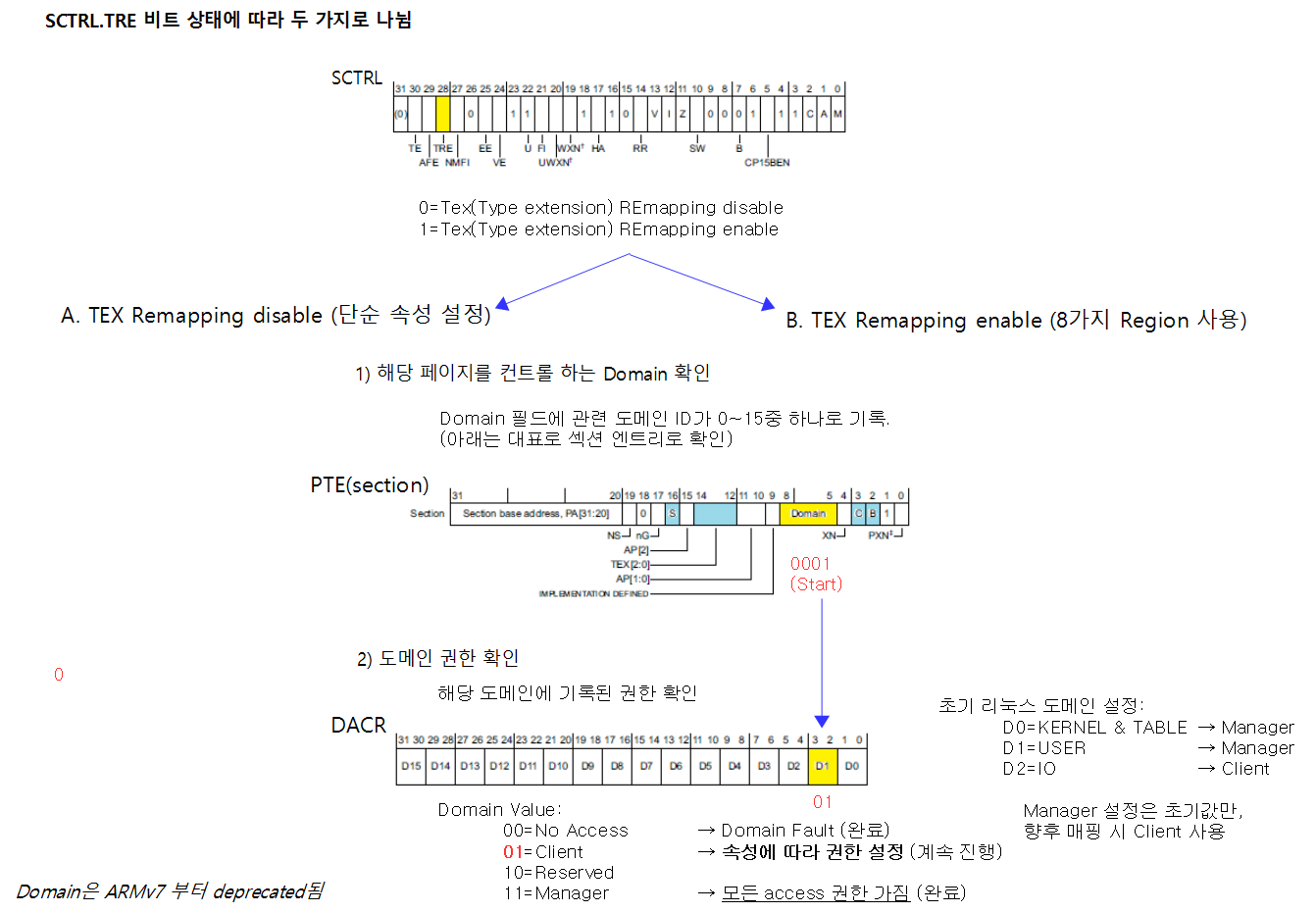
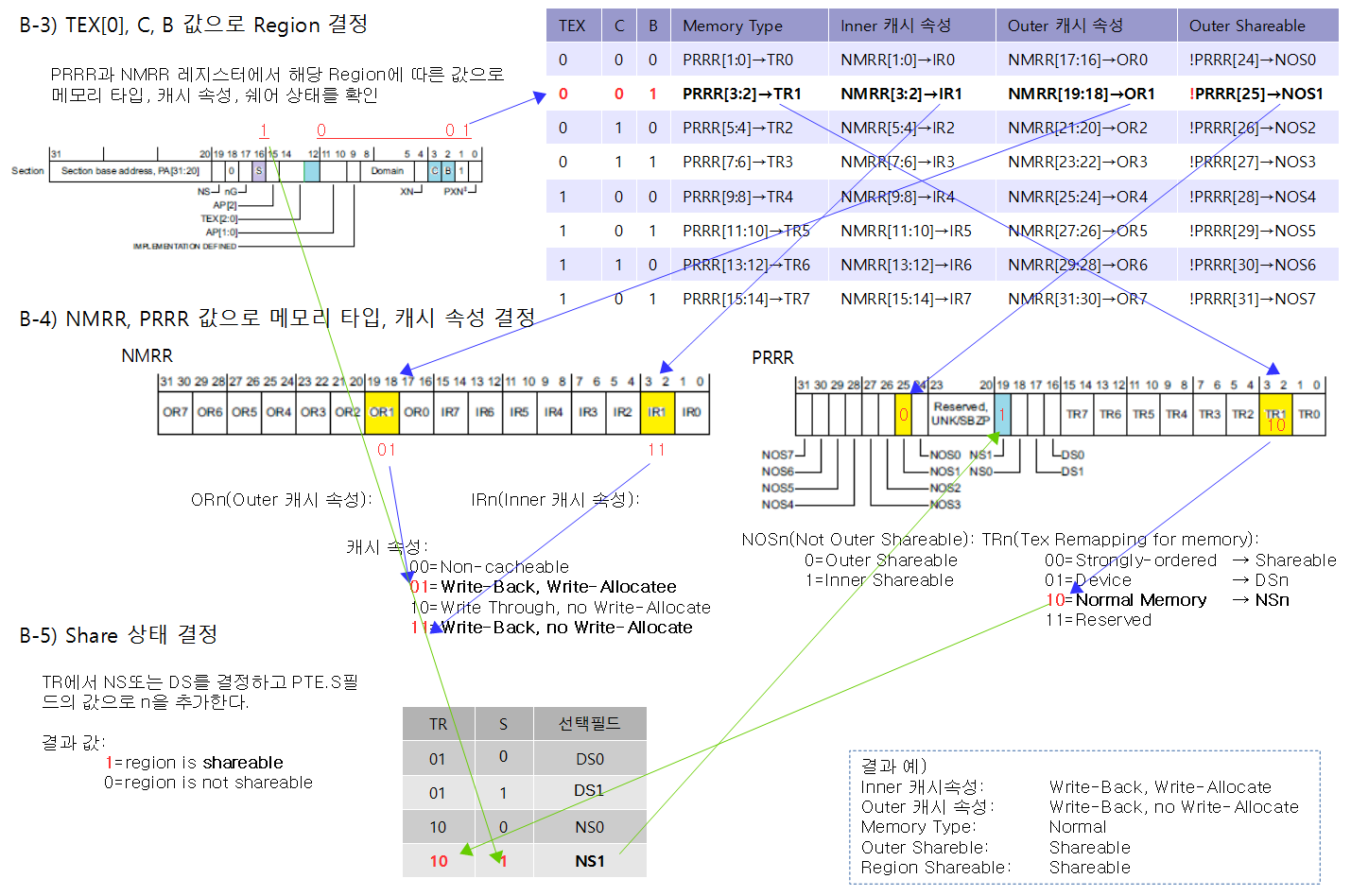
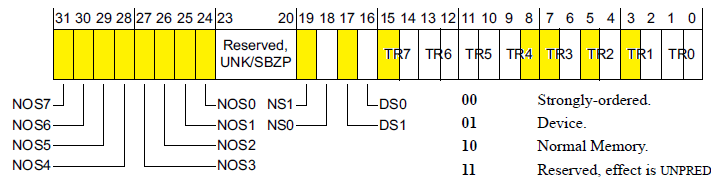
다음 글에 통합하였습니다
- 참고: Cache Coherent | 문c
다음 글에 통합하였습니다
<kernel v5.10>
컴파일러나 아키텍처는 성능 향상을 위해 처리 순서에 개연성(dependency)이 없는 경우 순서를 변경하여 처리하는 최적화 동작을 한다. 그러나 개연성이 있지만 컴파일러나 아키텍처가 보기에 개연성이 없어 보이는 것으로 잘못 판단하는 경우도 있으므로 이러한 경우 미리 특정 상황에서 순서를 바꾸지 못하도록 강제해야 하는 경우가 있다. 이럴 때 명령 순서 또는 메모리 접근 동작들 사이에 순서를 바꾸지 못하게 배리어를 사용한다.
명령들이 실행될 때 성능 향상을 위해 다음과 같이 컴파일러 또는 H/W 아키텍처 내부에서의 최적화를 통해 명령 실행 순서를 바꾸는 경우들이 있다.
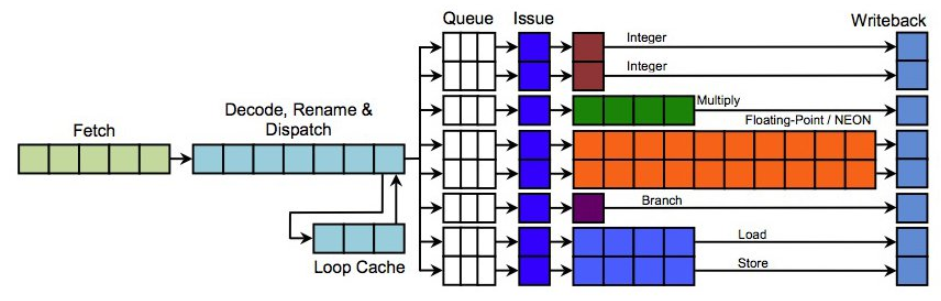
다음은 1개의 프로세스(HW 스레드)에서 Fetch된 명령들이 동시에 처리를 시작할 수 있다.
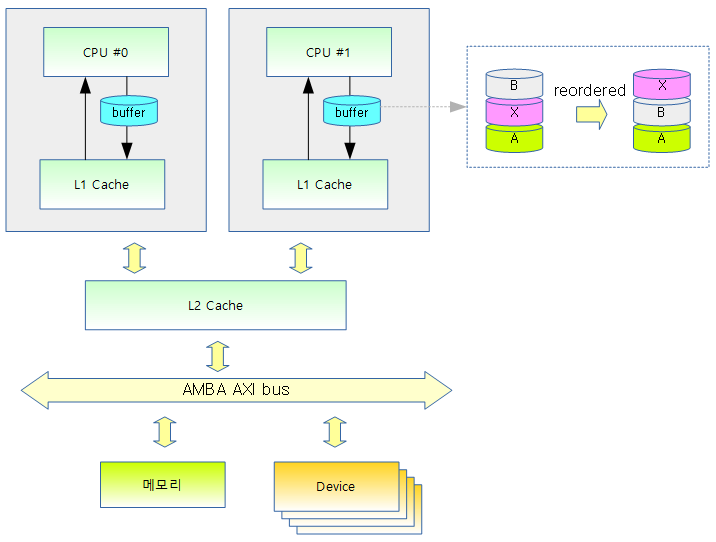
공유 메모리 공간을 CPU들과 디바이스들이 접근하는데 성능 향상을 위해 다음과 같이 컴파일러 또는 H/W 아키텍처 내부에서의 최적화를 통해 접근 순서를 바꾸는 경우들이 있다.
예 1) 같은 캐시 라인의 주소를 같이 처리
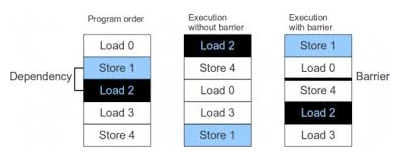
다음 그림과 같이 메모리 액세스 순서가 바뀔 수도 있다.
예 2) 디바이스 주소 레지스터와 데이터 레지스터를 사용 시 Store와 Load 순서 바뀌면서 생기는 문제
컴파일러 최적화 장벽으로 최적화 시 실행 코드가 생략, 축약 또는 실행 순서가 변경되지 못하도록 막아야하는 경우에 사용된다.
barrier()와 다르게 특정 액세스에 대해서만 동작하는 컴파일러 베리어 API를 알아본다.
다음과 같은 여러 가지 상황들에서 컴파일러 베리어를 사용하여 원하지 않는 최적화를 피해야 한다.

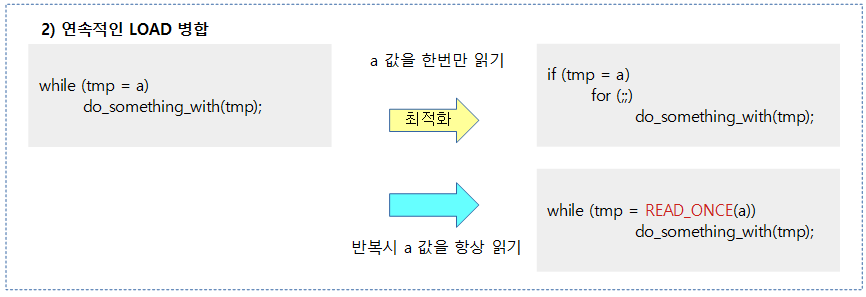
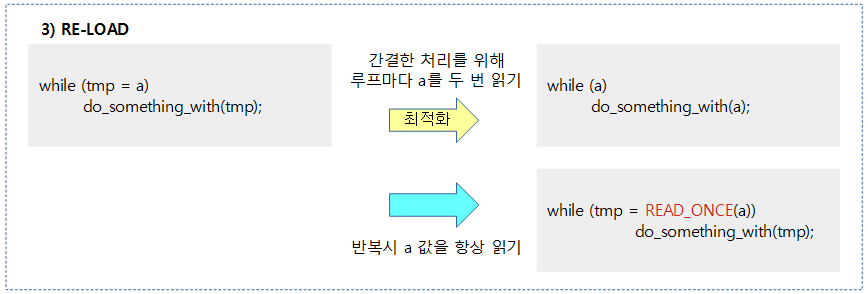
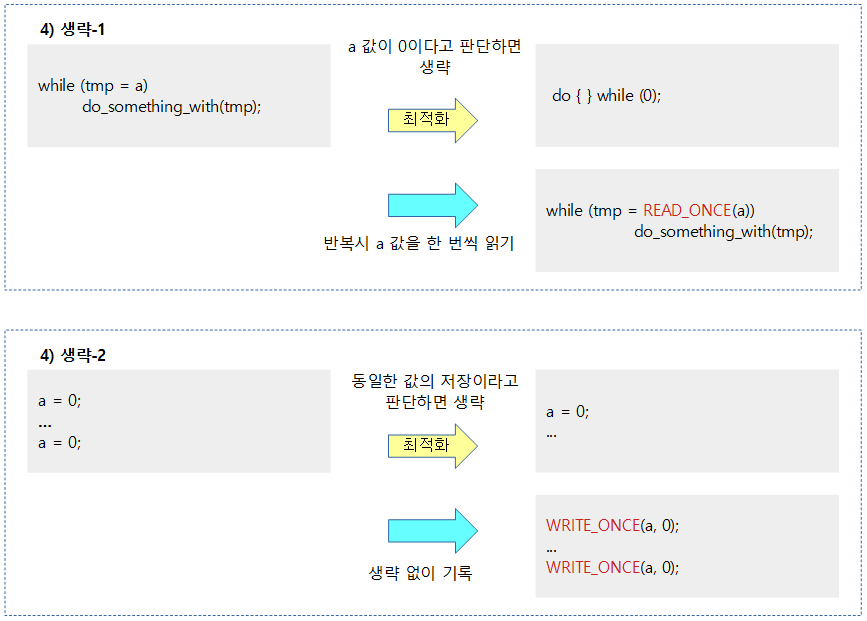
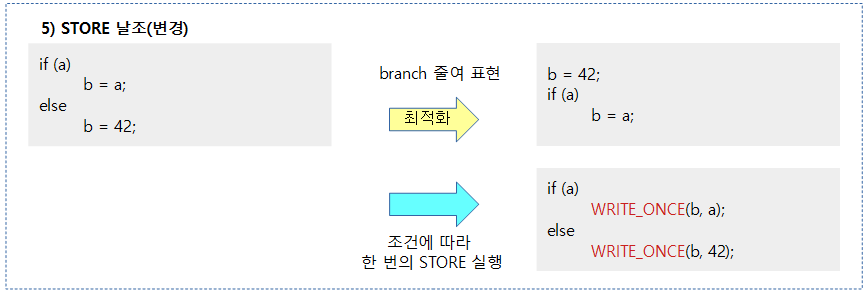

컴파일러는 컨트롤 의존성 배리어를 이해하지 못한다.
예) 컴파일러의 최적화에 의해 a와 b의 읽는 순서를 보장할 수 없다.
q = READ_ONCE(a);
if (q) {
p = READ_ONCE(b);
}
예) 컴파일러의 최적화에 의해 b의 기록에 대해 순서를 보장한다.
q = READ_ONCE(a);
if (q) {
WRITE_ONCE(b, 1);
}
그런데 위의 예에서 READ_ONCE() 및 WRITE_ONCE() 없이 사용하면서 컴파일러가 a 값이 0이 아닌 상수라고 판단한 경우 다음과 같이 컴파일러가 최적화를 수행할 수 도 있다.
q = a;
b = 1;
예) 다음 코드를 통해 제대로 순서를 지킬 수 있지 않을까 기대해본다.
q = READ_ONCE(a);
if (q) {
barrier();
WRITE_ONCE(b, 1);
do_something();
} else {
barrier();
WRITE_ONCE(b, 1);
do_something_else();
}
문제 발생) 불행히도 위의 코드는 컴파일러에 의해서 다음과 같이 바꿔버린다.
q = READ_ONCE(a);
barrier();
WRITE_ONCE(b, 1);
if (q) {
do_something();
} else {
do_something_else();
}
해결) 위의 문제를 해결하기 위해 다음과 같이 변경이 필요하다.
q = READ_ONCE(a);
if (q) {
smp_store_release(&b, 1);
do_something();
} else {
smp_store_release(&b, 1);
do_something_else();
}
아키텍처 메모리 베리어 또는 CPU 메모리 베리어라고 불리운다. 가장 기본 아키텍처 barrier인 mb(), rmb(), wmb()를 사용하면 full 배리어로 처리 성능이 가장 느려 성능이 저하된다. 따라서 성능을 더 높이고자 여러가지 barrier를 추가하였는데 그들간의 성능 관계는 다음 그림과 같다.
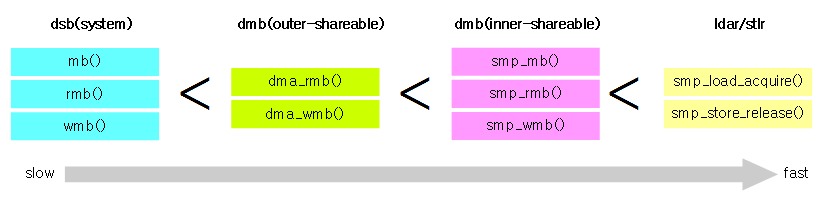
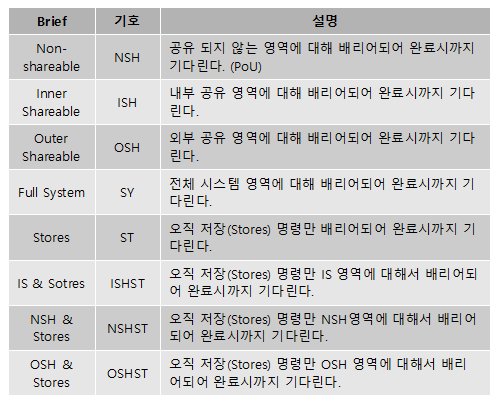
아키텍처가 공유 메모리에 접근 시 생략, 축약 또는 접근 순서를 변경하지 못하도록 막는다. 다음과 같이 기본 4가지 타입의 API를 제공한다.
추가로 다음 2가지의 묵시적인 one-way 배리어 타입이 있다. (자세한 설명은 좀 뒤에..)
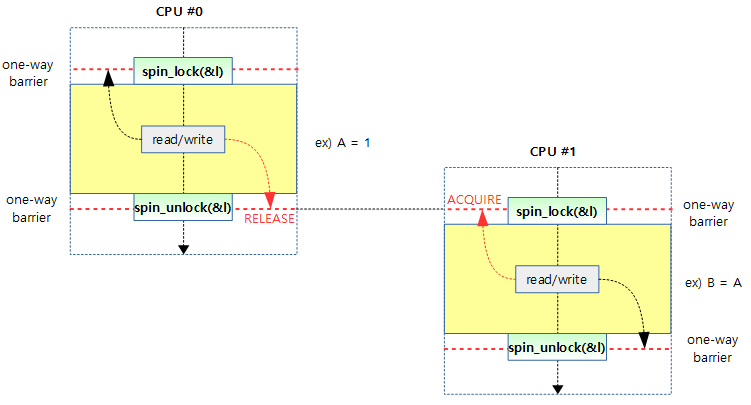
다음 그림은 ACQUIRE 및 RELEASE operation이 spinlock에 구현된 사례를 보여준다.
디바이스를 위해 rmb(), wmb()보다 더 가볍고 smp 지원 barrier보다는 좀 더 무거운 outer share 영역까지 공유 가능한 명령을 커널 v3.19-rc1에 추가하였다.
SMP 시스템의 inner share 영역에서 캐시 일관성을 같이 사용하는 코어 및 디바이스들간 메모리 정합성을 보장하기 위해 다음 함수들을 사용한다.
커널내의 Locking 구조, pthread 동기화 연산들도 implicit 배리어로 동작한다. 하지만 이 자원들을 외부로 공유시에는 명시적인 배리어가 필요할 수 있다.
메모리 배리어 요구 시 대부분의 아키텍처는 Read/Write에 관여하는 버퍼가 모두 다 처리되어 비워질(flush) 때까지 기다리는 것으로 처리한다. 그러나 이러한 처리에 상당한 사이클을 사용하므로 성능을 떨어뜨리는 이유가 된다. 보다 빠른 처리를 위해 TSO(Total Store Order)가 지원되는 x86 및 sparc 아키텍처와 Load-Acquire/Store-Release 명령(ldar/stlr)이 지원되는 ARM64 아키텍처를 위해 커널 v3.14-rc1에서 특별한 구현이 소개되었다.
non-TSO 아키텍처에서는 load/store 연산들이 순차적으로 진행되어 순서가 바뀌는 일이 없다. 그러나 성능 향상을 위해 TSO를 지원하는 아키텍처의 경우 Store만 순서대로 처리하고, Load는 weakly(out-of) order로 처리 할 수 있다.
다음 그림은 non-TSO 와 TSO 지원 아키텍처를 비교한 그림이다.

다음 그림은 ARMv8 아키텍처에서의 양방향 barrier와 단방향 barrier의 차이를 보여준다.
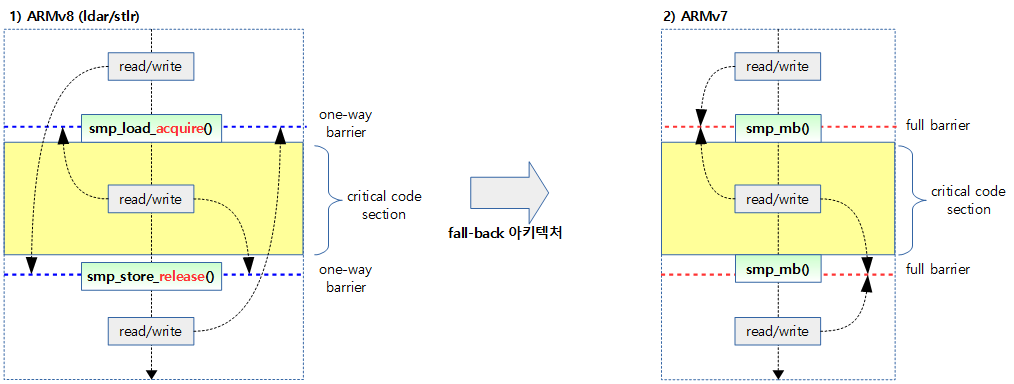
arch/arm/include/asm/barrier.h
#define mb() barrier() #define rmb() barrier() #define wmb() barrier() #define dma_rmb() barrier() #define dma_wmb() barrier()
CPU가 하나만 사용된 시스템에서는 메모리 접근 순서가 바뀌더라도 특별히 영향을 주지 않으므로 컴파일러 배리어만 사용한다.
include/asm-generic/barrier.h
#define smp_mb() __smp_mb() #define smp_rmb() __smp_rmb() #define smp_wmb() __smp_wmb()
arch/arm/include/asm/barrier.h
#define isb(option) __asm__ __volatile__ ("isb " #option : : : "memory")
#define dsb(option) __asm__ __volatile__ ("dsb " #option : : : "memory")
#define dmb(option) __asm__ __volatile__ ("dmb " #option : : : "memory")
#define __arm_heavy_mb(x...) dsb(x)
#define mb() __arm_heavy_mb()
#define rmb() dsb()
#define wmb() __arm_heavy_mb(st)
#define dma_rmb() dmb(osh)
#define dma_wmb() dmb(oshst)
#define __smp_mb() dmb(ish)
#define __smp_rmb() __smp_mb()
#define __smp_wmb() dmb(ishst)
include/asm-generic/barrier.h
#define smp_mb() __smp_mb() #define smp_rmb() __smp_rmb() #define smp_wmb() __smp_wmb()
arch/arm64/include/asm/barrier.h
#define mb() dsb(sy) #define rmb() dsb(ld) #define wmb() dsb(st) #define dma_rmb() dmb(oshld) #define dma_wmb() dmb(oshst) #define __smp_mb() dmb(ish) #define __smp_rmb() dmb(ishld) #define __smp_wmb() dmb(ishst)
arch/arm64/include/asm/barrier.h
#define sev() asm volatile("sev" : : : "memory")
#define wfe() asm volatile("wfe" : : : "memory")
#define wfi() asm volatile("wfi" : : : "memory")
#define isb() asm volatile("isb" : : : "memory")
#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
다음 그림과 같이 ARM 아키텍처별 명령어를 비교하였다.

include/asm-generic/barrier.h
#ifndef smp_load_acquire #define smp_load_acquire(p) __smp_load_acquire(p) #endif
단방향 베리어와 함께 주소 p에 해당하는 값을 해당 스칼라 데이터 타입 사이즈(1, 2, 4, 8)에 맞게 읽어온다.
arch/arm64/include/asm/barrier.h
#define __smp_load_acquire(p) \
({ \
union { __unqual_scalar_typeof(*p) __val; char __c[1]; } __u; \
typeof(p) __p = (p); \
compiletime_assert_atomic_type(*p); \
kasan_check_read(__p, sizeof(*p)); \
switch (sizeof(*p)) { \
case 1: \
asm volatile ("ldarb %w0, %1" \
: "=r" (*(__u8 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 2: \
asm volatile ("ldarh %w0, %1" \
: "=r" (*(__u16 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 4: \
asm volatile ("ldar %w0, %1" \
: "=r" (*(__u32 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
case 8: \
asm volatile ("ldar %0, %1" \
: "=r" (*(__u64 *)__u.__c) \
: "Q" (*__p) : "memory"); \
break; \
} \
(typeof(*p))__u.__val; \
})
단방향 베리어 명령인 ldsr을 사용하여 주소 p에 해당하는 값을 해당 스칼라 데이터 타입 사이즈(1, 2, 4, 8)에 맞게 읽어온다.
include/asm-generic/barrier.h
#ifndef smp_store_release #define smp_store_release(p, v) __smp_store_release(p, v) #endif
단방향 베리어 명령과 함께 주소 p에 값 v를 해당 스칼라 데이터 타입 사이즈(1, 2, 4, 8)에 맞게 기록한다.
arch/arm64/include/asm/barrier.h
#define __smp_store_release(p, v) \
do { \
typeof(p) __p = (p); \
union { __unqual_scalar_typeof(*p) __val; char __c[1]; } __u = \
{ .__val = (__force __unqual_scalar_typeof(*p)) (v) }; \
compiletime_assert_atomic_type(*p); \
kasan_check_write(__p, sizeof(*p)); \
switch (sizeof(*p)) { \
case 1: \
asm volatile ("stlrb %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u8 *)__u.__c) \
: "memory"); \
break; \
case 2: \
asm volatile ("stlrh %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u16 *)__u.__c) \
: "memory"); \
break; \
case 4: \
asm volatile ("stlr %w1, %0" \
: "=Q" (*__p) \
: "r" (*(__u32 *)__u.__c) \
: "memory"); \
break; \
case 8: \
asm volatile ("stlr %1, %0" \
: "=Q" (*__p) \
: "r" (*(__u64 *)__u.__c) \
: "memory"); \
break; \
} \
} while (0)
단방향 베리어 명령인 stlr을 사용하여 주소 p에 값 v를 해당 스칼라 데이터 타입 사이즈(1, 2, 4, 8)에 맞게 기록한다.
arch/arm64/include/asm/barrier.h
#define smp_cond_load_acquire(ptr, cond_expr) \
({ \
typeof(ptr) __PTR = (ptr); \
__unqual_scalar_typeof(*ptr) VAL; \
for (;;) { \
VAL = smp_load_acquire(__PTR); \
if (cond_expr) \
break; \
__cmpwait_relaxed(__PTR, VAL); \
} \
(typeof(*ptr))VAL; \
})
주소 ptr의 데이터를 읽은 후 조건 cond_expr이 true인 경우 읽은 데이터를 반환한다. 데이터를 읽을 때 단방향 acquire 베리어를 사용한다. 만일 조건을 만족하지 못하는 경우 반복하며 시도한다.
arch/arm64/include/asm/barrier.h
#define smp_cond_load_relaxed(ptr, cond_expr) \
({ \
typeof(ptr) __PTR = (ptr); \
__unqual_scalar_typeof(*ptr) VAL; \
for (;;) { \
VAL = READ_ONCE(*__PTR); \
if (cond_expr) \
break; \
__cmpwait_relaxed(__PTR, VAL); \
} \
(typeof(*ptr))VAL; \
})
주소 ptr의 데이터를 읽은 후 조건 cond_expr이 true인 경우 읽은 데이터를 반환한다. 만일 조건을 만족하지 못하는 경우 반복하며 시도한다.
arch/arm64/include/asm/cmpxchg.h
#define __cmpwait_relaxed(ptr, val) \
__cmpwait((ptr), (unsigned long)(val), sizeof(*(ptr)))
아래 __CMPWAIT_GEN() 매크로 함수를 통해 __cmp_wait() 인라인 함수가 만들어진다.
arch/arm64/include/asm/cmpxchg.h
#define __CMPWAIT_GEN(sfx) \
static __always_inline void __cmpwait##sfx(volatile void *ptr, \
unsigned long val, \
int size) \
{ \
switch (size) { \
case 1: \
return __cmpwait_case##sfx##_8(ptr, (u8)val); \
case 2: \
return __cmpwait_case##sfx##_16(ptr, (u16)val); \
case 4: \
return __cmpwait_case##sfx##_32(ptr, val); \
case 8: \
return __cmpwait_case##sfx##_64(ptr, val); \
default: \
BUILD_BUG(); \
} \
\
unreachable(); \
}
__CMPWAIT_GEN()
주소 @ptr의 데이터를 @size 만큼 읽은 후 입력 인자 @val 값과 변동이 없는 경우 대기한다. (절전을 위해 wfe 명령을 사용하여 대기)
아래 __CMPWAIT_CASE() 매크로 함수를 통해 비트 사이즈 8, 16, 32, 64에 해당하는 __cmpwait_case__<size>() 인라인 함수가 만들어진다.
arch/arm64/include/asm/cmpxchg.h
#define __CMPWAIT_CASE(w, sfx, sz) \
static inline void __cmpwait_case_##sz(volatile void *ptr, \
unsigned long val) \
{ \
unsigned long tmp; \
\
asm volatile( \
" sevl\n" \
" wfe\n" \
" ldxr" #sfx "\t%" #w "[tmp], %[v]\n" \
" eor %" #w "[tmp], %" #w "[tmp], %" #w "[val]\n" \
" cbnz %" #w "[tmp], 1f\n" \
" wfe\n" \
"1:" \
: [tmp] "=&r" (tmp), [v] "+Q" (*(unsigned long *)ptr) \
: [val] "r" (val)); \
}
__CMPWAIT_CASE(w, b, 8);
__CMPWAIT_CASE(w, h, 16);
__CMPWAIT_CASE(w, , 32);
__CMPWAIT_CASE( , , 64);
주소 @ptr의 데이터를 읽어온 값이 입력 인자 @val 값과 같아 변동이 없는 경우 대기한다.
sevl과 wfe 명령을 연속으로 사용하는 이유는 다음과 같다.


/*
* Memory region attributes with SCTLR.TRE=1
*
* n = TEX[0],C,B
* TR = PRRR[2n+1:2n] - memory type
* IR = NMRR[2n+1:2n] - inner cacheable property
* OR = NMRR[2n+17:2n+16] - outer cacheable property
*
* n TR IR OR
* UNCACHED 000 00
* BUFFERABLE 001 10 00 00
* WRITETHROUGH 010 10 10 10
* WRITEBACK 011 10 11 11
* reserved 110
* WRITEALLOC 111 10 01 01
* DEV_SHARED 100 01
* DEV_NONSHARED 100 01
* DEV_WC 001 10
* DEV_CACHED 011 10
*
* Other attributes:
*
* DS0 = PRRR[16] = 0 - device shareable property
* DS1 = PRRR[17] = 1 - device shareable property
* NS0 = PRRR[18] = 0 - normal shareable property
* NS1 = PRRR[19] = 1 - normal shareable property
* NOS = PRRR[24+n] = 1 - not outer shareable
*/
.equ PRRR, 0xff0a81a8
.equ NMRR, 0x40e040e0
TEX[0], C, B Shareable Memory Property ================== =================== ==================== 0 0 0 Outer Shareable Strongly-ordered 0 0 1 Outer Shareable Normal Memory 0 1 0 Outer Shareable Normal Memory 0 1 1 Outer Shareable Normal Memory 1 0 0 Outer Shareable Device 1 0 1 Outer Shareable Strongly-ordered 1 1 0 Outer Shareable Strongly-ordered 1 1 1 Outer Shareable Normal Memory

TEX[0], C, B Outer Cache Inner Cache ================== =================== ==================== 0 0 0 Non-Cacheable Non-Cacheable 0 0 1 Non-Cacheable Non-Cacheable 0 1 0 WT, no WA WT, no WA 0 1 1 WB, no WA WB, no WA 1 0 0 Non-Cacheable Non-Cacheable 1 0 1 Non-Cacheable Non-Cacheable 1 1 0 Non-Cacheable Non-Cacheable 1 1 1 WB, WA WB, WA
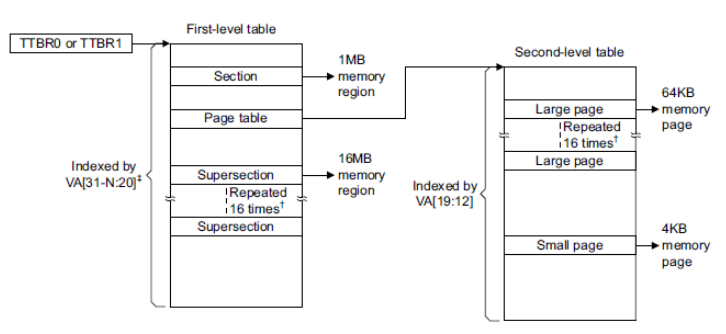
리눅스는 32비트 및 64비트 등 모든 아키텍처를 지원하기 위해 최대 4레벨 변환을 사용
![]()

ARM32 리눅스는 3 레벨의 페이지 테이블을 관리한다. 그러나 하드웨어 레벨에서는 LPAE를 사용하지 않는 경우 ARM32는 2 레벨의 페이지 테이블만을 운용하고, LPAE를 사용하는 경우에만 3레벨 페이지 테이블을 사용한다.
다음 그림과 같이 LPAE를 사용하지 않는 경우 pmd 테이블은 pgd와 동일하다. 실제 4K 바이트로 구성된 PTE 테이블은 매우 독특하게 구성된다. PTE 테이블은 리눅스용 PTE 테이블 1 개와 h/w용 PTE 테이블 2 개가 기록되어 운용된다.
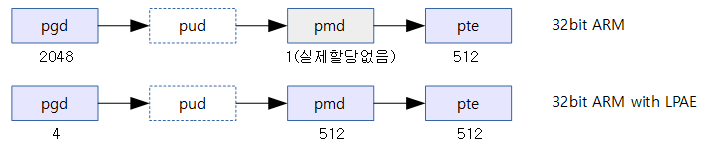

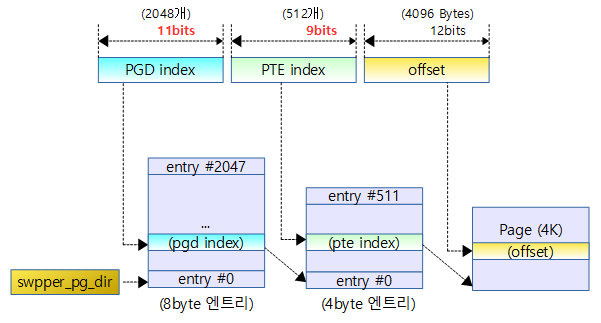
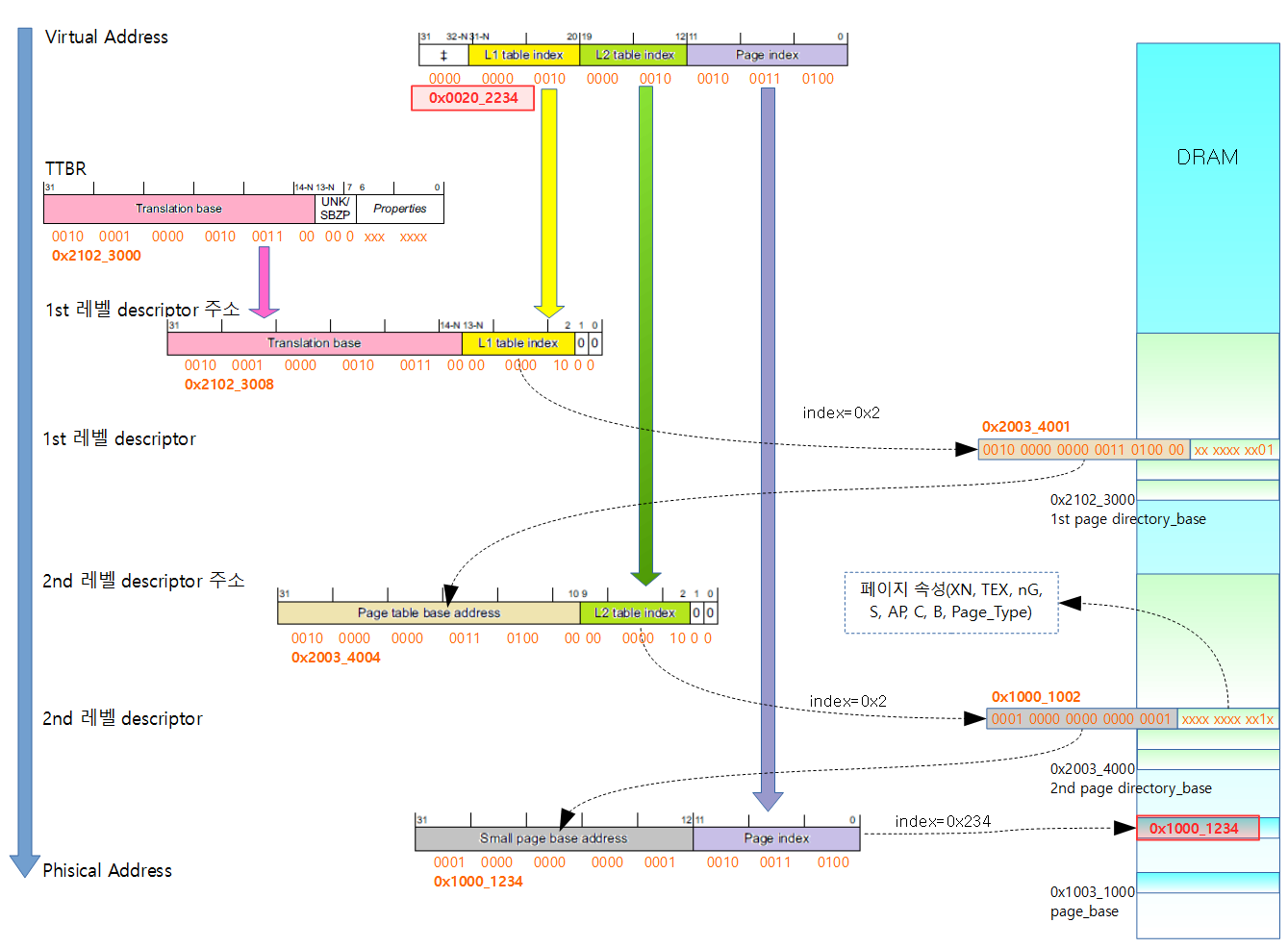
LPAE를 사용하지 않아 하드웨어 2 레벨 페이지 테이블을 사용하는 경우 리눅스의 3 레벨 테이블과 어떻게 매치되는가 알아본다.
다음 그림은 2 레벨로 연결된 페이지 테이블로 8바이트인 하나의 엔트리가 4바이트씩 두 개로 나뉘어 두 개의 페이지 테이블에 페어로 연결되는 모습을 보여준다.
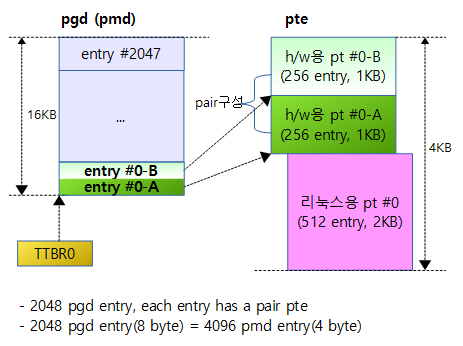
pgd 엔트리가 2048개이며, pgd 엔트리 하나는 pmd 엔트리 2개로 구성된다.
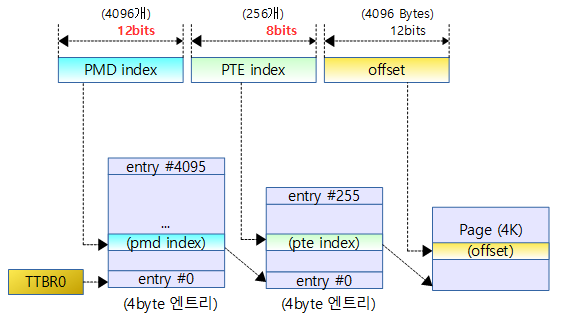
pmd 엔트리가 4096개이며, 두 개의 pdm 엔트리가 쌍으로 사용되어 pgd 엔트리 하나에 대응된다.


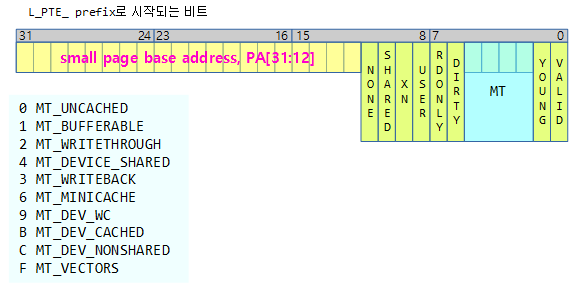
ARM32 PTE용 속성은 리눅스 속성과 약간 다르다.
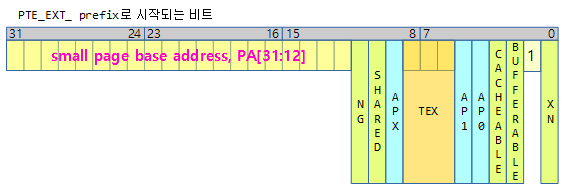
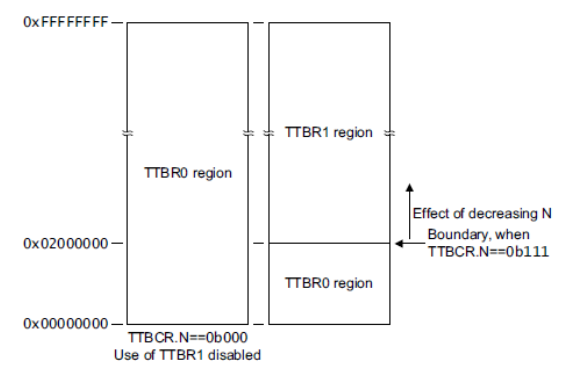
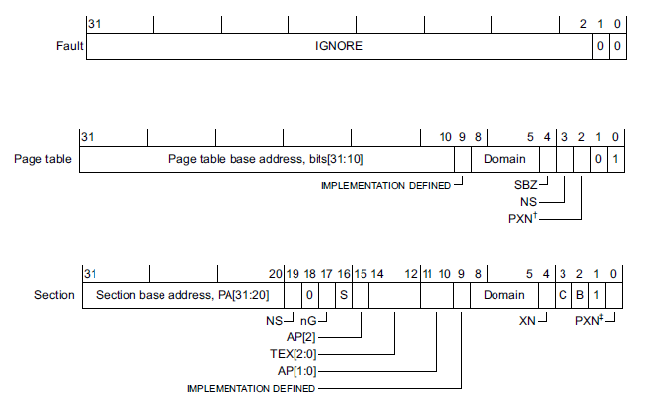
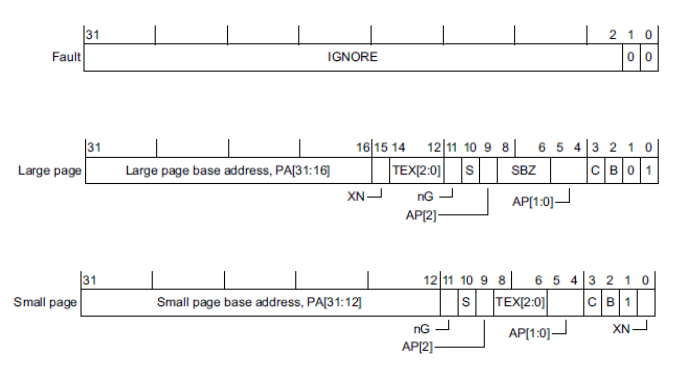
32bit ARM 리눅스의 경우 유저용 페이지 테이블을 가리키는 TTBR0 레지스터를 사용한다. 이 레지스터가 각각의 유저 태스크의 pgd 페이지 테이블 간 스위칭을 한다. 중요한 것은 pgd 테이블은 커널 영역과 유저 영역을 모두 포함한다. 단 커널 영역의 관리는 컴파일 타임에 static 하게 생성된 별도의 pgd 페이지 테이블(&swapper_pg_dir)을 사용하여 유지 보수를 한다. 이렇게 유지 보수가 된 경우 각 사용자 테이블의 커널 영역을 담당하는 엔트리들로 모두 복사한다. 커널 페이지 테이블 엔트리가 갱신되면 시퀀스 카운터만 증가시키고, 각 태스크가 VM 스위칭될 때 자신의 커널 영역의 페이지 엔트리들이 갱신되어야 할 지 여부를 이 시퀀스 카운터를 비교하여 복사한다.
다음 그림은 ARM32에서 각각 3G 크기의 유저 영역을 갖는 2 개의 태스크가 동작할 때 운용되는 페이지 테이블의 모습을 보여준다.
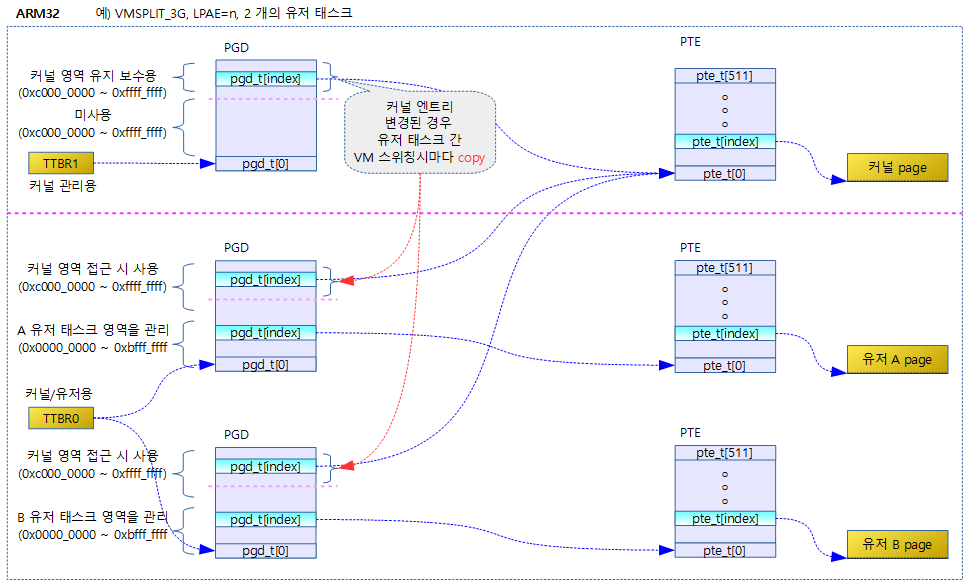
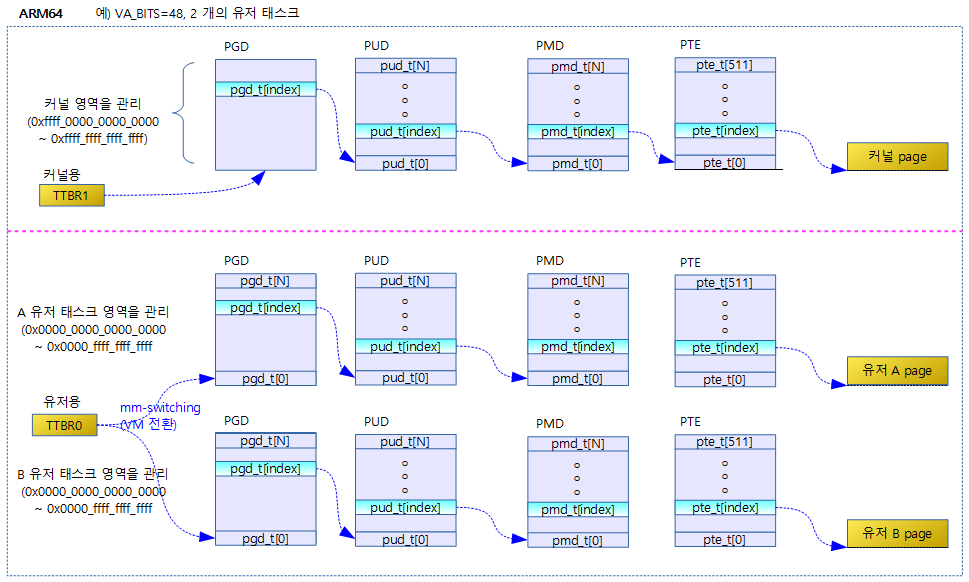
ARM32에서 하나의 pgd 유저 페이지 테이블이 커널과 유저 영역을 통합하여 사용하고, 커널 엔트리들을 복사하는 등 복잡하게 운용하는 것과 달리 ARM64의 경우 간단히 커널과 유저용 페이지 테이블을 별도로 운용한다.
다음 그림은 ARM64에서 각각 256T 크기의 유저 영역을 갖는 2 개의 태스크가 동작할 때 운용되는 페이지 테이블의 모습을 보여준다.