu_slab);
#endif
p = ___slab_alloc(s, gfpflags, node, addr, c);
local_irq_restore(flags);
return p;
}
local cpu의 인터럽트를 블러킹한 상태에서 슬랩 object 할당을 위해 slowpath 루틴을 수행한다.
___slab_alloc()
mm/slub.c
/* * Slow path. The lockless freelist is empty or we need to perform * debugging duties. * * Processing is still very fast if new objects have been freed to the * regular freelist. In that case we simply take over the regular freelist * as the lockless freelist and zap the regular freelist. * * If that is not working then we fall back to the partial lists. We take the * first element of the freelist as the object to allocate now and move the * rest of the freelist to the lockless freelist. * * And if we were unable to get a new slab from the partial slab lists then * we need to allocate a new slab. This is the slowest path since it involves * a call to the page allocator and the setup of a new slab. * * Version of __slab_alloc to use when we know that interrupts are * already disabled (which is the case for bulk allocation). */
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
page = c->page;
if (!page)
goto new_slab;
redo:
if (unlikely(!node_match(page, node))) {
int searchnode = node;
if (node != NUMA_NO_NODE && !node_present_pages(node))
searchnode = node_to_mem_node(node);
if (unlikely(!node_match(page, searchnode))) {
stat(s, ALLOC_NODE_MISMATCH);
deactivate_slab(s, page, c->freelist, c);
goto new_slab;
}
}
/*
* By rights, we should be searching for a slab page that was
* PFMEMALLOC but right now, we are losing the pfmemalloc
* information when the page leaves the per-cpu allocator
*/
if (unlikely(!pfmemalloc_match(page, gfpflags))) {
deactivate_slab(s, page, c->freelist, c);
goto new_slab;
}
/* must check again c->freelist in case of cpu migration or IRQ */
freelist = c->freelist;
if (freelist)
goto load_freelist;
freelist = get_freelist(s, page);
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
stat(s, ALLOC_REFILL);
load_freelist:
/*
* freelist is pointing to the list of objects to be used.
* page is pointing to the page from which the objects are obtained.
* That page must be frozen for per cpu allocations to work.
*/
VM_BUG_ON(!c->page->frozen);
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;
new_slab:
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
freelist = new_slab_objects(s, gfpflags, node, &c);
if (unlikely(!freelist)) {
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
page = c->page;
if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))
goto load_freelist;
/* Only entered in the debug case */
if (kmem_cache_debug(s) &&
!alloc_debug_processing(s, page, freelist, addr))
goto new_slab; /* Slab failed checks. Next slab needed */
deactivate_slab(s, page, get_freepointer(s, freelist), c);
return freelist;
}
슬랩 object 할당을 위해 단계별 slowpath 루틴을 수행한다. s->page->freelist –> s->partial –> n->partial 단계별로 refill을 시도하고 그래도 안되면 마지막 단계에선 페이지 할당자에서 직접 슬랩 페이지를 할당 받는다.
- 코드 라인 7~9에서 c->page가 지정되지 않은 경우 c->partial 리스트로부터 새로운 슬랩 페이지를 가져오기 위해 new_slab으로 이동한다.
- 코드 라인 10에서 redo: 레이블이다. c->partial 또는 n->partial 리스트로부터 슬랩 페이지를 충전 받은 후에 이 레이블로 되돌아와서 object 할당을 재 시도할 목적으로 이동해오는 레이블이다.
- 코드 라인 12~23에서 낮은 확률로 c->page의 노드와 인수로 요청한 노드가 서로 다른 경우이다. 메모리리스 노드 구성일 수도 있으므로 c->page의 노드와 인접한 노드와 다시 한 번 비교하여도 서로 다른 경우이면 ALLOC_NODE_MISMATCH 카운터를 증가시키고 s->page에 연결된 슬랩 페이지를 deactivate 시키고 page와 freelist에 null을 대입한 후 c->partial 리스트로부터 새로운 슬랩 페이지를 가져오기 위해 new_slab으로 이동한다.
- 보통 태스크가 preemption되어 리스케쥴링 되는 경우 이 태스크가 다시 그 위치부터 재개되는 경우 가능하면 원래 cpu 또는 해당 노드에 소속된 cpu로 리스케쥴링되는데 해당 노드의 cpu들이 바쁜 경우 다른 노드의 cpu로 스케쥴링될 수도 있다. 바로 이러한 경우 원래 요청했던 노드와 현재 cpu의 노드가 달라질 수 있는 경우에 해당한다.
- 코드 라인 30~33에서 낮은 확률로 현재 요청이 비상 상황이 아닌데 비상용 slub 페이지가 선택된 경우 s->page에 연결된 슬랩 페이지를 deactivate 시키고 page와 freelist에 null을 대입한 후 c->partial 리스트로부터 새로운 슬랩 페이지를 가져오기 위해 new_slab으로 이동한다.
- swap for NBD 드라이버를 사용하는 경우 슬랩 object 할당 요청 시 ALLOC_NO_WATERMARKS 플래그를 사용하여 TCP socket 송수신이 비상용 slub 페이지도 활용할 수 있게 한다.
- 코드 라인 36~38에서 다시 한 번 c->freelist가 비어있는지 확인한다. 인터럽트를 막기 직전 반납한 object가 freelist에 남아 있으면 c->freelist에서 슬랩 object를 할당받기 위해 load_freelist 레이블로 이동한다.
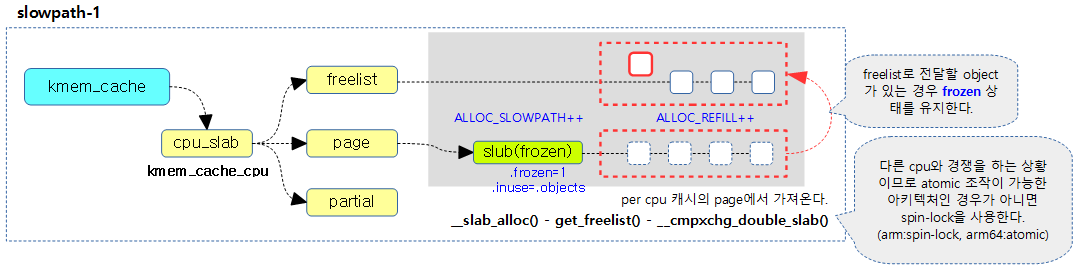
- 코드 라인 40에서 c->page->freelist를 c->freelist로 이동시킨다. (slowpath 1단계)
- 코드 라인 42~46에서 만일 c->freelist에 free 슬랩 object가 하나도 없는 경우 슬랩 페이지가 모두 사용중인 상태이므로 c->page에 null을 대입하여 조용히 슬랩 할당자에서 해당 슬랩 페이지를 관리하지 않게한 후, DEACTIVATE_BYPASS 카운터를 증가시킨다. 그런 후 새로운 슬랩 페이지를 할당받기 위해 new_slab 레이블로 이동한다. (slowpath 1단계에서 실패한 경우이다)
- 코드 라인 48에서 c->freelist가 다시 채워진 경우이므로 ALLOC_REFILL 카운터를 증가시킨다. (slowpath 1단계에서 성공된 경우이다)
- 코드 라인 50~59에서 load_freelist: 레이블이다. c->freelist가 다음 free object를 가리키게 하고, 트랜잭션 id도 증가시킨 후 할당받은 슬랩 object를 반환한다.
- 코드 라인 61에서 new_slab: 레이블이다.
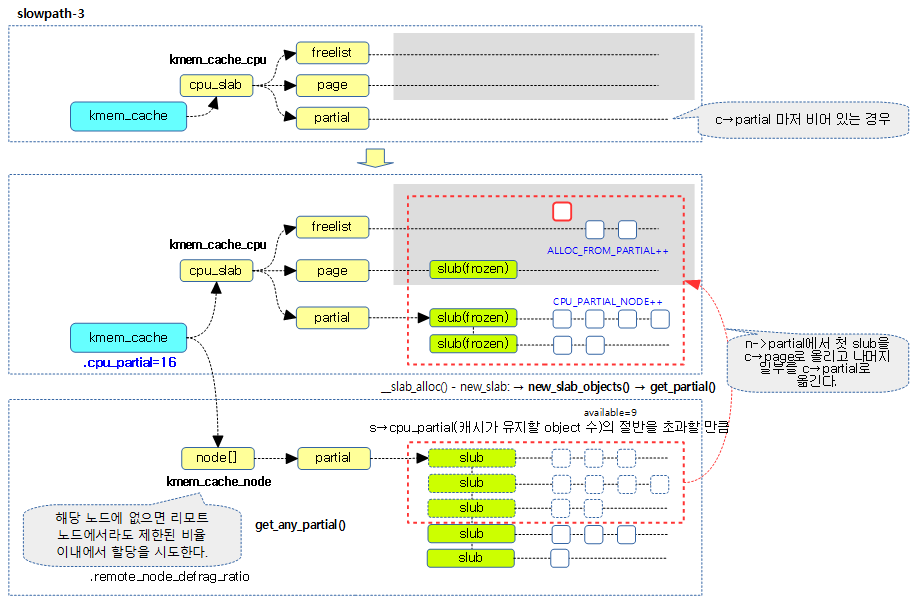
- 코드 라인 63~68에서 c->partial에 슬랩 페이지가 존재하는 경우 c->page로 하나의 슬랩 페이지만 옮긴다. 그런 후 CPU_PARTIAL_ALLOC 카운터를 증가시키고 슬랩 object의 할당을 재시도하러 redo: 레이블로 이동한다. (slowpath 2단계)
- 코드 라인 70에서 n->partial 리스트 또는 버디 할당자에서 새 슬랩 페이지를 할당받을 new_slab_objects()함수를 호출하여 c->page 및 c->freelist에 연결하고새 free object를 할당 받아온다. (slowpath 3~4단계)
- 코드 라인 72~75에서 새로운 slab object를 할당 받아 오지 못한 경우 OOM(Out Of Memory) 처리를 한 후 null을 반환한다.
- 코드 라인 77~79에서 높은 확률로 다음 상황들을 모두 만족하는 경우 load_freelist 레이블로 이동하여 free object 할당을 재시도한다.
- slub 디버깅이 필요 없는 경우
- 현재 요청이 비상 상황이 아닌데 비상용 slub 페이지가 선택된 경우
- 코드 라인 82~84에서 SLAB_CONSISTENCY_CHECKS 디버그 요청으로 consistency 체크에서 문제가 발견되는 경우 새로운 슬랩 페이지를 할당받으러 new_slab 레이블로 이동한다.
- 코드 라인 86에서 s->page에 연결된 슬랩 페이지를 deactivate 시키고 page와 freelist에 null을 대입한다.
- 코드 라인 87에서 할당 받은 슬랩 object를 반환한다.
다음 그림은 c->page->freelist –> c->freelist로 옮기는 slowpath 1 단계 과정을 보여준다.
다음 그림은 c->partial –> c->page & c->freelist로 옮기는 slowpath 2 단계 과정을 보여준다.
- 직전까지 관리하던 슬랩 페이지의 모든 object가 할당되었으므로 슬랩 캐시 할당자가 직접 관리하지 않는다.

slowpath 1 단계 처리
get_freelist()
mm/slub.c
/* * Check the page->freelist of a page and either transfer the freelist to the * per cpu freelist or deactivate the page. * * The page is still frozen if the return value is not NULL. * * If this function returns NULL then the page has been unfrozen. * * This function must be called with interrupt disabled. */
static inline void *get_freelist(struct kmem_cache *s, struct page *page)
{
struct page new;
unsigned long counters;
void *freelist;
do {
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
VM_BUG_ON(!new.frozen);
new.inuse = page->objects;
new.frozen = freelist != NULL;
} while (!__cmpxchg_double_slab(s, page,
freelist, counters,
NULL, new.counters,
"get_freelist"));
return freelist;
}
per cpu 캐시의 page의 freelist를 반환하고 그 slub 페이지의 freelist에 null을 대입하고 모두 사용중으로 변경한다. (slowpath 1 단계)
- c->page->freelist –> c->freelist로 모든 free object가 옮겨지는 순간 사용중인 object 수가 담기는 inuse에 s->objects 값을 대입하여 모두 사용중인 것으로 변경한다.
- page->freelist에 null을 대입하고, page->counter에 new.counters를 대입하되 실패하면 반복한다
slowpath 3 & 4 단계 처리
new_slab_objects()
mm/slub.c
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
WARN_ON_ONCE(s->ctor && (flags & __GFP_ZERO));
freelist = get_partial(s, flags, node, c);
if (freelist)
return freelist;
page = new_slab(s, flags, node);
if (page) {
c = raw_cpu_ptr(s->cpu_slab);
if (c->page)
flush_slab(s, c);
/*
* No other reference to the page yet so we can
* muck around with it freely without cmpxchg
*/
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
c->page = page;
*pc = c;
} else
freelist = NULL;
return freelist;
}
n->partial 리스트에 있는 몇 개의 슬랩 페이지들을 c->freelist, c->page 및 c->partial 리스트로 이동시킨다. 만일 옮길 슬랩 페이지가 없는 경우 버디 시스템으로부터 새로운 슬랩 페이지를 할당받아 c->freelist 및 c->page에 대입한다. 페이지 할당마저도 실패하는 경우 null을 반환한다. (Slowpath 3~4 단계)
- 코드 라인 10~13에서 로컬 및 리모트 노드의 partial 리스트에 있는 몇 개 의 슬랩 페이지들을 c->freelist, c->page 및 c->partial 리스트로 이동시키고, 정상적으로 할당할 슬랩 object가 있으면 반환한다. (Slowpath 3 단계)
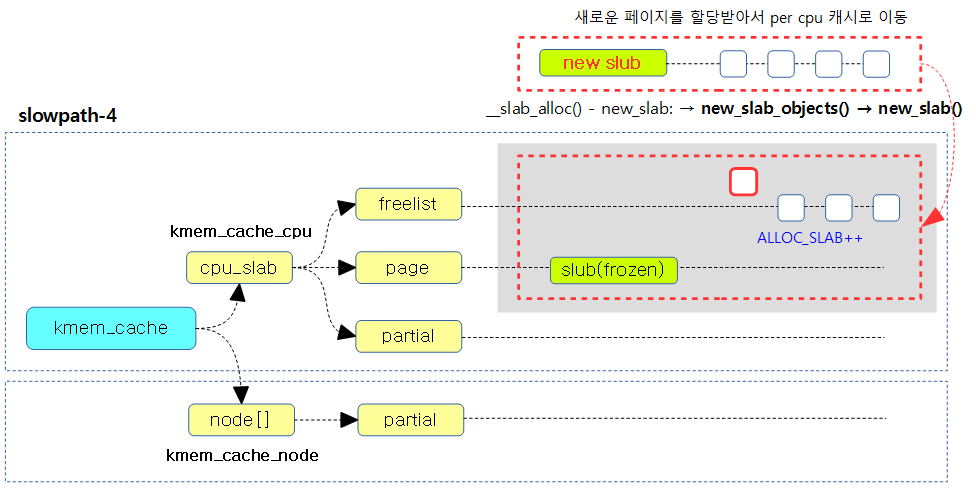
- 코드 라인 15~30에서 버디 시스템으로부터 새로운 페이지를 할당받아 온다. 그런 후 c->page에 연결하고 c->page->freelist에 null을 대입한 후 ALLOC_SLAB 카운터를 증가시킨다. cpu는 변경이 될 수 있으므로 출력 인자 @pc에 per-cpu 캐시를 대입한다. 그런 후 freelist를 반환한다. (Slowpath 4 단계)
- 코드 라인 31~32에서 메모리 부족으로 인해 버디 시스템에서 할당을 못한 경우이다. NULL을 반환한다.
다음 그림은 n->partial –> c->page & c->freelist & c->partial로 옮기는 slowpath 3 단계 과정을 보여준다.
- 해당(this) 노드 마저도 부족하면 리모트 노드를 검색하여 수행한다.
다음 그림은 슬랩 페이지가 부족한 경우 버디 시스템으로 부터 할당 받아 c->page & c->freelist로 옮기는 slowpath 4 단계 과정을 보여준다.
slowpath 3 단계 처리 호출
get_partial()
mm/slub.c
/* * Get a partial page, lock it and return it. */
static void *get_partial(struct kmem_cache *s, gfp_t flags, int node,
struct kmem_cache_cpu *c)
{
void *object;
int searchnode = node;
if (node == NUMA_NO_NODE)
searchnode = numa_mem_id();
else if (!node_present_pages(node))
searchnode = node_to_mem_node(node);
object = get_partial_node(s, get_node(s, searchnode), c, flags);
if (object || node != NUMA_NO_NODE)
return object;
return get_any_partial(s, flags, c);
}
n->partial 리스트의 일정 슬랩 페이지들을 c->freelist, c->page, c->partial 리스트로 이동시킨다. 만일 지정 노드의 partial 리스트가 비어 있는 경우 리모트 노드들에서 시도한다. (Slowpath 3 단계)
- 코드 라인 7~14에서 지정한 노드(메모리리스 노드인 경우 인접 노드)의 partial 리스트의 슬랩 페이지들을 per cpu 캐시의 page와 partial로 이주시킨다. 만일 정상적으로 할당할 free object가 있는 경우 object를 반환한다.
- 코드 라인 16에서 리모트 노드들을 통해 위와 동일한 처리를 수행한다.
Slowpath 3 단계 – 요청 노드에서 처리
get_partial_node()
mm/slub.c
/* * Try to allocate a partial slab from a specific node. */
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
struct page *page, *page2;
void *object = NULL;
int available = 0;
int objects;
/*
* Racy check. If we mistakenly see no partial slabs then we
* just allocate an empty slab. If we mistakenly try to get a
* partial slab and there is none available then get_partials()
* will return NULL.
*/
if (!n || !n->nr_partial)
return NULL;
spin_lock(&n->list_lock);
list_for_each_entry_safe(page, page2, &n->partial, lru) {
void *t;
if (!pfmemalloc_match(page, flags))
continue;
t = acquire_slab(s, n, page, object == NULL, &objects);
if (!t)
break;
available += objects;
if (!object) {
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else {
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
if (!kmem_cache_has_cpu_partial(s)
|| available > s->cpu_partial / 2)
break;
}
spin_unlock(&n->list_lock);
return object;
}
per 노드의 partial 리스트에서 일정 양의 슬랩 페이지들을 가져와서 per cpu 캐시로 이주시킨다. 이주할 슬랩 페이지가 없는 null을 반환한다. (Slowpath 3 단계 – 로컬 노드)
- 코드 라인 15~16에서 per 노드의 슬랩 페이지 수가 0이된 경우 null을 반환한다.
- 노드 락이 없는 상태이기 때문에 노드 락 경쟁 상황에서 0이 될 수 있다.
- 코드 라인 18~23에서 노드 락을 획득한 상태에서 요청한 노드의 partial 리스트에 있는 슬랩 페이지들을 순회하며 pfmemalloc 매치되지 않는 슬랩 페이지는 skip 한다.
- 코드 라인 25~33에서 첫 슬랩 페이지를 가져온 경우 per cpu 캐시의 page로 이동시키고, ALLOC_FROM_PARTIAL 카운터를 증가시킨다.
- 코드 라인 34~37에서 두 번째 슬랩 페이지부터 per cpu 캐시의 partial 리스트로 이동시키고, CPU_PARTIAL_NODE 카운터를 증가시킨다.
- put_cpu_partial() 함수
- 코드 라인 38~40에서 per-cpu가 관리할 object 수를 담는 s->cpu_partial 값의 절반을 초과하면 루프를 벗어난다.
- 코드 라인 44에서 이동 시킨 첫 페이지의 free object를 반환한다.
acquire_slab()
mm/slub.c
/* * Remove slab from the partial list, freeze it and * return the pointer to the freelist. * * Returns a list of objects or NULL if it fails. */
static inline void *acquire_slab(struct kmem_cache *s,
struct kmem_cache_node *n, struct page *page,
int mode, int *objects)
{
void *freelist;
unsigned long counters;
struct page new;
lockdep_assert_held(&n->list_lock);
/*
* Zap the freelist and set the frozen bit.
* The old freelist is the list of objects for the
* per cpu allocation list.
*/
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
*objects = new.objects - new.inuse;
if (mode) {
new.inuse = page->objects;
new.freelist = NULL;
} else {
new.freelist = freelist;
}
VM_BUG_ON(new.frozen);
new.frozen = 1;
if (!__cmpxchg_double_slab(s, page,
freelist, counters,
new.freelist, new.counters,
"acquire_slab"))
return NULL;
remove_partial(n, page);
WARN_ON(!freelist);
return freelist;
}
per 노드의 partial 리스트에서 하나의 슬랩 페이지를 cpu 캐시로 이동시키기 위해 frozen 상태로 만들어 분리한다. 반환되는 값은 첫 번째 free object이고, 실패한 경우 null을 반환한다. @mode에 따라 다음과 같이 동작한다.
- @mode가 true인 경우 얻어온 슬랩 페이지를 c->page로 이동시킬 목적으로 얻어온다. 슬랩 페이지의 모든 free object들도 사용중인 상태로 만들기 위해 page->inuse를 page->objects로 대입시키고, page->freelist에는 null을 지정한다.
- @mode가 false인 경우얻어온 슬랩 페이지를 c->partial 리스트로 이동시킬 목적으로 얻어온다.
Slowpath 3단계 – 리모트 노드들에서 처리
get_any_partial()
mm/slub.c
/*
* Get a page from somewhere. Search in increasing NUMA distances.
*/
static void *get_any_partial(struct kmem_cache *s, gfp_t flags,
struct kmem_cache_cpu *c)
{
#ifdef CONFIG_NUMA
struct zonelist *zonelist;
struct zoneref *z;
struct zone *zone;
enum zone_type high_zoneidx = gfp_zone(flags);
void *object;
unsigned int cpuset_mems_cookie;
/*
* The defrag ratio allows a configuration of the tradeoffs between
* inter node defragmentation and node local allocations. A lower
* defrag_ratio increases the tendency to do local allocations
* instead of attempting to obtain partial slabs from other nodes.
*
* If the defrag_ratio is set to 0 then kmalloc() always
* returns node local objects. If the ratio is higher then kmalloc()
* may return off node objects because partial slabs are obtained
* from other nodes and filled up.
*
* If /sys/kernel/slab/xx/remote_node_defrag_ratio is set to 100
* (which makes defrag_ratio = 1000) then every (well almost)
* allocation will first attempt to defrag slab caches on other nodes.
* This means scanning over all nodes to look for partial slabs which
* may be expensive if we do it every time we are trying to find a slab
* with available objects.
*/
if (!s->remote_node_defrag_ratio ||
get_cycles() % 1024 > s->remote_node_defrag_ratio)
return NULL;
do {
cpuset_mems_cookie = read_mems_allowed_begin();
zonelist = node_zonelist(mempolicy_slab_node(), flags);
for_each_zone_zonelist(zone, z, zonelist, high_zoneidx) {
struct kmem_cache_node *n;
n = get_node(s, zone_to_nid(zone));
if (n && cpuset_zone_allowed(zone, flags) &&
n->nr_partial > s->min_partial) {
object = get_partial_node(s, n, c, flags);
if (object) {
/*
* Don't check read_mems_allowed_retry()
* here - if mems_allowed was updated in
* parallel, that was a harmless race
* between allocation and the cpuset
* update
*/
return object;
}
}
}
} while (read_mems_allowed_retry(cpuset_mems_cookie));
#endif
return NULL;
}
리모트 노드들의 partial 리스트에서 슬랩 페이지를 cpu 캐시의 per cpu 캐시의 page 및 partial 리스트로 이동시킨다.
- 코드 라인 39~42에서 delay 타이머를 이용하여 “/sys/kernel/slab/<slab 명>/remote_node_defrag_ratio=” 비율(디폴트=1000(99.8%), 1024=100%)로 루틴을 수행하게 한다. 확률에서 제외되면 null을 반환한다.
- Delay Loop Timer | 문c
- 코드 라인 44~45에서 cpuset 변동이 있는 경우 재시도되기 위해 cpuset 시퀀스 락 값을 읽어온다
- 코드 라인 46~47에서 mempolicy에서 찾아준 노드의 zonelist에서 high_zoneidx 이하의 존을 위에서 아래로 순회한다.
- 코드 라인 50~65에서 순회 중인 존의 노드가 cpuset에 허용된 노드이고 노드의 partial 리스트의 수가 캐시가 요구하는 최소 s->min_partial 보다 큰 경우에 한해 해당 노드의 partial 리스트에서 일정 분량의 슬랩 페이지를 cpu 캐시의 per cpu 캐시의 page 및 partial 리스트로 이동시킨다. 성공한 경우 첫 free object를 반환한다.
- 코드 라인 67에서 cpuset 변동이 있는 경우 재시도를 한다
- 코드 라인 zonelist를 다 순회하도록 처리가 되지 않은 경우이다. 실패로 null을 반환한다.
슬랩에서 2 개의 값 atomic 교체
x86, arm64, s390 등에서 2(double) 개의 값을 동시에 변경할 수 있는 atomic API를 제공하는 아키텍처에서는 조금 더 빠른 성능으로 처리하고, 그렇지 않은 아키텍처의 경우 인터럽트를 블러킹한채로 교체한다.
다음 2 개의 관련된 API가 있다.
- this_cpu_cmpxchg_double()
- per-cpu 변수와 관련된 두 개의 값을 교체할 때 사용한다.
- cmpxchg_double()
- 글로벌 변수와 관련된 두 개의 값을 교체할 때 사용한다.
슬랩에서 2 개의 값을 atomic 하게 교체하는 함수들
- cmpxchg_double_slab()
- 아키텍처가 2개의 값을 atomic하게 교체하는 API를 지원하지 않는 경우 함수내에서 인터럽트를 disable하고 bit_spin_lock을 걸고 처리한다.
- __cmpxchg_double_slab()
- 아키텍처가 2개의 값을 atomic하게 교체하는 API를 지원하지 않는 경우 함수내에서 bit_spin_lock을 걸고 처리한다.
- 함수호출 전에 인터럽트가 disable되어 있어야 한다.
__cmpxchg_double_slab()
mm/slub.c
/* Interrupts must be disabled (for the fallback code to work right) */
static inline bool __cmpxchg_double_slab(struct kmem_cache *s, struct page *page,
void *freelist_old, unsigned long counters_old,
void *freelist_new, unsigned long counters_new,
const char *n)
{
VM_BUG_ON(!irqs_disabled());
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
if (s->flags & __CMPXCHG_DOUBLE) {
if (cmpxchg_double(&page->freelist, &page->counters,
freelist_old, counters_old,
freelist_new, counters_new))
return 1;
} else
#endif
{
slab_lock(page);
if (page->freelist == freelist_old &&
page->counters == counters_old) {
page->freelist = freelist_new;
page->counters = counters_new;
slab_unlock(page);
return 1;
}
slab_unlock(page);
}
cpu_relax();
stat(s, CMPXCHG_DOUBLE_FAIL);
#ifdef SLUB_DEBUG_CMPXCHG
pr_info("%s %s: cmpxchg double redo ", n, s->name);
#endif
return 0;
}
page->freelist와 counter를 old 값과 비교하여 동일한 경우 new 값으로 바꾼다. CONFIG_HAVE_CMPXCHG_DOUBLE을 지원하는 아키텍처에서 두 개의 워드 값의 교체를 atomic하게 처리를 한다. 지원하지 않는 아키텍처의 경우 bit_spin_lock()을 사용하여 처리한다.
- if @page->freelist == @freelist_old && @page->counters == @counters_old
- @page->freelist <— @freelist_new
- @page->counters <— @counters_new
CONFIG_HAVE_CMPXCHG_DOUBLE
2(double) 개의 값을 교체하는 atomic API를 지원하는 아키텍처가 사용하는 커널 옵션이다.
- x86, arm64, s390 아키텍처 등이 지원하고 있다.
다음 그림에서는 per cpu 캐시에서 사용된 fastpath와 per node에서 사용된 slowpath에서 사용된 두 개의 atomic operation을 보여준다.

다음과 같이 두 개의 값을 한꺼번에 atomic하게 교체하는 방법은 다음과 같다.
- 인터럽트를 블러킹한 후 두 개의 값을 교체하는 generic 방법
- 빠른 성능을 위해 아키텍처가 지원하는 atomic API 방법 – ARM64 아키텍처 등이 지원한다.
this_cpu_cmpxchg_double()
include/linux/percpu-defs.h
#define this_cpu_cmpxchg_double(pcp1, pcp2, oval1, oval2, nval1, nval2) \
__pcpu_double_call_return_bool(this_cpu_cmpxchg_double_, pcp1, pcp2, oval1, oval2, nval1, nv
al2)
두 개(double)의 per-cpu 변수 값 pcp1과 pcp2이 oval1과 oval2와 동일한 경우 nval1과 nval2로 변경한다.
- if pcp1 == oval1 && pcp2 == oval2
- pcp1 = nval1
- pcp2 = nval2
__pcpu_double_call_return_bool()
include/linux/percpu-defs.h
/* * Special handling for cmpxchg_double. cmpxchg_double is passed two * percpu variables. The first has to be aligned to a double word * boundary and the second has to follow directly thereafter. * We enforce this on all architectures even if they don't support * a double cmpxchg instruction, since it's a cheap requirement, and it * avoids breaking the requirement for architectures with the instruction. */
#define __pcpu_double_call_return_bool(stem, pcp1, pcp2, ...) \
({ \
bool pdcrb_ret__; \
__verify_pcpu_ptr(&(pcp1)); \
BUILD_BUG_ON(sizeof(pcp1) != sizeof(pcp2)); \
VM_BUG_ON((unsigned long)(&(pcp1)) % (2 * sizeof(pcp1))); \
VM_BUG_ON((unsigned long)(&(pcp2)) != \
(unsigned long)(&(pcp1)) + sizeof(pcp1)); \
switch(sizeof(pcp1)) { \
case 1: pdcrb_ret__ = stem##1(pcp1, pcp2, __VA_ARGS__); break; \
case 2: pdcrb_ret__ = stem##2(pcp1, pcp2, __VA_ARGS__); break; \
case 4: pdcrb_ret__ = stem##4(pcp1, pcp2, __VA_ARGS__); break; \
case 8: pdcrb_ret__ = stem##8(pcp1, pcp2, __VA_ARGS__); break; \
default: \
__bad_size_call_parameter(); break; \
} \
pdcrb_ret__; \
})
cmpxchg_double 핸들링을 위해 @stem으로 시작하는 함수명에 1, 2, 4, 8 단위의 접미사를 붙여 함수를 호출하도록 한다.
- 예) @stem=this_cpu_cmpxchg_double_
- this_cpu_cmpxchg_double_1(pcp1, pcp2, …)
- this_cpu_cmpxchg_double_2(pcp1, pcp2, …)
- this_cpu_cmpxchg_double_3(pcp1, pcp2, …)
- this_cpu_cmpxchg_double_4(pcp1, pcp2, …)
this_cpu_cmpxchg_double_8()
include/asm-generic/percpu.h
#ifndef this_cpu_cmpxchg_double_8
#define this_cpu_cmpxchg_double_8(pcp1, pcp2, oval1, oval2, nval1, nval2) \
this_cpu_generic_cmpxchg_double(pcp1, pcp2, oval1, oval2, nval1, nval2)
인터럽트 블러킹을 사용하는 generic 방법
this_cpu_generic_cmpxchg_double() – generic
include/asm-generic/percpu.h
#define this_cpu_generic_cmpxchg_double(pcp1, pcp2, oval1, oval2, nval1, nval2) \
({ \
int __ret; \
unsigned long __flags; \
raw_local_irq_save(__flags); \
__ret = raw_cpu_generic_cmpxchg_double(pcp1, pcp2, \
oval1, oval2, nval1, nval2); \
raw_local_irq_restore(__flags); \
__ret; \
})
generic 한 방법으로 인터럽트를 마스킹한 후 두 개의 per-cpu 변수 값을 비교하고, 새 값으로 변경한다.
raw_cpu_generic_cmpxchg_double()
include/asm-generic/percpu.h
#define raw_cpu_generic_cmpxchg_double(pcp1, pcp2, oval1, oval2, nval1, nval2) \
({ \
typeof(&(pcp1)) __p1 = raw_cpu_ptr(&(pcp1)); \
typeof(&(pcp2)) __p2 = raw_cpu_ptr(&(pcp2)); \
int __ret = 0; \
if (*__p1 == (oval1) && *__p2 == (oval2)) { \
*__p1 = nval1; \
*__p2 = nval2; \
__ret = 1; \
} \
(__ret); \
})
두 개의 per-cpu 변수 값을 비교하고, 새 값으로 변경한다.
아키텍처가 지원하는 atomic API 방법
this_cpu_generic_cmpxchg_double() – ARM64
arch/arm64/include/asm/percpu.h
/* * It would be nice to avoid the conditional call into the scheduler when * re-enabling preemption for preemptible kernels, but doing that in a way * which builds inside a module would mean messing directly with the preempt * count. If you do this, peterz and tglx will hunt you down. */
#define this_cpu_cmpxchg_double_8(ptr1, ptr2, o1, o2, n1, n2) \
({ \
int __ret; \
preempt_disable_notrace(); \
__ret = cmpxchg_double_local( raw_cpu_ptr(&(ptr1)), \
raw_cpu_ptr(&(ptr2)), \
o1, o2, n1, n2); \
preempt_enable_notrace(); \
__ret; \
})
아키텍처가 지원하는 atomic 명령을 사용하여 preemption을 마스킹한 후 두 개의 per-cpu 변수 값을 비교하고, 새 값으로 변경한다.
cmpxchg_double_local() – ARM64
arch/arm64/include/asm/cmpxchg.h
#define cmpxchg_double_local(ptr1, ptr2, o1, o2, n1, n2) \
({\
int __ret;\
__cmpxchg_double_check(ptr1, ptr2); \
__ret = !__cmpxchg_double((unsigned long)(o1), (unsigned long)(o2), \
(unsigned long)(n1), (unsigned long)(n2), \
ptr1); \
__ret; \
})
ARM64 아키텍처가 지원하는 atomic 명령을 사용하여 두 개의 unsigned long 값을 비교하고, 새 값으로 변경한다.
__cmpxchg_double() 시리즈 – ARM64 – ll_sc 방식
include/asm/atomic_ll_sc.h
#define __CMPXCHG_DBL(name, mb, rel, cl) \
__LL_SC_INLINE long \
__LL_SC_PREFIX(__cmpxchg_double##name(unsigned long old1, \
unsigned long old2, \
unsigned long new1, \
unsigned long new2, \
volatile void *ptr)) \
{ \
unsigned long tmp, ret; \
\
asm volatile("// __cmpxchg_double" #name "\n" \
" prfm pstl1strm, %2\n" \
"1: ldxp %0, %1, %2\n" \
" eor %0, %0, %3\n" \
" eor %1, %1, %4\n" \
" orr %1, %0, %1\n" \
" cbnz %1, 2f\n" \
" st" #rel "xp %w0, %5, %6, %2\n" \
" cbnz %w0, 1b\n" \
" " #mb "\n" \
"2:" \
: "=&r" (tmp), "=&r" (ret), "+Q" (*(unsigned long *)ptr) \
: "r" (old1), "r" (old2), "r" (new1), "r" (new2) \
: cl); \
\
return ret; \
} \
__LL_SC_EXPORT(__cmpxchg_double##name);
__CMPXCHG_DBL( , , , )
__CMPXCHG_DBL(_mb, dmb ish, l, "memory")
ARM64 아키텍처가 지원하는 ll_sc 방식의 atomic 명령을 사용하여 두 개의 unsigned long 값을 비교하고, 새 값으로 변경한다.
__cmpxchg_double() 시리즈 – ARM64 – lse 방식
#define __LL_SC_CMPXCHG_DBL(op) __LL_SC_CALL(__cmpxchg_double##op)
#define __CMPXCHG_DBL(name, mb, cl...) \
static inline long __cmpxchg_double##name(unsigned long old1, \
unsigned long old2, \
unsigned long new1, \
unsigned long new2, \
volatile void *ptr) \
{ \
unsigned long oldval1 = old1; \
unsigned long oldval2 = old2; \
register unsigned long x0 asm ("x0") = old1; \
register unsigned long x1 asm ("x1") = old2; \
register unsigned long x2 asm ("x2") = new1; \
register unsigned long x3 asm ("x3") = new2; \
register unsigned long x4 asm ("x4") = (unsigned long)ptr; \
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
__LL_SC_CMPXCHG_DBL(name) \
__nops(3), \
/* LSE atomics */ \
" casp" #mb "\t%[old1], %[old2], %[new1], %[new2], %[v]\n"\
" eor %[old1], %[old1], %[oldval1]\n" \
" eor %[old2], %[old2], %[oldval2]\n" \
" orr %[old1], %[old1], %[old2]") \
: [old1] "+&r" (x0), [old2] "+&r" (x1), \
[v] "+Q" (*(unsigned long *)ptr) \
: [new1] "r" (x2), [new2] "r" (x3), [ptr] "r" (x4), \
[oldval1] "r" (oldval1), [oldval2] "r" (oldval2) \
: __LL_SC_CLOBBERS, ##cl); \
\
return x0; \
}
__CMPXCHG_DBL( , )
__CMPXCHG_DBL(_mb, al, "memory")
ARM64 아키텍처가 지원하는 lse 방식의 atomic 명령을 사용하여 두 개의 unsigned long 값을 비교하고, 새 값으로 변경한다.
cmpxchg_double() – generic
include/asm-generic/atomic-instrumented.h
#define cmpxchg_double(p1, p2, o1, o2, n1, n2) \
({ \
typeof(p1) __ai_p1 = (p1); \
kasan_check_write(__ai_p1, 2 * sizeof(*__ai_p1)); \
arch_cmpxchg_double(__ai_p1, (p2), (o1), (o2), (n1), (n2)); \
})
cmpxchg_double() – ARM64
arch/arm64/include/asm/cmpxchg.h
#define cmpxchg_double(ptr1, ptr2, o1, o2, n1, n2) \
({\
int __ret;\
__cmpxchg_double_check(ptr1, ptr2); \
__ret = !__cmpxchg_double_mb((unsigned long)(o1), (unsigned long)(o2), \
(unsigned long)(n1), (unsigned long)(n2), \
ptr1); \
__ret; \
})
참고
- Slab Memory Allocator -1- (구조) | 문c
- Slab Memory Allocator -2- (캐시 초기화) | 문c
- Slub Memory Allocator -3- (캐시 생성) | 문c
- Slub Memory Allocator -4- (Order 계산) | 문c
- Slub Memory Allocator -5- (Slub 할당) | 문c
- Slub Memory Allocator -6- (Object 할당) | 문c – 현재 글
- Slub Memory Allocator -7- (Object 해제) | 문c
- Slub Memory Allocator -8- (Drain/Flash 캐시) | 문c
- Slub Memory Allocator -9- (캐시 Shrink) | 문c
- Slub Memory Allocator -10- (Slub 해제) | 문c
- Slub Memory Allocator -11- (캐시 삭제) | 문c
- Slub Memory Allocator -12- (Slub 디버깅) | 문c
- Slub Memory Allocator -13- (slabinfo) | 문c
안녕하세요, 공부하다가 질문이 생겨서 댓글 남깁니다. 다름이 아니라 slowpath – 1에서 get_freelist 함수가 있는데,
이 인라인 함수 안에서 new의 값을 변경하는데 new는 지역변수입니다.
new.inuse = page->objects;
new.frozen = freelist != NULL;
그럼 new라는 구조체를 변경하는 이유가 뭘까요? 이걸 get_freelist 함수 바깥에서 접근할 수가 있나요?
제가 C언어나 경쟁 조건 둘 중 하나를 놓친 것 같습니다.
안녕하세요?
page 구조체로 만든 지역 변수 new는 말씀하신 것처럼 임시로 사용되고 있습니다.
다만 new.counter는 union 선언되어 있으므로 이를 확인하시면 금방 이해되실겁니다.
new.counter = new.inuse | new.objects | new.frozen
참고) include/linux/mm_types.hunion {
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
감사합니다.
답변 감사드립니다. 그런데 제 질문의 요지는 get_freelist에서 사용하는 임시변수인 new에 값을 저장한
다음에 전혀 사용하지 않으면 무슨 의미가 있는지였습니다.
함수는 아래와 같이 생겼는데 new를 변경한 후에 전혀 사용하지 않아서요.
static inline void *get_freelist(struct kmem_cache *s, struct page *page)
{
struct page new;
unsigned long counters;
void *freelist;
do {
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
VM_BUG_ON(!new.frozen);
new.inuse = page->objects;
new.frozen = freelist != NULL;
} while (!__cmpxchg_double_slab(s, page,
freelist, counters,
NULL, new.counters,
“get_freelist”));
return freelist;
}
cmpxchg_double_slab() 명령은 두 개의 값을 두 개의 old 값과 비교한 후 동일한 경우에만 새로운 두 개 값으로 대입(교체)하는 명령입니다.
결국 page->freelist 및 page->counters 값이 freelist 및 counters와 비교하여 동일한 경우
page->freelist = NULL, 그리고 page->counters = new.counters 값으로 대입하겠다는 명령입니다.
따라서 new의 변경된 값을 사용한 것입니다. (new.inuse, new.frozen이 new.counters에 반영되었죠)
new 구조체를 전부 사용한 것은 아니지만, new.counters 부분을 이용하였습니다.
감사합니다.
아…!! counters가 inuse/frozen/objects의 union이란걸 잊고 있었습니다.
비트 연산이 아니라 union을 사용하기 위해서였군요! 감사합니다.
네. 다행히 금방 아셨군요. 좋은 하루되세요. ^^
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=cc09ee80c3b1
최근에 PREEMPT_RT가 머지되면서 슬랩도 그렇고 이것저것 많이 바뀌고 있군요
좋은 정보 감사드립니다. 잘 읽어봐야 겠네요.
PREEMPT_RT가 현재 커널로 머지되었지만 실제 RT 커널에서 작업한 일부분들은 안정성 및 기존 커널의 호환 이유로 아직도 마이그레이션되지 않고 남아있습니다.
따라서 CONFIG_PREMPT_RT 커널 옵션은 개인이 활성화시켜 사용하는 경우에는 CONFIG_PREEMPT 보다 약간 더 preemtinable 해지지만 이전의 RT 커널과는 조금 다릅니다.
이 부족한 부분은 SoC 업체들이 별도로 더 작업을 해서 release 해야하는 상황입니다.
감사합니다.
안녕하세요
get_freelist() 함수에서 잘 이해가 안되어서 질문드립니다.
do-while 문에서 freelist와 page->freelist, counters와 page->counters를 비교해서 같으면 while문을 빠져나오는 구문으로 이해를 했습니다. 한 가지 궁금한 것은 두 가지 조건이 같지 않은 경우가 언제 발생하는 지 입니다. freelist와 counters 변수 값을 다시 대입하는 구문도 없고, page 구조체도 변경하는 부분이 없어 보이는 데 혹시 두 가지 조건이 같지 않는 것에는 어떤 경우가 있을까요?
안녕하세요?
SMP 시스템에서 다른 cpu가 __slab_free() 함수를 통해 페이지의 슬랩 오브젝트를 free 할 때 page->freelist가 경쟁될 수 있습니다.
감사합니다.
아 그렇군요!
요즘 스터디에서 slub 할당자를 보고 있는데, 정리해 두신 자료가 정말 많이 도움이 되는 것 같습니다.
항상 감사합니다!
분석하는데 도움이 되었으면 합니다. 좋은 하루되세요!