ARMv7에서의 cache on
cache 기능을 사용하기 위해서는 MMU 장치를 동작시켜야 하는데 이 MMU 사용을 위해 1차 페이지 테이블(pgd)을 임시로 구성하여 사용한다.
- 페이지 테이블은 arch/arm/boot/decompress/head.S에서 압축된 커널의 relocation 또는 decompression 등에서만 사용한다.
- 가상주소와 물리주소가 서로 동등한 주소로 1:1 매핑을 하는 것이 특징이다.
- 구성되는 엔트리들은 1M 바이트 크기의 페이지 테이블을 갖는 섹션 엔트리로 만들어지며 다.
- DRAM 영역 뿐만 아니라 ROM에서 동작하는 경우 2M 페이지 즉 2개의 섹션 엔트리도 추가 배정한다.
- 아래 순서도는 cache_on을 통해 페이지 테이블을 구성하고 MMU를 켜는 전체 흐름을 나타낸다.
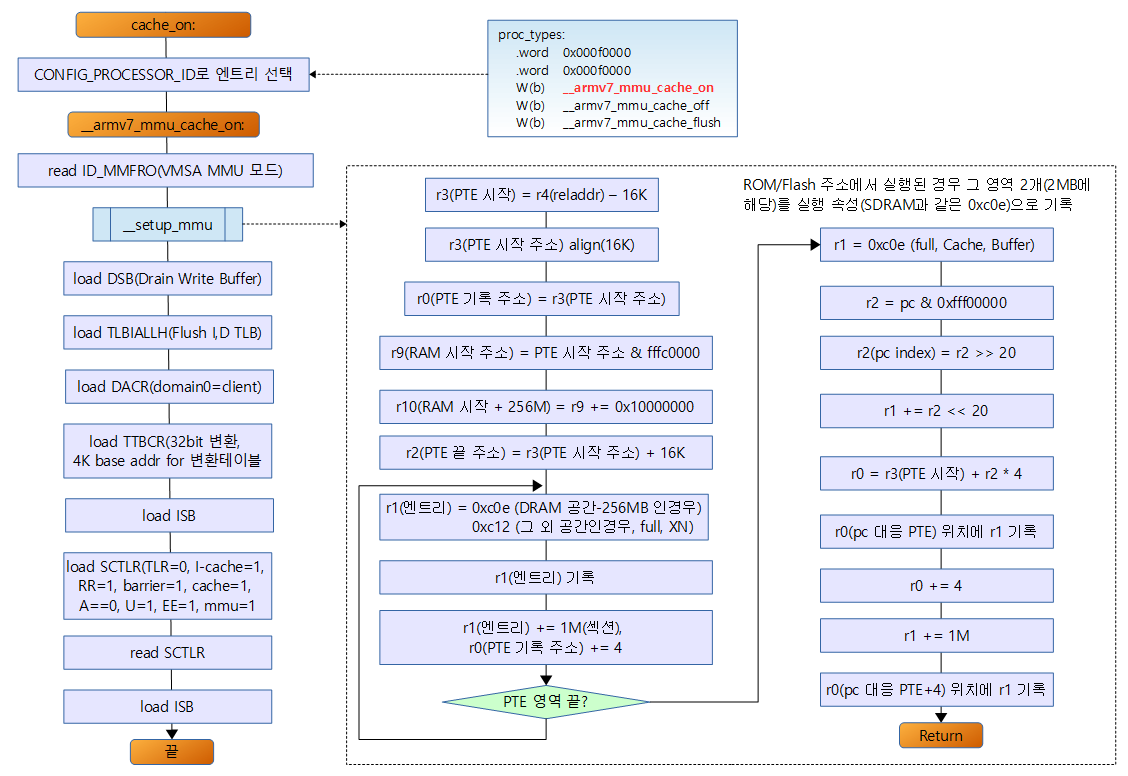
cache_on:
/*
* Turn on the cache. We need to setup some page tables so that we
* can have both the I and D caches on.
*
* We place the page tables 16k down from the kernel execution address,
* and we hope that nothing else is using it. If we're using it, we
* will go pop!
*
* On entry,
* r4 = kernel execution address
* r7 = architecture number
* r8 = atags pointer
* On exit,
* r0, r1, r2, r3, r9, r10, r12 corrupted
* This routine must preserve:
* r4, r7, r8
*/
.align 5
cache_on: mov r3, #8 @ cache_on function
b call_cache_fn
- align 5
- 32byte align
- r3 <- #8번을 넣은 이유는 객체의 멤버가 8byte에 있는 곳을 가리킨다.
- 그 객체의 8바이트 위치에는 해당 아키텍처의 cache_on 함수의 포인터가 담겨 있다.
- b call_cache_fn
- 위 루틴을 통해 __armv7_mmu_cache_on: 주소를 찾아서 점프한다.
call_cache_fn:
/*
* Here follow the relocatable cache support functions for the
* various processors. This is a generic hook for locating an
* entry and jumping to an instruction at the specified offset
* from the start of the block. Please note this is all position
* independent code.
*
* r1 = corrupted
* r2 = corrupted
* r3 = block offset
* r9 = corrupted
* r12 = corrupted
*/
call_cache_fn: adr r12, proc_types
#ifdef CONFIG_CPU_CP15
mrc p15, 0, r9, c0, c0 @ get processor ID
#else
ldr r9, =CONFIG_PROCESSOR_ID
#endif
1: ldr r1, [r12, #0] @ get value
ldr r2, [r12, #4] @ get mask
eor r1, r1, r9 @ (real ^ match)
tst r1, r2 @ & mask
ARM( addeq pc, r12, r3 ) @ call cache function
THUMB( addeq r12, r3 )
THUMB( moveq pc, r12 ) @ call cache function
add r12, r12, #PROC_ENTRY_SIZE
b 1b
- r3에 offset을 주고 이 레이블로 점프하면 동작하고 있는 CPU 아키텍처를 찾아 해당 캐시 함수를 호출하게된다.
- adr r12, proc_types
- proc_types 객체의 주소를 알아온다.
- CONFIG_CPU_CP15
- CPU가 CP15 레지스터를 가지고 있을 경우 설정되는 옵션으로 ARM Cortex A 시리즈들은 CP15 레지스터를 가지고 있다.
- r3에 #8-cache_on, #12-cache_off, #16-cache_flush가 들어갈 수 있다.
- rpi2:
- #8: __armv7_mmu_cache_on:
- #12: __armv7_mmu_cache_on:
- #16: __armv7_mmu_cache_flush:
- rpi2:
- r12: proc_types 레이블의 주소를 알아온다. (proc_type별 데이터가 담긴 객체)
- r9: MIDR 값을 가져온다.
- r1: architecture code
- r2: architecture mask
proc_types:
/*
* Table for cache operations. This is basically:
* - CPU ID match
* - CPU ID mask
* - 'cache on' method instruction
* - 'cache off' method instruction
* - 'cache flush' method instruction
*
* We match an entry using: ((real_id ^ match) & mask) == 0
*
* Writethrough caches generally only need 'on' and 'off'
* methods. Writeback caches _must_ have the flush method
* defined.
*/
.align 2
.type proc_types,#object
proc_types:
(다른 ARM 아키텍처들은 생략하고 아래는 ARMv7 아키텍처)
.word 0x000f0000 @ new CPU Id
.word 0x000f0000
W(b) __armv7_mmu_cache_on
W(b) __armv7_mmu_cache_off
W(b) __armv7_mmu_cache_flush
.word 0 @ unrecognised type
.word 0
mov pc, lr
THUMB( nop )
mov pc, lr
THUMB( nop )
mov pc, lr
THUMB( nop )
.size proc_types, . - proc_types
/*
* If you get a "non-constant expression in ".if" statement"
* error from the assembler on this line, check that you have
* not accidentally written a "b" instruction where you should
* have written W(b).
*/
.if (. - proc_types) % PROC_ENTRY_SIZE != 0
.error "The size of one or more proc_types entries is wrong."
.endif
__armv7_mmu_cache_on:
__armv7_mmu_cache_on:
mov r12, lr
#ifdef CONFIG_MMU
mrc p15, 0, r11, c0, c1, 4 @ read ID_MMFR0
tst r11, #0xf @ VMSA
movne r6, #CB_BITS | 0x02 @ !XN
blne __setup_mmu
mov r0, #0
mcr p15, 0, r0, c7, c10, 4 @ drain write buffer
tst r11, #0xf @ vmsa
mcrne p15, 0, r0, c8, c7, 0 @ flush I,D TLBs
#endif
- ARMv7에서 사용하는 캐시 on 루틴이다.
- mrc p15, 0, r11, c0, c1, 4
- ID_MMFR0.vmsa를 읽어온다.
- MMU가 있는지 확인해서 있는경우 mmu를 동작시키기 위함
- movne r6, #CB_BITS | 0x02
- r6=페이지 속성
- rpi2 SoC는 Write-Back 캐시 기능이 지원된다.
- rpi2: 0xE(!XN(0) | C | B | SECTION)
- blne __setup_mmu
- MMU를 사용하기 전에 먼저 임시로 사용할 1차 페이지 테이블을 준비한다.
- mov r0, #0
- blne __setup_mmu의 수행 이후에 mcr 명령이 동작하게 하기 위해 r0에 0을 넣은 후 이를 다음 명령에서 사용하게 되면 CPU가 out-of-order execution으로 동작한다 하더라도 레지스터 dependency인해 수행 순서가 바뀌지 않게 하는 효과가 있다. (in-order execution)
- mcr p15, 0, r0, c7, c10, 4
- DSB (Data Syncronization Barrior operation)
- 참고: Barriers of ARMv7 | 문c
- mcrne p15, 0, r0, c8, c7, 0
- TLBIALL (unified TLB Invalidate All)
mrc p15, 0, r0, c1, c0, 0 @ read control reg
bic r0, r0, #1 << 28 @ clear SCTLR.TRE
orr r0, r0, #0x5000 @ I-cache enable, RR cache replacement
orr r0, r0, #0x003c @ write buffer
bic r0, r0, #2 @ A (no unaligned access fault)
orr r0, r0, #1 << 22 @ U (v6 unaligned access model)
@ (needed for ARM1176)
- mrc p15, 0, r0, c1, c0, 0
- read SCTLR
- RAO: Read As One
- SBOP: Should Be One Preserved
- RAO/SBOP <- 앞쪽은 read 뒤쪽이 write option
- SCTLR 레지스터를 읽은 후 몇 가지 비트들을 조작해놓는다.
- 마지막 루틴에서 SCTLR에 저장할 계획
- I-Cache를 사용하는 것으로 설정, cache replacement 방법은 Round Robin 사용
- Write buffer 사용
- A: unaligned access fault를 지원하기 위한 mask
- U: unaligned access 를 지원하려면 1. (armv7에서는 항상 1)
#ifdef CONFIG_MMU
ARM_BE8( orr r0, r0, #1 << 25 ) @ big-endian page tables
mrcne p15, 0, r6, c2, c0, 2 @ read ttb control reg
orrne r0, r0, #1 @ MMU enabled
movne r1, #0xfffffffd @ domain 0 = client
bic r6, r6, #1 << 31 @ 32-bit translation system
bic r6, r6, #3 << 0 @ use only ttbr0
mcrne p15, 0, r3, c2, c0, 0 @ load page table pointer
mcrne p15, 0, r1, c3, c0, 0 @ load domain access control
mcrne p15, 0, r6, c2, c0, 2 @ load ttb control
#endif
mcr p15, 0, r0, c7, c5, 4 @ ISB
mcr p15, 0, r0, c1, c0, 0 @ load control register
mrc p15, 0, r0, c1, c0, 0 @ and read it back
mov r0, #0
mcr p15, 0, r0, c7, c5, 4 @ ISB
mov pc, r12
- VMSA(MMU)를 지원하지 않는 경우 뒤 조건 명령 3개는 동작하지 않음.
- mrcne p15, 0, r6, c2, c0, 2
- TTBCR(Transalation Table Base Control Register)를 읽는다.
- MMU 비트를 enable
- DOMAIN0만 client(0b01)로 설정, 나머지 DOMAIN1~DOMAIN15까지는 manager(0b00)으로 설정
- TTBCR.N을 0으로 설정하여 16K 페이지 테이블을 사용
- TTBCR.PXN을 0으로 설정하여 32bit 페이지 변환을 사용
- r3(start page table) -> TTBR0
- r1(domain…) -> DACR
- r6(32bit, N) -> TTBCR
- r0(시스템 관련 비트들) -> SCTLR
- 여기서 MMU를 켬. (캐시 기능 on)
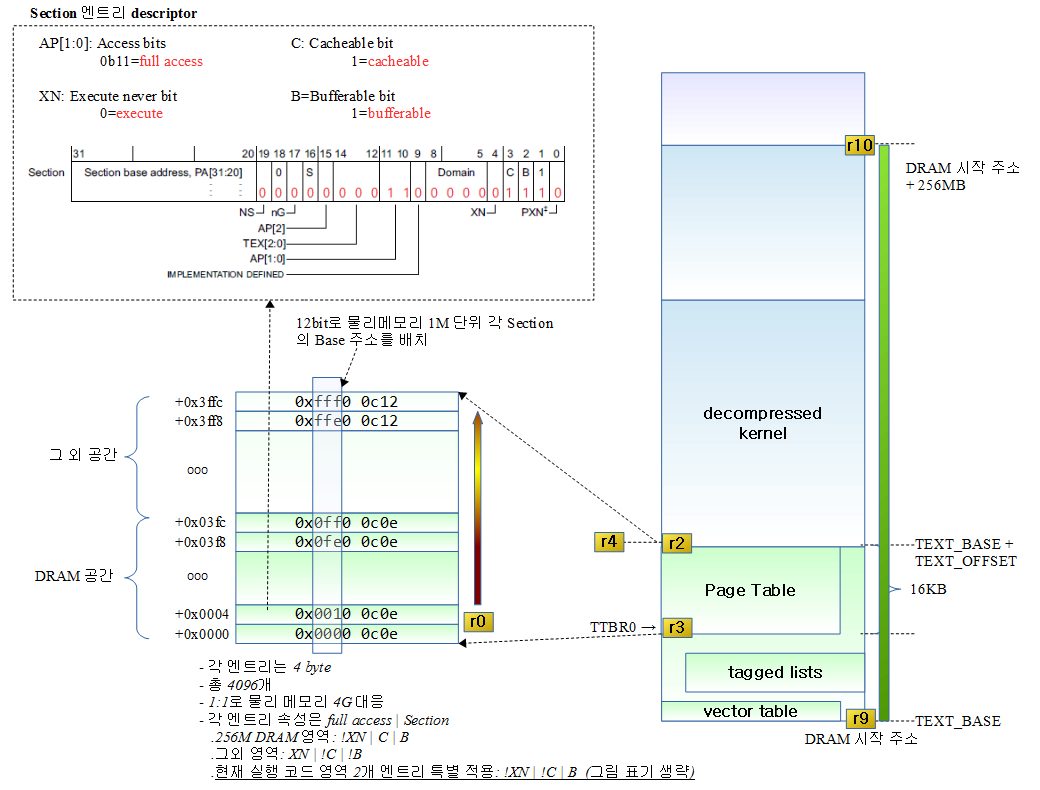
Page Table 영역 초기화
매핑 영역 및 규칙
- 전체 4G 공간을 1:1로 가상주소와 물리주소가 동일하게 매핑
- 각 엔트리에 대한 메모리 속성 부여
- DRAM 256M 영역에 read/write, !XN, Cache-able, Buffer-able, Section
- ROM에서 커널이 동작하는 경우를 위해 현재 실행되는 코드 영역에 대응하는 2개 엔트리에 read/write, !XN, !Cache-able, Buffer-able, Section
- 전체 ROM 영역이 아니라 현재 코드가 동작하는 ROM 2M 영역만 특별히 !XN을 두는 이유는 당연히 지금 코드가 동작하는 piggy(relocation 코드와 압축해제 코드가 담긴 영역) 영역이 수K~수십K 정도로 아주 작기 때문에 현재 코드가 동작하는 곳만 !XN으로 설정하여 실행 영역으로 변경한다. 추가로 1개의 섹션을 더 매핑을 하는 이유는 코드가 동작하면서 섹션 경계를 넘어갈 수 있으므로 그 위로 하나 더 섹션을 사용하는 것으로 만들면 충분하다. (2 개의 섹션)
- Cache-able을 사용하지 않는 이유는 이 2개의 엔트리에 대응하는 현재 실행 영역이 ROM인지 RAM인지 특별히 구분하지 않게 하기 위해 ROM 속성을 위주로 설정한다. 참고로 ROM에서는 캐시를 사용하지 못하고 버퍼만 사용가능하다.
- 그외 영역에는 read/write, XN, !Cache-able, !Buffer-able, Section을 설정하여 실행되지 않는 섹션 매핑 속성으로 둔다.
__setup_mmu:
16KB의 페이지 테이블을 초기화하는데 이 영역은 relocation 및 decompressed 루틴에서 잠시 이용하므로 물리메모리 변환을 1단계로만 만들며 페이지를 1M 단위로 4G 전체 메모리에 대응하는 섹션 엔트리(총 4096개)로 구성한다.
__setup_mmu: sub r3, r4, #16384 @ Page directory size
bic r3, r3, #0xff @ Align the pointer
bic r3, r3, #0x3f00
/*
* Initialise the page tables, turning on the cacheable and bufferable
* bits for the RAM area only.
*/
mov r0, r3
mov r9, r0, lsr #18
mov r9, r9, lsl #18 @ start of RAM
add r10, r9, #0x10000000 @ a reasonable RAM size
mov r1, #0x12 @ XN|U + section mapping
orr r1, r1, #3 << 10 @ AP=11
add r2, r3, #16384
- r3=decompressed kernel-16K 부터 page direcotry의 시작
- r3의 align을 16K단위로 맞춘다. (14 bits)
- 인스트럭션을 구성하는 immediate의 길이가 제한되어 있어 2번에 나누어 처리
- bic r3, r3, #3fff 를 하려는 목적
- mov r0, r3
- r0=r3(페이지 디렉토리 시작) 부터 시작하는 카운터로 초기화할 엔트리를 가리키며 페이지 디렉토리의 끝을 만날때까지 4바이트 단위로 증가시킨다.
- r9=DRAM 시작 주소(align 256KB:18비트 쉬프트)
- r10=resonable DRAM(256M) 영역의 끝(r9 + 256M)
- r1=엔트리 값으로 처음에 XN | Section | AP=full access로 시작한다.
- 0xc12
- r2=페이지 디렉토리의 끝(시작 + 16KB)
- U: Uncache로 추정(0)
- AP(11): full access – read/write
1: cmp r1, r9 @ if virt > start of RAM
cmphs r10, r1 @ && end of RAM > virt
bic r1, r1, #0x1c @ clear XN|U + C + B
orrlo r1, r1, #0x10 @ Set XN|U for non-RAM
orrhs r1, r1, r6 @ set RAM section settings
str r1, [r0], #4 @ 1:1 mapping
add r1, r1, #1048576
teq r0, r2
bne 1b
- 엔트리가 RAM 영역에 대응하면 r1 += full access | C | B | !XN | Section으로 그 외 영역인 경우 r1 += full access | XN | Section으로 기록
- r1을 1M씩 증가시킨 후 page directory의 끝을 만날때까지 반복한다.
- 256M 영역내: 0xc0e, 영역외: 0xc12
/*
* If ever we are running from Flash, then we surely want the cache
* to be enabled also for our execution instance... We map 2MB of it
* so there is no map overlap problem for up to 1 MB compressed kernel.
* If the execution is in RAM then we would only be duplicating the above.
*/
orr r1, r6, #0x04 @ ensure B is set for this
orr r1, r1, #3 << 10
mov r2, pc
mov r2, r2, lsr #20
orr r1, r1, r2, lsl #20
add r0, r3, r2, lsl #2
str r1, [r0], #4
add r1, r1, #1048576
str r1, [r0]
mov pc, lr
ENDPROC(__setup_mmu)
- r1 값은 0xc0e (full access | C | B | section)
- ROM에서 시작한 경우 플래쉬에 대응하는 페이지 테이블을 !XN | B를 하여 2칸(2MB) 기록한다. DRAM에서 시작한 경우에는 그냥 2번 겹쳐 기록 하게 되는데 겹쳐 기록해도 무방하므로 상관없다.
- 현재 실행되고 있는 위치의 하위 20비트를 제거하면 페이지테이블의 index가 된다. 이를 r1(short descriptor page table entry)에 추가
- r0(현위치에 대응하는 PTE) = r3(page directory 시작) + index(r2 * 4)
- 1M를 증가시켜 한 번 더한다. (총 2M까지면 충분하다고 판단)
참고
- start: | 문c
- 영역 검사를 하여 하단부가 중복된 경우만 캐시 on 보류 | 문c
- cache_on: | 문c
- cache_clean_flush: | 문c
- 영역 검사를 하여 하단부가 중복된 경우만 캐시 on 보류 | 문c
- restart: | 문c
- wont_overwrite: | 문c
- 2-level 페이지 테이블(PT) | 문c
- 2-level 페이지 테이블 엔트리(PTE) 속성 | 문c
- ARM 시스템 주요 레지스터 | 문c
- Barriers of ARMv7 | 문c
- Cache – Branch Predictors | 문c
- Cache – Coherent | 문c
- Cache – LoC vs LoU | 문c
- Cache – PoC vs PoU | 문c
- Cache – Write Allocate vs no Write Allocate | 문c
- Cache – 구성 타입 | 문c