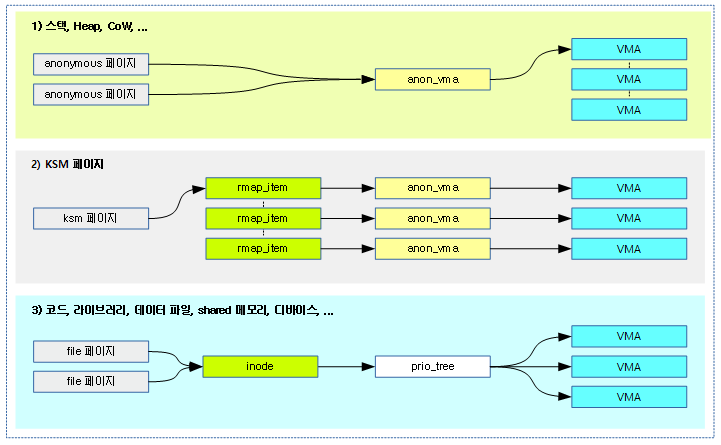
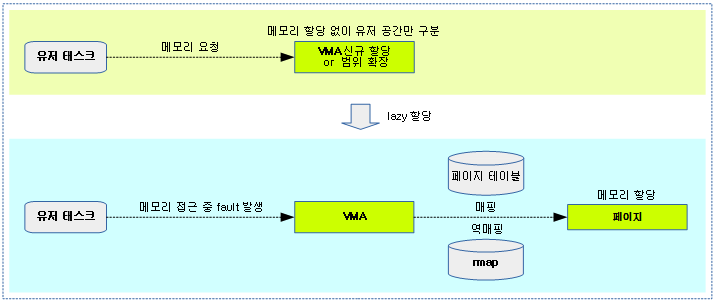
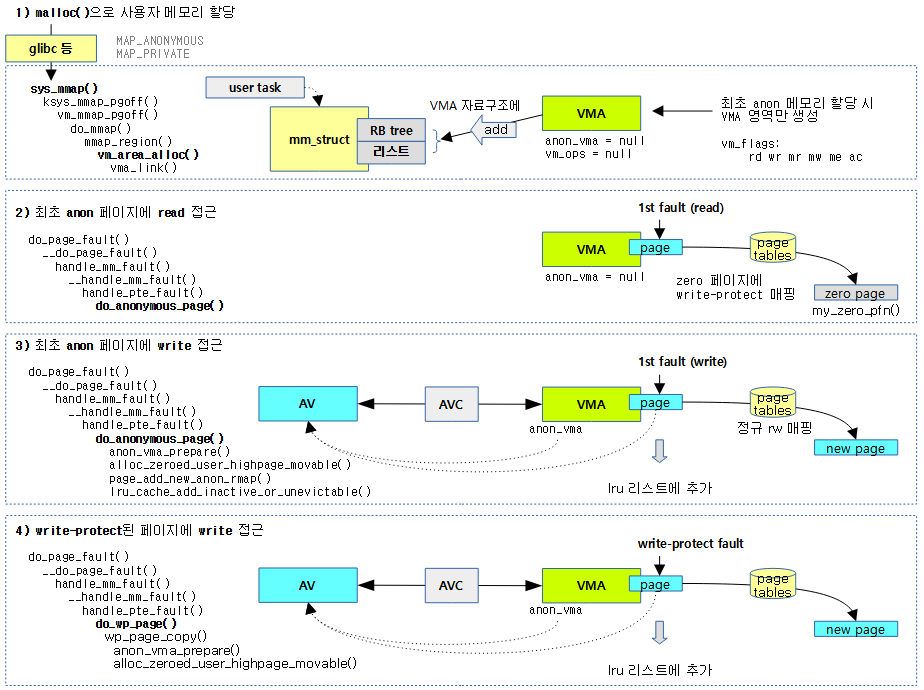
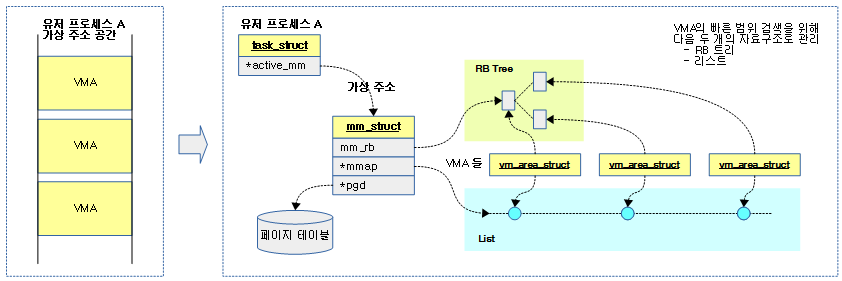
<kernel v5.0>
VMPressure
Memory Control Ggroup을 통해 스캔한 페이지와 회수한 페이지 비율을 분석하여 메모리 압박률을 산출하고, 이에 대응하는 스레졸드별 3 가지 이벤트 레벨로 memcg에 등록한 vmpressure 리스너들에 통지할 수 있게 하였다. vmpressure 리스너들은 eventfd를 사용하여 이러한 이벤트를 수신할 수 있다.
이벤트 레벨
- low
- memcg로 지정한 메모리 압박이 적은 편이다.
- medium
- memcg로 지정한 메모리 압박이 많은 편이다.
- critical
- memcg로 지정한 메모리 압박이 심해 곧 OOM killer가 동작할 예정이다.
vmpressure_win
mm/vmpressure.c
/* * The window size (vmpressure_win) is the number of scanned pages before * we try to analyze scanned/reclaimed ratio. So the window is used as a * rate-limit tunable for the "low" level notification, and also for * averaging the ratio for medium/critical levels. Using small window * sizes can cause lot of false positives, but too big window size will * delay the notifications. * * As the vmscan reclaimer logic works with chunks which are multiple of * SWAP_CLUSTER_MAX, it makes sense to use it for the window size as well. * * TODO: Make the window size depend on machine size, as we do for vmstat * thresholds. Currently we set it to 512 pages (2MB for 4KB pages). */
static const unsigned long vmpressure_win = SWAP_CLUSTER_MAX * 16;
- SWAP_CLUSTER_MAX(32) * 16 = 512 페이지로 설정되어 있다.
- 이 윈도우 사이즈는 scanned/reclaim 비율을 분석을 시도하기 전에 사용하는 scanned 페이지 수이다.
- low 레벨 notification에 사용되고 medium/critical 레벨의 평균 비율을 위해서도 사용된다.
vmpressure_level_med & vmpressure_level_critical
mm/vmpressure.c
/* * These thresholds are used when we account memory pressure through * scanned/reclaimed ratio. The current values were chosen empirically. In * essence, they are percents: the higher the value, the more number * unsuccessful reclaims there were. */
static const unsigned int vmpressure_level_med = 60; static const unsigned int vmpressure_level_critical = 95;
- vmpressure_level_med
- scanned/reclaimed 비율로 메모리 pressure 계량시 사용되는 medium 레벨의 스레졸드 값
- vmpressure_level_critical
- scanned/reclaimed 비율로 메모리 pressure 계량시 사용되는 critical 레벨의 스레졸드 값
vmpressure_prio()
mm/vmpressure.c
/** * vmpressure_prio() - Account memory pressure through reclaimer priority level * @gfp: reclaimer's gfp mask * @memcg: cgroup memory controller handle * @prio: reclaimer's priority * * This function should be called from the reclaim path every time when * the vmscan's reclaiming priority (scanning depth) changes. * * This function does not return any value. */
void vmpressure_prio(gfp_t gfp, struct mem_cgroup *memcg, int prio)
{
/*
* We only use prio for accounting critical level. For more info
* see comment for vmpressure_level_critical_prio variable above.
*/
if (prio > vmpressure_level_critical_prio)
return;
/*
* OK, the prio is below the threshold, updating vmpressure
* information before shrinker dives into long shrinking of long
* range vmscan. Passing scanned = vmpressure_win, reclaimed = 0
* to the vmpressure() basically means that we signal 'critical'
* level.
*/
vmpressure(gfp, memcg, true, vmpressure_win, 0);
}
우선 순위가 높아져 스캔 depth가 깊어지는 경우 vmpressure 정보를 갱신한다.
- 코드 라인 7~8에서 요청 우선 순위가 vmpressure_level_critical_prio(3)보다 낮아 함수를 빠져나간다.
- prio는 낮을 수록 우선 순위가 높다.
- 코드 라인 17에서 스레졸드 이하로 prio가 떨어진 경우, 즉 우선 순위가 높아진 경우 shrinker가 오랫 동안 스캔하기 전에 vmpressure 정보를 업데이트한다.
vmpressure()
mm/vmpressure.c
/** * vmpressure() - Account memory pressure through scanned/reclaimed ratio * @gfp: reclaimer's gfp mask * @memcg: cgroup memory controller handle * @tree: legacy subtree mode * @scanned: number of pages scanned * @reclaimed: number of pages reclaimed * * This function should be called from the vmscan reclaim path to account * "instantaneous" memory pressure (scanned/reclaimed ratio). The raw * pressure index is then further refined and averaged over time. * * If @tree is set, vmpressure is in traditional userspace reporting * mode: @memcg is considered the pressure root and userspace is * notified of the entire subtree's reclaim efficiency. * * If @tree is not set, reclaim efficiency is recorded for @memcg, and * only in-kernel users are notified. * * This function does not return any value. */
void vmpressure(gfp_t gfp, struct mem_cgroup *memcg, bool tree,
unsigned long scanned, unsigned long reclaimed)
{
struct vmpressure *vmpr = memcg_to_vmpressure(memcg);
/*
* Here we only want to account pressure that userland is able to
* help us with. For example, suppose that DMA zone is under
* pressure; if we notify userland about that kind of pressure,
* then it will be mostly a waste as it will trigger unnecessary
* freeing of memory by userland (since userland is more likely to
* have HIGHMEM/MOVABLE pages instead of the DMA fallback). That
* is why we include only movable, highmem and FS/IO pages.
* Indirect reclaim (kswapd) sets sc->gfp_mask to GFP_KERNEL, so
* we account it too.
*/
if (!(gfp & (__GFP_HIGHMEM | __GFP_MOVABLE | __GFP_IO | __GFP_FS)))
return;
/*
* If we got here with no pages scanned, then that is an indicator
* that reclaimer was unable to find any shrinkable LRUs at the
* current scanning depth. But it does not mean that we should
* report the critical pressure, yet. If the scanning priority
* (scanning depth) goes too high (deep), we will be notified
* through vmpressure_prio(). But so far, keep calm.
*/
if (!scanned)
return;
if (tree) {
spin_lock(&vmpr->sr_lock);
scanned = vmpr->tree_scanned += scanned;
vmpr->tree_reclaimed += reclaimed;
spin_unlock(&vmpr->sr_lock);
if (scanned < vmpressure_win)
return;
schedule_work(&vmpr->work);
} else {
enum vmpressure_levels level;
/* For now, no users for root-level efficiency */
if (!memcg || memcg == root_mem_cgroup)
return;
spin_lock(&vmpr->sr_lock);
scanned = vmpr->scanned += scanned;
reclaimed = vmpr->reclaimed += reclaimed;
if (scanned < vmpressure_win) {
spin_unlock(&vmpr->sr_lock);
return;
}
vmpr->scanned = vmpr->reclaimed = 0;
spin_unlock(&vmpr->sr_lock);
level = vmpressure_calc_level(scanned, reclaimed);
if (level > VMPRESSURE_LOW) {
/*
* Let the socket buffer allocator know that
* we are having trouble reclaiming LRU pages.
*
* For hysteresis keep the pressure state
* asserted for a second in which subsequent
* pressure events can occur.
*/
memcg->socket_pressure = jiffies + HZ;
}
}
}
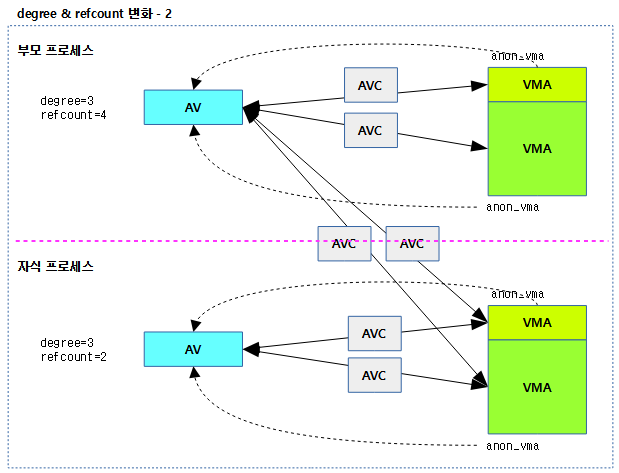
scaned 및 reclaimed 비율로 메모리 pressure를 계량한다.
- 코드 라인 4에서 요청한 memcg의 vmpressure 정보를 반환한다.
- 코드 라인 17~18에서 highmem, movable, FS, IO 플래그 요청이 하나도 없는 경우 pressure 계량을 하지 않는다.
- 코드 라인 28~29에서 인수 scanned가 0인 경우 함수를 중단한다.
- 코드 라인 31~39에서 기존 tree 방식의 presssure를 계량한다. tree_scanned와 tree_reclaimed 각각 그 만큼 증가시키고 vmpr->work에 등록한 작업을 실행시킨다. 만일 vmpr->scanned가 vmpressure_win 보다 작은 경우 함수를 중단한다.
- vmpressure_work_fn()
- 코드 라인 40~45에서 @tree가 0이면 커널 내부 사용자에게 통지하기 위해 @memcg를 위한 회수 효율성이 기록된다. memcg가 지정되지 않은 경우 함수를 중단한다.
- 코드 라인 47~55에서 scanned와 reclaimed 각각 그 만큼 증가시키고 만일 scanned가 vmpressure_win 보다 작은 경우 함수를 중단한다. 중단하지 않은 경우 vmpr의 scanned와 reclaimed는 0으로 리셋한다.
- 코드 라인 57~69에서 산출된 vmpressure 레벨이 VMPRESSURE_LOW를 초과하면 memcg의 socket_pressure를 현재 시각보다 1초 뒤인 틱 값을 설정한다.
- mem_cgroup_under_socket_pressure() 함수에서 이 값을 사용한다.
- 참고: mm: memcontrol: hook up vmpressure to socket pressure
다음 그림은 vmpressure() 함수가 처리되는 과정을 보여준다.
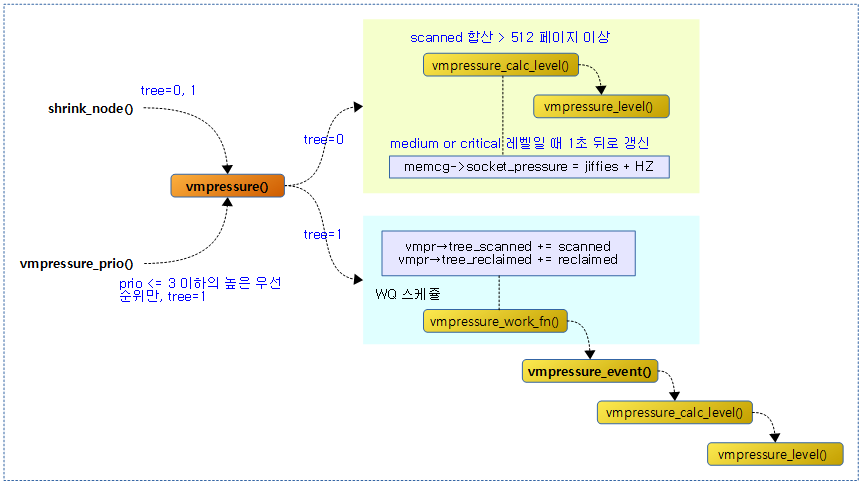
워크 큐에서 vmpressure에 따른 이벤트 통지
vmpressure_work_fn()
mm/vmpressure.c
static void vmpressure_work_fn(struct work_struct *work)
{
struct vmpressure *vmpr = work_to_vmpressure(work);
unsigned long scanned;
unsigned long reclaimed;
enum vmpressure_levels level;
bool ancestor = false;
bool signalled = false;
spin_lock(&vmpr->sr_lock);
/*
* Several contexts might be calling vmpressure(), so it is
* possible that the work was rescheduled again before the old
* work context cleared the counters. In that case we will run
* just after the old work returns, but then scanned might be zero
* here. No need for any locks here since we don't care if
* vmpr->reclaimed is in sync.
*/
scanned = vmpr->tree_scanned;
if (!scanned) {
spin_unlock(&vmpr->sr_lock);
return;
}
reclaimed = vmpr->tree_reclaimed;
vmpr->tree_scanned = 0;
vmpr->tree_reclaimed = 0;
spin_unlock(&vmpr->sr_lock);
level = vmpressure_calc_level(scanned, reclaimed);
do {
if (vmpressure_event(vmpr, level, ancestor, signalled))
signalled = true;
ancestor = true;
} while ((vmpr = vmpressure_parent(vmpr)));
}
메모리 압박 레벨을 산출하고 레벨 및 모드 조건을 만족시키는 vmpressure 리스너에 이벤트를 전송한다.
- 코드 라인 10~28에서 tree_scanned 값과 tree_reclaimed 값을 가져오고 리셋한다.
- 코드 라인 30에서 scanned 값과 reclaimed 값으로 레벨을 산출한다.
- 코드 라인 32~36에서 하이라키로 구성된 memcg의 vmpressure 값을 최상위 루트까지 순회하며 조건을 만족시키는 vmpressure 리스너에 이벤트를 통지한다.
memcg_to_vmpressure()
mm/memcontrol.c
/* Some nice accessors for the vmpressure. */
struct vmpressure *memcg_to_vmpressure(struct mem_cgroup *memcg)
{
if (!memcg)
memcg = root_mem_cgroup;
return &memcg->vmpressure;
}
요청한 memcg의 vmpressure 정보를 반환한다. memcg가 지정되지 않은 경우 root memcg의 vmpressure를 반환한다.
다음 그림은 등록된 vmpressure 리스너들 중 조건에 맞는 리스너들을 대상으로 이벤트를 보내는 과정을 보여준다.
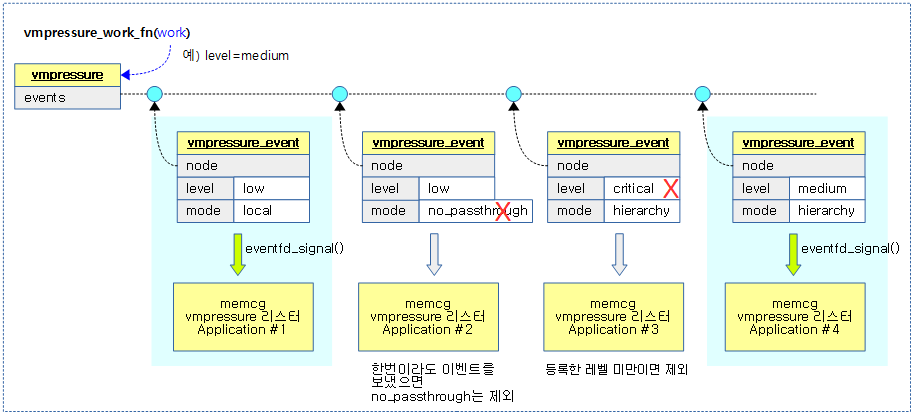
vmpressure 이벤트 통지
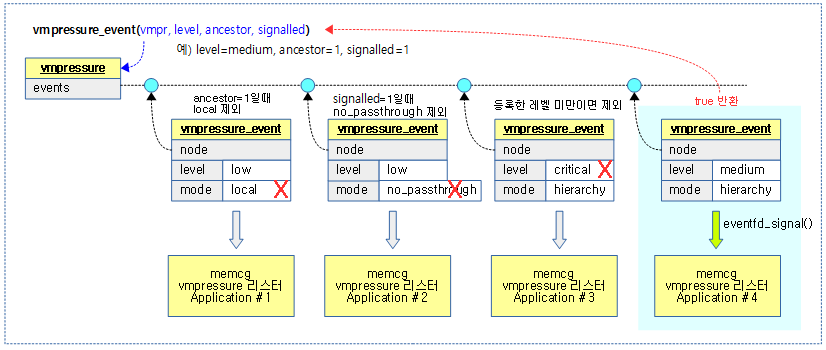
vmpressure_event()
mm/vmpressure.c
static bool vmpressure_event(struct vmpressure *vmpr,
const enum vmpressure_levels level,
bool ancestor, bool signalled)
{
struct vmpressure_event *ev;
bool ret = false;
mutex_lock(&vmpr->events_lock);
list_for_each_entry(ev, &vmpr->events, node) {
if (ancestor && ev->mode == VMPRESSURE_LOCAL)
continue;
if (signalled && ev->mode == VMPRESSURE_NO_PASSTHROUGH)
continue;
if (level < ev->level)
continue;
eventfd_signal(ev->efd, 1);
ret = true;
}
mutex_unlock(&vmpr->events_lock);
return ret;
}
vmpressure에 등록된 이벤트들을 대상으로 요청 @level 이하로 등록한 vmpressure 리스터 application에 eventfd 시그널을 통지한다.
- 통지 대상이 아닌 경우는 다음과 같다.
- @ancestor=1일 때, local 모드는 제외한다.
- @signalled=1일 때, no_passthrough 모드는 제외한다.
- @level보다 큰 레벨로 등록한 경우는 제외한다.
다음 그림은 memcg에 등록한 vmpressure 리스너에 이벤트를 통지하는 조건들을 보여준다.
vmpressure 레벨 산출
vmpressure_calc_level()
mm/vmpressure.c
static enum vmpressure_levels vmpressure_calc_level(unsigned long scanned,
unsigned long reclaimed)
{
unsigned long scale = scanned + reclaimed;
unsigned long pressure = 0;
/*
* reclaimed can be greater than scanned for things such as reclaimed
* slab pages. shrink_node() just adds reclaimed pages without a
* related increment to scanned pages.
*/
if (reclaimed >= scanned)
goto out;
/*
* We calculate the ratio (in percents) of how many pages were
* scanned vs. reclaimed in a given time frame (window). Note that
* time is in VM reclaimer's "ticks", i.e. number of pages
* scanned. This makes it possible to set desired reaction time
* and serves as a ratelimit.
*/
pressure = scale - (reclaimed * scale / scanned);
pressure = pressure * 100 / scale;
out:
pr_debug("%s: %3lu (s: %lu r: %lu)\n", __func__, pressure,
scanned, reclaimed);
return vmpressure_level(pressure);
}
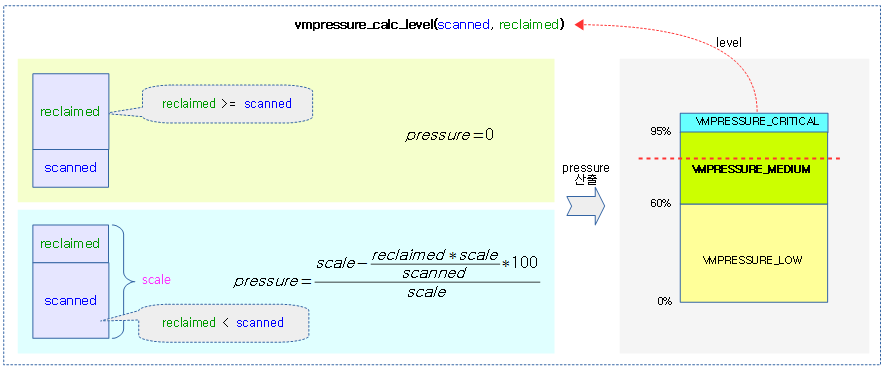
scanned, reclaimed 비율에 따라 pressure 값을 산출하고, 이에 따른 레벨을 반환한다.
다음과 예와 같이 scanned 페이지 수와 reclaimed 페이지 수에 대한 pressure 값과 레벨을 확인해보자.
- scanned=5, reclaimed=0
- pressure=100%, level=critical
- scanned=5, reclaimed=1
- pressure=66%, level=medium
- scanned=5, reclaimed=2
- pressure=57%, level=low
- scanned=5, reclaimed=3
- pressure=37%, level=low
- scanned=5, reclaimed=4
- pressure=11%, level=low
- scanned=5, reclaimed=5
- pressure=0%, level=low
다음 그림은 scanned, reclaimed 비율에 따른 pressure 값을 산출하고, 이에 따른 레벨을 결정하는 과정을 보여준다.
vmpressure_level()
mm/vmpressure.c
static enum vmpressure_levels vmpressure_level(unsigned long pressure)
{
if (pressure >= vmpressure_level_critical)
return VMPRESSURE_CRITICAL;
else if (pressure >= vmpressure_level_med)
return VMPRESSURE_MEDIUM;
return VMPRESSURE_LOW;
}
@pressure에 따른 레벨을 반환한다.
- critical
- 디폴트 값 95% 이상
- med
- 디폴트 값 60% 이상
- low
- 그 외
이벤트 수신 프로그램 데모
cgroup_event_listener
tools/cgroup 위치에서 make를 실행하면 다음 소스를 빌드하여 cgroup_event_listener 파일이 생성된다.
tools/cgroup/cgroup_event_listener.c
#include <assert.h>
#include <err.h>
#include <errno.h>
#include <fcntl.h>
#include <libgen.h>
#include <limits.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/eventfd.h>
#define USAGE_STR "Usage: cgroup_event_listener <path-to-control-file> <args>"
int main(int argc, char **argv)
{
int efd = -1;
int cfd = -1;
int event_control = -1;
char event_control_path[PATH_MAX];
char line[LINE_MAX];
int ret;
if (argc != 3)
errx(1, "%s", USAGE_STR);
cfd = open(argv[1], O_RDONLY);
if (cfd == -1)
err(1, "Cannot open %s", argv[1]);
ret = snprintf(event_control_path, PATH_MAX, "%s/cgroup.event_control",
dirname(argv[1]));
if (ret >= PATH_MAX)
errx(1, "Path to cgroup.event_control is too long");
event_control = open(event_control_path, O_WRONLY);
if (event_control == -1)
err(1, "Cannot open %s", event_control_path);
efd = eventfd(0, 0);
if (efd == -1)
err(1, "eventfd() failed");
ret = snprintf(line, LINE_MAX, "%d %d %s", efd, cfd, argv[2]);
if (ret >= LINE_MAX)
errx(1, "Arguments string is too long");
ret = write(event_control, line, strlen(line) + 1);
if (ret == -1)
err(1, "Cannot write to cgroup.event_control");
while (1) {
uint64_t result;
ret = read(efd, &result, sizeof(result));
if (ret == -1) {
if (errno == EINTR)
continue;
err(1, "Cannot read from eventfd");
}
assert(ret == sizeof(result));
ret = access(event_control_path, W_OK);
if ((ret == -1) && (errno == ENOENT)) {
puts("The cgroup seems to have removed.");
break;
}
if (ret == -1)
err(1, "cgroup.event_control is not accessible any more");
printf("%s %s: crossed\n", argv[1], argv[2]);
}
return 0;
}
사용 방법
다음과 같이 pressure 레벨이 medium일 때 이벤트를 수신할 수 있게 한다.
- 참고: memcg: Add memory.pressure_level events | LWN.net
# cd /sys/fs/cgroup/memory/ $ mkdir foo $ cd foo $ cgroup_event_listener memory.pressure_level medium & $ echo 8000000 > memory.limit_in_bytes $ echo 8000000 > memory.memsw.limit_in_bytes $ echo $$ > tasks $ dd if=/dev/zero | read x
PSI(Process Stall Information)
메모리 압박을 감시하고자 하는 유저 application(안드로이드의 lmkd 등)이 메모리 회수 동작에서 받는 압박 레벨을 catch 하고자 2018년 커널 v4.20-rc1에서 소개되었다.
- 참고
참고
- Memory Resource Controller (Documentation/cgroups/memory.txt) | LWN.net
- 로우 메모리 킬러 데몬 | Android