<kernel v5.10>
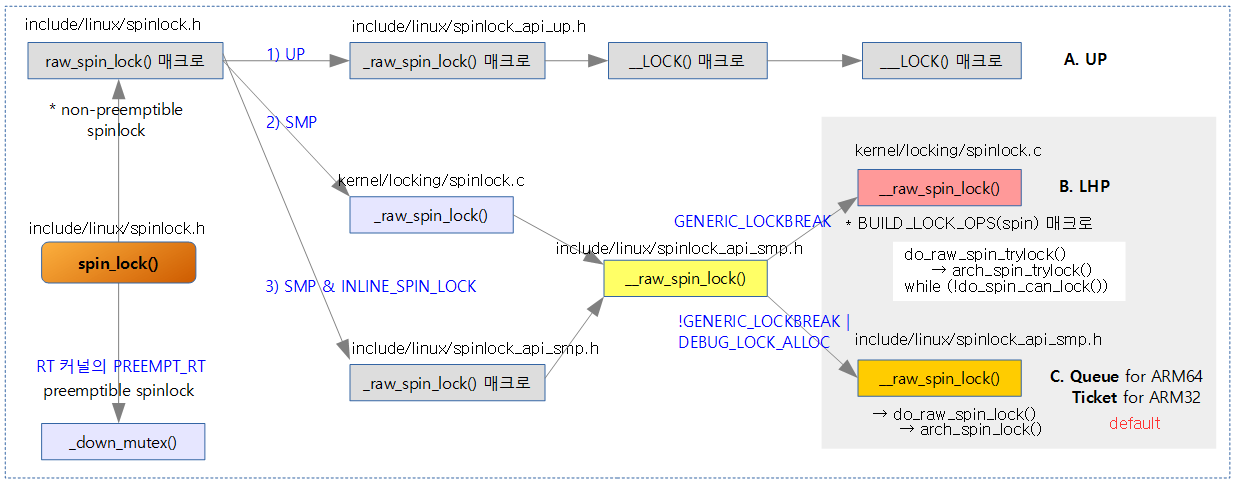
Spin-Lock
critical section에 동시 접근한 스레드들 중 먼저 접근 요청한 스레드만이 critical section을 실행하는 동안 lock을 소유하고, 그 외의 스레드는 spin wait 한다. 다음으로 요청한 스레드들은 먼저 lock을 점유한 스레드의 점유 기간이 아주 짧다는 보장하에 lock 대기 시간 동안 spin wait 한다.
예) 간단한 대표 spin-lock API 사용 예
- 병렬 프로그래밍을 위해 여러 cpu 또는 여러 context 에서 아래 safe_foo() 함수를 동시에 호출하더라도 <critical section>이 동시에 실행되지 않고, 순서대로(시리얼하게) 실행되는 것을 보장한다.
static DEFINE_SPINLOCK(foo);
void safe_foo()
{
spin_lock(&foo);
<critical section>
spin_unlock(&foo);
}
critical section 구간에서 preemption
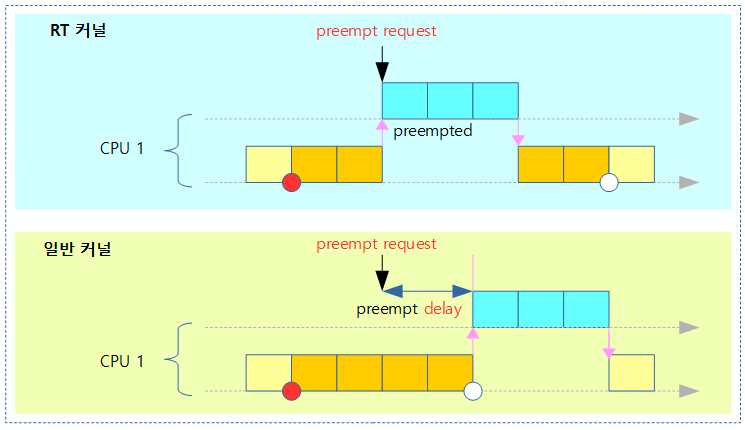
2009 Kernel summit에서 결정된 사항으로 RT 커널을 지원하면서 spinlock이 preemption이 가능해졌다. spin-lock API는 일반 커널의 경우 critical section 구간에서 preemption을 금지 시키지만, RT 커널의 경우 preemption을 허용한다. 따라서 협의하에 다음과 같이 두 개의 API 구성으로 변경하였다.
- spin_lock()
- preemption 될 수 있는 spin lock이다. (RT 커널에서 preemption 된다)
- raw_spin_lock()
- preemption 될 수 없는 spin lock이다. (RT 커널에서도 preemption 되지 않는다)
-
-
- critical section 내에서 오랜 시간동안 머무르면 다른 스레드 역시 이 critical section 내부를 접근하지 못하고 장시간 대기하므로 최소한의 시간내에 사용을 마치고 lock을 풀어줘야 한다.
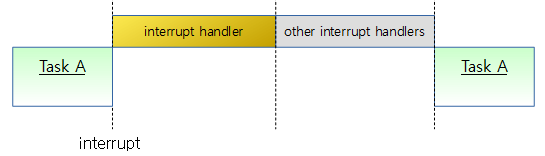
다음 그림은 높은 우선 순위의 태스크가 preemption 요청을 해온 상황이다.
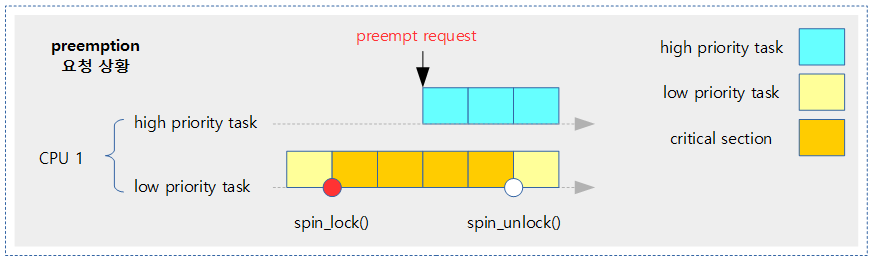
위 그림의 preemption 요청에 대한 두 가지 커널에서 처리하는 방법이다.
raw_spin_lock의 spin 구간에서 처리 방법
- critical section 구간과는 다르게 lock을 얻지 못해 spin을 하는 구간에서는 preemption 여부가 구현 방법에 따라 다른데 최근 3가지 구현 방법은 다음과 같다.
- UP 시스템에서는 preemption을 무조건 금지 시킨다.
- SMP + LHP(Lock-holder Preemption) 방식에서는 spin 하는 동안에는 preemption을 허용한다.
- SMP + ticket 또는 SMP + queued 방식에서는 순서대로 lock을 획득하는 것이 보장된다. (default)
- hardware bus locking 사용
- ARMv6부터 lock 대기시간 시 전력을 줄이고자 lock 대기 시 ARM 이벤트 명령(wfe)을 사용하여 이벤트를 기다린다.
- unlock을 할 때에는 lock 카운터도 감소 시키면서 ARMv6 이상에서 이벤트 전송 명령(sev)을 보내 lock을 종료시킨다.
Spinning, busy-waitting, busy-looping
CPU가 쉬지 않고(Non-sleep-able) 특정 컨디션이 될 때 까지 루프를 도는 일을 spinning, busy-waiting 또는 busy-looping 이라 불린다.
루프를 탈출 할 수 있는 컨디션은 주로 다른 CPU에서 전달(조작)하는 특정 변수 값(카운터나 플래그) 또는 시그널로 판단을 한다.
- CPU가 Non-sleep 한다는 말은 다른 태스크로 전환되지 않도록 preemption 되지 않는다는 의미다.
- ARM32/64의 경우 절전을 위해 wfe(wait for event) 명령을 사용하여 대기하는 코드를 사용하였다.
Spinner
spinner를 굳이 표현하자면 위와 같이 쉬지 않고 도는actor(CPU)를 의미한다.
- spinner가 spinning을 하는 동안 다른 CPU가 빠르게 시그널(카운터 값 등)을 설정하지 않으면 spinner는 그 시간만큼 계속 루프를 돌아야 한다.
- 보통 일반 적인 루프들은 조건에 부합되지 않으면 기다리는 동안 자신을 sleep시켜 다른 태스크로 CPU 자원을 양보(yield)를 하는데 그러한 양보로 문맥교환(context switch)이 일어나는 비용이 비싸다고 판단되는 경우에 사용하는 기법이다. 다시 말하면 더 빠르게 루프를 빠져 나갈때 spin을 사용하여 설계된다.
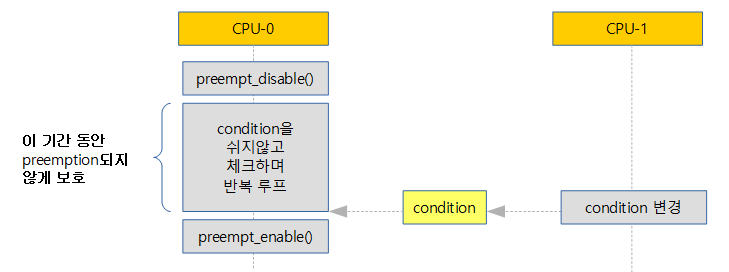
Spin 탈출을 위한 컨디션
- 사용 목적에 따라 preempt_disable() 뿐만 irq_disable()까지 사용할 수도 있다.
- non-preemption spin lock에 대해서는 아래 그림처럼 spin 하는 동안 preemption 되는 것을 방지하기 위해 critical section의 앞뒤로 preempt_disable()과 preempt_enable() 명령어로 보호를 받고있다.
CONFIG_GENERIC_LOCKBREAK
- 이 커널 옵션은 spin lock이 lock을 얻지 못한 상태에서 spinning 상태인지를 알아내기 위해 다음과 같이 구현되었다.
- raw_spinlock 구조체에 break_lock이라는 변수를 추가하여 spinning 상태 여부를 나타낸다.
- SMP + LHP 방식에 break_lock을 설정/해제 하도록 구현되었다.
- 단점으로 int 하나면 구현되는 raw_spinlock 구조체가 두 배로 커지는 문제가 있다.
- 현재 커널은 어떠한 아키텍처도 이 옵션을 사용하지 않는다.
- SMP + ticket에 대한 루틴이 구현되면서 spin_is_contended()라는 함수가 만들어졌다.
- lock이 spin중인지를 break_lock 변수 없이 ticket.owner와 ticket.next의 차이가 1을 초과하는 경우 spinning 상태인지 알아낼 수 있게 되었다.
- 2013년 12월 마지막으로 사용했었던 arm64 아키텍처 코드에서도 삭제되면서 이제는 필요 없어진 옵션이다.
- 참고:
Spinlock의 명명 체계
spinlock에 대한 명명은 다음 3단계로 이루어진다.
- 1) spin_lock:
- RT 커널에서는 preemptible spinlock으로 동작하지만, 일반 커널에서는 raw_spin_lock을 호출하여 non-preemptible spinlock으로 동작한다.
- 2) raw_spin_lock:
- RT 커널이든 일반 커널이든 non-preemptible spinlock으로 동작한다.
- raw_spin_lock -> _raw_spin_lock -> __raw_spin_lock 으로 구현되었다.
- UP 방식과 SMP 방식을 나누었다.
- UP 방식에서는 아키텍처별 전용 코드를 사용하지 않고, generic 코드로만 구성했다.
- SMP 방식에서는 높은 성능 구현을 위해 아키텍처별 전용 코드를 사용한다.
- LHP 방식에서는 대부분의 코드가 generic 코드이지만 Queued or Ticket 방식에서 사용하는 arch_spin_trylock()를 필요로한다.
- Ticket 및 Queue 방식은 아래의 아키텍처 전용 코드를 사용한다.
- 3) arch_spin_lock:
- 하드웨어 레벨의 아키텍처별 구현
- UP를 위한 하드웨어 레벨의 코드는 없다.
- SMP인 경우
- ARM32에서 ticket based spin lock 구현 (ARM64도 v4.1까지 사용)
- ARM64에서 queued spin lock 구현(v4.2 부터)
3가지 구현 방법: UP vs LHP vs Ticket or Queue
UP
- 1개의 cpu 만을 사용하는 UP 시스템의 경우 두 개 이상의 태스크에서 동시에 critical section을 진입하는 것을 방지하려면 preemption을 disable하는 것만으로도 다른 태스크로의 전환이 불가능해진다. 따라서 spin_lock() 함수는 내부에서 preempt_disable() 함수만을 사용한다.
- 다만 preemption을 disable 하여 다른 태스크로의 전환을 금지하여도 irq 또는 nmi가 발생하여 동작하는 루틴에서 critical section을 보호해야 하는 경우 preemption disable 만으로는 불가능해진다. 이러한 경우에는 spin_lock_irq() 또는 spin_lock_irqsave()를 사용해야 한다.
LHP(Lock-Holder Preemption)
- lock 획득 후 critical section에서 preemption을 차단하지만, lock 획득 전에 spin wait을 하는 구간에서 preemption을 허용하는 기능이다.
- 어떤 알고리즘에서 사용한 spin lock이 오랜 시간 spin wait 될 수 밖에 없을 때에 preemption이 가능하게 해주는 구조로 preemption latency를 줄일 수 있어 뛰어난 real time application을 지원하기 위해 효과적이다.
Ticket base 또는 Queued spin-lock
- lock 획득 시 순서를 지키도록 한다.
- 64비트 시스템의 경우 기존 Ticket 기반의 spin lock을 사용하다 커널 v4.2-rc1에서 새롭게 queued spin lock이 적용되었다.
다음 그림은 spin_lock() 호출 후 3가지 구현 방법에 대한 호출 과정을 보여준다.
- ARM64의 경우 C. SMP & Ticket(or Queue)을 사용한다.
- 주의: PREEMPT_RT 커널 옵션은 RT 커널용이다.
다음 그림은 LHP 구현의 경우 spin wait 중에 preemption을 허용하는 모습을 보여준다.

spin_lock API
다음은 RT Linux용 spin lock과 일반 Linux용 spin lock이다.
1) RT Linux용 spin_lock()
- preemption이 가능한 down_mutex를 호출함.
static inline void spin_lock(spinlock_t *lock)
static void __spin_lock(spinlock_t *lock, unsigned long eip)
{
SAVE_BKL(_down_mutex(&lock->lock, eip));
}
2) 일반 Linux 용 spin_lock()
- 일반 리눅스 커널은 spin lock에서 preemption이 지원되지 않는다. 그러므로 spin_lock()은 raw_spin_lock()을 호출한다.
- raw_spin_lock() 내부에서 preempt_disable()을 동작시키므로 결국 spinlock은 preemption 되지 않음을 알 수 있다.
includelinux/spinlock.h
/*
* Define the various spin_lock methods. Note we define these
* regardless of whether CONFIG_SMP or CONFIG_PREEMPT are set. The
* various methods are defined as nops in the case they are not
* required.
*/
#define raw_spin_lock(lock) _raw_spin_lock(lock)
raw_spin_lock API
- raw_spin_lock()은 preemption이 되지 않는 것으로 규정되어 있다.
- raw_spin_lock()의 명명 체계는 다음과 같다.
- raw_spin_lock() -> _raw_spin_lock() -> __raw_spin_lock()
- 3가지 구현 방법은 다음과 같다.
1) raw_spin_lock() – UP
include/linux/spinlock_api_up.h
#define _raw_spin_lock(lock) __LOCK(lock)
- UP 시스템에서는 단순히 __LOCK()을 호출한다.
__LOCK()
include/linux/spinlock_api_up.h
#define __LOCK(lock) \
do { preempt_disable(); ___LOCK(lock); } while (0)
- preempt_disable() 한 후 ___LOCK() 함수에서는 Sparse 정적 코드 분석 툴을 위한 매크로를 호출한다.
___LOCK()
include/linux/spinlock_api_up.h
/*
* In the UP-nondebug case there's no real locking going on, so the
* only thing we have to do is to keep the preempt counts and irq
* flags straight, to suppress compiler warnings of unused lock
* variables, and to add the proper checker annotations:
*/
#define ___LOCK(lock) \
do { __acquire(lock); (void)(lock); } while (0)
- __acquire() 매크로는 Sparse 정적 코드 분석툴을 사용하여 lock에 대한 적절한 체크를 수행한다.
- #define __acquire(x) __context__(x,1)
2) raw_spin_lock() – SMP
_raw_spin_trylock()
kernel/locking/spinlock.c
int __lockfunc _raw_spin_trylock(raw_spinlock_t *lock)
{
return __raw_spin_trylock(lock);
}
EXPORT_SYMBOL(_raw_spin_trylock);
_raw_spin_lock()
kernel/locking/spinlock.c
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
EXPORT_SYMBOL(_raw_spin_lock);
_raw_spin_unlock()
kernel/locking/spinlock.c
void __lockfunc _raw_spin_unlock(raw_spinlock_t *lock)
{
__raw_spin_unlock(lock);
}
EXPORT_SYMBOL(_raw_spin_unlock);
__raw_spin_trylock()
include/linux/spinlock_api_smp.h
static inline int __raw_spin_trylock(raw_spinlock_t *lock)
{
preempt_disable();
if (do_raw_spin_trylock(lock)) {
spin_acquire(&lock->dep_map, 0, 1, _RET_IP_);
return 1;
}
preempt_enable();
return 0;
}
__raw_spin_lock()
LHP용과 그 외(Queued or Ticket) 구현 방식의 코드가 각각이므로 이 부분만 아래로 옮겼다.
__raw_spin_unlock()
include/linux/spinlock_api_smp.h
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
spin_release(&lock->dep_map, _RET_IP_);
do_raw_spin_unlock(lock);
preempt_enable();
}
2-1) SMP for LHP
아래 그림과 같이 critical section에서는 preemption이 불가능하지만 루프를 돌며 spin하는 동안은 preemption이 가능한 구조이다.
- LHP에서 spin 하는 cpu들간의 우선 순위별 진입은 지원하지 않는다.
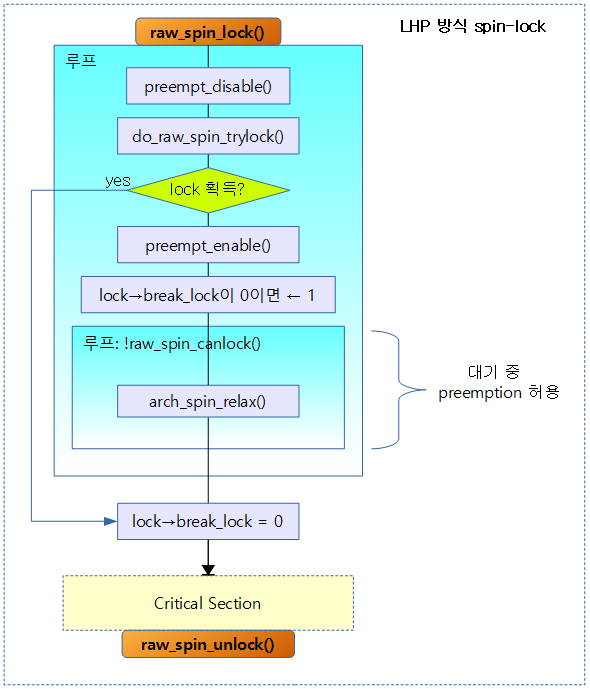
__raw_spin_lock() – for LHP
__raw_spin_lock() 함수는 아래 BUILD_LOCK_OPS() 매크로 함수를 사용하여 만들어진다.
kernel/locking/spinlock.c
#define BUILD_LOCK_OPS(op, locktype) \
void __lockfunc __raw_##op##_lock(locktype##_t *lock) \
{ \
for (;;) { \
preempt_disable(); \
if (likely(do_raw_##op##_trylock(lock))) \
break; \
preempt_enable(); \
\
if (!(lock)->break_lock) \
(lock)->break_lock = 1; \
while (!raw_##op##_can_lock(lock) && (lock)->break_lock)\
arch_##op##_relax(&lock->raw_lock); \
} \
(lock)->break_lock = 0; \
} \
BUILD_LOCK_OPS(spin, raw_spinlock);
BUILD_LOCK_OPS(read, rwlock);
BUILD_LOCK_OPS(write, rwlock);
LHP 방식의 spin lock을 획득한다. spin 하는 동안 preemption을 잠깐씩 활성화하여 우선 순위가 높은 태스크가 있는지 확인하고, 스케줄링할 준비를 한다.
- 코드 라인 4~8에서 lock을 획득할 수 있는지 시도한다. 그 동안 preemption을 끈다. 일반적으로 lock contension 상황이 아닌 경우가 대부분이므로 높은 확률로 do_raw_spin_trylock() 함수가 true가 될 수 있다고 판단하여 likely 함수를 사용하였다.
- 코드 라인 10~11에서 spin하는 동안은 항상 1로 설정된다.
- raw_spin_in_contended() 함수를 통해 spin 중인지 알아내기 위한 플래그로 사용된다.
- 코드 라인 12~14에서 lock을 획득할 수 있는 상태가 될 때까지 spin하며 내부 루프를 돈다. lock 획득 가능 상태가 되면 다시 외부 루프를 돈다.
- 코드 라인 15에서 spin에서 빠져나왔으므로 spin 하지 않는다고 플래그를 설정한다.
BUILD_LOCK_OPS() 매크로를 사용하여 다음 함수들이 만들어진다. (단 irqsave, irq, bh 접미사로 끝나는 함수 코드는 생략)
- __raw_spin_lock()
- __raw_spin_lock_irqsave()
- __raw_spin_lock_irq()
- __raw_spin_lock_bh()
- __raw_read_lock()
- __raw_read_lock_irqsave()
- __raw_read_lock_irq()
- __raw_read_lock_bh()
- __raw_write_lock()
- __raw_write_lock_irqsave()
- __raw_write_lock_irq()
- __raw_write_lock_bh()
raw_spin_can_lock()
kernel/locking/spinlock.c
/**
* raw_spin_can_lock - would raw_spin_trylock() succeed?
* @lock: the spinlock in question.
*/
#define raw_spin_can_lock(lock) (!raw_spin_is_locked(lock))
lock을 얻을 수 있는지 여부를 판단한다.
raw_spin_is_locked()
include/linux/spinlock.h
#define raw_spin_is_locked(lock) arch_spin_is_locked(&(lock)->raw_lock)
lock이 걸려 있는지 여부를 판단을 한다.
2-2) SMP for Queued or Ticket
- Queue / Ticket 기능을 구현하여 다음과 같은 장점을 갖게되었다.
- 공정성
- 초기 spin lock은 lock 획득 순서가 공정하지 않았었는데 커널 2.6.25 부터 ticket을 부여받아 차례 대로 획득 가능해졌다.
- cache bouncing 문제 제거
- cache coherent 기능에 의해 두 개 이상의 CPU가 lock을 획득하기 위해 spin 하는 동안 strex 명령을 반복하여 사용하므로 spin 하는 CPU들에서 cache line의 로드와 invalidate(강제적인 eviction)를 반복하면서 성능이 저하된다. 이를 막기 위해 lock 값을 둘로 나누어 둘 값을 비교하면서 자기 차례가 아닌 경우에는 write 즉 strex 동작을 하지 않도록 하여 이 문제를 해결하였다.
- cache bouncing 문제도 심각하게 lock contention을 야기하고 lock contention은 성능을 떨어뜨리는 큰 원인이된다.

__raw_spin_lock() – for Queued or Ticket
include/linux/spinlock_api_smp.h
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
Queued 또는 Ticket 방식의 spin lock을 획득한다.
- 코드 라인 3에서 preemption을 비활성화한다.
- 코드 라인 4에서 Lockdep 디버깅용 코드를 수행한다.
- 코드 라인 5에서 실제 spin lock을 얻기 위해 spin 한다.
- 내부에서는 do_raw_spin_try_lock() 함수를 먼저 이용해보고 안되면 do_raw_spin_lock() 함수를 호출하여 spin한다.
LOCK_CONTENDED()
include/linux/lockdep.h
#define LOCK_CONTENDED(_lock, try, lock) \
do { \
if (!try(_lock)) { \
lock_contended(&(_lock)->dep_map, _RET_IP_); \
lock(_lock); \
} \
lock_acquired(&(_lock)->dep_map, _RET_IP_); \
} while (0)
@try 함수를 수행시켜 lock 획득을 시도하고, 실패하는 경우 lock contension 표시를 한 후 @lock 함수를 실행시켜 lock을 획득한다.
- lock_contended() 함수는 lock contension 설정을 하여 lockdep 디버깅에서 추적을 위해 수행하는 함수이다.
- lock_acquired() 함수는 lock 획득 설정을 하여 lockdep 디버깅에서 오류 추적을 위해 수행하는 함수이다.
arch_spinlock API
SMP 시스템을 위해 Queued 방식과 Ticket 방식의 두 가지 하드웨어 레벨 구현이 준비되어 있다.
Queued 방식 spin-lock – Generic
Queued spin-lock은 현재 다음 아키텍처에 구현되어 사용가능하다. 그 외의 아키텍처는 앞으로 구현되어야 한다.
- arm64
- mips
- openrisc
- sparc
- x86
- xtensa
include/asm-generic/qspinlock.h
/*
* Remapping spinlock architecture specific functions to the corresponding
* queued spinlock functions.
*/
#define arch_spin_is_locked(l) queued_spin_is_locked(l)
#define arch_spin_is_contended(l) queued_spin_is_contended(l)
#define arch_spin_value_unlocked(l) queued_spin_value_unlocked(l)
#define arch_spin_lock(l) queued_spin_lock(l)
#define arch_spin_trylock(l) queued_spin_trylock(l)
#define arch_spin_unlock(l) queued_spin_unlock(l)
Queued 방식 spin lock 구현을 위해 arch_* 함수들이 queued_spin_* 함수들로 매핑되었다.
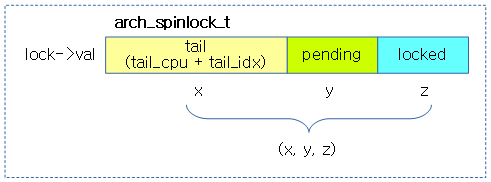
다음 그림은 queued spin-lock에서 사용하는 arch_spinlock_t 타입과 멤버 및 관련 매크로 상수들을 보여준다.
- tail_cpu
- 0 값을 사용할 수 없다. 따라서 cpu 번호 + 1로 인코딩 값을 사용한다.
- tail_idx
- spin lock은 각 cpu 마다 최대 4번 nest될 수 있다. 이를 구분하기 위해 4개의 노드를 나누어 처리한다.
- 최대 4번 nest된 경우 다음과 같은 순서로 tail_idx가 증가된다.
- task, softirq, hardirq, nmi

다음과 같이 spin-lock 값은 간단히 (x,y,z)로 표현할 수 있다.
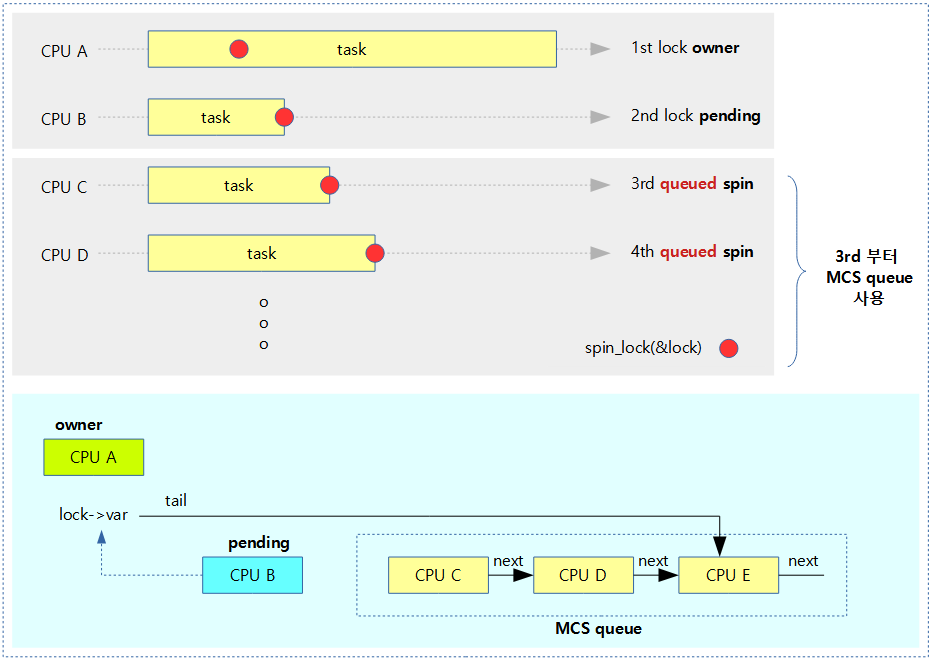
다음 그림과 같이 lock owner를 제외한 나머지 spin-lock들은 모두 대기하며, 세 번째 요청부터는 별도의 mcs queue를 구성하여 대기한다.
queued_spin_trylock()
include/asm-generic/qspinlock.h
/**
* queued_spin_trylock - try to acquire the queued spinlock
* @lock : Pointer to queued spinlock structure
* Return: 1 if lock acquired, 0 if failed
*/
static __always_inline int queued_spin_trylock(struct qspinlock *lock)
{
u32 val = atomic_read(&lock->val);
if (unlikely(val))
return 0;
return likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL));
}
queued spin-lock을 획득 시도한다. 만일 획득한 경우 1을 반환하고, 실패한 경우 0을 반환한다.
- 코드 라인 3~6에서 lock 값을 읽어와서 낮은 확률로 이미 lock이 걸려 있는 상태라면 0을 반환한다.
- 코드 라인 8에서 lock 값을 1로 변경 시도한다. 성공한 경우 1을 반환하고, 실패한 경우 0을 반환한다.
queued_spin_lock()
include/asm-generic/qspinlock.h
/**
* queued_spin_lock - acquire a queued spinlock
* @lock: Pointer to queued spinlock structure
*/
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{
u32 val = 0;
if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL)))
return;
queued_spin_lock_slowpath(lock, val);
}
queued spin-lock을 획득한다.
첫 번째 cpu의 lock 획득(lock owner)
- 코드 라인 5~6에서 fast-path queued spin-lock을 얻는다.
- lock 값이 0인 경우, 즉 lock 경합이 없는 첫 cpu인 경우 손쉽게 lock을 획득할 수 있다. (uncontended)
- 코드 라인 8에서 slow-path queued spin-lock으로 전환한다.
queued_spin_unlock()
include/asm-generic/qspinlock.h
/**
* queued_spin_unlock - release a queued spinlock
* @lock : Pointer to queued spinlock structure
*/
static __always_inline void queued_spin_unlock(struct qspinlock *lock)
{
/*
* unlock() needs release semantics:
*/
smp_store_release(&lock->locked, 0);
}
queued spin-lock을 획득 해제한다.
Lock Contension
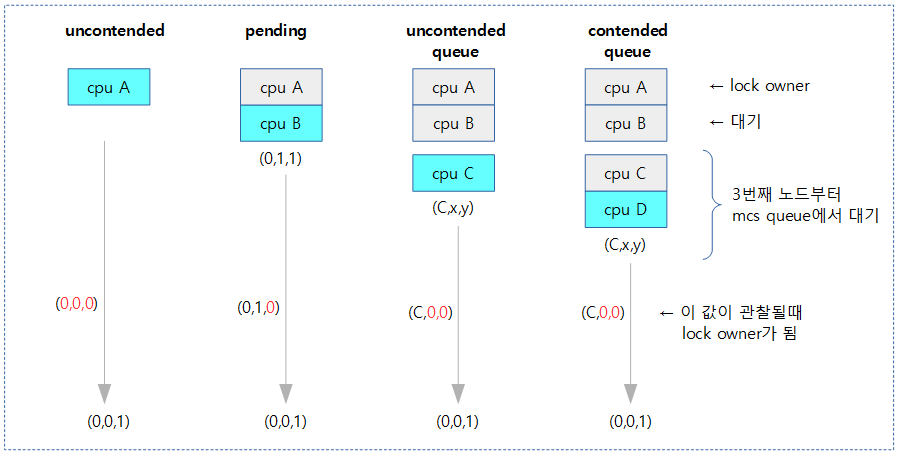
queued spin lock의 경우 lock을 획득할 때 다음과 같이 4개의 lock contension 상황을 구별하였다.
- uncontended
- 경쟁하는 스레드가 없이 한 번에 lock owner가 된 경우이다.
- (0,0,0) –> (0,0,1)
- pending
- 이미 먼저 처리 중인 lock owner가 있고, 그 후에 첫 번째로 spin wait 중에 lock owner가 된 경우이다.
- (0,1,1) –> (0,1,0) –> (0,0,1)
- uncontended queue
- queue의 head에서 대기 중이고, 먼저 처리 중인 lock owner와 pending 중인 스레드의 lock 처리가 모두 완료되어 lock owner가 된 경우이다.
- (n,x,y) –> (n,0,0) –> (0,0,1)
- contended queue
- queue에서 대기 중이고, head가 아니지만 먼저 처리 중인 lock owner와 pending 중인 스레드 그리고 queue의 내 앞에서 대기중인 스레드들의 lock 처리가 모두 완료되어 lock owner가 된 경우이다.
- (*,x,y) –> (*,0,0) –> (0,0,1)
다음 그림은 파란 박스의 lock 요청자가 lock을 소유할 때 각각의 lock contension 상태를 보여준다.
- contended queue 상태에 있는 cpu는 mcs 노드의 locked가 1로 풀릴 때 까지 spin 한다.
queued_spin_lock_slowpath()
kernel/locking/qspinlock.c -1/4-
/**
* queued_spin_lock_slowpath - acquire the queued spinlock
* @lock: Pointer to queued spinlock structure
* @val: Current value of the queued spinlock 32-bit word
*
* (queue tail, pending bit, lock value)
*
* fast : slow : unlock
* : :
* uncontended (0,0,0) -:--> (0,0,1) ------------------------------:--> (*,*,0)
* : | ^--------.------. / :
* : v \ \ | :
* pending : (0,1,1) +--> (0,1,0) \ | :
* : | ^--' | | :
* : v | | :
* uncontended : (n,x,y) +--> (n,0,0) --' | :
* queue : | ^--' | :
* : v | :
* contended : (*,x,y) +--> (*,0,0) ---> (*,0,1) -' :
* queue : ^--' :
*/
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
struct mcs_spinlock *prev, *next, *node;
u32 old, tail;
int idx;
BUILD_BUG_ON(CONFIG_NR_CPUS >= (1U << _Q_TAIL_CPU_BITS));
if (pv_enabled())
goto pv_queue;
if (virt_spin_lock(lock))
return;
/*
* Wait for in-progress pending->locked hand-overs with a bounded
* number of spins so that we guarantee forward progress.
*
* 0,1,0 -> 0,0,1
*/
if (val == _Q_PENDING_VAL) {
int cnt = _Q_PENDING_LOOPS;
val = atomic_cond_read_relaxed(&lock->val,
(VAL != _Q_PENDING_VAL) || !cnt--);
}
/*
* If we observe any contention; queue.
*/
if (val & ~_Q_LOCKED_MASK)
goto queue;
/*
* trylock || pending
*
* 0,0,* -> 0,1,* -> 0,0,1 pending, trylock
*/
val = queued_fetch_set_pending_acquire(lock);
/*
* If we observe contention, there is a concurrent locker.
*
* Undo and queue; our setting of PENDING might have made the
* n,0,0 -> 0,0,0 transition fail and it will now be waiting
* on @next to become !NULL.
*/
if (unlikely(val & ~_Q_LOCKED_MASK)) {
/* Undo PENDING if we set it. */
if (!(val & _Q_PENDING_MASK))
clear_pending(lock);
goto queue;
}
/*
* We're pending, wait for the owner to go away.
*
* 0,1,1 -> 0,1,0
*
* this wait loop must be a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because not all
* clear_pending_set_locked() implementations imply full
* barriers.
*/
if (val & _Q_LOCKED_MASK)
atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK));
/*
* take ownership and clear the pending bit.
*
* 0,1,0 -> 0,0,1
*/
clear_pending_set_locked(lock);
lockevent_inc(lock_pending);
return;
queued spin-lock을 slow-path 방법으로 획득한다.
- 코드 라인 9~10에서 커널 설정이 para-virtual 스핀락을 지원하는 경우 pv_queue로 이동한다.
- 코드 라인 12~13에서 virtual 스핀락을 지원하는 경우 그냥 함수를 빠져나간다.
두 번째 cpu가 lock owner로 핸드오버되는 순간이다. 그 동안 세 번째 cpu는 잠시 대기
- 코드 라인 21~25에서 lock owner인 첫 번째 cpu가 lock을 이미 해제하였고, 두 번째 cpu가 pending 상태에서 lock owner로 아직 전환되지 않은 짧은 순간이다. 이런 경우 세 번째 cpu는 잠시 spin 한다. (펏 번째 lock owner가 없어졌으므로, 세 번째 cpu -> 두 번째 cpu로 포지션 변경)
- 0,1,0 -> 0,0,1로 변경될 때까지 대기한다.
세 번째 cpu 이상은 mcs queue로 이동
- 코드 라인 30~31에서 이미 두 번째 cpu가 lock을 획득하기 위해 대기하는 중이다. 세 번째 cpu 부터는 queue로 이동한다.
두 번째 cpu는 pending 상태로 대기
- 코드 라인 38에서 lock->val 값을 val 변수로 읽어오고, lock->val에는 pending 비트를 설정한다.
- 코드 라인 47~54에서 낮은 확률로 lock contension 상황이되어 두 번째 cpu가 세 번째 이상으로 밀려난 경우이다. 즉 위 코드에서 pending 비트를 설정하기 전부터 이미 두 번째 cpu 이상이 끼어들어 대기중인 경우(조금 전에 읽어온 val 값이 tail 또는 pending 설정) queue로 이동한다. 이 때 기존에 읽은 값에서 pending 설정이 없었으면 원래대로 돌리기 위해 lock->pending 비트를 제거한다.
- 코드 라인 67~68에서 val 값에 lock 설정된 경우 lock 값이 0이될 때까지 spin 하며 대기한다. 즉 두 번째 cpu는 여기에서 lock이 풀릴때까지 대기한다.
- 코드 라인 76~79에서 두 번째 cpu는 lock owner가 된다. 즉 lock->pending을 클리어하고 lock->locked를 설정한다. 그리고 lock_pending 통계를 증가시킨 후 함수를 빠져나간다.
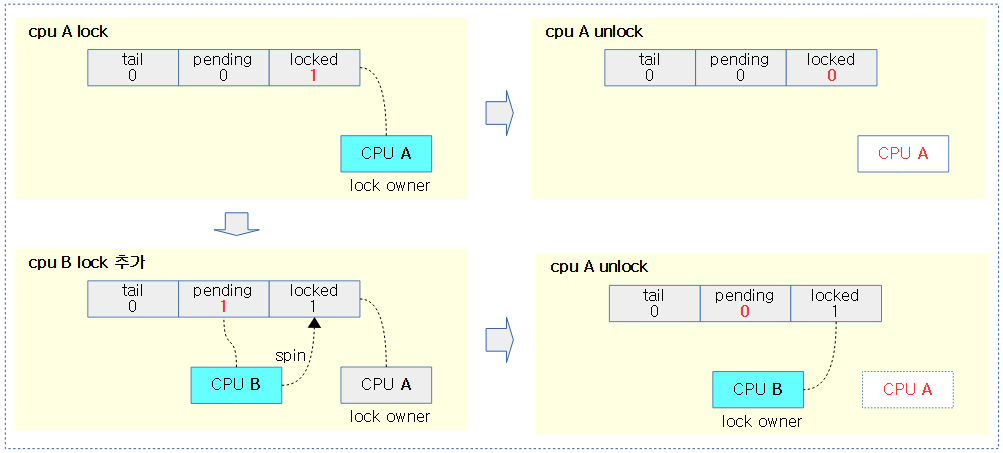
다음 그림은 2개의 spin-lock 요청을 처리할 때에는 mcs queue(3개 이상 요청 시 사용)를 사용할 필요없이 단순하게 처리되는 모습을 보여준다.
- spin-lock 요청은 tail cpu id와 tail index id에 대해서 정확히 표시해야 하지만, 시각적으로 단순한게 표시하기 위해 CPU A, B, C, … 로 처리하였다.
kernel/locking/qspinlock.c -2/4-
/*
* End of pending bit optimistic spinning and beginning of MCS
* queuing.
*/
queue:
lockevent_inc(lock_slowpath);
pv_queue:
node = this_cpu_ptr(&qnodes[0].mcs);
idx = node->count++;
tail = encode_tail(smp_processor_id(), idx);
/*
* 4 nodes are allocated based on the assumption that there will
* not be nested NMIs taking spinlocks. That may not be true in
* some architectures even though the chance of needing more than
* 4 nodes will still be extremely unlikely. When that happens,
* we fall back to spinning on the lock directly without using
* any MCS node. This is not the most elegant solution, but is
* simple enough.
*/
if (unlikely(idx >= MAX_NODES)) {
lockevent_inc(lock_no_node);
while (!queued_spin_trylock(lock))
cpu_relax();
goto release;
}
node = grab_mcs_node(node, idx);
/*
* Keep counts of non-zero index values:
*/
lockevent_cond_inc(lock_use_node2 + idx - 1, idx);
/*
* Ensure that we increment the head node->count before initialising
* the actual node. If the compiler is kind enough to reorder these
* stores, then an IRQ could overwrite our assignments.
*/
barrier();
node->locked = 0;
node->next = NULL;
pv_init_node(node);
/*
* We touched a (possibly) cold cacheline in the per-cpu queue node;
* attempt the trylock once more in the hope someone let go while we
* weren't watching.
*/
if (queued_spin_trylock(lock))
goto release;
/*
* Ensure that the initialisation of @node is complete before we
* publish the updated tail via xchg_tail() and potentially link
* @node into the waitqueue via WRITE_ONCE(prev->next, node) below.
*/
smp_wmb();
세 번째 cpu부터 처리하는 mcs queue
- 코드 라인 5에서 queue: 레이블이다. 3 개 이상의 cpu가 spin lock 경합을 할 때 이곳에서 mcs queue 기반의 처리를 수행한다.
- 코드 라인 6에서 lock_slowpath 카운터를 증가시킨다.
- 코드 라인 7에서 pv_queue: 레이블이다.
- 코드 라인 8~10에서 현재 cpu에 대해 spin lock의 tail 값을 구한다.
- 참고로 같은 cpu로 spin_lock이 호출되는 경우는 최대 4번이며 처음 idx 값은 0부터 사용되므로 최대 idx 값은 3이다.
- 코드 라인 21~26에서 예외 처리 로직이다. 가능성은 없지만 혹시라도 idx 값이 4 이상인 경우 lock_no_node 카운터를 증가시키고, try lock 방법으로만 락을 반복하여 획득 시도를 하고, 획득 후에는 release 레이블을 통해 함수를 빠져나간다.
- 코드 라인 28에서 현재 cpu의 idx에 대한 mcs 노드를 가져온다.
- 코드 라인 33에서 idx가 0이 아닌 경우에만 다음과 같은 카운터를 증가시킨다.
- idx가 1인 경우 lock_use_node2
- idx가 2인 경우 lock_use_node3
- idx가 3인 경우 lock_use_node4
- 코드 라인 40에서 mcs 노드를 초기화 전에 node->count의 기록이 확실히 먼저 수행되도록 컴파일러 베리어를 사용했다.
- 코드 라인 42~44에서 mcs 노드를 초기화한다. (node->count 값은 초기화하지 않는다)
- para-virtual qspin lock을 사용하는 경우 노드 초기화를 위해 kernel/locking/qspinlock_paravirt.h 파일에 있는 pv_init_node()를 사용한다. 그리고 cpu_running 상태로 시작한다.
- 코드 라인 51~52에서 혹시나 앞선 두 cpu들의 lock이 모두 release되어 lock을 획득 시도하여 성공한 경우 release 레이블을 통해 함수를 빠져나간다.
- 코드 라인 59에서 노드의 tail을 갱신하기 전에 앞서 초기화된 노드를 먼저 publish하기 위해 smp 베리어를 수행한다.
다음 그림은 동일한 cpu에서 spin-lock이 호출될 때 최대 4번까지 nest하여 호출되므로, mcs queue에서 대기할 cpu 정보를 표현하는 per-cpu mcs 노드가 최대 4개까지 사용됨을 보여준다.

다음 그림은 nest된 spin-lock의 자료 상태를 보여준다.

Spin-lock Revisit
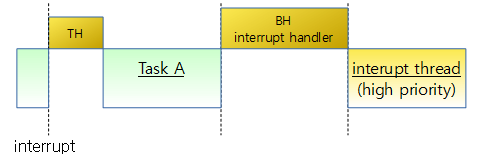
동일 cpu에서 spin_lock() 함수 호출이 두 번 발생할 수 있는 케이스가 있다.
아래 그림과 같은 상황을 고려해보자.
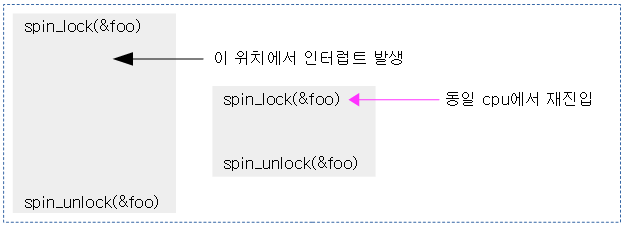
위와 같은 사례가 발생하면 irq context의 spin_lock() 함수를 호출하자 마자 spin wait 상태를 반복하여 누가 풀어줄 방법도 없이 정지하게 된다.
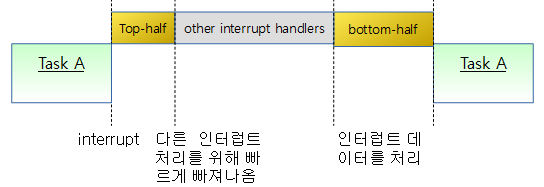
- 이를 방지하기 위해 task 및 irq context에서 spin_lock(&foo) 함수를 사용하는 대신 spin_lock_irq(&foo) 함수를 사용해여 irq가 진입하지 못하도록 원천적으로 막아야 한다.
- bh(bottom-half) context에서도 spin-lock의 재진입을 막기 위해 spin_lock_bh() 함수를 사용한다.
kernel/locking/qspinlock.c -3/4-
. /*
* Publish the updated tail.
* We have already touched the queueing cacheline; don't bother with
* pending stuff.
*
* p,*,* -> n,*,*
*/
old = xchg_tail(lock, tail);
next = NULL;
/*
* if there was a previous node; link it and wait until reaching the
* head of the waitqueue.
*/
if (old & _Q_TAIL_MASK) {
prev = decode_tail(old);
/* Link @node into the waitqueue. */
WRITE_ONCE(prev->next, node);
pv_wait_node(node, prev);
arch_mcs_spin_lock_contended(&node->locked);
/*
* While waiting for the MCS lock, the next pointer may have
* been set by another lock waiter. We optimistically load
* the next pointer & prefetch the cacheline for writing
* to reduce latency in the upcoming MCS unlock operation.
*/
next = READ_ONCE(node->next);
if (next)
prefetchw(next);
}
/*
* we're at the head of the waitqueue, wait for the owner & pending to
* go away.
*
* *,x,y -> *,0,0
*
* this wait loop must use a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because the set_locked() function below
* does not imply a full barrier.
*
* The PV pv_wait_head_or_lock function, if active, will acquire
* the lock and return a non-zero value. So we have to skip the
* atomic_cond_read_acquire() call. As the next PV queue head hasn't
* been designated yet, there is no way for the locked value to become
* _Q_SLOW_VAL. So both the set_locked() and the
* atomic_cmpxchg_relaxed() calls will be safe.
*
* If PV isn't active, 0 will be returned instead.
*
*/
if ((val = pv_wait_head_or_lock(lock, node)))
goto locked;
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));
세 번째 cpu부터 mcs 큐에 노드 추가
- 코드 라인 8에서 lock->tail이 새롭게 추가할 노드를 가리키도록 변경한다.
- 코드 라인 9에서 일단 next에 null을 대입한다.
차순위 노드들의 대기
- 코드 라인 15~16에서 tail에 이미 기존 노드가 존재하는 경우이다. tail에 연결된 노드의 앞에 있는 노드를 prev에 알아온다.
- 코드 라인 19에서 대기 큐의 가장 마지막에 연결한다.
- 코드 라인 21에서 pv_wait_node()의 경우도 para-virtual spin lock 에 대한 추가 코드로 대기하는 동안 vcpu를 끈다. vcpu_halted 상태에서 대기하다가 깨어난 후 vcpu_running 상태로 변경된다.
- 코드 라인 22에서 mcs queue에서 내 노드가 가장 선두가 될 때까지 스핀하며 대기한다.
- mcs 큐에서 나보다 이전에 진입한 mcs 노드가 있기 때문에 내 노드의 locked가 0인동안 spin 하면서 대기한다.
- 앞선 노드가 락 owner가 되어 큐에서 빠져 나가는 순간 내 노드의 locked를 1로 변경해준다. 이 때 내 mcs 노드는 mcs 큐에서 가장 선두가 됨을 의미한다.
- 코드 라인 30~32에서 현재 추가하는 노드의 다음에 값이 있는 경우 추가된 노드를 먼저 캐시에 로드한다.
헤드 노드의 대기
- 코드 라인 56~57에서 mcs queue에서 내 노드가 선두에서 대기하기 위해 vcpu를 끄기 위한 para-virtual spin lock에 대한 추가 코드이다.
- 코드 라인 59에서 mcs 큐의 선두에서 lock을 획득할 때 까지 대기한다.
- lock->lock_pending=0 이어야 lock 획득이 가능하다
- (*,x,y) -> (n,0,0)
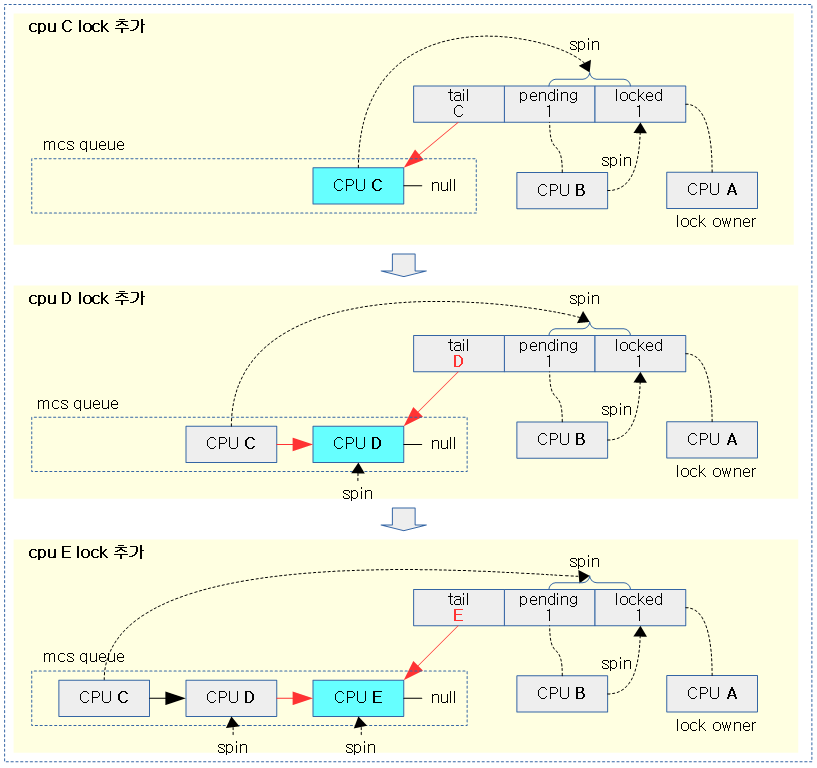
다음 그림은 세 번째 spin-lock 요청할 때 mcs queue를 이용하여 대기 큐에 추가되는 모습을 보여준다.
- val->tail은 mcs queue에 가장 마지막에 진입한 cpu를 가리킨다.
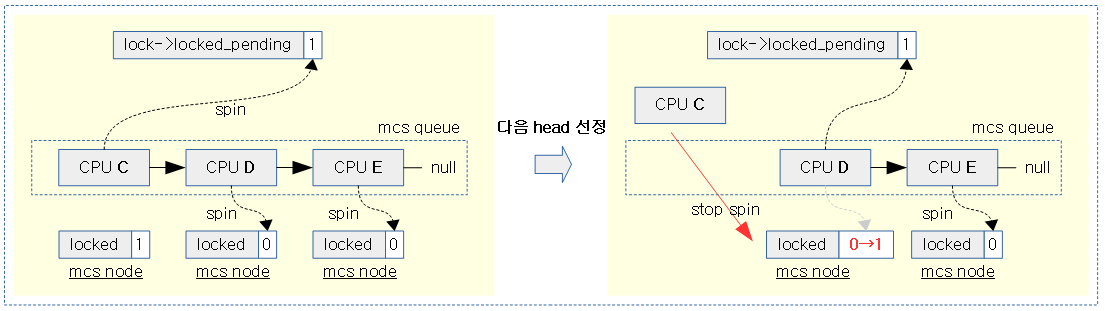
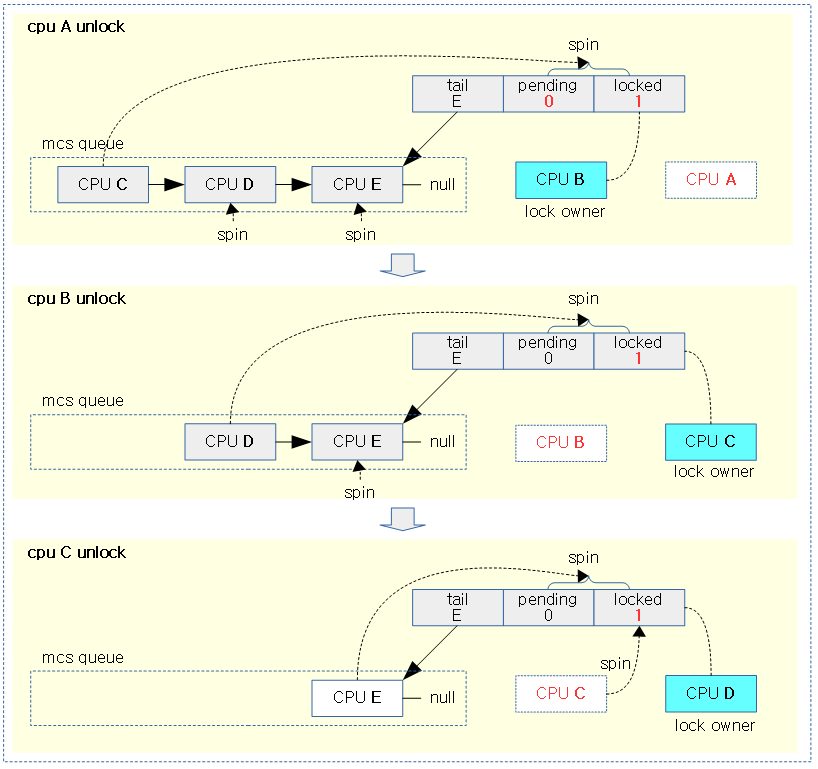
다음 그림은 head 노드(CPU C)가 lock을 획득하여 빠져나갈 때 다음 노드를 head 노드로 만드는 과정을 보여준다.
- 다음 노드의 locked 값을 0으로 만들어 spin wait 중인 차순위 노드를 깨워 head를 만들고 lock->locked_pending에서 다시 spin wait하게 한다.
kernel/locking/qspinlock.c -4/4-
locked:
/*
* claim the lock:
*
* n,0,0 -> 0,0,1 : lock, uncontended
* *,*,0 -> *,*,1 : lock, contended
*
* If the queue head is the only one in the queue (lock value == tail)
* and nobody is pending, clear the tail code and grab the lock.
* Otherwise, we only need to grab the lock.
*/
/*
* In the PV case we might already have _Q_LOCKED_VAL set, because
* of lock stealing; therefore we must also allow:
*
* n,0,1 -> 0,0,1
*
* Note: at this point: (val & _Q_PENDING_MASK) == 0, because of the
* above wait condition, therefore any concurrent setting of
* PENDING will make the uncontended transition fail.
*/
if ((val & _Q_TAIL_MASK) == tail) {
if (atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL))
goto release; /* No contention */
}
/*
* Either somebody is queued behind us or _Q_PENDING_VAL got set
* which will then detect the remaining tail and queue behind us
* ensuring we'll see a @next.
*/
set_locked(lock);
/*
* contended path; wait for next if not observed yet, release.
*/
if (!next)
next = smp_cond_load_relaxed(&node->next, (VAL));
arch_mcs_spin_unlock_contended(&next->locked);
pv_kick_node(lock, next);
release:
/*
* release the node
*/
__this_cpu_dec(qnodes[0].mcs.count);
}
EXPORT_SYMBOL(queued_spin_lock_slowpath);
헤드 노드의 lock 획득
- 코드 라인 1에서 locked: 레이블이다. 큐의 헤드 노드가 lock을 획득하였다.
- 코드 라인 23~26에서 노드가 큐의 가장 마지막인 경우이고, lock contension 없이 lock을 획득한 경우(tail=0, pending=0, lock=1) release 레이블을 통해 함수를 빠져나간다.
- 코드 라인 33에서 lock contension 상태이다. 이러한 경우 tail=0, pending=0, lock=1로 기록한다.
- 코드 라인 38~39에서 현재 노드의 현재 추가한 노드 뒤로 새로운 노드가 끼어들어왔는지 알기 위해 next 노드를 다시 읽어온다.
- 코드 라인 41에서 헤드의 다음 노드를 locked=1로 변경하여 다음 노드가 spin에서 깨어나 헤드가 될 수 있게 해준다.
- 코드 라인 42에서 vcpu_halted -> vcpu_hashed 상태로 변경하는 para-virtual spin-lock 대한 추가 코드이다.
- 코드 라인 44에서 release: 레이블이다.
- 코드 라인 48에서 lock을 획득했으므로 mcs 큐에서 대기중인 cpu 수를 감소시킨다.
다음 그림은 mcs queue에서 대기하던 cpu들이 spin-lock을 획득하는 순서를 보여준다.
- mcs queue에서 가장 처음 진입하여 대기하고 있던 cpu는 spin-lock을 획득하기 위해 val->pending과 val->locked가 0이되는 것을 감시한다.
락 이벤트 카운터
LOCK_EVENT_COUNTS 커널 옵션을 사용하여 다음 락들에 대해 디버깅 목적의 락 이벤트 카운터를 관리한다. 이들을 보려면 CONFIG_DEBUG_FS 커널 옵션이 준비되어 있을 때 debugfs(디폴트 마운트: /sys/kernel/debug)를 마운트하여 사용하는데 lock_event_counts 디렉토리에서 각 이벤트들을 읽거나 기록할 수 있다.
- queued spin lock
- lock_pending
- lock_slowpath
- lock_use_node2
- 동일한 cpu에서 context 전환하여 nest 하여 두 번째 spin-lock 요청한 경우
- lock_use_node3
- 동일한 cpu에서 context 전환하여 nest 하여 세 번째 spin-lock 요청한 경우
- lock_use_node4
- 동일한 cpu에서 context 전환하여 nest 하여 네 번째 spin-lock 요청한 경우
- lock_no_node
- 동일한 cpu에서 context 전환하여 nest 하여 다섯 번째 이상에서 spin-lock 요청한 경우 (노드 오버플로우 오류)
- para-virtual queued spin lock
- rw semaphore
Ticket 방식 spin-lock
다음 그림은 Ticket spin-lock에서 사용하는 arch_spinlock_t 타입과 멤버를 보여준다.

arch_spin_trylock() – ARM32
arch/arm/include/asm/spinlock.h
static inline int arch_spin_trylock(arch_spinlock_t *lock)
{
unsigned long contended, res;
u32 slock;
prefetchw(&lock->slock);
do {
__asm__ __volatile__(
" ldrex %0, [%3]\n"
" mov %2, #0\n"
" subs %1, %0, %0, ror #16\n"
" addeq %0, %0, %4\n"
" strexeq %2, %0, [%3]"
: "=&r" (slock), "=&r" (contended), "=&r" (res)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
} while (res);
if (!contended) {
smp_mb();
return 1;
} else {
return 0;
}
}
Ticket 방식의 spin lock 획득을 시도한다. lock contension 이 없는 경우 1을 반환하고, lock contension이 있으면 0을 반환한다.
- 코드 라인 6에서 lock->slock을 미리 캐시에 로드해둔다.
- pldw 명령을 호출하여 해당 lock 변수를 미리 캐시에 로드한다.
- 이렇게 미리 로드를 하는 이유는 ldrex 부터 strex 까지의 atomic operation 격으로 동작하는 critical section 영역의 코드를 동작시키는 동안 cpu clock을 적게 소모하게 하여 확률적으로 strex의 실패가 적어지게 유도한다
- 코드 라인 7~17에서 lock->slock에 ticket 값을 증가시켜 atomic 기록한다.
- 한 번이라도 실패하는 경우 contended가 1로 설정된다.
- 코드 라인 19~24에서 lock contension 이 없는 경우 1을 반환하고, lock contension이 있으면 0을 반환한다.
티켓 기록 규칙
- tickets.next 와 tickets.owner가 같으면 아무도 spin_lock을 획득하지 않은 상태(contended == 0)이므로 성공리에 spin_lock을 획득하는 조건이된다.
- spin lock 획득이 성공하면 tickets.next를 1 증가시킨 후 lock 변수에 저장한다.
- res가 0이 아닌 경우는 strex 명령으로 저장을 시도 했을 때 실패한 경우이므로 atomic operation을 완료하기 위해 다시 재시도한다.
- tickets.owner와 tickets.next의 증감 규칙
- spin_lock을 누군가 획득하는 경우 tickets.next가 1 증가된다.
- spin_lock을 해제하는 경우 tickets.owner를 1 증가한다.
- tickets 비트 규칙
- next: msb 16bits – lock에서 증가(Asm에서 사용), overflow 시 onwer에 영향 없음)
- owner: lsb 16bits – unlock에서 증가(C에서 사용)
어셈블러 문장을 좀 더 로직화하여 편하게 보기위해 바꿔보았다.
prefetch &lock->slock
do {
slock = [&lock->slock]
res = #0
contended = (tickets.owner != tickets.next)
if (contended == 0) {
tickets.next++
[&lock->slock] = slock (결과값은 res에 저장)
}
} while (res)
arch_spin_lock() – ARM32
arch/arm/include/asm/spinlock.h
/*
* ARMv6 ticket-based spin-locking.
*
* A memory barrier is required after we get a lock, and before we
* release it, because V6 CPUs are assumed to have weakly ordered
* memory.
*/
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
prefetchw(&lock->slock);
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
smp_mb();
}
Ticket 방식의 spin lock을 획득한다. 다른 스레드들이 spin lock을 획득한 경우 자기 차례가 올 때까지 spin 한다.
- 코드 라인 7에서 lock->slock을 미리 캐시에 로드해둔다
- 코드 라인 8~16에서 인라인 어셈블리 문장은 atomic operation으로 lock->tickets.next++ 를 수행한것이다.
- 코드 라인 18~21에서 lock을 획득할 때까지 spin 한다.
- 값을 증가시키기 전의 lockval.tickets.next와 lockval.tickets.owner가 다른 경우는 이 루틴을 들어오기 전에 이미 lock이 걸려 있었다는 경우로 루프를 돌며 대기 상태로 빠진다.
- 대기 상태를 빠지는 방법은 다른 CPU에서 arch_spin_unlock()을 호출할 때 sev 명령을 수행하는데 이 이벤트를 수신하여 wfe(wait for event) 함수를 탈출한다.
- wfe()를 탈출한 후에 lockval.tickets.owner를 갱신 받아 다시 while()문의 조건이 부합될 때까지 루프를 돌며 기다린다.
- 자기 순번이 올 때까지 (다른 CPU에서 arch_spin_unlock()을 호출할 때 owner 값을 증가시켜 내가 가진 next 값과 동일할 때까지) 루프를 탈출할 수 없다.
- 코드 라인 23에서 lock->slock의 기록 순서를 보호하기 위해 메모리 베리어를 수행한다.
어셈블러 문장을 좀 더 로직화하여 편하게 보기위해 바꿔보았다.
prefetch &lock->slock
do {
lockval = [&lock->slock]
newval = lockval.next + 1
[&lock->slock] = newval (strex에 대한 결과값은 tmp에 저장)
while (tmp)
arch_spin_unlock() – ARM32
arch/arm/include/asm/spinlock.h
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
smp_mb();
lock->tickets.owner++;
dsb_sev();
}
Ticket 방식의 spin lock을 획득 해제한다.
- 코드 라인 3에서 lock 변수의 로드 순서를 후 순위 보장하기 위해 메모리 베리어를 수행한다.
- 코드 라인 4에서 owner 티켓을 증가시킨다.
- 여기서 락 변수를 atomic operation을 이용하지 않고 대범(?)하게 증가 시킨 이유
- 락 획득 시에는 CPU들 끼리 경쟁을 하므로 atomic inc가 중요하지만 락을 헤제 시에는 락 오너만이 해제하므로(경쟁을 하지 않음) atomic inc를 해야 할 이유가 없다.
- 코드 라인 5에서 혹시 wfe 명령을 사용하여 대기 중인 spinner가 있으면 wfe(wait for event) 상태에서 빠져나오게 한다.
arch_spin_is_locked() – ARM32
arch/arm/include/asm/spinlock.h
static inline int arch_spin_is_locked(arch_spinlock_t *lock)
{
return !arch_spin_value_unlocked(READ_ONCE(*lock));
}
unlock 상태를 판별하여 반대로 리턴한다.
- READ_ONCE()
- 인수의 사이즈에 따라 volatile 방식으로 읽어온다.
arch_spin_value_unlocked() – ARM32
arch/arm/include/asm/spinlock.h
static inline int arch_spin_value_unlocked(arch_spinlock_t lock)
{
return lock.tickets.owner == lock.tickets.next;
}
락 카운터인 ticket.owner와 ticket.next가 같은 경우가 unlock 상태이다.
- 기존 spinlock 구현 방식에서는 lock과 unlock시 lock 변수의 증/감 상태로 lock/unlock 상태를 알았었는데 ticket based spinlock이 구현되면서 lock/unlock 상태 여부는 tickets.owner와 tickets.next 값의 동일 여부로 확인할 수 있게 바뀌었다.
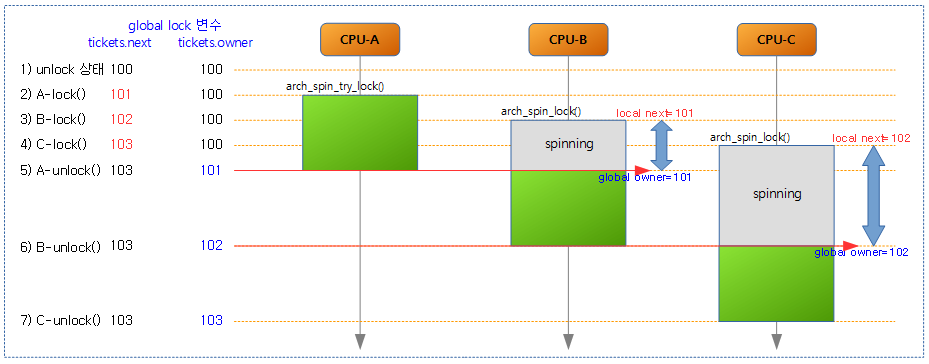
Ticket based spinlock 에서 ticket 값 추적
- 3개의 CPU에서 중첩이 되어 2 개의 CPU에서 spinning을 하는 과정에서 lock 값이 변화되는 것을 보였다.
- global lock 변수는 메모리에 위치한 lock 값
- local lock 변수는 arch_spin_lock() 루틴에서 임시로 lock을 획득할 때까지만 사용하는 레지스터이다.
- 1) 초기 lock 값을 next와 owner 100부터 시작하였다.
- 100 번 spin_lock()과 spin_unlock()을 반복한 것과 동일하다.
- 2) CPU-A가 lock이 없는 상태에서 lock 획득을 시도한다. 이 때 성공하면 ticket.next를 증가시키고 critical section에 진입한다.
- 3) CPU-B가 arch_spin_try_lock()을 시도했다가 실패 한 후 arch_spin_lock()에 진입하여 local lock 변수에 자기 순번을 의미하는 global lock 변수의 ticket.next(101) 값을 받아오고 global lock 변수의 tickets.next는 102로 증가시킨 후 spinning(wfe를 포함하여)한다.
- 4) CPU-C도 arch_spin_try_lock()을 시도했다가 실패 한 후 arch_spin_lock()에 진입하여 local lock 변수에 자기 순번을 의미하는 global lock 변수의 ticket.next(102) 값을 받아오고 global lock 변수의 tickets.next는 103으로 증가시킨 후 spinning(wfe를 포함하여)한다.
- 5) CPU-A가 unlock하면서 global tickets.owner를 101로 증가시키고 sev를 호출한다. 이 때 CPU-B는 sev 명령에 의해 wfe 명령에서 깨어나고 global tickets.owner(101)가 자기 순번인 local tickets.next(101)가 동일하기 때문에 spin 루프를 빠져나가면서 critical section에 진입하게 된다.
- 6) CPU-B도 unlock하면서 global tickets.owner를 102로 증가시키고 sev를 호출한다. 이 때 CPU-C는 sev 명령에 의해 wfe 명령에서 깨어나고 global tickets.owner(102)가 자기 순번인 local tickets.next(102)가 동일하기 때문에 spin 루프를 빠져나가면서 critical section에 진입하게 된다.
- 7) CPU-C가 unlock하면서 global tickets.owner를 103으로 증가시키고 sev를 호출한다. 하지만 wfe에서 대기하고 있는 CPU가 없어서 깨어날 CPU가 없어서 무시된다.
- tickets.next와 tickets.owner는 동일하게 103인 상태가 되며 이는 unlock 상태임을 의미한다.
- 녹색 박스는 critical section을 의미하며 CPU-A, B, C 간에 서로 중첩되지 않음을 확인할 수 있다.
Lock 디버깅을 위한 Lockdep 코드 관련
lock_acquire()
kernel/locking/lockdep.c
void lock_acquire(struct lockdep_map *lock, unsigned int subclass,
int trylock, int read, int check,
struct lockdep_map *nest_lock, unsigned long ip)
{
unsigned long flags;
if (unlikely(current->lockdep_recursion))
return;
raw_local_irq_save(flags);
check_flags(flags);
current->lockdep_recursion = 1;
trace_lock_acquire(lock, subclass, trylock, read, check, nest_lock, ip);
__lock_acquire(lock, subclass, trylock, read, check,
irqs_disabled_flags(flags), nest_lock, ip, 0);
current->lockdep_recursion = 0;
raw_local_irq_restore(flags);
}
EXPORT_SYMBOL_GPL(lock_acquire);
lock_release()
kernel/locking/lockdep.c
void lock_release(struct lockdep_map *lock, int nested,
unsigned long ip)
{
unsigned long flags;
if (unlikely(current->lockdep_recursion))
return;
raw_local_irq_save(flags);
check_flags(flags);
current->lockdep_recursion = 1;
trace_lock_release(lock, ip);
__lock_release(lock, nested, ip);
current->lockdep_recursion = 0;
raw_local_irq_restore(flags);
}
Spin-lock 변형
Interrupt context에서의 spin-lock
dead-lock 이외에도 lock을 소유한 상태에서 interrupt 되고 동일한 lock을 호출하는 루틴으로 들어가는 경우 spin되어 빠져나오지 못하게 된다. 따라서 spinlock을 사용 시에는 최우선적으로 local cpu에 대해 interrupt를 disable할 수 있는 함수가 유용하다.
- spin_trylock_irq()
- spin_lock_irq()
- spin_unlock_irq()
- spin_lock_irqsave()
- spin_unlock_irqrestore()
bottom-half context에서의 spin-lock
- spin_trylock_bh()
- spin_lock_bh()
- spin_unlock_bh()
기타 매크로
define 문
arch/arm/include/asm/spinlock.h
#define WFE(cond) __ALT_SMP_ASM("wfe" cond, "nop")
#define SEV __ALT_SMP_ASM(WASM(sev), WASM(nop))
부트 타임에 SMP 시스템인 경우 wfe 및 sev 명령을 사용하게 하고, 그렇지 않은 경우 아무 일도 하지 않는 nop 명령을 수행하게 한다.
#define isb(option) __asm__ __volatile__ ("isb " #option : : : "memory")
#define dsb(option) __asm__ __volatile__ ("dsb " #option : : : "memory")
#define dmb(option) __asm__ __volatile__ ("dmb " #option : : : "memory")
__ALT_SMP_ASM()
arch/arm/include/asm/processor.h
#define __ALT_SMP_ASM(smp, up) \
"9998: " smp "\n" \
" .pushsection \".alt.smp.init\", \"a\"\n" \
" .long 9998b\n" \
" " up "\n" \
" .popsection\n"
구조체 타입
spinlock_t
include/linux/spinlock_types.h
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
lock 디버깅용 커널이 아니면 rlock 멤버 하나만 사용한다.
raw_spinlock_t
include/linux/spinlock_types.h
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
디버그 용도이외에는 raw_lock 멤버 하나만 사용한다.
arch_spinlock_t – GENERIC(ARM64 포함)
include/asm-generic/qspinlock_types.h
typedef struct qspinlock {
union {
atomic_t val;
/*
* By using the whole 2nd least significant byte for the
* pending bit, we can allow better optimization of the lock
* acquisition for the pending bit holder.
*/
#ifdef __LITTLE_ENDIAN
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
#else
struct {
u16 tail;
u16 locked_pending;
};
struct {
u8 reserved[2];
u8 pending;
u8 locked;
};
#endif
};
} arch_spinlock_t;
queued spin-lock 구현에 사용한 arch_spnlock_t 타입이다.
- val
- 32bit spin-lock 값 (유니온 타입으로 아래 값들을 모두 포함한 값이다)
- locked
- pending
- 두 번째 spin-lock 요청자가 대기 중인지 여부를 나타낸다. 1=pending, 0=no pending
- locked_pending
- 위의 locked 비트들과 pending 비트들이 같이 16바이트로 구성된 값이다.
- tail
- mcs queue에 대기하는 가장 마지막 cpu와 인덱스(tail_idx) 값이 담겨있다.
- 단 cpu 번호는 1부터 시작하므로 cpu 0번의 경우 1 값이 사용된다. (based 1)
arch_spinlock_t – ARM32
arch/arm/include/asm-generic/qspinlock_types.h
typedef struct {
union {
u32 slock;
struct __raw_tickets {
#ifdef __ARMEB__
u16 next;
u16 owner;
#else
u16 owner;
u16 next;
#endif
} tickets;
};
} arch_spinlock_t;
ticket spin-lock 구현에 사용한 arch_spnlock_t 타입이다.
- 32bit slock과 tickets.next(msb-16bits) + tickets.owner(lsb-16bits)가 union으로 묶여 있다.
- 기존 slock에 대해 ticket을 구현하기 위해 slock을 둘로 나누어 사용하였다.
- next: lock 획득 시 증가
- owner: unlock 시 증가
- lock을 여러 CPU가 요청한 경우 각 CPU들은 자신의 lock 값(lock 획득 당시의 ticket.next 증가 전 값)이 다른데 owner 값과 비교하여 같은 경우 자기 차례가 되어 lock을 획득 할 수 있다.
mcs_spinlock 구조체
kernel/locking/mcs_spinlock.h
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked; /* 1 if lock acquired */
int count; /* nesting count, see qspinlock.c */
};
queued spin-lock 구현에 사용되는 mcs 노드에 대한 구조체이다.
- *next
- 다음 mcs spinlock 노드를 가리킨다.
- locked
- count
qnode 구조체
kernel/locking/qspinlock.c
/*
* On 64-bit architectures, the mcs_spinlock structure will be 16 bytes in
* size and four of them will fit nicely in one 64-byte cacheline. For
* pvqspinlock, however, we need more space for extra data. To accommodate
* that, we insert two more long words to pad it up to 32 bytes. IOW, only
* two of them can fit in a cacheline in this case. That is OK as it is rare
* to have more than 2 levels of slowpath nesting in actual use. We don't
* want to penalize pvqspinlocks to optimize for a rare case in native
* qspinlocks.
*/
struct qnode {
struct mcs_spinlock mcs;
#ifdef CONFIG_PARAVIRT_SPINLOCKS
long reserved[2];
#endif
};
queued spin-lock 구현에 사용되는 mcs 노드에 대하 구조체이다.
참고