<kernel v5.0>
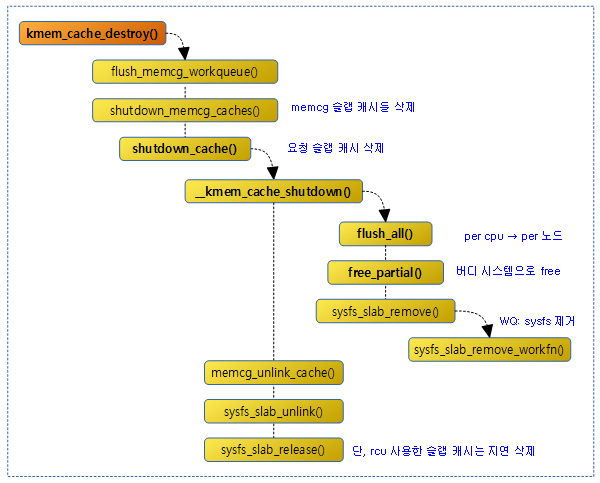
슬랩 Object 할당 해제
지정한 kmem_cache의 slub page에서 슬랩 object를 해제한다.
다음 그림은 슬랩 object를 해제할 때 호출되는 함수들의 흐름을 보여준다.
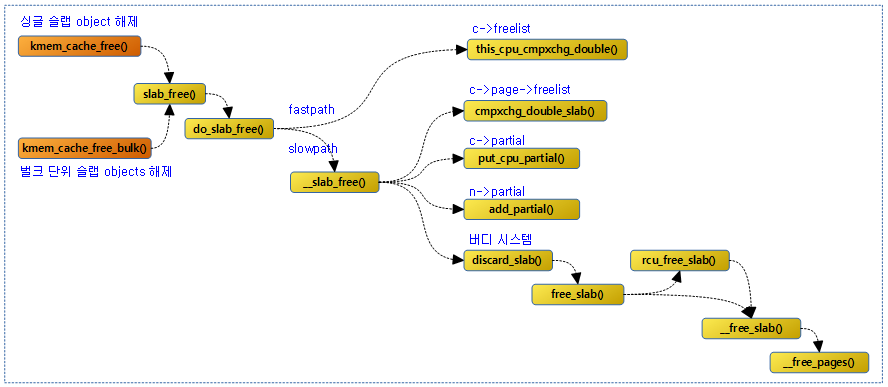
슬랩 object 할당 해제
슬랩 object의 할당 해제와 관련된 API는 다음 두 가지로 구분된다.
- 싱글 슬랩 object 할당 해제
- 벌크 단위 슬랩 object 할당 해제
kmem_cache_free()
mm/slub.c
void kmem_cache_free(struct kmem_cache *s, void *x)
{
s = cache_from_obj(s, x);
if (!s)
return;
slab_free(s, virt_to_head_page(x), x, _RET_IP_);
trace_kmem_cache_free(_RET_IP_, x);
}
EXPORT_SYMBOL(kmem_cache_free);
싱글 슬랩 object를 할당 해제한다.
- 코드 라인 3~5에서 슬랩 object가 가리키는 슬랩 캐시를 알아온다. 알아온 슬랩 캐시가 루트 캐시일 수도 있다. 그 외의 경우 인자로 요청한 슬랩 캐시를 그대로 사용한다.
- 코드 라인 6에서 슬랩 object를 free한다.
cache_from_obj()
mm/slab.h
static inline struct kmem_cache *cache_from_obj(struct kmem_cache *s, void *x)
{
struct kmem_cache *cachep;
struct page *page;
/*
* When kmemcg is not being used, both assignments should return the
* same value. but we don't want to pay the assignment price in that
* case. If it is not compiled in, the compiler should be smart enough
* to not do even the assignment. In that case, slab_equal_or_root
* will also be a constant.
*/
if (!memcg_kmem_enabled() &&
!unlikely(s->flags & SLAB_CONSISTENCY_CHECKS))
return s;
page = virt_to_head_page(x);
cachep = page->slab_cache;
if (slab_equal_or_root(cachep, s))
return cachep;
pr_err("%s: Wrong slab cache. %s but object is from %s\n",
__func__, cachep->name, s->name);
WARN_ON_ONCE(1);
return s;
}
슬랩 object가 가리키는 슬랩 캐시를 알아온다. 알아온 슬랩 캐시가 루트 캐시일 수도 있다. 그 외의 경우 인자로 요청한 슬랩 캐시를 반환한다.
- 코드 라인 13~15에서 memcg를 활성화시키지 않았으면서 작은 확률로 SLAB_DEBUG_FREE 플래그를 사용하지 않은 경우 주어진 캐시를 그냥 반환한다.
- 코드 라인 17~20에서 슬랩 페이지가 가리키는 슬랩 캐시가 인자로 요청한 슬랩 캐시와 동일하거나 루트 캐시인 경우 슬랩 페이지가 가리키는 슬랩 캐시를 반환한다.
- 코드 라인 22~25에서 지정된 캐시가 잘못된 경우 에러 메시지를 출력하고 인자로 요청한 슬랩 캐시를 그대로 반환한다.
슬랩 object 할당 해제 – Fastpath & Slowpath
slab_free()
mm/slub.c
static __always_inline void slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
/*
* With KASAN enabled slab_free_freelist_hook modifies the freelist
* to remove objects, whose reuse must be delayed.
*/
if (slab_free_freelist_hook(s, &head, &tail))
do_slab_free(s, page, head, tail, cnt, addr);
}
슬랩 object 할당 해제 전 디버그 관련 전처리 루틴을 수행하고, 문제 없는 경우 @head ~ @tail 까지의 슬랩 object를 할당해제한다. @tail이 null인 경우 @head 하나만 할당해제한다.
do_slab_free()
mm/slub.c
/*
* Fastpath with forced inlining to produce a kfree and kmem_cache_free that
* can perform fastpath freeing without additional function calls.
*
* The fastpath is only possible if we are freeing to the current cpu slab
* of this processor. This typically the case if we have just allocated
* the item before.
*
* If fastpath is not possible then fall back to __slab_free where we deal
* with all sorts of special processing.
*
* Bulk free of a freelist with several objects (all pointing to the
* same page) possible by specifying head and tail ptr, plus objects
* count (cnt). Bulk free indicated by tail pointer being set.
*/
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
redo:
/*
* Determine the currently cpus per cpu slab.
* The cpu may change afterward. However that does not matter since
* data is retrieved via this pointer. If we are on the same cpu
* during the cmpxchg then the free will succeed.
*/
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
/* Same with comment on barrier() in slab_alloc_node() */
barrier();
if (likely(page == c->page)) {
set_freepointer(s, tail_obj, c->freelist);
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
c->freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
stat(s, FREE_FASTPATH);
} else
__slab_free(s, page, head, tail_obj, cnt, addr);
}
@head ~ @tail 까지의 슬랩 object를 할당해제한다. @tail이 null인 경우 @head 하나만 할당해제한다. (Fastpath, Slowpath)
- 코드 라인 8에서 redo: 레이블이다. fastpath 용도로 per cpu 캐시로 부터 object 할당 해제 시도 시 트랜잭션 id가 바뀌어 실패한 경우 다시 반복할 위치다.
- 코드 라인 15~19에서 tid 및 per-cpu 캐시를 atomic하게 읽어온다. 현재 이 시점에서 preemption이 언제라도 가능하기 때문에 수행 중 태스크 전환되었다 다시 돌아왔을 수 있다. 따라서 이 루틴에서는 tid와 캐시가 같은 cpu에서 획득된 것을 보장하게 하기 위해 뒤에서 확인 과정을 수행한다.
- 코드 라인 22에서 인터럽트 마스크 없이 slab의 할당/해제 알고리즘이 동작하려면 cpu_slab 데이터를 읽는 순서에 의존하게 된다. object와 page보다 먼저 tid를 읽기 위해 컴파일러로 하여금 optimization을 하지 않도록 컴파일러 배리어를 사용하여 명확히 동작 순서를 구분하게 하였다.
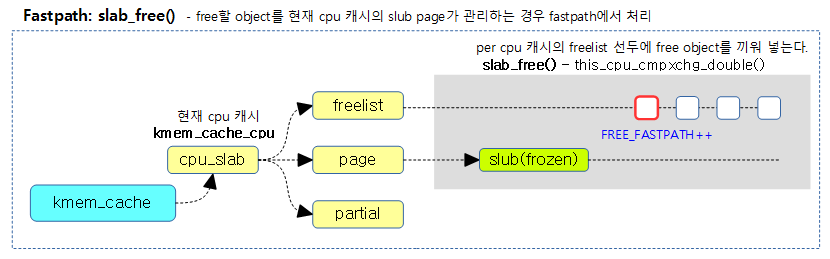
- 코드 라인 24~35에서 높은 확률로 슬랩 페이지가 c->page와 같은 경우 per cpu 캐시의 freelist 선두에 끼워 넣을 1 개 이상의 object들을 추가하고, FREE_FASTPATH 카운터를 증가시킨다. 만일 atomic 치환이 실패한 경우 redo: 레이블로 이동하여 다시 시도한다. (Fastpath)
- 코드 라인 36~37에서 슬랩 페이지가 현재 per cpu 캐시의 페이지와 다른 경우 slowpath 방식으로 object를 free 한다. (Slowpath 호출)
다음 그림은 object를 해제할 때 fastpath 루틴이 동작하여 현재의 per cpu 캐시의 freelist의 선두에 1개의 free object만 insert한 것을 보여준다.
슬랩 object 할당 해제 – Slowpath
__slab_free()
mm/slub.c -1/2-
/*
* Slow path handling. This may still be called frequently since objects
* have a longer lifetime than the cpu slabs in most processing loads.
*
* So we still attempt to reduce cache line usage. Just take the slab
* lock and free the item. If there is no additional partial page
* handling required then we can return immediately.
*/
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
void *prior;
int was_frozen;
struct page new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long uninitialized_var(flags);
stat(s, FREE_SLOWPATH);
if (kmem_cache_debug(s) &&
!free_debug_processing(s, page, head, tail, cnt, addr))
return;
do {
if (unlikely(n)) {
spin_unlock_irqrestore(&n->list_lock, flags);
n = NULL;
}
prior = page->freelist;
counters = page->counters;
set_freepointer(s, tail, prior);
new.counters = counters;
was_frozen = new.frozen;
new.inuse -= cnt;
if ((!new.inuse || !prior) && !was_frozen) {
if (kmem_cache_has_cpu_partial(s) && !prior) {
/*
* Slab was on no list before and will be
* partially empty
* We can defer the list move and instead
* freeze it.
*/
new.frozen = 1;
} else { /* Needs to be taken off a list */
n = get_node(s, page_to_nid(page));
/*
* Speculatively acquire the list_lock.
* If the cmpxchg does not succeed then we may
* drop the list_lock without any processing.
*
* Otherwise the list_lock will synchronize with
* other processors updating the list of slabs.
*/
spin_lock_irqsave(&n->list_lock, flags);
}
}
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));
@head ~ @tail 까지의 슬랩 object를 할당해제한다 (slowpath)
- 코드 라인 13에서 FREE_SLOWPATH 카운터를 증가시킨다.
- 코드 라인 15~17에서 SLAB_DEBUG_FLAGS 플래그를 사용한 경우 slub object free 디버깅을 위해 object를 해제하기 전에 체크하여 문제가 있는 경우 경고 메시지를 출력하여 알리고 처리를 중단하고 루틴을 빠져나간다.
- 코드 라인 19에서 atomic 교체가 실패한 경우 반복될 위치이다.
- 코드 라인 20~23에서 낮은 확률로 노드가 지정된 경우 노드락을 해제하고, 노드 지정을 포기한다.
- 코드 라인 24~29에서 page->freelist 앞에 free object를 insert할 준비를 한다. inuse 카운터는 free할 object 수 만큼 감소시킨다.
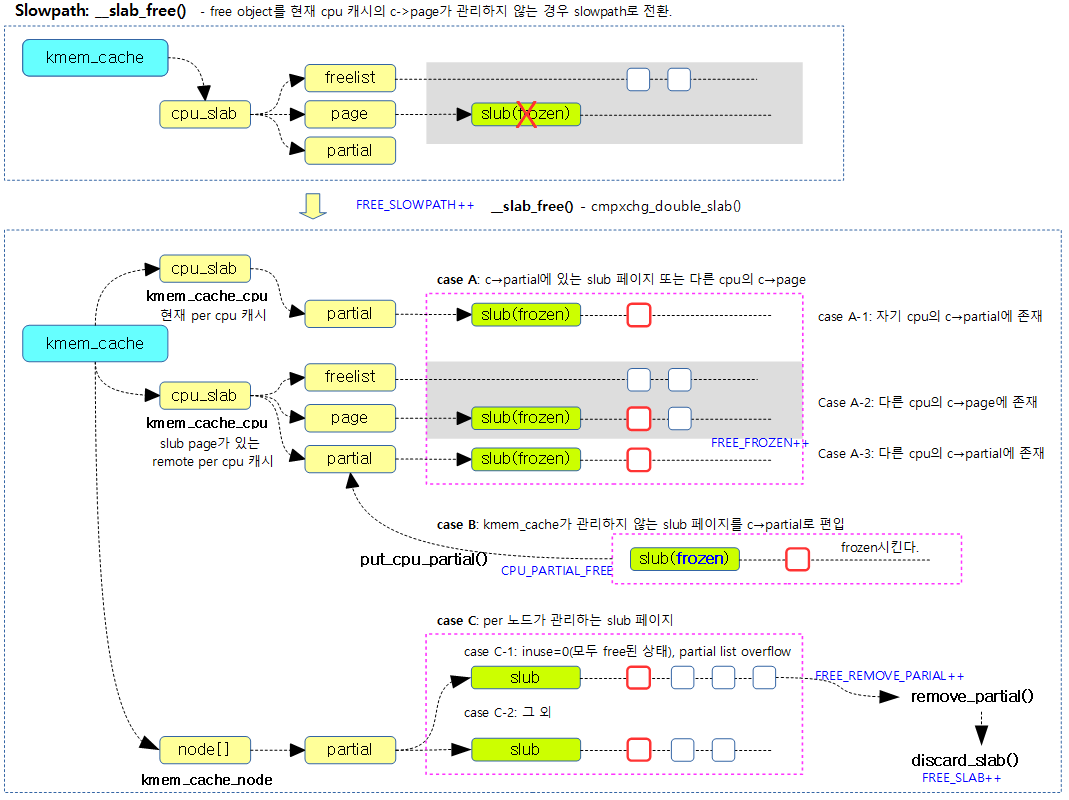
- 코드 라인 30~40에서 frozen 상태의 슬랩 페이지가 아니면서(!was_frozen) c->freelist에 남은 free object들이 없는 경우 c->partial 리스트에 추가할 준비를 위해 슬랩 페이지를 forzen 상태로 바꿀 준비를 한다.
- 코드 라인 42~55에서 frozen 상태의 슬랩 페이지가 아니면서(!was_frozen) 슬랩 페이지의 모든 object가 모두 사용 중이었다가 첫 free object가 발생한 경우라면 소속된 노드를 알아오고 노드락을 획득한다.
- 코드 라인 58~61에서 atomic 하게 교체를 다음과 같이 수행하고실패하는경우반복한다.
- if page->freelist == prior && page->counters == counters
- page->freelist = @head (해지할 object들의 선두)
- page->counters = new.counters
mm/slub.c -2/2-
if (likely(!n)) {
/*
* If we just froze the page then put it onto the
* per cpu partial list.
*/
if (new.frozen && !was_frozen) {
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
/*
* The list lock was not taken therefore no list
* activity can be necessary.
*/
if (was_frozen)
stat(s, FREE_FROZEN);
return;
}
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
goto slab_empty;
/*
* Objects left in the slab. If it was not on the partial list before
* then add it.
*/
if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
if (kmem_cache_debug(s))
remove_full(s, n, page);
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
spin_unlock_irqrestore(&n->list_lock, flags);
return;
slab_empty:
if (prior) {
/*
* Slab on the partial list.
*/
remove_partial(n, page);
stat(s, FREE_REMOVE_PARTIAL);
} else {
/* Slab must be on the full list */
remove_full(s, n, page);
}
spin_unlock_irqrestore(&n->list_lock, flags);
stat(s, FREE_SLAB);
discard_slab(s, page);
}
- 코드 라인 1~18에서 per 노드로의 접근이 필요없는 경우이다. 다음 조건 항목들을 수행한 후 함수를 빠져나간다.
- 만일 새롭게 frozen된 슬랩 페이지인 경우 c->partial 리스트에 추가하고 CPU_PARTIAL_FREE 카운터를 증가시킨다.
- 기존에 frozen 상태였던 경우 FREE_FROZEN 카운터를 증가시킨다.
- 코드 라인 20~21에서 낮은 확률로 슬랩 페이지의 모든 object가 free object가 된 경우이면서 노드의 partial 슬랩 수가 overflow된 경우 슬랩을 버디 시스템으로 반환하기 위해 slab_empty: 레이블로 이동한다.
- 코드 라인 27~32에서 per cpu 캐시에서 partial 리스트가 지원되지 않으면서 낮은 확률로 c->freelist에 하나의 free object도 없었던 경우 n->partial 리스트의 마지막에 추가하고, FREE_ADD_PARTIAL 리스트에 추가한다.
- 코드 라인 36에서 slab_empty: 레이블이다. free object로만 이루어진 슬랩 페이지를 버디 시스템으로 보내기 위해 이동해 올 레이블이다.
- 코드 라인37~42에서 기존에 free object가 있었으면 n->partial 리스트에서 제거한 후 FREE_REMOVE_PARTIAL 카운터를 증가시킨다.
- 코드 라인 43~46에서 기존에 free object가 하나도 없었으면 SLUB 디버깅 중에 연결되어 있던 full 리스트에서 제거한다
- 코드 라인 48~50에서 노드 락을 풀고, FREE_SLAB 카운터를 증가시킨 후 슬랩 페이지를 버디 시스템으로 돌려보낸다.
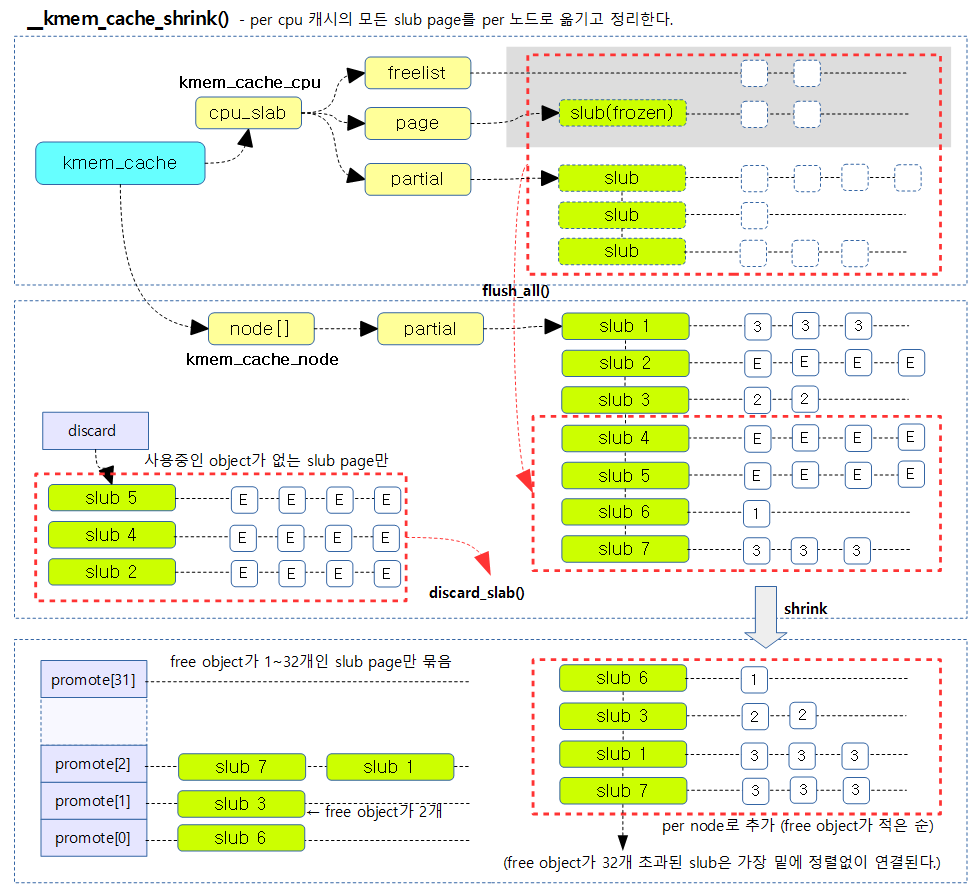
다음 그림은 slub object를 Slowpath 단계에서 처리하는 방법을 보여준다.
c->partial에 지정한 슬랩 페이지 추가
put_cpu_partial()
mm/slub.c
/*
* Put a page that was just frozen (in __slab_free) into a partial page
* slot if available.
*
* If we did not find a slot then simply move all the partials to the
* per node partial list.
*/
static void put_cpu_partial(struct kmem_cache *s, struct page *page, int drain)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *oldpage;
int pages;
int pobjects;
preempt_disable();
do {
pages = 0;
pobjects = 0;
oldpage = this_cpu_read(s->cpu_slab->partial);
if (oldpage) {
pobjects = oldpage->pobjects;
pages = oldpage->pages;
if (drain && pobjects > s->cpu_partial) {
unsigned long flags;
/*
* partial array is full. Move the existing
* set to the per node partial list.
*/
local_irq_save(flags);
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
local_irq_restore(flags);
oldpage = NULL;
pobjects = 0;
pages = 0;
stat(s, CPU_PARTIAL_DRAIN);
}
}
pages++;
pobjects += page->objects - page->inuse;
page->pages = pages;
page->pobjects = pobjects;
page->next = oldpage;
} while (this_cpu_cmpxchg(s->cpu_slab->partial, oldpage, page)
!= oldpage);
if (unlikely(!s->cpu_partial)) {
unsigned long flags;
local_irq_save(flags);
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
local_irq_restore(flags);
}
preempt_enable();
#endif
}
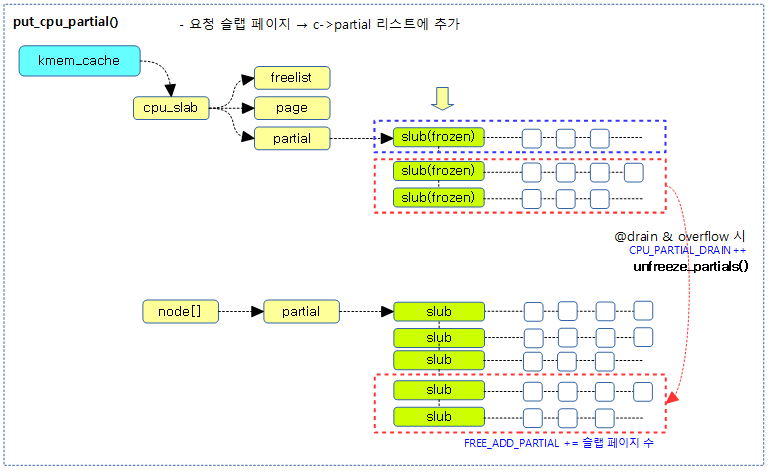
지정한 슬렙 페이지를 c->partial 리스트에 추가한다. 단 @drain이 true인 경우 c->partial 리스트가 overflow될 경우 기존에 있던 슬랩 페이지들을 모두 n->partial 리스트로 이동시킨다.
- 코드 라인 8~41에서 preemption을 disable 한 상태에서 @c->partial에 슬랩 페이지를 추가한다. page->pobjects에는 기존 슬랩 페이지의 pobject 값과 이번 슬랩 페이지의 free object 수를 더해 대입한다. 만일 @drain이 true이고 슬랩 캐시내의 free object 수가 overflow된 경우 인 경우 c->partial 리스트 가 overflow될 경우 기존에 있던 c->partial 리스트의 슬랩 페이지들을 모두 n->partial 리스트로 이동시키고 CPU_PARTIAL_DRAIN 카운터를 증가시킨다.
- 코드 라인 42~48에서 작은 확률로 per cpu 캐시의 partial 리스트에서 관리하는 제한 object 수가 0으로 설정된 경우 c->partial 리스트에 있는 모든 슬랩 페이지들을 n->partial 리스트로 옮긴다
다음 그림은 슬랩 페이지를 c->partial 리스트의 선두에 추가하는 것을 보여준다.
n->partial에 지정한 슬랩 페이지 추가
add_partial()
mm/slub.c
static inline void add_partial(struct kmem_cache_node *n,
struct page *page, int tail)
{
lockdep_assert_held(&n->list_lock);
__add_partial(n, page, tail);
}
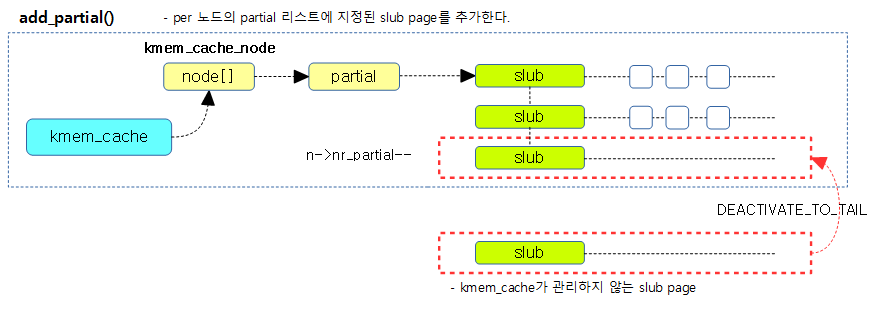
지정된 슬랩 페이지를 n->partial 리스트의 지정된 위치(선두 또는 후미)에 추가한다.
__add_partial()
mm/slub.c
/*
* Management of partially allocated slabs.
*/
static inline void
__add_partial(struct kmem_cache_node *n, struct page *page, int tail)
{
n->nr_partial++;
if (tail == DEACTIVATE_TO_TAIL)
list_add_tail(&page->lru, &n->partial);
else
list_add(&page->lru, &n->partial);
}
지정된 슬랩 페이지를 n->partial 리스트의 지정된 위치(선두 또는 후미)에 추가하고 n->nr_partial을 증가 시킨다.
다음 그림은 slub page를 per 노드의 partial 리스트의 지정된 위치(선두 또는 후미)에 추가하는 모습을 보여준다.
n->partial에서 지정한 슬랩 페이지 제거
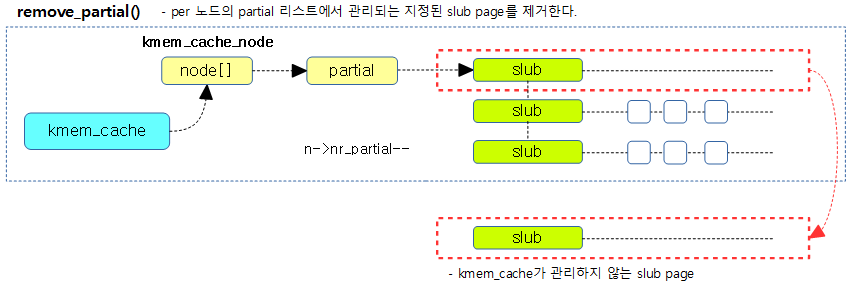
remove_partial()
mm/slub.c
static inline void remove_partial(struct kmem_cache_node *n,
struct page *page)
{
lockdep_assert_held(&n->list_lock);
__remove_partial(n, page);
}
지정된 슬랩 페이지를 n->partial 리스트에서 제거한다.
__remove_partial()
mm/slub.c
static inline void
__remove_partial(struct kmem_cache_node *n, struct page *page)
{
list_del(&page->lru);
n->nr_partial--;
}
지정된 슬랩 페이지를 n->partial 리스트에서 제거하고, n->nr_partial 을 감소시킨다.
다음 그림은 per 노드의 partial 리스트에서 제거하여 kmem_cache가 관리하지 않는 상태로 바꾼다.
c->freelist의 모든 슬랩 페이지 -> n->freelist로 이동
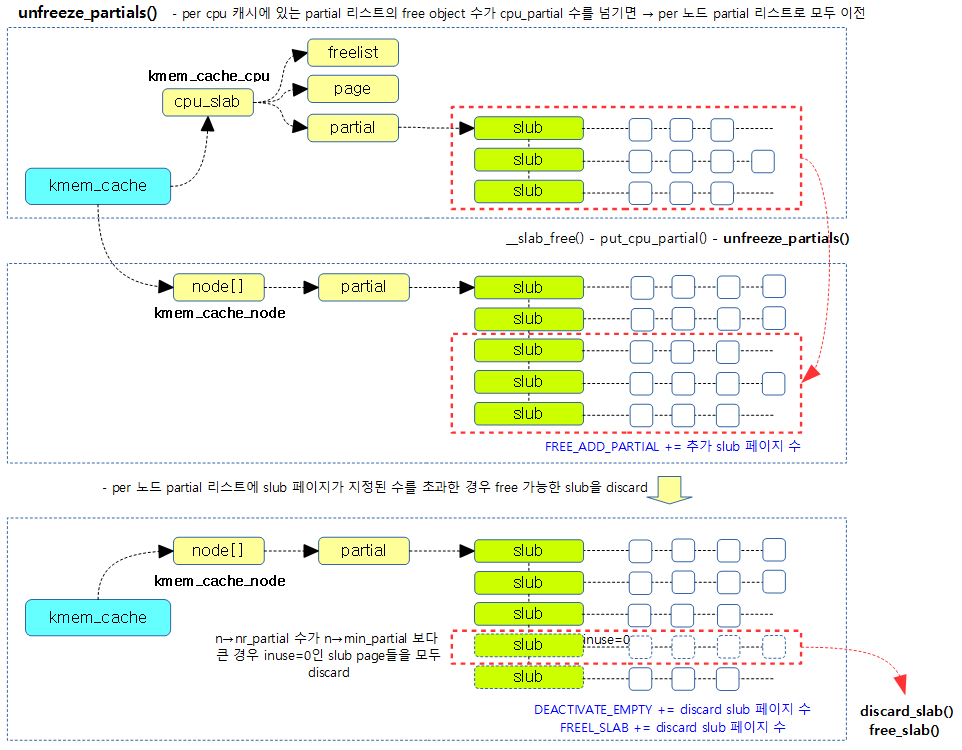
unfreeze_partials()
mm/slub.c
/*
* Unfreeze all the cpu partial slabs.
*
* This function must be called with interrupts disabled
* for the cpu using c (or some other guarantee must be there
* to guarantee no concurrent accesses).
*/
static void unfreeze_partials(struct kmem_cache *s,
struct kmem_cache_cpu *c)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct kmem_cache_node *n = NULL, *n2 = NULL;
struct page *page, *discard_page = NULL;
while ((page = c->partial)) {
struct page new;
struct page old;
c->partial = page->next;
n2 = get_node(s, page_to_nid(page));
if (n != n2) {
if (n)
spin_unlock(&n->list_lock);
n = n2;
spin_lock(&n->list_lock);
}
do {
old.freelist = page->freelist;
old.counters = page->counters;
VM_BUG_ON(!old.frozen);
new.counters = old.counters;
new.freelist = old.freelist;
new.frozen = 0;
} while (!__cmpxchg_double_slab(s, page,
old.freelist, old.counters,
new.freelist, new.counters,
"unfreezing slab"));
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) {
page->next = discard_page;
discard_page = page;
} else {
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
}
if (n)
spin_unlock(&n->list_lock);
while (discard_page) {
page = discard_page;
discard_page = discard_page->next;
stat(s, DEACTIVATE_EMPTY);
discard_slab(s, page);
stat(s, FREE_SLAB);
}
#endif
}
c->partial 리스트에서 관리하는 모든 슬랩 페이지들을 n->partial 리스트의 후미에 추가한다. 만일 n->partial 리스트가 overflow되는 경우 overflow된 슬랩 페이지들 중 할당된 object가 없는 슬랩 페이지들을 버디 시스템으로 되돌려 준다.
다음 그림은 per cpu 캐시의 partial 리스트의 모든 slub page들을 per 노드의 partial 리스트로 옮기는 과정을 보여준다.
슬랩 페이지 -> 버디 시스템
discard_slab()
mm/slub.c
static void discard_slab(struct kmem_cache *s, struct page *page)
{
dec_slabs_node(s, page_to_nid(page), page->objects);
free_slab(s, page);
}
슬랩 페이지를 해제하여 버디 시스템으로 돌려보낸다. 그리고 n->nr_slabs(슬랩 페이지 수)를 감소시키고, n->total_objects 값도 그 objects 수 만큼 감소시킨다.
dec_slabs_node()
mm/slub.c
static inline void dec_slabs_node(struct kmem_cache *s, int node, int objects)
{
struct kmem_cache_node *n = get_node(s, node);
atomic_long_dec(&n->nr_slabs);
atomic_long_sub(objects, &n->total_objects);
}
n->nr_slabs(슬랩 페이지 수)를 감소시키고, n->total_objects 값도 그 objects 수 만큼 감소시킨다.
참고