페이지 테이블 관련 명령(pgd, pud, pmd, pte)은 32bit ARM 리눅스용에 대해 제한하여 설명한다.
- ARM 리눅스에서는 3단계 페이지 테이블 관리를 사용
- ARM h/w에서는 2단계 페이지 테이블 관리를 사용한다.
엔트리 타입
- pgd_t
- typedef struct { pmdval_t pgd[2]; } pgd_t;
- pmdval_t는 u32형이다.
- pmd_t
- typedef struct { pmdval_t pmd; } pmd_t;
- pte_t
- typedef struct { pteval_t pte; } pte_t;
- pteval_t는 u32형이다.
pgd 관련
pgd_val()
arch/arm/include/asm/pgtable-2level-types.h
#define pgd_val(x) ((x).pgd[0])
- 두 개의 pgd 엔트리 중 첫 번째 pgd 엔트리 값을 리턴한다.
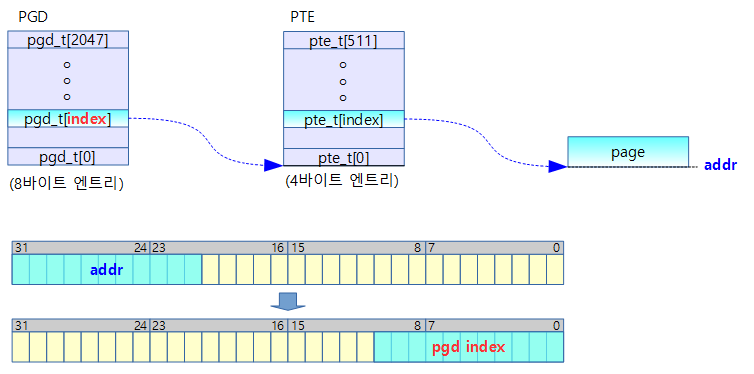
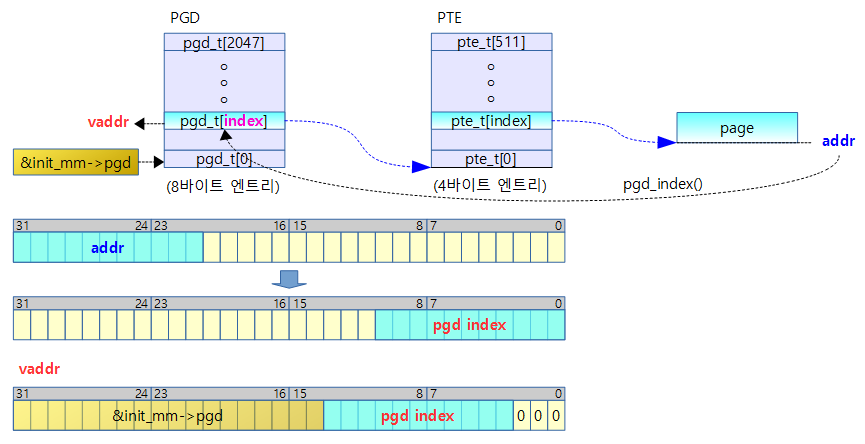
pgd_index()
arch/arm/include/asm/pgtable.h
/* to find an entry in a page-table-directory */
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
- 주어진 주소의 pgd 인덱스 값(0~2047)을 리턴한다.
- PGDIR_SHIFT=21 (=2M round down)
addr[31:21] 값을 우측으로 PGDIR_SHIFT(21) 비트 만큼 쉬프트하여 인덱스로 활용 (0~2047(0x7ff))
- rpi2 예) pgd_index(0x8a00_0000) = 0x450
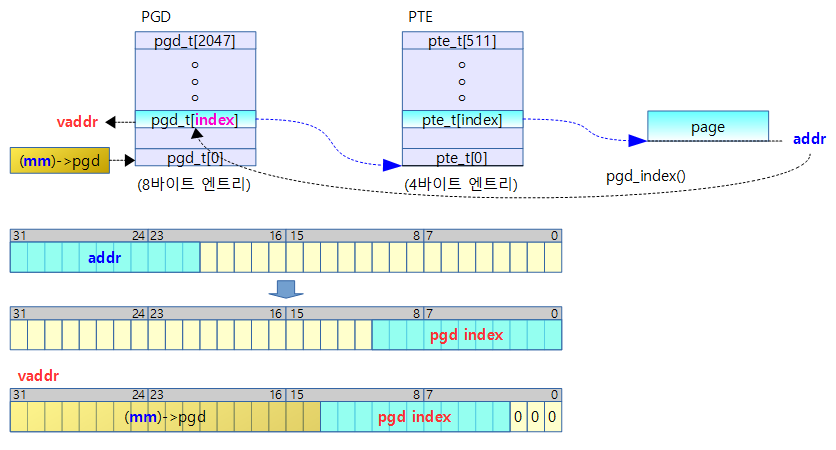
pgd_offset()
arch/arm/include/asm/pgtable.h
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
- mm_struct 구조체가 가리키는 pgd 주소 + pgd 인덱스를 하여 pgd의 offset 주소를 알아올 수 있다.
pgd_offset_k()
arch/arm/include/asm/pgtable.h
/* to find an entry in a kernel page-table-directory */
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
- “_k” suffix(접미) 는 커널이라는 뜻이다. 즉 커널이 사용하는 level-1 PGD 에서 pgd 엔트리 가상 주소를 알아온다.
pgd_addr_end()
include/asm-generic/pgtable.h
/*
* When walking page tables, get the address of the next boundary,
* or the end address of the range if that comes earlier. Although no
* vma end wraps to 0, rounded up __boundary may wrap to 0 throughout.
*/
#define pgd_addr_end(addr, end) \
({ unsigned long __boundary = ((addr) + PGDIR_SIZE) & PGDIR_MASK; \
(__boundary - 1 < (end) - 1)? __boundary: (end); \
})
- addr 값에 2M를 더한 값을 round down 하고 end 주소 보다 작은 경우 리턴한다. 그렇지 않은 경우 end를 리턴한다.
- 예) addr=0x1000_0000, end=0x1040_0000
- 호출1=0x1020_0000, 호출2=0x1040_0000
- 예) addr=0x1000_0004, end=0x1040_0004
- 호출1=0x1020_0000, 호출2=0x1040_0000, 호출3=0x1040_0004
pud 관련
pud_val()
include/asm-generic/pgtable-nopud.h
#define pud_val(x) (pgd_val((x).pgd))
- pud 엔트리 값을 리턴한다.
- 실제 pud 테이블이 없으므로 pgd 값을 사용한다.
pud_offset()
include/asm-generic/pgtable-nopud.h
static inline pud_t * pud_offset(pgd_t * pgd, unsigned long address)
{
return (pud_t *)pgd;
}
- pud의 offset은 pud 테이블이 없으므로 그냥 첫 번째 인수인 pgd만 리턴한다.
pmd 관련
pmd_val()
arch/arm/include/asm/pgtable-2level-types.h
#define pmd_val(x) ((x).pmd)
pmd_index()
pmd_offset()
arch/arm/include/asm/pgtable-2level.h
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long addr)
{
return (pmd_t *)pud;
}
- pmd의 offset은 pmd 테이블이 없으므로 그냥 첫 번째 인수인 pud만 리턴한다.
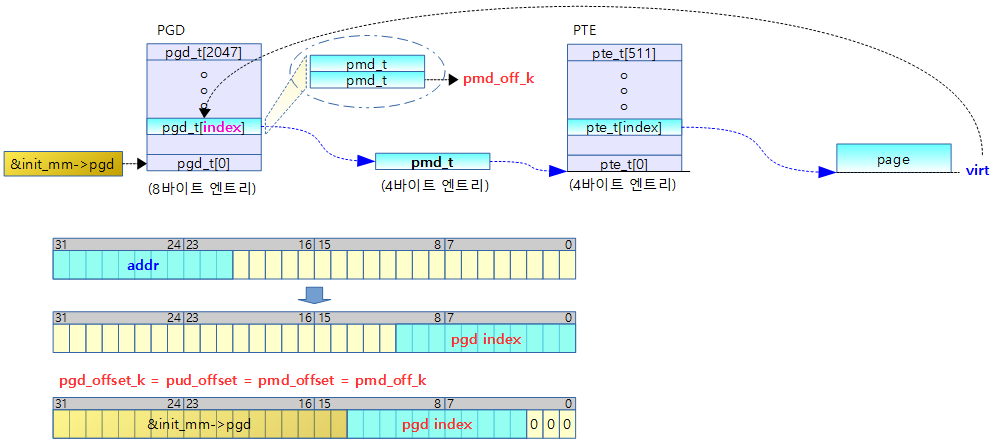
pmd_off_k()
arch/arm/mm/mm.h
static inline pmd_t *pmd_off_k(unsigned long virt)
{
return pmd_offset(pud_offset(pgd_offset_k(virt), virt), virt);
}
가상 주소에 대응하는 pmd 엔트리 가상 주소를 알아온다.
- pgd_offset_k()
- 커널이 사용하는 level-1 PGD 에서 가상 주소에 대응하는 pgd 엔트리 가상 주소를 알아온다
- pud_offset()
- 첫 번째 인수인 pgd 엔트리 가상 주소를 리턴한다.
- pmd_offset()
- 첫 번째 인수가 가리키는 pmd 테이블에서 가상 주소에 대응하는 pmd 엔트리 가상 주소를 알아온다.
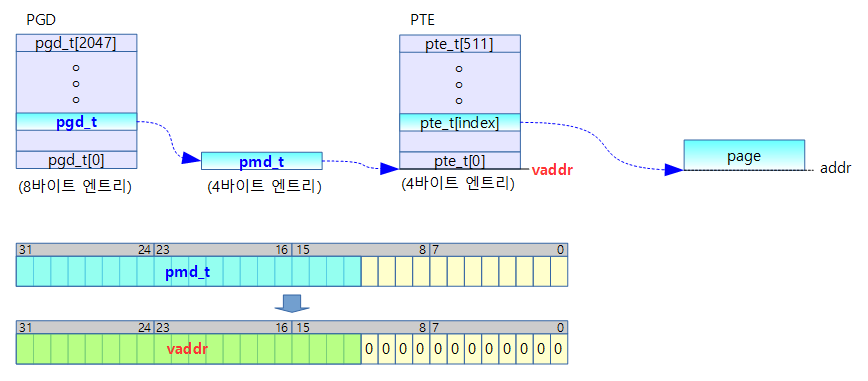
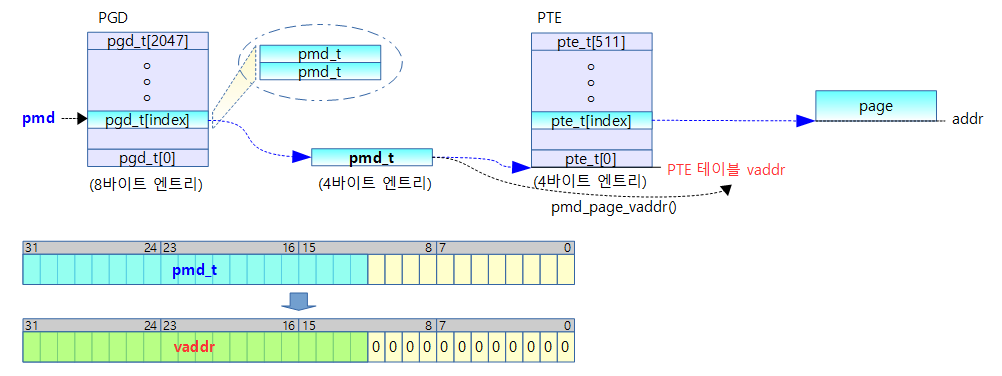
pmd_page_vaddr()
arch/arm/include/asm/pgtable.h
arch/arm/include/asm/pgtable.h
static inline pte_t *pmd_page_vaddr(pmd_t pmd)
{
return __va(pmd_val(pmd) & PHYS_MASK & (s32)PAGE_MASK);
}
- pmd 테이블의 가상 주소값을 알아온다.
- pmd 값을 4K round down 한 후 가상 주소로 변환한다.
pmd[31:12] 값을 가상주소로 변환하여 pte 테이블을 가리키는 가상 주소를 알아낸다.
- 예) rpi2: pmd_page_vaddr(0x0234_5678) = 0x8234_5000
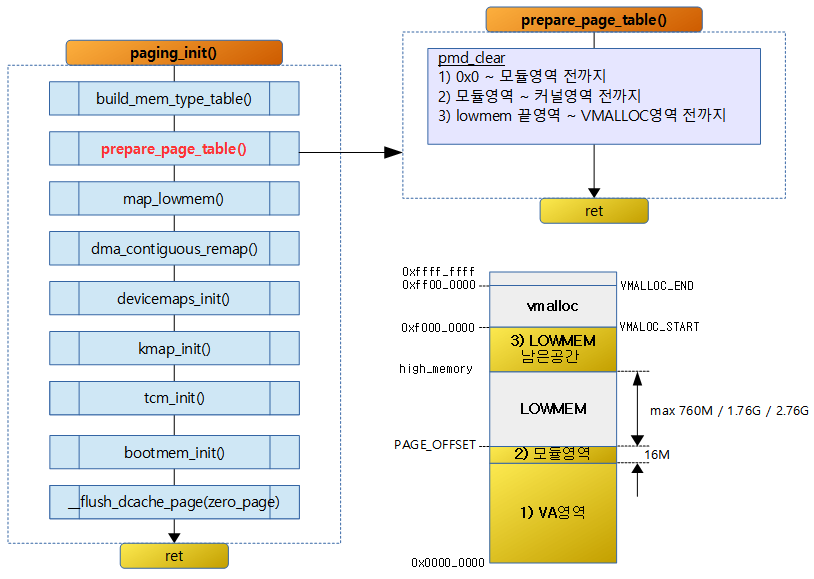
pmd_clear()
arch/arm/include/asm/pgtable-2level.h
#define pmd_clear(pmdp) \
do { \
pmdp[0] = __pmd(0); \
pmdp[1] = __pmd(0); \
clean_pmd_entry(pmdp); \
} while (0)
- pmd 엔트리 2개를 삭제한다.
- pgd 엔트리 하나가 pmd 엔트리 2개 이므로 결국 pgd 엔트리를 지우는 것과 동일하다.
- clean_pmd_entry(pmdp);
clean_pmd_entry()
arch/arm/include/asm/tlbflush.h
static inline void clean_pmd_entry(void *pmd)
{
const unsigned int __tlb_flag = __cpu_tlb_flags;
tlb_op(TLB_DCLEAN, "c7, c10, 1 @ flush_pmd", pmd);
tlb_l2_op(TLB_L2CLEAN_FR, "c15, c9, 1 @ L2 flush_pmd", pmd);
}
- L1-TLB 엔트리와 L2-TLB 엔트리를 flush(여기서는 invalidate) 한다.
pte 관련
pte_val()
arch/arm/include/asm/pgtable-2level-types.h
#define pte_val(x) ((x).pte)
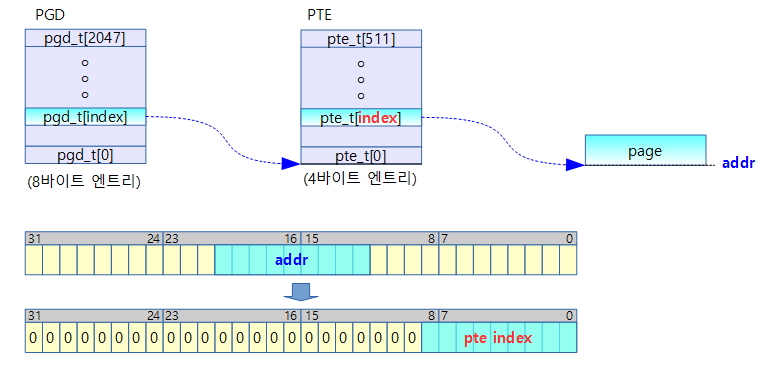
pte_index()
arch/arm/include/asm/pgtable.h
#define pte_index(addr) (((addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
- 주어진 주소의 pte 인덱스 값(0~511)을 리턴한다.
- PTRS_PER_PTE=512
- PAGE_SHIFT=12 (=4K round down)
addr[12:20] 값을 우측으로 12bit 쉬프트하여 인덱스로 활용 (0~511(0x1ff))
- rpi2 예) pte_index(0x8a12_0000) = 0x120
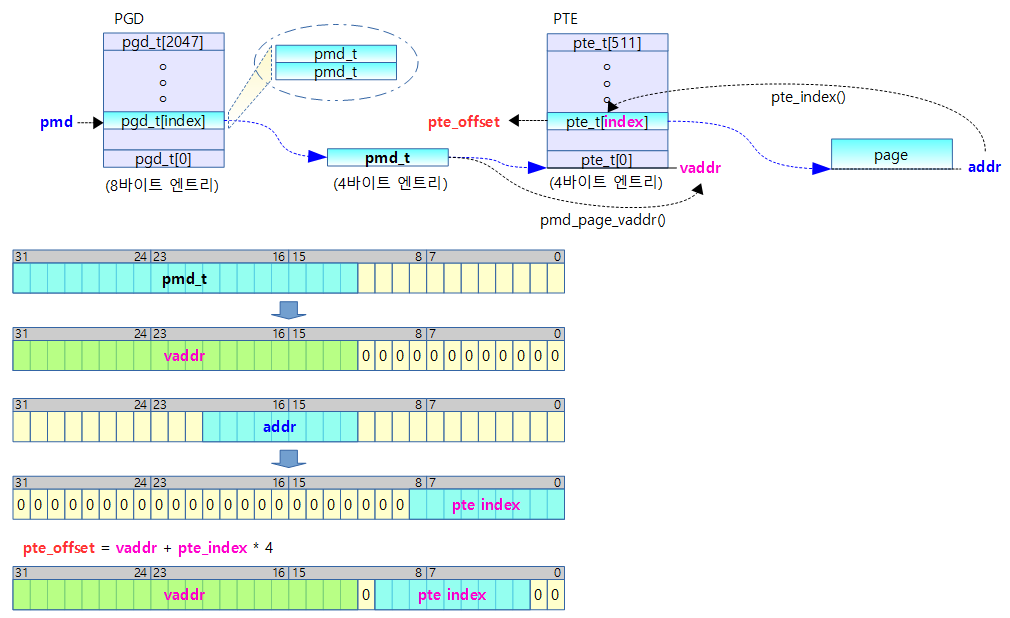
pte_offset_kernel()
arch/arm/include/asm/pgtable.h
#define pte_offset_kernel(pmd,addr) (pmd_page_vaddr(*(pmd)) + pte_index(addr))
level-1 테이블에서 pmd 포인터가 가리키는 pmd_t 값에 연동된 level-2 테이블에서 addr 값으로 pte index를 알아내어 해당 pte_t의 주소를 알아낸다.
- 예) rpi2: *pmd=0x0a00_0000
- pte_offset_kernel(0x8000_6008, 0x8234_5000) = 0x8a00_0514
__pte_map() & __pte_unmap()
CONFIG_HIGHPTE
- pte 테이블을 highmem에서 운용하고자 할 때 사용하는 커널 옵션이다.
- highmem에 있는 페이지 테이블을 access 할 때 kmap_atomic()을 사용하여 highmem에 위치한 페이지 테이블을 fixmap에 매핑 후 그 페이지 access 할 수 있다. 사용한 후에는 kunmap_atomic()을 사용하여 페이지 테이블을 fixmap에서 언매핑하여야 한다.
pte 페이지 테이블을 lowmem에서 운영하는 경우에는 별도의 매핑을 할 필요가 없으므로 곧바로 해당 영역의 주소를 알아와서 access할 수 있다.
arch/arm/include/asm/pgtable.h
#ifndef CONFIG_HIGHPTE
#define __pte_map(pmd) pmd_page_vaddr(*(pmd))
#define __pte_unmap(pte) do { } while (0)
#else
#define __pte_map(pmd) (pte_t *)kmap_atomic(pmd_page(*(pmd)))
#define __pte_unmap(pte) kunmap_atomic(pte)
#endif
level-1 테이블에서 pmd 포인터가 가리키는 pmd_t 값에 연동된 pte 테이블의 가상 주소 값을 알아낸다.
- 예) rpi2: *pmd = 0x0a10_0000
- __pte_map(0x8000_6004) = 0x8a10_0000
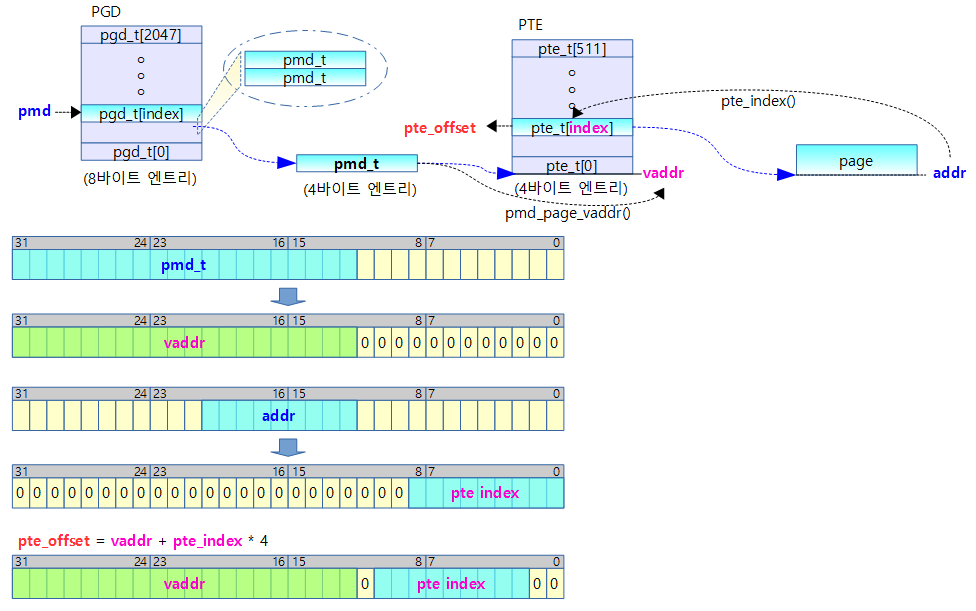
pte_offset_map()
arch/arm/include/asm/pgtable.h
#define pte_offset_map(pmd,addr) (__pte_map(pmd) + pte_index(addr))
level-1 테이블에서 pmd 포인터가 가리키는 pmd_t 값에 연동된 level-2 테이블에서 addr 값으로 pte index를 알아내어 해당 pte_t의 가상 주소를 알아낸다.
- 예) rpi2: *pmd=0x0a00_0000
- pte_offset_kernel(0x8000_6008, 0x8234_5000) = 0x8a00_0514
set_pte_ext()
arch/arm/include/asm/pgtable-2level.h
#define set_pte_ext(ptep,pte,ext) cpu_set_pte_ext(ptep,pte,ext)
pte_clear()
arch/arm/include/asm/pgtable.h
#define pte_clear(mm,addr,ptep) set_pte_ext(ptep, __pte(0), 0)
cpu_set_pte_ext()
arch/arm/include/asm/proc-fns.h
#define cpu_set_pte_ext processor.set_pte_ext
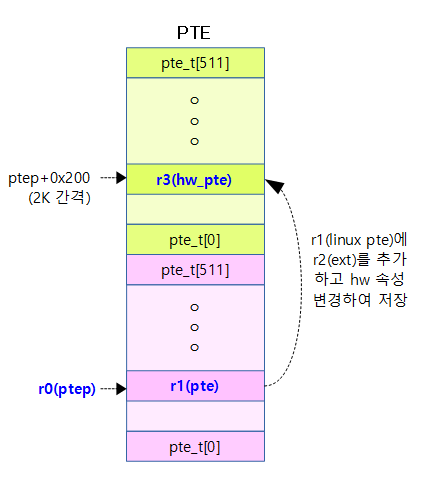
cpu_v7_set_pte_ext()
arch/arm/mm/proc-v7-2level.S
/*
* cpu_v7_set_pte_ext(ptep, pte)
*
* Set a level 2 translation table entry.
*
* - ptep - pointer to level 2 translation table entry
* (hardware version is stored at +2048 bytes)
* - pte - PTE value to store
* - ext - value for extended PTE bits
*/
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMU
str r1, [r0] @ linux version
bic r3, r1, #0x000003f0
bic r3, r3, #PTE_TYPE_MASK
orr r3, r3, r2
orr r3, r3, #PTE_EXT_AP0 | 2
tst r1, #1 << 4
orrne r3, r3, #PTE_EXT_TEX(1)
eor r1, r1, #L_PTE_DIRTY
tst r1, #L_PTE_RDONLY | L_PTE_DIRTY
orrne r3, r3, #PTE_EXT_APX
tst r1, #L_PTE_USER
orrne r3, r3, #PTE_EXT_AP1
tst r1, #L_PTE_XN
orrne r3, r3, #PTE_EXT_XN
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_VALID
eorne r1, r1, #L_PTE_NONE
tstne r1, #L_PTE_NONE
moveq r3, #0
ARM( str r3, [r0, #2048]! )
THUMB( add r0, r0, #2048 )
THUMB( str r3, [r0] )
ALT_SMP(W(nop))
ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endif
bx lr
ENDPROC(cpu_v7_set_pte_ext)
ptep 주소에 위치한 pte 엔트리를 설정하는 경우 ptep로부터 2K byte 윗 쪽에 위치한 hw pte 엔트리 역시 linux pte 속성 값을 h/w pte 속성 값으로 변환하여 설정한다.
r1(linux pte 엔트리 값)
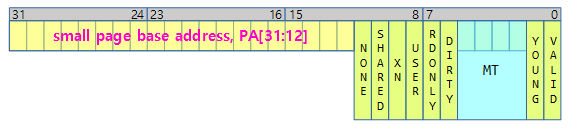
- MT(Memory Type)
- 0: MT_UNCACHED
- 1: MT_BUFFERABLE
- 2: MT_WRITETHROUGH
- 3: MT_WRITEBACK
- 4: MT_DEVICE_SHARED
- 6: MT_MINICACHE
- 9: MT_DEV_WC
- B: MT_DEV_CACHED
- C: MT_DEV_NONSHARED
- F: MT_VECTORS
r3(hw pte 엔트리 값), r2(ext, hw용 확장 pte 플래그)
- r3 값의 h/w pte AP, TEX, Table, XN 비트는 linux pte 값을 사용하여 재 설정하기 위해 일단 clear 한다.

- r3에 인수로 받은 h/w용 pte 플래그를 합치고 privileged access 권한에서 read 또는 read/write 권한을 주기위해 EXT_AP0을 설정하고 2차 테이블을 지원하기 위해 TABLE 비트를 설정한다.
- r3 | ext(hw용 확장 pte 플래그) | PTE_EXT_AP0(0x10) | 2

- pte의 bit4가 1인 경우 TRE를 설정한다.

- pte의 L_PTE_DIRTY가 없거나 L_PTE_RDONLY가 있으면 EXT_APX를 설정하여 read only로 만든다.

- pte의 L_PTE_USER가 있으면 unprivileged access 권한에서도 read 또는 read/write 권한을 주기 위해 EXT_AP1을 설정한다.

- pte의 L_PTE_XN가 있으면 페이지에서 실행코드가 동작하지 않도록 XN을 설정한다.

- pte의 L_PTE_YOUNG이 없거나 L_PTE_VALID(L_PTE_PRESENT)가 없거나 L_PTE_NONE이 있으면 r3을 모두 0으로 변경
- 리눅스 PTE 엔트리에만 있는 L_PTE_YOUNG이 있으면서 L_PTE_PRESENT가 없는 경우 pte 엔트리가 아니라 swap 엔트리를 의미한다. (H/W PTE 값은 0을 대입)
- 리눅스 PTE 엔트리에만 있는 L_PTE_NONE은 PAGE_NONE 매핑으로 automatic NUMA balancing을 위해 일부러 유저 페이지에 대한 fault를 발생시켜 사용하기 위해 이용한다. (H/W PTE 값은 0을 대입)
- 리눅스용 pte 엔트리 속성 -> h/w pte 엔트리 속성 변환 예)
- linux pte 엔트리=0x1234_565f(0b0001_0010_0011_0100_0101_0110_0101_1111)
- pfn=0x12345, prot=MT_MEMORY_RW = SHARE | XN | DIRTY | WA(0b0111) | YOUNG | PRESENT
- h/w pte 엔트리=0x1234_545f(0b0001_0010_0011_0100_0101_0100_0101_1111)
- pfn=0x12345, prot=SHARE | AP(0b001=RW,NA) | TEX(0b001) | C | B | TABLE | XN
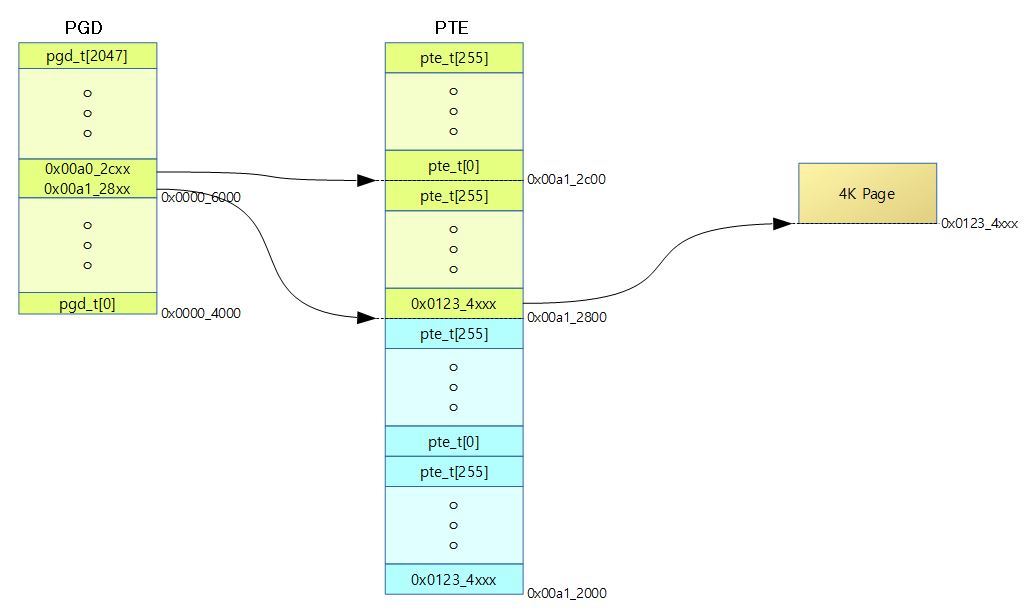
실제 연결된 페이지 테이블 예)
xxx_page() 관련
pgd_page()
include/asm-generic/pgtable-nopud.h
#define pgd_page(pgd) (pud_page((pud_t){ pgd }))
- pud page()를 호출 -> pmd_page() 호출하여 pmd 테이블에 대응하는 page를 리턴한다.
pud_page()
pmd_page()
arch/arm/include/asm/pgtable.h
#define pmd_page(pmd) pfn_to_page(__phys_to_pfn(pmd_val(pmd) & PHYS_MASK))
pte_page()
arch/arm/include/asm/pgtable.h
#define pte_page(pte) pfn_to_page(pte_pfn(pte))
- pte 값에 대응하는 pfn 값을 알아온 후 해당 page를 리턴한다.
pte_pfn()
arch/arm/include/asm/pgtable.h
#define pte_pfn(pte) ((pte_val(pte) & PHYS_MASK) >> PAGE_SHIFT)
- pte 엔트리 값을 12 bit 우측 쉬프트하여 pfn(물리 주소 frame 번호) 값으로 변환한다.
pfn_to_page()
include/asm-generic/memory_model.h
#define pfn_to_page __pfn_to_page
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
- pfn 번호에 대응하는 page 구조체 주소를 알아온다.
- __pfn_to_page
- 메모리 모델에 따라 구현이 다르다.
- CONFIG_FLATMEM
- ARCH_PFN_OFFSET = 물리주소 PFN
- rpi2: mem_map + pfn
- mem_map은 PFN0부터 시작되는 물리메모리 페이지의 정보인 page[] 구조체 배열을 가리킨다.
참고