ldrex/strex가 쌍이되어 특정 메모리 값을 읽고 저장하기 전에 값이 다른 요인(preemption, 다른 CPU, cache coherent port를 가진 장치 등)에 의해 바뀌었는지 알아낼 수 있다.
preemption되는 경우 실패하게 하는 테크닉은 s/w 루틴으로 해결
preemption되는 경우를 대비하여 context switch에서 무조건 clrex를 수행하여 강제로 실패를 만든다. 그렇게 하여 원래 수행하던 태스크로 다시 돌아왔을 때 strex가 항상 실패를 하게 할 수 있다.
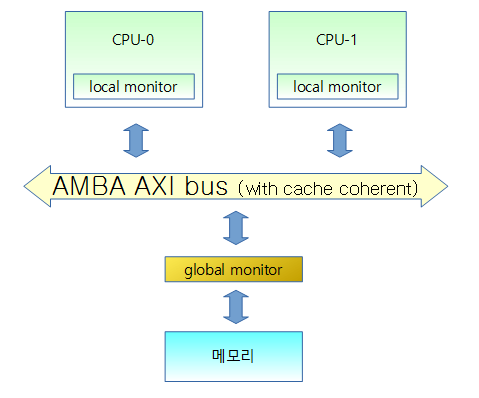
local monitor
각 CPU(core)에 연결되도록 설계되었다.
non-shared 메모리에서 exclusive 명령을 사용 할 때에는 local monitor를 사용하여 exclusive/open access 상태를 확인할 수 있다.
global monitor
cache coherent 기능이 있는 AXI 버스와 메모리 인터페이스 중간에 연결되도록 설계되었다.
CPU(core) 뿐만 아니라 cache coherent port가 부착된 device 장치들도 AXI 버스를 통해 메모리와 연결되어 이의 중간에 연결된 global monitor를 사용할 수 있다.
shareable 메모리에서 exclusive 명령을 사용할 때에는 global monitor를 사용하여 exclusive/open access 상태를 확인할 수 있다.
local monitor와 global monitor는 단순한 state machine으로 구현되었고 ldrex/strex 사용 시 최근에 access한 CPU(core), tag 주소 및 상태(state) 들이 저장되고 이 tag 주소와 상태를 사용하여 strex의 수행 여부를 결정한다.
참고: Cache Coherent Protocol | 문c
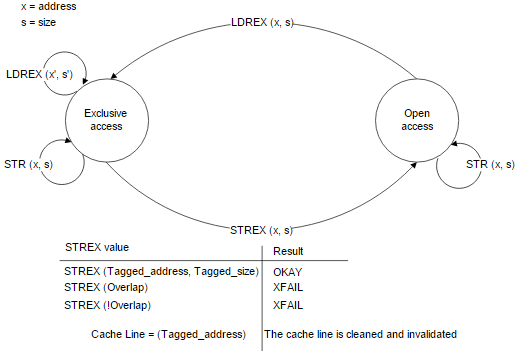
Exclusive monitor State machine
메모리가 ldr/str 등으로 사용될 때에는 open access 상태에 있다.
메모리가 ldrex를 사용할 때에는 exclusive 상태로 마크된다.
ldrex를 수행한 메모리 주소(캐시 라인에 포함된 주소)의 데이터가 변화되면 open access 상태로 바뀐다.
또 한 번 다른 CPU에 의해 strex를 수행하려고 하는 경우 exclusive 상태가 아니므로 실패한다.
strex를 하는 경우 항상 cache line은 clean & invalidate 된다.
주소 지정이 항상 cache line에 관련되어 있기 때문에 원하지 않게 실패가 될 수도 있음을 고려해야 한다.
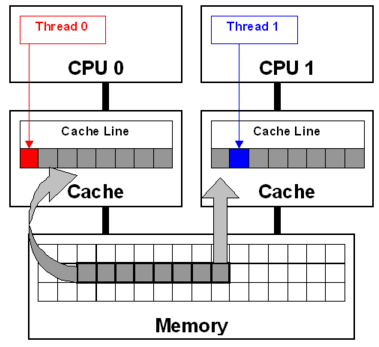
Cache bouncing (Cache line contention)
spin lock에서 CPU가 lock을 얻기 위해 쉬지 않고 서로 ldrex/strex를 반복적으로 호출(spin)하는 경우 해당 cache line 역시 반복적으로 clean & invalidate 후 해당 CPU에서 load 되면서 성능이 급격히 떨어지게 된다. 이러한 문제를 해결하기 위해 항상 ldrex/strex의 명령을 사용하지 않고 먼저 읽어 확인 한 후 정상일 때 기록을 시도하는 방법으로 수정하여 락 메커니즘에서 cache bouncing 문제를 해결하였다.
old ARM 아키텍처에서는 ldrex/strex 대신 swp 명령 하나로 동작하여 cache bouncing에 대해 대처하기 어려웠다.
swp(deprecated) → ldrex/strex
swp 명령을 사용하게 되면 메모리 장치의 값을 바꾸기 위해 fetch interface 장치와 store interface 장치를 순서대로 사용하는데 이의 수행은 CPU cycle이 많이 소요된다.
소요되는 CPU cycle만큼 인터럽트가 pending이 되는데 이로 인해 인터럽트 latency의 증가 이슈 발생하였다.
이를 해결하기 위해 swp를 한 쌍의 ldrex와 strex를 추가하여 swp 명령을 대치하였다.
swp 명령은 ARMv6 이후 부터 deprecated.
참고: ARM Synchronization Primitives | ARM infocenter – 다운로드 pdf