다음에 통합
<kernel v5.4>
h/w 독립적인 타임카운터 API를 제공하며 이 카운터를 사용하는 드라이버가 많지 않아 원래 코드가 있었던 clocksource에서 코드를 제거하여 별도의 파일로 분리하였다.
주로 고속 이더넷 드라이버의 PTP(Precision Time Protocol) 기능을 위해 h/w 타이머를 연동하였고 인텔 HD 오디오 드라이버에서도 사용되었음을 확인할 수 있다.
kernel/time/timecounter.c
/** * timecounter_init - initialize a time counter * @tc: Pointer to time counter which is to be initialized/reset * @cc: A cycle counter, ready to be used. * @start_tstamp: Arbitrary initial time stamp. * * After this call the current cycle register (roughly) corresponds to * the initial time stamp. Every call to timecounter_read() increments * the time stamp counter by the number of elapsed nanoseconds. */
void timecounter_init(struct timecounter *tc,
const struct cyclecounter *cc,
u64 start_tstamp)
{
tc->cc = cc;
tc->cycle_last = cc->read(cc);
tc->nsec = start_tstamp;
tc->mask = (1ULL << cc->shift) - 1;
tc->frac = 0;
}
EXPORT_SYMBOL_GPL(timecounter_init);
요청한 timecount 및 cyclecounter 구조체에 시작 값(ns)으로 초기화하고 cycle_last에는 h/w 타이머로부터 cycle 값을 읽어 저장한다.
아래 그림은 rpi2의 armv7 아키텍처 generic 타이머를 사용하여 56비트 타임카운터를 초기화하는 모습을 보여준다.
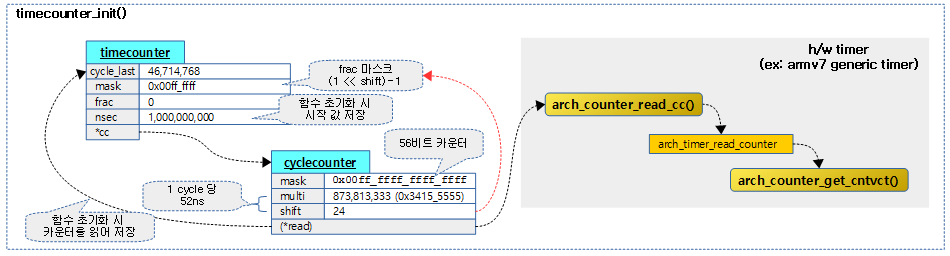
kernel/time/timecounter.c
/** * timecounter_read - return nanoseconds elapsed since timecounter_init() * plus the initial time stamp * @tc: Pointer to time counter. * * In other words, keeps track of time since the same epoch as * the function which generated the initial time stamp. */
u64 timecounter_read(struct timecounter *tc)
{
u64 nsec;
/* increment time by nanoseconds since last call */
nsec = timecounter_read_delta(tc);
nsec += tc->nsec;
tc->nsec = nsec;
return nsec;
}
EXPORT_SYMBOL_GPL(timecounter_read);
마지막 호출로부터 경과한 delta(ns) 값을 추가한 값(ns)을 tc->nsec에 갱신하고 반환한다.
다음 그림은 timecouter_init()으로 초기화한 후 100 사이클(5208ns 소요)이 지난 후 처음 timecounter_read() 함수를 호출한 경우 처리되는 모습을 보여준다.
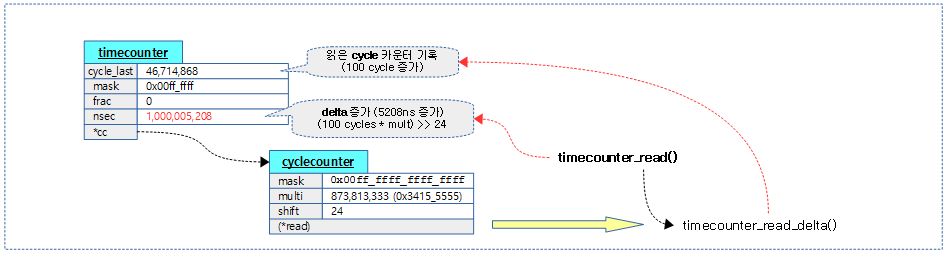
kernel/time/timecounter.c
/** * timecounter_read_delta - get nanoseconds since last call of this function * @tc: Pointer to time counter * * When the underlying cycle counter runs over, this will be handled * correctly as long as it does not run over more than once between * calls. * * The first call to this function for a new time counter initializes * the time tracking and returns an undefined result. */
static u64 timecounter_read_delta(struct timecounter *tc)
{
cycle_t cycle_now, cycle_delta;
u64 ns_offset;
/* read cycle counter: */
cycle_now = tc->cc->read(tc->cc);
/* calculate the delta since the last timecounter_read_delta(): */
cycle_delta = (cycle_now - tc->cycle_last) & tc->cc->mask;
/* convert to nanoseconds: */
ns_offset = cyclecounter_cyc2ns(tc->cc, cycle_delta,
tc->mask, &tc->frac);
/* update time stamp of timecounter_read_delta() call: */
tc->cycle_last = cycle_now;
return ns_offset;
}
cycle 카운트 값을 읽어 tc->cycle_last에 저장하고 마지막 호출로부터 경과한 delta(ns) 값을 반환한다.
include/linux/timecounter.h
/** * cyclecounter_cyc2ns - converts cycle counter cycles to nanoseconds * @cc: Pointer to cycle counter. * @cycles: Cycles * @mask: bit mask for maintaining the 'frac' field * @frac: pointer to storage for the fractional nanoseconds. */
static inline u64 cyclecounter_cyc2ns(const struct cyclecounter *cc,
cycle_t cycles, u64 mask, u64 *frac)
{
u64 ns = (u64) cycles;
ns = (ns * cc->mult) + *frac;
*frac = ns & mask;
return ns >> cc->shift;
}
cycle 카운터 값을 nano 초로 변환한다.
include/linux/timecounter.h
/** * timecounter_adjtime - Shifts the time of the clock. * @delta: Desired change in nanoseconds. */
static inline void timecounter_adjtime(struct timecounter *tc, s64 delta)
{
tc->nsec += delta;
}
타임카운터의 시간 ns만 delta 만큼 더해 조정한다. (cycle 값은 바꾸지 않는다.)
include/linux/timecounter.h
/** * struct timecounter - layer above a %struct cyclecounter which counts nanoseconds * Contains the state needed by timecounter_read() to detect * cycle counter wrap around. Initialize with * timecounter_init(). Also used to convert cycle counts into the * corresponding nanosecond counts with timecounter_cyc2time(). Users * of this code are responsible for initializing the underlying * cycle counter hardware, locking issues and reading the time * more often than the cycle counter wraps around. The nanosecond * counter will only wrap around after ~585 years. * * @cc: the cycle counter used by this instance * @cycle_last: most recent cycle counter value seen by * timecounter_read() * @nsec: continuously increasing count * @mask: bit mask for maintaining the 'frac' field * @frac: accumulated fractional nanoseconds */
struct timecounter {
const struct cyclecounter *cc;
cycle_t cycle_last;
u64 nsec;
u64 mask;
u64 frac;
};
include/linux/timecounter.h
/** * struct cyclecounter - hardware abstraction for a free running counter * Provides completely state-free accessors to the underlying hardware. * Depending on which hardware it reads, the cycle counter may wrap * around quickly. Locking rules (if necessary) have to be defined * by the implementor and user of specific instances of this API. * * @read: returns the current cycle value * @mask: bitmask for two's complement * subtraction of non 64 bit counters, * see CYCLECOUNTER_MASK() helper macro * @mult: cycle to nanosecond multiplier * @shift: cycle to nanosecond divisor (power of two) */
struct cyclecounter {
u64 (*read)(const struct cyclecounter *cc);
u64 mask;
u32 mult;
u32 shift;
};
안녕하세요?
제 메일의 용량이 넘쳐서 저에게 메일이 수신되지 않았었습니다.
혹시 연락되지 않으신 분들은 다시 한 번 보내주시기 바랍니다 ^^;
이제서야 파악이되서 메일함을 비워두었습니다.
by 문c (jake9999 @ dreamwiz.com)
불안정한 클럭 소스 처리를 위한 워치독으로 현재는 x86 아키텍처에만 적용되어 있다.
kernel/time/clocksource.c
static void clocksource_enqueue_watchdog(struct clocksource *cs)
{
unsigned long flags;
spin_lock_irqsave(&watchdog_lock, flags);
if (cs->flags & CLOCK_SOURCE_MUST_VERIFY) {
/* cs is a clocksource to be watched. */
list_add(&cs->wd_list, &watchdog_list);
cs->flags &= ~CLOCK_SOURCE_WATCHDOG;
} else {
/* cs is a watchdog. */
if (cs->flags & CLOCK_SOURCE_IS_CONTINUOUS)
cs->flags |= CLOCK_SOURCE_VALID_FOR_HRES;
/* Pick the best watchdog. */
if (!watchdog || cs->rating > watchdog->rating) {
watchdog = cs;
/* Reset watchdog cycles */
clocksource_reset_watchdog();
}
}
/* Check if the watchdog timer needs to be started. */
clocksource_start_watchdog();
spin_unlock_irqrestore(&watchdog_lock, flags);
}
요청 클럭 소스에 must_verify 플래그 요청이 있는 경우 워치독 리스트에 등록하고 0.5초 타이머 후에 워치독 스레드를 동작시켜 클럭의 안정 여부를 판단하게 한다. 플래그 요청이 없는 경우 rating이 가장 좋은 클럭 소스를 전역 watchdog이 가리키게한다.
다음 그림은 must_verify 플래그가 있는 클럭 소스를 워치독 리스트에 추가하고 클럭 소스의 안정성 여부를 확인하도록 0.5초 만료시간으로 타이머를 가동시킨 후 워치독 스레드를 동작시키는 과정을 보여준다.
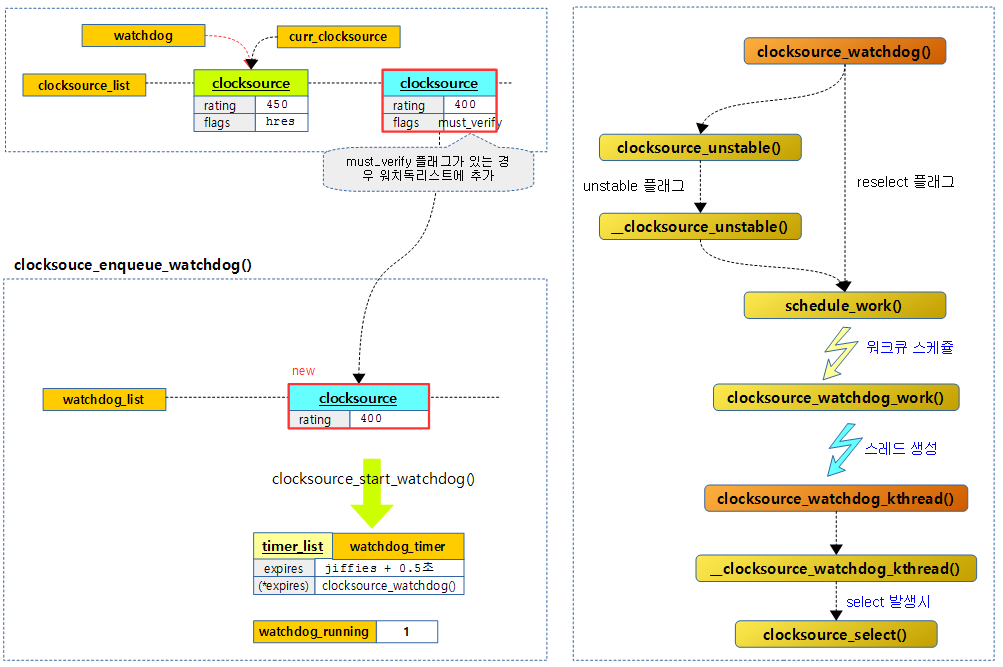
kernel/time/clocksource.c
static inline void clocksource_reset_watchdog(void)
{
struct clocksource *cs;
list_for_each_entry(cs, &watchdog_list, wd_list)
cs->flags &= ~CLOCK_SOURCE_WATCHDOG;
}
워치독 리스트에 등록된 모든 클럭 소스의 플래그 중 watchdog 비트만 클리어한다.
kernel/time/clocksource.c
static inline void clocksource_start_watchdog(void)
{
if (watchdog_running || !watchdog || list_empty(&watchdog_list))
return;
init_timer(&watchdog_timer);
watchdog_timer.function = clocksource_watchdog;
watchdog_timer.expires = jiffies + WATCHDOG_INTERVAL;
add_timer_on(&watchdog_timer, cpumask_first(cpu_online_mask));
watchdog_running = 1;
}
클럭 소스 워치독으로 만료 시간 0.5초 lowres 타이머를 요청한다.
kernel/time/clocksource.c
static void clocksource_watchdog(unsigned long data)
{
struct clocksource *cs;
cycle_t csnow, wdnow, delta;
int64_t wd_nsec, cs_nsec;
int next_cpu, reset_pending;
spin_lock(&watchdog_lock);
if (!watchdog_running)
goto out;
reset_pending = atomic_read(&watchdog_reset_pending);
list_for_each_entry(cs, &watchdog_list, wd_list) {
/* Clocksource already marked unstable? */
if (cs->flags & CLOCK_SOURCE_UNSTABLE) {
if (finished_booting)
schedule_work(&watchdog_work);
continue;
}
local_irq_disable();
csnow = cs->read(cs);
wdnow = watchdog->read(watchdog);
local_irq_enable();
/* Clocksource initialized ? */
if (!(cs->flags & CLOCK_SOURCE_WATCHDOG) ||
atomic_read(&watchdog_reset_pending)) {
cs->flags |= CLOCK_SOURCE_WATCHDOG;
cs->wd_last = wdnow;
cs->cs_last = csnow;
continue;
}
delta = clocksource_delta(wdnow, cs->wd_last, watchdog->mask);
wd_nsec = clocksource_cyc2ns(delta, watchdog->mult,
watchdog->shift);
delta = clocksource_delta(csnow, cs->cs_last, cs->mask);
cs_nsec = clocksource_cyc2ns(delta, cs->mult, cs->shift);
cs->cs_last = csnow;
cs->wd_last = wdnow;
if (atomic_read(&watchdog_reset_pending))
continue;
/* Check the deviation from the watchdog clocksource. */
if ((abs(cs_nsec - wd_nsec) > WATCHDOG_THRESHOLD)) {
clocksource_unstable(cs, cs_nsec - wd_nsec);
continue;
}
워치독 이벤트 핸들러로 클럭 소스 리스트에 있는 모든 클럭에 대해 워치독 클럭 소스와 비교하여 스레졸드(0.625초) 시간을 초과한 경우 unstable 처리 후 워치독 스레드에 맡긴다.
if (!(cs->flags & CLOCK_SOURCE_VALID_FOR_HRES) &&
(cs->flags & CLOCK_SOURCE_IS_CONTINUOUS) &&
(watchdog->flags & CLOCK_SOURCE_IS_CONTINUOUS)) {
/* Mark it valid for high-res. */
cs->flags |= CLOCK_SOURCE_VALID_FOR_HRES;
/*
* clocksource_done_booting() will sort it if
* finished_booting is not set yet.
*/
if (!finished_booting)
continue;
/*
* If this is not the current clocksource let
* the watchdog thread reselect it. Due to the
* change to high res this clocksource might
* be preferred now. If it is the current
* clocksource let the tick code know about
* that change.
*/
if (cs != curr_clocksource) {
cs->flags |= CLOCK_SOURCE_RESELECT;
schedule_work(&watchdog_work);
} else {
tick_clock_notify();
}
}
}
/*
* We only clear the watchdog_reset_pending, when we did a
* full cycle through all clocksources.
*/
if (reset_pending)
atomic_dec(&watchdog_reset_pending);
/*
* Cycle through CPUs to check if the CPUs stay synchronized
* to each other.
*/
next_cpu = cpumask_next(raw_smp_processor_id(), cpu_online_mask);
if (next_cpu >= nr_cpu_ids)
next_cpu = cpumask_first(cpu_online_mask);
watchdog_timer.expires += WATCHDOG_INTERVAL;
add_timer_on(&watchdog_timer, next_cpu);
out:
spin_unlock(&watchdog_lock);
}
kernel/time/clocksource.c
static void clocksource_unstable(struct clocksource *cs, int64_t delta)
{
printk(KERN_WARNING "Clocksource %s unstable (delta = %Ld ns)\n",
cs->name, delta);
__clocksource_unstable(cs);
}
불안정한 클럭 소스에 대해 경고 메시지를 출력하고 이에 대한 처리를 하도록 워치독 처리 함수를 스케쥴하여 호출한다.
kernel/time/clocksource.c
static void __clocksource_unstable(struct clocksource *cs)
{
cs->flags &= ~(CLOCK_SOURCE_VALID_FOR_HRES | CLOCK_SOURCE_WATCHDOG);
cs->flags |= CLOCK_SOURCE_UNSTABLE;
if (finished_booting)
schedule_work(&watchdog_work);
}
불안정한 클럭 소스의 처리를 위해 아래 워크큐에 등록된 함수를 스케쥴하여 호출한다.
kernel/time/clocksource.c
static DECLARE_WORK(watchdog_work, clocksource_watchdog_work);
워치독 스레드를 생성하고 동작시키는 워크큐이다.
kernel/time/clocksource.c
static void clocksource_watchdog_work(struct work_struct *work)
{
/*
* If kthread_run fails the next watchdog scan over the
* watchdog_list will find the unstable clock again.
*/
kthread_run(clocksource_watchdog_kthread, NULL, "kwatchdog");
}
워치독 스레드를 생성하고 동작시킨다.
kernel/time/clocksource.c
static int clocksource_watchdog_kthread(void *data)
{
mutex_lock(&clocksource_mutex);
if (__clocksource_watchdog_kthread())
clocksource_select();
mutex_unlock(&clocksource_mutex);
return 0;
}
워치독 리스트에 있는 불안정한 클럭들은 rating을 0으로 바꾼 후 다시 클럭 소스 리스트로 옮기고 클럭 소스를 다시 선택하는 과정을 거치게 한다.
kernel/time/clocksource.c
static int __clocksource_watchdog_kthread(void)
{
struct clocksource *cs, *tmp;
unsigned long flags;
LIST_HEAD(unstable);
int select = 0;
spin_lock_irqsave(&watchdog_lock, flags);
list_for_each_entry_safe(cs, tmp, &watchdog_list, wd_list) {
if (cs->flags & CLOCK_SOURCE_UNSTABLE) {
list_del_init(&cs->wd_list);
list_add(&cs->wd_list, &unstable);
select = 1;
}
if (cs->flags & CLOCK_SOURCE_RESELECT) {
cs->flags &= ~CLOCK_SOURCE_RESELECT;
select = 1;
}
}
/* Check if the watchdog timer needs to be stopped. */
clocksource_stop_watchdog();
spin_unlock_irqrestore(&watchdog_lock, flags);
/* Needs to be done outside of watchdog lock */
list_for_each_entry_safe(cs, tmp, &unstable, wd_list) {
list_del_init(&cs->wd_list);
__clocksource_change_rating(cs, 0);
}
return select;
}
워치독 리스트에 있는 클럭 소스 중 불안정한 클럭 소스들의 rating을 0으로 바꿔서 다시 클럭 소스 리스트로 옮긴다.
kernel/time/clocksource.c
static void __clocksource_change_rating(struct clocksource *cs, int rating)
{
list_del(&cs->list);
cs->rating = rating;
clocksource_enqueue(cs);
}
지정한 클럭 소스의 rating을 변경하고 다시 클럭 소스 리스트에 추가한다.
kernel/time/clocksource.c
/*
* clocksource_done_booting - Called near the end of core bootup
*
* Hack to avoid lots of clocksource churn at boot time.
* We use fs_initcall because we want this to start before
* device_initcall but after subsys_initcall.
*/
static int __init clocksource_done_booting(void)
{
mutex_lock(&clocksource_mutex);
curr_clocksource = clocksource_default_clock();
finished_booting = 1;
/*
* Run the watchdog first to eliminate unstable clock sources
*/
__clocksource_watchdog_kthread();
clocksource_select();
mutex_unlock(&clocksource_mutex);
return 0;
}
fs_initcall(clocksource_done_booting);
unstable한 클럭 소스를 제거하고 가장 best한 클럭 소스를 선택한다.
<kernel v5.4>
sched_clock은 시간 계산에 사용하는 ns 단위의 카운터를 제공하며 클럭 소스 서브시스템에서 제공하는 고정밀도 카운터를 사용하여 sched_clock으로 등록한다.
다음 그림은 jiffies 클럭 카운터에서 56비트 아키텍트 카운터 기반의 스케줄 클럭으로 등록되어 전환되는 과정을 보여준다.
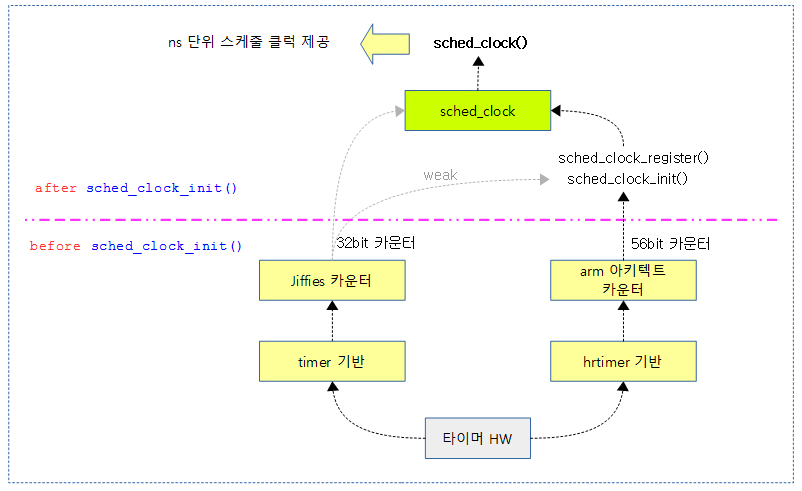
arm 및 arm64에서는 CONFIG_HAVE_UNSTABLE_SCHED_CLOCK 커널 옵션이 사용되지 않는다. 따라서 이 옵션이 사용되지 않는 함수를 분석한다.
kernel/sched/clock.c
void __init sched_clock_init(void)
{
static_branch_inc(&sched_clock_running);
local_irq_disable();
generic_sched_clock_init();
local_irq_enable();
}
irq를 블럭한 상태에서 generic 스케줄 클럭 초기화를 수행한다.
kernel/time/sched_clock.c
void __init generic_sched_clock_init(void)
{
/*
* If no sched_clock() function has been provided at that point,
* make it the final one one.
*/
if (cd.actual_read_sched_clock == jiffy_sched_clock_read)
sched_clock_register(jiffy_sched_clock_read, BITS_PER_LONG, HZ);
update_sched_clock();
/*
* Start the timer to keep sched_clock() properly updated and
* sets the initial epoch.
*/
hrtimer_init(&sched_clock_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
sched_clock_timer.function = sched_clock_poll;
hrtimer_start(&sched_clock_timer, cd.wrap_kt, HRTIMER_MODE_REL);
}
sched_clock을 초기화한다.
kernel/time/sched_clock.c
static struct clock_data cd ____cacheline_aligned = {
.read_data[0] = { .mult = NSEC_PER_SEC / HZ,
.read_sched_clock = jiffy_sched_clock_read, },
.actual_read_sched_clock = jiffy_sched_clock_read,
};
스케줄 클럭은 지정되지 않는 경우 위의 jiffies 후크 함수가 사용된다.
kernel/time/sched_clock.c
static u64 notrace jiffy_sched_clock_read(void)
{
/*
* We don't need to use get_jiffies_64 on 32-bit arches here
* because we register with BITS_PER_LONG
*/
return (u64)(jiffies - INITIAL_JIFFIES);
}
커널 부트업 시 초반에는 jiffy_sched_clock_read()를 사용한다.
kernel/time/sched_clock.c
static enum hrtimer_restart sched_clock_poll(struct hrtimer *hrt)
{
update_sched_clock();
hrtimer_forward_now(hrt, cd.wrap_kt);
return HRTIMER_RESTART;
}
스케줄 클럭을 갱신하고, 다시 hrtimer의 forward 기능을 사용하여 프로그램한다. (약 1시간 주기)
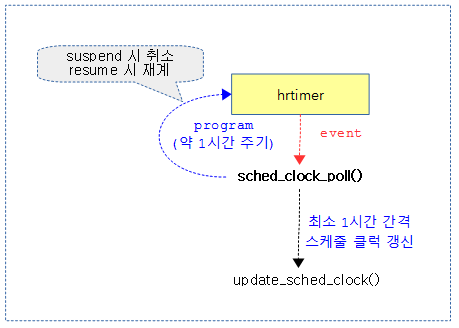
kernel/time/sched_clock.c
void __init
sched_clock_register(u64 (*read)(void), int bits, unsigned long rate)
{
u64 res, wrap, new_mask, new_epoch, cyc, ns;
u32 new_mult, new_shift;
unsigned long r;
char r_unit;
struct clock_read_data rd;
if (cd.rate > rate)
return;
WARN_ON(!irqs_disabled());
/* Calculate the mult/shift to convert counter ticks to ns. */
clocks_calc_mult_shift(&new_mult, &new_shift, rate, NSEC_PER_SEC, 3600);
new_mask = CLOCKSOURCE_MASK(bits);
cd.rate = rate;
/* Calculate how many nanosecs until we risk wrapping */
wrap = clocks_calc_max_nsecs(new_mult, new_shift, 0, new_mask, NULL);
cd.wrap_kt = ns_to_ktime(wrap);
rd = cd.read_data[0];
/* Update epoch for new counter and update 'epoch_ns' from old counter*/
new_epoch = read();
cyc = cd.actual_read_sched_clock();
ns = rd.epoch_ns + cyc_to_ns((cyc - rd.epoch_cyc) & rd.sched_clock_mask, rd.mult, rd.shift);
cd.actual_read_sched_clock = read;
rd.read_sched_clock = read;
rd.sched_clock_mask = new_mask;
rd.mult = new_mult;
rd.shift = new_shift;
rd.epoch_cyc = new_epoch;
rd.epoch_ns = ns;
update_clock_read_data(&rd);
if (sched_clock_timer.function != NULL) {
/* update timeout for clock wrap */
hrtimer_start(&sched_clock_timer, cd.wrap_kt, HRTIMER_MODE_REL);
}
r = rate;
if (r >= 4000000) {
r /= 1000000;
r_unit = 'M';
} else {
if (r >= 1000) {
r /= 1000;
r_unit = 'k';
} else {
r_unit = ' ';
}
}
/* Calculate the ns resolution of this counter */
res = cyc_to_ns(1ULL, new_mult, new_shift);
pr_info("sched_clock: %u bits at %lu%cHz, resolution %lluns, wraps every %lluns\n",
bits, r, r_unit, res, wrap);
/* Enable IRQ time accounting if we have a fast enough sched_clock() */
if (irqtime > 0 || (irqtime == -1 && rate >= 1000000))
enable_sched_clock_irqtime();
pr_debug("Registered %pS as sched_clock source\n", read);
}
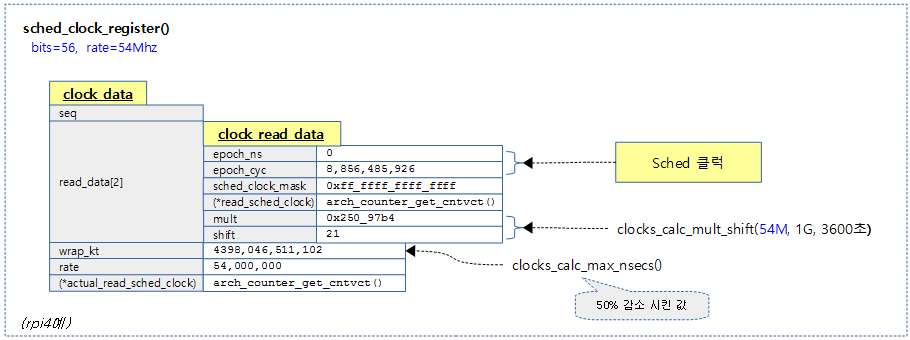
클럭 소스의 카운터 읽기 함수를 sched_clock으로 등록하여 사용한다.
다음 그림은 rpi4 시스템이 사용하는 56비트 아키텍트 카운터를 스케줄 클럭으로 등록시킨 모습을 보여준다.
스케줄 클럭은 nmi 인터럽트 핸들러에서 dead-lock을 없애고 빠르게 읽어낼 수 있도록 시퀀스 카운터를 사용한 lock-less 구현을 사용하였고, 다음과 같이 두 개의 clock_read_data 구조체를 사용하여 관리한다.
다음 그림은 두 개의 클럭 데이터로 운영되는 모습을 보여준다.

kernel/time/sched_clock.c
/* * Atomically update the sched_clock() epoch. */
static void update_sched_clock(void)
{
u64 cyc;
u64 ns;
struct clock_read_data rd;
rd = cd.read_data[0];
cyc = cd.actual_read_sched_clock();
ns = rd.epoch_ns + cyc_to_ns((cyc - rd.epoch_cyc) & rd.sched_clock_mask, rd.mult, rd.shift);
rd.epoch_ns = ns;
rd.epoch_cyc = cyc;
update_clock_read_data(&rd);
}
스케줄 클럭을 읽어 갱신한다.
kernel/time/sched_clock.c
/* * Updating the data required to read the clock. * * sched_clock() will never observe mis-matched data even if called from * an NMI. We do this by maintaining an odd/even copy of the data and * steering sched_clock() to one or the other using a sequence counter. * In order to preserve the data cache profile of sched_clock() as much * as possible the system reverts back to the even copy when the update * completes; the odd copy is used *only* during an update. */
static void update_clock_read_data(struct clock_read_data *rd)
{
/* update the backup (odd) copy with the new data */
cd.read_data[1] = *rd;
/* steer readers towards the odd copy */
raw_write_seqcount_latch(&cd.seq);
/* now its safe for us to update the normal (even) copy */
cd.read_data[0] = *rd;
/* switch readers back to the even copy */
raw_write_seqcount_latch(&cd.seq);
}
@rd 값을 사용하여 스케줄 클럭을 홀/짝 두 개의 클럭 데이터에 갱신한다.
kernel/time/sched_clock.c
unsigned long long notrace sched_clock(void)
{
u64 cyc, res;
unsigned int seq;
struct clock_read_data *rd;
do {
seq = raw_read_seqcount(&cd.seq);
rd = cd.read_data + (seq & 1);
cyc = (rd->read_sched_clock() - rd->epoch_cyc) &
rd->sched_clock_mask;
res = rd->epoch_ns + cyc_to_ns(cyc, rd->mult, rd->shift);
} while (read_seqcount_retry(&cd.seq, seq));
return res;
}
스케줄 클럭을 읽어 반환한다.
다음 그림은 suspend/resume에 대해 스케줄 클럭이 전환되도록 핸들러를 초기화하는 과정을 보여준다.
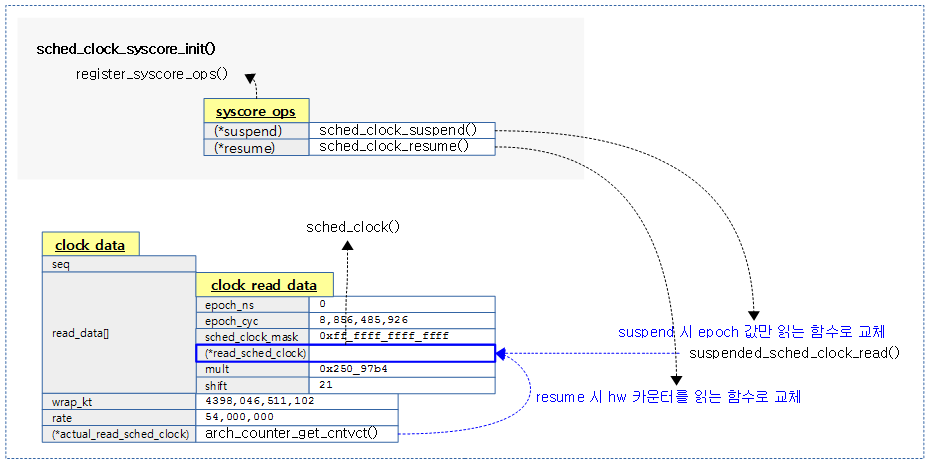
kernel/time/sched_clock.c
static int __init sched_clock_syscore_init(void)
{
register_syscore_ops(&sched_clock_ops);
return 0;
}
device_initcall(sched_clock_syscore_init);
suspend/resume을 위해 sched_clock_ops를 등록한다.
kernel/time/sched_clock.c
static struct syscore_ops sched_clock_ops = {
.suspend = sched_clock_suspend,
.resume = sched_clock_resume,
};
kernel/time/sched_clock.c
int sched_clock_suspend(void)
{
struct clock_read_data *rd = &cd.read_data[0];
update_sched_clock();
hrtimer_cancel(&sched_clock_timer);
rd->read_sched_clock = suspended_sched_clock_read;
return 0;
}
suspend 시 호출되어 스케줄 클럭의 동작 방식을 변경한다.
kernel/time/sched_clock.c
void sched_clock_resume(void)
{
struct clock_read_data *rd = &cd.read_data[0];
rd->epoch_cyc = cd.actual_read_sched_clock();
hrtimer_start(&sched_clock_timer, cd.wrap_kt, HRTIMER_MODE_REL);
rd->read_sched_clock = cd.actual_read_sched_clock;
}
resume 시 호출되어 스케줄 클럭의 동작 방식을 변경한다.
kernel/time/sched_clock.c
/* * Clock read function for use when the clock is suspended. * * This function makes it appear to sched_clock() as if the clock * stopped counting at its last update. * * This function must only be called from the critical * section in sched_clock(). It relies on the read_seqcount_retry() * at the end of the critical section to be sure we observe the * correct copy of 'epoch_cyc'. */
static u64 notrace suspended_sched_clock_read(void)
{
unsigned int seq = raw_read_seqcount(&cd.seq);
return cd.read_data[seq & 1].epoch_cyc;
}
suspend 시 읽어들일 스케줄 클럭 값을 반환한다.
arm64 시스템에서 cpu는 cfe를 사용한 busy-wait 루프를 사용하여 대기한다. atomic context에서 ndelay() 또는 udelay() API들이 사용된다. 그러나 mdelay() API는 너무 오랫동안 busy-wait을 하므로 권장되지 않으며 가능하면 non-atomic context에서 사용되는 msleep() API를 사용하는 것이 좋다.
다음 그림은 arm64용 delay 관련 함수의 호출 관계를 보여준다.
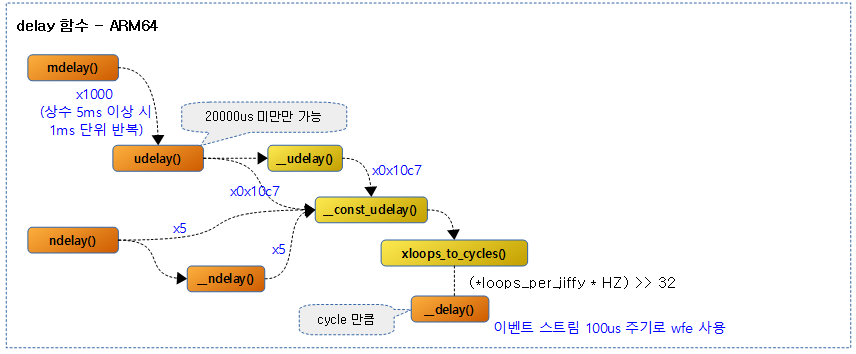
include/linux/delay.h
#define mdelay(n) (\
(__builtin_constant_p(n) && (n)<=MAX_UDELAY_MS) ? udelay((n)*1000) : \
({unsigned long __ms=(n); while (__ms--) udelay(1000);}))
#endif
@n 밀리 세컨드 만큼 delay 한다.
include/asm-generic/delay.h
/* * The weird n/20000 thing suppresses a "comparison is always false due to * limited range of data type" warning with non-const 8-bit arguments. */ /* 0x10c7 is 2**32 / 1000000 (rounded up) */
#define udelay(n) \
({ \
if (__builtin_constant_p(n)) { \
if ((n) / 20000 >= 1) \
__bad_udelay(); \
else \
__const_udelay((n) * 0x10c7ul); \
} else { \
__udelay(n); \
} \
})
@n 마이크로 세컨드 만큼 delay 한다.
arch/arm64/lib/delay.c
void __udelay(unsigned long usecs)
{
__const_udelay(usecs * 0x10C7UL); /* 2**32 / 1000000 (rounded up) */
}
EXPORT_SYMBOL(__udelay);
@usec 마이크로 세컨드 만큼 delay 한다.
arch/arm64/lib/delay.c
inline void __const_udelay(unsigned long xloops)
{
__delay(xloops_to_cycles(xloops));
}
EXPORT_SYMBOL(__const_udelay);
@xloops 루프 만큼 delay 한다.
include/asm-generic/delay.h
/* 0x5 is 2**32 / 1000000000 (rounded up) */
#define ndelay(n) \
({ \
if (__builtin_constant_p(n)) { \
if ((n) / 20000 >= 1) \
__bad_ndelay(); \
else \
__const_udelay((n) * 5ul); \
} else { \
__ndelay(n); \
} \
})
#endif /* __ASM_GENERIC_DELAY_H */
@n 나노 세컨드 만큼 delay 한다.
arch/arm64/lib/delay.c
void __ndelay(unsigned long nsecs)
{
__const_udelay(nsecs * 0x5UL); /* 2**32 / 1000000000 (rounded up) */
}
EXPORT_SYMBOL(__ndelay);
@nsec 나노 세컨드 만큼 delay 한다.
arch/arm64/lib/delay.c
static inline unsigned long xloops_to_cycles(unsigned long xloops)
{
return (xloops * loops_per_jiffy * HZ) >> 32;
}
@xloops 루프 단위를 사이클 단위로 변환하여 반환한다.
arch/arm64/lib/delay.c
void __delay(unsigned long cycles)
{
cycles_t start = get_cycles();
if (arch_timer_evtstrm_available()) {
const cycles_t timer_evt_period =
USECS_TO_CYCLES(ARCH_TIMER_EVT_STREAM_PERIOD_US);
while ((get_cycles() - start + timer_evt_period) < cycles)
wfe();
}
while ((get_cycles() - start) < cycles)
cpu_relax();
}
EXPORT_SYMBOL(__delay);
@cycles 사이클 단위의 수 만큼 delay 한다.
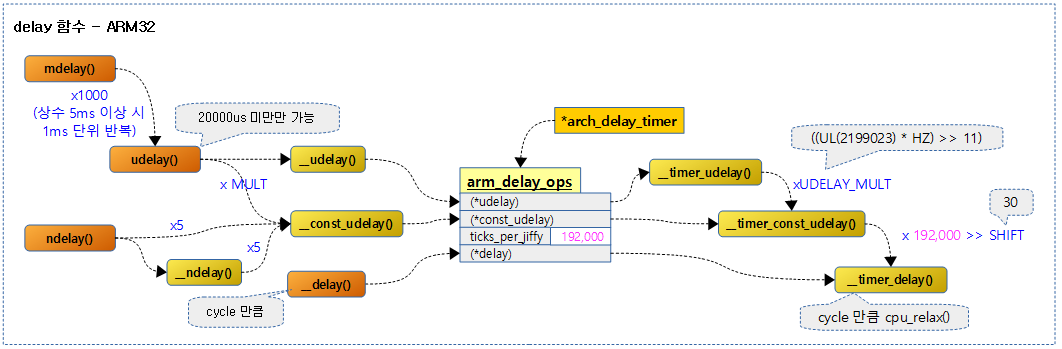
arm32 시스템에서는 busy-wait 기반의 delay 타이머를 사용한다.
다음 그림은 arm32용 delay 관련 함수의 호출 관계를 보여준다.
arch_timer_delay_timer_register()
arch/arm/kernel/arch_timer.c
static void __init arch_timer_delay_timer_register(void)
{
/* Use the architected timer for the delay loop. */
arch_delay_timer.read_current_timer = arch_timer_read_counter_long;
arch_delay_timer.freq = arch_timer_get_rate();
register_current_timer_delay(&arch_delay_timer);
}
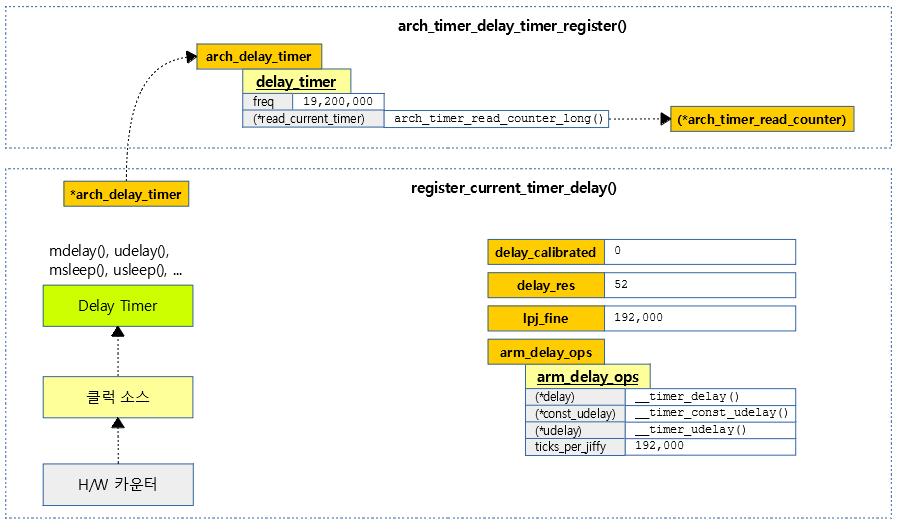
armv7 아키텍처에 내장된 generic 타이머를 delay 타이머로 사용할 수 있도록 등록한다.
다음 그림은 100hz로 구성된 generic 타이머를 딜레이 타이머로 등록하는 과정을 보여준다.
arch/arm/lib/delay.c
void __init register_current_timer_delay(const struct delay_timer *timer)
{
u32 new_mult, new_shift;
u64 res;
clocks_calc_mult_shift(&new_mult, &new_shift, timer->freq,
NSEC_PER_SEC, 3600);
res = cyc_to_ns(1ULL, new_mult, new_shift);
if (!delay_calibrated && (!delay_res || (res < delay_res))) {
pr_info("Switching to timer-based delay loop, resolution %lluns\n", res);
delay_timer = timer;
lpj_fine = timer->freq / HZ;
delay_res = res;
/* cpufreq may scale loops_per_jiffy, so keep a private copy */
arm_delay_ops.ticks_per_jiffy = lpj_fine;
arm_delay_ops.delay = __timer_delay;
arm_delay_ops.const_udelay = __timer_const_udelay;
arm_delay_ops.udelay = __timer_udelay;
} else {
pr_info("Ignoring duplicate/late registration of read_current_timer delay\n");
}
}
딜레이 타이머를 등록하고 calibration 한다. 처음 설정 시에는 반드시 calibration을 한다.
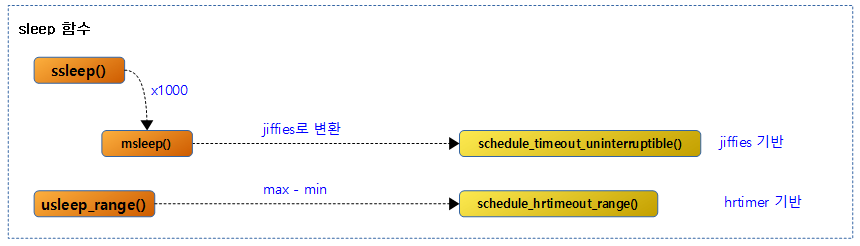
non-atomic context에서 사용할 수 있는 함수들은 다음과 같다. 10us ~ 20ms까지는 usleep() 보다 atomic context 사용 가능한 udelay()를 사용하길 권장한다.
다음 그림은 sleep 관련 함수의 호출 관계를 보여준다.
include/linux/delay.h
static inline void ssleep(unsigned int seconds)
{
msleep(seconds * 1000);
}
@seconds 세컨드만큼 슬립한다.
kernel/time/timer.c
/** * msleep - sleep safely even with waitqueue interruptions * @msecs: Time in milliseconds to sleep for */
void msleep(unsigned int msecs)
{
unsigned long timeout = msecs_to_jiffies(msecs) + 1;
while (timeout)
timeout = schedule_timeout_uninterruptible(timeout);
}
EXPORT_SYMBOL(msleep);
@msec 밀리 세컨드만큼 jiffies 스케줄 틱 기반으로 슬립한다.
kernel/time/timer.c
/** * usleep_range - Sleep for an approximate time * @min: Minimum time in usecs to sleep * @max: Maximum time in usecs to sleep * * In non-atomic context where the exact wakeup time is flexible, use * usleep_range() instead of udelay(). The sleep improves responsiveness * by avoiding the CPU-hogging busy-wait of udelay(), and the range reduces * power usage by allowing hrtimers to take advantage of an already- * scheduled interrupt instead of scheduling a new one just for this sleep. */
void __sched usleep_range(unsigned long min, unsigned long max)
{
ktime_t exp = ktime_add_us(ktime_get(), min);
u64 delta = (u64)(max - min) * NSEC_PER_USEC;
for (;;) {
__set_current_state(TASK_UNINTERRUPTIBLE);
/* Do not return before the requested sleep time has elapsed */
if (!schedule_hrtimeout_range(&exp, delta, HRTIMER_MODE_ABS))
break;
}
}
EXPORT_SYMBOL(usleep_range);
@max – @min 마이크로 세컨드만큼 jiffies 스케줄 틱 기반으로 슬립한다.