<kernel v5.15>
Memory Model -2- (mem_map)
PFN(Page Frame Number)와 물리 모델별로 mem_map을 관리하는 방법에 대해 알아본다.
PFN(Page Frame Number)
PFN은 물리 주소에 사용되는 페이지 단위의 번호이고, 0부터 시작된다. 페이지 단위는 보통 4K를 사용하며, ARM64의 경우 대단위 데이터 베이스등의 운영을 목적으로 16K 및 64K로 설정되어 운영되는 시스템들도 있다.
- 예) 4K Page 기준: 0x0000_0000
- PFN 값은 0이다.
- 예) 4K Page 기준: 0x1234_5678
- PFN 값은 0x12345이다.
mem_map
- mem_map은 모든 물리 메모리 페이지 프레임에 대한 정보를 담아둔 page 구조체 배열이다.
- 처음 리눅스에서는 unsigned short 타입의 참조 카운터 배열로 시작하다가 점점 필요 멤버가 늘어나 오늘날의 page 구조체가 되었다.
- NUMA 시스템과 UMA 시스템에서의 접근 방법이 다르고 물리 메모리 모델별로도 접근 방법이 다르다.
- mem_map의 초기화 함수 경로는 아키텍처 및 커널 설정마다 다르다.
- arm with flatmem
- setup_arch() → paging_init() → bootmem_init() → zone_sizes_init() → free_area_init_node()
- arm/arm64 with sparsemem
- setup_arch() → bootmem_init() → sparse_init()
- arm with flatmem
PFN vs page 변환 API
리눅스 커널은 PFN 값으로 page 구조체를 접근하는 변환과, 그 반대의 변환이 매우 빈번하게 사용한다. 이에 대응하는 API는 다음과 같다.
- pfn_to_page()
- pfn 번호로 page 구조체 포인터를 반환한다.
- page_to_pfn()
- page 구조체 포인터로 pfn 번호를 반환한다.
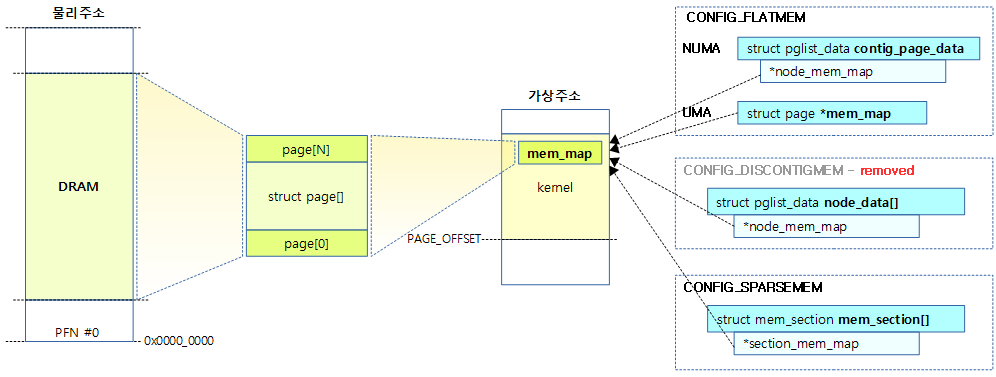
Flat Memory with mem_map
- NEED_MULTIPLE_NODES 커널 옵션이 사용되지 않을 때 *mem_map 포인터 변수는 하나의 page[] 구조체 배열을 가리킨다.
- FLAT_NODE_MEM_MAP 커널 옵션을 사용하는 경우 contig_page_data.node_mem_map를 통해서 page[] 구조체 배열을 가리킨다.
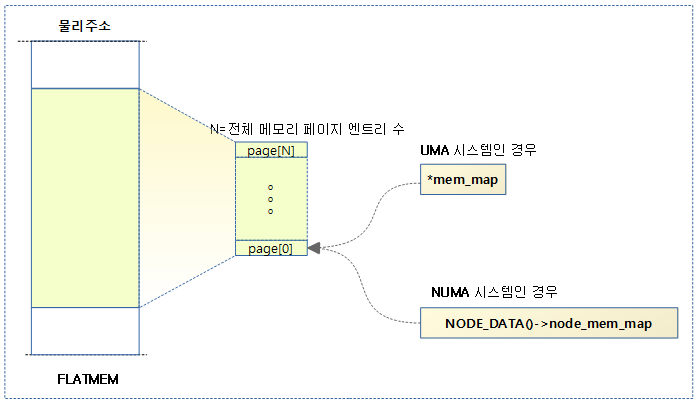
Discontiguous Memory with mem_map
- node_data[].node_mem_map를 통해서 page[] 구조체 배열을 가리킨다.
- x86_32에서는 섹션 to 노드 매핑을 하는 테이블을 별도로 구현하여 사용한다.
- 실제 사용하는 메모리에 대해서만 관리하고 hole 영역에 대해서는 전혀 관리하지 않는다.
- 커널 메인라인에서 이 모델은 더 이상 사용하지 않게 완전히 제거하였다.
- mm: remove CONFIG_DISCONTIGMEM (2021, v5.14-rc1)
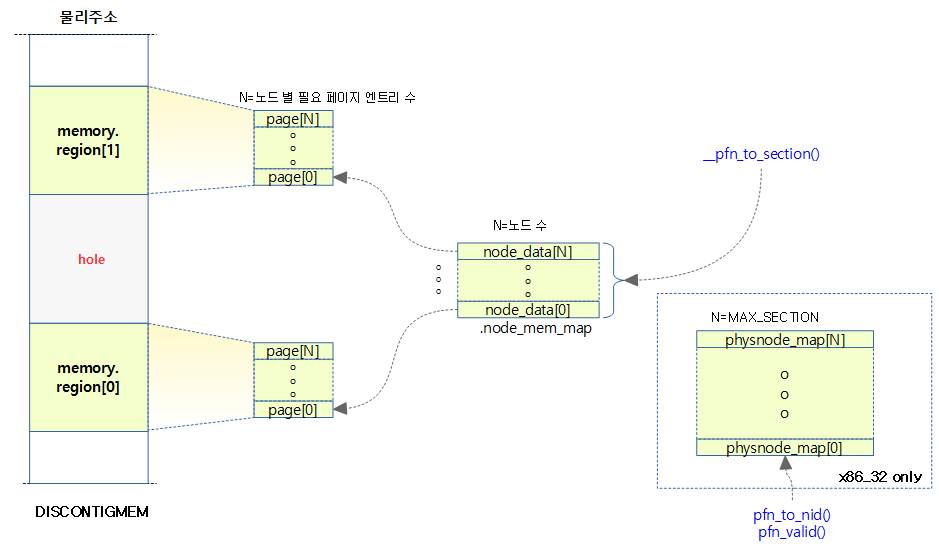
Sparse Memory with mem_map
- mem_map을 여러 개의 섹션을 통해 관리하며, 하나의 섹션을 관리하기 위해 mem_section 구조체를 사용한다.
- 한 개의 섹션의 크기는 수십MB ~ 수GB 크기를 사용한다.
- 주의: 페이지 테이블에서 사용하는 섹션 용어와 혼동하면 안된다.
- arm64 시스템의 경우 최초 1G를 사용하였지만 조금 더 작은 단위인 128M로 변경하였다.
- 참고: arm64/sparsemem: reduce SECTION_SIZE_BITS (2021, v5.12-rc1)
- 하나의 mem_section 구조체는 PAGES_PER_SECTION 개수 만큼의 page[] 배열을 가리키고 관리한다.
- 메모리 할당 관리를 위해 섹션을 관리하는 mem_section 구조체의 구현이 두 개로 나뉘어 있다.
- SPARSEMEM_STATIC
- 32비트 시스템등 물리 메모리 크기가 작은 시스템에서 mem_secton 구조체를 한꺼번에 컴파일 타임에 생성한다.
- mem_section[][1] 이중 배열이지만 두 번째 인덱스는 사용하지 않는다.
- SPARSEMEM_EXTREME
- 64비트 시스템등 물리 메모리 크기가 큰 시스템에서 mem_secton 구조체를 필요할 때 런타임에 생성하여 사용한다.
- hole size가 매우 큰 경우를 대비하여 메모리 낭비를 줄일 수 있도록 설계되었다.
- **mem_section 이중 포인터를 사용하고, mem_section[SECTIONS_PER_ROOT][SECTIONS_PER_ROOT] 형태로 접근하여 사용하고, 다음과 같이 사용된다.
- 첫 번째 배열 인덱스의 경우 섹션 루트를 의미
- NR_SECTION_ROOTS(섹션 루트 수) = NR_MEM_SECTIONS(전체 메모리에 사용할 섹션 수) / SECTIONS_PER_ROOT(1 페이지 프레임에 들어갈 수 있는 mem_section 구조체 수)
- 두 번째 배열 인덱스는 루트 섹션 내에서의 mem_section 인덱스를 의미
- SECTIONS_PER_ROOT(1 페이지 프레임에 들어갈 수 있는 mem_section 구조체 수)
- 첫 번째 배열 인덱스의 경우 섹션 루트를 의미
- 64비트 시스템등 물리 메모리 크기가 큰 시스템에서 mem_secton 구조체를 필요할 때 런타임에 생성하여 사용한다.
- SPARSEMEM_STATIC
다음 그림은 SPARSEMEM_EXTREME을 사용하지 않는 것으로 32bit arm – Realview-PBX 보드의 사용예이다.
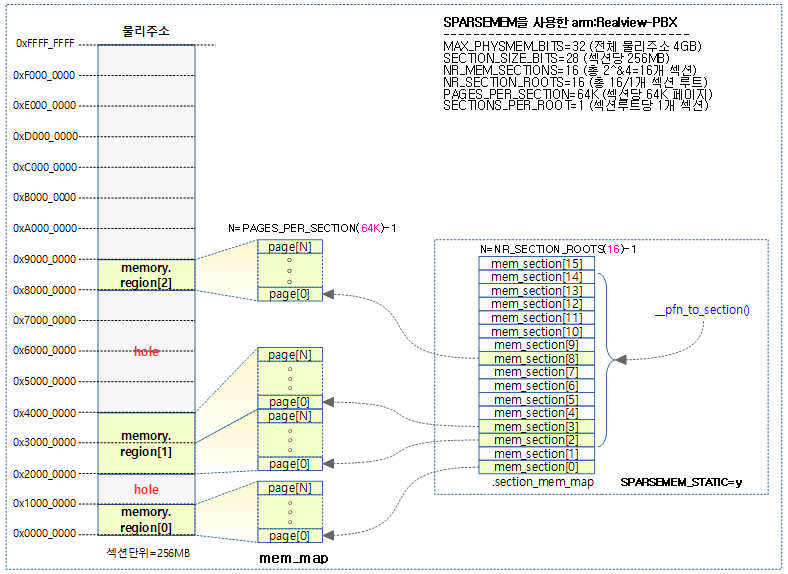
다음 그림은 SPARSEMEM_EXTREME을 사용하는 것으로 arm64 아키텍처에서 4G DRAM을 사용한 예이다.
- 아래에서 섹션 사이즈는 1G를 사용한 예를 보였지만, 최근 128M로 변경하였으므로 커널 버전에 따라 이를 고려하여야 한다.
- 참고: arm64/sparsemem: reduce SECTION_SIZE_BITS (2021, v5.12-rc1)

page 디스크립터
모든 물리 메모리 페이지마다 하나의 페이지 디스크립터가 할당된다. 모든 메모리 페이지마다 생성되므로 사이즈에 민감하다. 따라서 사이즈를 최대한 줄이기위해 페이지 디스크립터내에서 관리되는 멤버들을 유니온 타입으로 묶어 사용하도록 설계되었다.
다음은 32bit 시스템에서 동작하는 page 디스크립터를 보여준다. (모든 옵션을 제외한 최소 구성으로 32바이트를 사용한다.)

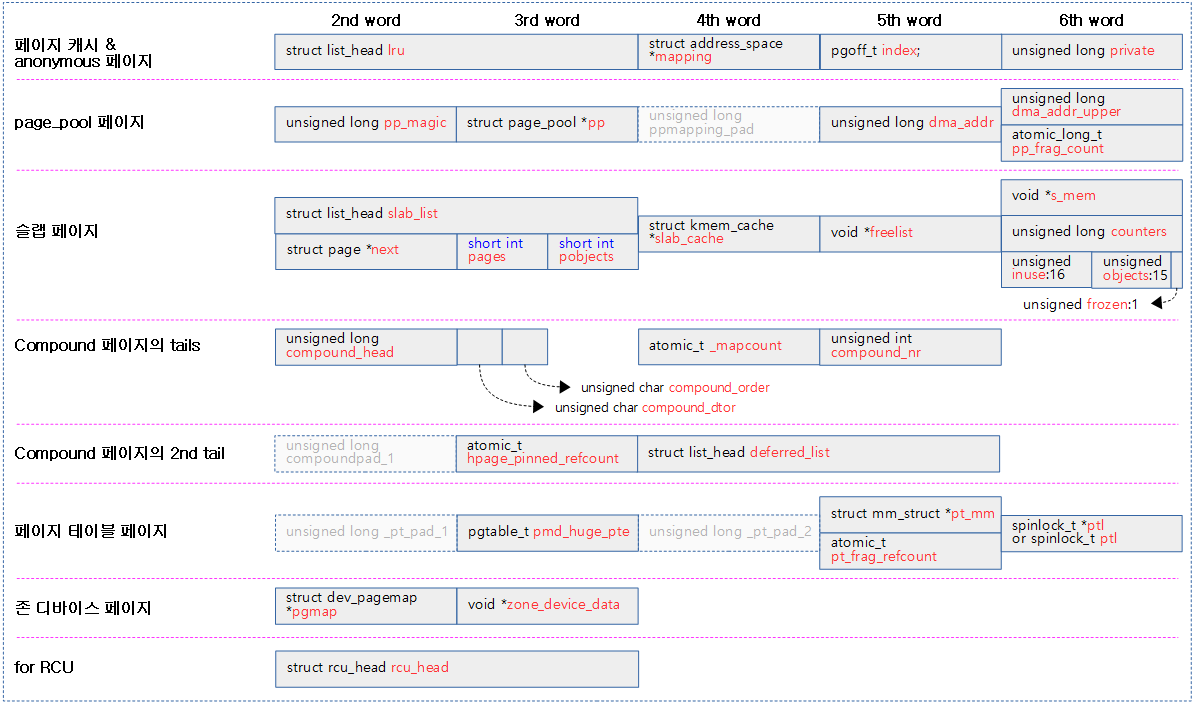
다음은 64bit 시스템에서 동작하는 page 디스크립터를 보여준다. (디폴트 옵션을 사용 시 64바이트이다.)

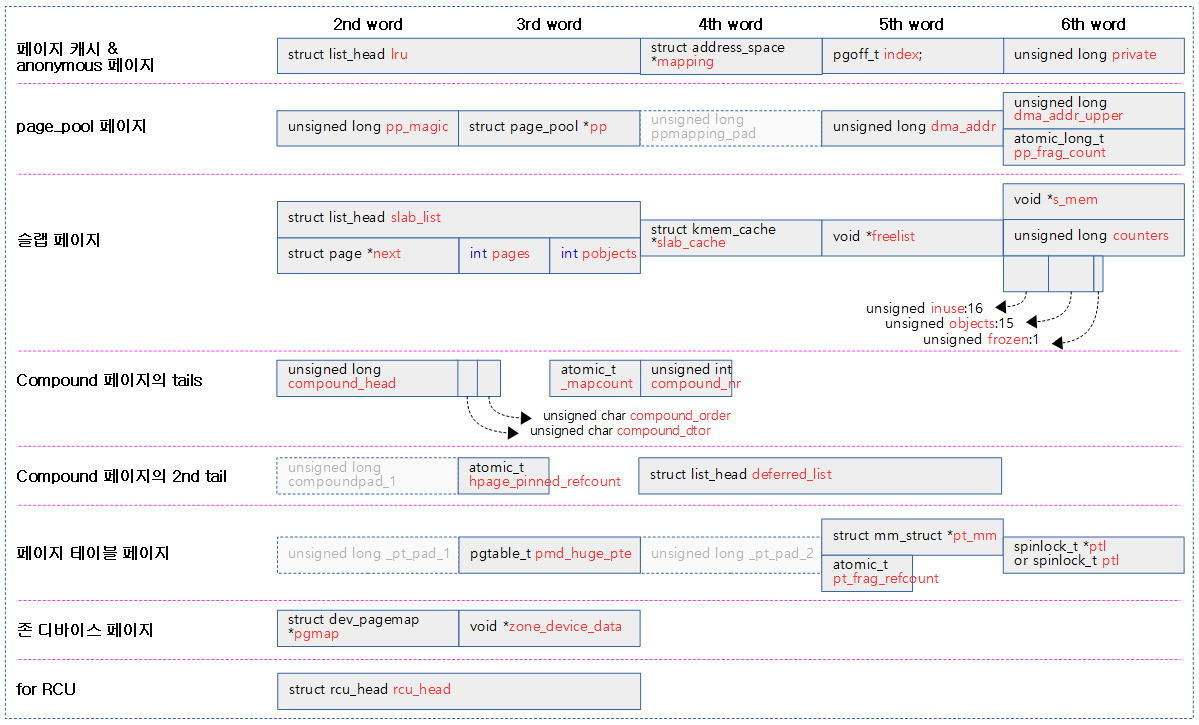
struct page
include/linux/mm_types.h -1/4-
/* * Each physical page in the system has a struct page associated with * it to keep track of whatever it is we are using the page for at the * moment. Note that we have no way to track which tasks are using * a page, though if it is a pagecache page, rmap structures can tell us * who is mapping it. * * If you allocate the page using alloc_pages(), you can use some of the * space in struct page for your own purposes. The five words in the main * union are available, except for bit 0 of the first word which must be * kept clear. Many users use this word to store a pointer to an object * which is guaranteed to be aligned. If you use the same storage as * page->mapping, you must restore it to NULL before freeing the page. * * If your page will not be mapped to userspace, you can also use the four * bytes in the mapcount union, but you must call page_mapcount_reset() * before freeing it. * * If you want to use the refcount field, it must be used in such a way * that other CPUs temporarily incrementing and then decrementing the * refcount does not cause problems. On receiving the page from * alloc_pages(), the refcount will be positive. * * If you allocate pages of order > 0, you can use some of the fields * in each subpage, but you may need to restore some of their values * afterwards. * * SLUB uses cmpxchg_double() to atomically update its freelist and * counters. That requires that freelist & counters be adjacent and * double-word aligned. We align all struct pages to double-word * boundaries, and ensure that 'freelist' is aligned within the * struct. */
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct { /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* lruvec->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
};
struct { /* page_pool used by netstack */
/**
* @pp_magic: magic value to avoid recycling non
* page_pool allocated pages.
*/
unsigned long pp_magic;
struct page_pool *pp;
unsigned long _pp_mapping_pad;
unsigned long dma_addr;
union {
/**
* dma_addr_upper: might require a 64-bit
* value on 32-bit architectures.
*/
unsigned long dma_addr_upper;
/**
* For frag page support, not supported in
* 32-bit architectures with 64-bit DMA.
*/
atomic_long_t pp_frag_count;
};
};
First 워드
- flags
- 페이지 플래그
1) 페이지 캐시 또는 anonymous 페이지
- _lru
- LRU 리스트에 연결될 때 사용한다.
- *mapping
- 유저 매핑 관련 포인터가 담기며 하위 2비트는 이의 용도를 구분하는 플래그로 사용한다.
- 페이지 캐시로 사용되는 경우 address_space 구조체를 가리킨다.
- non-lru movable 페이지들은 address_space 구조체 포인터에 PAGE_MAPPING_MOVABLE 플래그를 추가하여 관리한다.
- 예) zram, balloon 드라이버
- non-lru movable 페이지들은 address_space 구조체 포인터에 PAGE_MAPPING_MOVABLE 플래그를 추가하여 관리한다.
- 유저용 가상 메모리 페이지(anonymous page)인 경우 CONFIG_KSM 커널 옵션 사용 여부에 따라 달라진다.
- KSM 커널 옵션 사용하지 않을 때에는 PAGE_MAPPING_ANON(1) 플래그만 추가되고 anon 매핑 영역인 anon_vma 구조체 포인터를 가리킨다.
- KSM 커널 옵션을 사용하는 경우에는 PAGE_MAPPING_ANON(1) 및 PAGE_MAPPING_MOVABLE(2) 플래그를 추가하고, KSM용 private 구조체 포인터를 가리킨다.
- 페이지 캐시로 사용되는 경우 address_space 구조체를 가리킨다.
- 유저 매핑 관련 포인터가 담기며 하위 2비트는 이의 용도를 구분하는 플래그로 사용한다.
- index
- 매핑 영역안의 offset 값이 담긴다.
- private
- 매핑에 사용하는 private 데이터가 담긴다.
- Private 페이지에서 buffer_heads를 위해 사용된다.
- 스웝 페이지 캐시의 swp_entry_t를 위해 사용된다.
- 버디 페이지의 order가 담긴다.
- 매핑에 사용하는 private 데이터가 담긴다.
2) netstack에서 사용하는 page_pool 페이지
- pp_magic
- 네트워크 page_pool에서 사용하였음을 식별할 목적이다.
- *pp
- page_pool 구조체를 가리키는 포인터이다.
- _pp_mapping_pad
- padding 용도이며 실제 사용되지 않는다.
- dma_addr
- dma 주소
- dma_addr_upper
- 32비트 시스템에서 64비트 DMA를 사용할 때 dma 주소의 하위 32비트는 위의 dma_addr에 저장하고, 상위 32비트는 이 멤버에 저장한다.
- pp_frag_count
- atomic 으로 관리되는 frag 카운터이다.
- 64비트 DMA를 사용하는 32비트 시스템에서는 지원하지 않는다.
include/linux/mm_types.h -2/3-
struct { /* slab, slob and slub */
union {
struct list_head slab_list; /* uses lru */
struct { /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union {
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
struct { /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
unsigned int compound_nr; /* 1 << compound_order */
};
struct { /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
atomic_t hpage_pinned_refcount;
/* For both global and memcg */
struct list_head deferred_list;
};
3) 슬랩(slab, slob, slub) 페이지
- slab_list
- LRU 리스트에 연결될 때 사용한다.
- *next
- partial 페이지를 관리한다.
- pages
- partial 페이지 수가 담긴다.
- 자신을 포함하여 뒤(next)로 연결되어 있는 slub page들의 수가 담긴다.
- partial 페이지 수가 담긴다.
- pobjects
- 대략적인 object 수
- 정확하지는 않지만 대략적으로 내 slub page를 포함한 다음(next) slub page들의 총 free object 수가 담긴다.
- 이 카운터는 종종 free 되는 object들로 인해 정확히 산출되지 않는다
- 대략적인 object 수
- *slab_cache
- 연결된 슬랩 캐시를 가리킨다.
- *freelist
- free 오브젝트들이 대기하는 리스트이다.
- *s_mem
- slab:의 first object를 가리킨다.
- counters
- 아래 32바이트를 한꺼번에 access할 때 사용한다.
- inuse:16
- 사용 중인 object 수.
- objects:15
- 슬랩이 관리하는 object 수
- frozen:1
- per-cpu로 관리하고 있는 슬랩 페이지 여부를 가리킨다.
4) Compound tail 페이지들
참고로 Compound 페이지의 헤드 페이지(page[0])에는 PG_head 플래그가 설정된다.
- compound_head
- compound 페이지의 헤더가 아닌 모든 tail 페이지에서 compound 헤더 페이지 디스크립터 포인터를 담고, bit0를 1로 설정한다.
- compound_dtor
- 첫 번째 tail 페이지(page[1])에 compound 페이지 소멸자 구분 id를 담는다.
- 다음과 같은 compound 페이지 소멸자 id들 중 하나를 담는다.
- NULL_COMPOUND_DTOR
- COMPOUND_PAGE_DTOR
- HUGETLB_PAGE_DTOR
- TRANSHUGE_PAGE_DTOR
- compound_order
- 첫 번째 tail 페이지(page[1])에 compound 페이지의 order가 담긴다.
- compound_mapcount
- 첫 번째 tail 페이지(page[1])에 매핑 카운트 수가 담긴다.
- _compound_pad_1
- 사용하지 않는다.
- _compound_pad_2
- 사용하지 않는다.
- deferred_list
- 두 번째 tail 페이지(page[2])에서 huge 페이지를 분리시킬 때 곧바로 unmap하지 않고 잠시 유예시킬 때 사용한다.
- 참고: thp: introduce deferred_split_huge_page()
include/linux/mm_types.h -3/4-
struct { /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union {
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
};
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
};
struct { /* ZONE_DEVICE pages */
/** @pgmap: Points to the hosting device page map. */
struct dev_pagemap *pgmap;
void *zone_device_data;
/*
* ZONE_DEVICE private pages are counted as being
* mapped so the next 3 words hold the mapping, index,
* and private fields from the source anonymous or
* page cache page while the page is migrated to device
* private memory.
* ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also
* use the mapping, index, and private fields when
* pmem backed DAX files are mapped.
*/
};
/** @rcu_head: You can use this to free a page by RCU. */
struct rcu_head rcu_head;
};
5) 페이지 테이블(pgd, pud, pmd, pte)용 페이지
- _pt_pad_1
- 사용하지 않는다.
- pmd_huge_pte
- huge용 pte 테이블을 가리키는 page 디스크립터 포인터가 담긴다.
- _pt_pad_2
- 사용하지 않는다.
- *pt_mm
- x86 pgds only
- *pt_frag_refcount
- powerpc only
- *ptl or ptl
- 페이지 테이블 spinlock이다.
- spinlock_t 사이즈가 unsigned long 단위에 포함되는 경우 ptl을 사용하고 그렇지 않은 경우 spinlock_t를 할당하고 이를 가리킬 때 *ptl을 사용한다.
6) 존 디바이스 페이지
- *pgmap
- 존 디바이스를 위한 dev_pagemap 구조체 포인터가 담긴다.
- hmm_data
- hmm 디바이스 메모리용 드라이버 데이터가 담긴다.
- _zd_pad_1
- 사용하지 않는다.
include/linux/mm_types.h -4/4-
union { /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
unsigned int active; /* SLAB */
int units; /* SLOB */
};
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
#ifdef CONFIG_MEMCG
unsigned long memcg_data;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... 😉
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
} _struct_page_alignment;
기타-1
아래 _mapcount, page_type, active, units는 페이지 유형에 따라 선택되어 사용되는 union 타입으로 정의되어 있다.
- _mapcount
- 유저에서 사용하는 매핑 카운트
- 여러 개의 유저 공간에 매핑될 때마다 카운터가 증가된다.
- 공유 페이지를 여러 유저 프로세스에서 공유하는 경우 다중 매핑되어 그 수만큼 매핑 카운터가 증가한다.
- page_type
- 유저 매핑 페이지 및 슬랩 페이지를 제외한 나머지 커널 페이지에서 페이지 타입을 지정하여 다음과 같은 플래그를 저장하여 사용한다.
- PG_buddy
- PG_ballon
- PG_kmemcg
- PG_table
- 유저 매핑 페이지 및 슬랩 페이지를 제외한 나머지 커널 페이지에서 페이지 타입을 지정하여 다음과 같은 플래그를 저장하여 사용한다.
- active
- slab: 할당자에서 사용된다.
- units
- slob: 할당자에서 사용된다.
기타-2
- _refcount
- 참조 카운터로 사용자가 직접 액세스하면 안된다.
- memcg_data
- CONFIG_MEMCG 커널 옵션이 사용된 시스템에서 메모리 cgroup을 사용할 때 사용할 obj_cgroup 구조체 포인터가 담기는데 할당 형태에 따라 다음과 같은 2 가지 플래그를 같이 사용한다.
- MEMCG_DATA_OBJCGS
- MEMCG_DATA_KMEM
- CONFIG_MEMCG 커널 옵션이 사용된 시스템에서 메모리 cgroup을 사용할 때 사용할 obj_cgroup 구조체 포인터가 담기는데 할당 형태에 따라 다음과 같은 2 가지 플래그를 같이 사용한다.
- *virtual
- WANT_PAGE_VIRTUAL 커널 옵션을 사용하는 경우 highmem을 사용하는 일부 32비트 아키텍처에서 highmem 페이지가 커널 주소 공간에 매핑된 경우 매핑된 커널 가상 주소가 담긴다.
- ARM32의 경우 HASHED_PAGE_VIRTUAL을 사용한다.
- highmem 페이지를 매핑 시 page_address_map 구조체를 별도로 할당하여 사용하므로 이 멤버를 사용하지 않는다.
- 64비트 시스템들은 highmem을 사용하므로 이 멤버를 사용할 필요 없다.
- _last_cpupid
- 페이지의 flags 멤버에 cpu 및 pid를 담아야 하는데 32비트 시스템에서 32비트에 모두 포함시킬 수 없는 경우가 있다. 이러한 경우 LAST_CPUPID_NOT_IN_PAGE_FLAGS 커널 옵션을 사용하여 이 멤버에 마지막 사용한 cpu 및 pid를 담는다. 이들은 NUMA 밸런싱을 위해 사용된다.
- 64비트 시스템들은 flags 멤버를 사용하여 last cpu 및 pid 정보를 저장하므로 이 멤버를 사용할 필요 없다.
참고
- Memory Model -1- (Basic) | 문c
- Memory Model -2- (mem_map) | 문c – 현재 글
- Memory Model -3- (Sparse Memory) | 문c
- Memory Model -4- (APIs) | 문c
- ZONE 타입 | 문c
- bootmem_init | 문c
- zone_sizes_init() | 문c
- NUMA -1- (ARM64 초기화) | 문c
- build_all_zonelists() | 문c
- Memory: the flat, the discontiguous, and the sparse(2019) | LWN.net
- Generic page-pool recycle facility? (2016) | Jesper Dangaard Brouer – 다운로드 pdf
제가 정확히 이해를 못한것 같은데요.
page 구조체를 알고 있을때 해당 page 구조체가 가리키는 physical memory, 즉 page frame #는 어떻게 알수 있는지 궁금합니다.
안녕하세요? 문c 블로그의 문영일입니다.
page_to_pfn() API를 사용하여 해당 페이지를 가리키는 page 구조체 포인터로 pfn(page frame number)을 알아올 수 있습니다.
반대의 역할을 수행하는 API는 pfn_to_page() API 입니다.
수고하세요.
안녕하세요 좋은글 잘 읽어보고 있습니다.
mm-7b, mm-9a 그림이 없습니다.
그림 다시 포함시켰습니다.
알려주셔서 감사합니다.
안녕하세요. 혹시 리눅스 부팅 시에 메모리가 어떻게 초기화 되는지 알 수 있을까요? (mem_map 배열 등.) 저런 배열을 할당하려 해도 메모리 할당 정책이 필요할텐데.. 맨 처음에 어떻게 초기화 시키는지가 궁금합니다.
안녕하세요?
리눅스 부팅 후 사용되는 대표적인 메모리 할당 시스템은 buddy, slab, per-cpu, cma, … 등이 있습니다.
이를 초기화하여 운용하기 전에는 memblock을 사용하여 영역 정보만을 관리하고 있습니다.
메모리 할당자를 사용하기 전에 memblock을 통해 미리 필요한 영역을 reserve하여 등록하고, 사용할 때에는 원시적으로 직접 해당 주소 영역에 직접 기록하는 방법을 사용합니다. 그런 후 추후 페이지 할당자인 buddy 시스템을 준비할 때 그 reserve 영역을 피한 나머지 메모리 영역만 buddy 시스템에 free 페이지로 등록하여 사용합니다.
감사합니다.