<kernel v5.0>
kernel/head.S – ARM64 (old for v5.0)
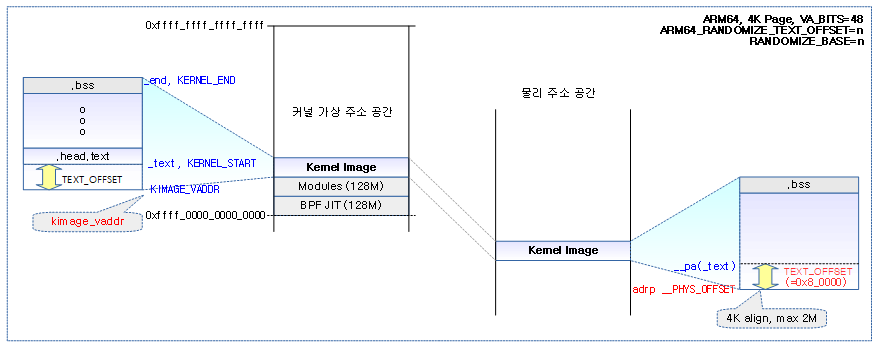
커널 이미지 위치
DRAM 가상 주소 위치
arch/arm64/kernel/head.S
#define __PHYS_OFFSET (KERNEL_START - TEXT_OFFSET)
#if (TEXT_OFFSET & 0xfff) != 0
#error TEXT_OFFSET must be at least 4KB aligned
#elif (PAGE_OFFSET & 0x1fffff) != 0
#error PAGE_OFFSET must be at least 2MB aligned
#elif TEXT_OFFSET > 0x1fffff
#error TEXT_OFFSET must be less than 2MB
#endif
__PHYS_OFFSET는 커널의 시작 물리 주소를 알고자 할 때 adrp 명령과 함께 사용된다.
- 커널 이미지 시작 주소에서 곧바로 어셈블리 코드가 동작하지 않는다. 실제 시작 코드 사이에는 TEXT_OFFSET 만큼 공간을 분리한 후 실제 첫 어셈블리 코드가 MMU가 disable된 물리 주소에서 동작되는 커널의 시작 위치이다.
KERNEL_START & KERNEL_END
arch/arm64/include/asm/memory.h
#define KERNEL_START _text
#define KERNEL_END _end
커널 이미지의 시작 가상 주소에 TEXT_OFFSET 만큼 공간을 가진 후 시작되는 첫 코드의 가상 주소가 KERNEL_START 이다. 그리고 커널 이미지의 끝이 _end로 .bss 섹션도 포함된다.
TEXT_OFFSET
arch/arm64/Makefile
# The byte offset of the kernel image in RAM from the start of RAM.
ifeq ($(CONFIG_ARM64_RANDOMIZE_TEXT_OFFSET), y)
TEXT_OFFSET := $(shell awk "BEGIN {srand(); printf \"0x%06x\n\", \
int(2 * 1024 * 1024 / (2 ^ $(CONFIG_ARM64_PAGE_SHIFT)) * \
rand()) * (2 ^ $(CONFIG_ARM64_PAGE_SHIFT))}")
else
TEXT_OFFSET := 0x00080000
endif
ARM64에서 이미지 로드 offset인 TEXT_OFFSET은 다음 둘 중 하나로 설정된다.
- 컴파일 타임에 커널 위치를 숨기기 위한 보안 옵션 중 하나로 런타임에 커널 위치를 숨기는 KASLR과 다르게 컴파일 타임에 커널 코드의 실행 위치를 0에서 2M 미만 범위에서 PAGE_SIZE 단위의 랜덤한 값을 사용하여 변경할 수 있다.
- 이 옵션을 사용하지 않는 디폴트 설정의 경우 TEXT_OFFSET는 0x8_0000으로 고정된다.
다음 그림은 가상 주소 공간에 배치될 때의 커널 이미지 위치를 보여주며, TEXT_OFFSET 만큼 떨어진 위치에서 커널 코드가 수행됨을 보여준다.
- CONFIG_RANDOMIZE_BASE 커널 옵션을 사용하여 KASLR((Kernel Address Sanitizer Location Randomization)을 동작시키는 경우 런타임에 커널 위치가 변경된다. 다음 그림 예에서는 KASLR을 사용하지 않은 경우이다.
- CONFIG_RANDOMIZE_TEXT_OFFSET 커널 옵션을 사용하면 KASLR 여부와 상관 없이 컴파일 타임에 커널의 offset 실행 위치를 변경할 수 있다. 다음 그림 예에서는 offset을 이동시키지 않고 고정된 0x8_0000 위치를 사용한다.
Static 페이지 테이블
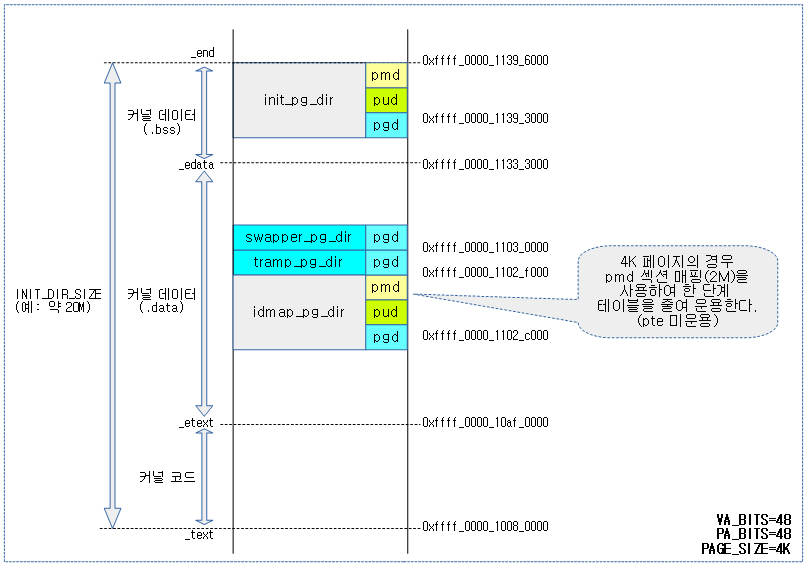
커널이 컴파일될 때 미리 준비되는 5개 페이지 테이블의 용도는 다음과 같다.
- init_pg_dir
- swapper_pg_dir
- 커널 부트업 과정에서 정규 매핑이 가능해지는 순간부터 커널 페이지 테이블로 사용된다.
- reserved_ttbr0
- 보안 상향을 위해 copy_from_user() 등의 별도의 전용 API 사용을 제외하고 무단으로 커널 space에서 유저 공간에 접근 못하게 금지하는 SW 에뮬레이션 방식에서 필요한 zero 페이지 테이블이다.
- ARMv8.0까지 사용되며, ARMv8.1-PAN HW 기능을 사용하면서 이 테이블은 사용하지 않는다.
- tramp_pg_dir
- Speculation 공격을 회피하기 위해 보안 상향을 목적으로 유저 space에서 커널 공간에 접근 못하게 하고, 또한 커널 주소를 감추는 KASLR(Kernel Address Sanitizer Location Randomization)을 위해 커널 영역이 매핑되어 사용되는 페이지 테이블이다. (trampoline 페이지 테이블)
- idmap_pg_dir
- 가상 주소와 물리 주소가 1:1로 매핑되어 사용될 때 필요한 테이블이다.
- 예) MMU enable 시 사용
다음 그림은 컴파일 타임에 static하게 만들어지는 페이지 테이블의 용도를 보여준다.
- pgd 테이블만 준비되는 항목들은 다음 단계의 페이지 테이블이 정규 매핑 준비된 경우 dynamic 하게 생성된다.

다음 그림은 static 페이지 테이블들이 배치된 사례를 보여준다.
- init_pg_dir
- 4K 페이지 및 VA_BITS=48 조건에서 4 단계 페이지 테이블이 2M 블럭 매핑을 사용하면서 1단계 줄어 3단계로 구성된다.
- idmap_pg_dir
- 4K 페이지 및 PA_BITS=48 조건에서 4 단계 페이지 테이블이 2M 블럭 매핑을 사용하면서 1단계 줄어 3단계로 구성된다.
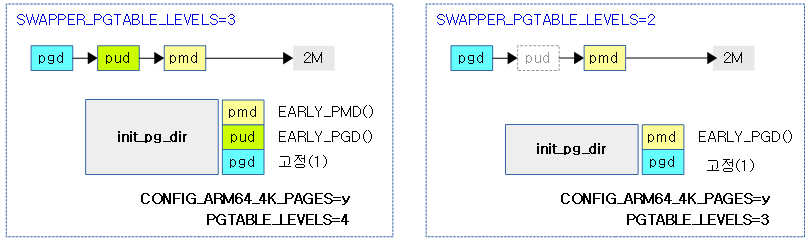
섹션(블럭) 매핑
ARM64 시스템에서 4K 페이지를 사용하는 경우 2M 단위의 섹션(블럭) 매핑을 하여 필요한 페이지 테이블 단계를 1 단계 더 줄일 수 있다. 이 방법으로 init_pg_dir 및 idmap_pg_dir 역시 1 단계를 줄여 사용할 수 있다.
다음 그림은 init_pg_dir에서 기존 페이지 테이블 단계(4단계, 3단계)를 1 단계 더 줄여 2M 단위 섹션 (블럭) 매핑된 모습을 보여준다.
- SWAPPER_PGTABLE_LEVELS가 PGTABLE_LEVELS 보다 1 단계 더 적다.
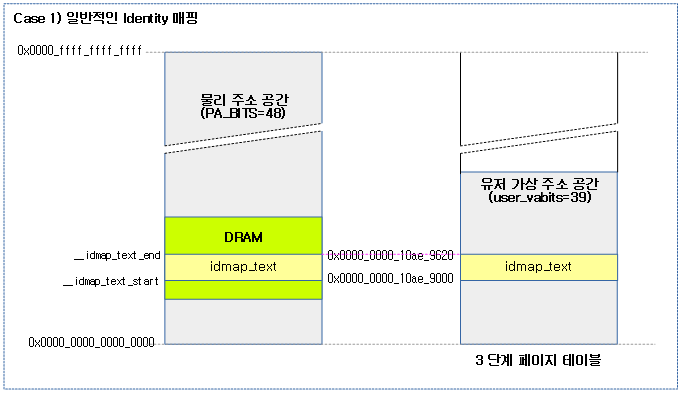
Identity 매핑
물리 주소와 가상 주소가 동일하도록 매핑을 할 때 다음과 같은 3가지 상황이 발생한다.
다음 그림은 물리 주소의 idmap 코드 영역이 동일한 주소의 유저 가상 주소 공간에 배치 가능한 경우이다. 가장 일반적인 상황이다.
다음 그림은 물리 주소의 idmap 코드 영역이 동일한 주소의 유저 가상 주소 공간에 배치가 불가능할 때 페이지 테이블 단계를 증가시켜 유저 가상 주소 공간을 키워 매핑을 하게한 상황이다.

다음 그림은 물리 주소의 idmap 코드 영역이 동일한 주소의 유저 가상 주소 공간에 배치가 불가능하고, VA_BITS=48 공간을 최대치인 52 비트로 확장시킬 수 있는 방법이다.
- 조건: ARMv8.2-LPA 기능을 지원하는 아키텍처에서 64K 페이지 및 3단계 페이지 테이블을 사용할 때 가능하다.
- 참고:
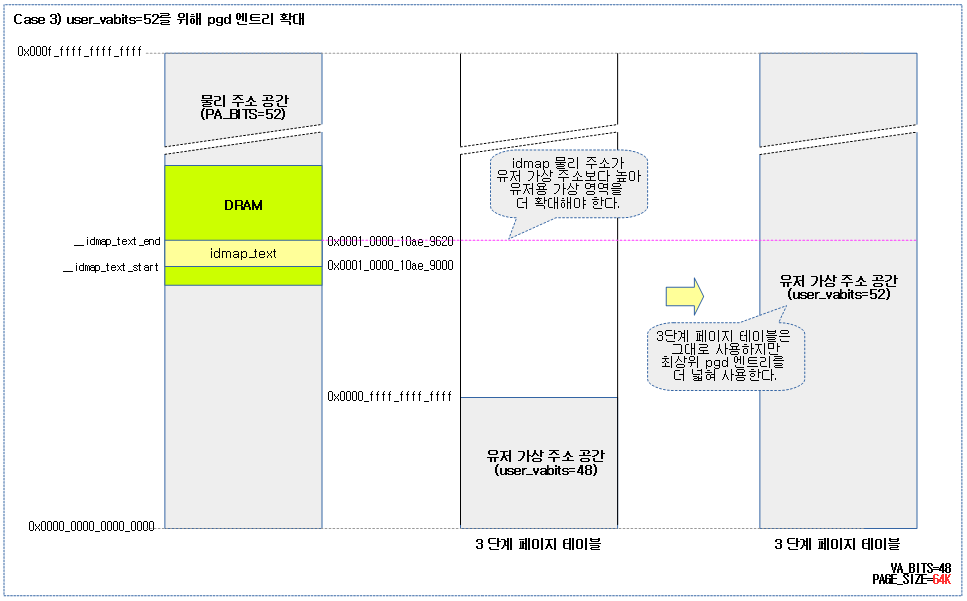
52bit 유저 공간
커널 v5.0-rc1에서 52비트 유저 공간을 지원한다. (4 Peta Bytes)
커널(어셈블리) 시작
_head:
arch/arm64/kernel/head.S
/*
* Kernel startup entry point.
* ---------------------------
*
* The requirements are:
* MMU = off, D-cache = off, I-cache = on or off,
* x0 = physical address to the FDT blob.
*
* This code is mostly position independent so you call this at
* __pa(PAGE_OFFSET + TEXT_OFFSET).
*
* Note that the callee-saved registers are used for storing variables
* that are useful before the MMU is enabled. The allocations are described
* in the entry routines.
*/
__HEAD
_head:
/*
* DO NOT MODIFY. Image header expected by Linux boot-loaders.
*/
#ifdef CONFIG_EFI
/*
* This add instruction has no meaningful effect except that
* its opcode forms the magic "MZ" signature required by UEFI.
*/
add x13, x18, #0x16
b stext
#else
b stext // branch to kernel start, magic
.long 0 // reserved
#endif
le64sym _kernel_offset_le // Image load offset from start of RAM, little-endiaa
n
le64sym _kernel_size_le // Effective size of kernel image, little-endian
le64sym _kernel_flags_le // Informative flags, little-endian
.quad 0 // reserved
.quad 0 // reserved
.quad 0 // reserved
.ascii ARM64_IMAGE_MAGIC // Magic number
#ifdef CONFIG_EFI
.long pe_header - _head // Offset to the PE header.
pe_header:
__EFI_PE_HEADER
#else
.long 0 // reserved
#endif
부트 로더로 부터 커널 코드 시작인 _head에 진입하기 전에 다음 규칙이 적용된다.
- MMU는 off 되어 있어야 한다.
- D-Cache는 off 되어 있어야 한다.
- I-Cache는 on/off 상관 없다.
- x0 레지스터에는 DTB 시작 물리 주소가 담겨 있어야 한다.
stext:
arch/arm64/kernel/head.S
__INIT
/*
* The following callee saved general purpose registers are used on the
* primary lowlevel boot path:
*
* Register Scope Purpose
* x21 stext() .. start_kernel() FDT pointer passed at boot in x0
* x23 stext() .. start_kernel() physical misalignment/KASLR offset
* x28 __create_page_tables() callee preserved temp register
* x19/x20 __primary_switch() callee preserved temp registers
*/
ENTRY(stext)
bl preserve_boot_args
bl el2_setup // Drop to EL1, w0=cpu_boot_mode
adrp x23, __PHYS_OFFSET
and x23, x23, MIN_KIMG_ALIGN - 1 // KASLR offset, defaults to 0
bl set_cpu_boot_mode_flag
bl __create_page_tables
/*
* The following calls CPU setup code, see arch/arm64/mm/proc.S for
* details.
* On return, the CPU will be ready for the MMU to be turned on and
* the TCR will have been set.
*/
bl __cpu_setup // initialise processor
b __primary_switch
ENDPROC(stext)
커널 코드가 처음 시작되는 .init.text 섹션이다. 어셈블리 코드를 통해 임시 페이지 매핑을 수행한 후 mmu를 켜고 C 함수로 작성된 커널의 시작 위치인 start_kernel() 함수로 진입한다.
- 코드 라인 2에서 부트로더가 전달해준 x0 ~ x3 레지스터들을 boot_args 위치에 보관해둔다.
- setup_arch() 마지막 부분에서 저장된 boot_args[] 값들 중 x1~x3에 해당하는 값이 0이 아닌 값이 있는 경우 다음과 같은 경고 메시지를 출력한다.
- “”WARNING: x1-x3 nonzero in violation of boot protocol: …”
- 코드 라인 3에서 하이퍼 바이저에 관련된 설정들을 수행한다.
- 코드 라인 4~5에서 커널 물리 시작 위치를 2M 단위로 내림 정렬한다.
- 코드 라인 6에서 커널 모드(el1)에서 부트했는지 하이퍼바이저(el2)에서 부트했는지 알 수 있도록 부트 모드 플래그를 __boot_cpu_mode에 저장한다.
- 코드 라인 7에서 커널에 대해 임시로 사용할 init 및 idmap 페이지 테이블을 생성한다.
- 코드 라인 14에서 프로세서를 초기화한다.
- 코드 라인 15에서 MMU를 활성화시킨 후 start_kernel() 함수로 점프한다.
부트 시 전달된 인자(x0~x3) 저장
preserve_boot_args:
arch/arm64/kernel/head.S
/*
* Preserve the arguments passed by the bootloader in x0 .. x3
*/
preserve_boot_args:
mov x21, x0 // x21=FDT
adr_l x0, boot_args // record the contents of
stp x21, x1, [x0] // x0 .. x3 at kernel entry
stp x2, x3, [x0, #16]
dmb sy // needed before dc ivac with
// MMU off
mov x1, #0x20 // 4 x 8 bytes
b __inval_dcache_area // tail call
ENDPROC(preserve_boot_args)
부트로더가 전달해준 x0 ~ x3 레지스터들을 boot_args 위치에 보관해둔다. x0는 DTB 주소로 사용되고, 나머지는 추후 사용하기 위해 예약되었다.
- 코드 라인 2~6에서 부트로더가 전달해준 x0 ~ x3 레지스터들을 boot_args 위치에 보관해둔다.
- 코드 라인 8에서 메모리 베리어를 사용하여 데이터 캐시 clean & invalidate를 수행하기 전에 MMU가 꺼진 상태에서 기존 요청한 저장 동작을 완전히 마무리하게 한다. 참고로 MMU가 꺼저 있어도 predictive 로딩은 가능한 상태이다.
- 코드 라인 11~12에서 캐시는 아직 가동되지는 않았지만 boot_args 영역에 해당하는 캐시를 비워두기 위해 clean & invalidate 수행한다.
하이퍼 바이저 지원 코드 설정
el2_setup:
arch/arm64/kernel/head.S
/*
* If we're fortunate enough to boot at EL2, ensure that the world is
* sane before dropping to EL1.
*
* Returns either BOOT_CPU_MODE_EL1 or BOOT_CPU_MODE_EL2 in w0 if
* booted in EL1 or EL2 respectively.
*/
ENTRY(el2_setup)
msr SPsel, #1 // We want to use SP_EL{1,2}
mrs x0, CurrentEL
cmp x0, #CurrentEL_EL2
b.eq 1f
mov_q x0, (SCTLR_EL1_RES1 | ENDIAN_SET_EL1)
msr sctlr_el1, x0
mov w0, #BOOT_CPU_MODE_EL1 // This cpu booted in EL1
isb
ret
1: mov_q x0, (SCTLR_EL2_RES1 | ENDIAN_SET_EL2)
msr sctlr_el2, x0
(...생략...)
cpu가 el2 레벨로 진입한 것은 즉 하이퍼 바이저를 사용하여 부팅된 경우로 이에 대한 설정 코드를 수행한다. 만일 el1 레벨로 부팅한 경우 아무것도 처리하지 않는다.
- 코드 라인 2에서 SP_EL1 스택을 선택하게 한다.
- 코드 라인 3~7에서 현재 EL 레벨을 읽어와서 el1인 경우 시스템 레지스터에 엔디안 설정 비트를 지정한다.
- 코드 라인 8~10에서 w0에 el1 모드를 담아 함수를 빠져나간다.
- 하이퍼 바이저를 위해 레지스터를 설정하는 코드는 분석하지 않는다.
부트 cpu 모드 저장
set_cpu_boot_mode_flag:
arch/arm64/kernel/head.S
/*
* Sets the __boot_cpu_mode flag depending on the CPU boot mode passed
* in w0. See arch/arm64/include/asm/virt.h for more info.
*/
set_cpu_boot_mode_flag:
adr_l x1, __boot_cpu_mode
cmp w0, #BOOT_CPU_MODE_EL2
b.ne 1f
add x1, x1, #4
1: str w0, [x1] // This CPU has booted in EL1
dmb sy
dc ivac, x1 // Invalidate potentially stale cache line
ret
ENDPROC(set_cpu_boot_mode_flag)
커널 부트 진입 시 cpu 모드(el0 ~ el2)를 파악하여 변수 __boot_cpu_mode[0~1]에 저장한다.
- 코드 라인 2~6에 첫 번째 인자 w0 값이 el2 모드가 아닌 경우 w0를 __boot_cpu_mode[0]에 저장하고, el2 모드로 부팅한 경우 __boot_cpu_mode[1]에 w0를 저장한다.
- 코드 라인 7~8에서 모든 메모리 읽기/쓰기 작업이 완료될 때 까지 기다린 후 방금 전에 저장한 주소에 해당하는 캐시 라인에 대해 캐시를 clean & invalidate 한다.
__boot_cpu_mode:
arch/arm64/kernel/head.S
/*
* These values are written with the MMU off, but read with the MMU on.
* Writers will invalidate the corresponding address, discarding up to a
* 'Cache Writeback Granule' (CWG) worth of data. The linker script ensures
* sufficient alignment that the CWG doesn't overlap another section.
*/
.pushsection ".mmuoff.data.write", "aw"
/*
* We need to find out the CPU boot mode long after boot, so we need to
* store it in a writable variable.
*
* This is not in .bss, because we set it sufficiently early that the boot-time
* zeroing of .bss would clobber it.
*/
ENTRY(__boot_cpu_mode)
.long BOOT_CPU_MODE_EL2
.long BOOT_CPU_MODE_EL1
__boot_cpu_mode[]의 초기 값은 다음과 같이 두 개 값이 담겨있다.
- BOOT_CPU_MODE_EL2=0xe12
- BOOT_CPU_MODE_EL1=0xe11
페이지 테이블 관련 매크로
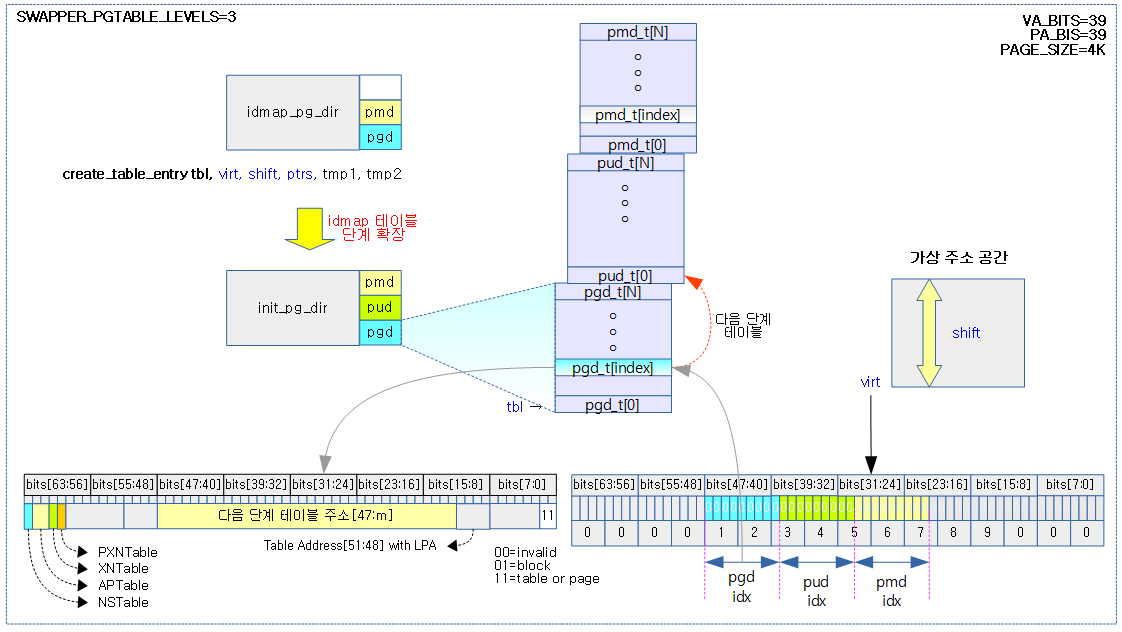
create_table_entry 매크로
이 매크로는 VA_BITS가 48보다 작고 identity 매핑할 물리 주소가 VA_BITS 커버 범위를 벗어나는 경우에 사용된다. Identity 매핑의 Case 2)에 해당한다.
arch/arm64/kernel/head.S
/*
* Macro to create a table entry to the next page.
*
* tbl: page table address
* virt: virtual address
* shift: #imm page table shift
* ptrs: #imm pointers per table page
*
* Preserves: virt
* Corrupts: ptrs, tmp1, tmp2
* Returns: tbl -> next level table page address
*/
.macro create_table_entry, tbl, virt, shift, ptrs, tmp1, tmp2
add \tmp1, \tbl, #PAGE_SIZE
phys_to_pte \tmp2, \tmp1
orr \tmp2, \tmp2, #PMD_TYPE_TABLE // address of next table and entry type
lsr \tmp1, \virt, #\shift
sub \ptrs, \ptrs, #1
and \tmp1, \tmp1, \ptrs // table index
str \tmp2, [\tbl, \tmp1, lsl #3]
add \tbl, \tbl, #PAGE_SIZE // next level table page
.endm
테이블 단계를 1 단계 확장할 때 호출된다. 최상위 테이블 @tbl에서 다음 단계 페이지 테이블에 연결하기 위해 가상 주소 @virt에 해당하는 최상위 페이지 테이블의 인덱스 엔트리에 기록한다.
- 코드 라인 2~4에서 다음 단계 페이지 테이블의 시작 물리 주소와 table 타입 디스크립터 속성을 추가하여 pte 엔트리로 사용될 @tmp2를 구성한다.
- 참고로 첫 번째 단계에 사용되는 pgd 엔트리의 디스크립터 타입에는 항상 table 타입을 사용한다.
- idmap_pg_dir에는 idmap 섹션 영역을 커버하기 위해 pgd부터 pud, pmd, pte까지 사용될 모든 테이블이 포함되어 있다.
- 코드 라인 5~7에서 가상 주소 @virt 를 @shift 만큼 우측 쉬프트한 값에 extra 엔트리 수 범위로 한정한 테이블 인덱스 값을 tmp1에 저장한다.
- 코드 라인 8에서 pte 엔트리 값인 @tmp2 값을 산출된 테이블 인덱스 위치에 저장하여 다음 테이블을 연결한다.
- 코드 라인 9에서 테이블 주소가 다음 단계의 페이지 테이블을 가리키게 한다.
다음 그림은 2단계로 사용될 예정인 idmap 페이지 테이블이 가상 주소 공간이 부족하여 테이블 단계를 확장하여 사용되는 모습을 보여준다.
- 컴파일 타임에 init 페이지 테이블이 VA_BITS를 사용하여 페이지 테이블들을 준비하는 것에 반해, idmap 페이지 테이블은 PA_BITS를 사용하여 페이지 테이블들을 준비한다.
phys_to_pte 매크로
include/asm/assembler.h
.macro phys_to_pte, pte, phys
#ifdef CONFIG_ARM64_PA_BITS_52
/*
* We assume \phys is 64K aligned and this is guaranteed by only
* supporting this configuration with 64K pages.
*/
orr \pte, \phys, \phys, lsr #36
and \pte, \pte, #PTE_ADDR_MASK
#else
mov \pte, \phys
#endif
.endm
물리 주소 @phys를 사용하여 @pte 엔트리 값을 구성한다. (속성 값은 아직 더하지 않은 상태이다)
- 코드 라인 7~8에서 52비트 물리 주소를 지원하는 경우 @phys 값에 36비트 우측 시프트한 @phys 값을 더한 후 필요 주소 영역(bits[47:12])만 사용할 수 있도록 마스크하여 @pte에 저장한다. 저장되는 @pte 값은 다음과 같이 구성된다.
- @pte bits[47:16] <– 물리 주소 @phys bits[47:16]
- @pte bits[15:12] <– 물리 주소 @phys bits[51:48]
- 코드 라인 10에서 52비트 물리 주소를 사용하지 않는 경우 @phys 값을 @pte로 그대로 사용한다.
다음 그림은 연결될 물리 주소 phys를 사용하여 pte 엔트리로 변경된 모습을 보여준다.
- VABITS=52를 사용하는 경우 phys의 bits[35:0]이 제거되고, bits[51:48]이 아래 그림(녹색)과 같이 이동된다.

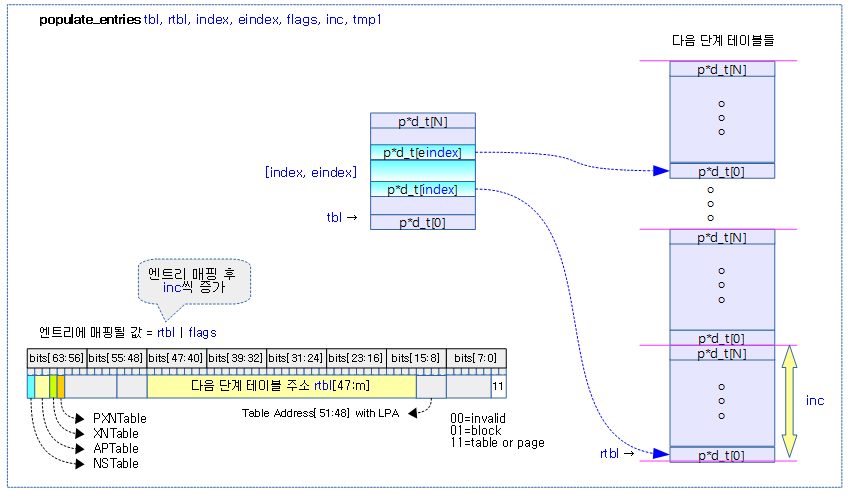
populate_entries 매크로
arch/arm64/kernel/head.S
/*
* Macro to populate page table entries, these entries can be pointers to the next level
* or last level entries pointing to physical memory.
*
* tbl: page table address
* rtbl: pointer to page table or physical memory
* index: start index to write
* eindex: end index to write - [index, eindex] written to
* flags: flags for pagetable entry to or in
* inc: increment to rtbl between each entry
* tmp1: temporary variable
*
* Preserves: tbl, eindex, flags, inc
* Corrupts: index, tmp1
* Returns: rtbl
*/
.macro populate_entries, tbl, rtbl, index, eindex, flags, inc, tmp1
.Lpe\@: phys_to_pte \tmp1, \rtbl
orr \tmp1, \tmp1, \flags // tmp1 = table entry
str \tmp1, [\tbl, \index, lsl #3]
add \rtbl, \rtbl, \inc // rtbl = pa next level
add \index, \index, #1
cmp \index, \eindex
b.ls .Lpe\@
.endm
@tbl 페이지 테이블의 [@index, @eindex] 범위까지 다음 단계 테이블 또는 페이지인 @rtbl에 속성 @flags를 mix하여 만든 pte 엔트리 값으로 매핑한다.
- 코드 라인 3~4에서 @rtbl 물리 주소로 pte 엔트리 값으로 변환하고 속성 값 @flags를 추가하여 pte 엔트리 값을 구한다.
- 코드 라인 5에서 pte 엔트리 값을 @tbl 페이지 테이블의 @index*8 주소 위치에 저장하여 매핑한다.
- 코드 라인 6~8에서 다음 매핑할 물리 주소를 산출하기 위해 @inc를 더하고, @eindex 까지 반복한다.
다음 그림은 페이지 테이블이 static하게 연속된 페이지 다음 단계 테이블들에 연결되는 모습을 보여준다.
- [index, eindex] 엔트리들이 다음 단계 페이지 테이블들로 연결된다.
compute_indices 매크로
arch/arm64/kernel/head.S
/*
* Compute indices of table entries from virtual address range. If multiple entries
* were needed in the previous page table level then the next page table level is assumed
* to be composed of multiple pages. (This effectively scales the end index).
*
* vstart: virtual address of start of range
* vend: virtual address of end of range
* shift: shift used to transform virtual address into index
* ptrs: number of entries in page table
* istart: index in table corresponding to vstart
* iend: index in table corresponding to vend
* count: On entry: how many extra entries were required in previous level, scales
* our end index.
* On exit: returns how many extra entries required for next page table level
*
* Preserves: vstart, vend, shift, ptrs
* Returns: istart, iend, count
*/
.macro compute_indices, vstart, vend, shift, ptrs, istart, iend, count
lsr \iend, \vend, \shift
mov \istart, \ptrs
sub \istart, \istart, #1
and \iend, \iend, \istart // iend = (vend >> shift) & (ptrs - 1)
mov \istart, \ptrs
mul \istart, \istart, \count
add \iend, \iend, \istart // iend += (count - 1) * ptrs
// our entries span multiple tables
lsr \istart, \vstart, \shift
mov \count, \ptrs
sub \count, \count, #1
and \istart, \istart, \count
sub \count, \iend, \istart
.endm
페이지 테이블에서 가상 주소 범위 [@vstart, vend]에 해당하는 인덱스 번호 [@istart, @iend]를 산출한다. @count는 입출력 인자로 입력시에는 전단계에서 산출된 추가 필요 테이블 수를 담아오고, 출력시에는 다음 단계에서 사용할 기본 테이블 1개를 제외하고 추가로 필요로하는 테이블 수가 담긴다. (@count 변수 명을 @extra_count라고 생각하면 쉽다)
- 코드 라인 2~5에서 가상 주소 @vend를 @shift 만큼 우측 시프트하여 @ptrs 엔트리 수 이내로 제한하면 현재 테이블의 끝 인덱스인 @iend가 산출된다.
- @iend = (@vend >> @shift) & (@ptrs – 1)
- 코드 라인 6~8에서 전단계 산출된 결과인 추가 필요한 @count 테이블 수만큼 @ptrs 엔트리를 곱한후 끝 인덱스 @iend에 더한다.
- @iend += @count * @ptrs
- 코드의 주석 내용이 잘못된 것 처럼 보이지만 @count는 -1된 상태로 운영된다.
- 예) count = 10 = @count + 1
- 코드 라인 11~14에서 가상 주소 @vstart를 @shift 만큼 우측 시프트하여 @ptrs 엔트리 수 이내로 제한하면 현재 테이블의 시작 인덱스인 @istart가 산출된다.
- @istart = (@vstart >> @shift) & (@ptrs – 1)
- 코드 라인 16에서 끝 인덱스 번호 – 시작 인덱스 번호를 @count에 대입한다. 산출된 엔트리 수에서 기본 테이블 1개를 제외하여 추가 필요로하는 테이블 수를 @count 값으로 출력한다.
- @count = @iend – @istart
- 예) @istart=0, @iend=9인 경우 엔트리 개수는 10개지만 기본 1개 테이블을 제외하고 추가로 필요한 테이블 수 @count=9를 출력한다.
다음 그림은 compute_indices가 init 페이지 테이블에 대해 단계별로 3번 호출되는 모습을 보여준다.
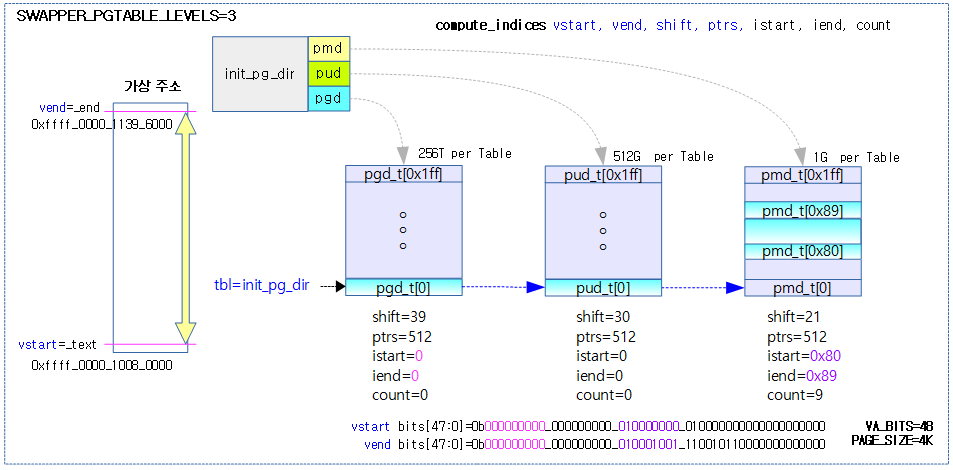
다음 그림은 compute_indices가 init 페이지 테이블에 대해 단계별로 3번 호출되며 3개의 테이블이 더 추가된 모습을 보여준다.
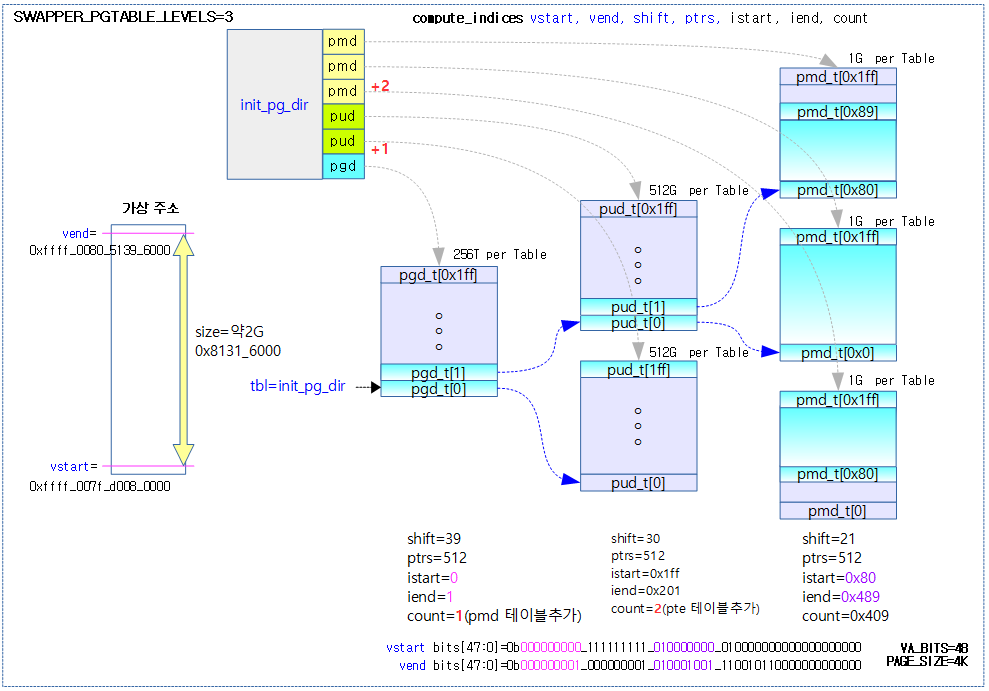
다음 그림은 compute_indices가 작은 크기의 idmap 페이지 테이블에 대해 단계별로 3번 호출되며 2개의 테이블이 더 추가된 모습을 보여준다.
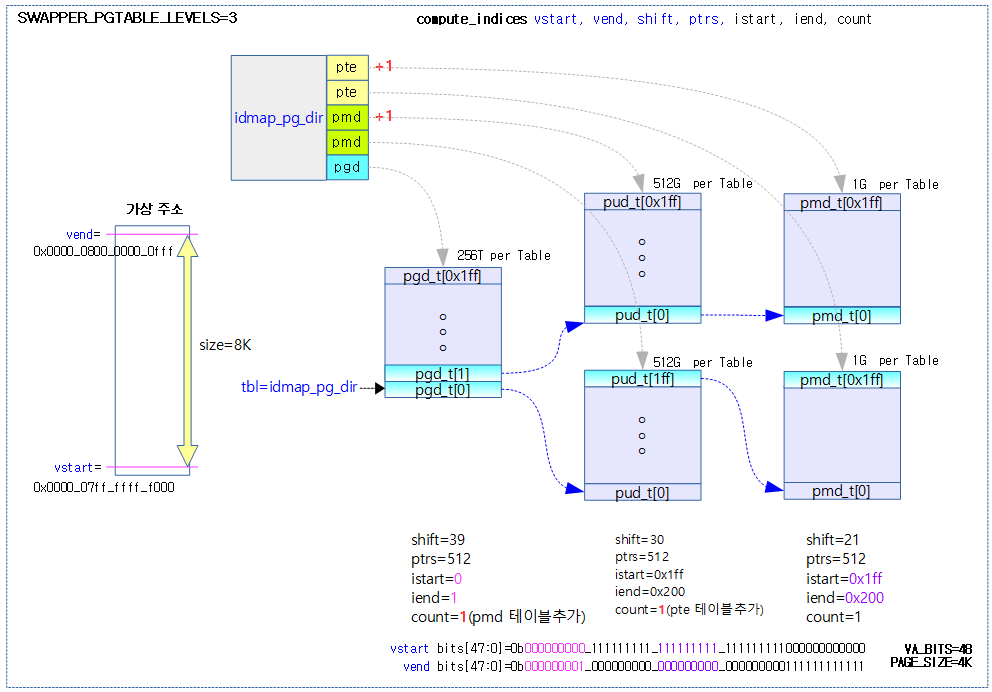
map_memory 매크로
arch/arm64/kernel/head.S
/*
* Map memory for specified virtual address range. Each level of page table needed supports
* multiple entries. If a level requires n entries the next page table level is assumed to be
* formed from n pages.
*
* tbl: location of page table
* rtbl: address to be used for first level page table entry (typically tbl + PAGE_SIZE)
* vstart: start address to map
* vend: end address to map - we map [vstart, vend]
* flags: flags to use to map last level entries
* phys: physical address corresponding to vstart - physical memory is contiguous
* pgds: the number of pgd entries
*
* Temporaries: istart, iend, tmp, count, sv - these need to be different registers
* Preserves: vstart, vend, flags
* Corrupts: tbl, rtbl, istart, iend, tmp, count, sv
*/
.macro map_memory, tbl, rtbl, vstart, vend, flags, phys, pgds, istart, iend, tmp, count, sv
add \rtbl, \tbl, #PAGE_SIZE
mov \sv, \rtbl
mov \count, #0
compute_indices \vstart, \vend, #PGDIR_SHIFT, \pgds, \istart, \iend, \count
populate_entries \tbl, \rtbl, \istart, \iend, #PMD_TYPE_TABLE, #PAGE_SIZE, \tmp
mov \tbl, \sv
mov \sv, \rtbl
#if SWAPPER_PGTABLE_LEVELS > 3
compute_indices \vstart, \vend, #PUD_SHIFT, #PTRS_PER_PUD, \istart, \iend, \count
populate_entries \tbl, \rtbl, \istart, \iend, #PMD_TYPE_TABLE, #PAGE_SIZE, \tmp
mov \tbl, \sv
mov \sv, \rtbl
#endif
#if SWAPPER_PGTABLE_LEVELS > 2
compute_indices \vstart, \vend, #SWAPPER_TABLE_SHIFT, #PTRS_PER_PMD, \istart, \iend, \count
populate_entries \tbl, \rtbl, \istart, \iend, #PMD_TYPE_TABLE, #PAGE_SIZE, \tmp
mov \tbl, \sv
#endif
compute_indices \vstart, \vend, #SWAPPER_BLOCK_SHIFT, #PTRS_PER_PTE, \istart, \iend, \count
bic \count, \phys, #SWAPPER_BLOCK_SIZE - 1
populate_entries \tbl, \count, \istart, \iend, \flags, #SWAPPER_BLOCK_SIZE, \tmp
.endm
pgd 테이블 @tbl에 가상 주소 영역 [@vstart, @vend]을 필요한 전체 단계의 테이블에 매핑한다. 4K 페이지를 지원하는 경우 2M 단위로 블럭 매핑한다.
- 코드 라인 2~8에서 다음 단계의 페이지 테이블을 pgd 테이블의 [@vstart, @vend] 가상 주소에 해당하는 인덱스 엔트리에 연결한다.
- 코드 라인 11~14에서 다음 단계의 페이지 테이블을 pud 테이블의 [@vstart, @vend] 가상 주소에 해당하는 인덱스 엔트리에 연결한다.
- SWAPPER_PGTABLE_LEVELS이 4단계 이상에서만 pud 테이블을 사용한다.
- 코드 라인 18~20에서 다음 단계의 페이지 테이블을 pmd 테이블의 [@vstart, @vend] 가상 주소에 해당하는 인덱스 엔트리에 연결한다.
- SWAPPER_PGTABLE_LEVELS이 3단계 이상에서만 pmd 테이블을 사용한다.
- 코드 라인 23~25에서 페이지 또는 2M 섹션(블럭)을 pte 테이블의 [@vstart, @vend] 가상 주소에 해당하는 인덱스 엔트리에 매핑할 때 @flags 속성을 추가하여 매핑한다.
다음 그림은 커널 이미지 영역을 map_memory 매크로를 통해 init_pg_dir에 매핑하는 모습을 보여준다.

페이지 테이블 생성
__create_page_tables:
init 페이지 테이블에 커널 이미지를 매핑하고, idmap 페이지 테이블에 idmap 섹션 영역을 identity 매핑한다. identity 매핑을 위해 매핑할 가상 주소 공간 크기가 부족한 경우 idmap 페이지 테이블의 단계를 상향 시키거나 최상위 idmap 페이지 테이블의 엔트리를 확대한다.
arch/arm64/kernel/head.S -1/3-
/*
* Setup the initial page tables. We only setup the barest amount which is
* required to get the kernel running. The following sections are required:
* - identity mapping to enable the MMU (low address, TTBR0)
* - first few MB of the kernel linear mapping to jump to once the MMU has
* been enabled
*/
__create_page_tables:
mov x28, lr
/*
* Invalidate the init page tables to avoid potential dirty cache lines
* being evicted. Other page tables are allocated in rodata as part of
* the kernel image, and thus are clean to the PoC per the boot
* protocol.
*/
adrp x0, init_pg_dir
adrp x1, init_pg_end
sub x1, x1, x0
bl __inval_dcache_area
/*
* Clear the init page tables.
*/
adrp x0, init_pg_dir
adrp x1, init_pg_end
sub x1, x1, x0
1: stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
subs x1, x1, #64
b.ne 1b
mov x7, SWAPPER_MM_MMUFLAGS
- 코드 라인 10~13에서 init 페이지 테이블 영역에 대해 캐시를 무효화한다.
- x0에는 init 테이블 시작 주소
- x1에는 init 테이블 사이즈
- 코드 라인18~26에서 init 페이지 테이블 영역을 모두 0으로 클리어한다.
- 코드 라인 28에서 x7 레지스터에 매핑 시 사용할 속성 플래그를 담아둔다.
arch/arm64/kernel/head.S -2/3-
/*
* Create the identity mapping.
*/
adrp x0, idmap_pg_dir
adrp x3, __idmap_text_start // __pa(__idmap_text_start)
#ifdef CONFIG_ARM64_USER_VA_BITS_52
mrs_s x6, SYS_ID_AA64MMFR2_EL1
and x6, x6, #(0xf << ID_AA64MMFR2_LVA_SHIFT)
mov x5, #52
cbnz x6, 1f
#endif
mov x5, #VA_BITS
1:
adr_l x6, vabits_user
str x5, [x6]
dmb sy
dc ivac, x6 // Invalidate potentially stale cache line
/*
* VA_BITS may be too small to allow for an ID mapping to be created
* that covers system RAM if that is located sufficiently high in the
* physical address space. So for the ID map, use an extended virtual
* range in that case, and configure an additional translation level
* if needed.
*
* Calculate the maximum allowed value for TCR_EL1.T0SZ so that the
* entire ID map region can be mapped. As T0SZ == (64 - #bits used),
* this number conveniently equals the number of leading zeroes in
* the physical address of __idmap_text_end.
*/
adrp x5, __idmap_text_end
clz x5, x5
cmp x5, TCR_T0SZ(VA_BITS) // default T0SZ small enough?
b.ge 1f // .. then skip VA range extension
adr_l x6, idmap_t0sz
str x5, [x6]
dmb sy
dc ivac, x6 // Invalidate potentially stale cache line
#if (VA_BITS < 48)
#define EXTRA_SHIFT (PGDIR_SHIFT + PAGE_SHIFT - 3)
#define EXTRA_PTRS (1 << (PHYS_MASK_SHIFT - EXTRA_SHIFT))
/*
* If VA_BITS < 48, we have to configure an additional table level.
* First, we have to verify our assumption that the current value of
* VA_BITS was chosen such that all translation levels are fully
* utilised, and that lowering T0SZ will always result in an additional
* translation level to be configured.
*/
#if VA_BITS != EXTRA_SHIFT
#error "Mismatch between VA_BITS and page size/number of translation levels"
#endif
mov x4, EXTRA_PTRS
create_table_entry x0, x3, EXTRA_SHIFT, x4, x5, x6
#else
/*
* If VA_BITS == 48, we don't have to configure an additional
* translation level, but the top-level table has more entries.
*/
mov x4, #1 << (PHYS_MASK_SHIFT - PGDIR_SHIFT)
str_l x4, idmap_ptrs_per_pgd, x5
#endif
1:
ldr_l x4, idmap_ptrs_per_pgd
mov x5, x3 // __pa(__idmap_text_start)
adr_l x6, __idmap_text_end // __pa(__idmap_text_end)
map_memory x0, x1, x3, x6, x7, x3, x4, x10, x11, x12, x13, x14
idmap_pg_dir 테이블에 __idmap_text_start 주소부터 __idmap_text_end 영역까지 가상 주소와 물리 주소가 일치하는 identity 매핑을 생성한다.
- 코드 라인 7~16에서 커널에 설정된 vabits를 전역 변수 vabits_user에 저장한다. 만일 커널이 52bit 가상 주소 영역을 지원하고 mmfr_el1 레지스터에서 lva 기능이 지원되는 것을 확인한 경우에는 유저 가상 주소를 표현하는 비트 수를 52로하여 저장한다.
- 코드 라인 17~18에서 모든 메모리 읽기/쓰기 작업이 완료될 때 까지 기다린 후 vabits_user가 저장된 캐시 라인에 대해 clean & invalidate 한다.
- 코드 라인 32~35에서 idmap 코드의 마지막 주소가 설정된 커널용 가상 주소 공간보다 크거나 같은 경우 정상적으로 identity 매핑을 하기 위해 1: 레이블로 이동한다.
- clz(count leading zero) 명령을 사용하여 idmap 코드의 마지막 주소를 대상으로 0으로 시작하는 비트가 몇 개인지 센다.
- 예) clz(0x0000_00f1_1234_0000) = 24
- 커널에 설정된 VABITS=48일 때 가상 주소 공간의 크기는 256T이다.
- 코드 라인 37~38에서 가상 주소 영역의 확장을 위해 필요한 유저 비트 수를 변수 idmap_t0sz에 저장한다.
- 코드 라인 39~40에서 모든 메모리 읽기/쓰기 작업이 완료될 때 까지 기다린 후 idmap_t0sz이 저장된 캐시 라인에 대해 clean & invalidate 한다.
- 코드 라인 42~58에서 커널이 VA_BITS<48과 같은 작은 설정을 사용하는 경우 페이지 테이블 단계를 1 단계 더 상향한다.
- 4K 페이지, VABITS=39일 떄 PGDIR_SHIFT=30이다. 이 때 EXTRA_SHIFT=39와 같이 엔트리가 커버하는 공간이 1 단계 더 상향된다.
- 최상위 페이지 테이블이 사용할 엔트리 수인 EXTRA_PTRS에는 1 << (ARM64_PA_BITS – EXTRA_SHIFT) 이므로 1 << (48 – 39) = 512 이다.
- 코드 라인 59~66에서 커널이 VA_BITS=48과 같은 설정을 사용하는 경우 페이지 테이블 단계를 더 상향시키지는 못하므로 최상위 pgd 테이블의 엔트리 수를 추가한다.
- 코드 라인 67~72에서 1: 레이블이다. idmap_pg_dir 테이블에 __idmap_text_start 주소부터 __idmap_text_end 영역까지 가상 주소와 물리 주소가 일치하는 identity 매핑을 생성한다.
arch/arm64/kernel/head.S -3/3-
/*
* Map the kernel image (starting with PHYS_OFFSET).
*/
adrp x0, init_pg_dir
mov_q x5, KIMAGE_VADDR + TEXT_OFFSET // compile time __va(_text)
add x5, x5, x23 // add KASLR displacement
mov x4, PTRS_PER_PGD
adrp x6, _end // runtime __pa(_end)
adrp x3, _text // runtime __pa(_text)
sub x6, x6, x3 // _end - _text
add x6, x6, x5 // runtime __va(_end)
map_memory x0, x1, x5, x6, x7, x3, x4, x10, x11, x12, x13, x14
/*
* Since the page tables have been populated with non-cacheable
* accesses (MMU disabled), invalidate the idmap and swapper page
* tables again to remove any speculatively loaded cache lines.
*/
adrp x0, idmap_pg_dir
adrp x1, init_pg_end
sub x1, x1, x0
dmb sy
bl __inval_dcache_area
ret x28
ENDPROC(__create_page_tables)
.ltorg
- 코드 라인 4~13에서 물리 주소에 위치한 커널 이미지를 init_pg_dir 테이블의 가상 주소 __text ~ _end 범위에 매핑한다.
- KASLR이 동작하는 경우 이 함수에 두 번째 진입 시 x23 레지스터에 KASLR offset이 담겨 들어온다.
- 코드 라인 20~24에서 모든 메모리 읽기/쓰기 작업이 완료될 때 까지 기다린 후 idmap_pg_dir ~ init_pg_dir 범위에 대해 캐시를 무효화한다.
부트 CPU 스위치
다음 그림은 KASLR의 활성화 여부와 관련된 처리 흐름을 보여준다.
- KASLR이 활성화된 경우 __primary_switched: 및 __create_page_tables: 레이블이 한 번 더 호출되는 모습을 볼 수 있다.
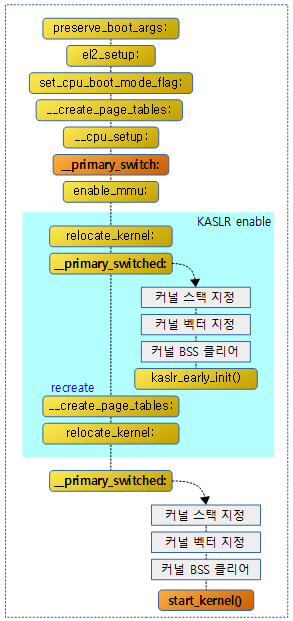
MMU 스위치 전
__primary_switch:
arch/arm64/kernel/head.S
__primary_switch:
#ifdef CONFIG_RANDOMIZE_BASE
mov x19, x0 // preserve new SCTLR_EL1 value
mrs x20, sctlr_el1 // preserve old SCTLR_EL1 value
#endif
adrp x1, init_pg_dir
bl __enable_mmu
#ifdef CONFIG_RELOCATABLE
bl __relocate_kernel
#ifdef CONFIG_RANDOMIZE_BASE
ldr x8, =__primary_switched
adrp x0, __PHYS_OFFSET
blr x8
/*
* If we return here, we have a KASLR displacement in x23 which we need
* to take into account by discarding the current kernel mapping and
* creating a new one.
*/
pre_disable_mmu_workaround
msr sctlr_el1, x20 // disable the MMU
isb
bl __create_page_tables // recreate kernel mapping
tlbi vmalle1 // Remove any stale TLB entries
dsb nsh
msr sctlr_el1, x19 // re-enable the MMU
isb
ic iallu // flush instructions fetched
dsb nsh // via old mapping
isb
bl __relocate_kernel
#endif
#endif
ldr x8, =__primary_switched
adrp x0, __PHYS_OFFSET
br x8
ENDPROC(__primary_switch)
MMU를 활성화 한 후 __primary_switched로 점프한다. MMU 활성화 후 커널 리로케이션 옵션을 사용하는 경우 잠시 mmu를 껀채로 리로케이션을 수행 후 다시 페이지 테이블을 매핑하고 mmu를 켠다.
- 코드 라인 2~5에서 KASLR(커널 랜덤 위치) 옵션이 지정된 경우 기존 sctlr_el1과 현재 sctlr_el1을 각각 x20, x19에 보존해둔다.
- 코드 라인 7~8에서 init 페이지 테이블을 사용하여 mmu를 활성화한다.
- 코드 라인 10에서 재배치 정보를 담고 있는 .rela.dyn 섹션에 위치한 엔트리들을 옮긴다.
- KASLR 옵션 설정 시에도 CONFIG_RELOCATABLE이 설정된다.
- 코드 라인 12~14에서 CONFIG_RANDOMIZE_BASE 커널 옵션을 사용하는 경우 x0에 커널 이미지의 물리 주소 위치 담긴 주소를 담고 __primary_switched()를 수행한 후 돌아온다.
- 코드 라인 21에서 qualcom사의 FALKOR SoC에 Speculative 명령이 발생하는 case가 있어서 isb 명령을 워크어라운드 코드로 추가하였다.
- 코드 라인 22~24에서 잠시 mmu를 끈 상태로 페이지 테이블을 다시 만든다.
- 코드 라인 26~27에서 모든 tlb 엔트리를 무효화후 dsb 명령을 통해 페이지 테이블의 변화가 모든 cpu들에 적용되게 한다.
- 코드 라인 29~33에서 mmu를 다시 켜고 명령 캐시를 모두 모효화하고, 페이지 테이블의 변화가 모든 cpu들에 적용되게 한다.
- 중간에 isb를 사용하는 경우 isb 전후로 명령 실행 순서가 바뀌지 않아야 하는 경우 사용된다.
- 코드 라인 35에서 재배치 정보를 담고 있는 .rela.dyn 섹션에 위치한 엔트리들을 옮긴다.
- 코드 라인 38~40에서 x0에 커널 이미지의 물리 주소 위치(offset 구간 포함)가 담긴 주소를 담고 __primary_switched로 점프한다.
- __primary_switch() 함수와 enable_mmu() 등의 함수는 idmap 테이블에 매핑되어 있고, __primary_switched() 함수로 점프할 때부터 init 페이지 테이블을 사용한다.
MMU 활성화
__enable_mmu:
arch/arm64/kernel/head.S
/*
* Enable the MMU.
*
* x0 = SCTLR_EL1 value for turning on the MMU.
* x1 = TTBR1_EL1 value
*
* Returns to the caller via x30/lr. This requires the caller to be covered
* by the .idmap.text section.
*
* Checks if the selected granule size is supported by the CPU.
* If it isn't, park the CPU
*/
ENTRY(__enable_mmu)
mrs x2, ID_AA64MMFR0_EL1
ubfx x2, x2, #ID_AA64MMFR0_TGRAN_SHIFT, 4
cmp x2, #ID_AA64MMFR0_TGRAN_SUPPORTED
b.ne __no_granule_support
update_early_cpu_boot_status 0, x2, x3
adrp x2, idmap_pg_dir
phys_to_ttbr x1, x1
phys_to_ttbr x2, x2
msr ttbr0_el1, x2 // load TTBR0
offset_ttbr1 x1
msr ttbr1_el1, x1 // load TTBR1
isb
msr sctlr_el1, x0
isb
/*
* Invalidate the local I-cache so that any instructions fetched
* speculatively from the PoC are discarded, since they may have
* been dynamically patched at the PoU.
*/
ic iallu
dsb nsh
isb
ret
ENDPROC(__enable_mmu)
MMU를 enable 한다. MMU를 enable 한 후에는 init 페이지 테이블을 사용하는데, enable 하는 순간의 현재 코드들은 idmap 페이지 테이블을 사용한다.
- 코드 라인 1~4에서 MMFR0_EL1 (Memory Model Feature Register 0 Register – EL1)을 통해 커널이 설정한 페이지 타입을 지원하는지 확인하고, 지원하지 않는 경우 __no_granule_support 레이블로 이동한다.
- 코드 라인 5에서 boot cpu 상태를 저장하는 변수 __early_cpu_boot_status의 값을 0으로 초기화한다.
- 코드 라인 6~14에서 ttbr0 레지스터에 idmap 페이지 테이블을 지정하고, ttbr1 레지스터에 init 페이지 테이블을 지정한다. 그 후 mmu를 enable 한다. mmu를 enable 하기 전/후로 isb 명령을 사용하여 명령 파이프를 비운다.
- 코드 라인 20~23에서 명령 캐시를 모두 무효화 시키고, 페이지 테이블 등이 변경되었으므로 dsb 명령을 사용하여 모든 cpu들에 대해 반영되도록 한다. 그런 후 다시 명령 파이프를 비운 후 리턴한다.
재배치 엔트리 리로케이션
__relocate_kernel:
arch/arm64/kernel/head.S
#ifdef CONFIG_RELOCATABLE
__relocate_kernel:
/*
* Iterate over each entry in the relocation table, and apply the
* relocations in place.
*/
ldr w9, =__rela_offset // offset to reloc table
ldr w10, =__rela_size // size of reloc table
mov_q x11, KIMAGE_VADDR // default virtual offset
add x11, x11, x23 // actual virtual offset
add x9, x9, x11 // __va(.rela)
add x10, x9, x10 // __va(.rela) + sizeof(.rela)
0: cmp x9, x10
b.hs 1f
ldp x11, x12, [x9], #24
ldr x13, [x9, #-8]
cmp w12, #R_AARCH64_RELATIVE
b.ne 0b
add x13, x13, x23 // relocate
str x13, [x11, x23]
b 0b
1: ret
ENDPROC(__relocate_kernel)
#endif
재배치 정보를 담고 있는 .rela.dyn 섹션에 위치한 엔트리들을 옮긴다. 리로케이션 시 상대 주소 표현을 사용한 어셈블리 코드에 relocation offset(x23)를 더해 적용한다.
- 코드 라인 6~12에서 x9 레지스터에 __rela_offset + KIMAGE_VADDR + relocation offset(x23) 값인 시작 주소를 산출한다. 그리고 x10 레지스터에 __rela_size를 더한 끝 주소를 대입한다.
- 코드 라인 14~15에서 x9 레지스터 값이 끝 주소 이상이면 리로케이션이 모두 완료되었으므로 함수를 빠져나간다.
- 코드 라인 16~19에서 x9 주소의 16바이트를 x11과 x12 레지스터로 읽고, 다음 엔트리를 위해 x9 주소에 #24를 더 한다. 그리고 x9 – 8 주소 위치의 값을 x13 레지스터로 읽는다. w12 레지스터의 값이 #R_AARCH64_RELATIVE가 아닌 경우 skip 하고 다시 0 레이블로 반복한다.
- 코드 라인 20~22에서 상대 주소 값에 relocation offset을 더해 x11+ relocation offset 위치에 복사하고 0레이블로 이동하여 반복한다.
.rela.dyn 섹션
먼저 .rela.dyn 섹션에서 offset 값을 알아본다.
$ readelf -S vmlinux
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .head.text PROGBITS ffff000010080000 00010000
0000000000001000 0000000000000000 AX 0 0 4096
[ 2] .text PROGBITS ffff000010081000 00011000
0000000000a9b7e8 0000000000000008 AX 0 0 2048
(...생략...)
[16] .init.data PROGBITS ffff000011136000 010c6000
000000000008e5f0 0000000000000000 WA 0 0 256
[17] .data..percpu PROGBITS ffff0000111c5000 01155000
000000000000db18 0000000000000000 WA 0 0 64
[18] .rela.dyn RELA ffff0000111d2b18 01162b18
00000000003231a8 0000000000000018 A 0 0 8
[19] .data PROGBITS ffff000011500000 01490000
000000000017e240 0000000000000000 WA 0 0 4096
(...생략...)
다음과 같이 .relay.dyn 섹션에 위치한 137,063개의 리로케이션 엔트리들을 볼 수 있다.
$ readelf -r vmlinux
Relocation section '.rela.dyn' at offset 0x1162b18 contains 137063 entries:
Offset Info Type Sym. Value Sym. Name + Addend
ffff0000100aed68 000000000403 R_AARCH64_RELATIV -ffffeff4e7f4
ffff0000100aed70 000000000403 R_AARCH64_RELATIV -ffffeff4e7dc
ffff0000100fbbc8 000000000403 R_AARCH64_RELATIV -ffffeef9da40
ffff00001015e658 000000000403 R_AARCH64_RELATIV -ffffef24c520
ffff00001015e660 000000000403 R_AARCH64_RELATIV -ffffef107fa8
(...생략...)
위의 엔트리들의 실제 덤프 값을 확인해본다.
- 엔트리 하나 당 24 바이트임을 알 수 있다.
$ xxd -s 0x01162b18 -l 0x78 -g 8 -e vmlinux
01162b18: ffff0000100aed68 0000000000000403 h...............
01162b28: ffff0000100b180c ffff0000100aed70 ........p.......
01162b38: 0000000000000403 ffff0000100b1824 ........$.......
01162b48: ffff0000100fbbc8 0000000000000403 ................
01162b58: ffff0000110625c0 ffff00001015e658 .%......X.......
01162b68: 0000000000000403 ffff000010db3ae0 .........:......
01162b78: ffff00001015e660 0000000000000403 `...............
01162b88: ffff000010ef8058 X.......
부트 CPU MMU 스위치 후
__primary_switched:
arch/arm64/kernel/head.S
/*
* The following fragment of code is executed with the MMU enabled.
*
* x0 = __PHYS_OFFSET
*/
__primary_switched:
adrp x4, init_thread_union
add sp, x4, #THREAD_SIZE
adr_l x5, init_task
msr sp_el0, x5 // Save thread_info
adr_l x8, vectors // load VBAR_EL1 with virtual
msr vbar_el1, x8 // vector table address
isb
stp xzr, x30, [sp, #-16]!
mov x29, sp
str_l x21, __fdt_pointer, x5 // Save FDT pointer
ldr_l x4, kimage_vaddr // Save the offset between
sub x4, x4, x0 // the kernel virtual and
str_l x4, kimage_voffset, x5 // physical mappings
// Clear BSS
adr_l x0, __bss_start
mov x1, xzr
adr_l x2, __bss_stop
sub x2, x2, x0
bl __pi_memset
dsb ishst // Make zero page visible to PTW
#ifdef CONFIG_KASAN
bl kasan_early_init
#endif
#ifdef CONFIG_RANDOMIZE_BASE
tst x23, ~(MIN_KIMG_ALIGN - 1) // already running randomized?
b.ne 0f
mov x0, x21 // pass FDT address in x0
bl kaslr_early_init // parse FDT for KASLR options
cbz x0, 0f // KASLR disabled? just proceed
orr x23, x23, x0 // record KASLR offset
ldp x29, x30, [sp], #16 // we must enable KASLR, return
ret // to __primary_switch()
0:
#endif
add sp, sp, #16
mov x29, #0
mov x30, #0
b start_kernel
ENDPROC(__primary_switched)
MMU를 켠 후 동작하는 코드로 커널용 스택과 벡터 포인터를 지정하고 BSS 영역을 클리어한 후 start_kernel() 함수로 점프한다.
- 코드 라인 2~3에서 스택 레지스터에 커널 스택 용도로 사용할 메모리 위치를 지정한다.
- init_thread_union
- include/asm-generic/vmlinux.lds.h 에 심볼이 정의되어 있고 커널 스택의 사이즈는 THREAD_SIZE이다.
- 코드 라인 4~5에서 컴파일 타임에 준비된 최초 커널용 태스크인 init_task의 주소를 임시로 sp_el0에 저장해둔다.
- sp_el0는 유저 공간에서 사용할 때 유저용 스택 위치로 사용된다.
- 그러나 현재 커널 부트업 중에는 사용하지 않으므로 여러 용도로 임시 사용될 수 있다.
- 코드 라인 7~9에서 vbar_el1 레지스터에 vector 위치를 지정한 후 isb를 수행하여 이후 실행되는 명령이 isb 전에 변경한 컨텍스트가 적용되어 동작하도록 한다.
- 코드 라인 11~12에서 0과 x30 내용을 스택에 보관한다.
- 코드 라인 14에서 fdt 시작 물리 주소를 담고 있는 x21 레지스터를 변수 __fdt_pointer에 저장한다.
- 코드 라인 16~18에서 커널 시작 가상 주소에서 커널 시작 물리 주소(x0=__PHYS_OFFSET)를 뺀 offset을 변수 kimage_voffset에 저장한다.
- x0에는 이 루틴이 호출되기 전에 __PHYS_OFFSET이 담겨 호출된다.
- 예) kimage_vaddr=0xffff_0000_1000_0000, __PHYS_OFFSET=0x4000_0000
- kimage_voffset=0xfffe_ffff_d000_0000
- 코드 라인 21~26에서 BSS 영역을 0으로 모두 클리어한 후 기록된 0 값이 다른 inner-share 영역의 cpu들이 볼 수 있도록 반영한다.
- 코드 라인 32~33에서 CONFIG_RANDOMIZE_BASE 옵션이 사용되는 경우 커널이 이미 relocation된 경우 0 레이블로 전진한다.
- 코드 라인 34~36에서 kaslr_early_init()을 수행하는데 /chosen 노드의 bootargs에서 “nokaslr” 커널 파라미터가 사용된 경우 0 레이블로 전진한다. kaslr_early_init() 함수는 64바이트의 kaslr-seed 속성 값을 사용한 내부 연산을 통해 커널의 시작 위치가 변동된 offset 값을 반환한다. KASLR offset이 결정되었으므로 루틴을 빠져나간뒤 매핑을 다시 해야 한다.
- 예) kaslr-seed = <0xfeedbeef 0xc0def00d>;
- 이후 C 루틴으로 동작하는 최초 커널 함수인 start_kernel()부터 랜덤 가상 주소에서 실행된다.
- 코드 라인 37~39에서 KASLR offset 값을 x23 레지스터에 저장하고, 스택에 보관해둔 값을 x29(0 값)와 x30에는 반환 받은 후 프로시져를 리턴한다.
- 코드 라인 42~45에서 사용 했던 16바이트의 스택 포인터를 원위치시키고, x29, x30 레지스터에 0을 담은 후 start_kernel() 함수로 점프한다.
kimage_vaddr 변수
arch/arm64/kernel/head.S
/*
* end early head section, begin head code that is also used for
* hotplug and needs to have the same protections as the text region
*/
.section ".idmap.text","awx"
ENTRY(kimage_vaddr)
.quad _text - TEXT_OFFSET
EXPORT_SYMBOL(kimage_vaddr)
kimage_vaddr은 MMU 상태와 관계없이 동작해야 하므로 .idmap.text 섹션에 위치해 있고, 컴파일 타임에 커널 시작 가상 주소 _text 에서 TEXT_OFFSET 을 뺀 주소가 저장되어 있다.
kimage_voffset 변수
arch/arm64/mm/mmu.c
u64 kimage_voffset __ro_after_init;
EXPORT_SYMBOL(kimage_voffset);
부트업 타임에 다음과 같은 값으로 한 번만 저장된 후 읽기 전용으로 사용된다.
- kimage_voffset = kimage_vaddr – __PHYS_OFFSET
- kimage_voffset 값은 다음 함수에서 사용된다.
- __kimg_to_phys()
- __phys_to_kimg()
다음 그림은 이미지의 가상 주소에서 물리 주소의 차이를 kimage_voffset 값에 담았고, 이 값을 통해 이미지의 가상 주소와 물리 주소의 변환 API에 활용되는 모습을 보여준다.

커널 스택 크기
arch/arm64/include/asm/memory.h
#define THREAD_SIZE (UL(1) << THREAD_SHIFT)
커널 스택 사이즈는 디폴트 커널 설정(4K 페이지)에서 16K를 사용한다.
arch/arm64/include/asm/memory.h
/*
* VMAP'd stacks are allocated at page granularity, so we must ensure that such
* stacks are a multiple of page size.
*/
#if defined(CONFIG_VMAP_STACK) && (MIN_THREAD_SHIFT < PAGE_SHIFT)
#define THREAD_SHIFT PAGE_SHIFT
#else
#define THREAD_SHIFT MIN_THREAD_SHIFT
#endif
페이지 사이즈로 64K를 vmap을 사용한 커널 스택은 1 개의 64K 페이지를 사용한다. 그렇지 않은 경우 MIN_THREAD_SHIFT 단위의 커널 스택을 사용한다.
arch/arm64/include/asm/memory.h
#define MIN_THREAD_SHIFT (14 + KASAN_THREAD_SHIFT)
커널 스택 최소 단위는 16K이며 KASAN을 사용하는 경우 32K를 사용하고, KASAN Extra를 사용하는 경우 64K를 사용한다.
Secondary CPU 부팅
secondary_entry:
arch/arm64/kernel/head.S
/*
* Secondary entry point that jumps straight into the kernel. Only to
* be used where CPUs are brought online dynamically by the kernel.
*/
ENTRY(secondary_entry)
bl el2_setup // Drop to EL1
bl set_cpu_boot_mode_flag
b secondary_startup
ENDPROC(secondary_entry)
부트 cpu를 제외한 나머지 cpu들이 깨어날 때 수행될 루틴들이다. 하이퍼 바이저 설정 코드를 수행하고, 부트 cpu 모드를 저장한 후 secondary_startup 레이블로 이동하여 계속 처리한다.
- 잠들어 있는 cpu들은 wfe 동작과 같은 상태로 클럭이 멈춰있는 상태이고 부트가 되어야 할지 여부가 기록된 스핀 테이블 내용이 변경되지 않는 한 루프를 돌며 다시 wfe 상태가 된다.
secondary_startup:
arch/arm64/kernel/head.S
secondary_startup:
/*
* Common entry point for secondary CPUs.
*/
bl __cpu_secondary_check52bitva
bl __cpu_setup // initialise processor
adrp x1, swapper_pg_dir
bl __enable_mmu
ldr x8, =__secondary_switched
br x8
ENDPROC(secondary_startup)
프로세서를 초기화하고 MMU를 켠 후 __secondary_switched()루틴으로 점프한다.
- 코드 라인 5에서 부트 cpu가 52bit 유저 가상 주소를 사용한 경우 secondary cpu가 이를 지원하는지 여부를 체크하는데, 지원하지 않는 경우 stuck한다.
- 코드 라인 6에서 프로세서를 초기화한다.
- 코드 라인 7~8에서 swapper_pg_dir 에서 커널이 동작하도록 MMU를 켠다.
- 코드 라인 9~10에서 __secondary_switched 루틴으로 점프한다.
__cpu_secondary_check52bitva:
arch/arm64/kernel/head.S
ENTRY(__cpu_secondary_check52bitva)
#ifdef CONFIG_ARM64_USER_VA_BITS_52
ldr_l x0, vabits_user
cmp x0, #52
b.ne 2f
mrs_s x0, SYS_ID_AA64MMFR2_EL1
and x0, x0, #(0xf << ID_AA64MMFR2_LVA_SHIFT)
cbnz x0, 2f
update_early_cpu_boot_status \
CPU_STUCK_IN_KERNEL | CPU_STUCK_REASON_52_BIT_VA, x0, x1
1: wfe
wfi
b 1b
#endif
2: ret
ENDPROC(__cpu_secondary_check52bitva)
secondary cpu의 52 비트 가상 주소 지원 여부를 체크한다. 지원하지 않는 cpu는 부팅되지 않고 stuck한다.
- 코드 라인 3~5에서 부트 cpu에서 저장한 변수 vabits_user에 담긴 값이 52가 아니면 함수를 빠져나간다.
- 코드 라인 7~9에서 mmfr2_el1 레지스터의 VARange 필드 값이 1이면 유저 가상 주소로 52비트를 지원하는 것이므로 함수를 빠져나간다.
- 코드 라인 11~15에서 52bit를 지원하지 않아 변수 __early_cpu_boot_status에 0x102를 저장하고 cpu가 정지(stuck)한다.
__secondary_switched:
arch/arm64/kernel/head.S
__secondary_switched:
adr_l x5, vectors
msr vbar_el1, x5
isb
adr_l x0, secondary_data
ldr x1, [x0, #CPU_BOOT_STACK] // get secondary_data.stack
mov sp, x1
ldr x2, [x0, #CPU_BOOT_TASK]
msr sp_el0, x2
mov x29, #0
mov x30, #0
b secondary_start_kernel
ENDPROC(__secondary_switched)
커널용 벡터 포인터와 스택을 지정한 후 C 루틴인 secondary_start_kernel() 루틴으로 점프한다.
update_early_cpu_boot_status 매크로
arch/arm64/kernel/head.S
/*
* The booting CPU updates the failed status @__early_cpu_boot_status,
* with MMU turned off.
*
* update_early_cpu_boot_status tmp, status
* - Corrupts tmp1, tmp2
* - Writes 'status' to __early_cpu_boot_status and makes sure
* it is committed to memory.
*/
.macro update_early_cpu_boot_status status, tmp1, tmp2
mov \tmp2, #\status
adr_l \tmp1, __early_cpu_boot_status
str \tmp2, [\tmp1]
dmb sy
dc ivac, \tmp1 // Invalidate potentially stale cache line
.endm
변수 __early_cpu_boot_status에 부트 상태 @status를 저장한다.
- @tmp1과 @tmp2에는 파괴되도 상관이 없는 임시 레지스터를 지정한다.
- 주석 내용에서 인자가 잘못되어 있음을 확인할 수 있다.
CPU stuck 시 Reason 코드 확인
__early_cpu_boot_status 변수
arch/arm64/kernel/head.S
/*
* The booting CPU updates the failed status @__early_cpu_boot_status,
* with MMU turned off.
*/
ENTRY(__early_cpu_boot_status)
.long 0
다음과 같이 하위 8비트는 cpu boot 상태를 표시하고, 상위 비트에서 stuck 이유를 담는다.
arch/arm64/include/asm/smp.h
/* Values for secondary_data.status */
#define CPU_STUCK_REASON_SHIFT (8)
#define CPU_BOOT_STATUS_MASK ((UL(1) << CPU_STUCK_REASON_SHIFT) - 1)
#define CPU_MMU_OFF (-1)
#define CPU_BOOT_SUCCESS (0)
/* The cpu invoked ops->cpu_die, synchronise it with cpu_kill */
#define CPU_KILL_ME (1)
/* The cpu couldn't die gracefully and is looping in the kernel */
#define CPU_STUCK_IN_KERNEL (2)
/* Fatal system error detected by secondary CPU, crash the system */
#define CPU_PANIC_KERNEL (3)
#define CPU_STUCK_REASON_52_BIT_VA (UL(1) << CPU_STUCK_REASON_SHIFT)
#define CPU_STUCK_REASON_NO_GRAN (UL(2) << CPU_STUCK_REASON_SHIFT)
__no_granule_support:
arch/arm64/kernel/head.S
__no_granule_support:
/* Indicate that this CPU can't boot and is stuck in the kernel */
update_early_cpu_boot_status \
CPU_STUCK_IN_KERNEL | CPU_STUCK_REASON_NO_GRAN, x1, x2
1:
wfe
wfi
b 1b
ENDPROC(__no_granule_support)
커널이 설정한 페이지 테이블 단위를 해당 cpu의 아키텍처가 지원하지 않아 stuck 한다.
PC 상대(PC-relative) 주소 지정 매크로
현재 위치 PC 레지스터로부터 +- 4G 주소 범위 이내에 위치한 심볼 위치에 접근할 때 사용되는 매크로 3개를 알아본다.
adr_l 매크로
include/asm/assembler.h
/*
* Pseudo-ops for PC-relative adr/ldr/str <reg>, <symbol> where
* <symbol> is within the range +/- 4 GB of the PC.
*/
/*
* @dst: destination register (64 bit wide)
* @sym: name of the symbol
*/
.macro adr_l, dst, sym
adrp \dst, \sym
add \dst, \dst, :lo12:\sym
.endm
현재 주소에서 +-4G 이내 범위에 위치한 심볼 주소 @sym에 대한 주소를 @dst 레지스터에 알아온다.
ldr_l 매크로
include/asm/assembler.h
/*
* @dst: destination register (32 or 64 bit wide)
* @sym: name of the symbol
* @tmp: optional 64-bit scratch register to be used if <dst> is a
* 32-bit wide register, in which case it cannot be used to hold
* the address
*/
.macro ldr_l, dst, sym, tmp=
.ifb \tmp
adrp \dst, \sym
ldr \dst, [\dst, :lo12:\sym]
.else
adrp \tmp, \sym
ldr \dst, [\tmp, :lo12:\sym]
.endif
.endm
현재 주소에서 +-4G 이내범위에 위치한 심볼 @sym 주소의 값을 32비트 또는 64비트 @dst 레지스터에 담아온다. 만일 @dst 레지스터가 32비트인 경우 @tmp에 64비트 레지스터를 지정해야 한다. @tmp 레지스터는 사용 후 파손된다.
str_l 매크로
include/asm/assembler.h
/*
* @src: source register (32 or 64 bit wide)
* @sym: name of the symbol
* @tmp: mandatory 64-bit scratch register to calculate the address
* while <src> needs to be preserved.
*/
.macro str_l, src, sym, tmp
adrp \tmp, \sym
str \src, [\tmp, :lo12:\sym]
.endm
현재 주소에서 +-4G 이내 범위에 위치한 심볼 @sym 주소에 32비트 또는 64비트 @dst 레지스터 값을 기록한다.
참고