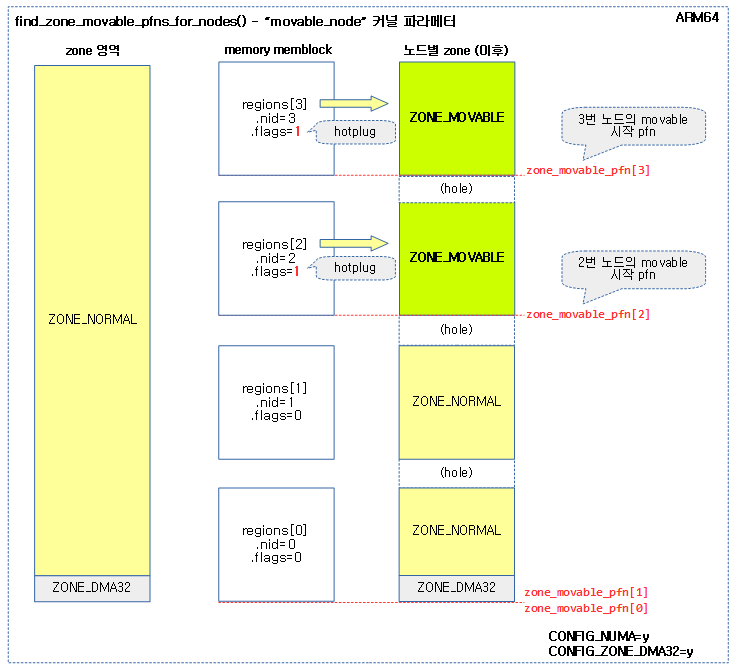
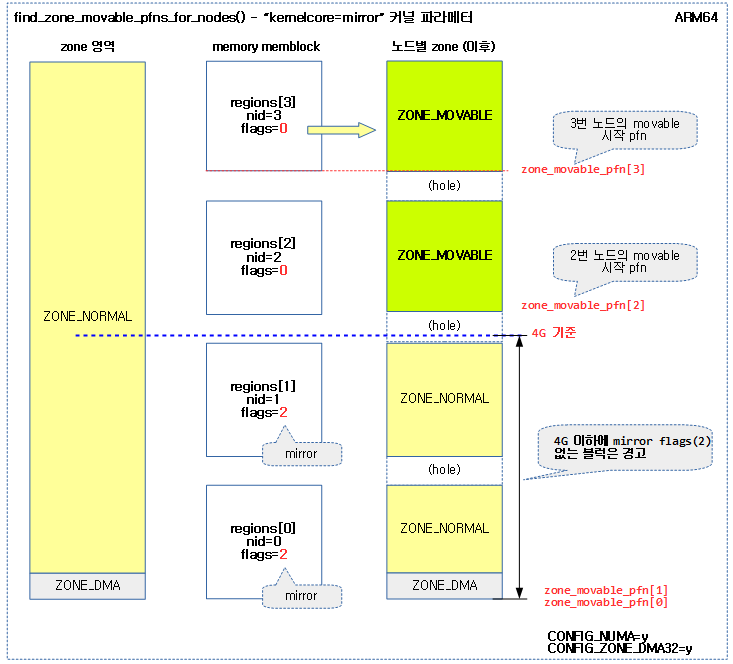
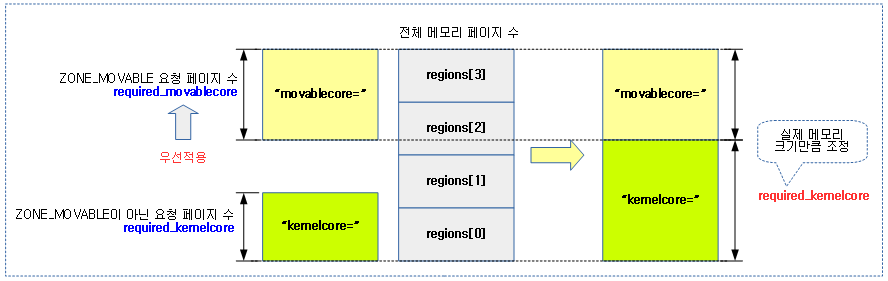
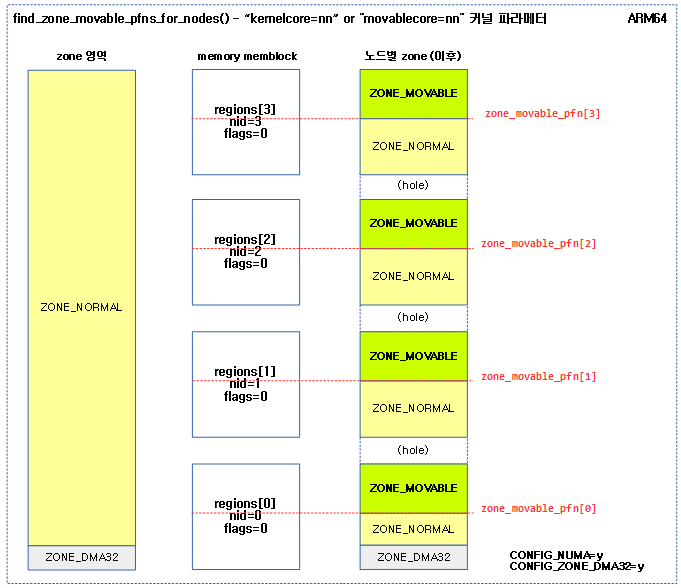
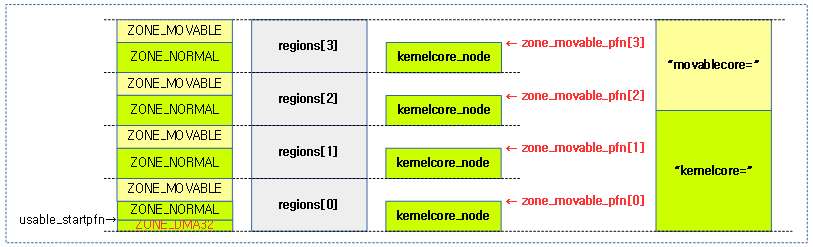
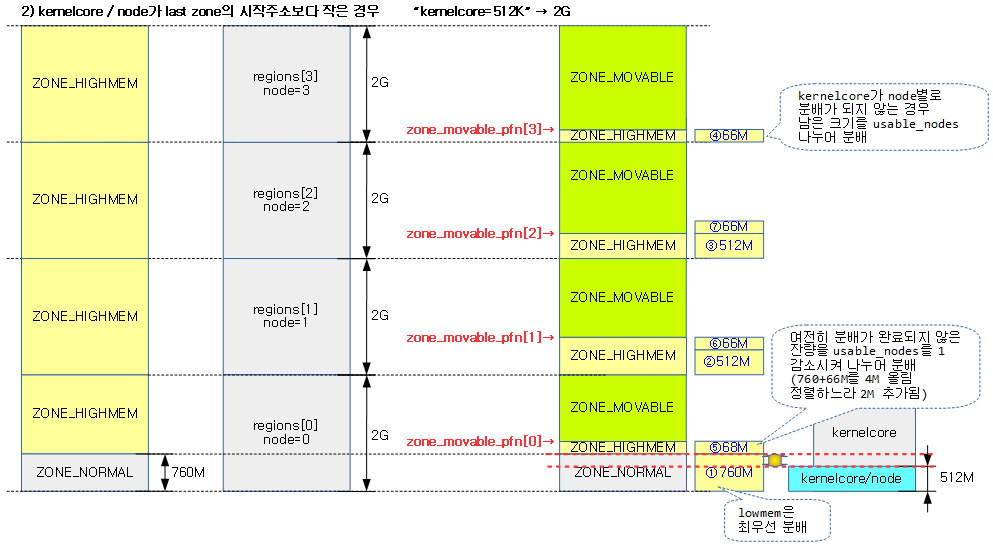
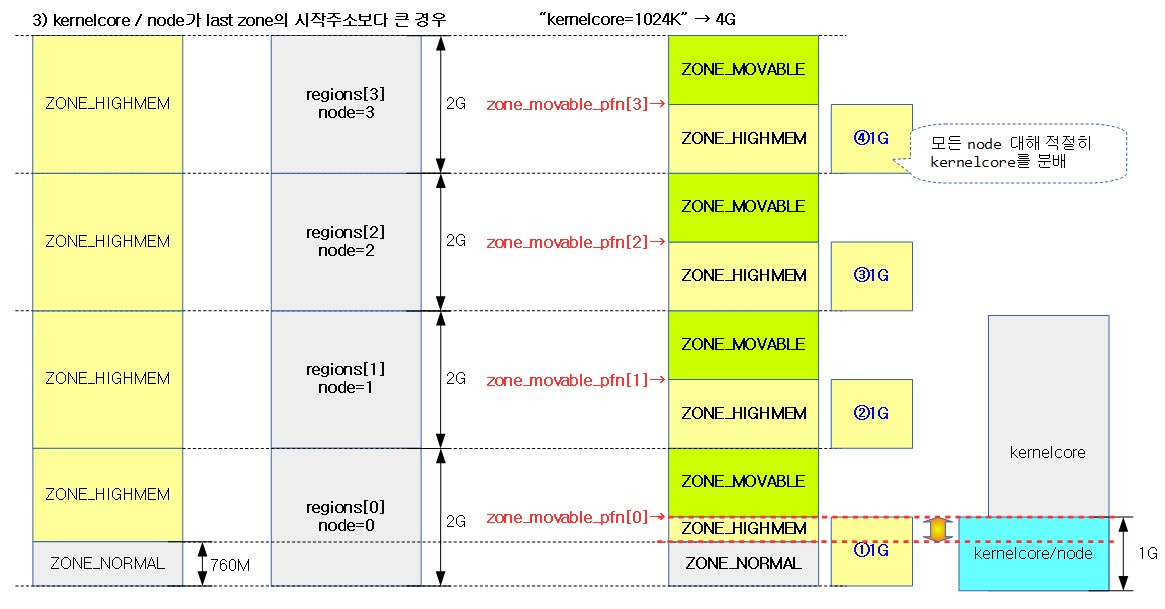
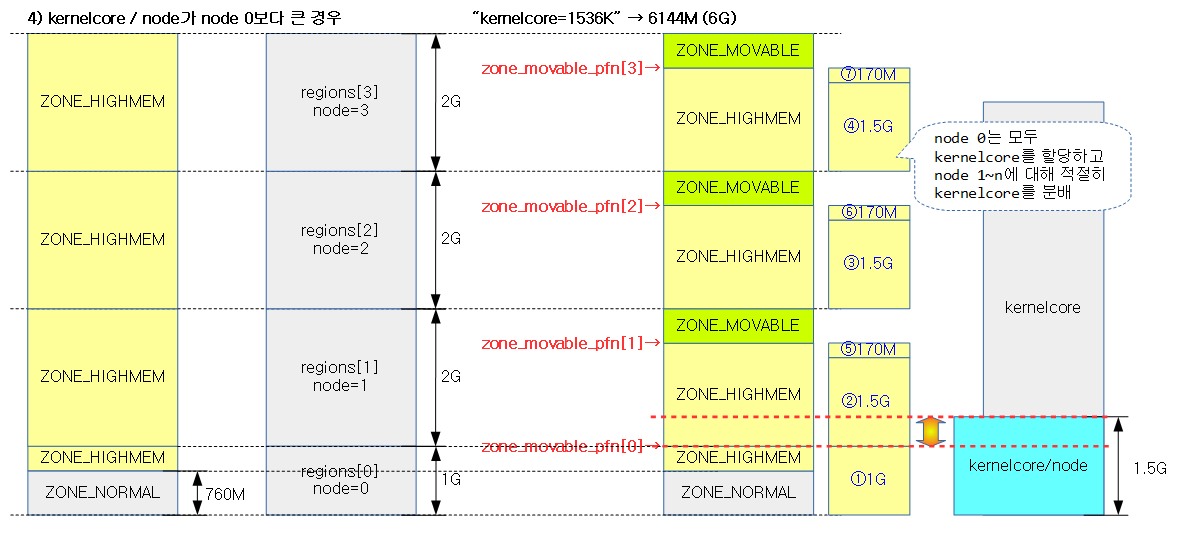
<kernel v5.15>
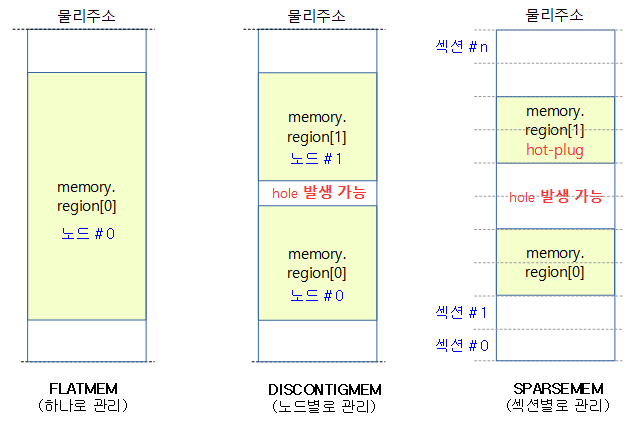
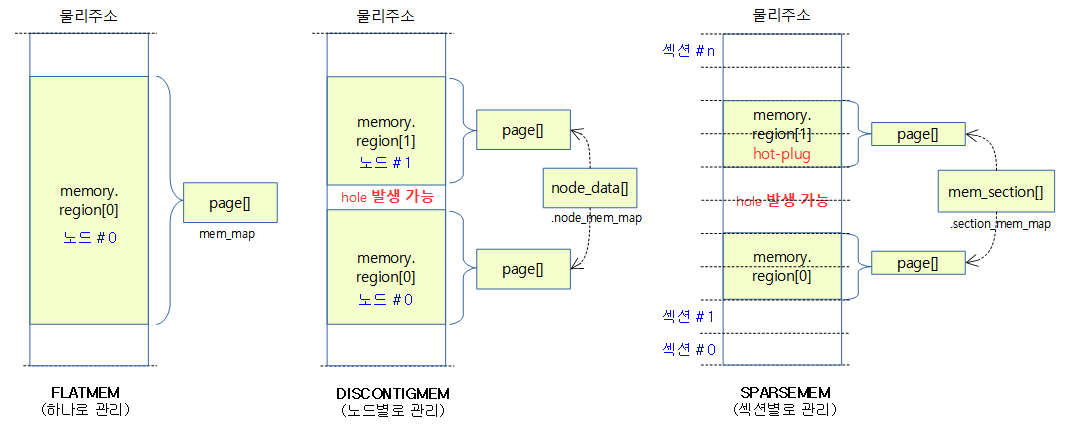
Sparse memory 모델은 섹션 메모리 단위로 mem_section 구조체를 통해 다음과 같은 자료를 관리한다.
- mem_map
- usemap (페이지블럭)
섹션
Sparse memory 모델에서 섹션은 메모리의 online/offlline(hotplug memory)을 관리하는 최소 메모리 크기 단위이다. 전체 메모리를 섹션들로 나누어 사용하는데 적절한 섹션 사이즈로 나누어 사용하는데 아키텍처 마다 다르다.
- 보통 섹션 크기는 수십MB~수GB를 사용한다.
- arm64의 경우 디폴트 값으로 1G를 사용다가 최근 128M로 변경하였다.
- 참고: arm64/sparsemem: reduce SECTION_SIZE_BITS (2021, v5.12-rc1)
- 주의: 본문 그림 등에서는 섹션 크기를 1G로 사용한 예를 보여주고 있음.
- 주의: 매핑 테이블에서 사용하는 섹션(2M) 용어와 다름.
- arm64의 경우 디폴트 값으로 1G를 사용다가 최근 128M로 변경하였다.
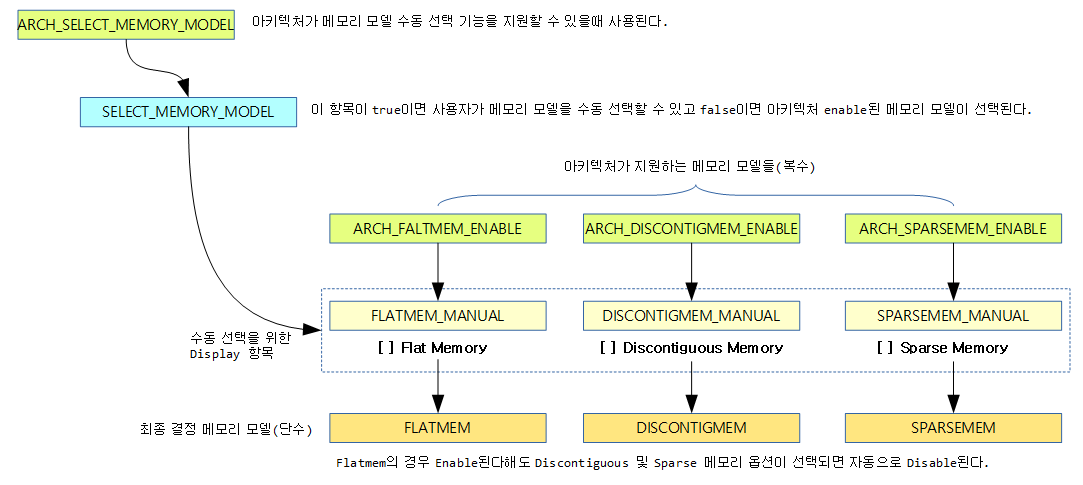
섹션 배열 2 가지 관리 방법
섹션에서 mem_map을 관리하는 다음 두 가지 방법을 알아본다.
- static
- 컴파일 타임에 1단계 mem_section[] 배열을 결정하여 사용하는 방법이다.
- 주로 32bit 시스템에서 섹션 수가 적을 때 사용한다.
- extream
- 런타임에 1단계 **mem_section[] 포인터 배열을 할당하고, 2 단계는 필요 시마다 mem_section[] 배열을 할당하여 사용하는 방법으로 메모리 낭비를 막는 방법이다.
- 주로 64bit 시스템에서 섹션 수가 많을 때 사용한다.
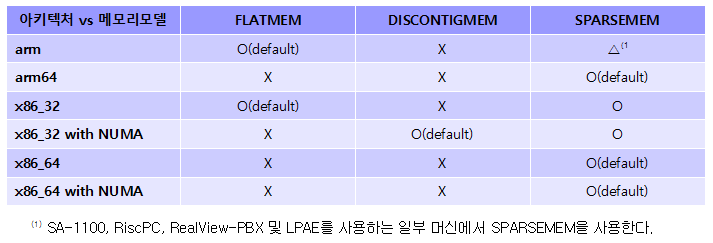
CONFIG_SPARSEMEM_STATIC
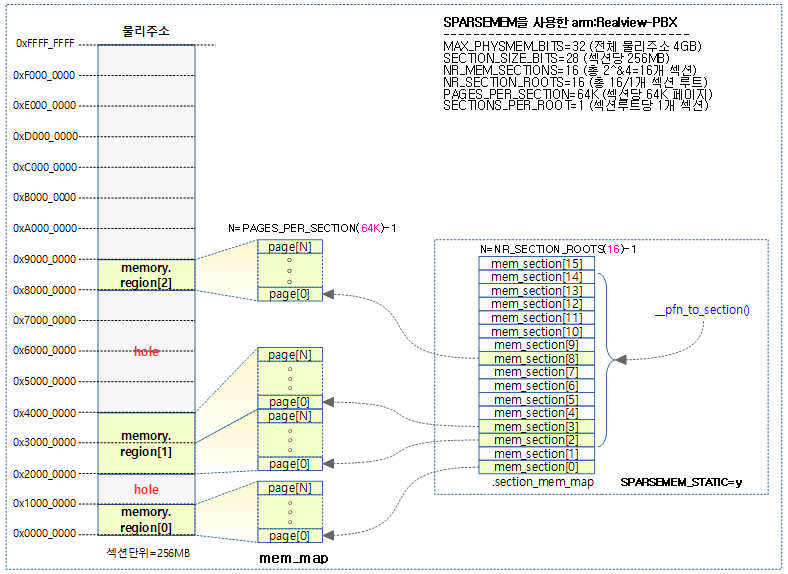
32bit ARM에서 Sparse Memory를 사용하는 Realview-PBX 보드가 섹션당 256MB 크기로 구성된 사례를 사용한다.
- Realview-PBX
- 3개의 메모리
- 256MB @ 0x00000000 -> PAGE_OFFSET
- 512MB @ 0x20000000 -> PAGE_OFFSET + 0x10000000
- 256MB @ 0x80000000 -> PAGE_OFFSET + 0x30000000
- MAX_PHYSMEM_BITS=32 (4G 메모리 크기)
- SECTION_SIZE_BITS=28 (256MB 섹션 크기)
- PFN_SECTION_SHIFT=(SECTION_SIZE_BITS – PAGE_SHIFT)=16
- SECTIONS_PER_ROOT=1
- SECTIONS_SHIFT=(MAX_PHYSMEM_BITS – SECTION_SIZE_BITS)=4
- NR_MEM_SECTIONS=2^SECTIONS_SHIFT=16
- PAGES_PER_SECTION=2^PFN_SECTION_SHIFT=64K
- PAGE_SECTION_MASK=(~(PAGES_PER_SECTION-1))=0xffff_0000
- 3개의 메모리
CONFIG_SPARSEMEM_EXTREME
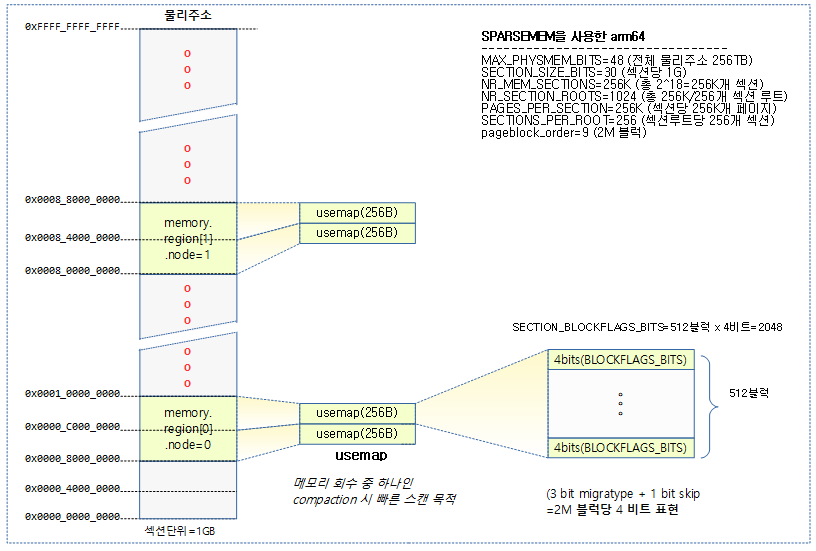
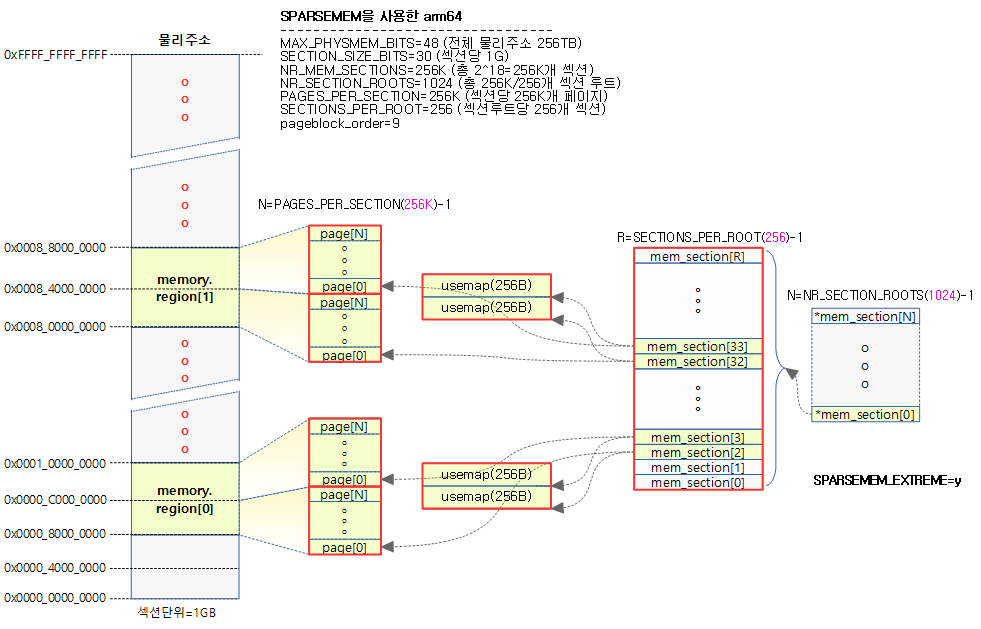
64bit ARM에서 Sparse Memory를 사용하는 경우의 사례로 1GB 크기로 구성된 사례를 사용한다.
- arm64
- 2개의 메모리
- 2GB @ 0x0_8000_0000
- 2GB @ 0x8_0000_0000
- 2개의 메모리
- MAX_PHYSMEM_BITS=48 (256 TB 메모리 크기)
- SECTION_SIZE_BITS=30 (1GB 섹션 크기)
- PFN_SECTION_SHIFT=(SECTION_SIZE_BITS – PAGE_SHIFT)=18
- SECTIONS_PER_ROOT=(PAGE_SIZE / sizeof (struct mem_section))=256
- SECTIONS_SHIFT=(MAX_PHYSMEM_BITS – SECTION_SIZE_BITS)=18
- NR_MEM_SECTIONS=2^SECTIONS_SHIFT=256K
- PAGES_PER_SECTION=2^PFN_SECTION_SHIFT=256K
- PAGE_SECTION_MASK=(~(PAGES_PER_SECTION-1))=0xffff_ffff_fffc_0000

usemap
usemap은 메모리 회수 매커니즘 중 하나인 compaction에서 전체 메모리를 스캔할 때 사용되는 페이지 블럭 당 4비트로 구성된다.
- compaction에서 빠른 스캔을 위해 블럭 단위(arm64 디폴트=2M)로 묶어 사용한다.
- 페이지 블럭 당 사용되는 4비트는 3비트의 mobility(migratype) 속성과 1 비트의 skip 비트로 구성된다.
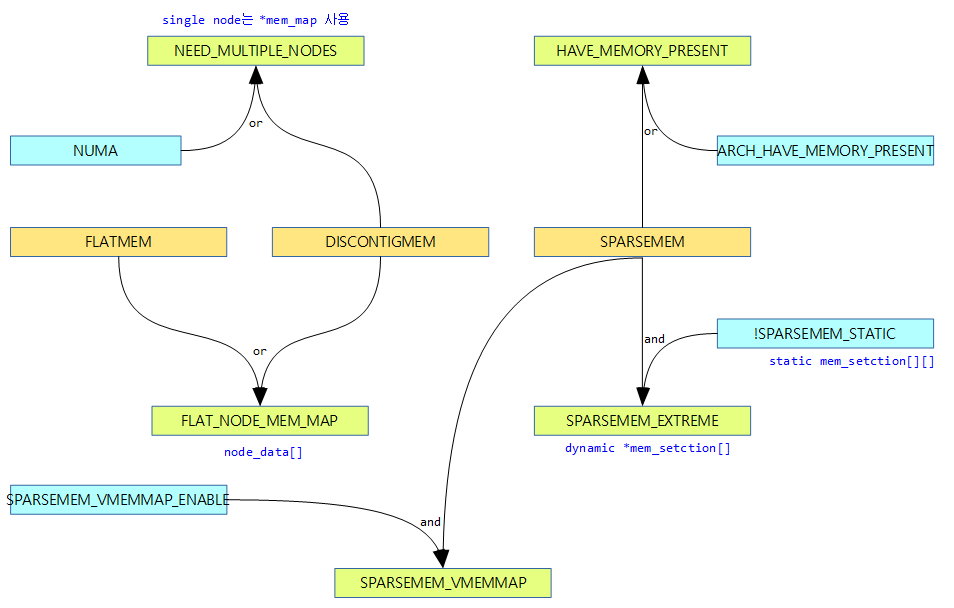
VMEMMAP
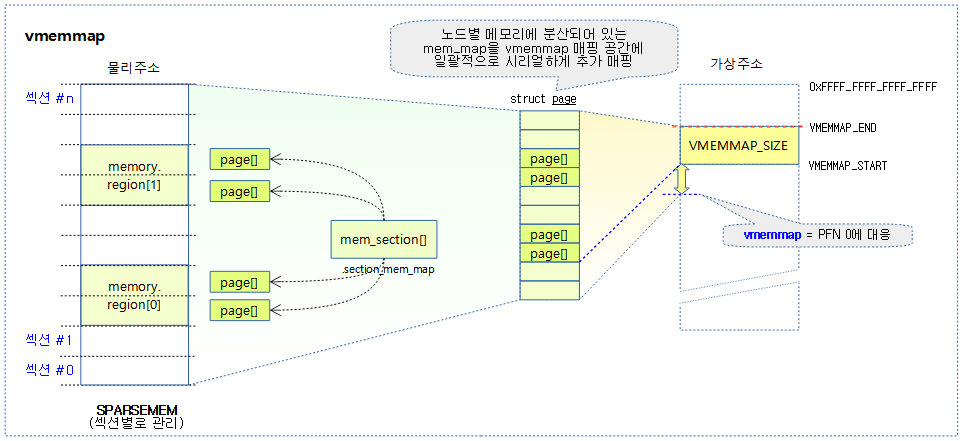
32bit arm 에서는 사용하지 않는다. CONFIG_SPARSEMEM_VMEMMAP 커널 옵션을 사용할 수 있는 arm64를 포함하는 일부 64비트 아키텍처에서 Flat Memory 모델처럼 빠르게 운용할 수 있다.
- 64비트 시스템에서 vmemmap 매핑 공간이 별도로 구성되어 있어 그 영역에 section_mem_map으로 구성된 mem_map들을 매핑한다.
- vmemmap을 사용하는 경우 노드별 메모리에 분산되어 있는 페이지 descriptor로 serial하게 접근할 수 있어 page_to_pfn() 또는 pfn_to_page() 함수의 성능을 빠르게 얻을 수 있다.
다음 그림은 vmemmap이 VMEMMAP_START 아래의 PFN #0 위치에 대응하는 page 구조체의 위치를 가리키는 예를 보여준다.
- VMEMMAP_START는 실제 DRAM이 위치한 PFN에 대한 page 구조체를 가리키고,
- vmemmap은 PFN#0에 대한 page 구조체를 가리킨다.
- 주의: DRAM 시작 주소가 0이 아니면 vmemmap은 VMEMMAP_START 아래에 위치하게 된다. 이 때 아래에 위치한 vmemmap의 주소는 실제 mem_map이 매핑된 공간이 아니므로 커널이 이 공간을 액세스하면 fault 발생하여 시스템이 멈춘다.)
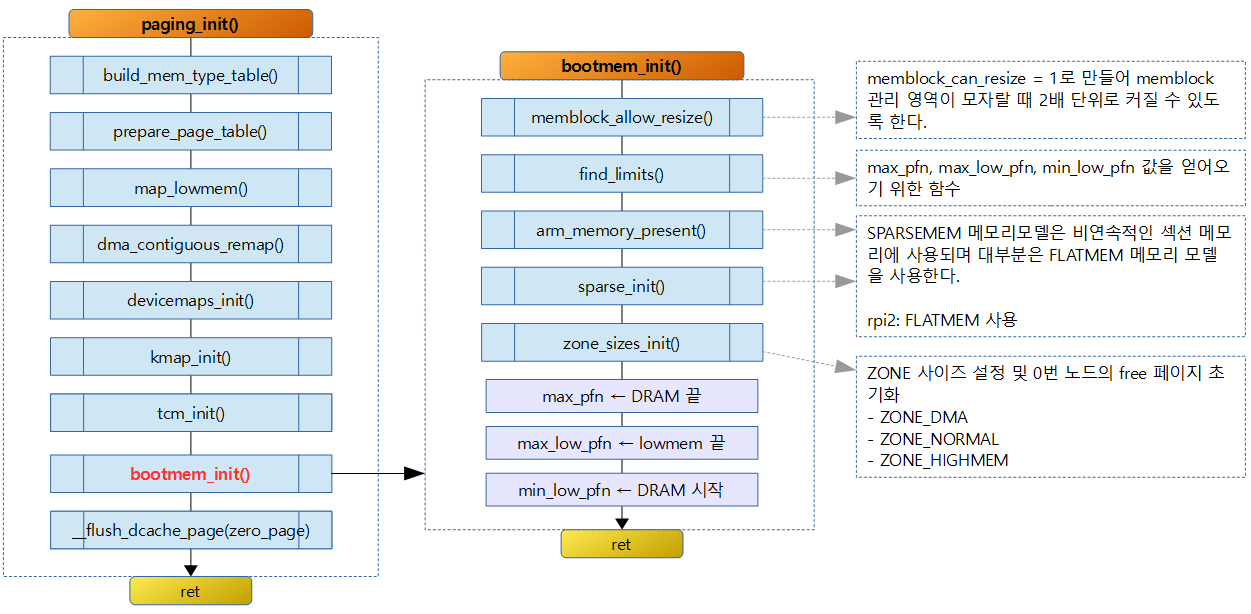
Sparse 메모리 모델 초기화
다음 순서도는 Sparse 메모리 초기화에 대한 로직으로 다음과 같은 일들을 한다.
- 노드별 usemap을 할당하고 임시로 사용되는 usemap_map에 연결한다.
- CONFIG_SPARSEMEM_VMEMMAP 커널 옵션을 사용하면 mem_map을 vmemmap에 매핑하여 사용한다.
- CONFIG_SPARSEMEM_VMEMMAP 커널 옵션을 사용하지 않는 경우 노드마다 활성화된 섹션들의 mem_map을 가능하면 한꺼번에 할당하다. (이전 버전의 x86 커널에 적용했었던 CONFIG_SPARSEMEM_ALLOC_MEM_MAP_TOGETHER 커널 옵션과 유사)

다음 그림은 sparse_init() 에서 만들어지는 mem_map, usemap, mem_section[] 들을 보여준다.
sparse_init()
mm/sparse.c
/* * Allocate the accumulated non-linear sections, allocate a mem_map * for each and record the physical to section mapping. */
void __init sparse_init(void)
{
unsigned long pnum_end, pnum_begin, map_count = 1;
int nid_begin;
memblocks_present();
pnum_begin = first_present_section_nr();
nid_begin = sparse_early_nid(__nr_to_section(pnum_begin));
/* Setup pageblock_order for HUGETLB_PAGE_SIZE_VARIABLE */
set_pageblock_order();
for_each_present_section_nr(pnum_begin + 1, pnum_end) {
int nid = sparse_early_nid(__nr_to_section(pnum_end));
if (nid == nid_begin) {
map_count++;
continue;
}
/* Init node with sections in range [pnum_begin, pnum_end) */
sparse_init_nid(nid_begin, pnum_begin, pnum_end, map_count);
nid_begin = nid;
pnum_begin = pnum_end;
map_count = 1;
}
/* cover the last node */
sparse_init_nid(nid_begin, pnum_begin, pnum_end, map_count);
vmemmap_populate_print_last();
}
sparse 물리 메모리 모델을 사용하기 위해 페이지 디스크립터들이 집합되어 있는 mem_map들을 섹션 단위로 할당하고 관리하기 위해 초기화하는 과정을 알아본다.
분산된 메모리를 섹션 단위로 관리하기 위해 각 섹션이 mem_map과 usemap을 할당하여 관리할 수 있도록 한다. usemap은 페이지 블록 단위를 결정한 후 페이지 블록당 4비트의 비트맵으로 mobility 특성을 관리한다.
- 코드 라인 6에서 memblock에 등록된 메모리들을 모두 mem_section 연결하고, 섹션별로 활성화시킨다.
- 코드 라인 8~9에서 시작 섹션 번호와 이에 대한 nid를 알아온다.
- 코드 라인 12에서 전체 메모리에 대해 페이지 블록 크기 단위로 4비트의 mobility 특성을 기록하고 관리하기 위해 먼저 전역 변수 pageblock_order를 설정한다.
- ARM64 시스템의 디폴트 설정은 pageblock_order 값에 9을 사용한다.
- 코드 라인 14~20에서 present 섹션을 순회하며 동일 노드인 경우 map_count를 증가시켜 mem_map등을 한꺼번에 같은 노드에서 할당 받게 한다.
- present 섹션을 순회 중일 때 pnum_end에는 순회중인 present 섹션 번호가 담긴다.
- 코드 라인 22~25에서 바뀐 노드인 경우 해당 present 범위의 섹션들을 초기화한다.
- 코드 라인 28에서 위의 루프에서 처리하지 않은 마지막 남은 노드에 대해서도 해당 present 범위의 섹션들을 초기화한다.
- 코드 라인 29에서 arm과 arm64에서는 구현되지 않아 출력하는 메시지가 없다.
메모리 활성화
memblocks_present()
mm/sparse.c
/* * Mark all memblocks as present using memory_present(). * This is a convenience function that is useful to mark all of the systems * memory as present during initialization. */
static void __init memblocks_present(void)
{
unsigned long start, end;
int i, nid;
for_each_mem_pfn_range(i, MAX_NUMNODES, &start, &end, &nid)
memory_present(nid, start, end);
}
memblock에 등록된 메모리들을 순회하며 mem_section 연결하고, 섹션별로 활성화시킨다.
memory_present()
mm/sparse.c
/* Record a memory area against a node. */
static void __init memory_present(int nid, unsigned long start, unsigned long end)
{
unsigned long pfn;
#ifdef CONFIG_SPARSEMEM_EXTREME
if (unlikely(!mem_section)) {
unsigned long size, align;
size = sizeof(struct mem_section*) * NR_SECTION_ROOTS;
align = 1 << (INTERNODE_CACHE_SHIFT);
mem_section = memblock_alloc(size, align);
if (!mem_section)
panic("%s: Failed to allocate %lu bytes align=0x%lx\n",
__func__, size, align);
}
#endif
start &= PAGE_SECTION_MASK;
mminit_validate_memmodel_limits(&start, &end);
for (pfn = start; pfn < end; pfn += PAGES_PER_SECTION) {
unsigned long section = pfn_to_section_nr(pfn);
struct mem_section *ms;
sparse_index_init(section, nid);
set_section_nid(section, nid);
ms = __nr_to_section(section);
if (!ms->section_mem_map) {
ms->section_mem_map = sparse_encode_early_nid(nid) |
SECTION_IS_ONLINE;
__section_mark_present(ms, section);
}
}
}
memory_present() 함수는 CONFIG_HAVE_MEMORY_PRESENT 커널 옵션을 사용하는 경우에만 동작하며 각 섹션에 노드 id를 기록하는데, 자세한 내용은 코드를 보고 알아보기로 한다.
- 코드 라인 6~15에서 CONFIG_SPARSEMEM_EXTREME 커널 옵션을 사용하는 경우 처음 mem_section이 초기화되지 않은 경우 mem_section[] 배열을 생성한다.
- arm64 예) 4K 페이지, sizeof(struct mem_section)=16
- NR_SECTION_ROOTS=1024
- arm64 예) 4K 페이지, sizeof(struct mem_section)=16
- 코드 라인 18~19에서 요청한 범위의 시작 pfn을 섹션 단위로 내림 정렬한 주소로 변환한 후 해당 범위의 pfn이 실제로 지정할 수 있는 물리 메모리 범위에 포함되는지 검증하고 초과 시 그 주소를 강제로 제한한다.
- 코드 라인 20~21에서 시작 pfn부터 섹션 단위로 증가시키며 이 값으로 section 번호를 구한다.
- 코드 라인 24에서 CONFIG_SPARSEMEM_EXTREME 커널 옵션을 사용하는 경우에만 동작하며, 이 함수에서 해당 섹션에 대한 mem_section[]을 동적으로(dynamic) 할당받는다. CONFIG_SPARSEMEM_STATIC 커널 옵션을 사용하는 경우에는 이미 정적(static) 배열이 준비되어 있으므로 아무런 동작도 요구되지 않는다.
- 코드 라인 25에서 NODE_NOT_IN_PAGE_FLAGS가 정의된 경우 별도의 전역 section_to_node_table[] 배열에 해당 섹션을 인덱스로 해당 노드 id를 가리키게 한다.
- NODE_NOT_IN_PAGE_FLAGS 커널 옵션은 page 구조체의 flags 필드에 노드 번호를 저장할 비트가 부족한 32비트 아키텍처에서 사용되는 옵션이다.
- 코드 라인 27~32에서 해당 섹션의 mem_section 구조체내의 section_mem_map에 노드 id와 online 및 present 플래그를 설정한다.
아래 그림은 memory_present() 함수가 호출되는 과정에서 mem_section[] 배열이 할당되는 것을 나타낸다.
- 붉은 색 박스는 sparse_index_alloc() 함수에 의해 dynamic 하게 메모리 할당을 받는 것을 의미한다.
- 푸른 색 박스는 컴파일 타임에 static하게 배열이 할당됨을 의미한다.
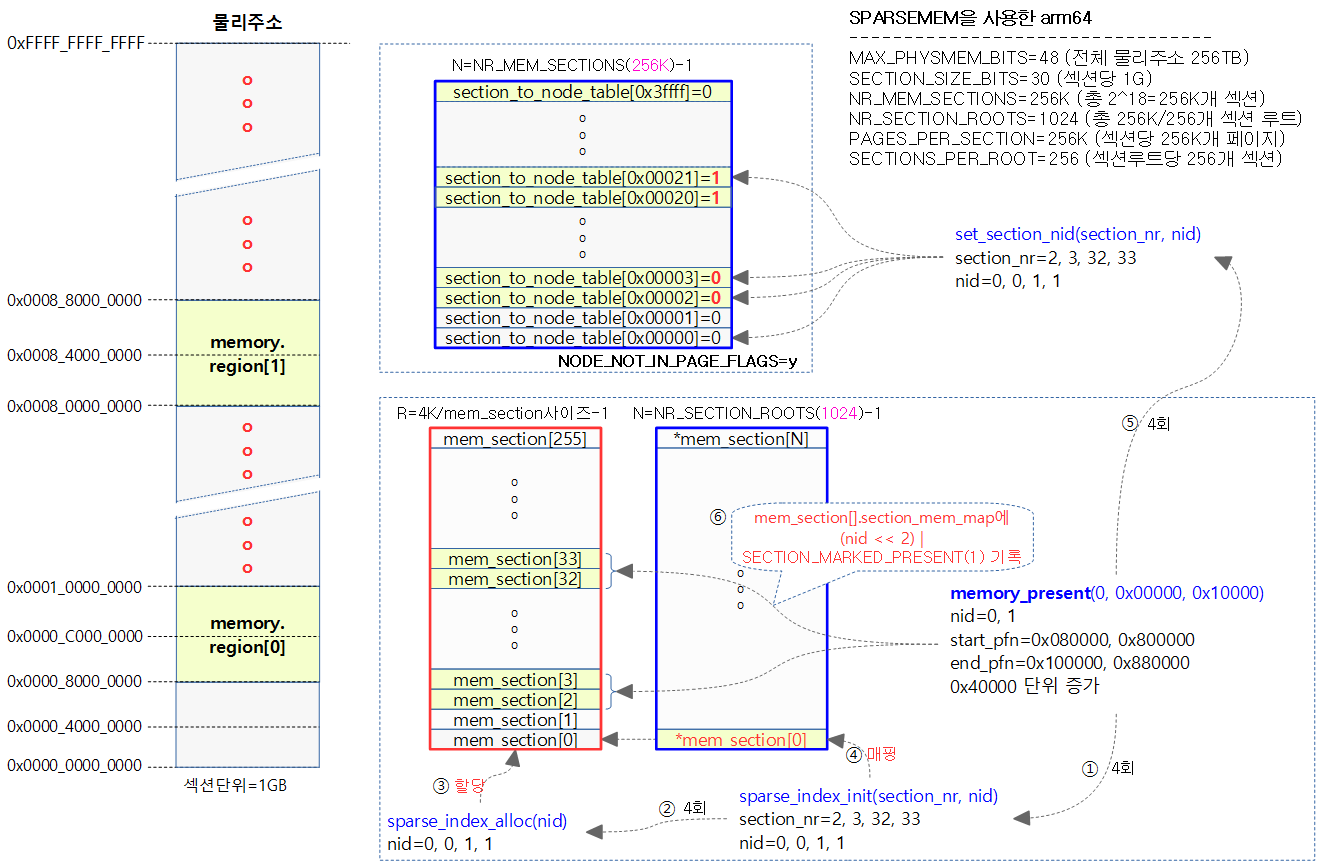
mminit_validate_memmodel_limits()
mm/sparse.c
/* Validate the physical addressing limitations of the model */
void __meminit mminit_validate_memmodel_limits(unsigned long *start_pfn,
unsigned long *end_pfn)
{
unsigned long max_sparsemem_pfn = 1UL << (MAX_PHYSMEM_BITS-PAGE_SHIFT);
/*
* Sanity checks - do not allow an architecture to pass
* in larger pfns than the maximum scope of sparsemem:
*/
if (*start_pfn > max_sparsemem_pfn) {
mminit_dprintk(MMINIT_WARNING, "pfnvalidation",
"Start of range %lu -> %lu exceeds SPARSEMEM max %lu\n",
*start_pfn, *end_pfn, max_sparsemem_pfn);
WARN_ON_ONCE(1);
*start_pfn = max_sparsemem_pfn;
*end_pfn = max_sparsemem_pfn;
} else if (*end_pfn > max_sparsemem_pfn) {
mminit_dprintk(MMINIT_WARNING, "pfnvalidation",
"End of range %lu -> %lu exceeds SPARSEMEM max %lu\n",
*start_pfn, *end_pfn, max_sparsemem_pfn);
WARN_ON_ONCE(1);
*end_pfn = max_sparsemem_pfn;
}
}
인자로 사용된 시작 pfn, 끝 pfn 값이 물리 메모리 주소 최대 pfn 값을 초과하지 않도록 제한한다.
- 코드 라인 10~16에서 시작 pfn이 max_sparsemem_pfn보다 크면 경고를 출력하고, start_pfn과 end_pfn에 max_sparsemem_pfn을 설정한다.
- 코드 라인 17~23에서 끝 pfn이 max_sparsemem_pfn보다 크면 경고를 출력하고, end_pfn에 max_sparsemem_pfn을 설정한다.
섹션 인덱스 초기화
sparse_index_init()
mm/sparse.c
#ifdef CONFIG_SPARSEMEM_EXTREME
static int __meminit sparse_index_init(unsigned long section_nr, int nid)
{
unsigned long root = SECTION_NR_TO_ROOT(section_nr);
struct mem_section *section;
/*
* An existing section is possible in the sub-section hotplug
* case. First hot-add instantiates, follow-on hot-add reuses
* the existing section.
*
* The mem_hotplug_lock resolves the apparent race below.
*/
if (mem_section[root])
return 0;
section = sparse_index_alloc(nid);
if (!section)
return -ENOMEM;
mem_section[root] = section;
return 0;
}
#endif
CONFIG_SPARSEMEM_EXTREME 커널 옵션을 사용하는 경우 dynamic하게 mem_section 테이블을 할당 받아 구성한다.
- 코드 라인 4에서 섹션 번호로 루트 번호를 구한다.
- 코드 라인 14~15에서 해당 루트 인덱스의 루트 섹션에 값이 존재하는 경우 이미 mem_section[] 테이블이 구성되었으므로 함수를 빠져나간다.
- 코드 라인 17~19에서 해당 노드에서 2 단계용 섹션 테이블을 할당받아 구성한다. 핫플러그 메모리를 위해 각 mem_section[] 테이블은 해당 노드에 위치해야 한다.
- 코드 라인 21에서 루트 번호에 해당하는 1단계 mem_section[] 포인터 배열에 새로 할당받은 2 단계 mem_section[] 테이블의 시작 주소를 설정한다.
- 코드 라인 23에서 정상 결과 0을 반환한다.
sparse_index_alloc()
mm/sparse.c
#ifdef CONFIG_SPARSEMEM_EXTREME
static noinline struct mem_section __ref *sparse_index_alloc(int nid)
{
struct mem_section *section = NULL;
unsigned long array_size = SECTIONS_PER_ROOT *
sizeof(struct mem_section);
if (slab_is_available()) {
section = kzalloc_node(array_size, GFP_KERNEL, nid);
} else {
section = memblock_alloc_node(array_size, SMP_CACHE_BYTES,
nid);
if (!section)
panic("%s: Failed to allocate %lu bytes nid=%d\n",
__func__, array_size, nid);
}
return section;
}
#endif
CONFIG_SPARSEMEM_EXTREME 커널 옵션을 사용하는 경우 mem_section[] 테이블용 메모리를 할당 받는다.
- 코드 라인 5~6에서 루트 엔트리는 1개의 페이지로 구성되며, 가득 구성될 mem_section 구조체 배열의 크기를 구한다. SECTIONS_PER_ROOT는 루트 엔트리당 mem_section 수를 의미한다. 이 상수는 다음과 같이 정의되어 있다.
- #define SECTIONS_PER_ROOT (PAGE_SIZE / sizeof(struct mem_section))
- 예) arm64: 4K / 16 bytes = 256개
- #define SECTIONS_PER_ROOT (PAGE_SIZE / sizeof(struct mem_section))
- 코드 라인 8~9에서 슬랩 메모리 할당자가 동작하는 경우 kzalloc( ) 함수를 통해 메모리를 할당한다.
- 코드 라인 10~16에서 슬랩 메모리 할당자가 동작하지 않는 경우 해당 노드의 memblock에 할당한다
- 코드 라인 18에서 할당 받은 mem_section 배열을 반환한다.
set_section_nid()
mm/sparse.c
#ifdef NODE_NOT_IN_PAGE_FLAGS
static void set_section_nid(unsigned long section_nr, int nid)
{
section_to_node_table[section_nr] = nid;
}
#else /* !NODE_NOT_IN_PAGE_FLAGS */
static inline void set_section_nid(unsigned long section_nr, int nid)
{
}
#endif
NODE_NOT_IN_PAGE_FLAGS 옵션을 사용하는 경우 section_to_node_table[]에 섹션 번호에 1:1로 대응하는 노드 번호를 저장한다.
- page 구조체 멤버 변수 flags에 노드 번호를 저장할 비트가 부족한 32비트 아키텍처에서 사용되는 옵션이다.
아래 그림은 set_section_nid() 함수를 통해 주어진 섹션 번호에 노드 번호를 저장한다.
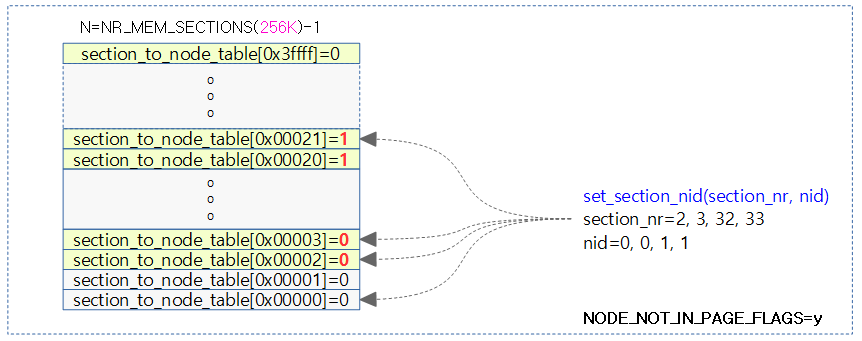
__nr_to_section()
mm/sparse.c
static inline struct mem_section *__nr_to_section(unsigned long nr)
{
#ifdef CONFIG_SPARSEMEM_EXTREME
if (!mem_section)
return NULL;
#endif
if (!mem_section[SECTION_NR_TO_ROOT(nr)])
return NULL;
return &mem_section[SECTION_NR_TO_ROOT(nr)][nr & SECTION_ROOT_MASK];
}
섹션 번호에 해당하는 mem_section 구조체 정보를 알아온다.
아래 그림은 __nr_to_section() 함수를 사용하여 섹션 번호로 mem_section 구조체 정보를 알아오는 단계를 2 가지 예로 나타내었다.
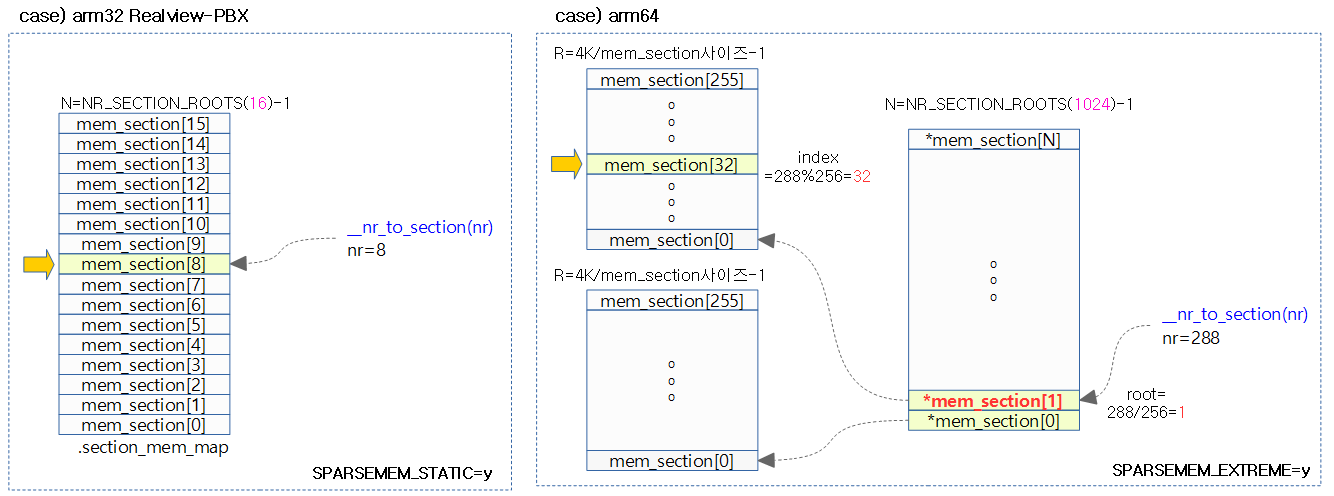
__section_mark_present()
mm/sparse.c
/* * There are a number of times that we loop over NR_MEM_SECTIONS, * looking for section_present() on each. But, when we have very * large physical address spaces, NR_MEM_SECTIONS can also be * very large which makes the loops quite long. * * Keeping track of this gives us an easy way to break out of * those loops early. */
unsigned long __highest_present_section_nr;
static void __section_mark_present(struct mem_section *ms,
unsigned long section_nr)
{
if (section_nr > __highest_present_section_nr)
__highest_present_section_nr = section_nr;
ms->section_mem_map |= SECTION_MARKED_PRESENT;
}
섹션 메모리가 존재함을 표시한다.
- 코드 라인 5~6에서 전역 변수 __highest_present_section_nr를 가장 높은 섹션 번호로 갱신한다.
- 코드 라인 8에서 mem_section을 가리키는 ms->section_mem_map에 SECTION_MARKED_PRESENT 플래그 비트를 추가한다.
for_each_present_section_nr()
mm/sparse.c
#define for_each_present_section_nr(start, section_nr) \
for (section_nr = next_present_section_nr(start-1); \
((section_nr >= 0) && \
(section_nr <= __highest_present_section_nr)); \
section_nr = next_present_section_nr(section_nr))
@start 섹션을 포함하여 마지막 present 섹션까지 present 섹션마다 순회한다. @section_nr는 출력 인자로 present 섹션 번호이다.
next_present_section_nr()
mm/sparse.c
static inline int next_present_section_nr(int section_nr)
{
do {
section_nr++;
if (present_section_nr(section_nr))
return section_nr;
} while ((section_nr <= __highest_present_section_nr));
return -1;
}
요청한 @section_nr 다음 섹션번호부터 마지막 섹션까지 순회하며 present 섹션을 발견하면 해당 섹션 번호를 반환한다.
pageblock order 설정
set_pageblock_order()
mm/page_alloc.c
#ifdef CONFIG_HUGETLB_PAGE_SIZE_VARIABLE
/* Initialise the number of pages represented by NR_PAGEBLOCK_BITS */
void __init set_pageblock_order(void)
{
unsigned int order;
/* Check that pageblock_nr_pages has not already been setup */
if (pageblock_order)
return;
if (HPAGE_SHIFT > PAGE_SHIFT)
order = HUGETLB_PAGE_ORDER;
else
order = MAX_ORDER - 1;
/*
* Assume the largest contiguous order of interest is a huge page.
* This value may be variable depending on boot parameters on IA64 and
* powerpc.
*/
pageblock_order = order;
}
#else /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
/*
* When CONFIG_HUGETLB_PAGE_SIZE_VARIABLE is not set, set_pageblock_order()
* is unused as pageblock_order is set at compile-time. See
* include/linux/pageblock-flags.h for the values of pageblock_order based on
* the kernel config
*/
void __init set_pageblock_order(void)
{
}
#endif /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
CONFIG_HUGETLB_PAGE_SIZE_VARIABLE 커널 옵션을 사용하는 경우에만 런타임에 pageblock_order를 설정한다.
pageblock_order
include/linux/pageblock-flags.h
#ifdef CONFIG_HUGETLB_PAGE #ifdef CONFIG_HUGETLB_PAGE_SIZE_VARIABLE /* Huge page sizes are variable */ extern unsigned int pageblock_order; #else /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */ /* Huge pages are a constant size */ #define pageblock_order HUGETLB_PAGE_ORDER #endif /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */ #else /* CONFIG_HUGETLB_PAGE */ /* If huge pages are not used, group by MAX_ORDER_NR_PAGES */ #define pageblock_order (MAX_ORDER-1) #endif /* CONFIG_HUGETLB_PAGE */
페이지 블럭 오더 크기는 CONFIG_HUGETLB_PAGE 및 CONFIG_HUGETLB_PAGE_SIZE_VARIABLE 커널 옵션에 사용 유무에 따라 결정된다.
- CONFIG_HUGETLB_PAGE 사용 시
- CONFIG_HUGETLB_PAGE_SIZE_VARIABLE 커널 옵션 사용 시
- pageblock_order를 런타임에 set_pageblock_order() 함수에서 결정한다.
- CONFIG_HUGETLB_PAGE_SIZE_VARIABLE 커널 옵션 미 사용 시
- 컴파일 타임에 HUGETLB_PAGE_ORDER 값으로 결정된다.
- =HPAGE_SHIFT(21) – PAGE_SHIFT(12)=9 (arm64 디폴트 설정 사용 시)
- 컴파일 타임에 HUGETLB_PAGE_ORDER 값으로 결정된다.
- CONFIG_HUGETLB_PAGE_SIZE_VARIABLE 커널 옵션 사용 시
- CONFIG_HUGETLB_PAGE 커널 옵션을 사용하지 않을 경우
- 컴파일 타임에 MAX_ORDER-1 값으로 결정된다.
노드별 sparse 초기화
sparse_init_nid()
mm/sparse.c
/* * Initialize sparse on a specific node. The node spans [pnum_begin, pnum_end) * And number of present sections in this node is map_count. */
static void __init sparse_init_nid(int nid, unsigned long pnum_begin,
unsigned long pnum_end,
unsigned long map_count)
{
struct mem_section_usage *usage;
unsigned long pnum;
struct page *map;
usage = sparse_early_usemaps_alloc_pgdat_section(NODE_DATA(nid),
mem_section_usage_size() * map_count);
if (!usage) {
pr_err("%s: node[%d] usemap allocation failed", __func__, nid);
goto failed;
}
sparse_buffer_init(map_count * section_map_size(), nid);
for_each_present_section_nr(pnum_begin, pnum) {
unsigned long pfn = section_nr_to_pfn(pnum);
if (pnum >= pnum_end)
break;
map = __populate_section_memmap(pfn, PAGES_PER_SECTION,
nid, NULL);
if (!map) {
pr_err("%s: node[%d] memory map backing failed. Some memory will not be available.",
__func__, nid);
pnum_begin = pnum;
sparse_buffer_fini();
goto failed;
}
check_usemap_section_nr(nid, usage);
sparse_init_one_section(__nr_to_section(pnum), pnum, map, usage,
SECTION_IS_EARLY);
usage = (void *) usage + mem_section_usage_size();
}
sparse_buffer_fini();
return;
failed:
/* We failed to allocate, mark all the following pnums as not present */
for_each_present_section_nr(pnum_begin, pnum) {
struct mem_section *ms;
if (pnum >= pnum_end)
break;
ms = __nr_to_section(pnum);
ms->section_mem_map = 0;
}
}
@nid 노드에 해당하는 @pnum_begin ~ @pnum_end 미만 까지의 섹션 범위들에 대해 @map_count 만큼의 present 섹션과 관련된 mem_map 및 usemap을 할당하고 초기화한다.
- 코드 라인 9~14에서 @map_count 섹션 수 만큼의 usemap[] 배열을 노드 @nid에서 한꺼번에 할당한다.
- 코드 라인 15에서 @map_count 섹션 수 만큼의 sparse 버퍼를 노드 @nid에서 한꺼번에 할당하여 준비해 놓는다.
- 코드 라인 16~30에서 @pnum_begin 섹션 부터 끝 present 섹션까지 순회하며 해당 섹션의 mem_map을 할당받는다.
- 가능하면 sparse 버퍼에서 할당받는다.
- 코드 라인 31에서 할당받은 usemap과 노드 정보(pgdat)가 기록된 섹션과 같지 않으면 경고 메시지를 출력한다. usemap 정보가 같은 노드 공간에 구성되지 않으면 메모리 핫리무브(hot remove) 동작 시 노드별로 메모리를 제거해야 할 때 circular dependancy 문제가 발생할 수 있다.
- 코드 라인 32~33에서 해당 섹션 하나를 초기화한다.
- 코드 라인 36에서 할당하고 남은 sparse 버퍼를 할당 해제한다.
브라켓 표현법
begin이 1이고 end가 5라고 할 때
- [begin, end]
- begin 이상 ~ end 이하
- 1~5
- (begin, end)
- bigin 초과 ~ end 미만
- 2~4
- [begin, end)
- begin 이상 ~ end 미만
- 1~4
- (begin, end]
- begin 초과, end 이하
- 2~5
usemap 할당
sparse_early_usemaps_alloc_pgdat_section()
mm/sparse.c
#ifdef CONFIG_MEMORY_HOTREMOVE
static unsigned long * __init
sparse_early_usemaps_alloc_pgdat_section(struct pglist_data *pgdat,
unsigned long size)
{
struct mem_section_usage *usage;
unsigned long goal, limit;
int nid;
/*
* A page may contain usemaps for other sections preventing the
* page being freed and making a section unremovable while
* other sections referencing the usemap remain active. Similarly,
* a pgdat can prevent a section being removed. If section A
* contains a pgdat and section B contains the usemap, both
* sections become inter-dependent. This allocates usemaps
* from the same section as the pgdat where possible to avoid
* this problem.
*/
goal = pgdat_to_phys(pgdat) & (PAGE_SECTION_MASK << PAGE_SHIFT);
limit = goal + (1UL << PA_SECTION_SHIFT);
nid = early_pfn_to_nid(goal >> PAGE_SHIFT);
again:
usage = memblock_alloc_try_nid(size, SMP_CACHE_BYTES, goal, limit, nid);
if (!usage && limit) {
limit = 0;
goto again;
}
return usage;
}
#endif
CONFIG_MEMORY_HOTREMOVE 커널 옵션을 사용하는 경우 usemap을 할당한다. 가능하면 노드 정보(pgdat)가 담겨 있는 섹션에 usemap이 들어갈 수 있도록 메모리 할당을 시도한다. 실패한 경우 위치에 상관없이 다시 한번 할당을 시도한다.
- 코드 라인 19~20에서 goal에는 노드에서의 섹션 시작 물리 주소를 구하고 limit를 1개의 섹션 크기로 제한한다.
- 코드 라인 21에서 기존에 mem_map에 저장해놓은 섹션별 노드 정보를 가져온다.
- 코드 라인 22~23에서 again: 레이블이다. 지정된 노드의 goal~limit 범위, 즉 노드 정보가 담겨 있는 섹션 영역 내에서 SMP_CACHE_BYTES align으로 size만큼의 memblock 공간 할당을 요청한다.
- 코드 라인 24~27에서 한 번 시도해서 할당이 안 되면 limit를 0으로 만들어 다시 한번 시도한다.
- 코드 라인 28에서 할당된 usemap을 반환한다.
mem_map용 Sparse 버퍼 할당/해제
노드에 해당하는 전체 present 섹션 메모리에 대한 mem_map[] 배열을 한꺼번에 할당을 시도한다. 이렇게 시도하여 할당이 된 경우 이 sparse 버퍼 메모리를 mem_map[] 배열로 사용한다. 만일 할당이 실패하는 경우 fallback되어 그냥 섹션별로 할당한다.
- 참고:
sparse_buffer_init()
mm/sparse.c
static void __init sparse_buffer_init(unsigned long size, int nid)
{
WARN_ON(sparsemap_buf); /* forgot to call sparse_buffer_fini()? */
sparsemap_buf =
memblock_alloc_try_nid_raw(size, PAGE_SIZE,
__pa(MAX_DMA_ADDRESS),
MEMBLOCK_ALLOC_ACCESSIBLE, nid);
sparsemap_buf_end = sparsemap_buf + size;
}
요청한 @size만큼 노드 @nid에서 페이지 단위로 sparse 버퍼를 할당한다.
sparse_buffer_alloc()
mm/sparse.c
void * __meminit sparse_buffer_alloc(unsigned long size)
{
void *ptr = NULL;
if (sparsemap_buf) {
ptr = PTR_ALIGN(sparsemap_buf, size);
if (ptr + size > sparsemap_buf_end)
ptr = NULL;
else
sparsemap_buf = ptr + size;
}
return ptr;
}
Sparse 버퍼에서 @size 만큼의 메모리를 할당한다. (for mem_map)
sparse_buffer_fini()
mm/sparse.c
static void __init sparse_buffer_fini(void)
{
unsigned long size = sparsemap_buf_end - sparsemap_buf;
if (sparsemap_buf && size > 0)
memblock_free_early(__pa(sparsemap_buf), size);
sparsemap_buf = NULL;
}
사용하고 남은 sparse 버퍼를 할당 해제한다.
usemap 할당 섹션 또는 노드 체크
check_usemap_section_nr()
mm/sparse.c
#ifdef CONFIG_MEMORY_HOTREMOVE
static void __init check_usemap_section_nr(int nid,
struct mem_section_usage *usage)
{
unsigned long usemap_snr, pgdat_snr;
static unsigned long old_usemap_snr;
static unsigned long old_pgdat_snr;
struct pglist_data *pgdat = NODE_DATA(nid);
int usemap_nid;
/* First call */
if (!old_usemap_snr) {
old_usemap_snr = NR_MEM_SECTIONS;
old_pgdat_snr = NR_MEM_SECTIONS;
}
usemap_snr = pfn_to_section_nr(__pa(usage) >> PAGE_SHIFT);
pgdat_snr = pfn_to_section_nr(pgdat_to_phys(pgdat) >> PAGE_SHIFT);
if (usemap_snr == pgdat_snr)
return;
if (old_usemap_snr == usemap_snr && old_pgdat_snr == pgdat_snr)
/* skip redundant message */
return;
old_usemap_snr = usemap_snr;
old_pgdat_snr = pgdat_snr;
usemap_nid = sparse_early_nid(__nr_to_section(usemap_snr));
if (usemap_nid != nid) {
pr_info("node %d must be removed before remove section %ld\n",
nid, usemap_snr);
return;
}
/*
* There is a circular dependency.
* Some platforms allow un-removable section because they will just
* gather other removable sections for dynamic partitioning.
* Just notify un-removable section's number here.
*/
pr_info("Section %ld and %ld (node %d) have a circular dependency on usemap and pgdat allocations\n",
usemap_snr, pgdat_snr, nid);
}
#endif
CONFIG_MEMORY_HOTREMOVE 커널 옵션을 사용하는 경우 usemap 섹션은 pgdat가 위치한 섹션에 있거나 그렇지 않다면 다른 섹션이 모두 삭제될 때까지 usemap이 위치한 섹션은 삭제되면 안 된다. 따라서 이에 대한 관계를 메시지로 알아보기 위한 루틴이다. 할당받은 usemap과 노드 정보(pgdat)가 기록된 섹션과 같지 않으면 정보를 출력한다. usemap 정보가 같은 노드 공간에 구성되지 않으면 메모리 핫리무브(hot remove) 동작 시 노드별로 메모리를 제거해야 할 때 circular dependancy 문제가 발생할 수 있다.
- 코드 라인 12~15에서 처음 호출 시 초깃값으로 진행 중인 섹션 번호를 담는다.
- 코드 라인 17~20에서 usemap이 할당된 섹션과 노드 정보가 기록된 섹션이 같은 경우 정상이므로 함수를 빠져나간다.
- 코드 라인 22~24에서 이미 한 번 진행하였던 섹션인 경우 skip 하기 위해 함수를 빠져나간다.
- 코드 라인 26~27에서 같은 섹션 번호로 다시 한 번 진행하는 경우 skip 하기 위해 섹션 번호들을 기억해둔다.
- 코드 라인 29~34에서 요청한 @nid에 usemap 노드가 없는 경우 use_map이 있는 섹션 정보를 먼저 hot remove 하여야 한다는 정보를 출력한다.
- 코드 라인 41~42에서 요청한 @nid에 usemap이 있는 경우 메모리 핫리무브(hot remove) 동작 시 노드별로 메모리를 제거해야 할 때 circular dependancy 문제가 발생할 수 있다는 정보를 출력한다.
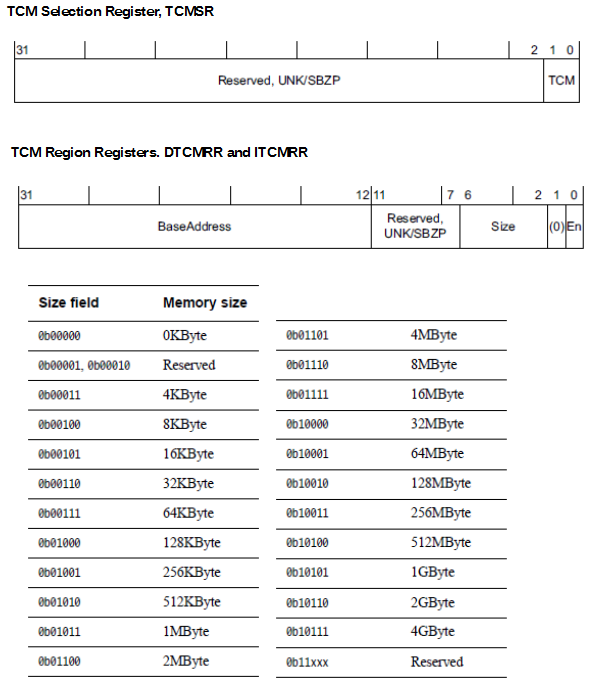
usemap_size()
mm/sparse.c
unsigned long usemap_size(void)
{
return BITS_TO_LONGS(SECTION_BLOCKFLAGS_BITS) * sizeof(unsigned long);
}
usemap 사이즈를 리턴한다.
- SECTION_BLOCKFLAGS_BITS
- 섹션당 pageblock 비트 수 (pageblock_order=9일 때)
- arm64=2048
- 섹션당 pageblock 비트 수 (pageblock_order=9일 때)
- 예) arm64
- 2048 / 8=256(byte)
sparse_mem_map_populate()
vmemmap을 사용하지 않을 때의 함수이다. arm64 디폴트 설정에서는 vmemmap을 사용하므로 이 함수를 사용하지 않는다.
mm/sparse.c
#ifndef CONFIG_SPARSEMEM_VMEMMAP
struct page __init *sparse_mem_map_populate(unsigned long pnum, int nid,
struct vmem_altmap *altmap)
{
unsigned long size = section_map_size();
struct page *map = sparse_buffer_alloc(size);
if (map)
return map;
map = memblock_alloc_try_nid(size,
PAGE_SIZE, __pa(MAX_DMA_ADDRESS),
MEMBLOCK_ALLOC_ACCESSIBLE, nid);
return map;
}
#endif /* !CONFIG_SPARSEMEM_VMEMMAP */
CONFIG_SPARSEMEM_VMEMMAP 커널 옵션을 사용하지 않는 시스템에서 미리 할당한 sparse 버퍼를 사용하여 mem_map[]을 할당해준다. 만일 실패하는 경우 별도로 섹션마다 mem_map[] 배열을 memblock 할당 요청한다.
sparse_init_one_section()
mm/sparse.c
static void __meminit sparse_init_one_section(struct mem_section *ms,
unsigned long pnum, struct page *mem_map,
struct mem_section_usage *usage, unsigned long flags)
{
ms->section_mem_map &= ~SECTION_MAP_MASK;
ms->section_mem_map |= sparse_encode_mem_map(mem_map, pnum)
| SECTION_HAS_MEM_MAP | flags;
ms->usage = usage;
}
mem_map 영역을 엔코딩하여 mem_section에 연결하고 usemap 영역도 연결한다.
mem_map 주소의 엔코딩/디코딩
각 섹션을 관리하는 mem_section 구조체의 section_mem_map 멤버는 다음과 같이 2가지 정보를 담아사용한다. 단 동시에 사용되지는 않는다.
- 부트 타임에 잠시 섹션에 대한 early 노드 번호를 담아 사용한다.
- sparse_encode_early_nid() 및 sparse_early_nid() 함수를 사용한다.
- mem_map이 활성화된 이후 노드 번호는 page->flags에 저장하여 사용된다.
- 각 섹션이 관리하는 mem_map – 섹션에 대한 pfn 값에 몇 개의 플래그들을 엔코딩하여 사용한다.
- sparse_encode_mem_map() 및 sparse_decode_mem_map() 함수를 사용한다.
- 섹션에 대한 pfn 값을 빼서 저장하면 vmemmap을 사용하지 않는 시스템에서 pfn_to_page() 함수를 사용할 때 한 번의 산술연산이 절감되는 효과가 있다.
- 예) 0x8000_0000 ~ 0xC000_0000 (1G)을 관리하는 섹션에 대한 mem_map 주소 – 0x80000(섹션 pfn) + 플래그 값으로 엔코딩한다.
early 노드 번호 엔코딩/디코딩
sparse_encode_early_nid()
mm/sparse.c
/* * During early boot, before section_mem_map is used for an actual * mem_map, we use section_mem_map to store the section's NUMA * node. This keeps us from having to use another data structure. The * node information is cleared just before we store the real mem_map. */
static inline unsigned long sparse_encode_early_nid(int nid)
{
return (nid << SECTION_NID_SHIFT);
}
노드 번호는 SECTION_NID_SHIFT(6) 비트부터 사용되므로 그만큼 좌측으로 쉬프트한다.
sparse_early_nid()
mm/sparse.c
static inline int sparse_early_nid(struct mem_section *section)
{
return (section->section_mem_map >> SECTION_NID_SHIFT);
}
mem_section 구조체 멤버 변수인 section_mem_map에서 노드 정보를 추출하여 리턴한다.
정규 mem_map 엔코딩/디코딩
sparse_encode_mem_map()
mm/sparse.c
/* * Subtle, we encode the real pfn into the mem_map such that * the identity pfn - section_mem_map will return the actual * physical page frame number. */
static unsigned long sparse_encode_mem_map(struct page *mem_map, unsigned long pnum)
{
unsigned long coded_mem_map =
(unsigned long)(mem_map - (section_nr_to_pfn(pnum)));
BUILD_BUG_ON(SECTION_MAP_LAST_BIT > (1UL<<PFN_SECTION_SHIFT));
BUG_ON(coded_mem_map & ~SECTION_MAP_MASK);
return coded_mem_map;
}
할당 받은 mem_map의 주소 – 섹션에 해당하는 base pfn 값을 엔코딩 값으로 반환한다.
- vmemmap을 사용하지 않는 경우 pfn_to_page() 함수에서 산술 연산을 한 번 제거하는 효과가 있다.
sparse_decode_mem_map()
mm/sparse.c
/* * Decode mem_map from the coded memmap */
struct page *sparse_decode_mem_map(unsigned long coded_mem_map, unsigned long pnum)
{
/* mask off the extra low bits of information */
coded_mem_map &= SECTION_MAP_MASK;
return ((struct page *)coded_mem_map) + section_nr_to_pfn(pnum);
}
엔코딩된 mem_map 주소에서 플래그 정보를 제거한 후 디코딩하여 mem_map 주소만 반환한다.
VMEMMAP 관련
- arm64에서는 CONFIG_SPARSEMEM_VMEMMAP을 기본적으로 사용한다.
- 시스템 리소스가 충분하여 vmemmap을 사용하는 경우 pfn_to_page() 및 page_to_pfn() 함수의 동작이 가장 효과적으로 빨라진다.
__populate_section_memmap()
mm/sparse-vmemmap.c
struct page * __meminit __populate_section_memmap(unsigned long pfn,
unsigned long nr_pages, int nid, struct vmem_altmap *altmap)
{
unsigned long start = (unsigned long) pfn_to_page(pfn);
unsigned long end = start + nr_pages * sizeof(struct page);
if (WARN_ON_ONCE(!IS_ALIGNED(pfn, PAGES_PER_SUBSECTION) ||
!IS_ALIGNED(nr_pages, PAGES_PER_SUBSECTION)))
return NULL;
if (vmemmap_populate(start, end, nid, altmap))
return NULL;
return pfn_to_page(pfn);
}
CONFIG_SPARSEMEM_VMEMMAP 커널 옵션을 사용하는 경우 mem_map 영역에 해당하는 @pfn을 vmemmap 영역에 @nr_pages만큼 매핑한다. 요청한 섹션으로 주소 범위를 구한 후 해당 주소 범위와 관련한 pgd, pud 및 pmd 테이블들에 구성되지 않은 테이블이 있는 경우 노드에서 페이지를 할당하여 구성하고 매핑한다.
- sparse 버퍼에 할당된 mem_map 용 공간들을 pte 엔트리에 연결하여 매핑한다.
vmemmap_populate()
arch/arm64/mm/mmu.c
#if !ARM64_KERNEL_USES_PMD_MAPS
int __meminit vmemmap_populate(unsigned long start, unsigned long end, int node,
struct vmem_altmap *altmap)
{
WARN_ON((start < VMEMMAP_START) || (end > VMEMMAP_END));
return vmemmap_populate_basepages(start, end, node, altmap);
}
#else /* !ARM64_KERNEL_USES_PMD_MAPS */
int __meminit vmemmap_populate(unsigned long start, unsigned long end, int node,
struct vmem_altmap *altmap)
{
unsigned long addr = start;
unsigned long next;
pgd_t *pgdp;
p4d_t *p4dp;
pud_t *pudp;
pmd_t *pmdp;
WARN_ON((start < VMEMMAP_START) || (end > VMEMMAP_END));
do {
next = pmd_addr_end(addr, end);
pgdp = vmemmap_pgd_populate(addr, node);
if (!pgdp)
return -ENOMEM;
p4dp = vmemmap_p4d_populate(pgdp, addr, node);
if (!p4dp)
return -ENOMEM;
pudp = vmemmap_pud_populate(p4dp, addr, node);
if (!pudp)
return -ENOMEM;
pmdp = pmd_offset(pudp, addr);
if (pmd_none(READ_ONCE(*pmdp))) {
void *p = NULL;
p = vmemmap_alloc_block_buf(PMD_SIZE, node, altmap);
if (!p) {
if (vmemmap_populate_basepages(addr, next, node, altmap))
return -ENOMEM;
continue;
}
pmd_set_huge(pmdp, __pa(p), __pgprot(PROT_SECT_NORMAL));
} else
vmemmap_verify((pte_t *)pmdp, node, addr, next);
} while (addr = next, addr != end);
return 0;
}
#endif /* !ARM64_KERNEL_USES_PMD_MAPS */
요청 주소 범위와 관련한 pgd, p4d, pud 및 pmd 테이블들에 구성되지 않은 테이블이 있는 경우 노드에서 페이지를 할당하여 구성하고 매핑한다.
- 4K 페이지를 사용하는 경우 ARM64_KERNEL_USES_PMD_MAPS 값은 1이다.
- @start: mem_map이 매핑될 시작 가상 주소(vmemmap 영역에 매핑)
- @end: mem_map이 매핑될 끝 가상 주소 (vmemmap 영역에 매핑)
- 코드 라인 6에서 mem_map을 4K 단위로 매핑을 수행한다.
- 코드 라인 20~21에서 addr을 순회하며, pmd 단위로 매핑할 예정이므로 pmd 단위의 끝 주소를 구해 next에 대입한다.
- 코드 라인 23~25에서 해당 가상 주소 위치에 대응하는 pgd 엔트리를 populate 한다.
- 코드 라인 27~29에서 해당 가상 주소 위치에 대응하는 p4d 엔트리를 populate 한다.
- 코드 라인 31~33에서 해당 가상 주소 위치에 대응하는 pud 엔트리를 populate 한다.
- 코드 라인 35~46에서 pmd 엔트리 주소에 매핑되어 있지 않은 경우 PMD 사이즈(2M)의 메모리를 할당한 후 pmd_set_huge() 명령으로 매핑한다.
- 코드 라인 47~48에서 이미 pmd 매핑이 되어 있는 경우 vmemmap_verify() 함수를 통해 mem_map이 다른 노드에 할당된 경우 경고 로그를 출력한다.
- 코드 라인 49에서 대음 pmd 단위의 주소로 이동하고 루프를 계속한다.
- 코드 라인 51에서 정상 결과 0을 반환한다.
vmemmap_populate_basepages()
mm/sparse-vmemmap.c
int __meminit vmemmap_populate_basepages(unsigned long start, unsigned long end,
int node, struct vmem_altmap *altmap)
{
unsigned long addr = start;
pgd_t *pgd;
p4d_t *p4d;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
for (; addr < end; addr += PAGE_SIZE) {
pgd = vmemmap_pgd_populate(addr, node);
if (!pgd)
return -ENOMEM;
p4d = vmemmap_p4d_populate(pgd, addr, node);
if (!p4d)
return -ENOMEM;
pud = vmemmap_pud_populate(p4d, addr, node);
if (!pud)
return -ENOMEM;
pmd = vmemmap_pmd_populate(pud, addr, node);
if (!pmd)
return -ENOMEM;
pte = vmemmap_pte_populate(pmd, addr, node, altmap);
if (!pte)
return -ENOMEM;
vmemmap_verify(pte, node, addr, addr + PAGE_SIZE);
}
return 0;
}
mem_map을 4K 단위로 매핑을 수행한다.
- @start: mem_map이 매핑될 시작 가상 주소(vmemmap 영역에 매핑)
- @end: mem_map이 매핑될 끝 가상 주소 (vmemmap 영역에 매핑)
- 코드 라인 11에서 페이지 단위로 순회한다.
- 코드 라인 12~14에서 해당 가상 주소 위치에 대응하는 pgd 엔트리를 populate 한다.
- 코드 라인 15~17에서 해당 가상 주소 위치에 대응하는 p4d 엔트리를 populate 한다.
- 코드 라인 18~20에서 해당 가상 주소 위치에 대응하는 pud 엔트리를 populate 한다.
- 코드 라인 21~23에서 해당 가상 주소 위치에 대응하는 pmd 엔트리를 populate 한다.
- 코드 라인 24~26에서 해당 가상 주소 위치에 대응하는 pte 엔트리에 @altmap을 매핑한다.
- 코드 라인 27에서 vmemmap_verify() 함수를 통해 mem_map이 다른 노드에 할당된 경우 경고 로그를 출력한다.
- 코드 라인 30에서 정상 결과 0을 반환한다.
vmemmap_verify()
mm/sparse-vmemmap.c
void __meminit vmemmap_verify(pte_t *pte, int node,
unsigned long start, unsigned long end)
{
unsigned long pfn = pte_pfn(*pte);
int actual_node = early_pfn_to_nid(pfn);
if (node_distance(actual_node, node) > LOCAL_DISTANCE)
pr_warn("[%lx-%lx] potential offnode page_structs\n",
start, end - 1);
}
@pte가 가리키는 mem_map 노드와 @node가 같은 로컬 노드에 있지 않고, remote distance로 떨어져 있는 경우 경고 로그를 출력한다.
다음 함수들의 코드 및 설명은 생략한다.
- vmemmap_pgd_populate()
- vmemmap_p4d_populate()
- vmemmap_pud_populate()
- vmemmap_pmd_populate()
구조체 및 주요 변수
mem_section[]
mm/sparse.c
#ifdef CONFIG_SPARSEMEM_EXTREME extern struct mem_section **mem_section; #else extern struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT]; #endif
mem_section은 섹션 별로 mem_map[] 배열과 usemap[] 배열 정보와 연결된다.
mem_section 구조체
include/linux/mmzone.h
struct mem_section {
/*
* This is, logically, a pointer to an array of struct
* pages. However, it is stored with some other magic.
* (see sparse.c::sparse_init_one_section())
*
* Additionally during early boot we encode node id of
* the location of the section here to guide allocation.
* (see sparse.c::memory_present())
*
* Making it a UL at least makes someone do a cast
* before using it wrong.
*/
unsigned long section_mem_map;
struct mem_section_usage *usage;
#ifdef CONFIG_PAGE_EXTENSION
/*
* If SPARSEMEM, pgdat doesn't have page_ext pointer. We use
* section. (see page_ext.h about this.)
*/
struct page_ext *page_ext;
unsigned long pad;
#endif
/*
* WARNING: mem_section must be a power-of-2 in size for the
* calculation and use of SECTION_ROOT_MASK to make sense.
*/
};
- section_mem_map
- 여기엔 실제 섹션에 대한 mem_map을 직접 가리키지 않고, 다음과 같이 엔코딩된 값을 사용한다.
- 섹션의 mem_map을 가리키는 주소 – 섹션에 대한 pfn 값에 플래그들을 엔코딩하여 사용된다. (mem_map은 페이지 단위로 정렬되어 사용된다.)
- 다음은 엔코딩에 사용할 플래그 정보들이다.
- bit0: SECTION_MARKED_PRESENT
- 섹션에 메모리가 있는지 여부를 표현한다.
- bit1: SECTION_HAS_MEM_MAP
- 섹션에 mem_map이 연결되었는지 여부를 표현한다.
- 연결된 mem_map은 섹션 base pfn 값을 빼고 저장된다(엔코딩)
- bit2: SECTION_IS_ONLINE
- online 섹션 여부를 표현한다.
- bit3: SECTION_IS_EARLY
- early 섹션 여부를 표현한다.
- bit4: SECTION_TAINT_ZONE_DEVICE
- 존 디바이스 여부를 표현한다.
- bits[6~]: 노드 번호
- 노드 번호와 mem_map 정보가 동시에 저장되지 않는다.
- 노드 번호는 early 부트업 중에만 잠깐 사용된다. 이후 노드 번호는 page 구조체의 flags 멤버에서 관리한다.
- bit0: SECTION_MARKED_PRESENT
- 여기엔 실제 섹션에 대한 mem_map을 직접 가리키지 않고, 다음과 같이 엔코딩된 값을 사용한다.
- *usage
- mem_section_usage 구조체를 가리킨다. (usemap과 subsection 비트맵을 관리한다)
- *page_ext
- 디버그를 위해 CONFIG_PAGE_EXTENSION 커널 옵션을 사용하였을 때 사용되며, page_ext 구조체들이 있는 곳을 가리킨다.
mem_section_usage 구조체
include/linux/mmzone.h
struct mem_section_usage {
#ifdef CONFIG_SPARSEMEM_VMEMMAP
DECLARE_BITMAP(subsection_map, SUBSECTIONS_PER_SECTION);
#endif
/* See declaration of similar field in struct zone */
unsigned long pageblock_flags[0];
};
- subsection_map
- 섹션 메모리내에서 서브 섹션 단위(2M)의 메모리 존재 여부를 표현하는 비트맵
- pageblock_flags[]
- usemap을 가리키는 주소
기타
SECTION_SIZE_BITS 및 MAX_PHYSMEM_BITS
- arm
- 28, 32 (256M, 4G, Realview-PBX)
- 26, 29 (64M, 512M, RPC)
- 27, 32 (128M, 4G, SA1100)
- 32bit arm with LPAE
- 34, 36 (16G, 64G, Keystone)
- arm64
- 27, 48 (128M, 256T)
- x86
- 26, 32 (64M, 4G)
- x86_32 with PAE
- 29, 36 (512M, 64G)
- x86_64
- 27, 46 (128M, 64T)
참고
- Memory Model -1- (Basic) | 문c
- Memory Model -2- (mem_map) | 문c
- Memory Model -3- (Sparse Memory) | 문c – 현재 글
- Memory Model -4- (APIs) | 문c
- ZONE 타입 | 문c
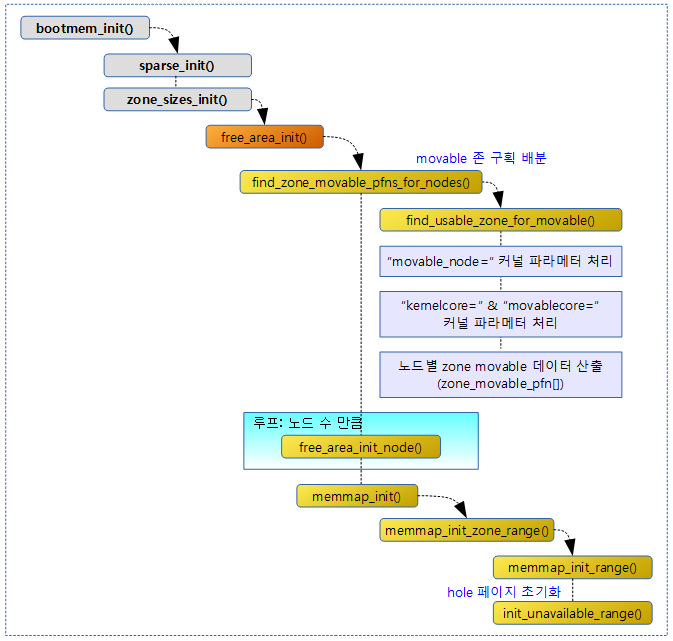
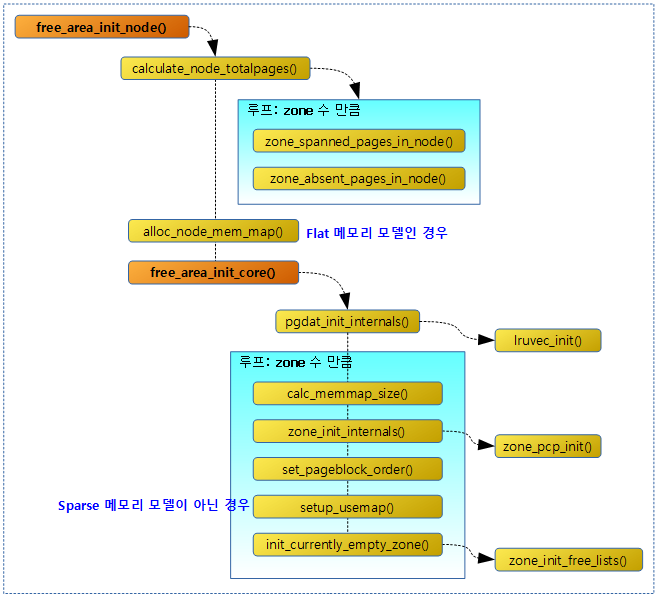
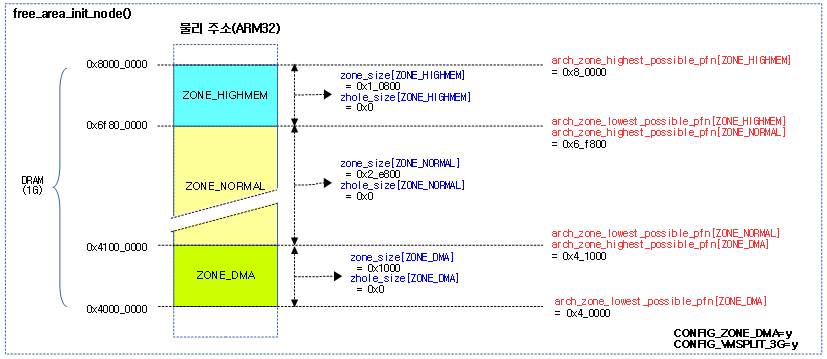
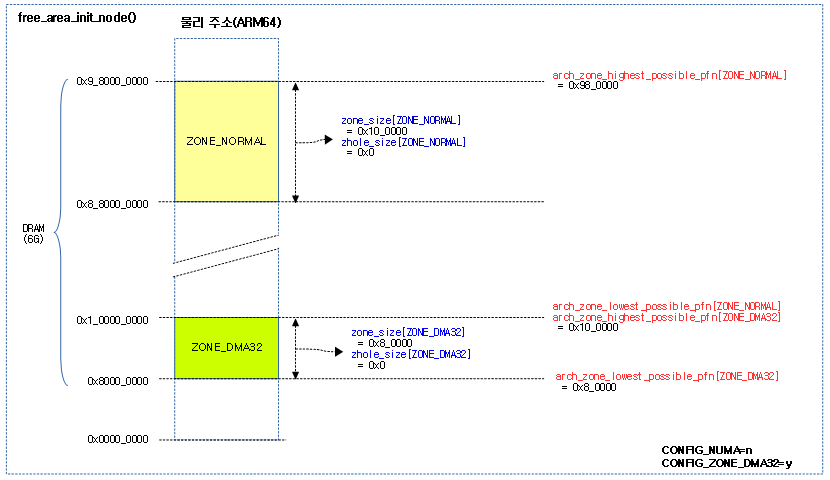
- bootmem_init | 문c
- zone_sizes_init() | 문c
- NUMA -1- (ARM64 초기화) | 문c
- build_all_zonelists() | 문c