<kernel v5.4>
hrtimer
- hrtimer(High Resolution kernel Timer)는 커널 v2.6.21에서 mainline에 채용되었고 1ns 단위의 고해상도로 관리한다.
- 기존 오리지날 커널 타이머는 jiffies 기반의 lowres 타이머를 사용하여 구현되었고 HZ기반 tick에 의해 해상도가 수 ms ~ 수십 ms의 낮은 해상도만을 관리할 수 있었다.
- lowres timer를 사용하여 수 ms ~ 수십ms로 동작하는 스케줄 tick 단위 보다 더 높은 해상도의 타이머가 필요한 경우 사용된다.
- 사용 가능한 타이머 h/w
- hrtimer는 high resolution h/w 타이머를 사용하는 것을 기본으로 하지만 low resolution h/w 타이머도 사용할 수 있다.
- hrtimer의 요청 타임들은 RB 트리 기반으로 관리된다.
주의: 용어 혼동이 있을 수 있으므로 가급적 다음과 같이 해석을 요함.
- hrtimer
- 고해상도를 지원하는 hw 여부와 상관없이 나노초(ns) 단위를 사용하는 커널 API 및 서브 시스템
- timer (lowres timer)
- 틱(100ms, 25ms, 50ms, 10ms, …) 단위를 사용하는 커널 API 및 서브 시스템
- high resolution timer
- 고해상도로 동작하는 hw 타이머 (보통 수ns ~ 수십ns를 지원)
- 최근 ARM 시스템들은 (armv7, armv8, …)들은 대부분 고해상도 타이머를 지원한다.
- low resolution timer
- 저해상도로 동작하는 hw 타이머 (수백 ns 이상 지원)
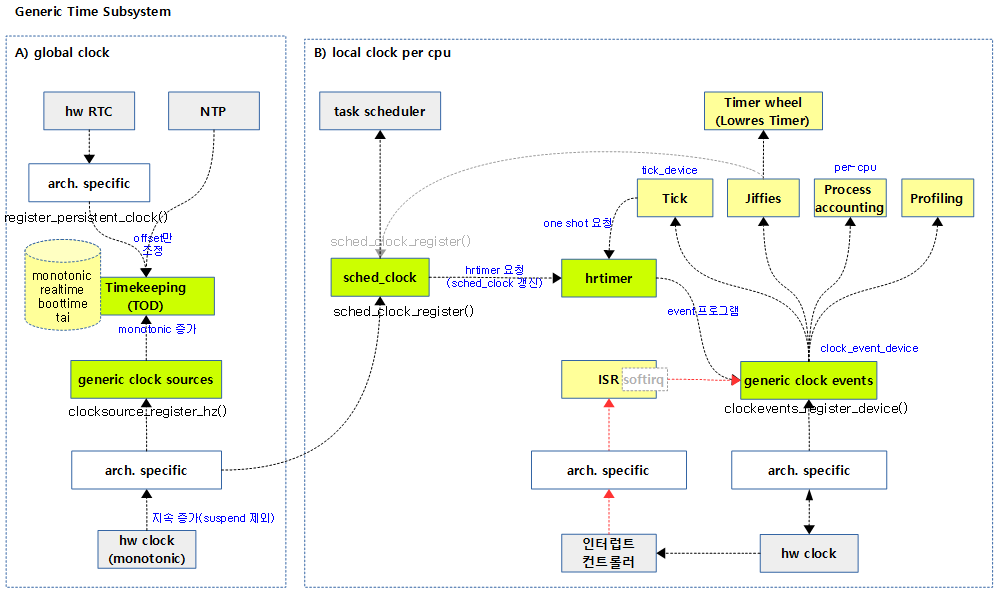
hrtimer와 generic time subsystem
hrtimer 통해 다음과 같은 기능들을 수행한다.
- 리눅스 시간 관리 (가능하면 hrtimer를 사용한다)
- monotonic(0부터 시작한 nano 단위 타임)
- realtime (실 세계 시간)
- boottime(0부터 시작한 nano 단위 타임이며 suspend 시에도 동작하는 시간)
- taiclock(윤초를 포함하는 천문에 사용하는 우주 시계)
- 고 정밀도 타이머
- nano 단위의 정확도로 callback 함수를 수행할 수 있다.
- 스케쥴 tick
- 위의 고정밀도 타이머 기능을 사용하여 주기적 또는 oneshot 기반 클럭 이벤트를 사용하여 스케쥴 tick을 제공한다.
- lowres timer의 기반 클럭
- jiffies로 동작하는 lowres timer(기존 kernel timer로 불림)에 제공되는 클럭
- process accounting, profileing, …
주변 시스템과의 연동 관계
실제 legacy 코드들은 무척 방만(?)하게 구현되어 셀 수 없이 많은 방법으로 여러 subsystem과 연결되어 있다.
- 수 백개의 구현 코드들이 재활용 없이 copy & paste로 이쪽 저쪽에서 짜집기되어 있다.
- 32bit arm embedded 시스템들에 구현된 많은 다양성으로 인해 리눅스의 누구 누구는 거의 포기했다는 말이 있다.
- 그럼에도 불구하고 common subsystem 등이 계속 정리되어 가고 있고 근래에는 device tree를 통해서 더 표준화 되어 가고 있다.
다음 그림은 최근 커널의 Time subsystem 간의 연동 관계를 보여준다.
- 좌측은 4개의 리눅스 시간을 관리하는 timekeeping을 clock source로 부터 지속적으로 공급받는 것을 보여준다.
- 우측은 hrtimer의 만료 시간에 인터럽트가 깨어나 clock event 를 통해 tick 디바이스에 공급되고 각 서브시스템으로 전달되는 과정을 보여준다.
주요 API
nano 단위로 이용가능한 hrtimer API는 다음과 같다.
- hrtimer_init()
- hrtimer_start()
- hrtimer_start_range_ns()
- hrtimer_start_expires()
- hrtimer_restart()
- hrtimer_cancel()
- hrtimer_try_to_cancel()
- hrtimer_forward()
ktime 관련 API
hrtimer 값은 다음과 같이 하나의 signed 64비트 값으로 나노초(ns)를 담고 있다.
include/linux/ktime.h
/* Nanosecond scalar representation for kernel time values */
typedef s64 ktime_t;
ktime 로드/설정 관련한 api는 다음과 같다.
- ktime_get()
- 현재 monotonic 시각을 ktime_t 타입으로 알아온다.
- ktime_get_ns()
- 현재 monotonic 시각을 나노초(ns)로 값으로 알아온다.
- ktime_get_with_offset(offs)
- 다음 클럭 타입 @offs에 해당하는 시각을 ktime_t 타입으로 알아온다.
- TK_OFFS_REAL
- TK_OFFS_BOOT
- TK_OFFS_TAI
- 예) ktime_get_with_offset(TK_OFFS_REAL)
- ktime_mono_to_any(tmono)
- 요청한 monotonic ktime_t 타입 시각 @tmono를 클럭 타입에 해당하는 시각으로 변환하여 ktime_t 타입으로 알아온다.
- 예) ktime_mono_to_any(tmono, TK_OFFS_REAL)
- ktime_get_raw()
- 현재 raw monotonic 시각을 ktime_t 타입으로 알아온다.
- ktime_get_raw_ns()
- 현재 raw monotonic 시각을 나노초(ns) 값으로 알아온다.
- ktime_get_real()
- 현재 realtime 시각을 ktime_t 타입으로 알아온다.
- ktime_get_real_ns()
- 현재 realtime 시각을 나노초(ns) 값으로 알아온다.
- ktime_get_boottime()
- 현재 boottime 시각을 ktime_t 타입으로 알아온다.
- ktime_get_clocktai()
- 현재 tai 시각을 ktime_t 타입으로 알아온다.
- ktime_set(secs, nsecs)
- 초 @secs와 나노초 @nsecs를 사용하여 ktime_t 타입 시각으로 설정하여 반환한다.
- ktime_mono_to_real(mono)
- 요청한 monotonic ktime_t 타입 @mono를 realtime 시각으로 변환하여 ktime_t 타입으로 알아온다.
ktime 설정, 연산, 비교와 관련한 api는 다음과 같다
- ktime_add(kt1, kt2)
- 두 개의 ktime_t 타입 시각 @kt1과 @kt2를 더해 ktime_t 타입으로 반환한다. (overflow 무시)
- ktime_add_ns(kt, ns)
- ktime_t 타입 시각 @kt와 나노초 @ns를 더해 ktime_t 타입으로 반환한다. (overflow 무시)
- ktime_add_us(kt, ms)
- ktime_t 타입 시각 @kt와 밀리초 @ms를 나노초로 변환한 후 더해 ktime_t 타입으로 반환한다. (overflow 무시)
- ktime_sub(kt1, kt2)
- 두 개의 ktime_t 타입 시각 @kt1에서 @kt2를 뺀 값을 반환한다. (underflow 무시)
- ktime_sub_ns(kt, ns)
- ktime_t 타입 시각 @kt에서 나노초 @ns를 뺀 후 ktime_t 타입으로 반환한다. (underflow 무시)
- ktime_sub_us(kt, us)
- ktime_t 타입 시각 @kt에서 밀리초 @ms를 나노초로 변환한 값을 뺀 후 ktime_t 타입으로 반환한다. (underflow 무시)
- ktime_compare(cm1, cmp2)
- 두 개의 ktime_t 타입 시각 @cmp1과 @cmp2를 비교한 결과를 반환한다.
- @cmp1 < @cmp2 : return < 0 (음수)
- @cmp1 == @cmp2 : return 0
- @cmp1 > @cmp2 : return > 0 (양수)
- ktime_after(cmp1, cmp2)
- 두 개의 ktime_t 타입 시각 @cmp1이 @cmp2 뒤에 있는지 여부를 반환한다.
- ktime_before(cmp1, cmp2)
- 두 개의 ktime_t 타입 시각 @cmp1이 @cmp2 앞에 있는지 여부를 반환한다.
- ktime_divns(kt, div)
- ktime_t 타입 시각 @kt에서 나노초 @ns로 나눈 s64 값을 반환한다.
ktime 변환 관련한 api는 다음과 같다.
- ktime_to_timespec(kt)
- ktime_t 타입 시각 @kt를 timespec 타입으로 반환한다.
- ktime_to_timespec_cond(@kt, @ts)
- ktime_t 타입 시각 @kt를 timespec 타입 @ts 출력 인자에 저장한다. 변환 값이 성공이면 1을 반환한다.
- ns_to_timespec(nsec)
- 나노초 @nsec를 timespec 타입으로 반환한다.
- ktime_to_timespec64(kt)
- ktime_t 타입 시각 @kt를 timespec64 타입으로 반환한다.
- ktime_to_timespec64_cond(kt)
- ktime_t 타입 시각 @kt를 timespec64 타입 @ts 출력 인자에 저장한다. 변환 값이 성공이면 1을 반환한다.
- ns_to_timespec64(nsec)
- 나노초 @nsec를 timespec64 타입으로 반환한다.
- timespec_to_ktime()
- timespec 타입 @ts를 ktime_t 타입으로 반환한다.
- timespec64_to_ktime()
- timespec64 타입 @ts를 ktime_t 타입으로 반환한다.
- ktime_to_timeval(kt)
- ktime_t 타입 시각 @kt를 timeval 타입으로 반환한다.
- ns_to_timeval(nsec)
- 나노초 @nsec를 timeval 타입으로 반환한다.
- timeval_to_ktime(tv)
- timeval 타입 @tv를 ktime_t 타입으로 반환한다.
- ktime_to_ns(kt)
- ktime_t 타입 시각 @kt를 나노초 단위로 반환한다.
- ktime_to_us(kt)
- ktime_t 타입 시각 @kt를 마이크로초 단위로 반환한다.
- ktime_to_ms()
- ktime_t 타입 시각 @kt를 밀리초 단위로 반환한다.
- ns_to_ktime()
- 나노초 @ns를 ktime_t 타입 시각으로 반환한다.
- ms_to_ktime()
- 밀리초 @ms를 ktime_t 타입 시각으로 반환한다.
- ktime_us_delta(later, earlier)
- 두 개의 ktime_t 타입 시각 @later와 @earlier의 시간차를 마이크로초로 반환한다.
- ktime_ms_delta()
- 두 개의 ktime_t 타입 시각 @later와 @earlier의 시간차를 밀리초로 반환한다.
시스템 realtime 시각 설정 관련한 api는 다음과 같다.
- do_settimeofday64()
- timespec64 타입 realtime 시각으로 시스템 realtime 시각을 설정한다.
- do_sys_settimeofday()
- timespec64 타입 realtime 시각 및 타임존을 사용하여 시스템 realtime 시각을 설정한다.
do_gettimeofday() – [removed]
per cpu 베이스 및 클럭 베이스 관리
다음 그림과 같이 hrtimer를 각각의 cpu별로 관리하는 cpu 베이스가 있고, 내부에서 다시 각각의 클럭 타입별로 관리하는 클럭 베이스가 있다.
- 클럭 타입은 4가지이며 hardirq에서 동작할 클럭과 softirq에서 동작할 클럭을 나누어 관리하므로 총 8개의 타입이 사용된다.

8가지 클럭 베이스 타입
hardirq에서 관리하는 4가지 타입
- HRTIMER_BASE_MONOTONIC
- 부팅 후 0에서 시작하여 단조롭게 계속 전진하는 것을 보장하며 jiffies tick 수와 유사하다. 단 suspend 된 시간은 포함되지 않는다.
- HRTIMER_BASE_REALTIME
- 실제 클럭을 관리한다. (real world clock)
- HRTIMER_BASE_BOOTTIME
- HRTIMER_BASE_TAI
- 천문학에서 사용하는 우주 표준시
- UTC(Coordinated Universal Time) 기반의 클럭을 유사하지만 윤초가 추가되어 2016 년 12 월 31 일부터 TAI 클럭은 UTC보다 37초 앞당겨진다. 그 전에는 27초가 앞당겨져 있었다.
- International Atomic Time | Wikipedia
softirq에서 관리하는 4가지 타입으로 사용 방법은 hardirq와 동일하다.
- HRTIMER_BASE_MONOTONIC_SOFT
- HRTIMER_BASE_REALTIME_SOFT
- HRTIMER_BASE_BOOTTIME_SOFT
- HRTIMER_BASE_TAI_SOFT
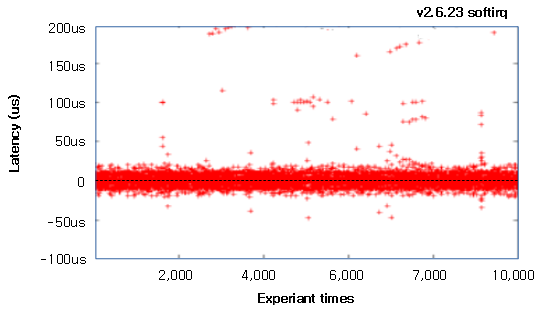
hrtimer Latency
hrtimer들은 1 ns 단위의 고해상도로 동작하지만 리눅스의 hrtimer 인터럽트 처리 루틴이 bottom-half로 구현된 softirq에서 처리되므로 수ns ~ 수백 us(평균: 수십 us)의 latency가 발생함을 주의해야 한다.
- 참고: KTAS: Analysis of Timer Latency for Embedded Linux Kernel – 다운로드 pdf
다음 그림은 위의 참고 자료에 나온 hrtimer에 대한 softirq의 latency를 10,000번 테스트한 결과를 보여준다.
RT(RealTime) 리눅스 커널을 사용하는 경우 일반 리눅스 커널보다 더 빠른 latency를 보장받을 수 있다.
- 참고: Evaluation of Real-time property in Embedded Linux | Hitachi – 다운로드 pdf
다음 그림은 위의 참고 자료에 나온 RT 커널과 일반 커널간 인터럽트 response time에 대한 대략적인 latency 비교를 보여준다.

CONFIG_PREEMPT_RT 커널 옵션을 사용하면 hrtimer도 softirq로 동작하는 타이머 스레드의 preemption을 허용한다.
hrtimers 서브시스템 초기화
hrtimers_init()
kernel/time/hrtimer.c
void __init hrtimers_init(void)
{
hrtimers_prepare_cpu(smp_processor_id());
open_softirq(HRTIMER_SOFTIRQ, hrtimer_run_softirq);
}
로컬 cpu에 대한 hrtimer 서브 시스템을 초기화한다. 그리고 hrtimer용 softirq로 hrtimer_run_softirq() 함수를 등록한다.
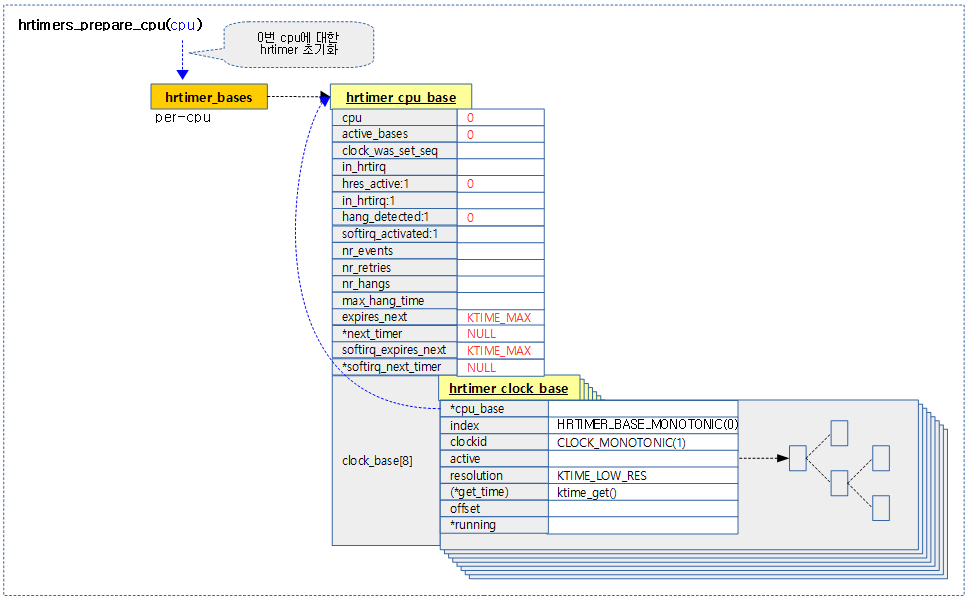
hrtimers_prepare_cpu()
kernel/time/hrtimer.c
/*
* Functions related to boot-time initialization:
*/
int hrtimers_prepare_cpu(unsigned int cpu)
{
struct hrtimer_cpu_base *cpu_base = &per_cpu(hrtimer_bases, cpu);
int i;
for (i = 0; i < HRTIMER_MAX_CLOCK_BASES; i++) {
cpu_base->clock_base[i].cpu_base = cpu_base;
timerqueue_init_head(&cpu_base->clock_base[i].active);
}
cpu_base->cpu = cpu;
cpu_base->active_bases = 0;
cpu_base->hres_active = 0;
cpu_base->hang_detected = 0;
cpu_base->next_timer = NULL;
cpu_base->softirq_next_timer = NULL;
cpu_base->expires_next = KTIME_MAX;
cpu_base->softirq_expires_next = KTIME_MAX;
return 0;
}
요청 cpu에 대한 hritimer의 cpu_base와 clock_base를 초기화한다.
- 코드 라인 3에서 요청 cpu의 hrtimer cpu 베이스를 알아온다.
- 코드 라인 6~9에서 HRTIMER_MAX_CLOCK_BASES(8)개 까지 순회하며 각 클럭 베이스의 active 타이머큐에 사용되는 RB 트리 자료구조를 초기화한다.
- 코드 라인 11~19에서 요청 cpu에 대해 cpu 베이스의 각 멤버를 초기화한다.
다음 그림은 0번 cpu에 대한 hrtimer cpu 베이스를 초기화한 모습을 보여준다.
timerqueue_init_head()
include/linux/timerqueue.h
static inline void timerqueue_init_head(struct timerqueue_head *head)
{
head->rb_root = RB_ROOT_CACHED;
}
hrtimer 큐를 초기화한다.
hrtimer hardirq & softirq 핸들러
hardirq 핸들러
__hrtimer_peek_ahead_timers()
kernel/time/hrtimer.c
/* called with interrupts disabled */
static inline void __hrtimer_peek_ahead_timers(void)
{
struct tick_device *td;
if (!hrtimer_hres_active())
return;
td = this_cpu_ptr(&tick_cpu_device);
if (td && td->evtdev)
hrtimer_interrupt(td->evtdev);
}
hrtimer 요청이 발생한 경우 처리할 이벤트 디바이스를 통해 hrtimer 인터럽트를 처리한다.
- 코드 라인 6~7에서 고해상도 hw 타이머가 지원되지 않으면 처리 없이 함수를 빠져나간다.
- 코드 라인 9~11에서 tick 디바이스의 이벤트 디바이스가 등록된 경우 hrtimer 인터럽트를 처리한다.
hrtimer_hres_active()
kernel/time/hrtimer.c
static inline int hrtimer_hres_active(void)
{
return __hrtimer_hres_active(this_cpu_ptr(&hrtimer_bases));
}
아래 함수 호출
__hrtimer_hres_active()
kernel/time/hrtimer.c
/*
* Is the high resolution mode active ?
*/
static inline int hrtimer_hres_active(void)
{
return IS_ENABLED(CONFIG_HIGH_RES_TIMERS) ?
cpu_base->hres_active : 0;
}
현재 cpu에 고해상도 hw 타이머가 활성화되었는지 여부를 알아온다. 0=비활성화 상태, 1=활성화 상태
hrtimer_interrupt()
kernel/time/hrtimer.c -1/2-
/*
* High resolution timer interrupt
* Called with interrupts disabled
*/
void hrtimer_interrupt(struct clock_event_device *dev)
{
struct hrtimer_cpu_base *cpu_base = this_cpu_ptr(&hrtimer_bases);
ktime_t expires_next, now, entry_time, delta;
unsigned long flags;
int retries = 0;
BUG_ON(!cpu_base->hres_active);
cpu_base->nr_events++;
dev->next_event = KTIME_MAX;
raw_spin_lock_irqsave(&cpu_base->lock, flags);
entry_time = now = hrtimer_update_base(cpu_base);
retry:
cpu_base->in_hrtirq = 1;
/*
* We set expires_next to KTIME_MAX here with cpu_base->lock
* held to prevent that a timer is enqueued in our queue via
* the migration code. This does not affect enqueueing of
* timers which run their callback and need to be requeued on
* this CPU.
*/
cpu_base->expires_next = KTIME_MAX;
if (!ktime_before(now, cpu_base->softirq_expires_next)) {
cpu_base->softirq_expires_next = KTIME_MAX;
cpu_base->softirq_activated = 1;
raise_softirq_irqoff(HRTIMER_SOFTIRQ);
}
__hrtimer_run_queues(cpu_base, now, flags, HRTIMER_ACTIVE_HARD);
/* Reevaluate the clock bases for the next expiry */
expires_next = __hrtimer_get_next_event(cpu_base, HRTIMER_ACTIVE_ALL);
/*
* Store the new expiry value so the migration code can verify
* against it.
*/
cpu_base->expires_next = expires_next;
cpu_base->in_hrtirq = 0;
raw_spin_unlock_irqrestore(&cpu_base->lock, flags);
/* Reprogramming necessary ? */
if (!tick_program_event(expires_next, 0)) {
cpu_base->hang_detected = 0;
return;
}
hardirq용 hrtimer 인터럽트 핸들러 루틴으로 이 함수는 clock_event_device의 tick_device를 통해 이 함수를 직접 호출한다.
- 코드 라인 9에서 로컬 cpu에서 hrtimer 핸들러가 호출될 때마다 nr_events 카운터를 1 증가시킨다.
- 코드 라인 10에서 다음 이벤트에 KTIME_MAX 값을 대입한다.
- 코드 라인 12~13에서 락을 얻은 후 timekeeper를 위한 clocksource로부터 읽은 값으로 real, boot, tail 시간의 offset를 갱신하고 monotonic 시간을 알아와서 entry_time과 now에 대입한다.
- 코드 라인 14~15에서 retry: 레이블이다. hrtimer irq 처리가 진행중임을 표시한다.
- 코드 라인 23~29에서 expires_next에 KTIME_MAX를 대입하고, softirq_expires_next의 시각이 현재 시각을 넘어선 경우 softirq_expires_next 역시 KTIME_MAX를 대입하고, softirq용 hrtimer 인터럽트 핸들러 루틴을 호출한다.
- 코드 라인 31에서 만료된 hardirq용 hrtimer를 호출한다.
- 코드 라인 34~41에서 hardirq 및 softirq 모두에서 다음 타이머 설정을 위해 다음 타이머 만료 시각을 알아와서 expires_next에 대입하고 락을 해제한다.
- 코드 라인 44~47에서 다음 hrtimer를 프로그래밍한다. 만일 처리할 hrtimer 요청이 없거나 요청이 실패한 경우 hang_detected에 0을 대입하고 함수를 빠져나간다.
- 틱을 프로그램하는 과정에서 이미 지나간 시간에 대해 요청을 하려는 경우 틱 프로그래밍이 불가능하다.
kernel/time/hrtimer.c -2/2-
/*
* The next timer was already expired due to:
* - tracing
* - long lasting callbacks
* - being scheduled away when running in a VM
*
* We need to prevent that we loop forever in the hrtimer
* interrupt routine. We give it 3 attempts to avoid
* overreacting on some spurious event.
*
* Acquire base lock for updating the offsets and retrieving
* the current time.
*/
raw_spin_lock_irqsave(&cpu_base->lock, flags);
now = hrtimer_update_base(cpu_base);
cpu_base->nr_retries++;
if (++retries < 3)
goto retry;
/*
* Give the system a chance to do something else than looping
* here. We stored the entry time, so we know exactly how long
* we spent here. We schedule the next event this amount of
* time away.
*/
cpu_base->nr_hangs++;
cpu_base->hang_detected = 1;
raw_spin_unlock_irqrestore(&cpu_base->lock, flags);
delta = ktime_sub(now, entry_time);
if ((unsigned int)delta > cpu_base->max_hang_time)
cpu_base->max_hang_time = (unsigned int) delta;
/*
* Limit it to a sensible value as we enforce a longer
* delay. Give the CPU at least 100ms to catch up.
*/
if (delta > 100 * NSEC_PER_MSEC)
expires_next = ktime_add_ns(now, 100 * NSEC_PER_MSEC);
else
expires_next = ktime_add(now, delta);
tick_program_event(expires_next, 1);
pr_warn_once("hrtimer: interrupt took %llu ns\n", ktime_to_ns(delta));
}
- 코드 라인 14~18에서 락을 획득하고 timekepping을 갱신하고 monotonic 시간을 가져와 now에 대입한다. 재시도 카운터를 증가시키고, 2번 재시도 할 수 있도록 retry 레이블로 이동한다.
- tracing을 하거나 시간 소요가 긴 callback 등으로 인해 이미 타이머가 만료되었을 수 있다. 이러한 경우 곧바로 해당 타이머를 처리한다. 이를 위해 최대 3회까지 시도한다.
- 코드 라인 25~27 에서 hang이 걸릴때의 처리 방법이다. nr_hangs 카운터를 증가시키고 hang_detected에 1을 대입한 후 lock을 해제한다.
- 코드 라인 29~31에서 인터럽트 처리를 위해 소모된 시간을 delta(ns 단위)에 담는다. 만일 max_hang_time보다 큰 경우 갱신한다.
- 코드 라인 36~40에서 현재 monotonic 시간에 delta 시간을 더해 tick을 리프로그램 요청한다. 단 delta가 100ms을 초과하는 경우 delta 대신 100ms을 추가한다.
- 코드 라인 41에서 hrtimer가 처리한 소요시간을 경고 메시지로 딱 한 번 출력한다.
softirq 핸들러
hrtimer_run_softirq()
kernel/time/hrtimer.c
static __latent_entropy void hrtimer_run_softirq(struct softirq_action *h)
{
struct hrtimer_cpu_base *cpu_base = this_cpu_ptr(&hrtimer_bases);
unsigned long flags;
ktime_t now;
hrtimer_cpu_base_lock_expiry(cpu_base);
raw_spin_lock_irqsave(&cpu_base->lock, flags);
now = hrtimer_update_base(cpu_base);
__hrtimer_run_queues(cpu_base, now, flags, HRTIMER_ACTIVE_SOFT);
cpu_base->softirq_activated = 0;
hrtimer_update_softirq_timer(cpu_base, true);
raw_spin_unlock_irqrestore(&cpu_base->lock, flags);
hrtimer_cpu_base_unlock_expiry(cpu_base);
}
hrtimer용 softirq의 진입함수이다. hrtimer로 요청된 후 만료되어 인터럽트 처리로 넘어온 경우 요청한 hrtimer에 연동된 핸들러 함수를 처리한다.
만료 타이머 호출
__hrtimer_run_queues()
kernel/time/hrtimer.c
static void __hrtimer_run_queues(struct hrtimer_cpu_base *cpu_base, ktime_t now,
unsigned long flags, unsigned int active_mask)
{
struct hrtimer_clock_base *base;
unsigned int active = cpu_base->active_bases & active_mask;
for_each_active_base(base, cpu_base, active) {
struct timerqueue_node *node;
ktime_t basenow;
basenow = ktime_add(now, base->offset);
while ((node = timerqueue_getnext(&base->active))) {
struct hrtimer *timer;
timer = container_of(node, struct hrtimer, node);
/*
* The immediate goal for using the softexpires is
* minimizing wakeups, not running timers at the
* earliest interrupt after their soft expiration.
* This allows us to avoid using a Priority Search
* Tree, which can answer a stabbing querry for
* overlapping intervals and instead use the simple
* BST we already have.
* We don't add extra wakeups by delaying timers that
* are right-of a not yet expired timer, because that
* timer will have to trigger a wakeup anyway.
*/
if (basenow < hrtimer_get_softexpires_tv64(timer))
break;
__run_hrtimer(cpu_base, base, timer, &basenow, flags);
if (active_mask == HRTIMER_ACTIVE_SOFT)
hrtimer_sync_wait_running(cpu_base, flags);
}
}
}
@active_mask에 설정된 hrtimer 베이스들에 한하여 만료된 hrtimer를 호출한다.
- 코드 라인 7~11에서 @active_mask에 설정된 hrtimer 클럭 베이스들을 순회하며 해당 클럭 기준으로 변환하여 basenow에 대입한다.
- 예) realtime 클럭으로 요청된 hrtimer를 처리하는 경우
- realtime 시간(basenow) = monotonic 시간(now) + realtime offset(base->offset)
- 코드 라인 13~36에서 처리할 base 클럭에서 다음 처리할 hrtimer 요청을 읽어와서 현재 시간이 타이머의 soft 만료 시간 보다 이전인 경우 처리를 하지 않고 루프를 빠져나간다. 그렇지 않은 경우 만료된 hrtimer를 처리한다. 결국 하나의 인터럽트로 인근에 있는 soft 만료 시간이 지난 타이머들을 같이 처리한다.
__run_hrtimer()
kernel/time/hrtimer.c
/*
* The write_seqcount_barrier()s in __run_hrtimer() split the thing into 3
* distinct sections:
*
* - queued: the timer is queued
* - callback: the timer is being ran
* - post: the timer is inactive or (re)queued
*
* On the read side we ensure we observe timer->state and cpu_base->running
* from the same section, if anything changed while we looked at it, we retry.
* This includes timer->base changing because sequence numbers alone are
* insufficient for that.
*
* The sequence numbers are required because otherwise we could still observe
* a false negative if the read side got smeared over multiple consequtive
* __run_hrtimer() invocations.
*/
static void __run_hrtimer(struct hrtimer_cpu_base *cpu_base,
struct hrtimer_clock_base *base,
struct hrtimer *timer, ktime_t *now,
unsigned long flags)
{
enum hrtimer_restart (*fn)(struct hrtimer *);
int restart;
lockdep_assert_held(&cpu_base->lock);
debug_deactivate(timer);
base->running = timer;
/*
* Separate the ->running assignment from the ->state assignment.
*
* As with a regular write barrier, this ensures the read side in
* hrtimer_active() cannot observe base->running == NULL &&
* timer->state == INACTIVE.
*/
raw_write_seqcount_barrier(&base->seq);
__remove_hrtimer(timer, base, HRTIMER_STATE_INACTIVE, 0);
fn = timer->function;
/*
* Clear the 'is relative' flag for the TIME_LOW_RES case. If the
* timer is restarted with a period then it becomes an absolute
* timer. If its not restarted it does not matter.
*/
if (IS_ENABLED(CONFIG_TIME_LOW_RES))
timer->is_rel = false;
/*
* The timer is marked as running in the CPU base, so it is
* protected against migration to a different CPU even if the lock
* is dropped.
*/
raw_spin_unlock_irqrestore(&cpu_base->lock, flags);
trace_hrtimer_expire_entry(timer, now);
restart = fn(timer);
trace_hrtimer_expire_exit(timer);
raw_spin_lock_irq(&cpu_base->lock);
/*
* Note: We clear the running state after enqueue_hrtimer and
* we do not reprogram the event hardware. Happens either in
* hrtimer_start_range_ns() or in hrtimer_interrupt()
*
* Note: Because we dropped the cpu_base->lock above,
* hrtimer_start_range_ns() can have popped in and enqueued the timer
* for us already.
*/
if (restart != HRTIMER_NORESTART &&
!(timer->state & HRTIMER_STATE_ENQUEUED))
enqueue_hrtimer(timer, base, HRTIMER_MODE_ABS);
/*
* Separate the ->running assignment from the ->state assignment.
*
* As with a regular write barrier, this ensures the read side in
* hrtimer_active() cannot observe base->running.timer == NULL &&
* timer->state == INACTIVE.
*/
raw_write_seqcount_barrier(&base->seq);
WARN_ON_ONCE(base->running != timer);
base->running = NULL;
}
하나의 hrtimer를 처리한다. 반복을 원하는 hrtimer인 경우 다시 엔큐된다.
- 코드 라인 12에서 요청한 클럭 베이스에서 hrtimer가 처리 중인 것을 알리기 위해 base->running에 타이머를 대입한다.
- 코드 라인 21에서 hrtimer_active() 함수에서 사용하는 base->running 및 timer->state를 동기화하기 위해 시퀀스를 증가시키고 메모리 베리어를 사용하였다.
- 코드 라인 23에서 타이머를 클럭 큐에서 제거하고 enqueue 상태를 클리어한다.
- 코드 라인 31~32에서 저해상도 hw 타이머를 사용하는 경우 상대 처리 플래그를 클리어한다.
- 코드 라인 41에서 hrtimer에 해당하는 콜백 함수를 실행한다. 결과 값으로 재반복 여부를 담아온다.
- 코드 라인 54~56에서 콜백 함수의 결과가 재반복 결과이고, enqueue 상태가 아니면 클럭 베이스에 hrtimer를 다시 큐잉한다.
- 코드 라인 68에서 요청한 클럭 베이스에서 hrtimer가 처리 중이 아닌 것을 알리기 위해 base->running에 null을 대입한다.
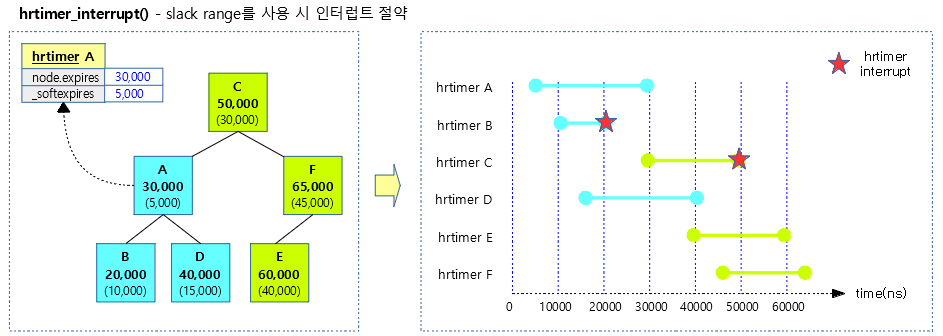
다음 그림은 hrtimer를 사용 시 slack range를 사용하여 인터럽트 발생 횟수를 줄이는 모습을 보여준다.
시각 변동 시 클럭 베이스내의 각 클럭 타입들 시각 갱신
hrtimer_update_base()
kernel/time/hrtimer.c
static inline ktime_t hrtimer_update_base(struct hrtimer_cpu_base *base)
{
ktime_t *offs_real = &base->clock_base[HRTIMER_BASE_REALTIME].offset;
ktime_t *offs_boot = &base->clock_base[HRTIMER_BASE_BOOTTIME].offset;
ktime_t *offs_tai = &base->clock_base[HRTIMER_BASE_TAI].offset;
ktime_t now = ktime_get_update_offsets_now(&base->clock_was_set_seq,
offs_real, offs_boot, offs_tai);
base->clock_base[HRTIMER_BASE_REALTIME_SOFT].offset = *offs_real;
base->clock_base[HRTIMER_BASE_BOOTTIME_SOFT].offset = *offs_boot;
base->clock_base[HRTIMER_BASE_TAI_SOFT].offset = *offs_tai;
return now;
}
현재 monotonic 시스템 시각(타임 키핑)을 알아와서 지정한 hrtimer cpu base의 각 클럭들을 모두 갱신한다.
- 코드 라인 3~8에서 시스템의 시각을 관리하는 timekeeper를 통해 monotonic 클럭을 제외한 나머지 클럭들의 offset 값을 갱신한다.
- 코드 라인 10~12에서 softirq용 클럭 베이스들도 갱신한다.
hrtimer cpu 베이스
hrtimer_bases
kernel/time/hrtimer.c
/*
* The timer bases:
*
* There are more clockids than hrtimer bases. Thus, we index
* into the timer bases by the hrtimer_base_type enum. When trying
* to reach a base using a clockid, hrtimer_clockid_to_base()
* is used to convert from clockid to the proper hrtimer_base_type.
*/
DEFINE_PER_CPU(struct hrtimer_cpu_base, hrtimer_bases) =
{
.lock = __RAW_SPIN_LOCK_UNLOCKED(hrtimer_bases.lock),
.clock_base =
{
{
.index = HRTIMER_BASE_MONOTONIC,
.clockid = CLOCK_MONOTONIC,
.get_time = &ktime_get,
},
{
.index = HRTIMER_BASE_REALTIME,
.clockid = CLOCK_REALTIME,
.get_time = &ktime_get_real,
},
{
.index = HRTIMER_BASE_BOOTTIME,
.clockid = CLOCK_BOOTTIME,
.get_time = &ktime_get_boottime,
},
{
.index = HRTIMER_BASE_TAI,
.clockid = CLOCK_TAI,
.get_time = &ktime_get_clocktai,
},
{
.index = HRTIMER_BASE_MONOTONIC_SOFT,
.clockid = CLOCK_MONOTONIC,
.get_time = &ktime_get,
},
{
.index = HRTIMER_BASE_REALTIME_SOFT,
.clockid = CLOCK_REALTIME,
.get_time = &ktime_get_real,
},
{
.index = HRTIMER_BASE_BOOTTIME_SOFT,
.clockid = CLOCK_BOOTTIME,
.get_time = &ktime_get_boottime,
},
{
.index = HRTIMER_BASE_TAI_SOFT,
.clockid = CLOCK_TAI,
.get_time = &ktime_get_clocktai,
},
}
};
hrtimer가 사용하는 8개의(hardirq용 4개 + softirq용 4개) clock base가 per-cpu 마다 관리된다.
다음 만료 시각 구하기
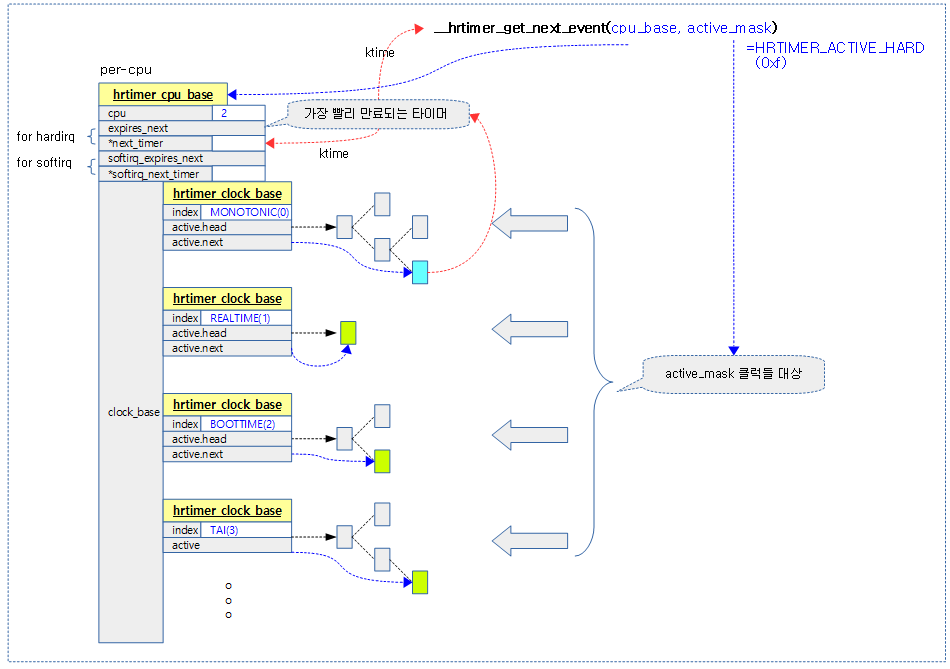
__hrtimer_get_next_event()
kernel/time/hrtimer.c
/*
* Recomputes cpu_base::*next_timer and returns the earliest expires_next but
* does not set cpu_base::*expires_next, that is done by hrtimer_reprogram.
*
* When a softirq is pending, we can ignore the HRTIMER_ACTIVE_SOFT bases,
* those timers will get run whenever the softirq gets handled, at the end of
* hrtimer_run_softirq(), hrtimer_update_softirq_timer() will re-add these bases.
*
* Therefore softirq values are those from the HRTIMER_ACTIVE_SOFT clock bases.
* The !softirq values are the minima across HRTIMER_ACTIVE_ALL, unless an actual
* softirq is pending, in which case they're the minima of HRTIMER_ACTIVE_HARD.
*
* @active_mask must be one of:
* - HRTIMER_ACTIVE_ALL,
* - HRTIMER_ACTIVE_SOFT, or
* - HRTIMER_ACTIVE_HARD.
*/
static ktime_t
__hrtimer_get_next_event(struct hrtimer_cpu_base *cpu_base, unsigned int active_mask)
{
unsigned int active;
struct hrtimer *next_timer = NULL;
ktime_t expires_next = KTIME_MAX;
if (!cpu_base->softirq_activated && (active_mask & HRTIMER_ACTIVE_SOFT)) {
active = cpu_base->active_bases & HRTIMER_ACTIVE_SOFT;
cpu_base->softirq_next_timer = NULL;
expires_next = __hrtimer_next_event_base(cpu_base, NULL,
active, KTIME_MAX);
next_timer = cpu_base->softirq_next_timer;
}
if (active_mask & HRTIMER_ACTIVE_HARD) {
active = cpu_base->active_bases & HRTIMER_ACTIVE_HARD;
cpu_base->next_timer = next_timer;
expires_next = __hrtimer_next_event_base(cpu_base, NULL, active,
expires_next);
}
return expires_next;
}
요청한 cpu_base에서 active_mask로 지정된 클럭 베이스의 hrtimer 들 중 가장 빠른 hrtimer의 monotonic 만료 시각(ktime)을 반환한다.
다음 그림은 요청 cpu 베이스의 active_mask 비트로 요청한 클럭 베이스들 중 hw 타이머에 프로그램될 가장 빨리 만료될 hrtimer를 찾아 시각(ktime)을 구하는 모습을 보여준다.
__hrtimer_next_event_base()
kernel/time/hrtimer.c
static ktime_t __hrtimer_next_event_base(struct hrtimer_cpu_base *cpu_base,
const struct hrtimer *exclude,
unsigned int active,
ktime_t expires_next)
{
struct hrtimer_clock_base *base;
ktime_t expires;
for_each_active_base(base, cpu_base, active) {
struct timerqueue_node *next;
struct hrtimer *timer;
next = timerqueue_getnext(&base->active);
timer = container_of(next, struct hrtimer, node);
if (timer == exclude) {
/* Get to the next timer in the queue. */
next = timerqueue_iterate_next(next);
if (!next)
continue;
timer = container_of(next, struct hrtimer, node);
}
expires = ktime_sub(hrtimer_get_expires(timer), base->offset);
if (expires < expires_next) {
expires_next = expires;
/* Skip cpu_base update if a timer is being excluded. */
if (exclude)
continue;
if (timer->is_soft)
cpu_base->softirq_next_timer = timer;
else
cpu_base->next_timer = timer;
}
}
/*
* clock_was_set() might have changed base->offset of any of
* the clock bases so the result might be negative. Fix it up
* to prevent a false positive in clockevents_program_event().
*/
if (expires_next < 0)
expires_next = 0;
return expires_next;
}
cpu 베이스의 비트마스크로 표현된 @active 클럭들에 대해 @exclude 타이머를 제외하고 가장 빠른 만료 시각을 반환한다. 없는 경우 @expires_next를 그대로 반환한다.
- 코드 라인 9~22에서 @active 클럭들을 대상으로 순회하며 만료 시각이 가장 빠른 타이머를 알아온다. 만일 알아온 타이머가 @exclude인 경우 그 다음 타이머를 알아온다.
- 코드 라인 23~35에서 만료 시각이 @expires_next보다 더 빠른 경우 이를 갱신한다. 클럭 베이스에 hrtimer를 기록해둔다.
- 코드 라인 42~44에서 @expires_next를 반환하되 0보다 작은 경우 0을 반환한다.
HRTimer APIs
hrtimer 초기화
hrtimer_init()
kernel/time/hrtimer.c
/**
* hrtimer_init - initialize a timer to the given clock
* @timer: the timer to be initialized
* @clock_id: the clock to be used
* @mode: The modes which are relevant for intitialization:
* HRTIMER_MODE_ABS, HRTIMER_MODE_REL, HRTIMER_MODE_ABS_SOFT,
* HRTIMER_MODE_REL_SOFT
*
* The PINNED variants of the above can be handed in,
* but the PINNED bit is ignored as pinning happens
* when the hrtimer is started
*/
void hrtimer_init(struct hrtimer *timer, clockid_t clock_id,
enum hrtimer_mode mode)
{
debug_init(timer, clock_id, mode);
__hrtimer_init(timer, clock_id, mode);
}
EXPORT_SYMBOL_GPL(hrtimer_init);
요청한 @clock_id 타입 및 @mode를 사용한 hrtimer를 초기화한다.
hrtimer_mode 타입
include/linux/hrtimer.h
/*
* Mode arguments of xxx_hrtimer functions:
*
* HRTIMER_MODE_ABS - Time value is absolute
* HRTIMER_MODE_REL - Time value is relative to now
* HRTIMER_MODE_PINNED - Timer is bound to CPU (is only considered
* when starting the timer)
* HRTIMER_MODE_SOFT - Timer callback function will be executed in
* soft irq context
* HRTIMER_MODE_HARD - Timer callback function will be executed in
* hard irq context even on PREEMPT_RT.
*/
enum hrtimer_mode {
HRTIMER_MODE_ABS = 0x00,
HRTIMER_MODE_REL = 0x01,
HRTIMER_MODE_PINNED = 0x02,
HRTIMER_MODE_SOFT = 0x04,
HRTIMER_MODE_HARD = 0x08,
HRTIMER_MODE_ABS_PINNED = HRTIMER_MODE_ABS | HRTIMER_MODE_PINNED,
HRTIMER_MODE_REL_PINNED = HRTIMER_MODE_REL | HRTIMER_MODE_PINNED,
HRTIMER_MODE_ABS_SOFT = HRTIMER_MODE_ABS | HRTIMER_MODE_SOFT,
HRTIMER_MODE_REL_SOFT = HRTIMER_MODE_REL | HRTIMER_MODE_SOFT,
HRTIMER_MODE_ABS_PINNED_SOFT = HRTIMER_MODE_ABS_PINNED | HRTIMER_MODE_SOFT,
HRTIMER_MODE_REL_PINNED_SOFT = HRTIMER_MODE_REL_PINNED | HRTIMER_MODE_SOFT,
HRTIMER_MODE_ABS_HARD = HRTIMER_MODE_ABS | HRTIMER_MODE_HARD,
HRTIMER_MODE_REL_HARD = HRTIMER_MODE_REL | HRTIMER_MODE_HARD,
HRTIMER_MODE_ABS_PINNED_HARD = HRTIMER_MODE_ABS_PINNED | HRTIMER_MODE_HARD,
HRTIMER_MODE_REL_PINNED_HARD = HRTIMER_MODE_REL_PINNED | HRTIMER_MODE_HARD,
};
- 다음과 같은 싱글 플래그가 지정될 수 있다.
- HRTIMER_MODE_ABS (0x00)
- 절대 시각 사용
- 예: realtime 시각으로부터 xx 분 xx초에 만료
- HRTIMER_MODE_REL (0x01)
- 상대 시간 사용
- 예: 현재 realtime 시각으로 부터 xx 분 후에 만료
- HRTIMER_MODE_PINNED (0x02)
- HRTIMER_MODE_SOFT (0x04)
- HRTIMER_MODE_HARD (0x08)
- 추가적으로 사용 가능한 복합 플래그들은 다음과 같다.
- HRTIMER_MODE_ABS_PINNED
- 절대 시각 사용 + 타이머가 수행될 cpu 고정
- HRTIMER_MODE_REL_PINNED
- 상대 시간 사용 + 타이머가 수행될 cpu 고정
- HRTIMER_MODE_ABS_SOFT
- 절대 시각 사용 + softirq context에서 동작
- HRTIMER_MODE_REL_SOFT
- 상대 시간 사용 + softirq context에서 동작
- HRTIMER_MODE_ABS_PINNED_SOFT
- 절대 시각 사용 + 타이머가 수행될 cpu 고정 + softirq context에서 동작
- HRTIMER_MODE_REL_PINNED_SOFT
- 상대 시간 사용 + 타이머가 수행될 cpu 고정 + softirq context에서 동작
- HRTIMER_MODE_ABS_HARD
- 절대 시각 사용 + hardirq context에서 동작
- HRTIMER_MODE_REL_HARD
- 상대 시간 사용 + hardirq context에서 동작
- HRTIMER_MODE_ABS_PINNED_HARD
- 절대 시각 사용 + 타이머가 수행될 cpu 고정 + hardirq context에서 동작
- HRTIMER_MODE_REL_PINNED_HARD
- 상대 시간 사용 + 타이머가 수행될 cpu 고정 + hardirq context에서 동작
__hrtimer_init()
kernel/time/hrtimer.c
static void __hrtimer_init(struct hrtimer *timer, clockid_t clock_id,
enum hrtimer_mode mode)
{
bool softtimer = !!(mode & HRTIMER_MODE_SOFT);
struct hrtimer_cpu_base *cpu_base;
int base;
/*
* On PREEMPT_RT enabled kernels hrtimers which are not explicitely
* marked for hard interrupt expiry mode are moved into soft
* interrupt context for latency reasons and because the callbacks
* can invoke functions which might sleep on RT, e.g. spin_lock().
*/
if (IS_ENABLED(CONFIG_PREEMPT_RT) && !(mode & HRTIMER_MODE_HARD))
softtimer = true;
memset(timer, 0, sizeof(struct hrtimer));
cpu_base = raw_cpu_ptr(&hrtimer_bases);
/*
* POSIX magic: Relative CLOCK_REALTIME timers are not affected by
* clock modifications, so they needs to become CLOCK_MONOTONIC to
* ensure POSIX compliance.
*/
if (clock_id == CLOCK_REALTIME && mode & HRTIMER_MODE_REL)
clock_id = CLOCK_MONOTONIC;
base = softtimer ? HRTIMER_MAX_CLOCK_BASES / 2 : 0;
base += hrtimer_clockid_to_base(clock_id);
timer->is_soft = softtimer;
timer->is_hard = !softtimer;
timer->base = &cpu_base->clock_base[base];
timerqueue_init(&timer->node);
}
요청한 @clock_id 타입 및 @mode를 사용한 hrtimer를 초기화한다.
- hard 또는 soft 모드를 지정하지 않은 디폴트의 경우 RT 커널 여부에 따라 다르다.
- RT 커널에서는 디폴트로 softirq를 사용한다.
- RT 커널이 아닌 경우 디폴트로 hardirq를 사용한다.
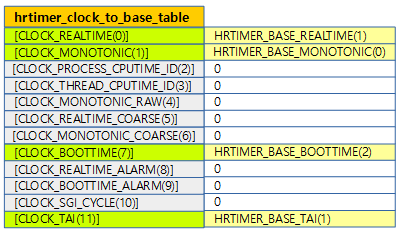
hrtimer_clockid_to_base()
kernel/time/hrtimer.c
static inline int hrtimer_clockid_to_base(clockid_t clock_id)
{
if (likely(clock_id < MAX_CLOCKS)) {
int base = hrtimer_clock_to_base_table[clock_id];
if (likely(base != HRTIMER_MAX_CLOCK_BASES))
return base;
}
WARN(1, "Invalid clockid %d. Using MONOTONIC\n", clock_id);
return HRTIMER_BASE_MONOTONIC;
}
@clock_id에 해당하는 hrtimer 클럭 베이스 인덱스를 반환한다.
- 범위를 벗어나거나 사용할 수 없는 클럭 id를 요청한 경우 경고 메시지를 출력하고 monotomic 클럭 베이스를 반환한다.
hrtimer_clock_to_base_table
kernel/time/hrtimer.c
static const int hrtimer_clock_to_base_table[MAX_CLOCKS] = {
/* Make sure we catch unsupported clockids */
[0 ... MAX_CLOCKS - 1] = HRTIMER_MAX_CLOCK_BASES,
[CLOCK_REALTIME] = HRTIMER_BASE_REALTIME,
[CLOCK_MONOTONIC] = HRTIMER_BASE_MONOTONIC,
[CLOCK_BOOTTIME] = HRTIMER_BASE_BOOTTIME,
[CLOCK_TAI] = HRTIMER_BASE_TAI,
};
clock id에 해당하는 hrtimer 클럭 베이스를 구한다.
timerqueue_init()
include/linux/timerqueue.h
static inline void timerqueue_init(struct timerqueue_node *node)
{
RB_CLEAR_NODE(&node->node);
}
RB 트리로 관리하는 타이머큐를 초기화한다.
hrtimer 시작
hrtimer_start()
kernel/time/hrtimer.c
/**
* hrtimer_start - (re)start an hrtimer
* @timer: the timer to be added
* @tim: expiry time
* @mode: timer mode: absolute (HRTIMER_MODE_ABS) or
* relative (HRTIMER_MODE_REL), and pinned (HRTIMER_MODE_PINNED);
* softirq based mode is considered for debug purpose only!
*/
static inline void hrtimer_start(struct hrtimer *timer, ktime_t tim,
const enum hrtimer_mode mode)
{
hrtimer_start_range_ns(timer, tim, 0, mode);
}
EXPORT_SYMBOL_GPL(hrtimer_start);
hrtimer를 요청한 ktime으로 상대 시간 또는 절대 시각에 동작하도록 요청한다.
예) 다음은 monotonic 시계를 사용하는 hrtimer를 100ms 후에 my_hrtimer_callback() 함수가 호출되게 사용하였다.

다음 그림은 monotonic 시계를 사용하는 hrtimer 두 개를 추가하였을 때의 모습을 보여준다.

hrtimer_start_range_ns()
kernel/time/hrtimer.c
/**
* hrtimer_start_range_ns - (re)start an hrtimer
* @timer: the timer to be added
* @tim: expiry time
* @delta_ns: "slack" range for the timer
* @mode: timer mode: absolute (HRTIMER_MODE_ABS) or
* relative (HRTIMER_MODE_REL), and pinned (HRTIMER_MODE_PINNED);
* softirq based mode is considered for debug purpose only!
*/
void hrtimer_start_range_ns(struct hrtimer *timer, ktime_t tim,
u64 delta_ns, const enum hrtimer_mode mode)
{
struct hrtimer_clock_base *base;
unsigned long flags;
/*
* Check whether the HRTIMER_MODE_SOFT bit and hrtimer.is_soft
* match on CONFIG_PREEMPT_RT = n. With PREEMPT_RT check the hard
* expiry mode because unmarked timers are moved to softirq expiry.
*/
if (!IS_ENABLED(CONFIG_PREEMPT_RT))
WARN_ON_ONCE(!(mode & HRTIMER_MODE_SOFT) ^ !timer->is_soft);
else
WARN_ON_ONCE(!(mode & HRTIMER_MODE_HARD) ^ !timer->is_hard);
base = lock_hrtimer_base(timer, &flags);
if (__hrtimer_start_range_ns(timer, tim, delta_ns, mode, base))
hrtimer_reprogram(timer, true);
unlock_hrtimer_base(timer, &flags);
}
EXPORT_SYMBOL_GPL(hrtimer_start_range_ns);
hrtimer를 요청한 ktime 및 @delta(slack 범위)를 주어 상대 시간 또는 절대 시각에 동작하도록 요청한다.
__hrtimer_start_range_ns()
kernel/time/hrtimer.c
static int __hrtimer_start_range_ns(struct hrtimer *timer, ktime_t tim,
u64 delta_ns, const enum hrtimer_mode mode,
struct hrtimer_clock_base *base)
{
struct hrtimer_clock_base *new_base;
/* Remove an active timer from the queue: */
remove_hrtimer(timer, base, true);
if (mode & HRTIMER_MODE_REL)
tim = ktime_add_safe(tim, base->get_time());
tim = hrtimer_update_lowres(timer, tim, mode);
hrtimer_set_expires_range_ns(timer, tim, delta_ns);
/* Switch the timer base, if necessary: */
new_base = switch_hrtimer_base(timer, base, mode & HRTIMER_MODE_PINNED);
return enqueue_hrtimer(timer, new_base, mode);
}
hrtimer를 요청한 ktime + delta로 상대 시간 또는 절대 시간 후에 동작하도록 요청한다. slack range가 적용되는 방식인데 실제 타이머의 만료시각은 delta가 적용된 hard 만료 타임을 사용한다. 하지만 다른 타이머 처리 시 soft 만료 시간 범위가 포함되면 다른 타이머에 의해 같이 처리할 수 있도록 slack range를 부여하는 기법이다
- 코드 라인 8에서 요청한 hrtimer가 큐에 동작중인 경우 삭제한다.
- 코드 라인 10~11에서 상대 시간을 요청한 경우 현재 monotonic 시각에 @tim을 더한 절대 시각을 산출한다.
- 코드 라인 13에서 저해상도 hw 타이머를 사용하고 상대 시간을 요청한 경우 1 틱을 추가한다.
- 코드 라인 15에서 hrtimer에 만료 시각을 설정한다.
- timer->_softexpires에는 time만 저장하고, timer->node.expires에는 time + delta를 저장한다.
- 코드 라인 18에서 가능(현재 cpu가 hrtimer를 사용할 수 있는 경우)하면 현재 cpu의 클럭을 사용하고 그렇게 하지 못할 경우 다른 cpu의 클럭으로 변경한다.
- 코드 라인 20에서 generic 타이머 큐(RB 트리로 구현)에 hrtimer를 추가한다.
다음 그림은 20us 만료시간(soft)에서 slack 20us를 추가한 40us 만료시간(hard)까지의 범위를 갖는 타이머의 모습을 보여준다.
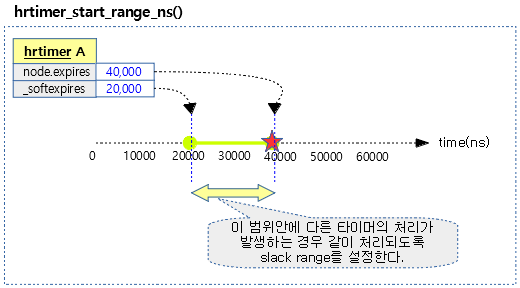
hrtimer_set_expires_range_ns()
include/linux/hrtimer.h
static inline void hrtimer_set_expires_range_ns(struct hrtimer *timer, ktime_t time, u64 delta)
{
timer->_softexpires = time;
timer->node.expires = ktime_add_safe(time, ns_to_ktime(delta));
}
hrtimer의 만료 시간을 기록한다.
- timer->_softexpires에는 time만 저장하고, timer->node.expires에는 time + delta를 저장한다.
타이머 베이스 스위치
switch_hrtimer_base()
kernel/time/hrtimer.c
/*
* We switch the timer base to a power-optimized selected CPU target,
* if:
* - NO_HZ_COMMON is enabled
* - timer migration is enabled
* - the timer callback is not running
* - the timer is not the first expiring timer on the new target
*
* If one of the above requirements is not fulfilled we move the timer
* to the current CPU or leave it on the previously assigned CPU if
* the timer callback is currently running.
*/
static inline struct hrtimer_clock_base *
switch_hrtimer_base(struct hrtimer *timer, struct hrtimer_clock_base *base,
int pinned)
{
struct hrtimer_cpu_base *new_cpu_base, *this_cpu_base;
struct hrtimer_clock_base *new_base;
int basenum = base->index;
this_cpu_base = this_cpu_ptr(&hrtimer_bases);
new_cpu_base = get_target_base(this_cpu_base, pinned);
again:
new_base = &new_cpu_base->clock_base[basenum];
if (base != new_base) {
/*
* We are trying to move timer to new_base.
* However we can't change timer's base while it is running,
* so we keep it on the same CPU. No hassle vs. reprogramming
* the event source in the high resolution case. The softirq
* code will take care of this when the timer function has
* completed. There is no conflict as we hold the lock until
* the timer is enqueued.
*/
if (unlikely(hrtimer_callback_running(timer)))
return base;
/* See the comment in lock_hrtimer_base() */
WRITE_ONCE(timer->base, &migration_base);
raw_spin_unlock(&base->cpu_base->lock);
raw_spin_lock(&new_base->cpu_base->lock);
if (new_cpu_base != this_cpu_base &&
hrtimer_check_target(timer, new_base)) {
raw_spin_unlock(&new_base->cpu_base->lock);
raw_spin_lock(&base->cpu_base->lock);
new_cpu_base = this_cpu_base;
timer->base = base;
goto again;
}
WRITE_ONCE(timer->base, new_base);
} else {
if (new_cpu_base != this_cpu_base &&
hrtimer_check_target(timer, new_base)) {
new_cpu_base = this_cpu_base;
goto again;
}
}
return new_base;
}
hrtimer를 위해 현재 cpu의 clock base를 사용하지 못하는 경우에 다른 cpu의 clock base로 변경한다.
- 코드 라인 10에서 타이머를 이주시키기 위해 가장 가까운 cpu 도메인에서 바쁜 cpu의 hrtimer cpu 베이스를 얻어온다.
- 코드 라인 14~40에서 새 cpu의 클럭 base로 변경하되 다음의 예외 케이스가 있다.
- 낮은 확률로 요청한 hrtimer의 callback이 이미 실행중인 경우 원래 clock base를 반환한다.
- 현재 타이머의 만료 시간이 새 cpu의 clock base의 다음 타이머의 만료 시간 이전인 경우 그냥 현재 cpu로 재시도한다.
- 코드 라인 41~47에서 cpu가 변경된 경우이면서 현재 타이머의 만료 시간이 새 cpu의 clock base의 다음 타이머의 만료 시간 이전인 경우 그냥 현재 cpu로 재시도한다
- 코드 라인 48에서 산출한 새 cpu의 hrtimer 클럭 베이스를 반환한다.
nohz를 위한 hrtimer cpu 베이스 찾기
get_target_base()
kernel/time/hrtimer.c
static inline
struct hrtimer_cpu_base *get_target_base(struct hrtimer_cpu_base *base,
int pinned)
{
#if defined(CONFIG_SMP) && defined(CONFIG_NO_HZ_COMMON)
if (static_branch_likely(&timers_migration_enabled) && !pinned)
return &per_cpu(hrtimer_bases, get_nohz_timer_target());
#endif
return base;
}
타이머를 동작시킬 타겟 hrtimer cpu 베이스를 반환한다. @pinned가 설정된 경우 요청한 @base를 그대로 반환한다.
- 이주시키기 위해 가장 가까운 cpu 도메인에서 바쁜 cpu를 얻어온다. (nohz idle 상태인 cpu를 제외한 busy cpu를 찾는다)
hrtimer_check_target()
kernel/time/hrtimer.c
/*
* We do not migrate the timer when it is expiring before the next
* event on the target cpu. When high resolution is enabled, we cannot
* reprogram the target cpu hardware and we would cause it to fire
* late. To keep it simple, we handle the high resolution enabled and
* disabled case similar.
*
* Called with cpu_base->lock of target cpu held.
*/
static int
hrtimer_check_target(struct hrtimer *timer, struct hrtimer_clock_base *new_base)
{
ktime_t expires;
expires = ktime_sub(hrtimer_get_expires(timer), new_base->offset);
return expires < new_base->cpu_base->expires_next;
}
요청 타이머의 만료 시간이 새 clock base의 다음 타이머 만료 시간보다 앞서는 경우 true를 반환한다. (target cpu 변경을 금지하기 위함)
- 코드 라인 6에서 요청한 타이머의 만료 시각을 가져와서 새 클럭 베이스로 변환한 새 만료 시각을 산출한다.
- 코드 라인 7에서 새 만료 시각이 기존 타이머의 만료 시각보다 앞서는 경우 true를 반환한다.
다음 그림은 요청 hrtimer를 new_base(target clock base)로 이주 가능한지 체크하여 true(이주 불가능)가 반환되는 경우를 보여준다.
- 이주할 clock base의 만료될 타이머보다 앞서는 경우 끼워 넣지 못하여 true를 반환한다.
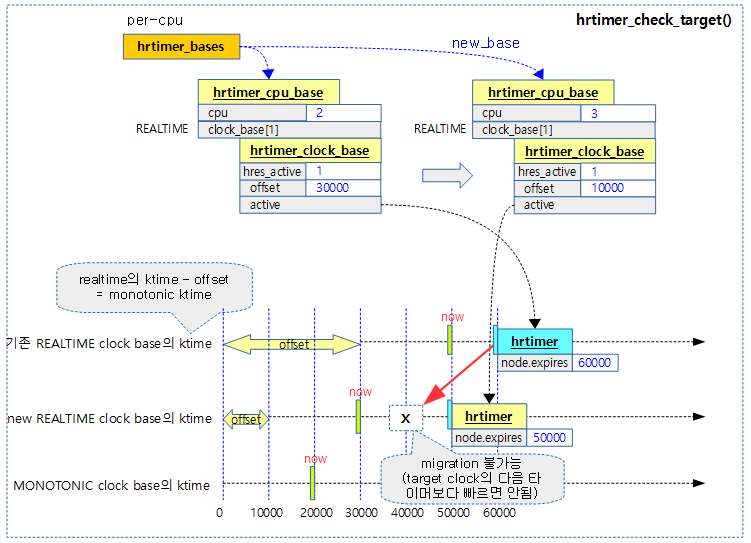
nohz를 위한 타겟 cpu 찾기
get_nohz_timer_target()
kernel/sched/core.c
/*
* In the semi idle case, use the nearest busy CPU for migrating timers
* from an idle CPU. This is good for power-savings.
*
* We don't do similar optimization for completely idle system, as
* selecting an idle CPU will add more delays to the timers than intended
* (as that CPU's timer base may not be uptodate wrt jiffies etc).
*/
int get_nohz_timer_target(void)
{
int i, cpu = smp_processor_id();
struct sched_domain *sd;
if (!idle_cpu(cpu) && housekeeping_cpu(cpu, HK_FLAG_TIMER))
return cpu;
rcu_read_lock();
for_each_domain(cpu, sd) {
for_each_cpu(i, sched_domain_span(sd)) {
if (cpu == i)
continue;
if (!idle_cpu(i) && housekeeping_cpu(i, HK_FLAG_TIMER)) {
cpu = i;
goto unlock;
}
}
}
if (!housekeeping_cpu(cpu, HK_FLAG_TIMER))
cpu = housekeeping_any_cpu(HK_FLAG_TIMER);
unlock:
rcu_read_unlock();
return cpu;
}
타이머를 이주시키기 위해 가장 가까운 cpu 도메인에서 바쁜 cpu를 얻어온다. (nohz로 동작 중인 현재 cpu를 제외하고 다른 busy cpu를 찾는다)
- 코드 라인 6~7에서 idle(task 없이 쉬는) cpu가 아니고 타이머 처리가 가능한 cpu이면 로컬 cpu를 반환한다.
- nohz idle 상태인 경우 절전을 위해 타이머 처리를 하지 않으려 하고, nohz full 상태인 경우 성능을 위해 다른 cpu에서 타이머를 처리하려 한다
- 코드 라인 10~20에서 cpu 도메인 수 만큼 루프를 돌며 그 안에 있는 각 cpu에 대해 idle cpu가 아니고 타이머 처리가 가능한 cpu id를 반환한다.
- 코드 라인 22~23에서 타이머 처리가 가능한 cpu가 없으면 아무 cpu나 반환한다.
- /proc/sys/kernel/timer_migration 파일의 디폴트 값은 1이다.
Housekeeping cpu
housekeeping_cpu()
include/linux/sched/isolation.h
static inline bool housekeeping_cpu(int cpu, enum hk_flags flags)
{
#ifdef CONFIG_CPU_ISOLATION
if (static_branch_unlikely(&housekeeping_overridden))
return housekeeping_test_cpu(cpu, flags);
#endif
return true;
}
@flags에 대해 처리 가능한 cpu인지 여부를 반환한다.
- CONFIG_CPU_ISOLATION 커널 옵션을 사용하지 않은 경우 항상 true를 반환한다.
housekeeping_test_cpu()
kernel/sched/isolation.c
bool housekeeping_test_cpu(int cpu, enum hk_flags flags)
{
if (static_branch_unlikely(&housekeeping_overridden))
if (housekeeping_flags & flags)
return cpumask_test_cpu(cpu, housekeeping_mask);
return true;
}
EXPORT_SYMBOL_GPL(housekeeping_test_cpu);
@flags에 대해 처리 가능한 cpu인지 여부를 반환한다.
cpu가 여러 이유로(성능 또는 절전, cpu 분리(isolation), …) 다음 플래그에 따른 처리를 수행할 수 있는지 여부를 나타낸다.
- HK_FLAG_TIMER
- HK_FLAG_RCU
- HK_FLAG_SCHED
- HK_FLAG_TICK
- HK_FLAG_DOMAIN
- HK_FLAG_WQ
hrtimer_callback_running()
include/linux/hrtimer.h
/*
* Helper function to check, whether the timer is running the callback
* function
*/
static inline int hrtimer_callback_running(struct hrtimer *timer)
{
return timer->base->running == timer;
}
hrtimer의 콜백 함수가 실행되고 있는 상태인 경우 true를 반환한다.
hrtimer 큐에 추가
enqueue_hrtimer()
kernel/time/hrtimer.c
/*
* enqueue_hrtimer - internal function to (re)start a timer
*
* The timer is inserted in expiry order. Insertion into the
* red black tree is O(log(n)). Must hold the base lock.
*
* Returns 1 when the new timer is the leftmost timer in the tree.
*/
static int enqueue_hrtimer(struct hrtimer *timer,
struct hrtimer_clock_base *base,
enum hrtimer_mode mode)
{
debug_activate(timer);
base->cpu_base->active_bases |= 1 << base->index;
timer->state |= HRTIMER_STATE_ENQUEUED;
return timerqueue_add(&base->active, &timer->node);
}
지정한 clock base의 active 타이머 큐(RB 트리)에 hrtimer를 노드로 추가한다. 추가한 타이머가 타이머큐(RB 트리)에서 가장 먼저 만료 시간이되는 경우 1을 반환한다.
- 코드 라인 7에서 cpu_base->active_bases 마스크에 요청 타이머가 사용한 clock base에 해당하는 비트를 설정하여 사용됨을 표시한다.
- 해당 cpu base에서 활성화된 hrtimer가 어느 clock base에 있는지 빠른 확인을 위해 사용한다.
- 코드 라인 9에서 hrtimer를 enque 상태로 설정한다.
- 코드 라인 11에서 지정한 clock base의 active 타이머 큐(RB 트리)에 hrtimer를 노드로 추가한다.
timerqueue_add()
lib/timerqueue.c
/**
* timerqueue_add - Adds timer to timerqueue.
*
* @head: head of timerqueue
* @node: timer node to be added
*
* Adds the timer node to the timerqueue, sorted by the node's expires
* value. Returns true if the newly added timer is the first expiring timer in
* the queue.
*/
bool timerqueue_add(struct timerqueue_head *head, struct timerqueue_node *node)
{
struct rb_node **p = &head->rb_root.rb_root.rb_node;
struct rb_node *parent = NULL;
struct timerqueue_node *ptr;
bool leftmost = true;
/* Make sure we don't add nodes that are already added */
WARN_ON_ONCE(!RB_EMPTY_NODE(&node->node));
while (*p) {
parent = *p;
ptr = rb_entry(parent, struct timerqueue_node, node);
if (node->expires < ptr->expires) {
p = &(*p)->rb_left;
} else {
p = &(*p)->rb_right;
leftmost = false;
}
}
rb_link_node(&node->node, parent, p);
rb_insert_color_cached(&node->node, &head->rb_root, leftmost);
return leftmost;
}
EXPORT_SYMBOL_GPL(timerqueue_add);
타이머 큐(RB 트리)에 노드(hrtimer)를 추가한다.
nohz full 관련
wake_up_nohz_cpu()
kernel/sched/core.c
void wake_up_nohz_cpu(int cpu)
{
if (!wake_up_full_nohz_cpu(cpu))
wake_up_idle_cpu(cpu);
}
nohz full cpu를 깨우거나 nohz idle 상태의 cpu를 깨운다.
wake_up_full_nohz_cpu()
kernel/sched/core.c
static bool wake_up_full_nohz_cpu(int cpu)
{
/*
* We just need the target to call irq_exit() and re-evaluate
* the next tick. The nohz full kick at least implies that.
* If needed we can still optimize that later with an
* empty IRQ.
*/
if (cpu_is_offline(cpu))
return true; /* Don't try to wake offline CPUs. */
if (tick_nohz_full_cpu(cpu)) {
if (cpu != smp_processor_id() ||
tick_nohz_tick_stopped())
tick_nohz_full_kick_cpu(cpu);
return true;
}
return false;
}
요청한 cpu가 nohz full로 동작하는 경우 현재 cpu가 아니거나 nohz tick이 멈춘 경우 해당 cpu를 nohz full 모드에서 제거하도록 요청 하고 true를 반환한다.
tick_nohz_tick_stopped()
include/linux/tick.h
static inline int tick_nohz_tick_stopped(void)
{
return __this_cpu_read(tick_cpu_sched.tick_stopped);
}
스케쥴 tick이 멈춘 상태인지 여부를 알아온다.
tick_nohz_full_kick_cpu()
kernel/time/tick-sched.c
/*
* Kick the CPU if it's full dynticks in order to force it to
* re-evaluate its dependency on the tick and restart it if necessary.
*/
void tick_nohz_full_kick_cpu(int cpu)
{
if (!tick_nohz_full_cpu(cpu))
return;
irq_work_queue_on(&per_cpu(nohz_full_kick_work, cpu), cpu);
}
요청한 cpu가 nohz full로 동작할 때 work queue를 사용하여 해당 cpu를 nohz full 모드에서 제거하게 한다.
tick_nohz_full_cpu()
include/linux/tick.h
static inline bool tick_nohz_full_cpu(int cpu)
{
if (!tick_nohz_full_enabled())
return false;
return cpumask_test_cpu(cpu, tick_nohz_full_mask);
}
요청한 cpu가 nohz full로 동작하는지 여부를 반환한다.
hrtimer 프로그램
hrtimer_reprogram()
kernel/time/hrtimer.c
/*
* When a timer is enqueued and expires earlier than the already enqueued
* timers, we have to check, whether it expires earlier than the timer for
* which the clock event device was armed.
*
* Called with interrupts disabled and base->cpu_base.lock held
*/
static void hrtimer_reprogram(struct hrtimer *timer, bool reprogram)
{
struct hrtimer_cpu_base *cpu_base = this_cpu_ptr(&hrtimer_bases);
struct hrtimer_clock_base *base = timer->base;
ktime_t expires = ktime_sub(hrtimer_get_expires(timer), base->offset);
WARN_ON_ONCE(hrtimer_get_expires_tv64(timer) < 0);
/*
* CLOCK_REALTIME timer might be requested with an absolute
* expiry time which is less than base->offset. Set it to 0.
*/
if (expires < 0)
expires = 0;
if (timer->is_soft) {
/*
* soft hrtimer could be started on a remote CPU. In this
* case softirq_expires_next needs to be updated on the
* remote CPU. The soft hrtimer will not expire before the
* first hard hrtimer on the remote CPU -
* hrtimer_check_target() prevents this case.
*/
struct hrtimer_cpu_base *timer_cpu_base = base->cpu_base;
if (timer_cpu_base->softirq_activated)
return;
if (!ktime_before(expires, timer_cpu_base->softirq_expires_next))
return;
timer_cpu_base->softirq_next_timer = timer;
timer_cpu_base->softirq_expires_next = expires;
if (!ktime_before(expires, timer_cpu_base->expires_next) ||
!reprogram)
return;
}
/*
* If the timer is not on the current cpu, we cannot reprogram
* the other cpus clock event device.
*/
if (base->cpu_base != cpu_base)
return;
/*
* If the hrtimer interrupt is running, then it will
* reevaluate the clock bases and reprogram the clock event
* device. The callbacks are always executed in hard interrupt
* context so we don't need an extra check for a running
* callback.
*/
if (cpu_base->in_hrtirq)
return;
if (expires >= cpu_base->expires_next)
return;
/* Update the pointer to the next expiring timer */
cpu_base->next_timer = timer;
cpu_base->expires_next = expires;
/*
* If hres is not active, hardware does not have to be
* programmed yet.
*
* If a hang was detected in the last timer interrupt then we
* do not schedule a timer which is earlier than the expiry
* which we enforced in the hang detection. We want the system
* to make progress.
*/
if (!__hrtimer_hres_active(cpu_base) || cpu_base->hang_detected)
return;
/*
* Program the timer hardware. We enforce the expiry for
* events which are already in the past.
*/
tick_program_event(expires, 1);
}
hrtimer가 요청한 clock base 큐에 있거나 현재 동작 중인 경우를 제외하고 다시 프로그램한다.
- 코드 라인 13~14에서 만일 해당 클럭의 만료 시각으로 변환된 expires 값이 0보다 작은 경우 0으로 리셋한다.
- 코드 라인 16~38에서 softirq context에서 동작해야 할 hrtimer인 경우이고, 다음과 같이 리프로그램이 필요하지 않은 조건인 경우 함수를 빠져나간다.
- softirq가 activate된 상태가 아닌 경우
- 다음 softirq용 만료 시각보다 늦은 경우
- 다음 hardirq용 만료 시각보다 늦은 경우
- 코드 라인 44~45에서 cpu 베이스가 바뀐 경우 함수를 빠져나간다.
- 코드 라인 54~55에서 hardirq context에서 hrtimer가 실행중인 경우 함수를 빠져나간다.
- 코드 라인 57~58에서 만료 시각이 cpu 베이스의 다른 hrtimer에 비해 후순위이면 함수를 빠져나간다.
- 코드 라인 61~62에서 다음 만료 타이머로 요청한 hrtimer를 지정하고, 만료 시각도 갱신한다.
- 코드 라인 73~74에서 현재 cpu base에서 hang이 검출된 경우 0을 반환한다.
- 코드 라인 80에서 hrtimer를 틱 디바이스(hw)를 통해 one-shot 프로그램한다.
만료 시간을 forward
hrtimer_forward()
kernel/time/hrtimer.c
/**
* hrtimer_forward - forward the timer expiry
* @timer: hrtimer to forward
* @now: forward past this time
* @interval: the interval to forward
*
* Forward the timer expiry so it will expire in the future.
* Returns the number of overruns.
*
* Can be safely called from the callback function of @timer. If
* called from other contexts @timer must neither be enqueued nor
* running the callback and the caller needs to take care of
* serialization.
*
* Note: This only updates the timer expiry value and does not requeue
* the timer.
*/
u64 hrtimer_forward(struct hrtimer *timer, ktime_t now, ktime_t interval)
{
u64 orun = 1;
ktime_t delta;
delta = ktime_sub(now, hrtimer_get_expires(timer));
if (delta < 0)
return 0;
if (WARN_ON(timer->state & HRTIMER_STATE_ENQUEUED))
return 0;
if (interval < hrtimer_resolution)
interval = hrtimer_resolution;
if (unlikely(delta >= interval)) {
s64 incr = ktime_to_ns(interval);
orun = ktime_divns(delta, incr);
hrtimer_add_expires_ns(timer, incr * orun);
if (hrtimer_get_expires_tv64(timer) > now)
return orun;
/*
* This (and the ktime_add() below) is the
* correction for exact:
*/
orun++;
}
hrtimer_add_expires(timer, interval);
return orun;
}
EXPORT_SYMBOL_GPL(hrtimer_forward);
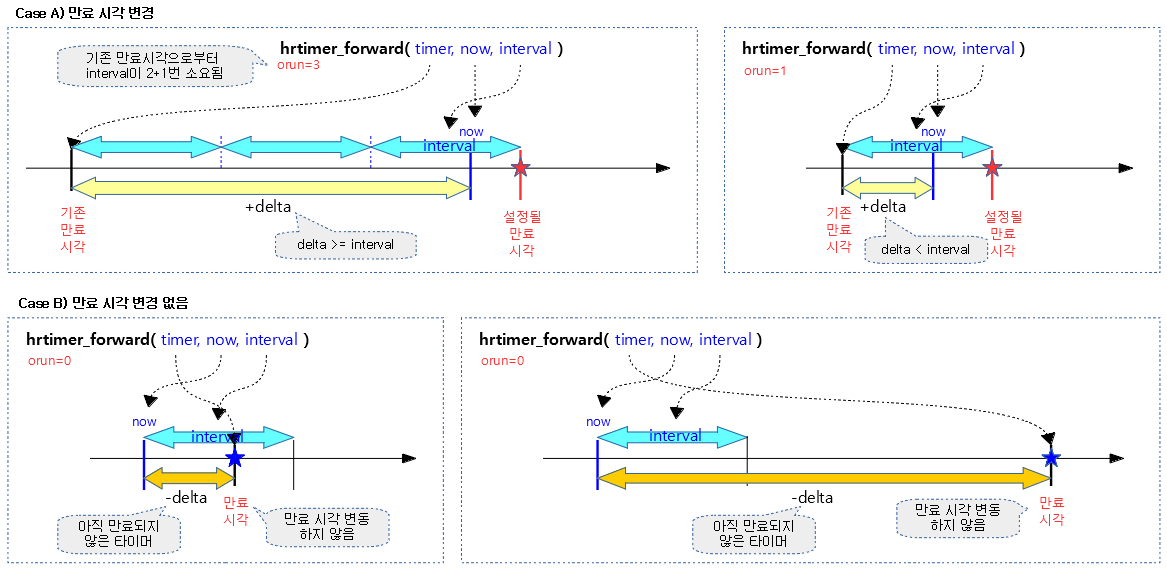
만료된 타이머에 한해 만료 시각으로부터 @interval 기간의 배수 간격으로 @now를 지난 시각을 만료 시각으로 재설정한다. 결과 값으로 forward된 interval 이 몇 회 사용되었는지를 반환한다. 재설정되지 않은 경우 0을 반환한다.
- 코드 라인 6~9에서 @now로부터 기존 타이머 만료 시각을 빼서 delta에 대입한다. 만일 기존 타이머가 만료되지 않은 경우 0을 결과 값으로 함수를 빠져나간다.
- 코드 라인 11~12에서 hrtimer가 엔큐 상태이면 경고 메시지를 출력하고 0을 결과 값으로 함수를 빠져나간다.
- 코드 라인 14~15에서 타이머의 해상도보다 인터벌이 작은 경우 인터벌 값을 타이머의 해상도로 바꾼다.
- 코드 라인 17~29에서 낮은 확률로 기존 만료된 타이머가 인터벌보다 길게 오래된 경우 orun에 인터벌이 들어갈 횟수를 대입하고 hrtimer의 만료시각을 orun x 인터벌 기간만큼 추가한다. 단 추가한 시각이 현재 시각을 넘어간 경우 orun을 반환한다.
- 코드 라인 30~32에서 hrtimer를 재설정한 후 orun 값을 반환한다.
다음 그림은 hrtimer_forward() 함수로 만료 시각이 변경되지 않는 사례와 변경되는 사례를 보여준다.
구조체
cpu 베이스
hrtimer_cpu_base 구조체
include/linux/hrtimer.h
/**
* struct hrtimer_cpu_base - the per cpu clock bases
* @lock: lock protecting the base and associated clock bases
* and timers
* @cpu: cpu number
* @active_bases: Bitfield to mark bases with active timers
* @clock_was_set_seq: Sequence counter of clock was set events
* @hres_active: State of high resolution mode
* @in_hrtirq: hrtimer_interrupt() is currently executing
* @hang_detected: The last hrtimer interrupt detected a hang
* @softirq_activated: displays, if the softirq is raised - update of softirq
* related settings is not required then.
* @nr_events: Total number of hrtimer interrupt events
* @nr_retries: Total number of hrtimer interrupt retries
* @nr_hangs: Total number of hrtimer interrupt hangs
* @max_hang_time: Maximum time spent in hrtimer_interrupt
* @softirq_expiry_lock: Lock which is taken while softirq based hrtimer are
* expired
* @timer_waiters: A hrtimer_cancel() invocation waits for the timer
* callback to finish.
* @expires_next: absolute time of the next event, is required for remote
* hrtimer enqueue; it is the total first expiry time (hard
* and soft hrtimer are taken into account)
* @next_timer: Pointer to the first expiring timer
* @softirq_expires_next: Time to check, if soft queues needs also to be expired
* @softirq_next_timer: Pointer to the first expiring softirq based timer
* @clock_base: array of clock bases for this cpu
*
* Note: next_timer is just an optimization for __remove_hrtimer().
* Do not dereference the pointer because it is not reliable on
* cross cpu removals.
*/
struct hrtimer_cpu_base {
raw_spinlock_t lock;
unsigned int cpu;
unsigned int active_bases;
unsigned int clock_was_set_seq;
unsigned int hres_active : 1,
in_hrtirq : 1,
hang_detected : 1,
softirq_activated : 1;
#ifdef CONFIG_HIGH_RES_TIMERS
unsigned int nr_events;
unsigned short nr_retries;
unsigned short nr_hangs;
unsigned int max_hang_time;
#endif
#ifdef CONFIG_PREEMPT_RT
spinlock_t softirq_expiry_lock;
atomic_t timer_waiters;
#endif
ktime_t expires_next;
struct hrtimer *next_timer;
ktime_t softirq_expires_next;
struct hrtimer *softirq_next_timer;
struct hrtimer_clock_base clock_base[HRTIMER_MAX_CLOCK_BASES];
} ____cacheline_aligned;
- lock
- base와 연결된 clock base와 타이머들을 보호하기 위해 lock을 사용한다.
- cpu
- active_bases
- 활성화된 타이머가 있는 clock base에 해당하는 비트 필드를 운영한다.
- 예) 0x13 -> softirq context에서 동작할 HRTIMER_BASE_MONOTONIC_SOFT 클럭과 hardirq context에서 동작할 HRTIMER_BASE_MONOTONIC 및 HRTIMER_BASE_REALTIME 클럭 들에 현재 활성화된 hrtimer가 있다.
- clock_was_set_seq
- 클럭이 변경(설정)되었는지 여부를 확인하기 위한 시퀀스 값
- hres_active:1
- in_hrtirq:1
- hardirq 인터럽트 context가 현재 수행중인지 여부 (hrtimer_interrupt()가 실행중일 때 1, 완료 시 0)
- hang_detected:1
- 지난 인터럽트에서 hang이 발견된 경우 설정된다.
- softirq_activated:1
- softirq 인터럽트 context가 수행중인지 여부
- nr_events
- nr_hangs
- max_hang_time
- hrtimer 인터럽트 context가 수행된 시간 중 최대 시간
- softirq_expiry_lock
- softirq 타이머가 expire되어 처리되는 동안 사용되는 lock
- timer_waiters
- hrtimer_cancel() 함수를 호출하여 타이머 콜백 함수가 종료되도록 대기하는 대기자 수
- expires_next
- 4개의 hardirq 관련 클럭들 중 monotonic 기준 클럭으로 가장 먼저 만료되는 타이머의 만료 시각
- *next_timer
- softirq_expires_next
- 4개의 softirq 관련 클럭들 중 monotonic 기준 클럭으로 가장 먼저 만료되는 타이머의 만료 시각
- *softirq_next_timer
- clock_base[]
클럭 베이스
hrtimer_clock_base 구조체
include/linux/hrtimer.h
/**
* struct hrtimer_clock_base - the timer base for a specific clock
* @cpu_base: per cpu clock base
* @index: clock type index for per_cpu support when moving a
* timer to a base on another cpu.
* @clockid: clock id for per_cpu support
* @seq: seqcount around __run_hrtimer
* @running: pointer to the currently running hrtimer
* @active: red black tree root node for the active timers
* @get_time: function to retrieve the current time of the clock
* @offset: offset of this clock to the monotonic base
*/
struct hrtimer_clock_base {
struct hrtimer_cpu_base *cpu_base;
unsigned int index;
clockid_t clockid;
seqcount_t seq;
struct hrtimer *running;
struct timerqueue_head active;
ktime_t (*get_time)(void);
ktime_t offset;
} __hrtimer_clock_base_align;
- *cpu_base
- index
- clockid
- seq
- __run_hrtimer() 수행 시퀀스 번호
- running
- active
- (*get_time)
- 현재 clock 베이스의 시각 조회 함수가 등록되어 있다.
- offset
- 현재 clock과 monotonic 클럭과의 offset 시간(ns)
- 현재 clock이 monotonic인 경우 이 값은 0이다.
hrtimer 구조체
include/linux/hrtimer.h
/**
* struct hrtimer - the basic hrtimer structure
* @node: timerqueue node, which also manages node.expires,
* the absolute expiry time in the hrtimers internal
* representation. The time is related to the clock on
* which the timer is based. Is setup by adding
* slack to the _softexpires value. For non range timers
* identical to _softexpires.
* @_softexpires: the absolute earliest expiry time of the hrtimer.
* The time which was given as expiry time when the timer
* was armed.
* @function: timer expiry callback function
* @base: pointer to the timer base (per cpu and per clock)
* @state: state information (See bit values above)
* @is_rel: Set if the timer was armed relative
* @is_soft: Set if hrtimer will be expired in soft interrupt context.
* @is_hard: Set if hrtimer will be expired in hard interrupt context
* even on RT.
*
* The hrtimer structure must be initialized by hrtimer_init()
*/
struct hrtimer {
struct timerqueue_node node;
ktime_t _softexpires;
enum hrtimer_restart (*function)(struct hrtimer *);
struct hrtimer_clock_base *base;
u8 state;
u8 is_rel;
u8 is_soft;
};
- node
- RB 트리에 연결될 노드로 slack이 적용된 실제 만료시간을 가지고 있다.
- _softexpires
- slack이 적용되지 않은 만료 시각(soft 만료 시각)
- (*function)
- *base
- state
- 타이머 상태
- HRTIMER_STATE_INACTIVE (0x00)
- HRTIMER_STATE_ENQUEUED (0x01)
- is_rel
- is_soft
- softirq context 사용 여부
- is_hard와 항상 반대로 설정된다.
- is_hard
- hardirq context 사용 여부
- is_soft와 항상 반대로 설정된다.
타이머 정보
다음과 같이 모든 cpu에서 동작하는 hrtimer의 동작상태를 확인할 수 있다.
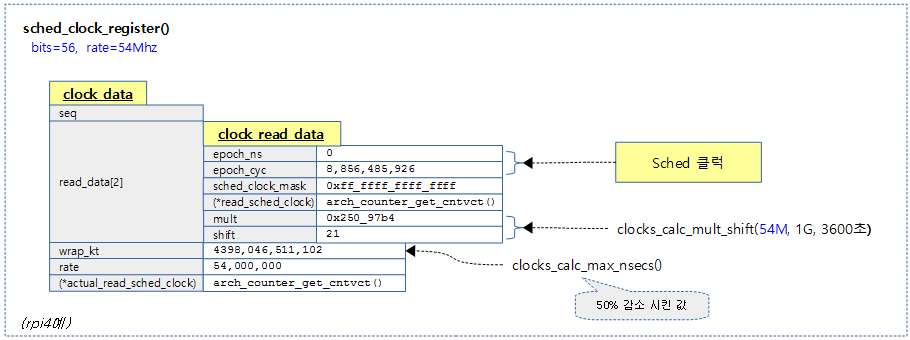
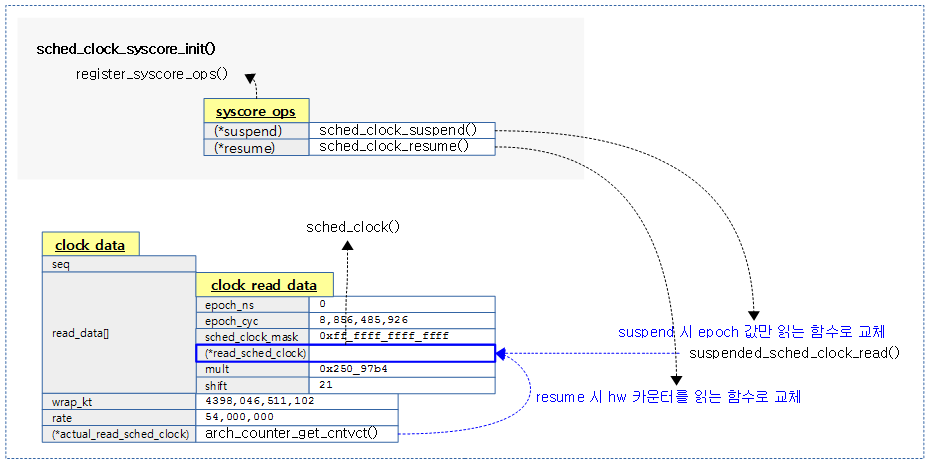
- 아래 monotonic 클럭인 clock 0을 보면 offset이 0임을 확인할 수 있다.
- 아래 boottime 클럭인 clock 2 역시 supend된 적이 없어 clock 0과 동일한 offset을 사용하는 것을 확인할 수 있다.
$ cat /proc/timer_list
Timer List Version: v0.8
HRTIMER_MAX_CLOCK_BASES: 8
now at 1396737667102735 nsecs
cpu: 0
clock 0:
.base: ffffffc07ff6a7c0
.index: 0
.resolution: 1 nsecs
.get_time: ktime_get
.offset: 0 nsecs
active timers:
#0: <ffffffc07ff6ac78>, tick_sched_timer, S:01
# expires at 1396737704000000-1396737704000000 nsecs [in 36897265 to 36897265 nsecs]
#1: <ffffff800b18b920>, hrtimer_wakeup, S:01
# expires at 1396738000463329-1396738010452327 nsecs [in 333360594 to 343349592 nsecs]
#2: <ffffffc07abd0400>, timerfd_tmrproc, S:01
# expires at 1396761589001000-1396761589001000 nsecs [in 23921898265 to 23921898265 nsecs]
#3: <ffffff800b37bc00>, hrtimer_wakeup, S:01
# expires at 1396780922286140-1396780922336140 nsecs [in 43255183405 to 43255233405 nsecs]
#4: <ffffff800b3a3c00>, hrtimer_wakeup, S:01
# expires at 1396916185370677-1396916185420677 nsecs [in 178518267942 to 178518317942 nsecs]
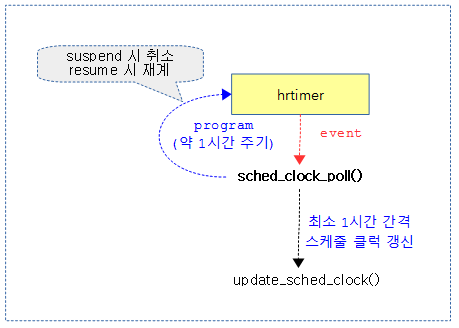
#5: sched_clock_timer, sched_clock_poll, S:01
# expires at 1398578790530436-1398578790530436 nsecs [in 1841123427701 to 1841123427701 nsecs]
clock 1:
.base: ffffffc07ff6a800
.index: 1
.resolution: 1 nsecs
.get_time: ktime_get_real
.offset: 1575075653300352953 nsecs
active timers:
#0: <ffffffc070a11300>, timerfd_tmrproc, S:01
# expires at 9223372036854775807-9223372036854775807 nsecs [in 7646899645887320119 to 7646899645887320119 nsecs]
clock 2:
.base: ffffffc07ff6a840
.index: 2
.resolution: 1 nsecs
.get_time: ktime_get_boottime
.offset: 0 nsecs
active timers:
#0: , timerfd_tmrproc, S:01
# expires at 1399988673897000-1399988673897000 nsecs [in 3251006794265 to 3251006794265 nsecs]
clock 3:
.base: ffffffc07ff6a880
.index: 3
.resolution: 1 nsecs
.get_time: ktime_get_clocktai
.offset: 1575075653300352953 nsecs
...
$ cat /proc/timer_list
Timer List Version: v0.7
HRTIMER_MAX_CLOCK_BASES: 4
now at 6680679880466542 nsecs
cpu: 0
clock 0:
.base: b9b483d0
.index: 0
.resolution: 1 nsecs
.get_time: ktime_get
.offset: 0 nsecs
active timers:
#0: <b9b48628>, tick_sched_timer, S:01, hrtimer_start, swapper/0/0
# expires at 6680679900000000-6680679900000000 nsecs [in 19533458 to 19533458 nsecs]
#1: <b6e19a48>, hrtimer_wakeup, S:01, hrtimer_start_range_ns, ifplugd/1632
# expires at 6680680247387930-6680680248387924 nsecs [in 366921388 to 367921382 nsecs]
(...생략...)
참고