캐시를 모두(d-cache, i-cache) flush(clean & invalidate) 한다. 아키텍처마다 캐시를 flush하는 구현이 각각 다르기 때문에 현재 동작하는 CPU 아키텍처코드를 알아내어 해당 아키텍처에서 구현해놓은 cache flush 루틴을 수행하게 한다. 아래 순서도는 ARMv7에 대응하는 cache flush 루틴의 순서도이다.
Flush & Clean
Data 캐시에서 flush와 Clean이라는 용어는 여러 아키텍처에 따라 각각 의미가 다르게 해석되어 사용되므로 유의해야 한다.
- flush는 arm에 해당하는 clean, invalidate, clean & invalidate의 3가지 의미로 혼용 사용된다.
- clean은 arm에 해당하는 clean, clean & invalidate의 2가지 의미로 혼용 사용된다.
따라서 arm 매뉴얼에서는 flush라는 용어를 가급적 사용하지 않고 clean, invalidate, clean & invalidate의 3가지로 정확히 나누어 사용한다.
- clean
- dirty(기록) 설정된 캐시 라인 -> 메모리로 기록하고 캐시에서 그대로 유지
- dirty를 0으로 변경, valid는 1로 유지
- dirty(기록) 설정된 캐시 라인 -> 메모리로 기록하고 캐시에서 그대로 유지
- invalidate
- dirty 유무와 상관 없이 캐시 라인을 버린다. (캐시 라인은 메모리에 기록하지 않는다)
- valid를 0으로 변경
- dirty 유무와 상관 없이 캐시 라인을 버린다. (캐시 라인은 메모리에 기록하지 않는다)
- clean & invalidate
- dirty(기록) 설정된 캐시 라인이 있는 경우 메모리로 기록하고 캐시 라인을 버린다.
- dirty 및 valid를 0으로 변경
- dirty(기록) 설정되지 않은 캐시 라인은 곧바로 캐시 라인을 버린다.
- valid를 0으로 변경
- dirty(기록) 설정된 캐시 라인이 있는 경우 메모리로 기록하고 캐시 라인을 버린다.
Instruction 캐시, Branch Pridict 캐시, TLB 캐시 등은 Dirty 비트가 없으므로 flush, clean 및 invalidate 모두 같은 의미로 사용된다.
- arm 매뉴얼에서는 invalidate를 표준으로 사용하고 flush 라는 용어도 사용된다.
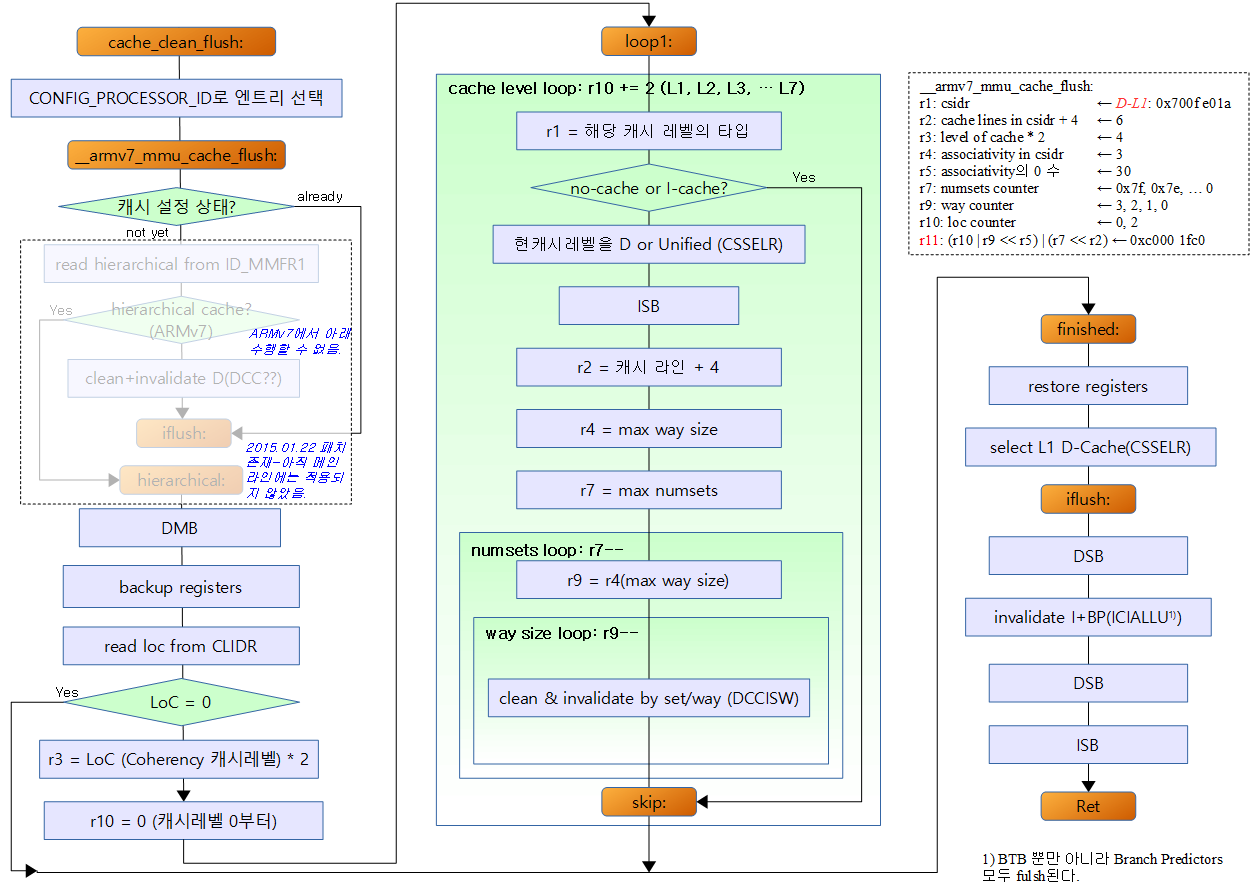
cache_clean_flush:
/*
* Clean and flush the cache to maintain consistency.
*
* On exit,
* r1, r2, r3, r9, r10, r11, r12 corrupted
* This routine must preserve:
* r4, r6, r7, r8
*/
.align 5
cache_clean_flush:
mov r3, #16
b call_cache_fn
- 캐시 clean & flush를 수행한다.
- rpi2: ARMv7 아키텍처를 사용하므로 __armv7_mmu_cache_flush로 진행
__armv7_mmu_cache_flush:
__armv7_mmu_cache_flush:
tst r4, #1
bne iflush
mrc p15, 0, r10, c0, c1, 5 @ read ID_MMFR1
tst r10, #0xf << 16 @ hierarchical cache (ARMv7)
mov r10, #0
beq hierarchical
mcr p15, 0, r10, c7, c14, 0 @ clean+invalidate D
b iflush
- tst r4, #1
- r4에는 decompressed 커널 시작 주소가 담겨있는데 임시로 하위 1비트를 캐시 on 유보 비트로 이용하고 있다.
- 캐시 유보 비트가 설정되어 있으면 d-cache를 사용하지 않았으모로 d-cache에 대해 flush 하지 않고 i-cache만 flush하도록 iflush: 루틴으로 이동한다.
- mrc p15, 0, r10, c0, c1, 5
- ID.MMFR1.L1_Harvard_cache 설정 상태를 읽어온다.
- ARMv7은 hierarchical 캐시를 사용하므로 값이 0으로 설정되어 있다.
- ID.MMFR1.L1_Harvard_cache 설정 상태를 읽어온다.
- mov r10, #0
- 아래 mcr 명령을 수행할 일이 있는 경우 register dependency 기법을 이용하여 CPU의 in-order execution을 보장하게 한다.
- beq hierarchical
- ARMv7 의 모든 캐시들은 hierarchical 캐시를 사용하는 것으로 알려져 있다. 따라서 모두 이루틴으로 진입한다.
- 2015년 1월 22일 이 부분의 패치가 제출되어 있는 상태로 아직 메인 스트림에 반영되지 않고 있다.
- mcr p15, 0, r10, c7, c14, 0
- clean & invalidate d-cache all을 수행하는 명령이지만 ARMv7은 모두 hierarchical 캐시를 사용하므로 이 루틴으로 들어올 일이 없다.
hierarchical:
- 캐시 레벨 관리
- ARMv7 이전의 아키텍처는 직접적으로 관리하는 캐시가 L1 밖에 없었다.
- ARMv7 아키텍처가 만들어지면서 다중 캐시를 지원하게 되었다.
- 캐시는 Level 1부터 Level 7까지의 정보로 구성될 수 있는데 아키텍처나 SoC를 제조하는 회사마다 캐시의 구성방법과 LoC(Level of Cache Coherency)가 모두 다르다.
- 캐시 flush 방법
- ARMv7 이전의 아키텍처
- L1 i-cache는 한 번의 명령으로 삭제 가능
- L1 d-cache는 한 번의 명령으로 삭제 가능
- ARMv7 아키텍처
- 각 레벨별로 i-cache를 한 번의 명령으로 삭제 가능
- 각 레벨별로 d-cache를 한 번의 명령으로 삭제 불가능
- 모든 캐시 레벨에 대해 set/way 방식으로 하나씩 지워나간다.
- 각 cache line 하나에 대해 한 번의 명령으로 삭제하므로 모두를 지우기 까지 상당한 overhead가 소모되는 것이 단점이다. (최대 수 ms 시간 소모)
- ARMv7 이전의 아키텍처
hierarchical:
mcr p15, 0, r10, c7, c10, 5 @ DMB
stmfd sp!, {r0-r7, r9-r11}
mrc p15, 1, r0, c0, c0, 1 @ read clidr
ands r3, r0, #0x7000000 @ extract loc from clidr
mov r3, r3, lsr #23 @ left align loc bit field
beq finished @ if loc is 0, then no need to clean
- mcr p15, 0, r10, c7, c10, 5
- 캐시를 set/way 방식으로 하나씩 지워나가기 전에 DMB (Data Memory Barrier operation)를 사용하여 이미 사용중인 memory 작업이 완료할 때까지 기다린다.
- stmfd sp!, {r0-r7, r9-r11}
- 이 루틴이 동작하는 동안 레지스터들을 보호하기 대부분의 레지스터들을 백업해둔다.
- mrc p15, 1, r0, c0, c0, 1
- CLIDR(Cache Level ID Register)를 사용하여 캐시 레벨 정보를 읽어온다.
- ands r3, r0, #0x7000000
- LoC가 담긴 비트들만 and 연산으로 확보한다.
- pi2: LoC=2 (Level 2 Coherency를 가지고 있다.)
- mov r3, r3, lsr #23
- 잃어온 LoC 값을 24비트 우측으로 쉬프트하지 않고 23비트만큼만 우측으로 쉬프트한다.
- r3 = LoC x 2와 동일하다.
- rpi2: r3=4
- beq finished
- LoC가 0이면 finish로 빠져나간다.
mov r10, #0 @ start clean at cache level 0
loop1:
add r2, r10, r10, lsr #1 @ work out 3x current cache level
mov r1, r0, lsr r2 @ extract cache type bits from clidr
and r1, r1, #7 @ mask of the bits for current cache only
cmp r1, #2 @ see what cache we have at this level
blt skip @ skip if no cache, or just i-cache
- mov r10, #0
- 가장 바깥쪽 루프(loop1) 카운터로 사용되는 r10(캐시 레벨)을 0으로 설정한다.
- 이 값은 2씩 증가하여 r3(LoC x 2)이 될 때까지 증가한다.
- rpi2: 0(L1 캐시 삭제), 2(L2 캐시 삭제), 4(루프 종료)
- 가장 바깥쪽 루프(loop1) 카운터로 사용되는 r10(캐시 레벨)을 0으로 설정한다.
- add r2, r10, r10, lsr #1
- r2: 해당 캐시레벨의 타입을 가져오기 위해 3bit씩 위치를 곱한다.
- 0, 3, 6, 9, …씩 증가
- mov r1, r0, lsr r2
- r1 = r0(CLIDR) 값을 r2만큼 우측으로 쉬프트하면 해당 캐시 레벨 타입 정보가 있는 곳까지 쉬프트한다.
- and r1, r1, #7
- 캐시 타입 정보 비트는 3비트로 구성되어 있다.
- cmp r1, #2
- r1: 캐시 타입 정보
- 0=0=no cache
- 1=instrunction cache only
- 2=data cache only
- 3=seperate inst & data cache
- 4=unified cache (inst + data)
- 5~7=reserved
- r1: 캐시 타입 정보
- blt skip
- r1(현재 캐시 레벨이 지원하는 캐시 타입)이 2보다 작으면 d-cache가 없으므로 skip으로 이동
- d-cache에서만 루프에서 flush 작업을 수행할 예정이다.
mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr
mcr p15, 0, r10, c7, c5, 4 @ isb to sych the new cssr&csidr
mrc p15, 1, r1, c0, c0, 0 @ read the new csidr
and r2, r1, #7 @ extract the length of the cache lines
add r2, r2, #4 @ add 4 (line length offset)
ldr r4, =0x3ff
ands r4, r4, r1, lsr #3 @ find maximum number on the way size
clz r5, r4 @ find bit position of way size increment
ldr r7, =0x7fff
ands r7, r7, r1, lsr #13 @ extract max number of the index size
- mcr p15, 2, r10, c0, c0, 0
- r1: CCSIDR을 읽어온다.
- 선택된 캐시의 정보가 담김.
- WT(Write Through) 지원 여부 bit
- WB (Write Back) 지원 여부 bit
- RA(Read Allocation) 지원 여부 bit
- WA(Write Allocation) 지원 여부 bit
- LineSize: cache line 바이트 수
- 1=8 words, 2=16 bytes, 3=32 words, …
- rpi2: 2 (L1 & L2 data cache line size = 16 words)
- Associativity
- way 수 – 1
- rpi2: L1 i-cache=1(2 way), L1 d-cache=3(4 way), L2 cache=7(8 way)
- Numsets
- Set(index) 수 – 1
- rpi2: L1 i-cache=0x1ff, L1 d-cache=0x7f, L2 d-cache=0x3ff
- and r2, r1, #7
- cache line 정보 비트를 읽어온다.
- add r2, r2, #4
- r2 += 4를 취한다.
- 5=8 words, 6=16 words, 7=32 words, …
- rp2: 6
- ldr r4, =0x3ff
- associativity(way – 1) 추출을 위한 비트마스크를 0x3ff로 한다.
- ands r4, r4, r1, lsr #3
- r4 = loop2용 max associativity(way – 1) 값
- r1(CLIDR)값을 우측으로 3 쉬프트하여 associativity(way – 1) 값 만을 읽어온다.
- rpi2: L1 d-cache=0x7f, L2 d-cache=0x3ff
- clz r5, r4
- r5: clz: MSB(최상위 비트)부터 시작하여 비트가 0인 갯수를 알아낸다.
- 예) 0b 00000000 00000000 00000000 00000011 -> 30
- r5: clz: MSB(최상위 비트)부터 시작하여 비트가 0인 갯수를 알아낸다.
- ldr r7, =0x7fff
- NumSets(index-1) 추출을 위한 비트마스크를 0x7fff로 한다.
- ands r7, r7, r1, lsr #13
- r7: loop2용 NumSets(index-1) 카운터
- for (r7 = Max NumSets(r1에서 추출) ; r7 >= 0; r7–)
- rpi2:
- L1 d-cache: 0x7f, 0x7e, ……, 0까지 루프 수행(-1이면 루프2 탈출)
- L2 d-cache: 0x3ff, 0x3fe, ……, 0까지 루프 수행(-1이면 루프2 탈출)
- r7: loop2용 NumSets(index-1) 카운터
loop2:
mov r9, r4 @ create working copy of max way size
loop3:
ARM( orr r11, r10, r9, lsl r5 ) @ factor way and cache number into r11
ARM( orr r11, r11, r7, lsl r2 ) @ factor index number into r11
THUMB( lsl r6, r9, r5 )
THUMB( orr r11, r10, r6 ) @ factor way and cache number into r11
THUMB( lsl r6, r7, r2 )
THUMB( orr r11, r11, r6 ) @ factor index number into r11
mcr p15, 0, r11, c7, c14, 2 @ clean & invalidate by set/way
subs r9, r9, #1 @ decrement the way
bge loop3
subs r7, r7, #1 @ decrement the index
bge loop2
- mov r9, r4
- r9(loop3용 way 카운터): r4(현재 캐시 레벨의 way 값-1)를 사용하여 0까지 루프를 돈다.
- for (r9 = r4; r9 >= 0; r9–)
- rpi2:
- L1 d-cache: 3, 2, 1, 0까지 루프 수행(-1이면 루프3 탈출)
- L2 d-cache: 7, 6, …, 0까지 루프 수행(-1이면 루프3 탈출)
- r9(loop3용 way 카운터): r4(현재 캐시 레벨의 way 값-1)를 사용하여 0까지 루프를 돈다.
- orr r11, r10, r9, lsl r5
- r11: DCCISW 캐시 삭제 명령을 수행하기 위해 필요한 r9(Way) 및 r10(캐시 레벨값)을 저장.
- orr r11, r11, r7, lsl r2
- r11: DCCISW 캐시 삭제 명령을 수행하기 위해 필요한 r7(Set)값을 저장.
- mcr p15, 0, r11, c7, c14, 2
- DCCISW(Data Cache Clean & Invalidate by Set/Way)를 사용하여 캐시 한 라인을 삭제
- subs r9, r9, #1
- way 카운터를 1 감소
- bge loop3
- r9 값이 0보다 같거나 크면 loop3로 다시 반복
- subs r7, r7, #1
- NumSets 카운터를 1 감수
- bge loop2
- r7 값이 0보다 같거나 크면 loop2로 다시 반복
skip:
add r10, r10, #2 @ increment cache number
cmp r3, r10
bgt loop1
finished:
ldmfd sp!, {r0-r7, r9-r11}
mov r10, #0 @ swith back to cache level 0
mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr
- add r10, r10, #2
- r10(캐시 레벨 카운터)을 2 증가 시킨다.
- cmp r3, r10
- r3(Loc x 2)와 r10(캐시 레벨 카운터)를 비교
- bgt loop1
- r3(Loc x 2)가 r10(캐시레벨 카운터)보다 큰 경우 loop1으로 다시 반복
- rpi2: LoC=L2 이므로 L1에서 Loc(L2) 캐시 레벨까지 수행한다. (두 번의 루프가 수행)
- ldmfd sp!, {r0-r7, r9-r11}
- 백업해두었던 레지스터들을 복원한다.
- mov r10, #0
- 동작할 캐시 레벨을 다시 L1(0) 처음으로 돌리려한다.
- mcr p15, 2, r10, c0, c0, 0
- CSSELR 레지스터로 동작할 캐시 레벨을 지정한다.
iflush:
i-cache는 한 번에 flush 한다.
iflush:
mcr p15, 0, r10, c7, c10, 4 @ DSB
mcr p15, 0, r10, c7, c5, 0 @ invalidate I+BTB
mcr p15, 0, r10, c7, c10, 4 @ DSB
mcr p15, 0, r10, c7, c5, 4 @ ISB
mov pc, lr
- mcr p15, 0, r10, c7, c10, 4
- DSB (Data Synchronization Barrier operation)를 사용하여 이미 동작중인 모든 캐시 조작 명령이 완료될 때 까지 기다린다.
- mcr p15, 0, r10, c7, c5, 0
- ICIALLU(Instruction Cache Invalidate ALL for LoU)를 사용하여 i-cache를 모두 비운다.
- mcr p15, 0, r10, c7, c10, 4
- DSB
- mcr p15, 0, r10, c7, c5, 4
- ISB(Instruction Synchronization Barrier operation)를 사용하여 명령 파이프 라인을 비운다.
- mov pc, lr
- 호출한 곳으로 리턴한다.
참고
- start: | 문c
- 영역 검사를 하여 하단부가 중복된 경우만 캐시 on 보류 | 문c
- cache_on: | 문c
- cache_clean_flush: – (현재 글)
- 영역 검사를 하여 하단부가 중복된 경우만 캐시 on 보류 | 문c
- restart: | 문c
- wont_overwrite: | 문c
- ARM 시스템 주요 레지스터 | 문c
- Barriers of ARMv7 | 문c
- Cache – Branch Predictors | 문c
- Cache – Coherent | 문c
- Cache – LoC vs LoU | 문c
- Cache – PoC vs PoU | 문c