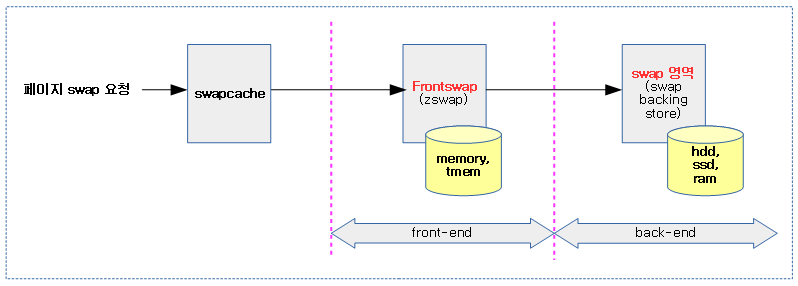
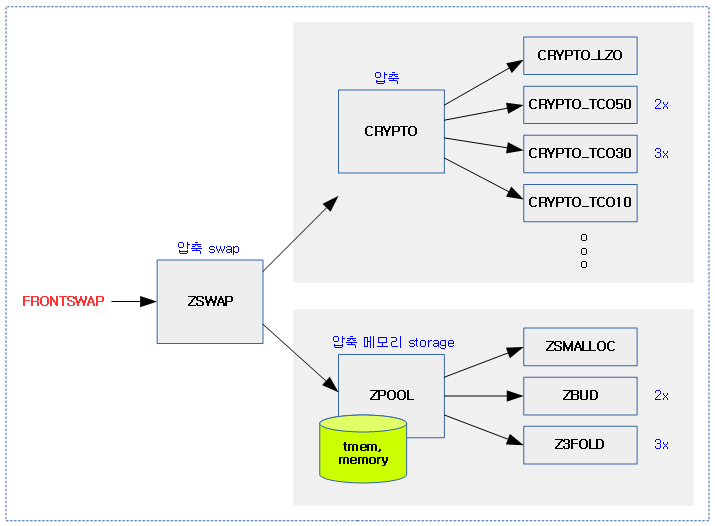
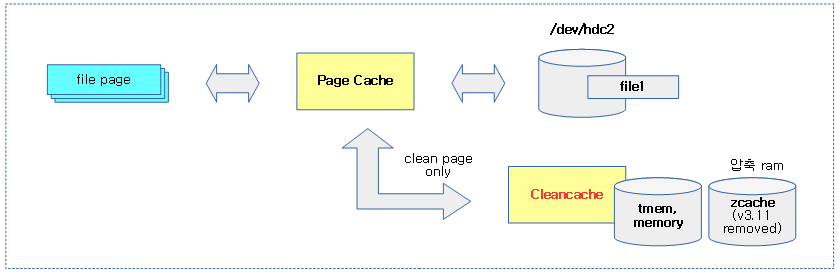
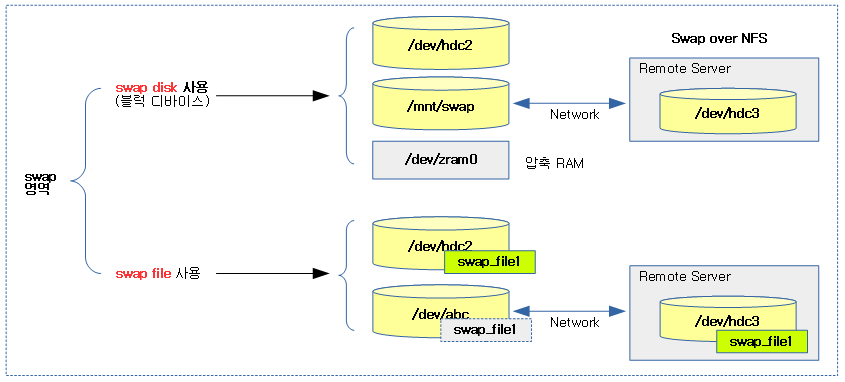
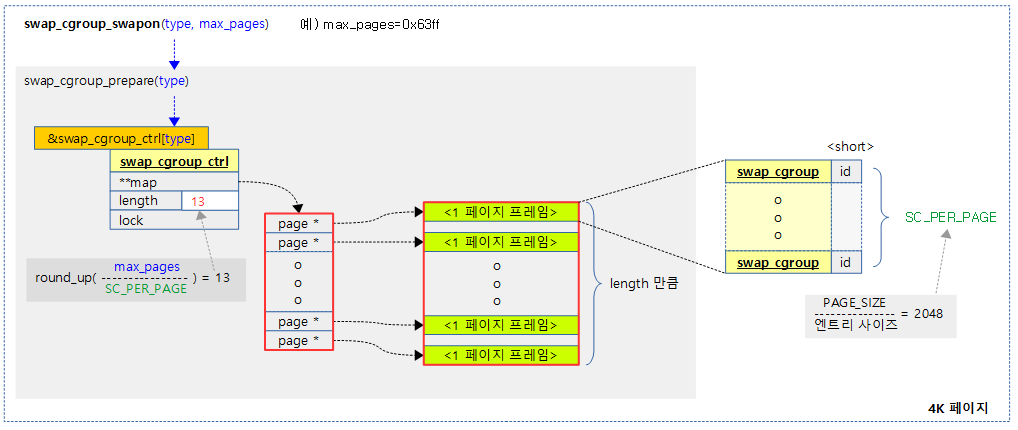
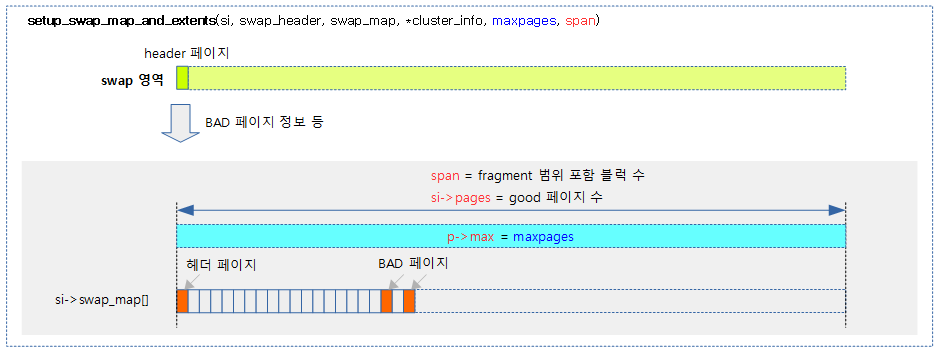
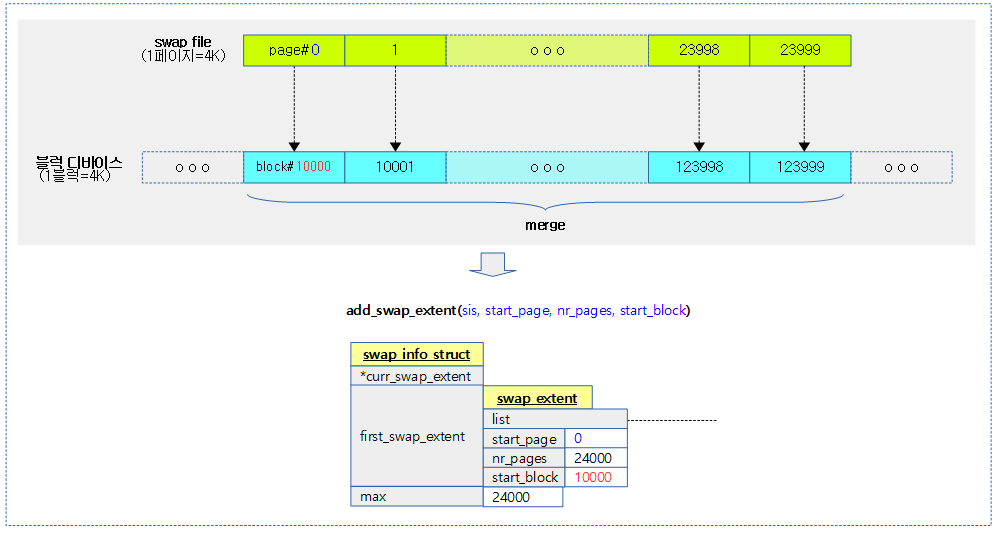
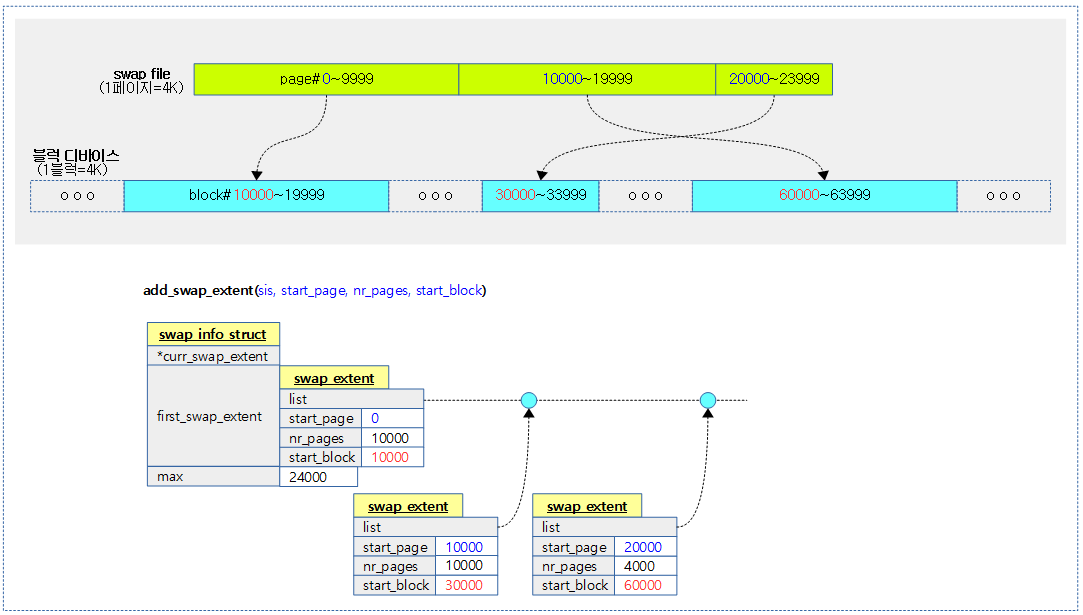
<kernel v5.0>
Swapin & Swapout
유저 프로세스가 swap되어 언매핑된 빈 가상 주소에 접근하는 경우 swap 영역에서 swap 페이지를 로드하여 복구해야 한다. 이 때 swap 캐시를 거쳐 swap 영역에서 swap된 페이지를 로드하는 과정을 swap-in 이라고 하고, 반대로 저장하는 과정을 swap-out이라고 한다.
Swap readahead
swap-in 과정에서 swap되어 빈 영역에 접근하는 경우 fault 에러가 발생한다. 이 때 fault된 가상 주소로 페이지 테이블에 저장된 swap 엔트리를 알아온 후 이를 키로 관련 swap 영역에서 swap 페이지를 로드하는데 주변 페이지들을 미리 로드하여 처리 성능을 올릴 수 있다. 이러한 방법을 readahead라고 하는데 swap 과정에 사용되는 readahead는 다음과 같이 두 가지 방법이 사용되고 있다.
- vma 기반 swap readahead
- cluster 기반 swap readahead (for SSD)
readahead 기능으로 같이 읽혀온 페이지들에 swap 캐시에 있을때 해당 페이지에 PG_reclaim (플래그 사용을 절약하기 위해 readahead 시에는 reclaim이 아니라 PG_readahead 용도로 사용된다.) 플래그가 붙는다.
VMA 기반 swap readahead
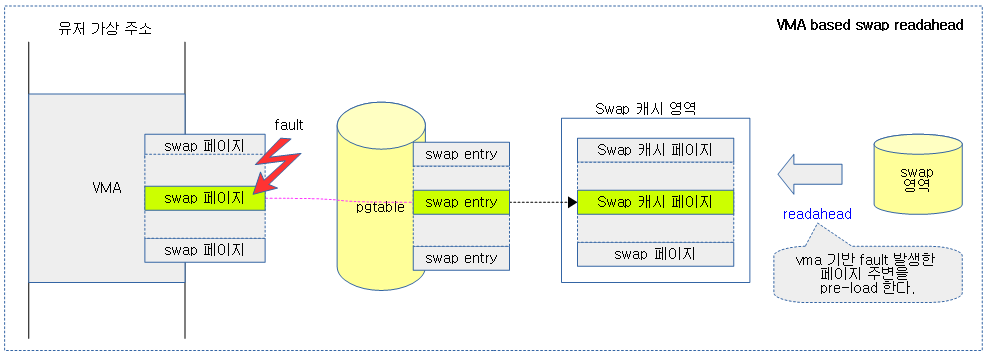
유저 프로세스가 swap 된 페이지에 접근하여 fault가 발생하면, swap 캐시에서 페이지를 찾아보고, swap 캐시에서 발견하지 못하면 swap 영역으로 부터 vma 영역내의 fault된 페이지 주변을 조금 더 읽어와서 주변 페이지에 접근하여 fault될 때 이미 읽어온 페이지가 swap 캐시 영역에서 찾을 수 있어 이를 빠르게 anon 페이지로 변환 및 매핑할 수 있다.
- 이 방식을 사용하려면 커널 설정에서 vma_ra_enabled 속성(디폴트=true)이 설정되어 있어야 하며 SSD 타입의 블럭 디바이스에서만 사용할 수 있다. HDD를 사용하는 swap 영역에서는 성능 저하를 이유로 더 이상 VMA based swap readahead를 사용하지 못하게 하였다.
- 참고:
- mm, swap: don’t use VMA based swap readahead if HDD is used as swap (v4.14-rc1)
- mm, swap: VMA based swap readahead (2017) | LWN.net
- mm, swap: VMA based swap readahead (2017, patch) | LWN.net
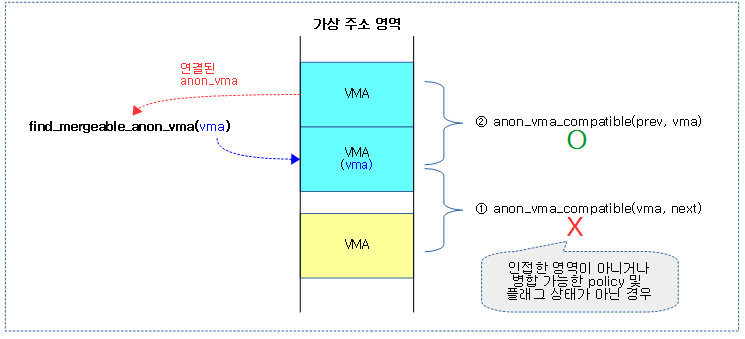
다음 그림은 swap된 페이지가 swap 영역에서 로드될 때 fault 페이지의 vma내 주변 페이지 일부를 미리 swap 캐시에 로드하는 과정을 보여준다.
클러스터 기반 swap readahead
VMA 기반과 다르게 fault된 swap 페이지의 주변이 아니라 swap 영역의 주변 페이지를 더 읽어온다.
다음 그림은 swap된 페이지가 swap 영역에서 로드될 때 swap 영역의 주변 페이지 일부를 미리 swap 캐시에 로드하는 과정을 보여준다.

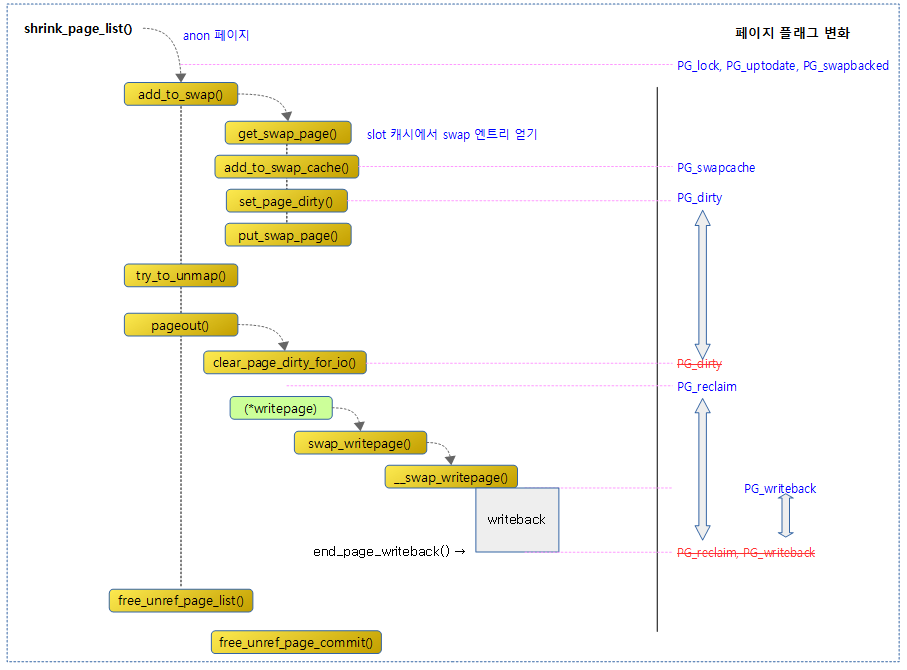
Swap 관련 페이지 플래그
- PG_swapbacked
- swap 영역을 가졌는지 여부이다.
- 이 플래그를 가지면 swap이 가능한 일반 anon 페이지이다.
- 이 플래그가 없으면 swap이 불가능한 clean anon 페이지이다.
- swap 영역을 가졌는지 여부이다.
- PG_swapcached
- swap 되어 swap 캐시 영역에 존재하는 상태이다. 유저가 swap된 가상 주소 페이지에 접근 시 fault 핸들러를 통해 swap 영역보다 먼저 swap 캐시를 찾는다.
- swap 영역에 기록되었는지 여부는 이 플래그로 알 수 없고 page_swapped() 함수를 통해서 알아낼 수 있다.
- swap-in이 진행될 때 swap 영역에서 읽을 때 성능 향상을 위해 주변 페이지도 읽어 swap 캐시 영역에 로드한다.
- swap-out이 진행할 때 이 swap 캐시를 swap 영역에 저장한다.
- swap 되어 swap 캐시 영역에 존재하는 상태이다. 유저가 swap된 가상 주소 페이지에 접근 시 fault 핸들러를 통해 swap 영역보다 먼저 swap 캐시를 찾는다.
- PG_writeback
- swap 영역에 기록(sync 또는 async) 하는 동안 설정된다.
- pageout() 에서 swap writeback 후크 함수인 swap_writepage() 함수에서 설정되고, writeback이 완료되면 클리어된다.
- PG_reclaim (2가지 용도)
- swap-out 시 PageReclaim()으로 사용된다.
- reclaim을 위해 swap 영역에 기록하는 중에 설정되고, 이 플래그가 제거될 때 회수할 수 있다.
- pageout() 에서 writeback 직전에 설정되고, writeback이 완료되면 클리어된다.
- swap-in 시 PageReadahead()으로 사용된다.
- readahead로 미리 읽어온 swap 캐시 페이지에 설정된다.
- swap-out 시 PageReclaim()으로 사용된다.
- PG_dirty
- swap 영역에 기록하기 위해 설정되며, 이 플래그를 보고 pageout()이 호출된다.
- add_to_swap_cache() 함수에서 설정되고, pageout() 에서 writeback 직전에 클리어된다.
- PG_workingset
- 페이지가 작업중임을 알리기 위한 플래그이다.
- file 페이지가 inactive lru 리스트에서 refault될 때 그 fault 간격을 메모리 크기와 비교하여 메모리 크기보다 작은 fault 간격인 경우 이를 체크하여 thrashing을 감지하는데 사용하기 위해 workingset 플래그를 사용한다.
- 자주 사용되는 페이지가 여러 번 fualt되어 캐시를 교체하느라 성능 저하되는 현상을 막는 솔루션이다.
- 참고: mm: workingset: tell cache transitions from workingset thrashing (2018, v4.20-rc1)
- file 페이지가 처음 access되면 inactive lru 리스트의 선두에서 출발한다. 그리고 두 번의 access를 감지하면 active lru로 승격한다. 그러나 anon 페이지는 처음 access되면 active lru 리스트의 선두에서 출발하므로 처음부터 workingset으로 설정한다.
- 페이지가 작업중임을 알리기 위한 플래그이다.
다음 그림은 swap 관련 페이지 플래그의 변화를 보여준다.
Swap 초기화
swap_init_sysfs()
mm/swap_state.c
static int __init swap_init_sysfs(void)
{
int err;
struct kobject *swap_kobj;
swap_kobj = kobject_create_and_add("swap", mm_kobj);
if (!swap_kobj) {
pr_err("failed to create swap kobject\n");
return -ENOMEM;
}
err = sysfs_create_group(swap_kobj, &swap_attr_group);
if (err) {
pr_err("failed to register swap group\n");
goto delete_obj;
}
return 0;
delete_obj:
kobject_put(swap_kobj);
return err;
}
subsys_initcall(swap_init_sysfs);
swap 시스템을 위해 /sys/kernel/mm/swap 디렉토리를 생성하고 관련 속성(vma_ra_enabled) 파일을 생성한다.
vma_ra_enabled 속성
mm/swap_state.c
static ssize_t vma_ra_enabled_show(struct kobject *kobj,
struct kobj_attribute *attr, char *buf)
{
return sprintf(buf, "%s\n", enable_vma_readahead ? "true" : "false");
}
static ssize_t vma_ra_enabled_store(struct kobject *kobj,
struct kobj_attribute *attr,
const char *buf, size_t count)
{
if (!strncmp(buf, "true", 4) || !strncmp(buf, "1", 1))
enable_vma_readahead = true;
else if (!strncmp(buf, "false", 5) || !strncmp(buf, "0", 1))
enable_vma_readahead = false;
else
return -EINVAL;
return count;
}
static struct kobj_attribute vma_ra_enabled_attr =
__ATTR(vma_ra_enabled, 0644, vma_ra_enabled_show,
vma_ra_enabled_store);
static struct attribute *swap_attrs[] = {
&vma_ra_enabled_attr.attr,
NULL,
};
static struct attribute_group swap_attr_group = {
.attrs = swap_attrs,
};
vma 기반 readahead 기능을 enable 하는 속성 파일이다.
- “/sys/kernel/mm/swap/vma_ra_enabled” 속성의 디폴트 값은 true이다.
- swap_vma_readahead -> vma_ra_enabled 속성으로 이름이 바뀌었다.
- swap_use_vma_readahead() 함수를 통해 이 속성의 설정 여부를 알아온다.
Swap-out
normal anon 페이지가 swap 영역에 기록된 후 페이지가 free되는 순서는 다음과 같다.
- normal anon 페이지 → swapcache → unmap → write out → free 페이지
- add_to_swap()
- try_to_unmap()
- pageout()
- free_unref_page_commit()
다음 그림은 swap-out 과정을 보여준다.
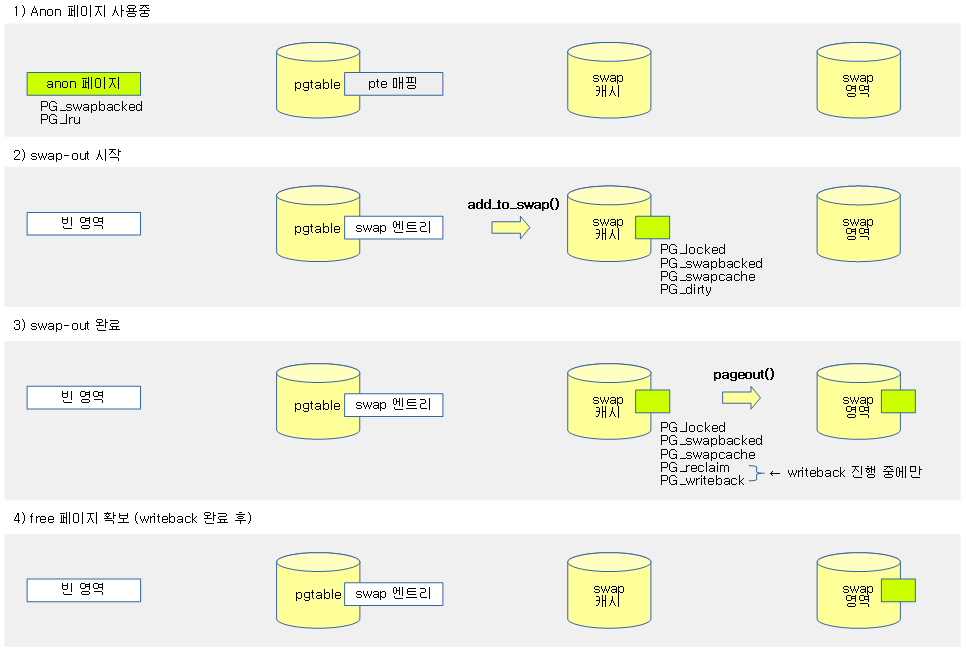
Swap 영역에 추가
add_to_swap()
mm/swap_state.c
/** * add_to_swap - allocate swap space for a page * @page: page we want to move to swap * * Allocate swap space for the page and add the page to the * swap cache. Caller needs to hold the page lock. */
int add_to_swap(struct page *page)
{
swp_entry_t entry;
int err;
VM_BUG_ON_PAGE(!PageLocked(page), page);
VM_BUG_ON_PAGE(!PageUptodate(page), page);
entry = get_swap_page(page);
if (!entry.val)
return 0;
/*
* XArray node allocations from PF_MEMALLOC contexts could
* completely exhaust the page allocator. __GFP_NOMEMALLOC
* stops emergency reserves from being allocated.
*
* TODO: this could cause a theoretical memory reclaim
* deadlock in the swap out path.
*/
/*
* Add it to the swap cache.
*/
err = add_to_swap_cache(page, entry,
__GFP_HIGH|__GFP_NOMEMALLOC|__GFP_NOWARN);
if (err)
/*
* add_to_swap_cache() doesn't return -EEXIST, so we can safely
* clear SWAP_HAS_CACHE flag.
*/
goto fail;
/*
* Normally the page will be dirtied in unmap because its pte should be
* dirty. A special case is MADV_FREE page. The page'e pte could have
* dirty bit cleared but the page's SwapBacked bit is still set because
* clearing the dirty bit and SwapBacked bit has no lock protected. For
* such page, unmap will not set dirty bit for it, so page reclaim will
* not write the page out. This can cause data corruption when the page
* is swap in later. Always setting the dirty bit for the page solves
* the problem.
*/
set_page_dirty(page);
return 1;
fail:
put_swap_page(page, entry);
return 0;
}
swap 엔트리를 할당한 후 이 값을 키로 anon 페이지를 swap 캐시 및 swap 영역에 저장한다. 성공 시 1을 반환한다.
- 코드 라인 6~7에서 swap-out을 하기 전에 PG_lock과 PG_uptodate가 반드시 설정되어 있어야 한다.
- 코드 라인 9~11에서 swap할 anon 페이지에 사용할 swap 엔트리를 얻어온다.
- 코드 라인 24~31에서 swap 엔트리를 키로 swap할 anon 페이지를 swap 캐시에 추가한다.
- 코드 라인 42~44에서 페이지에 dirty 설정을 한다. 그 후 성공하였으므로 1을 반환한다.
- address_space에 매핑된 페이지의 경우 드라이버를 통해 dirty 설정을 하고, 페이지에도 PG_dirty 플래그를 설정한다.
- dirty된 페이지는 reclaim 과정에서 pageout() 함수가 호출되어 swap 영역에 저장되며, 완료된 후에 PG_dirty 플래그가 클리어된다.
- 코드 라인 46~48에서 fail: 레이블이다. 실패한 경우이므로 0을 반환한다.
Swap 캐시에 추가
add_to_swap_cache()
mm/swap_state.c
/* * add_to_swap_cache resembles add_to_page_cache_locked on swapper_space, * but sets SwapCache flag and private instead of mapping and index. */
int add_to_swap_cache(struct page *page, swp_entry_t entry, gfp_t gfp)
{
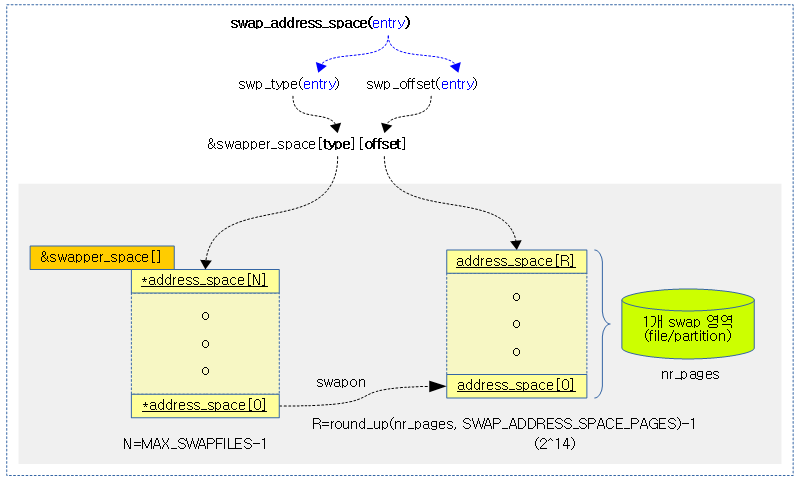
struct address_space *address_space = swap_address_space(entry);
pgoff_t idx = swp_offset(entry);
XA_STATE_ORDER(xas, &address_space->i_pages, idx, compound_order(page));
unsigned long i, nr = 1UL << compound_order(page);
VM_BUG_ON_PAGE(!PageLocked(page), page);
VM_BUG_ON_PAGE(PageSwapCache(page), page);
VM_BUG_ON_PAGE(!PageSwapBacked(page), page);
page_ref_add(page, nr);
SetPageSwapCache(page);
do {
xas_lock_irq(&xas);
xas_create_range(&xas);
if (xas_error(&xas))
goto unlock;
for (i = 0; i < nr; i++) {
VM_BUG_ON_PAGE(xas.xa_index != idx + i, page);
set_page_private(page + i, entry.val + i);
xas_store(&xas, page + i);
xas_next(&xas);
}
address_space->nrpages += nr;
__mod_node_page_state(page_pgdat(page), NR_FILE_PAGES, nr);
ADD_CACHE_INFO(add_total, nr);
unlock:
xas_unlock_irq(&xas);
} while (xas_nomem(&xas, gfp));
if (!xas_error(&xas))
return 0;
ClearPageSwapCache(page);
page_ref_sub(page, nr);
return xas_error(&xas);
}
swap 엔트리 정보를 키로 anon 페이지를 swap 캐시에 추가한다. 성공 시 0을 반환한다.
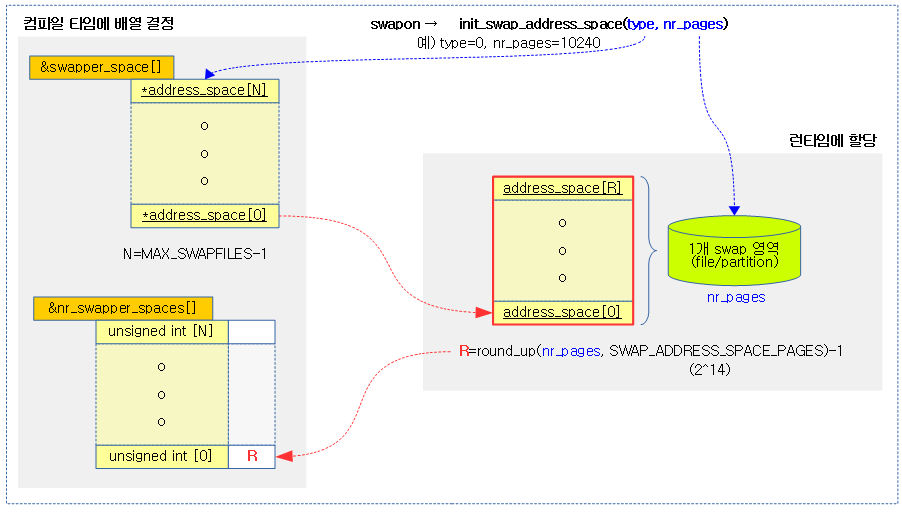
- 코드 라인 3에서 swap 엔트리를 사용하여 swap용 address_space 포인터를 알아온다.
- 코드 라인 4에서 swap 엔트리로 offset 부분만을 읽어 idx에 대입한다.
- 코드 라인 5에서 xarray operation state를 선언한다.
- 작업할 xarray는 &address_space->i_pages이고, 초기 인덱스(idx) 및 엔트리의 order를 지정한다.
- The XArray data structure (2018) | LWN.net
- 코드 라인 6에서 nr에 compound 페이지의 수 만큼 대입한다.
- 일반 페이지는 1이 대입되지만, thp의 경우 compound 구성된 페이지들의 수를 대입한다.
- 코드 라인 8~10에서 xarray로 관리되는 swap 캐시 영역에 추가할 페이지는 PG_locked, PG_swapbacked 플래그 설정이 반드시 있어야 하고, PG_swapcache 플래그는 없어야 한다.
- 코드 라인 12~13에서 swap 캐시 영역에 추가할 페이지의 참조 카운터를 nr 만큼 증가시키고, PG_swapcache 플래그를 설정한다.
- thp swap이 지원되는 경우 head 페이지의 참조 카운터를 nr 만큼 증가시킨다.
- 코드 라인 15~19에서 idx 부터 nr 페이지 수 범위의 xarray가 생성되도록 미리 준비한다.
- 코드 라인 20~25에서 페이지 수 만큼 순회하며 p->private에 swap 엔트리를 저장하고, 페이지를 xarray에 저장한다.
- 코드 라인 26~27에서 nr 페이지 수만큼 다음 카운터들을 증가시킨다.
- address_space가 관리하는 전체 페이지 수
- NR_FILE_PAGES 카운터
- swap_cache_info->add_total 카운터
- 코드 라인 29~31에서 unlock: 레이블이다. xa_node 할당 실패 시 다시 할당하고 반복한다.
- 코드 라인 33~34에서 할당이 성공한 경우 0을 반환한다.
- 코드 라인 36~38에서 할당이 실패한 경우 PG_swapcache를 클리어하고, 참조 카운터를 nr 만큼 다시 내린 후 에러 코드를 반환한다.
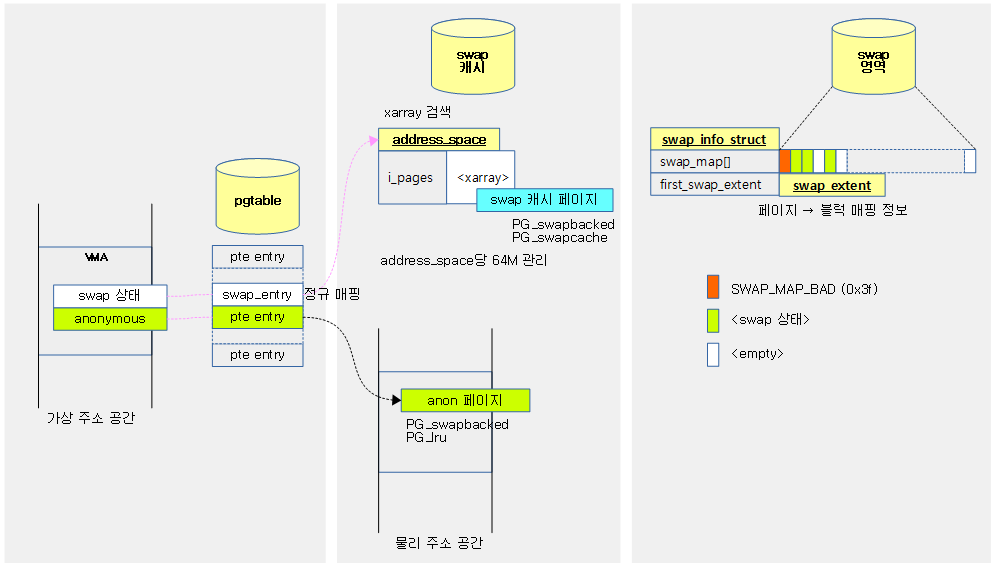
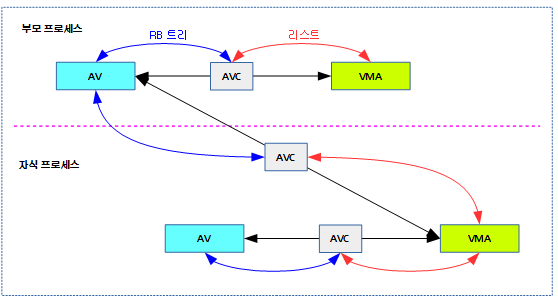
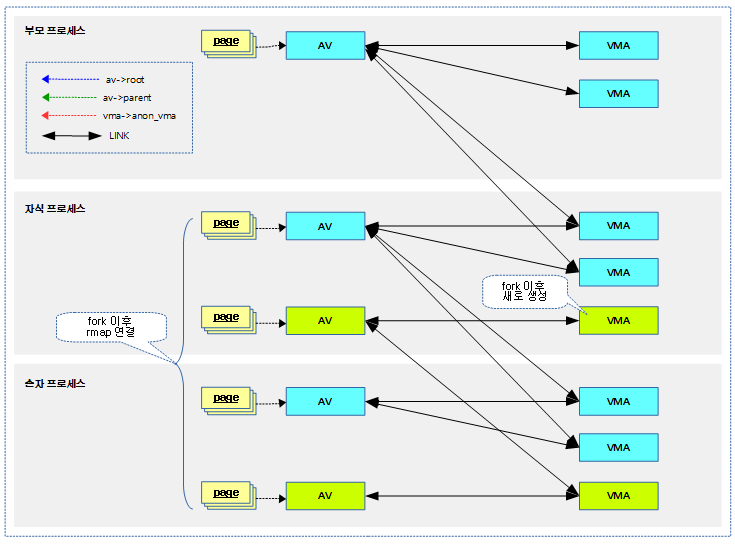
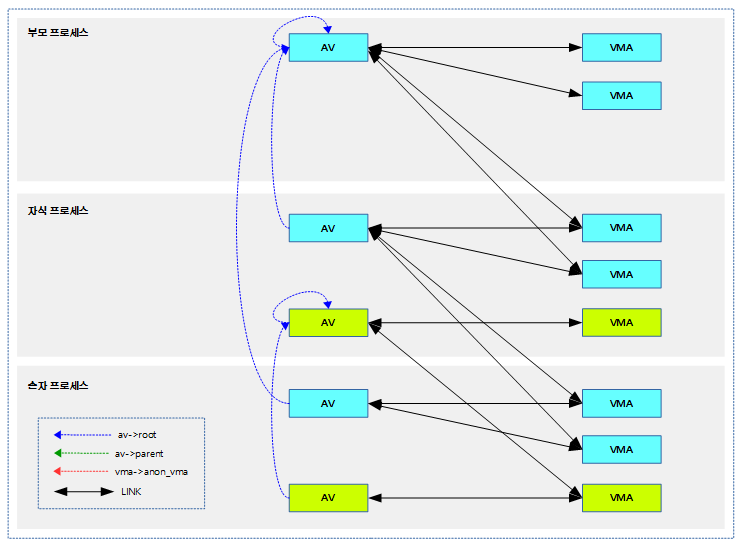
Swap-in
다음과 같은 순서로 swap된 페이지가 복구된다.
- 새 페이지 할당 → swapcache로 변경 → swap 영역(파일/파티션)에서 읽기 → 매핑
다음 그림은 swap-in 과정을 보여준다.

swapin_readahead()
mm/swap_state.c
/** * swapin_readahead - swap in pages in hope we need them soon * @entry: swap entry of this memory * @gfp_mask: memory allocation flags * @vmf: fault information * * Returns the struct page for entry and addr, after queueing swapin. * * It's a main entry function for swap readahead. By the configuration, * it will read ahead blocks by cluster-based(ie, physical disk based) * or vma-based(ie, virtual address based on faulty address) readahead. */
struct page *swapin_readahead(swp_entry_t entry, gfp_t gfp_mask,
struct vm_fault *vmf)
{
return swap_use_vma_readahead() ?
swap_vma_readahead(entry, gfp_mask, vmf) :
swap_cluster_readahead(entry, gfp_mask, vmf);
}
swap 엔트리에 대한 swapin을 수행하여 페이지를 읽어들인다.
- “/sys/kernel/mm/swap/vma_ra_enabled” 속성의 사용 시 vma based readahead를 사용하고, 그렇지 않은 경우 ssd 등에서 사용하는 클러스터 기반의 readahead 방식을 사용한다.
VMA 기반 readhead 방식으로 swap-in
vma 내에서 fault된 swap 페이지를 위해 fault된 가상 주소 그 전후로 산출된 readahead 페이지 수 만큼 swap-in을 하는 방식이다. (SSD only)
- readahead할 페이지들은 vma 경계 또는 pte 테이블 한 개의 범위를 초과할 수 없다.
swap_vma_readahead()
mm/swap_state.c
static struct page *swap_vma_readahead(swp_entry_t fentry, gfp_t gfp_mask,
struct vm_fault *vmf)
{
struct blk_plug plug;
struct vm_area_struct *vma = vmf->vma;
struct page *page;
pte_t *pte, pentry;
swp_entry_t entry;
unsigned int i;
bool page_allocated;
struct vma_swap_readahead ra_info = {0,};
swap_ra_info(vmf, &ra_info);
if (ra_info.win == 1)
goto skip;
blk_start_plug(&plug);
for (i = 0, pte = ra_info.ptes; i < ra_info.nr_pte;
i++, pte++) {
pentry = *pte;
if (pte_none(pentry))
continue;
if (pte_present(pentry))
continue;
entry = pte_to_swp_entry(pentry);
if (unlikely(non_swap_entry(entry)))
continue;
page = __read_swap_cache_async(entry, gfp_mask, vma,
vmf->address, &page_allocated);
if (!page)
continue;
if (page_allocated) {
swap_readpage(page, false);
if (i != ra_info.offset) {
SetPageReadahead(page);
count_vm_event(SWAP_RA);
}
}
put_page(page);
}
blk_finish_plug(&plug);
lru_add_drain();
skip:
return read_swap_cache_async(fentry, gfp_mask, vma, vmf->address,
ra_info.win == 1);
}
swap 엔트리에 대해 vma 기반 swap readahead를 수행한다.
- 코드 라인 11~15에서 swap용 readahead 정보를 구성한다. 만일 swapin할 페이지가 최소 값 1이면 곧바로 skip 레이블로 이동한다.
- 코드 라인 17에서 blk_plug를 초기화하고, blk_finish_plug()가 끝나기 전까지 블럭 디바이스에 submit 을 유보하게 한다.
- 코드 라인 18~27에서 pte 엔트리 수 만큼 순회하며 swap 엔트리 정보가 기록된 pte가 아니면 스킵한다.
- 코드 라인 28~31에서 swap 캐시 영역에서 페이지를 찾아온다.
- 코드 라인 32~38에서 새로 할당된 페이지이면 swap 영역으로 부터 비동기로 bio 요청을 하여 페이지를 읽어온다. 그리고 할당한 페이지가 요청한 offset 페이지가 아니면 PG_reclaim(swap-in시 readahead 기능) 플래그를 설정하고, SWAP_RA 카운터를 증가시킨다.
- 코드 라인 41에서 blk_start_plug() 함수와 짝이되는 함수를 통해 블럭 디바이스의 submit 실행을 지금부터 가능하게 한다.
- 코드 라인 42에서 per-cpu lru 캐시들을 lru로 되돌린다.
- 코드 라인 43~45에서 skip: 레이블이다. 다시 한 번 swap 캐시 영역에서 페이지를 찾아온다. 단 한 페이지만(win=1) 처리할 때 swap 캐시에서 싱크 모드로 페이지를 읽어온다.
swapin 시 readahed를 위한 페이지 수 산출
swapin_nr_pages()
mm/swap_state.c
static unsigned long swapin_nr_pages(unsigned long offset)
{
static unsigned long prev_offset;
unsigned int hits, pages, max_pages;
static atomic_t last_readahead_pages;
max_pages = 1 << READ_ONCE(page_cluster);
if (max_pages <= 1)
return 1;
hits = atomic_xchg(&swapin_readahead_hits, 0);
pages = __swapin_nr_pages(prev_offset, offset, hits, max_pages,
atomic_read(&last_readahead_pages));
if (!hits)
prev_offset = offset;
atomic_set(&last_readahead_pages, pages);
return pages;
}
@offset 페이지에 대해 swapin 시 readahead할 페이지 수를 산출한다.
- 코드 라인 3~5에서 최근 readahead 산출 시 사용했던 offset 값이 prev_offset에, 그리고 최근 산출된 readahead 페이지 수가 last_readahead_pages에 저장되어 있다.
- 코드 라인 7~9에서 최대 페이지 제한으로 1 << page_cluster 값을 지정한다. 만일 그 값이 1이면 추가 산출할 필요 없이 가장 작은 수인 1을 반환한다.
- 코드 라인 11에서 swap-in시 readahead 히트 페이지 수를 알아온다.
- 코드 라인 12~13에서 최근 offset(prev_offset), @offset, readahead 히트 페이지(hits), 최대 페이지 수 제한(@max_pages) 및 최근 산출되었었던 readahead 페이지 수(last_readahead_pages) 값을 사용하여 적절한 readahead 페이지 수를 산출한다.
- 코드 라인 14~15에서 readahead 히트 페이지 수가 0인 경우 offset을 prev_offset에 기억해둔다.
- 코드 라인 16~18에서 산출한 readahead 페이지 수를 last_readahead_pages에 기억하고 반환한다.
__swapin_nr_pages()
mm/swap_state.c
static unsigned int __swapin_nr_pages(unsigned long prev_offset,
unsigned long offset,
int hits,
int max_pages,
int prev_win)
{
unsigned int pages, last_ra;
/*
* This heuristic has been found to work well on both sequential and
* random loads, swapping to hard disk or to SSD: please don't ask
* what the "+ 2" means, it just happens to work well, that's all.
*/
pages = hits + 2;
if (pages == 2) {
/*
* We can have no readahead hits to judge by: but must not get
* stuck here forever, so check for an adjacent offset instead
* (and don't even bother to check whether swap type is same).
*/
if (offset != prev_offset + 1 && offset != prev_offset - 1)
pages = 1;
} else {
unsigned int roundup = 4;
while (roundup < pages)
roundup <<= 1;
pages = roundup;
}
if (pages > max_pages)
pages = max_pages;
/* Don't shrink readahead too fast */
last_ra = prev_win / 2;
if (pages < last_ra)
pages = last_ra;
return pages;
}
최근 offset(@prev_offset), @offset, readahead 히트페이지(@hits), 최대 페이지 수 제한(@max_pages) 및 최근 결정된 readahead 페이지 수(@prev_win) 값을 사용하여 적절한 readahead 페이지 수를 산출하여 반환한다.
- 코드 라인 14~22에서 최근 readahead 히트 페이지가 없는 경우 2개 페이지로 지정한다. 단 offset이 최근 offset과 +- 1 차이를 벗어나면 1개 페이지로 지정한다.
- 코드 라인 23~28에서 최근 readahead 히트 페이지가 존재하는 경우 4부터 시작하여 두 배씩 증가하는 값(4, 8, 16, …) 중 하나로 결정하는데 증가 값이 (히트 페이지 + 2)를 초과한 수 증 작은 값이어야 한다.
- 예) hits=10
- pages = 16
- 예) hits=10
- 코드 라인 30~31에서 산출한 페이지 수가 최대 페이지 수를 초과하지 않도록 제한한다.
- 코드 라인 34~36에서 산출한 페이지 수가 급격히 작아지지 않도록, 최근 readahead한 페이지의 절반 이하로 내려가지 않도록 제한한다.
- 코드 라인 38에서 산출한 readahead 페이지 수를 반환한다.
- 참고:
- swap: add a simple detector for inappropriate swapin readahead (v3.14-rc2)
- mm, swap: VMA based swap readahead (v4.14-rc1)
- 참고:
swap 캐시에서 페이지를 읽어오기
read_swap_cache_async()
mm/swap_state.c
/* * Locate a page of swap in physical memory, reserving swap cache space * and reading the disk if it is not already cached. * A failure return means that either the page allocation failed or that * the swap entry is no longer in use. */
struct page *read_swap_cache_async(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr, bool do_poll)
{
bool page_was_allocated;
struct page *retpage = __read_swap_cache_async(entry, gfp_mask,
vma, addr, &page_was_allocated);
if (page_was_allocated)
swap_readpage(retpage, do_poll);
return retpage;
}
swap 캐시 영역에서 swap 엔트리에 해당하는 페이지를 읽어온다. swap 캐시에서 찾을 수 없으면 swap 캐시를 할당하여 등록한 후 swap 영역에서 블럭 디바이스를 비동기로 읽어오도록 요청한다. 만일 @do_poll을 true로 요청한 경우 swap 캐시로 읽어올 때까지 기다린다.(sync)
- 코드 라인 5~6에서 swap 캐시 영역에서 페이지를 찾아온다. 만일 swap 캐시에서 발견할 수 없으면 swap 영역에서 읽어올 때 필요한 새 swap 캐시 페이지를 미리 준비해둔다. 이러한 경우 page_was_allocated 값에 true가 담겨온다.
- 코드 라인 8~9에서 새 swap 캐시 페이지가 할당된 경우 swap 영역에서 읽어오도록 bio 요청을 한다.
- 코드 라인 11에서 읽어온 페이지를 반환한다.
__read_swap_cache_async()
mm/swap_state.c
struct page *__read_swap_cache_async(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr,
bool *new_page_allocated)
{
struct page *found_page, *new_page = NULL;
struct address_space *swapper_space = swap_address_space(entry);
int err;
*new_page_allocated = false;
do {
/*
* First check the swap cache. Since this is normally
* called after lookup_swap_cache() failed, re-calling
* that would confuse statistics.
*/
found_page = find_get_page(swapper_space, swp_offset(entry));
if (found_page)
break;
/*
* Just skip read ahead for unused swap slot.
* During swap_off when swap_slot_cache is disabled,
* we have to handle the race between putting
* swap entry in swap cache and marking swap slot
* as SWAP_HAS_CACHE. That's done in later part of code or
* else swap_off will be aborted if we return NULL.
*/
if (!__swp_swapcount(entry) && swap_slot_cache_enabled)
break;
/*
* Get a new page to read into from swap.
*/
if (!new_page) {
new_page = alloc_page_vma(gfp_mask, vma, addr);
if (!new_page)
break; /* Out of memory */
}
/*
* Swap entry may have been freed since our caller observed it.
*/
err = swapcache_prepare(entry);
if (err == -EEXIST) {
/*
* We might race against get_swap_page() and stumble
* across a SWAP_HAS_CACHE swap_map entry whose page
* has not been brought into the swapcache yet.
*/
cond_resched();
continue;
} else if (err) /* swp entry is obsolete ? */
break;
/* May fail (-ENOMEM) if XArray node allocation failed. */
__SetPageLocked(new_page);
__SetPageSwapBacked(new_page);
err = add_to_swap_cache(new_page, entry, gfp_mask & GFP_KERNEL);
if (likely(!err)) {
/* Initiate read into locked page */
SetPageWorkingset(new_page);
lru_cache_add_anon(new_page);
*new_page_allocated = true;
return new_page;
}
__ClearPageLocked(new_page);
/*
* add_to_swap_cache() doesn't return -EEXIST, so we can safely
* clear SWAP_HAS_CACHE flag.
*/
put_swap_page(new_page, entry);
} while (err != -ENOMEM);
if (new_page)
put_page(new_page);
return found_page;
}
swap 캐시 영역에서 페이지를 찾아온다. 만일 swap 캐시에서 발견할 수 없으면 swap 영역에서 읽어오기 위해 새 swap 캐시를 할당하여 준비한 후 반환한다. 새 swap 캐시를 준비한 경우 출력 인자 @new_page_allocated에 true를 저장한다.
- 코드 라인 16~18에서 swap 캐시 영역에서 swap 엔트리의 offset을 사용하여 swap 캐시 페이지를 찾아온다.
- 코드 라인 28~29에서 swapoff되어 더 이상 swap 엔트리가 유효하지 않은 경우 null 페이지를 반환하러 루프를 벗어난다.
- 참고: mm/swap: skip readahead only when swap slot cache is enabled (v4.11-rc1)
- 코드 라인 34~38에서 swap 영역에서 읽어올 페이지 데이터를 저장하기 위해 새 swap 캐시 페이지를 할당한다.
- 코드 라인 43~65에서 추가할 새 swap 캐시 페이지의 PG_locked, PG_swapbacked 플래그를 먼저 설정하고 swap 캐시에 추가한다. 추가가 완료하면 새 swap 캐시 페이지를 반환한다.
- 코드 라인 66~72에서 swap 캐시에 추가가 실패하는 경우 새 swap 캐시 페이지의 참조 카운터를 감소시키고 메모리가 부족하지 않는 한 다시 반복한다.
- 코드 라인 75에서 swap 캐시에서 찾은 페이지를 반환한다.
swap 영역에서 읽어 swap 캐시에 저장하기
swap_readpage()
mm/page_io.c
int swap_readpage(struct page *page, bool synchronous)
{
struct bio *bio;
int ret = 0;
struct swap_info_struct *sis = page_swap_info(page);
blk_qc_t qc;
struct gendisk *disk;
VM_BUG_ON_PAGE(!PageSwapCache(page) && !synchronous, page);
VM_BUG_ON_PAGE(!PageLocked(page), page);
VM_BUG_ON_PAGE(PageUptodate(page), page);
if (frontswap_load(page) == 0) {
SetPageUptodate(page);
unlock_page(page);
goto out;
}
if (sis->flags & SWP_FS) {
struct file *swap_file = sis->swap_file;
struct address_space *mapping = swap_file->f_mapping;
ret = mapping->a_ops->readpage(swap_file, page);
if (!ret)
count_vm_event(PSWPIN);
return ret;
}
ret = bdev_read_page(sis->bdev, swap_page_sector(page), page);
if (!ret) {
if (trylock_page(page)) {
swap_slot_free_notify(page);
unlock_page(page);
}
count_vm_event(PSWPIN);
return 0;
}
ret = 0;
bio = get_swap_bio(GFP_KERNEL, page, end_swap_bio_read);
if (bio == NULL) {
unlock_page(page);
ret = -ENOMEM;
goto out;
}
disk = bio->bi_disk;
/*
* Keep this task valid during swap readpage because the oom killer may
* attempt to access it in the page fault retry time check.
*/
get_task_struct(current);
bio->bi_private = current;
bio_set_op_attrs(bio, REQ_OP_READ, 0);
if (synchronous)
bio->bi_opf |= REQ_HIPRI;
count_vm_event(PSWPIN);
bio_get(bio);
qc = submit_bio(bio);
while (synchronous) {
set_current_state(TASK_UNINTERRUPTIBLE);
if (!READ_ONCE(bio->bi_private))
break;
if (!blk_poll(disk->queue, qc, true))
io_schedule();
}
__set_current_state(TASK_RUNNING);
bio_put(bio);
out:
return ret;
}
swap 영역에서 읽어온 데이터를 swap 캐시 페이지에 저장하도록 bio 요청 한다. 요청 시 @synchronous가 1인 경우 동기 요청한다. 결과는 성공한 경우 0을 반환한다.
- 코드 라인 5에서 swap 캐시 페이지의 private 멤버에 저장된 swap 엔트리 정보로 swap_info_struct 정보를 알아온다.
- 코드 라인 9~11에서 페이지에 PG_swapcache, PG_locked 플래그가 반드시 설정되어 있어야 하고, PG_uptodate는 클리어된 상태여야 한다.
- 코드 라인 12~16에서 front swap을 지원하는 경우 front swap 로드 후 PG_uptodate를 설정하고 성공을 반환한다.
- 코드 라인 18~26에서 파일 시스템을 통해 사용되는 swap 영역인 경우 해당 드라이버의 (*readpage) 후크 함수를 통해 페이지를 읽어오고 PSWPIN 카운터를 증가시키고 결과를 반환한다.
- 코드 라인 28~37에서 블럭 디바이스를 통해 사용되는 swap 영역인 경우 블럭 디바이스를 통해 페이지를 읽어오고 PSWPIN을 증가시키고 결과를 반환한다.
- 코드 라인 40~56에서 bio를 통해 swap 영역을 읽어오도록 요청 준비를 한 PSWPIN 카운터를 증가시킨다.
- 코드 라인 57~68에서 bio를 통해 요청을 한다. 그런 후 @synchronous가 설정된 경우 완료될 때까지 대기한다.
- 코드 라인 70~71에서 out: 레이블에서 곧바로 결과를 반환한다.
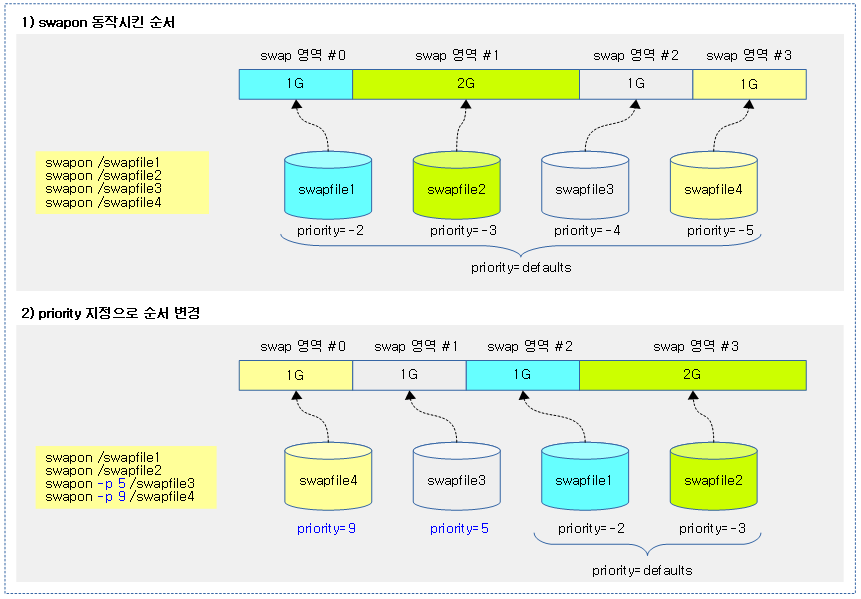
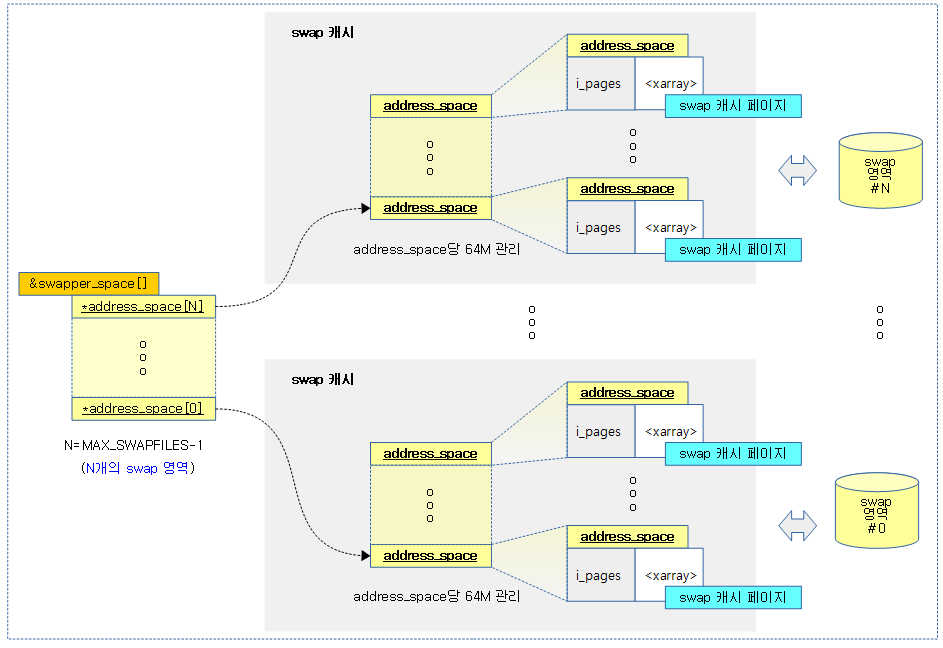
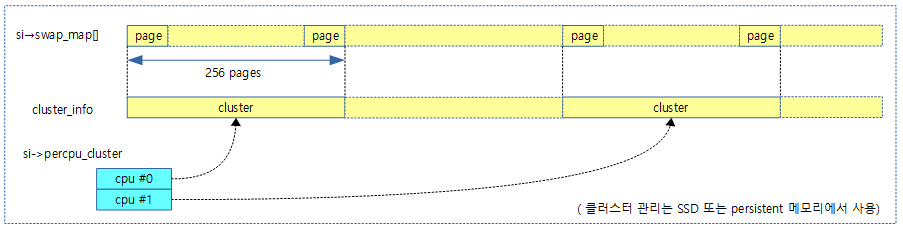
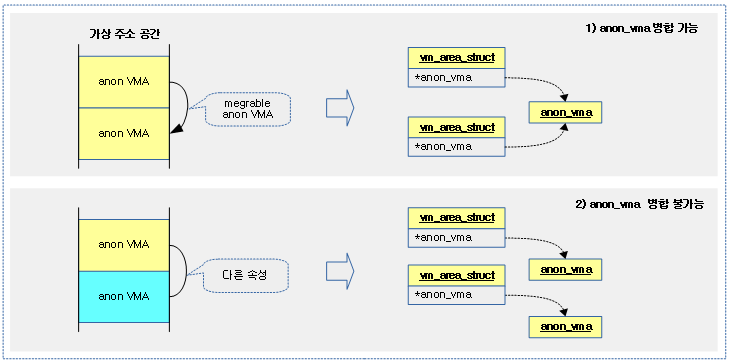
VMA 기반 Swap readahead 정보 구성
다음 그림은 vma 기반 swap readahead 과정을 보여준다.
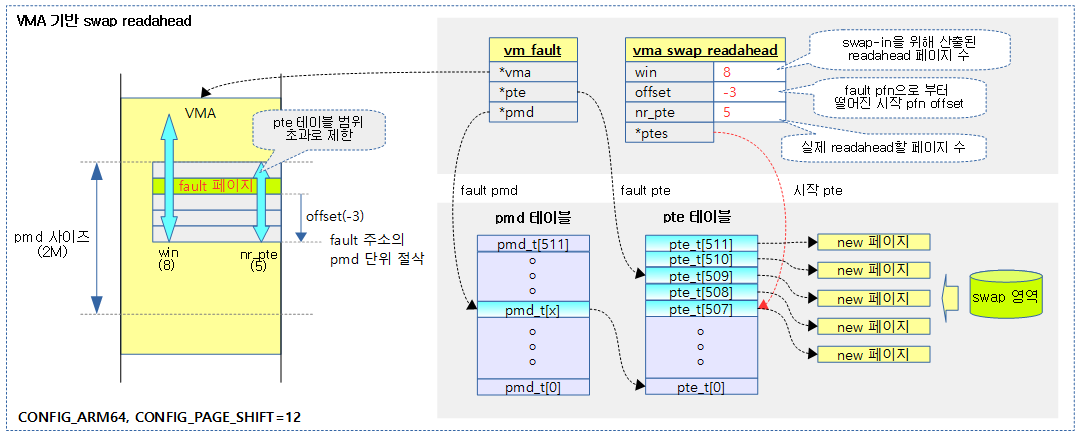
vma_swap_readahead 구조체
include/linux/swap.h
struct vma_swap_readahead {
unsigned short win;
unsigned short offset;
unsigned short nr_pte;
#ifdef CONFIG_64BIT
pte_t *ptes;
#else
pte_t ptes[SWAP_RA_PTE_CACHE_SIZE];
#endif
};
pmd 사이즈 범위내에서, 즉 1개의 pte 페이지 테이블내에서 pte
- win
- swapin 시 readahead할 산출된 페이지 수
- offset
- fault pfn을 기준으로 readahead할 시작 pfn offset
- nr_pte
- swapin 시 readahead할 pte 엔트리 수 (vma 및 pmd 단위 경계로 win 값과 다를 수 있다)
- *ptes
- fault 페이지 pte + offset에 해당하는 pte 주소
swap_ra_info()
mm/swap_state.c
static void swap_ra_info(struct vm_fault *vmf,
struct vma_swap_readahead *ra_info)
{
struct vm_area_struct *vma = vmf->vma;
unsigned long ra_val;
swp_entry_t entry;
unsigned long faddr, pfn, fpfn;
unsigned long start, end;
pte_t *pte, *orig_pte;
unsigned int max_win, hits, prev_win, win, left;
#ifndef CONFIG_64BIT
pte_t *tpte;
#endif
max_win = 1 << min_t(unsigned int, READ_ONCE(page_cluster),
SWAP_RA_ORDER_CEILING);
if (max_win == 1) {
ra_info->win = 1;
return;
}
faddr = vmf->address;
orig_pte = pte = pte_offset_map(vmf->pmd, faddr);
entry = pte_to_swp_entry(*pte);
if ((unlikely(non_swap_entry(entry)))) {
pte_unmap(orig_pte);
return;
}
fpfn = PFN_DOWN(faddr);
ra_val = GET_SWAP_RA_VAL(vma);
pfn = PFN_DOWN(SWAP_RA_ADDR(ra_val));
prev_win = SWAP_RA_WIN(ra_val);
hits = SWAP_RA_HITS(ra_val);
ra_info->win = win = __swapin_nr_pages(pfn, fpfn, hits,
max_win, prev_win);
atomic_long_set(&vma->swap_readahead_info,
SWAP_RA_VAL(faddr, win, 0));
if (win == 1) {
pte_unmap(orig_pte);
return;
}
/* Copy the PTEs because the page table may be unmapped */
if (fpfn == pfn + 1)
swap_ra_clamp_pfn(vma, faddr, fpfn, fpfn + win, &start, &end);
else if (pfn == fpfn + 1)
swap_ra_clamp_pfn(vma, faddr, fpfn - win + 1, fpfn + 1,
&start, &end);
else {
left = (win - 1) / 2;
swap_ra_clamp_pfn(vma, faddr, fpfn - left, fpfn + win - left,
&start, &end);
}
ra_info->nr_pte = end - start;
ra_info->offset = fpfn - start;
pte -= ra_info->offset;
#ifdef CONFIG_64BIT
ra_info->ptes = pte;
#else
tpte = ra_info->ptes;
for (pfn = start; pfn != end; pfn++)
*tpte++ = *pte++;
#endif
pte_unmap(orig_pte);
}
swap용 readahead 정보를 구성한다.
- 코드 라인 4에서 폴트 핸들러가 전달해준 vmf의 vma를 활용한다.
- 코드 라인 15~20에서 최대 readahead 페이지 수를 구한 후 max_win에 대입한다. 이 값이 1일 때 추가 산출할 필요 없으므로 ra_info->win에 1을 대입하고 함수를 빠져나간다.
- 1 << page_cluster와 SWAP_RA_ORDER_CEILING 중 작은 수
- page_cluster의 초기 값은 2~3(메모리가 16M 이하인 경우 2이고, 그 외의 경우 3)이고, “/proc/sys/vm/page-cluster” 값을 통해 조정된다.
- SWAP_RA_ORDER_CEILING 값은 64비트 시스템에서 5이고, 32비트 시스템에서 3이다.
- arm64 디폴트 설정에서 max_win 값은 2^3=8이다.
- 1 << page_cluster와 SWAP_RA_ORDER_CEILING 중 작은 수
- 코드 라인 22~28에서 fault 주소로 페이지 테이블에서 orig_pte 값을 알아오고, 이 값으로 swap 엔트리를 구한다. swap 엔트리가 아닌 경우 pte를 언맵하고 함수를 빠져나간다.
- 코드 라인 30에서 fault 주소에 해당하는 pfn 값을 구한다.
- 코드 라인 31~34에서 vma에 지정된 ra_val 값을 알아오고, 이 값에서 pfn, prev_win과 hits 값을 알아온다.
- ra_val 값에는 세 가지 값이 담겨 있다.
- PAGE_SHIFT 비트 수를 초과하는 비트들에 pfn 값을 담는다.
- PAGE_SHIFT 비트 수의 상위 절반에 win 값을 담는다.
- PAGE_SHIFT 비트 수의 하위 절반에 hits 값을 담는다.
- 예) ra_val=0b111_101010_100001
- SWAP_RA_ADDR(ra_val)=0b111_000000_000000
- PFN_DOWN() 하면 0b111
- SWAP_RA_WIN(ra_val)=0b101010
- SWAP_RA_HITS(ra_val)=0b100001
- SWAP_RA_ADDR(ra_val)=0b111_000000_000000
- 지정되지 않은 경우 prev_win=0, hists=4부터 시작한다.
- ra_val 값에는 세 가지 값이 담겨 있다.
- 코드 라인 35~36에서 pfn, 폴트 pfn, hits, max_win, prev_win 값을 사용하여 readahead할 페이지 수를 산출한다.
- 코드 라인 37~38에서 vma->swap_readahead_info 값에 faddr, win, hits=0 값을 사용하여 ra_val 값을 만들어 저장한다.
- 코드 라인 40~43에서 만일 win 값이 1인 경우 pte 수와 ptes를 수정할 필요 없으므로 기존 pte 매핑을 언맵하고 함수를 빠져나간다.
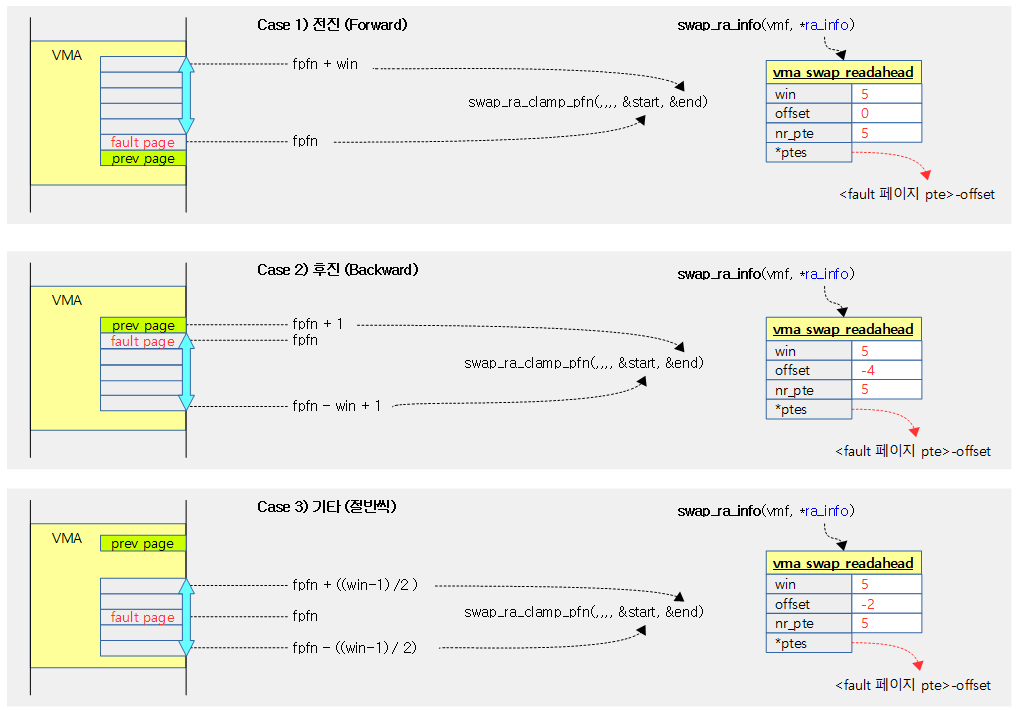
- 코드 라인 46~55에서 다음 세 가지 조건으로 시작과 끝 pfn을 산출한다.
- 지난번에 사용한 페이지 다음에서 fault가 발생한 경우
- 지난번에 사용한 페이지 이전에서 fault가 발생한 경우
- 그 외의 경우
- 코드 라인 56~65에서 출력 인자인 @ra_info에 pte 정보들을 대입한다.
- 코드 라인 66에서 오리지널 pte는 매핑 해제한다.
다음 그림은 지난 번에 사용했던 페이지와 fault 페이지의 위치에 따라 swap 캐시에 읽어올 readahead 페이지 수를 산출하는 과정을 보여준다.
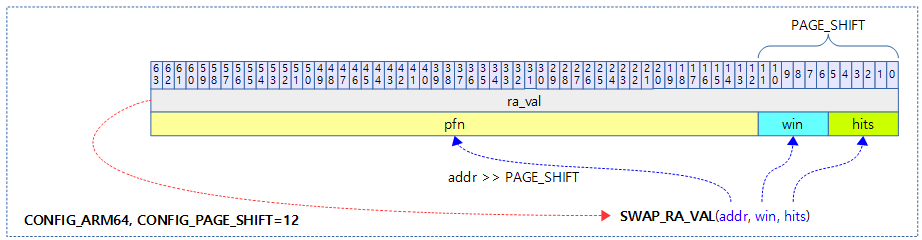
ra_val 값 관련 매크로
mm/swap_state.c
#define SWAP_RA_WIN_SHIFT (PAGE_SHIFT / 2)
#define SWAP_RA_HITS_MASK ((1UL << SWAP_RA_WIN_SHIFT) - 1)
#define SWAP_RA_HITS_MAX SWAP_RA_HITS_MASK
#define SWAP_RA_WIN_MASK (~PAGE_MASK & ~SWAP_RA_HITS_MASK)
#define SWAP_RA_HITS(v) ((v) & SWAP_RA_HITS_MASK)
#define SWAP_RA_WIN(v) (((v) & SWAP_RA_WIN_MASK) >> SWAP_RA_WIN_SHIFT)
#define SWAP_RA_ADDR(v) ((v) & PAGE_MASK)
#define SWAP_RA_VAL(addr, win, hits) \
(((addr) & PAGE_MASK) | \
(((win) << SWAP_RA_WIN_SHIFT) & SWAP_RA_WIN_MASK) | \
((hits) & SWAP_RA_HITS_MASK))
다음 그림은 swap_ra 값에서 addr, win, hits 값을 가져오는 세 매크로들을 보여준다.
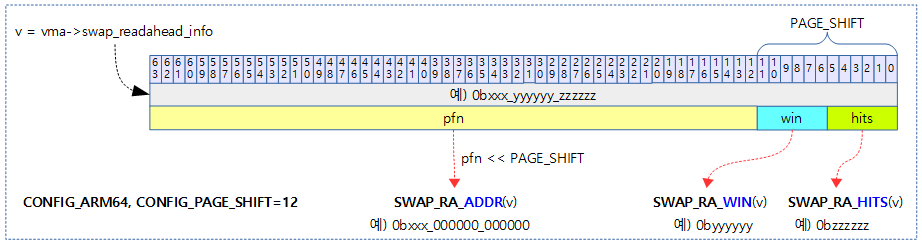
다음 그림은 SWAP_RA_VAL() 매크로를 사용하여 addr, win, hits 인자로 swap_ra 값을 만드는 과정을 보여준다.
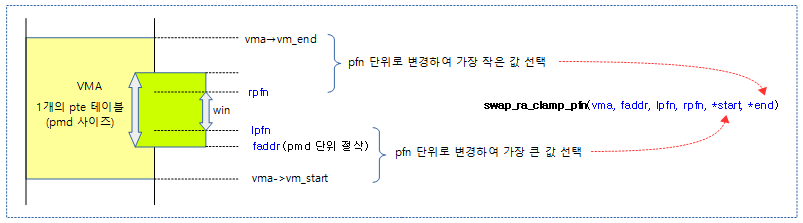
swap_ra_clamp_pfn()
mm/swap_state.c
static inline void swap_ra_clamp_pfn(struct vm_area_struct *vma,
unsigned long faddr,
unsigned long lpfn,
unsigned long rpfn,
unsigned long *start,
unsigned long *end)
{
*start = max3(lpfn, PFN_DOWN(vma->vm_start),
PFN_DOWN(faddr & PMD_MASK));
*end = min3(rpfn, PFN_DOWN(vma->vm_end),
PFN_DOWN((faddr & PMD_MASK) + PMD_SIZE));
}
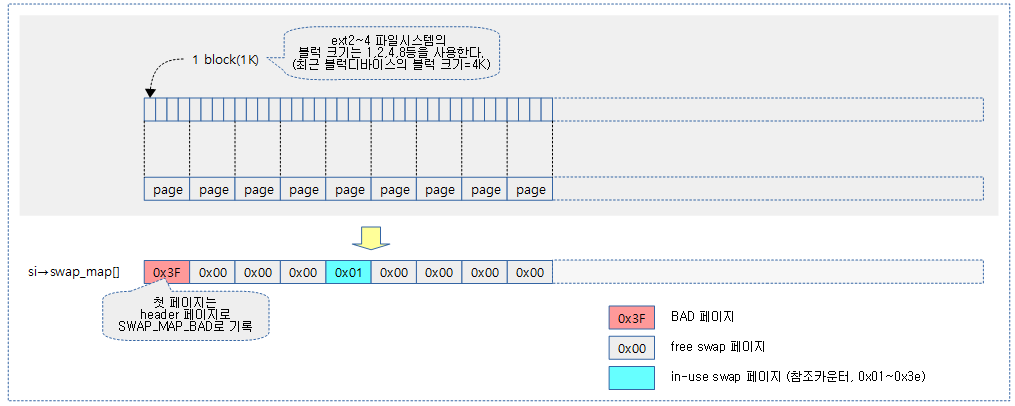
다음 그림은 한 개의 pte 페이지 테이블에서 가져올 pte 엔트리들에 대한 시작 주소와 끝 주소를 알아내는 과정을 보여준다.
클러스터 기반 readhead 방식으로 swap-in
swap_cluster_readahead()
mm/swap_state.c
/** * swap_cluster_readahead - swap in pages in hope we need them soon * @entry: swap entry of this memory * @gfp_mask: memory allocation flags * @vmf: fault information * * Returns the struct page for entry and addr, after queueing swapin. * * Primitive swap readahead code. We simply read an aligned block of * (1 << page_cluster) entries in the swap area. This method is chosen * because it doesn't cost us any seek time. We also make sure to queue * the 'original' request together with the readahead ones... * * This has been extended to use the NUMA policies from the mm triggering * the readahead. * * Caller must hold down_read on the vma->vm_mm if vmf->vma is not NULL. */
struct page *swap_cluster_readahead(swp_entry_t entry, gfp_t gfp_mask,
struct vm_fault *vmf)
{
struct page *page;
unsigned long entry_offset = swp_offset(entry);
unsigned long offset = entry_offset;
unsigned long start_offset, end_offset;
unsigned long mask;
struct swap_info_struct *si = swp_swap_info(entry);
struct blk_plug plug;
bool do_poll = true, page_allocated;
struct vm_area_struct *vma = vmf->vma;
unsigned long addr = vmf->address;
mask = swapin_nr_pages(offset) - 1;
if (!mask)
goto skip;
do_poll = false;
/* Read a page_cluster sized and aligned cluster around offset. */
start_offset = offset & ~mask;
end_offset = offset | mask;
if (!start_offset) /* First page is swap header. */
start_offset++;
if (end_offset >= si->max)
end_offset = si->max - 1;
blk_start_plug(&plug);
for (offset = start_offset; offset <= end_offset ; offset++) {
/* Ok, do the async read-ahead now */
page = __read_swap_cache_async(
swp_entry(swp_type(entry), offset),
gfp_mask, vma, addr, &page_allocated);
if (!page)
continue;
if (page_allocated) {
swap_readpage(page, false);
if (offset != entry_offset) {
SetPageReadahead(page);
count_vm_event(SWAP_RA);
}
}
put_page(page);
}
blk_finish_plug(&plug);
lru_add_drain(); /* Push any new pages onto the LRU now */
skip:
return read_swap_cache_async(entry, gfp_mask, vma, addr, do_poll);
}
swap 엔트리에 대해 클러스터 기반 swap readahead를 수행한다.
- 코드 라인 9에서 swap 엔트리로 swap 정보를 알아온다.
- 코드 라인 12에서 폴트 핸들러가 전달해준 vmf의 vma를 활용한다.
- 코드 라인 15~22에서 fault pnf에 대한 상대 offset pfn이 시작 pfn인데 이 값으로 swapin할 페이지 수 단위로 align한 시작 offset과 끝 offset을 구한다.
- 예) offset=0x3, mask=0xf
- start_offset=0x0
- end_offset=0xf
- 예) offset=0xffff_ffff_ffff_fffd(-3), mask=0xf
- start_offset=0xffff_ffff_ffff_fff0(-16)
- end_offset=0xffff_ffff_ffff_ffff(-1)
- 예) offset=0x3, mask=0xf
- 코드 라인 23~26에서 시작 offset이 0이면 swap 헤더이므로 그 다음을 사용하도록 증가시키고, 끝 offset이 최대값 미만이 되도록 제한한다.
- 코드 라인 28에서 blk_plug를 초기화하고, blk_finish_plug()가 끝나기 전까지 블럭 디바이스에 submit 을 유보하게 한다.
- 코드 라인 29~35에서 pte 엔트리 수 만큼 순회하며 swap 캐시 영역에서 swap 엔트리를 사용하여 페이지를 찾아온다.
- 코드 라인 36~42에서 새로 할당된 페이지이면 swap 영역으로 부터 비동기로 bio 요청을 하여 페이지를 읽어온다. 그리고 할당한 페이지가 요청한 offset 페이지가 아니면 PG_reclaim(swap-in시 readahead 기능) 플래그를 설정하고, SWAP_RA 카운터를 증가시킨다.
- 코드 라인 45에서 blk_start_plug() 함수와 짝이되는 함수를 통해 블럭 디바이스의 submit 실행을 지금부터 가능하게 한다.
- 코드 라인 47에서 per-cpu lru 캐시들을 lru로 되돌린다.
- 코드 라인 48~49에서 skip: 레이블이다. 다시 한 번 swap 캐시 영역에서 페이지를 async 모드로 찾아온다.
Swap 캐시 페이지 찾기
fault 핸들러에서 fault된 pte 엔트리 값에 swap 엔트리가 기록되어 있는 경우 do_swap_page() 함수를 호출하여 swap 캐시 영역에서 찾아 anon 페이지로 매핑해주는데 이 때 swap 캐시 영역을 찾는 함수를 알아본다.
lookup_swap_cache()
mm/swap_state.c
/* * Lookup a swap entry in the swap cache. A found page will be returned * unlocked and with its refcount incremented - we rely on the kernel * lock getting page table operations atomic even if we drop the page * lock before returning. */
struct page *lookup_swap_cache(swp_entry_t entry, struct vm_area_struct *vma,
unsigned long addr)
{
struct page *page;
page = find_get_page(swap_address_space(entry), swp_offset(entry));
INC_CACHE_INFO(find_total);
if (page) {
bool vma_ra = swap_use_vma_readahead();
bool readahead;
INC_CACHE_INFO(find_success);
/*
* At the moment, we don't support PG_readahead for anon THP
* so let's bail out rather than confusing the readahead stat.
*/
if (unlikely(PageTransCompound(page)))
return page;
readahead = TestClearPageReadahead(page);
if (vma && vma_ra) {
unsigned long ra_val;
int win, hits;
ra_val = GET_SWAP_RA_VAL(vma);
win = SWAP_RA_WIN(ra_val);
hits = SWAP_RA_HITS(ra_val);
if (readahead)
hits = min_t(int, hits + 1, SWAP_RA_HITS_MAX);
atomic_long_set(&vma->swap_readahead_info,
SWAP_RA_VAL(addr, win, hits));
}
if (readahead) {
count_vm_event(SWAP_RA_HIT);
if (!vma || !vma_ra)
atomic_inc(&swapin_readahead_hits);
}
}
return page;
}
swap 엔트리 값으로 swap 캐시 페이지를 찾아온다.
- 코드 라인 6에서 swap 엔트리에 매핑된 address_space와 swap 엔트리의 offset 값으로 페이지를 찾아온다.
- 코드 라인 8에서 swap 캐시 stat의 find_total 카운터를 증가시킨다.
- 코드 라인 9~10에서 캐시된 페이지를 찾은 경우 vma 기반 readahead가 enable 되었는지 여부를 vam_ra에 대입한다.
- 코드 라인 13에서 swap 캐시 stat의 find_success 카운터를 증가시킨다.
- 코드 라인 18~19에서 낮은 확률로 thp 또는 hugetlbfs 페이지인 경우 anon THP에 대한 readahead를 지원하지 않아 그냥 해당 페이지를 반환한다.
- 코드 라인 21에서 페이지의 PG_reclaim(swap-in시 readahed 플래그로 동작) 플래그 값을 readahead에 대입한 후 클리어한다.
- 코드 라인 22~33에서 vma 기반 readahead를 사용하는 경우 vma에 저장한 ra_val 값을 갱신한다. 이 때 readahead 플래그가 있었던 페이지인 경우 ra_val내의 hits 값은 증가시킨다.
- 코드 라인 35~39에서 readahead 플래그가 있었던 페이지인 경우 SWAP_RA_HIT 카운터를 증가시킨다. 만일 vma가 지정되지 않았거나 vma 기반 readahead를 사용하지 않는 경우 swapin_readahead_hits 카운터를 증가시킨다.
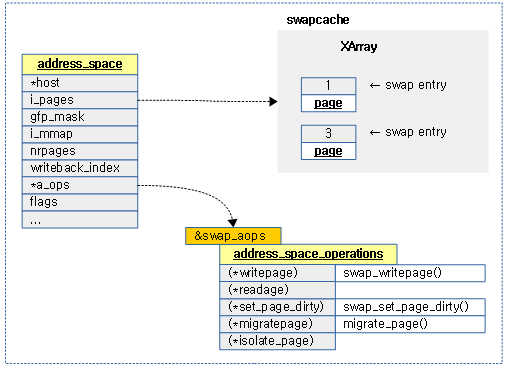
swap operations
address_space_operations 구조체
mm/swap_state.c
/* * swapper_space is a fiction, retained to simplify the path through * vmscan's shrink_page_list. */
static const struct address_space_operations swap_aops = {
.writepage = swap_writepage,
.set_page_dirty = swap_set_page_dirty,
#ifdef CONFIG_MIGRATION
.migratepage = migrate_page,
#endif
};
swap 영역에 기록
anon 페이지를 swap 캐시에 저장한 후 dirty를 설정하고 빠져나온다음 매핑을 해제한다. 그런 후 pageout()을 통한 swap 캐시를 swap 영역에 기록할 수 있다.
swap_writepage()
mm/page_io.c
/* * We may have stale swap cache pages in memory: notice * them here and get rid of the unnecessary final write. */
int swap_writepage(struct page *page, struct writeback_control *wbc)
{
int ret = 0;
if (try_to_free_swap(page)) {
unlock_page(page);
goto out;
}
if (frontswap_store(page) == 0) {
set_page_writeback(page);
unlock_page(page);
end_page_writeback(page);
goto out;
}
ret = __swap_writepage(page, wbc, end_swap_bio_write);
out:
return ret;
}
dirty 상태의 swap 캐시를 swap 영역에 기록한다.
- 코드 라인 5~8에서 다음의 경우가 아니면 swap 캐시에서 이 페이지를 제거하고 out: 레이블로 이동한다.
- 이미 swap 캐시에서 제거되었다. (PG_swapcache 플래그가 없는 상태)
- writeback이 완료되었다. (PG_writeback이 없는 상태)
- 이미 swap 영역에 저장한 상태이다. (swap_map[]에 비트가 설정된 상태)
- 코드 라인 9~14에서 frontswap을 지원하는 경우의 처리이다.
- 코드 라인 15~17에서 페이지를 swap 영역에 기록 요청하고 결과를 반환한다. sync/async 기록이 완료되면 end_swap_bio_write() 함수를 호출하여 writeback이 완료되었음을 페이지 플래그를 변경한다.
swap_set_page_dirty()
mm/page_io.c
int swap_set_page_dirty(struct page *page)
{
struct swap_info_struct *sis = page_swap_info(page);
if (sis->flags & SWP_FS) {
struct address_space *mapping = sis->swap_file->f_mapping;
VM_BUG_ON_PAGE(!PageSwapCache(page), page);
return mapping->a_ops->set_page_dirty(page);
} else {
return __set_page_dirty_no_writeback(page);
}
}
swap 페이지에 dirty 표식을 한다. 새롭게 dirty로 변경된 경우 1을 반환한다.
- 코드 라인 5~9에서 SWP_FS가 설정된 swap 영역인 경우 해당 드라이버가 제공하는 set_page_dirty() 함수를 사용하여 dirty 표식을 한다.
- SWP_FS는 sunrpc, nfs, xfs, btrfs 등에서 사용된다.
- 코드 라인 10~12에서 그 외의 일반 swap 영역을 사용하는 경우 swap 캐시 페이지에 dirty 설정을 한다.
__set_page_dirty_no_writeback()
mm/page-writeback.c
/* * For address_spaces which do not use buffers nor write back. */
int __set_page_dirty_no_writeback(struct page *page)
{
if (!PageDirty(page))
return !TestSetPageDirty(page);
return 0;
}
해당 페이지에 dirty 플래그를 설정한다. 새롭게 dirty 설정한 경우 1을 반환한다.
참고
- Swap -1- (Basic, 초기화) | 문c
- Swap -2- (Swapin & Swapout) | 문c – 현재글
- Swap -3- (swap 영역 할당/해제) | 문c
- Swap -4- (Swap 엔트리) | 문c