<kernel v5.0>
이 함수는 부팅 시 호출이 되는 경우 전체 노드에 대해 zonelist를 구성하고 현재 cpu에 대해 모든 노드의 메모리를 access 할 수 있도록 설정한다. 또한 운영 중에 핸들러에 의해 호출(hotplug memory)되는 경우 전체 cpu를 멈추고 zone에 대한 boot pageset 테이블 구성 및 전체 노드에 대해 zonelist를 다시 구성한다. 구성 후 free 페이지가 적은 경우 전역 변수 page_group_by_mobility_disabled를 1로 하여 mobility 기능을 잠시 disable하고 나중에 enable한다.
zone 구성
- zone은 하나 이상 구성할 수 있다. 32bit 시스템에서는 최대 4개까지 조합이 가능하다.
- ZONE_DMA
- ZONE_DMA32
- ZONE_NORMAL
- ZONE_HIGHMEM
- ZONE_MOVABLE
- ZONE_DEVICE
zonelists
- fallback
- 각 노드에 존들이 구성되어 있고 특정 노드에서 메모리를 할당해야 할 때 할당할 영역(노드 + 존)을 선택하는데, 그 영역에서 메모리 부족(out of memory)으로 인해 할당이 실패하는 경우 대체(fallback) 영역에서 할당을 재시도해야 한다. 그때마다 영역을 찾지 않고 일정한 규칙에 의해 할당 우선순위 리스트를 만들어두어 사용하는데, 이것을 zonelist라고 한다.
- zonelist order
- 우선순위를 두어 단계적인 fallback용 zonelist를 구성한다. 시스템 설계에 따라 노드 우선(node order) 또는 존 우선(zone order)을 결정하여 순서를 정할 수 있다. 디폴트로 32비트 시스템은 존 우선으로 되어 있고, 64비트 시스템은 노드 우선으로 구성한다. 단 커널 버전 4.14-rc1부터 존 우선(zone order)으로 zonelist를 생성하는 루틴을 삭제하고 노드 우선(node order)만사용한다.
- 리눅스 시스템은 zonelist order와 관련하여 다음과 같이 두 가지 중 하나를 선택하여 동작한다.
- 노드 우선(node order)
- 베스트 노드부터 역순으로 정렬한 존 타입으로 zonelist를 구성한다. 노드 우선으로 동작하더라도 ZONE_DMA 또는 ZONE_DMA32에 대해서는 아키텍처에 따라 할당을 제한하기도 한다.
- 존 우선(zone order)
- 역순으로 정렬한 존 타입부터 베스트 노드 순서대로 zonelist를 구성한다. ZONE_NORMAL 영역에 대해 충분히 free 영역을 확보할 필요가 있기 때문에, 보통 메모리가 적은 32비트 시스템에서는 존 우선 방식을 디폴트로 사용하여 ZONE_HIGHMEM(ZONE_MOVABLE)부터 우선 사용할 수 있게 한다. 32비트 시스템에서는 보통 메모리가 충분하지 않으므로 ZONE_DMA 및 ZONE_NORMAL 메모리를 보호하기 위해 존 우선을 사용한다
- 노드 우선(node order)
- node와 zone의 검색 방향
- 노드(순방향)
- 노드 간 접근 속도가 다르므로 현재 노드부터 가장 빠른 노드(best)를 우선순위로 둔다.
- 존(역방향)
- 존에 대해 높은 번호부터 아래 번호 순서로 할당 시도를 한다. DMA 영역은 가장 낮은 순위로 메모리 할당을 하여 보호받는다.
- ZONE_DEVICE(최상위 우선 순위)
- ZONE_MOVABLE
- ZONE_HIGHMEM(64비트 시스템에서는 사용되지 않는다.)
- ZONE_NORMAL
- ZONE_DMA32
- ZONE_DMA
- 존에 대해 높은 번호부터 아래 번호 순서로 할당 시도를 한다. DMA 영역은 가장 낮은 순위로 메모리 할당을 하여 보호받는다.
- 노드(순방향)
- NUMA 시스템에서는 2개의 zonelists를 사용한다.
- zonelists[0]은 전체 노드를 대상으로 만들어진다.
- zonelists[1]은 현재 노드만을 대상으로 만들어진다(NUMA only). _ _GFP_THISNODE 사용 시 활용한다.
MOVABLE 존
이 영역은 특별히 버디 시스템으로 구현된 페이지 할당자가 메모리 단편화를 막기 위해 전용으로 사용하는 영역이며, 동시에 메모리 핫플러그를 지원하기 위해 구성돼야 하는 영역이다. 버디 시스템에서 메모리 단편화를 막기 위해 사용하는 방법으로 가능하면 마이그레이션 타입별로 관리를 하는데, 좀 더 확실한 영역을 지정하여 더 효율적으로 사용할 수 있다.
두 가지 구성 방법을 알아보자.
- 크기로 설정
- 커널 파라미터로 ‘kernelcore=’ 또는 ‘movablecore’를 사용해 크기를 지정하여 사용한다. kernelcore=를 사용하는 경우 전체 메모리에서 지정된 크기를 제외한 나머지 크기가 ZONE_MOVABLE로 설정된다. movablecore=를 사용하여 지정된 크기가 ZONE_MOVABLE로 설정된다.
- 특정 노드 메모리를 지정
- CONFIG_MOVABLE_NODE 커널 옵션을 사용하면서 커널 파라미터로 movable_node를 사용하고 memory memblock regions의 flags에 MEMBLOCK
_HOTPLUG 플래그 비트를 설정한 메모리 블록을 통째로 ZONE_MOVABLE로 지정할 수 있다. 메모리 핫플러그가 가능한 메모리 영역을 지정하여 사용한다.
- CONFIG_MOVABLE_NODE 커널 옵션을 사용하면서 커널 파라미터로 movable_node를 사용하고 memory memblock regions의 flags에 MEMBLOCK
리눅스에서 메모리 핫플러그 구현은 완료되었고, 이 기능을 응용하여 유연하게 메모리의 동적 구성이 가능하다. 실제 하드웨어로 메모리 핫플러그가 시험되었는지 여부는 미지수다. 구현 당시에는 하드웨어가 준비되지 않은 상태였다.
movable(_ _GFP_MOVABLE) 속성을 가진 페이지들만 ZONE_MOVABLE에 들어갈 수 있다. 버디 시스템으로 구현된 페이지 할당자에서 연속된 페이지 요청을 수행하기 힘든 경우 메모리 컴팩션이 일어나는데, 이때 movable 속성을 가진 페이지를 다른 주소로 마이그레이션(migration) 시킨다.
메모리 컴팩션은 버디 시스템에서 연속된 free 메모리가 부족하여 요청한 오더 페이지에 대한 할당이 불가능할 때 해당 오더의 앞쪽에 있는 사용된 페이지를 뒤쪽으로 옮겨서 앞부분에 필요한 공간을 만드는 메커니즘이라고 할 수 있다.
ZONE_MOVABLE은 highest 존의 메모리를 분할하여 사용한다. 또한 아키텍처와 메모리 크기에 따라 해당 시스템의 highest 존이 다르다.
- ARM32 예) CONFIG_HIGHMEM을 선택하고, 만일 없으면 CONFIG_NORMAL을 선택함
- ARM64 예) CONFIG_NORMAL을 선택하고, 만일 없으면 ZONE_DMA32를 선택함
- x86_32 예) ZONE_HIGHMEM을 선택하고, 만일 없으면 ZONE_NORMAL을 선택함
- x86_64 예) ZONE_NORMAL을 선택하고, 만일 없으면 ZONE_DMA32를 선택함
zonelist 초기화
이 함수는 부팅 시에 호출되는 경우 전체 노드에 대해 zonelist를 구성하고 현재 cpu에 대해 모든 노드의 메모리를 액세스할 수 있도록 설정한다. 또한 운영 중에 핸들러에 의해 호출(핫플러그 메모리)되는 경우 전체 cpu를 멈추고 존에 대한 boot pageset 테이블 구성 및 전체 노드에 대해 zonelist를 다시 구성한다. 구성 후 free 페이지가 적은 경우 전역 변수 page_group_by_mobility_disabled를 1로 하여 mobility 기능을 잠시 disable하고 나중에 enable한다.
다음 그림은 zonelist를 구성할 때의 함수 호출 관계이다.
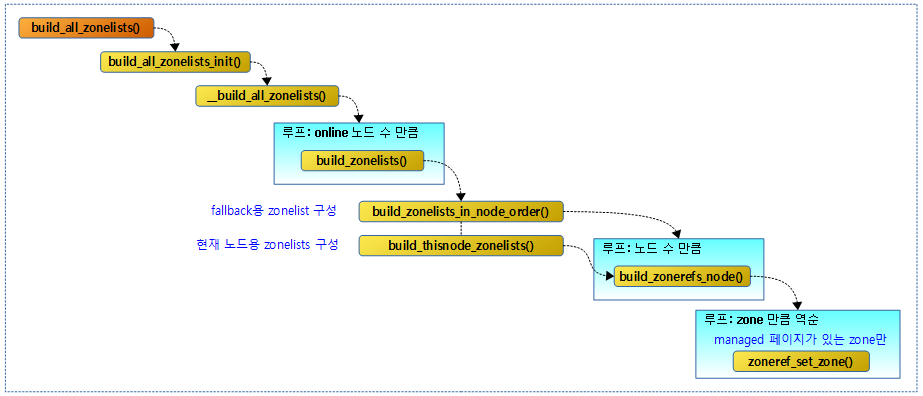
build_all_zonelists()
mm/page_alloc.c
/* * unless system_state == SYSTEM_BOOTING. * * __ref due to call of __init annotated helper build_all_zonelists_init * [protected by SYSTEM_BOOTING]. */
void __ref build_all_zonelists(pg_data_t *pgdat)
{
if (system_state == SYSTEM_BOOTING) {
build_all_zonelists_init();
} else {
__build_all_zonelists(pgdat);
/* cpuset refresh routine should be here */
}
vm_total_pages = nr_free_pagecache_pages();
/*
* Disable grouping by mobility if the number of pages in the
* system is too low to allow the mechanism to work. It would be
* more accurate, but expensive to check per-zone. This check is
* made on memory-hotadd so a system can start with mobility
* disabled and enable it later
*/
if (vm_total_pages < (pageblock_nr_pages * MIGRATE_TYPES))
page_group_by_mobility_disabled = 1;
else
page_group_by_mobility_disabled = 0;
pr_info("Built %i zonelists, mobility grouping %s. Total pages: %ld\n",
nr_online_nodes,
page_group_by_mobility_disabled ? "off" : "on",
vm_total_pages);
#ifdef CONFIG_NUMA
pr_info("Policy zone: %s\n", zone_names[policy_zone]);
#endif
}
각 노드의 활성화된 존에 fallback list인 zonelist를 생성한다. 첫 번째 인자로 주어지는 pgdat의 타입 pg_data_t는 노드 정보를 담고 있는 pglist_data 구조체를 타입 정의(define)하여 사용했다.
- 코드 라인 3~8에서 최초 부팅 시에 호출된 경우 곧바로 최초 zonelist를 구성한다. 최초 부팅 시가 아니면 zonelist를 재구성한다. 만일 핫플러그 메모리가 지원되는 경우 존에 대한 per-cpu 페이지 세트 프레임 캐시를 할당받고 구성한다.
- 코드 라인 9에서 zonelist에서 high 워터마크까지의 페이지 개수를 제외한 free 페이지를 재계산한다.
- 코드 라인 17~20에서 vm_total_pages가 migrate 타입 수(최대 6개) * 페이지 블록 크기보다 작으면 free 메모리가 매우 부족한 상태이므로 전역 page_group_by_mobility_disabled 변수를 true로 설정하여 페이지 블록에 migratetype 저장 시 항상 unmovable 타입을 사용하여 mobility 기능을 제한한다.
- 코드 라인 22~25에서 zonelist 순서(order) 정보와 모빌리티 그루핑 동작 여부와 전체 페이지 수 정보등을 출력한다.
- 예) “Built 1 zonelists in Zone order, mobility grouping on. Total pages: 999432”
- 코드 라인 27에서 NUMA 시스템인 경우 policy 존 정보를 출력한다.
- 예) “Policy zone: Normal”
policy_zone
- vma_migrate() 함수를 통해 사용되는 movable을 제외한 최상위 존을 담은 변수로 policy 존 미만을 사용하는 존으로 migrate를 제한할 목적으로 사용된다.
- zonelist를 만드는 과정에서 build_zonerefs_node() -> check_highest_zone() 함수를 통해 policy_zone이 설정된다.
system_states
include/linux/kernel.h
/* * Values used for system_state. Ordering of the states must not be changed * as code checks for <, <=, >, >= STATE. */
extern enum system_states {
SYSTEM_BOOTING,
SYSTEM_SCHEDULING,
SYSTEM_RUNNING,
SYSTEM_HALT,
SYSTEM_POWER_OFF,
SYSTEM_RESTART,
SYSTEM_SUSPEND,
} system_state;
build_all_zonelists_init()
mm/page_alloc.c
static noinline void __init
build_all_zonelists_init(void)
{
int cpu;
__build_all_zonelists(NULL);
/*
* Initialize the boot_pagesets that are going to be used
* for bootstrapping processors. The real pagesets for
* each zone will be allocated later when the per cpu
* allocator is available.
*
* boot_pagesets are used also for bootstrapping offline
* cpus if the system is already booted because the pagesets
* are needed to initialize allocators on a specific cpu too.
* F.e. the percpu allocator needs the page allocator which
* needs the percpu allocator in order to allocate its pagesets
* (a chicken-egg dilemma).
*/
for_each_possible_cpu(cpu)
setup_pageset(&per_cpu(boot_pageset, cpu), 0);
mminit_verify_zonelist();
cpuset_init_current_mems_allowed();
}
노드별로 zonelist를 생성하고 현재 태스크의 mems_allowed 노드마스크를 모두 설정하여 전체 메모리 노드에서 할당받을 수 있음을 나타낸다.
__build_all_zonelists()
mm/page_alloc.c
static void __build_all_zonelists(void *data)
{
int nid;
int __maybe_unused cpu;
pg_data_t *self = data;
static DEFINE_SPINLOCK(lock);
spin_lock(&lock);
#ifdef CONFIG_NUMA
memset(node_load, 0, sizeof(node_load));
#endif
/*
* This node is hotadded and no memory is yet present. So just
* building zonelists is fine - no need to touch other nodes.
*/
if (self && !node_online(self->node_id)) {
build_zonelists(self);
} else {
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
build_zonelists(pgdat);
}
#ifdef CONFIG_HAVE_MEMORYLESS_NODES
/*
* We now know the "local memory node" for each node--
* i.e., the node of the first zone in the generic zonelist.
* Set up numa_mem percpu variable for on-line cpus. During
* boot, only the boot cpu should be on-line; we'll init the
* secondary cpus' numa_mem as they come on-line. During
* node/memory hotplug, we'll fixup all on-line cpus.
*/
for_each_online_cpu(cpu)
set_cpu_numa_mem(cpu, local_memory_node(cpu_to_node(cpu)));
#endif
}
spin_unlock(&lock);
}
인자를 통해 지정한 노드 또는 모든 노드에 대해 zonelist와 per-cpu 페이지 프레임 캐시를 구성한다.
- 코드 라인 5에서 최초 build_zonelists_all() 함수 호출 시 NULL이 data 인자로 주어졌다.
- 코드 라인 18~19에서 인자로 요청한 노드가 온라인 노드가 아니면 zonelists를 구성한다.
- 코드 라인 21~25에서 모든 온라인 노드를 순회하며 각 노드의 zonelists를 구성한다.
- 코드 라인 36~37에서 커널이 메모리리스 노드를 지원하는 경우 온라인 cpu별로 메모리가 있는 인접 노드를 지정한다.
build_zonelists()
mm/page_alloc.c
/* * Build zonelists ordered by zone and nodes within zones. * This results in conserving DMA zone[s] until all Normal memory is * exhausted, but results in overflowing to remote node while memory * may still exist in local DMA zone. */
static void build_zonelists(pg_data_t *pgdat)
{
static int node_order[MAX_NUMNODES];
int node, load, nr_nodes = 0;
nodemask_t used_mask;
int local_node, prev_node;
/* NUMA-aware ordering of nodes */
local_node = pgdat->node_id;
load = nr_online_nodes;
prev_node = local_node;
nodes_clear(used_mask);
memset(node_order, 0, sizeof(node_order));
while ((node = find_next_best_node(local_node, &used_mask)) >= 0) {
/*
* We don't want to pressure a particular node.
* So adding penalty to the first node in same
* distance group to make it round-robin.
*/
if (node_distance(local_node, node) !=
node_distance(local_node, prev_node))
node_load[node] = load;
node_order[nr_nodes++] = node;
prev_node = node;
load--;
}
build_zonelists_in_node_order(pgdat, node_order, nr_nodes);
build_thisnode_zonelists(pgdat);
}
유저 설정 또는 디폴트 설정에 따라 노드 우선 또는 존 우선을 선택하여 zonelist를 만들어낸다.
- 코드 라인 15~코드 used_mask 비트맵에 포함되지 않은 노드 중 가장 인접한 노드 id를 구한다.
- 코드 라인 21~23에서 현재 노드와 알아온 인접 노드의 거리가 현재 노드와 기존 노드의 거리와 다르다면, 즉 이전 노드와 거리가 다르다면 node_load[node]에 load 값을 설정한다.
- 코드 라인 26~27에서 prev_node에 방금 처리한 현재 노드 id를 설정하고 load 값을 감소시킨다.
- 코드 라인 30에서 노드 오더용 zonelist를 구성하여 zonelists[0]에 추가한다.
- 코드 라인 31에서 현재 노드에 대해서만 활성화된 존을 zonelists[1]에 추가한다.
- GFP_THISNODE 플래그 옵션이 주어지는 경우 노드 fallback 기능을 사용하지 않도록 이 zonelists[1]을 사용한다.
“numa_zonelist_order” 커널 파라메터 & “/proc/sys/vm/numa_zonelist_order”
setup_numa_zonelist_order()
mm/page_alloc.c
static __init int setup_numa_zonelist_order(char *s)
{
if (!s)
return 0;
return __parse_numa_zonelist_order(s);
}
early_param("numa_zonelist_order", setup_numa_zonelist_order);
누마 시스템에서 zonelist order를 다음 중 하나로 선택하였었으나 커널 v4.14-rc1 이후로는 이러한 커널 파라미터를 사용하는 경우 경고 메시지를 출력한다.
- “numa_zonelist_order=d”
- automatic configuration
- “numa_zonelist_order=n”
- node order (노드 거리에 따른 가장 가까운 best 노드 순)
- “numa_zonelist_order=z”
- zone order (zone type 역순)
__parse_numa_zonelist_order()
mm/page_alloc.c
static int __parse_numa_zonelist_order(char *s)
{
/*
* We used to support different zonlists modes but they turned
* out to be just not useful. Let's keep the warning in place
* if somebody still use the cmd line parameter so that we do
* not fail it silently
*/
if (!(*s == 'd' || *s == 'D' || *s == 'n' || *s == 'N')) {
pr_warn("Ignoring unsupported numa_zonelist_order value: %s\n", s);
return -EINVAL;
}
return 0;
}
문자열이 Default 및 Node 약자인 d, D, n, N 문자를 사용하면 경고 메시지를 출력한다.
- 그 외의 문자는 skip 한다. (“Z”, “z” 등)
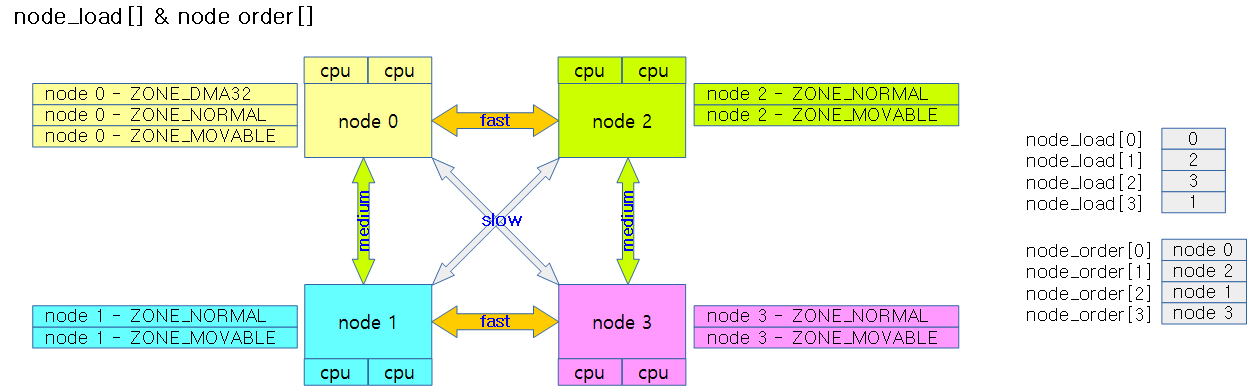
node_load[] 및 node_order[]
다음 그림은 NUMA 시스템에서 node_load[] 및 node_order[]를 알아본 사례이다.
- node_order[]
- 현재 부팅한 cpu가 있는 로컬 노드를 대상으로 가장 빠른(가까운) 순서의 노드 번호를 저장한다.
- node_load[]
- 다음 best 노드를 찾을 때 사용할 노드별 가중치 값
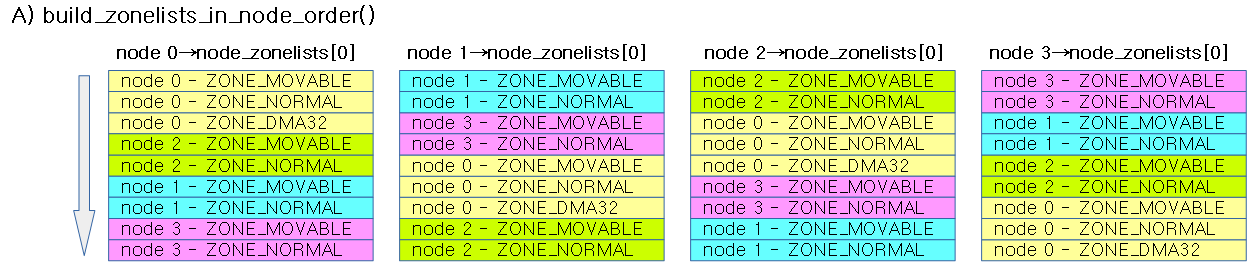
build_zonelists_in_node_order()
mm/page_alloc.c
/* * Build zonelists ordered by node and zones within node. * This results in maximum locality--normal zone overflows into local * DMA zone, if any--but risks exhausting DMA zone. */
static void build_zonelists_in_node_order(pg_data_t *pgdat, int *node_order,
unsigned nr_nodes)
{
struct zoneref *zonerefs;
int i;
zonerefs = pgdat->node_zonelists[ZONELIST_FALLBACK]._zonerefs;
for (i = 0; i < nr_nodes; i++) {
int nr_zones;
pg_data_t *node = NODE_DATA(node_order[i]);
nr_zones = build_zonerefs_node(node, zonerefs);
zonerefs += nr_zones;
}
zonerefs->zone = NULL;
zonerefs->zone_idx = 0;
}
zonelist를 노드 우선으로 만든다.
아래 그림은 4개 노드에 대해 node order로 구축한 zonelists를 보여준다.
- 경우에 따라서는 DMA(DMA32)만 특별히 가장 밑으로 옮긴 경우도 있다.
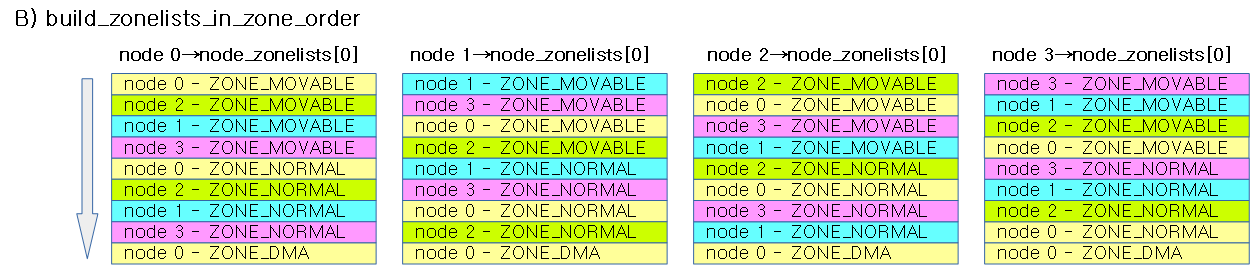
아래 그림은 4개 노드에 대해 zone order로 구축한 zonelists를 보여준다. (커널 4.14-rc1 부터 사용하지 않음)
build_zonerefs_node()
mm/page_alloc.c
/* * Builds allocation fallback zone lists. * * Add all populated zones of a node to the zonelist. */
static int build_zonerefs_node(pg_data_t *pgdat, struct zoneref *zonerefs)
{
struct zone *zone;
enum zone_type zone_type = MAX_NR_ZONES;
int nr_zones = 0;
do {
zone_type--;
zone = pgdat->node_zones + zone_type;
if (managed_zone(zone)) {
zoneref_set_zone(zone, &zonerefs[nr_zones++]);
check_highest_zone(zone_type);
}
} while (zone_type);
return nr_zones;
}
노드에 관련된 zone 정보를 구성하고, 구성한 존 수를 반환한다.
- 코드 라인 4~9에서 MAX_NR_ZONES(3)가 가리키는 최상위 존부터 ~ 최하위 0번을 제외한 1번 존까지 순회한다.
- 코드 라인 10~13에서 실제 사용할 페이지가 있는 zone인 경우 출력 인자 @zonerefs 배열에 zone 정보를 추가하고 최상위 존인 경우 policy zone을 갱신한다.
build_thisnode_zonelists()
mm/page_alloc.c
/* * Build gfp_thisnode zonelists */
static void build_thisnode_zonelists(pg_data_t *pgdat)
{
struct zoneref *zonerefs;
int nr_zones;
zonerefs = pgdat->node_zonelists[ZONELIST_NOFALLBACK]._zonerefs;
nr_zones = build_zonerefs_node(pgdat, zonerefs);
zonerefs += nr_zones;
zonerefs->zone = NULL;
zonerefs->zone_idx = 0;
}
요청한 단일 노드용 zonelist를 구성한다.
Zonelist 캐시
zonelist 캐시는 커널 v4.4-rc1에서 제거되었다.
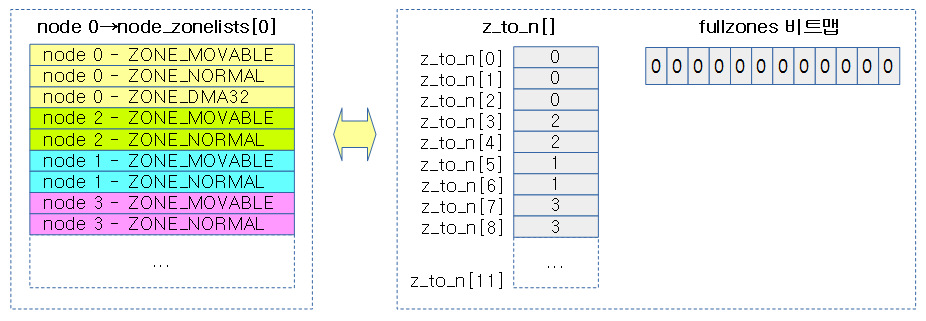
아래 그림은 zonelist_cache를 구성한 모습이다. fullzones 비트맵은 0으로 clear한다.
mminit_verify_zonelist()
mm/mm_init.c
/* The zonelists are simply reported, validation is manual. */
void __init mminit_verify_zonelist(void)
{
int nid;
if (mminit_loglevel < MMINIT_VERIFY)
return;
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
struct zone *zone;
struct zoneref *z;
struct zonelist *zonelist;
int i, listid, zoneid;
BUG_ON(MAX_ZONELISTS > 2);
for (i = 0; i < MAX_ZONELISTS * MAX_NR_ZONES; i++) {
/* Identify the zone and nodelist */
zoneid = i % MAX_NR_ZONES;
listid = i / MAX_NR_ZONES;
zonelist = &pgdat->node_zonelists[listid];
zone = &pgdat->node_zones[zoneid];
if (!populated_zone(zone))
continue;
/* Print information about the zonelist */
printk(KERN_DEBUG "mminit::zonelist %s %d:%s = ",
listid > 0 ? "thisnode" : "general", nid,
zone->name);
/* Iterate the zonelist */
for_each_zone_zonelist(zone, z, zonelist, zoneid)
pr_cont("%d:%s ", zone_to_nid(zone), zone->name);
printk("\n");
}
}
}
모든 노드의 존에 대해서 zonelists를 출력한다.
cpuset_init_current_mems_allowed()
kernel/cpuset.c
void __init cpuset_init_current_mems_allowed(void)
{
nodes_setall(current->mems_allowed);
}
현재 태스크가 모든 노드의 메모리를 사용할 수 있도록 설정한다.
- 현재 태스크의 mems_allowed 노드마스크 비트맵에 대해 모든 비트를 1로 설정한다.
nodes_setall()
include/linux/nodemask.h
#define nodes_setall(dst) __nodes_setall(&(dst), MAX_NUMNODES)
static inline void __nodes_setall(nodemask_t *dstp, unsigned int nbits)
{
bitmap_fill(dstp->bits, nbits);
}
지정된 dst 노드 비트맵 마스크에 대해 모든 노드의 메모리를 사용할 수 있도록 설정한다.
- dstp 노드마스크 비트맵에 대해 MAX_NUMNODES 수 만큼의 비트를 1로 설정한다
managed_zone()
include/linux/mmzone.h
/* * Returns true if a zone has pages managed by the buddy allocator. * All the reclaim decisions have to use this function rather than * populated_zone(). If the whole zone is reserved then we can easily * end up with populated_zone() && !managed_zone(). */
static inline bool managed_zone(struct zone *zone)
{
return zone_managed_pages(zone);
}
해당 존이 버디 할당자가 관리하는 페이지인지 여부를 반환한다.
zone_managed_pages()
include/linux/mmzone.h
static inline unsigned long zone_managed_pages(struct zone *zone)
{
return (unsigned long)atomic_long_read(&zone->managed_pages);
}
해당 존에서 버디 할당자가 관리하는 페이지 수를 반환한다.
zoneref_set_zone()
mm/page_alloc.c
static void zoneref_set_zone(struct zone *zone, struct zoneref *zoneref)
{
zoneref->zone = zone;
zoneref->zone_idx = zone_idx(zone);
}
zoneref 구조체에 zone 정보를 기록한다.
check_highest_zone()
include/linux/mempolicy.h
static inline void check_highest_zone(enum zone_type k)
{
if (k > policy_zone && k != ZONE_MOVABLE)
policy_zone = k;
}
인자로 요청한 존이 최상인 경우 policy 존으로 갱신한다. movable 존을 제외하고, device 존 -> highmem 존 -> normal 존 순서이다.
빈 페이지 캐시 페이지 산출
nr_free_pagecache_pages()
mm/page_alloc.c
/** * nr_free_pagecache_pages - count number of pages beyond high watermark * * nr_free_pagecache_pages() counts the number of pages which are beyond the * high watermark within all zones. */
unsigned long nr_free_pagecache_pages(void)
{
return nr_free_zone_pages(gfp_zone(GFP_HIGHUSER_MOVABLE));
}
유저 페이지 캐시용(movable 가능한 페이지)으로 사용할 수 있는 빈 페이지 수를 반환한다. 단 high 워터마크 미만 페이지들은 제외한다.
- highmem 존 또는 movable 존 이하 대상
nr_free_zone_pages()
mm/page_alloc.c
/** * nr_free_zone_pages - count number of pages beyond high watermark * @offset: The zone index of the highest zone * * nr_free_zone_pages() counts the number of counts pages which are beyond the * high watermark within all zones at or below a given zone index. For each * zone, the number of pages is calculated as: * * nr_free_zone_pages = managed_pages - high_pages */
static unsigned long nr_free_zone_pages(int offset)
{
struct zoneref *z;
struct zone *zone;
/* Just pick one node, since fallback list is circular */
unsigned long sum = 0;
struct zonelist *zonelist = node_zonelist(numa_node_id(), GFP_KERNEL);
for_each_zone_zonelist(zone, z, zonelist, offset) {
unsigned long size = zone_managed_pages(zone);
unsigned long high = high_wmark_pages(zone);
if (size > high)
sum += size - high;
}
return sum;
}
zonelist의 존들 중 offset 존 이하의 zone에 대해 free 페이지 수를 알아오는데 high 워터마크 페이지 수를 제외한다.
- 코드 라인 9에서 현재 cpu의 노드용 zonelist이다.
- 코드 라인 11~16에서 zonelist에 포함된 모든 zone들 중 offset 이하의 존을 순회하며 버디 시스템이 관리하는 free 페이지인 managed 페이지를 누적하되 high 워터마크 이하의 페이지는 제외시킨다.
numa_node_id()
include/linux/topology.h
#ifndef numa_node_id
/* Returns the number of the current Node. */
static inline int numa_node_id(void)
{
return raw_cpu_read(numa_node);
}
#endif
per-cpu 데이터인 numa_node 값을 알아온다. 즉 해당 cpu에 대한 numa_node id 값을 리턴한다.
- 이 값은 set_numa_node() 또는 set_cpu_numa_node() 함수에 의해 설정된다.
node_zonelist()
include/linux/gfp.h
/* * We get the zone list from the current node and the gfp_mask. * This zone list contains a maximum of MAXNODES*MAX_NR_ZONES zones. * There are two zonelists per node, one for all zones with memory and * one containing just zones from the node the zonelist belongs to. * * For the normal case of non-DISCONTIGMEM systems the NODE_DATA() gets * optimized to &contig_page_data at compile-time. */
static inline struct zonelist *node_zonelist(int nid, gfp_t flags)
{
return NODE_DATA(nid)->node_zonelists + gfp_zonelist(flags);
}
노드에 대응하는 2 개의 zonelists 중 하나를 다음 조건으로 리턴한다.
- NUMA 시스템에서 __GFP_THISNODE 플래그 비트가 있는 경우 오직 자신의 노드에 대한 zone 만 포함된 zonelists[1]
- otherwise, 모든 노드에 대한 zone이 포함된 zonelists[0]
gfp_zonelist()
include/linux/gfp.h
/* * There is only one page-allocator function, and two main namespaces to * it. The alloc_page*() variants return 'struct page *' and as such * can allocate highmem pages, the *get*page*() variants return * virtual kernel addresses to the allocated page(s). */
static inline int gfp_zonelist(gfp_t flags)
{
#ifdef CONFIG_NUMA
if (unlikely(flags & __GFP_THISNODE))
return ZONELIST_NOFALLBACK;
#endif
return ZONELIST_FALLBACK;
}
요청 플래그에 따른 zonelist 인덱스를 반환한다. ZONELIST_FALLBACK(0) 또는 ZONELIST_NOFALLBACK(1)
- __GFP_THISNODE 플래그가 유무에 따라
- 플래그가 있으면 zonelist의 fallback을 허용하지 않고 현재 노드에서만 할당하도록 1번 인덱스를 반환한다.
- 플래그가 없으면 fallback 가능한 여러 노드에서 할당할 수 있게 0번 인덱스를 반환한다.
구조체
zonelist 구조체
include/linux/mmzone.h
/* * One allocation request operates on a zonelist. A zonelist * is a list of zones, the first one is the 'goal' of the * allocation, the other zones are fallback zones, in decreasing * priority. * * To speed the reading of the zonelist, the zonerefs contain the zone index * of the entry being read. Helper functions to access information given * a struct zoneref are * * zonelist_zone() - Return the struct zone * for an entry in _zonerefs * zonelist_zone_idx() - Return the index of the zone for an entry * zonelist_node_idx() - Return the index of the node for an entry */
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};
- _zonerefs[]
- 메모리 할당을 위해 fallback을 위한 zone들로 구성된다.
zoneref 구조체
include/linux/mmzone.h
/* * This struct contains information about a zone in a zonelist. It is stored * here to avoid dereferences into large structures and lookups of tables */
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
- *zone
- 존 포인터
- zone_idx
- 존에 대한 인덱스(0~3)
참고
- Bit Operations | 문c
- Bitmap Operations | 문c
- NODE 비트맵 (API) | 문c
- CPU 비트맵 (API) | 문c
- ZONE 비트맵 (API) | 문c
- setup_per_cpu_pageset() | 문c
- Per-CPU Page Frame Cache (zone->pageset) | 문c