<kernel v5.0>
유저 프로세스의 힙 또는 스택 메모리 증/감 요청
Heap Manager
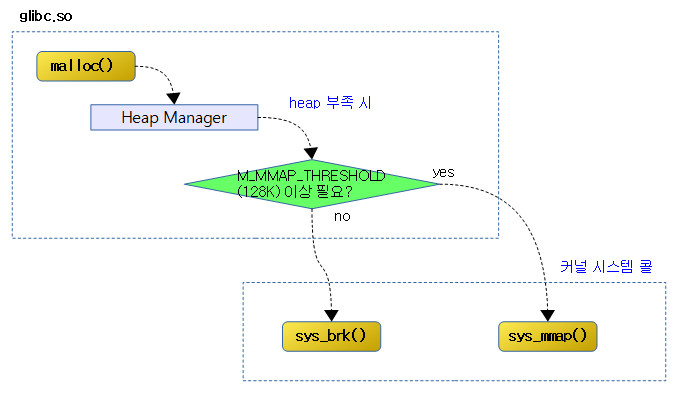
user space에서 malloc() 함수를 사용 시 glibc등의 라이브러리에 포함된 힙 메모리 관리자가 힙 pool을 관리한다. 만일 힙 메모리가 더 필요한 경우 커널에게 Posix system call을 통해 유저 anon 메모리 요청을 하게되는데 이 때 커널에서 호출되는 함수는 brk() 또는 mmap()이다.
- M_MMAP_THRESHOLD (128K)
- mallopt() 함수를 사용하여 스레졸드 기준치를 변경할 수 있다.
- 스레졸드 이하의 힙을 확장하려할 때 brk() 함수가 호출되며 이는 mmap()의 간단한 버전으로 anonymouse 타입의 메모리만 취급한다.
- 스레졸드 이상의 힙을 확장하는 경우에는 mmap() 함수가 호출된다.
Custom Heap Manager
대부분의 경우 힙 관리를 위해 C에서는 GNU의 glibc 라이브러리, 그리고 assembly에서는 FASMLIB 라이브러리를 사용하는 것이 쉽고 편하다. 그런데 이러한 라이브러리를 사용하지 않고 특별히 custom 힙 관리자를 사용해야 하는 경우도 있다. 당연히 개발자가 직접 복잡한 스레드들을 위해 특별한 힙 관리자를 만들기 위해 brk() 또는 map() 시스템 콜 함수를 호출하는 custom 힙 메모리 관리자를 작성할 수 있다.
sys_brk()
mm/mmap.c -1/2-
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long retval;
unsigned long newbrk, oldbrk, origbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
unsigned long min_brk;
bool populate;
bool downgraded = false;
LIST_HEAD(uf);
if (down_write_killable(&mm->mmap_sem))
return -EINTR;
origbrk = mm->brk;
#ifdef CONFIG_COMPAT_BRK
/*
* CONFIG_COMPAT_BRK can still be overridden by setting
* randomize_va_space to 2, which will still cause mm->start_brk
* to be arbitrarily shifted
*/
if (current->brk_randomized)
min_brk = mm->start_brk;
else
min_brk = mm->end_data;
#else
min_brk = mm->start_brk;
#endif
if (brk < min_brk)
goto out;
/*
* Check against rlimit here. If this check is done later after the test
* of oldbrk with newbrk then it can escape the test and let the data
* segment grow beyond its set limit the in case where the limit is
* not page aligned -Ram Gupta
*/
if (check_data_rlimit(rlimit(RLIMIT_DATA), brk, mm->start_brk,
mm->end_data, mm->start_data))
goto out;
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk) {
mm->brk = brk;
goto success;
}
/*
* Always allow shrinking brk.
* __do_munmap() may downgrade mmap_sem to read.
*/
if (brk <= mm->brk) {
int ret;
/*
* mm->brk must to be protected by write mmap_sem so update it
* before downgrading mmap_sem. When __do_munmap() fails,
* mm->brk will be restored from origbrk.
*/
mm->brk = brk;
ret = __do_munmap(mm, newbrk, oldbrk-newbrk, &uf, true);
if (ret < 0) {
mm->brk = origbrk;
goto out;
} else if (ret == 1) {
downgraded = true;
}
goto success;
}
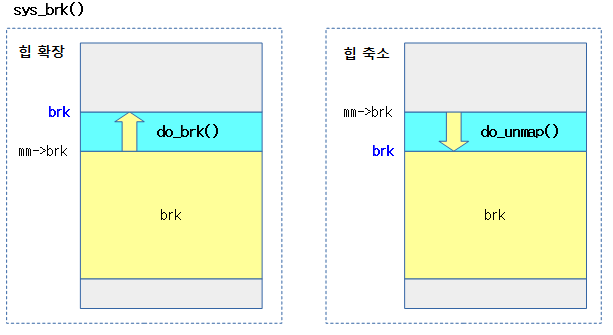
힙(데이터) 영역을 확장하거나 축소한다. 확장 시 anon 유저 페이지로 할당하고, 축소 시 해당 영역을 언매핑 한다.
- 코드 라인 23~28에서 보안 목적으로 user space에 배치되는 힙 위치를 랜덤하게 사용하는데 레거시 libc5 등 호환 목적으로 이 커널 옵션을 사용하여 힙 시작 위치 랜덤 기능을 사용하지 않게 한다.
- “echo 2 > /proc/sys/kernel/randomize_va_space”를 수행하는 경우 힙 시작 위치 랜덤 기능을 사용하게 한다.
- “norandmaps” 커널 파라메터를 사용하는 경우에도 힙 시작 위치 랜덤 기능을 사용하지 않게 할 수 있다.
- 코드 라인 30~31에서 태스크에 설정된 힙 시작 주소 보다 낮은 힙 주소를 요청하는 경우 할당을 포기하고 out 레이블로 이동한다.
- 코드 라인 39~41에서 현재 태스크가 사용하는 데이터 크기가 현재 태스크에 설정된 data 영역 한계 용량을 초과하는 경우 할당을 포기하고 out 레이블로 이동한다.
- RLIMIT_DATA: 데이터(힙 사용량 + 데이터 섹션) 사이즈 limit
- 코드 라인 43~48에서 요청한 힙 주소의 페이지 단위 변화가 없는 경우 success 레이블로 이동한다.
- 코드 라인 54~71에서 요청한 힙 주소가 태스크에 설정한 기존 힙 주소 이하인 경우 힙을 그 줄어든 차이 언매핑하여 축소(shrink) 한다. 축소가 성공하면 success 레이블로 이동하고 그렇지 않은 경우 out 레이블로 이동한다.
- 참고: mm: brk: downgrade mmap_sem to read when shrinking (2018, v4.20-rc1)
mm/mmap.c -2/2-
/* Check against existing mmap mappings. */
next = find_vma(mm, oldbrk);
if (next && newbrk + PAGE_SIZE > vm_start_gap(next))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk_flags(oldbrk, newbrk-oldbrk, 0, &uf) < 0)
goto out;
mm->brk = brk;
success:
populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0;
if (downgraded)
up_read(&mm->mmap_sem);
else
up_write(&mm->mmap_sem);
userfaultfd_unmap_complete(mm, &uf);
if (populate)
mm_populate(oldbrk, newbrk - oldbrk);
return brk;
out:
retval = origbrk;
up_write(&mm->mmap_sem);
return retval;
}
- 코드 라인 2~4에서 늘어날 힙 공간이 기존에 이미 매핑되어 있는 경우 할당을 포기하고 out 레이블로 이동한다.
- 코드 라인 7~8에서 기존 vm을 확장하여 반환하거나 새 vm을 구성하여 가져온다. 실패하는 경우 out 레이블로 이동한다.
- 코드 라인 11~19에서 success: 레이블이다. 늘어난 힙이 있으면서 mlocked 영역의 vma인 경우 해당 영역에 대한 유저 페이지를 모두 할당하여 매핑한다.
- 코드 라인 20에서 새 힙의 끝 주소를 반환한다.
- 코드 라인 22~25에서 out: 레이블이다. 기존 힙 끝 주소를 반환한다.
다음 그림은 do_brk() 함수가 호출될 때 힙이 확장되거나 줄어드는 모습을 보여준다.
check_data_rlimit()
include/linux/mm.h
static inline int check_data_rlimit(unsigned long rlim,
unsigned long new,
unsigned long start,
unsigned long end_data,
unsigned long start_data)
{
if (rlim < RLIM_INFINITY) {
if (((new - start) + (end_data - start_data)) > rlim)
return -ENOSPC;
}
return 0;
}
데이터 사용 크기가 rlim을 초과하는 경우 -ENOSPC 에러 값을 반환한다.
- 데이터=힙 사용량 + 데이터 섹션
do_brk_flags()
mm/mmap.c
/* * this is really a simplified "do_mmap". it only handles * anonymous maps. eventually we may be able to do some * brk-specific accounting here. */
static int do_brk_flags(unsigned long addr, unsigned long len, unsigned long flags, struct list_headd
*uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
/* Until we need other flags, refuse anything except VM_EXEC. */
if ((flags & (~VM_EXEC)) != 0)
return -EINVAL;
flags |= VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags;
error = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED);
if (offset_in_page(error))
return error;
error = mlock_future_check(mm, mm->def_flags, len);
if (error)
return error;
/*
* Clear old maps. this also does some error checking for us
*/
while (find_vma_links(mm, addr, addr + len, &prev, &rb_link,
&rb_parent)) {
if (do_munmap(mm, addr, len, uf))
return -ENOMEM;
}
/* Check against address space limits *after* clearing old maps... */
if (!may_expand_vm(mm, flags, len >> PAGE_SHIFT))
return -ENOMEM;
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
/* Can we just expand an old private anonymous mapping? */
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* create a vma struct for an anonymous mapping
*/
vma = vm_area_alloc(mm);
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
vma_set_anonymous(vma);
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
mm->data_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return 0;
}
현재 태스크 유저 영역에서 요청한 가상 주소와 길이만큼의 영역을 고정 매핑한다. 성공 시 0을 반환한다.
- 코드 라인 7에서 가상 주소에 대한 페이지 번호를 pgoff에 담는다.
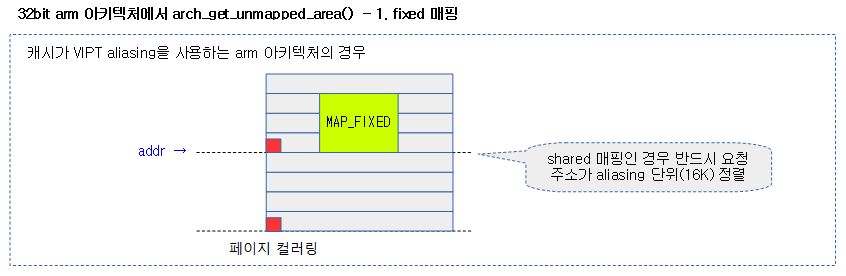
- 캐시 aliasing을 사용하는 시스템에서 시작 주소가 적절한지 비교하기 위해 사용된다.
- 코드 라인 11~12에서 VM_EXEC를 제외한 모든 플래그의 사용을 허용하지 않는다.
- 코드 라인 13에서 코드 라인 19에서 VM_DATA_DEFAULT_FLAGS와 VM_ACCOUNT 및 현재 태스크의 def_flags를 담는다.
- VM_DATA_DEFAULT_FLAGS:
- VM_EXEC(옵션) | VM_READ | VM_WRITE | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC
- VM_DATA_DEFAULT_FLAGS:
- 코드 라인 15~17에서 현재 태스크 유저 영역의 요청 가상 주소부터 길이 len만큼의 빈 공간이 있어 고정 매핑시킬 수 있는지 여부를 알아온다. 만일 매핑할 공간이 없으면 error를 반환한다.
- 코드 라인 19~21에서 현재 태스크에서 VM_LOCKED 플래그를 사용한 페이지들의 수가 최대 locked 페이지 수 제한을 초과하는 경우 -EAGAIN 에러를 반환한다.
- 코드 라인 26~30에서 vma들에서 요청 가상 주소 영역과 겹치는 경우 언맵을 수행한다.
- 코드 라인 33~34에서 현재 태스크의 전체 vm 페이지 수가 주소 공간 제한(RLIMIT_AS)을 초과하는 경우 -ENOMEM 에러를 반환한다.
- 코드 라인 36~37에서 현재 태스크의 vma 수가 최대 매핑 카운트 수를 초과하는 경우 -ENOMEM을 반환한다.
- sysctl_max_map_count
- 디폴트로 65530이며 이 값은 “/proc/sys/vm/max_map_count” 를 통해 변경할 수 있다.
- sysctl_max_map_count
- 코드 라인 39~40에서 LSM(Linux Security Module)을 통해 새로운 가상 매핑의 할당이 충분한지 여부를 체크한다.
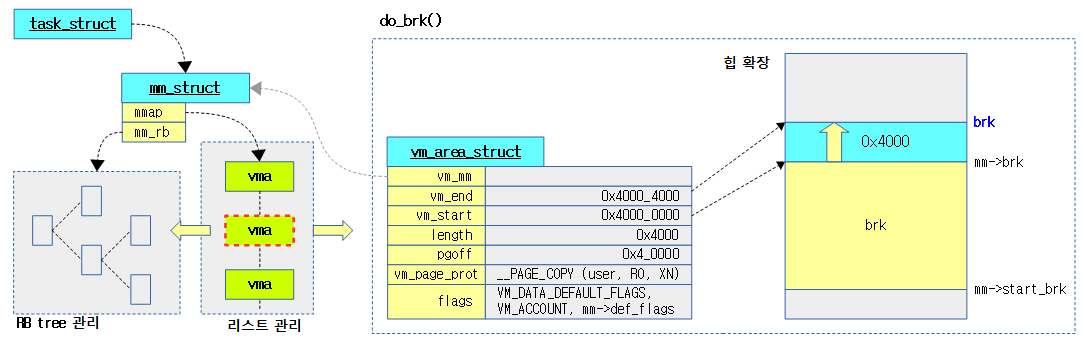
- 코드 라인 43~46에서 기존 vma가 private anonymous 매핑을 사용하는 경우 merge하여 확장할 수 있는지 확인하고 가능하면 out 레이블로 이동한다.
- 코드 라인 51~55에서 vma 구조체용 메모리를 할당하고 실패시 이미 증가시킨 vm commit 페이지 수를 다시 원상복귀 시키고 -ENOMEM 에러를 반환한다.
- 코드 라인 57~63에서 vma 정보를 구성하고 추가한다.
- vm_page_prot에 들어가는 매핑 속성은 메모리 디스크립터에 특별히 추가된 속성(mm->def_flags)이 없어도 기본적으로 __PAGE_COPY이다.
- 코드 라인 64~67에서 out 레이블의 시작 위치이며 메모리 디스크립터에 전체 사용 vm 페이지 수를 갱신한다.
- 코드 라인 68~69에서 VM_LOCKED 플래그를 사요하는 경우 메모리 디스크립터의 locked_vm 페이지 카운터를 갱신한다.
- 코드 라인 70에서 vma의 플래그에 VM_SOFTDIRTY를 추가한다.
- 코드 라인 71에서 성공 0을 반환한다.
다음 그림은 brk() 요청에 대하여 기존 vma를 사용하여 확장하는 모습을 보여준다.
vm 플래그 -> 페이지 매핑 속성
vm_get_page_prot()
mm/mmap.c
pgprot_t vm_get_page_prot(unsigned long vm_flags)
{
return __pgprot(pgprot_val(protection_map[vm_flags &
(VM_READ|VM_WRITE|VM_EXEC|VM_SHARED)]) |
pgprot_val(arch_vm_get_page_prot(vm_flags)));
}
EXPORT_SYMBOL(vm_get_page_prot);
vm 플래그들 중 read, write, exec, shared 플래그 값의 사용 우무로 필요한 페이지 매핑 속성 값들을 알아온다.
전역 protection_map[] 배열
mm/mmap.c
/* description of effects of mapping type and prot in current implementation. * this is due to the limited x86 page protection hardware. The expected * behavior is in parens: * * map_type prot * PROT_NONE PROT_READ PROT_WRITE PROT_EXEC * MAP_SHARED r: (no) no r: (yes) yes r: (no) yes r: (no) yes * w: (no) no w: (no) no w: (yes) yes w: (no) no * x: (no) no x: (no) yes x: (no) yes x: (yes) yes * * MAP_PRIVATE r: (no) no r: (yes) yes r: (no) yes r: (no) yes * w: (no) no w: (no) no w: (copy) copy w: (no) no * x: (no) no x: (no) yes x: (no) yes x: (yes) yes * */
pgprot_t protection_map[16] __ro_after_init = {
__P000, __P001, __P010, __P011, __P100, __P101, __P110, __P111,
__S000, __S001, __S010, __S011, __S100, __S101, __S110, __S111
};
4개의 플래그 비트로 16개의 배열이 작성된다.
16개의 페이지 매핑 속성 – ARM32
arch/arm/include/asm/pgtable.h
/* * The table below defines the page protection levels that we insert into our * Linux page table version. These get translated into the best that the * architecture can perform. Note that on most ARM hardware: * 1) We cannot do execute protection * 2) If we could do execute protection, then read is implied * 3) write implies read permissions */
#define __P000 __PAGE_NONE #define __P001 __PAGE_READONLY #define __P010 __PAGE_COPY #define __P011 __PAGE_COPY #define __P100 __PAGE_READONLY_EXEC #define __P101 __PAGE_READONLY_EXEC #define __P110 __PAGE_COPY_EXEC #define __P111 __PAGE_COPY_EXEC #define __S000 __PAGE_NONE #define __S001 __PAGE_READONLY #define __S010 __PAGE_SHARED #define __S011 __PAGE_SHARED #define __S100 __PAGE_READONLY_EXEC #define __S101 __PAGE_READONLY_EXEC #define __S110 __PAGE_SHARED_EXEC #define __S111 __PAGE_SHARED_EXEC
read, write, exec, shared 플래그 비트로 조합한 16개의 매크로 상수 값
arch/arm/include/asm/pgtable.h
#define __PAGE_NONE __pgprot(_L_PTE_DEFAULT | L_PTE_RDONLY | L_PTE_XN | L_PTE_NONE) #define __PAGE_SHARED __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_XN) #define __PAGE_SHARED_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER) #define __PAGE_COPY __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY | L_PTE_XN) #define __PAGE_COPY_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY) #define __PAGE_READONLY __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY | L_PTE_XN) #define __PAGE_READONLY_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY)
- __PAGE_NONE
- NUMA 시스템에서 해당 페이지를 읽을 때 accesss 권한 실패로 인해 abort exception이 발생되어 fault된 후 해당 페이지를 사용하는 태스크의 migration을 고려하는 Automatic NUMA balancing을 위해 사용된다.
- __PAGE_COPY
- L_PTE_PRESENT: 매핑됨
- L_PTE_YOUNG: 페이지에 접근 가능
- L_PTE_USER: 유저 허용
- L_PTE_RDONLY: 읽기 전용
- L_PTE_XN: 실행 금지(Excute Never)
16개의 페이지 매핑 속성 – ARM64
arch/arm64/include/asm/pgtable-prot.h
#define __P000 PAGE_NONE #define __P001 PAGE_READONLY #define __P010 PAGE_READONLY #define __P011 PAGE_READONLY #define __P100 PAGE_EXECONLY #define __P101 PAGE_READONLY_EXEC #define __P110 PAGE_READONLY_EXEC #define __P111 PAGE_READONLY_EXEC #define __S000 PAGE_NONE #define __S001 PAGE_READONLY #define __S010 PAGE_SHARED #define __S011 PAGE_SHARED #define __S100 PAGE_EXECONLY #define __S101 PAGE_READONLY_EXEC #define __S110 PAGE_SHARED_EXEC #define __S111 PAGE_SHARED_EXEC
arch/arm64/include/asm/pgtable-prot.h
#define PAGE_NONE __pgprot(((_PAGE_DEFAULT) & ~PTE_VALID) | PTE_PROT_NONE | PTE_RDONLYY | PTE_NG | PTE_PXN | PTE_UXN) #define PAGE_SHARED __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN | PTE_UXN | PTEE _WRITE) #define PAGE_SHARED_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN | PTE_WRITE) #define PAGE_READONLY __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_RDONLY | PTE_NG | PTE_PXN | PTE_UXN) #define PAGE_READONLY_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_RDONLY | PTE_NG | PTE_PXN) #define PAGE_EXECONLY __pgprot(_PAGE_DEFAULT | PTE_RDONLY | PTE_NG | PTE_PXN)
- _PAGE_DEFAULT
- PTE_ATTRINDX(MT_NORMAL) | PTE_TYPE_PAGE | PTE_AF | PTE_SHARED
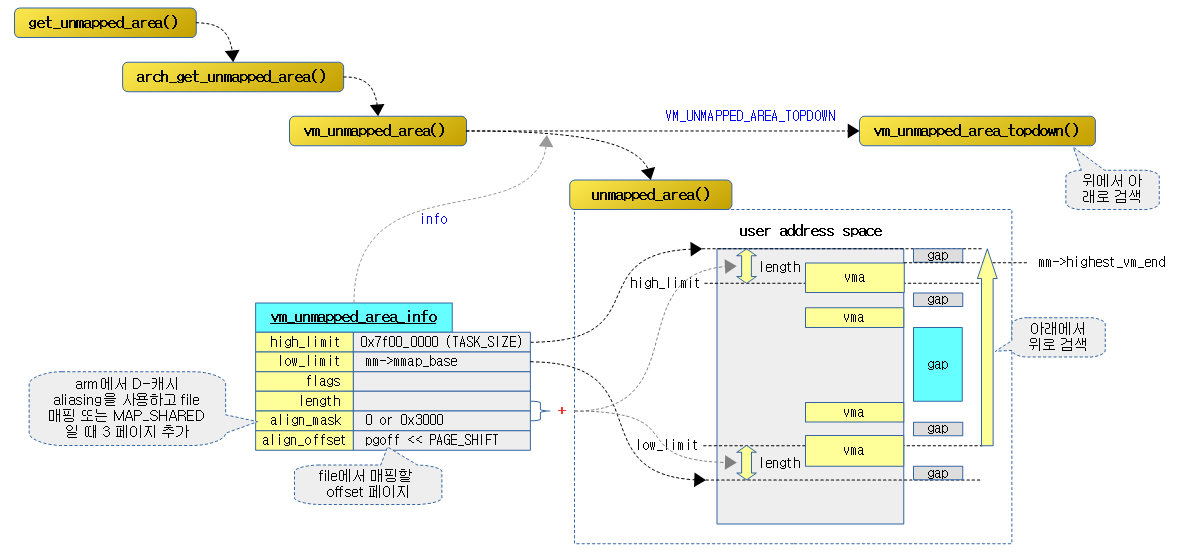
매핑되지 않은 주소 영역 찾기
get_unmapped_area()
mm/mmap.c
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
unsigned long error = arch_mmap_check(addr, len, flags);
if (error)
return error;
/* Careful about overflows.. */
if (len > TASK_SIZE)
return -ENOMEM;
get_area = current->mm->get_unmapped_area;
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
} else if (flags & MAP_SHARED) {
/*
* mmap_region() will call shmem_zero_setup() to create a file,
* so use shmem's get_unmapped_area in case it can be huge.
* do_mmap_pgoff() will clear pgoff, so match alignment.
*/
pgoff = 0;
get_area = shmem_get_unmapped_area;
}
addr = get_area(file, addr, len, pgoff, flags);
if (IS_ERR_VALUE(addr))
return addr;
if (addr > TASK_SIZE - len)
return -ENOMEM;
if (offset_in_page(addr))
return -EINVAL;
error = security_mmap_addr(addr);
return error ? error : addr;
}
EXPORT_SYMBOL(get_unmapped_area);
현재 태스크 유저 영역의 mmap 매핑 공간에서 검색하여 요청 길이가 들어갈 수 있는 매핑되지 않은 빈 영역의 가상 시작 주소를 알아온다.
- 코드 라인 8~10에서 요청한 유저 공간이 아키텍처가 지원하지 않는 매핑 공간인 경우 에러를 반환한다.
- 코드 라인 13~14에서 요청 할당 길이가 유저 공간 크기보다 큰 경우 -ENOMEM 에러를 반환한다.
- TASK_SIZE: 유저 공간의 크기
- 예) rpi2: 2G – 16M (arm에서는 커널 공간과 모듈(16M) 공간을 제외한 크기)
- TASK_SIZE: 유저 공간의 크기
- 코드 라인 16~32에서 언맵된 영역을 알아온다.
- file 매핑인 경우 file 디스크립터로부터 언맵된 영역을 알아오는 핸들러 함수를 사용한다.
- 참고로 do_brk()는 file 매핑을 사용하지 않고 anon 매핑을 위해 file 인수에 null을 대입하여 호출한다.
- shared 영역에 대한 핸들러 함수는 shmem_get_unmapped_area() 함수를 사용한다.
- file 매핑인 경우 file 디스크립터로부터 언맵된 영역을 알아오는 핸들러 함수를 사용한다.
- 코드 라인 34~35에서 알아온 가상 주소를 유저 공간에 배치할 수 없는 경우 -ENOMEM 에러를 반환한다.
- 코드 라인 36~37에서 알아온 가상 주소가 0페이지인 경우 -EINVAL 에러를 반환한다.
- 코드 라인 39~30에서 보안을 위해 사용되는 selinux가 사용될 때, 해당 가상 주소가 허가된 주소인 경우 그 주소를 반환하고 그렇지 않은 경우 에러를 반환한다.
arch_mmap_check()
arch/arm/include/uapi/asm/mman.h
#define arch_mmap_check(addr, len, flags) \
(((flags) & MAP_FIXED && (addr) < FIRST_USER_ADDRESS) ? -EINVAL : 0)
요청한 가상주소로 고정 매핑을 요구하는 경우 그 가상 주소가 시작 유저 공간 주소 이하인 경우 -EINVAL을 반환한다.
- FIRST_USER_ADDRESS: (PAGE_SIZE * 2)
- arm에서 로우 벡터를 사용하는 경우 하위 2개 페이지는 사용자가 사용할 수 없는 공간이다.
- ARM64 및 x86의 경우 항상 성공 0을 반환한다.
arch_get_unmapped_area() – ARM32
arch/arm/mm/mmap.c
/* * We need to ensure that shared mappings are correctly aligned to * avoid aliasing issues with VIPT caches. We need to ensure that * a specific page of an object is always mapped at a multiple of * SHMLBA bytes. * * We unconditionally provide this function for all cases, however * in the VIVT case, we optimise out the alignment rules. */
unsigned long
arch_get_unmapped_area(struct file *filp, unsigned long addr,
unsigned long len, unsigned long pgoff, unsigned long flags)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
int do_align = 0;
int aliasing = cache_is_vipt_aliasing();
struct vm_unmapped_area_info info;
/*
* We only need to do colour alignment if either the I or D
* caches alias.
*/
if (aliasing)
do_align = filp || (flags & MAP_SHARED);
/*
* We enforce the MAP_FIXED case.
*/
if (flags & MAP_FIXED) {
if (aliasing && flags & MAP_SHARED &&
(addr - (pgoff << PAGE_SHIFT)) & (SHMLBA - 1))
return -EINVAL;
return addr;
}
if (len > TASK_SIZE)
return -ENOMEM;
if (addr) {
if (do_align)
addr = COLOUR_ALIGN(addr, pgoff);
else
addr = PAGE_ALIGN(addr);
vma = find_vma(mm, addr);
if (TASK_SIZE - len >= addr &&
(!vma || addr + len <= vma->vm_start))
return addr;
}
info.flags = 0;
info.length = len;
info.low_limit = mm->mmap_base;
info.high_limit = TASK_SIZE;
info.align_mask = do_align ? (PAGE_MASK & (SHMLBA - 1)) : 0;
info.align_offset = pgoff << PAGE_SHIFT;
return vm_unmapped_area(&info);
}
arm 아키텍처용으로 구현된 함수로 현재 태스크 유저 영역의 mmap 매핑 공간에서 아래에서 위로 검색하여 요청 길이가 들어갈 수 있는 매핑되지 않은 빈 영역의 가상 시작 주소를 알아온다.
- 코드 라인 8에서 현재 아키텍처의 데이터 캐시가 vipt aliasing을 사용하는지 여부를 알아온다.
- rpi2: aliasing을 사용하지 않는다.
- 코드 라인 15~16에서 aliasing이 사용되는 경우 do_align 값에 flip(파일 구조체 포인터) 값 + MAP_SHARED(1) 플래그를 대입하여 align이 필요한지 여부를 구한다.
- 코드 라인 21~26에서 vm 고정 매핑을 요청한 경우 요청한 가상 주소를 그대로 사용해야 하므로 가상 주소를 변경하지 않고 함수를 빠져나간다. 단 aliasing 및 공유맵을 요청받은 경우 pgoff 페이지 만큼을 감소시킨 가상 주소가 aliasing에 필요한 SHMLBA 사이즈 단위로 정렬되지 않는 경우 -EINVAL을 반환한다.
- SHMLBA: armv7 이전 아키텍처에서 aliasing에 대한 보정때문에 매핑 페이지를 공유해야하는 경우 태스크들 간에 4개 페이지(16K) 이내의 가상 주소 매핑을 사용하지 못하게 한다.
- 참고: Cache – VIPT 캐시 컬러링 | 문c
- SHMLBA: armv7 이전 아키텍처에서 aliasing에 대한 보정때문에 매핑 페이지를 공유해야하는 경우 태스크들 간에 4개 페이지(16K) 이내의 가상 주소 매핑을 사용하지 못하게 한다.
- 코드 라인 28~29에서 길이가 유저 공간 크기를 초과하는 경우 -ENOMEM 에러를 반환한다.
- 코드 라인 31~35에서 가상 주소가 지정된 경우 페이지 단위로 정렬하되 do_align이 설정되어 있으면 가상 주소를 aliasing에 맞게 정렬시킨다.
- 코드 라인 37에서 현재 태스크에 등록된 vma 정보에서 vma를 찾아온다.
- 코드 라인 38~40에서 조절된 가상 주소가 유저 공간에 배치 가능하고 vma 영역 이하인 경우 함수를 빠져나간다.
- 코드 라인 43~49에서 다음과 같이 vm 언맵된 영역 정보를 구성한 후 언맵된 영역을 찾아 반환한다.
- low_limit에는 매핑 영역 하한 주소를 대입한다.
- high_limit에는 user 공간의 상한 주소를 대입한다.
- align_mask는 aliasing이 필요한 arm 아키텍처에 대해 필요한 크기-1 페이지(3 페이지=0x3000)를 대입하여 매핑할 영역 뒷부분을 사용하지 못하게 하는 용도로 배정한다.
- align_offset는 페이지에서 읽어올 offset 페이지 번호를 대입한다.
아래 두 개의 그림은 fixed 매핑 여부에 따라 매핑 공간의 시작 주소와 크기가 캐시 aliasing에 의해 변경될 수 있음을 보여준다.

COLOUR_ALIGN()
mm/mmap.c
#define COLOUR_ALIGN(addr,pgoff) \
((((addr)+SHMLBA-1)&~(SHMLBA-1)) + \
(((pgoff)<<PAGE_SHIFT) & (SHMLBA-1)))
데이터 캐시가 vipt aliasing을 사용하는 경우 페이지 컬러링에 맞추어 요청 가상 주소를 정렬한다.
- 예) SHMLBA=16K , addr=0x1234_6000, pgoff=7
- 가상 주소를 16K 단위로 정렬 + pgoff 페이지를 16K 페이지단위로 나눈 나머지
- 0x1234_8000 + 0x3000 = 0x1234_b000
- 가상 주소를 16K 단위로 정렬 + pgoff 페이지를 16K 페이지단위로 나눈 나머지
arch_get_unmapped_area() – Generic (x86, ARM64, …)
mm/mmap.c
/* Get an address range which is currently unmapped. * For shmat() with addr=0. * * Ugly calling convention alert: * Return value with the low bits set means error value, * ie * if (ret & ~PAGE_MASK) * error = ret; * * This function "knows" that -ENOMEM has the bits set. */
#ifndef HAVE_ARCH_UNMAPPED_AREA
unsigned long
arch_get_unmapped_area(struct file *filp, unsigned long addr,
unsigned long len, unsigned long pgoff, unsigned long flags)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct vm_unmapped_area_info info;
const unsigned long mmap_end = arch_get_mmap_end(addr);
if (len > mmap_end - mmap_min_addr)
return -ENOMEM;
if (flags & MAP_FIXED)
return addr;
if (addr) {
addr = PAGE_ALIGN(addr);
vma = find_vma_prev(mm, addr, &prev);
if (mmap_end - len >= addr && addr >= mmap_min_addr &&
(!vma || addr + len <= vm_start_gap(vma)) &&
(!prev || addr >= vm_end_gap(prev)))
return addr;
}
info.flags = 0;
info.length = len;
info.low_limit = mm->mmap_base;
info.high_limit = mmap_end;
info.align_mask = 0;
return vm_unmapped_area(&info);
}
#endif
generic(x86, ARM64 등이 포함됨)으로 구현된 함수로 현재 태스크 유저 영역의 mmap 매핑 공간에서 아래에서 위로 검색하여 요청 길이가 들어갈 수 있는 매핑되지 않은 빈 영역의 가상 시작 주소를 알아온다.
- 코드 라인 11~12에서 아키텍처가 지원하는 최대 크기를 넘어서면 -ENOMEM 에러를 반환한다.
- 코드 라인 14~15에서 MAP_FIXED 플래그를 사용한 경우 주소 변환 없이 @addr을 그대로 반환한다.
- 코드 라인 17~24에서 가상 주소 @addr가 지정된 경우 페이지 단위로 정렬하고, 현재 태스크에 등록된 vma 정보에서 vma를 찾아온다. 만일 가상 주소가 유저 공간에 배치 가능하고 vma 영역 이하인 경우 함수를 빠져나간다.
- 코드 라인 26~31에서 다음 정보로 언맵된 영역을 찾아 그 가상 주소를 반환한다.
- low_limit에는 매핑 영역 하한 주소를 대입한다.
- high_limit에는 user 공간의 상한 주소를 대입한다.
arch_get_mmap_base() & arch_get_mmap_end() – ARM64
arch/arm64/include/asm/processor.h
#ifndef CONFIG_ARM64_FORCE_52BIT
#define arch_get_mmap_end(addr) ((addr > DEFAULT_MAP_WINDOW) ? TASK_SIZE :\
DEFAULT_MAP_WINDOW)
#define arch_get_mmap_base(addr, base) ((addr > DEFAULT_MAP_WINDOW) ? \
base + TASK_SIZE - DEFAULT_MAP_WINDOW :\
base)
#endif /* CONFIG_ARM64_FORCE_52BIT */
vm_unmapped_area()
include/linux/mm.h
/* * Search for an unmapped address range. * * We are looking for a range that: * - does not intersect with any VMA; * - is contained within the [low_limit, high_limit) interval; * - is at least the desired size. * - satisfies (begin_addr & align_mask) == (align_offset & align_mask) */
static inline unsigned long
vm_unmapped_area(struct vm_unmapped_area_info *info)
{
if (!(info->flags & VM_UNMAPPED_AREA_TOPDOWN))
return unmapped_area(info);
else
return unmapped_area_topdown(info);
}
언맵된 영역의 가상 주소를 알아온다.
- VM_UNMAPPED_AREA_TOPDOWN 플래그 사용 여부에 따라 검색 방향이 결정된다.
아래에서 위로 주소 영역 찾기
unmapped_area()
mm/mmap.c -1/2-
unsigned long unmapped_area(struct vm_unmapped_area_info *info)
{
/*
* We implement the search by looking for an rbtree node that
* immediately follows a suitable gap. That is,
* - gap_start = vma->vm_prev->vm_end <= info->high_limit - length;
* - gap_end = vma->vm_start >= info->low_limit + length;
* - gap_end - gap_start >= length
*/
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
unsigned long length, low_limit, high_limit, gap_start, gap_end;
/* Adjust search length to account for worst case alignment overhead */
length = info->length + info->align_mask;
if (length < info->length)
return -ENOMEM;
/* Adjust search limits by the desired length */
if (info->high_limit < length)
return -ENOMEM;
high_limit = info->high_limit - length;
if (info->low_limit > high_limit)
return -ENOMEM;
low_limit = info->low_limit + length;
/* Check if rbtree root looks promising */
if (RB_EMPTY_ROOT(&mm->mm_rb))
goto check_highest;
vma = rb_entry(mm->mm_rb.rb_node, struct vm_area_struct, vm_rb);
if (vma->rb_subtree_gap < length)
goto check_highest;
while (true) {
/* Visit left subtree if it looks promising */
gap_end = vm_start_gap(vma);
if (gap_end >= low_limit && vma->vm_rb.rb_left) {
struct vm_area_struct *left =
rb_entry(vma->vm_rb.rb_left,
struct vm_area_struct, vm_rb);
if (left->rb_subtree_gap >= length) {
vma = left;
continue;
}
}
augmented rbtrees를 사용하여 구현된 함수로 유저 공간의 요청 범위에서 아래에서 위로 검색하여 vma 영역들 사이의 매핑되지 않은 빈(gap) 영역들 중 요청 길이가 들어갈 수 있는 빈(gap) 영역의 가상 시작 주소를 알아온다.
- 코드 라인 16~18에서 align_mask를 추가한 길이를 구하고, 길이가 시스템 주소 영역을 초과하는 경우 -ENOMEM 에러를 반환한다.
- 코드 라인 21~23에서 high_limit을 산출한다. 범위를 벗어나는 경우 -ENOMEM 에러를 반환한다.
- 기존 high_limit 에서 길이만큼 뺸 값
- 코드 라인 25~27에서 low_limit을 산출한다. 범위를 벗어나는 경우 -ENOMEM 에러를 반환한다.
- 기존 low_limit 에서 길이만큼 추가한 값
- 코드 라인 30~31에서 메모리 디스크립터의 rb 트리가 비어있는 경우 check_highest 레이블로 이동한다.
- 코드 라인 32~34에서 메모리 디스크립터의 루트 노드에서 vma를 가져온다. 만일 루트 노드의 rb_subtree_gap이 길이보다 작은 경우 루트 노드 이하의 노드들에는 빈 공간이 없으므로 최상위 공간을 체크하기 위해 check_highest 레이블로 이동한다.
- 루트 노드의 rb_subtree_gap이 length보다 작은 경우 즉, 각 vma 간 gap이 length보다 작아 그 사이에 추가할 수 없으므로 최상위 영역을 조사한다.
- 코드 라인 36~47에서 현재 태스크의 가상 메모리 영역 vma 들을 대상으로 루프를 돌며 rb 트리에서 좌측 노드 방향으로 길이 만큼의 gap 공간이 발견되는 노드를 찾는다.
mm/mmap.c -2/2-
gap_start = vma->vm_prev ? vm_end_gap(vma->vm_prev) : 0;
check_current:
/* Check if current node has a suitable gap */
if (gap_start > high_limit)
return -ENOMEM;
if (gap_end >= low_limit &&
gap_end > gap_start && gap_end - gap_start >= length)
goto found;
/* Visit right subtree if it looks promising */
if (vma->vm_rb.rb_right) {
struct vm_area_struct *right =
rb_entry(vma->vm_rb.rb_right,
struct vm_area_struct, vm_rb);
if (right->rb_subtree_gap >= length) {
vma = right;
continue;
}
}
/* Go back up the rbtree to find next candidate node */
while (true) {
struct rb_node *prev = &vma->vm_rb;
if (!rb_parent(prev))
goto check_highest;
vma = rb_entry(rb_parent(prev),
struct vm_area_struct, vm_rb);
if (prev == vma->vm_rb.rb_left) {
gap_start = vm_end_gap(vma->vm_prev);
gap_end = vm_start_gap(vma);
goto check_current;
}
}
}
check_highest:
/* Check highest gap, which does not precede any rbtree node */
gap_start = mm->highest_vm_end;
gap_end = ULONG_MAX; /* Only for VM_BUG_ON below */
if (gap_start > high_limit)
return -ENOMEM;
found:
/* We found a suitable gap. Clip it with the original low_limit. */
if (gap_start < info->low_limit)
gap_start = info->low_limit;
/* Adjust gap address to the desired alignment */
gap_start += (info->align_offset - gap_start) & info->align_mask;
VM_BUG_ON(gap_start + info->length > info->high_limit);
VM_BUG_ON(gap_start + info->length > gap_end);
return gap_start;
}
- 코드 라인 1에서 gap 시작 주소를 산출한다.
- 코드 라인 2~5에서 check_current: 레이블이다. gap 시작 주소가 high_limit을 벗어나는 경우 -ENOMEM 에러를 반환한다.
- 코드 라인 6~8에서 gap_end가 low_limit 이상이면서 gap 영역이 길이 보다 큰 경우 found 레이블로 이동한다.
- 코드 라인 11~19에서 이 번에는 반대로 노드의 하위 우측 노드가 있고 그 노드의 gap 영역이 길이 보다 큰 경우 그 우측 노드를 vma 영역에 대입하고 루프를 계속 진행한다.
- 코드 라인 22~33에서 하위에 적당한 gap 영역이 없는 경우 다시 상위 노드로 올라가는데 좌측 노드에서 상위 노드로 올라간 경우라면 gap 시작과 끝을 갱신하고 check_current 레이블로 이동한다.
- 코드 라인 36~41에서 check_highest: 레이블이다. 이 곳에서는 rb 트리의 빈 영역에 필요한 공간이 없어 그 상위의 빈자리를 찾는데 이 곳에서도 적절한 공간이 확보되지 않으면 -ENOMEM 에러를 반환한다.
- 코드 라인 43~46에서 found: 레이블이다. 찾은 gap의 시작 위치를 최소한 info->low_limit으로 조절한다.
- 코드 라인 49~53에서 gap의 시작 위치는 조절된 gap offset 만큼을 추가한 후 info->align_mask로 절삭하여 조절하고 반환한다.
- file 및 캐시 aliasing으로 인해 찾은 언매핑 영역(gap)의 시작위치가 조절될 수 있다.
vm_start_gap()
include/linux/mm.h
static inline unsigned long vm_start_gap(struct vm_area_struct *vma)
{
unsigned long vm_start = vma->vm_start;
if (vma->vm_flags & VM_GROWSDOWN) {
vm_start -= stack_guard_gap;
if (vm_start > vma->vm_start)
vm_start = 0;
}
return vm_start;
}
스택 가드 갭이 적용된 vma 시작 주소를 반환한다.
vm_end_gap()
include/linux/mm.h
static inline unsigned long vm_end_gap(struct vm_area_struct *vma)
{
unsigned long vm_end = vma->vm_end;
if (vma->vm_flags & VM_GROWSUP) {
vm_end += stack_guard_gap;
if (vm_end < vma->vm_end)
vm_end = -PAGE_SIZE;
}
return vm_end;
}
스택 가드 갭이 적용된 vma 끝 주소를 반환한다.
Augmented rbtrees
레드 블랙 트리를 확장하여 augmented rbtree를 사용할 수 있는데 노드들에 대해 추가 정보를 저장할 수 있다. 노드에 대해 전파(propagation), 복사(copy), 회전(rotation)에 대한 콜백 함수를 사용자가 작성하여 등록하면 노드에 대해 변경이 일어날 때 마다 호출되어 추가적인 정보의 관리가 가능하게 만들어졌다. 커널에서도 vma 영역을 rbtree로 관리하는데 augmented rbtrees 방식이 도입되어 매핑되지 않은 빈 영역을 찾을 때 사용하기 위해 서브 트리들이 관리하는 gap 영역에 대한 추가 정보를 관리한다.
아래 그림은 각 노드가 하위 노드들에서 가장 큰 gap 정보를 선택하여 관리하고 있는 모습을 보여준다.

최대 VM_LOCKED 페이지 수 제한
mlock_future_check()
mm/mmap.c
static inline int mlock_future_check(struct mm_struct *mm,
unsigned long flags,
unsigned long len)
{
unsigned long locked, lock_limit;
/* mlock MCL_FUTURE? */
if (flags & VM_LOCKED) {
locked = len >> PAGE_SHIFT;
locked += mm->locked_vm;
lock_limit = rlimit(RLIMIT_MEMLOCK);
lock_limit >>= PAGE_SHIFT;
if (locked > lock_limit && !capable(CAP_IPC_LOCK))
return -EAGAIN;
}
return 0;
}
현재 태스크에서 VM_LOCKED 플래그를 사용한 페이지들의 수가 최대 locked 페이지 수 제한을 초과하는 경우 -EAGAIN 에러를 반환한다. 그 외 성공리에 0을 반환한다.
- VM_LOCKED된 매핑 영역은 페이지 회수(compaction 및 reclaim) 시스템에서 skip 한다.
참고
- User virtual maps (mmap) | 문c
- LSM (Linux Security Module) -1- | 문c
- LIM (Linux Integrity Module) -1- | 문c
- Understanding glibc malloc | sploitfun
- Get User Page | 문c
- Mlock | 문c