<kernel v5.4>
RCU 기초
RCU History
- RCU는 읽기 동작에서 블러킹 되지 않는 read/write 동기화 메커니즘
- 2002년 커널 버전 2.5.43에서 소개됨
- 2005년 PREEMPT_RCU가 추가됨
- 2009년 user-level RCU도 소개됨
장/단점
RCU는 read-side overhead를 최소화하는데 목적이 있기 때문에 동기화 로직이 읽기 동작에 더 많은 비율로 사용되는 경우에만 사용한다. 수정(Update) 동작이 10%이상인 경우 오히려 성능이 떨어지므로 RCU 대신 다른 동기화 기법을 선택해야 한다.
- 장점
- read side overhead가 거의 없음. zero wait, zero overhead
- rcu non-preempt 커널 모델인 경우 zero wait 이지만, rcu preemptible 커널 모델의 경우 태스크 구조체의 rcu_read_lock_nesting 카운터를 증감시켜 사용하므로 zero wait은 아니고 그래도 빠른 편이다.
- deadlock 이슈 없음
- priority inversion 이슈 없음 (priority inversion & priority inheritance)
- unbounded latency 이슈 없음
- 메모리 leak hazard 이슈 없음
- read side overhead가 거의 없음. zero wait, zero overhead
- 단점
- 사용이 약간 복잡
- 쓰기 동작에서는 다른 동기화 기법보다 조금 더 느리다.
RCU 구현 옵션
- Classical RCU – a.k.a tiny RCU
- CONFIG_TINY_RCU 커널 옵션
- single 데이터 스트럭처
- CPU가 많아지는 경우 성능 떨어짐
- 현재 커널이 SMP가 아니고 non-preemptible로 빌드된 경우 디폴트로 선택되는 RCU 옵션이다.
- Hierarchical RCU – a.k.a tree RCU
- CONFIG_TREE_RCU 커널 옵션
- tree 확장된 RCU 구현
- 현재 커널이 SMP이고 non-preempt-able로 빌드된 경우 디폴트로 선택되는 RCU 옵션이다.
- Preemptible tree-based hierarchical RCU
- tree 확장된 RCU 구현이면서 preemptible(CONFIG_PREEMPT_RCU 커널 옵션)을 사용하는 최근 linux kernel의 기본 RCU이다. (코드 분석에서 이 모델을 우선)
- read-side critical section에서 preemption이 지원된다. (주의: 그렇다고 슬립 api를 사용하면 안된다)
- SRCU
- CONFIG_SRCU 커널 옵션을 추가하고 RCU API 대신 별도의 SRCU API를 사용하는 경우 read-side critical section에서 sleep api를 사용할 수 있다.
- rcu_read_lock() -> srcu_read_lock()
- CONFIG_SRCU 커널 옵션을 추가하고 RCU API 대신 별도의 SRCU API를 사용하는 경우 read-side critical section에서 sleep api를 사용할 수 있다.
- URCU
- Userspace RCU (liburcu)
RCU 구현 옵션 선택
RCU를 선택하여 사용할 때 커널 옵션은 일반적으로 다음과 같이 나누어 선택할 수 있다.
- CONFIG_TINY_RCU
- 조건: !PREEMPTION && !SMP
- footprint가 작은 시스템에서 운영할 때 적절하다.
- CONFIG_TREE_RCU
- 조건: !PREEMPTION && SMP
- SMP 시스템이고 서버로 운영할 때 적절하다.
- CONFIG_PREEMPT_RCU (기존 CONFIG_TREE_PREEMPT_RCU)
- 조건: PREEMPTION
- 빠른 응답을 요구하는 임베디드 시스템에서 운영할 때 적절하다.
- 커널 v5.6-rc1 부터 이 옵션이 없이 위의 CONFIG_TREE_RCU 만으로 동작하게 변경하였다.
추가적으로 절전을 요구하는 시스템에서 다음과 같은 설정을 사용한다.
- CONFIG_RCU_FAST_NO_HZ=y
- CONFIG_RCU_NOCB_CPU=y
더 자세한 커널 파라메터 설정은 다음 문서를 참고한다.
RCU 성능
reader-side에서의 성능 비교 (rwlock vs RCU)

(통계: lwn.net 참고)
리눅스 커널에서의 사용율 증가
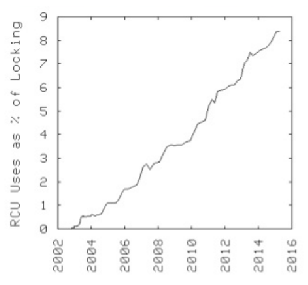
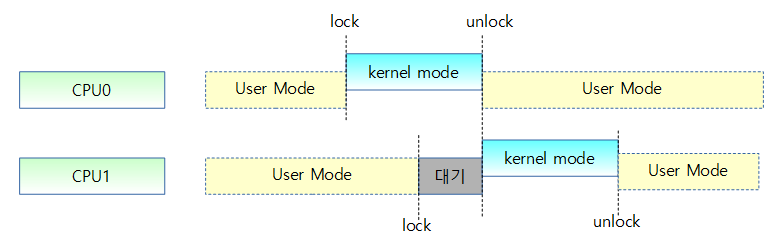
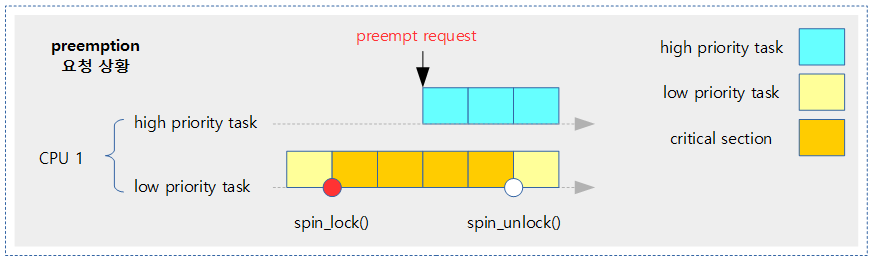
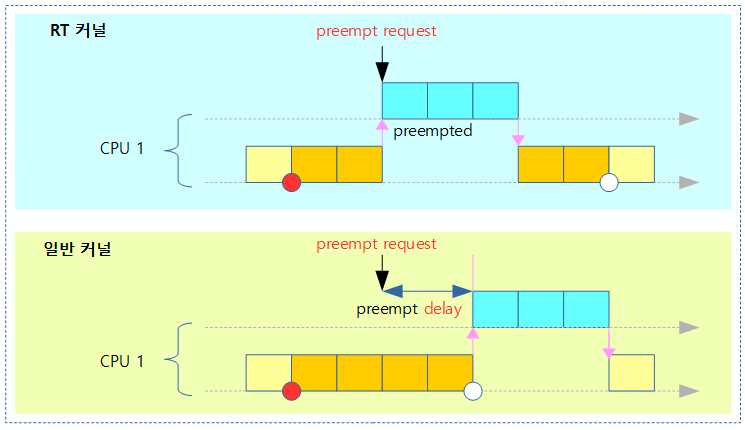
일반 lock 획득시의 나쁜 성능
- lock 획득하는데 소요하는 자원이 critical section을 수행하는 것에 비해 수백배 이상 over-head가 발생한다.
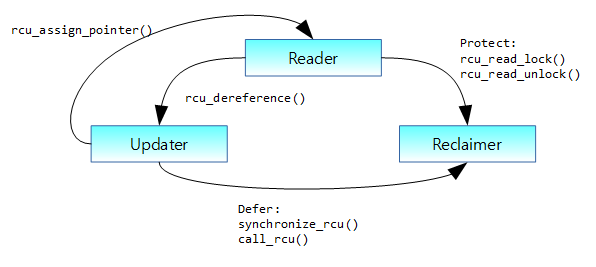
RCU 기본 요소
RCU는 다음과 같이 3가지의 기본 요소와 특징이 있다.
- Reader
- rcu_read_lock()과 rcu_read_unlock() 코드 범위의 Read-side critical section이다.
- 접근에 대한 주의
- 가장 주의 할 것으로 보호 받아야 할 데이터(protected rcu data)에 접근할 때 항상 이 영역내에서만 접근하여야 한다.
- 이 영역을 벗어난 사용은 RCU 규칙을 벗어나는 것이며 존재하지 않는 자료 또는 잘못된 데이터로의 접근이될 수 있다.
- 실제 보호 받아야 할 데이터에 접근하기 전에 메모리 배리어를 사용한 후에 참조하여야 한다.
- rcu_dereference() 매크로 함수를 사용하면 간단하다.
- 구현에 따른 차이
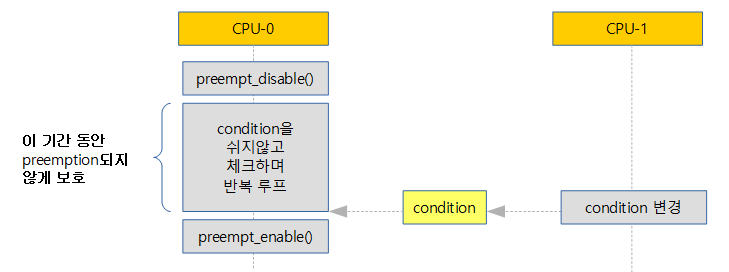
- non-preemptible RCU 커널을 사용하는 경우에는 read_rcu_lock() 내부에서 preemption을 금지하는 코드만 적용된다. sleep하는 blocked api를 사용하면 안되고 가급적 빨리 빠져나와야 한다.
- preemptible RCU 커널을 사용하는 경우에는 read_rcu_lock() 내부에서 로컬 카운터를 증가시키고 read_rcu_unlock() 내부에서 로컬 카운터를 감소시킨다. read-side critical section 내에서 preemption될 수 있다. 만일 SRCU 커널 옵션도 사용하는 경우 sleep 가능한 blocked api의 사용도 가능하다.
- Updater
- 기존의 여러 가지 락 중 하나를 사용하여 데이터를 보호하고 수정한다.
- 실제 보호 받아야 할 데이터에 접근하기 전에 메모리 배리어를 사용한 후에 참조하여야 한다.
- rcu_dereference() 및 rcu_assign_pointer() 매크로 함수를 사용하면 간단하다.
- 보호 받을 자료를 복사하여 수정한 후 기존 자료의 회수(free)를 위해 동기 함수인 synchronize_rcu() 또는 비동기 함수인 call_rcu() 함수를 호출하여 아래의 reclaimer를 동작하게 하다.
- 이 구성요소에서 Read, Copy, Update 과정을 사용한다.
- Reclaimer
- Update에서 최종 수정한 객체가 아닌 사용이 완료된 객체들에 대해 cleanup한다.
- 안전하게 cleanup되도록 삭제할 데이터에 접근하는 Reader 들이 없음을 보장하기 위해 Grace period가 지난 후에 Reclaimer가 동작한다.
RCU 기본 API
RCU에는 5개의 기본 API가 사용된다.
- rcu_read_lock()
- read side critical section의 시작 부분에 사용되어야 한다.
- rcu_read_unlock()
- read side critical section의 끝 부분에 사용되어야 한다.
- rcu_assign_pointer()
- 일반 object 포인터를 rcu 보호 포인터에 지정할 때 사용한다.
- 내부 구현에서 일반 object 포인터와 rcu 보호 포인터 사이에 메모리 베리어가 사용된다.
- rcu_dereference()
- rcu 보호 포인터로부터 일반 object 포인터를 알아올 때 사용한다.
- 내부 구현에서 rcu 보호 포인터와 일반 object 포인터 사이에 메모리 베리어가 사용된다.
- synchronize_rcu() & call_rcu()
- synchronize_rcu()
- sync 방식으로 GP(Grace Period)가 끝나기를 기다린다.
- call_rcu()
- async 방식으로 GP(Grace Period)가 끝나면 호출되도록 함수를 지정하여 사용한다.
- synchronize_rcu()
RCU 기본 API만을 사용한 단순 접근 방법
Reader: RCU node를 사용할 때
- Read side critical section의 시작은 rcu_read_lock()으로 시작한다.
- non-preemptible RCU 커널을 사용하는 경우에는 이 구간에서 preemption을 금지시킨다.
- 이 영역에서는 sleep하는 blocked api를 사용하면 안되고 가급적 빨리 빠져나와야 한다.
- preemptible RCU 커널을 사용하는 경우에는 로컬 카운터를 증가시킨다.
- 이 영역에서도 preemption이 가능하다. 그러나 내부에서 sleep이 가능한 block-api를 사용하면 안된다.
- non-preemptible RCU 커널을 사용하는 경우에는 이 구간에서 preemption을 금지시킨다.
- 실제 보호 받아야 할 데이터에 접근하기 전에 메모리 배리어를 사용한 후에 참조하여야 하는데 이를 쉽게 할 수 있도록 rcu_dereference()와 같은 매크로 함수를 사용하면 편리하다. 이를 사용하여 안전하게 dereference된 RCU-protected pointer 값을 얻어온다.
- read critical section을 완료하면 더 이상 dereference된 pointer를 사용할 수 없으므로 이 포인터를 이용하여 얻어올 해당 자료의 l-value 값 들을 읽어온다.(구조체 전체를 복사하여 가져오거나…)
- Read side critical section의 끝은 read_rcu_unlock() 함수로 완료한다.
- non-preemptible RCU 커널을 사용하는 경우에는 preemption를 다시 허용시킨다.
- preemptible RCU 커널을 사용하는 경우에는 로컬 카운터를 감소시킨다.
다음 동기화되어 보호받아야 할 데이터의 멤버 a를 얻어오는 코드를 확인한다. (preemptible rcu)
- 글로벌 참조 카운터의 증가는 conceptual한 것이다.
- 실제 구현에서의 참조카운터 증가는 현재 태스크 디스크립터에 저장된다. 태스크 디스크립터는 캐시 되어 있을 것이므로 매우 빠른 액세스가 보장된다.
- (p->rcu_read_lock_nesting)

int foo_get_a(void)
{
int retval;
rcu_read_lock();
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock();
return retval;
}
Updater: RCU node의 수정
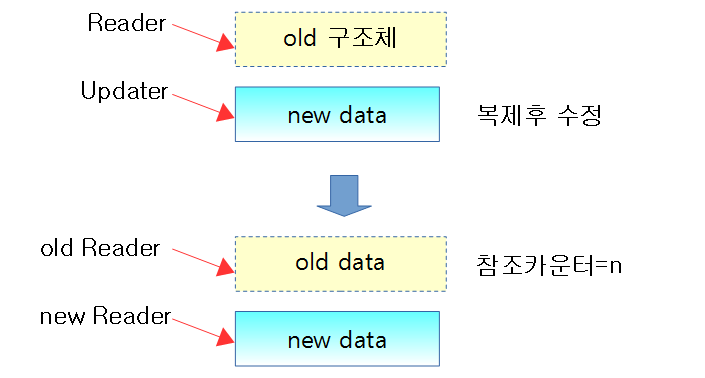
- 기존 노드 데이터를 곧바로 수정하지 않고 복사(Read-Copy)한 후 그 복사한 자료를 수정(Update)해야 하므로 준비 과정으로 새로운 노드 데이터를 먼저 할당한다.
- Write side critical section의 시작은 기존 lock 중 적절한 하나를 사용한다.
- rcu_dereference_protected() 매크로 함수를 사용하여 매모리 배리어를 사용한 후 안전하게 노드를 가리키는 포인터를 얻어온다.
- 기존 노드 데이터에 대한 직접 수정은 금지된다. 곧바로 수정하지 않고 복사한 후에 수정 작업을 진행해야 다른 Reader 들이 안전하게 기존 노드 데이터를 사용할 수 있다.
- rcu_assign_pointer()를 사용하여 먼저 매모리 배리어를 사용한 후 안전하게 노드 포인터를 교체한다.
- 교체가 완료되었으면 Write side critical section의 끝으로 사용한 lock을 닫는다.
- 마지막으로 기존 노드 메모리 삭제를 위해 다른 Reader 들이 접근하지 않는 것이 보장되는 시간에 기존 노드 메모리를 삭제할 수 있도록 rcu 동기 또는 비동기 호출을 한다.
- call_rcu:
- rcu 비동기 호출로 non-blocking 함수이다.
- 모든 기존 RCU read-side critical sections들이 끝나면 인수로 요청한 함수를 호출한다.
- synchronize_rcu():
- rcu 동기 호출로 blocking 함수이다.
- 모든 기존 RCU read-side critical sections들이 끝날 때까지 이 함수내에서 기다리며 그 후 인수로 요청한 함수를 호출한다.
- call_rcu:
아래 그림과 같이 기존 노드를 안전하게 수정하기 위해 복제 후 수정하고 기존 노드는 삭제 요청한다.
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = rcu_dereference_protected(gbl_foo,
lockdep_is_held(&foo_mutex));
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
call_rcu(&old_fp->rcu, foo_reclaim);
}
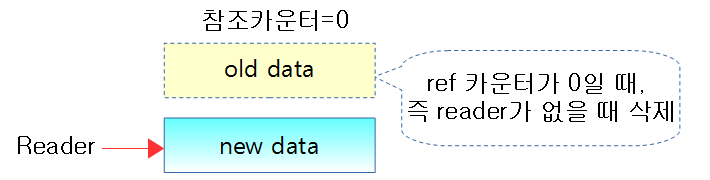
Reclaimer: RCU node 사용 완료 후 폐기
- 기존 데이터의 다른 Reader 들에 의해 사용되지 않음이 확인되면 grace periods 이후에 삭제하여 메모리를 회수한다.
- 참조 카운터가 0이되면 삭제하는 것은 conceptual한 것이다. 글로벌 참조 카운터를 atomic하게 업데이트하는 구조(spin-lock)의 동기화를 사용하지 않아야 하므로 실제 구현은 더 복잡한다.
void foo_reclaim(struct rcu_head *rp)
{
struct foo *fp = container_of(rp, struct foo, rcu);
foo_cleanup(fp->a);
kfree(fp);
}
리스트에서의 RCU 사용
list 전용 API를 사용하여 간단히 interation을 할 수 있다. iteration 중에 방향(direction)을 바꿀 수는 없다.
Reader: RCU node를 사용할 때
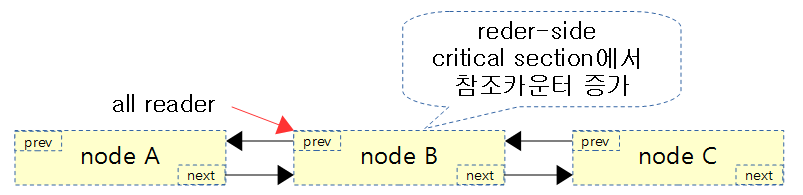
void disp_foo(void)
{
rcu_read_lock();
list_for_each_entry_rcu(p, head, list) {
disp_foo();
}
rcu_read_unlock();
}
Updater: RCU node의 수정
- list_replace_rcu()를 수행한 순간 역방향 연결은 끊어진 반면 순방향 연결은 계속 살아있다.
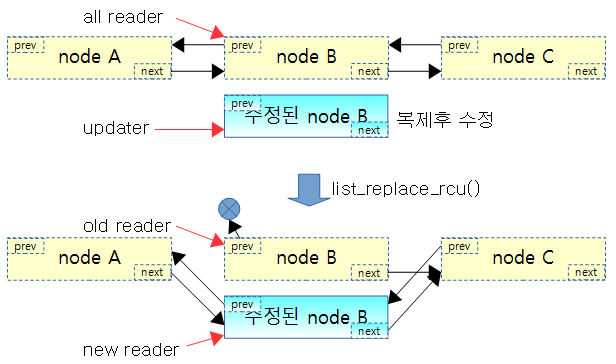
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp = search(head, key);
if (old_fp == NULL) {
/* Take appropriate action, unlock, and return. */
}
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
*new_fp = *old_fp;
new_fp->a = new_a;
list_replace_rcu(&old_fp->list, &new_fp->list);
call_rcu(&old_fp->rcu, foo_reclaim);
}
static inline void list_replace_rcu(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->prev = old->prev;
rcu_assign_pointer(list_next_rcu(new->prev), new);
new->next->prev = new;
old->prev = LIST_POISON2;
}
Reclaimer: RCU node 사용 완료 후 폐기
- Grace periods를 지난 후 삭제 대상 노드를 모두 clean-up한다.
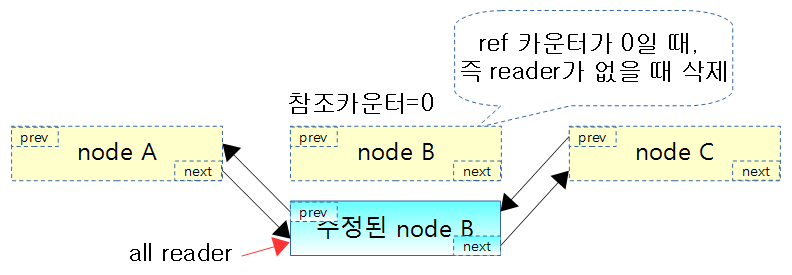
void foo_reclaim(struct rcu_head *rp)
{
struct foo *fp = container_of(rp, struct foo, rcu);
foo_cleanup(fp->a);
kfree(fp);
}
GP(Grace Period)
사용자는 특정 자료의 동기화를 위해 두 가지의 관점에서 처리한다.
- 읽기 처리만 수행하는 read-side critical section이 있고 이를 Reader로 부른다.
- 변경 처리가 포함된 write-side critical section이 있고 이를 Updater 또는 Writer로 부른다.
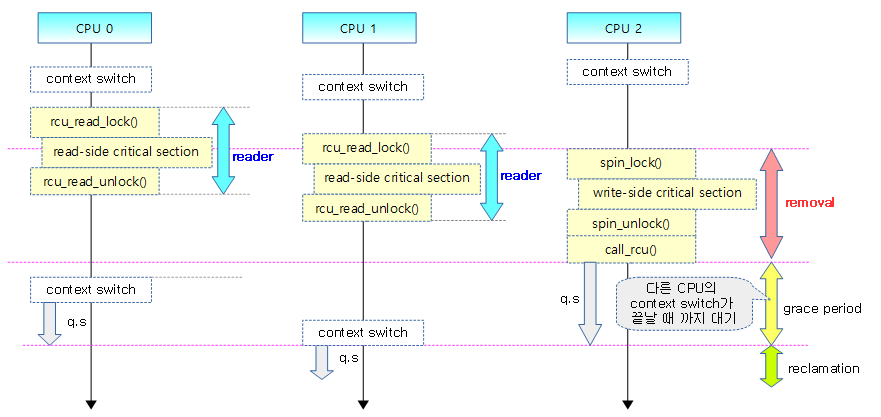
Writer 발생되는 시점, 즉 write-side critical section 부터 시작되는 구간 3가지를 정리해보았다.
- Removal 구간: write-side critical section 구간에서는 읽어서(Read() 사본(Copy)을 만들고 변경(Update) 작업을 한다.
- Grace Period 구간: Removal을 수행하는 자료에 관련된 Reader들의 처리가 완료됨을 보장할 수 있도록 대기하는 구간이다.
- Reclamation 구간: 기존 사본을 원본에 적용하는 구간이다.
Removal(Read-Copy-Update)이 진행되는 동안 해당 데이터에 접근하고 있는 Reader들을 보호하기 위해 Removal은 기존 Reader들이 접근하고 있는 자료는 곧바로 수정하지 않고 이를 먼저 Copy한 후 Update하여 사용한다. 결국 Reader들은 원본 자료에만 접근하므로 안전하게 데이터에 접근할 수 있다.
Removal이 완료된 후 작업된 사본을 원본에 반영해야 하는데 곧바로 반영하면 각 cpu에서 동시에 처리되고 있는 Reader들에 문제가 발생한다. 따라서 Removal 기간 동안 같은 자료에 접근한 Reader들의 처리가 모두 완료될 때까지 기다려야 하는데 이 구간을 GP라고 한다.
GP의 완료를 인지하면 사본을 원본에 반영하고 필요 없어진 자료는 폐기하는 Reclamation 구간이 시작된다. 이러한 처리들은 RCU의 후CB(Call-Back) 함수를 리스트에 보관해 두었다가 Reclamation 구간에서 호출하여 처리한다.
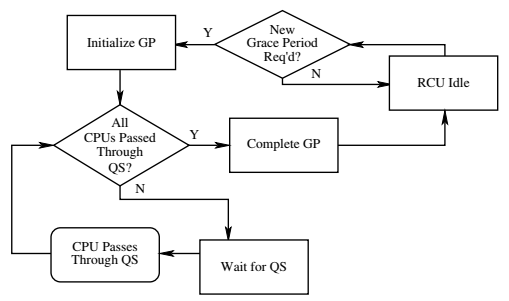
다음 그림을 보고 Writer에 의해 발생되는 3가지 구간을 확인한다. 아래의 Grace Period는 conceptual한 의미이고, Min Grace Period로 불린다. Removal 기간 중 관련된 Reader들의 끝 부분이 곧바로 인식되지 않으므로 Grace Period가 끝나는 지점을 감지(detection) 하는 방법을 사용한다.
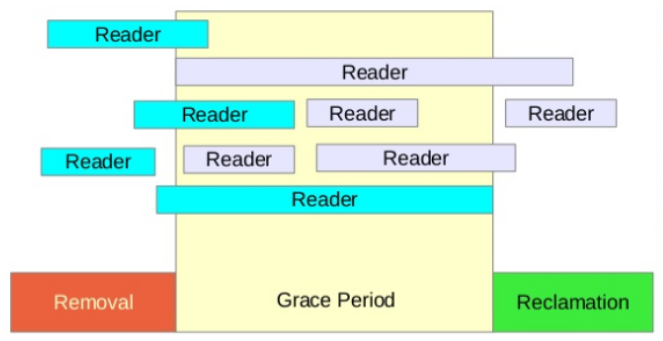
Grace Period의 종료 감지
커널이 Min Grace Period가 완료됨을 곧바로 인식하지 못하므로 실제 GP가 완료된 것을 감지하는 것은 특수한 기법이 필요하다. Reader(read-side critical section) 구간에서 성능을 저하시키는 추가 작업을 하지 않는 것이 핵심이므로 이 구간이 완료됨을 알아내기 위해 모든 cpu들이 QS(Quiescent State) 상태를 지나간 경우 GP가 완료된 것으로 판정한다.
- preemptible RCU를 사용하는 시스템의 경우 GP 종료는 아래 그림의 모든 QS의 완료이외에도 추가로 read-side critical section내에서 preemption된 태스크의 복귀 상태도 확인한다.
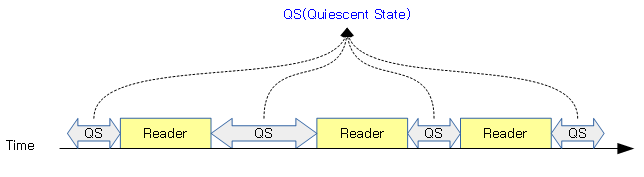
QS(Quiescent State)
QS(Quiescent State)는 Reader 간의 사이 시간 상태로 GP 구간 전 이미 진행되고 있었던 Reader의 구간이 끝난 것을 인지할 목적으로 사용한다. QS 상태가 패스되었는지 확인하는 방법은 여러 가지가 사용되며 특히 preemption 커널 모델에 따라 조금씩 상이하다. 더 자세한 것은 다음 글의 “Quiscent State 체크 & 리포트”를 참조한다.
RCU non-preemptible 커널
- context switch
- context switch 발생 시 해당 cpu를 q.s로 체크한다.
- 유저 모드 또는 idle에서 스케줄 틱
- 유저 태스크 수행 중이거나 idle 중인 경우 해당 cpu를 q.s로 체크한다.
- softirqd 실행 중
- 현재 cpu에서 동작 중인 태스크가 softirqd인 경우 q.s로 체크한다.
- voluntry 커널에서 cond_resched() 사용
- preemption pointer 중 하나인 cond_resched() 사용 시 해당 cpu를 q.s로 체크한다.
- voluntry 커널에서 cond_resched_tasks_rcu_qs() 사용
- cb용 gp 커널 스레드 또는 nocb용 콜백 처리 루틴의 long loop에서 이 함수를 사용 시 해당 cpu를 q.s로 체크한다.
다음 그림과 같이 conceptual 수준에서의 QS는 Reader들 간의 시간으로 각 QS는 기존 Reader의 처리가 완료되었음을 보장하는 기간이다.
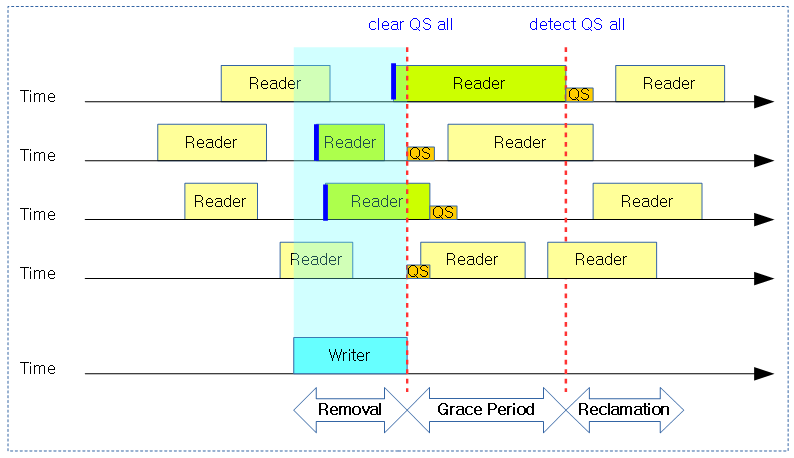
Candidate Quiescent State & Observed Quiescent State
다음 그림은 Min GP 이후 detect된 Q.S가 검정색 원으로 표시되었다. 각 cpu의 Q.S가 검출되면 실제 GP가 완료되었음을 알 수 있다.

조금 더 conceptual 수준을 구현 레벨로 약간 확장해보면 Write가 끝나면 GP가 시작하는데 이 때 각 cpu의 QS 상태를 모두 클리어한다. 그 후 모든 cpu의 QS가 한 번 이상 패스되면 GP가 끝나고 Reclamation이 진행된다.
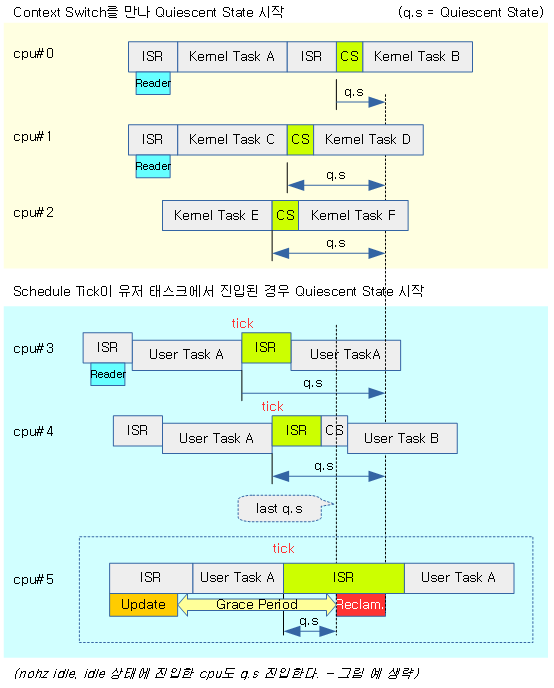
다음 그림은 커널에서 실제 구현 레벨에서 QS 인지를 하는 과정을 보여준다. RCU Reader 이후 곧바로 cpu가 Quiescent State로 변경되는 것이 아니라 context switch 등이 일어났음을 알 수 있는 포인트에서 Quiescent State가 시작한다.
- 구현 레벨이 상당히 복잡하므로 아래 그림만 보아서는 쉽게 이해가 가지 않을 수 있다.
- cpu#0번의 경우를 먼저 살펴보자. conceptual 레벨과 다르게 실제 구현에서는 reader가 완료되자마자 q.s를 인식하지 못한다. 유저 태스크에 진입하면 q.s가 시작하지만 GP가 시작됨과 동시에 q.s가 모두 클리어되었었음을 기억해야 한다. 때문에 다른 태스크의 전환을 수행하는 context switch를 통해 q.s를 인지하게 된다.
- cpu#3번을 보면 역시 reader가 끝난 후 유저 태스크에 진입하는 것으로 q.s가 시작됨을 알 수 있다. 이 또한 GP가 시작됨과 동시에 클리어되고 스케줄 틱이 발생하여 q.s를 인지하게된다.
- cpu#5번의 경우 q.s를 인지하였고 모든 cpu의 q.s가 설정되었음을 알게되었다. 이 때 Reclamation 구간이 시작된다.
Force Quiescent State
GP가 시작된 후 각 cpu의 qs를 대기하는데 너무 오랫동안 gp가 끝나지 않으면 강제로 qs를 패스상태로 만든다.
Brute-Force RCU GP
synchronize_rcu() 함수를 호출하여 gp가 완료되어 동기화를 요청하면 gp가 완료할 때까지 기다린 후 콜백들을 처리한다. 만일 수천 개의 cpu가 가동되는 시스템에서 이러한 요청이 있으면 매우 오랜 시간을 대기해야 하는데 cpu를 그룹별로 묶어 파티셔닝하여 처리하는 구현 방법으로 빠른 처리를 사용하는 방법이 있다. 이 기능은 preemptible rcu 커널 옵션을 사용할 때 synchronize_rcu() 함수의 사용에 대한 급행처리를 할 수 있게하는 기능이다.
Deferrable QS
preemptible RCU의 경우 rcu_read_unlock() 시 해당 cpu의 interrupt, bh(softirq), preemption이 하나라도 disable되어 있는 경우 deferred qs로 보고한다.
- deferred qs로 보고된 이후 해당 cpu의 interrupt, bh(softirq) 및 preemption이 모두 enable됨을 확인한 경우 qs가 보고된다.
- 참고: rcu: Defer reporting RCU-preempt quiescent states when disabled (2018, v4.20-rc1)
RCU 콜백 처리
3가지 rcu_state
rcu는 스케줄 틱마다 콜백을 처리하기 위해 설계되었고, 한동안 각각의 gp를 관리하는 3개의 state에서 관리하였다가 최근에는 1개의 state로 통합되었다.
통합전
- rcu_sched
- rcu read-side critical section 내에서 preemption되는 것을 막아야 하는 상황에서 사용되며, rcu 콜백은 rcu_sched용 gp가 끝난 후에 처리된다.
- rcu_bh
- DDOS attack 상황에서 OOM(Out Of Memory)이 발생하는 것을 방지하기 위해 softirq를 사용하는 네트워크 처리 시 rcu_bh 상태를 추가하여 별도로 관리하는 gp가 끝난 후에 처리한다.
- rcu_preempt
- preemptible 커널에서 read side critical 섹션 내에서 preemption을 허용하는 방식을 지원하기 위해 별도록 관리하는 gp가 끝난 후에 처리한다.
통합후
- rcu_preempt
- preemptible 커널을 사용하는 경우 read side critical 섹션 내에서 preemption을 허용한다.
RCU 콜백
synchronize_rcu() & call_rcu()
- RCU updater가 콜백 요청을 하는데 모든 RCU read-side critical sections들이 끝난 후에 즉, gp가 끝난 후에 콜백이 처리되기를 기다린다.
- read-side critical section 사용시 규칙: 모든 read-side critical section 즉 rcu_read_lock() 과 rcu_read_unlock()사이에는 block or sleep되면 안된다. (SRCU는 가능하다)
- 모든 CPU의 context switch가 완료되면 RCU read-side critical section period는 완전히 끝난것으로 보장할 수 있게 되므로 모든 read-side critical section들이 안전하게 끝난것을 의미한다.
- 삭제될 old 데이터들은 다른 Reader가 참조하고 있는 동안(Grace Period) 삭제 보류된 채로 있다가 old data를 참조하는 마지막 Reader의 사용이 끝나면 Reclamation을 진행하게 된다.
read-side critical section period 보장
- qs는 위에서 언급하였듯이 context switch이외에도 user 모드 또는 idle 시 스케줄 틱이 호출된 경우도 qs가 패스된다.
- 모든 cpu의 qs가 패스되면 gp가 완료되어 reclmation이 진행된다.
- preemptible rcu 구현이 추가되어 조금 더 복잡해졌다.
- 최대 두 번의 gp가 완료되어야 reclamation이 진행될 수도 있다.
RCU NO-CB
절전 기능을 위해 콜백들을 인터럽트 context에서 호출하지 않고 별도의 cpu에 전용 no-cb 처리용 커널 스레드를 생성하여 운영하는 방법이다.
기존 rwlock 구현 소스를 rcu 구현 소스로 변경 예제
struct el {
struct list_head list;
long key;
spinlock_t mutex;
int data;
};
spinlock_t listmutex;
struct el head;
search()
int search(long key, int *result)
{
struct list_head *lp;
struct el *p;
read_lock();
list_for_each_entry(p, head, lp) {
if (p->key == key) {
*result = p->data;
read_unlock();
return 1;
}
}
read_unlock();
return 0;
}
int search(long key, int *result)
{
struct list_head *lp;
struct el *p;
rcu_read_lock();
list_for_each_entry_rcu(p, head, lp) {
if (p->key == key) {
*result = p->data;
rcu_read_unlock();
return 1;
}
}
rcu_read_unlock();
return 0;
}
delete()
int delete(long key)
{
struct el *p;
write_lock(&listmutex);
list_for_each_entry(p, head, lp) {
if (p->key == key) {
list_del(&p->list);
write_unlock(&listmutex);
kfree(p);
return 1;
}
}
write_unlock(&listmutex);
return 0;
}
int delete(long key)
{
struct el *p;
spin_lock(&listmutex);
list_for_each_entry(p, head, lp) {
if (p->key == key) {
list_del_rcu(&p->list);
spin_unlock(&listmutex);
synchronize_rcu();
kfree(p);
return 1;
}
}
spin_unlock(&listmutex);
return 0;
}
RCU API 목록
RCU list traversal:
- list_entry_rcu
- list_first_entry_rcu
- list_next_rcu
- list_for_each_entry_rcu
- list_for_each_entry_continue_rcu
- hlist_first_rcu
- hlist_next_rcu
- hlist_pprev_rcu
- hlist_for_each_entry_rcu
- hlist_for_each_entry_rcu_bh
- hlist_for_each_entry_continue_rcu
- hlist_for_each_entry_continue_rcu_bh
- hlist_nulls_first_rcu
- hlist_nulls_for_each_entry_rcu
- hlist_bl_first_rcu
- hlist_bl_for_each_entry_rcu
RCU pointer/list update:
- rcu_assign_pointer
- list_add_rcu
- list_add_tail_rcu
- list_del_rcu
- list_replace_rcu
- hlist_add_behind_rcu
- hlist_add_before_rcu
- hlist_add_head_rcu
- hlist_del_rcu
- hlist_del_init_rcu
- hlist_replace_rcu
- list_splice_init_rcu
- hlist_nulls_del_init_rcu
- hlist_nulls_del_rcu
- hlist_nulls_add_head_rcu
- hlist_bl_add_head_rcu
- hlist_bl_del_init_rcu
- hlist_bl_del_rcu
- hlist_bl_set_first_rcu
RCU:
- rcu_read_lock
- synchronize_net
- rcu_barrier
- rcu_read_unlock
- synchronize_rcu
- rcu_dereference
- synchronize_rcu_expedited
- rcu_read_lock_held
- call_rcu
- rcu_dereference_check
- kfree_rcu
- rcu_dereference_protected
bh:
- rcu_read_lock_bh
- rcu_read_unlock_bh
- rcu_dereference_bh
- rcu_dereference_bh_check
- rcu_read_lock_bh_held
call_rcu_bhrcu_barrier_bhsynchronize_rcu_bhsynchronize_rcu_bh_expeditedrcu_dereference_bh_protected
sched:
- rcu_read_lock_sched
- rcu_read_unlock_sched
- rcu_read_lock_sched_notrace
- rcu_read_unlock_sched_notrace
- rcu_dereference_sched
- rcu_dereference_sched_check
- rcu_read_lock_sched_held
synchronize_schedrcu_barrier_schedcall_rcu_schedsynchronize_sched_expeditedrcu_dereference_sched_protected
SRCU:
- srcu_read_lock
- synchronize_srcu
- srcu_barrier
- srcu_read_unlock
- call_srcu
- srcu_dereference
- synchronize_srcu_expedited
- srcu_dereference_check
- srcu_read_lock_held
- init_srcu_struct
- cleanup_srcu_struct
All: lockdep-checked RCU-protected pointer access
- rcu_access_pointer
- rcu_dereference_raw
- RCU_LOCKDEP_WARN
- rcu_sleep_check
- RCU_NONIDLE
Core RCU API
rcu_read_lock()
- read-side critical section 시작
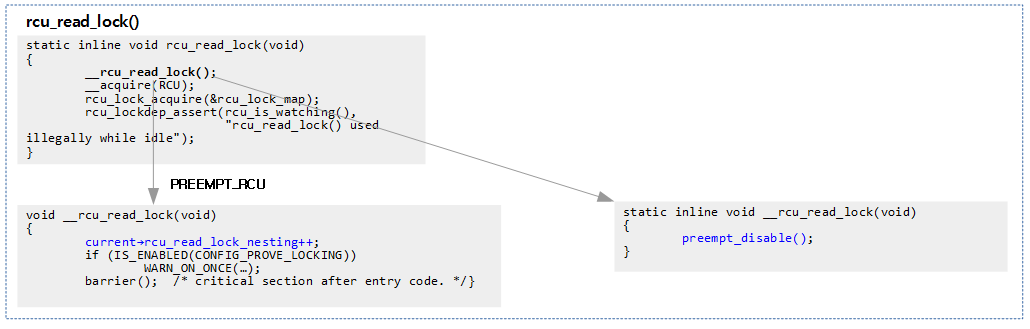
- preemptible RCU의 경우 current task의 rcu_read_lock_nesting++ 명령만을 포함한다.
- 참고로 non-preempt 커널에서는 preempt_disable()은 빈 함수이다.
rcu_read_unlock()

rcu_assign_pointer()
- RCU로 보호되는 포인터(RCU-protecte pointer)에 새로운 값을 할당하기 위해 사용

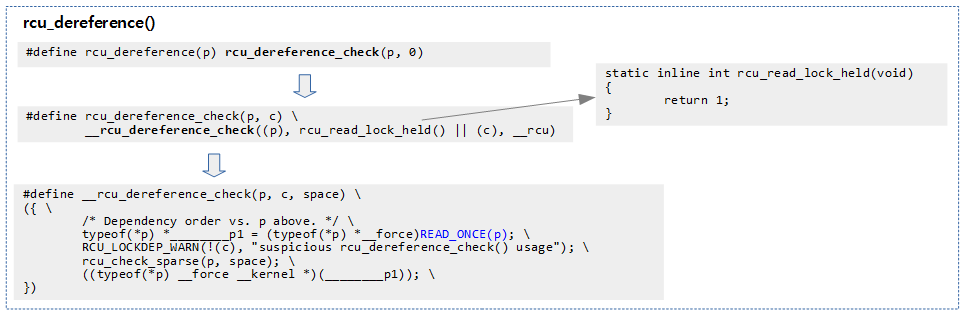
rcu_dereference()
- rcu_dereference()는 안전하게 참조(dereference)된 RCU-protected pointer 값을 얻어온다.
- weakly ordered CPU(out of order execution)를 위해 메모리 접근에 대한 order를 적절히 관리해야 하는데 rcu_dereference()를 사용하면 이를 완벽히 수행할 수 있다.
RCU_INIT_POINTER() 매크로
include/linux/rcupdate.h
/** * RCU_INIT_POINTER() - initialize an RCU protected pointer * @p: The pointer to be initialized. * @v: The value to initialized the pointer to. * * Initialize an RCU-protected pointer in special cases where readers * do not need ordering constraints on the CPU or the compiler. These * special cases are: * * 1. This use of RCU_INIT_POINTER() is NULLing out the pointer *or* * 2. The caller has taken whatever steps are required to prevent * RCU readers from concurrently accessing this pointer *or* * 3. The referenced data structure has already been exposed to * readers either at compile time or via rcu_assign_pointer() *and* * * a. You have not made *any* reader-visible changes to * this structure since then *or* * b. It is OK for readers accessing this structure from its * new location to see the old state of the structure. (For * example, the changes were to statistical counters or to * other state where exact synchronization is not required.) * * Failure to follow these rules governing use of RCU_INIT_POINTER() will * result in impossible-to-diagnose memory corruption. As in the structures * will look OK in crash dumps, but any concurrent RCU readers might * see pre-initialized values of the referenced data structure. So * please be very careful how you use RCU_INIT_POINTER()!!! * * If you are creating an RCU-protected linked structure that is accessed * by a single external-to-structure RCU-protected pointer, then you may * use RCU_INIT_POINTER() to initialize the internal RCU-protected * pointers, but you must use rcu_assign_pointer() to initialize the * external-to-structure pointer *after* you have completely initialized * the reader-accessible portions of the linked structure. * * Note that unlike rcu_assign_pointer(), RCU_INIT_POINTER() provides no * ordering guarantees for either the CPU or the compiler. */
#define RCU_INIT_POINTER(p, v) \
do { \
rcu_check_sparse(p, __rcu); \
WRITE_ONCE(p, RCU_INITIALIZER(v)); \
} while (0)
RCU 포인터영역을 Sparse 체크하고 RCU 변수 v를 초기화한다.
- sparse:
- 리눅스 커널의 문제를 찾아주는 툴
- 스파스는 정적 분석 도구이고, 설치된 후 gcc extension으로 동작
- 지원 속성으로 noderef, address_space, lock(acquires, releases), …
- __rcu:
- __attribute__((noderef, address_space(4)))
- noderef:
- 포인터 변수를 사용하여 직접 참조할 수 없다.
- & 연산자를 사용해서 직접 참조해야 한다
- address_space:
- 커널에는 몇개의 주소공간이 있다.
- 0 : kernel, 1: user, 2: iomem, 3: percpu, 4: __rcu 공간
참고
- RCU(Read Copy Update) -1- (Basic) | 문c – 현재글
- RCU(Read Copy Update) -2- (Callback process) | 문c
- RCU(Read Copy Update) -3- (RCU threads) | 문c
- RCU(Read Copy Update) -4- (NOCB process) | 문c
- RCU(Read Copy Update) -5- (Callback list) | 문c
- RCU(Read Copy Update) -6- (Expedited GP) | 문c
- RCU(Read Copy Update) -7- (Preemptible RCU) | 문c
- rcu_init() | 문c
- wait_for_completion() | 문c
- RCU(Read Copy Update)에 대한 이해 | 김민찬 – 다운로드 doc
- Userspace RCU | liburcu.org
- RCU 관련 함수 | 매화나무
- Introduction to RCU | Paul E. McKenney
- What is RCU, Fundamentally? | LWN.net
- What is RCU? Part 2: Usage | LWN.net
- RCU part 3: the RCU API | LWN.net
- RCU requirements part 2 — parallelism and software engineering | LWN.net
- RCU requirements part 3 | LWN.net
- The RCU API, 2010 Edition | LWN.net
- The RCU API, 2014 Edition | LWN.net
- The RCU API, 2019 edition | LWN.net
- RCU-walk: faster pathname lookup in Linux | LWN.net
- RCU: The Bloatwatch Edition | LWN.net
- Hierarchical RCU | LWN.net
- The design of preemptible read-copy-update | LWN.net
- Integrating and Validating dynticks and Preemptable RCU | LWN.net
- Expedited-Grace-Periods | Kernel.org
- Data Structures | Kernel.org
- Tree-RCU-Memory-Ordering | Kernel.org
- A Tour Through RCU’s Requirements | Kernel.org
- Verification of the Tree-Based Hierarchical Read-Copy Update in the Linux Kernel | Paul E. McKenney외 3인 – 다운로드 pdf
- Read-Log-Update – 다운로드 pdf
- Predicate RCU: An RCU for Scalable Concurrent Updates – 다운로드 pdf
- Yet another introduction to linux rcu | Viller Hsiao – Slideshare
- RCU’s First-Ever CVE | Paul E. McKenney, IBM – 다운로드 pdf