<kernel v5.10>
Early 메모리 할당
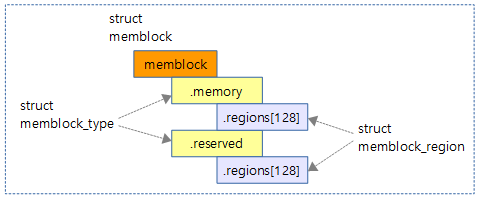
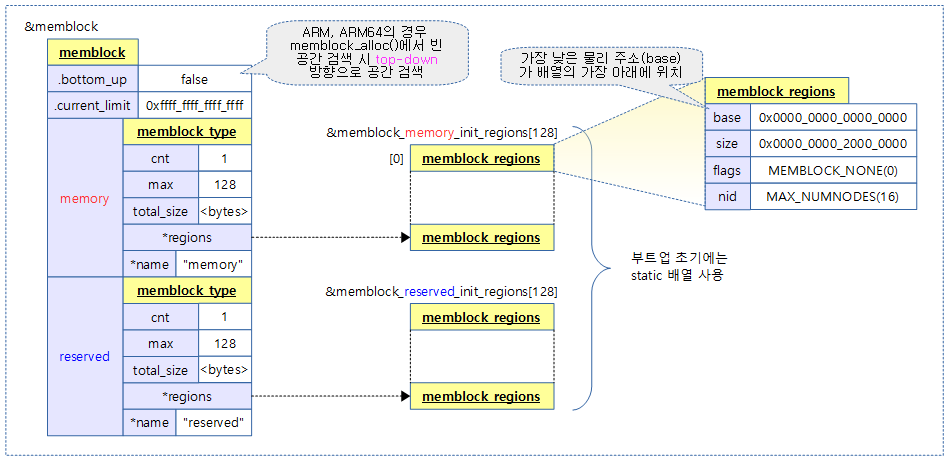
early 메모리 할당자로서 커널 부트업 프로세스 및 메모리 핫스왑(hot-swap) 과정에서 memblock API를 사용하여 메모리의 할당과 해제를 요청하게 된다.
paging_init()이 완료되기 전 memblock 사용
paging_init()이 완료되기 전에도 memblock_add() 함수로 메모리를 추가할 수 있고, memblock_reserve() 함수로 reserve 공간을 등록할 수 있다. 그러나 커널 메모리에 대해 아직 리니어 매핑되지 않은 상태이므로 memblock_alloc()으로 메모리 할당을 할 수 없다. 따라서 paging_init()이 완료된 후에 memblock_alloc()을 사용하여야 한다.
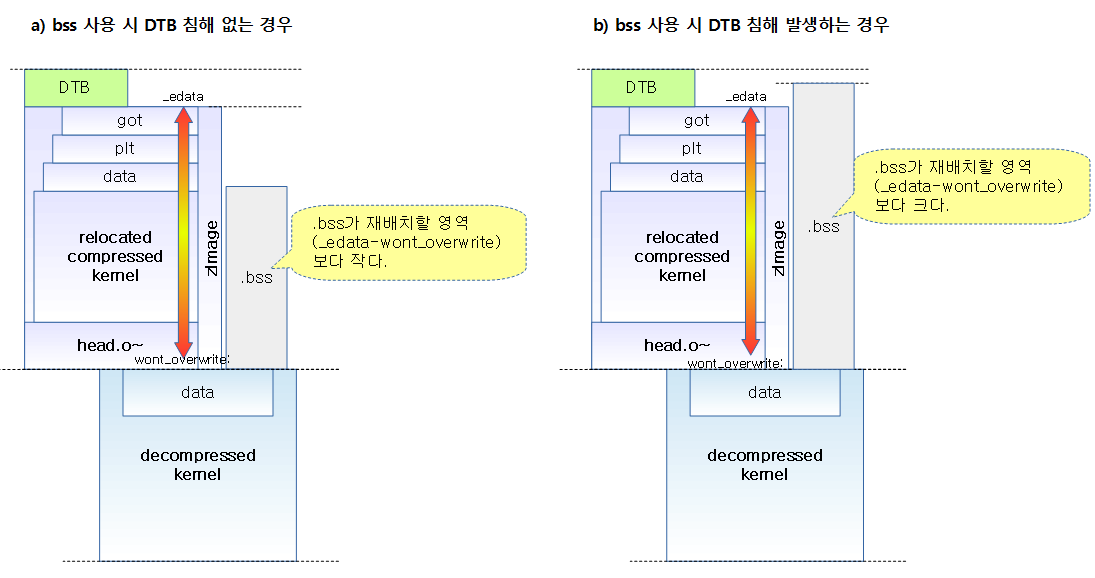
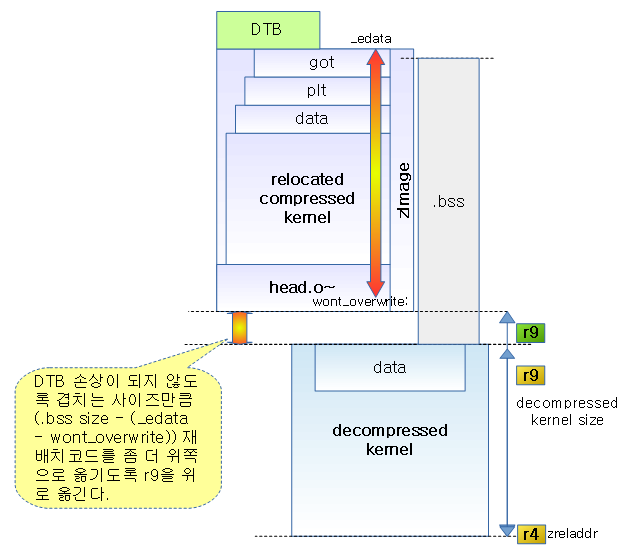
다음 그림은 정규 메모리 할당자가 준비되기 전의 주요 메모리 매핑과 할당자들의 단계별 상태를 보여준다.

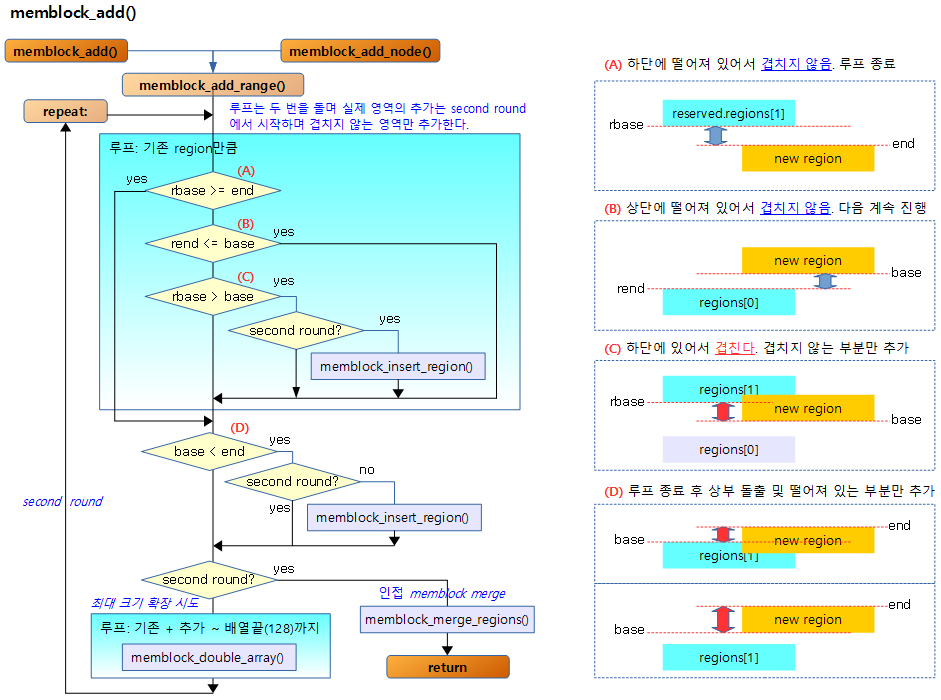
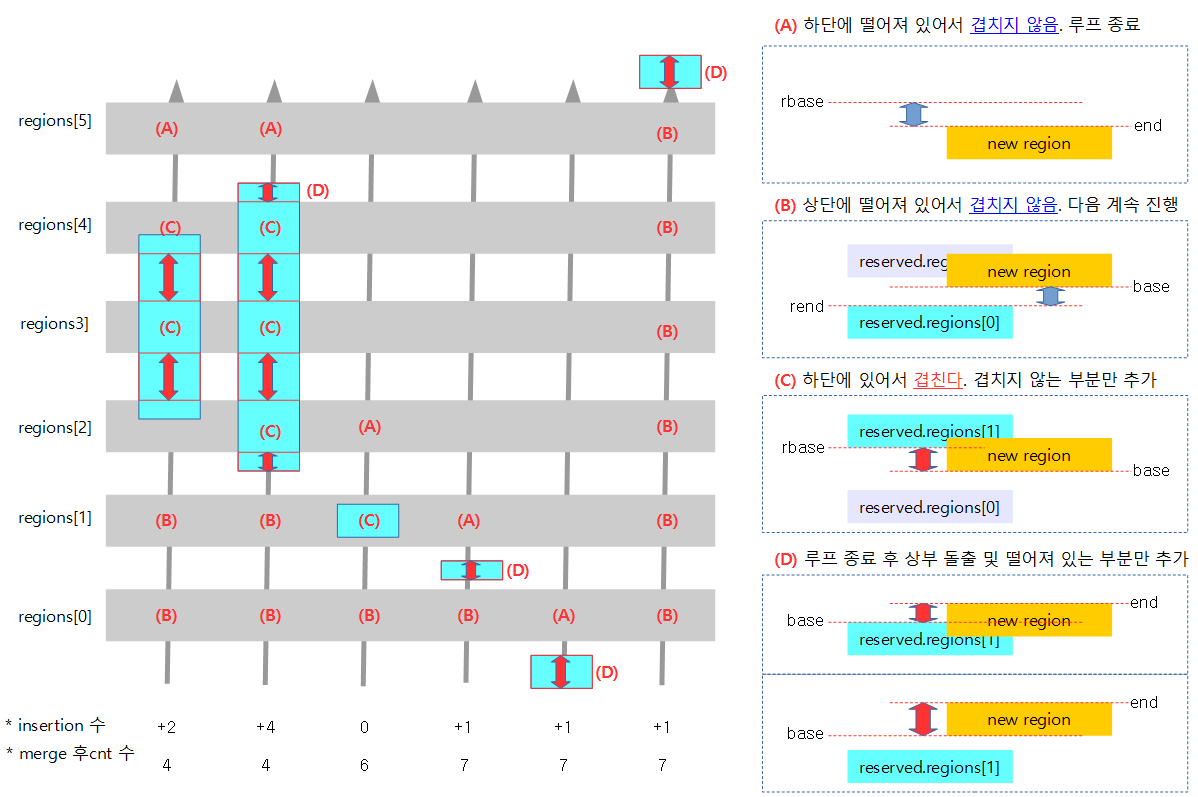
다음 그림은 memblock 할당과 관련한 API들의 흐름을 보여준다.

memblock_alloc()
mm/memblock.c
static inline void * __init memblock_alloc(phys_addr_t size, phys_addr_t align)
{
return memblock_alloc_try_nid(size, align, MEMBLOCK_LOW_LIMIT,
MEMBLOCK_ALLOC_ACCESSIBLE, NUMA_NO_NODE);
}
@align 단위로 정렬된 @size만큼의 memblock을 할당 요청한다. 성공 시 할당된 메모리의 가상 주소를 반환하고, 실패 시 null 을 반환한다.
- MEMBLOCK_LOW_LIMIT(0)
- 할당 시 top down으로 할당할 메모리의 아래쪽 끝을 제한한다.
- MEMBLOCK_ALLOC_ACCESSIBLE(0)
- 할당 시 memblock의 current_limit 값으로 제한한다.
- NUMA_NO_NODE(-1)
- 어떠한 노드에서 할당하든 제한 없이 요청한다.
memblock_alloc_try_nid()
mm/memblock.c
/**
* memblock_alloc_try_nid - allocate boot memory block with panicking
* @size: size of memory block to be allocated in bytes
* @align: alignment of the region and block's size
* @min_addr: the lower bound of the memory region from where the allocation
* is preferred (phys address)
* @max_addr: the upper bound of the memory region from where the allocation
* is preferred (phys address), or %MEMBLOCK_ALLOC_ACCESSIBLE to
* allocate only from memory limited by memblock.current_limit value
* @nid: nid of the free area to find, %NUMA_NO_NODE for any node
*
* Public function, provides additional debug information (including caller
* info), if enabled. This function zeroes the allocated memory.
*
* Return:
* Virtual address of allocated memory block on success, NULL on failure.
*/
void * __init memblock_alloc_try_nid(
phys_addr_t size, phys_addr_t align,
phys_addr_t min_addr, phys_addr_t max_addr,
int nid)
{
void *ptr;
memblock_dbg("%s: %llu bytes align=0x%llx nid=%d from=%pa max_addr=%pa %pS\n",
__func__, (u64)size, (u64)align, nid, &min_addr,
&max_addr, (void *)_RET_IP_);
ptr = memblock_alloc_internal(size, align,
min_addr, max_addr, nid, false);
if (ptr)
memset(ptr, 0, size);
return ptr;
}
노드 @nid에서 @align 단위로 정렬된 @size만큼의 memblock 영역을 할당 요청한다. 성공 시 할당된 메모리의 가상 주소를 반환하고, 실패 시 null 을 반환한다.
memblock_alloc_internal()
mm/memblock.c
/**
* memblock_alloc_internal - allocate boot memory block
* @size: size of memory block to be allocated in bytes
* @align: alignment of the region and block's size
* @min_addr: the lower bound of the memory region to allocate (phys address)
* @max_addr: the upper bound of the memory region to allocate (phys address)
* @nid: nid of the free area to find, %NUMA_NO_NODE for any node
* @exact_nid: control the allocation fall back to other nodes
*
* Allocates memory block using memblock_alloc_range_nid() and
* converts the returned physical address to virtual.
*
* The @min_addr limit is dropped if it can not be satisfied and the allocation
* will fall back to memory below @min_addr. Other constraints, such
* as node and mirrored memory will be handled again in
* memblock_alloc_range_nid().
*
* Return:
* Virtual address of allocated memory block on success, NULL on failure.
*/
static void * __init memblock_alloc_internal(
phys_addr_t size, phys_addr_t align,
phys_addr_t min_addr, phys_addr_t max_addr,
int nid, bool exact_nid)
{
phys_addr_t alloc;
/*
* Detect any accidental use of these APIs after slab is ready, as at
* this moment memblock may be deinitialized already and its
* internal data may be destroyed (after execution of memblock_free_all)
*/
if (WARN_ON_ONCE(slab_is_available()))
return kzalloc_node(size, GFP_NOWAIT, nid);
if (max_addr > memblock.current_limit)
max_addr = memblock.current_limit;
alloc = memblock_alloc_range_nid(size, align, min_addr, max_addr, nid,
alloc = memblock_alloc_range_nid(size, align, 0, max_addr, nid,
exact_nid);
/* retry allocation without lower limit */
if (!alloc && min_addr)
alloc = memblock_alloc_range_nid(size, align, 0, max_addr, nid,
exact_nid);
if (!alloc)
return NULL;
return phys_to_virt(alloc);
}
요청한 노드 @nid에서 @align 단위로 정렬된 @size만큼의 memblock 영역을 할당 요청한다. 할당된 물리 주소를 가상 주소로 변환하여 반환한다.
- 코드 라인 13~14에서 정규 메모리 슬랩 할당자가 동작한 이후에 이 함수가 호출된 경우 슬랩할당자를 사용하여 메모리를 할당한다.
- 코드 라인 16~17에서 @max_addr가 memblock의 current_limit을 초과하지 않도록 제한한다.
- 코드 라인 19~21에서 제한된 limit 범위내에서 메모리 할당을 시도한다.
- 코드 라인 24~26에서 할당이 실패한 경우 limit 범위를 해제한 다음 메모리 할당을 시도한다.
- 코드 라인 28~29에서 그래도 할당이 실패한 경우 null을 반환한다.
- 코드 라인 31에서 할당이 성공한 경우 가상 주소(lm)로 변환하여 반환한다.
memblock_alloc_range_nid()
mm/memblock.c
/**
* memblock_alloc_range_nid - allocate boot memory block
* @size: size of memory block to be allocated in bytes
* @align: alignment of the region and block's size
* @start: the lower bound of the memory region to allocate (phys address)
* @end: the upper bound of the memory region to allocate (phys address)
* @nid: nid of the free area to find, %NUMA_NO_NODE for any node
* @exact_nid: control the allocation fall back to other nodes
*
* The allocation is performed from memory region limited by
* memblock.current_limit if @end == %MEMBLOCK_ALLOC_ACCESSIBLE.
*
* If the specified node can not hold the requested memory and @exact_nid
* is false, the allocation falls back to any node in the system.
*
* For systems with memory mirroring, the allocation is attempted first
* from the regions with mirroring enabled and then retried from any
* memory region.
*
* In addition, function sets the min_count to 0 using kmemleak_alloc_phys for
* allocated boot memory block, so that it is never reported as leaks.
*
* Return:
* Physical address of allocated memory block on success, %0 on failure.
*/
phys_addr_t __init memblock_alloc_range_nid(phys_addr_t size,
phys_addr_t align, phys_addr_t start,
phys_addr_t end, int nid,
bool exact_nid)
{
enum memblock_flags flags = choose_memblock_flags();
phys_addr_t found;
if (WARN_ONCE(nid == MAX_NUMNODES, "Usage of MAX_NUMNODES is deprecated. Use NUMA_NO_NODE instead\n"))
nid = NUMA_NO_NODE;
if (!align) {
/* Can't use WARNs this early in boot on powerpc */
dump_stack();
align = SMP_CACHE_BYTES;
}
again:
found = memblock_find_in_range_node(size, align, start, end, nid,
flags);
if (found && !memblock_reserve(found, size))
goto done;
if (nid != NUMA_NO_NODE && !exact_nid) {
found = memblock_find_in_range_node(size, align, start,
end, NUMA_NO_NODE,
flags);
if (found && !memblock_reserve(found, size))
goto done;
}
if (flags & MEMBLOCK_MIRROR) {
flags &= ~MEMBLOCK_MIRROR;
pr_warn("Could not allocate %pap bytes of mirrored memory\n",
&size);
goto again;
}
return 0;
done:
/* Skip kmemleak for kasan_init() due to high volume. */
if (end != MEMBLOCK_ALLOC_KASAN)
/*
* The min_count is set to 0 so that memblock allocated
* blocks are never reported as leaks. This is because many
* of these blocks are only referred via the physical
* address which is not looked up by kmemleak.
*/
kmemleak_alloc_phys(found, size, 0, 0);
return found;
}
요청한 노드 @nid에서 @align 단위로 정렬된 @size만큼의 memblock 영역을 @start ~ @end 범위에서 할당 요청한다. 성공한 경우 할당된 물리 주소가 반환된다.
- 코드 라인 6에서 할당에 사용할 플래그를 가져온다. (미러 플래그)
- 코드 라인 9~10에서 nid 값으로 MAX_NUMNODES(디폴트=16)을 사용한 경우 대신 NUMA_NO_NODE(-1) 값을 사용해야 한다. 이를 메시지로 경고한다.
- 코드 라인 12~16에서 @align 요청 값이 없는 경우 호출한 함수를 알아보기 위해 스택 덤프를 수행한 후 @aline 값에 L1 캐시 단위로 정렬하도록 SMP_CACHE_BYTES(ARM64:64) 값을 사용한다.
- 코드 라인 18~22에서 again: 레이블이다. 빈 영역이 있는지 찾아보고 이를 할당하기 위해 reserve 한다.
- 코드 라인 24~30에서 @nid가 지정되었지만, @exact_nid가 false인 경우 노드 제한을 풀고 다시 한 번 빈 영역이 있는지 찾아본 후 이를 할당하기 위해 reserve 한다.
- 코드 라인 32~37에서 시스템 메모리에 미러 설정이 있는 경우 미러 영역이 아닌 곳에서도 할당을 시도하기 위해 미러 플래그를 제거한 후 다시 시도하기 위해 again: 레이블로 이동한다.
- 코드 라인 39에서 최종적으로 할당할 영역을 못찾은 경우 0을 반환한다.
- 코드 라인 41~52에서 out: 레이블이다. 정상적으로 할당한 경우 찾은 물리 주소를 반환한다.
memblock_reserve()
mm/memblock.c
int __init_memblock memblock_reserve(phys_addr_t base, phys_addr_t size)
{
phys_addr_t end = base + size - 1;
memblock_dbg("memblock_reserve: [%pa-%pa] %pF\n",
&base, &end, (void *)_RET_IP_);
return memblock_add_range(&memblock.reserved, base, size, MAX_NUMNODES, 0);
}
물리 주소 @base 부터 @size 만큼의 영역을 memblock의 reserved 영역에 추가한다.
Memblock 빈 영역 찾기
memblock_find_in_range()
mm/memblock.c
/**
* memblock_find_in_range - find free area in given range
* @start: start of candidate range
* @end: end of candidate range, can be %MEMBLOCK_ALLOC_ANYWHERE or
* %MEMBLOCK_ALLOC_ACCESSIBLE
* @size: size of free area to find
* @align: alignment of free area to find
*
* Find @size free area aligned to @align in the specified range.
*
* Return:
* Found address on success, 0 on failure.
*/
phys_addr_t __init_memblock memblock_find_in_range(phys_addr_t start,
phys_addr_t end, phys_addr_t size,
phys_addr_t align)
{
phys_addr_t ret;
enum memblock_flags flags = choose_memblock_flags();
again:
ret = memblock_find_in_range_node(size, align, start, end,
NUMA_NO_NODE, flags);
if (!ret && (flags & MEMBLOCK_MIRROR)) {
pr_warn("Could not allocate %pap bytes of mirrored memory\n",
&size);
flags &= ~MEMBLOCK_MIRROR;
goto again;
}
return ret;
}
@start ~ @end 범위에서 @align 요청된 @size 만큼의 공간을 reserved memblock 타입에서 찾는다.
- 미러 플래그가 요청된 상태에서 공간을 찾지 못한 경우 미러 플래그를 제거하고 다시 공간을 찾아본다.
memblock_find_in_range_node()
mm/memblock.c
/**
* memblock_find_in_range_node - find free area in given range and node
* @size: size of free area to find
* @align: alignment of free area to find
* @start: start of candidate range
* @end: end of candidate range, can be %MEMBLOCK_ALLOC_ANYWHERE or
* %MEMBLOCK_ALLOC_ACCESSIBLE
* @nid: nid of the free area to find, %NUMA_NO_NODE for any node
* @flags: pick from blocks based on memory attributes
*
* Find @size free area aligned to @align in the specified range and node.
*
* When allocation direction is bottom-up, the @start should be greater
* than the end of the kernel image. Otherwise, it will be trimmed. The
* reason is that we want the bottom-up allocation just near the kernel
* image so it is highly likely that the allocated memory and the kernel
* will reside in the same node.
*
* If bottom-up allocation failed, will try to allocate memory top-down.
*
* Return:
* Found address on success, 0 on failure.
*/
phys_addr_t __init_memblock memblock_find_in_range_node(phys_addr_t size,
phys_addr_t align, phys_addr_t start,
phys_addr_t end, int nid,
enum memblock_flags flags)
{
phys_addr_t kernel_end, ret;
/* pump up @end */
if (end == MEMBLOCK_ALLOC_ACCESSIBLE ||
end == MEMBLOCK_ALLOC_KASAN)
end = memblock.current_limit;
/* avoid allocating the first page */
start = max_t(phys_addr_t, start, PAGE_SIZE);
end = max(start, end);
kernel_end = __pa_symbol(_end);
/*
* try bottom-up allocation only when bottom-up mode
* is set and @end is above the kernel image.
*/
if (memblock_bottom_up() && end > kernel_end) {
phys_addr_t bottom_up_start;
/* make sure we will allocate above the kernel */
bottom_up_start = max(start, kernel_end);
/* ok, try bottom-up allocation first */
ret = __memblock_find_range_bottom_up(bottom_up_start, end,
size, align, nid, flags);
if (ret)
return ret;
/*
* we always limit bottom-up allocation above the kernel,
* but top-down allocation doesn't have the limit, so
* retrying top-down allocation may succeed when bottom-up
* allocation failed.
*
* bottom-up allocation is expected to be fail very rarely,
* so we use WARN_ONCE() here to see the stack trace if
* fail happens.
*/
WARN_ONCE(IS_ENABLED(CONFIG_MEMORY_HOTREMOVE),
"memblock: bottom-up allocation failed, memory hotremove may be affected\nn
");
}
return __memblock_find_range_top_down(start, end, size, align, nid,
flags);
}
요청한 노드 @nid에서 @start ~ @end 범위에서 @align 요청된 @size 만큼의 공간을 reserved memblock 타입에서 찾는다.
- 코드 라인 9~11에서 limit 범위내에서 검색을 하라고 한 경우 @end를 memblock의 current_limit로 제한한다.
- 코드 라인 14에서 @start는 0 페이지를 제외한다.
- 코드 라인 22~48에서 아키텍처에 따라 bottom-up으로 검색을 시도한다. 이 때 @end가 커널 공간보다는 상위에 있어야 한다.
- 커널 버전 3.13-rc1부터 bottom up 메모리 할당 기능이 추가되었다.
- 코드 라인 49~50에서 top-down으로 검색을 시도한다.
- ARM, ARM64, x86 NUMA, 등등에서 top-down을 사용한다.
MEMBLOCK_HOTPLUG
- 리눅스에 메모리 hotplug 기능이 추가되면서 메모리 노드에 movable 속성 필드가 새롭게 생겨났다.
- movable 가능한 노드들은 hotplug 기능으로 인해 탈착 기능을 수행하는 동안 해당 노드 전체의 사용중인 페이지들이 다른 노드로 이주(migration)를 하게 하는 코드가 추가되었다.
- 커널과 커널이 사용하는 메모리는 hotplug 기능을 지원하지 않는 노드에 설치가 되며 이 노드는 항상 non-movable 속성을 갖는다.
- 현재 x86 64비트 대용량 서버들이 hotplug 기능을 지원하는데 이러한 노드들은 최소 16G 용량씩을 가지고 보통 커널이미지가 있는 non-moveable 속성의 노드의 위쪽으로 떨어져 있다. 이러한 조건에서 커널이 메모리를 할당하게 되면 메모리의 최 상단 movable 노드부터 할당을 하게된다. 이러한 경우 moveable 노드를 탈착하게 되면 그 동안 할당하여 사용한 많은 메모리들이 movable 노드에서 대량으로 다른 노드로 이주(migration)이 되어야 하는 경우가 발생한다.
- hotplug 기능으로 인하여 데이터 페이지의 이주가 발생하는 빈도를 낮추기 위해 메모리 할당을 bottom up으로(낮은 주소부터 높은 주소 방향으로) 할당할 수 있는 기능이 필요하게 되었고 커널이 있는 곳에서 즉, 커널의 끝(_end)부터 상단으로 메모리 할당이 가능할 수 있도록 코드가 추가되었다. 이렇게 하여 할당된 메모리는 커널이 있는 non-movable 노드에 같이 있게될 확률이 매우 높다.
- ARM 아키텍처는 현재(커널 v4.4)까지 CPU hotplug 기능과는 달리 메모리 hotplug 기능이 적용되지 않았다. 따라서 메모리 할당은 top down 방식 을 사용한다.
- CONFIG_MEMORY_HOTPLUG, CONFIG_HOTPLUG_CPU
- 참고: mm/memblock.c: introduce bottom-up allocation mode
MEMBLOCK_MIRROR
- x86 XEON 서버 시스템 기능 중에 메모리를 dual로 mirror 설정하여 고신뢰성을 확보할 수 있다. 전체 메모리를 mirror 설정하는 경우에는 커널 소프트웨어가 개입할 필요가 없다. 그러나 전체 메모리가 아닌 일부 메모리만 mirror 설정하여 사용하여야 할 때에는 커널 메모리에 우선 순위를 두고 사용할 수 있도록 등록된 memory memblock 영역에 이 플래그를 설정하여 사용한다. 이러한 정보는 서버 시스템의 UEFI 펌웨어가 mirror 설정을 커널에 전달하여 구성한다.
참고: address range mirror (2016) | Taku Izumi – 다운로드 pdf
다음 그림은 memblock_find_in_range() 함수의 처리 과정을 보여준다.
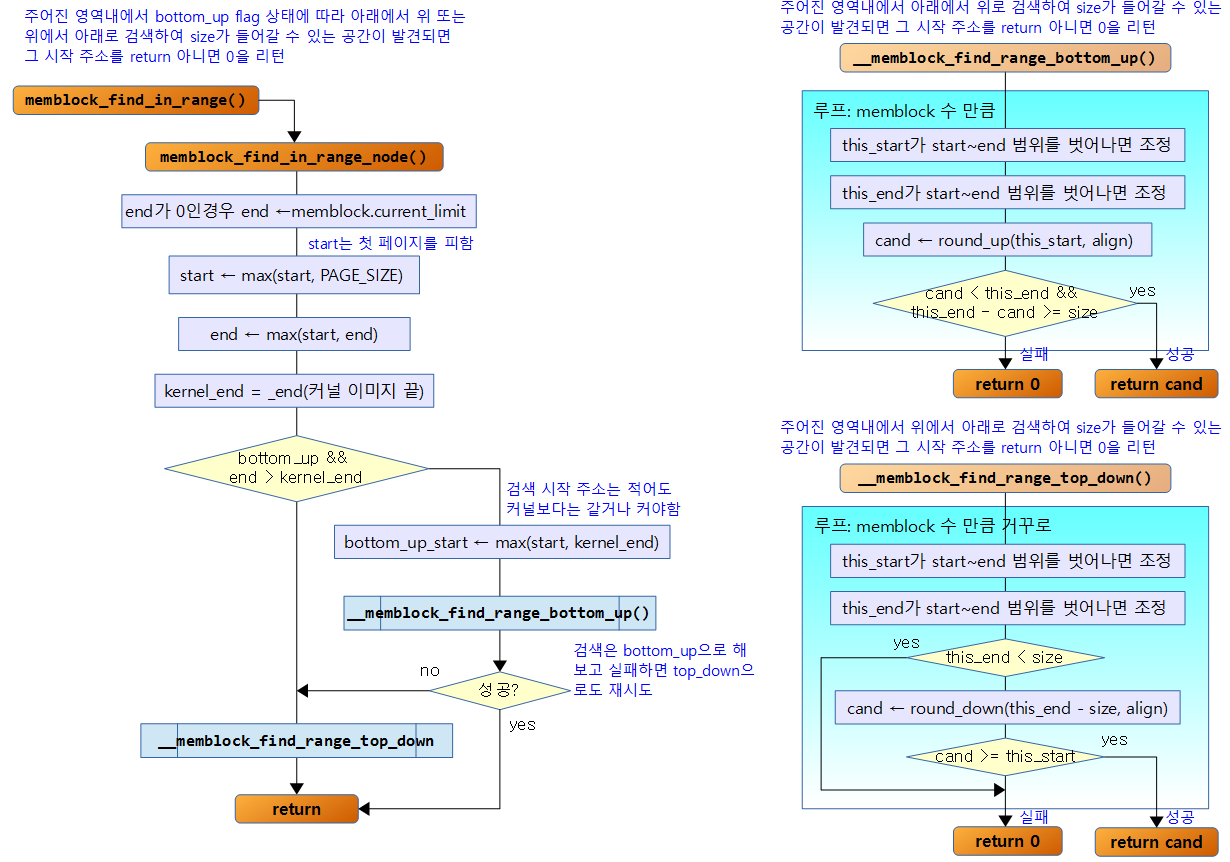
__memblock_find_range_top_down()
mm/memblock.c
/**
* __memblock_find_range_top_down - find free area utility, in top-down
* @start: start of candidate range
* @end: end of candidate range, can be %MEMBLOCK_ALLOC_ANYWHERE or
* %MEMBLOCK_ALLOC_ACCESSIBLE
* @size: size of free area to find
* @align: alignment of free area to find
* @nid: nid of the free area to find, %NUMA_NO_NODE for any node
* @flags: pick from blocks based on memory attributes
*
* Utility called from memblock_find_in_range_node(), find free area top-down.
*
* Return:
* Found address on success, 0 on failure.
*/
static phys_addr_t __init_memblock
__memblock_find_range_top_down(phys_addr_t start, phys_addr_t end,
phys_addr_t size, phys_addr_t align, int nid,
enum memblock_flags flags)
{
phys_addr_t this_start, this_end, cand;
u64 i;
for_each_free_mem_range_reverse(i, nid, flags, &this_start, &this_end,
NULL) {
this_start = clamp(this_start, start, end);
this_end = clamp(this_end, start, end);
if (this_end < size)
continue;
cand = round_down(this_end - size, align);
if (cand >= this_start)
return cand;
}
return 0;
}
메모리가 존재하는 구간의 reserved 안된 공간을 대상으로 위에서 아래로 검색하며 요청한 노드 @nid의 @start ~ @end 범위내에 @align된 @size 만큼의 공간이 발견되면 그 물리 주소의 시작주소를 반환한다.
- 코드 라인 9~12에서 빈 memblock 공간을 루프를 돌며 하나씩 알아온다.
- 코드 라인 14~15에서 아래 cand를 산출할 때 this_end – size를 수행해야 하는데 산출된 결과가 0보다 작아 under-flow 시 미리 skip을 하도록 한다.
- 코드 라인 17~19에서 요청 사이즈의 비교는 align된 크기로 한다. 알아온 free 영역의 범위에 size가 포함될 수 있으면 성공적으로 cand 주소를 리턴한다.
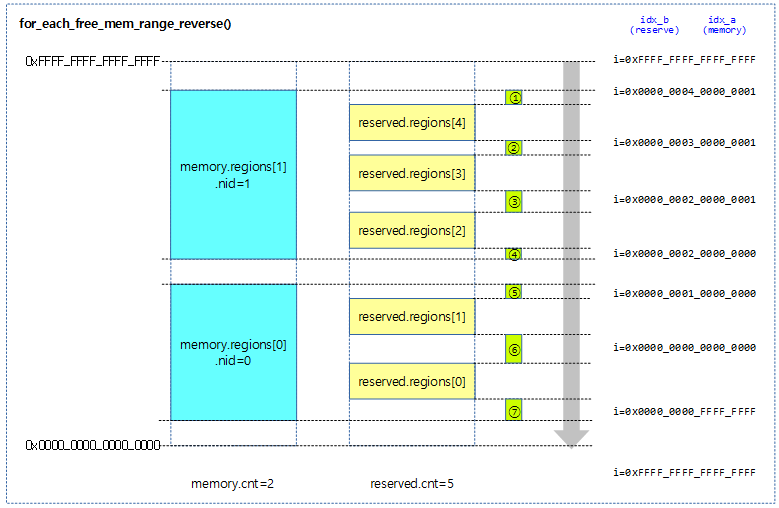
아래의 그림에서 __memblock_find_range_top_down() 함수가 동작하면 for_each_free_mem_range_reverse()를 통해 7개의 free 공간이 얻어지며, start 에서 end까지의 범위에 포함되는 케이스가 4개로 압축이 되고 1번 부터 4번 까지 순서로 요청 사이즈가 포함되는 매치 조건에 적합하면 이 공간의 주소를 리턴한다.

Iteration 매크로
for_each_mem_region()
mm/memblock.c
/**
* for_each_mem_region - itereate over memory regions
* @region: loop variable
*/
#define for_each_mem_region(region) \
for (region = memblock.memory.regions; \
region < (memblock.memory.regions + memblock.memory.cnt); \
region++)
memblock의 memory 영역을 처음부터 끝까지 @region에 지정하며 순회한다.
for_each_reserved_mem_region()
mm/memblock.c
/**
* for_each_reserved_mem_region - itereate over reserved memory regions
* @region: loop variable
*/
#define for_each_reserved_mem_region(region) \
for (region = memblock.reserved.regions; \
region < (memblock.reserved.regions + memblock.reserved.cnt); \
region++)
memblock의 reserved 영역을 처음부터 끝까지 @region에 지정하며 순회한다.
for_each_memblock_type()
mm/memblock.c
#define for_each_memblock_type(i, memblock_type, rgn) \
for (i = 0, rgn = &memblock_type->regions[0]; \
i < memblock_type->cnt; \
i++, rgn = &memblock_type->regions[i])
요청한 @memblock_type의 영역을 처음부터 끝까지 @rgn에 지정하고, 0번부터 시작하는 순번은 @i에 지정하며 순회한다.
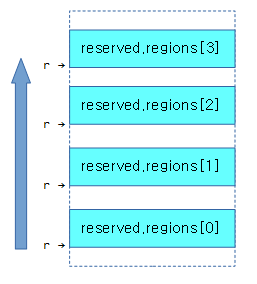
동작 과정 예)
. struct memblock_region *r;
for_each_reserved_mem_region(r) {
print_info(“base=0x%x, size=0x%x\n”, r.base, r.size);
}
reserved 영역이 아래와 같이 4개가 있을 때 r 값은 가장 하단의 memblock region부터 최상단 memblock region까지 반복하여 memblock_region 구조체 포인터를 지정한다.
for_each_mem_pfn_range()
include/linux/memblock.h
/**
* for_each_mem_pfn_range - early memory pfn range iterator
* @i: an integer used as loop variable
* @nid: node selector, %MAX_NUMNODES for all nodes
* @p_start: ptr to ulong for start pfn of the range, can be %NULL
* @p_end: ptr to ulong for end pfn of the range, can be %NULL
* @p_nid: ptr to int for nid of the range, can be %NULL
*
* Walks over configured memory ranges.
*/
#define for_each_mem_pfn_range(i, nid, p_start, p_end, p_nid) \
for (i = -1, __next_mem_pfn_range(&i, nid, p_start, p_end, p_nid); \
i >= 0; __next_mem_pfn_range(&i, nid, p_start, p_end, p_nid))
요청한 노드 @nid에서 파편화된 페이지를 제외한 즉 온전한 페이지가 1개 이상인 memblock 영역을 조건으로 루프를 돈다. 매치된 memblock 영역의 정보로 @i에는 memblock 영역의 인덱스 번호, @p_start에는 파편화된 페이지가 아닌 온전한 페이지의 시작 pfn, @p_end에는 파편화된 페이지가 아닌 온전한 페이지의 끝 pfn + 1을 담고, 마지막으로 노드 id를 @p_nid에 알아온다.
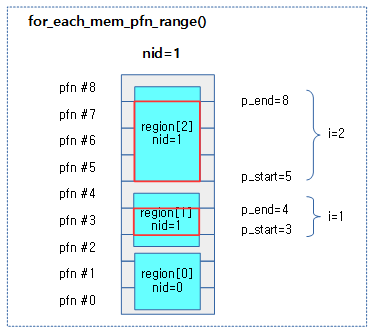
아래의 그림은 nid=1 값으로 for_each_mem_pfn_range() 매크로 루프를 동작시킬 때 조건에 매치되는 경우를 붉은 박스로 표현하였고 각각의 값은 다음과 같다.
- 다음과 같이 가장 하단의 nid=0인 memblock 영역을 제외하고, 2번의 매치 건이 발생한다.
- i 값이 1로 p_start=3, p_end=4, p_nid=1을 얻어온다.
- i값이 2로 p_start=5, p_end=8, p_nid=1을 얻어온다.
- 실제 memory memblock 들은 아래 그림과 다르게 매우 큰 페이지들로 이루어졌고 거의 대부분 align 된 상태이므로 아래 그림과는 많이 다르지만 계산 방법에 대해 이해를 돕는 것으로 활용해야 한다.
__next_mem_pfn_range()
mm/memblock.c
/*
* Common iterator interface used to define for_each_mem_range().
*/
void __init_memblock __next_mem_pfn_range(int *idx, int nid,
unsigned long *out_start_pfn,
unsigned long *out_end_pfn, int *out_nid)
{
struct memblock_type *type = &memblock.memory;
struct memblock_region *r;
while (++*idx < type->cnt) {
r = &type->regions[*idx];
if (PFN_UP(r->base) >= PFN_DOWN(r->base + r->size))
continue;
if (nid == MAX_NUMNODES || nid == r->nid)
break;
}
if (*idx >= type->cnt) {
*idx = -1;
return;
}
if (out_start_pfn)
*out_start_pfn = PFN_UP(r->base);
if (out_end_pfn)
*out_end_pfn = PFN_DOWN(r->base + r->size);
if (out_nid)
*out_nid = r->nid;
}
다음 memblock 영역부터 시작하여 요청한 @nid 이면서 파편화되지 않은 페이지들을 대상으로 시작 pfn과 끝 pfn+1값을 @out_start_pfn 및 @out_end_pfn에 알아온다. 그리고 매치된 노드의 id 값도 @out_nid에 알아온다.
- 코드 라인 8~12에서 memory memblock 타입에 등록된 영역 중 요청한 @idx 영역을 제외하고 그 영역부터 루프를 돈다.
- 코드 라인 14~15에서 memblock 영역에 파편화되지 않은 온전한 1개 이상의 페이지가 포함되지 않은 경우 skip 한다.
- 코드 라인 16~17에서 요청 노드 @nid와 영역의 노드가 매치되었거나 또는 any 노드 요청인 경우 루프를 탈출한다.
- 코드 라인 19~22에서 루프가 끝날 때까지 매치되지 않았으면 idx에 -1을 담고 리턴한다.
- 코드 라인 24~25에서 out_start_pfn에 페이지가 파편화되지 않고 온전히 포함된 시작 pfn을 담는다.
- 코드 라인 26~27에서 out_end_pfn에 페이지가 파편화되지 않고 온전히 포함된 끝 pfn을 담는다.
- 코드 라인 28~29에서 out_nid에 memblock 영역의 노드 id를 담는다.
아래 그림은 7개의 case 별로 __next_mem_pfn_range() 함수가 실행될 때 요청 idx+1부터 조건에 매치되는 블럭을 찾는 모습을 보여준다. 아래 그림 역시도 실제 memory memblock 들의 사이즈보다 훨씬 축소를 해놨기 때문에 계산 방법에 대해 이해를 돕는 것으로 활용해야 한다
- A)의 경우 파편화되지 않은 온전한 1개 페이지가 없는 경우이다.
- B)의 경우 노드 id를 지정한 경우이다.
- @idx
- @out_start_pfn
- @out_end_pfn
- @out_nid

for_each_free_mem_range()
include/linux/memblock.h
/**
* for_each_free_mem_range - iterate through free memblock areas
* @i: u64 used as loop variable
* @nid: node selector, %NUMA_NO_NODE for all nodes
* @flags: pick from blocks based on memory attributes
* @p_start: ptr to phys_addr_t for start address of the range, can be %NULL
* @p_end: ptr to phys_addr_t for end address of the range, can be %NULL
* @p_nid: ptr to int for nid of the range, can be %NULL
*
* Walks over free (memory && !reserved) areas of memblock. Available as
* soon as memblock is initialized.
*/
#define for_each_free_mem_range(i, nid, flags, p_start, p_end, p_nid) \
for_each_mem_range(i, &memblock.memory, &memblock.reserved, \
nid, flags, p_start, p_end, p_nid)
루프를 돌며 지정된 노드 @nid의 memory 영역에서 reserved 영역을 제외한 영역이 free 메모리이며 이 영역을 순서대로 시작 물리 주소를 @p_start, 끝 물리 주소를 @p_end, 노드 id를 @p_nid, 플래그를 @flags에 알아온다.
for_each_mem_range()
include/linux/memblock.h
/**
* for_each_mem_range - iterate through memblock areas from type_a and not
* included in type_b. Or just type_a if type_b is NULL.
* @i: u64 used as loop variable
* @type_a: ptr to memblock_type to iterate
* @type_b: ptr to memblock_type which excludes from the iteration
* @nid: node selector, %NUMA_NO_NODE for all nodes
* @flags: pick from blocks based on memory attributes
* @p_start: ptr to phys_addr_t for start address of the range, can be %NULL
* @p_end: ptr to phys_addr_t for end address of the range, can be %NULL
* @p_nid: ptr to int for nid of the range, can be %NULL
*/
#define for_each_mem_range(i, type_a, type_b, nid, flags, \
p_start, p_end, p_nid) \
for (i = 0, __next_mem_range(&i, nid, flags, type_a, type_b, \
p_start, p_end, p_nid); \
i != (u64)ULLONG_MAX; \
__next_mem_range(&i, nid, flags, type_a, type_b, \
p_start, p_end, p_nid))
루프를 돌며 지정된 노드 id의 A 타입 영역에서 B 타입 영역을 제외한 영역이 주어질 때 이 영역을 순서대로 p_start, p_end, p_nid 인수에 지정한다.
- 인자 @type_b는 null로 주어질 수도 있다.
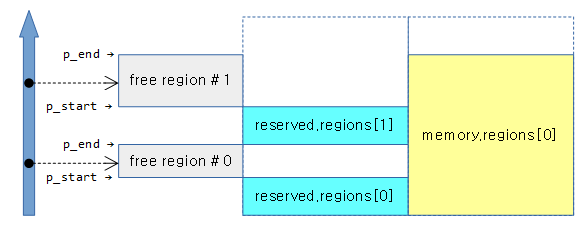
아래와 같이 우측 memory memblock 타입의 영역내에서 reserved memblock 타입의 영역들을 제외한 영역이 좌측 회색 박스의 free 영역이 매치된 영역이다. 그 매치된 영역들을 대상으로 루프가 제공된다.
__next_mem_range()
mm/memblock.c
/**
* __next__mem_range - next function for for_each_free_mem_range() etc.
* @idx: pointer to u64 loop variable
* @nid: node selector, %NUMA_NO_NODE for all nodes
* @flags: pick from blocks based on memory attributes
* @type_a: pointer to memblock_type from where the range is taken
* @type_b: pointer to memblock_type which excludes memory from being taken
* @out_start: ptr to phys_addr_t for start address of the range, can be %NULL
* @out_end: ptr to phys_addr_t for end address of the range, can be %NULL
* @out_nid: ptr to int for nid of the range, can be %NULL
*
* Find the first area from *@idx which matches @nid, fill the out
* parameters, and update *@idx for the next iteration. The lower 32bit of
* *@idx contains index into type_a and the upper 32bit indexes the
* areas before each region in type_b. For example, if type_b regions
* look like the following,
*
* 0:[0-16), 1:[32-48), 2:[128-130)
*
* The upper 32bit indexes the following regions.
*
* 0:[0-0), 1:[16-32), 2:[48-128), 3:[130-MAX)
*
* As both region arrays are sorted, the function advances the two indices
* in lockstep and returns each intersection.
*/
void __init_memblock __next_mem_range(u64 *idx, int nid,
enum memblock_flags flags,
struct memblock_type *type_a,
struct memblock_type *type_b,
phys_addr_t *out_start,
phys_addr_t *out_end, int *out_nid)
{
int idx_a = *idx & 0xffffffff;
int idx_b = *idx >> 32;
if (WARN_ONCE(nid == MAX_NUMNODES,
"Usage of MAX_NUMNODES is deprecated. Use NUMA_NO_NODE instead\n"))
nid = NUMA_NO_NODE;
for (; idx_a < type_a->cnt; idx_a++) {
struct memblock_region *m = &type_a->regions[idx_a];
phys_addr_t m_start = m->base;
phys_addr_t m_end = m->base + m->size;
int m_nid = memblock_get_region_node(m);
/* only memory regions are associated with nodes, check it */
if (nid != NUMA_NO_NODE && nid != m_nid)
continue;
/* skip hotpluggable memory regions if needed */
if (movable_node_is_enabled() && memblock_is_hotpluggable(m))
continue;
/* if we want mirror memory skip non-mirror memory regions */
if ((flags & MEMBLOCK_MIRROR) && !memblock_is_mirror(m))
continue;
/* skip nomap memory unless we were asked for it explicitly */
if (!(flags & MEMBLOCK_NOMAP) && memblock_is_nomap(m))
continue;
if (!type_b) {
if (out_start)
*out_start = m_start;
if (out_end)
*out_end = m_end;
if (out_nid)
*out_nid = m_nid;
idx_a++;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
reserved memblock 영역들 사이에서 노드 @nid 값과 플래그 @flags에 해당하는 영역을 대상으로 요청한 인덱스 @idx의 다음 free 공간을 찾아 반환한다. 64비트 @idx에 memory 타입 memblock 영역들의 인덱스와 reserved 타입 memblock 영역들의 인덱스를 반반 합쳐서 인덱스를 지정하여 요청한다. 출력 인자인 @out_start 및 @out_end에 찾은 free 영역의 시작 물리 주소와 끝 물리 주소를 알아온다. 또한 @out_nid에도 노드 id를 알아온다.
- 코드 라인 8~9에서 idx 값을 절반으로 나누어 lsb 쪽을 idx_a의 카운터로 사용하고, msb 쪽을 idx_b의 카운터로 사용한다.
- 코드 라인 11~13에서 노드 id 인수 값으로 deprecated된 MAX_NUMNODES를 사용하면 경고문을 출력한다.
- 코드 라인 15~24에서 type_a의 memblock 영역을 대상으로 루프를 돌며 요청한 @nid가 아니면서 any 노드를 요청한 경우도 아니면 skip 한다.
- 이 함수가 호출될 떄 type_a는 memory 타입, type_b는 reserved 타입이다.
- m_start와 m_end는 현재 1차 루프 인덱스의 memblock 영역의 시작 주소와 끝 주소이다.
- 코드 라인 27~28에서 hotplug 및 movable 노드 전용인 경우 skip 한다.
- 코드 라인 31~32에서 mirror 플래그 요청되었지만 mirror 영역이 아닌 경우 skip 한다.
- 코드 라인 35~36에서 nomap 플래그가 없는데 nomap 영역인 경우 skip 한다.
- 코드 라인 38~48에서 type_b에 대한 영역이 지정되지 않으면(null) 현재 1차 루프 인덱스의 memblock에 대한 영역으로 out_start와 out_end를 결정하고 idx_a 만을 1 증가 시키고 함수를 성공리에 빠져나간다.
/* scan areas before each reservation */
for (; idx_b < type_b->cnt + 1; idx_b++) {
struct memblock_region *r;
phys_addr_t r_start;
phys_addr_t r_end;
r = &type_b->regions[idx_b];
r_start = idx_b ? r[-1].base + r[-1].size : 0;
r_end = idx_b < type_b->cnt ?
r->base : PHYS_ADDR_MAX;
/*
* if idx_b advanced past idx_a,
* break out to advance idx_a
*/
if (r_start >= m_end)
break;
/* if the two regions intersect, we're done */
if (m_start < r_end) {
if (out_start)
*out_start =
max(m_start, r_start);
if (out_end)
*out_end = min(m_end, r_end);
if (out_nid)
*out_nid = m_nid;
/*
* The region which ends first is
* advanced for the next iteration.
*/
if (m_end <= r_end)
idx_a++;
else
idx_b++;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
}
}
/* signal end of iteration */
*idx = ULLONG_MAX;
}
- 코드 라인 2~10에서 type_b의 memblock 영역들 + 1만큼 2차 루프를 돈다.
- r 영역은 현재 2차 루프 인덱스가 가리킨 곳의 영역을 가리킨다.
- r_start는 idx_b가 0보다 크면 현재 이전 memblock의 끝 주소를 가리키고 idx_b가 0이면 0번 주소를 지정한다.
- r_end는 idx_b가 등록된 갯수보다 작은 경우 r 영역의 시작주소를 지정하고 아니면 시스템 최대 주소를 지정한다.
- 코드 라인 16~17에서 reserve memblock 영역이 memory memblock 영역을 벗어난 경우 2차 루프를 빠져나가서 다음 memory memblock을 준비하도록 한다.
- 코드 라인 19~26에서 두 영역이 교차하는 경우이다. out_start에 하단 reserve 영역값의 끝 주소나 memory 영역값의 시작 주소중 가장 큰 주소를 담는다. 그리고 out_end에 상단 reserve 영역값의 시작 주소나 memory 영역값의 끝 주소중에 가장 작은 주소를 담는다.
- 코드 라인 31~36에서 reserve 영역의 끝 주소가 memory 영역의 끝주소와 비교하여 큰 경우 idx_a를 증가시키고 다음 memory block을 준비하기 위해 빠져나가고, 크지 않은 경우 idx_b를 증가시키고 계속하여 다음 reserve 영역을 준비하기 위해 빠져나간다.
- 코드 라인 42에서 1차 루프를 끝까지 완료하면 더 이상 처리할 수 없으므로 idx에 ULLONG_MAX(시스템 최대 주소) 값을 부여하고 빠져나간다.
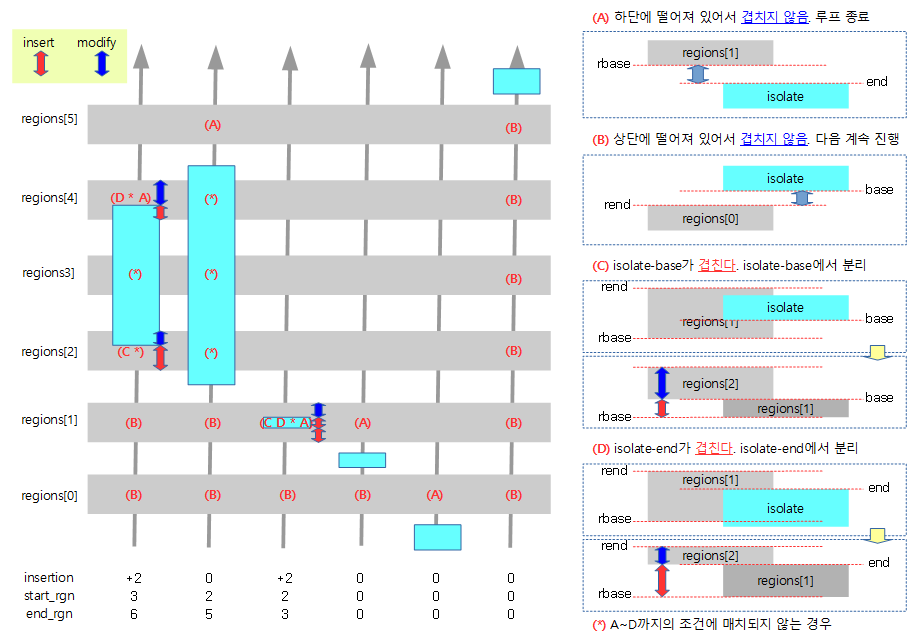
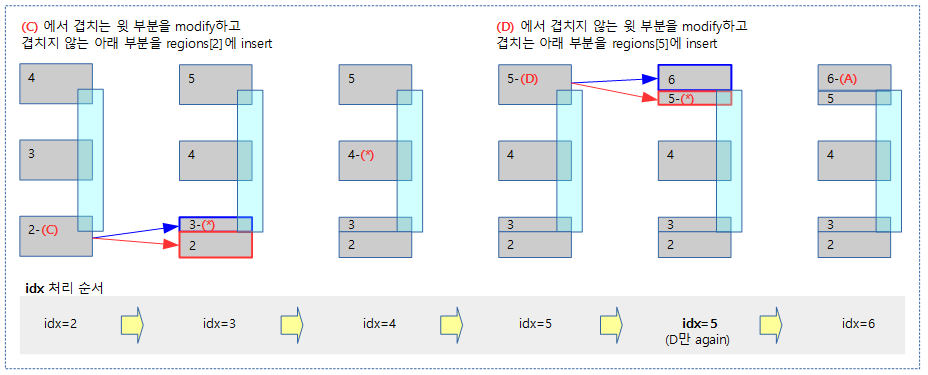
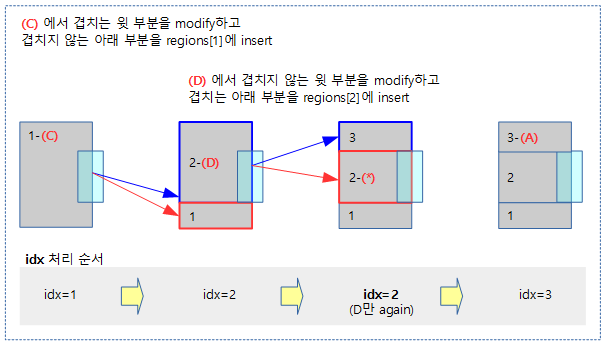
다음 그림은 __next_mem_range() 함수가 reserve된 영역들 사이의 free 영역을 찾아 루프를 돌 때 free 영역의 산출에 사용되는 case 들을 보여준다.

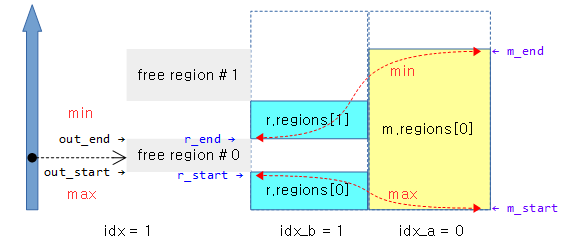
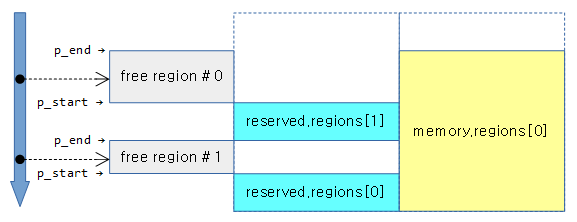
아래 1개의 meory memblock과 2개의 reserve memblock가 등록되어 있는 상태에서 __next__mem_range(0x1UUL) 매크로를 사용한 경우의 예이다.
- 루프 1의 idx_a 인덱스는 0으로 memory.regions[0]의 정보 사용
- 루프 2의 idx_b 인덱스는 1로 reserve.regions[1]과 이전 reserve memblock의 영역 정보를 사용하는 중이다.
- 확정된 free 영역으로 r_start는 reserve.regions[0]의 끝 주소로 지정되고 r_end는 reserve.regions[1]의 시작 주소로 지정된다.
아래 2개의 meory memblock과 4개의 reserve memblock이 등록되어 있는 상태에서 __next__mem_range(0x1UUL) 매크로를 사용하여 free 영역이 검색되는 범위를 표현한다.
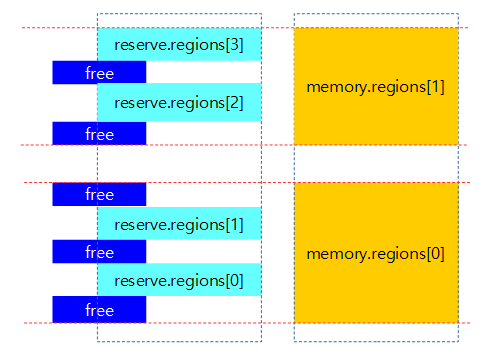
for_each_free_mem_range_reverse()
mm/memblock.c
/**
* for_each_free_mem_range_reverse - rev-iterate through free memblock areas
* @i: u64 used as loop variable
* @nid: node selector, %NUMA_NO_NODE for all nodes
* @flags: pick from blocks based on memory attributes
* @p_start: ptr to phys_addr_t for start address of the range, can be %NULL
* @p_end: ptr to phys_addr_t for end address of the range, can be %NULL
* @p_nid: ptr to int for nid of the range, can be %NULL
*
* Walks over free (memory && !reserved) areas of memblock in reverse
* order. Available as soon as memblock is initialized.
*/
#define for_each_free_mem_range_reverse(i, nid, flags, p_start, p_end, \
p_nid) \
for_each_mem_range_rev(i, &memblock.memory, &memblock.reserved, \
nid, flags, p_start, p_end, p_nid)
루프를 역순으로 돌며 지정된 노드 id의 memory 영역에서 reserved 영역을 제외한 영역이 free 메모리이며 이 영역을 순서대로 p_start, p_end, p_nid 인수에 지정한다.
for_each_mem_range_rev()
mm/memblock.c
/**
* for_each_mem_range_rev - reverse iterate through memblock areas from
* type_a and not included in type_b. Or just type_a if type_b is NULL.
* @i: u64 used as loop variable
* @type_a: ptr to memblock_type to iterate
* @type_b: ptr to memblock_type which excludes from the iteration
* @nid: node selector, %NUMA_NO_NODE for all nodes
* @flags: pick from blocks based on memory attributes
* @p_start: ptr to phys_addr_t for start address of the range, can be %NULL
* @p_end: ptr to phys_addr_t for end address of the range, can be %NULL
* @p_nid: ptr to int for nid of the range, can be %NULL
*/
#define for_each_mem_range_rev(i, type_a, type_b, nid, flags, \
p_start, p_end, p_nid) \
for (i = (u64)ULLONG_MAX, \
__next_mem_range_rev(&i, nid, flags, type_a, type_b,\
p_start, p_end, p_nid); \
i != (u64)ULLONG_MAX; \
__next_mem_range_rev(&i, nid, flags, type_a, type_b, \
p_start, p_end, p_nid))
루프를 역순으로 돌며 지정된 노드 id의 A 타입 영역에서 B 타입 영역을 제외한 영역이 주어질 때 이 영역을 순서대로 p_start, p_end, p_nid 인수에 지정한다. B 타입 영역이 null일 수도 있다.
- 인덱스는 64비트 값이며 절반씩 나누어 상위 32비트는 memory memblock 영역에 대한 인덱스를 가리키고, 하위 32비트는 reserved memblock 영역에 대한 인덱스를 가리킨다.
- 처음 시작 시 역순으로 루프를 시작하므로 ~0UUL 값이 대입되어 시작한다.
- ARM은 free 메모리를 할당하기 위해 검색시 이 top down 방식의 매크로를 사용한다.
아래와 같이 memory 영역내에서 reserved 영역을 제외한 영역이 free 영역이고 2개의 영역이 역순 루프로 제공된다.
아래와 같이 memory region이 여러 개일 때 i 값의 추적을 표현하였다.
- i 값의 최초 시작은 0xffff_ffff_ffff_ffff로 시작하고 free 영역을 리턴할 때 마다 아래와 같이 변화가 됨을 알 수 있다.
- for each 루프를 종료하는 순간 i 값은 다시 0xffff_ffff_ffff_ffff로 바뀐다.
__next_mem_range_rev()
mm/memblock.c
idx 값이 ~0UUL로 진입한 경우 idx_a에는 type_a 형태의 memblock 갯수에서 -1을 대입하고, idx_b에는 type_b 형태의 memblock 갯수 값을 대입한다. 더 이상 매치되는 값이 없어서 루프를 다 돌고 함수를 종료하는 경우에는 idx 값이 다시 ~0UUL로 지정된다. (no more data)
- 아래 코드는 __next_mem_range()를 reverse하는 것 이외에 코드가 동일하므로 소스 해석은 하지 않는다.
/**
* __next_mem_range_rev - generic next function for for_each_*_range_rev()
*
* @idx: pointer to u64 loop variable
* @nid: node selector, %NUMA_NO_NODE for all nodes
* @flags: pick from blocks based on memory attributes
* @type_a: pointer to memblock_type from where the range is taken
* @type_b: pointer to memblock_type which excludes memory from being taken
* @out_start: ptr to phys_addr_t for start address of the range, can be %NULL
* @out_end: ptr to phys_addr_t for end address of the range, can be %NULL
* @out_nid: ptr to int for nid of the range, can be %NULL
*
* Finds the next range from type_a which is not marked as unsuitable
* in type_b.
*
* Reverse of __next_mem_range().
*/
void __init_memblock __next_mem_range_rev(u64 *idx, int nid,
enum memblock_flags flags,
struct memblock_type *type_a,
struct memblock_type *type_b,
phys_addr_t *out_start,
phys_addr_t *out_end, int *out_nid)
{
int idx_a = *idx & 0xffffffff;
int idx_b = *idx >> 32;
if (WARN_ONCE(nid == MAX_NUMNODES, "Usage of MAX_NUMNODES is deprecated. Use NUMA_NO_NODE inn
stead\n"))
nid = NUMA_NO_NODE;
if (*idx == (u64)ULLONG_MAX) {
idx_a = type_a->cnt - 1;
if (type_b != NULL)
idx_b = type_b->cnt;
else
idx_b = 0;
}
for (; idx_a >= 0; idx_a--) {
struct memblock_region *m = &type_a->regions[idx_a];
phys_addr_t m_start = m->base;
phys_addr_t m_end = m->base + m->size;
int m_nid = memblock_get_region_node(m);
/* only memory regions are associated with nodes, check it */
if (nid != NUMA_NO_NODE && nid != m_nid)
continue;
/* skip hotpluggable memory regions if needed */
if (movable_node_is_enabled() && memblock_is_hotpluggable(m))
continue;
/* if we want mirror memory skip non-mirror memory regions */
if ((flags & MEMBLOCK_MIRROR) && !memblock_is_mirror(m))
continue;
/* skip nomap memory unless we were asked for it explicitly */
if (!(flags & MEMBLOCK_NOMAP) && memblock_is_nomap(m))
continue;
if (!type_b) {
if (out_start)
*out_start = m_start;
if (out_end)
*out_end = m_end;
if (out_nid)
*out_nid = m_nid;
idx_a--;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
/* scan areas before each reservation */
for (; idx_b >= 0; idx_b--) {
struct memblock_region *r;
phys_addr_t r_start;
phys_addr_t r_end;
r = &type_b->regions[idx_b];
r_start = idx_b ? r[-1].base + r[-1].size : 0;
r_end = idx_b < type_b->cnt ?
r->base : PHYS_ADDR_MAX;
/*
* if idx_b advanced past idx_a,
* break out to advance idx_a
*/
if (r_end <= m_start)
break;
/* if the two regions intersect, we're done */
if (m_end > r_start) {
if (out_start)
*out_start = max(m_start, r_start);
if (out_end)
*out_end = min(m_end, r_end);
if (out_nid)
*out_nid = m_nid;
if (m_start >= r_start)
idx_a--;
else
idx_b--;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
}
}
/* signal end of iteration */
*idx = ULLONG_MAX;
}
기타 Memblock API
- memblock_type_name()
- memblock_cap_size()
- 영역이 시스템의 최대 주소를 넘어가는 경우 overflow 된 만큼 잘라낸다.
- memblock_addrs_overlap()
- memblock_overlaps_region()
- 등록된 memblock 영역들과 인수로 주어진 영역이 겹치는지 검사하여 겹치는 영역의 index를 리턴하고 아니면 -1 리턴
- get_allocated_memblock_reserved_regions_info()
- reserved 타입의 영역이 초기화 시 할당 받은 주소가 아니고 새롭게 buddy/slab memory 할당자에 의해 재 할당 받은 경우라면 해당 할당 영역의 시작주소를 리턴하고 아니면 0을 리턴한다. 이 함수는 free_low_memory_core_early() 함수를 통하여 bootmem 영역의 사용을 종료하고 buddy allocator로 전환할 때 호출된다.
- get_allocated_memblock_memory_regions_info()
- memory 타입의 영역이 초기화 시 할당 받은 주소가 아니고 새롭게 buddy/slab memory 할당자에 의해 재 할당 받은 경우라면 해당 할당 영역의 시작주소를 리턴하고 아니면 0을 리턴한다.이 함수는 free_low_memory_core_early() 함수를 통하여 bootmem 영역의 사용을 종료하고 buddy allocator로 전환할 때 호출된다.
- memblock_double_array()
- 주어진 타입의 memblock_region 배열을 2배 크기로 확장한다.
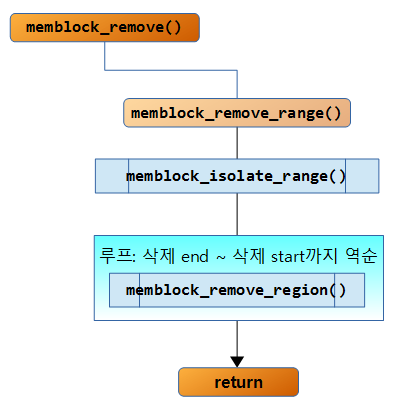
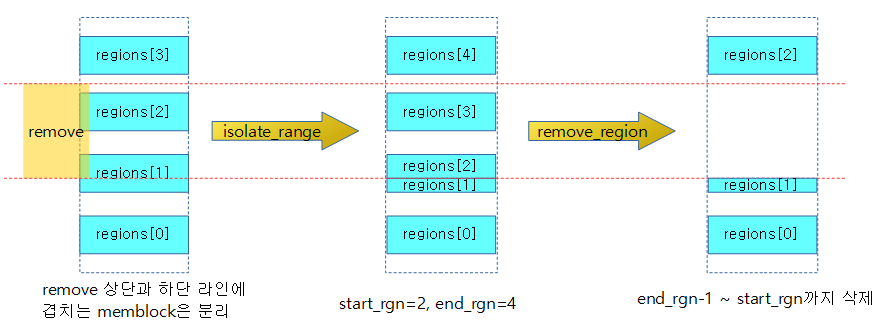
- memblock_free()
- reserved 영역에서 주어진 영역을 삭제한다.
- memblock_set_node()
- 주어진 영역에 해당하는 모든 memblock의 노드id를 설정한다. 영역이 memblock의 중간에 걸치면 분리하여 노드id를 설정한다.
- memblock_phys_mem_size()
- memory 영역에 등록된 memblock의 전체 사이즈
- memblock_mem_size()
- 주어진 limit_pfn까지 총 등록된 memory memblock 페이지 수를 알아온다.
- memblock_start_of_DRAM()
- memory 영역에 등록된 첫 memblock의 시작 주소(DRAM 시작 주소)
- memblock_end_of_DRAM()
- memory 영역에 등록된 마지막 memblock의 끝 주소(DRAM 끝 주소)
- memblock_enforce_memory_limit()
- 메모리 영역이 limit를 초과하는 경우 truncate ?
- memblock_search()
- 주어진 type의 memblock에서 주어진 주소로 2진 탐색 알고리즘을 사용하여 memblock을 찾고 해당 인덱스 값을 얻는다.
- memblock_is_reserved()
- reserved 영역에 주소가 포함되어 있는지 reserved 영역을 검색하여 판단한다.
- memblock_is_memory()
- memory 영역에 주소가 포함되어 있는지 memory 영역을 검색하여 판단한다.
- memblock_search_pfn_nid()
- memory 영역에서 주어진 주소로 2진 탐색 알고리즘으로 memblock을 찾은 후, 찾은 영역의 시작 페이지와 끝 페이지를 알아온다.
- memblock_is_region_reserved()
- 주어진 영역이 reserved memblock 영역과 겹치는지 확인한다.
- memblock_trim_memory()
- memory memblock들 모두 지정된 align 바이트로 정렬한다. 사이즈가 align 크기보다 작은 경우 삭제한다.
- memblock_set_current_limit()
- memblock_dump()
- 주어진 타입의 memblock들 정보를 출력한다.
- memblock_dump_all()
- memory와 reserved 타입의 memblock들 정보를 출력한다.
- memblock_allow_resize()
- 전역변수 memblock_can_resize=1로 설정(resize 허용)
- early_memblock()
- early_param()으로 등록한 함수이며 인수로 “debug” 문자열을 받게되면 전역 변수 memblock_debug=1로 설정하여 memblock_dbg() 함수를 동작하게 한다.
- memblock_debug_show()
- DEBUG_FS가 동작중이면 debug 출력할 수 있다.
디버그 출력
CONFIG_DEBUG_FS 커널 옵션을 사용한 경우 다음과 같이 memblock 등록 상황을 확인할 수 있다.
예) rpi2 – ARM32
# cat /sys/kernel/debug/memblock/memory
0: 0x00000000..0x3affffff
# cat /sys/kernel/debug/memblock/reserved
0: 0x00004000..0x00007fff <- 페이지 테이블
1: 0x00008240..0x0098c1ab <- 커널
2: 0x2fffbf00..0x2fffff08
3: 0x39e9e000..0x39f95fff
4: 0x39f989c4..0x3a7fefff
5: 0x3a7ff540..0x3a7ff583
6: 0x3a7ff5c0..0x3a7ff603
7: 0x3a7ff640..0x3a7ff6b7
8: 0x3a7ff6c0..0x3a7ff6cf
9: 0x3a7ff700..0x3a7ff70f
10: 0x3a7ff740..0x3a7ff743
11: 0x3a7ff780..0x3a7ff916
12: 0x3a7ff940..0x3a7ffad6
13: 0x3a7ffb00..0x3a7ffc96
14: 0x3a7ffc9c..0x3a7ffd14
15: 0x3a7ffd18..0x3a7ffd60
16: 0x3a7ffd64..0x3a7ffd7e
17: 0x3a7ffd80..0x3a7ffd9b
18: 0x3a7ffda4..0x3a7ffdbe
19: 0x3a7ffdc0..0x3a7ffe37
20: 0x3a7ffe40..0x3a7ffe43
21: 0x3a7ffe48..0x3affffff
예) rock960 – ARM64
$ /sys/kernel/debug/memblock$ cat memory
0: 0x0000000000200000..0x00000000f7ffffff
$ /sys/kernel/debug/memblock$ cat reserved
0: 0x0000000002080000..0x00000000033b5fff <- 커널
1: 0x00000000ef400000..0x00000000f5dfffff
2: 0x00000000f5eef000..0x00000000f5f01fff
3: 0x00000000f6000000..0x00000000f7bfffff
4: 0x00000000f7df4000..0x00000000f7df4fff
5: 0x00000000f7df5e00..0x00000000f7df5fff
6: 0x00000000f7e74000..0x00000000f7f61fff
7: 0x00000000f7f62600..0x00000000f7f6265f
8: 0x00000000f7f62680..0x00000000f7f626df
9: 0x00000000f7f62700..0x00000000f7f6282f
10: 0x00000000f7f62840..0x00000000f7f62857
11: 0x00000000f7f62880..0x00000000f7f62887
12: 0x00000000f7f648c0..0x00000000f7f6492b
13: 0x00000000f7f64940..0x00000000f7f649ab
14: 0x00000000f7f649c0..0x00000000f7f64a2b
15: 0x00000000f7f64a40..0x00000000f7f64a47
16: 0x00000000f7f64a64..0x00000000f7f64aea
17: 0x00000000f7f64aec..0x00000000f7f64b1a
18: 0x00000000f7f64b1c..0x00000000f7f64b4a
19: 0x00000000f7f64b4c..0x00000000f7f64b7a
20: 0x00000000f7f64b7c..0x00000000f7f64baa
21: 0x00000000f7f64bac..0x00000000f7fcdff7
22: 0x00000000f7fce000..0x00000000f7ffffff
참고