이동: Interrupts -6- (IPI Cross-call) | 문c
작성자: 문영일
Exception -2- (ARM32 Handler 1)
<kernel v5.4>
Exception Entry
32bit ARM 프로세스에 exception이 발생하면 가상 벡터 주소의 각 exception을 담당하는 8개의 엔트리로 jump를 하게된다.
가장 첫 exception 엔트리가 reset 벡터가 있고 그 뒤로 나머지 7개의 exception 엔트리가 위치한다. 다음 8개의 exception 별로 호출되는 부분을 알아보자.
- Reset
- vector_rst 레이블로 jump 하고 swi 0을 호출하여 swi exception을 발생하게 한 후 이어서 vector_und: 레이블로 jump 한다.
- Undefined
- vector_und 레이블로 jump 하고 exception 당시의 프로세스 모드에 따라 __und_usr, __und_svc 또는 __und_invalid 레이블로 점프한다.
- exception 처리를 마치고 돌아가는 주소는 exception 당시의 pc 위치로 복귀한다.
- SWI
- 벡터 테이블 바로 다음 페이지에 위치한 첫 엔트리에 vector_swi 레이블의 위치가 담겨있고 이 위치로 jump 한다.
- exception 처리를 마치고 돌아가는 주소는 exception 당시의 pc-4 위치로 복귀한다.
- Prefetch Abort
- vector_pabt 레이블로 jump 하고 exception 당시의 프로세스 모드에 따라 __pabt_usr, __pabt_svc 또는 __pabt_invalid 레이블로 점프한다.
- exception 처리를 마치고 돌아가는 주소는 exception 당시의 pc-4 위치로 복귀한다.
- Data Abort
- vector_dabt 레이블로 jump 하고 exception 당시의 프로세스 모드에 따라 __dabt_usr, __dabt_svc 또는 __dabt_invalid 레이블로 점프한다.
- exception 처리를 마치고 돌아가는 주소는 exception 당시의 pc-8 위치로 복귀한다.
- Address
- vector_addrexcptn 레이블로 jump 한다. 이 주소는 현재 사용하지 않으므로 이 곳으로 진입하면 매우 위험하다.
- IRQ
- vector_irq 레이블로 jump 하고 exception 당시의 프로세스 모드에 따라 __irq_usr, __irq_svc 또는 __irq_invalid 레이블로 점프한다.
- exception 처리를 마치고 돌아가는 주소는 exception 당시의 pc-4 위치로 복귀한다.
- FIQ
- vector_fiq 레이블로 jump 하고 exception 당시의 프로세스 모드에 따라 __fiq_usr, __fiq_svc 또는 __fiq_abt 레이블로 점프한다.
- exception 처리를 마치고 돌아가는 주소는 exception 당시의 pc-4 위치로 복귀한다.
Exception시 모드 전환
아래 그림은 exception 발생 시 모드의 변환과 주요 처리 내용을 보여준다.
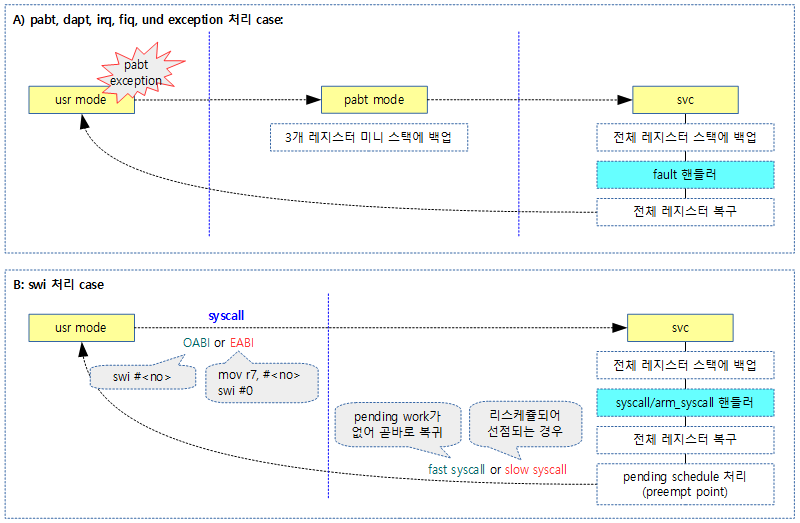
- swi에서 syscall 처리 후 전체 레지스터 중 r0는 제외한다. (r0는 syscall에 대한 결과 값)
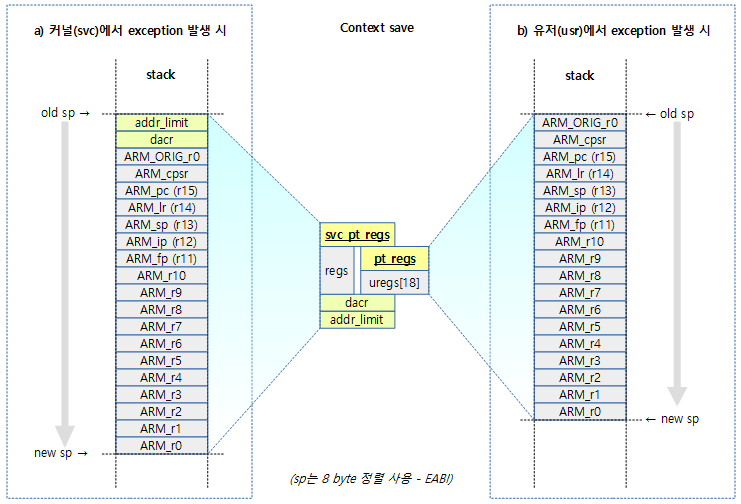
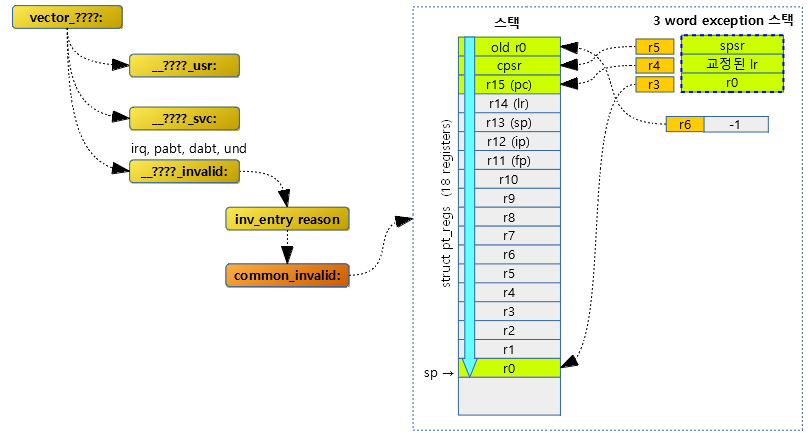
Context 저장 및 복원
exception으로 인해 context(레지스터들)를 보호하기 위해 스택에 저장한다.
- 리눅스 커널은 AEABI 규칙을 사용하므로 sp 주소 증가시 8바이트 정렬하여야 하다.
다음 그림은 커널(svc) 및 유저(usr) 동작 시 exception이 발생하여 context를 저장하는 크기를 비교하여 보여준다.
svc_pt_regs 구조체
arch/arm/include/asm/ptrace.h
struct svc_pt_regs {
struct pt_regs regs;
u32 dacr;
u32 addr_limit;
};
커널(svc)에서 exception이 발생 시 dacr, addr_limit 및 pt_regs를 포함한 svc_pt_regs 구조체를 사용하여 저장과 복원을 한다.
pt_regs 구조체
arch/arm/include/asm/ptrace.h
struct pt_regs {
unsigned long uregs[18];
};
context 백업 및 복원에 사용하는 레지스터들이다.
C 루틴에서 참고되는 매크로 레지스터들
include/uapi/asm/ptrace.h
#define ARM_cpsr uregs[16] #define ARM_pc uregs[15] #define ARM_lr uregs[14] #define ARM_sp uregs[13] #define ARM_ip uregs[12] #define ARM_fp uregs[11] #define ARM_r10 uregs[10] #define ARM_r9 uregs[9] #define ARM_r8 uregs[8] #define ARM_r7 uregs[7] #define ARM_r6 uregs[6] #define ARM_r5 uregs[5] #define ARM_r4 uregs[4] #define ARM_r3 uregs[3] #define ARM_r2 uregs[2] #define ARM_r1 uregs[1] #define ARM_r0 uregs[0] #define ARM_ORIG_r0 uregs[17]
- uregs[0] ~ uregs[15]는 r0~r15 레지스터를 보관하는데 사용한다.
- uregs[16]의 경우 cpsr 레지스터를 보관한다.
- uregs[17]의 경우 호출 당시의 r0 레지스터를 보관한다.
Assembly 루틴에서 참고되는 매크로 상수들
arch/arm/kernel/asm-offsets.c
DEFINE(S_R0, offsetof(struct pt_regs, ARM_r0)); DEFINE(S_R1, offsetof(struct pt_regs, ARM_r1)); DEFINE(S_R2, offsetof(struct pt_regs, ARM_r2)); DEFINE(S_R3, offsetof(struct pt_regs, ARM_r3)); DEFINE(S_R4, offsetof(struct pt_regs, ARM_r4)); DEFINE(S_R5, offsetof(struct pt_regs, ARM_r5)); DEFINE(S_R6, offsetof(struct pt_regs, ARM_r6)); DEFINE(S_R7, offsetof(struct pt_regs, ARM_r7)); DEFINE(S_R8, offsetof(struct pt_regs, ARM_r8)); DEFINE(S_R9, offsetof(struct pt_regs, ARM_r9)); DEFINE(S_R10, offsetof(struct pt_regs, ARM_r10)); DEFINE(S_FP, offsetof(struct pt_regs, ARM_fp)); DEFINE(S_IP, offsetof(struct pt_regs, ARM_ip)); DEFINE(S_SP, offsetof(struct pt_regs, ARM_sp)); DEFINE(S_LR, offsetof(struct pt_regs, ARM_lr)); DEFINE(S_PC, offsetof(struct pt_regs, ARM_pc)); DEFINE(S_PSR, offsetof(struct pt_regs, ARM_cpsr)); DEFINE(S_OLD_R0, offsetof(struct pt_regs, ARM_ORIG_r0)); DEFINE(PT_REGS_SIZE, sizeof(struct pt_regs)); DEFINE(SVC_DACR, offsetof(struct svc_pt_regs, dacr)); DEFINE(SVC_ADDR_LIMIT, offsetof(struct svc_pt_regs, addr_limit)); DEFINE(SVC_REGS_SIZE, sizeof(struct svc_pt_regs));
- PT_REGS_SIZE
- pt_regs 구조체 사이즈
- SVC_REGS_SIZE
- svc_pt_regs 구조체 사이즈
공통 핸들러
유저 모드에서 진입 시 레지스터 백업
usr_entry 매크로
arch/arm/kernel/entry-armv.S (THUMB 코드 생략)
/* * User mode handlers * * EABI note: sp_svc is always 64-bit aligned here, so should PT_REGS_SIZE */
#if defined(CONFIG_AEABI) && (__LINUX_ARM_ARCH__ >= 5) && (PT_REGS_SIZE & 7) #error "sizeof(struct pt_regs) must be a multiple of 8" #endif
.macro usr_entry, trace=1, uaccess=1
UNWIND(.fnstart )
UNWIND(.cantunwind ) @ don't unwind the user space
sub sp, sp, #PT_REGS_SIZE
ARM( stmib sp, {r1 - r12} )
ATRAP( mrc p15, 0, r7, c1, c0, 0)
ATRAP( ldr r8, .LCcralign)
ldmia r0, {r3 - r5}
add r0, sp, #S_PC @ here for interlock avoidance
mov r6, #-1 @ "" "" "" ""
str r3, [sp] @ save the "real" r0 copied
@ from the exception stack
ATRAP( ldr r8, [r8, #0])
@
@ We are now ready to fill in the remaining blanks on the stack:
@
@ r4 - lr_<exception>, already fixed up for correct return/restart
@ r5 - spsr_<exception>
@ r6 - orig_r0 (see pt_regs definition in ptrace.h)
@
@ Also, separately save sp_usr and lr_usr
@
stmia r0, {r4 - r6}
ARM( stmdb r0, {sp, lr}^ )
.if \uaccess
uaccess_disable ip
.endif
@ Enable the alignment trap while in kernel mode
ATRAP( teq r8, r7)
ATRAP( mcrne p15, 0, r8, c1, c0, 0)
@
@ Clear FP to mark the first stack frame
@
zero_fp
.if \trace
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_off
#endif
ct_user_exit save = 0
.endif
.endm
유저 프로세스에 exception이 발생한 경우이다. 레지스터들을 스택에 백업한다.
- 해당 exception 모드(fiq, irq, pabt, dabt, und)에서 3개의 레지스터를 3 word로 구성된 mini stack에 백업한다.
- svc 모드로 전환하고 다음과 같이 처리한다.
- 스택에 18개의 레지스터를 보관할 수 있는 pt_regs 구조체 사이즈만큼 키운 후 레지스터들을 백업한다.
- alignment trap을 enable하기 위해 cr_alignment 값을 읽어 SCTLR에 저장한다.
- 그 외 irq disable된 기간 및 컨텍스트 트래킹 등을 수행한다.
- 코드 라인 4에서 스택을 pt_regs 구조체 사이즈만큼 키운다. (grows down)
- 코드 라인 5에서 r1~r12 레지스터들의 정보를 스택의 pt_regs 영역에 저장한다.
- stmib (Store Memory Increment Before)를 사용하여 sp를 워드만큼 먼저 증가 시킨 후 레지스터들을 저장한다.
- 코드 라인 7~8에서 SCTLR 값을 r7 레지스터에 읽어오고 전역 변수 cr_alignment 주소를 r8 레지스터에 대입한다.
- ATRAP() 매크로는 CONFIG_ALIGNMENT_TRAP 커널 옵션이 사용되는 아키텍처에서 사용된다. (대부분의 arm에 적용됨)
- 잠시 후 매크로 종료전에 cr_alignment 값과 SCTLR 값을 비교하여 alignment trap을 enable하기 위해 cr_alignment 값을 읽어서 SCTLR에 저장한다.
- 코드 라인 10에서 mini 스택에서 백업한 값들을 r3~r5 레지스터에 로드한다.
- 코드 라인 11에서 r0에 스택의 &ptregs.pc 주소를 알아온다.
- 코드 라인 12에서 r6에 -1 값을 대입한다.
- 코드 라인 14에서 r3(original r0) 레지스터 값을 pt_regs의 가장 첫 엔트리(r0)에 저장한다.
- 코드 라인 17에서 전역 변수 cr_alignment 값을 읽어서 r8 레지스터에 저장한다.
- 코드 라인 28에서 교정된 lr 값, psr 값, -1 값을 pt_regs 구조체의 pc, psr, old-rq에 순서대로 저장한다.
- 코드 라인 29에서 sp와 lr 값을 pt_regs 구조체의 sp와 lr 위치에 그대로 저장한다.
- 코드 라인 31~33에서 커널에서 유저 영역의 액세스를 제한한다. 그 전의 액세스 여부 값을 ip 레지스터에 담아온다.
- 커널에서 유저 영역의 액세스 제어에 대해서는 다음을 참고한다.
- ARM: entry: provide uaccess assembly macro hooks (2015, v4.3-rc1)
- copy_from_user() | 문c
- 커널에서 유저 영역의 액세스 제어에 대해서는 다음을 참고한다.
- 코드 라인 36~37에서 SCTLR 값을 읽은 r7 레지스터와 cr_alignment 값을 읽은 r8 레지스터 값을 비교해서 다른 경우에만 cr_alignment 값을 SCTLR에 저장한다.
- SCTLR을 저장하는데 약 100 사이클 정도의 시간이 걸리므로 성능을 위해 변경 사항이 있는 경우에만 저장한다.
- 코드 라인 42에서 fp 레지스터를 0으로 설정한다.
- gcc 툴에서 tracing에 사용하는 fp 레지스터를 0으로 초기화한다.
- exception 모드가 바뀌면 그 전 stack back trace 정보를 사용할 수 없으므로 이 시점에서 초기화한다.
- 코드 라인 44~47에서 CONFIG_IRQSOFF_TRACER 커널 옵션이 사용되는 경우 얼마나 오랫동안 인터럽트가 disable 되었는지 그 주기를 알아보기 위한 트래킹 디버깅을 수행한다.
- 코드 라인 48에서 컨텍스트 트래킹 디버깅이 enable된 경우에 수행된다.
다음 그림은 유저 모드에서 exception에 의해 해당 모드에 진입 시 레지스터들을 백업하는 usr_entry 매크로의 기능을 보여준다.

zero_fp 매크로
arch/arm/kernel/entry-header.S
.macro zero_fp
#ifdef CONFIG_FRAME_POINTER
mov fp, #0
#endif
.endm
CONFIG_FRAME_POINTER 커널 옵션을 사용하는 경우 커널에서 문제가 발생했을 때 다양한 보고가 가능하도록 한다. 이 커널 옵션을 사용하지 않으면 보고되는 정보가 심각하게 제한된다.
trace_hardirqs_off()
kernel/trace/trace_irqsoff.c
void trace_hardirqs_off(void)
{
if (!preempt_trace() && irq_trace())
start_critical_timing(CALLER_ADDR0, CALLER_ADDR1);
}
EXPORT_SYMBOL(trace_hardirqs_off);
얼마나 오랫동안 인터럽트가 disable 되었는지 그 주기를 알아보기 위한 트래킹 디버깅을 수행한다.
ct_user_exit 매크로
arch/arm/kernel/entry-header.S
/* * Context tracking subsystem. Used to instrument transitions * between user and kernel mode. */
.macro ct_user_exit, save = 1
#ifdef CONFIG_CONTEXT_TRACKING
.if \save
stmdb sp!, {r0-r3, ip, lr}
bl context_tracking_user_exit
ldmia sp!, {r0-r3, ip, lr}
.else
bl context_tracking_user_exit
.endif
#endif
.endm
CONFIG_CONTEXT_TRACKING 커널 옵션을 사용하면서 전역 static key 변수 context_tracking_enabled이 설정된 경우 컨텍스트 트래킹에 관련한 후처리 디버그 활동을 수행한다.
SVC 모드에서 진입 시 레지스터 백업
svc_entry
arch/arm/kernel/entry-armv.S (THUMB 코드 생략)
/* * SVC mode handlers */
.macro svc_entry, stack_hole=0, trace=1, uaccess=1
UNWIND(.fnstart )
UNWIND(.save {r0 - pc} )
sub sp, sp, #(SVC_REGS_SIZE + \stack_hole - 4)
SPFIX( tst sp, #4 )
SPFIX( subeq sp, sp, #4 )
stmia sp, {r1 - r12}
ldmia r0, {r3 - r5}
add r7, sp, #S_SP - 4 @ here for interlock avoidance
mov r6, #-1 @ "" "" "" ""
add r2, sp, #(SVC_REGS_SIZE + \stack_hole - 4)
SPFIX( addeq r2, r2, #4 )
str r3, [sp, #-4]! @ save the "real" r0 copied
@ from the exception stack
mov r3, lr
@
@ We are now ready to fill in the remaining blanks on the stack:
@
@ r2 - sp_svc
@ r3 - lr_svc
@ r4 - lr_<exception>, already fixed up for correct return/restart
@ r5 - spsr_<exception>
@ r6 - orig_r0 (see pt_regs definition in ptrace.h)
@
stmia r7, {r2 - r6}
get_thread_info tsk
ldr r0, [tsk, #TI_ADDR_LIMIT]
mov r1, #TASK_SIZE
str r1, [tsk, #TI_ADDR_LIMIT]
str r0, [sp, #SVC_ADDR_LIMIT]
uaccess_save r0
.if \uaccess
uaccess_disable r0
.endif
.if \trace
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_off
#endif
.endif
.endm
커널(svc) 처리 중 exception이 발생한 경우이다. 레지스터들을 스택에 백업한다.
- 해당 exception 모드(fiq, irq, pabt, dabt, und)에서 3개의 레지스터를 3 word로 구성된 mini stack에 백업한다.
- svc 모드로 전환하고 다음과 같이 처리한다.
- 스택을 18개의 레지스터를 포함하여 보관할 수 있는 svc_pt_regs 구조체 사이즈만큼 키운 후 레지스터들을 백업한다.
- 그 외 irq disable된 기간 및 컨텍스트 트래킹 등을 수행한다. (for debug)
- 코드 라인 4에서 스택을 svc_pt_regs 구조체 크기 + stack_hole – 4 만큼 확보한다.
- stack_hole을 추가하는 이유
- __und_svc() 레이블에서만 사용되는데 CONFIG_KPROBES 커널 옵션을 사용하고 kprobe를 이용하여 디버깅을 할 때 “stmdb sp!, {…}” 등의 문장에서 single step으로 디버깅을 하면 스택이 깨지는 문제가 발생하여 그러한 경우를 피하고자 64바이트(멀티 store 명령으로 최대 16개 레지스터를 저장할 수 있는 공간 크기)의 hole을 더 준비하였다.
- 참고: ARM kprobes: don’t let a single-stepped stmdb corrupt the exception stack
- -4를 하는 이유
- r0를 제외한 스택 주소가 아래에서 설명하는 AEABI 규격으로 인해 정렬되어야 한다.루틴의 마지막 즈음에서 4 바이트를 증가시켜 짝수 워드로 정렬시킬 예정이므로 지금은 홀수 워드로 정렬되어야 한다.
- stack_hole을 추가하는 이유
- 코드 라인 5~6에서 AEABI(ARM Embedded Application Binary Interface) 규격에 맞게 스택을 사용 시 64비트(8 바이트) 정렬을 해야 한다.
- 코드 라인 7에서 r1에서 r12까지 레지스터를 모두 스택에 확보된 pt_regs에서 r1 위치부터 저장한다.
- 코드 라인 9에서 기존 루틴에서 미니 스택에 저장해 놓은 old r0, 교정된 lr, spsr 값을 r3~r5 레지스터에 읽어 온다.
- 코드 라인 10에서 r7 레지스터가 pt_regs의 sp 주소를 가리키게 한다.
- 코드 라인 11에서 r6 레지스터에 -1을 대입한다.
- 코드 라인 12~13에서 r2 레지스터가 stack_hole을 가리키게 한다. 만일 sp가 64비트 정렬을 한 경우라면 stack_hole 위치도 4 바이트만큼 위로 올린다. (stack_hole이 4바이트 커진다.)
- 코드 라인 14에서 original r0를 읽어온 r3 레지스터의 내용을 pt_regs의 r0 주소에 저장한다. sp 주소는 4바이트 주소를 밑으로 이동시켜 정상적으로 sp가 pt_regs의 처음을 가리키게 한다.
- 코드 라인 17~28에서 r3 레지스터에 lr_svc를 대입하고 sp_svc, lr_svc, lr_<exception>, spsr_<exception>, original r0 값이 담긴 r2~r6 레지스터 값을 pt_regs의 sp 주소부터 저장한다.
- 코드 라인 30~34에서 현재 태스크의 thread_info.addr_limit 값을 읽어 스택에 위치한 svc_pt_regs.addr_limit에 백업하고, TASK 사이즈로 변경한다.
- ARM: save and reset the address limit when entering an exception (2016, v4.8-rc1)
- 코드 라인 36~39에서 유저 영역의 액세스 여부를 svc_pt_regs.dacr 에 백업하고, @uaccess가 요청된 경우 보안을 위해 커널에서 유저 영역의 액세스를 제한한다.
- 커널에서 유저 영역의 액세스 제어에 대해서는 다음을 참고한다.
- ARM: entry: provide uaccess assembly macro hooks (2015, v4.3-rc1)
- copy_from_user() | 문c
- 커널에서 유저 영역의 액세스 제어에 대해서는 다음을 참고한다.
- 코드 라인 41~44에서 CONFIG_TRACE_IRQFLAGS 커널 옵션이 사용되는 경우 얼마나 오랫동안 인터럽트가 disable 되었는지 그 주기를 알아보기 위한 트래킹 디버깅을 수행한다.
다음 그림과 같이 커널이 v4.9-rc1으로 버전업되면서 svc 모드에서 진입된 레지스터들을 백업하는데 기존 pt_regs를 사용하지 않고 svc_pt_regs를 사용한다. 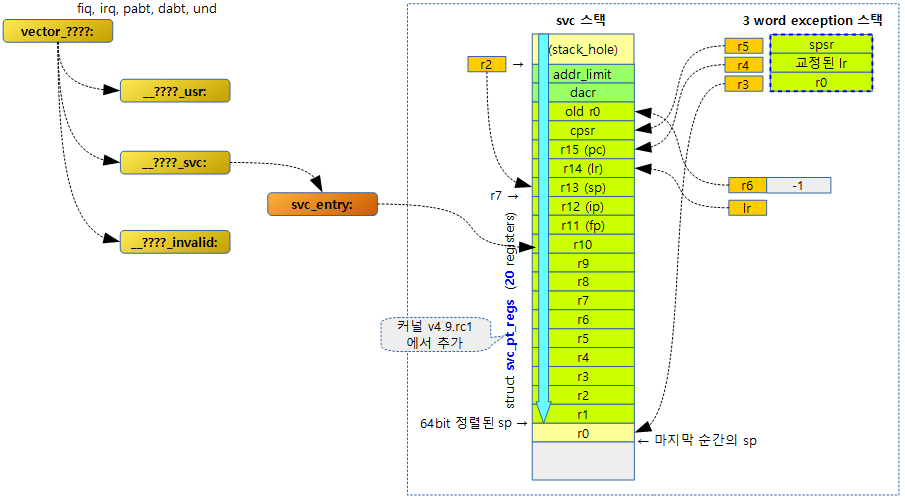
레지스터 복구하고 서비스 모드로 복귀
svc_exit 매크로
arch/arm/kernel/entry-header.S (THUMB 코드 생략)
.macro svc_exit, rpsr, irq = 0
.if \irq != 0
@ IRQs already off
#ifdef CONFIG_TRACE_IRQFLAGS
@ The parent context IRQs must have been enabled to get here in
@ the first place, so there's no point checking the PSR I bit.
bl trace_hardirqs_on
#endif
.else
@ IRQs off again before pulling preserved data off the stack
disable_irq_notrace
#ifdef CONFIG_TRACE_IRQFLAGS
tst \rpsr, #PSR_I_BIT
bleq trace_hardirqs_on
tst \rpsr, #PSR_I_BIT
blne trace_hardirqs_off
#endif
.endif
ldr r1, [sp, #SVC_ADDR_LIMIT]
uaccess_restore
str r1, [tsk, #TI_ADDR_LIMIT]
@ ARM mode SVC restore
msr spsr_cxsf, \rpsr
#if defined(CONFIG_CPU_V6) || defined(CONFIG_CPU_32v6K)
@ We must avoid clrex due to Cortex-A15 erratum #830321
sub r0, sp, #4 @ uninhabited address
strex r1, r2, [r0] @ clear the exclusive monitor
#endif
ldmia sp, {r0 - pc}^ @ load r0 - pc, cpsr
.endm
exception 전의 svc 모드로 다시 복귀하기 위해 백업해두었던 레지스터들을 복구한다.
- 코드 라인 2~7에서 irq exception에 대한 ISR을 수행 후 종료 전에 hard irq에 대한 latency 트래킹을 수행한다.
- __irq_svc에서 irq=1로 호출된다.
- 코드 라인 9~18에서 irq=0으로 설정되는 경우 현재 cpu에 대해 irq를 mask하여 인터럽트가 진입하지 못하게 한다. @rpsr은 exception 되었을 때 SPSR 값이 담겨있다. 즉 복귀 전 모드에서 irq가 enable 상태인 경우 hardirq에 대한 trace on을 수행하고, 그렇지 않은 경우 trace off를 수행한다.
- disable_irq_notrace 매크로에서 “cpsid i” 명령을 수행한다.
- 참고: tracing: Centralize preemptirq tracepoints and unify their usage (2018, v4.19-rc1)
- 코드 라인 19에서 스택에 위치한 svc_pt_regs.addr_limit 값을 r1 레지스터에 알아온다.
- 코드 라인 20에서 커널에서 유저 모드 액세스 여부에 대한 값을 스택으로부터 복구한다.
- 코드 라인 21에서 읽어온 addr_limit 값을 태스크의 thread_info.addr_limit에 기록한다.
- 코드 라인 24에서 spsr에 \rpsr을 대입한다.
- 코드 라인 25~29에서 strex로 clrex 기능을 수행한다. (erratum for Cortex-A15)
- 복귀 시 마다 exclusive 모니터를 클리어하여 복귀 전에 exclusive 모니터를 사용하던 context에서 재시도하게 한다.
- 참고: ARM: 8129/1: errata: work around Cortex-A15 erratum 830321 using dummy strex
- 코드 라인 30에서 스택으로부터 r0~pc까지 레지스터를 복구한다.
- pc 위치에 이미 correction된 lr을 백업했었다.
허용하지 않은 모드에서 진입 시 레지스터 백업
inv_entry
arch/arm/kernel/entry-armv.S
/* * Invalid mode handlers */
.macro inv_entry, reason
sub sp, sp, #PT_REGS_SIZE
ARM( stmib sp, {r1 - lr} )
THUMB( stmia sp, {r0 - r12} )
THUMB( str sp, [sp, #S_SP] )
THUMB( str lr, [sp, #S_LR] )
mov r1, #\reason
.endm
스택에 레지스터들을 백업하기 위한 공간(struct pt_regs)을 확보하고 r1~r14(lr)까지 백업해둔다. r1 레지스터에는 reason 값을 대입한다.
-
- pt_regs에 백업되지 않은 나머지 레지스터들은 common_invalid 레이블에서 백업을 계속 진행한다.
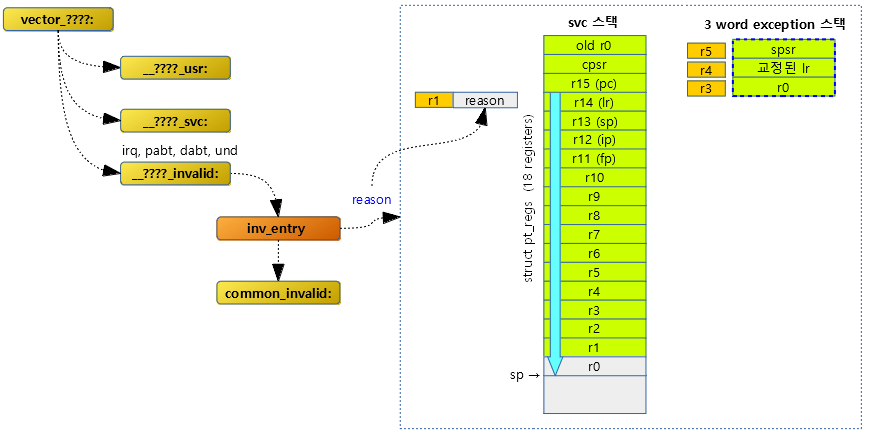
common_invalid
arch/arm/kernel/entry-armv.S
@ @ common_invalid - generic code for failed exception (re-entrant version of handlers) @
common_invalid:
zero_fp
ldmia r0, {r4 - r6}
add r0, sp, #S_PC @ here for interlock avoidance
mov r7, #-1 @ "" "" "" ""
str r4, [sp] @ save preserved r0
stmia r0, {r5 - r7} @ lr_<exception>,
@ cpsr_<exception>, "old_r0"
mov r0, sp
b bad_mode
ENDPROC(__und_invalid)
각 exception 핸들러들에서 허용하지 않은 모드에서 진입하여 실패처리를 위한 루틴이다.
- 코드 라인 2에서 fp 레지스터에 0을 대입한다.
- 코드 라인 4에서 스택에 백업해두었던 old r0, 교정된 lr, spsr 값을 r4~r6 레지스터로 읽어온다.
- 코드 라인 5에서 스택에 백업해두었던 pt_regs 구조체 영역에서 pc 주소를 r0에 대입한다.
- 코드 라인 6에서 r7에 -1을 대입한다.
- 코드 라인 7에서 old r0 값을 읽어온 r4 레지스터 값을 pt_regs의 가장 첫 위치 r0에 저장한다.
- 코드 라인 8에서 교정된 lr, spsr, -1 값을 담고 있는 r5~r7 레지스터 값을 스택의 pt_regs 위치 중 old r0, cpsr, r15(pc) 주소에 저장한다.
- 코드 라인 11에서 스택 값을 r0에 대입한다.
- 코드 라인 12에서 bad_mode 레이블로 이동하여 “Oops” 출력 및 panic() 처리한다.
bad_mode()
arch/arm/kernel/traps.c
/* * bad_mode handles the impossible case in the vectors. If you see one of * these, then it's extremely serious, and could mean you have buggy hardware. * It never returns, and never tries to sync. We hope that we can at least * dump out some state information... */
asmlinkage void bad_mode(struct pt_regs *regs, int reason, unsigned int esr)
{
console_verbose();
pr_crit("Bad mode in %s handler detected on CPU%d, code 0x%08x -- %s\n",
handler[reason], smp_processor_id(), esr,
esr_get_class_string(esr));
local_daif_mask();
panic("bad mode");
}
허용하지 않은 모드에서 진입 시 “Oops – bad mode”를 출력하고 panic 처리 한다.
- “/proc/sys/kernel/panic” 초(secs) 만큼 대기하였다가 셀프 부팅한다. (0인 경우 그냥 부팅없이 정지해있다.)
kuser_cmpxchg_check
arch/arm/kernel/entry-armv.S
.macro kuser_cmpxchg_check
#if !defined(CONFIG_CPU_32v6K) && defined(CONFIG_KUSER_HELPERS) && \
!defined(CONFIG_NEEDS_SYSCALL_FOR_CMPXCHG)
#ifndef CONFIG_MMU
#warning "NPTL on non MMU needs fixing"
#else
@ Make sure our user space atomic helper is restarted
@ if it was interrupted in a critical region. Here we
@ perform a quick test inline since it should be false
@ 99.9999% of the time. The rest is done out of line.
cmp r4, #TASK_SIZE
blhs kuser_cmpxchg64_fixup
#endif
#endif
.endm
Kernel-provided User Helper code 중 시스템이 POSIX syscall을 이용하여 cmpxchg를 이용하는 방식인 경우 커널 space에서 exception되어 이 루틴에 진입하게 되면 kuser_cmpchg64_fixup을 수행하고 온다.
- r4에는 exception 처리 후 되돌아갈 주소(lr)이 담겨 있기 때문에 이 값을 TASK_SIZE와 비교하여 user space에서 진입하였는지 아니면 kernel space에서 진입하였는지 구분할 수 있다.
- 참고: Kernel-provided User Helper | 문c
get_thread_info 매크로
include/asm/assembler.h
/* * Get current thread_info. */
.macro get_thread_info, rd
ARM( mov \rd, sp, lsr #THREAD_SIZE_ORDER + PAGE_SHIFT )
THUMB( mov \rd, sp )
THUMB( lsr \rd, \rd, #THREAD_SIZE_ORDER + PAGE_SHIFT )
mov \rd, \rd, lsl #THREAD_SIZE_ORDER + PAGE_SHIFT
.endm
현재 프로세스의 스택 하위에 위치한 thread_info 객체의 주소를 인수 @rd에 반환한다.
IRQ 핸들러
arm 아키텍처는 nested 인터럽트를 처리할 수 있게 설계되어 있다. 그러나 현재 까지 arm 리눅스에서는 FIQ를 제외하고는 중첩하여 처리하지 못하게 하였다. 당연히 arm 리눅스가 아닌 펌웨어 레벨의 os에서는 사용자가 nested 인터럽트를 구현하여 사용할 수 있다.
다음 그림은 irq exception이 발생한 후 인터럽트 컨트롤러의 인터럽트 핸들러까지 흐름을 보여준다.
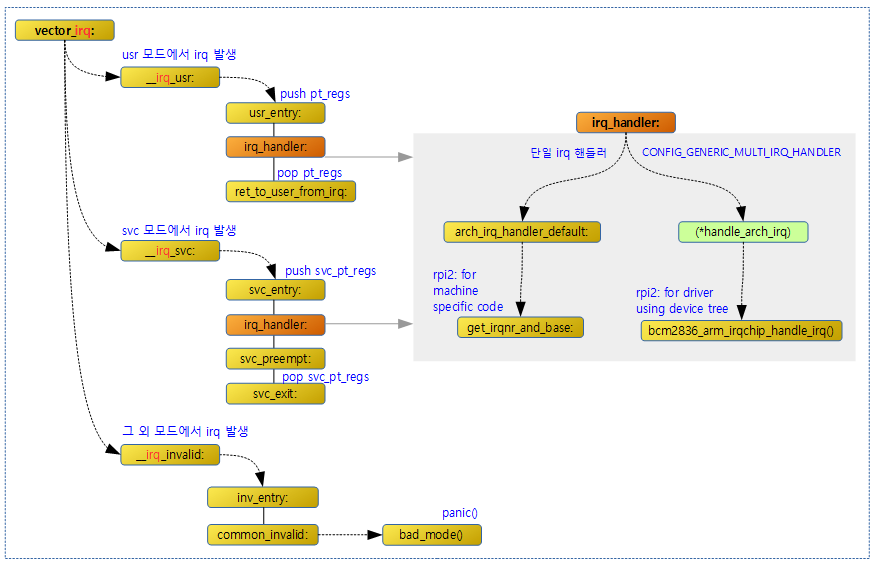
- CONFIG_GENERIC_IRQ_MULTI_HANDLER
- 런타임에 등록하는 multi irq 핸들러이다.
- Device Tree를 사용하는 경우 런타임에 해당 인터럽트 컨트롤러의 초기화 및 각 인트럽트에 대한 처리 방법 및 핸들러등을 준비해야 한다.
- 전역 handle_arch_irq 변수는 set_handle_irq() 함수에 의해 핸들러 주소가 설정된다.
- rpi2: Device Tree용 armctrl_of_init() 초기화 함수에서 두 개의 인터럽트 컨트롤러 초기화 함수를 호출하는데 그 중 부모 인터럽트 콘트롤러를 초기화할 때 핸들러로 bcm2836_arm_irqchip_handle_irq() 함수가 설정된다.
__irq_usr
arch/arm/kernel/entry-armv.S
.align 5
__irq_usr:
usr_entry
kuser_cmpxchg_check
irq_handler
get_thread_info tsk
mov why, #0
b ret_to_user_from_irq
UNWIND(.fnend )
ENDPROC(__irq_usr)
유저 태스크 처리 중 인터럽트가 발생되어 irq exception 모드에서 3개의 레지스터를 3 word로 구성된 mini stack에 백업한 후 svc 모드에 진입하였고 그 이후 이 레이블에 진입을하면 관련 인터럽트 번호에 등록되어 있는 1개 이상의 ISR(Interrupt Service Routing)을 호출한다.
- 코드 라인 3에서 전체 레지스터를 스택에 백업한다.
- 코드 라인 4에서 atomic 연산을 지원하지 못하는 아키텍처에서 atomic 하게 처리해야 하는 구간에서 인터럽트를 맞이하고 복귀할 때 그 atomic operation 구간의 시작부분으로 다시 돌아가도록 pt_regs의 pc를 조작한다.
- 코드 라인 5에서 관련 인터럽트 번호에 등록되어 있는 1개 이상의 ISR(Interrupt Service Routing)을 호출한다
- 코드 라인 6에서 tsk 레지스터에 thread_info 객체의 주소를 알아온다.
- 코드 라인 7~8에서 스택에 백업해둔 레지스터들을 다시 불러 읽은 후 user 모드로 복귀한다.
__irq_svc
arch/arm/kernel/entry-armv.S
.align 5
__irq_svc:
svc_entry
irq_handler
#ifdef CONFIG_PREEMPT
ldr r8, [tsk, #TI_PREEMPT] @ get preempt count
ldr r0, [tsk, #TI_FLAGS] @ get flags
teq r8, #0 @ if preempt count != 0
movne r0, #0 @ force flags to 0
tst r0, #_TIF_NEED_RESCHED
blne svc_preempt
#endif
svc_exit r5, irq = 1 @ return from exception
UNWIND(.fnend )
ENDPROC(__irq_svc)
커널 처리 중 인터럽트가 발생되어 irq exception 모드에서 3개의 레지스터를 3 word로 구성된 mini stack에 백업한 후 svc 모드에 진입하였고 그 이후 이 레이블에 진입을하면 관련 인터럽트 번호에 등록되어 있는 1개 이상의 처리 핸들러를 호출한다.
- 코드 라인 3에서 전체 레지스터를 포함한 svc_pt_regs 구조체를 스택에 백업한다.
- 코드 라인 4에서 관련 인터럽트 번호에 등록되어 있는 1개 이상의 ISR(Interrupt Service Routing)을 호출한다
- 코드 라인 7~12에서 preempt 커널에서 현재 프로세스 컨텍스트가 preempt 허용(preempt 카운트가 0) 상태인 경우에 한해 리스케쥴(_TIF_NEED_RESCHED) 요청이 있는 경우 리스케쥴을 위해 svc_preempt 레이블로 이동한다.
- thread_info->preempt가 0인 경우 preempt 가능한 상태이다.
- flags에 _TIF_NEED_RESCHED 설정된 경우 리스케쥴 요청이 들어온 경우이다.
- 코드 라인 15에서 스택에 백업해둔 레지스터들을 다시 불러 읽은 후 svc 모드로 복귀한다.
svc_preempt 레이블
arch/arm/kernel/entry-armv.S
#ifdef CONFIG_PREEMPT
svc_preempt:
mov r8, lr
1: bl preempt_schedule_irq @ irq en/disable is done inside
ldr r0, [tsk, #TI_FLAGS] @ get new tasks TI_FLAGS
tst r0, #_TIF_NEED_RESCHED
reteq r8 @ go again
b 1b
#endif
더 이상의 리스케쥴 요청이 없을 때까지 preemption 리스케쥴을 수행한다.
- 코드 라인 3에서 r8 레지스터에 복귀할 주소를 담고 있는 lr 레지스터를 백업해둔다.
- 코드 라인 4에서 현 태스크의 preemption을 포함한 리스케쥴을 수행한다.
- 리스케쥴되어 현재 태스크보다 더 우선 순위 높은 태스크가 실행되는 경우 현재의 태스크는 잠든다. 그 후 깨어난 후 계속 진행한다.
- 코드 라인 5~8에서 현재 프로세서 컨텍스트에 리스케쥴 요청이 있으면 다시 1: 레이블로 이동하여 계속 처리하고, 리스케쥴 요청이 없으면 루틴을 끝마치고 복귀한다.
irq_handler 매크로
arch/arm/kernel/entry-armv.S
/* * Interrupt handling. */
.macro irq_handler
#ifdef CONFIG_GENERIC_IRQ_MULTI_HANDLER
ldr r1, =handle_arch_irq
mov r0, sp
badr lr, 9997f
ldr pc, [r1]
#else
arch_irq_handler_default
#endif
9997:
.endm
아키텍처에 따른 irq 핸들러를 호출한다.
- CONFIG_MULTI_IRQ_HANDLER 커널 옵션을 사용 여부에 따라
- 설정한 경우 커널이 여러 개의 머신에 해당하는 IRQ 핸들러 함수를 같이 컴파일하고 실제 커널 부팅 시 IRQ 관련하여 선택한 호출 함수를 handle_arch_irq에 저장하여야 한다.
- 설정하지 않은 경우 현재 커널이 IRQ 처리 방식을 고정한 경우로 컴파일 시 결정된 arch_irq_handler_default 매크로를 호출한다.
인터럽트 핸들러 for rpi2
- rpi2 드라이버 참고: Interrupts -11- (IC Driver for rpi2) | 문c
ret_to_user_from_irq 및 no_work_pending 레이블
arch/arm/kernel/entry-common.S
ENTRY(ret_to_user_from_irq)
ldr r2, [tsk, #TI_ADDR_LIMIT]
cmp r2, #TASK_SIZE
blne addr_limit_check_failed
ldr r1, [tsk, #TI_FLAGS]
tst r1, #_TIF_WORK_MASK
bne slow_work_pending
no_work_pending:
asm_trace_hardirqs_on save = 0
/* perform architecture specific actions before user return */
arch_ret_to_user r1, lr
ct_user_enter save = 0
restore_user_regs fast = 0, offset = 0
ENDPROC(ret_to_user_from_irq)
irq 처리를 마치고 유저로 복귀하기 전에 pending된 작업이 있으면 수행한 후 백업해 두었던 레지스터들을 다시 읽어 들인 후 복귀한다.
- 코드 라인 2~4에서 thread_info->addr_limit값이 태스크 사이즈를 초과하는 경우 addr_limit_check_failed 레이블로 이동한다.
- 코드 라인 5~7에서 thread_info->flags를 검사하여 _TIF_WORK_MASK에 속한 플래그가 있는 경우 slow_work_pending 레이블로 이동한다.
- _TIF_WORK_MASK
- _TIF_NEED_RESCHED | _TIF_SIGPENDING | _TIF_NOTIFY_RESUME | _TIF_UPROBE
- _TIF_WORK_MASK
- 코드 라인 12에서 user process로 다시 복귀 전에 처리할 아키텍처 specific한 일이 있는 경우 수행한다.
- rpi2: 없음
- 코드 라인 13에서 CONFIG_CONTEXT_TRACKING 커널 옵션을 사용한 context 트래킹 디버그가 필요한 경우 수행한다.
- 코드 라인 15에서 백업해 두었던 레지스터들을 읽어들이며 다시 user space로 복귀한다.
지연 작업 처리
slow_work_pending
arch/arm/kernel/entry-common.S
slow_work_pending:
mov r0, sp @ 'regs'
mov r2, why @ 'syscall'
bl do_work_pending
cmp r0, #0
beq no_work_pending
movlt scno, #(__NR_restart_syscall - __NR_SYSCALL_BASE)
ldmia sp, {r0 - r6} @ have to reload r0 - r6
b local_restart @ ... and off we go
ENDPROC(ret_fast_syscall)
지연된 작업이 있는 경우 완료 시킨 후 no_work_pending 레이블로 이동하는데 pending 시그널을 처리하다 restart 에러가 발생한 경우 local_restart 레이블로 이동한다.
- 코드 라인 2~4에서 do_work_pending() 함수를 호출하여 지연된 작업을 수행한다.
- 코드 라인 5~6에서 더 이상 할 작업이 없는 경우 no_work_pending 레이블로 이동한다.
- 코드 라인 7에서 결과가 음수인 경우 scno에 sys_restart_syscall() 함수를 처리하기 위한 syscall 인덱스 번호를 대입한다.
- EABI(Embedded Application Binary Interface)를 사용하는 경우 0x0 – 0x0을 적용하여 0이된다.
- OABI(Old Application Binary Interface)를 사용하는 경우 0x90000 – 0x90000을 적용하여 0이된다.
- 코드 라인 8~9에서 스택으로부터 r0~r6 레지스터에 로드한 후 local_restart 레이블로 이동한다.
do_work_pending()
arch/arm/kernel/signal.c
asmlinkage int
do_work_pending(struct pt_regs *regs, unsigned int thread_flags, int syscall)
{
/*
* The assembly code enters us with IRQs off, but it hasn't
* informed the tracing code of that for efficiency reasons.
* Update the trace code with the current status.
*/
trace_hardirqs_off();
do {
if (likely(thread_flags & _TIF_NEED_RESCHED)) {
schedule();
} else {
if (unlikely(!user_mode(regs)))
return 0;
local_irq_enable();
if (thread_flags & _TIF_SIGPENDING) {
int restart = do_signal(regs, syscall);
if (unlikely(restart)) {
/*
* Restart without handlers.
* Deal with it without leaving
* the kernel space.
*/
return restart;
}
syscall = 0;
} else if (thread_flags & _TIF_UPROBE) {
uprobe_notify_resume(regs);
} else {
clear_thread_flag(TIF_NOTIFY_RESUME);
tracehook_notify_resume(regs);
rseq_handle_notify_resume(NULL, regs);
}
}
local_irq_disable();
thread_flags = current_thread_info()->flags;
} while (thread_flags & _TIF_WORK_MASK);
return 0;
}
지연된 작업이 있는 경우 완료될 때까지 처리한다. 정상 처리되면 0을 반환하는데 만일 pending 시그널을 처리하다 에러가 발생한 경우 restart 값을 반환한다.
- 코드 라인 9에서 harirq 트레이스를 off한다.
- 코드 라인 11~12에서 현재 태스크의 플래그들 중 리스케쥴 요청(_TIF_NEED_RESCHED 플래그)이 있는 경우 리스케쥴한다.
- 인터럽트 처리를 빠져나가기 전에 이 코드가 실제 preemption 요청을 처리하는 곳이다.
- 코드 라인 14~15에서 낮은 확률로 유저 모드 진입이 아닌 경우 그냥 빠져나간다.
- 코드 라인 17~27에서 pending 시그널(_TIF_SIGPENDING 플래그) 이 있는 경우 시그널을 처리한다. 만일 restart 응답을 받은 경우 restart 값으로 함수를 빠져나간다.
- 코드 라인 28~29에서 uprobe break point가 hit(_TIF_UPROBE 플래그)되어 진입된 경우이었던 경우 resume 관련 처리를 수행한다.
- 코드 라인 30~34에서 4개의 pending 관련 비트들 중 마지막 플래그 TIF_NOTIFY_RESUME를 클리어한다. 이 플래그는 user로 되돌아가기 전에 호출할 콜백함수들을 수행하게 한다.
- task_work_add() 함수에서 인수 notify가 설정되어 요청한 경우 task->task_works 리스트에 추가된 콜백 함수들을 수행한다.
- 코드 라인 37~38에서 현재 프로세서의 플래그에 pending 작업이 존재한다고 표시된 경우 계속 루프를 돈다.
- 코드 라인 39에서 펜딩 작업이 더 이상 없으므로 0을 반환한다.
restore_user_regs 매크로
arch/arm/kernel/entry-header.S (THUMB 코드 생략)
.macro restore_user_regs, fast = 0, offset = 0
uaccess_enable r1, isb=0
@ ARM mode restore
mov r2, sp
ldr r1, [r2, #\offset + S_PSR] @ get calling cpsr
ldr lr, [r2, #\offset + S_PC]! @ get pc
tst r1, #PSR_I_BIT | 0x0f
bne 1f
msr spsr_cxsf, r1 @ save in spsr_svc
#if defined(CONFIG_CPU_V6) || defined(CONFIG_CPU_32v6K)
@ We must avoid clrex due to Cortex-A15 erratum #830321
strex r1, r2, [r2] @ clear the exclusive monitor
#endif
.if \fast
ldmdb r2, {r1 - lr}^ @ get calling r1 - lr
.else
ldmdb r2, {r0 - lr}^ @ get calling r0 - lr
.endif
mov r0, r0 @ ARMv5T and earlier require a nop
@ after ldm {}^
add sp, sp, #\offset + PT_REGS_SIZE
movs pc, lr @ return & move spsr_svc into cpsr
1: bug "Returning to usermode but unexpected PSR bits set?", \@
#elif defined(CONFIG_CPU_V7M)
@ V7M restore.
@ Note that we don't need to do clrex here as clearing the local
@ monitor is part of the exception entry and exit sequence.
.if \offset
add sp, #\offset
.endif
v7m_exception_slow_exit ret_r0 = \fast
.endm
백업해 두었던 레지스터들을 읽어들인 후 다시 user space로 복귀한다.
- 코드 라인 2에서 커널의 유저 액세스를 허용하게 한다.
- 코드 라인 4~9에서 스택에 백업해둔 pt_regs의 cpsr을 r1 레지스터를 통해 spsr 레지스터에 저장하고, pc 값을 lr 레지스터에 대입한다.
- 만일 백업한 cpsr의 irq 비트가 마스크되어 있는 경우 1f 레이블에서 버그 출력을 한다.
- 코드 라인 12에서 Cortex-A15 아키텍처에서 strex를 사용하여 clrex를 대신하였다.
- 복귀 시 마다 exclusive 모니터를 클리어하여 복귀 전에 exclusive 모니터를 사용하던 context에서 재시도하게 한다.
- 참고: ARM: 8129/1: errata: work around Cortex-A15 erratum 830321 using dummy strex
- 코드 라인 14~18에서 fast 요청이 있는 경우 스택에 백업해 둔 pt_regs의 r1~lr 까지의 레지스터를 읽어오고 fast 요청이 아닌 경우 r0 레지스터를 포함해서 불러온다.
- 코드 라인 19에서 ARMv5T 및 그 이전 arm 아키텍처에서 multiple load 명령을 사용 후 nop을 사용해야 한다.
- 코드 라인 21~22에서 스택에서 pt_regs를 제외시킨 후 user space로 복귀한다.
preempt_schedule_irq()
kernel/sched/core.c
/* * this is the entry point to schedule() from kernel preemption * off of irq context. * Note, that this is called and return with irqs disabled. This will * protect us against recursive calling from irq. */
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
BUG_ON(preempt_count() || !irqs_disabled());
prev_state = exception_enter();
do {
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
exception_exit(prev_state);
}
리스케쥴 요청이 있는 동안 인터럽트는 허용하되 preemption은 허용되지 않게 한 후 스케쥴한다.
- 코드 라인 8에서 리스케쥴 전에 context 트래킹 디버깅을 위한 선 처리 작업을 한다.
- 코드 라인 10~14에서 인터럽트는 허용하되 preemption은 허용되지 active 구간을 증가시킨다. 않게 한 후 스케쥴한다. 완료 후 다시 인터럽트를 막고 preemption이 허용되도록 active 구간을 감소시킨다.
- 코드 라인 15~16에서 리스케쥴 요청이 없을 때까지 반복한다.
- 코드 라인 18에서리스케쥴이 완료되었으므로 context 트래킹 디버깅을 위한 후 처리 작업을 한다.
FIQ 핸들러
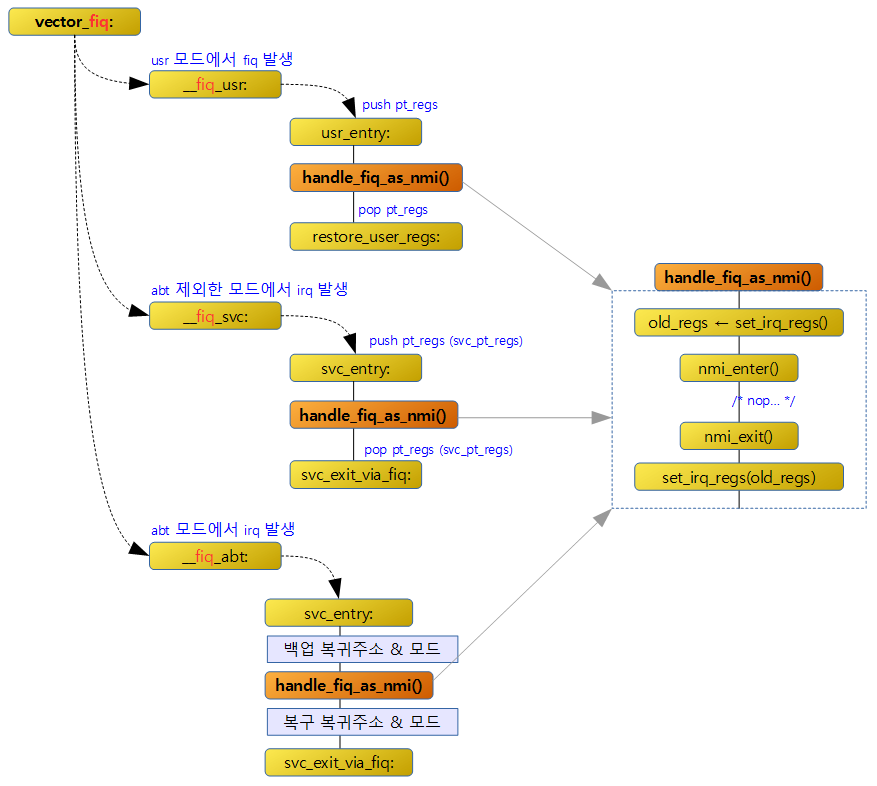
__fiq_usr
arch/arm/kernel/entry-armv.S
.align 5
__fiq_usr:
usr_entry trace=0
kuser_cmpxchg_check
mov r0, sp @ struct pt_regs *regs
bl handle_fiq_as_nmi
get_thread_info tsk
restore_user_regs fast = 0, offset = 0
UNWIND(.fnend )
ENDPROC(__fiq_usr)
유저모드에서 fiq가 발생되어 fiq exception 모드로 진입하였고, 3개의 레지스터를 3 word로 구성된 mini stack에 백업한 후 svc 모드에 진입한 상황이다. 그 이후 이 레이블에 진입하여 관련 fiq 핸들러를 호출한다. (ARM에서는 기본적으로 fiq 관련 처리는 비어있는 상태이다)
- 코드 라인 3에서 전체 레지스터를 스택에 백업한다. 속도를 중시하므로 trace를 제한한다.
- 코드 라인 4에서 atomic 연산을 지원하지 못하는 아키텍처에서 atomic 하게 처리해야 하는 구간에서 인터럽트를 맞이하고 복귀할 때 그 atomic operation 구간의 시작부분으로 다시 돌아가도록 pt_regs의 pc를 조작한다.
- 코드 라인 5~6에서 fiq 관련 등록된 ISR을 수행한다.
- 코드 라인 7에서 tsk 레지스터에 thread_info 객체의 주소를 알아온다.
- 코드 라인 8에서 스택에 백업해둔 레지스터들을 다시 불러 읽은 후 user 모드로 복귀한다.
handle_fiq_as_nmi()
arch/arm/kernel/traps.c
/* * Handle FIQ similarly to NMI on x86 systems. * * The runtime environment for NMIs is extremely restrictive * (NMIs can pre-empt critical sections meaning almost all locking is * forbidden) meaning this default FIQ handling must only be used in * circumstances where non-maskability improves robustness, such as * watchdog or debug logic. * * This handler is not appropriate for general purpose use in drivers * platform code and can be overrideen using set_fiq_handler. */
asmlinkage void __exception_irq_entry handle_fiq_as_nmi(struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
nmi_enter();
/* nop. FIQ handlers for special arch/arm features can be added here. */
nmi_exit();
set_irq_regs(old_regs);
}
arm 아키텍처에서는 fiq 처리를 위한 루틴이 비어있다. 필요한 경우 임베디드 개발자가 추가하게 되어 있다.
nmi_enter()
include/linux/hardirq.h
#define nmi_enter() \
do { \
arch_nmi_enter(); \
printk_nmi_enter(); \
lockdep_off(); \
ftrace_nmi_enter(); \
BUG_ON(in_nmi()); \
preempt_count_add(NMI_OFFSET + HARDIRQ_OFFSET); \
rcu_nmi_enter(); \
trace_hardirq_enter(); \
} while (0)
nmi 처리 시작 진입점에서 수행해야 할 일들을 처리한다. preempt count를 증가시켜 preemption되지 않도록 하고 nmi가 진행 중임을 rcu가 알 수 있도록 한다.
- 코드 라인 3에서 nmi 처리 직전 아키텍처 specific 한 처리가 필요할 때 수행한다. (arm32는 없음)
- 코드 라인 4에서 CONFIG_PRINTK_NMI를 지원하는 시스템에서 현재 cpu의 printk_context에 PRINTK_NMI_CONTEXT_MASK 마스크를 추가한다.
- 코드 라인 5에서 lockdep 디버그를 끈다.
- 코드 라인 6에서 nmi 처리 전에 대한 ftrace 트래킹을 지원한다.
- 코드 라인 7에서 nmi 처리 중에 재진입된 경우 버그 처리한다.
- 코드 라인 8에서 nmi 및 hard irq에 대한 preempt 카운터를 증가시킨다.
- 코드 라인 9에서 nmi 처리 중인 것을 RCU도 알아야하기 때문에 &rcu_dynticks->dynticks를 1로 설정한다.
- 코드 라인 10에서 nmi 처리 전 hard irq 처리에 대한 trace 출력을 한다.
nmi_exit()
include/linux/hardirq.h
#define nmi_exit() \
do { \
trace_hardirq_exit(); \
rcu_nmi_exit(); \
BUG_ON(!in_nmi()); \
preempt_count_sub(NMI_OFFSET + HARDIRQ_OFFSET); \
ftrace_nmi_exit(); \
lockdep_on(); \
printk_nmi_exit(); \
arch_nmi_exit(); \
} while (0)
nmi 처리 종료 후 수행해야 할 일들을 처리한다. rcu도 종료를 알 수 있도록 보고하고, 처리 전 증가된 preempt count도 감소시킨다.
- 코드 라인 3에서 nmi 처리 후 hard irq 처리에 대한 trace 출력을 한다.
- 코드 라인 4에서 nmi 처리 완료된 것을 RCU도 알아야하기 때문에 &rcu_dynticks->dynticks를 0으로 클리어한다.
- 코드 라인 5에서 여전히 nmi 처리 중인 경우 버그 처리한다.
- 코드 라인 6에서 nmi 및 hard irq에 대한 preempt 카운터를 감소시킨다.
- 코드 라인 7에서 nmi 처리 완료에 대한 ftrace 트래킹을 지원한다.
- 코드 라인 8에서 lockdep 디버그를 다시 켠다.
- 코드 라인 9에서 CONFIG_PRINTK_NMI를 지원하는 시스템에서 현재 cpu의 printk_context에 PRINTK_NMI_CONTEXT_MASK 마스크를 제거한다.
- 코드 라인 10에서 nmi 처리 완료 후 아키텍처 specific 한 처리가 필요할 때 수행한다. (arm32는 없음)
set_irq_regs()
include/asm-generic/irq_regs.h
static inline struct pt_regs *set_irq_regs(struct pt_regs *new_regs)
{
struct pt_regs *old_regs;
old_regs = __this_cpu_read(__irq_regs);
__this_cpu_write(__irq_regs, new_regs);
return old_regs;
}
pt_regs 레지스터들을 백업하고 기존 레지스터들을 반환한다.
__fiq_svc
arch/arm/kernel/entry-armv.S
.align 5
__fiq_svc:
svc_entry trace=0
mov r0, sp @ struct pt_regs *regs
bl handle_fiq_as_nmi
svc_exit_via_fiq
UNWIND(.fnend )
ENDPROC(__fiq_svc)
커널 처리 중 fiq가 발생되어 fiq exception 모드로 진입하였고, 3개의 레지스터를 3 word로 구성된 mini stack에 백업한 후 svc 모드에 진입한 상황이다. 그 이후 이 레이블에 진입을하여 관련 ifiq 핸들러를 호출한다. (ARM에서는 기본적으로 fiq 관련 처리는 비어있는 상태이다)
- 코드 라인 3에서 전체 레지스터를 스택에 백업한다. 속도를 중시하므로 trace를 제한한다.
- 코드 라인 4~5에서 fiq 관련 등록된 ISR을 수행한다.
- 코드 라인 6에서 스택에 백업해둔 레지스터들을 다시 불러 읽은 후 exception 전 해당 모드로 복귀한다.
svc_exit_via_fiq 매크로
arch/arm/kernel/entry-header.S (THUMB 코드 생략)
. @
@ svc_exit_via_fiq - like svc_exit but switches to FIQ mode before exit
@
@ This macro acts in a similar manner to svc_exit but switches to FIQ
@ mode to restore the final part of the register state.
@
@ We cannot use the normal svc_exit procedure because that would
@ clobber spsr_svc (FIQ could be delivered during the first few
@ instructions of vector_swi meaning its contents have not been
@ saved anywhere).
@
@ Note that, unlike svc_exit, this macro also does not allow a caller
@ supplied rpsr. This is because the FIQ exceptions are not re-entrant
@ and the handlers cannot call into the scheduler (meaning the value
@ on the stack remains correct).
@
. .macro svc_exit_via_fiq
ldr r1, [sp, #SVC_ADDR_LIMIT]
uaccess_restore
str r1, [tsk, #TI_ADDR_LIMIT]
@ ARM mode restore
mov r0, sp
ldmib r0, {r1 - r14} @ abort is deadly from here onward (it will
@ clobber state restored below)
msr cpsr_c, #FIQ_MODE | PSR_I_BIT | PSR_F_BIT
add r8, r0, #S_PC
ldr r9, [r0, #S_PSR]
msr spsr_cxsf, r9
ldr r0, [r0, #S_R0]
ldmia r8, {pc}^
.endm
exception 전의 모드로 다시 복귀하기 위해 백업해두었던 레지스터들을 복구한다. (종료 전에 fiq 모드로 switch하는 것만 제외하고 svc_exit와 유사하다)
- 코드 라인 2에서 스택에 저장된 svc_pt_regs.addr_limit 값을 r1 레지스터에 읽어온다.
- 코드 라인 3에서 스택에 저장된 유저 액세스 여부를 백업한다.
- 코드 라인 4에서 읽어온 addr_limit 값을 태스크에 기록한다.
- 코드 라인 6~7에서 스택으로 부터 r1 ~ r14 레지스터까지 복구한다.
- 코드 라인 9에서 irq, fiq bit를 마스크한 상태로 fiq mode로 진입한다.
- 코드 라인 10에서 r8에 스택에서 pt_regs의 pc 값을 읽어온다.
- 가장 마지막에 복귀할 주소가 담긴다.
- 코드 라인 11~12에서 스택에서 pt_regs의 psr 값을 읽어 spsr에 대입하여 기존 모드로 복귀한다.
- 코드 라인 13에서 다시 스택에서 pt_regs의 r0 값을 읽어 r0 레지스터에 복구한다.
- 코드 라인 14에서 복귀할 주소가 담긴 r8레지스터 값 주소로 jump 한다.
__fiq_abt
arch/arm/kernel/entry-armv.S (THUMB 코드 생략)
/* * Abort mode handlers */ @ @ Taking a FIQ in abort mode is similar to taking a FIQ in SVC mode @ and reuses the same macros. However in abort mode we must also @ save/restore lr_abt and spsr_abt to make nested aborts safe. @
.align 5
__fiq_abt:
svc_entry trace=0
ARM( msr cpsr_c, #ABT_MODE | PSR_I_BIT | PSR_F_BIT )
mov r1, lr @ Save lr_abt
mrs r2, spsr @ Save spsr_abt, abort is now safe
ARM( msr cpsr_c, #SVC_MODE | PSR_I_BIT | PSR_F_BIT )
stmfd sp!, {r1 - r2}
add r0, sp, #8 @ struct pt_regs *regs
bl handle_fiq_as_nmi
ldmfd sp!, {r1 - r2}
ARM( msr cpsr_c, #ABT_MODE | PSR_I_BIT | PSR_F_BIT )
mov lr, r1 @ Restore lr_abt, abort is unsafe
msr spsr_cxsf, r2 @ Restore spsr_abt
ARM( msr cpsr_c, #SVC_MODE | PSR_I_BIT | PSR_F_BIT )
svc_exit_via_fiq
UNWIND(.fnend )
ENDPROC(__fiq_abt)
abt 모드에서 fiq exception이 발생되어 3개의 레지스터를 3 word로 구성된 mini stack에 백업한 후 svc 모드에 진입하였고 그 이후 이 레이블에 진입을하면 관련 fiq 핸들러를 수행한다. (ARM에서는 기본적으로 fiq 관련 처리는 비어있는 상태이다)
- 코드 라인 3에서 전체 레지스터를 스택에 백업한다.
- 코드 라인 5~9에서 abt 모드의 lr, spsr을 스택에 백업한다.
- irq 및 fiq를 disable한 상태로 다시 abt 모드로 진입하여 abt 모드에서의 lr 및 spsr을 r1, r2 레지스터에 잠시 저장하고 svc 모드로 바꾼 후 스택에 백업한다.
- 코드 라인 11~12에서 fiq 관련 등록된 ISR을 수행한다. (ARM에서는 기본적으로 등록되어 있지 않다)
- 코드 라인 14~18에서 irq와 fiq를 금지한 상태로 abt 모드에 진입하고, 백업해 두었던 2개의 lr, spsr을 다시 복구한 후 svc 모드로 돌아온다.
- 코드 라인 20에서 스택에 백업해둔 레지스터들을 다시 불러 읽은 후 exceptino 전 해당 모드로 복귀한다.
SWI 핸들러
arm에서 소프트 인터럽트 발생 시 호출되며 8개의 exception 벡터 주소가 있는 페이지의 바로 다음 페이지 첫 엔트리에 vector_swi 레이블 주소가 담겨 있고, 이 주소를 호출한다.
다음 그림은 유저 모드에서 syscall 호출 시 vector_swi 레이블부터 swi 처리에 대한 함수 호출 관계를 보여준다.
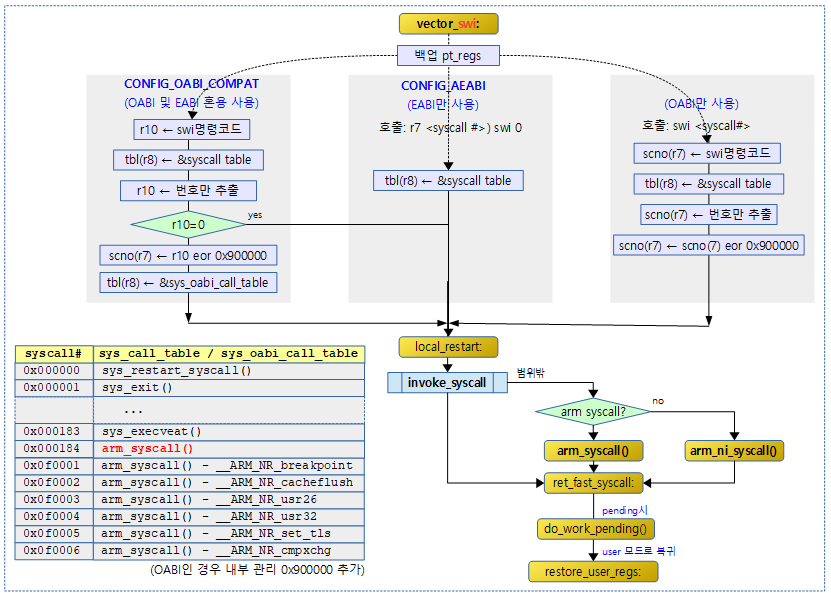
Fast syscall vs Slow syscall
syscall이 처리된 후 다시 유저로 복귀하기 전에 처리할 스케쥴 워크가 남아 있는 경우 이를 처리한다. 즉 곧바로 유저로 복귀하지 않고 우선 순위가 높아 먼저 처리할 태스크를 위해 스케쥴이 다시 재배치되면서 다른 태스크를 수행하고 돌아오게 된다. 이렇게 syscall 처리 후 곧바로 돌아오는 경우 fast syscall이라 하고 곧바로 돌아오지 못하고 preemption 되었다가 돌아오는 경우를 slow syscall이라한다. slow syscall 상태가 되면 유저 입장에서 보면 blocked 함수를 호출한 것처럼 느리게 처리된다.
- Fast syscall
- syscall 처리 후 곧바로 유저로 복귀
- Slow syscall
- syscall 처리 후 유저 복귀 전에 먼저 처리할 태스크를 수행하도록 스케쥴을 바꾼다.
vector_swi:
arch/arm/kernel/entry-common.S -1/2-
/*============================================================================= * SWI handler *----------------------------------------------------------------------------- */
.align 5
ENTRY(vector_swi)
#ifdef CONFIG_CPU_V7M
v7m_exception_entry
#else
sub sp, sp, #PT_REGS_SIZE
stmia sp, {r0 - r12} @ Calling r0 - r12
ARM( add r8, sp, #S_PC )
ARM( stmdb r8, {sp, lr}^ ) @ Calling sp, lr
mrs saved_psr, spsr @ called from non-FIQ mode, so ok.
TRACE( mov saved_pc, lr )
str saved_pc, [sp, #S_PC] @ Save calling PC
str saved_psr, [sp, #S_PSR] @ Save CPSR
str r0, [sp, #S_OLD_R0] @ Save OLD_R0
#endif
zero_fp
alignment_trap r10, ip, __cr_alignment
asm_trace_hardirqs_on save=0
enable_irq_notrace
ct_user_exit save=0
/*
* Get the system call number.
*/
#if defined(CONFIG_OABI_COMPAT)
/*
* If we have CONFIG_OABI_COMPAT then we need to look at the swi
* value to determine if it is an EABI or an old ABI call.
*/
USER( ldr r10, [saved_pc, #-4] ) @ get SWI instruction
ARM_BE8(rev r10, r10) @ little endian instruction
#elif defined(CONFIG_AEABI)
/*
* Pure EABI user space always put syscall number into scno (r7).
*/
/* Legacy ABI only. */
USER( ldr scno, [saved_pc, #-4] ) @ get SWI instruction
#endif
/* saved_psr and saved_pc are now dead */
uaccess_disable tbl
adr tbl, sys_call_table @ load syscall table pointer
#if defined(CONFIG_OABI_COMPAT)
/*
* If the swi argument is zero, this is an EABI call and we do nothing.
*
* If this is an old ABI call, get the syscall number into scno and
* get the old ABI syscall table address.
*/
bics r10, r10, #0xff000000
eorne scno, r10, #__NR_OABI_SYSCALL_BASE
ldrne tbl, =sys_oabi_call_table
#elif !defined(CONFIG_AEABI)
bic scno, scno, #0xff000000 @ mask off SWI op-code
eor scno, scno, #__NR_SYSCALL_BASE @ check OS number
#endif
get_thread_info tsk
/*
* Reload the registers that may have been corrupted on entry to
* the syscall assembly (by tracing or context tracking.)
*/
TRACE( ldmia sp, {r0 - r3} )
소프트 인터럽트 핸들러로 user space에서 POSIX 시스템 콜 호출을 하는 경우 커널에서 “sys_”로 시작하는 syscall 함수 및 arm용 syscall 함수를 호출한다. (thumb 소스는 생략하였다)
- 리눅스는 3개의 ABI(Application Binary Interface) 관련 모드를 준비하였다.
- CONFIG_OABI_COMPAT 커널 옵션은 Old ABI(legacy ABI) 및 AEABI 두 방식을 동시에 지원하기 위해 제공한다.
- CONFIG_AEABI 커널 옵션은 AEABI 방식만 제공한다.
- 위 두 커널 옵션을 사용하지 않는 경우 OABI를 지원한다.
- 참고: ABI(Application Binary Interface) | 문c
- 코드 라인 6~7에서 PT_REGS_SIZE만큼 스택을 키운다. (grows down) 그런 후 r0~r12까지의 레지스터 값들을 스택에 저장한다.
- 코드 라인 8~9에서 스택에 비워둔 레지스터 저장 장소 중 sp와 lr 레지스터 값을 해당 위치에 저장한다.
- 코드 라인 10에서 스택의 pt_regs.psr 값을 읽어와 spsr에 대입한다.
- 코드 라인 12~14에서 스택에 있는 pt_regs 구조체의 pc 위치에 돌아갈 주소가 담긴 lr을 저장하고, psr 위치에는 현재 모드의 spsr을 저장한다. 마지막으로 old_r0 위치에 r0 레지스터를 저장하다.
- 코드 라인 16에서 fp 레지스터에 0을 대입한다
- 코드 라인 17에서 CONFIG_ALIGNMENT_TRAP 커널 옵션을 사용하는 경우 alignment trap 기능을 적용한다.
- 코드 라인 19에서 local irq를 enable 한다.
- 코드 라인 20에서 컨텍스트 트래킹에 관련한 후처리 디버그 활동을 수행한다.
- 코드 라인 26~63에서 ABI 모드에 따라 swi 호출당시의 syscall 번호를 scno(r7)에 대입하고 tbl(r8)에 syscall 테이블 주소를 대입한다.
- CONFIG_OABI_COMPAT: AEABI 및 OABI 두 모드를 동시에 지원한다.
- swi 호출 당시의 숫자 부분만을 떼어 r10에 대입하고 그 값에 따라
- 0인 경우 AEABI로 인식하여 아무것도 수행하지 않는다. (AEABI 규약에 의거 swi 0 호출 전에 r7에 syscall 번호가 담겨온다)
- 0이 아닌 경우 OABI로 인식하여 r10에서 __NR_OABI_SYSCALL_BASE(0x900000)값을 더한 후 scno(r7)에 대입하고 tbl(r8)에 sys_oabi_call_table을 지정한다.
- swi 호출 당시의 숫자 부분만을 떼어 r10에 대입하고 그 값에 따라
- CONFIG_AEABI: AEABI 모드만 지원한다.
- 아무것도 수행하지 않는다. (AEABI 규약에 의거 swi 0 호출 전에 r7에 syscall 번호가 담겨온다)
- CONFIG_OABI
- swi 호출 당시의 숫자 부분만을 떼어 scno(r7)에 대입하고 __NR_SYSCALL_BASE(0x900000)값을 더한다.
- CONFIG_OABI_COMPAT: AEABI 및 OABI 두 모드를 동시에 지원한다.
- 코드 라인 64에서 tsk(r9) 레지스터에 현재 cpu의 thread_info 주소를 알아온다.
arch/arm/kernel/entry-common.S -2/2-
local_restart:
ldr r10, [tsk, #TI_FLAGS] @ check for syscall tracing
stmdb sp!, {r4, r5} @ push fifth and sixth args
tst r10, #_TIF_SYSCALL_WORK @ are we tracing syscalls?
bne __sys_trace
invoke_syscall tbl, scno, r10, __ret_fast_syscall
add r1, sp, #S_OFF
2: cmp scno, #(__ARM_NR_BASE - __NR_SYSCALL_BASE)
eor r0, scno, #__NR_SYSCALL_BASE @ put OS number back
bcs arm_syscall
mov why, #0 @ no longer a real syscall
b sys_ni_syscall @ not private func
#if defined(CONFIG_OABI_COMPAT) || !defined(CONFIG_AEABI)
/*
* We failed to handle a fault trying to access the page
* containing the swi instruction, but we're not really in a
* position to return -EFAULT. Instead, return back to the
* instruction and re-enter the user fault handling path trying
* to page it in. This will likely result in sending SEGV to the
* current task.
*/
9001:
sub lr, saved_pc, #4
str lr, [sp, #S_PC]
get_thread_info tsk
b ret_fast_syscall
#endif
ENDPROC(vector_swi)
local_restart 레이블
- 코드 라인 2에서 현재 태스크의 플래그 값을 r10 레지스터로 읽어온다.
- 코드 라인 3에서 syscall 호출 시의 5번째 인수와 6번째 인수를 스택에 저장한다.
- 코드 라인 5~6에서 syscall tracing이 요청된 경우 트레이스 관련 함수를 호출하여 처리한다.
- __sys_trace 레이블에서 slow_syscall 루틴이 동작한다. (코드 설명 생략)
- 코드 라인 8에서 syscall 번호가 syscall 처리 범위 이내인 경우 syscall 테이블에서 해당 syscall 번호에 해당하는 “sys_”로 시작하는 함수로 jump 하고 수행이 완료된 후 ret_fast_syscall 레이블 주소로 이동한다.
- 0번 syscall은 커널 내부 사용목적의 syscall 함수이다. (sys_restart_syscall())
- 코드 라인 10~15에서 syscall 번호가 ARM용 syscall 범위이내인 경우 arm_syscall() 함수를 호출한다. 만일 범위를 벗어난 경우 sys_ni_syscall() 함수를 호출하여 private한 syscall을 처리하게 한다. 만일 특별히 private syscall을 등록하지 않은 경우 -ENOSYS 에러로 함수를 빠져나온다.
- 커널 4.0 기준 5개의 ARM syscall 함수들이 등록되어 있다.
- 코드 라인 27~30에서 OABI 사용 시 다른 cpu에 의해 swi 명령이 있는 페이지를 mkold한 상태와 동시에 현재 cpu에서 swi 호출 시 panic 되는 경우를 막기 위해 다시 한번 해당 명령으로 복귀한다.
- 참고: ARM: 7748/1: oabi: handle faults when loading swi instruction from userspace (2013, v3.11-rc1)
alignment_trap 매크로
arch/arm/kernel/entry-header.S
.macro alignment_trap, rtmp1, rtmp2, label
#ifdef CONFIG_ALIGNMENT_TRAP
mrc p15, 0, \rtmp2, c1, c0, 0
ldr \rtmp1, \label
ldr \rtmp1, [\rtmp1]
teq \rtmp1, \rtmp2
mcrne p15, 0, \rtmp1, c1, c0, 0
#endif
.endm
CONFIG_ALIGNMENT_TRAP 커널 옵션을 사용하는 경우 alignment trap 기능을 적용한다.
- alignment trap을 사용하면 정렬되지 않은 주소 및 데이터에 접근 할 때 prefect abort 또는 data abort exception이 발생한다.
- 기존에 저장해 두었던 cr_alignment 값과 SCTLR 값이 다른 경우에만 SCTLR에 cr_alignment 값을 저장하는 방식으로 성능 저하를 막는다.
ret_fast_syscall 레이블
arch/arm/kernel/entry-common.S
/* * This is the fast syscall return path. We do as little as possible here, * such as avoiding writing r0 to the stack. We only use this path if we * have tracing, context tracking and rseq debug disabled - the overheads * from those features make this path too inefficient. */
ret_fast_syscall:
__ret_fast_syscall:
UNWIND(.fnstart )
UNWIND(.cantunwind )
disable_irq_notrace @ disable interrupts
ldr r2, [tsk, #TI_ADDR_LIMIT]
cmp r2, #TASK_SIZE
blne addr_limit_check_failed
ldr r1, [tsk, #TI_FLAGS] @ re-check for syscall tracing
tst r1, #_TIF_SYSCALL_WORK | _TIF_WORK_MASK
bne fast_work_pending
/* perform architecture specific actions before user return */
arch_ret_to_user r1, lr
restore_user_regs fast = 1, offset = S_OFF
UNWIND(.fnend )
ENDPROC(ret_fast_syscall)
syscall 처리를 마치고 복귀하기 전에 pending된 작업이 있으면 수행한 후 백업해 두었던 레지스터들을 다시 읽어 들인 후 복귀한다.
invoke_syscall 매크로
arch/arm/kernel/entry-header.S
.macro invoke_syscall, table, nr, tmp, ret, reload=0
#ifdef CONFIG_CPU_SPECTRE
mov \tmp, \nr
cmp \tmp, #NR_syscalls @ check upper syscall limit
movcs \tmp, #0
csdb
badr lr, \ret @ return address
.if \reload
add r1, sp, #S_R0 + S_OFF @ pointer to regs
ldmiacc r1, {r0 - r6} @ reload r0-r6
stmiacc sp, {r4, r5} @ update stack arguments
.endif
ldrcc pc, [\table, \tmp, lsl #2] @ call sys_* routine
#else
cmp \nr, #NR_syscalls @ check upper syscall limit
badr lr, \ret @ return address
.if \reload
add r1, sp, #S_R0 + S_OFF @ pointer to regs
ldmiacc r1, {r0 - r6} @ reload r0-r6
stmiacc sp, {r4, r5} @ update stack arguments
.endif
ldrcc pc, [\table, \nr, lsl #2] @ call sys_* routine
#endif
.endm
@nr 번호가 syscall 범위에 있는 경우 해당하는 syscall 함수를 호출한 후 @ret 주소로 복귀한다. 범위 밖인 경우 그냥 빠져나온다.
sys_ni_syscall()
kernel/sys_ni.c
/* * Non-implemented system calls get redirected here. */
asmlinkage long sys_ni_syscall(void)
{
return -ENOSYS;
}
범위 밖의 syscall 요청이 수행되는 루틴이다. private syscall이 필요한 경우 이곳에 작성되는데 없으면 -ENOSYS 에러를 반환한다.
참고
- Exception -1- (ARM32 Vector) | 문c
- Exception -2- (ARM32 Handler 1) | 문c – 현재 글
- Exception -3- (ARM32 Handler 2) | 문c
- Exception -4- (ARM32 VFP & FPE) | 문c
- Exception -5- (Extable) | 문c
- Exception -6- (MM Fault Handler) | 문c
- Interrupts -1- (Interrupt Controller) | 문c
- Interrupts -6- (IPI Cross-call) | 문c
- ABI(Application Binary Interface) | 문c
- x86 OS에서의 인터럽트와 예외 | arsenals
ABI(Application Binary Interface)
ABI(Application Binary Interface) 표준
Application간 binary 데이터를 어떻게 교환해야 하는지 다음과 같은 규칙들을 정한다.
- 데이터 타입과 정렬 방법
- 함수 호출 시 인수 및 결과에 대해 레지스터 교환 방법
- 시스템 콜 호출 방법
- 프로그램 코드의 시작과 데이터에 대한 초기화 방법
- 파일 교환 방법(ELF 등)
EABI 표준
EABI(Embeded ABI)는 임베디드 환경의 ABI를 다룬다. ARM 아키텍처에서 리눅스 버전에 따라 ABI를 사용하는 방식이 다음 두 가지로 나뉜다.
- arm/OABI
- 커널 v2.6.15 (mainline v2.6.16) 이전에 사용되던 ABI 방식(Old ABI 또는 legacy ABI라고도 불린다)
- glibc 2.3.6 까지 사용
- gcc: linux-arm-none-gnu
- arm/EABI
- 커널 v2.6.16 부터 사용되는 ARM EABI 방식
- glibc v2.3.7 및 v2.4 부터 사용
- gcc: linux-arm-none-gnueabi
arm/OABI 및 arm/EABI 차이점
소프트 인터럽트 호출방식
- OABI
- swi __NR_SYSCALL_BASE(==0x900000)+1
- EABI
- mov r7, #1 (시스템콜 인덱스)
- swi 0
구조체 패키징
- OABI
- 구조체는 4 바이트 단위로 정렬
- EABI
- 구조체 사이즈대로 사용
스택에 인수 정렬
- OABI
- 스택에 저장할 때 4 바이트 단위로 저장
- EABI
- 스택에 저장할 때 8 바이트 단위로 저장
64bit 타입 인수 정렬
- OABI
- 4 바이트 단위로 정렬
- EABI
- 8 바이트 단위로 정렬
Enum 타입 사이즈
- OABI
- 4 바이트 단위
- EABI
- 가변으로 지정할 수 있음
인수 전달 시 레지스터 수
- OABI
- 4개 (r0~r3)
- EABI
- 7개(r0~r6)
차이점 예제
소프트 인터럽트 + 64bit 타입 인수 정렬
예) long sum64(unsigned int start, size_t size); syscall no=100
- arm/OABI
- r0에 start 대입
- r1과 r2에 size를 64비트로 대입
- swi #(0x900000 + 100)
- arm/EABI
- r0에 start 대입
- r2와 r3에 size를 64비트로 대입
- r7에 100 대입
- swi 0
툴체인(toolchain)
포맷: arch[-vendor][-os]-abi- arch
- 사용 아키텍처
- 예) arm, armeb, aarch64, aarch64_eb, mips, x86, i686…
- eb = be = Endian Big
- vendor
- 툴체인 공급자
- 예) gnu, apple, bcm2708, bcm2708hardfp, none(특정 벤더와 관련 없는)
- os
- 운영체제
- 예) linux, none(bare metal, 운영체제와 관련 없는)
- abi
- 지원하는 ABI(Application Binary Interface)
- 예) eabi, gnueabi, gbueabihf
Floating Point Unit
- FPU(Floationg Point Unit) 사용
- VFP (Coretex 시리즈 등)
- 여러 아키텍처가 FPU를 사용하지 않거나 서로 다른 FP instruction set을 사용한다.
- softfloat
- FP instruction을 만들지 않고 GCC가 컴파일타임에 라이브러리에서 함수로 준비
- hardfloat
- FP instruction을 에뮬레이션한다.
ARM Tool Chain
- arm-linux-gnueabi
- GNU에서 softfloat을 사용하는 armel 아키텍처를 위해 사용한다.
- FP(Floating Point)가 없는 arm 아키텍처에서 softfloat 방식을 사용한다.
- arm-linux-gnueabihf
- GNU에서 hard float을 사용하는 armhf 아키텍처를 위해 사용한다.
- 참고로 응용 프로그램을 컴파일 하여 구동하는 경우 hardfloat을 사용한 라이브러리도 같이 준비되어 있어야 한다.
- arm-bcm2708-linux-gnueabi
- armv7 아키텍처용 softfloat 방식 사용
- arm-bcm2708hardfp-linux-gnueabi
- armv7 아키텍처용 hardfloat 방식 사용
- 참고: linaro 툴체인을 사용하는 경우 gcc에 비해 조금 더 성능을 향상시키기 위한 변경을 가했다.
참고
- Linaro Toolchain Working Group | linaro.org
- ARM EABI port | wiki.debian.org
- Application Binary Interface for the ARM® Architecture | arm – pdf 다운로드
User virtual maps (mmap)
<kernel v5.0>
Memory Mapped 파일 & anon 매핑
현재 유저 주소 공간의 vm(가상 메모리)에 file(디바이스 포함) 또는 anon 매핑/해제를 요청한다. 다음과 같은 api를 사용한다.
- mmap()
- 현재 유저 주소 공간의 vm(가상 메모리)에 file 또는 anon 매핑을 요청한다.
- munmap()
- 현재 유저 주소 공간의 vm(가상 메모리)에 file 또는 anon 매핑 해제를 요청한다.
- mmap2()
- 가장 마지막 인자가 페이지 단위의 offset을 사용한다는 것만 제외하고 mmap()과 동일하다.
- mmap_pgoff()
- 가장 마지막 인자가 페이지 단위의 offset을 사용한다는 것만 제외하고 mmap()과 동일하다.
mmap() – for user application
#include <sys/mman.h> void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
파일 및 디바이스를 메모리에 매핑한다. anon 매핑 속성을 주어 anon 메모리를 매핑할 수도 있다.
mmap2() – for user application
#include <sys/mman.h> void *mmap2(void *addr, size_t length, int prot, int flags, int fd, off_t pgoffset);
mmap_pgoff() – for user application
#include <sys/mman.h> void *mmap_pgoff(void *addr, size_t length, int prot, int flags, int fd, unsigned long pgoffset);
인수
- addr
- 매핑을 원하는 시작 가상 주소 값으로 커널이 이를 hint로 이용하여 적절한 주소를 찾으려고 한다. null이 입력되는 경우 커널이 빈 공간을 찾는다.
- length
- 매핑할 길이(bytes)
- prot
- 메모리 보호 속성
- PROT_EXEC: 페이지는 실행 가능하다.
- PROT_READ: 페이지는 읽기 가능하다.
- PROT_WRITE: 페이지는 쓰기 가능하다.
- PROT_NONE: 페이지는 접근할 할 수 없다.
- 메모리 보호 속성
- flags
- 플래그
- fd
- 파일 디스크립터
- offset
- 바이트 offset
- pgoff
- 페이지 offset
- file 매핑하는 경우 skip 할 페이지 수를 사용한다.
요청 플래그
- MAP_FIXED
- 지정된 시작 가상 주소로 매핑한다. 지정된 주소를 사용할 수 없는 경우 mmap()은 실패한다.
- 가상 시작 주소 addr는 페이지 사이즈의 배수여야 한다.
- 요청 영역이 기존 매핑과 중복되는 경우 중복되는 영역의 기존 매핑은 제거된다.
- MAP_ANONYMOUS
- 어떠한 파일하고도 연결되지 않고 0으로 초기화된 영역.
- fd는 무시되지만 어떤 경우에는 -1이 요구된다.
- offset는 0으로 한다.
- MAP_SHARED와 같이 사용될 수도 있다. (커널 v2.4)
- MAP_FILE
- 파일 매핑
- MAP_SHARED
- 다른 프로세스와 영역에 대해 공유 매핑.
- MAP_PRIVATE
- private COW(Copy On Write) 매핑을 만든다. 이 영역은 다른 프로세스와 공유되지 않는다.
- MAP_DENYWRITE
- 쓰기 금지된 매핑 영역
- MAP_EXECUTABLE
- 실행 가능한 매핑 영역
- MAP_GROWSDOWN
- 하향으로 자라는 스택에 사용된다.
- MAP_HUGETLB (커널 v2.6.32)
- huge page들을 사용하여 할당하게 한다.
- MAP_HUGE_2MB, MAP_HUGE_1GB (커널 v3.8)
- MAP_HUGETLB와 같이 사용되며 huge page를 선택할 수 있다.
- “/sys/kernel/mm/hugepages” 디렉토리에 사용할 수 있는 huge page 종류를 볼 수 있다.
- MAP_LOCKED
- mlock()과 동일하게 요청 영역은 물리메모리가 미리 할당되어 매핑된다.
- mlock()과 다르게 물리메모리를 미리 할당하고 매핑할 때 실패하더라도 곧바로 -ENOMEM 에러를 발생시키지 않는다.
- MAP_NONBLOCK
- 오직 MAP_POPULATE와 같이 사용될 때에만 의미가 있다.
- MAP_NORESERVE
- 이 영역은 swap 공간을 준비하지 않는다.
- MAP_POPULATE
- 매핑에 대한 페이지 테이블을 활성화(prefault)한다.
- private 매핑에서만 사용된다. (커널 v2.6.23)
- MAP_STACK (커널 v2.6.27)
- 프로세스 또는 스레드 스택을 할당한다.
- MAP_UNINITIALIZED (커널 v2.6.33)
- anonymous 페이지들을 클리어하지 않는다.
Memory Mapped Mapping 사례
private anon 예)
- mmap((void *) 0x200000000000ULL, 4096 * 30, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
- 첫 번째 인수 addr에 보통 null을 사용한다. 결과 확인을 위해 쉽게 하기 위해 주소를 지정하였다.
- anon vma 영역이 만들어지지만 Rss 값이 0으로 보이는 것과 같이실제 메모리가 매핑된 상태는 아니다. 추후 메모리에 액세스할 때 fault가 발생하고 fault 핸들러에 의해 물리 메모리가 할당된 후 매핑된다. (lazy allocation)
200000000000-20000001e000 rw-p 00000000 00:00 0 Size: 120 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Rss: 0 kB Pss: 0 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 0 kB Referenced: 0 kB Anonymous: 0 kB LazyFree: 0 kB AnonHugePages: 0 kB ShmemPmdMapped: 0 kB Shared_Hugetlb: 0 kB Private_Hugetlb: 0 kB Swap: 0 kB SwapPss: 0 kB Locked: 0 kB THPeligible: 1 VmFlags: rd wr mr mw me ac
private file 예)
- mmap(NULL, 15275, PROT_READ, MAP_PRIVATE, fd, 0);
- fd는 abc.txt를 open한 file 디스크립터이다.
- file vma 영역이 만들어지지만 Rss 값이 0으로 보이는 것과 같이실제 메모리가 매핑된 상태는 아니다. 추후 메모리에 액세스할 때 fault가 발생하고 fault 핸들러에 의해 물리 메모리가 할당된 후 파일 내용이 읽히고 그 후 매핑된다. (lazy allocation)
ffffb2d14000-ffffb2d15000 r--p 00000000 fe:00 416016 /root/workspace/test/mmap/abc.txt Size: 4 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Rss: 0 kB Pss: 0 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 0 kB Referenced: 0 kB Anonymous: 0 kB LazyFree: 0 kB AnonHugePages: 0 kB ShmemPmdMapped: 0 kB Shared_Hugetlb: 0 kB Private_Hugetlb: 0 kB Swap: 0 kB SwapPss: 0 kB Locked: 0 kB THPeligible: 0 VmFlags: rd mr mw me
locked private file 예)
- mmap(NULL, 15275, PROT_READ, MAP_PRIVATE | MAP_LOCKED, fd, 0);
- MAP_LOCKED를 사용하여 파일의 내용을 실제 메모리에 모두 선(pre) 매핑하였다. Size 항목과 Rss 항목이 동일함을 알 수 있다.
ffffba677000-ffffba67b000 r--p 00000000 fe:00 416016 /root/workspace/test/mmap/abc.txt Size: 16 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Rss: 16 kB Pss: 16 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 16 kB Private_Dirty: 0 kB Referenced: 16 kB Anonymous: 0 kB LazyFree: 0 kB AnonHugePages: 0 kB ShmemPmdMapped: 0 kB Shared_Hugetlb: 0 kB Private_Hugetlb: 0 kB Swap: 0 kB SwapPss: 0 kB Locked: 16 kB THPeligible: 0 VmFlags: rd mr mw me lo
ARM32용 Memory Mapped 매핑
다음 그림은 mmap syscall 호출에 따른 커널에서의 함수 호출 관계를 보여준다.

sys_mmap2() – ARM32
arch/arm/kernel/entry-common.S
/* * Note: off_4k (r5) is always units of 4K. If we can't do the requested * offset, we return EINVAL. */
sys_mmap2:
streq r5, [sp, #4]
beq sys_mmap_pgoff
ENDPROC(sys_mmap2)
파일 및 디바이스를 메모리에 매핑한다. anon 매핑 속성을 주어 anon 메모리를 매핑할 수도 있다.
sys_mmap_pgoff() – Generic (ARM32, …)
mm/mmap.c
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
return ksys_mmap_pgoff(addr, len, prot, flags, fd, pgoff);
}
ARM64용 Memory Mapped 매핑
sys_mmap() – ARM64
arch/arm64/kernel/sys.c
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, off_t, off)
{
if (offset_in_page(off) != 0)
return -EINVAL;
return ksys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
}
sys_mmap_pgoff() – ARM64
arch/arm64/kernel/sys.c
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
return ksys_mmap_pgoff(addr, len, prot, flags, fd, pgoff);
}
공통부 – Memory Mapped 매핑
ksys_mmap_pgoff()
mm/mmap.c
unsigned long ksys_mmap_pgoff(unsigned long addr, unsigned long len,
unsigned long prot, unsigned long flags,
unsigned long fd, unsigned long pgoff)
{
struct file *file = NULL;
unsigned long retval;
if (!(flags & MAP_ANONYMOUS)) {
audit_mmap_fd(fd, flags);
file = fget(fd);
if (!file)
return -EBADF;
if (is_file_hugepages(file))
len = ALIGN(len, huge_page_size(hstate_file(file)));
retval = -EINVAL;
if (unlikely(flags & MAP_HUGETLB && !is_file_hugepages(file)))
goto out_fput;
} else if (flags & MAP_HUGETLB) {
struct user_struct *user = NULL;
struct hstate *hs;
hs = hstate_sizelog((flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
if (!hs)
return -EINVAL;
len = ALIGN(len, huge_page_size(hs));
/*
* VM_NORESERVE is used because the reservations will be
* taken when vm_ops->mmap() is called
* A dummy user value is used because we are not locking
* memory so no accounting is necessary
*/
file = hugetlb_file_setup(HUGETLB_ANON_FILE, len,
VM_NORESERVE,
&user, HUGETLB_ANONHUGE_INODE,
(flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
if (IS_ERR(file))
return PTR_ERR(file);
}
flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE);
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
out_fput:
if (file)
fput(file);
return retval;
}
file 디스크립터에서 pgoff 페이지 부터 요청 길이만큼 요청한 가상 주소에 prot 속성으로 매핑한다.
- 코드 라인 8~17에서 file 매핑인 경우 audit 설정하고, huge 페이지를 사용하는 파일인 경우 길이를 huge 페이지에 맞춰 정렬한다.
- 현재 태스크의 audit_context가 설정된 경우 audit_context에 요청 fd와 flags를 설정하고 타입으로 AUDIT_MMAP을 대입한다.
- file 디스크립터를 통해 file을 알아오는데 실패하는 경우 out 레이블을 통해 -EBADF 에러를 반환한다.
- hugetlbfs 또는 huge 페이지 매핑을 이용하는 공유 파일인 경우 길이를 huge 페이지 단위로 정렬한다.
- MAP_HUGETLB 플래그 요청을 하였지만 file이 huge 페이지 요청 타입이 아닌 경우 -EINVAL 에러를 반환한다.
- 코드 라인 18~39에서 MAP_HUGETLB 요청이 있는 경우 길이를 huge 페이지 단위로 정렬하여 HUGETLB_ANON_FILE 형태의 파일을 준비한다. 플래그에 기록된 huge 페이지 정보가 발견되지 않으면 -EINVAL 에러를 반환한다.
- 플래그의 bit26~bit31에 사이즈를 로그 단위로 변환하여 저장하였다.
- x86 예) 21 -> 2M huge page, 30 -> 1G huge page
- 플래그의 bit26~bit31에 사이즈를 로그 단위로 변환하여 저장하였다.
- 코드 라인 41~43에서 플래그에서 MAP_EXECUTABLE 및 MAP_DENYWRITE를 제외하고 매핑을 한다.
is_file_hugepages()
include/linux/hugetlb.h
static inline int is_file_hugepages(struct file *file)
{
if (file->f_op == &hugetlbfs_file_operations)
return 1;
if (is_file_shm_hugepages(file))
return 1;
return 0;
}
file이 hugetlbfs에서 사용하는 파일이거나 huge 페이지를 사용하는 공유 메모리 파일인 경우 1을 반환한다. 그 외에는 0을 반환한다.
Audit 관련 함수
audit_mmap_fd()
include/linux/audit.h
static inline void audit_mmap_fd(int fd, int flags)
{
if (unlikely(!audit_dummy_context()))
__audit_mmap_fd(fd, flags);
}
작은 확률로 현재 태스크의 audit_context가 설정된 경우 audit_context에 요청 fd와 flags를 설정하고 타입으로 AUDIT_MMAP을 대입한다.
audit_dummy_context()
include/linux/audit.h
static inline int audit_dummy_context(void)
{
void *p = current->audit_context;
return !p || *(int *)p;
}
현재 태스크의 audit_context가 설정된 경우 0을 반환하고, 설정되지 않은 경우 0이 아닌 값을 반환한다.
__audit_mmap_fd()
kernel/auditsc.c
void __audit_mmap_fd(int fd, int flags)
{
struct audit_context *context = current->audit_context;
context->mmap.fd = fd;
context->mmap.flags = flags;
context->type = AUDIT_MMAP;
}
현재 태스크의 audit_context에 요청 fd와 flags를 설정하고 타입으로 AUDIT_MMAP을 대입한다.
vm_mmap_pgoff()
mm/util.c
unsigned long vm_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long pgoff)
{
unsigned long ret;
struct mm_struct *mm = current->mm;
unsigned long populate;
LIST_HEAD(uf);
ret = security_mmap_file(file, prot, flag);
if (!ret) {
if (down_write_killable(&mm->mmap_sem))
return -EINTR;
ret = do_mmap_pgoff(file, addr, len, prot, flag, pgoff,
&populate, &uf);
up_write(&mm->mmap_sem);
userfaultfd_unmap_complete(mm, &uf);
if (populate)
mm_populate(ret, populate);
}
return ret;
}
@file을 @pgoff 페이지 부터 요청 길이만큼 가상 주소 @addr에 @prot 속성으로 매핑한다.
- 코드 라인 10에서 LSM 및 LIM을 통해 파일 매핑의 허가 여부를 알아온다. 0=성공
- LSM(Linux Security Module)과 LIM(Linux Integrity Module)의 hook api를 호출하여 한다.
- 코드 라인 10~15에서 mmap_sem write 세마포어 락을 사용하여 vm 매핑을 요청한다.
- 코드 라인 16에서 userfaultfd 언맵 완료를 지시한다.
- userfaultfd
- on demand paging을 사용하는 리눅스는 메모리 할당 요청 시 실제 매모리를 할당하지 않고, 유저 application이 해당 할당된 영역에 접근 시 fault가 발생 후 커널이 이에 대한 실제 메모리를 할당하여 매핑한다. 이러한 것을 유저 application에게 처리하도록 설계된 것이 userfaultfd이다.
- userfaultfd
- 코드 라인 17~18에서 매핑 영역을 활성화(물리 RAM을 매핑)한다.
do_mmap_pgoff()
mm/mmap.c
static inline unsigned long
do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot, unsigned long flags,
unsigned long pgoff, unsigned long *populate,
struct list_head *uf)
{
return do_mmap(file, addr, len, prot, flags, 0, pgoff, populate, uf);
}
do_mmap()
mm/mmap.c -1/3-
/* * The caller must hold down_write(¤t->mm->mmap_sem). */
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, vm_flags_t vm_flags,
unsigned long pgoff, unsigned long *populate,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
int pkey = 0;
*populate = 0;
if (!len)
return -EINVAL;
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && path_noexec(&file->f_path)))
prot |= PROT_EXEC;
/* force arch specific MAP_FIXED handling in get_unmapped_area */
if (flags & MAP_FIXED_NOREPLACE)
flags |= MAP_FIXED;
if (!(flags & MAP_FIXED))
addr = round_hint_to_min(addr);
/* Careful about overflows.. */
len = PAGE_ALIGN(len);
if (!len)
return -ENOMEM;
/* offset overflow? */
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
/* Too many mappings? */
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (offset_in_page(addr))
return addr;
if (flags & MAP_FIXED_NOREPLACE) {
struct vm_area_struct *vma = find_vma(mm, addr);
if (vma && vma->vm_start < addr + len)
return -EEXIST;
}
if (prot == PROT_EXEC) {
pkey = execute_only_pkey(mm);
if (pkey < 0)
pkey = 0;
}
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
vm_flags |= calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
if (flags & MAP_LOCKED)
if (!can_do_mlock())
return -EPERM;
if (mlock_future_check(mm, vm_flags, len))
return -EAGAIN;
file을 pgoff 페이지 부터 요청 길이만큼 가상 주소 addr에 prot 속성으로 매핑한다. 실제 메모리가 매핑된 경우 출력 인수 populate에 길이를 대입한다.
- 코드 라인 12~13에서 길이가 0인 경우 -EINVAL 에러를 반환한다.
- 코드 라인 21~23에서 read 속성이 요청되는 경우 현재 태스크의 personality에 READ_IMPLIES_EXEC가 설정된 경우 exec 속성을 추가한다. 단 sysfs 및 proc 마운트 위의 file과 같이 마운트 플래그가 MNT_NOEXEC 설정이 있는경우는 제외한다.
- 코드 라인 26~27에서
- 코드 라인 29~30에서 고정 매핑을 요청한 경우가 아니면 페이지 정렬한 주소를 사용하되 mmap_min_addr 보다 작은 경우 mmap_min_addr 주소로 변경한다.
- 코드 라인 33~35에서 길이를 페이지 단위로 정렬한다. 단 0인 경우 -ENOMEM 에러를 반환한다.
- 코드 라인 38~39에서 pgoff 페이지+ len 페이지가 시스템 주소 범위를 초과하는 경우 -EOVERFLOW 에러를 반환한다.
- 코드 라인 42~43에서 현재 태스크의 메모리 디스크립터에 매핑된 수가 최대치 허용을 초과한 경우 -ENOMEM 에러를 반환한다.
- 기본 매핑 최대치: 65530 (“/proc/sys/vm/max_map_count”에서 설정)
- 코드 라인 48~50에서 매핑되지 않은 영역을 찾아 시작 가상 주소를 알아온다. 만일 에러인 경우 에러 코드를 반환한다.
- 코드 라인 52~57에서 MAP_FIXED_NOREPLACE 플래그 요청이 있는 경우 해당 주소에 대해 vma에 영역이 없는 경우에만 매핑할 수 있다. 따라서 이미 존재하는 경우 -EEXIST 에러를 반환한다.
- 코드 라인 59~63에서 실행 속성이 있는 경우 Protection Key를 확인한다.
- x86 및 powerpc 아키텍처에서만 지원하고 아직 ARM, ARM64에서는 사용되지 않고 있다.
- 코드 라인 69~70에서 vm_flags에 vm 플래그로 변환한 prot 플래그, vm 플래그로 변환한 flags, 메모리 디스크립터의 기본 플래그에 mayread, maywrite, mayexec를 추가한다.
- 코드 라인 72~74에서 MAP_LOCKED 플래그 요청이 있는 경우 mlock 최대치 제한 등으로 인해 수행할 수 없으면 -EPERM 에러를 반환한다.
- 코드 라인 76~77에서 VM_LOCKED 요청이 있고 기존 mlock 페이지에 요청 길이를 추가하여 mlock 페이지 최대치 제한에 걸리는 경우 -EAGAIN 에러를 반환한다.
mm/mmap.c -2/3-
if (file) {
struct inode *inode = file_inode(file);
unsigned long flags_mask;
if (!file_mmap_ok(file, inode, pgoff, len))
return -EOVERFLOW;
flags_mask = LEGACY_MAP_MASK | file->f_op->mmap_supported_flags;
switch (flags & MAP_TYPE) {
case MAP_SHARED:
/*
* Force use of MAP_SHARED_VALIDATE with non-legacy
* flags. E.g. MAP_SYNC is dangerous to use with
* MAP_SHARED as you don't know which consistency model
* you will get. We silently ignore unsupported flags
* with MAP_SHARED to preserve backward compatibility.
*/
flags &= LEGACY_MAP_MASK;
/* fall through */
case MAP_SHARED_VALIDATE:
if (flags & ~flags_mask)
return -EOPNOTSUPP;
if ((prot&PROT_WRITE) && !(file->f_mode&FMODE_WRITE))
return -EACCES;
/*
* Make sure we don't allow writing to an append-only
* file..
*/
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
/*
* Make sure there are no mandatory locks on the file.
*/
if (locks_verify_locked(file))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
if (path_noexec(&file->f_path)) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op->mmap)
return -ENODEV;
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
break;
default:
return -EINVAL;
}
- 코드 라인 1~8에서 file 매핑인 경우 inode 값을 가져온다.
- 코드 라인 10~42에서 공유 파일 매핑(MAP_SHARED) 플래그 요청인 경우 다음과 같이 처리한다.
- write 속성이 없는 파일에 write 요청을 한 경우 -EACCESS 에러를 반환한다.
- append only 파일인 경우 write 요청을 한 경우 -EACCESS 에러를 반환한다.
- mandatory 락이 걸려있는 파일인 경우 -EAGAIN 에러를 반환한다.
- vm_flags에 share 및 mayshare 속성을 추가한다.
- write 속성이 없는 파일인 경우 maywrite와 shared를 제거한다. 아래 private 요청을 계속 진행한다.
- 코드 라인 45~58에서 private 파일 매핑(MAP_PRIVATE) 플래그 요청인 경우 다음과 같이 처리한다.
- read 속성이 없는 파일인 경우 -EACCESS 에러를 반환한다.
- file이 마운트 곳의 마운트 플래그에 실행 금지가 설정된 경우 mayexec를 제거한다. 단 VM_EXEC 요청이 있는 경우에는 -EPERM 에러를 반환한다.
- “/proc 및 /sys”가 마운트 되어 있는 곳은 실행 파일이 있을 수 없다.
- 매핑이 없는 파일은 -ENODEV 에러를 반환한다.
- growsdown 및 growsup 요청된 경우 -EINVAL 에러를 반환한다.
mm/mmap.c -3/3-
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
/*
* Ignore pgoff.
*/
pgoff = 0;
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
if (flags & MAP_NORESERVE) {
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE;
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
addr = mmap_region(file, addr, len, vm_flags, pgoff, uf);
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}
- 코드 라인 1~21에서 anon 매핑인 경우 다음 두 가지 요청을 수행한다.
- shared anon 매핑인 경우 pgoff=0, shared 및 maysahre 플래그를 추가한다. 단 growsdown 및 growsup 요청된 경우 -EINVAL 에러를 반환한다.
- private anon 매핑인 경우 pgoff에 가상 주소 페이지 번호를 대입한다.
- 코드 라인 27~35에서 no reserve 요청인 경우 over commit 모드가 OVERCOMMIT_NEVER가 아닌 경우 또는 또한 huge page 파일인 경우 vm_noreserve 플래그를 추가한다.
- 코드 라인 37에서 file을 pgoff 페이지 부터 가상 주소 addr에 길이 len 만큼 vm_flags 속성을 사용하여 vma를 구성하고 등록한다.
- 코드 라인 38~41에서 실제 메모리가 매핑된 경우 출력 인수 populate에 길이를 대입한다.
round_hint_to_min()
mm/mmap.c
/* * If a hint addr is less than mmap_min_addr change hint to be as * low as possible but still greater than mmap_min_addr */
static inline unsigned long round_hint_to_min(unsigned long hint)
{
hint &= PAGE_MASK;
if (((void *)hint != NULL) &&
(hint < mmap_min_addr))
return PAGE_ALIGN(mmap_min_addr);
return hint;
}
가상 주소 hint를 페이지 단위로 절삭하고 반환한다. 단 그 주소가 mmap_min_addr 보다 낮은 경우 페이지 단위로 정렬한 mmap_min_addr 주소를 반환한다.
calc_vm_prot_bits()
include/linux/mman.h
/* * Combine the mmap "prot" argument into "vm_flags" used internally. */
static inline unsigned long
calc_vm_prot_bits(unsigned long prot)
{
return _calc_vm_trans(prot, PROT_READ, VM_READ ) |
_calc_vm_trans(prot, PROT_WRITE, VM_WRITE) |
_calc_vm_trans(prot, PROT_EXEC, VM_EXEC) |
arch_calc_vm_prot_bits(prot);
}
prot 값에 PROT_READ, PROT_WRITE, PROT_EXEC 비트가 있는 경우 각각 VM_READ, VM_WRITE, VM_EXEC 플래그 속성으로 변환하여 반환한다.
- 특정 아키텍처에 맞게 속성을 추가할 수 있다. (arm은 추가 없음)
_calc_vm_trans()
include/linux/mman.h
/*
* Optimisation macro. It is equivalent to:
* (x & bit1) ? bit2 : 0
* but this version is faster.
* ("bit1" and "bit2" must be single bits)
*/
#define _calc_vm_trans(x, bit1, bit2) \ ((!(bit1) || !(bit2)) ? 0 : \ ((bit1) <= (bit2) ? ((x) & (bit1)) * ((bit2) / (bit1)) \ : ((x) & (bit1)) / ((bit1) / (bit2))))
x 플래그에서 bi1 속성이 있는 경우 bit 속성으로 변환하여 반환한다. 없는 경우 0을 반환한다.
calc_vm_flag_bits()
include/linux/mman.h
/* * Combine the mmap "flags" argument into "vm_flags" used internally. */
static inline unsigned long
calc_vm_flag_bits(unsigned long flags)
{
return _calc_vm_trans(flags, MAP_GROWSDOWN, VM_GROWSDOWN ) |
_calc_vm_trans(flags, MAP_DENYWRITE, VM_DENYWRITE ) |
_calc_vm_trans(flags, MAP_LOCKED, VM_LOCKED ) |
_calc_vm_trans(flags, MAP_SYNC, VM_SYNC );
}
flags 값에 MAP_GROWSDOWN, MAP_DENYWRITE, MAP_LOCKED, MAP_SYNC 비트가 있는 경우 각각 VM_GROWSDOWN, VM_DENYWRITE, VM_LOCKED, VM_SYNC 플래그 속성으로 변환하여 반환한다.
VMA 영역 구성(확장/병합/신규)
mmap_region()
mm/mmap.c -1/3-
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
/* Check against address space limit. */
if (!may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)) {
unsigned long nr_pages;
/*
* MAP_FIXED may remove pages of mappings that intersects with
* requested mapping. Account for the pages it would unmap.
*/
nr_pages = count_vma_pages_range(mm, addr, addr + len);
if (!may_expand_vm(mm, vm_flags,
(len >> PAGE_SHIFT) - nr_pages))
return -ENOMEM;
}
/* Clear old maps */
while (find_vma_links(mm, addr, addr + len, &prev, &rb_link,
&rb_parent)) {
if (do_munmap(mm, addr, len, uf))
return -ENOMEM;
}
/*
* Private writable mapping: check memory availability
*/
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
if (security_vm_enough_memory_mm(mm, charged))
return -ENOMEM;
vm_flags |= VM_ACCOUNT;
}
/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = vm_area_alloc(mm);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
file을 pgoff 페이지 부터 요청 길이만큼 가상 주소 addr에 prot 속성으로 vma를 구성하고 등록한다. 기존 vma 영역을 확장하거나 병합할 수 있고, 없으면 신규로 생성한다.
- 코드 라인 12 ~24에서 len 페이지 만큼의 공간을 확장할 수 없는 경우 fix 매핑 여부에 따라 다음과 같이 처리한다.
- fix 매핑이 아닌 경우 -ENOMEM 에러를 반환한다.
- fix 매핑인 경우 겹치는 영역만큼은 뺴고 매핑할 계획이다. 기존 영역과 겹치지 않는 페이지 만큼이 확장 가능하지 않으면 -ENOMEM 에러를 반환환다.
- 코드 라인 27~31에서 요청 영역과 겹치는 기존 영역들을 언매핑한다.
- 코드 라인 36~41에서 vm 메모리 계량이 필요한 매핑인 경우 LSM을 통해 charged 페이지 만큼 vm 메모리 할당으로 commit하고 허용된 경우 VM_ACCOUNT 플래그를 추가한다.
- accountable 매핑 확인(private writable 매핑)
- huge 파일 매핑이 아니고 noreserve 및 shared가 없고 write 요청은 있는 경우이다.
- LSM 모듈에서 SELinux 모듈을 사용 여부에 따라 selinux_vm_enough_memory() 함수를 먼저 호출하여 admin 권한만큼의 추가 영역을 확보한 후 __vm_enough_memory() 함수를 호출하여 commit 량에 대해 commit 옵션에 따라 vm 허용치 제한을 통해 할당 여부를 반환한다.
- LSM 모듈에서 기본 Posix Capability 모듈만을 사용하는 경우 cap_vm_enough_memory() 함수를 먼저 호출하여 admin권한만큼의 추가 영역을 확보한 후 __vm_enough_memory() 함수를 호출하여 commit 량에 대해 commit 옵션에 따라 vm 허용치 제한을 통해 할당 여부를 반환한다.
- accountable 매핑 확인(private writable 매핑)
- 코드 라인 46~49에서 기존 영역과 병합하고, 성공한 경우 out 레이블로 이동한다.
- 코드 라인 56~66에서 새로운 vma(vm_area_struct 구조체)를 할당하고 구성한다.
mm/mmap.c -2/3-
. if (file) {
if (vm_flags & VM_DENYWRITE) {
error = deny_write_access(file);
if (error)
goto free_vma;
}
if (vm_flags & VM_SHARED) {
error = mapping_map_writable(file->f_mapping);
if (error)
goto allow_write_and_free_vma;
}
/* ->mmap() can change vma->vm_file, but must guarantee that
* vma_link() below can deny write-access if VM_DENYWRITE is set
* and map writably if VM_SHARED is set. This usually means the
* new file must not have been exposed to user-space, yet.
*/
vma->vm_file = get_file(file);
error = call_mmap(file, vma);
if (error)
goto unmap_and_free_vma;
/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
* Bug: If addr is changed, prev, rb_link, rb_parent should
* be updated for vma_link()
*/
WARN_ON_ONCE(addr != vma->vm_start);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
error = shmem_zero_setup(vma);
if (error)
goto free_vma;
} else {
vma_set_anonymous(vma);
}
vma_link(mm, vma, prev, rb_link, rb_parent);
/* Once vma denies write, undo our temporary denial count */
if (file) {
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
}
file = vma->vm_file;
- 코드 라인 1~33에서 file 매핑인 경우 다음과 같이 처리한다.
- denywrite 요청이 있는 경우 file을 denywrite 상태로 만든다. 실패하는 경우 free_vma 레이블로 이동한다.
- shared 요청이 있는 경우 매핑 영역에 대해 다음 writable 파일 매핑 요청이 거절되게 설정한다. 실패하는 경우 allow_write_and_free_vma 레이블로 이동한다.
- file의 사용 카운터 f_count를 증가시키고 file을 vma_vm_file에 대입한다.
- vma 정보로 file 매핑을 수행한다. 실패하는 경우 unmap_and_free_vma 레이블로 이동한다.
- 코드 라인 34~37에서 shared anon 매핑을 준비한다. 실패하는 경우 free_vma 레이블로 이동한다.
- “/dev/zero” 파일을 vma->vm_file에 지정하고 vma->vm_ops에 전역 shmem_vm_ops를 대입한다.
- 코드 라인 38~40에서 private anon 매핑을 준비한다.
- 코드 라인 42에서 vma 정보를 추가한다.
- 코드 라인 44~49에서 파일 매핑인 경우 다음과 같이 처리한다.
- shared file 매핑인 경우 매핑 영역에 대해 writable 매핑이 가능하게 바꾼다.
- 그리고 denywrite 요청을 가진 file 매핑인 경우 file에 대해 writable 매핑이 가능하도록 설정한다.
mm/mmap.c -3/3-
out:
perf_event_mmap(vma);
vm_stat_account(mm, vm_flags, len >> PAGE_SHIFT);
if (vm_flags & VM_LOCKED) {
if ((vm_flags & VM_SPECIAL) || vma_is_dax(vma) ||
is_vm_hugetlb_page(vma) ||
vma == get_gate_vma(current->mm))
vma->vm_flags &= VM_LOCKED_CLEAR_MASK;
else
mm->locked_vm += (len >> PAGE_SHIFT);
}
if (file)
uprobe_mmap(vma);
/*
* New (or expanded) vma always get soft dirty status.
* Otherwise user-space soft-dirty page tracker won't
* be able to distinguish situation when vma area unmapped,
* then new mapped in-place (which must be aimed as
* a completely new data area).
*/
vma->vm_flags |= VM_SOFTDIRTY;
vma_set_page_prot(vma);
return addr;
unmap_and_free_vma:
vma->vm_file = NULL;
fput(file);
/* Undo any partial mapping done by a device driver. */
unmap_region(mm, vma, prev, vma->vm_start, vma->vm_end);
charged = 0;
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
allow_write_and_free_vma:
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
free_vma:
vm_area_free(vma);
unacct_error:
if (charged)
vm_unacct_memory(charged);
return error;
}
- 코드 라인 1~2에서 out: 레이블이다. mmap에 대한 performance events 정보를 출력한다.
- 코드 라인 4에서 메모리 디스크립터에 대해 가상 메모리에 대한 몇 개의 vm stat 카운터를 len 페이지만큼 추가한다.
- 코드 라인 5~12에서 mlock(VM_LOCKED) 요청인 경우 VM_SPECIAL, hugetlb 페이지 또는 gate vma 요청인 경우 VM_LOCKED 플래그를 삭제한다. 그렇지 않은 경우 mm->locked_vm에 len 페이지를 추가한다.
- 코드 라인 14~15에서 file 매핑인 경우 uprobe가 설정되어 있고 uprobe filter 체인이 걸려있는 경우 는 요청 주소에 break point 명령 코드로 업데이트한다.
- 코드 라인 24~28에서 softdirty 플래그를 추가하고 vma에 기록하고 정상적으로 가상 주소를 반환한다.
- 코드 라인 30~38에서 unmap_and_free_vma: 레이블이다. 여기에서는 매핑을 해제하는 루틴이 수행된다.
- 코드 라인 39~41에서 allow_write_and_free_vma: 레이블은 denywrite 요청이 있는 경우 inode의 i_writecount를 증가 시킨다.
- 코드 라인 42~43에서 free_vma: 레이블은 vma object를 할당 해제 한다.
- 코드 라인 44~47에서 unacct_error: 레이블은 vm 계량을 했었던(Private writable 매핑) 경우 commit 양을 되돌리기 위해 charged 만큼 다시 감소시킨다.
count_vma_pages_range()
mm/mmap.c
static unsigned long count_vma_pages_range(struct mm_struct *mm,
unsigned long addr, unsigned long end)
{
unsigned long nr_pages = 0;
struct vm_area_struct *vma;
/* Find first overlaping mapping */
vma = find_vma_intersection(mm, addr, end);
if (!vma)
return 0;
nr_pages = (min(end, vma->vm_end) -
max(addr, vma->vm_start)) >> PAGE_SHIFT;
/* Iterate over the rest of the overlaps */
for (vma = vma->vm_next; vma; vma = vma->vm_next) {
unsigned long overlap_len;
if (vma->vm_start > end)
break;
overlap_len = min(end, vma->vm_end) - vma->vm_start;
nr_pages += overlap_len >> PAGE_SHIFT;
}
return nr_pages;
}
요청 영역과 기존 vma 영역과 겹치는 페이지 수를 반환한다. 겹치는 영역이 없으면 0을 반환한다.
- 코드 라인 8~10에서 기존 vma 영역과 요청 영역이 겹치는 경우 관련 vma를 알아온다. 겹치는 영역이 없는 경우 0을 반환한다.
- 코드 라인 12~13에서 현재 vma에서 겹치는 페이지 수를 산출한다.
- 코드 라인 16~26에서 다음 vma 영역들과도 비교하여 겹치는 페이지 수를 산출한 후 반환한다.
accountable_mapping()
mm/mmap.c
/* * We account for memory if it's a private writeable mapping, * not hugepages and VM_NORESERVE wasn't set. */
static inline int accountable_mapping(struct file *file, vm_flags_t vm_flags)
{
/*
* hugetlb has its own accounting separate from the core VM
* VM_HUGETLB may not be set yet so we cannot check for that flag.
*/
if (file && is_file_hugepages(file))
return 0;
return (vm_flags & (VM_NORESERVE | VM_SHARED | VM_WRITE)) == VM_WRITE;
}
vm 메모리 계량이 필요한 매핑인지 확인한다.
- accountable 매핑 확인(private writable 매핑)
- huge 파일 매핑이 아니고 noreserve 및 shared가 없고 write 요청은 있는 경우이다.
writable 파일 매핑(1)
inode->i_writecount 값 상태
- 0(writable)
- write 권한이 허용되지 않은 상태로 새로운 writable 권한 요청이 가능한 상태
- 1(write)
- write 권한이 허용된 상태로 새로운 write 권한 요청은 금지된 상태
- 음수(denywrite)
- denywrite 요청에 의해 모든 write 권한 요청이 금지된 상태
get_write_access()
include/linux/fs.h
/*
* get_write_access() gets write permission for a file.
* put_write_access() releases this write permission.
* This is used for regular files.
* We cannot support write (and maybe mmap read-write shared) accesses and
* MAP_DENYWRITE mmappings simultaneously. The i_writecount field of an inode
* can have the following values:
* 0: no writers, no VM_DENYWRITE mappings
* < 0: (-i_writecount) vm_area_structs with VM_DENYWRITE set exist
* > 0: (i_writecount) users are writing to the file.
*
* Normally we operate on that counter with atomic_{inc,dec} and it's safe
* except for the cases where we don't hold i_writecount yet. Then we need to
* use {get,deny}_write_access() - these functions check the sign and refuse
* to do the change if sign is wrong.
*/
static inline int get_write_access(struct inode *inode)
{
return atomic_inc_unless_negative(&inode->i_writecount) ? 0 : -ETXTBSY;
}
inode에 대해 write 권한을 요청한다. 성공하면 0을 반환하고, 실패하는 경우 -ETXTBSY 에러를 반환한다.
- inode->i_writecount를 음수(-)가 아닌한 증가시킨다. 성공한 경우 0을 반환하고 , 이미 음수(-)여서 증가가 불가능한 경우 -ETXTBSY 에러를 반환한다.
put_write_access()
include/linux/fs.h
static inline void put_write_access(struct inode * inode)
{
atomic_dec(&inode->i_writecount);
}
inode에 대해 write 권한을 제거한다.
- inode->i_writecount를 감소시킨다.
deny_write_access()
include/linux/fs.h
static inline int deny_write_access(struct file *file)
{
struct inode *inode = file_inode(file);
return atomic_dec_unless_positive(&inode->i_writecount) ? 0 : -ETXTBSY;
}
요청 file을 denywrite 상태로 만들어 writable 매핑을 만들 수 없게 금지한다. 성공한 경우 0을 반환하고 그렇지 않은 경우 -ETXTBSY 에러를 반환한다.
- 요청 file의 inode->i_writecount를 양수(+)가 아닌한 감소시킨다. 성공한 경우 0을 반환하고 이미 양수(+)여서 감소가 불가능한 경우 -ETXTBSY 에러를 반환한다.
allow_write_access()
include/linux/fs.h
static inline void allow_write_access(struct file *file)
{
if (file)
atomic_inc(&file_inode(file)->i_writecount);
}
요청 파일에 대해 denywrite를 제거하여 새로운 writable 매핑을 허용할 수 있는 상태로 변경한다.
- 요청 file의 inode->i_writecount를 증가시킨다.
writable 파일 매핑(2)
mapping->i_mapwritable 값 상태 (VM_SHARED 카운터)
- 0(writable)
- 공유 write 매핑되어 있지 않은 상태로 새로운 writable 매핑 요청이 가능한 상태
- 양수(write)
- 공유 write 매핑되어 있는 상태로 새로운 write 매핑 요청은 금지된 상태
- 음수(denywrite)
- 공유 denywrite 요청에 의해 모든 write 매핑이 금지된 상태이다.
mapping_map_writable()
include/linux/fs.h
static inline int mapping_map_writable(struct address_space *mapping)
{
return atomic_inc_unless_negative(&mapping->i_mmap_writable) ?
0 : -EPERM;
}
매핑 영역을 writable 공유 매핑 상태로 요청한다. 성공하면 0을 반환하고, 실패하는 경우 -EPERM을 반환한다.
- mapping->i_mmapwritable을 음수(-)가 아닌한 증가시킨다. 성공한 경우 0을 반환하고 , 이미 음수(-)여서 증가가 불가능한 경우 -EPERM 에러를 반환한다.
mapping_unmap_writable()
include/linux/fs.h
static inline void mapping_unmap_writable(struct address_space *mapping)
{
atomic_dec(&mapping->i_mmap_writable);
}
writable 공유 매핑 영역을 언맵 요청하여 writable 상태로 변경한다. 다시 새로운 writable 매핑 요청을 받을 수 있는 상태이다.
- mapping->i_mmap_writable을 감소시킨다.
mapping_deny_writable()
include/linux/fs.h
static inline int mapping_deny_writable(struct address_space *mapping)
{
return atomic_dec_unless_positive(&mapping->i_mmap_writable) ?
0 : -EBUSY;
}
요청 매핑 영역에 대해 denywritable 상태로 변경하여 writable 매핑을 만들 수 없게 금지한다. 성공하면 0을 반환하고, 실패하는 경우 -EBUSY를 반환한다.
- mapping->i_writecount를 양수(+)가 아닌한 감소시킨다. 성공한 경우 0을 반환하고 , 이미 양수(+)여서 감소가 불가능한 경우 -EPERM 에러를 반환한다.
mapping_allow_writable()
include/linux/fs.h
static inline void mapping_allow_writable(struct address_space *mapping)
{
atomic_inc(&mapping->i_mmap_writable);
}
요청 매핑 영역에 대해 denywrite를 제거하여 새로운 writable 매핑을 받을 수 있는 상태로 변경한다.
vm_stat_account()
mm/mmap.c
void vm_stat_account(struct mm_struct *mm, vm_flags_t flags, long npages)
{
mm->total_vm += npages;
if (is_exec_mapping(flags))
mm->exec_vm += npages;
else if (is_stack_mapping(flags))
mm->stack_vm += npages;
else if (is_data_mapping(flags))
mm->data_vm += npages;
}
매핑 용도에 맞게 각각의 vm stat에 대해 pages 만큼 추가한다.
- 코드 라인 3에서 mm->total_vm 카운터에 페이지 수를 추가한다.
- 코드 라인 5~6에서 실행 코드인 경우 mm->exec_vm 카운터에 페이지 수를 추가한다.
- 코드 라인 7~8에서 stack 매핑인 경우 mm->stack_vm 카운터에 페이지 수를 추가한다.
- 코드 라인 9~10에서 데이터 매핑인 경우 mm->data_vm 카운터에 페이지 수를 추가한다.
VMA용 페이지 테이블 매핑 속성 지정
vma_set_page_prot()
mm/mmap.c
/* Update vma->vm_page_prot to reflect vma->vm_flags. */
void vma_set_page_prot(struct vm_area_struct *vma)
{
unsigned long vm_flags = vma->vm_flags;
vma->vm_page_prot = vm_pgprot_modify(vma->vm_page_prot, vm_flags);
if (vma_wants_writenotify(vma)) {
vm_flags &= ~VM_SHARED;
vm_page_prot = vm_pgprot_modify(vma->vm_page_prot, vm_flags);
}
/* remove_protection_ptes reads vma->vm_page_prot without mmap_sem */
WRITE_ONCE(vma->vm_page_prot, vm_page_prot);
}
vma->vm_flags에 맞는 메모리 속성 값으로 vma->vm_page_prot 속성 값을 업데이트한다.
- 요청 vma 영역의 vm_page_prot 속성에 대해 아키텍처에 커스트마이즈된 캐시 변환이 필요한 경우 변환된 vm_flags 값을 저장한다. 매칭되지 않으면 그냥 vm_flags 속성을 저장한다.
- vma가 write notify를 사용하고자 하는 경우 shared 플래그를 제거한다.
- vma 영역이 shared 매핑이고 페이지들이 read only 설정이된 경우 write 이벤트를 트래킹하고자 할 때 true를 반환한다.
vm_pgprot_modify()
mm/mmap.c
static pgprot_t vm_pgprot_modify(pgprot_t oldprot, unsigned long vm_flags)
{
return pgprot_modify(oldprot, vm_get_page_prot(vm_flags));
}
oldprot에 해당하는 아키텍처별로 미리 정의된 프로토콜 변환이 있으면 변환하여 속성을 반환한다.
- arm에서는 요청하는 oldprot 속성이 noncache, writecombine, device가 있는 경우 각각 noncache, buffer, noncache 형태로 변환한다. 매칭되지 않는 속성은 newprot 속성을 변환없이 그대로 반환한다.
pgprot_modify()
include/asm-generic/pgtable.h
static inline pgprot_t pgprot_modify(pgprot_t oldprot, pgprot_t newprot)
{
if (pgprot_val(oldprot) == pgprot_val(pgprot_noncached(oldprot)))
newprot = pgprot_noncached(newprot);
if (pgprot_val(oldprot) == pgprot_val(pgprot_writecombine(oldprot)))
newprot = pgprot_writecombine(newprot);
if (pgprot_val(oldprot) == pgprot_val(pgprot_device(oldprot)))
newprot = pgprot_device(newprot);
return newprot;
}
아키텍처에서 매핑 시 old 마스크사용하는 odl 캐시 속성을 new 캐시 속성에 맞게 변환한다.
- arm: no cache 또는 buffer
ARM32 매핑 속성
arch/arm/include/asm/pgtable.h
#define __pgprot_modify(prot,mask,bits) \
__pgprot((pgprot_val(prot) & ~(mask)) | (bits))
#define pgprot_noncached(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_UNCACHED)
#define pgprot_writecombine(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_BUFFERABLE)
#define pgprot_stronglyordered(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_UNCACHED)
#ifdef CONFIG_ARM_DMA_MEM_BUFFERABLE
#define pgprot_dmacoherent(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_BUFFERABLE | L_PTE_XN)
#else
#define pgprot_dmacoherent(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_UNCACHED | L_PTE_XN)
#endif
arm 아키텍처에서 매핑 시 사용하는 캐시 속성을 선택한다. (uncached 또는 buffrable)
- noncache -> no cache 속성 사용
- writecombine -> buffer 속성 사용
- stronglyordered -> no cache 속성 사용
- dmacoherennt -> CONFIG_ARM_DMA_MEM_BUFFERABLE 커널 옵션에 따라 buffer 또는 no cache 사용
- armv6 또는 armv7에서 dma가 buffer 사용 가능하다.
ARM64 매핑 속성
arch/arm64/include/asm/pgtable.h
/* * Mark the prot value as uncacheable and unbufferable. */
#define pgprot_noncached(prot) \
__pgprot_modify(prot, PTE_ATTRINDX_MASK, PTE_ATTRINDX(MT_DEVICE_nGnRnE) | PTE_PXN | PTE_UXN)
#define pgprot_writecombine(prot) \
__pgprot_modify(prot, PTE_ATTRINDX_MASK, PTE_ATTRINDX(MT_NORMAL_NC) | PTE_PXN | PTE_UXN)
#define pgprot_device(prot) \
__pgprot_modify(prot, PTE_ATTRINDX_MASK, PTE_ATTRINDX(MT_DEVICE_nGnRE) | PTE_PXN | PTE_UXN)
#define __HAVE_PHYS_MEM_ACCESS_PROT
arm64 아키텍처에서 매핑 시 사용하는 캐시 속성을 선택한다. (uncached 또는 buffrable)
- noncache -> nGnRnE 속성 사용
- writecombine -> no cache 속성 사용
- device -> nGnRE 속성 사용
vma_wants_writenotify()
mm/mmap.c
/* * Some shared mappigns will want the pages marked read-only * to track write events. If so, we'll downgrade vm_page_prot * to the private version (using protection_map[] without the * VM_SHARED bit). */
int vma_wants_writenotify(struct vm_area_struct *vma)
{
vm_flags_t vm_flags = vma->vm_flags;
/* If it was private or non-writable, the write bit is already clear */
if ((vm_flags & (VM_WRITE|VM_SHARED)) != ((VM_WRITE|VM_SHARED)))
return 0;
/* The backer wishes to know when pages are first written to? */
if (vma->vm_ops && vma->vm_ops->page_mkwrite || vm_ops->pfn_mkwrite))
return 1;
/* The open routine did something to the protections that pgprot_modify
* won't preserve? */
if (pgprot_val(vma->vm_page_prot) !=
pgprot_val(vm_pgprot_modify(vma->vm_page_prot, vm_flags)))
return 0;
/* Do we need to track softdirty? */
if (IS_ENABLED(CONFIG_MEM_SOFT_DIRTY) && !(vm_flags & VM_SOFTDIRTY))
return 1;
/* Specialty mapping? */
if (vm_flags & VM_PFNMAP)
return 0;
/* Can the mapping track the dirty pages? */
return vma->vm_file && vma->vm_file->f_mapping &&
mapping_cap_account_dirty(vma->vm_file->f_mapping);
}
vma 영역이 shared 매핑이고 페이지들이 read only 설정이된 경우 write 이벤트를 트래킹하고자 할 때 true를 반환한다.
- 코드 라인 6~7에서 write 및 shared 요청이 없는 vma의 경우 false(0)를 반환한다.
- 코드 라인 10~11에서 vm_ops->mkwrite 콜백 함수가 지정된 경우 true(1)를 반환한다.
- 코드 라인 15~17에서 vm_page_prot 속성에 변화를 줄 필요가 없는 경우 false(0)를 반환한다.
- 코드 라인 20~21에서 CONFIG_MEM_SOFT_DIRTY 커널 옵션을 사용하면서 soft dirty 기능을 요청하지 않은 경우 true(1)를 반환한다.
- 코드 라인 24~25에서 pfnmap 매핑을 요청한 경우 false(0)을 반환한다.
- 코드 라인 28~29에서 file 매핑이면서 bdi 에 dirty capable 설정된 경우 true(1)를 반환한다. 그렇지 않으면 flase(0)을 반환한다.
참고
- User virtual maps (brk) | 문c
- Understanding glibc malloc | sploitfun
LIM(Linux Integrity Module) -1-
LIM (Linux Integrity Module) -1-
다양한 공격으로부터 보호받아 신뢰할 수 있는 시스템을 구동하기 위해 사용되는 모듈이다.
- Remote Attacks
- trojan 같은 공격자의 악의적인 코드를 사용자가 구동시키게 하거나 시스템 소프트으ㅞ어의 또는 감염하게 하여 원격 소프트웨어 공격으로
- 가장 일반적인 공격은 원격 소프트웨어 공격이다. 공격자가 사용자를 속여 공격자의 악성 코드 (트로이 목마)를 실행하거나 공격자가 시스템 소프트웨어의 취약점을 악용하기 위해 악성 데이터를 전송하도록 시도한다. (injection, overflow)
- Local Attacks
- 로컬 공격은 공격자가 악의적 인 내부자 (운영자)와 같은 시스템에 물리적으로 액세스하거나 시스템을 도용 한 경우를 가정한다.
- 로컬 공격은 오프라인 공격과 같은 소프트웨어 기반 일 수도 있고 단순한 JTAG 메모리 프로브와 같은 하드웨어 기반 일 수도 있고 민감한 데이터를 읽기 위해 칩을 분리하는 매우 정교하고 비싼 공격 일 수도 있다.
- 가장 간단하고 가장 일반적인 로컬 공격은 대체 운영 체제가 CD 또는 USB 드라이브에서 부팅되는 오프라인 공격이며이 운영 체제는 공격자가 대상 시스템을 수정하는 데 사용된다.
- 오프라인 공격은 일반적으로 기존 암호를 해독하거나 알려진 암호를 삽입하는 것으로 공격자가 단순히 로그인 할 수 있다.
- 보다 정교한 오프라인 공격의 경우 악의적 인 코드가 삽입되어 나중에 은행 비밀번호와 같은 중요한 데이터를 캡처 할 수 있다.
Integrity 서브 시스템
커널에서 CONFIG_INTEGRITY 커널 옵션을 사용하여 다음 서브시스템들을 사용할 수 있다.
- IMA
- IMA-Appraisal
- IMA-Appraisal-Directory-Extension
- IMA-Appraisal-Signature-Extension
- EVM
- Trusted and Encrypted Keys
Application
- Trousers
- 커널에 기본 TPM 장치 드라이버가 포함되어 있고 커널에 키 관리를 위해 TPM을 직접 사용하는 신뢰할 수있는 키가 포함되어 있다. 그렇지만 Trouser를 사용하는 경우 TPM 초기화, 관리 및 사용을위한 표준 준수 TPM 액세스 라이브러리 및 관련 TPM 유틸리티를 제공한다.
- OpenPTS
- OpenPTS는 Trousers 라이브러리를 사용하여 TPM 및 IMA 측정 목록에 액세스하고 참조 목록 및 현재 무결성 목록을 만들고 서명 된 TPM 따옴표를 사용하여 측정 목록을 고정 (인증)한다. 이러한 보고서는 응용 프로그램과 공급 업체 간의 상호 운용성을 위해 PTS 표준 형식으로 작성된다.
참고
- LIM(Linux Integrity Module) -1- | 문c – 현재 글
- LIM -2- (IMA) | 문c – not yet
- LIM -3- (EVM) | 문c – not yet
- LSM(Linux Security Module) -1- | 문c
- integrity: Linux Integrity Module(LIM) | LWN.net
- integrity: IMA as an integrity service provider | LWN.net
- Integrity Measurement Architecture (IMA) | sourceforge