<kernel v5.0>
DMA -5- (DMA-IOMMU)
디바이스가 DMA(Direct Memory Access)로 IOMMU를 통과하여 메모리에 접근하기 위해 커널에서 제공하는 두 가지의 방법이 있다.
- IOMMU API
- drivers/iommu/iommu.c 파일에 IOMMU core API들이 제공된다.
- IOMMU API들 대부분이 iommu prefix로 이루어진 함수이다.
- iommu_*()
- drivers/iommu 디렉토리에 iommu 칩 드라이버들이 구현되어 있다.
- drivers/iommu/arm-smmu.c
- drivers/iommu/arm-smmu-v3.c
- drivers/iommu/intel-iommu.c
- drivers/iommu/amd_iommu.c
- …
- DMA-IOMMU API
- drivers/iommu/dma-iommu.c 파일에 DMA-IOMMU core API들이 제공된다.
- DMA-IOMMU API들 대부분이 iommu_dma prefix로 이루어진 함수이다.
- iommu_dma_*()
- drivers/iommu 디렉토리에 iommu 칩 드라이버들이 구현되어 있다.
- arch/arm/mm/dma-mapping.c (2가지 구현)
- arch/arm64/mm/dma-mapping.c
- arch/x86/kernel/amd-gart_64.c
- …
다음 그림은 IOMMU에 연결된 사용자 디바이스가 IOMMU 매핑을 위해 IOMMU API 또는 DMA-IOMMU API 를 통해 접근할 수 있음을 보여준다.
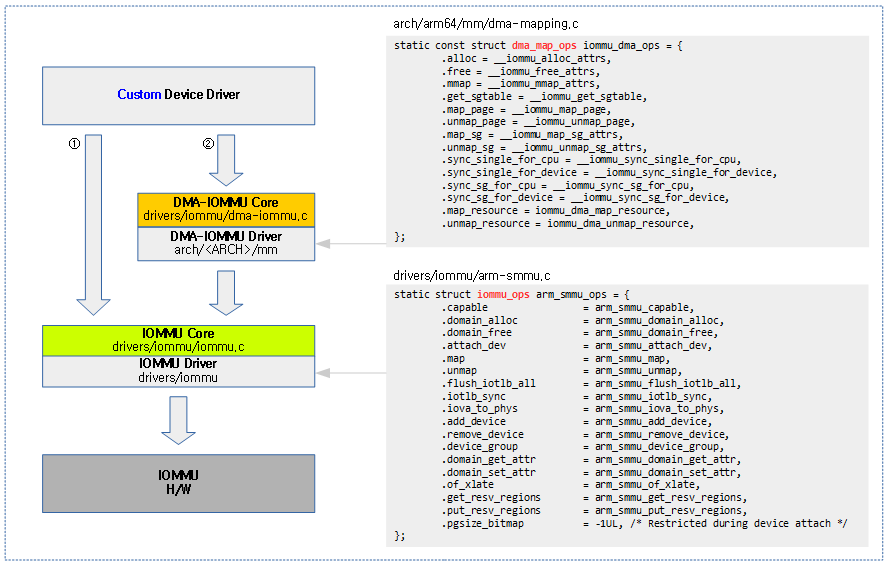
DMA-IOMMU
IOMMU를 통해 시스템 메모리의 물리 주소에 접근할 수 있는 디바이스가 dma coherent 메모리를 할당하는 방법은 각 시스템의 IOMMU 장치마다 다른 구현을 가진다. 이 글에서는 DMA-IOMMU에 대한 core API를 위주로 분석하고, 조금씩 이에 대응하는 ARM64 아키텍처에 코드를 추가로 분석한다.
- DMA-IOMMU API가 아닌 IOMMU API와 관련된 문서는 다음을 참고한다.
- IOMMU | 문c
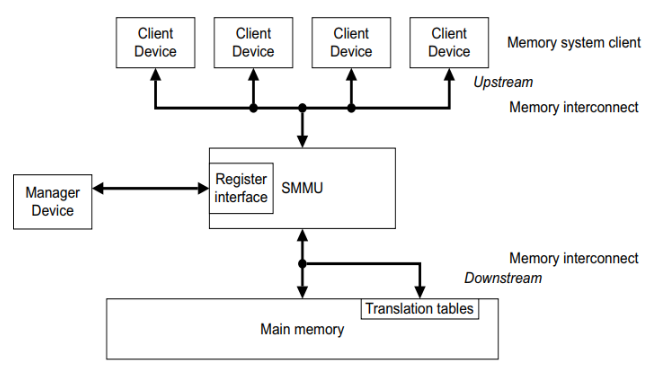
ARM, ARM64 – CoreLink MMU-500 System
다음 그림은 ARM, ARM64에서 사용하는 SMMU를 보여준다.
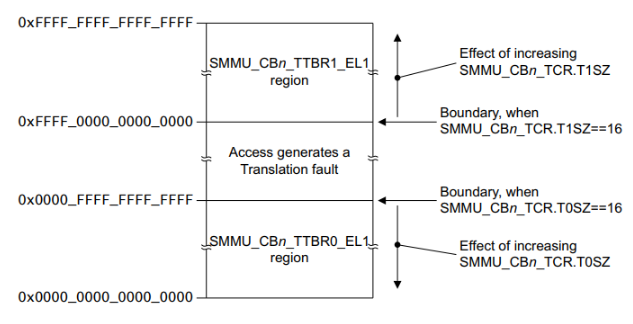
다음 그림은 SMMU가 관리하는 두 개의 공간 모습을 보여준다.
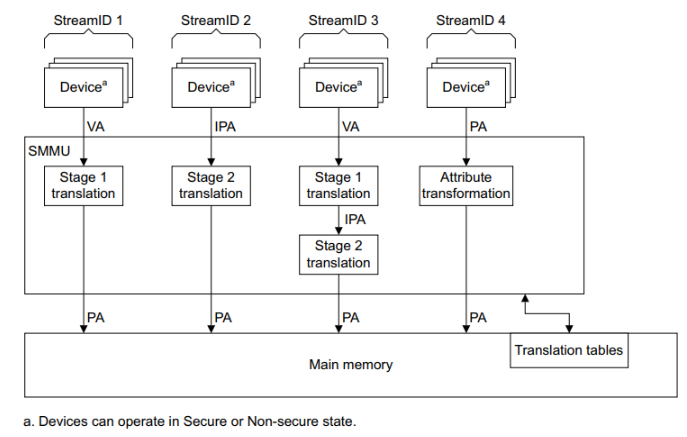
다음 그림은 SMMU를 사용한 매핑들을 보여준다.
초기화
ARM64 IOMMU-DMA 초기화
arch/arm64/mm/dma-mapping.c
static int __init __iommu_dma_init(void)
{
return iommu_dma_init();
}
arch_initcall(__iommu_dma_init);
iommu dma를 초기화한다.
drivers/iommu/dma-iommu.c
int iommu_dma_init(void)
{
return iova_cache_get();
}
iommu dma를 위해 iova 캐시를 생성한다.
iova_cache_get()
drivers/iommu/iova.c
int iova_cache_get(void)
{
mutex_lock(&iova_cache_mutex);
if (!iova_cache_users) {
iova_cache = kmem_cache_create(
"iommu_iova", sizeof(struct iova), 0,
SLAB_HWCACHE_ALIGN, NULL);
if (!iova_cache) {
mutex_unlock(&iova_cache_mutex);
printk(KERN_ERR "Couldn't create iova cache\n");
return -ENOMEM;
}
}
iova_cache_users++;
mutex_unlock(&iova_cache_mutex);
return 0;
}
EXPORT_SYMBOL_GPL(iova_cache_get);
iova 캐시를 생성한다.
- 코드 라인 4~13에서 처음 iova 캐시를 사용할 때 iova 구조체를 공급할 수 있도록 kmem 캐시를 생성한다.
- 코드 라인 15에서 한 번만 kmem 캐시가 생성되도록 카운트를 증가시킨다.
디바이스 트리를 통한 DMA 준비
of_dma_configure()
drivers/of/device.c
/** * of_dma_configure - Setup DMA configuration * @dev: Device to apply DMA configuration * @np: Pointer to OF node having DMA configuration * @force_dma: Whether device is to be set up by of_dma_configure() even if * DMA capability is not explicitly described by firmware. * * Try to get devices's DMA configuration from DT and update it * accordingly. * * If platform code needs to use its own special DMA configuration, it * can use a platform bus notifier and handle BUS_NOTIFY_ADD_DEVICE events * to fix up DMA configuration. */
int of_dma_configure(struct device *dev, struct device_node *np, bool force_dma)
{
u64 dma_addr, paddr, size = 0;
int ret;
bool coherent;
unsigned long offset;
const struct iommu_ops *iommu;
u64 mask;
ret = of_dma_get_range(np, &dma_addr, &paddr, &size);
if (ret < 0) {
/*
* For legacy reasons, we have to assume some devices need
* DMA configuration regardless of whether "dma-ranges" is
* correctly specified or not.
*/
if (!force_dma)
return ret == -ENODEV ? 0 : ret;
dma_addr = offset = 0;
} else {
offset = PFN_DOWN(paddr - dma_addr);
/*
* Add a work around to treat the size as mask + 1 in case
* it is defined in DT as a mask.
*/
if (size & 1) {
dev_warn(dev, "Invalid size 0x%llx for dma-range\n",
size);
size = size + 1;
}
if (!size) {
dev_err(dev, "Adjusted size 0x%llx invalid\n", size);
return -EINVAL;
}
dev_dbg(dev, "dma_pfn_offset(%#08lx)\n", offset);
}
- 코드 라인 10~20에서 “dma-ranges” 속성을 읽어 dma 주소와, 물리 주소, 사이즈를 알아온다. 만일 속성이 없이 사용된 legacy를 위해 1:1 direct 매핑으로 판단하여 dma 주소와 offset 을 모두 0으로 한다.
- 코드 라인 21~39에서 물리 주소에서 dma 주소를 뺀 값을 offset으로 한다. 워크어라운드 이슈로 size는 짝수로 round up한다.
/*
* If @dev is expected to be DMA-capable then the bus code that created
* it should have initialised its dma_mask pointer by this point. For
* now, we'll continue the legacy behaviour of coercing it to the
* coherent mask if not, but we'll no longer do so quietly.
*/
if (!dev->dma_mask) {
dev_warn(dev, "DMA mask not set\n");
dev->dma_mask = &dev->coherent_dma_mask;
}
if (!size && dev->coherent_dma_mask)
size = max(dev->coherent_dma_mask, dev->coherent_dma_mask + 1);
else if (!size)
size = 1ULL << 32;
dev->dma_pfn_offset = offset;
/*
* Limit coherent and dma mask based on size and default mask
* set by the driver.
*/
mask = DMA_BIT_MASK(ilog2(dma_addr + size - 1) + 1);
dev->coherent_dma_mask &= mask;
*dev->dma_mask &= mask;
/* ...but only set bus mask if we found valid dma-ranges earlier */
if (!ret)
dev->bus_dma_mask = mask;
coherent = of_dma_is_coherent(np);
dev_dbg(dev, "device is%sdma coherent\n",
coherent ? " " : " not ");
iommu = of_iommu_configure(dev, np);
if (IS_ERR(iommu) && PTR_ERR(iommu) == -EPROBE_DEFER)
return -EPROBE_DEFER;
dev_dbg(dev, "device is%sbehind an iommu\n",
iommu ? " " : " not ");
arch_setup_dma_ops(dev, dma_addr, size, iommu, coherent);
return 0;
}
EXPORT_SYMBOL_GPL(of_dma_configure);
디바이스 트리로부터 dma 매핑 값을 읽어 디바이스의 dma 매핑 지원을 위해 설정한다. 1:1 direct 매핑이 아닌 경우 iommu 설정도 수행한다.
- 코드 라인 7~10에서 디바이스에 dma 주소제한이 설정되어 있지 않은 경우 경고 메시지를 출력한 후 디바이스의 coherent 주소 제한 값을 사용한다.
- 코드 라인 12~15에서 size가 0(“dma-ranges”를 사용하지 않은 legacy)일 때 다음과 같이 size를 설정한다.
- coherent 주소 제한이 설정된 경우 size 값은 coherent 주소 제한 값+1로 한다. 주소가 경계를 넘어가지 않게 제한한다.
- 예) coherent_dma_mask=0xffff_ffff 인 경우
- 32비트 시스템에서 size=0xffff_ffff
- 64비트 시스템에서 size=0x1_0000_0000
- 예) coherent_dma_mask=0xffff_ffff 인 경우
- coherent 주소 제한이 설정되지 않은 경우 size 값은 0x1_0000_0000 (4G)로 한다.
- coherent 주소 제한이 설정된 경우 size 값은 coherent 주소 제한 값+1로 한다. 주소가 경계를 넘어가지 않게 제한한다.
- 코드 라인 17에서 디바이스의 dma_pfn_offset 값에 offset 값을 대입한다. (paddr – dma_addr)
- 코드 라인 23~25에서 dma 주소 + size 를 적용한 마스크 값으로 디바이스의 coherent 및 dma 주소 제한을 한다.
- 코드 라인 27~28에서 “dma-ranges” 속성이 발견된 경우에 한해서 디바이스의 버스 주소 제한값에 dma 주소 + size를 적용한 마스크 값을 사용한다.
- 코드 라인 30~32에서 “dma-coherent” 속성이 있는지 찾아 coherent 디바이스인지 여부를 디버그 메시지로 출력한다.
- 코드 라인 34~36에서 디바이스를 위해 iommu를 설정한다.
- 코드 라인 38~39에서 iommu 아래에 디바이스가 동작하는지 여부를 디버그 메시지로 출력한다.
- 코드 라인 41에서 디바이스에 대한 dma opeation을 셋업한다.
of_dma_get_range()
drivers/of/address.c
/** * of_dma_get_range - Get DMA range info * @np: device node to get DMA range info * @dma_addr: pointer to store initial DMA address of DMA range * @paddr: pointer to store initial CPU address of DMA range * @size: pointer to store size of DMA range * * Look in bottom up direction for the first "dma-ranges" property * and parse it. * dma-ranges format: * DMA addr (dma_addr) : naddr cells * CPU addr (phys_addr_t) : pna cells * size : nsize cells * * It returns -ENODEV if "dma-ranges" property was not found * for this device in DT. */
int of_dma_get_range(struct device_node *np, u64 *dma_addr, u64 *paddr, u64 *size)
{
struct device_node *node = of_node_get(np);
const __be32 *ranges = NULL;
int len, naddr, nsize, pna;
int ret = 0;
u64 dmaaddr;
if (!node)
return -EINVAL;
while (1) {
naddr = of_n_addr_cells(node);
nsize = of_n_size_cells(node);
node = of_get_next_parent(node);
if (!node)
break;
ranges = of_get_property(node, "dma-ranges", &len);
/* Ignore empty ranges, they imply no translation required */
if (ranges && len > 0)
break;
/*
* At least empty ranges has to be defined for parent node if
* DMA is supported
*/
if (!ranges)
break;
}
if (!ranges) {
pr_debug("no dma-ranges found for node(%pOF)\n", np);
ret = -ENODEV;
goto out;
}
len /= sizeof(u32);
pna = of_n_addr_cells(node);
/* dma-ranges format:
* DMA addr : naddr cells
* CPU addr : pna cells
* size : nsize cells
*/
dmaaddr = of_read_number(ranges, naddr);
*paddr = of_translate_dma_address(np, ranges);
if (*paddr == OF_BAD_ADDR) {
pr_err("translation of DMA address(%pad) to CPU address failed node(%pOF)\n",
dma_addr, np);
ret = -EINVAL;
goto out;
}
*dma_addr = dmaaddr;
*size = of_read_number(ranges + naddr + pna, nsize);
pr_debug("dma_addr(%llx) cpu_addr(%llx) size(%llx)\n",
*dma_addr, *paddr, *size);
out:
of_node_put(node);
return ret;
}
디바이스 트리의 @np 노드에서 “dma-ranges” 속성을 읽어 dma 주소와, 물리 주소, 사이즈를 알아온다.
- 코드 라인 13에서 상위 노드에서 “#address-cells” 값을 알아온다.
- “dma-ranges” 속성의 주소에 32비트 주소 값을 사용하려면 1, 64비트 주소 값을 사용하려면 2를 사용한다.
- 코드 라인 14에서 상위 노드에서 “#size-cells” 값을 알아온다.
- 코드 라인 15~17에서 부모 노드가 없으면 루프를 빠져나간다.
- 코드 라인 19에서 “dma-ranges” 속성을 읽어온다. len에는 읽은 속성의 길이가 담긴다.
- 코드 라인 22~23에서 정상적으로 읽어온 경우 루프를 빠져나간다.
- 코드 라인 29~30에서 정상적으로 읽어오지 못한 경우 루프를 빠져나간다.
- 코드 라인 33~37에서 “dma-ranges” 속성을 못찾은 경우 디버그 메시지를 출력하고 -ENODEV 에러로 함수를 빠져나간다.
- 코드 라인 49~56에서 dma 주소와 물리 주소를 얻어 @dma_addr 및 @paddr에 대입한다.
- 코드 라인 58에서 size를 얻어 @size에 대입한다.
- 코드 라인 60~61에서 dma range에 대한 디버그 정보를 출력한다.
예) ARM64 juno 보드
DMA 주소 0x0 ~ 0x100_0000_0000 128G를 동일한 cpu 물리주소에 매핑한다. (inbound 매핑)
arch/arm64/boot/dts/arm/juno-base.dtsi
{
dma-ranges = <0 0 0 0 0x100 0>;
...
- <dma_addr:msb> <dma_addr:lsb> <cpu_addr:msb> <cpu_addr:lsb> <len:msb> <len:lsb>
예) ARM rpi2 & rpi3 보드
DMA 주소 0xc000_0000 ~ 0xff00_0000 1008M를 cpu 물리주소 0x0 ~ 0x3f00_0000에 매핑한다. (inbound 매핑)
boot/dts/bcm2836.dtsi & bcm2837.dtsi
soc {
ranges = <0x7e000000 0x3f000000 0x1000000>,
<0x40000000 0x40000000 0x00001000>;
dma-ranges = <0xc0000000 0x00000000 0x3f000000>;
...
- <dma_addr> <cpu_addr> <len>
of_dma_is_coherent()
drivers/of/address.c
/** * of_dma_is_coherent - Check if device is coherent * @np: device node * * It returns true if "dma-coherent" property was found * for this device in DT. */
bool of_dma_is_coherent(struct device_node *np)
{
struct device_node *node = of_node_get(np);
while (node) {
if (of_property_read_bool(node, "dma-coherent")) {
of_node_put(node);
return true;
}
node = of_get_next_parent(node);
}
of_node_put(node);
return false;
}
EXPORT_SYMBOL_GPL(of_dma_is_coherent);
디바이스 트리의 @np 노드 또는 상위노드에서 “dma-coherent” 속성 발견 여부로 dma coherent 디바이스 여부를 반환한다.
of_iommu_configure()
drivers/iommu/of_iommu.c
const struct iommu_ops *of_iommu_configure(struct device *dev,
struct device_node *master_np)
{
const struct iommu_ops *ops = NULL;
struct iommu_fwspec *fwspec = dev_iommu_fwspec_get(dev);
int err = NO_IOMMU;
if (!master_np)
return NULL;
if (fwspec) {
if (fwspec->ops)
return fwspec->ops;
/* In the deferred case, start again from scratch */
iommu_fwspec_free(dev);
}
/*
* We don't currently walk up the tree looking for a parent IOMMU.
* See the `Notes:' section of
* Documentation/devicetree/bindings/iommu/iommu.txt
*/
if (dev_is_pci(dev)) {
struct of_pci_iommu_alias_info info = {
.dev = dev,
.np = master_np,
};
err = pci_for_each_dma_alias(to_pci_dev(dev),
of_pci_iommu_init, &info);
} else if (dev_is_fsl_mc(dev)) {
err = of_fsl_mc_iommu_init(to_fsl_mc_device(dev), master_np);
} else {
struct of_phandle_args iommu_spec;
int idx = 0;
while (!of_parse_phandle_with_args(master_np, "iommus",
"#iommu-cells",
idx, &iommu_spec)) {
err = of_iommu_xlate(dev, &iommu_spec);
of_node_put(iommu_spec.np);
idx++;
if (err)
break;
}
}
/*
* Two success conditions can be represented by non-negative err here:
* >0 : there is no IOMMU, or one was unavailable for non-fatal reasons
* 0 : we found an IOMMU, and dev->fwspec is initialised appropriately
* <0 : any actual error
*/
if (!err) {
/* The fwspec pointer changed, read it again */
fwspec = dev_iommu_fwspec_get(dev);
ops = fwspec->ops;
}
/*
* If we have reason to believe the IOMMU driver missed the initial
* probe for dev, replay it to get things in order.
*/
if (!err && dev->bus && !device_iommu_mapped(dev))
err = iommu_probe_device(dev);
/* Ignore all other errors apart from EPROBE_DEFER */
if (err == -EPROBE_DEFER) {
ops = ERR_PTR(err);
} else if (err < 0) {
dev_dbg(dev, "Adding to IOMMU failed: %d\n", err);
ops = NULL;
}
return ops;
}
디바이스 트리에서 디바이스가 연결된 iommu를 찾아 fwspec을 전달한 후 해당 iommu 드라이버를 probe 한다. (fwspec은 iommu 드라이버에 전달할 id 등의 값)
- 코드 라인 8~9에서 노드가 지정되지 않은 경우 null을 반환한다.
- 코드 라인 11~17에서 디바이스에 iommu configure가 이미 완료된 경우 디바이스가 사용하고 있는 iommu_ops를 반환한다.
- 코드 라인 24~31에서 pci 디바이스인 경우 “iommu-map” 속성 값을 읽어들여 of_iommu_xlate() 함수를 호출한다.
- 코드 라인 32~33에서 NXP의 QoriQ DPAA2 “fsl-mc” 버스를 사용하는 디바이스인 경우에 “iommu-map” 속성 값을 읽어들여 of_iommu_xlate() 함수를 호출한다.
- 코드 라인 34~47에서 그 외의 일반 iommu인 경우 “iommus” 속성에 담긴 값을 읽고, 해당 iommu가 원하는 셀 수만큼 인자를 읽어들여 of_iommu_xlate() 함수를 호출한다.
- 코드 라인 55~59에서 iommu를 찾은 경우 디바이스에 지정된 iommu ops를 알아온다.
- 코드 라인 64~73에서 디바이스가 아직 iommu에 probe되지 않은 경우 probe를 시도한다. probe 시도 시 나중에 probe 해달라는 -EPROBE_DEFER 에러를 받을 수도 있다.
of_iommu_xlate()
drivers/iommu/of_iommu.c
static int of_iommu_xlate(struct device *dev,
struct of_phandle_args *iommu_spec)
{
const struct iommu_ops *ops;
struct fwnode_handle *fwnode = &iommu_spec->np->fwnode;
int err;
ops = iommu_ops_from_fwnode(fwnode);
if ((ops && !ops->of_xlate) ||
!of_device_is_available(iommu_spec->np))
return NO_IOMMU;
err = iommu_fwspec_init(dev, &iommu_spec->np->fwnode, ops);
if (err)
return err;
/*
* The otherwise-empty fwspec handily serves to indicate the specific
* IOMMU device we're waiting for, which will be useful if we ever get
* a proper probe-ordering dependency mechanism in future.
*/
if (!ops)
return driver_deferred_probe_check_state(dev);
return ops->of_xlate(dev, iommu_spec);
}
요청한 @iommu_spec phandle 인자를 iommu 드라이버의 (*of_xlate) 후크 함수를 통해 전달한다.
smmu에 연결된 디바이스 예)
smmu에 연결된 sdhci 디바이스가 0x6002, 0x0000 인자를 전달한다. (두 개 값을 조합하여 0x6002_0000라는 id를 지정한다.)
sdio0: sdhci@3f1000 {
compatible = "brcm,sdhci-iproc";
reg = <0x003f1000 0x100>;
interrupts = <GIC_SPI 204 IRQ_TYPE_LEVEL_HIGH>;
bus-width = <8>;
clocks = <&sdio0_clk>;
iommus = <&smmu 0x6002 0x0000>;
status = "disabled";
};
smmu 디바이스 예)
#iommu-cells 속성 값과 같이 2개의 인자를 전달받는 것을 알 수 있다.
smmu: mmu@3000000 {
compatible = "arm,mmu-500";
reg = <0x03000000 0x80000>;
...
#iommu-cells = <2>;
}
iommu_fwspec_init()
drivers/iommu/iommu.c
int iommu_fwspec_init(struct device *dev, struct fwnode_handle *iommu_fwnode,
const struct iommu_ops *ops)
{
struct iommu_fwspec *fwspec = dev_iommu_fwspec_get(dev);
if (fwspec)
return ops == fwspec->ops ? 0 : -EINVAL;
fwspec = kzalloc(sizeof(*fwspec), GFP_KERNEL);
if (!fwspec)
return -ENOMEM;
of_node_get(to_of_node(iommu_fwnode));
fwspec->iommu_fwnode = iommu_fwnode;
fwspec->ops = ops;
dev_iommu_fwspec_set(dev, fwspec);
return 0;
}
EXPORT_SYMBOL_GPL(iommu_fwspec_init);
iommu용 fwspec이 처음 초기화되는 경우 fwspec을 할당한 후 @iommu_fwnode 및 @ops를 설정한다. 성공 시 0을 반환한다.
arm_smmu_of_xlate() – ARM, ARM64
drivers/iommu/arm-smmu.c
static int arm_smmu_of_xlate(struct device *dev, struct of_phandle_args *args)
{
u32 mask, fwid = 0;
if (args->args_count > 0)
fwid |= (u16)args->args[0];
if (args->args_count > 1)
fwid |= (u16)args->args[1] << SMR_MASK_SHIFT;
else if (!of_property_read_u32(args->np, "stream-match-mask", &mask))
fwid |= (u16)mask << SMR_MASK_SHIFT;
return iommu_fwspec_add_ids(dev, &fwid, 1);
}
smmu에 phandle argument인 @args를 전달받아 디바이스에 설정한다.
- smmu의 경우 fwspec에 id 값으로 지정한다.
- @args의 첫 번째 인자는 low 16bit 값이고, 두 번째 인자는 high 16bit 값으로 이를 더한 id를 추가 할당한다.
- “stream-match-mask” 속성이 지정된 경우 id 값에 이 마스크 값을 16비트 좌측 shift 한 후 id 값에 or 한다.
smmu에 연결된 디바이스
“iommu-map” 속성에 지정된 id 값 0(u-boot에 의해 수정)을 iommu 드라이버에 전달
. fsl_mc: fsl-mc@80c000000 {
compatible = "fsl,qoriq-mc";
reg = <0x00000008 0x0c000000 0 0x40>, /* MC portal base */
<0x00000000 0x08340000 0 0x40000>; /* MC control reg */
msi-parent = <&its>;
iommu-map = <0 &smmu 0 0>; /* This is fixed-up by u-boot */
dma-coherent;
...
}
smmu 디바이스
전달받은 id 값에 “stream-match-mask” 속성 값 0x7c00 를 smmu 드라이버가 16bit 좌로 쉬프트한 id 값을 or 연산하여 사용한다.
. smmu: iommu@5000000 {
compatible = "arm,mmu-500";
reg = <0 0x5000000 0 0x800000>;
#global-interrupts = <12>;
#iommu-cells = <1>;
stream-match-mask = <0x7C00>;
dma-coherent;
...
}
iommu_fwspec_add_ids()
drivers/iommu/iommu.c
int iommu_fwspec_add_ids(struct device *dev, u32 *ids, int num_ids)
{
struct iommu_fwspec *fwspec = dev_iommu_fwspec_get(dev);
size_t size;
int i;
if (!fwspec)
return -EINVAL;
size = offsetof(struct iommu_fwspec, ids[fwspec->num_ids + num_ids]);
if (size > sizeof(*fwspec)) {
fwspec = krealloc(fwspec, size, GFP_KERNEL);
if (!fwspec)
return -ENOMEM;
dev_iommu_fwspec_set(dev, fwspec);
}
for (i = 0; i < num_ids; i++)
fwspec->ids[fwspec->num_ids + i] = ids[i];
fwspec->num_ids += num_ids;
return 0;
}
EXPORT_SYMBOL_GPL(iommu_fwspec_add_ids);
디바이스에 요청한 ids[] 배열에서 @num_ids 수 만큼 디바이스의 fwspc의 id 공간을 확보하고 전달받은 ids를 복사한다.
ARM64 IOMMU Operations 준비
arch_setup_dma_ops()
arch/arm64/mm/dma-mapping.c
void arch_setup_dma_ops(struct device *dev, u64 dma_base, u64 size,
const struct iommu_ops *iommu, bool coherent)
{
dev->dma_coherent = coherent;
__iommu_setup_dma_ops(dev, dma_base, size, iommu);
#ifdef CONFIG_XEN
if (xen_initial_domain())
dev->dma_ops = xen_dma_ops;
#endif
}
arm64용 dma operation를 준비한다. @coherent는 cohrent 디바이스 여부를 나타낸다.
- of_dma_configure() 함수에서 “dma-ranges” 속성을 읽어들인 후 dma_base 및 size 등을 인자로 주고 이 함수에 진입하였다.
__iommu_setup_dma_ops()
arch/arm64/mm/dma-mapping.c
static void __iommu_setup_dma_ops(struct device *dev, u64 dma_base, u64 size,
const struct iommu_ops *ops)
{
struct iommu_domain *domain;
if (!ops)
return;
/*
* The IOMMU core code allocates the default DMA domain, which the
* underlying IOMMU driver needs to support via the dma-iommu layer.
*/
domain = iommu_get_domain_for_dev(dev);
if (!domain)
goto out_err;
if (domain->type == IOMMU_DOMAIN_DMA) {
if (iommu_dma_init_domain(domain, dma_base, size, dev))
goto out_err;
dev->dma_ops = &iommu_dma_ops;
}
return;
out_err:
pr_warn("Failed to set up IOMMU for device %s; retaining platform DMA ops\n",
dev_name(dev));
}
iommu를 사용하는 dma 디바이스인 경우 dma 매핑 도메인을 초기화하고 디바이스에 generic iommu_dma_ops를 지정한다.
도메인 초기화
iommu_dma_init_domain()
drivers/iommu/dma-iommu.c
/** * iommu_dma_init_domain - Initialise a DMA mapping domain * @domain: IOMMU domain previously prepared by iommu_get_dma_cookie() * @base: IOVA at which the mappable address space starts * @size: Size of IOVA space * @dev: Device the domain is being initialised for * * @base and @size should be exact multiples of IOMMU page granularity to * avoid rounding surprises. If necessary, we reserve the page at address 0 * to ensure it is an invalid IOVA. It is safe to reinitialise a domain, but * any change which could make prior IOVAs invalid will fail. */
int iommu_dma_init_domain(struct iommu_domain *domain, dma_addr_t base,
u64 size, struct device *dev)
{
struct iommu_dma_cookie *cookie = domain->iova_cookie;
struct iova_domain *iovad = &cookie->iovad;
unsigned long order, base_pfn, end_pfn;
int attr;
if (!cookie || cookie->type != IOMMU_DMA_IOVA_COOKIE)
return -EINVAL;
/* Use the smallest supported page size for IOVA granularity */
order = __ffs(domain->pgsize_bitmap);
base_pfn = max_t(unsigned long, 1, base >> order);
end_pfn = (base + size - 1) >> order;
/* Check the domain allows at least some access to the device... */
if (domain->geometry.force_aperture) {
if (base > domain->geometry.aperture_end ||
base + size <= domain->geometry.aperture_start) {
pr_warn("specified DMA range outside IOMMU capability\n");
return -EFAULT;
}
/* ...then finally give it a kicking to make sure it fits */
base_pfn = max_t(unsigned long, base_pfn,
domain->geometry.aperture_start >> order);
}
/* start_pfn is always nonzero for an already-initialised domain */
if (iovad->start_pfn) {
if (1UL << order != iovad->granule ||
base_pfn != iovad->start_pfn) {
pr_warn("Incompatible range for DMA domain\n");
return -EFAULT;
}
return 0;
}
init_iova_domain(iovad, 1UL << order, base_pfn);
if (!cookie->fq_domain && !iommu_domain_get_attr(domain,
DOMAIN_ATTR_DMA_USE_FLUSH_QUEUE, &attr) && attr) {
cookie->fq_domain = domain;
init_iova_flush_queue(iovad, iommu_dma_flush_iotlb_all, NULL);
}
if (!dev)
return 0;
return iova_reserve_iommu_regions(dev, domain);
}
EXPORT_SYMBOL(iommu_dma_init_domain);
dma 매핑 도메인을 초기호한다.
- 코드 라인 9~10에서 도메인에 지정된 iova 쿠키가 없거나 IOMMU_DMA_IOVA_COOKIE 타입이 아닌 경우 -EINVAL 에러를 반환한다.
- IOMMU_DMA_MSI_COOKIE 타입인 경우 에러
- 코드 라인 13~15에서 도메인이 지원하는 페이지 사이지 중 가장 작은 페이지 단위의 order 값을 사용한 후 dma 주소인 @base와 @size로 base_pfn과 end_pfn을 산출한다.
- 예) 4K 페이지, @base=0x1000_0000, @size=0x2000
- base_pfn=0x1_0000, end_pfn=0x1_0001과 같이 2 개의 페이지 범위가 산출된다.
- 예) 4K 페이지, @base=0x1000_0000, @size=0x2000
- 코드 라인 18~27에서 주소 범위가 도메인 주소 경계를 초과하는 경우 경고 메시지를 출력하고 -EFAULT 에러를 반환한다.
- 코드 라인 30~38에서 iova 도메인이 초기화되어 이미 시작 pfn이 지정된 경우에는 아무것도 하지 않고 성공(0)을 반환한다.
- 코드 라인 40에서 iova 도메인을 초기화한다.
- 코드 라인 42~46에서 flush queue 콜백을 사용하지 않으면서 flush queue 속성 요청이 있으면 이 도메인을 fq_domain에 지정하고, flush queue를 초기화한다.
- 코드 라인 51에서 도메인 영역을 reserve 한다.
DMA 준비
다음 그림은 DMA coherent 메모리 할당 및 매핑 관련 operation을 설정하는 과정을 보여준다.
- AMBA 버스, Platform 버스 또는 PCI 버스에 연결된 디바이스가 probe될 때각 버스의 dma configure 함수들이 호출되고, 아래에서는 ACPI는 제외하고 디바이스 트리를 통해 셋업하는 과정만을 보여준다.
- 또한 디바이스 트리의 reserve-memory가 지정되는 경우에도 of_dma_configure() 함수가 호출되는 것을 알 수 있다.
- 자세한 과정의 소스는 여기에서 분석하지 않고, (*alloc) 후크에 연결된 함수만을 보면 아래 붉은 글씨로 __iommu_alloc_attrs() 함수가 연결된 것을 확인할 수 있다. 이 소스만 잠깐 아래에서 분석해본다.
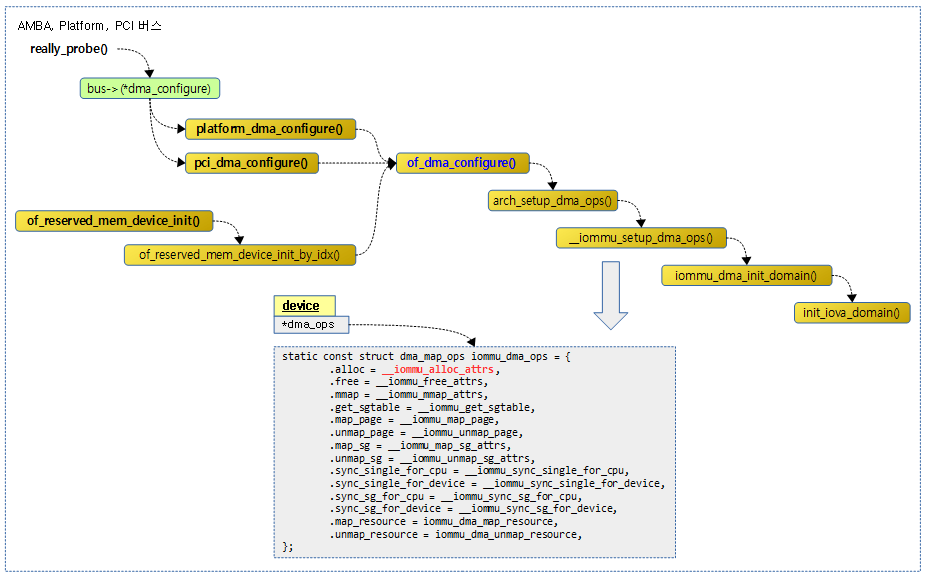
__iommu_alloc_attrs()
arch/arm64/mm/dma-mapping.c – 1/2-
static void *__iommu_alloc_attrs(struct device *dev, size_t size,
dma_addr_t *handle, gfp_t gfp,
unsigned long attrs)
{
bool coherent = dev_is_dma_coherent(dev);
int ioprot = dma_info_to_prot(DMA_BIDIRECTIONAL, coherent, attrs);
size_t iosize = size;
void *addr;
if (WARN(!dev, "cannot create IOMMU mapping for unknown device\n"))
return NULL;
size = PAGE_ALIGN(size);
/*
* Some drivers rely on this, and we probably don't want the
* possibility of stale kernel data being read by devices anyway.
*/
gfp |= __GFP_ZERO;
if (!gfpflags_allow_blocking(gfp)) {
struct page *page;
/*
* In atomic context we can't remap anything, so we'll only
* get the virtually contiguous buffer we need by way of a
* physically contiguous allocation.
*/
if (coherent) {
page = alloc_pages(gfp, get_order(size));
addr = page ? page_address(page) : NULL;
} else {
addr = dma_alloc_from_pool(size, &page, gfp);
}
if (!addr)
return NULL;
*handle = iommu_dma_map_page(dev, page, 0, iosize, ioprot);
if (*handle == DMA_MAPPING_ERROR) {
if (coherent)
__free_pages(page, get_order(size));
else
dma_free_from_pool(addr, size);
addr = NULL;
}
DMA를 위해 coherent 메모리를 할당한 후 매핑한다.
- 코드 라인 6에서 dma 방향, coherent 지원 여부, 속성을 통해 iommu 페이지 프로텍션 플래그를 구해온다.
- 코드 라인 13에서 매핑 사이즈는 페이지 단위로 정렬한다.
- 코드 라인 19에서 할당할 메모리는 0으로 초기화하도록 __GFP_ZERO 플래그를 추가한다.
- 코드 라인 21~35에서 interrupt context 등의 atomic 할당 요청인 경우이다. coherent 지원 디바이스인 경우 시스템 메모리에서 할당 받고, 아닌 경우 atomic pool에서 할당 받는다.
- 코드 라인 37~44에서 할당한 페이지를 iommu 매핑한다. 매핑이 실패한 경우 할당한 메모리를 할당 해제한다.
iommu 페이지 프로텍션 플래그
- IOMMU_READ
- RAM에서 읽기
- IOMMU_WRITE
- RAM으로 기록
- IOMMU_CACHE
- DMA 캐시 coherency
- IOMMU_NOEXEC
- IOMMU_MMIO
- IOMMU_PRIV
- privilege level (커널 레벨) 액세스
arch/arm64/mm/dma-mapping.c – 2/2-
} else if (attrs & DMA_ATTR_FORCE_CONTIGUOUS) {
pgprot_t prot = arch_dma_mmap_pgprot(dev, PAGE_KERNEL, attrs);
struct page *page;
page = dma_alloc_from_contiguous(dev, size >> PAGE_SHIFT,
get_order(size), gfp & __GFP_NOWARN);
if (!page)
return NULL;
*handle = iommu_dma_map_page(dev, page, 0, iosize, ioprot);
if (*handle == DMA_MAPPING_ERROR) {
dma_release_from_contiguous(dev, page,
size >> PAGE_SHIFT);
return NULL;
}
addr = dma_common_contiguous_remap(page, size, VM_USERMAP,
prot,
__builtin_return_address(0));
if (addr) {
if (!coherent)
__dma_flush_area(page_to_virt(page), iosize);
memset(addr, 0, size);
} else {
iommu_dma_unmap_page(dev, *handle, iosize, 0, attrs);
dma_release_from_contiguous(dev, page,
size >> PAGE_SHIFT);
}
} else {
pgprot_t prot = arch_dma_mmap_pgprot(dev, PAGE_KERNEL, attrs);
struct page **pages;
pages = iommu_dma_alloc(dev, iosize, gfp, attrs, ioprot,
handle, flush_page);
if (!pages)
return NULL;
addr = dma_common_pages_remap(pages, size, VM_USERMAP, prot,
__builtin_return_address(0));
if (!addr)
iommu_dma_free(dev, pages, iosize, handle);
}
return addr;
}
- 코드 라인 1~27에서 contiguous 메모리를 사용하라는 속성 요청이 있는 경우 contiguous 메모리 페이지를 할당 받은 후 iommu 매핑을 한다. 그런 후 아키텍처가 지원하는 페이지 속성으로 다시 리매핑한다.
- 코드 라인 28~41에서 iommu 디바이스를 위해 dma 버퍼 메모리를 할당하고 iova 영역에 매핑한다. 그 후 아키텍처가 지원하는 페이지 속성으로 다시 리매핑한다.
IOMMU-DMA 메모리 할당
iommu_dma_alloc()
drivers/iommu/dma-iommu.c
/** * iommu_dma_alloc - Allocate and map a buffer contiguous in IOVA space * @dev: Device to allocate memory for. Must be a real device * attached to an iommu_dma_domain * @size: Size of buffer in bytes * @gfp: Allocation flags * @attrs: DMA attributes for this allocation * @prot: IOMMU mapping flags * @handle: Out argument for allocated DMA handle * @flush_page: Arch callback which must ensure PAGE_SIZE bytes from the * given VA/PA are visible to the given non-coherent device. * * If @size is less than PAGE_SIZE, then a full CPU page will be allocated, * but an IOMMU which supports smaller pages might not map the whole thing. * * Return: Array of struct page pointers describing the buffer, * or NULL on failure. */
struct page **iommu_dma_alloc(struct device *dev, size_t size, gfp_t gfp,
unsigned long attrs, int prot, dma_addr_t *handle,
void (*flush_page)(struct device *, const void *, phys_addr_t))
{
struct iommu_domain *domain = iommu_get_dma_domain(dev);
struct iommu_dma_cookie *cookie = domain->iova_cookie;
struct iova_domain *iovad = &cookie->iovad;
struct page **pages;
struct sg_table sgt;
dma_addr_t iova;
unsigned int count, min_size, alloc_sizes = domain->pgsize_bitmap;
*handle = DMA_MAPPING_ERROR;
min_size = alloc_sizes & -alloc_sizes;
if (min_size < PAGE_SIZE) {
min_size = PAGE_SIZE;
alloc_sizes |= PAGE_SIZE;
} else {
size = ALIGN(size, min_size);
}
if (attrs & DMA_ATTR_ALLOC_SINGLE_PAGES)
alloc_sizes = min_size;
count = PAGE_ALIGN(size) >> PAGE_SHIFT;
pages = __iommu_dma_alloc_pages(dev, count, alloc_sizes >> PAGE_SHIFT,
gfp);
if (!pages)
return NULL;
size = iova_align(iovad, size);
iova = iommu_dma_alloc_iova(domain, size, dev->coherent_dma_mask, dev);
if (!iova)
goto out_free_pages;
if (sg_alloc_table_from_pages(&sgt, pages, count, 0, size, GFP_KERNEL))
goto out_free_iova;
if (!(prot & IOMMU_CACHE)) {
struct sg_mapping_iter miter;
/*
* The CPU-centric flushing implied by SG_MITER_TO_SG isn't
* sufficient here, so skip it by using the "wrong" direction.
*/
sg_miter_start(&miter, sgt.sgl, sgt.orig_nents, SG_MITER_FROM_SG);
while (sg_miter_next(&miter))
flush_page(dev, miter.addr, page_to_phys(miter.page));
sg_miter_stop(&miter);
}
if (iommu_map_sg(domain, iova, sgt.sgl, sgt.orig_nents, prot)
< size)
goto out_free_sg;
*handle = iova;
sg_free_table(&sgt);
return pages;
out_free_sg:
sg_free_table(&sgt);
out_free_iova:
iommu_dma_free_iova(cookie, iova, size);
out_free_pages:
__iommu_dma_free_pages(pages, count);
return NULL;
}
iommu 디바이스를 위해 dma 버퍼 메모리를 할당하고 iova 영역에 매핑한다.
- 코드 라인 15에서 지원하는 페이지들 중 가장 작은 페이지의 크기를 구한다.
- 예) 4K, 16K를 동시 지원하는 경우, pgsize_bitmap=0x5000(16K+4K)
- min_size=0x1000 (4K)
- 예) 4K, 16K를 동시 지원하는 경우, pgsize_bitmap=0x5000(16K+4K)
- 코드 라인 16~21에서 최소 사이즈가 페이지 사이즈보다 작은 경우 최소 사이즈를 페이지 사이즈로 하고, 할당 사이즈는 페이지 사이즈를 포함한다. 요청한 @size는 최소 사이즈 단위로 정렬해야 한다.
- 코드 라인 22~23에서 만일 싱글 페이지 요청이 있었던 경우 할당 사이즈는 최소 사이즈가 된다.
- 코드 라인 25~29에서 iommu 디바이스를 위해 dma 버퍼 메모리를 할당한다. 분산된 물리 페이지를 가리키는 페이지 디스크립터 배열을 반환한다.
- 코드 라인 31에서 요청한 @size를 iova 공간이 지원하는 granule 단위로 정렬한다.
- granule
- iommu의 최소 매핑 단위
- granule
- 코드 라인 32~34에서 iommu 디바이스를 위해 iova 영역을 할당한다.
- 코드 라인 36~37에서 페이지 배열 정보로 이 함수에서 임시로 사용하기 위해 sg 테이블을 할당하고 구성한다.
- 코드 라인 39~49에서 iommu가 캐시를 지원하지 않는 경우 페이지들을 플러시한다.
- 코드 라인 51~53에서 해당 iova 영역을 sg 매핑한다.
- 코드 라인 55~57에서 @handle에 dma 물리 주소를 대입하고, 임시로 할당받은 sg 테이블을 할당 해제한 후 페이지를 반환한다.
__iommu_dma_alloc_pages()
drivers/iommu/dma-iommu.c
static struct page **__iommu_dma_alloc_pages(struct device *dev,
unsigned int count, unsigned long order_mask, gfp_t gfp)
{
struct page **pages;
unsigned int i = 0, nid = dev_to_node(dev);
order_mask &= (2U << MAX_ORDER) - 1;
if (!order_mask)
return NULL;
pages = kvzalloc(count * sizeof(*pages), GFP_KERNEL);
if (!pages)
return NULL;
/* IOMMU can map any pages, so himem can also be used here */
gfp |= __GFP_NOWARN | __GFP_HIGHMEM;
while (count) {
struct page *page = NULL;
unsigned int order_size;
/*
* Higher-order allocations are a convenience rather
* than a necessity, hence using __GFP_NORETRY until
* falling back to minimum-order allocations.
*/
for (order_mask &= (2U << __fls(count)) - 1;
order_mask; order_mask &= ~order_size) {
unsigned int order = __fls(order_mask);
gfp_t alloc_flags = gfp;
order_size = 1U << order;
if (order_mask > order_size)
alloc_flags |= __GFP_NORETRY;
page = alloc_pages_node(nid, alloc_flags, order);
if (!page)
continue;
if (!order)
break;
if (!PageCompound(page)) {
split_page(page, order);
break;
} else if (!split_huge_page(page)) {
break;
}
__free_pages(page, order);
}
if (!page) {
__iommu_dma_free_pages(pages, i);
return NULL;
}
count -= order_size;
while (order_size--)
pages[i++] = page++;
}
return pages;
}
iommu dma 디바이스를 위해 @count 페이지 수 만큼 페이지를 할당한 후 page 구조체 배열로 반환한다. 물리 페이지들은 sg 방식을 사용할 계획이므로 order 페이지 단위로 분산될 수 있다. @order_mask에는 할당에 사용할 모든 order 비트들을 지정한다.
- 코드 라인 7~9에서 @order_mask를 버디 시스템에서 사용할 수 있는 모든 order 범위로 제한한다.
- 예) 4K, MAX_ORDER=11, @order_mask=0xf0f
- @order_mask=0x70f (11개 비트로 제한)
- 예) 4K, MAX_ORDER=11, @order_mask=0xf0f
- 코드 라인 11~13에서 @count 수 만큼 page 디스크립터 배열을 할당한다.
- 코드 라인 16에서 할당 가능한 영역으로 highmem 메모리 영역을 포함한다. 또한 높은 order 할당부터 내부 루프를 돌며 반복 시도를 할 예정이므로 nowarn 플래그를 추가한다.
- 코드 라인 18~29에서 할당 단위 @order_mask의 비트들 중 큰 order 부터 먼저 시도한다. 그 후 낮은 오더로 줄여나간다.
- 예) size=8M+56K, count=0x40e, order_mask=0x40e
- order = 10, 3, 2, 1 순으로 내려간다.
- 예) size=8M+56K, count=0x40e, order_mask=0x40e
- 코드 라인 32~34에서 할당할 order size가 order_mask보다 작은 경우 noretry 플래그를 추가한다.
- 코드 라인 35~37에서 2^order 만큼 페이지를 할당한다.
- 코드 라인 38~39에서 최소 order 0인 경우 for 루프를 중단한다.
- 코드 라인 40~46에서 compound 페이지 또는 huge 페이지인 경우 split한다음 버디로 돌려보내고 계속 루프를 진행한다.
- 코드 라인 47~50에서 할당한 페이지가 없는 경우 그 동안 할당한 모든 페이지들을 할당 해제한 후 null을 반환한다.
- 코드 라인 51~53에서 할당한 페이지 수 만큼 @count를 감소시킨다. 할당에 사용한 order_size만큼 pages[] 배열의 인덱스 i와 page 포인터를 증가시킨다.
다음 그림은 dma 용도로 사용할 메모리를 분산된 물리 메모리로 부터 order 단위로 할당한 페이지들에 대한 page 디스크립터 배열로 반환하는 모습을 보여준다. (예: 이해를 돕기 위해 4M+56K 할당)

iommu_dma_alloc_iova()
drivers/iommu/dma-iommu.c
static dma_addr_t iommu_dma_alloc_iova(struct iommu_domain *domain,
size_t size, dma_addr_t dma_limit, struct device *dev)
{
struct iommu_dma_cookie *cookie = domain->iova_cookie;
struct iova_domain *iovad = &cookie->iovad;
unsigned long shift, iova_len, iova = 0;
if (cookie->type == IOMMU_DMA_MSI_COOKIE) {
cookie->msi_iova += size;
return cookie->msi_iova - size;
}
shift = iova_shift(iovad);
iova_len = size >> shift;
/*
* Freeing non-power-of-two-sized allocations back into the IOVA caches
* will come back to bite us badly, so we have to waste a bit of space
* rounding up anything cacheable to make sure that can't happen. The
* order of the unadjusted size will still match upon freeing.
*/
if (iova_len < (1 << (IOVA_RANGE_CACHE_MAX_SIZE - 1)))
iova_len = roundup_pow_of_two(iova_len);
if (dev->bus_dma_mask)
dma_limit &= dev->bus_dma_mask;
if (domain->geometry.force_aperture)
dma_limit = min(dma_limit, domain->geometry.aperture_end);
/* Try to get PCI devices a SAC address */
if (dma_limit > DMA_BIT_MASK(32) && dev_is_pci(dev))
iova = alloc_iova_fast(iovad, iova_len,
DMA_BIT_MASK(32) >> shift, false);
if (!iova)
iova = alloc_iova_fast(iovad, iova_len, dma_limit >> shift,
true);
return (dma_addr_t)iova << shift;
}
iommu 디바이스를 위해 iova 영역을 할당하고, iova 주소를 반환한다.
- 코드 라인 8~11에서 pci msi 인터럽트를 사용하는 dma 디바이스인 경우 iova 쿠키의 msi_iova에서 @size만큼 더한다. 반환 값은 @size를 더하기 직전의 값을 반환한다.
- 코드 라인 13~14에서 @size에 맞게 iova 매핑할 개수를 iova_len에 담는다.
- 코드 라인 21~22에서 iova 매핑할 개수가 캐시 최대 사이즈의 절반인 16보다 작은 경우 iova_len 개수를 2의 제곱승 단위로 올림 처리한다.
- IOVA_RANGE_CACHE_MAX_SIZE(6)
- 캐시 최대 지원 order 페이지
- IOVA_RANGE_CACHE_MAX_SIZE(6)
- 코드 라인 24~25에서 버스가 지원하는 영역 범위 이내로 디바이스의 dma 주소 제한을 한다.
- 코드 라인 27~28에서 도메인이 지원하는 영역 범위 이내로 디바이스의 dma 주소 제한을 한다.
- 코드 라인 31~37에서 매핑할 페이지 수 @iova_len 만큼 iova 공간을 할당한다.
- 코드 라인 39에서 iova 주소를 반환한다.
IOMMU-DMA 메모리 페이지 매핑
iommu_dma_map_page()
drivers/iommu/dma-iommu.c
dma_addr_t iommu_dma_map_page(struct device *dev, struct page *page,
unsigned long offset, size_t size, int prot)
{
return __iommu_dma_map(dev, page_to_phys(page) + offset, size, prot,
iommu_get_dma_domain(dev));
}
dma 디바이스에서 물리 페이지 + @offset을 한 iova 공간에 @size 만큼 @prot 속성으로 매핑한다.
__iommu_dma_map()
drivers/iommu/dma-iommu.c
static dma_addr_t __iommu_dma_map(struct device *dev, phys_addr_t phys,
size_t size, int prot, struct iommu_domain *domain)
{
struct iommu_dma_cookie *cookie = domain->iova_cookie;
size_t iova_off = 0;
dma_addr_t iova;
if (cookie->type == IOMMU_DMA_IOVA_COOKIE) {
iova_off = iova_offset(&cookie->iovad, phys);
size = iova_align(&cookie->iovad, size + iova_off);
}
iova = iommu_dma_alloc_iova(domain, size, dma_get_mask(dev), dev);
if (!iova)
return DMA_MAPPING_ERROR;
if (iommu_map(domain, iova, phys - iova_off, size, prot)) {
iommu_dma_free_iova(cookie, iova, size);
return DMA_MAPPING_ERROR;
}
return iova + iova_off;
}
dma 디바이스에서 물리 주소 @phys @size 만큼 @prot 속성으로 매핑한다.
- 코드 라인 8~11에서 full 할당자인 iova 도메인을 사용하는 경우 iova offset 값과 size를 정렬한다.(smmu에서사용)
- 그 외의 쿠키 타입은 리니어 페이지 할당자를 사용하는 msi 방식이다. (vfio에서 사용)
- 코드 라인 13~15에서 @size 만큼 iova 공간을 할당한다.
- 코드 라인 17~20에서 할당한 공간을 물리 메모리가 있는 주소 공간에 매핑한다.
- iova (디바이스가 보는 io 주소) <—–> phys(메모리가 있는 물리 주소)
IOMMU-DMA 메모리 페이지 매핑 해제
iommu_dma_unmap()
drivers/iommu/dma-iommu.c
void iommu_dma_unmap_page(struct device *dev, dma_addr_t handle, size_t size,
enum dma_data_direction dir, unsigned long attrs)
{
__iommu_dma_unmap(iommu_get_dma_domain(dev), handle, size);
}
dma 디바이스가 사용한 dma용 물리 페이지 및 iova 공간을 size 만큼 매핑 해제한다.
__iommu_dma_unmap()
drivers/iommu/dma-iommu.c
static void __iommu_dma_unmap(struct iommu_domain *domain, dma_addr_t dma_addr,
size_t size)
{
struct iommu_dma_cookie *cookie = domain->iova_cookie;
struct iova_domain *iovad = &cookie->iovad;
size_t iova_off = iova_offset(iovad, dma_addr);
dma_addr -= iova_off;
size = iova_align(iovad, size + iova_off);
WARN_ON(iommu_unmap_fast(domain, dma_addr, size) != size);
if (!cookie->fq_domain)
iommu_tlb_sync(domain);
iommu_dma_free_iova(cookie, dma_addr, size);
}
IOVA 공간 관리
iova 영역 관리는 RB 트리와 rcache로 관리된다.
init_iova_domain()
drivers/iommu/iova.c
void
init_iova_domain(struct iova_domain *iovad, unsigned long granule,
unsigned long start_pfn)
{
/*
* IOVA granularity will normally be equal to the smallest
* supported IOMMU page size; both *must* be capable of
* representing individual CPU pages exactly.
*/
BUG_ON((granule > PAGE_SIZE) || !is_power_of_2(granule));
spin_lock_init(&iovad->iova_rbtree_lock);
iovad->rbroot = RB_ROOT;
iovad->cached_node = &iovad->anchor.node;
iovad->cached32_node = &iovad->anchor.node;
iovad->granule = granule;
iovad->start_pfn = start_pfn;
iovad->dma_32bit_pfn = 1UL << (32 - iova_shift(iovad));
iovad->max32_alloc_size = iovad->dma_32bit_pfn;
iovad->flush_cb = NULL;
iovad->fq = NULL;
iovad->anchor.pfn_lo = iovad->anchor.pfn_hi = IOVA_ANCHOR;
rb_link_node(&iovad->anchor.node, NULL, &iovad->rbroot.rb_node);
rb_insert_color(&iovad->anchor.node, &iovad->rbroot);
init_iova_rcaches(iovad);
}
EXPORT_SYMBOL_GPL(init_iova_domain);
iova 도메인을 초기화한다.
IOVA reserve 영역 관리
iova_reserve_iommu_regions()
drivers/iommu/dma-iommu.c
static int iova_reserve_iommu_regions(struct device *dev,
struct iommu_domain *domain)
{
struct iommu_dma_cookie *cookie = domain->iova_cookie;
struct iova_domain *iovad = &cookie->iovad;
struct iommu_resv_region *region;
LIST_HEAD(resv_regions);
int ret = 0;
if (dev_is_pci(dev))
iova_reserve_pci_windows(to_pci_dev(dev), iovad);
iommu_get_resv_regions(dev, &resv_regions);
list_for_each_entry(region, &resv_regions, list) {
unsigned long lo, hi;
/* We ARE the software that manages these! */
if (region->type == IOMMU_RESV_SW_MSI)
continue;
lo = iova_pfn(iovad, region->start);
hi = iova_pfn(iovad, region->start + region->length - 1);
reserve_iova(iovad, lo, hi);
if (region->type == IOMMU_RESV_MSI)
ret = cookie_init_hw_msi_region(cookie, region->start,
region->start + region->length);
if (ret)
break;
}
iommu_put_resv_regions(dev, &resv_regions);
return ret;
}
reserved iommu 영역을 iova 도메인에 등록한다.
- 코드 라인 10~11에서 pci 디바이스인 경우 호스트 브리지의 window 영역들을 iova 도메인에 reserve 한다.
- window
- pci 호스트 브리지의 메모리 BAR 영역
- window
- 코드 라인 13에서 임시로 resv_regions 리스트에 디바이스가 사용하는 iommu의 reserve 영역 정보를 사용하기 위해 추가한다.
- 코드 라인 14~19에서 4 가지 reserve 영역을 순회하며 reserve 타입 중 sw_msi 타입은 skip 한다.
- 코드 라인 21~23에서 시작과 끝 영역의 pfn 값을 사요하여 iova 도메인에 등록한다.
- pfn 영역은 iova 도메인의 rbroot 멤버에서 RB Tree로 운영한다.
- 코드 라인 25~29에서 reserve 타입이 msi 타입인 경우 쿠키 초기화를 한다.
- 코드 라인 31에서 임시로 사용한 resv_regions 리스트로부터 reserve 영역 정보를 제거하고 해제한다.
iommu_get_resv_regions()
drivers/iommu/iommu.c
void iommu_get_resv_regions(struct device *dev, struct list_head *list)
{
const struct iommu_ops *ops = dev->bus->iommu_ops;
if (ops && ops->get_resv_regions)
ops->get_resv_regions(dev, list);
}
iommu 디바이스가 사용하는 iommu 드라이버에서 reserve 영역을 준비하여 @list에 추가한다.
arm_smmu_get_resv_regions() – ARM, ARM64
drivers/iommu/arm-smmu.c
static void arm_smmu_get_resv_regions(struct device *dev,
struct list_head *head)
{
struct iommu_resv_region *region;
int prot = IOMMU_WRITE | IOMMU_NOEXEC | IOMMU_MMIO;
region = iommu_alloc_resv_region(MSI_IOVA_BASE, MSI_IOVA_LENGTH,
prot, IOMMU_RESV_SW_MSI);
if (!region)
return;
list_add_tail(®ion->list, head);
iommu_dma_get_resv_regions(dev, head);
}
smmu에 reserved된 영역을 할당하여 추가한다.
- 코드 라인 5에서 write 가능, 실행 금지, mmio 매핑 플래그를 지정한다.
- 코드 라인 7~10에서 0x800_0000 ~ 0x810_0000 까지 msi iova 영역을 reserve 한다.
- MSI_IOVA_BASE(0x800_0000)
- MSI_IOVA_LENGTH(0x10_0000)
- 코드 라인 12에서 인자로 전달받은 @head 리스트에 이 영역을 추가한다.
- 코드 라인 14에서 디바이스 트리가 아닌 서버에서 acpi를 통해 reserve 영역을 추가한다.
IOVA Rcaches
iova 도메인의 영역을 관리할 때 RB 트리를 이용하여 관리하지만, 더 빠른 fast-path 할당 관리를 지원하기 위해 rcache를 사용한다.
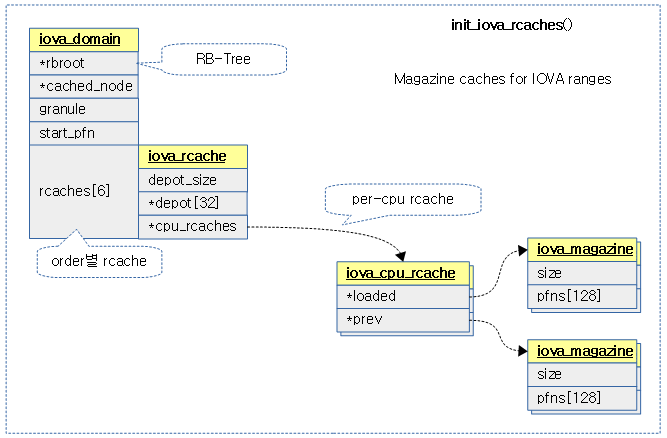
init_iova_rcaches()
drivers/iommu/iova.c
static void init_iova_rcaches(struct iova_domain *iovad)
{
struct iova_cpu_rcache *cpu_rcache;
struct iova_rcache *rcache;
unsigned int cpu;
int i;
for (i = 0; i < IOVA_RANGE_CACHE_MAX_SIZE; ++i) {
rcache = &iovad->rcaches[i];
spin_lock_init(&rcache->lock);
rcache->depot_size = 0;
rcache->cpu_rcaches = __alloc_percpu(sizeof(*cpu_rcache), cache_line_size());
if (WARN_ON(!rcache->cpu_rcaches))
continue;
for_each_possible_cpu(cpu) {
cpu_rcache = per_cpu_ptr(rcache->cpu_rcaches, cpu);
spin_lock_init(&cpu_rcache->lock);
cpu_rcache->loaded = iova_magazine_alloc(GFP_KERNEL);
cpu_rcache->prev = iova_magazine_alloc(GFP_KERNEL);
}
}
}
iova 영역을 Fast-Path로 할당 관리할 수 있도록 rcaches를 초기화한다.
다음 그림은 rcaches의 초기화된 모습을 보여준다.
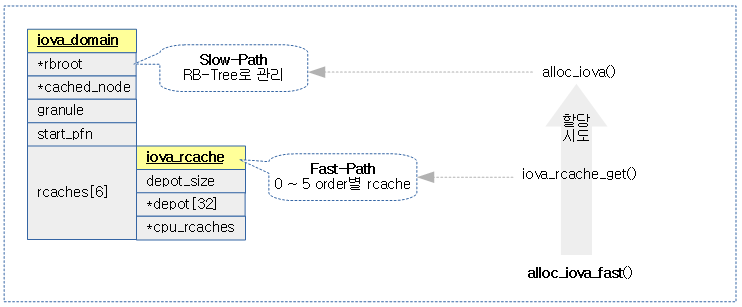
alloc_iova_fast()
drivers/iommu/iova.c
/** * alloc_iova_fast - allocates an iova from rcache * @iovad: - iova domain in question * @size: - size of page frames to allocate * @limit_pfn: - max limit address * @flush_rcache: - set to flush rcache on regular allocation failure * This function tries to satisfy an iova allocation from the rcache, * and falls back to regular allocation on failure. If regular allocation * fails too and the flush_rcache flag is set then the rcache will be flushed. */
unsigned long
alloc_iova_fast(struct iova_domain *iovad, unsigned long size,
unsigned long limit_pfn, bool flush_rcache)
{
unsigned long iova_pfn;
struct iova *new_iova;
iova_pfn = iova_rcache_get(iovad, size, limit_pfn + 1);
if (iova_pfn)
return iova_pfn;
retry:
new_iova = alloc_iova(iovad, size, limit_pfn, true);
if (!new_iova) {
unsigned int cpu;
if (!flush_rcache)
return 0;
/* Try replenishing IOVAs by flushing rcache. */
flush_rcache = false;
for_each_online_cpu(cpu)
free_cpu_cached_iovas(cpu, iovad);
goto retry;
}
return new_iova->pfn_lo;
}
EXPORT_SYMBOL_GPL(alloc_iova_fast);
iova 공간 할당을 한 후 iova pfn을 반환한다. fast-path인 rcache를 먼저 이용해보고, 안되면 slow-path인 RB 트리를 사용한다.
- 코드 라인 8~10에서 per-cpu rcache를 구해와서 존재하는 경우 이를 반환한다. (Fast-path)
- 코드 라인 13에서 iova 도메인의 limit_pfn 범위 이내에서 size 만큼의 영역을 할당한다.
- 코드 라인 14~25에서 만일 할당이 실패한 경우 0을 반환한다. 다만 flush_rcache 옵션이 지정된 경우 cpu 캐시를 해제한 후 재시도 해본다.
다음 그림은 Fast-Path인 rcache로 먼저 iova 영역을 할당 시도한 후 실패 시 Slow-Path인 RB-Tree를 사용한 정규 방법으로 시도한다.
iova_rcache_insert()
drivers/iommu/iova.c
static bool iova_rcache_insert(struct iova_domain *iovad, unsigned long pfn,
unsigned long size)
{
unsigned int log_size = order_base_2(size);
if (log_size >= IOVA_RANGE_CACHE_MAX_SIZE)
return false;
return __iova_rcache_insert(iovad, &iovad->rcaches[log_size], pfn);
}
요청한 iova 도메인에서 @size에 해당하는 order용 rcache를 선택하고, iova용 @pfn을 추가한다.
- rcache는 order 별로 관리되며, order는 0 ~ IOVA_RANGE_CACHE_MAX_SIZE(6) – 1까지 사용한다.
- 1, 2, 4, 8, 16, 32 페이지만 가능하다.
다음 그림은 order 별로 관리하는 rcache를 @size로 rcache를 선택한 후 iova pfn을 추가하는 모습을 보여준다.
- cpu rcache의 loaded에서 먼저 할당해준다.
- 만일 cpu rcache의 loaded가 full 상태이면 prev와 교체한 후 loaded에서 할당한다.
- 만일 prev 마저도 full 상태이면 loaded를 iova 영역으로 free한 후 새로운 magazine을 할당해서 loaded에 지정하고 여기서 다시 할당해준다.
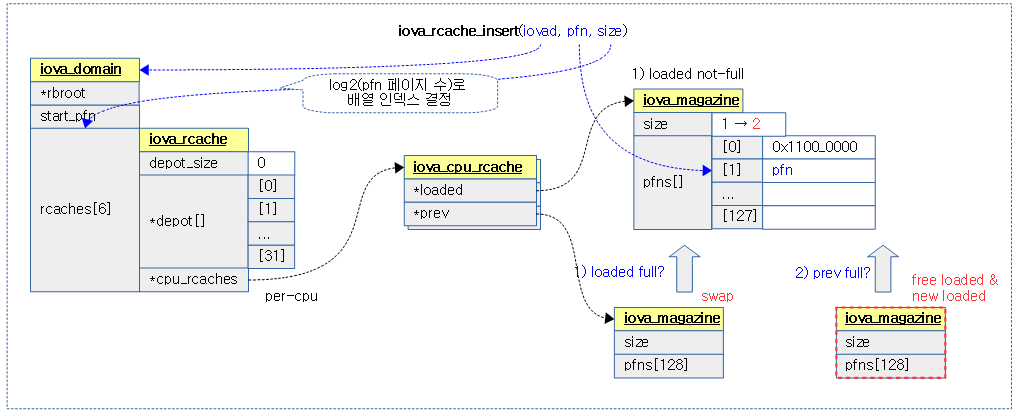
__iova_rcache_insert()
drivers/iommu/iova.c
/* * Try inserting IOVA range starting with 'iova_pfn' into 'rcache', and * return true on success. Can fail if rcache is full and we can't free * space, and free_iova() (our only caller) will then return the IOVA * range to the rbtree instead. */
static bool __iova_rcache_insert(struct iova_domain *iovad,
struct iova_rcache *rcache,
unsigned long iova_pfn)
{
struct iova_magazine *mag_to_free = NULL;
struct iova_cpu_rcache *cpu_rcache;
bool can_insert = false;
unsigned long flags;
cpu_rcache = raw_cpu_ptr(rcache->cpu_rcaches);
spin_lock_irqsave(&cpu_rcache->lock, flags);
if (!iova_magazine_full(cpu_rcache->loaded)) {
can_insert = true;
} else if (!iova_magazine_full(cpu_rcache->prev)) {
swap(cpu_rcache->prev, cpu_rcache->loaded);
can_insert = true;
} else {
struct iova_magazine *new_mag = iova_magazine_alloc(GFP_ATOMIC);
if (new_mag) {
spin_lock(&rcache->lock);
if (rcache->depot_size < MAX_GLOBAL_MAGS) {
rcache->depot[rcache->depot_size++] =
cpu_rcache->loaded;
} else {
mag_to_free = cpu_rcache->loaded;
}
spin_unlock(&rcache->lock);
cpu_rcache->loaded = new_mag;
can_insert = true;
}
}
if (can_insert)
iova_magazine_push(cpu_rcache->loaded, iova_pfn);
spin_unlock_irqrestore(&cpu_rcache->lock, flags);
if (mag_to_free) {
iova_magazine_free_pfns(mag_to_free, iovad);
iova_magazine_free(mag_to_free);
}
return can_insert;
}
요청한 iova 도메인의 rcache에 iova용 @pfn을 추가한다.
- 코드 라인 10~14에서 per-cpu rcache의 loaded에 있는 magazine이 full이 아니면 can_insert를 true로 한다.
- 코드 라인 15~17에서 per-cpu rcache의 prev에 있는 magazine이 full이 아니면 loaded로 옮기고 can_insert를 true로 한다.
- 코드 라인 18~32에서 depot이 충분한 경우 기존 loaded의 magazine을 push 한다. depot이 충분하지 않은 경우 loaded를 할당해제 하기 위해 임시 mag_to_free 변수에 대입한다. 할당한 magazine은 loaded에 대입한 후 can_insert를 true로 한다.
- 코드 라인 34~35에서 can_insert가 ture인 경우 magazine을 push한다.
- 코드 라인 39~42에서 depot이 full 된 경우 loaded를 모두 할당 해제한다.
iova_rcache_get()
drivers/iommu/iova.c
/* * Try to satisfy IOVA allocation range from rcache. Fail if requested * size is too big or the DMA limit we are given isn't satisfied by the * top element in the magazine. */
static unsigned long iova_rcache_get(struct iova_domain *iovad,
unsigned long size,
unsigned long limit_pfn)
{
unsigned int log_size = order_base_2(size);
if (log_size >= IOVA_RANGE_CACHE_MAX_SIZE)
return 0;
return __iova_rcache_get(&iovad->rcaches[log_size], limit_pfn - size);
}
요청한 iova 도메인의 size order를 관리하는 rcache의 @limit_pfn 범위이내에서 iova 공간을 할당하고, 이에 해당하는 iova pfn을 반환한다.
- rcache는 order 별로 관리되며, order는 0 ~ 5까지 사용한다.
__iova_rcache_get()
drivers/iommu/iova.c
/* * Caller wants to allocate a new IOVA range from 'rcache'. If we can * satisfy the request, return a matching non-NULL range and remove * it from the 'rcache'. */
static unsigned long __iova_rcache_get(struct iova_rcache *rcache,
unsigned long limit_pfn)
{
struct iova_cpu_rcache *cpu_rcache;
unsigned long iova_pfn = 0;
bool has_pfn = false;
unsigned long flags;
cpu_rcache = raw_cpu_ptr(rcache->cpu_rcaches);
spin_lock_irqsave(&cpu_rcache->lock, flags);
if (!iova_magazine_empty(cpu_rcache->loaded)) {
has_pfn = true;
} else if (!iova_magazine_empty(cpu_rcache->prev)) {
swap(cpu_rcache->prev, cpu_rcache->loaded);
has_pfn = true;
} else {
spin_lock(&rcache->lock);
if (rcache->depot_size > 0) {
iova_magazine_free(cpu_rcache->loaded);
cpu_rcache->loaded = rcache->depot[--rcache->depot_size];
has_pfn = true;
}
spin_unlock(&rcache->lock);
}
if (has_pfn)
iova_pfn = iova_magazine_pop(cpu_rcache->loaded, limit_pfn);
spin_unlock_irqrestore(&cpu_rcache->lock, flags);
return iova_pfn;
}
요청한 rcache의 @limit_pfn 범위이내에서 iova 공간을 할당하고, 이에 해당하는 iova pfn을 반환한다.
- 코드 라인 9~13에서 per-cpu rcache의 loaded에 있는 magazine이 있는 경우 has_pfn을 true로 한다.
- 코드 라인 14~16에서 prev magazie이 있는 경우 prev magazine을 load로 옮긴 후 has_pfn을 true로 한다.
- 코드 라인 17~25에서 그 외의 경우 depot_size가 있는 경우 rcache를 lock으로 보호한 후 혹시 lock 이전에 끼어든 loaded magazine이 있으면 할당 해제한다. 그런 후 depot[]을 하나 연결하고 has_pfn을 true로 한다.
- 코드 라인 27~28에서 has_pfn이 true인 경우 loaded magazine pop을 하여 iova_pfn을 알아온다.
참고
- DMA -1- (Basic) | 문c
- DMA -2- (DMA Coherent Memory) | 문c
- DMA -3- (DMA Pool) | 문c
- DMA -4- (DMA Mapping) | 문c
- DMA -5- (IOMMU) | 문c – 현재 글
- DMA -6- (DMAEngine Subsystem) | 문c
- IOMMU | 문c
- ARM® CoreLink™ MMU-500 System Memory Management Unit – Technical Reference Manual – 다운로드 pdf