radix tree를 사용하여 정수 ID를 관리하고 이에 연결된 포인터 값을 반환한다. 다음은 리눅스 IDR의 특징이다.
- ID 관리
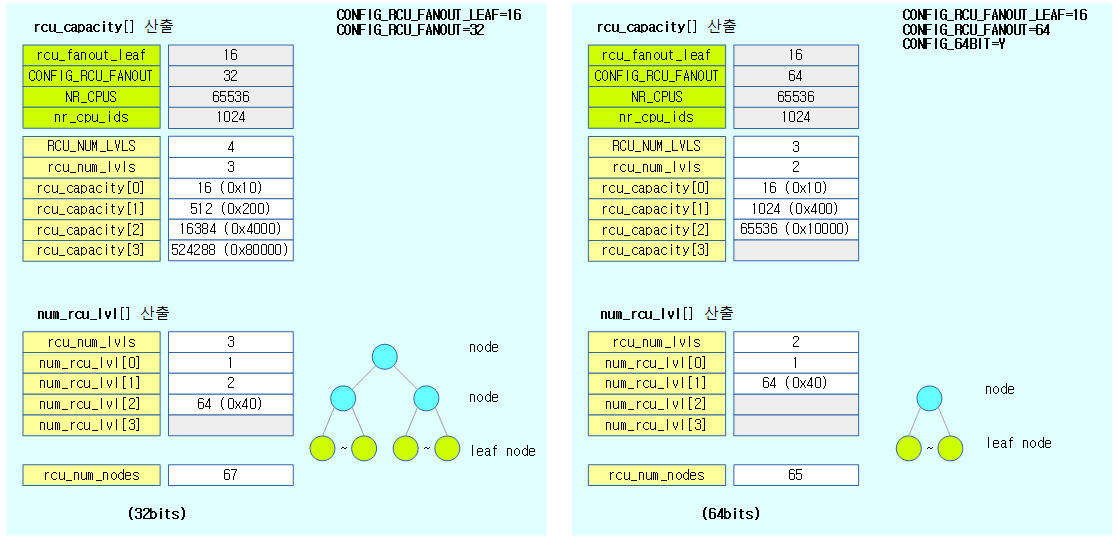
- Radix tree를 사용하여 레이어 단계 마다 256(0x100)배 단위로 ID를 관리할 수 있다.
- 32 bit 시스템에서 사용하는 레이어의 수에 따라
- 1 레이어: 0 ~ 0xff ID 관리
- 2 레이어: 0 ~ 0xffff ID 관리
- 3 레이어: 0 ~ 0xffffff ID 관리
- 4 레이어: 0 ~ 0x7fffffff ID 관리
- 64 bit 시스템에서사용하는 레이어의 수에 따라
- 1 레이어: 0 ~ 0xff ID 관리
- 2 레이어: 0 ~ 0xffff ID 관리
- 3 레이어: 0 ~ 0xffffff ID 관리
- 4 레이어: 0 ~ 0xffffffff ID 관리
- 5 레이어: 0 ~ 0xff_ffffffff ID 관리
- 6 레이어: 0 ~ 0xffff_ffffffff ID 관리
- 7 레이어: 0 ~ 0xffffff_ffffffff ID 관리
- 8 레이어: 0 ~ 0x7fffffff_ffffffff ID 관리
- 큰 번호의 ID를 요구하는 경우 레이어 관리 단계가 커져 cost가 더 많이 소모된다.
- IDR preload 버퍼
- idr_layer 구조체 할당은 slub 캐시를 통해 전달되는데 이를 미리 몇 개를 할당받아 IDR 레이어가 횡 또는 종으로 확장될 때 빠르게 공급할 수 있도록 설계되었다.
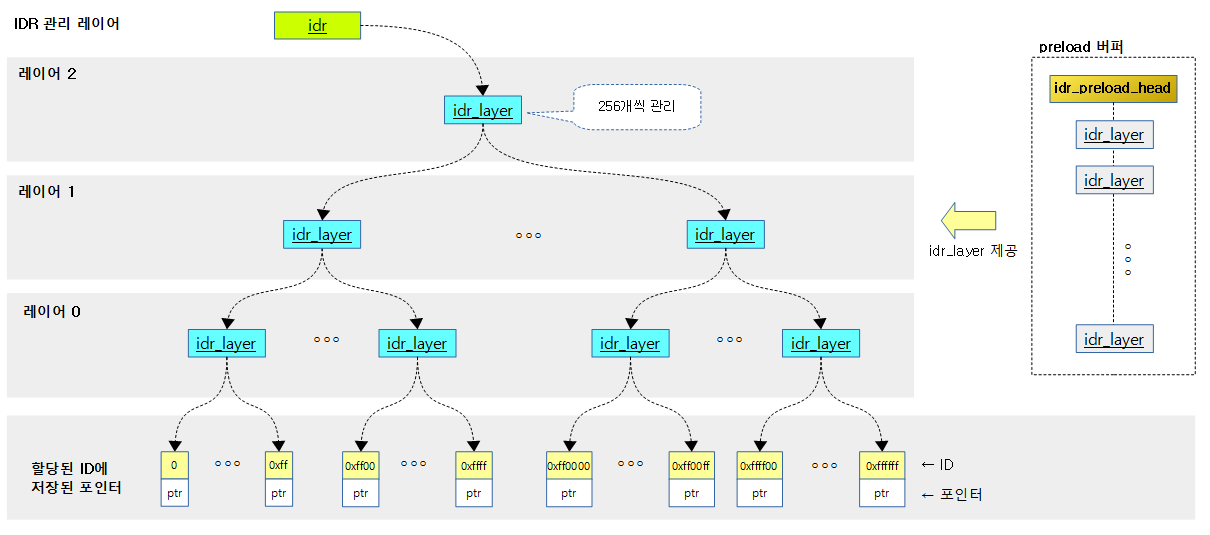
다음 그림은 IDR이 레이어별로 관리되는 모습을 보여준다.
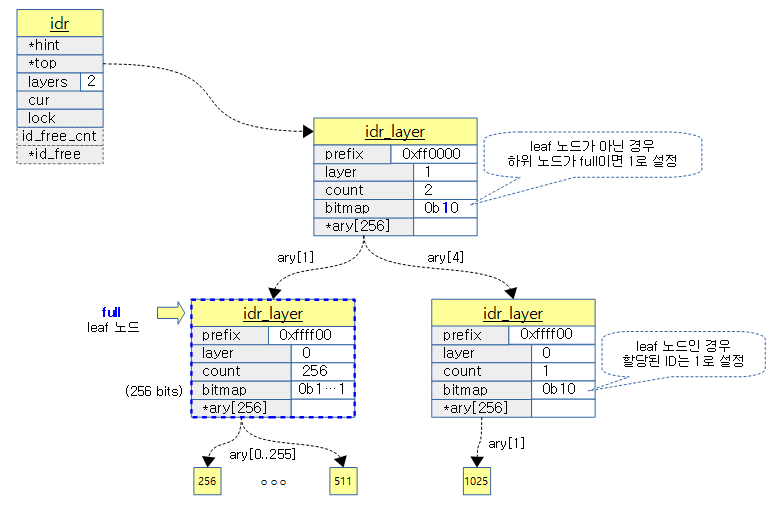
다음 그림은 256~511까지의 ID와 1025의 ID가 할당되어 관리되는 모습을 보여준다.
static IDR 선언 및 초기화
DEFINE_IDR()
include/linux/idr.h
#define DEFINE_IDR(name) struct idr name = IDR_INIT(name)
주어진 이름으로 idr 구조체를 선언하고 초기화한다.
IDR_INIT()
include/linux/idr.h
#define IDR_INIT(name) \
{ \
.lock = __SPIN_LOCK_UNLOCKED(name.lock), \
}
주어진 이름의 idr 구조체를 초기화한다.
dynamic IDR 초기화
idr_init()
/**
* idr_init - initialize idr handle
* @idp: idr handle
*
* This function is use to set up the handle (@idp) that you will pass
* to the rest of the functions.
*/
void idr_init(struct idr *idp)
{
memset(idp, 0, sizeof(struct idr));
spin_lock_init(&idp->lock);
}
EXPORT_SYMBOL(idr_init);
idr 구조체 멤버 변수를 모두 0으로 초기화하고 lock 멤버만 spinlock 초기화한다.
IDR 할당
- 기존(old) 방법으로 ID를 할당하는 경우 다음 2개의 API를 연달아 사용했었다.
- int idr_pre_get(struct idr *idp, gfp_t gfp_mask);
- int idr_get_new(struct idr *idp, void *ptr, int *id);
- 새로운(new) 방법으로 ID를 할당하는 경우 다음 3개의 API를 연달아 사용한다.
- void idr_preload(gfp_t gfp_mask);
- int idr_alloc(struct idr *idp, void *ptr, int start, int end, gfp_t gfp_mask);
- void idr_preload_end(void);
- 2013년 커널 v3.9-rc1부터 적용
idr_preload()
lib/idr.c
/**
* idr_preload - preload for idr_alloc()
* @gfp_mask: allocation mask to use for preloading
*
* Preload per-cpu layer buffer for idr_alloc(). Can only be used from
* process context and each idr_preload() invocation should be matched with
* idr_preload_end(). Note that preemption is disabled while preloaded.
*
* The first idr_alloc() in the preloaded section can be treated as if it
* were invoked with @gfp_mask used for preloading. This allows using more
* permissive allocation masks for idrs protected by spinlocks.
*
* For example, if idr_alloc() below fails, the failure can be treated as
* if idr_alloc() were called with GFP_KERNEL rather than GFP_NOWAIT.
*
* idr_preload(GFP_KERNEL);
* spin_lock(lock);
*
* id = idr_alloc(idr, ptr, start, end, GFP_NOWAIT);
*
* spin_unlock(lock);
* idr_preload_end();
* if (id < 0)
* error;
*/
void idr_preload(gfp_t gfp_mask)
{
/*
* Consuming preload buffer from non-process context breaks preload
* allocation guarantee. Disallow usage from those contexts.
*/
WARN_ON_ONCE(in_interrupt());
might_sleep_if(gfp_mask & __GFP_WAIT);
preempt_disable();
/*
* idr_alloc() is likely to succeed w/o full idr_layer buffer and
* return value from idr_alloc() needs to be checked for failure
* anyway. Silently give up if allocation fails. The caller can
* treat failures from idr_alloc() as if idr_alloc() were called
* with @gfp_mask which should be enough.
*/
while (__this_cpu_read(idr_preload_cnt) < MAX_IDR_FREE) {
struct idr_layer *new;
preempt_enable();
new = kmem_cache_zalloc(idr_layer_cache, gfp_mask);
preempt_disable();
if (!new)
break;
/* link the new one to per-cpu preload list */
new->ary[0] = __this_cpu_read(idr_preload_head);
__this_cpu_write(idr_preload_head, new);
__this_cpu_inc(idr_preload_cnt);
}
}
EXPORT_SYMBOL(idr_preload);
idr preload 버퍼에 8(32bit 시스템 기준)개의 idr_layer 엔트리를 미리 할당해둔다. 이 idr 프리로드 버퍼는 idr_alloc() 함수가 필요로하는 idr_layer를 미리 준비하여 필요할 때마다 최대한 짧은 시간에 제공하여 preemption disable 구간에서 동작하는 idr_alloc() 함수를 위해 preemption disable 기간을 최대한 줄이기 위해 사용된다.
- might_sleep_if(gfp_mask & __GFP_WAIT);
- __GFP_WAIT 플래그가 주어진 경우 현재 태스크보다 더 높은 우선순위의 처리할 태스크가 있는 경우 선점될 수 있다. 즉 sleep 가능하다.
- preempt_disable();
- while (__this_cpu_read(idr_preload_cnt) < MAX_IDR_FREE) {
- 현재 cpu에서 idr_preload_cnt가 MAX_IDR_FREE(최대 레벨의 2배)보다 적은 경우 루프를 계속 수행한다.
- MAX_IDR_FREE(최대 레벨의 2배) 수 만큼 idr 캐시를 미리 할당해두려는 목적이다.
- preempt_enable(); new = kmem_cache_zalloc(idr_layer_cache, gfp_mask); preempt_disable(); if (!new) break;
- preemption을 enable한 상태로 idr_layer_cache를 통해 idr_layer 구조체 영역을 할당받고 실패한 경우 루프를 탈출한다.
- new->ary[0] = __this_cpu_read(idr_preload_head); __this_cpu_write(idr_preload_head, new);
- 할당 받은 new idr_layer 구조체를 idr preload 버퍼 리스트에 추가한다.
- idr_preload_head 리스트에서 idr_layer들은 ary[0]을 이용하여 다음 엔트리가 연결되어 있는 구조이다.
- __this_cpu_inc(idr_preload_cnt);
- 추가하였으므로 idr_preload_cnt를 증가시킨다.
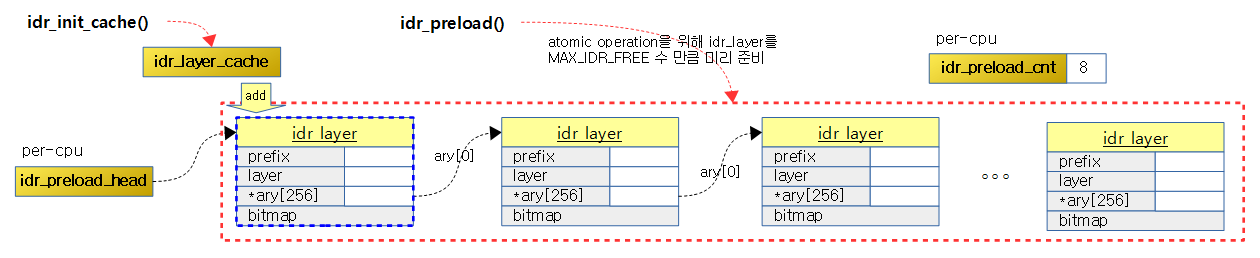
다음 그림은 idr_preload() 함수를 idr preload 버퍼에 미리 8(32bit 시스템)개의 idr_layer 구조체들을 할당해놓은 것을 보여준다.
idr_preload_end()
include/linux/idr.h
/**
* idr_preload_end - end preload section started with idr_preload()
*
* Each idr_preload() should be matched with an invocation of this
* function. See idr_preload() for details.
*/
static inline void idr_preload_end(void)
{
preempt_enable();
}
idr_alloc()이 끝났으므로 preemption을 enable하여 이제 선점 가능한 상태도 바꾼다.
idr_alloc()
lib/idr.c
/**
* idr_alloc - allocate new idr entry
* @idr: the (initialized) idr
* @ptr: pointer to be associated with the new id
* @start: the minimum id (inclusive)
* @end: the maximum id (exclusive, <= 0 for max)
* @gfp_mask: memory allocation flags
*
* Allocate an id in [start, end) and associate it with @ptr. If no ID is
* available in the specified range, returns -ENOSPC. On memory allocation
* failure, returns -ENOMEM.
*
* Note that @end is treated as max when <= 0. This is to always allow
* using @start + N as @end as long as N is inside integer range.
*
* The user is responsible for exclusively synchronizing all operations
* which may modify @idr. However, read-only accesses such as idr_find()
* or iteration can be performed under RCU read lock provided the user
* destroys @ptr in RCU-safe way after removal from idr.
*/
int idr_alloc(struct idr *idr, void *ptr, int start, int end, gfp_t gfp_mask)
{
int max = end > 0 ? end - 1 : INT_MAX; /* inclusive upper limit */
struct idr_layer *pa[MAX_IDR_LEVEL + 1];
int id;
might_sleep_if(gfpflags_allow_blocking(gfp_mask));
/* sanity checks */
if (WARN_ON_ONCE(start < 0))
return -EINVAL;
if (unlikely(max < start))
return -ENOSPC;
/* allocate id */
id = idr_get_empty_slot(idr, start, pa, gfp_mask, NULL);
if (unlikely(id < 0))
return id;
if (unlikely(id > max))
return -ENOSPC;
idr_fill_slot(idr, ptr, id, pa);
return id;
}
EXPORT_SYMBOL_GPL(idr_alloc);
start ~ (end-1) 정수 범위내에서 빈 id를 찾아 ptr을 저장하고 id를 반환한다. end가 0인 경우 시스템 최대 정수값인 INT_MAX로 지정된다.
- might_sleep_if(gfp_mask & __GFP_WAIT);
- 선점 가능한 상태에서 __GFP_WAIT 플래그가 요청된 경우 높은 순위이 태스크가 선점 요청한 경우 sleep 한다.
- id = idr_get_empty_slot(idr, start, pa, gfp_mask, NULL);
- start ~ end-1 까지 비어있는 ID를 찾아 반환한다. 이 과정에서 만일 레이어 확장이 필요한 경우 생성하게한다.
- if (unlikely(id < 0)) return id;
- 음수를 반환하는 경우 ID를 할당받지 못하여 에러로 리턴한다.
- if (unlikely(id > max)) return -ENOSPC;
- 요청 범위내에서 할당이 불가능한 경우 할당할 공간이 없다고 -ENOSPC 에러를 반환한다.
- idr_fill_slot(idr, ptr, id, pa);
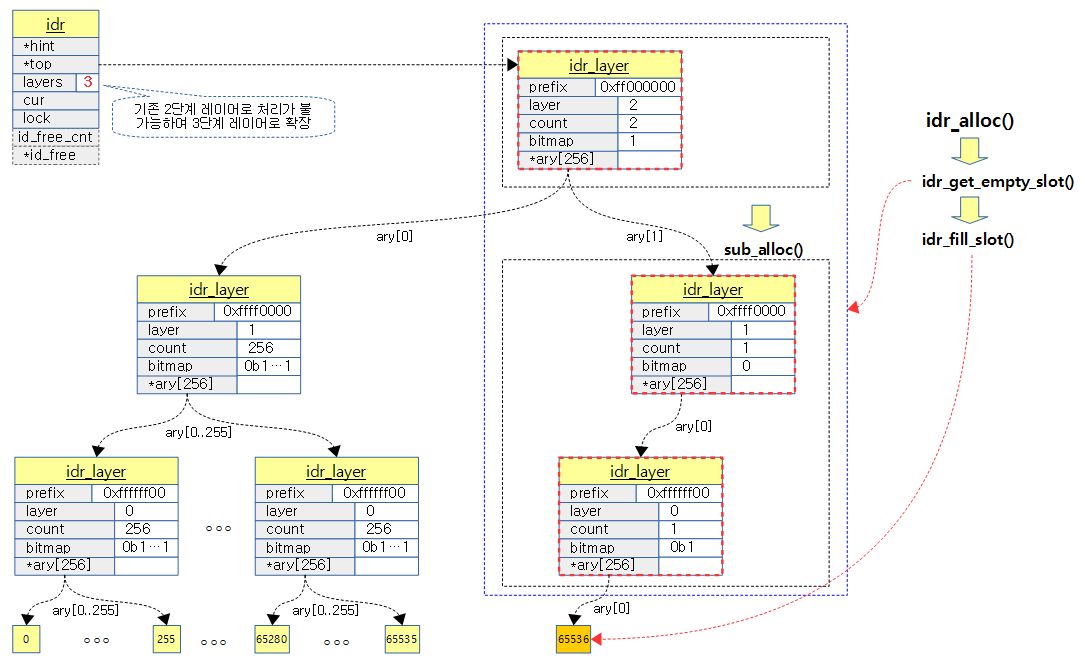
다음 그림은 0~65535 ID까지 full되어 2단계 레이어로 관리되고 있는 상태에서 65536번의 IDR이 추가 할당되어 3단계 레이어로 확장되는 모습을 보여준다.
idr_get_empty_slot()
lib/idr.c
static int idr_get_empty_slot(struct idr *idp, int starting_id,
struct idr_layer **pa, gfp_t gfp_mask,
struct idr *layer_idr)
{
struct idr_layer *p, *new;
int layers, v, id;
unsigned long flags;
id = starting_id;
build_up:
p = idp->top;
layers = idp->layers;
if (unlikely(!p)) {
if (!(p = idr_layer_alloc(gfp_mask, layer_idr)))
return -ENOMEM;
p->layer = 0;
layers = 1;
}
/*
* Add a new layer to the top of the tree if the requested
* id is larger than the currently allocated space.
*/
while (id > idr_max(layers)) {
layers++;
if (!p->count) {
/* special case: if the tree is currently empty,
* then we grow the tree by moving the top node
* upwards.
*/
p->layer++;
WARN_ON_ONCE(p->prefix);
continue;
}
if (!(new = idr_layer_alloc(gfp_mask, layer_idr))) {
/*
* The allocation failed. If we built part of
* the structure tear it down.
*/
spin_lock_irqsave(&idp->lock, flags);
for (new = p; p && p != idp->top; new = p) {
p = p->ary[0];
new->ary[0] = NULL;
new->count = 0;
bitmap_clear(new->bitmap, 0, IDR_SIZE);
__move_to_free_list(idp, new);
}
spin_unlock_irqrestore(&idp->lock, flags);
return -ENOMEM;
}
new->ary[0] = p;
new->count = 1;
new->layer = layers-1;
new->prefix = id & idr_layer_prefix_mask(new->layer);
if (bitmap_full(p->bitmap, IDR_SIZE))
__set_bit(0, new->bitmap);
p = new;
}
rcu_assign_pointer(idp->top, p);
idp->layers = layers;
v = sub_alloc(idp, &id, pa, gfp_mask, layer_idr);
if (v == -EAGAIN)
goto build_up;
return(v);
}
start ~ end-1 까지 비어있는 ID를 찾아 반환한다. 이 과정에서 만일 레이어 확장(tree depth)이 필요한 경우 생성하게한다.
- build_up: p = idp->top; layers = idp->layers;
- idr 구조체의 top이 가리키는 노드를 지정하고, 사용하는 레이어 계층 수를 알아온다.
- if (unlikely(!p)) { if (!(p = idr_layer_alloc(gfp_mask, layer_idr))) return -ENOMEM;
- 적은 확률로 노드가 지정되지 않은 경우이면서 idr_layer 구조체를 할당 받지 못한 경우 -ENOMEM 에러를 반환한다.
- p->layer = 0; layers = 1;
- leaf 노드이므로 layer 멤버 변수에 0을 대입하고, 레이어 수는 1로 대입한다.
- while (id > idr_max(layers)) {
- 요청한 id 값이 현재 idr 레이어가 처리할 수 있는 최대 수를 초과하는 경우 루프를 돈다.
- if (!(new = idr_layer_alloc(gfp_mask, layer_idr))) {
- 상위 레이어를 확장(tree depth)하다 할당이 실패하는 경우
- for (new = p; p && p != idp->top; new = p) { p = p->ary[0]; new->ary[0] = NULL; new->count = 0; bitmap_clear(new->bitmap, 0, IDR_SIZE); __move_to_free_list(idp, new); }
- 이미 레이어 확장을 위해 만들어 놓은 idr_layer들을 모두 id_free 리스트로 옮긴다.
- new->ary[0] = p; new->count = 1; new->layer = layers-1; new->prefix = id & idr_layer_prefix_mask(new->layer); if (bitmap_full(p->bitmap, IDR_SIZE)) __set_bit(0, new->bitmap); p = new;
- 새로 만들어진 레이어의 ary[0]이 기존 레이어를 향하도록 대입하고, 1개의 count를 갖게 대입한다.
- prefix 값도 지정하고 기존 레이어의 비트맵이 full된 경우 새로 만들어진 bitmap의 처음 비트를 1로 full 설정한다.
- rcu_assign_pointer(idp->top, p);
- idr 구조체의 top이 p 노드를 가리킬 수 있도록 대입한다.
- idp->layers = layers;
- v = sub_alloc(idp, &id, pa, gfp_mask, layer_idr);
- 상위 레이어 tree depth 확장은 위 while 문에서 완료되었고 여기에서는 ID를 할당하되 레이어의 depth를 변경하지 않고 그 범위 내의 하위 레이어 중 할당이 필요한 레이어들을 할당한다.
- if (v == -EAGAIN) goto build_up;
- ID 할당이 실패한 경우 build_up부터 다시 시작한다.
idr_layer_alloc()
lib/idr.c
/**
* idr_layer_alloc - allocate a new idr_layer
* @gfp_mask: allocation mask
* @layer_idr: optional idr to allocate from
*
* If @layer_idr is %NULL, directly allocate one using @gfp_mask or fetch
* one from the per-cpu preload buffer. If @layer_idr is not %NULL, fetch
* an idr_layer from @idr->id_free.
*
* @layer_idr is to maintain backward compatibility with the old alloc
* interface - idr_pre_get() and idr_get_new*() - and will be removed
* together with per-pool preload buffer.
*/
static struct idr_layer *idr_layer_alloc(gfp_t gfp_mask, struct idr *layer_idr)
{
struct idr_layer *new;
/* this is the old path, bypass to get_from_free_list() */
if (layer_idr)
return get_from_free_list(layer_idr);
/*
* Try to allocate directly from kmem_cache. We want to try this
* before preload buffer; otherwise, non-preloading idr_alloc()
* users will end up taking advantage of preloading ones. As the
* following is allowed to fail for preloaded cases, suppress
* warning this time.
*/
new = kmem_cache_zalloc(idr_layer_cache, gfp_mask | __GFP_NOWARN);
if (new)
return new;
/*
* Try to fetch one from the per-cpu preload buffer if in process
* context. See idr_preload() for details.
*/
if (!in_interrupt()) {
preempt_disable();
new = __this_cpu_read(idr_preload_head);
if (new) {
__this_cpu_write(idr_preload_head, new->ary[0]);
__this_cpu_dec(idr_preload_cnt);
new->ary[0] = NULL;
}
preempt_enable();
if (new)
return new;
}
/*
* Both failed. Try kmem_cache again w/o adding __GFP_NOWARN so
* that memory allocation failure warning is printed as intended.
*/
return kmem_cache_zalloc(idr_layer_cache, gfp_mask);
}
idr preload 버퍼 또는 idr_layer_cache에서 idr_layer 구조체를 할당받아온다.
- if (layer_idr) return get_from_free_list(layer_idr);
- 이 함수의 2번째 인수인 layer_idr이 null 값이 아닌 경우 기존 할당 방식을 호환하기 위해 idr 구조체의 id_free 멤버에서 idr_layer를 가져온다.
- idr preload 버퍼를 사용하는 새로운 방법은 layer_idr 값에 null이 인입되어 이 루틴을 skip 한다.
- new = kmem_cache_zalloc(idr_layer_cache, gfp_mask | __GFP_NOWARN); if (new) return new;
- idr_preload() 함수 없이 idr_alloc() 함수를 사용하는 경우를 배려하기 위해 idr preload 버퍼가 아닌 idr_layer_cache로 부터 직접 idr_layer 구조체를 할당받아온다.
- idr_preload() 함수를 사용한 경우 이 함수를 진행시켜 에러가 발생하면 __GFP_NOWARN 옵션에 의해 경고 메시지가 출력되지 않도록 하였다.
- if (!in_interrupt()) { preempt_disable();
- 인터럽트 핸들러에서 호출된 경우가 아니면 idr preload 버퍼를 사용하기 위해 선점을 막아둔다.
- new = __this_cpu_read(idr_preload_head); if (new) { __this_cpu_write(idr_preload_head, new->ary[0]); __this_cpu_dec(idr_preload_cnt); new->ary[0] = NULL; }
- idr_preload_head 리스트에서 idr_layer 구조체를 가져오고 리스트에서 제거한다.
- preempt_enable(); if (new) return new;
- 다시 선점 가능 상태로 돌리고 할당이 성공한 경우 반환한다.
- return kmem_cache_zalloc(idr_layer_cache, gfp_mask);
- 모두 실패한 경우 마지막으로 다시 한 번 idr_layer_cache로부터 직접 시도한다. 이 때에는 실패 시 경고 메시지가 출력된다.
get_from_free_list()
lib/idr.c
static struct idr_layer *get_from_free_list(struct idr *idp)
{
struct idr_layer *p;
unsigned long flags;
spin_lock_irqsave(&idp->lock, flags);
if ((p = idp->id_free)) {
idp->id_free = p->ary[0];
idp->id_free_cnt--;
p->ary[0] = NULL;
}
spin_unlock_irqrestore(&idp->lock, flags);
return(p);
}
id_free 리스트에 엔트리가 있는 경우 리스트에서 엔트리를 제거하고 그 엔트리를 반환한다.
idr_max()
lib/idr.c
/* the maximum ID which can be allocated given idr->layers */
static int idr_max(int layers)
{
int bits = min_t(int, layers * IDR_BITS, MAX_IDR_SHIFT);
return (1 << bits) - 1;
}
주어진 레이어에서 할당받을 수 있는 max ID(positive integer)를 알아온다.
- 예) 32bit 시스템
- 1단계 레이어: 0xff (8bit)
- 2단계 레이어: 0xffff (16bit)
- 3단계 레이어: 0xff_ffff (24bit)
- 4단계 레이어: 0x7fff_ffff (positive integer, 31bit로 제한)
__move_to_free_list()
lib/idr.c
/* only called when idp->lock is held */
static void __move_to_free_list(struct idr *idp, struct idr_layer *p)
{
p->ary[0] = idp->id_free;
idp->id_free = p;
idp->id_free_cnt++;
}
엔트리를 id_free 리스트에 추가한다.
idr_layer_prefix_mask()
lib/idr.c
/*
* Prefix mask for an idr_layer at @layer. For layer 0, the prefix mask is
* all bits except for the lower IDR_BITS. For layer 1, 2 * IDR_BITS, and
* so on.
*/
static int idr_layer_prefix_mask(int layer)
{
return ~idr_max(layer + 1);
}
요청 layer에 대한 prefix 값을 반환한다.
- 예) layer 0을 요청하는 경우 0xffffff00을 반환한다.
sub_alloc()
lib/idr.c
/**
* sub_alloc - try to allocate an id without growing the tree depth
* @idp: idr handle
* @starting_id: id to start search at
* @pa: idr_layer[MAX_IDR_LEVEL] used as backtrack buffer
* @gfp_mask: allocation mask for idr_layer_alloc()
* @layer_idr: optional idr passed to idr_layer_alloc()
*
* Allocate an id in range [@starting_id, INT_MAX] from @idp without
* growing its depth. Returns
*
* the allocated id >= 0 if successful,
* -EAGAIN if the tree needs to grow for allocation to succeed,
* -ENOSPC if the id space is exhausted,
* -ENOMEM if more idr_layers need to be allocated.
*/
static int sub_alloc(struct idr *idp, int *starting_id, struct idr_layer **pa,
gfp_t gfp_mask, struct idr *layer_idr)
{
int n, m, sh;
struct idr_layer *p, *new;
int l, id, oid;
id = *starting_id;
restart:
p = idp->top;
l = idp->layers;
pa[l--] = NULL;
while (1) {
/*
* We run around this while until we reach the leaf node...
*/
n = (id >> (IDR_BITS*l)) & IDR_MASK;
m = find_next_zero_bit(p->bitmap, IDR_SIZE, n);
if (m == IDR_SIZE) {
/* no space available go back to previous layer. */
l++;
oid = id;
id = (id | ((1 << (IDR_BITS * l)) - 1)) + 1;
/* if already at the top layer, we need to grow */
if (id > idr_max(idp->layers)) {
*starting_id = id;
return -EAGAIN;
}
p = pa[l];
BUG_ON(!p);
/* If we need to go up one layer, continue the
* loop; otherwise, restart from the top.
*/
sh = IDR_BITS * (l + 1);
if (oid >> sh == id >> sh)
continue;
else
goto restart;
}
ID를 할당하되 레이어의 depth를 변경하지 않고 그 범위 내의 하위 레이어 중 할당이 필요한 레이어들을 할당한다. 출력 인수 pa 포인터 배열에는 최상위 레이어부터 id에 해당하는 레이어까지 idr_layer의 포인터 주소를 담는다.
- pa[0]가 가장 하단 레이어를 가리키고 그 다음 배열은 id와 관련된 상위 레이어로 증가하면서 최상위 레이어까지 간다음 마지막에는 null로 종결한다.
- id = *starting_id;
- restart: p = idp->top;
- 처음부터 다시 수행해야 할 때 여기 restart: 레이블로 이동해와서 idr 구조체의 top에 연결된 최상위 노드를 준비한다.
- l = idp->layers; pa[l–] = NULL;
- l은 사용하는 레이어 수를 알아오고 처리할 마지막 pa[] 배열의 끝에 null을 대입한다.
- while (1) { n = (id >> (IDR_BITS*l)) & IDR_MASK; m = find_next_zero_bit(p->bitmap, IDR_SIZE, n);
- 루프를 돌며 n은 id 값을 현재 레이어 값 x 8로 나눈 몫에서 IDR_MASK한 값으로 bitmap 인덱스 n에 대입하고, bitmap에서 n값 뒤로 0으로 설정된 비트 위치를 m에 알아온다. 못 찾은 경우 IDR_SIZE 값을 반환한다.
- 예) 전체 레이어가 3단계이고, 현재 레벨에서 마지막 남은 ID를 할당받고자 할 때
- id=0, bitmap=0x7fffffff_ffffffff_ffffffff_ffffffff_ffffffff_ffffffff_ffffffff_ffffffff, l=2
- if (m == IDR_SIZE) {
- 지정된 번호 뒤로 빈 곳이 없는 경우는 현재 노드에 처리할 ID 공간이 없다는 것을 의미한다.
- l++; old = id; id = (id | ((1 << (IDR_BITS * l)) – 1)) + 1;
- 다시 상위 레이어로 돌아가기 위해 l을 증가시키고, 현재 id를 백업하며 다음 빈자리를 찾기 위해 현재 레이어에서 우측 형제 레이어의 첫 id를 지정한다.
- if (id > idr_max(idp->layers)) { *starting_id = id; return -EAGAIN; }
- 현재 레이어 레벨 구조로 더 이상 ID를 할당할 공간이 없는 경우 starting_id에 id값을 대입하고, -EAGAIN을 반환하여 레이어의 레벨을 확장하도록 요청한다.
- p = pa[l];
- sh = IDR_BITS * (l + 1); if (oid >> sh == id >> sh) continue; else goto restart;
- 새로 배정한 id가 상위 노드에서 처리 가능한 경우 계속 루프를 돌고 그렇지 않은 경우 restart 레이블로 이동하여 다시 처음부터 처리한다.
- if (m != n) { sh = IDR_BITS*l; id = ((id >> sh) ^ n ^ m) << sh; }
- 예) id=0, n=0, m=0xff, l=2
- if ((id >= MAX_IDR_BIT) || (id < 0)) return -ENOSPC;
- id 값이 positive 정수 범위를 벗어나는 경우 시스템이 처리할 수 없어서 -ENOSPC 에러를 반환한다.
- if (l == 0) break;
- 마지막 leaf 노드 레이어까지 처리한 경우 루프를 빠져나간다.
- if (!p->ary[m]) { new = idr_layer_alloc(gfp_mask, layer_idr); if (!new) return -ENOMEM;
- 하위 노드가 없는(missing) 경우 만든다.
- new->layer = l-1; new->prefix = id & idr_layer_prefix_mask(new->layer); rcu_assign_pointer(p->ary[m], new); p->count++;
- 하위 노드의 layer 및 prefix를 지정하고 현재 노드의 ary[]에 연결한다음 count를 증가시킨다.
if (m != n) {
sh = IDR_BITS*l;
id = ((id >> sh) ^ n ^ m) << sh;
}
if ((id >= MAX_IDR_BIT) || (id < 0))
return -ENOSPC;
if (l == 0)
break;
/*
* Create the layer below if it is missing.
*/
if (!p->ary[m]) {
new = idr_layer_alloc(gfp_mask, layer_idr);
if (!new)
return -ENOMEM;
new->layer = l-1;
new->prefix = id & idr_layer_prefix_mask(new->layer);
rcu_assign_pointer(p->ary[m], new);
p->count++;
}
pa[l--] = p;
p = p->ary[m];
}
pa[l] = p;
return id;
}
- if (m != n) { sh = IDR_BITS*l; id = ((id >> sh) ^ n ^ m) << sh; }
- m과 n이 다른 경우 빈 자리의 id를 찾는다.
- if ((id >= MAX_IDR_BIT) || (id < 0)) return -ENOSPC;
- id 값이 범위 밖이면 할당할 공간이 없다고 에러를 반환한다.
- if (l == 0) break;
- 최하위 레이어까지 내려온 경우 루프를 빠져나간다.
- if (!p->ary[m]) { new = idr_layer_alloc(gfp_mask, layer_idr); if (!new) return -ENOMEM;
- 만일 할당할 id 번호를 관리하는 하위 레이어 노드가 없는 경우 레이어를 할당받아온다.
- new->layer = l-1; new->prefix = id & idr_layer_prefix_mask(new->layer); rcu_assign_pointer(p->ary[m], new); p->count++;
- 할당 받아온 레이어의 번호와 prefix, count 등을 업데이트 하고 ary[m]에 할당한 레이어를 가리키게 한다.
- pa[l–] = p; p = p->ary[m]; }
- 다음 아래 레이어를 처리하기 위해 감소시켜 지정하고 계속 루프를 돈다.
- pa[l] = p; return id;
- 마지막 pa[0]를 갱신하고 id를 리턴한다.
idr_fill_slot()
lib/idr.c
/*
* @id and @pa are from a successful allocation from idr_get_empty_slot().
* Install the user pointer @ptr and mark the slot full.
*/
static void idr_fill_slot(struct idr *idr, void *ptr, int id,
struct idr_layer **pa)
{
/* update hint used for lookup, cleared from free_layer() */
rcu_assign_pointer(idr->hint, pa[0]);
rcu_assign_pointer(pa[0]->ary[id & IDR_MASK], (struct idr_layer *)ptr);
pa[0]->count++;
idr_mark_full(pa, id);
}
마지막에 ID를 할당한 leaf 노드의 주소를 idr 구조체의 hint 멤버에 대입하고, ary[]배열에 ptr을 저장하고, count를 증가시킨 후 full이된 레이어들의 bitmap을 1로 설정한다.
- rcu_assign_pointer(idr->hint, pa[0]);
- 마지막에 ID를 할당한 leaf 노드의 주소를 idr 구조체의 hint 멤버에 저장한다.
- idr_find() 함수에서 id로 검색시 hint가 가리키는 레이어가 요청하는 id를 커버하는 경우 빠르게 처리하기 위해 사용한다.
- rcu_assign_pointer(pa[0]->ary[id & IDR_MASK], (struct idr_layer *)ptr);
- 마지막에 ID를 할당한 leaf 노드의 id에 해당하는 ary[] 배열에 ptr 값을 저장한다.
- pa[0]->count++;
- 마지막에 ID를 할당한 leaf 노드의 카운터를 증가시킨다.
- idr_mark_full(pa, id);
- 마지막에 ID를 할당한 leaf 노드의 bitmap에 id에 해당하는 비트를 1로 설정하여 ID가 할당되었음을 표시한 후, 그 노드부터 최상위 노드중 full된 노드의 상위 노드 bitmap에 해당 비트를 1로 설정한다.
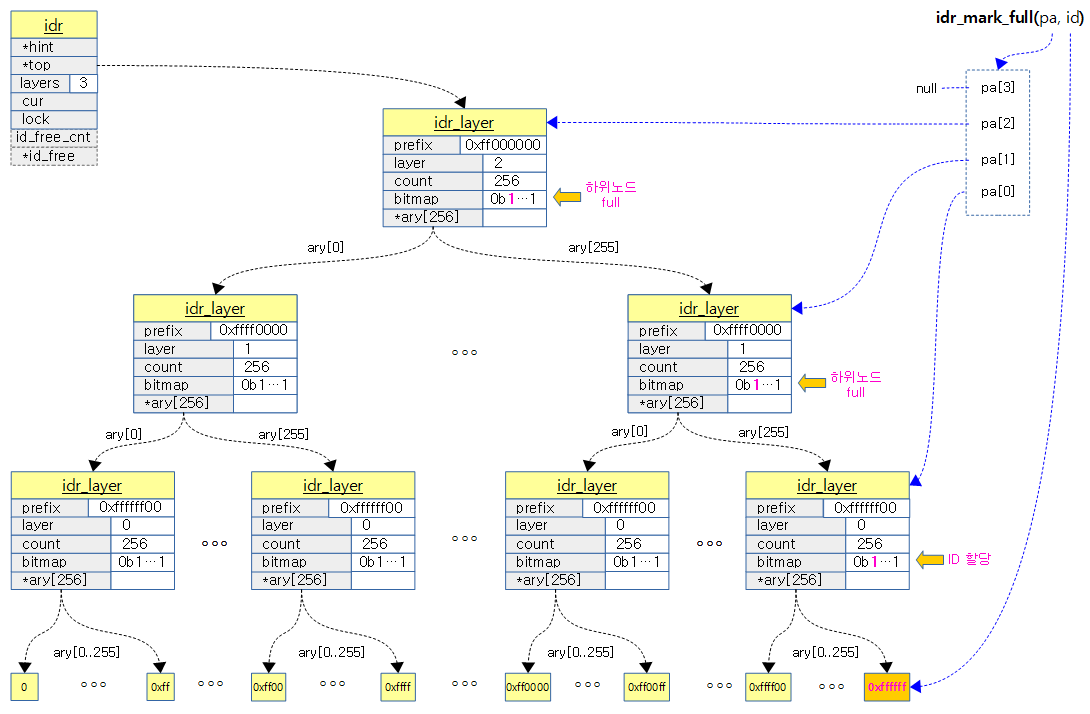
idr_mark_full()
lib/idr.c
static void idr_mark_full(struct idr_layer **pa, int id)
{
struct idr_layer *p = pa[0];
int l = 0;
__set_bit(id & IDR_MASK, p->bitmap);
/*
* If this layer is full mark the bit in the layer above to
* show that this part of the radix tree is full. This may
* complete the layer above and require walking up the radix
* tree.
*/
while (bitmap_full(p->bitmap, IDR_SIZE)) {
if (!(p = pa[++l]))
break;
id = id >> IDR_BITS;
__set_bit((id & IDR_MASK), p->bitmap);
}
}
마지막에 ID를 할당한 leaf 노드의 bitmap에 id에 해당하는 비트를 1로 설정하여 ID가 할당되었음을 표시한 후, 그 노드부터 최상위 노드중 full된 노드의 상위 노드 bitmap에 해당 비트를 1로 설정한다.
- struct idr_layer *p = pa[0];
- __set_bit(id & IDR_MASK, p->bitmap);
- 해당 idr_layer 노드의 bitmap에서 id에 해당하는 포지션을 1로 설정하여 ID가 할당되었음을 표시한다.
- while (bitmap_full(p->bitmap, IDR_SIZE)) {
- if (!(p = pa[++l])) break;
- 상위 노드가 지정되지 않은 경우 루프를 탈출한다.
- id = id >> IDR_BITS;
- __set_bit((id & IDR_MASK), p->bitmap);
- 현재 노드의 bitmap에서 id에 해당하는 포지션을 1로 설정하여 하위 노드가 full이 되었음을 표시한다.
다음 그림은 0xffffff ID를 할당받은 후 idr_mark_full() 함수에 의해 각 bitmap에 full 처리되는 모습을 보여준다.
IDR 해제
idr_remove()
lib/idr.c
/**
* idr_remove - remove the given id and free its slot
* @idp: idr handle
* @id: unique key
*/
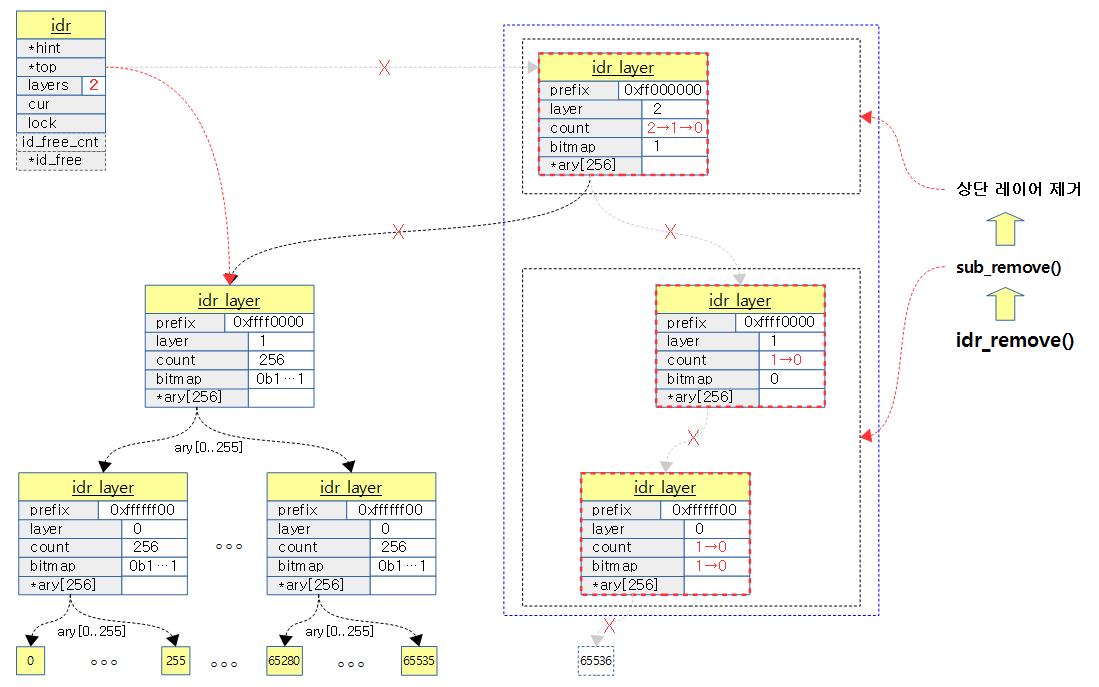
void idr_remove(struct idr *idp, int id)
{
struct idr_layer *p;
struct idr_layer *to_free;
if (id < 0)
return;
if (id > idr_max(idp->layers)) {
idr_remove_warning(id);
return;
}
sub_remove(idp, (idp->layers - 1) * IDR_BITS, id);
if (idp->top && idp->top->count == 1 && (idp->layers > 1) &&
idp->top->ary[0]) {
/*
* Single child at leftmost slot: we can shrink the tree.
* This level is not needed anymore since when layers are
* inserted, they are inserted at the top of the existing
* tree.
*/
to_free = idp->top;
p = idp->top->ary[0];
rcu_assign_pointer(idp->top, p);
--idp->layers;
to_free->count = 0;
bitmap_clear(to_free->bitmap, 0, IDR_SIZE);
free_layer(idp, to_free);
}
}
EXPORT_SYMBOL(idr_remove);
할당한 id를 제거하고, 제거하는 중에 empty된 레이어들은 제거된다. 필요에 따라 레이어 depth 까지도 줄어든다.
- if (id < 0) return; if (id > idr_max(idp->layers)) { idr_remove_warning(id); return; }
- IDR에서 처리할 수 있는 id 범위를 벗어난 경우 그냥 빠져나간다.
- sub_remove(idp, (idp->layers – 1) * IDR_BITS, id);
- tree depth를 줄이지 않은 상태에서 삭제할 id에 관여되는 레이어들 중 empty되는 레이어들을 연결에서 제거하여 id_free로 대입한다.
- if (idp->top && idp->top->count == 1 && (idp->layers > 1) && idp->top->ary[0]) {
- 최상위 레이어의 count가 1이면서 하위 레이어를 가리키는 경우
- to_free = idp->top; p = idp->top->ary[0]; rcu_assign_pointer(idp->top, p);
- 삭제 준비를 위해 최상위 레이어를 to_free에 대입하고, 최상위 레이어로 그 하위 레이어를 지정하게 한다.
- –idp->layers; to_free->count = 0; bitmap_clear(to_free->bitmap, 0, IDR_SIZE); free_layer(idp, to_free);
- 레이어 수(tree depth)를 줄이고, 삭제할 레이어의 count, bitmap을 clear한 후 해제한다.
다음 그림은 3단계의 레이어에서 65536번 id를 삭제하면서 레이어들이 삭제되고 tree depth가 줄어드는 과정을 보여준다.
sub_remove()
lib/idr.c
static void sub_remove(struct idr *idp, int shift, int id)
{
struct idr_layer *p = idp->top;
struct idr_layer **pa[MAX_IDR_LEVEL + 1];
struct idr_layer ***paa = &pa[0];
struct idr_layer *to_free;
int n;
*paa = NULL;
*++paa = &idp->top;
while ((shift > 0) && p) {
n = (id >> shift) & IDR_MASK;
__clear_bit(n, p->bitmap);
*++paa = &p->ary[n];
p = p->ary[n];
shift -= IDR_BITS;
}
n = id & IDR_MASK;
if (likely(p != NULL && test_bit(n, p->bitmap))) {
__clear_bit(n, p->bitmap);
RCU_INIT_POINTER(p->ary[n], NULL);
to_free = NULL;
while(*paa && ! --((**paa)->count)){
if (to_free)
free_layer(idp, to_free);
to_free = **paa;
**paa-- = NULL;
}
if (!*paa)
idp->layers = 0;
if (to_free)
free_layer(idp, to_free);
} else
idr_remove_warning(id);
}
tree depth를 줄이지 않은 상태에서 삭제할 id에 관여되는 레이어들 중 empty되는 레이어들을 연결에서 제거하고 할당을 해제한다.
- struct idr_layer ***paa = &pa[0]; *paa = NULL; *++paa = &idp->top;
- pa[0]에 null을 대입하고 pa[1]에 top 레이어를 담는다.
- while ((shift > 0) && p) { n = (id >> shift) & IDR_MASK; __clear_bit(n, p->bitmap); *++paa = &p->ary[n]; p = p->ary[n]; shift -= IDR_BITS; }
- 하위 leaf 레이어 전까지 내려가면서 pa[]에 각 레이어를 저장하고 bitmap의 연관 비트들을 clear한다.
- n = id & IDR_MASK;
- if (likely(p != NULL && test_bit(n, p->bitmap))) { __clear_bit(n, p->bitmap); RCU_INIT_POINTER(p->ary[n], NULL); to_free = NULL;
- 많은 확률로 leaf 레이어의 bitmap이 설정되어 있는 경우 비트를 clear 하고 ary[n]도 rcu를 사용하여 null로 대입한다.
- while(*paa && ! –((**paa)->count)){ if (to_free) free_layer(idp, to_free); to_free = **paa; **paa– = NULL; }
- pa[] 배열에 저장된 레이어를 다시 거꾸로 루프를 돌면서 해당 레이어의 count를 감소시켜 0인 경우 to_free에 지정된 레이어가 있는 경우 해제한다. 그리고 현재 레이어를 to_free에 담아두고 pa[]에 null을 저장하고 다음 감소시킨 pa[]를 지정한다.
- if (!*paa) idp->layers = 0;
- 마지막인 경우 idp->layers에 0을 대입하여 어떠한 하위 레이어도 없음을 나타내게 한다.
- if (to_free) free_layer(idp, to_free);
static inline void free_layer(struct idr *idr, struct idr_layer *p)
{
if (idr->hint == p)
RCU_INIT_POINTER(idr->hint, NULL);
call_rcu(&p->rcu_head, idr_layer_rcu_free);
}
idr->hint가 삭제할 p를 가리키는 경우 hint에 null을 대입한다 그런 후 rcu 기법으로 idr_layer_rcu_free 함수를 호출하여 해당 레이어를 해제하게 한다.
idr_layer_rcu_free()
lib/idr.c
static void idr_layer_rcu_free(struct rcu_head *head)
{
struct idr_layer *layer;
layer = container_of(head, struct idr_layer, rcu_head);
kmem_cache_free(idr_layer_cache, layer);
}
요청된 idr_layer를 해제한다.
IDR 소거
idr_destroy()
lib/idr.c
/**
* idr_destroy - release all cached layers within an idr tree
* @idp: idr handle
*
* Free all id mappings and all idp_layers. After this function, @idp is
* completely unused and can be freed / recycled. The caller is
* responsible for ensuring that no one else accesses @idp during or after
* idr_destroy().
*
* A typical clean-up sequence for objects stored in an idr tree will use
* idr_for_each() to free all objects, if necessary, then idr_destroy() to
* free up the id mappings and cached idr_layers.
*/
void idr_destroy(struct idr *idp)
{
__idr_remove_all(idp);
while (idp->id_free_cnt) {
struct idr_layer *p = get_from_free_list(idp);
kmem_cache_free(idr_layer_cache, p);
}
}
EXPORT_SYMBOL(idr_destroy);
모든 idr 레이어를 삭제시키고 id_free 리스트에 담겨있는 할당 대기중인 레이어들을 해제한다.
__idr_remove_all()
lib/idr.c
static void __idr_remove_all(struct idr *idp)
{
int n, id, max;
int bt_mask;
struct idr_layer *p;
struct idr_layer *pa[MAX_IDR_LEVEL + 1];
struct idr_layer **paa = &pa[0];
n = idp->layers * IDR_BITS;
*paa = idp->top;
RCU_INIT_POINTER(idp->top, NULL);
max = idr_max(idp->layers);
id = 0;
while (id >= 0 && id <= max) {
p = *paa;
while (n > IDR_BITS && p) {
n -= IDR_BITS;
p = p->ary[(id >> n) & IDR_MASK];
*++paa = p;
}
bt_mask = id;
id += 1 << n;
/* Get the highest bit that the above add changed from 0->1. */
while (n < fls(id ^ bt_mask)) {
if (*paa)
free_layer(idp, *paa);
n += IDR_BITS;
--paa;
}
}
idp->layers = 0;
}
idr 레이어를 모두 해제한다.
- n = idp->layers * IDR_BITS;
- 처리할 최대 비트 수
- 예) layer=3이면 n=24
- *paa = idp->top;
- RCU_INIT_POINTER(idp->top, NULL);
- idp->top에 null을 대입하여 idr_layer가 하나도 등록되지 않았음을 나타내게 한다.
- max = idr_max(idp->layers);
- id = 0; while (id >= 0 && id <= max) { p = *paa; while (n > IDR_BITS && p) { n -= IDR_BITS; p = p->ary[(id >> n) & IDR_MASK]; *++paa = p; }
- 마지막 leaf 레이어가 아닌 경우 pa[] 배열에 레이어를 추가해 나간다.
- bt_mask = id; id += 1 << n;
- id를 보관하고 id를 횡방향의 다음 레이어가 관리하는 id의 시작 번호로 대입한다.
- while (n < fls(id ^ bt_mask)) { if (*paa) free_layer(idp, *paa); n += IDR_BITS; –paa; }
구조체 및 주요 상수
idr_layer
include/linux/idr.h
struct idr_layer {
int prefix; /* the ID prefix of this idr_layer */
int layer; /* distance from leaf */
struct idr_layer __rcu *ary[1<<IDR_BITS];
int count; /* When zero, we can release it */
union {
/* A zero bit means "space here" */
DECLARE_BITMAP(bitmap, IDR_SIZE);
struct rcu_head rcu_head;
};
};
- prefix
- 각 레이어가 관리하는 id를 제외한 비트들만 사용되는 마스크
- 예) 32bit 시스템
- 0 layer (leaf 노드) -> 0xffffff00
- 1 layer -> 0xffff0000
- 2 layer -> 0xff000000
- 3 layer -> 0x80000000
- layer
- ary[256]
- leaf 노드가 아닌 경우 하위 레이어를 가리키고, leaf 노드인 경우 유저 포인터 값을 담아두는데 사용한다.
- count
- leaf 노드에서는 ID가 할당되어 사용중인 수가 담기고 leaf 노드가 아닌 경우 연결된 하위 노드의 수를 담아둔다.
- 이 값이 0이면 레이어는 해제될 수 있다.
- bitmap
- leaf 노드에서는 ID가 할당된 경우 1로 설정되고, leaf 노드가 아닌 경우 하위 노드가 full인 경우 1로 설정된다.
- rcu_head
- bitmap과 union으로 사용되는데 노드를 rcu 기법으로 삭제할 때 사용한다.
idr
include/linux/idr.h
struct idr {
struct idr_layer __rcu *hint; /* the last layer allocated from */
struct idr_layer __rcu *top;
int layers; /* only valid w/o concurrent changes */
int cur; /* current pos for cyclic allocation */
spinlock_t lock;
int id_free_cnt;
struct idr_layer *id_free;
};
- hint
- top
- layers
- 운용되는 레이어 단계(tree depth)로 최대 ID 값에 따라 증감되며 운용된다.
- 0인 경우 어떠한 레이어도 없고 노드도 사용되지 않는다.
- 32bit 시스템에서 0~4까지 운용되고, 64bit 시스템에서는 0~8까지 운용될 수 있다.
- 예) 최대 id가 255인 경우layers=1
- cur
- lock
- id_free_cnt
- 기존 id 할당 방식을 호환하기 위해 캐시역할로 미리 할당된 idr_layer 엔트리 갯수가 담긴다.
- id_free
- 기존 id 할당 방식을 호환하기 위해 캐시역할로 미리 할당된 idr_layer 엔트리가 이 리스트에 등록된다.
IDR_BITS
IDR_SIZE
- #define IDR_SIZE (1 << IDR_BITS)
IDR_MASK
- IDR_MASK ((1 << IDR_BITS)-1)
MAX_IDR_SHIFT
- #define MAX_IDR_SHIFT (sizeof(int) * 8 – 1)
- 부호를 제외한 정수에 사용되는 비트 수
- 31 (32bit 시스템)
- 63 (64bit 시스템)
MAX_IDR_BIT
- #define MAX_IDR_BIT (1U << MAX_IDR_SHIFT)
- 부호를 제외한 정수 최대수
- 2^31 (32bit 시스템)
- 2^63 (64bit 시스템)
MAX_IDR_LEVEL
- #define MAX_IDR_LEVEL ((MAX_IDR_SHIFT + IDR_BITS – 1) / IDR_BITS)
- MAX_IDR_SHIFT 값을 IDR_BITS 단위로 round up 한 수로 최대 확장될 수 있는 레벨
- 4 레벨 (32bit 시스템)
- 8 레벨 (64bit 시스템)
MAX_IDR_FREE
- #define MAX_IDR_FREE (MAX_IDR_LEVEL * 2)
- 8 (32bit 시스템)
- 16 (64bit 시스템)
참고