<kernel v5.10>
Fixmap 주요 용도
고정 매핑 영역(이하 fixmap 영역)은 컴파일 타임에 가상 주소가 결정(fix)되는 공간이다. 따라서 주로 다이나믹 매핑 서브 시스템(vmap 등)이 활성화되기 전에 매핑이 필요할 때 fixmap을 사용한다. 예를 들어, 콘솔 디바이스를 정식 초기화하기 전에 우선 사용하기 위해 이 공간에 임시 매핑한다. 런타임 시에도 커널 코드를 변경하거나 페이지 테이블의 갱신이 필요할 때 등의 용도로 사용한다.
fixmap은 용도별로 여러 블록으로 나뉜다. 가상 주소는 컴파일 타임에 결정되고, 물리 주소는 fixmap용 API를 사용하여 런타임 시에(부팅 타임 포함) 매핑하여 사용한다. 가상 주소 매핑(vmap)이 활성화되기 전에 소규모의 특정 자원들이 이러한 고정 매핑 주소 공간을 사용한다.
아키텍처 및 커널 버전에 따라 용도가 조금씩 다르지만 주로 사용하는 용도는 다음과 같다. 그 외의 용도는 Fixmap 슬롯 분류에서 추가 설명한다.
1) io 디바이스 early 매핑
- ioremap() 함수를 사용할 수 없는 이른 부트업 타임에 디바이스를 매핑할 수 있도록 아래와 같이 두 가지 방법으로 지원한다.
- 컴파일 타임에 static하게 설정한 디바이스를 고정 매핑 시 사용한다. (early console 등)
- 정규 디바이스 매핑(ioremap)을 사용할 수 없는 부트업 초반 러닝 타임에 early_ioremap() 함수를 통해 디바이스를 fixmap 가상 주소 영역에 임시로 매핑하여 사용할 수 있다.
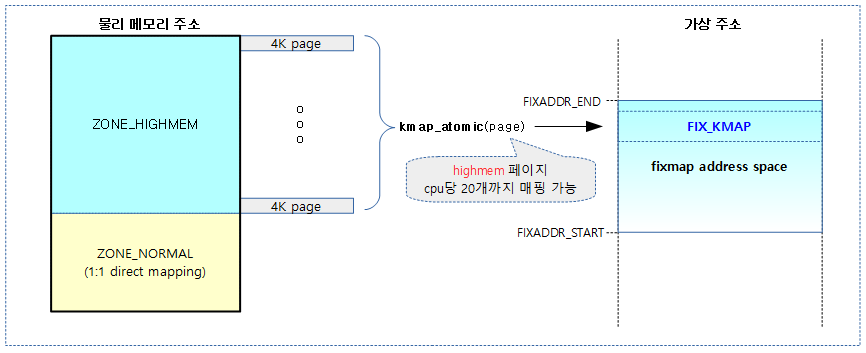
2) highmem 물리 메모리의 커널 매핑
- ARM32 커널의 경우 물리 영역의 highmem 페이지를 cpu id 별로 할당된 fixmap 가상 주소 영역에 매핑하여 사용한다.
- stack based kmap_atomic
- 초기 매핑할 수 있는 index slot은 기존에는 cpu id와 사용 타입에 따라 고정되었는데 현재는 cpu id에 KM_TYPE_NR(ARM=20) 수 만큼 스택과 같은 방법으로 push/pop을 이용하여 운영된다.
- 즉 cpu 마다 20개의 매핑 슬롯이 배정된다.
- 참고: mm: stack based kmap_atomic()
- kmap_atomic() 함수를 사용하여 highmem 페이지를 현재 cpu에 해당하는 fixmap 영역을 사용하여 매핑을 한다. 이미 kmap 영역에 매핑이 된 경우 해당 가상 주소를 리턴한다.
- ZONE_HIGHMEM은 커널에서 몇 가지 매핑 방법을 사용하여 항상 매핑과 언매핑을 반복 사용하며 사용하기 때문에 access 속도가 매핑을 위한 overhead가 발생하여 항상 pre 매핑된 ZONE_NORMAL에 비해 느린 성능을 보여준다. 물론 kernel과 다르게 user level 에서는 각 task 마다 매우 방대한 user address space(설정에 따라 1G, 2G 또는 3G)의 공간에 매핑하여 사용한다.
- 64비트 시스템은 가상 주소 공간이 무척 크므로 시스템 내의 모든 물리 메모리를 모두 매핑할 수 있다. 따라서 이러한 경우에는 highmem을 운용할 필요가 없다.
3) 커널 코드 변경
- Read only 설정된 커널 코드를 변경할 때 fixmap 가상 주소 영역을 임시로 사용한다.
다른 매핑 방법과 간단한 비교
- vmap
- 장시간 여러 페이지를 매핑하여 사용할 수 있고 꽤 큰 vmalloc address space에 매핑을 한다.
- ARM32
- ARM64
- CONFIG_VM_BITS 크기 마다 다르며 VM 공간의 절반에서 일부 vmemmap, pci io, fixmap, kimage, module image 영역등을 제외한 공간으로 거의 VM 공간의 절반이라고 생가하면 된다.
- 예를 들어 CONFIG_VM_BITS=39를 사용하는 경우 VM 크기는 512G이다. 이 중 vmalloc 공간은 약 246G 정도된다.
- kmap
- kmap address space에 일정 시간 동안 매핑을 하여 사용한다. 매핑이 완료되면 스케쥴되어 다른 태스크로 바뀌더라도 매핑을 유지한다.
- fixmap
- highmem 페이지에 대해 아주 극히 짧은 시간 매핑하여 사용할 수 있고 fixmap address space에 매핑을 한다. sleep 되지 않아 interrupt context에서 사용될 수 있다.
- 스케쥴되어 다른 태스크로 바뀌기 전에 unmap 되어야 한다.
- 다른 io 영역 등을 부트업 타임에 고정매핑하여 사용한다.
- ARM32
- ARM64
- 커널 버전과 커널 옵션마다 다르지만 현재 약 6M 공간
Fixmap 가상 주소 영역
- fixmap 가상 주소 영역은 아키텍처마다 위치가 다르고 크기도 다르다.
- ARM32
- 현재 3M의 가상 주소 공간을 사용하여 768개의 페이지에 높은 주소부터 아래로 인덱스 슬롯(0 ~ 767)을 붙여 사용한다.
- FIXADDR_START(0xffc0_0000) ~ FIXADDR_END(0xfff0_0000) 까지 3M 영역을 사용한다.
- FIXADDR_TOP 영역은 FIXADDR_END – PAGE_SIZE(4K ) 이다.
- 인덱스 지정은 FIXADDR_TOP(0xffef_f000)이 0번 인덱스로 아래 방향으로 인덱스 번호가 증가된다.
- 인덱스 번호는 0부터 최대 0x2ff (767)을 지정할 수 있다.
- ARM64
- 약 6M의 가상 주소 공간을 사용하고 높은 주소부터 아래로 인덱스 슬롯을 붙여 사용한다.
커널 버전별 커널 주소 공간 Layout
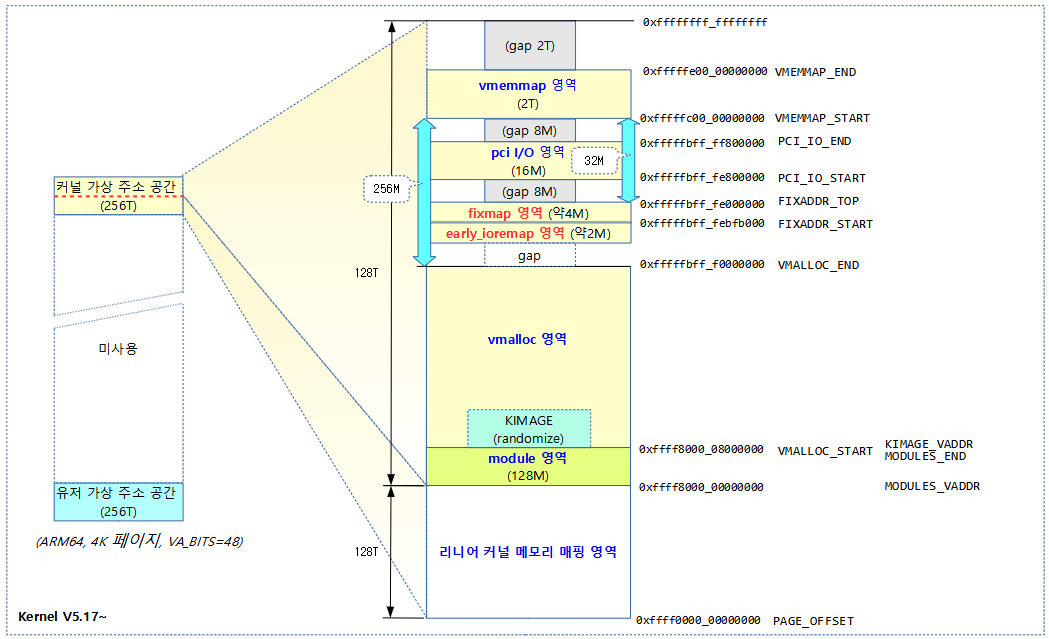
다음 그림은 커널 v5.17~ 커널 주소 공간 layout을 보여준다. (VA_BITS=48)
- 128M로 제한되었던 bpf 영역의 제한이 풀리면서 vmalloc 공간을 사용할 수 있게 되었다.
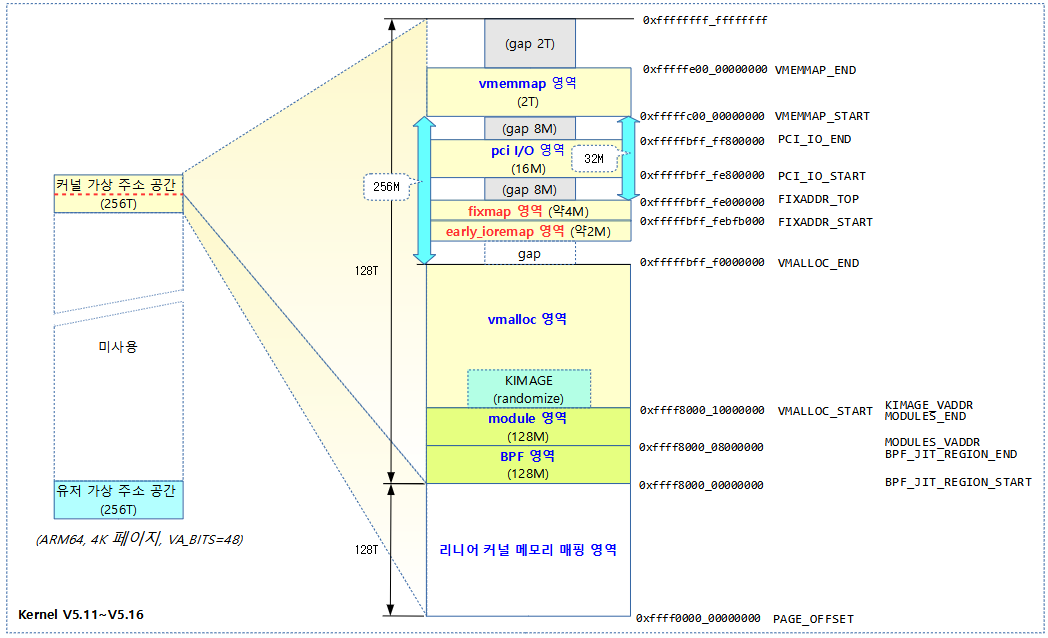
다음 그림은 커널 v5.11~ 커널 주소 공간 layout을 보여준다. (VA_BITS=48)
- vmemmap, pci, fixmap 영역이 일부 조정되었다.
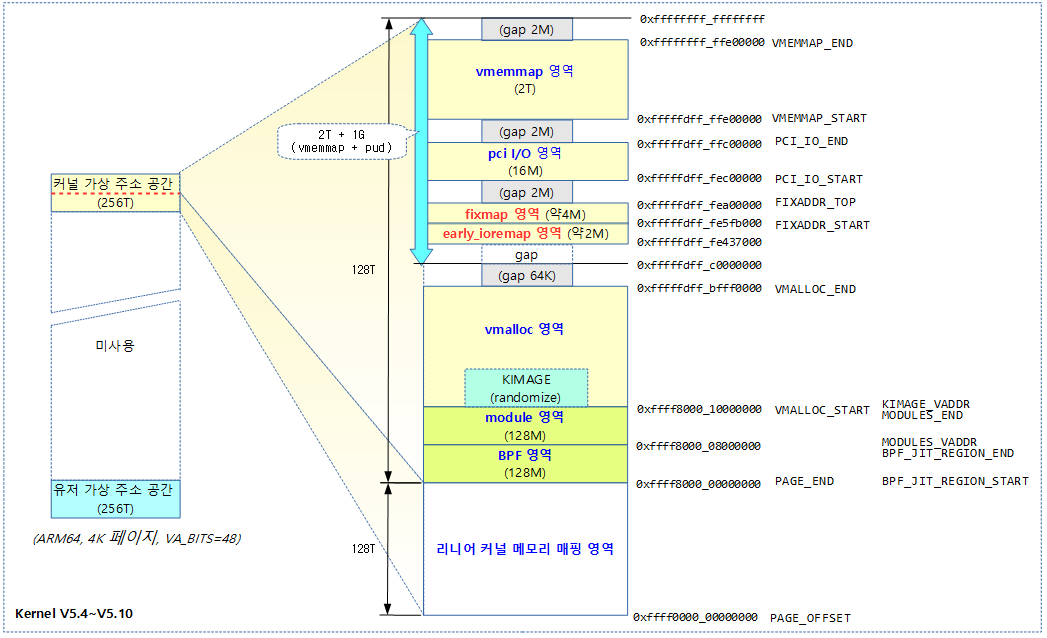
다음 그림은 커널 v5.4 부터 v5.10 까지의 커널 주소 공간 layout을 보여준다. (VA_BITS=48)
- 커널 v5.4부터 커널 영역의 절반이 flip된 것을 확인할 수 있다. VA_START 대신 PAGE_END로 이름을 변경하였다.
- 커널 v5.4부터 부트 타임에 KASAN의 shadow 사이즈를 변경할 수 있도록 1:1 매핑 영역을 아래로 내렸다.
- 32T 크기의 KASAN 영역은 생략하였으나 이 옵션을 사용하는 경우 bpf, module 및 vmalloc 시작이 그 만큼 위로 올라간다. (vmalloc의 끝은 동일하다)
- 커널 옵션에 따라 fixmap의 위치가 페이지 단위로 다를 수 있다.
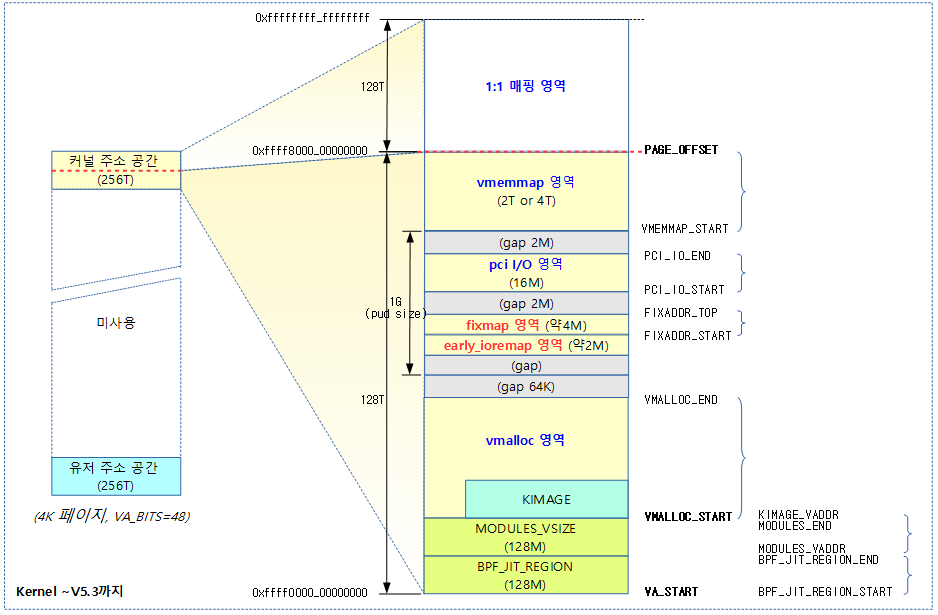
다음 그림은 커널 ~v5.3까지의 커널 주소 공간 layout을 보여준다. (VA_BITS=48)
- vmemmap 공간은 컴파일 옵션에 따라 달라지는 page 디스크립터(struct page) 사이즈에 따라 크기가 달라진다
- 64 바이트 이하인 경우 2T 영역을 사용한다.
- 64 바이트를 초과하는 경우 4T 영역을 사용한다.
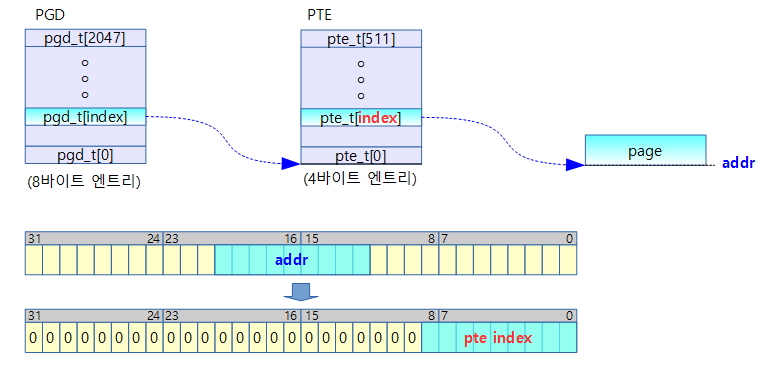
Fixmap 인덱스 슬롯
- fixmap 인덱스 슬롯 번호에 따라 가상 주소가 고정되어 있다.
- 예) ARM32
- index=0 -> vaddr=0xffef_f000 (FIXADDR_TOP)
- index=1 -> vaddr=0xffef_e000
- …
- index=767 -> vaddr=0xffc0_0000 (FIXADDR_START)
특정 페이지 매핑 예)
물리 주소 0x4000_0000로 시작하는 1 페이지를 fixmap 1번 슬롯 인덱스에 매핑한다.
- set_fixmap(1, 0x4000_0000)
Fixmap 슬롯 분류
Fixmap은 아키텍처 및 커널 버전에 따라 여러 가지 용도로 슬롯을 나누어 제공된다.
- HOLE
- ARM32의 경우 사용하지 않는다.
- ARM64의 경우 디버깅 목적으로 1 개의 슬롯이 제공되며, 예비 엔트리 페이지로 현재 사용하지 않는다.
- 커널 v3.19-rc1에서 추가되었다.
- FDT
- ARM32의 경우 사용하지 않는다.
- ARM64의 경우 4M의 디바이스 트리(FDT)를 커버하는 슬롯을 제공한다.
- FDT는 최대 2M이지만 2M 단위의 align을 사용하기 때문에 최대 4M의 영역이 필요하다.
- 커널 v4.2-rc1에서 추가되었다.
- EARLYCON
- 시리얼 디바이스를 콘솔로 사용할 목적으로 정규 매핑하기 전 입출력을 위해 1개의 인덱스 슬롯을 사용한다. (early console)
- 이 영역은 2015년 8월 kernel v4.3-rc1에 추가되었다.
- KMAP
- 32비트 시스템에서만 사용되는 highmem 물리 메모리 영역을 매핑할 때 사용되는 공간으로 cpu 수(NR_CPUS)에 따라 사용되는 인덱스 슬롯이 다르다.
- Fixmap이 처음 소개되었을 때 사용하였다.
- ARM32의 경우 cpu 수에 따라 20개씩 인덱스 슬롯이 주어진다.
- x86_32의 경우 cpu 수에 따라 41개씩 인덱스 슬롯이 주어진다.
- TEXT_POKE
- 커널 코드, kprobes, static key 등을 사용 시 read only 커널 코드가 변경되는데 이러한 코드를 이곳 한 두개의 슬롯을 사용하여 잠시 매핑 후 변경한다.
- ARM32의 경우 2개의 슬롯을 사용한다.
- ARM64의 경우 1개의 슬롯을 사용한다.
- APEI_GHES
- 현재 ARM64 및 X86_64에서 GHES 드라이버를 사용하는 경우 2 개의 슬롯이 주어진다.
- GHES 드라이버가 ioremap_page_range() 함수가 sleep될 수 있으므로 irq context에서 사용할 목적으로 sleep 되지 않도록 fixmap을 이용하여 사용한다.
- 커널 v4.15-rc에서 추가되었다.
- 커널 v5.1에서 추가된내용이다.
- ENTRY_TRAMP
- 보안을 위해 유저 스페이스에서 커널 위치를 감추는 KASLR(Kernel Address Sanitizer Location Randomization) 기술이 채용되었다. 또한 유저 스페이스에서 커널 영역을 접근하지 못하도록 커널 페이지 테이블을 별도로 준비하여 운영되는 KPTI(Kernel Page Table Isolation, aka KAISER)를 위한 별도의 최상위 페이지 테이블(pgd)이 이 ENTRY_TRAMP 페이지에서 사용된다. 이러한 옵션을 사용하는 커널은 커널과 유저 전환 시마다 TLB 플러시를 해야 하므로 약 5%의 성능이 다운된다. 미래에 나올 cpu 들은 유저 스페이스에서 커널 스페이의 액세스를 완전히 분리하는 기술을 사용하여 이 옵션을 사용하지 않고도 성능을 저하시키지 않게 설계된다고 한다.
- 커널 v4.16-rc1에서 추가되었다.
- BTMAPS
- 정규 ioremap()을 사용할 수 없는 이른 부트업 타임에 early_ioremap()을 통해 디바이스들을 임시 매핑하여 사용하는 곳이다.
- 최대 7 번의 매핑을 할 수 있으며, 각각은 256K를 사용할 수 있다.
- 커널 v3.15-rc1에서 추가되었다.
- FIX_PTE, FIX_PMD, FIX_PUD, FIX_PGD
- 런타임에 커널 페이지 테이블을 생성 시 TLB에 문제 없이 적용할 목적으로 atomic하게 처리하기 위해 사용되며 각각 1개씩 총 4개의 인덱스 슬롯을 사용한다.
- 커널 페이지 테이블은 읽기 전용으로 변경하였고, 페이지 테이블 엔트리를 수정할 때마다 이 영역을 사용하여 엔트리를 수정한다.
- 커널 v.4.6-rc1에서 추가되었다.
fixed_address – ARM64
arch/arm64/include/asm/fixmap.h
/*
* Here we define all the compile-time 'special' virtual
* addresses. The point is to have a constant address at
* compile time, but to set the physical address only
* in the boot process.
*
* Each enum increment in these 'compile-time allocated'
* memory buffers is page-sized. Use set_fixmap(idx,phys)
* to associate physical memory with a fixmap index.
*/
enum fixed_addresses {
FIX_HOLE,
/*
* Reserve a virtual window for the FDT that is 2 MB larger than the
* maximum supported size, and put it at the top of the fixmap region.
* The additional space ensures that any FDT that does not exceed
* MAX_FDT_SIZE can be mapped regardless of whether it crosses any
* 2 MB alignment boundaries.
*
* Keep this at the top so it remains 2 MB aligned.
*/
#define FIX_FDT_SIZE (MAX_FDT_SIZE + SZ_2M)
FIX_FDT_END,
FIX_FDT = FIX_FDT_END + FIX_FDT_SIZE / PAGE_SIZE - 1,
FIX_EARLYCON_MEM_BASE,
FIX_TEXT_POKE0,
#ifdef CONFIG_ACPI_APEI_GHES
/* Used for GHES mapping from assorted contexts */
FIX_APEI_GHES_IRQ,
FIX_APEI_GHES_SEA,
#ifdef CONFIG_ARM_SDE_INTERFACE
FIX_APEI_GHES_SDEI_NORMAL,
FIX_APEI_GHES_SDEI_CRITICAL,
#endif
#endif /* CONFIG_ACPI_APEI_GHES */
#ifdef CONFIG_UNMAP_KERNEL_AT_EL0
FIX_ENTRY_TRAMP_DATA,
FIX_ENTRY_TRAMP_TEXT,
#define TRAMP_VALIAS (__fix_to_virt(FIX_ENTRY_TRAMP_TEXT))
#endif /* CONFIG_UNMAP_KERNEL_AT_EL0 */
__end_of_permanent_fixed_addresses,
/*
* Temporary boot-time mappings, used by early_ioremap(),
* before ioremap() is functional.
*/
#define NR_FIX_BTMAPS (SZ_256K / PAGE_SIZE)
#define FIX_BTMAPS_SLOTS 7
#define TOTAL_FIX_BTMAPS (NR_FIX_BTMAPS * FIX_BTMAPS_SLOTS)
FIX_BTMAP_END = __end_of_permanent_fixed_addresses,
FIX_BTMAP_BEGIN = FIX_BTMAP_END + TOTAL_FIX_BTMAPS - 1,
/*
* Used for kernel page table creation, so unmapped memory may be used
* for tables.
*/
FIX_PTE,
FIX_PMD,
FIX_PUD,
FIX_PGD,
__end_of_fixed_addresses
};
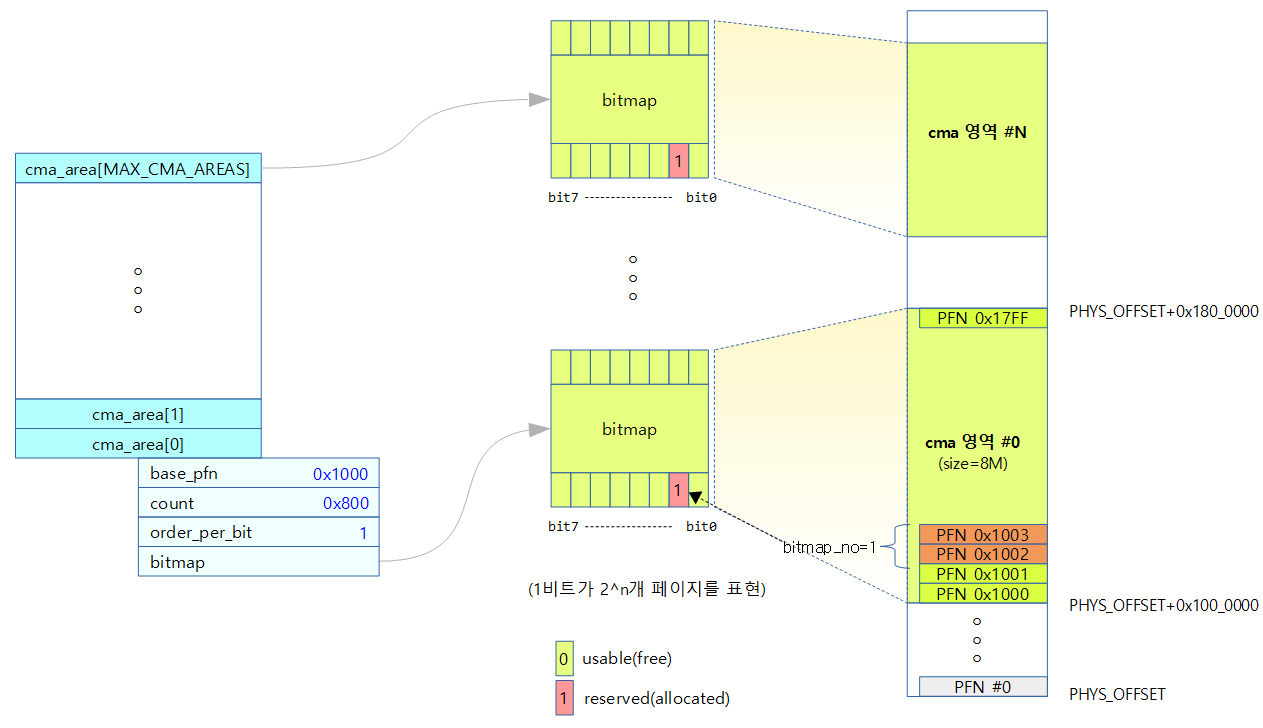
fixmap은 크게 두 영역으로 나뉘어 사용하고, 다음과 같은 특징을 가진다.
- __end_of_permanent_fixed_addresses
- 부팅 후 매핑을 해제하지 않는 영구 매핑 공간이다.
- __end_of_fixed_addresses
- fixmap의 마지막이며, __end_of_permanent_fixed_addresses 이후의 영역은 매핑과 언매핑이 가능한 공간이다.
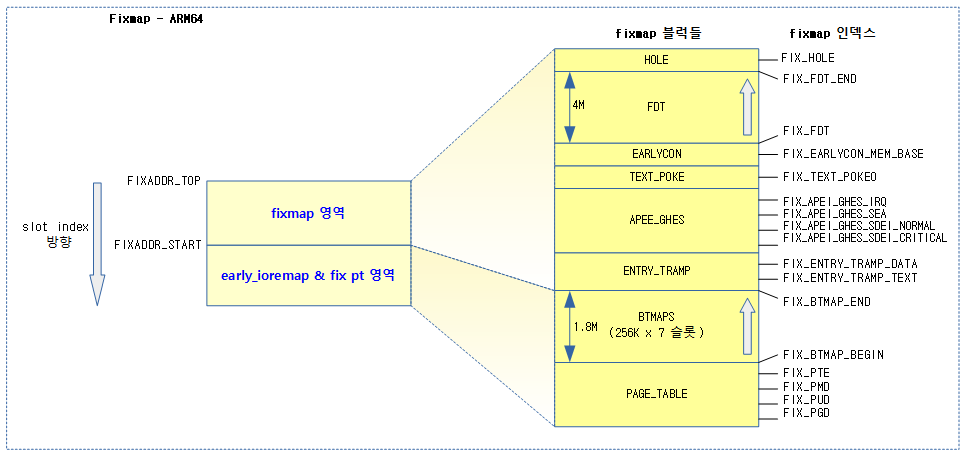
다음 그림은 ARM64 fixmap 블럭들을 보여준다.
fixed_address – ARM32
arch/arm/include/asm/fixmap.h
enum fixed_addresses {
FIX_EARLYCON_MEM_BASE,
__end_of_permanent_fixed_addresses,
FIX_KMAP_BEGIN = __end_of_permanent_fixed_addresses,
FIX_KMAP_END = FIX_KMAP_BEGIN + (KM_TYPE_NR * NR_CPUS) - 1,
/* Support writing RO kernel text via kprobes, jump labels, etc. */
FIX_TEXT_POKE0,
FIX_TEXT_POKE1,
__end_of_fixmap_region,
/*
* Share the kmap() region with early_ioremap(): this is guaranteed
* not to clash since early_ioremap() is only available before
* paging_init(), and kmap() only after.
*/
#define NR_FIX_BTMAPS 32
#define FIX_BTMAPS_SLOTS 7
#define TOTAL_FIX_BTMAPS (NR_FIX_BTMAPS * FIX_BTMAPS_SLOTS)
FIX_BTMAP_END = __end_of_permanent_fixed_addresses,
FIX_BTMAP_BEGIN = FIX_BTMAP_END + TOTAL_FIX_BTMAPS - 1,
__end_of_early_ioremap_region
};
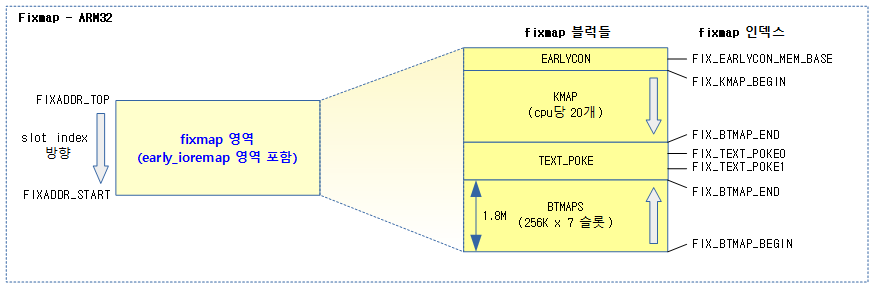
다음 그림은 ARM32 fixmap 블럭들을 보여준다.
초기화
early_fixmap_init() – ARM64
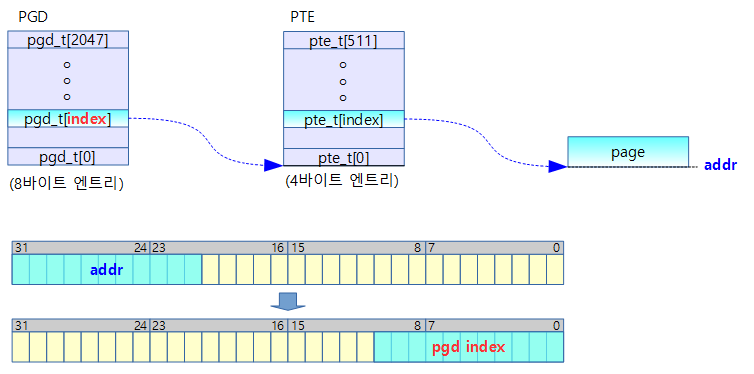
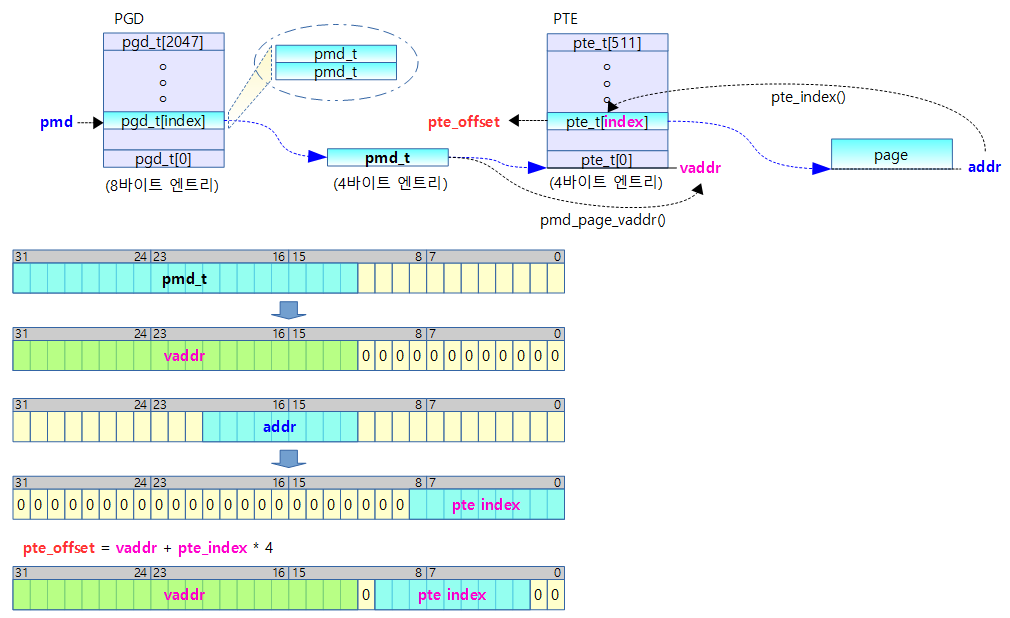
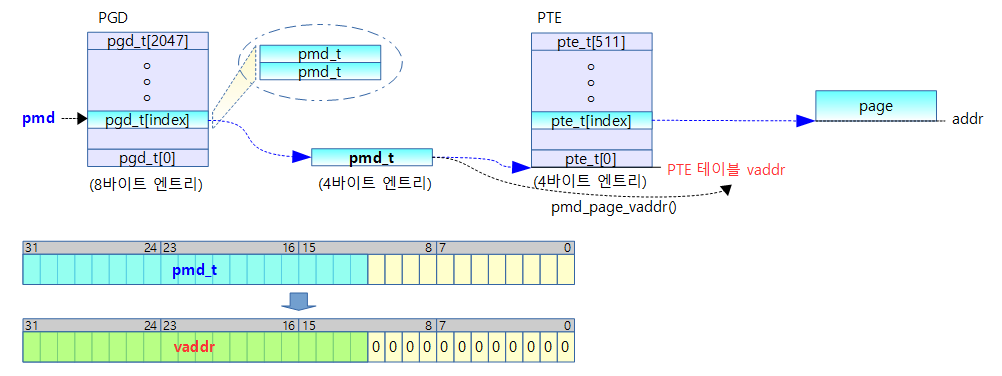
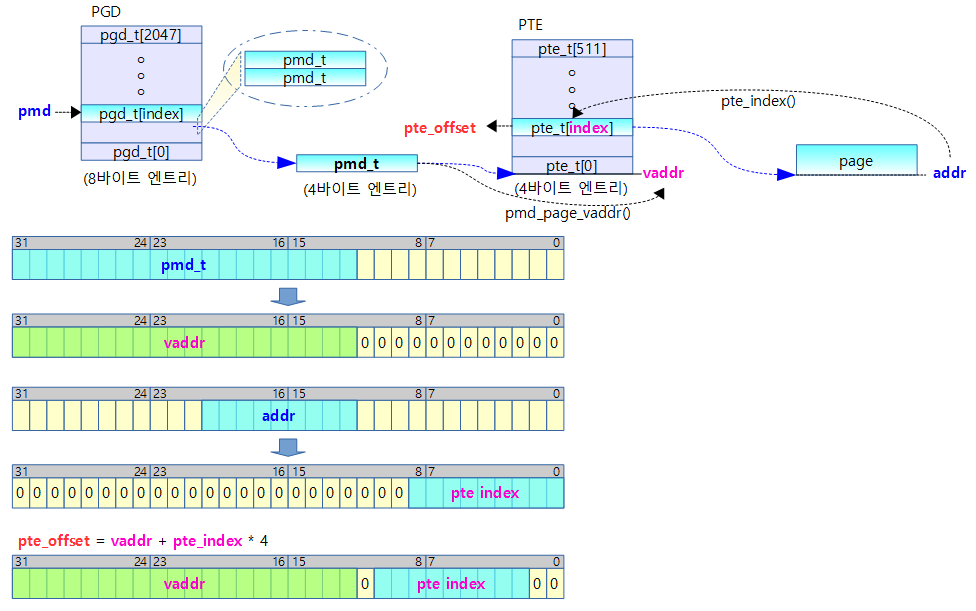
dynamic 매핑이 활성화되기 이전에 일부 고정된 가상 주소 영역에 특정 물리 주소를 매핑 시켜 사용할 수 있는 fixmap 가상 주소 영역을 먼저(early) 사용하려 한다. 이러한 fixmap 가상 주소 영역을 지원하기 위해 pgd 테이블의 fixmap 가상 주소에 해당하는 엔트리에 3개의 static 페이지 테이블 bm_pud[], bm_pmd[] 및 bm_pte[]를 연결 구성하여 fixmap 가상 주소 영역을 사용할 수 있는 완전한 매핑 테이블을 준비한다. 정규 매핑 함수 및 정규 메모리 할당자를 사용할 수 없으므로 3개의 페이지 테이블은 컴파일 타임에 static하게 생성하여 활용한다. 참고로 early_fixmap_init() 함수에서는 전체 fixmap 영역 중 FDT를 제외한 아랫 부분 2M를 먼저 커버하기 위해 매핑합니다.
arch/arm64/mm/mmu.c
/*
* The p*d_populate functions call virt_to_phys implicitly so they can't be used
* directly on kernel symbols (bm_p*d). This function is called too early to use
* lm_alias so __p*d_populate functions must be used to populate with the
* physical address from __pa_symbol.
*/
void __init early_fixmap_init(void)
{
pgd_t *pgdp;
p4d_t *p4dp, p4d;
pud_t *pudp;
pmd_t *pmdp;
unsigned long addr = FIXADDR_START;
pgdp = pgd_offset_k(addr);
p4dp = p4d_offset(pgdp, addr);
p4d = READ_ONCE(*p4dp);
if (CONFIG_PGTABLE_LEVELS > 3 &&
!(p4d_none(p4d) || p4d_page_paddr(p4d) == __pa_symbol(bm_pud))) {
/*
* We only end up here if the kernel mapping and the fixmap
* share the top level pgd entry, which should only happen on
* 16k/4 levels configurations.
*/
BUG_ON(!IS_ENABLED(CONFIG_ARM64_16K_PAGES));
pudp = pud_offset_kimg(p4dp, addr);
} else {
if (p4d_none(p4d))
__p4d_populate(p4dp, __pa_symbol(bm_pud), PUD_TYPE_TABLE);
pudp = fixmap_pud(addr);
}
if (pud_none(READ_ONCE(*pudp)))
__pud_populate(pudp, __pa_symbol(bm_pmd), PMD_TYPE_TABLE);
pmdp = fixmap_pmd(addr);
__pmd_populate(pmdp, __pa_symbol(bm_pte), PMD_TYPE_TABLE);
/*
* The boot-ioremap range spans multiple pmds, for which
* we are not prepared:
*/
BUILD_BUG_ON((__fix_to_virt(FIX_BTMAP_BEGIN) >> PMD_SHIFT)
!= (__fix_to_virt(FIX_BTMAP_END) >> PMD_SHIFT));
if ((pmdp != fixmap_pmd(fix_to_virt(FIX_BTMAP_BEGIN)))
|| pmdp != fixmap_pmd(fix_to_virt(FIX_BTMAP_END))) {
WARN_ON(1);
pr_warn("pmdp %p != %p, %p\n",
pmdp, fixmap_pmd(fix_to_virt(FIX_BTMAP_BEGIN)),
fixmap_pmd(fix_to_virt(FIX_BTMAP_END)));
pr_warn("fix_to_virt(FIX_BTMAP_BEGIN): %08lx\n",
fix_to_virt(FIX_BTMAP_BEGIN));
pr_warn("fix_to_virt(FIX_BTMAP_END): %08lx\n",
fix_to_virt(FIX_BTMAP_END));
pr_warn("FIX_BTMAP_END: %d\n", FIX_BTMAP_END);
pr_warn("FIX_BTMAP_BEGIN: %d\n", FIX_BTMAP_BEGIN);
}
}
fixmap 가상 주소 영역을 활성화한다.
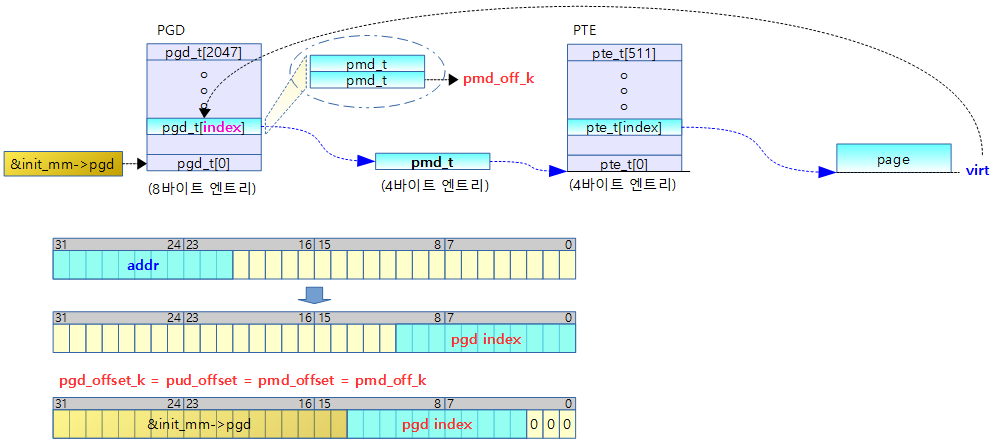
- 코드 라인 7에서 fixmap 영역의 가장 낮은 가상 주소를 addr에 대입한다.
- arm32와 달리 arm64에서는 fixmap의 상위 주소에 4M에 해당하는 DTB가 위치하고 처음에 사용하려고 하는 대부분의 항목들은 fixmap 영역의 아래에 위치하므로 주소가 낮은 부분을 먼저 활성화할 계획이다.
- 코드 라인 9~11에서 가상 주소 addr에 해당하는 p4d 엔트리 값을 읽어온다.
- pgd 테이블에서 pgd 엔트리 포인터인 pgdp를 알아오고, 이어서 다음 레벨인 p4dp를 알아온다음, 이 포인터를 통해 p4d 엔트리 값을 읽어 p4d에 대입한다.
- 코드 라인 12~20에서 페이지 테이블 변환 레벨이 4단계 이상이고, 페이지 크기로 16K를 사용하는 커널인 경우 p4d 엔트리가 최대 2개 밖에 존재하지 않는다. 그중 하나는 커널 메모리용 가상 주소 공간이고, 나머지 하나는 커널에서 여러 용도로 사용되는 몇 가지 공간 주소를 모두 포함하여 사용되며 그중에는 커널 이미지 영역이나 fixmap 영역도 포함된다. 즉, 커널 이미지와 fixmap 영역은 1개의 bm_pud[ ] 테이블에 존재하게 된다. 이러한 경우 bm_pud[ ] 페이지 테이블이 커널 이미지 용도로 이미 활성화되어 사용 중이므로 fixmap을 위해 다시 활성화할 필요가 없어진다. 따라서 곧바로 fixmap 시작 주소에 해당하는 pud 엔트리 포인터를 구한다.
- 이 조건은 4단계 + 16K 페이지를 사용하는 것만 허용하므로 그 외의 경우 버그 메시지를 출력한다.
- 코드 라인 21~25에서 그 외의 경우 bm_pud[ ] 테이블은 fixmap 영역 및 커널 이미지 영역과 같이 공유하지 않고 fixmap 영역 위주로 사용한다. 그래서 fixmap 영역을 사용하기 위해 bm_pud[ ] 테이블을 pgd 엔트리와 연결하여 활성화한 후에 fixmap 시작 주소에 해당하는 pud 엔트리 포인터를 구한다.
- 4 단계 + 4K 페이지 및 3단계의 모든 페이지(4K, 16K, 64K)를 포함한다.
- 코드 라인 26~27에서 pud에 연결된 pmd 테이블이 없는 경우 bm_pmd[] 테이블을 사용하여 연결한다.
- 코드 라인 28에서 addr 주소에 해당하는 pmd 엔트리 포인터를 알아온다.
- 코드 라인 29에서 pmd에 연결된 pte 테이블이 없는 경우 bm_pte[] 테이블을 사용하여 연결한다.
- 전체 fixmap 영역 중 FDT를 제외한 아랫부분 2M에 해당하는 부분을 매핑하여 커버합니다.
- 코드 라인 38~51에서 early_ioremap() 함수에서 사용하는 btmap 영역의 시작과 끝에 해당하는 pud 테이블의 pmd 엔트리 주소 값들이 위에서 읽어온 pmd 엔트리 주소 값과 다른 경우 경고 메시지를 출력한다.
bm_pte, bm_pmd, bm_pud는 fixmap에 대한 페이지 테이블로 별도의 페이지 할당 없이 커널 빌드 시 생성되는 static 배열을 이용한다
arch/arm64/mm/mmu.c
static pte_t bm_pte[PTRS_PER_PTE] __page_aligned_bss;
static pmd_t bm_pmd[PTRS_PER_PMD] __page_aligned_bss __maybe_unused;
static pud_t bm_pud[PTRS_PER_PUD] __page_aligned_bss __maybe_unused;
커널 이미지의 두 가상 공간 매핑
- 커널 이미지(kimage)는 부트업 타임에 두 개의 가상 공간에 매핑된다.
- 1) linear mapping 가상 공간
- 커널이 로드되어 있는 DRAM 전체가 매핑되는 공간이다.
- 예) 0xfff_0000_0000_0000~ (4K, 4레벨 페이지)
- 2) kimage 가상 공간
- 커널 이미지만 매핑된 공간이다.
- 예) 0xffff_8000_1000_0000~ (4K, 4레벨 페이지, KASLR=n)
가상 주소와 물리 주소의 변환 APIs
- 다음 API는 1)번의 lm(linear mapping) 가상 주소와 물리 주소의 변환에 사용한다.
- 사용 제한
- paging_init() 함수를 통해 리니어 매핑이 완료된 후 사용 가능하다.
- CONFIG_DEBUG_VIRTUAL 커널 옵션을 사용하여 lm 가상 주소를 사용하지 않는 경우에 경고 메시지를 출력한다.
- virt_to_phys(), __virt_to_phys(), __va()
- phys_to_virt(), __phys_to_virt(), __pa()
- lm_alias()
- 커널 심볼에 대한 lm 가상 주소로 변환한다.
- 다음 API는 2)번의 커널 심볼 가상 주소와 물리 주소의 변환에 사용한다.
- 사용 제한
- __kimg_to_phys()
- __phys_to_kimg()
- __pa_symbol()
- 커널 심볼 가상 주소를 물리 주소로 변환한다.
- 다음 API는 1)번의 lm(linear mapping) 가상 주소와 페이지의 변환에 사용한다.
- 사용 제한
- 페이지 디스크립터 배열로 구성된 vmemmap이 활성화된 후 사용 가능하다.
- virt_to_page()
- page_to_virt()
__p*d_populate() 함수 사용
early_fixmap_init() 함수에서 p*d_populate() 함수 대신 __p*d_populate() 함수를 사용하는 이유를 알아본다.
- p*d_populate() 함수는 세 번째 인자로 연결할 테이블의 가상 주소를 사용한다.
- p*d_populate() 함수는 내부에서 __pa() 함수를 사용하여 리니어용 가상 주소를 물리 주소로 변환한다. 그런데 __pa() 함수는 아직은 부트 업 초반 시점이라 리니어 매핑이 완료되지 않아서 사용할 수 없다. 따라서 bm_pud[] 등의 커널 심볼을 가상 주소 인자로 사용할 수 없어 이 함수를 사용하지 못한다.
- __p*d_populate() 함수는 두 번째 인자로 연결할 테이블의 물리 주소를 사용한다.
- 커널 심볼에 한하여 물리 주소로 바꿔주는 별도의 함수가 있다. __pa_symbol() 함수를 사용하여 커널 심볼 가상 주소를 물리 주소로 변환할 수 있다. 이렇게 변환한 물리 주소를 사용하여 __p*d_populate() 함수를 사용한다.
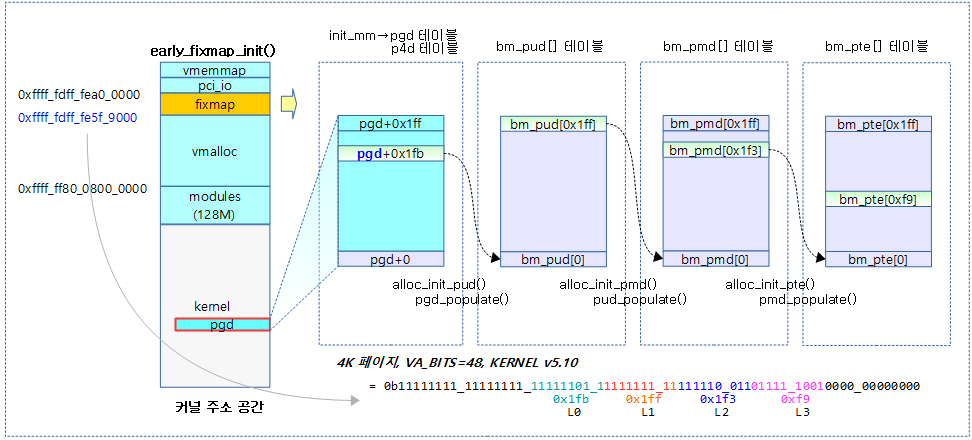
다음 그림은 fixmap을 위해 각 단계의 페이지 테이블이 활성화되는 모습을 보여준다.
- 4K 페이지, VA_BITS=48을 사용하면 4단계의 페이지 테이블을 사용하였고, pgd 다음의 p4d 테이블은 ARM64에서 pgd를 그대로 사용한다.
early_fixmap_init() – ARM32
arch/arm/mm/mmu.c
void __init early_fixmap_init(void)
{
pmd_t *pmd;
/*
* The early fixmap range spans multiple pmds, for which
* we are not prepared:
*/
BUILD_BUG_ON((__fix_to_virt(__end_of_early_ioremap_region) >> PMD_SHIFT)
!= FIXADDR_TOP >> PMD_SHIFT);
pmd = fixmap_pmd(FIXADDR_TOP);
pmd_populate_kernel(&init_mm, pmd, bm_pte);
pte_offset_fixmap = pte_offset_early_fixmap;
}
fixmap 영역을 활성화한다.
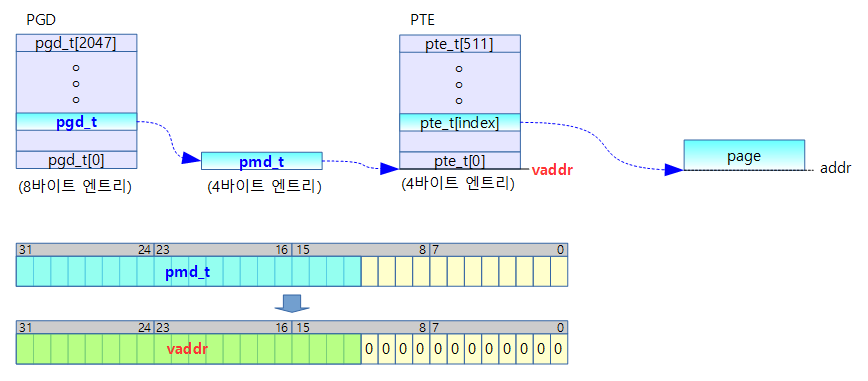
- 코드 라인 12에서 fixmap 가상 주소의 top 영역에 해당하는 pmd 엔트리를 알아온다.
- 코드 라인 13에서 컴파일 타임에 준비된 static bm_pte 페이지를 사용하여 fixmap을 운용할 pte 테이블을 연결하여 활성화한다.
- pte 테이블 하나당 2M를 커버한다. pte 영역이 4M라 두 개의 pte 테이블이 필요하지만 처음에는 최상위 영역만 활성화한다.
주요 Fixmap API
set_fixmap()
include/asm-generic/fixmap.h
#define set_fixmap(idx, phys) \
__set_fixmap(idx, phys, FIXMAP_PAGE_NORMAL)
fixmap의 요청 인덱스 @idx 에 물리 주소@phys에 해당하는 페이지 하나를 매핑하는데 normal 커널 페이지 매핑 속성으로 한다.
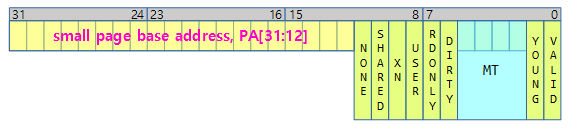
- ARM32
- L_PTE_YOUNG | L_PTE_PRESENT | L_PTE_XN | L_PTE_DIRTY | L_PTE_MT_WRITEBACK
- ARM64
- FIXMAP_PAGE_NORMAL -> PAGE_KERNEL -> __pgprot(PROT_NORMAL) 속성 사용
- PTE_TYPE_PAGE | PTE_AF | PTE_SHARED | PTE_MAYBE_NG | PTE_PXN | PTE_UXN | PTE_WRITE | PTE_ATTRINDX(MT_NORMAL)
clear_fixmap()
include/asm-generic/fixmap.h
#define clear_fixmap(idx) \
__set_fixmap(idx, 0, FIXMAP_PAGE_CLEAR)
fixmap의 요청 인덱스 @idx 영역에 매핑된 물리 주소 1개 페이지를 언매핑하는데 속성은 CLEAR(0)로 설정한다.
set_fixmap_nocache()
include/asm-generic/fixmap.h
#define set_fixmap_nocache(idx, phys) \
__set_fixmap(idx, phys, FIXMAP_PAGE_NOCACHE)
fixmap의 요청 인덱스 @idx 영역에 물리 주소 @phys에 해당하는 1개 페이지를 캐시 없이 매핑하는데 속성은 FIXMAP_PAGE_NOCACHE로 설정한다.
- ARM32
- L_PTE_YOUNG | L_PTE_PRESENT | L_PTE_XN | L_PTE_DIRTY | L_PTE_MT_DEV_SHARED | L_PTE_SHARE
- ARM64
- FIXMAP_PAGE_NOCACHE -> PAGE_KERNEL_NOCACHE -> __pgprot(PROT_NORMAL_NC) 속성 사용
- PTE_TYPE_PAGE | PTE_AF | PTE_SHARED | PTE_MAYBE_NG | PTE_PXN | PTE_UXN | PTE_WRITE | PTE_ATTRINDX(MT_NORMAL_NC)
set_fixmap_io()
include/asm-generic/fixmap.h
#define set_fixmap_io(idx, phys) \
__set_fixmap(idx, phys, FIXMAP_PAGE_IO)
fixmap의 요청 인덱스 @idx 영역에 물리 주소 @phys에 해당하는 1개 페이지를 매핑하는데 속성은 FIXMAP_PAGE_IO로 설정한다.
- ARM32
- ARM64
- FIXMAP_PAGE_IO -> PAGE_KERNEL_IO -> __pgprot(PROT_DEVICE_nGnRE) 속성 사용
- PTE_TYPE_PAGE | PTE_AF | PTE_SHARED | PTE_MAYBE_NG | PTE_PXN | PTE_UXN | PTE_WRITE | PTE_ATTRINDX(MT_DEVICE_nGnRE)
__set_fixmap() – ARM32
arch/arm/mm/mmu.c
/*
* To avoid TLB flush broadcasts, this uses local_flush_tlb_kernel_range().
* As a result, this can only be called with preemption disabled, as under
* stop_machine().
*/
void __set_fixmap(enum fixed_addresses idx, phys_addr_t phys, pgprot_t prot)
{
unsigned long vaddr = __fix_to_virt(idx);
pte_t *pte = pte_offset_kernel(pmd_off_k(vaddr), vaddr);
/* Make sure fixmap region does not exceed available allocation. */
BUILD_BUG_ON(FIXADDR_START + (__end_of_fixed_addresses * PAGE_SIZE) >
FIXADDR_END);
BUG_ON(idx >= __end_of_fixed_addresses);
if (pgprot_val(prot))
set_pte_at(NULL, vaddr, pte,
pfn_pte(phys >> PAGE_SHIFT, prot));
else
pte_clear(NULL, vaddr, pte);
local_flush_tlb_kernel_range(vaddr, vaddr + PAGE_SIZE);
}
물리 주소 @phys에 해당하는 페이지 1개를 fixmap 인덱스 @idx 번호 영역에 @prot 속성으로 매핑한다. 이 함수를 언매핑 용도로 사용할 수도 있는데, 이러한 경우에는 phys 물리 주소 및 flags 속성을 0으로 사용한다.
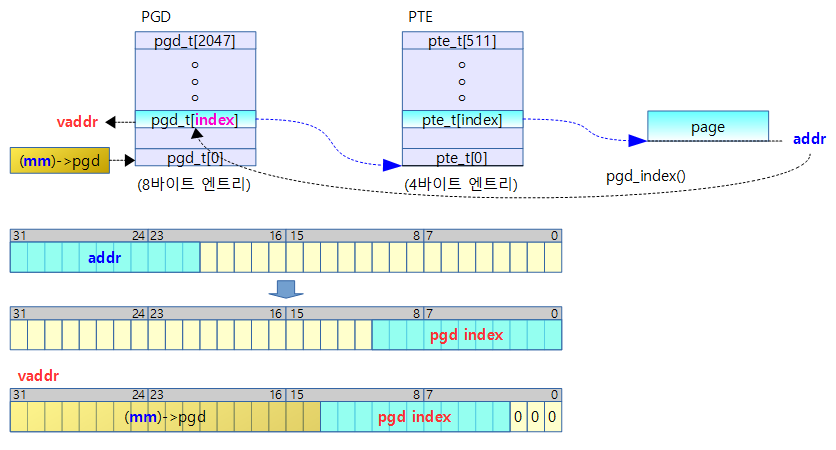
- 코드 라인 3에서 인덱스 번호 @idx에 매치되는 fixmap 영역의 가상 주소를 알아온다.
- 코드 라인 4에서 가상 주소에 해당하는 페이지 테이블의 엔트리 포인터를 알아온다.
- 코드 라인 11~13에서 매핑을 요청한 경우 플래그를 사용하여 fixmap 엔트리를 물리 주소 @phys에 매핑한다.
- 코드 라인 14~15에서 언매핑을 요청한 경우 fixmap 슬롯 인덱스에 해당하는 pte 엔트리를 클리어한다.
- 코드 라인 16에서 해당 가상 주소 페이지 영역에 대한 tlb 플러시를 수행한다.
__set_fixmap() – ARM64
arch/arm64/mm/mmu.c
/*
* Unusually, this is also called in IRQ context (ghes_iounmap_irq) so if we
* ever need to use IPIs for TLB broadcasting, then we're in trouble here.
*/
void __set_fixmap(enum fixed_addresses idx,
phys_addr_t phys, pgprot_t flags)
{
unsigned long addr = __fix_to_virt(idx);
pte_t *ptep;
BUG_ON(idx <= FIX_HOLE || idx >= __end_of_fixed_addresses);
ptep = fixmap_pte(addr);
if (pgprot_val(flags)) {
set_pte(ptep, pfn_pte(phys >> PAGE_SHIFT, flags));
} else {
pte_clear(&init_mm, addr, ptep);
flush_tlb_kernel_range(addr, addr+PAGE_SIZE);
}
}
@idx에 해당하는 슬롯 위치의 fixmap 가상 주소 공간에 @phys 물리 주소를 @flags 속성으로 매핑한다. 이 함수를 언매핑 용도로 사용할 수도 있는데, 이러한 경우에는 phys 물리 주소 및 flags 속성을 0으로 사용한다.
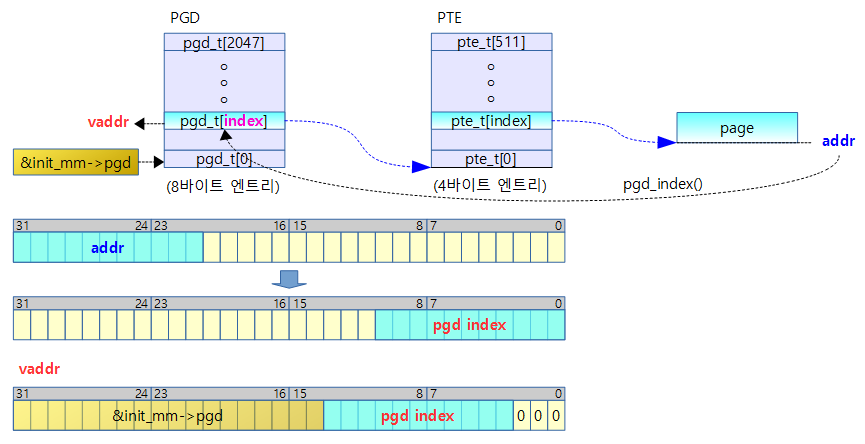
- 코드 라인 4에서 인덱스 번호 @idx에 매치되는 fixmap 영역의 가상 주소를 알아온다.
- 코드 라인 9에서 가상 주소에 해당하는 페이지 테이블의 엔트리 포인터를 알아온다.
- 코드 라인 11~12에서 매핑을 요청한 경우 플래그를 사용하여 fixmap 엔트리를 물리 주소 @phys에 매핑한다.
- 코드 라인 13~16에서 언매핑을 요청한 경우 fixmap 슬롯 인덱스에 해당하는 pte 엔트리를 클리어한 후 해당 가상 주소 1개 페이지 영역에 대한 tlb 플러시를 수행한다.
fix_to_virt()
include/asm-generic/fixmap.h
/*
* 'index to address' translation. If anyone tries to use the idx
* directly without translation, we catch the bug with a NULL-deference
* kernel oops. Illegal ranges of incoming indices are caught too.
*/
static __always_inline unsigned long fix_to_virt(const unsigned int idx)
{
BUILD_BUG_ON(idx >= __end_of_fixed_addresses);
return __fix_to_virt(idx);
}
fixmap 영역에 대한 인덱스로 가상 주소를 알아온다.
#define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
virt_to_fix()
include/asm-generic/fixmap.h
static inline unsigned long virt_to_fix(const unsigned long vaddr)
{
BUG_ON(vaddr >= FIXADDR_TOP || vaddr < FIXADDR_START);
return __virt_to_fix(vaddr);
}
fixmap area에 매치되는 fixmap 인덱스를 리턴한다.
__virt_to_fix()
include/asm-generic/fixmap.h
#define __virt_to_fix(x) ((FIXADDR_TOP - ((x)&PAGE_MASK)) >> PAGE_SHIFT)
Highmem 페이지 매핑
다음 그림은 fixmap 영역에서 highmem 페이지 매핑에 사용되는 FIX_KMAP 블럭을 보여준다.

highmem 매핑 예)
highmem 페이지를 fixmap의 kmap 블럭에 매핑한다. cpu id별로 할당된 수 만큼의 영역에서 스택처럼 push/pull로 운영하여 사용한다.
다음 그림은 highmem 물리 메모리 페이지를 fixmap 공간의 kmap 블럭에 매핑하여 사용하는 모습을 보여준다.
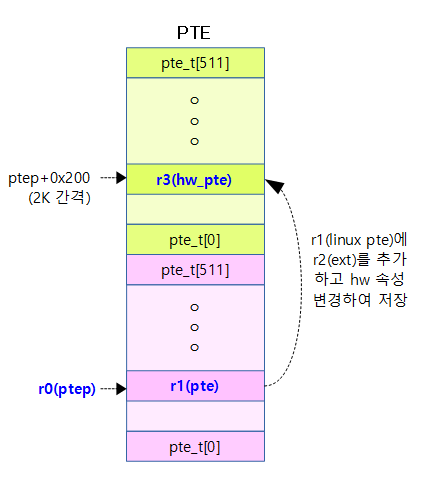
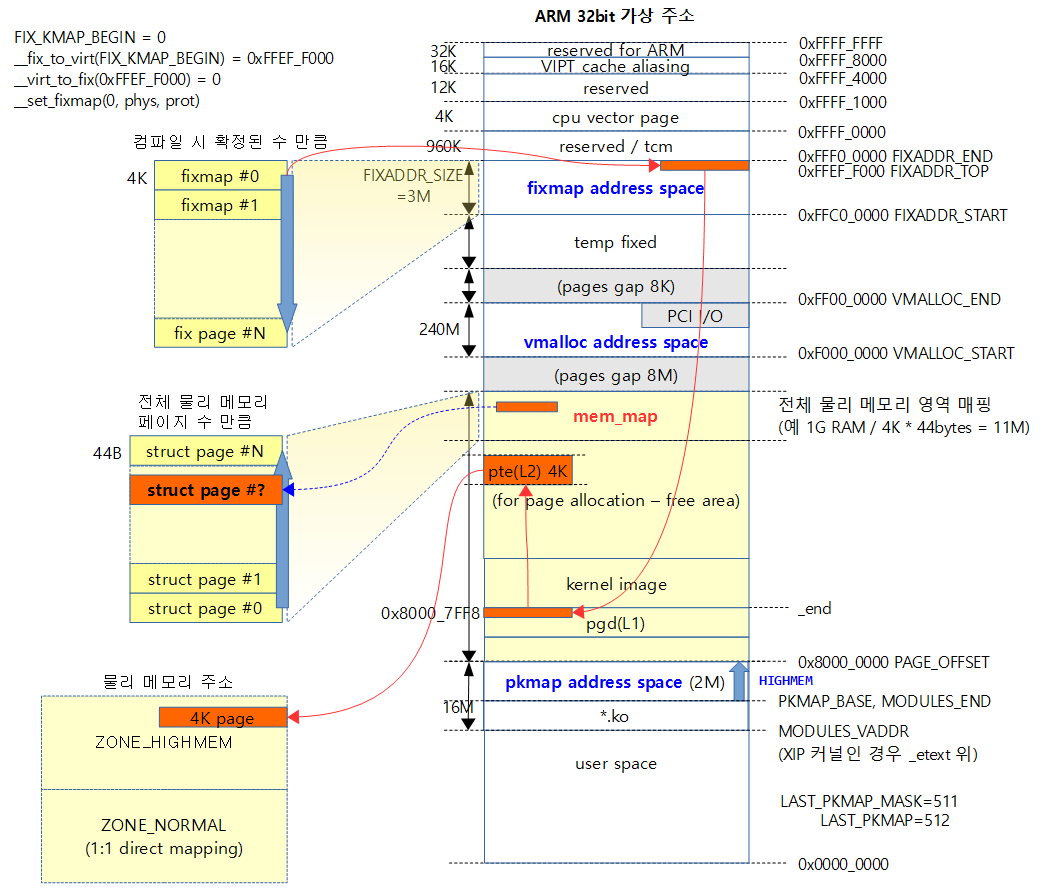
다음 그림은 ARM32에서 highmem 물리 페이지를 fixmap 영역에 매핑할 때 페이지 디스크립터와 페이지 테이블간의 관계를 보여준다.
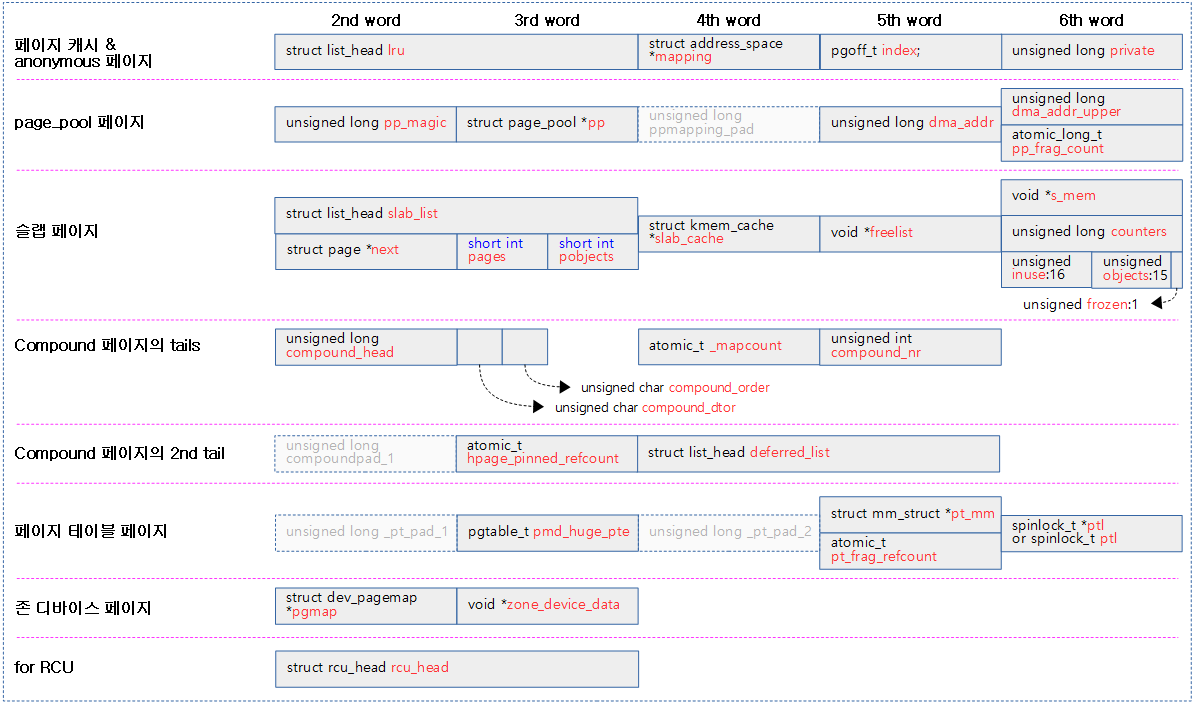
- mem_map에 포함된 page 디스크립터들, pgd 및 pte 페이지 테이블 등이 어우러져 복잡한 모습이다.
highmem 페이지 할당 & 해제
kmap_atomic() – ARM32
arch/arm/mm/highmem.c
void *kmap_atomic(struct page *page)
{
unsigned int idx;
unsigned long vaddr;
void *kmap;
int type;
preempt_disable();
pagefault_disable();
if (!PageHighMem(page))
return page_address(page);
#ifdef CONFIG_DEBUG_HIGHMEM
/*
* There is no cache coherency issue when non VIVT, so force the
* dedicated kmap usage for better debugging purposes in that case.
*/
if (!cache_is_vivt())
kmap = NULL;
else
#endif
kmap = kmap_high_get(page);
if (kmap)
return kmap;
type = kmap_atomic_idx_push();
idx = type + KM_TYPE_NR * smp_processor_id();
vaddr = __fix_to_virt(idx);
#ifdef CONFIG_DEBUG_HIGHMEM
/*
* With debugging enabled, kunmap_atomic forces that entry to 0.
* Make sure it was indeed properly unmapped.
*/
BUG_ON(!pte_none(get_fixmap_pte(vaddr)));
#endif
/*
* When debugging is off, kunmap_atomic leaves the previous mapping
* in place, so the contained TLB flush ensures the TLB is updated
* with the new mapping.
*/
set_fixmap_pte(idx, mk_pte(page, kmap_prot));
return (void *)vaddr;
}
EXPORT_SYMBOL(kmap_atomic);
highmem page를 atomic하게 fixmap 영역에 매핑한다. 이미 kmap 영역에 매핑된 경우 매핑된 가상 주소를 리턴한다.
- pagefault_disable()
- preemption 카운터를 증가시켜 preemption을 disable하고 barrier()를 수행한다.
- if (!PageHighMem(page))
- return page_address(page);
- kmap에 이미 매핑되어 있는 경우 page에 해당하는 가상 주소를 리턴한다.
- kmap = kmap_high_get(page);
- pkmap 참조 카운터를 증가시키고 highmem page에 해당하는 가상 주소를 리턴한다.
- if (kmap)
- type = kmap_atomic_idx_push();
- __kmap_atomic_idx 증가 시키고 이전 값을 알아온다.
- idx = type + KM_TYPE_NR * smp_processor_id();
- type 값 + KM_TYPE_NR(20) * cpu id
- vaddr = __fix_to_virt(idx);
- fixmap에서 해당 idx 번호로 가상 주소를 알아온다.
- fixmap은 idx 0번이 FIXADDR_TOP을 가리킨다.
- FIXADDR_TOP
- 0xffef_f000= (FIXADDR_END(0xfff00000UL) – PAGE_SIZE)
- 인덱스 번호는 0부터 최대 0x2ff (767)번 까지 가능하며 매핑 되는 가상 주소는 0xffc0_0000 ~ 0xffef_ffff까지 총 3M이다.
- 실제 허용 가능한 슬롯 인덱스 번호는 해당 cpu별로 KM_TYPE_NR(ARM=20) 개로 제한된다.
- set_fixmap_pte(idx, mk_pte(page, kmap_prot));
- mk_pte()
- page 주소와 kmap_prot 속성 값을 합쳐서 pte 엔트리를 만든다.
- idx 번호에 해당하는 fixmap 영역에 pte 엔트리를 매핑한다.
__fix_to_virt()
include/asm-generic/fixmap.h
#define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
mk_pte() – ARM & ARM64
arch/arm64/include/asm/pgtable.h
#define mk_pte(page,prot) pfn_pte(page_to_pfn(page), prot)
set_fixmap_pte() – ARM32
arch/arm/mm/highmem.c
static inline void set_fixmap_pte(int idx, pte_t pte)
{
unsigned long vaddr = __fix_to_virt(idx);
pte_t *ptep = pte_offset_kernel(pmd_off_k(vaddr), vaddr);
set_pte_ext(ptep, pte, 0);
local_flush_tlb_kernel_page(vaddr);
}
idx 번호에 해당하는 fixmap 영역에 pte 엔트리를 매핑한다.
- unsigned long vaddr = __fix_to_virt(idx);
- idx 번호에 해당하는 fixmap 영역의 가상 주소를 알아온다.
- pte_t *ptep = pte_offset_kernel(pmd_off_k(vaddr), vaddr);
- pmd_off_k()
- 가상 주소값으로 pmd 엔트리 주소 값을 알아온다.
- pte_offset_kernel()
- pmd 엔트리 주소 값과 vaddr 값을 사용하여 pte 엔트리 주소를 알아온다.
- set_pte_ext(ptep, pte, 0);
- pte 엔트리 주소에 pte 값을 저장한다.
- rpi2: cpu_v7_set_pte_ext() 호출
- local_flush_tlb_kernel_page(vaddr);
- vaddr에 해당하는 tlb 캐시를 flush한다.
local_flush_tlb_kernel_page() – ARM32
arch/arm/include/asm/tlbflush.h
static inline void local_flush_tlb_kernel_page(unsigned long kaddr)
{
const unsigned int __tlb_flag = __cpu_tlb_flags;
kaddr &= PAGE_MASK;
if (tlb_flag(TLB_WB))
dsb(nshst);
__local_flush_tlb_kernel_page(kaddr);
tlb_op(TLB_V7_UIS_PAGE, "c8, c7, 1", kaddr);
if (tlb_flag(TLB_BARRIER)) {
dsb(nsh);
isb();
}
}
__local_flush_tlb_kernel_page() – ARM32
arch/arm/include/asm/tlbflush.h
static inline void __local_flush_tlb_kernel_page(unsigned long kaddr)
{
const int zero = 0;
const unsigned int __tlb_flag = __cpu_tlb_flags;
tlb_op(TLB_V4_U_PAGE, "c8, c7, 1", kaddr);
tlb_op(TLB_V4_D_PAGE, "c8, c6, 1", kaddr);
tlb_op(TLB_V4_I_PAGE, "c8, c5, 1", kaddr);
if (!tlb_flag(TLB_V4_I_PAGE) && tlb_flag(TLB_V4_I_FULL))
asm("mcr p15, 0, %0, c8, c5, 0" : : "r" (zero) : "cc");
tlb_op(TLB_V6_U_PAGE, "c8, c7, 1", kaddr);
tlb_op(TLB_V6_D_PAGE, "c8, c6, 1", kaddr);
tlb_op(TLB_V6_I_PAGE, "c8, c5, 1", kaddr);
}
tlb_op() – ARM32
arch/arm/include/asm/tlbflush.h
#define tlb_op(f, regs, arg) __tlb_op(f, "p15, 0, %0, " regs, arg)
__tlb_op() – ARM32
arch/arm/include/asm/tlbflush.h
#define __tlb_op(f, insnarg, arg) \
do { \
if (always_tlb_flags & (f)) \
asm("mcr " insnarg \
: : "r" (arg) : "cc"); \
else if (possible_tlb_flags & (f)) \
asm("tst %1, %2\n\t" \
"mcrne " insnarg \
: : "r" (arg), "r" (__tlb_flag), "Ir" (f) \
: "cc"); \
} while (0)
kmap_atomic_idx_push() – 32bit
include/linux/highmem.h
static inline int kmap_atomic_idx_push(void)
{
int idx = __this_cpu_inc_return(__kmap_atomic_idx) - 1;
#ifdef CONFIG_DEBUG_HIGHMEM
WARN_ON_ONCE(in_irq() && !irqs_disabled());
BUG_ON(idx >= KM_TYPE_NR);
#endif
return idx;
}
해당 cpu에서 사용할 fixmap용 슬롯 인덱스를 리턴하고 그 값은 증가 시킨다.
- CONFIG_DEBUG_HIGHMEM 옵션을 사용하는 경우 fixmap 인덱스 슬롯이 KM_TYPE_NR(ARM=20)을 초과하는 경우 버그에 대한 메시지를 출력하고 멈춘다.
- int idx = __this_cpu_inc_return(__kmap_atomic_idx);
- __kmap_atomic_idx per-cpu 데이터를 1 증가
- idx 에는 증가전 값을 담아 리턴한다.
__this_cpu_inc_return()
#define __this_cpu_inc_return(pcp) __this_cpu_add_return(pcp, 1)
__this_cpu_add_return()
#define __this_cpu_add_return(pcp, val) \
({ \
__this_cpu_preempt_check("add_return"); \
raw_cpu_add_return(pcp, val); \
})
- preemption이 disable되어 있지 않거나 irq가 disable되어 있지 않으면 stack dump
- __kmap_atomic_idx per-cpu 데이터를 1 증가
raw_cpu_add_return()
#define raw_cpu_add_return(pcp, val) __pcpu_size_call_return2(raw_cpu_add_return_, pcp, val)
- scalar 데이터 타입 pcp의 사이즈에 따른 최적화된 덧셈 함수를 분류하기 위해 매크로 함수 호출
__pcpu_size_call_return2()
#define __pcpu_size_call_return2(stem, variable, ...) \
({ \
typeof(variable) pscr2_ret__; \
__verify_pcpu_ptr(&(variable)); \
switch(sizeof(variable)) { \
case 1: pscr2_ret__ = stem##1(variable, __VA_ARGS__); break; \
case 2: pscr2_ret__ = stem##2(variable, __VA_ARGS__); break; \
case 4: pscr2_ret__ = stem##4(variable, __VA_ARGS__); break; \
case 8: pscr2_ret__ = stem##8(variable, __VA_ARGS__); break; \
default: \
__bad_size_call_parameter(); break; \
} \
pscr2_ret__; \
})
- variable의 사이즈에 따라 stem(함수명 인수)+1/2/4/8 숫자를 붙여 호출
this_cpu_add_return_4()
#define this_cpu_add_return_4(pcp, val) this_cpu_generic_add_return(pcp, val)
- ARM 아키텍처는 사이즈와 관계 없이 generic 코드를 호출한다.
this_cpu_generic_add_return()
#define this_cpu_generic_add_return(pcp, val) \
({ \
typeof(pcp) __ret; \
unsigned long __flags; \
raw_local_irq_save(__flags); \
raw_cpu_add(pcp, val); \
__ret = raw_cpu_read(pcp); \
raw_local_irq_restore(__flags); \
__ret; \
})
- per-cpu 변수에 val 값을 더하고 다시 읽어 리턴한다.
raw_cpu_add()
#define raw_cpu_add(pcp, val) __pcpu_size_call(raw_cpu_add_, pcp, val)
- scalar 데이터 타입 pcp의 사이즈에 따른 최적화된 덧셈 함수를 분류하기 위해 매크로 함수 호출
__pcpu_size_call()
#define __pcpu_size_call(stem, variable, ...) \
do { \
__verify_pcpu_ptr(&(variable)); \
switch(sizeof(variable)) { \
case 1: stem##1(variable, __VA_ARGS__);break; \
case 2: stem##2(variable, __VA_ARGS__);break; \
case 4: stem##4(variable, __VA_ARGS__);break; \
case 8: stem##8(variable, __VA_ARGS__);break; \
default: \
__bad_size_call_parameter();break; \
} \
} while (0)
- variable의 사이즈에 따라 stem(함수명 인수)+1/2/4/8 숫자를 붙여 호출
raw_cpu_add_4()
#define raw_cpu_add_4(pcp, val) raw_cpu_generic_to_op(pcp, val, +=)
- ARM 아키텍처는 사이즈와 관계 없이 generic 코드를 호출한다.
raw_cpu_generic_to_op()
#define raw_cpu_generic_to_op(pcp, val, op) \
do { \
*raw_cpu_ptr(&(pcp)) op val; \
} while (0)
- 예) pcp=__kmap_atomic_idx, val=1, op= +=
- per-cpu int 데이터인 __kmap_atomic_idx += 1
kunmap_atomic() – 32bit
include/linux/highmem.h
/*
* Prevent people trying to call kunmap_atomic() as if it were kunmap()
* kunmap_atomic() should get the return value of kmap_atomic, not the page.
*/
#define kunmap_atomic(addr) \
do { \
BUILD_BUG_ON(__same_type((addr), struct page *)); \
__kunmap_atomic(addr); \
} while (0)
kmap_atomic()을 사용하여 fixmap 영역에 매핑되어 있는 highmem 영역을 해제한다.
__kunmap_atomic() – 32bit
arch/arm/mm/highmem.c
void __kunmap_atomic(void *kvaddr)
{
unsigned long vaddr = (unsigned long) kvaddr & PAGE_MASK;
int idx, type;
if (kvaddr >= (void *)FIXADDR_START) {
type = kmap_atomic_idx();
idx = type + KM_TYPE_NR * smp_processor_id();
if (cache_is_vivt())
__cpuc_flush_dcache_area((void *)vaddr, PAGE_SIZE);
#ifdef CONFIG_DEBUG_HIGHMEM
BUG_ON(vaddr != __fix_to_virt(idx));
set_fixmap_pte(idx, __pte(0));
#else
(void) idx; /* to kill a warning */
#endif
kmap_atomic_idx_pop();
} else if (vaddr >= PKMAP_ADDR(0) && vaddr < PKMAP_ADDR(LAST_PKMAP)) {
/* this address was obtained through kmap_high_get() */
kunmap_high(pte_page(pkmap_page_table[PKMAP_NR(vaddr)]));
}
pagefault_enable();
}
EXPORT_SYMBOL(__kunmap_atomic);
kmap_atomic()을 사용하여 fixmap 또는 kmap 영역에 매핑되어 있는 highmem 영역을 해제한다.
- if (kvaddr >= (void *)FIXADDR_START) {
- type = kmap_atomic_idx();
- __kmap_atomic_idx per-cpu 데이터값에서 1을 뺀 인덱스 값
- idx = type + KM_TYPE_NR * smp_processor_id();
- if (cache_is_vivt())
- L1 d-cache 타입이 VIVT인 경우
- rpi2:
- L1 d-cache는 CACHEID_VIPT_NONALIASING
- L1 i-cache는 CACHEID_VIPT_I_ALIASING
- __cpuc_flush_dcache_area((void *)vaddr, PAGE_SIZE);
- 해당 주소의 1 페이지 영역의 d-cache를 flush 한다.
- kmap_atomic_idx_pop();
- __kmap_atomic_idx per-cpu 데이터를 1 감소시킨다.
- } else if (vaddr >= PKMAP_ADDR(0) && vaddr < PKMAP_ADDR(LAST_PKMAP)) {
- kunmap_high(pte_page(pkmap_page_table[PKMAP_NR(vaddr)]));
- kmap 영역에 매핑된 highmem page 주소를 매핑 해제한다.
- pagefault_enable();
참고